
Extraction of Kenyan Grassland Information Using PROBA-V Based on RFE-RF Algorithm

 ,
, 
Abstract
:
1. Introduction
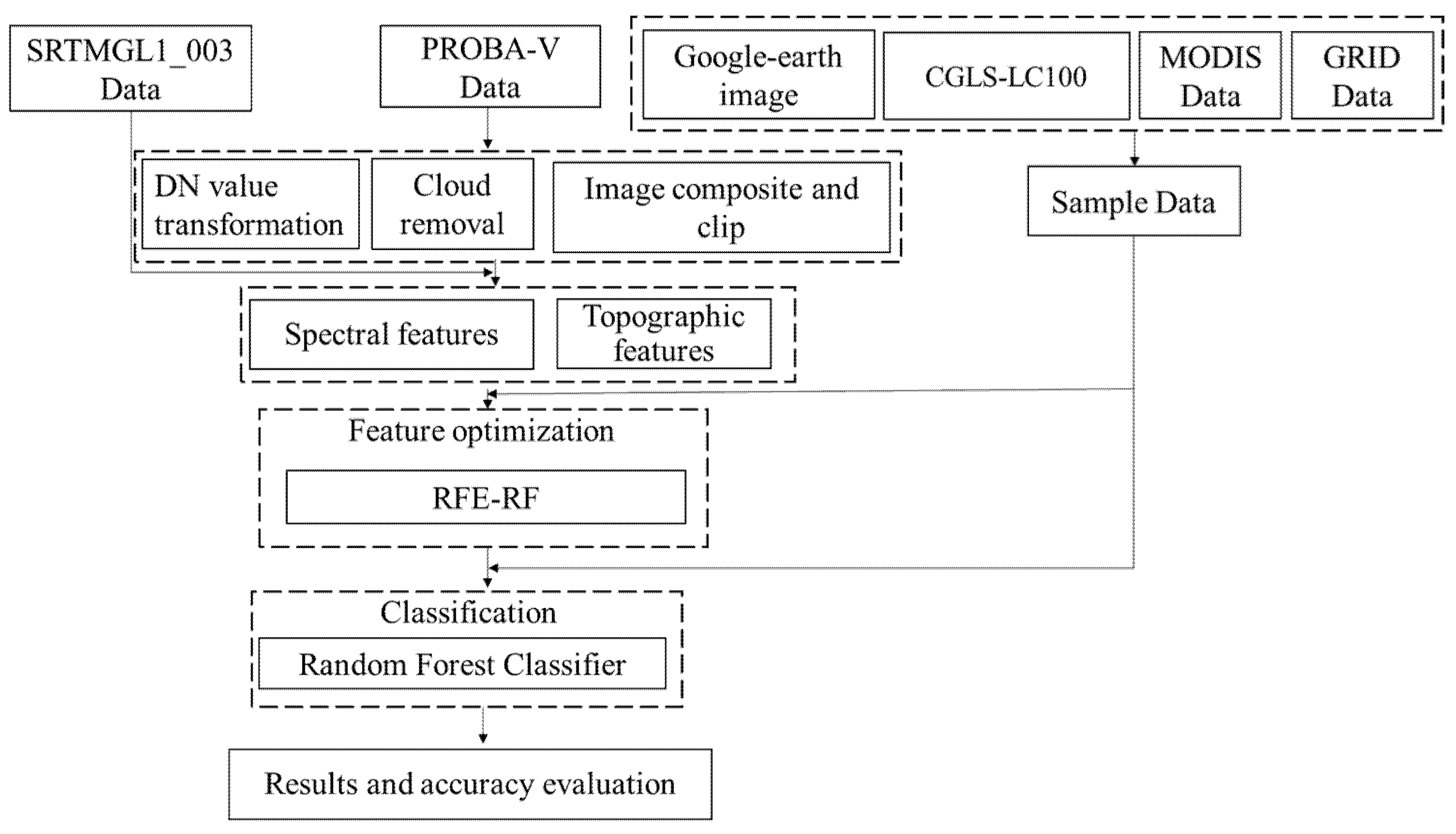
2. Materials and Methods
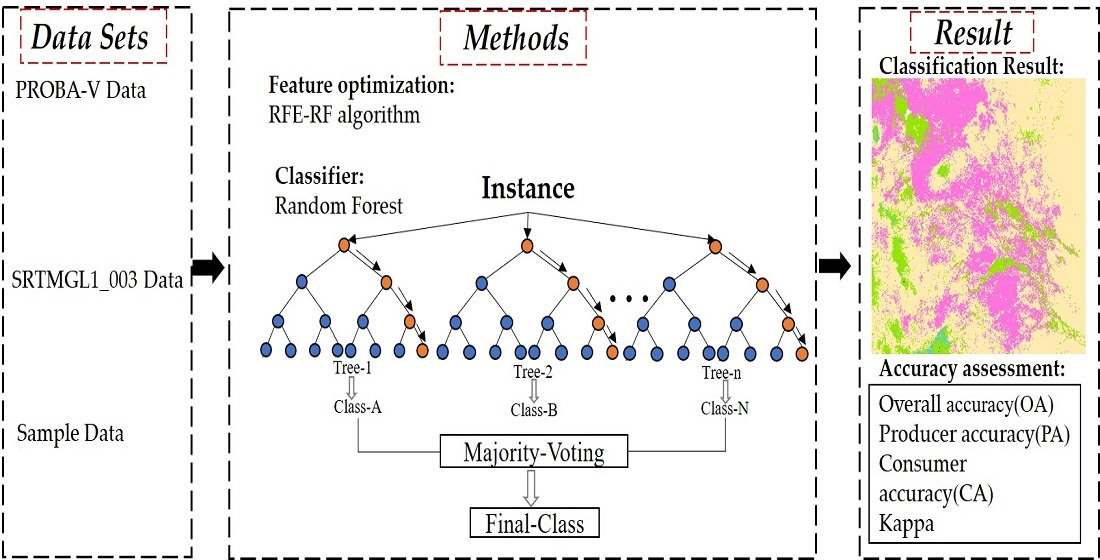
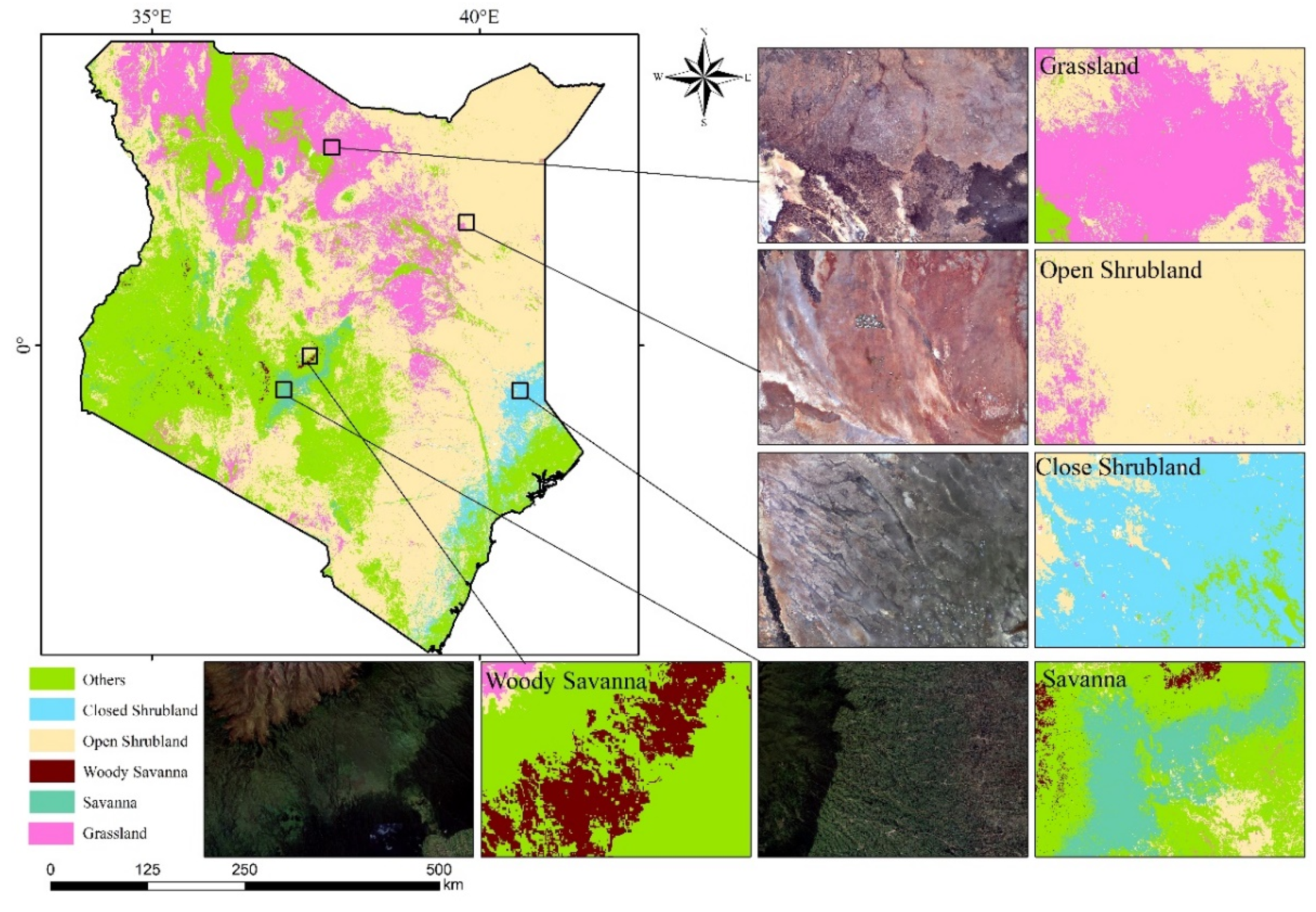
2.1. Study Area
2.2. Datasets and Processing
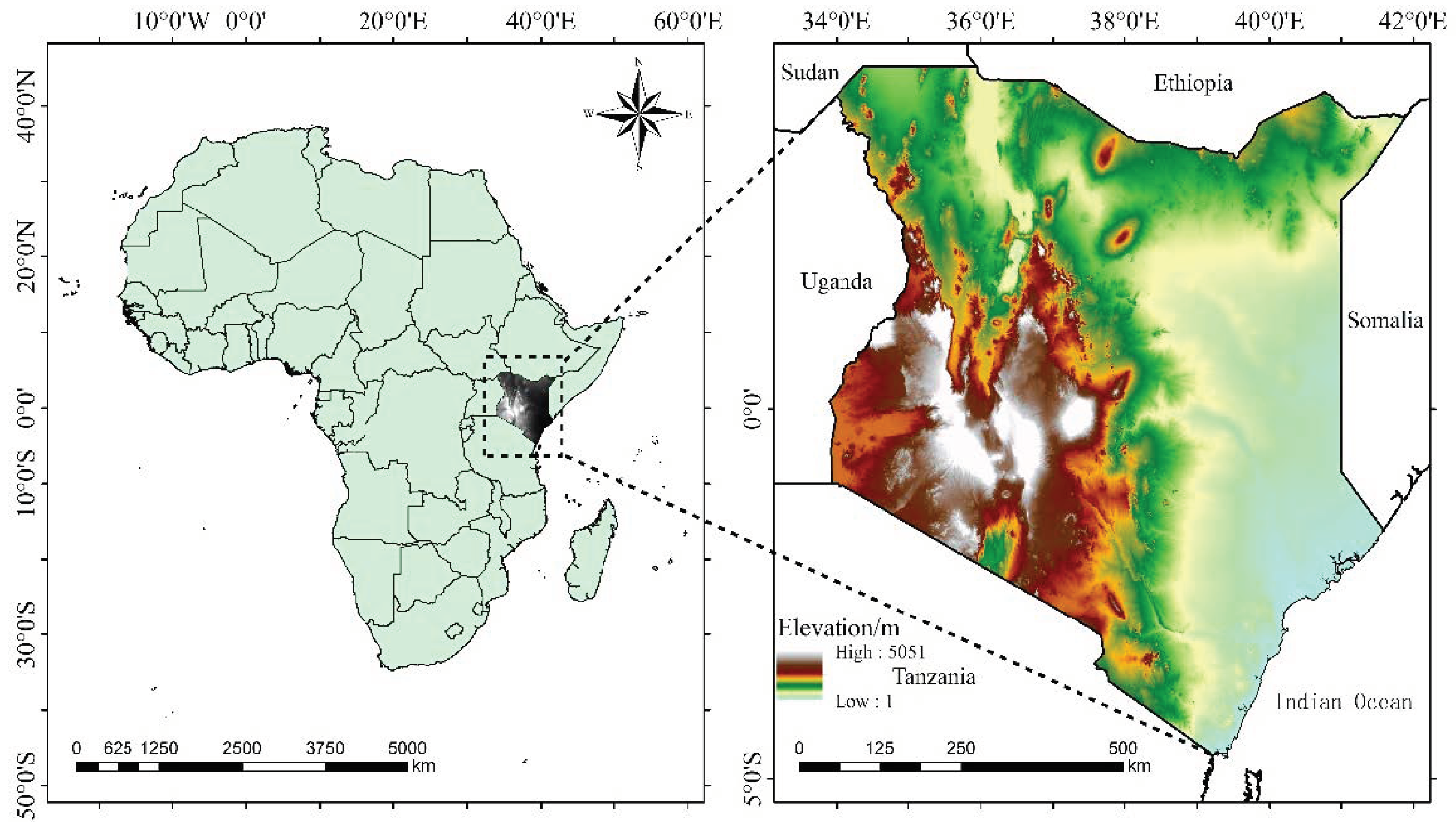
2.2.1. PROBA-V Image Data
2.2.2. SRTMGL1_003 Data
2.2.3. Sample Point Data
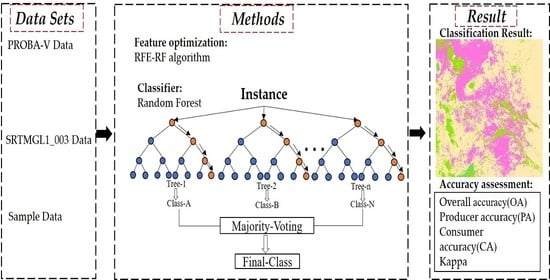
2.3. Methods
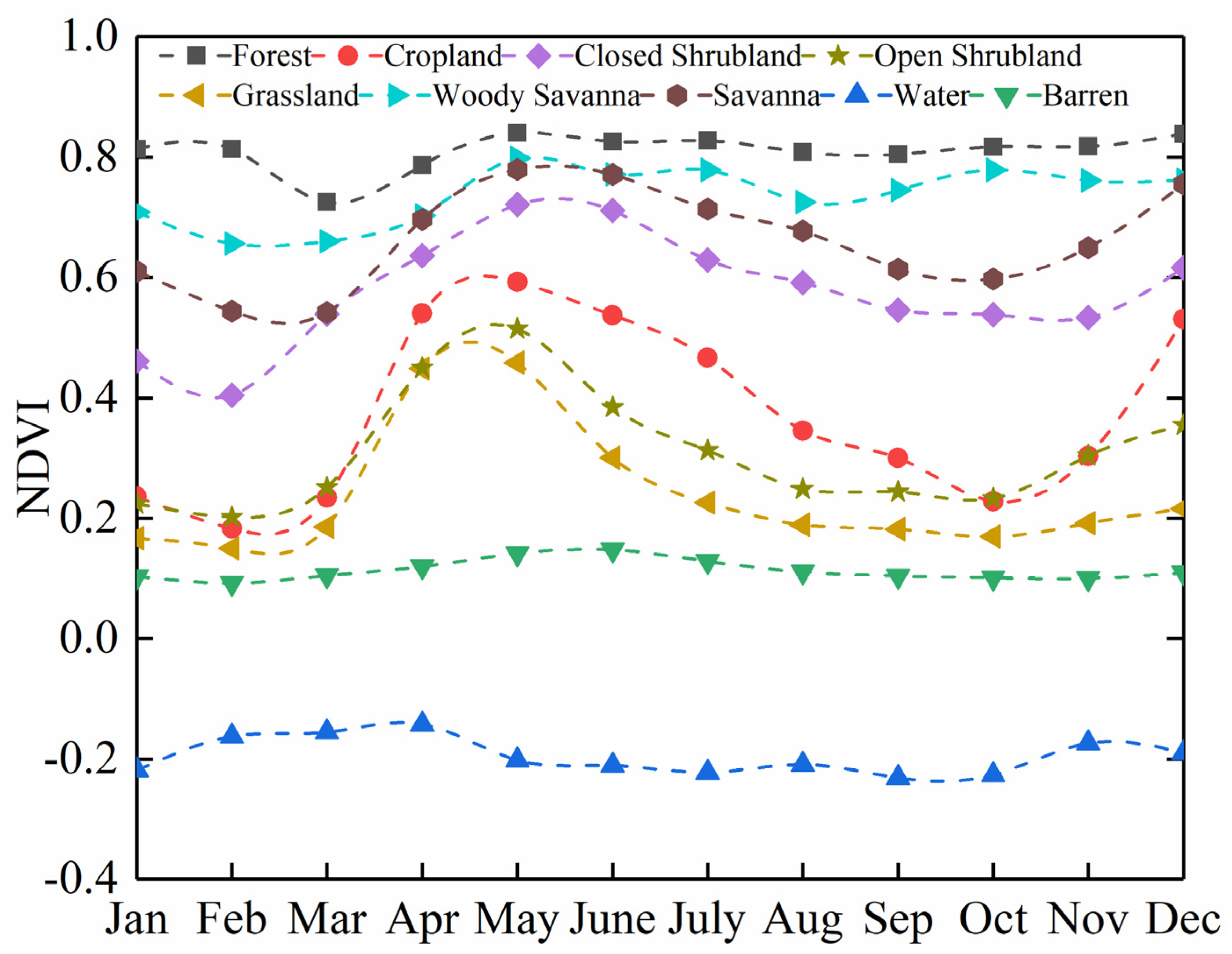
2.3.1. Spectral and Index Features
2.3.2. Topographic Features
2.3.3. Feature Optimization Methods
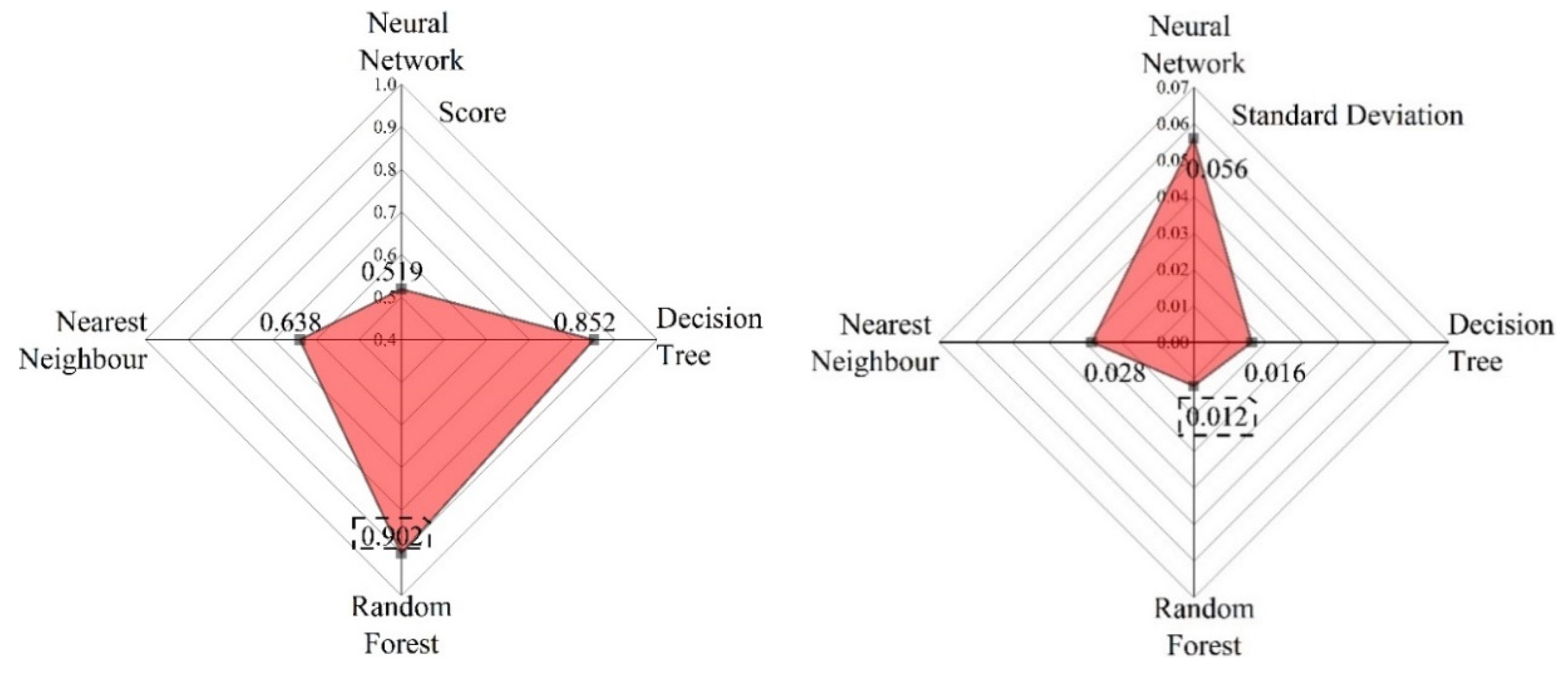
2.3.4. Classification Methods
2.3.5. Accuracy Verification Methods
3. Results
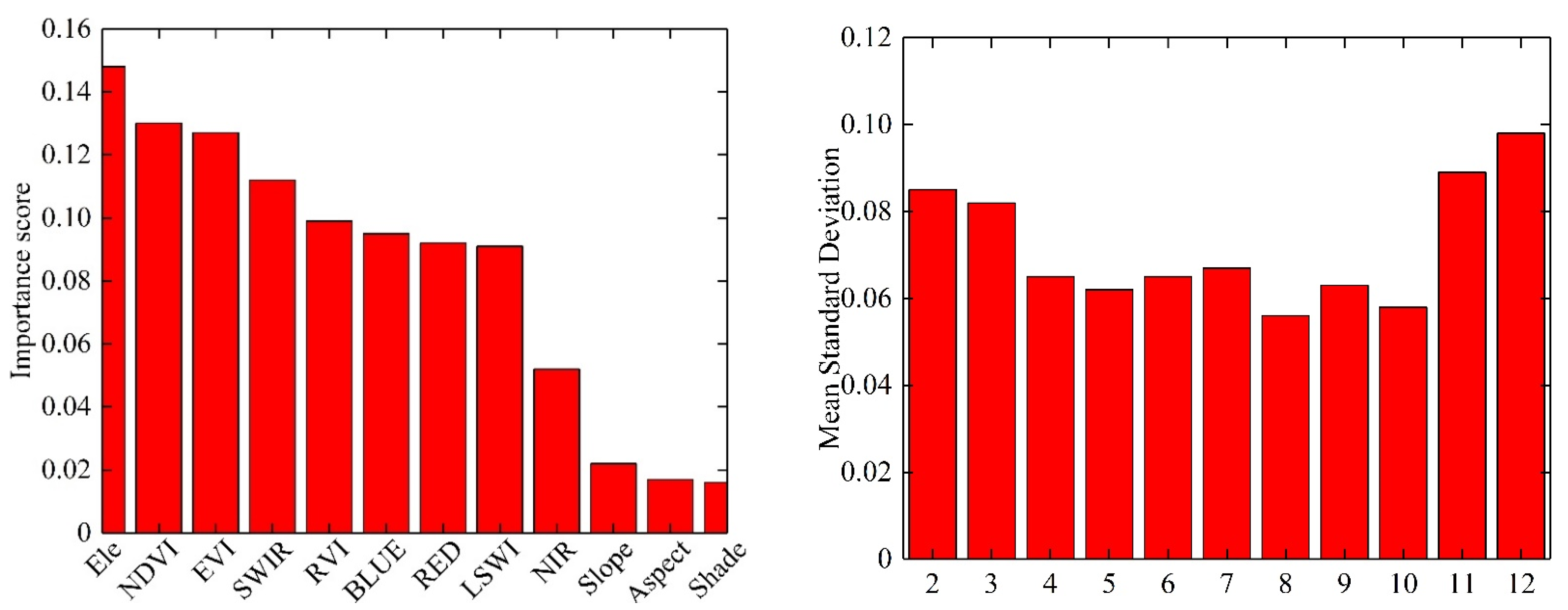
3.1. Feature Optimization Results
3.2. Classification Results and Analysis
4. Discussion
4.1. Effect of Timing on Classification
4.2. Effect of Auxiliary Data on Classification
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Chen, J.; Liu, Y.H.; Yu, Z.R. Planting Information Extraction of Winter Wheat Based on the Time-Series MODIS-EVI. J. Chin. Agric. Sci. Bull. 2011, 27, 446–450. [Google Scholar]
- Fang, P.; Zhang, X.; Wei, P.; Wang, Y.; Zhang, H.; Liu, F.; Zhao, J. The Classification Performance and Mechanism of Machine Learning Algorithms in Winter Wheat Mapping Using Sentinel-2 10 m Resolution Imagery. Appl. Sci. 2020, 10, 5075. [Google Scholar] [CrossRef]
- Fang, P.; Yan, N.; Wei, P.; Zhao, Y.; Zhang, X. Aboveground Biomass Mapping of Crops Supported by Improved CASA Model and Sentinel-2 Multispectral Imagery. Remote Sens. 2021, 13, 2755. [Google Scholar] [CrossRef]
- Liu, H. Extraction of crop planting structure in Hetao irrigated area based on Sentinel-2. J. Arid. Land Resour. Environ. 2021, 35, 88–95. [Google Scholar]
- Zhang, X.-W.; Liu, J.-F.; Qin, Z.; Qin, F. Winter wheat identification by integrating spectral and temporal information derived from multi-resolution remote sensing data. J. Integr. Agric. 2019, 18, 2628–2643. [Google Scholar] [CrossRef]
- Hao, P.; Wang, L.; Niu, Z. Comparison of Hybrid Classifiers for Crop Classification Using Normalized Difference Vegetation Index Time Series: A Case Study for Major Crops in North Xinjiang, China. PLOS ONE 2015, 10, e0137748. [Google Scholar] [CrossRef]
- Potgieter, A.B.; Apan, A.; Dunn, P.; Hammer, G. Estimating crop area using seasonal time series of Enhanced Vegetation Index from MODIS satellite imagery. Aust. J. Agric. Res. 2007, 58, 316–325. [Google Scholar] [CrossRef] [Green Version]
- Chen, Q.; Wang, R.C. Estimation of the rice planting area using digital elevation model and multitemporal moderate resolution imaging spectroradiometer. J. Trans. Chin. Soc. Agric. Eng. 2005, 5, 89–92. [Google Scholar]
- Zhang, X.; Qiu, F.; Qin, F. Identification and mapping of winter wheat by integrating temporal change information and Kullback–Leibler divergence. Int. J. Appl. Earth Obs. Geoinf. 2019, 76, 26–39. [Google Scholar] [CrossRef]
- He, Z.X.; Zhang, M.; Wu, B.F.; Xing, Q. Extraction of Summer Crop in Jiangsu based on Google Earth Engine. J. Geo-Inf. Sci. 2019, 21, 752–766. [Google Scholar]
- Huang, D.S. Research on Feature Selection and Semi-Supervised Classification. Ph.D. Thesis, Huazhong University of Science and Technology, Wuhan, China, 2011. [Google Scholar]
- Liu, H.; Yu, L. Toward integrating feature selection algorithms for classification and clustering. IEEE Trans. Knowl. Data Eng. 2005, 17, 491–502. [Google Scholar]
- Liu, X.X. Study on the Remote Sensing Feature Selection Method for Forest Biomass Estimation Based on RF-RFE. Master’s Thesis, Shandong Agricultural University, Tai’an, China, 2016. [Google Scholar]
- Guyon, I.; Weston, J.; Barnhill, S. Gene Selection for Cancer Classification using Support Vector Machines. J. Mach. Learn. 2002, 46, 389–422. [Google Scholar] [CrossRef]
- Lou, P.; Fu, B.; He, H.; Li, Y.; Tang, T.; Lin, X.; Fan, D.; Gao, E. An Optimized Object-Based Random Forest Algorithm for Marsh Vegetation Mapping Using High-Spatial-Resolution GF-1 and ZY-3 Data. Remote Sens. 2020, 12, 1270. [Google Scholar] [CrossRef] [Green Version]
- Demarchi, L.; Kania, A.; Ciężkowski, W.; Piórkowski, H.; Oświecimska-Piasko, Z.; Chormański, J. Recursive Feature Elimination and Random Forest Classification of Natura 2000 Grasslands in Lowland River Valleys of Poland Based on Airborne Hyperspectral and LiDAR Data Fusion. Remote Sens. 2020, 12, 1842. [Google Scholar] [CrossRef]
- Han, L.; Yang, G.; Dai, H.; Xu, B.; Yang, H.; Feng, H.; Li, Z.; Yang, X. Modeling maize above-ground biomass based on machine learning approaches using UAV remote-sensing data. Plant Methods 2019, 15, 1–19. [Google Scholar] [CrossRef] [Green Version]
- Luo, M.; Wang, Y.; Xie, Y.; Zhou, L.; Qiao, J.; Qiu, S.; Sun, Y. Combination of Feature Selection and CatBoost for Prediction: The First Application to the Estimation of Aboveground Biomass. Forests 2021, 12, 216. [Google Scholar] [CrossRef]
- Pullanagari, R.R.; Kereszturi, G.; Yule, I. Integrating Airborne Hyperspectral, Topographic, and Soil Data for Estimating Pasture Quality Using Recursive Feature Elimination with Random Forest Regression. Remote Sens. 2018, 10, 1117. [Google Scholar] [CrossRef] [Green Version]
- An, Y.; Chen, G.F.; Li, J. Research on Soybean Pre-Micro RNA Prediction Model Based on Recursive Feature Elimination and Random Forest Fusion Algorithm. J. Soybean Sci. 2020, 39, 401–405. [Google Scholar]
- Dai, H.; Fu, R.D.; Jin, W. Glioma grading prediction based on radiomics and ensemble learning. J. Ningbo Univ. (Nat. Sci. Eng. Ed.) 2021, 34, 28–34. [Google Scholar]
- Huang, X.; Zhang, L.; Wang, B.; Li, F.; Zhang, Z. Feature clustering-based support vector machine recursive feature elimination for gene selection. Appl. Intell. 2018, 48, 594–607. [Google Scholar] [CrossRef]
- Johannes, M.; Brase, J.C.; Fröhlich, H.; Gade, S.; Gehrmann, M.; Fälth, M.; Sültmann, H.; Beißbarth, T. Integration of pathway knowledge into a reweighted recursive feature elimination approach for risk stratification of cancer patients. Bioinformatics 2010, 26, 2136–2144. [Google Scholar] [CrossRef] [Green Version]
- Schlosser, A.; Szabó, G.; Bertalan, L.; Varga, Z.; Enyedi, P.; Szabó, S. Building Extraction Using Orthophotos and Dense Point Cloud Derived from Visual Band Aerial Imagery Based on Machine Learning and Segmentation. Remote Sens. 2020, 12, 2397. [Google Scholar] [CrossRef]
- Song, R. Successful launch of ESA proba-v microsatellite. J. Spacecr. Recovery Remote Sens. 2013, 34, 81. [Google Scholar]
- Cao, X.J. Study on Phenology Monitoring and Pest Response of Pinus Yunnanensis Based on Multi-source Remote Sensing Data Fusion. Master’s Thesis, Beijing Forestry University, Beijing, China, 2018. [Google Scholar]
- Farr, T.G.; Rosen, P.A.; Caro, E.; Crippen, R.; Duren, R.; Hensley, S.; Seal, D. The shuttle radar topography mission. Rev. Geophys. 2007, 45, 361. [Google Scholar] [CrossRef] [Green Version]
- Jia, K.; Li, Q.Z. Review of Features Selection in Crop Classification Using Remote Sensing Data. J. Resour. Sci. 2013, 35, 2507–2516. [Google Scholar]
- Song, K.S.; Liu, D.W.; Zhang, B.; Wang, Z.M.; Li, F.; Zhang, S.Q.; Zhang, C.-h.; Yang, T. Impacts of Topographic Features on Landuse/Cover Change in Sanjiang Plain. Bull. Soil Water Conserv. 2008, 28, 2, 10–15. [Google Scholar]
- Zhang, X.Y.; Feng, X.Z.; Jiang, H. Feature set optimization in object-oriented methodology. J. Remote Sens. 2009, 13, 659–669. [Google Scholar]
- De Sa, J.M. Pattern Recognition: Concepts, Methods and Applications; Springer Science & Business Media: Berlin, Germany, 2012. [Google Scholar]
- Bierman, L. Random Forests. Mach. Learn 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Xiangyu, G.; Jianli, D.; Jingzhe, W.; Fei, W.; Lianghong, C.; Huilan, S. Estimation of Soil Moisture Content Based on Competitive Adaptive Reweighted Sampling Algorithm Coupled with Machine Learning. Acta Opt. Sin. 2018, 38, 393–400. [Google Scholar] [CrossRef]
- Yan-bing, Q.; Yin-yin, W.; Yang, C.; Jiao-Jiao, L.; Liang-Liang, Z. Soli Orfanic Matter Prediction Based on Remote Sensing Data and Random Forest Model in Shaanxi Province. J. Nat. Resour. 2017, 32, 1074–1086. [Google Scholar]
- Roy, D.; Kovalskyy, V.; Zhang, H.; Vermote, E.; Yan, L.; Kumar, S.S.; Egorov, A. Characterization of Landsat-7 to Landsat-8 reflective wavelength and normalized difference vegetation index continuity. Remote Sens. Environ. 2016, 185, 57–70. [Google Scholar] [CrossRef] [Green Version]
- Feng, Q.; Liu, J.; Gong, J. UAV Remote Sensing for Urban Vegetation Mapping Using Random Forest and Texture Analysis. Remote Sens. 2015, 7, 1074–1094. [Google Scholar] [CrossRef] [Green Version]
- Yue, M.; Qigang, J.; Zhiguo, M.; Yuanhua, L.; Dong, W.; Huaxin, L. Classification of Land Use in Farming Area Based on Random Forest Algorithm. Trans. Chin. Soc. Agric. Mach. 2016, 47, 297–303. [Google Scholar]
- Rodriguez-Galiano, V.F.; Olmo, M.C.; Abarca-Hernandez, F.; Atkinson, P.; Jeganathan, C. Random Forest classification of Mediterranean land cover using multi-seasonal imagery and multi-seasonal texture. Remote Sens. Environ. 2012, 121, 93–107. [Google Scholar] [CrossRef]
- Chan, J.C.-W.; Paelinckx, D. Evaluation of Random Forest and Adaboost tree-based ensemble classification and spectral band selection for ecotope mapping using airborne hyperspectral imagery. Remote Sens. Environ. 2008, 112, 2999–3011. [Google Scholar] [CrossRef]
- van Beijma, S.; Comber, A.; Lamb, A. Random forest classification of salt marsh vegetation habitats using quad-polarimetric airborne SAR, elevation and optical RS data. Remote Sens. Environ. 2014, 149, 118–129. [Google Scholar] [CrossRef]
- Giles, M. Foody, Status of land cover classification accuracy assessment. Remote Sens. Environ. 2002, 80, 185–201. [Google Scholar] [CrossRef]
- Zheng, X. Three Common Classification Algorithms and Their Comparative Analysis. J. Chongqing Univ. Sci. Technol. (Nat. Sci. Ed.) 2020, 22, 101–106. [Google Scholar]
- Song, Q.; Hu, Q.; Zhou, Q.; Hovis, C.; Xiang, M.; Tang, H.; Wu, W. In-Season Crop Mapping with GF-1/WFV Data by Combining Object-Based Image Analysis and Random Forest. Remote Sens. 2017, 9, 1184. [Google Scholar] [CrossRef] [Green Version]
- Senf, C.; Leitão, P.J.; Pflugmacher, D.; van der Linden, S.; Hostert, P. Mapping landcover in complex Mediterranean landscapes using Landsat: Improved classification accuracies from integrating multi-seasonal and synthetic imagery. Remote Sens. Environ. 2015, 156, 527–536. [Google Scholar] [CrossRef]
- Zhao, Y.Y.; Feng, D.L.; Yu, L.; Wang, X.Y.; Chen, Y.L.; Bai, Y.Q.; Hernandez, H.J.; Galleguillos, M.; Estades, C.; Biging, G.S.; et al. Detailed dynamic land cover mapping of Chile: Accuracy improvement by integrating multi-temporal data. Remote Sens. Environ. 2016, 183, 170–185. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ground Class Code | Land Class Name | Number of Samples |
|---|---|---|
| 1 | Water | 121 |
| 2 | Savanna | 192 |
| 3 | Woody savanna | 237 |
| 4 | Closed shrubland | 263 |
| 5 | Barren | 268 |
| 6 | Grassland | 360 |
| 7 | Cropland | 545 |
| 8 | Forest | 695 |
| 9 | Open shrubland | 1098 |
| PROBA-V Spectral Bands | Centred at (nm) | Width Span (nm) |
|---|---|---|
| BLUE | 463 | 46 |
| RED | 655 | 79 |
| NIR | 85 | 144 |
| SWIR | 1600 | 73 |
| Features Type | Original Features | Number | Optimized Features | Number |
|---|---|---|---|---|
| Spectral features | BLUE, RED, NIR, SWIR | 4 | BLUE, RED, SWIR | 3 |
| Index features | NDVI, EVI, LSWI, RVI | 4 | NDVI, EVI, LSWI, RVI | 4 |
| Topographic features | Elevation, Aspect, Slope, Hillshade | 4 | Elevation | 1 |
| Total | 12 | 8 |
| Confusion Matrix | Forecast Category | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | Total | PA | ||
| Category | 1 | 314 | 5 | 3 | 5 | 11 | 3 | 0 | 0 | 0 | 341 | 0.92 |
| 2 | 8 | 223 | 0 | 17 | 0 | 5 | 0 | 0 | 0 | 253 | 0.88 | |
| 3 | 8 | 0 | 112 | 4 | 0 | 0 | 0 | 0 | 0 | 124 | 0.90 | |
| 4 | 1 | 31 | 5 | 478 | 0 | 0 | 30 | 0 | 2 | 547 | 0.87 | |
| 5 | 13 | 0 | 0 | 0 | 115 | 0 | 0 | 0 | 0 | 128 | 0.89 | |
| 6 | 4 | 7 | 0 | 0 | 0 | 84 | 0 | 0 | 0 | 95 | 0.88 | |
| 7 | 0 | 4 | 0 | 54 | 0 | 0 | 119 | 0 | 5 | 182 | 0.65 | |
| 8 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 60 | 0 | 60 | 1 | |
| 9 | 0 | 0 | 0 | 3 | 0 | 0 | 5 | 0 | 115 | 123 | 0.93 | |
| Total | 348 | 270 | 120 | 561 | 126 | 92 | 154 | 60 | 122 | 1853 | ||
| UA | 0.90 | 0.82 | 0.93 | 0.85 | 0.91 | 0.91 | 0.77 | 1 | 0.94 | |||
| OA | 0.87 | |||||||||||
| Kappa | 0.85 | |||||||||||
| Confusion Matrix | Forecast Category | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | Total | PA | ||
| Category | 1 | 301 | 2 | 10 | 7 | 10 | 0 | 0 | 0 | 0 | 330 | 0.91 |
| 2 | 7 | 247 | 0 | 38 | 1 | 10 | 0 | 0 | 0 | 303 | 0.81 | |
| 3 | 8 | 0 | 118 | 9 | 0 | 0 | 0 | 0 | 0 | 135 | 0.87 | |
| 4 | 4 | 25 | 8 | 478 | 0 | 3 | 33 | 0 | 0 | 551 | 0.86 | |
| 5 | 17 | 0 | 0 | 0 | 81 | 0 | 0 | 0 | 0 | 98 | 0.82 | |
| 6 | 5 | 9 | 0 | 2 | 0 | 74 | 0 | 0 | 0 | 90 | 0.82 | |
| 7 | 2 | 4 | 0 | 87 | 0 | 0 | 99 | 0 | 4 | 196 | 0.50 | |
| 8 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 60 | 0 | 60 | 1 | |
| 9 | 0 | 0 | 0 | 4 | 0 | 0 | 5 | 0 | 128 | 137 | 0.93 | |
| Total | 344 | 287 | 136 | 625 | 92 | 87 | 137 | 60 | 132 | 1900 | ||
| UA | 0.87 | 0.86 | 0.86 | 0.76 | 0.88 | 0.85 | 0.72 | 1 | 0.96 | |||
| OA | 0.83 | |||||||||||
| Kappa | 0.79 | |||||||||||
| Confusion Matrix | Forecast Category | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | Total | PA | ||
| Category | 1 | 325 | 5 | 4 | 0 | 9 | 0 | 0 | 0 | 0 | 343 | 0.94 |
| 2 | 7 | 237 | 0 | 21 | 0 | 6 | 4 | 0 | 0 | 275 | 0.86 | |
| 3 | 13 | 0 | 103 | 3 | 0 | 0 | 0 | 0 | 0 | 119 | 0.86 | |
| 4 | 5 | 16 | 13 | 519 | 0 | 0 | 30 | 0 | 0 | 583 | 0.89 | |
| 5 | 15 | 0 | 0 | 0 | 98 | 0 | 0 | 0 | 0 | 113 | 0.86 | |
| 6 | 12 | 17 | 0 | 0 | 0 | 79 | 0 | 0 | 0 | 108 | 0.73 | |
| 7 | 0 | 3 | 58 | 0 | 0 | 0 | 113 | 0 | 3 | 177 | 0.63 | |
| 8 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 57 | 0 | 57 | 1 | |
| 9 | 0 | 0 | 0 | 6 | 0 | 0 | 8 | 0 | 138 | 152 | 0.90 | |
| Total | 377 | 278 | 178 | 549 | 107 | 85 | 155 | 57 | 141 | 1927 | ||
| UA | 0.86 | 0.85 | 0.57 | 0.94 | 0.91 | 0.92 | 0.72 | 1 | 0.97 | |||
| OA | 0.86 | |||||||||||
| Kappa | 0.83 | |||||||||||
| Confusion Matrix | Forecast Category | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | Total | PA | ||
| Category | 1 | 307 | 24 | 3 | 11 | 5 | 4 | 0 | 0 | 0 | 354 | 0.86 |
| 2 | 19 | 222 | 1 | 24 | 0 | 9 | 0 | 0 | 0 | 275 | 0.80 | |
| 3 | 1 | 0 | 129 | 5 | 0 | 0 | 0 | 0 | 0 | 135 | 0.95 | |
| 4 | 6 | 25 | 10 | 439 | 0 | 0 | 34 | 0 | 5 | 519 | 0.84 | |
| 5 | 11 | 0 | 0 | 0 | 106 | 0 | 0 | 0 | 0 | 117 | 0.90 | |
| 6 | 0 | 11 | 0 | 0 | 0 | 83 | 0 | 0 | 0 | 94 | 0.88 | |
| 7 | 2 | 4 | 1 | 64 | 0 | 0 | 104 | 0 | 9 | 184 | 0.56 | |
| 8 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 58 | 0 | 58 | 1 | |
| 9 | 0 | 0 | 0 | 2 | 0 | 0 | 4 | 0 | 122 | 128 | 0.95 | |
| Total | 346 | 286 | 144 | 545 | 111 | 96 | 142 | 58 | 136 | 1864 | ||
| UA | 0.88 | 0.77 | 0.89 | 0.80 | 0.95 | 0.86 | 0.73 | 1 | 0.89 | |||
| OA | 0.84 | |||||||||||
| Kappa | 0.81 | |||||||||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wei, P.; Zhu, W.; Zhao, Y.; Fang, P.; Zhang, X.; Yan, N.; Zhao, H. Extraction of Kenyan Grassland Information Using PROBA-V Based on RFE-RF Algorithm. Remote Sens. 2021, 13, 4762. https://doi.org/10.3390/rs13234762
Wei P, Zhu W, Zhao Y, Fang P, Zhang X, Yan N, Zhao H. Extraction of Kenyan Grassland Information Using PROBA-V Based on RFE-RF Algorithm. Remote Sensing. 2021; 13(23):4762. https://doi.org/10.3390/rs13234762
Chicago/Turabian StyleWei, Panpan, Weiwei Zhu, Yifan Zhao, Peng Fang, Xiwang Zhang, Nana Yan, and Hao Zhao. 2021. "Extraction of Kenyan Grassland Information Using PROBA-V Based on RFE-RF Algorithm" Remote Sensing 13, no. 23: 4762. https://doi.org/10.3390/rs13234762
APA StyleWei, P., Zhu, W., Zhao, Y., Fang, P., Zhang, X., Yan, N., & Zhao, H. (2021). Extraction of Kenyan Grassland Information Using PROBA-V Based on RFE-RF Algorithm. Remote Sensing, 13(23), 4762. https://doi.org/10.3390/rs13234762