
Integrating Sentinel-1/2 Data and Machine Learning to Map Cotton Fields in Northern Xinjiang, China



Abstract
:1. Introduction
2. Materials and Methods
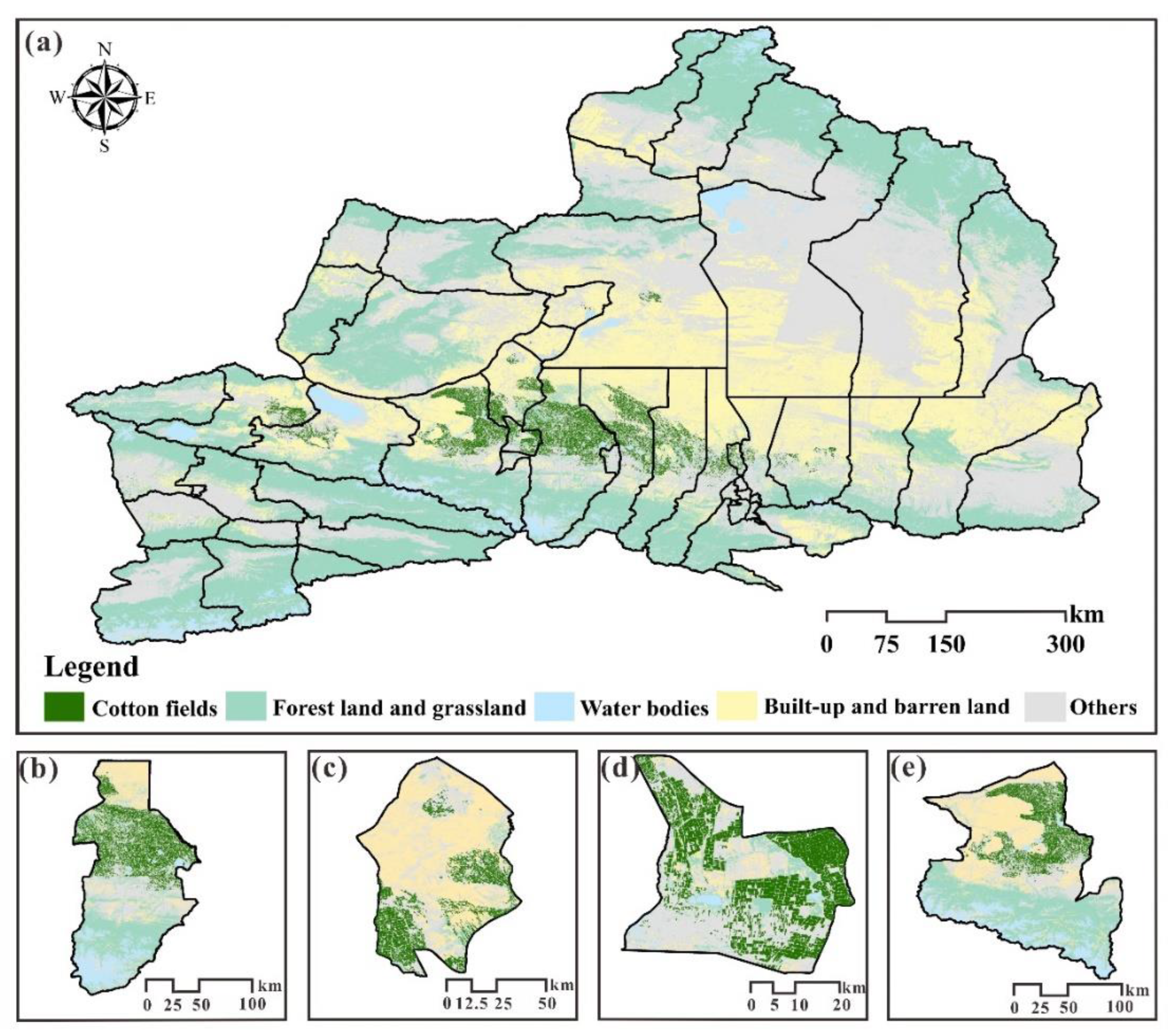
2.1. Study Area
2.2. Sentinel-1 and Sentinel-2 Data
2.3. Identifying Cotton Fields
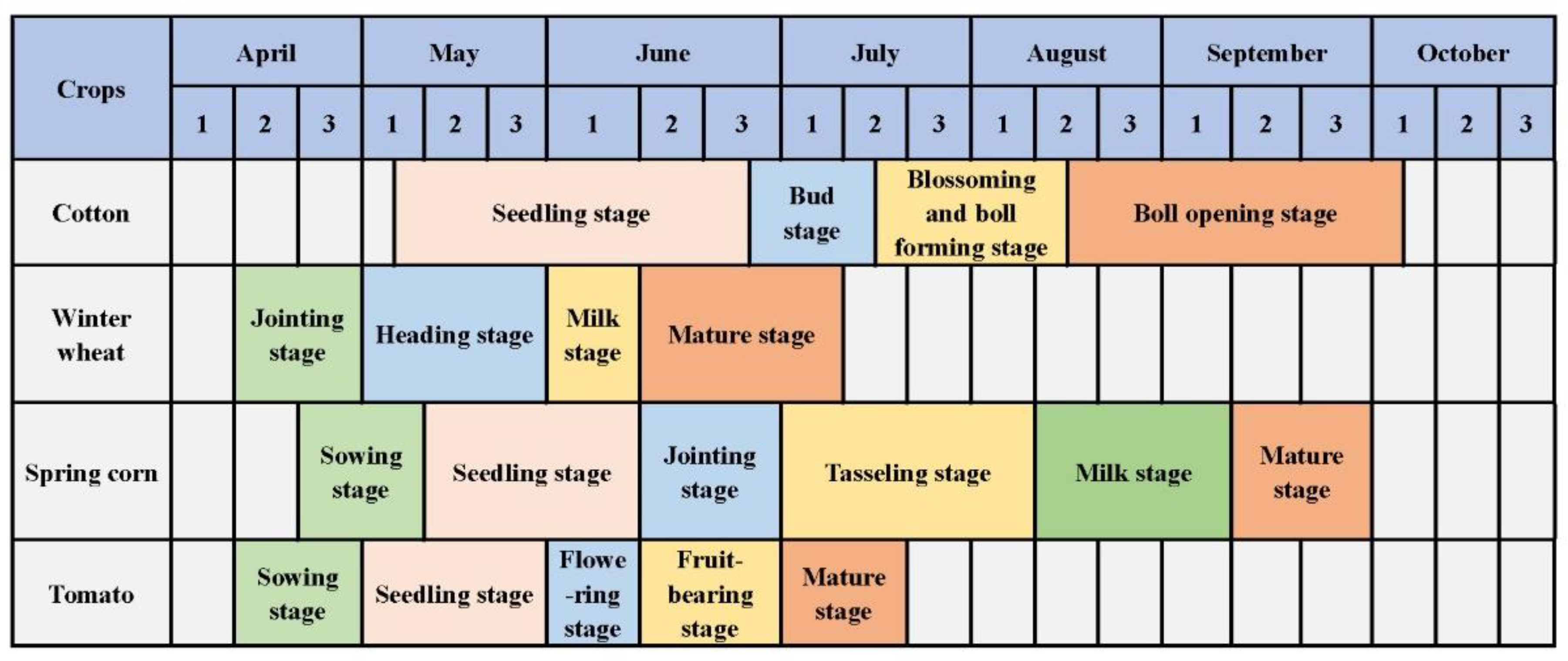
2.3.1. Calculating Vegetation Indices
2.3.2. Mapping Non-cropland Cover Types as Masks
2.3.3. Pixel-Based Classifier: Random Forest
2.3.4. Object-Based Segmentation: Multi-Scale Image Segmentation
2.3.5. Combination of Pixel-Based and Object-Based Approaches
2.4. Accuracy Assessment
3. Results
3.1. Key Parameter of Random Forest
3.2. Spatial Distribution of Cotton Fileds
3.3. Optimal Phenological Phase
4. Discussion
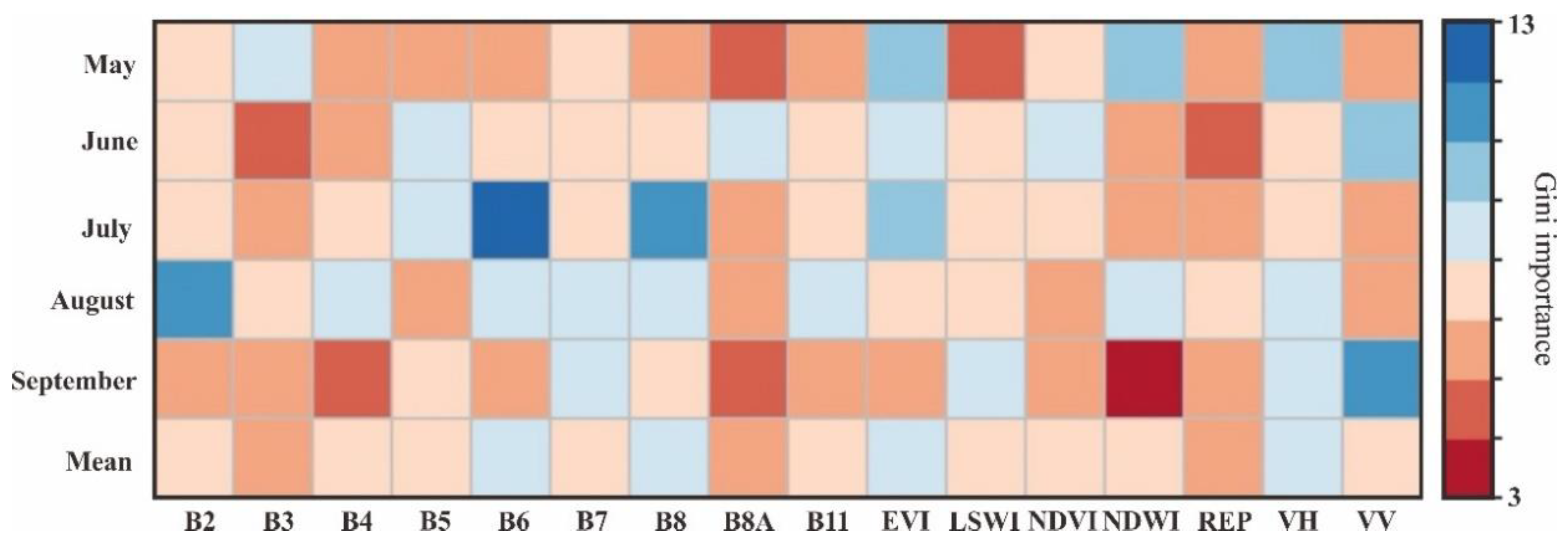
4.1. Key Classification Features
4.2. Appilications and Limitations
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- King, L.; Adusei, B.; Stehman, S.V.; Potapov, P.V.; Song, X.P.; Krylov, A.; Di Bella, C.; Loveland, T.R.; Johnson, D.M.; Hansen, M.C. A multi-resolution approach to national-scale cultivated area estimation of soybean. Remote Sens. Environ. 2017, 195, 13–29. [Google Scholar] [CrossRef]
- Xiao, X.; Boles, S.; Liu, J.Y.; Zhuang, D.F.; Frolking, S.; Li, C.S.; Salas, W.; Moore, B. Mapping paddy rice agriculture in southern China using multi-temporal MODIS images. Remote Sens. Environ. 2005, 95, 480–492. [Google Scholar] [CrossRef]
- Wang, J.; Xiao, X.M.; Liu, L.; Wu, X.C.; Qin, Y.W.; Steiner, J.L.; Dong, J.W. Mapping sugarcane plantation dynamics in Guangxi, China, by time series Sentinel-1, Sentinel-2 and Landsat images. Remote Sens. Environ. 2020, 247, 111951. [Google Scholar] [CrossRef]
- Qin, Y.; Xiao, X.M.; Dong, J.W.; Zhou, Y.T.; Zhou, Z.; Zhang, G.L.; Du, G.M.; Jin, C.; Kou, W.L.; Wang, J.; et al. Mapping paddy rice planting area in cold temperate climate region through analysis of time series Landsat 8 (OLI), Landsat 7 (ETM+) and MODIS imagery. ISPRS J. Photogramm. Remote Sens. 2015, 105, 220–233. [Google Scholar] [CrossRef] [Green Version]
- Liu, Z.H.; Yang, P.; Tang, H.J.; Wu, W.B.; Zhang, L.; Yu, Q.Y.; Li, Z.G. Shifts in the extent and location of rice cropping areas match the climate change pattern in China during 1980–2010. Reg. Environ. Chang. 2015, 15, 919–929. [Google Scholar] [CrossRef]
- Hao, P.Y.; Tang, H.J.; Chen, Z.X.; Meng, Q.Y.; Kang, Y.P. Early-season crop type mapping using 30-m reference time series. J. Integr. Agric. 2020, 19, 1897–1911. [Google Scholar] [CrossRef]
- Hao, P.Y.; Zhan, Y.L.; Wang, L.; Niu, Z.; Shakir, M. Feature selection of time series MODIS data for early crop classification using Random Forest: A case study in Kansas, USA. Remote Sens. 2015, 7, 5347–5369. [Google Scholar] [CrossRef] [Green Version]
- Bridhikitti, A.; Overcamp, T. Estimation of Southeast Asian rice paddy areas with different ecosystems from moderate-resolution satellite imagery. Agric. Ecosyst. Environ. 2012, 146, 113–120. [Google Scholar] [CrossRef]
- Chen, B.; Jin, Y.F.; Brown, P. Automatic mapping of planting year for tree crops with Landsat satellite time series stacks. ISPRS J. Photogramm. Remote Sens. 2019, 151, 176–188. [Google Scholar] [CrossRef]
- Wang, Z.L.; Lai, C.G.; Chen, X.H.; Yang, B.; Zhao, S.W.; Bai, X.Y. Flood hazard risk assessment model based on Random Forest. Water Resour. Res. 2015, 527, 1130–1141. [Google Scholar] [CrossRef]
- Jin, Z.N.; Azzari, G.; You, C.; di Tommaso, S.; Aston, S.; Burke, M.; Lobell, D.B. Smallholder maize area and yield mapping at national scales with Google Earth Engine. Remote Sens. Environ. 2019, 228, 115–128. [Google Scholar] [CrossRef]
- Son, N.T.; Chen, C.F.; Chen, C.R.; Toscano, P.; Cheng, Y.S.; Guo, H.Y.; Syu, C.H. A phenological object-based approach for rice crop classification using time-series Sentinel-1 Synthetic Aperture Radar (SAR) data in Taiwan. Int. J. Remote Sens. 2021, 42, 2722–2739. [Google Scholar] [CrossRef]
- Yang, H.J.; Pan, B.; Li, N.; Wang, W.; Zhang, J.; Zhang, X.L. A systematic method for spatio-temporal phenology estimation of paddy rice using time series Sentinel-1 images. Remote Sens. Environ. 2021, 259, 112394. [Google Scholar] [CrossRef]
- Gasparovic, M.; Klobucar, D. Mapping floods in lowland forest using Sentinel-1 and Sentinel-2 data and an object-based approach. Forests 2021, 12, 553. [Google Scholar] [CrossRef]
- Xiong, J.; Thenkabail, P.S.; Gumma, M.K.; Teluguntla, P.; Poehnelt, J.; Congalton, R.G.; Yadav, K.; Thau, D. Automated cropland mapping of continental Africa using Google Earth Engine cloud computing. ISPRS J. Photogramm. Remote Sens. 2017, 126, 225–244. [Google Scholar] [CrossRef] [Green Version]
- Hu, Q.; Wu, W.B.; Xia, T.; Yu, Q.Y.; Yang, P.; Li, Z.G.; Song, Q. Exploring the use of google earth imagery and object-based methods in land use/cover mapping. Remote Sens. 2013, 5, 6026–6042. [Google Scholar] [CrossRef] [Green Version]
- Zhou, W.Q.; Troy, A.; Grove, M. Object-based land cover classification and change analysis in the Baltimore metropolitan area using multitemporal high resolution remote sensing data. Sensors 2008, 8, 1613–1636. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhong, L.H.; Gong, P.; Biging, G.S. Efficient corn and soybean mapping with temporal extendability: A multi-year experiment using Landsat imagery. Remote Sens. Environ. 2014, 140, 1–13. [Google Scholar] [CrossRef]
- Liu, Z.H.; Hu, Q.; Tan, J.Y.; Zou, J.Q. Regional scale mapping of fractional rice cropping change using a phenology-based temporal mixture analysis. Int. J. Remote Sens. 2019, 40, 2703–2716. [Google Scholar] [CrossRef]
- Werner, J.P.S.; Oliveira, S.R.D.; Esquerdo, J.C.D.M. Mapping cotton fields using data mining and MODIS time-series. Int. J. Remote Sens. 2019, 41, 2457–2476. [Google Scholar] [CrossRef]
- Wu, W.B.; Yang, P.; Tang, H.J.; Zhou, Q.B.; Chen, Z.X.; Shibasaki, R. Characterizing spatial patterns of phenology in cropland of China based on remotely sensed data. Agric. Sci. China 2010, 9, 101–112. [Google Scholar] [CrossRef]
- Gorelick, N.; Hancher, M.; Dixon, M.; Ilyushchenko, S.; Thau, D.; Moore, R. Google Earth Engine: Planetary-scale geospatial analysis for everyone. Remote Sens. Environ. 2017, 202, 18–27. [Google Scholar] [CrossRef]
- Minasny, B.; Shah, R.M.; Che Soh, N.; Arif, C.; Indra Setiawan, B. Automated near-real-time mapping and monitoring of rice extent, cropping patterns, and growth stages in Southeast Asia using Sentinel-1 time series on a Google Earth Engine platform. Remote Sen. 2019, 11, 1666. [Google Scholar] [CrossRef] [Green Version]
- Fung, T.; Siu, W. Environmental quality and its changes, an analysis using NDVI. Int. J. Remote Sens. 2000, 21, 1011–1024. [Google Scholar] [CrossRef]
- Huete, A.; Didan, K.; Miura, T.; Rodriguez, E.P.; Gao, X.; Ferreira, L.G. Overview of the radiometric and biophysical performance of the MODIS vegetation indices. Remote Sens. Environ. 2002, 83, 195–213. [Google Scholar] [CrossRef]
- Gao, B.C. NDWI—A normal difference water index for remote sensing of vegetation liquid water from space. Remote Sens. Environ. 1996, 58, 257–266. [Google Scholar] [CrossRef]
- Dash, J.; Curran, P.J. The MERIS terrestrial chlorophyll index. Int. J. Remote Sens. 2004, 25, 5403–5413. [Google Scholar] [CrossRef]
- Gong, P.; Liu, H.; Zhang, M.N.; Li, C.C.; Wang, J.; Huang, H.B.; Clinton, N.; Ji, L.Y.; Li, W.Y.; Bai, Y.Q.; et al. Stable classification with limited sample: Transferring a 30-m resolution sample set collected in 2015 to mapping 10-m resolution global land cover in 2017. Sci. Bull. 2019, 64, 370–373. [Google Scholar] [CrossRef] [Green Version]
- Georganos, S.; Grippa, T.; Vanhuysse, S.; Lennert, M.; Shimoni, M.; Kalogirou, S.; Wolff, E. Less is more: Optimizing classification performance through feature selection in a very-high-resolution remote sensing object-based urban application. GISci. Remote Sens. 2018, 55, 221–242. [Google Scholar] [CrossRef]
- Goldblatt, R.; Stuhlmacher, M.F.; Tellman, B.; Clinton, N.; Hanson, G.; Georgescu, M.; Wang, C.Y.; Serrano-Candela, F.; Khandelwal, A.K.; Cheng, W.H.; et al. Using Landsat and nighttime lights for supervised pixel-based image classification of urban land cover. Remote Sens. Environ. 2018, 205, 253–275. [Google Scholar] [CrossRef]
- Lawrence, R.L.; Moran, C.J. The America View classification methods accuracy comparison project: A rigorous approach for model selection. Remote Sens. Environ. 2015, 17, 115–120. [Google Scholar] [CrossRef]
- Stevens, F.R.; Gaughan, A.E.; Linard, C.; Tatem, A.J. Disaggregating census data for population mapping using Random Forests with remotely-sensed and ancillary data. PLoS ONE 2015, 10, e0107042. [Google Scholar] [CrossRef] [Green Version]
- Rodriguez-Galiano, V.F.; Ghimire, B.; Rogan, J.; Chica-Olmo, M.; Rigol-Sanchez, J.P. An assessment of the effectiveness of a Random Forest classifier for land-cover classification. ISPRS J. Photogramm. Remote Sens. 2012, 67, 93–104. [Google Scholar] [CrossRef]
- Singha, M.; Dong, J.; Zhang, G.; Xiao, X. High resolution paddy rice maps in cloud-prone Bangladesh and Northeast India using Sentinel-1 data. Sci. Data. 2019, 6. [Google Scholar] [CrossRef]
- Wang, Y.J.; Qi, Q.W.; Liu, Y.; Jiang, L.L.; Wang, J. Unsupervised segmentation parameter selection using the local spatial statistics for remote sensing image segmentation. Int. J. Appl. Earth Obs. Geoinf. 2019, 81, 98–109. [Google Scholar] [CrossRef]
- Su, T.F.; Zhang, S.W. Local and global evaluation for remote sensing image segmentation. ISPRS J. Photogramm. Remote Sens. 2017, 130, 256–276. [Google Scholar] [CrossRef]
- Dragut, L.; Csillik, O.; Eisank, C.; Tiede, D. Automated parameterization for multi-scale image segmentation on multiple layers. ISPRS J. Photogramm. Remote Sens. 2014, 88, 119–127. [Google Scholar] [CrossRef] [Green Version]
- Dragut, L.; Tiede, D.; Levick, S.R. ESP: A tool to estimate scale parameter for multiresolution image segmentation of remotely sensed data. Int. J. Geogr. Inf. Sci. 2010, 24, 859–871. [Google Scholar] [CrossRef]
- Woodcock, C.; Strahler, A. The factor of scale in remote sensing. Remote Sens. Environ. 1987, 21, 311–332. [Google Scholar] [CrossRef]
- Ma, X.L.; Tong, X.H.; Liu, S.C.; Luo, X.; Xie, H.; Li, C.M. Optimized sample selection in SVM classification by combining with DMSP-OLS, Landsat NDVI and GlobeLand30 products for extracting urban built-up areas. Remote Sens. 2017, 9, 236. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.; Wu, B.F.; Ponce-Campos, G.E.; Zhang, M.; Chang, S.; Tian, F.Y. Mapping up-to-date paddy rice extent at 10 m resolution in China through the integration of optical and synthetic aperture radar images. Remote Sens. 2018, 10, 1200. [Google Scholar] [CrossRef] [Green Version]
- Chan, J.C.W.; Paelinckx, D. Evaluation of Random Forest and adaboost tree-based ensemble classification and spectral band selection for ecotope mapping using airborne hyperspectral imagery. Remote Sens. Environ. 2008, 112, 2999–3011. [Google Scholar] [CrossRef]
- Pan, Y.Z.; Li, L.; Zhang, J.S.; Liang, S.L.; Zhu, X.F.; Sulla-Menashe, D. Winter wheat area estimation from MODIS-EVI time series data using the Crop Proportion Phenology Index. Remote Sens. Environ. 2012, 119, 232–242. [Google Scholar] [CrossRef]
- Chen, B.Q.; Li, X.P.; Xiao, X.M.; Zhao, B.; Dong, J.W.; Kou, W.L.; Qin, Y.W.; Yang, C.; Wu, Z.X.; Sun, R.; et al. Mapping tropical forests and deciduous rubber plantations in Hainan Island, China by integrating PALSAR 25-m and multi-temporal Landsat images. Int. J. Appl. Earth Obs. Geoinf. 2016, 50, 117–130. [Google Scholar] [CrossRef]
- Grzegozewski, D.M.; Johann, J.A.; Uribe-Opazo, M.A.; Mercante, E.; Coutinho, A.C. Mapping soya bean and corn crops in the State of Parana, Brazil, using EVI images from the MODIS sensor. Int. J. Remote Sens. 2016, 37, 1257–1275. [Google Scholar] [CrossRef]
- Radoux, J.; Chome, G.; Jacques, D.C.; Waldner, F.; Bellemans, N.; Matton, N.; Lamarche, C.; d’Andrimont, R.; Defourny, P. Sentinel-2’s potential for sub-pixel landscape feature detection. Remote Sens. 2016, 8, 488. [Google Scholar] [CrossRef] [Green Version]
- Forkuor, G.; Dimobe, K.; Serme, I.; Tondoh, J.E. Landsat-8 vs. Sentinel-2: Examining the added value of sentinel-2’s red-edge bands to land-use and land-cover mapping in Burkina Faso. GISci. Remote Sens. 2017, 55, 331–354. [Google Scholar] [CrossRef]
- Immitzer, M.; Vuolo, F.; Atzberger, C. First experience with Sentinel-2 data for crop and tree species classification in central Europe. Remote Sen. 2016, 8, 166. [Google Scholar] [CrossRef]
- Vogelmann, J.E.; Tolk, B.; Zhu, Z.L. Monitoring orest changes in the southwestern United States using multitemporal Landsat data. Remote Sens. Environ. 2009, 113, 1739–1748. [Google Scholar] [CrossRef]
- Blasco, J.M.D.; Fitrzyk, M.; Patruno, J.; Ruiz-Armenteros, A.M.; Marconcini, M. Effects on the double bounce detection in urban areas based on SAR polarimetric characteristics. Remote Sens. 2020, 12, 1187. [Google Scholar] [CrossRef] [Green Version]
- Gella, G.W.; Bijker, W.; Belgiu, M. Mapping crop types in complex farming areas using SAR imagery with dynamic time warping. ISPRS J. Photogramm. Remote Sens. 2021, 175, 171–183. [Google Scholar] [CrossRef]
- Steinhausen, M.J.; Wagner, P.D.; Narasimhan, B.; Waske, B. Combining Sentinel-1 and Sentinel-2 data for improved land use and land cover mapping of monsoon regions. Int. J. Appl. Earth Obs. Geoinf. 2018, 73, 595–604. [Google Scholar] [CrossRef]
- Dong, J.W.; Xiao, X.M.; Menarguez, M.A.; Zhang, G.L.; Qin, Y.W.; Thau, D.; Biradar, C.; Moore, B. Mapping paddy rice planting area in northeastern Asia with Landsat 8 images, phenology-based algorithm and Google Earth Engine. Remote Sens. Environ. 2016, 185, 142–154. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- You, N.S.; Dong, J.W. Examining earliest identifiable timing of crops using all available Sentinel 1/2 imagery and Google Earth Engine. ISPRS J. Photogramm. Remote Sens. 2020, 161, 109–123. [Google Scholar] [CrossRef]
- Illera, P.; Delgado, A.J.; Calle, A. A navigation algorithm for satellite images. Int. J. Remote Sens. 1996, 17, 577–588. [Google Scholar] [CrossRef]
- Ryu, Y.; Berry, J.A.; Baldocchi, D.D. What is global photosynthesis? History, uncertainties and opportunities. Remote Sens. Environ. 2019, 223, 95–114. [Google Scholar] [CrossRef]
- Shelestov, A.; Lavreniuk, M.; Kussul, N.; Novikov, A.; Skakun, S. Exploring Google Earth Engine platform for big data processing: Classification of multi-temporal satellite imagery for crop mapping. Front. Earth Sci. 2017, 5, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Tamiminia, H.; Salehi, B.; Mahdianpari, M.; Quackebush, L.; Adeli, S.; Brisco, B. Google Earth Engine for geo-big data applications: A meta-analysis and systematic review. ISPRS J. Photogramm. Remote Sens. 2020, 164, 152–170. [Google Scholar] [CrossRef]
- Deines, J.M.; Kendall, A.D.; Crowley, M.A.; Rapp, J.; Cardille, J.A.; Hyndman, D.W. Mapping three decades of annual irrigation across the US High Plains Aquifer using Landsat and Google Earth Engine. Remote Sens. Environ. 2019, 233, 111400. [Google Scholar] [CrossRef]
- Defourny, P.; Bontemps, S.; Bellemans, N.; Cara, C.; Dedieu, G.; Guzzonato, E.; Hagolle, O.; Inglada, J.; Nicola, L.; Rabaute, T.; et al. Near real-time agriculture monitoring at national scale at parcel resolution: Performance assessment of the Sen2-Agri automated system in various cropping systems around the world. Remote Sens. Environ. 2019, 221, 551–568. [Google Scholar] [CrossRef]
- Phalke, A.R.; Ozdogan, M.; Thenkabail, P.S.; Erickson, T.; Gorelick, N.; Yadav, K.; Congalton, R.G. Mapping croplands of Europe, Middle East, Russia, and Central Asia using Landsat, Random Forest, and Google Earth Engine. ISPRS J. Photogramm. Remote Sens. 2020, 167, 104–122. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sensor | Resolution (m) | Revisit (Days) | Scenes | ||||
|---|---|---|---|---|---|---|---|
| May | Jun. | Jul. | Aug. | Sep. | |||
| Sentinel-2 | 10/20 | 5 | 149 | 161 | 214 | 223 | 183 |
| Sentinel-1 | 10 | 12 | 73 | 56 | 61 | 65 | 66 |
| Sensor | Spectral Band | Wavelength (Micron) | Resolution(m) |
|---|---|---|---|
| Sentinel-1 | VH | 10 | |
| VV | 10 | ||
| Sentinel-2 | Band 2—Blue | 496.6 (S2A)/492.1 (S2B) | 10 |
| Band 3—Green | 560.0 (S2A)/559.0 (S2B) | 10 | |
| Band 4—Red | 664.5 (S2A)/665.0 (S2B) | 10 | |
| Band 5—Red Edge 1 | 703.9 (S2A)/703.8 (S2B) | 20 | |
| Band 6—Red Edge 2 | 740.2 (S2A)/739.1 (S2B) | 20 | |
| Band 7—Red Edge 3 | 782.5 (S2A)/779.7 (S2B) | 20 | |
| Band 8—NIR | 835.1 (S2A)/833.0 (S2B) | 10 | |
| Band 8A—Red Edge 4 | 864.8 (S2A)/864.0 (S2B) | 20 | |
| Band 11—SWIR 1 | 1613.7 (S2A)/1610.4 (S2B) | 20 | |
| NDVI = (Band 8 − Band 4)/(Band8 + Band 4) | 10 | ||
| EVI = 2.5 × (Band 8 − Band 4)/(Band 8 + 6 × Band 4 − 7.5 × Band 2 +1) | 10 | ||
| NDWI = (Band 3 − Band 8)/(Band 3 + Band 8) | 10 | ||
| LSWI = (Band 8 − Band 11)/(Band 8 + Band 11) | 10 | ||
| REP = 705 + 35 × (0.5 × (Band 7 + Band 4) − Band 5)/(Band 6 − Band 5) | 10 |
| Month | Overall Accuracy | User’s Accuracy | Producer’s Accuracy | Kappa Coefficient |
|---|---|---|---|---|
| May | 0.838 | 0.685 | 0.591 | 0.532 |
| Jun. | 0.914 | 0.824 | 0.813 | 0.763 |
| Jul. | 0.902 | 0.797 | 0.787 | 0.728 |
| Aug. | 0.921 | 0.826 | 0.844 | 0.783 |
| Sep. | 0.899 | 0.784 | 0.791 | 0.721 |
| May and Jun. | 0.923 | 0.844 | 0.825 | 0.787 |
| May and Jul. | 0.916 | 0.817 | 0.835 | 0.771 |
| May and Aug. | 0.920 | 0.842 | 0.840 | 0.790 |
| May and Sep. | 0.915 | 0.834 | 0.804 | 0.764 |
| Jun. and Jul. | 0.923 | 0.830 | 0.849 | 0.789 |
| Jun. and Aug. | 0.925 | 0.847 | 0.835 | 0.792 |
| Jun. and Sep. | 0.910 | 0.809 | 0.813 | 0.752 |
| Jul. and Aug. | 0.921 | 0.820 | 0.853 | 0.784 |
| Jul. and Sep. | 0.920 | 0.825 | 0.840 | 0.780 |
| Aug. and Sep. | 0.921 | 0.818 | 0.858 | 0.785 |
| May, Jun., and Jul. | 0.916 | 0.832 | 0.813 | 0.768 |
| May, Jun., Jul., and Aug. | 0.928 | 0.849 | 0.849 | 0.802 |
| May, Jun., Jul., Aug., and Sep. | 0.932 | 0.846 | 0.871 | 0.813 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, T.; Hu, Y.; Dong, J.; Qiu, S.; Peng, J. Integrating Sentinel-1/2 Data and Machine Learning to Map Cotton Fields in Northern Xinjiang, China. Remote Sens. 2021, 13, 4819. https://doi.org/10.3390/rs13234819
Hu T, Hu Y, Dong J, Qiu S, Peng J. Integrating Sentinel-1/2 Data and Machine Learning to Map Cotton Fields in Northern Xinjiang, China. Remote Sensing. 2021; 13(23):4819. https://doi.org/10.3390/rs13234819
Chicago/Turabian StyleHu, Tao, Yina Hu, Jianquan Dong, Sijing Qiu, and Jian Peng. 2021. "Integrating Sentinel-1/2 Data and Machine Learning to Map Cotton Fields in Northern Xinjiang, China" Remote Sensing 13, no. 23: 4819. https://doi.org/10.3390/rs13234819
APA StyleHu, T., Hu, Y., Dong, J., Qiu, S., & Peng, J. (2021). Integrating Sentinel-1/2 Data and Machine Learning to Map Cotton Fields in Northern Xinjiang, China. Remote Sensing, 13(23), 4819. https://doi.org/10.3390/rs13234819