
Accelerated Multi-View Stereo for 3D Reconstruction of Transmission Corridor with Fine-Scale Power Line




Abstract
:1. Introduction
2. Materials and Methods
2.1. Study Sites and Test Data
2.1.1. Test Sites of High-Voltage Power Transmission Lines
2.1.2. Benchmark Datasets
2.2. Methodologies
2.2.1. Overview of PatchMatch-Based Dense Matching
2.2.2. Fast PatchMatch with Random Red-Black Checkerboard Propagation
| Algorithm 1 Updating schedule of sequence propagation in Colmap [35] |
| Input: All images, depth map, and normal map (randomly initialized or from previous propagation) |
| Output: Updated depth map and normal map, the visible probability for each pixel (—image index,—pixel index) |
| 1: For = L to 1 |
| 2: For = 1 to 3: Compute backward message 4: For = 1 to 5: For = 1 to 6: Compute forward message 7: Compute 8: Estimate by PatchMatch 9: For = 1 to 10: Recompute forward message |
| Algorithm 2 Updating schedule of random red-black checkerboard propagation |
| Input: All images, depth map, and normal map (randomly initialized or from previous propagation) |
| Output: Updated depth map and normal map, the visible probability for each pixel (—image index, —pixel index) |
| 1: procedure Update(,) |
| 2: For = to 1 |
| 3: For = 1 to 4: Compute backward message 5: For = 1 to 6: For = 1 to 7: Compute forward message 8: Compute 9: end procedure |
| 10: Initialize the traversal direction D |
| 11: Execute Update(q(Z), ,) in direction D |
| 12: Update the of back pattern pixels with the plane parameters of red pattern pixels by PatchMatch |
| 13: Rotate the direction D 90° clockwise, execute Update(,) in direction D |
| 14: Update the of red pattern pixels with the plane parameters of black pattern pixels by PatchMatch |
| 15: Repeat steps from 11 to 14 until reaching the maximum iteration number |
2.2.3. Strategies for Reducing Matching Cost Calculation
2.2.4. Fast Depth Map Fusion with GPU Acceleration
- (a)
- Initialize the global binary state values of all the depth maps as 0;
- (b)
- Load the reference image , source image , the corresponding depth maps , and normal maps into the GPU;
- (c)
- Iterate all the pixels in the reference image . For a current pixel in the image , if of is bigger than 3 and the state value of is 0, then the depth value of is back-projected to the source images and find the depths cluster that satisfies all the geometric constraints; otherwise, process the next pixel of the referenced image ;
- (d)
- Count the number in the depths cluster and the corresponding binary state values . If and the values in are 0, then use formulas (7)and (8) to fuse the depth and , average the corresponding normal, and set all the corresponding binary state values to 1; otherwise, process the next pixel . Algorithm 3 shows the details below.
| Algorithm 3 Fast depth maps fusion with GPU |
| Input: All images I, depth maps D, and normal maps |
| Output: Fused dense point cloud (—image index,—pixel index) |
| 1: Initialize the global binary state values of depth maps as 0 |
| 2: foreach image in 3: Load the reference image , the source images , the depth maps and , and the normal maps and into GPU 4: foreach pixel in 5: if and the binary state value of is 0 6: Compute the depth cluster that satisfies all the geometry constraints 7: Statistic the number in the depths cluster 8: if and all the binary state values of is 0 9: Set the binary state values of and as 1 10: Use formula (7) and (8) to fuse the depth and , 11: Average the corresponding normal 12: endif 13: endif 14: end foreach 15: end foreach |
3. Results
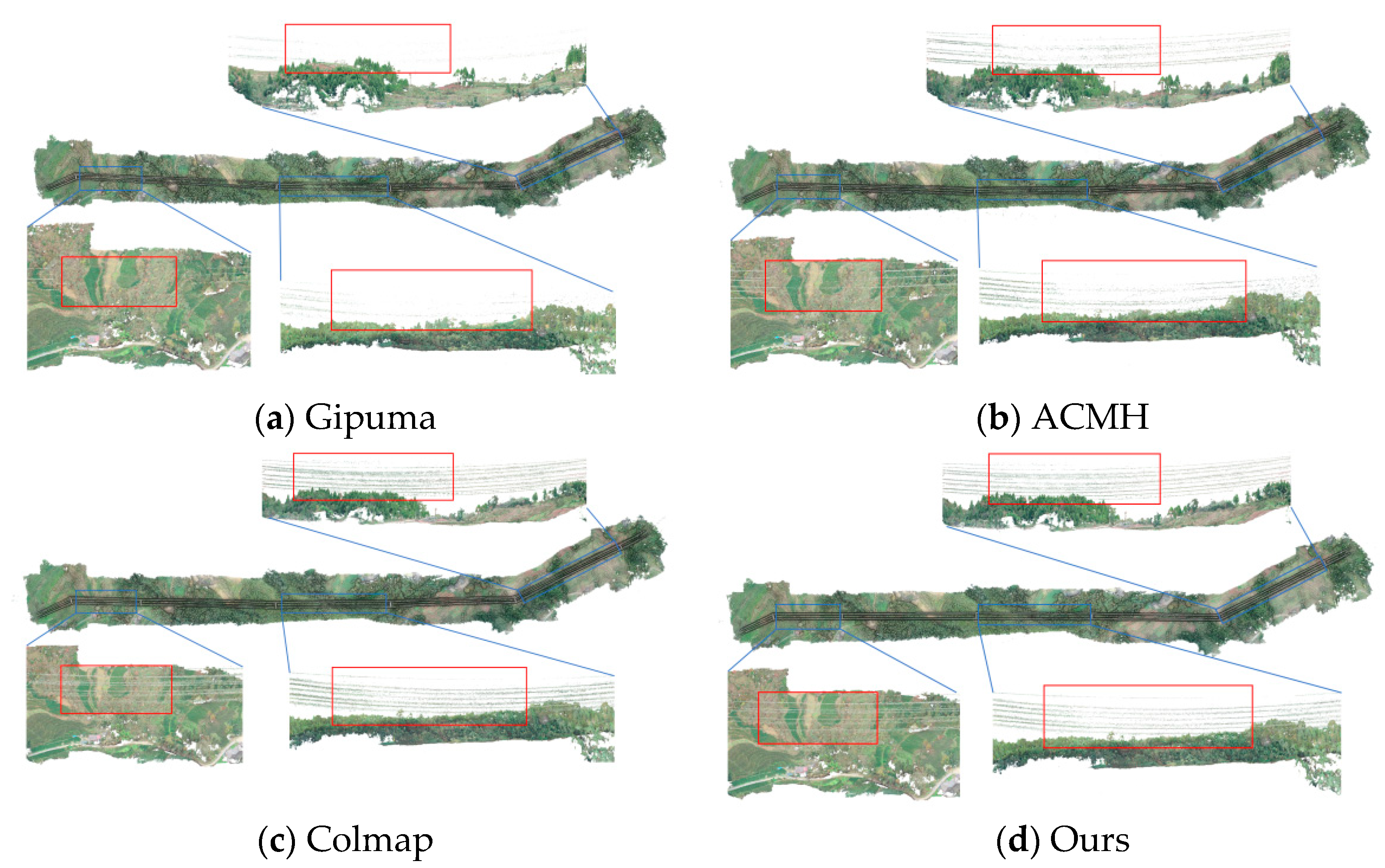
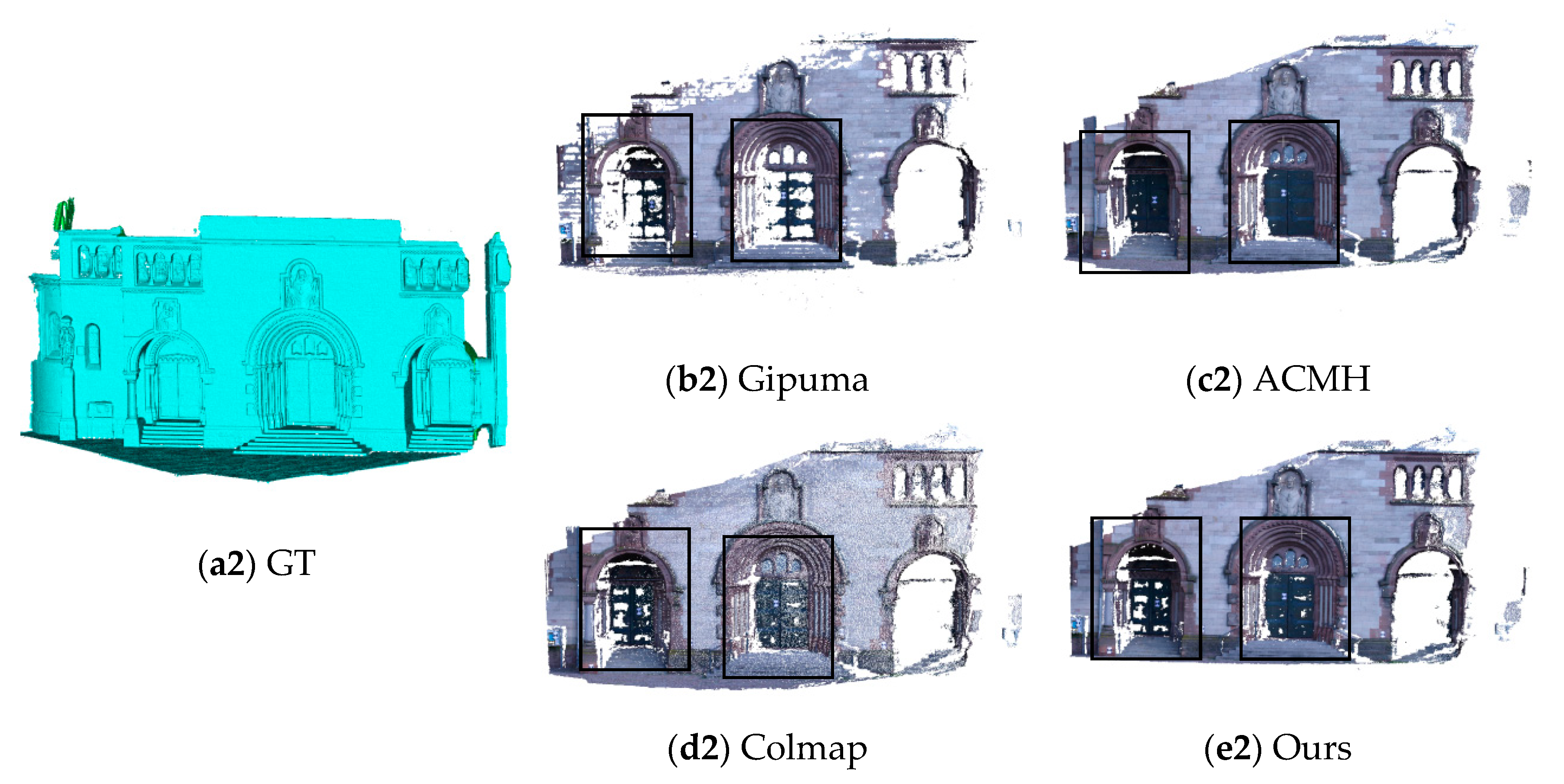
3.1. Analysis of the Power Line Reconstruction
3.2. Analysis of the Performance of Efficiency
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Jiang, S.; Jiang, W.; Huang, W.; Yang, L. UAV-Based Oblique Photogrammetry for Outdoor Data Acquisition and Offsite Visual Inspection of Transmission Line. Remote Sens. 2017, 9, 278. [Google Scholar] [CrossRef] [Green Version]
- Agarwal, S.; Furukawa, Y.; Snavely, N.; Simon, I.; Curless, B.; Seitz, S.; Szeliski, R. Building Rome in a Day. Commun. ACM. 2011, 54, 105–112. [Google Scholar] [CrossRef]
- Schönberger, J.L.; Frahm, J.-M. Structure-from-Motion Revisited. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; 2016; pp. 4104–4113. [Google Scholar] [CrossRef]
- Jiang, S.; Jiang, W. Efficient SfM for Oblique UAV Images: From Match Pair Selection to Geometrical Verification. Remote Sens. 2018, 10, 1246. [Google Scholar] [CrossRef] [Green Version]
- Jiang, S.; Jiang, W. Efficient Structure from Motion for Oblique UAV Images Based on Maximal Spanning Tree Expansion. ISPRS J. Photogramm. Remote Sens. 2017, 132, 140–161. [Google Scholar] [CrossRef]
- Jiang, S.; Jiang, C.; Jiang, W. Efficient Structure from Motion for Large-scale UAV Images: A Review and a Comparison of SfM Tools. ISPRS J. Photogramm. Remote Sens. 2020, 167, 230–251. [Google Scholar] [CrossRef]
- Stentoumis, C.; Grammatikopoulos, L.; Kalisperakis, I.; Karras, G. On Accurate Dense Stereo-matching Using a Local Adaptive Multi-cost Approach. ISPRS J. Photogramm. Remote Sens. 2014, 91, 29–49. [Google Scholar] [CrossRef]
- Furukawa, Y.; Hernandez, C. Multi-View Stereo: A Tutorial. Found. Trends Comput. Graph. Vis. 2015, 9, 1–148. [Google Scholar] [CrossRef] [Green Version]
- Chen, C.; Seff, A.; Kornhauser, A.; Xiao, J. Deepdriving: Learning Affordance for Direct Perception in Autonomous Driving. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Las Condes, Chile, 11–18 December 2015; pp. 2722–2730. [Google Scholar] [CrossRef] [Green Version]
- Haque, A.U.; Nejadpak, A. Obstacle Avoidance Using Stereo Camera. arXiv 2017, arXiv:1705.04114. [Google Scholar]
- Günen, M.; Beşdok, P.; Besdok, E. Use of Potree and Cesium Platforms for Presentation of Point Clouds. In Proceedings of the International Symposium on Innovative Approaches in Scientific Studies, Antalya, Turkey, 19 April 2018; p. 58. [Google Scholar]
- Rhee, S.; Kim, T. Automated DSM Extraction from UAV Images and Performance Analysis. In Proceedings of the International Conference on Unmanned Aerial Vehicles in Geomatics, Toronto, ON, Canada, 30 August–2 September 2015; pp. 351–354. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Yuan, X.; Li, W.; Chen, S. Automatic Power Line Inspection Using UAV Images. Remote Sens. 2017, 9, 824. [Google Scholar] [CrossRef] [Green Version]
- Seitz, S.M.; Curless, B.; Diebel, J.; Scharstein, D.; Szeliski, R. A Comparison and Evaluation of Multi-View Stereo Reconstruction Algorithms. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, New York, NY, USA , 17–22 June 2006; 2006; pp. 519–528. [Google Scholar] [CrossRef]
- Vu, H.H.; Keriven, R.; Labatut, P.; Pons, J.P. Towards High-resolution Large-scale Multi-view Stereo. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 1430–1437. [Google Scholar] [CrossRef] [Green Version]
- Cremers, D.; Kolev, K. Multiview Stereo and Silhouette Consistency via Convex Functionals over Convex Domains. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 1161–1174. [Google Scholar] [CrossRef] [Green Version]
- Sinha, S.N.; Mordohai, P.; Pollefeys, M. Multi-View Stereo via Graph Cuts on the Dual of an Adaptive Tetrahedral Mesh. In Proceedings of the IEEE International Conference on Computer Vision, Rio de Janeiro, Brazil, 14–21 October 2007; pp. 1–8. [Google Scholar] [CrossRef]
- Furukawa, Y.; Ponce, J. Accurate, Dense, and Robust Multiview Stereopsis. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1362–1376. [Google Scholar] [CrossRef]
- Goesele, M.; Snavely, N.; Curless, B.; Hoppe, H.; Seitz, S.M. Multi-View Stereo for Community Photo Collections. In Proceedings of the IEEE 11th International Conference on Computer Vision, Rio de Janeiro, Brazil, 14–21 October 2007; pp. 1–8. [Google Scholar] [CrossRef]
- Galliani, S.; Lasinger, K.; Schindler, K. Massively Parallel Multiview Stereopsis by Surface Normal Diffusion. In Proceedings of the IEEE International Conference on Computer Vision, Las Condes, Chile, 11–18 December 2015; pp. 873–881. [Google Scholar] [CrossRef]
- Schönberger, J.L.; Zheng, E.; Pollefeys, M.; Frahm, J.M. Pixelwise View Selection for Unstructured Multi-View Stereo. In Proceedings of the European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 501–518. [Google Scholar] [CrossRef]
- Xu, Q.; Tao, W. Multi-Scale Geometric Consistency Guided Multi-View Stereo. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–21 June 2019; pp. 5483–5492. [Google Scholar] [CrossRef] [Green Version]
- Hirschmüller, H. Stereo Processing by Semiglobal Matching and Mutual Information. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 328–341. [Google Scholar] [CrossRef]
- Barnes, C.; Shechtman, E.; Finkelstein, A.; Dan, B.G. PatchMatch: A Randomized Correspondence Algorithm for Structural Image Editing. ACM Trans. Graph. 2009, 28, 24. [Google Scholar] [CrossRef]
- Barnes, C.; Shechtman, E.; Dan, B.G.; Finkelstein, A. The Generalized PatchMatch Correspondence Algorithm. In Proceedings of the European Conference on Computer Vision, Heraklion, Greece, 5–11 September 2010; pp. 29–43. [Google Scholar] [CrossRef]
- Liao, J.; Fu, Y.; Yan, Q.; Xiao, C. Pyramid Multi-View Stereo with Local Consistency. Comput. Graph. Forum. 2019, 38, 335–346. [Google Scholar] [CrossRef]
- Bleyer, M.; Rhemann, C.; Rother, C. PatchMatch Stereo—Stereo Matching with Slanted Support Windows. In Proceedings of the British Machine Vision Conference, Dundee, UK, 29 August–2 September 2011; pp. 1–11. [Google Scholar]
- Heise, P.; Klose, S.; Jensen, B.; Knoll, A. PM-Huber: PatchMatch with Huber Regularization for Stereo Matching. In Proceedings of the IEEE International Conference on Computer Vision, Columbus, OH, USA, 23–28 June 2014; pp. 2360–2367. [Google Scholar] [CrossRef] [Green Version]
- Besse, F.; Rother, C.; Fitzgibbon, A.; Kautz, J. PMBP: PatchMatch Belief Propagation for Correspondence Field Estimation. Int. J. Comput. Vis. 2014, 110, 2–13. [Google Scholar] [CrossRef]
- Yu, L.; Min, D.; Brown, M.S.; Do, M.N.; Lu, J. SPM-BP: Sped-Up PatchMatch Belief Propagation for Continuous MRFs. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4006–4014. [Google Scholar] [CrossRef]
- Xu, S.; Zhang, F.; He, X.; Shen, X.; Zhang, X. PM-PM: PatchMatch with Potts Model for Object Segmentation and Stereo Matching. IEEE Trans. Image Process. 2015, 24, 2182–2196. [Google Scholar] [CrossRef]
- Lu, J.; Yu, L.; Yang, H.; Min, D.; Eng, W.; Do, M.N. PatchMatch Filter: Edge-Aware Filtering Meets Randomized Search for Visual Correspondence. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1866–1879. [Google Scholar] [CrossRef]
- Tian, M.; Yang, B.; Chen, C.; Huang, R.; Huo, L. HPM-TDP: An efficient hierarchical PatchMatch depth estimation approach using tree dynamic programming. ISPRS J. Photogramm. Remote Sens. 2019, 155, 37–57. [Google Scholar] [CrossRef]
- Shen, S. Accurate Multiple View 3D Reconstruction Using Patch-Based Stereo for Large-Scale Scenes. IEEE Trans. Image Process. 2013, 22, 1901–1914. [Google Scholar] [CrossRef]
- Zheng, E.; Dunn, E.; Jojic, V.; Frahm, J.M. PatchMatch Based Joint View Selection and Depthmap Estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1510–1517. [Google Scholar] [CrossRef]
- Romanoni, A.; Matteucci, M. TAPA-MVS: Textureless-Aware PAtchMatch Multi-View Stereo. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 10413–10422. [Google Scholar] [CrossRef] [Green Version]
- Xu, Q.; Tao, W. Planar Prior Assisted PatchMatch Multi-View Stereo. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 12516–12523. [Google Scholar] [CrossRef]
- Hou, Y.; Peng, J.; Hu, Z.; Tao, P.; Shan, J. Planarity Constrained Multi-view Depth Map Reconstruction for Urban Scenes. ISPRS J. Photogramm. Remote Sens. 2018, 139, 133–145. [Google Scholar] [CrossRef]
- Strecha, C.; Hansen, W.V.; Gool, L.V.; Fua, P.; Thoennessen, U. On Benchmarking Camera Calibration and Multi-View Stereo for High Resolution Imagery. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23-28 June 2008; pp. 1–8. [Google Scholar] [CrossRef]
- Cramer, M. The DGPF-test on digital airborne camera evaluation overview and test design. Photogramm. Fernerkund. Geoinf. 2010, 73–82. [Google Scholar] [CrossRef]
- Hane, C.; Zach, C.; Cohen, A.; Angst, R.; Pollefeys, M. Joint 3D Scene Reconstruction and Class Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 97–104. [Google Scholar] [CrossRef]
- Curless, B.; Levoy, M. A Volumetric Method for Building Complex Models from Range Images. In Proceedings of the 23rd Annual Conference on Computer Graphics and Interactive Techniques, New Orleans, LA, USA, 4–9 August 1996; pp. 303–312. [Google Scholar]
- Knapitsch, A.; Park, J.; Zhou, Q.-Y.; Koltun, V. Tanks and Temples: Benchmarking Large-scale Scene Reconstruction. ACM Trans. Graph. 2017, 36, 1–13. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Item Name | Test Site 1 | Test Site 2 | Test Site 3 |
|---|---|---|---|
| Flight mode | rectangle | S-shaped | multiple trajectories |
| Flight height (m) | 160 | 80 | 65 |
| Voltage (kV) | 500 | 220 | 110 |
| Bundled conductors | 4-bundled | 2-bundled | 1-bundled |
| Type of UAV | DJI Phantom 4 RTK | ||
| Image size | 5472 × 3078 | 4864 × 3648 | 5472 × 3078 |
| Image number | 222 | 191 | 103 |
| GSD (cm) | 4.70 | 2.72 | 1.75 |
| Methods | Test Site 1/(Min) | Test Site 2/(Min) | Test Site 3/(Min) | |
|---|---|---|---|---|
| Gipuma | PatchMatch | 139.04 | 52.74 | 34.12 |
| Depth fusion | 7.75 | 4.88 | 2.38 | |
| Total | 146.79 | 57.62 | 36.50 | |
| ACMH | PatchMatch | 92.39 | 31.82 | 19.56 |
| Depth fusion | 7.75 | 4.88 | 2.38 | |
| Total | 100.14 | 36.70 | 21.94 | |
| Colmap | PatchMatch | 201.03 | 117.28 | 75.04 |
| Depth fusion | 78.54 | 58.62 | 41.07 | |
| Total | 279.57 | 175.90 | 116.11 | |
| Ours | PatchMatch | 58.55 | 22.62 | 14.09 |
| Depth fusion | 7.07 | 3.86 | 2.35 | |
| Total | 65.62 | 26.48 | 16.44 | |
| Datasets | Methods | 2 cm/(%) | 10 cm/(%) | ||||
|---|---|---|---|---|---|---|---|
| A | C | A | C | ||||
| Fountain | Gipuma | 84.47 | 41.39 | 55.56 | 97.54 | 54.33 | 69.79 |
| ACMH | 74.83 | 48.95 | 59.19 | 95.83 | 60.32 | 74.04 | |
| Colmap | 75.08 | 44.72 | 56.05 | 95.18 | 58.71 | 72.62 | |
| Ours | 74.61 | 47.20 | 57.82 | 95.26 | 59.44 | 73.20 | |
| Herzjesu | Gipuma | 78.42 | 29.53 | 42.90 | 96.43 | 47.78 | 63.90 |
| ACMH | 74.08 | 39.51 | 51.53 | 94.52 | 54.75 | 69.34 | |
| Colmap | 67.28 | 32.84 | 44.13 | 92.26 | 55.20 | 69.07 | |
| Ours | 73.16 | 37.78 | 49.83 | 94.28 | 54.73 | 69.25 | |
| Datasets | Methods | 0.2 m (%) | 0.5 m(%) | ||||
|---|---|---|---|---|---|---|---|
| A | C | A | C | ||||
| Test site 1 | Gipuma | 37.11 | 23.35 | 28.66 | 71.68 | 50.32 | 59.13 |
| ACMH | 39.91 | 41.10 | 40.50 | 68.35 | 65.23 | 66.76 | |
| Colmap | 32.64 | 26.59 | 29.31 | 55.80 | 66.32 | 60.61 | |
| Ours | 38.62 | 42.11 | 40.29 | 66.29 | 67.58 | 66.93 | |
| Test site 3 | Gipuma | 36.47 | 16.27 | 22.50 | 73.85 | 41.43 | 53.08 |
| ACMH | 40.92 | 38.88 | 39.87 | 74.93 | 65.99 | 70.17 | |
| Colmap | 36.26 | 26.92 | 30.90 | 64.41 | 71.18 | 67.63 | |
| Ours | 37.04 | 37.40 | 37.22 | 72.08 | 69.78 | 70.91 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, W.; Jiang, S.; He, S.; Jiang, W. Accelerated Multi-View Stereo for 3D Reconstruction of Transmission Corridor with Fine-Scale Power Line. Remote Sens. 2021, 13, 4097. https://doi.org/10.3390/rs13204097
Huang W, Jiang S, He S, Jiang W. Accelerated Multi-View Stereo for 3D Reconstruction of Transmission Corridor with Fine-Scale Power Line. Remote Sensing. 2021; 13(20):4097. https://doi.org/10.3390/rs13204097
Chicago/Turabian StyleHuang, Wei, San Jiang, Sheng He, and Wanshou Jiang. 2021. "Accelerated Multi-View Stereo for 3D Reconstruction of Transmission Corridor with Fine-Scale Power Line" Remote Sensing 13, no. 20: 4097. https://doi.org/10.3390/rs13204097
APA StyleHuang, W., Jiang, S., He, S., & Jiang, W. (2021). Accelerated Multi-View Stereo for 3D Reconstruction of Transmission Corridor with Fine-Scale Power Line. Remote Sensing, 13(20), 4097. https://doi.org/10.3390/rs13204097