1. Introduction
Semantic segmentation, a pixel-level classification problem, is one of the high-level computer vision tasks. Numerous researchers have investigated the extensions of convolutional neural network (CNN) [
1] for semantic segmentation tasks [
2,
3], because CNN has outperformed traditional methods in many tasks such as image classification [
4,
5,
6], object detection [
7,
8,
9] and image generation [
10,
11] in the computer vision community. A semantic segmentation network generally retains the feature extraction part of CNN and uses the deconvolution to recover the feature map resolution similar to the size of the input image. A final convolution layer with the size of
is applied for pixel-wise labeling to classify every pixel of the last feature map into the corresponding class. Instead of using every patch around each pixel for prediction, semantic segmentation networks based on fully convolutional network (FCN) can efficiently produce pixel-wise predictions. Moreover, global and local relationships of pixels are considered to produce more accurate prediction results with an end-to-end framework.
Segmentation of remote sensing images is a key step for land-use and land-cover classifications, which are crucial in image interpretation and urban mapping [
12]. Considering the high resolution and large amounts of remote sensing images, accurate and efficient tools for semantic segmentation are urgently needed. As a result, the deep semantic segmentation networks developed in natural image processing have been noticed and applied in remote sensing image segmentation tasks. FCNs have received increasing attentions in the applications of remote sensing fields because these networks skillfully deal with pixel-wise classification for images of arbitrary sizes and complex textures. Some FCN-based networks have made good progresses on remote sensing image segmentation [
13,
14,
15].
Similar to many deep learning networks, the performance of semantic segmentation networks is highly related to the quality and quantity of training samples. A common phenomenon in practical work is the imbalance of training samples. If samples of one or some classes rarely appear in the training data set, then a deep network could learn limited knowledge of that class. This phenomenon will result in over-fitting problems in the training process and lead to poor generalization capabilities of models. Thus, applications on natural images usually attempt to collect additional samples or augment data by re-sampling or synthesis. These approaches are relatively feasible for natural images. However, using the above schemes on data sets for remote sensing image segmentation is considerably difficult. Substantially imbalanced data problems easily occur in remote sensing segmentation due to the variation of scales of different land-cover categories and man-made objects. Moreover, collecting remote sensing samples of rare classes is often difficult, which indicates that the collection of additional data is not practical for improving the experimental results.
Moreover, existing segmentation networks classify all categories commonly based on the same features extracted by CNN. However, features of categories can be different from each other, especially for remote sensing images. For example, objects in remote sensing images, such as buildings and trees, are quite distinguishable by colors, shapes, and edges. Thus, their features should be distinct for the classifier. By contrast, current segmentation networks only produce general features with a uniform CNN structure and leave all the identification tasks to the last single classification layer. Intuitively, a fine-designed network ought to extract category-specific features in addition to general features. Thus, the model can refine the segmentation results and provide accurate predictions.
Considering the aforementioned issues, a novel network named class-wise FCN (C-FCN) is proposed for remote sensing image segmentation. Inspired by the different characteristics of remote sensing semantic categories and the intuition of category-specific network architecture, various paths for different classes are designed in the proposed network. In this concept, features of each class have their specific flow path, wherein even some difficult or small categories are capable of fitting their model path properly. Consequently, the classifiers will become category-specific ones, which should merely distinguish whether a test sample belongs to one category or not. These binary classifiers will be more concise and dedicated, making them easier to train and fulfill.
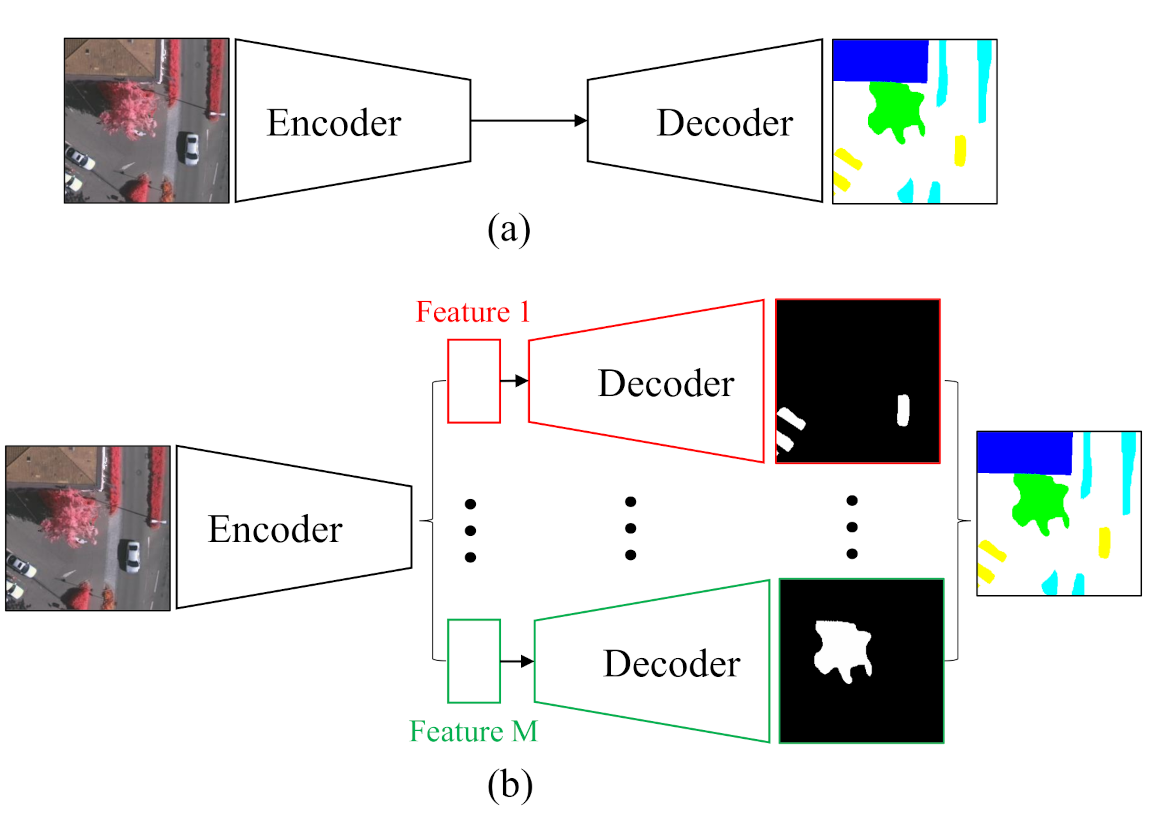
As a typical structure of the current semantic segmentation network, the encoder– decoder structure (
Figure 1a) proposed by SegNet [
16] has improved the original FCN on the feature map up-sampling method and achieved good performance with dense feature maps. Based on this benchmark network, a straightforward implementation of the above class-wise concept is to run the entire encoder–decoder path for each category in parallel. However, this scheme will suffer from heavy computational costs with the increase of category numbers. Moreover, the repetitive computations of some general features within different classes are unnecessary. Therefore, the proposed network is presented in
Figure 1b. In the proposed C-FCN, different classes share the backbone encoder part as much as possible, which extracts general features and reduces the computational burden. Each class possesses an individual decoder and a binary classifier to realize the class-wise feature extraction and specific high-level semantic understanding. In order to achieve the class-wise operation, a class-wise convolution is employed to build our pipeline. Eventually, an end-to-end class-wise network for remote sensing semantic segmentation is obtained by combining all the aforementioned approaches.
It’s widely acknowledged that CNN is a hierarchical network structure, and layers at different levels represent features of different hierarchies. Typically, shallow layers, namely, the layers near inputs, often capture some low-level and simple characteristics of the given image like lines or edges. By contrast, the subsequent layers seize more abstract and high-level features. Hence, skip-connection developed in U-Net [
17] is regarded as an essential structure in the building of a segmentation network. Skip-connection reuses the features from former layers to help decoders obtain more accurate segmentation results. In our pipeline, the particularity of the decoder cannot adapt to the original skip-connection structure. Therefore, this part is modified by a newly designed module (class-wise supervision module) such that features and information from the encoder can still skip and flow into the decoders. Meanwhile, the addition of this CS module can help to learn more specific features for each class and boost the realization of class-wise processing.
The main contributions of this paper are concluded as follows.
An end-to-end network for semantic segmentation of remote sensing images is built to extract and understand class-wise features and improve semantic segmentation performances;
Based on the above concept, class-wise transition (CT), class-wise up-sampling (CU), class-wise supervision (CS), and class-wise classification (CC) modules are designed in the proposed model to achieve class-wise semantic feature understanding and pixel labeling;
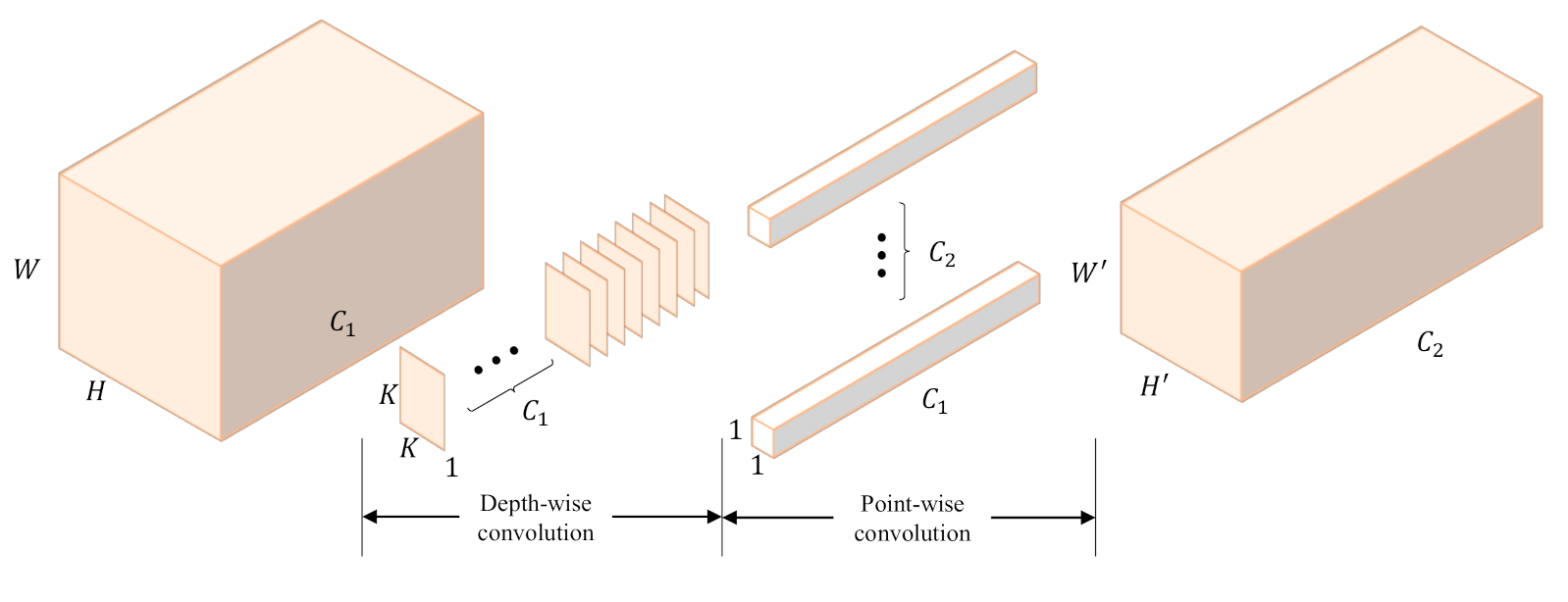
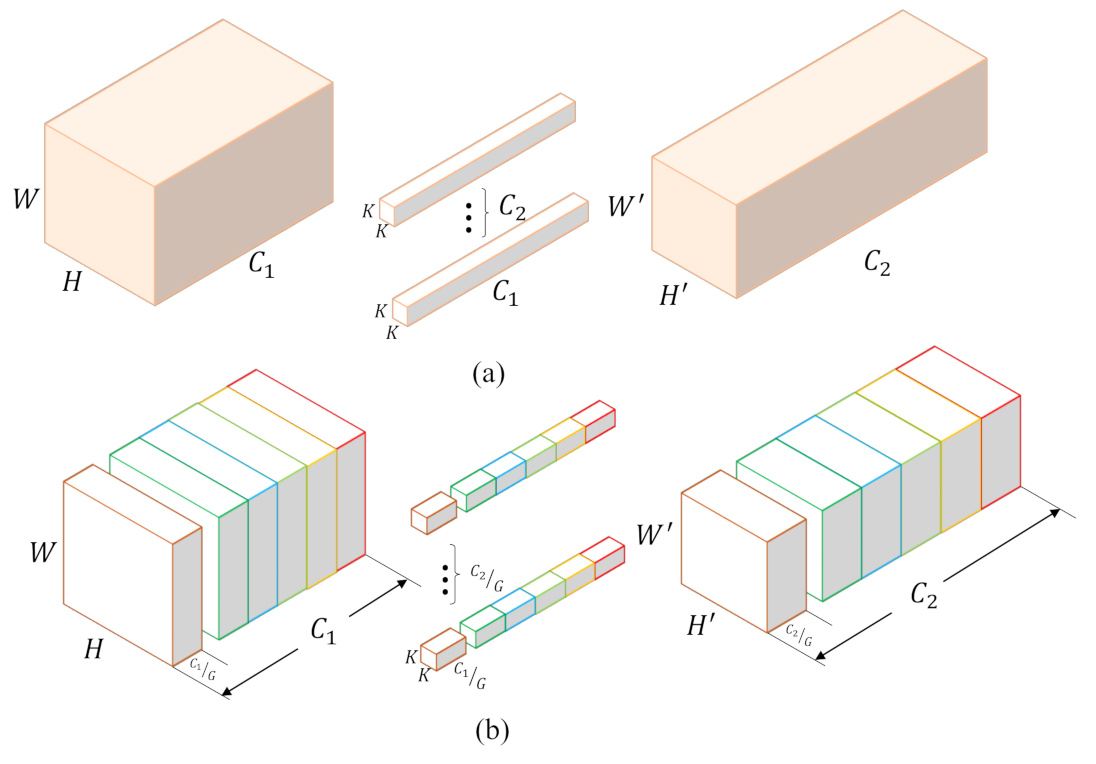
The network shares the encoder to reduce parameters and computational costs, and the depth-wise convolution and group convolution are employed to realize class-wise operations for each module;
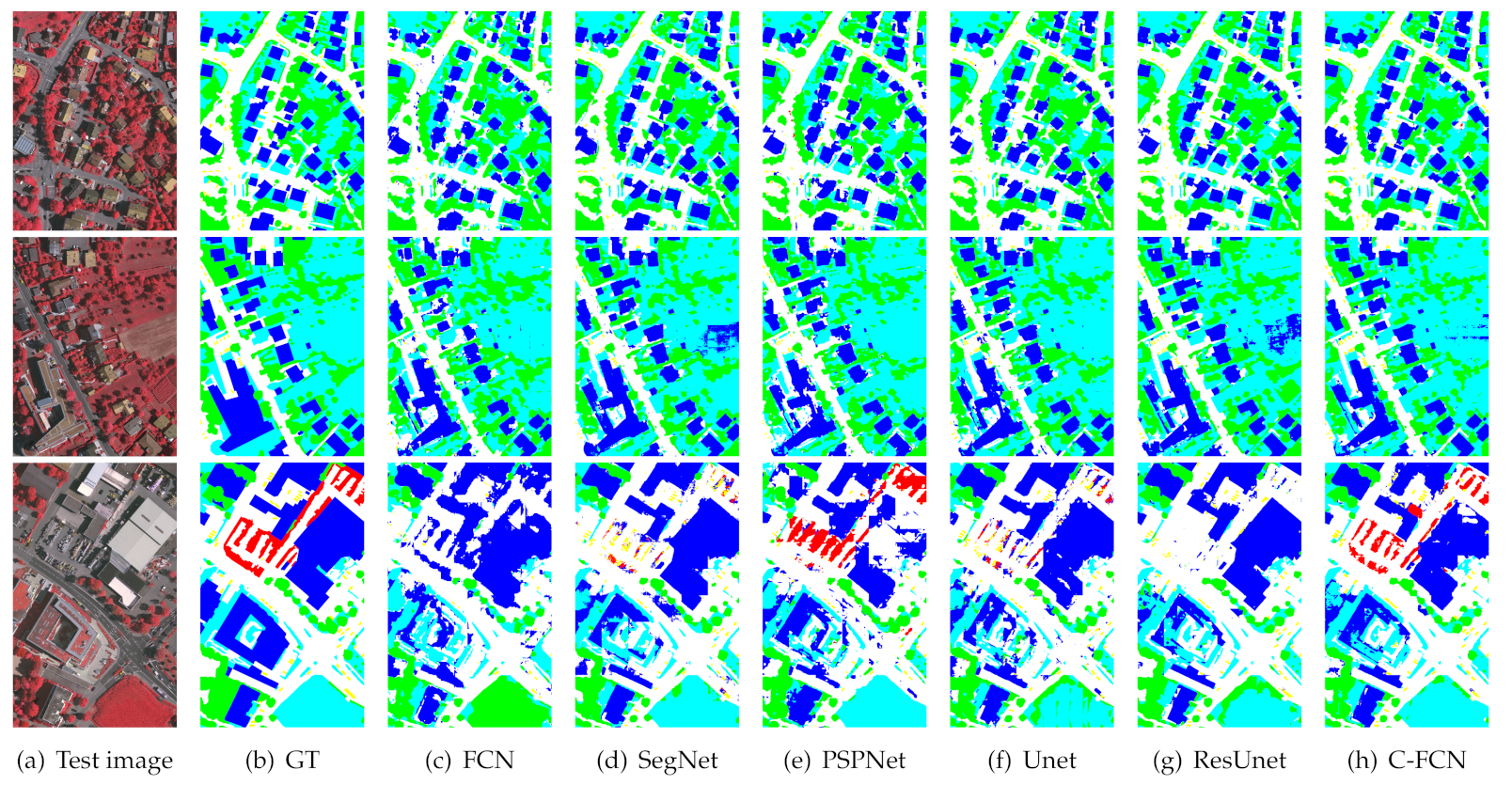
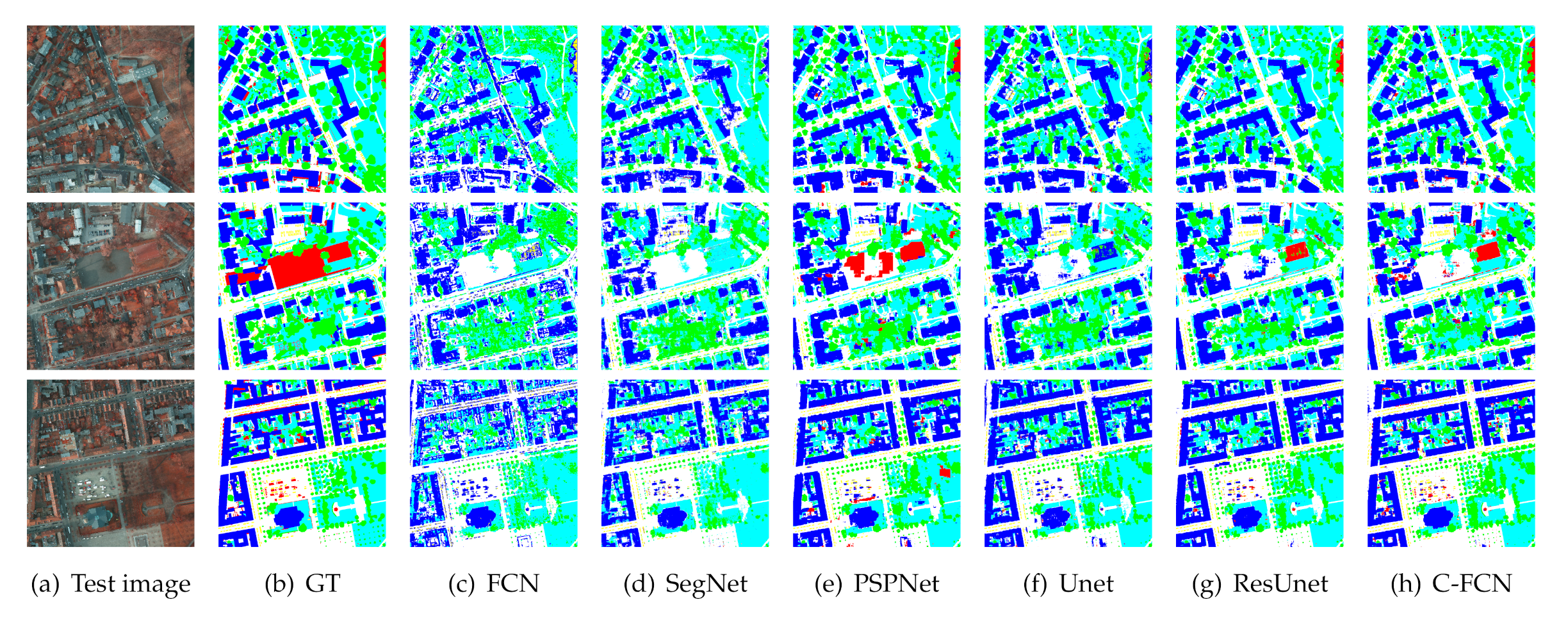
The proposed model is tested on two standard benchmark datasets offered by ISPRS. Experimental results show that the proposed method has exploited features of most categories and obviously improved segmentation performances compared with state-of-the-art benchmark FCNs.
The rest of this paper is organized as follows.
Section 2 presents the related work.
Section 3 introduces the details of our proposed network and demonstrates its key components.
Section 4 validates our approach on two datasets, and the conclusion is drawn in
Section 5.
3. Methods
In this paper, we design a novel end-to-end architecture named class-wise fully convolutional network (C-FCN) based on a straightforward idea. Most layers of traditional convolutional neural networks, either for classification or segmentation tasks, concentrate on extracting rich contextual features. Consequently, the classification procedure is left to a few simple convolutional layers or fully connected layers. For example, a segmentation network takes an image with the size of
as the input, and obtains the final feature maps
f with the size of
, then the classification from features to different categories can be formulated as a mapping:
where
is the feature vector at position
, and
M is the number of classes and
. It is noticed that all categories are identified by the features in the same space. However, features in a general form may be difficult to classify because categories can be very distinct from each other. Contrarily, if we transform the general features into specific features for different categories, the classification mapping can be decomposed to
M mappings of
, which will extract more specific features and reduce the classification difficulty.
Based on the above analysis, a straightforward way is to train a convolutional neural network with M paths concurrently, and then merge the outputs to obtain the final segmentation result. However, this scheme will result in a huge number of parameters which lead to expensive training. Therefore, we decide to take the parameter-sharing principle, which means all the M network branches will share one encoding structure. As for the decoder part, we separately decode every class on their own features to share the responsibility of semantic understanding for classifiers. Different from usual convolutional layers, we propose a class-wise convolution to implement all paths within one network.
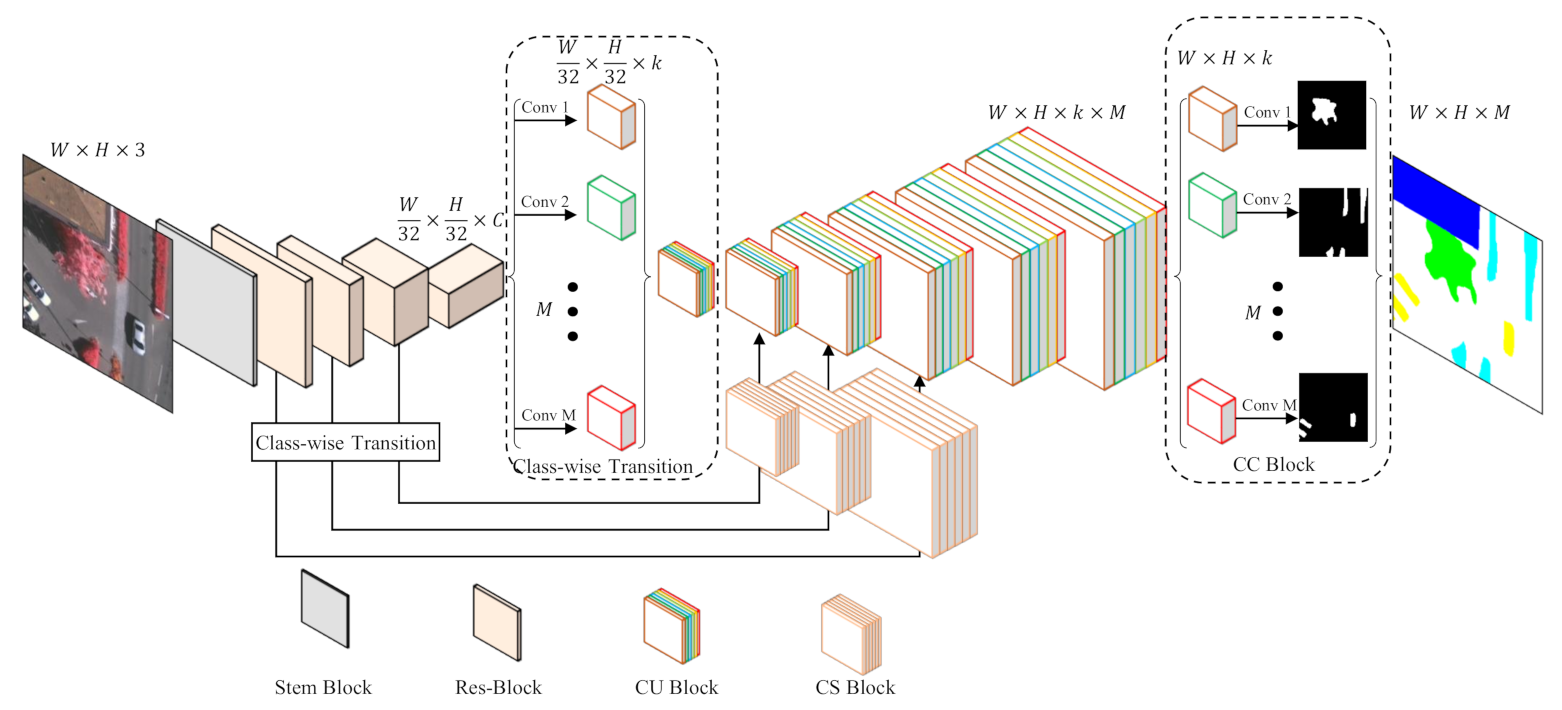
The overall structure of the proposed network is shown in
Figure 4. In terms of usual fully convolutional networks, the proposed network can also be parted into two sections: encoder and decoder.
The parameter-sharing encoder can be realized with an arbitrary benchmark network. Considering the performance and affordability, we use the pre-trained ResNet-50, which consists of a Stem Block and four Res-Blocks, as the backbone to extract general features for all categories. Assuming that the input image has the size of , the Stem Block will decrease the feature map size to , and the latter three blocks further downsize the feature maps by a scale of 8. In other words, the stride of the encoder will be 32. Considering the decoder, we customize features for every category by a class-wise transition block (CT), which applies M convolutional layers with k kernels for every category, where M denotes the number of classes and k is a hyper-parameter. By means of this approach, every category is separated to learn how to decode its specific features. Logically, there should be individual decoding paths for M different categories. To keep the network integrated, we design a class-wise up-sampling (CU) block, which is able to decode class-wise features of all classes within one structure by the group convolution. In this case, all categories are actually decoded separately but in a decent form. After five CU blocks, the size of features will be restored to as the original input image. Finally, we use a class-wise classification (CC) block to segment every class based on their specific features.
Since skip-connection is one of the most fundamental structures of segmentation networks, we prefer to retain this structure to fuse features from encoder to decoder. However, in our network, features from the encoder are general ones while those from the decoder are class-specific ones, which cannot be simply concatenated. Therefore, we design the class-wise supervision (CS) block to adapt features outflowing from the encoder to facilitate fusion with features in the decoder. Specifically, since CS block bridges the encoder and decoder, it involves the aforementioned Res-Block and CT block.
The four essential components of the proposed C-FCN will be presented in the succeeding sections. Class-wise transition (CT), class-wise up-sampling (CU), class-wise supervision (CS) and class-wise classification (CC) modules are presented in
Section 3.1,
Section 3.2,
Section 3.3 and
Section 3.4, respectively, to illustrate their formations and functions.
3.1. CT (Class-Wise Transition) Module
In the proposed network, we take ResNet-50 as the encoder, which extracts features of the input image by stacking Res-Blocks. Generally, feature maps from deeper layers are smaller and more abstract than those in shallow layers. All these features, whether deep or shallow, are called “general features” by us, and participate in the classification of all given categories. For the decoder part, the feature extraction and up-sampling path will be split and class-wise processing will be emphasized. In order to transform the general features to class-wise features and link the shared encoder with the class-wise decoder, we design the class-wise transition (CT) block. In brief, the CT block is employed to connect the general structure and the class-wise pipeline. Therefore, the CT block is also applied within the CS blocks besides the junction part between the encoder and decoder.
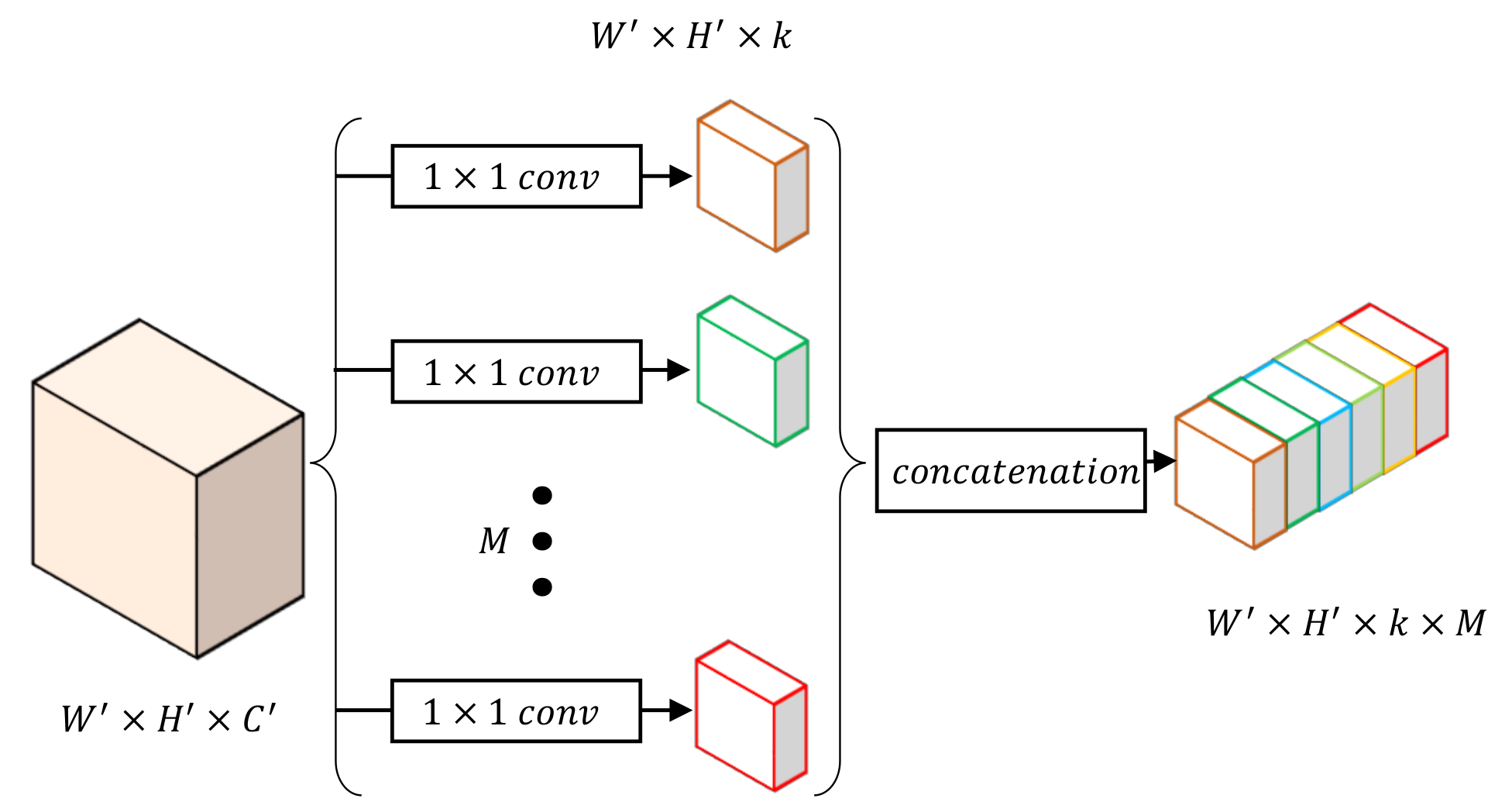
Figure 5 illustrates the details of a CT block. This module takes general features as the input and uses a
convolution layer to facilitate transformation into
M class-wise features, where
M denotes the number of classes. Moreover, the dimension of every class-wise features is reduced to
k during the class-wise convolution to decrease computational cost. After the above convolution, we concatenate the class-wise outputs together on their depth instead of parallel processing of all
M features. This specific feature map will then be further processed in CS and CU blocks.
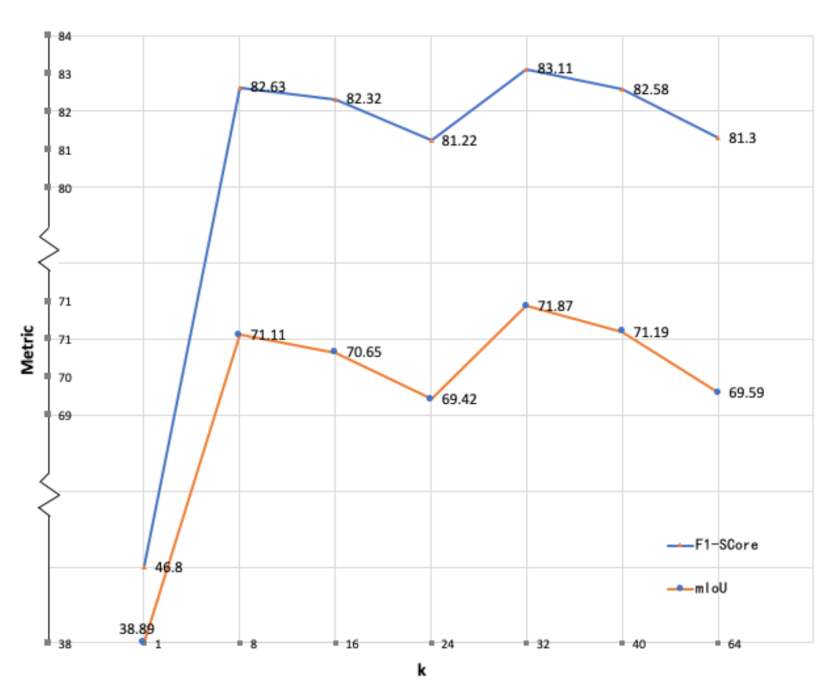
If we keep the same channels for each individual path as the original input, parameters of our network will overload because the class-wise convolution will multiply the channels of the input feature map. Notably, general features are still important in the pipeline, whereas class-wise features only serve individual categories that require relatively less information representation. In the proposed model, channels for each class are reduced by choosing a relatively smaller k than the number of input channel . Experiments will be conducted to evaluate network performance by setting different values of k and verify the scheme.
3.2. CU (Class-Wise Up-Sampling) Module
In the traditional FCN [
18], after the input image is transformed into highly abstract multi-channel feature maps in the encoder, the decoder will simply recover them to the original size of the input using bilinear interpolation. This implementation is straightforward, but quite rough and not learnable. Instead, we choose UNet [
17] as the decoder backbone, which adds a Res-Block after the interpolation layer such that the decoder can learn how to up-sample features. However, in our network, features from the encoder are class-wise, thus we design a class-wise up-sampling (CU) block to build the decoder.
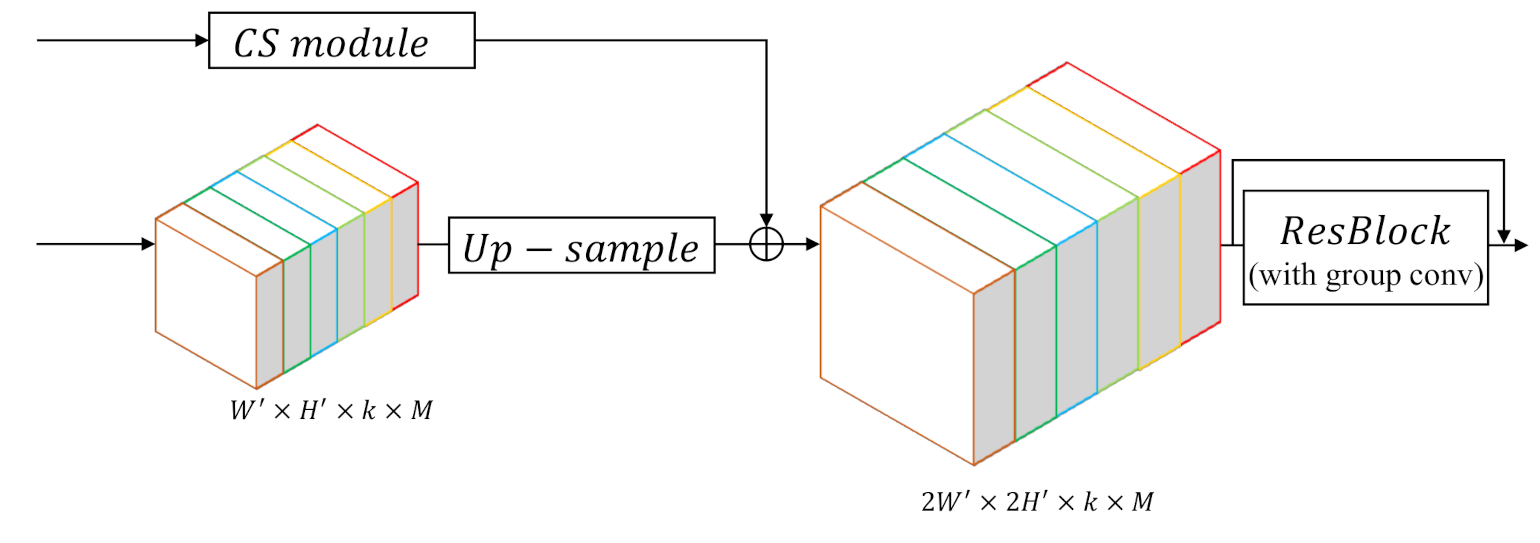
As shown in
Figure 4, the decoder includes five CU blocks, and each block will enlarge the feature map twice. Therefore, the final segmentation result can obtain the same resolution as the input image. As explained in the above-mentioned sections, a CT block, which transforms the general features to specific features for each category, emerges before the first CU block. After this transition, all the succeeding convolutions in CU layers should be replaced by group convolution to keep features of every category separated. Moreover, a corresponding CS module will bring in skip features from the encoder for each CU block. The detailed structure of each CU block is shown in
Figure 6.
Formally, for one CU block, suppose the input feature map:
has the size of
, where
k is a hyper-parameter, denoting the number of channels for the feature map of each category, and
M denotes the number of classes. We first use bilinear interpolation to up-sample the feature map to the size of
. Then the up-sampled feature map is added by the output of the corresponding CS module, which will be detailed in
Section 3.3. Finally, the feature map is sent into a Res-Block without changing its size, whose output will be the input of the next CU block. After the decoding of five CU blocks, the output feature map will become
times larger than the input of the first CU block, which is equal to the original resolution of the input image to be segmented.
3.3. CS (Class-Wise Supervision) Module
Some useful information may be lost as the network goes deep because different levels of CNN capture features of various abstraction levels. Therefore, reusing low level features from the encoder can be very helpful for the decoder to restore more contextual information and obtain improved segmentation result. Formally, the connection between the encoder and decoder is:
where the
is the input feature of the
layer in the decoder,
is its corresponding feature at the encoder,
denotes convolution options in the decoder, and
represents the set of learnable parameters of the
layer.
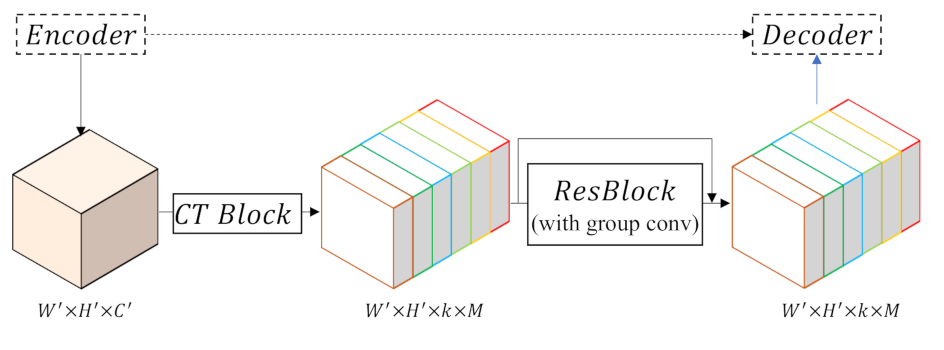
Though skip-connection fuses features from encoder and decoder to refine segmentation results, features from the two different parts may vary in some respects. Simple and crude fusion with disregard to their differences is inappropriate. Therefore, we add a Res-Block to the path such that features from the encoder can learn how to compensate for the difference and fuse with features in the decoder more appropriately:
Moreover, the skip connection is adapted by adding a CT block on the CS path to fit the proposed model. As shown in
Figure 7, taking the general features from the encoder as the input, the CT block will facilitate transformation into class-wise features. A Res-Block is employed to implement class-wise supervision by group convolution, which can be depicted as follows:
where
denotes the CT block. As shown in
Figure 4, we use three CS blocks, which indicate the presences of three connection paths between the encoder and decoder. Because the first Stem Block in ResNet has a different implementation from the Res-Block, we do not adopt feature fusion on this level.
3.4. CC (Class-Wise Classification) Module
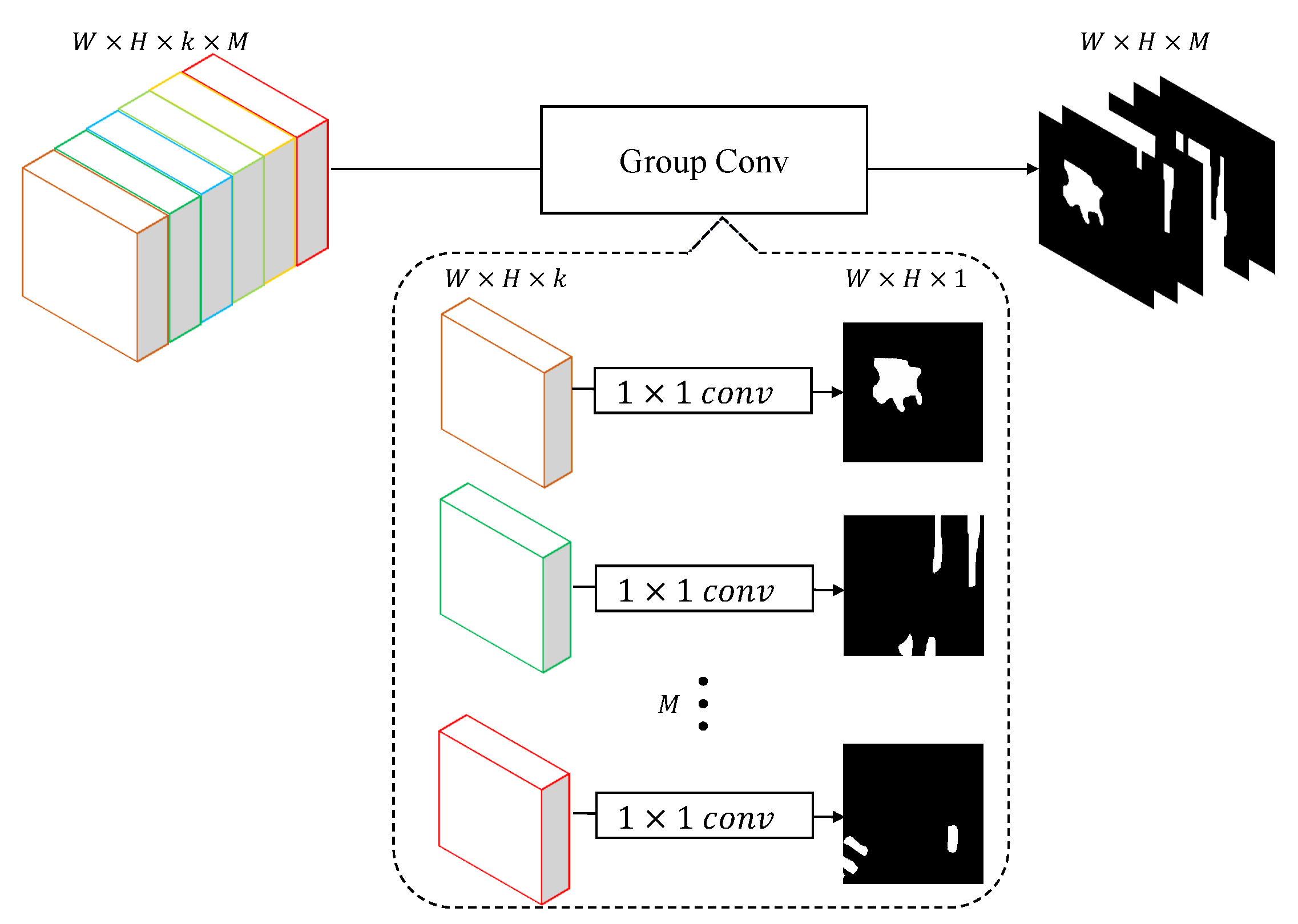
In traditional fully convolutional neural networks, the last layer is a convolution layer with the kernel size
. A
function is then applied to convert the feature vector of each pixel into the probability which presents the likelihood it belongs to a class. In this case, the operation can be defined as:
where
is the segmentation result. Since the features output by our model are specific for each class, the classification layer should be class-wise as well. Otherwise, the calculation method of original convolution will hamper the independence between categories. Different from traditional FCNs, the last layer in our C-FCN will be implemented by the group convolution. Details of a CC module are shown in
Figure 8. By means of group convolution, the classification module can be regarded as
M binary classification layers rather than one
M-class classification layer. Let
denote the
channels of the feature map
f, which is a particular feature of class
i, and the operation of CC layer in the proposed C-FCN is defined as follows:
where
,
M denotes the number of classes,
denotes the concatenation, and
is the probability volume of class belongings. During the training process,
is sent to the cross-entropy function for loss calculation. As for segmentation, an
function is then employed to identify the class labels.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}