
Unpaired Remote Sensing Image Super-Resolution with Multi-Stage Aggregation Networks


Abstract
:1. Introduction
- We introduce a multi-stage aggregation network for gradually optimizing the model with the degraded self-exemplars and unpaired references, which allows it to achieve effective optimization from content to perception. Specifically, the first stage can be adapted to better pixel-wise PSNR, and the subsequent stages can be adapted to more realistic texture and details reconstruction.
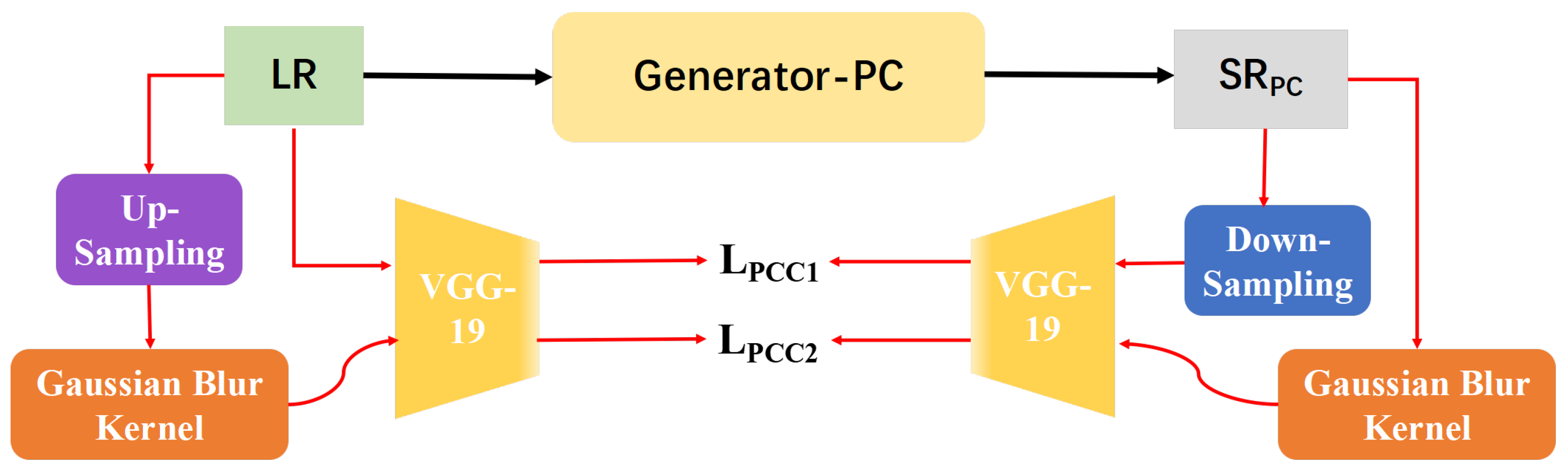
- Aiming at retaining the content on remote sensing images and excavating its underlying perceptual similarities from the low-quality images, we propose consistency loss functions for contents retainment and details reconstruction in different phases.
- We conducted experimental validation of multiple datasets on our method, and the results indicate the superiority of our method in remote sensing SR and have more intuitive visual effects.
2. Materials and Methods
2.1. Methods
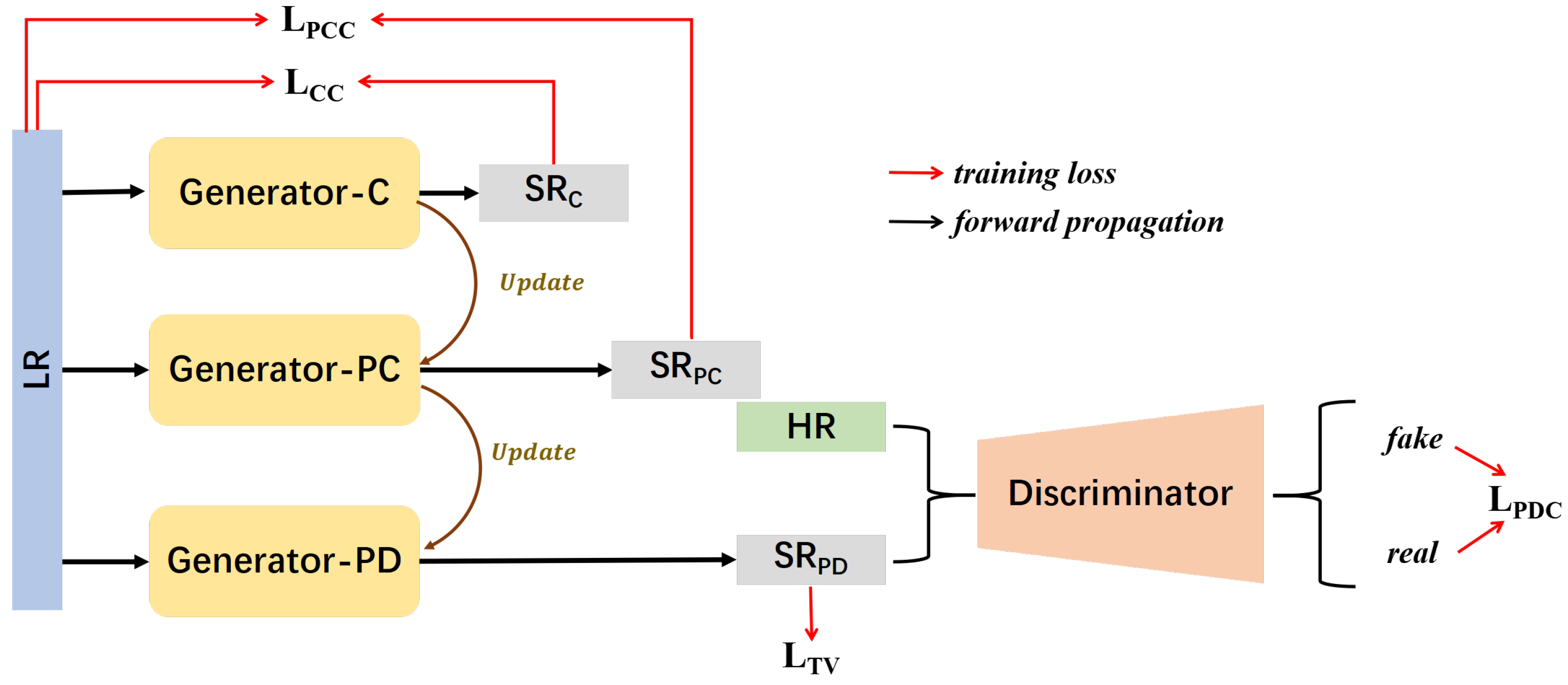
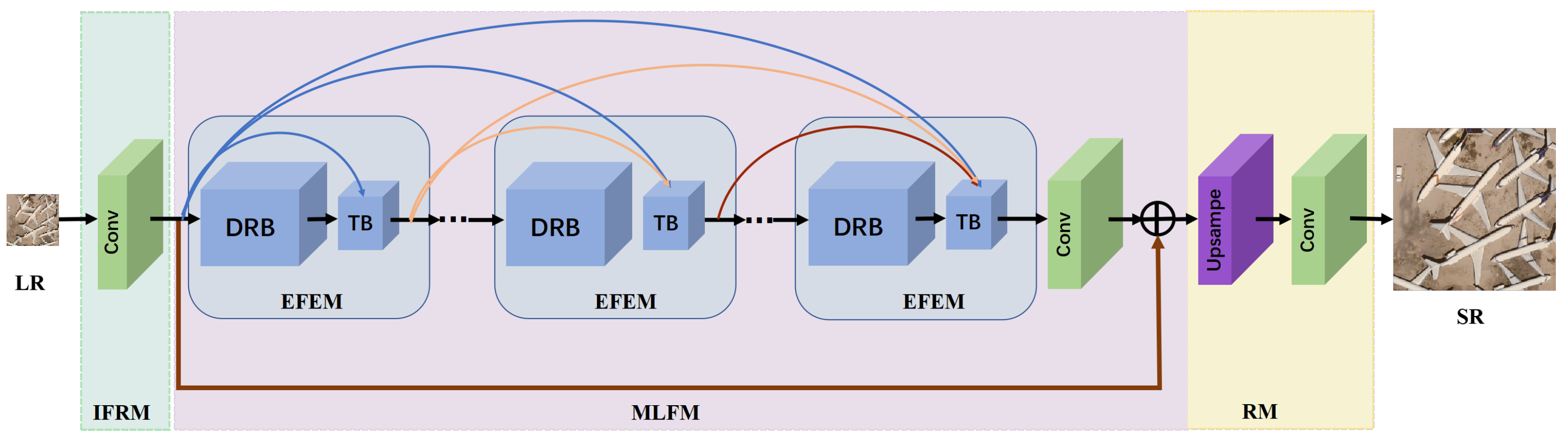
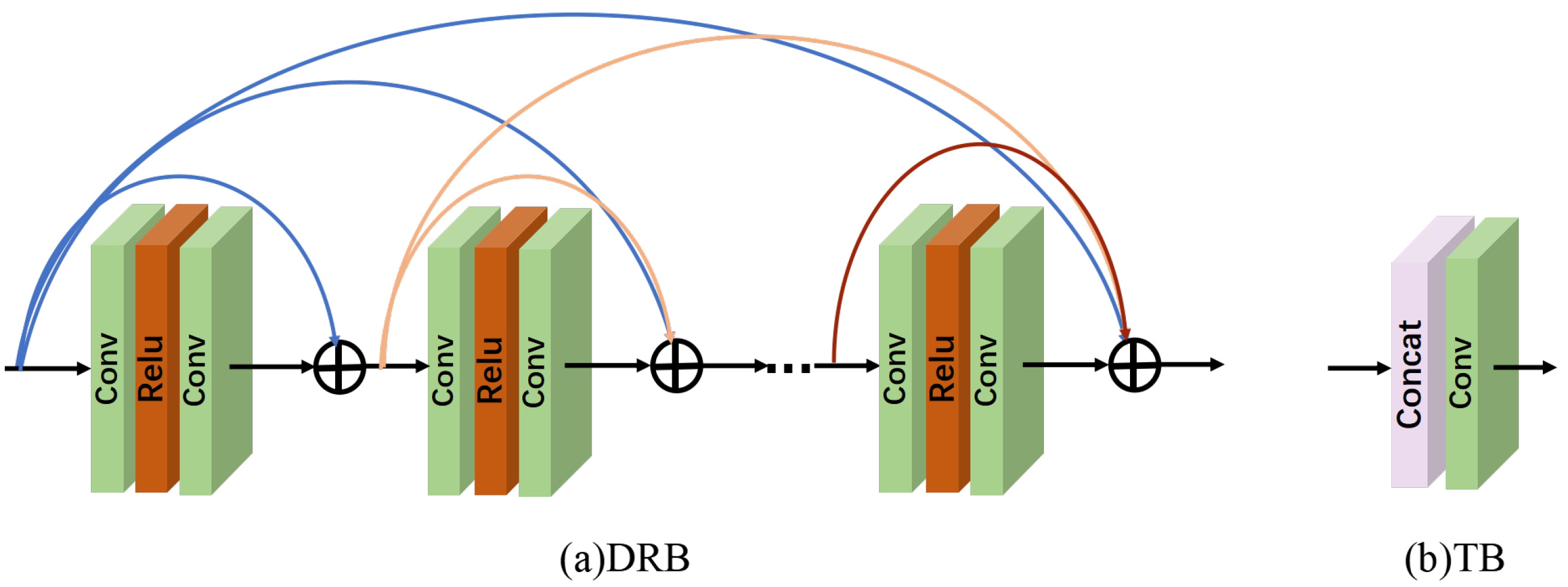
2.1.1. Network Architecture
2.1.2. Multi-Stage Architecture
2.2. Dataset and Implementation Details
2.2.1. Dataset
2.2.2. Implementation Details and Metrics
3. Results
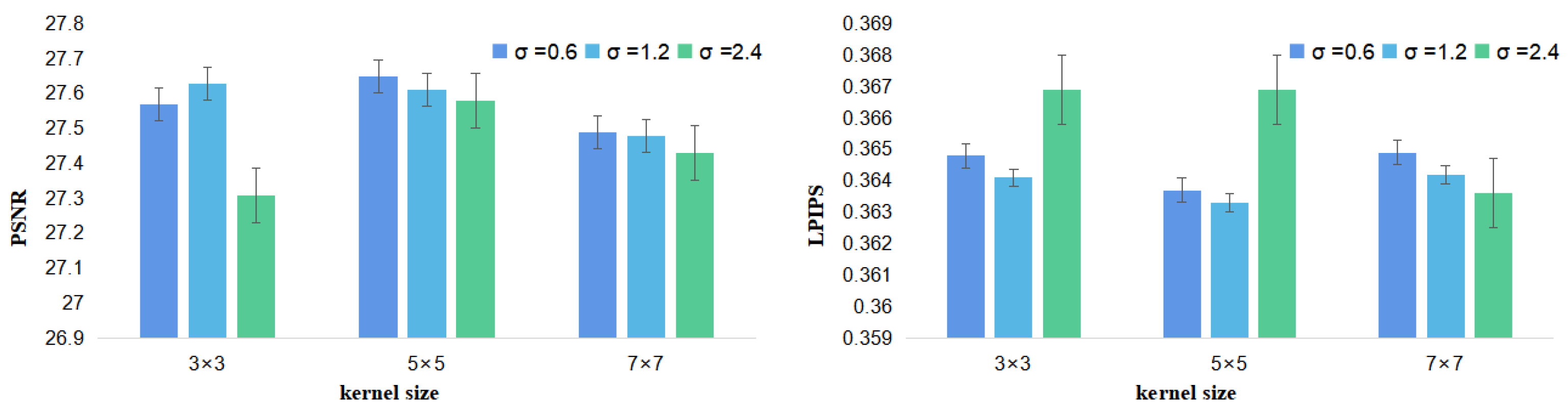
3.1. Model Analysis
3.1.1. The Effect of Content Consistency
3.1.2. The Effect of Perceptual-Content Consistency
3.1.3. The Effect of Perceptual-Distribution Consistency
3.2. Comparisons with State-of-the-Art Methods
3.2.1. Result on Bicubic Degradation

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Method | Scale | PSNR | SSIM | NIQE | LPIPS |
|---|---|---|---|---|---|---|
| UC Merced | SelfExSR [24] | ×4 | 21.40 | 0.5698 | 10.01 | 0.6882 |
| ZSSR [26] | ×4 | 22.67 | 0.6156 | 9.690 | 0.6850 | |
| CinCGAN [25] | ×4 | 23.46 | 0.6355 | 9.756 | 0.4259 | |
| DRN [44] | ×4 | 22.05 | 0.5477 | 12.69 | 0.6632 | |
| MSAN (ours) | ×4 | 23.94 | 0.6451 | 7.207 | 0.4197 | |
| WHU-RS19 | SelfExSR [24] | ×4 | 28.12 | 0.7398 | 6.625 | 0.3660 |
| ZSSR [26] | ×4 | 25.29 | 0.6882 | 7.667 | 0.4009 | |
| CinCGAN [25] | ×4 | 26.47 | 0.7073 | 6.516 | 0.3740 | |
| DRN [44] | ×4 | 28.85 | 0.7693 | 7.298 | 0.3547 | |
| MSAN (ours) | ×4 | 27.43 | 0.7157 | 6.403 | 0.3511 |
| Dataset | Method | Scale | PSNR | SSIM | NIQE | LPIPS |
|---|---|---|---|---|---|---|
| UC Merced | SRCNN [9] | ×4 | 22.25 | 0.5978 | 10.51 | 0.4435 |
| EDSR [15] | ×4 | 23.71 | 0.6412 | 9.219 | 0.6822 | |
| ESRGAN [18] | ×4 | 19.65 | 0.5192 | 18.90 | 0.6642 | |
| RCAN [19] | ×4 | 19.71 | 0.5207 | 14.08 | 0.6632 | |
| IMDN [42] | ×4 | 20.39 | 0.5484 | 11.73 | 0.6704 | |
| HAN [43] | ×4 | 20.04 | 0.5419 | 12.67 | 0.6589 | |
| MSAN (ours) | ×4 | 23.94 | 0.6451 | 7.207 | 0.4197 | |
| WHU-RS19 | SRCNN [9] | ×4 | 28.15 | 0.7414 | 6.891 | 0.3526 |
| EDSR [15] | ×4 | 27.83 | 0.7238 | 7.533 | 0.3890 | |
| ESRGAN [18] | ×4 | 25.62 | 0.6268 | 4.338 | 0.3724 | |
| RCAN [19] | ×4 | 28.74 | 0.7670 | 7.006 | 0.3535 | |
| IMDN [42] | ×4 | 28.65 | 0.7612 | 7.212 | 0.3520 | |
| HAN [43] | ×4 | 28.89 | 0.7705 | 7.247 | 0.3554 | |
| MSAN (ours) | ×4 | 27.43 | 0.7157 | 6.403 | 0.3511 |
3.2.2. Result on Complex Degradation
| Dataset | Method | Scale | PSNR | SSIM | NIQE | LPIPS |
|---|---|---|---|---|---|---|
| UC Merced | SelfExSR [24] | ×4 | 23.98 | 0.6109 | 9.417 | 0.7271 |
| ZSSR [26] | ×4 | 23.79 | 0.6059 | 9.111 | 0.7236 | |
| CinCGAN [25] | ×4 | 23.56 | 0.6156 | 9.369 | 0.4487 | |
| DRN [44] | ×4 | 24.11 | 0.6214 | 10.84 | 0.7182 | |
| MSAN (ours) | ×4 | 24.13 | 0.6315 | 7.855 | 0.7214 | |
| WHU-RS19 | SelfExSR [24] | ×4 | 26.42 | 0.6916 | 6.614 | 0.3993 |
| ZSSR [26] | ×4 | 26.65 | 0.7052 | 7.229 | 0.3896 | |
| CinCGAN [25] | ×4 | 25.68 | 0.6898 | 6.454 | 0.4011 | |
| DRN [44] | ×4 | 26.58 | 0.6835 | 7.548 | 0.4036 | |
| MSAN (ours) | ×4 | 26.61 | 0.7183 | 5.112 | 0.3936 |
| Dataset | Method | Scale | PSNR | SSIM | NIQE | LPIPS |
|---|---|---|---|---|---|---|
| UC Merced | SRCNN [9] | ×4 | 23.18 | 0.6403 | 9.305 | 0.4207 |
| EDSR [15] | ×4 | 24.10 | 0.6301 | 8.680 | 0.7089 | |
| ESRGAN [18] | ×4 | 21.11 | 0.4683 | 7.860 | 0.6340 | |
| RCAN [19] | ×4 | 23.96 | 0.6481 | 15.02 | 0.6810 | |
| IMDN [42] | ×4 | 22.97 | 0.5365 | 11.12 | 0.7736 | |
| HAN [43] | ×4 | 24.07 | 0.6511 | 10.64 | 0.6152 | |
| MSAN (ours) | ×4 | 24.13 | 0.6315 | 7.855 | 0.7214 | |
| WHU-RS19 | SRCNN [9] | ×4 | 25.37 | 0.6533 | 6.018 | 0.4354 |
| EDSR [15] | ×4 | 26.53 | 0.7011 | 7.366 | 0.3911 | |
| ESRGAN [18] | ×4 | 25.08 | 0.5910 | 4.583 | 0.4402 | |
| RCAN [19] | ×4 | 26.59 | 0.7127 | 6.894 | 0.3876 | |
| IMDN [42] | ×4 | 26.59 | 0.7085 | 7.007 | 0.3901 | |
| HAN [43] | ×4 | 26.55 | 0.6845 | 7.544 | 0.4171 | |
| MSAN (ours) | ×4 | 26.61 | 0.7183 | 5.112 | 0.3936 |
4. Discussion
4.1. Method of Application
4.2. Limitation
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Shirkolaei, M.M. High efficiency X-band series-fed microstrip array antenna. Prog. Electromagn. Res. C 2020, 105, 35–45. [Google Scholar] [CrossRef]
- Alibakhshikenari, M.; Babaeian, F.; Virdee, B.S.; Aïssa, S.; Azpilicueta, L.; See, C.H.; Althuwayb, A.A.; Huynen, I.; Abd-Alhameed, R.A.; Falcone, F.; et al. A Comprehensive Survey on “Various Decoupling Mechanisms With Focus on Metamaterial and Metasurface Principles Applicable to SAR and MIMO Antenna Systems”. IEEE Access 2020, 8, 192965–193004. [Google Scholar] [CrossRef]
- Qin, M.; Hu, L.; Du, Z.; Gao, Y.; Qin, L.; Zhang, F.; Liu, R. Achieving Higher Resolution Lake Area from Remote Sensing Images through an Unsupervised Deep Learning Super-Resolution Method. Remote. Sens. 2020, 12, 1937. [Google Scholar] [CrossRef]
- Allebach, J.; Wong, P.W. Edge-directed interpolation. In Proceedings of the IEEE International Conference on Image Processing, Lausanne, Switzerland, 16–19 September 1996; pp. 707–710. [Google Scholar]
- Dong, W.; Zhang, L.; Shi, G.; Wu, X. Nonlocal back-projection for adaptive image enlargement. In Proceeding of the IEEE International Conference on Image Processing, Cairo, Egypt, 7–10 November 2009; pp. 349–352. [Google Scholar]
- Yang, J.; Wright, J.; Huang, T.; Ma, Y. Image super-resolution as sparse representation of raw image patches. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Gu, S.; Zuo, W.; Xie, Q.; Meng, D.; Feng, X.; Zhang, L. Convolutional sparse coding for image super-resolution. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1823–1831. [Google Scholar]
- Peng, C.; Gao, X.; Wang, N.; Li, J. Graphical representation for heterogeneous face recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 301–312. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 295–307. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate image super-resolution using very deep convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1646–1654. [Google Scholar]
- Tai, Y.; Yang, J.; Liu, X. Image super-resolution via deep recursive residual network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3147–3155. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Zhang, Y.; Tian, Y.; Kong, Y.; Zhong, B.; Fu, Y. Residual dense network for image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2472–2481. [Google Scholar]
- Tong, T.; Li, G.; Liu, X.; Gao, Q. Image super-resolution using dense skip connections. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4799–4807. [Google Scholar]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Mu Lee, K. Enhanced deep residual networks for single image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 136–144. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. A. Courville, and Y. Bengio, Generative adversarial networks. In Proceedings of the International Conference on Neural Information Processing, Kyoto, Japan, 16–21 October 2016; pp. 2672–2680. [Google Scholar]
- Wang, X.; Yu, K.; Wu, S.; Gu, J.; Liu, Y.; Dong, C.; Qiao, Y.; Change Loy, C. Esrgan: Enhanced super-resolution generative adversarial networks. In Proceedings of the European Conference on Computer Vision Workshops, Munich, Germany, 8–14 September 2018; pp. 63–79. [Google Scholar]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image super-resolution using very deep residual channel attention networks. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 286–301. [Google Scholar]
- Huang, Y.; Li, J.; Gao, X.; Hu, Y.; Lu, W. Interpretable Detail-Fidelity Attention Network for Single Image Super-Resolution. IEEE Trans. Image Process. 2021, 30, 2325–2339. [Google Scholar] [CrossRef] [PubMed]
- Efrat, N.; Glasner, D.; Apartsin, A.; Nadler, B.; Levin, A. Accurate blur models vs. image priors in single image super-resolution. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, NSW, Australia, 1–8 December 2013; pp. 2832–2839. [Google Scholar]
- Yang, C.Y.; Ma, C.; Yang, M.H. Single-image super-resolution: A benchmark. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 372–386. [Google Scholar]
- Dai, D.; Yang, W. Satellite image classification via two-layer sparse coding with biased image representation. IEEE Geosci. Remote Sens. Lett. 2010, 8, 173–176. [Google Scholar] [CrossRef] [Green Version]
- Freedman, G.; Fattal, R. Image and video upscaling from local self-examples. ACM Trans. Graph. (TOG) 2011, 30, 474–484. [Google Scholar] [CrossRef] [Green Version]
- Yuan, Y.; Liu, S.; Zhang, J.; Zhang, Y.; Dong, C.; Lin, L. Unsupervised image super-resolution using cycle-in-cycle generative adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 701–710. [Google Scholar]
- Shocher, A.; Cohen, N.; Irani, M. “zero-shot” super-resolution using deep internal learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3118–3126. [Google Scholar]
- Ulyanov, D.; Vedaldi, A.; Lempitsky, V. Deep image prior. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 9446–9454. [Google Scholar]
- Zhang, N.; Wang, Y.; Zhang, X.; Xu, D.; Wang, X. An unsupervised remote sensing single-image super-resolution method based on generative adversarial network. IEEE Access 2020, 8, 29027–29039. [Google Scholar] [CrossRef]
- Wang, P.; Zhang, H.; Zhou, F.; Jiang, Z. Unsupervised remote sensing image super-resolution using cycle CNN. In Proceedings of the IGARSS 2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 3117–3120. [Google Scholar]
- Zhang, N.; Wang, Y.; Zhang, X.; Xu, D.; Wang, X.; Ben, G.; Zhao, Z.; Li, Z. A Multi-Degradation Aided Method for Unsupervised Remote Sensing Image Super Resolution with Convolution Neural Networks. IEEE Trans. Geosci. Remote Sens. 2020, 1–14. [Google Scholar] [CrossRef]
- Huang, Y.; Sun, X.; Lu, W.; Li, J.; Gao, X. Un-Paired Real World Super-Resolution with Degradation Consistency. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Seoul, Korea, 27–28 October 2019; pp. 3458–3466. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1874–1883. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large scale image recognition. In Proccedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Zhang, W.; Liu, Y.; Dong, C.; Qiao, Y. RankSRGAN: Generative adversarial networks with ranker for image Super-resolution. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Yang, Y.; Newsam, S. Bag-Of-Visual-Words and Spatial Extensions for Land-Use Classification. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 2–5 November 2010; pp. 270–279. [Google Scholar] [CrossRef]
- Xia, G.S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A large-scale dataset for object detection in aerial images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3974–3983. [Google Scholar]
- Kingma, D.P.; Ba, J.L. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [Green Version]
- Mittal, A.; Soundararajan, R.; Bovik, A.C. Making a “completely blind” image quality analyzer. IEEE Signal. Process. Lett. 2012, 20, 209–212. [Google Scholar] [CrossRef]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 586–595. [Google Scholar]
- Hui, Z.; Gao, X.; Yang, Y.; Wang, X. Lightweight image super-resolution with information multi-distillation network. In Proceedings of the MM’19: 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 2024–2032. [Google Scholar]
- Niu, B.; Wen, W.; Ren, W.; Zhang, X.; Yang, L.; Wang, S.; Zhang, K.; Cao, X.; Shen, H. Single image super-resolution via a holistic attention network. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 191–207. [Google Scholar]
- Guo, Y.; Chen, J.; Wang, J.; Chen, Q.; Cao, J.; Deng, Z.; Xu, Y.; Tan, M. Closed-loop matters: Dual regression networks for single image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5407–5416. [Google Scholar]











| Method | Scale | PSNR↑ | SSIM↑ | NIQE↓ | LPIPS↓ |
|---|---|---|---|---|---|
| HR Ground Truth | - | - | - | 4.541 | - |
| Bicubic | ×4 | 28.06 | 0.7233 | 8.005 | 0.4181 |
| MSAN w/o PCC & PDC | ×4 | 27.95 | 0.7067 | 8.958 | 0.3647 |
| MSAN w/o PDC | ×4 | 27.61 | 0.7285 | 8.219 | 0.3633 |
| MSAN w/o CC | ×4 | 26.83 | 0.7013 | 7.569 | 0.3677 |
| MSAN | ×4 | 27.43 | 0.7157 | 6.569 | 0.3511 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, L.; Lu, W.; Huang, Y.; Sun, X.; Zhang, H. Unpaired Remote Sensing Image Super-Resolution with Multi-Stage Aggregation Networks. Remote Sens. 2021, 13, 3167. https://doi.org/10.3390/rs13163167
Zhang L, Lu W, Huang Y, Sun X, Zhang H. Unpaired Remote Sensing Image Super-Resolution with Multi-Stage Aggregation Networks. Remote Sensing. 2021; 13(16):3167. https://doi.org/10.3390/rs13163167
Chicago/Turabian StyleZhang, Lize, Wen Lu, Yuanfei Huang, Xiaopeng Sun, and Hongyi Zhang. 2021. "Unpaired Remote Sensing Image Super-Resolution with Multi-Stage Aggregation Networks" Remote Sensing 13, no. 16: 3167. https://doi.org/10.3390/rs13163167
APA StyleZhang, L., Lu, W., Huang, Y., Sun, X., & Zhang, H. (2021). Unpaired Remote Sensing Image Super-Resolution with Multi-Stage Aggregation Networks. Remote Sensing, 13(16), 3167. https://doi.org/10.3390/rs13163167