1. Introduction
Passive remote sensing is the act of making observations from afar of light reflected from an object. This image data type is typically collected using a sensor mounted on an aircraft or spacecraft [
1]. Statistically grouping the data is required to classify the imagery in cover-types of similarity before extracting other quantitative information about the object or similar objects within the field of view.
Supervised classification refers to a class of methods used in the quantitative analysis of remote sensing image data. These methods require that the user provide the set of cover types in the image—e.g., water, cobble, deciduous forest, etc.—as well as a training field for each cover type. The training field typically corresponds to an area in the image that contains the cover type, and the collection of all training fields is known as the training set or ground-truth data. The ground-truth data is then used to assign each pixel to its most probable cover type.
Our objective in this paper is to present MATLAB software for the classification of remotely sensed images. Several well-known software packages exist for classifying remote sensing imagery, e.g., ArcGIS, however, these packages are expensive and tend to be complicated enough that a GIS specialist is required for their use. MATLAB is also expensive, but it is widely used in the imaging science and scientific computing communities, and our package is stripped-down and easy-to-use, requiring no special expertise. This software will provide the applied scientist who has access to MATLAB a software package containing a few of the highly effective classification methods presented in [
1]. The software is also unique in that it allows the user to create ground-truth data from a particular image via a graphical user interface (GUI). The software includes spectral-based classification as well as classifiers that incorporate the spatial correlation within typical images. We emphasize that we are not presenting any new classification methods in this paper, and so we do not provide comparisons with other algorithms.
A remotely sensed image contains both spectral and spatial information. In our software package, we advocate first computing a spectral-based classification using quadratic discriminant analysis (QDA) (also called maximum likelihood classification [
1]). QDA is popular due to its simplicity and compact training process [
2]. It assumes images are multivariate normally distributed, which suggests a natural thresholding method. A vast number of other supervised classification schemes exist [
3], however in [
4] it is noted that simpler methods, such as QDA, often achieve over 90% of the predictive power obtained by the most advanced methods, though such good performance is not guaranteed. Moreover, in the comparison studies of algorithms found in [
2], it is shown that the QDA classifier excels over artificial neural networks and decision trees in design effort, training time, and classification accuracy; and in [
5,
6] it was shown that although neural/connectionist algorithms make no assumption on statistical distribution, as does QDA, training time can be lengthy and the choice of design architecture is rather complex.
Nonetheless, a major drawback of QDA is that it ignores the spatial arrangement of the pixels within an image [
7]. The correlation that exists between neighboring pixels within an image (see, e.g., [
8,
9,
10]) should, in many instances, be incorporated into a classification scheme [
1,
11]. The effect of spatial autocorrelation and its relation to spatial resolution in an image has been explored in remote sensing [
9,
10,
12], but less has been done to directly incorporate spatial autocorrelation into classification. In our software, we use the pre-classification filters and neighborhood exploitation methods described in [
1,
12] for dealing with spatial autocorrelation. Each of these techniques may or may not reclassify a given pixel based on information about its neighbors. Finally, in order to test the effectiveness of our classification schemes, we have implemented k-fold cross validation.
The classification techniques used in remote sensing come from the field of mathematical pattern recognition and are extensively covered in work within that discipline. Particular references that give more background and more variation in algorithms than we have presented above are found in [
13,
14,
15]. We emphasize, again, that our goal here is to present a useful software package, not to present new classification algorithms, which would require comparisons and a longer list of references. However, we do point the reader to some recent references, first to habitat mapping algorithms incorporating Moran’s I spatial autocorrelation [
16,
17]. Spatial relationships of pixels in the image are also in object-based image analysis (OBIA), which is also utilized in underwater habitat mappying studies [
18,
19,
20].
This paper is arranged as follows. First, in
Section 2, we derive both non-spatial and spatial algorithms for supervised classification and present
k-fold cross validation, as well as a technique for thresholding. In
Section 3, classification is carried out on a variety of images using a sampling of the methods from
Section 2. A discussion and summary of the methods and the results is given in
Section 5.
2. Methods
We begin with a presentation our spectral-based classifier, QDA. The spatial-based techniques follow, and then we present a thresholding method, as well as k-fold cross validation for error assessment.
2.1. Spectral-Based Classification: Quadratic Discriminant Analysis
We begin by letting
be the
of the
M spectral classes, or cover types, in the image to be classified. When considering to which spectral class, or cover type, a particular pixel vector
belongs, we denote the conditional probability of
x belonging to
by
, for
. We are interested in the spectral class that attains the greatest probability given
x. Thus classification will yield
when
It remains to define
, which can be related to the conditional probability
via Bayes’ theorem
where
is the probability that the
spectral class occurs in the image; and
is the probability density associated with the spectral vector
x over all spectral classes. In Bayes’ terminology,
is referred to as the prior probability and is used to model
a priori knowledge.
Substituting (
1) into (
2), and assuming that
is the same for all
i, the inequality (
1) takes the form
We assume the probability distributions for the classes are multivariate normal, so that
where
and
are the mean vector and covariance matrix, respectively, of the data in class
.
To simplify the above equation, we use the discriminant functions
defined to be the natural logarithm of (
3), which preserves the inequality since the logarithm is a monotone increasing function. Thus our method classifies
x as an element of
when
where
From here, a variety of different classifiers can be derived based on assumptions on the discriminant function and the probability model. However, we have found quadratic discriminant analysis (QDA) to be both very effective, computationally efficient, as well as straightforward to implement. QDA is given by (
5), (
6), with the mean and covariance in (
6) approximated using the empirical mean and covariance of the data in ground-truth class
i. The effective
k-nearest neighbor method [
3] was not implemented due to its greater computational burden.
2.2. Spatial-Based Techniques
In QDA, the classification of a particular pixel does not depend on that of it’s neighbors. In certain instances, it is clear that neighbor information should be taken into account. For instance, in an image containing a river, the pixels in the “water class” should be distributed in a spatially uniform manner in the classified image. In order to take into account such prior information, additional techniques are needed.
Four separate approaches were taken for incorporating spatial autocorrelation of the remotely sensed data into classification: pre-classification filtering, probabilistic label relaxation, post-classification filtering, and Markov random Fields. Each of the four are described in detail in the following subsections.
2.2.1. Pre-Classification Filtering
Pre-classification filtering can be viewed as a denoising technique (low pass filter) for the image to be classified. The filtering is implemented prior to classification and hence does not directly incorporate spatial context into the classification scheme. However, it does impose a degree of homogeneity among neighboring pixels, increasing the probability that adjacent pixels will be classified into the same spectral class.
It requires a neighborhood matrix. In our implementation, we include a first-, second-, and third-order neighborhood:
Convolution of an image by one of these neighborhood matrices yields a new image in which each pixel value has been replaced by a weighted average of the neighboring pixels (including itself) of the original image, with the weighting given explicitly by the values in the chosen neighborhood matrix. If the neighborhood is too large comparative to the degree of spatial autocorrelation, the quantitative distinction between cover types could be lost, so the hope is that the neighborhoods used are large enough to incorporate neighboring information, but not so large that individuality of pixels is lost.
To incorporate pre-classification filtering into the algorithm, the conv2 function in MATLAB is used. Each band of the image was convolved separately with the neighborhood matrix and the same size matrix was asked to be returned so the buffer placed on the image was not returned as well.
2.2.2. Post-Classification Filtering
To filter post-classification, a classification labeling must first be performed. The classified map is then filtered with a defined neighborhood to develop a degree of spatial context. This is a similar idea to the pre-classification filtering method, however, the conv2 function from MATLAB cannot be used in this case due to the categorical response of the classified map; e.g., the spectral classes are not ordered such that a pixel in class 1 is closer in form to a pixel in class 2 than it is to a pixel in class 5. Thus a weighted average of neighboring pixels will not give us information about the central pixel.
Instead we must filter using a different approach [
21]. First, a window size is chosen to define the neighborhood size—in our implementation, we use a
window surrounding the central pixel—and each pixel is relabeled by selecting the spectral class that occurs most often in the neighborhood window.
To implement this in MATLAB, a 1-pixel buffer was placed around the entire image by replicating its closest pixel, since it is probable that the boundary pixel’s adjacent pixel is of the same spectral class. The nlfilter function was then used on the classified map with the mode function, and the buffer pixels were removed.
2.2.3. Probabilistic Label Relaxation
While post-classification filtering can be effective, it only uses the classified image to incorporate spatial context. Given that we have the values of the discriminant function (and hence the corresponding probabilities), it is tempting to want to use this information as well. Probability label relaxation (PLR) is a technique that uses this information to incorporate spatial homogeneity in the classification [
1].
The PLR algorithm begins with a classification—in our case using QDA—as well as with the corresponding set of probabilities
that pixel
x belongs to spectral class
. A neighborhood is then defined for
x and neighboring pixels are denoted by
y. The neighborhood should be large enough that all pixels considered to have spatial correlation with pixel
x are included [
1]; in our implementation, we simply use the pixels to the left, right, above, and below.
A neighborhood function
is then defined so that all pixels in the neighborhood have some influence over the probability of pixel
x belonging to
. The probabilities defined by
are then updated and normalized using
. This is done iteratively so that the PLR algorithm has the form
It remains to define the neighborhood function . We begin with the compatibility coefficient defined by the conditional probability , i.e., the probability that is the correct classification of pixel x given that is the correct classification for neighboring pixel y. We assume that is independent of location, so that it is only the relative location of y with respect to x, and whether or not it is one of its neighbors, that matters. Then, using the previously computed classification, we can compute by looking at the ratio of occurrences of a pixel x and its neighbors y being classified into and , respectively. A location dependent definition for can also be given, but we do not do that in our implementation.
The probabilities
, which we have in hand, are then modified via the equation
In the approach for computing
mentioned in the previous paragraph, this amounts to simple matrix multiplication. Our neighborhood function is then defined as a spatial average of the values of (
9), i.e.,
where
are the weights for each neighboring pixel
y. Generally the weights will all be the same—as is the case for us—unless there is prior knowledge about stronger spatial autocorrelation in one direction than another.
It is recommended that algorithm (
8) be iterated until the probabilities have stabilized. There is no predetermined number of iterations for this process to terminate, though in practice it has been observed that beyond the first several iterations the relaxation process can begin to deteriorate [
22]. Richards [
1] mentions that five to ten iterations will typically produce satisfactory results.
2.2.4. Markov Random Fields
The neighborhood function used in PLR, though intuitive, can only be justified heuristically. Another approach that incorporates spatial context, and that can be justified mathematically, from a Bayesian viewpoint, is Markov random fields (MRF).
Suppose the image of interest has pixel data , where N is the number of pixels. Let denote the spectral class of . Then the set of class labels for the entire image can be represented as , where i can be one of . Our task is to compute a random field that well-approximates the “true” class labeling of the image under investigation.
We now take a Bayesian point of view and assume that
is a random array with (prior) distribution
. In this context,
is sometimes referred to as a random field. Through classification, we seek the random field
that correctly identifies the ground-truth, and thus hopefully correctly identifies the entire image. For this we maximize the posterior probability
, i.e., from Bayes’ theorem we compute
Since spatial autocorrelation typically exists in images, we incorporate it into the posterior probability. Considering a neighborhood
around a pixel vector
, we denote the labels on this neighborhood
,
and our objective is now to maximize
. Using probability theory we can manipulate the conditional probability as follows
To simplify (
11), note that
is the probability distribution of
conditional on both its labeling as the
class and its given neighborhood labelings
for
. We assume that this conditional distribution is independent of the neighborhood labelings, i.e.,
. Then we also have that the measurement vector
is independent of its neighborhood labeling, and hence,
. Substituting these expressions into Equation (
11) then yields
The conditional prior probability
is the probability for class
i of pixel
n given the neighborhood labels
. This conditionality forces our random fields of labels to be known as Markov Random Fields (MRF). Knowing that we have a MRF gives us the ability to express
in the form of a Gibbs distribution
where
is based on the Ising model
The term
is the Kroneker delta, which takes value 1 if the arguments are equal and 0 otherwise. We will take
as suggested in [
1]. The parameter
, fixed by the user, controls the neighborhood effect. We can now take
to be given by (
4).
Taking the natural log of
, as in our derivation of QDA, yields the discriminant function for classification
Here is sometimes referred to as a regularization parameter, and it must be specified by the user.
Notice that before the Kroneker delta can be computed in the above MRF discriminant function, an initial classification must be computed. We do this using the QDA classifier. Thus the MRF discriminant function modifies a given set of labels based on a neighborhood effect. This process should be iterated until there are no further changes in labeling [
1]; 5–10 iterations is typically sufficient.
2.3. Error Assessment
2.3.1. Thresholding
The QDA method can only classify a pixel into one of the originally given spectral classes. The question arises, what happens if the ground-truth data is incomplete, i.e., there are missing classes? In such cases, it is useful to have an additional spectral class designed for pixels that, with some degree of certainty, do not fit into one of the original spectral classes noted by the user. The technique of thresholding addresses this problem.
Thresholding compares the probability value of to a user specified threshold. If the probability value is lower than the threshold, the pixel will be assigned to a discard class. Thus, thresholding extracts the pixels with a low probability of belonging to any of the training classes and places them into the discard class.
With thresholding, our classification schema now returns
x as an element of
when
where
is the threshold associated with spectral class
. It is only when the above does not hold for any
i that
x is then classified into the discard class.
To determine
, we examine the discriminant function; for QDA, it is given by (
6) and the second inequality in (
13) becomes
Assuming
x is normally distributed with mean
and covariance
, the left hand side of (
14) is known to have a
distribution with
k degrees of freedom (recall,
[
23]. The corresponding
value can be found using MATLAB’s
chi2inv function for the desired confidence, yielding a corresponding value for
.
2.3.2. K-Fold Cross Validation
Once a classification has been made, we are interested in how accurately it performed. Since the image in its entirety is unknown, we look to the ground-truth data. First, the ground-truth data set is partitioned into K approximately equal-sized parts. Remove the first part and set it aside to be used as the testing set while the remaining sets become the adjusted training set. The classifier is created with the adjusted training set and is then used to classify the testing set. For example, if , this is equivalent to using of the ground-truth to classify the remaining of the ground-truth. The classified set is then compared to the ground-truth pixels, respectively, and the percent of misclassified pixels is noted. This process is repeated K times (folds) so that each of the K sets is used exactly once as a testing set. The average percent of misclassified pixels is reported.
The recommended
K for
K-fold cross validation (CV) is
or 10 [
3]. If instead,
K is taken to be the total number of ground-truth pixels,
N, this process is known as the leave-one-out cross validation method. This is approximately unbiased, however it may result in high variance due to the similarities between the
N training sets and can be computationally costly. With
or 10, the variance is lower, but bias may play a role in the error assessment. If the classifier is highly affected by the size of the training set, it will overestimate the true prediction error [
3].
4. Discussion
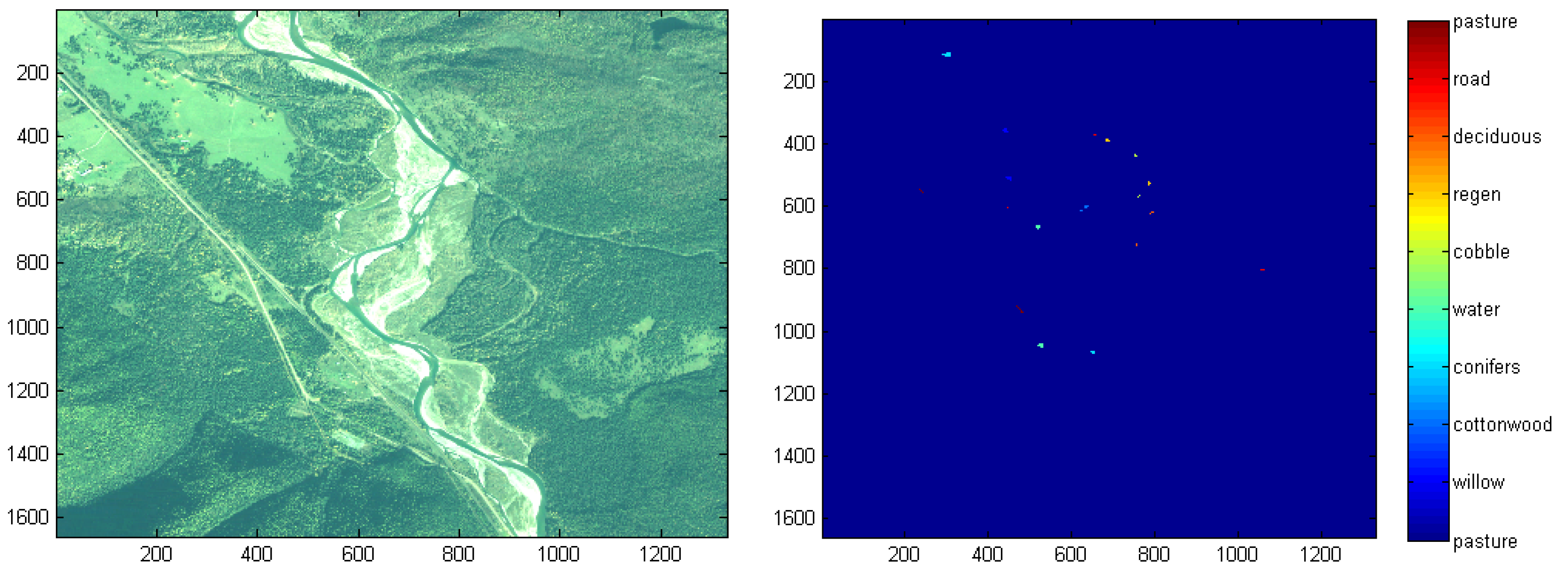
Assessment of habitat abundance and spatial distribution is a fundamental first order analytical requirement for many ecological questions regarding the structure and function of freshwater systems. Cover type mapping of habitat areas began shortly after introducing aerial photographic imagery to map landscape cover over broad areas. For 25 decades it was conducted by manually drawing polygons around standard features, common vegetation types or exposed substrate, and water surfaces of rivers and streams. The approach was helpful in early attempts to determine the available area of critical habitat for organisms and define corridors of connected habitat. Our software makes habitat mapping approachable to a wide range of practitioners working in freshwater systems (e.g., ecologists, fisheries biologists, wetland scientists) by allowing them to interact with the imagery in a long held and intuitive way of manually identifying points, drawing lines or polygons around habitats recognizable to those subject experts.
Subjective human interpretation regarding the visual choices of habitat similarity observed in the imagery limited cover type mapping. The time involved in creating the polygons and accurately determining polygon area due to distortion in images and mosaics also limited the approach. Hence, the onset of more modern multi-spectral imagery, airborne and satellite, coupled with automated rectification procedures enhanced habitat analysis. However, developing automatic and objective cover-type mapping approaches has been evolving since the onset of remote sensing of landscapes. Our software solves these obstacles and hence provides a robust, accurate and easy to use objective method of freshwater habitat assessment using remote sensing imagery as well as historical black and white aerial photographs. The ability to link habitat analysis through cover type mapping of historical aerial photographs to recent satellite imagery improves our understanding of change freshwater systems have undergone over the past decades of climate change.
To test our software, we consider images of river flood plains, which are among the most dynamic and threatened ecosystems on the planet [
24]. Flood plains are endangered worldwide because most have been permanently inundated by reservoirs which also reduce geomorphic forming flows or are disconnected by dikes and armored by bank stabilization structures [
25]. River ecosystems are in a state of constant change, both on the seasonal and yearly scales, as well as over the course of decades [
26]. Remote sensing of flood plain imagery has become a valuable tool for conserving and protecting ecosystem goods and services that are important to human well being through modeling river dynamics [
26,
27]. Modeling this change is crucial to river ecologists. In particular, analyzing cover type changes over time allows the river ecologist to address physical and ecological questions at scales relevant to large river ecology and management of those ecosystem components. To perform such an analysis, the collection of remotely sensed images is required, as is the classification of the collected imagery for which our software provides a key tool for practitioners to use that is easy to use and free to download.
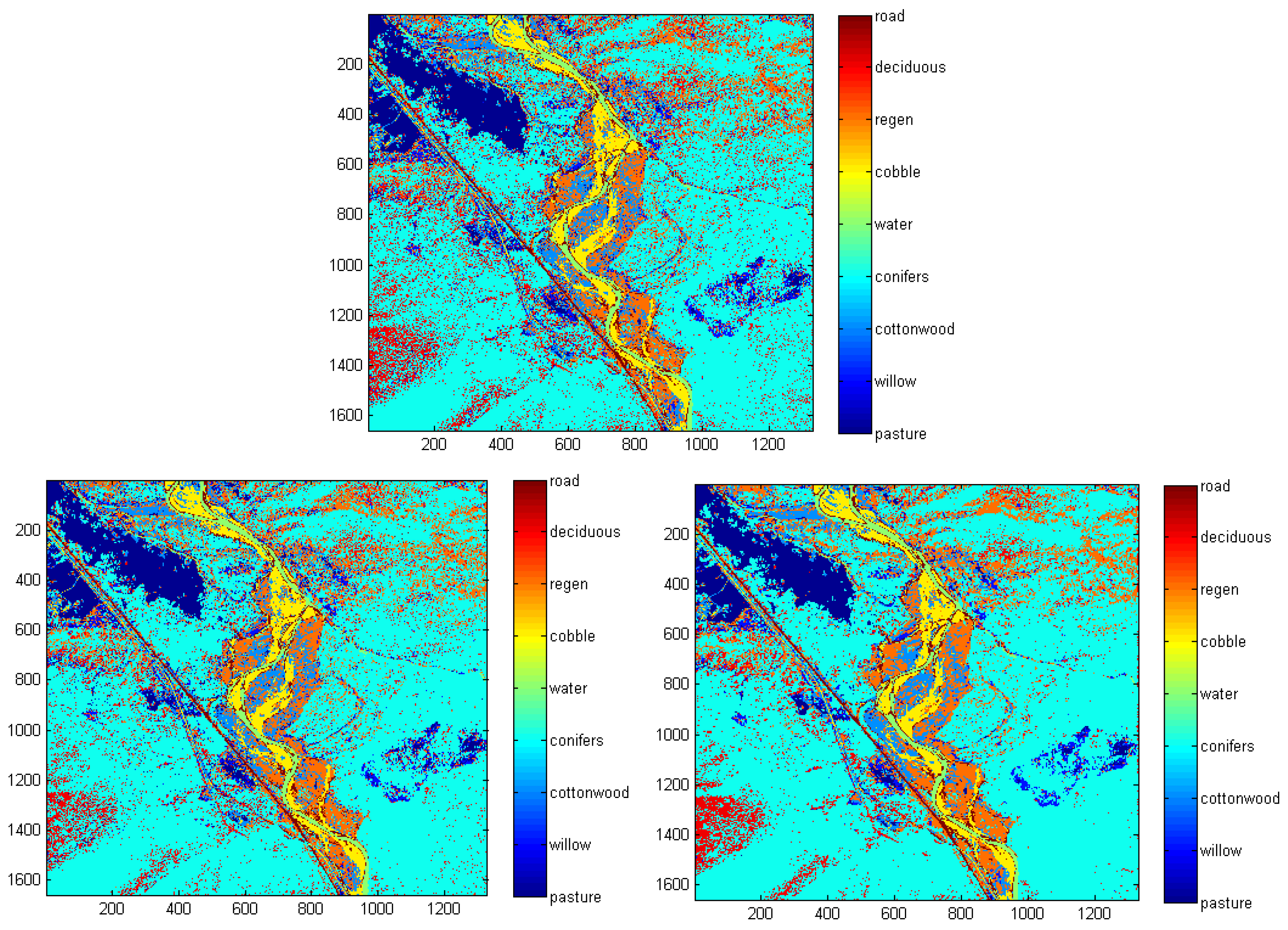
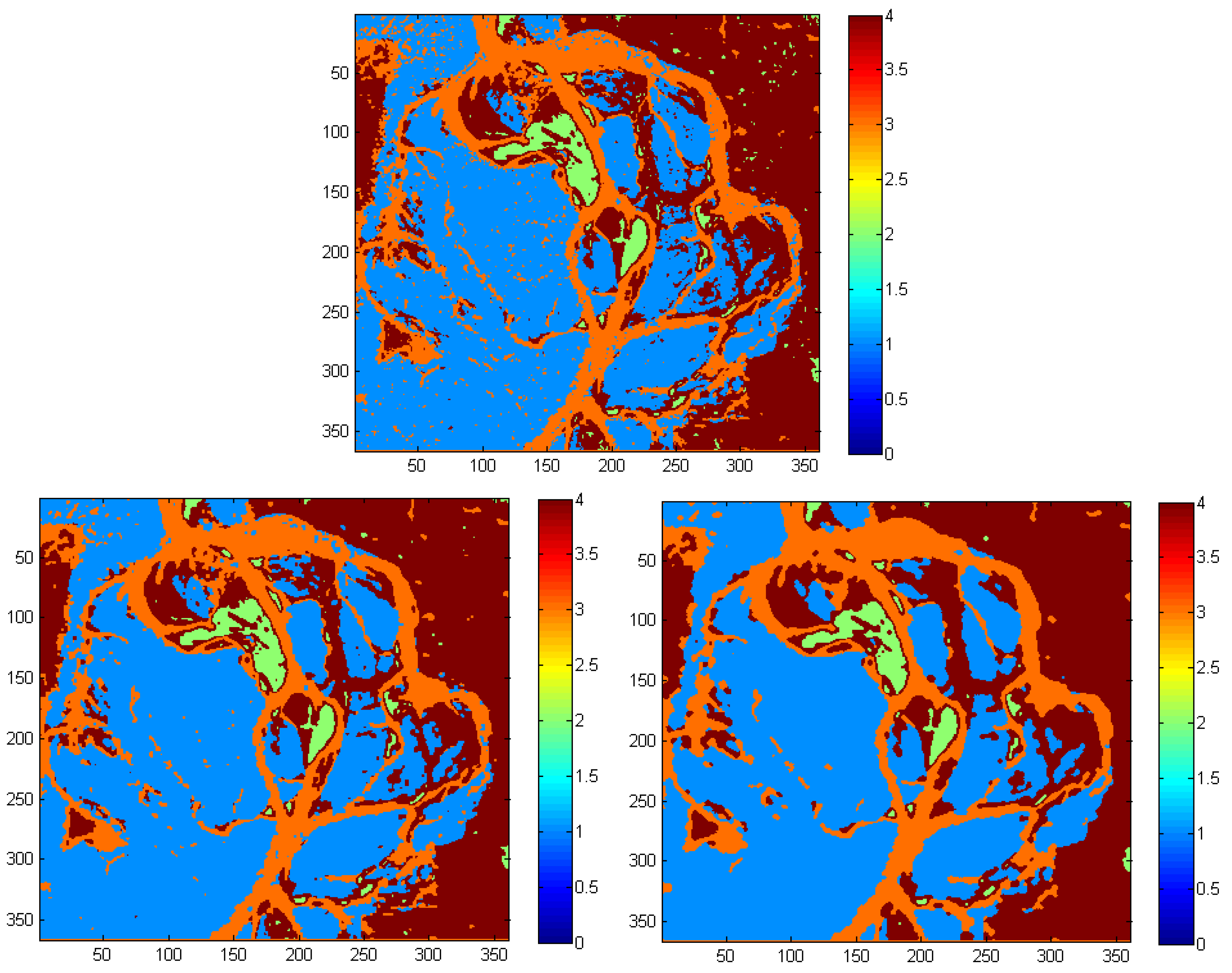
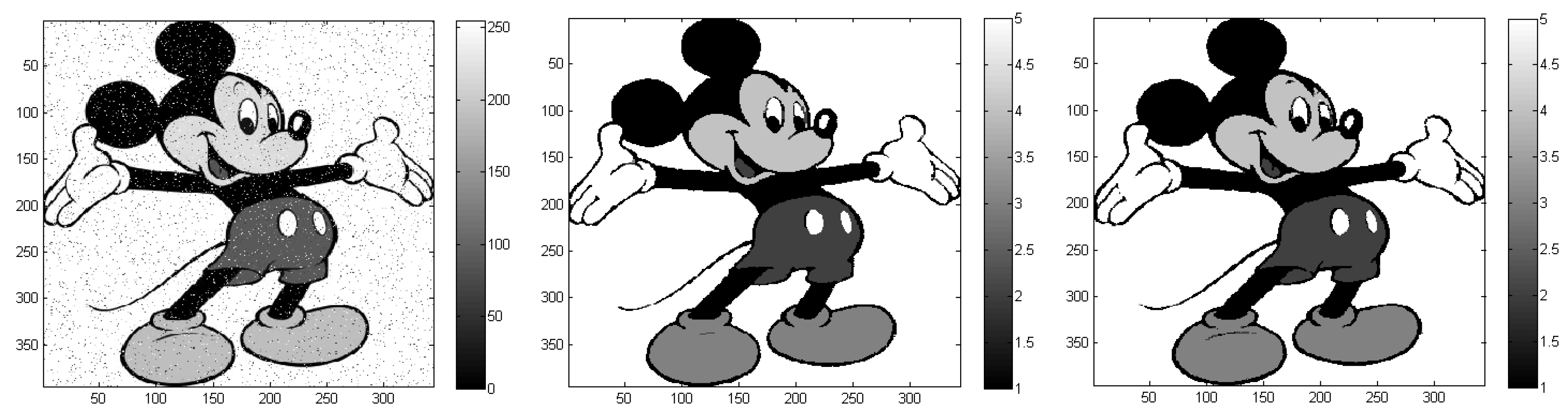
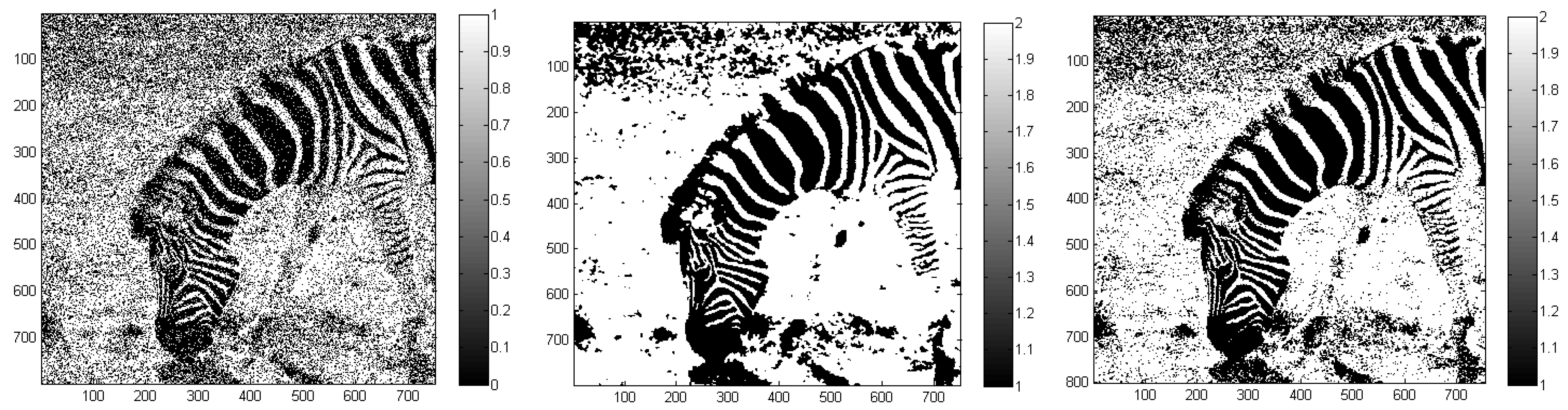
For example, we demonstrated that increased spatial homogeneity can be obtained when PLR, and more noticeably when MRF, are used (
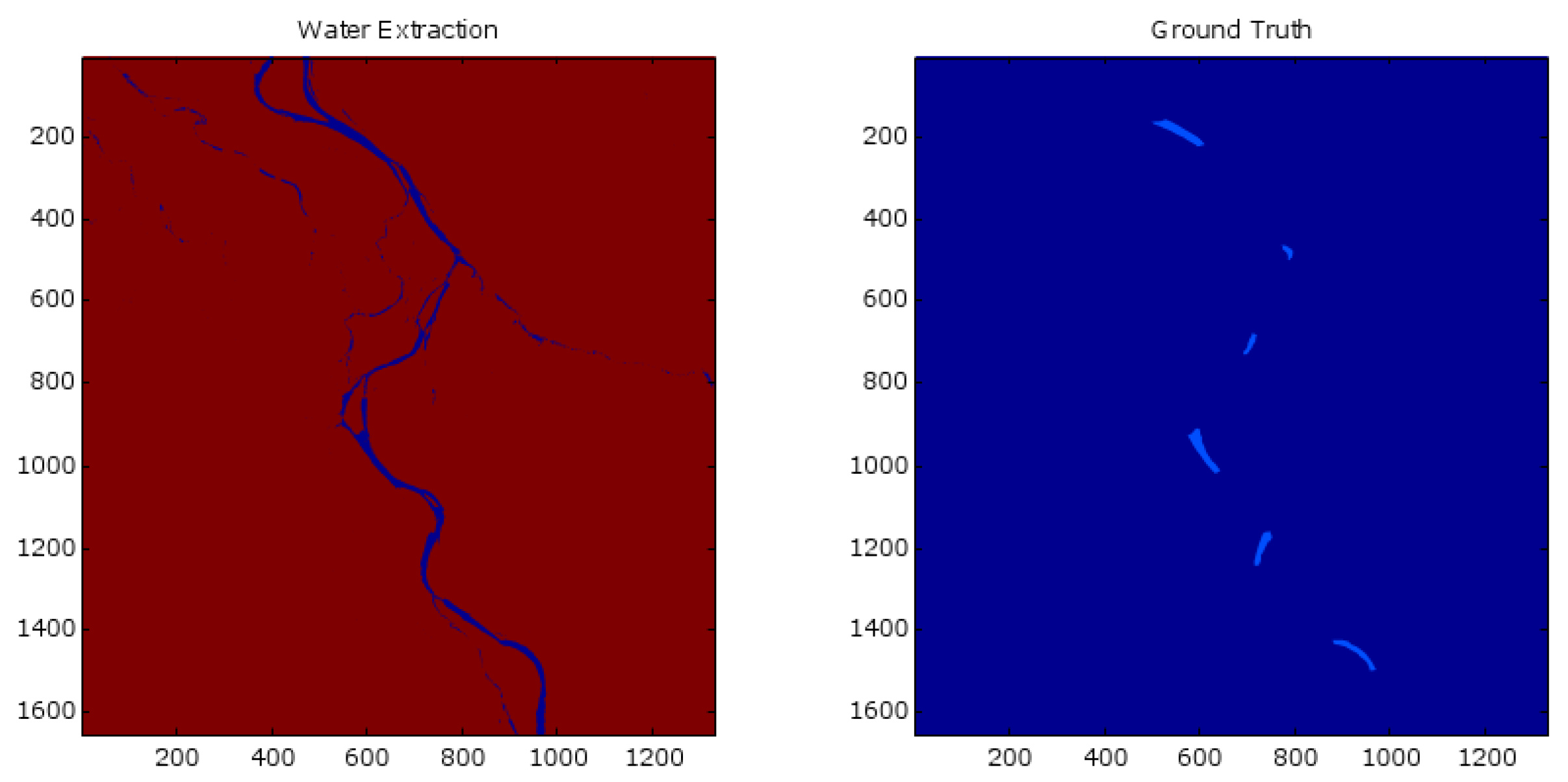
Figure 2). If the user knows, prior to classification, that spatial homogeneity exists, this can be enforced using PLR or MRFs in an efficient manner. When testing our software using imagery from river floodplains we purposefully choose ground truth data that was not necessarily optimal in the sense of yielding the most accurate classification, but was chosen to test the software as shown with the example from the Kwethulk River in Alaska (
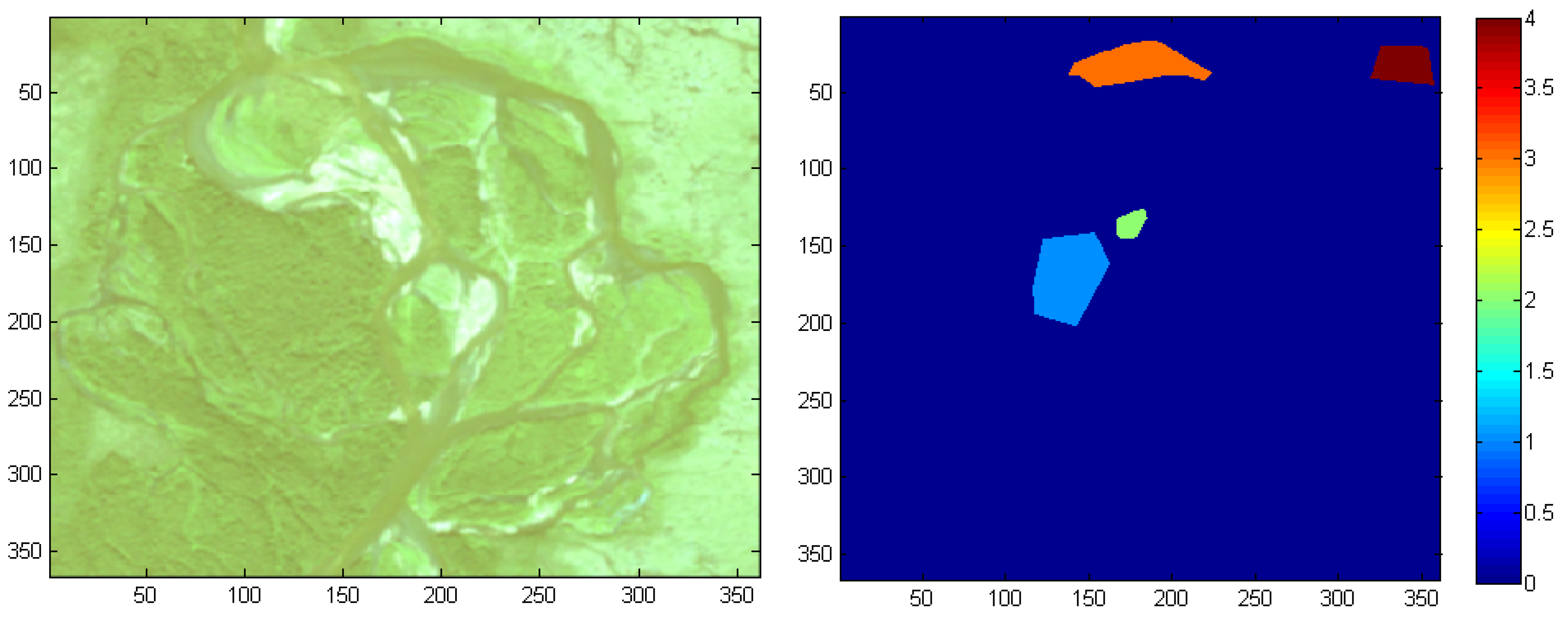
Figure 3). Ground truth pixels that represent a cover type (e.g., groups of similar trees) are isolated by enclosing within a polygon or by intersecting with a line or point. If the image requires being zoomed in to view ground-truth pixels for selection, this adjustment needs to be completed before selecting the preferred button for delineating ground-truth data. Therefore, smaller more precise polygons could have been added as well as simply increasing the number of ground truth data using lines or even individual points would increase the accuracy of the classification.
Thresholding is a method to increase classification accuracy. The QDA method can only classify a pixel into one of the originally given spectral classes. The question arises, what happens if the ground-truth data is incomplete resulting in missing classes? The technique of thresholding addresses this problem by allowing or expanding additional spectral classes designed for pixels that, with some degree of certainty, do not fit into one of the original spectral classes noted by the user. Once a classification has been made, we are interested in how accurately it performed. K-fold cross validation is the method we have employed in our software. The classified set is then compared to the ground-truth pixels, respectively, and the percent of misclassified pixels is noted.
Many questions and issues to be solved in freshwater systems require application of remote sensing data. Researchers in academia, government agencies and private sector consulting and engineering firms are pushing hard to solve global water problems related to climate change. Remote sensing of river discharge is a rapidly evolving application [
28,
29]. Mapping of river channel bathymetry is generally determined by applications of airborne LIDAR data but also through acoustic based sonar with some attention to also mapping the flow field [
27,
29,
30,
31,
32,
33]. Our software fills a need for objective, repeatable and robust cover type mapping of rivers especially when coupled with other methods and approaches to use remote sensing to address the structure and function of freshwater systems.
5. Conclusions
In this paper, we outline a MATLAB software package for the supervised classification of images. The software uses quadratic discriminant analysis (QDA) for spectral classification and contains three methods for spatial smoothing after a spectral classification has been computed. These spatial methods include mode filtering, probability label relaxation, and Markov random fields. Also included is a thresholding technique based on the multi-variate Gaussian assumption used in the motivation of QDA, as well as k-fold cross validation for error analysis.
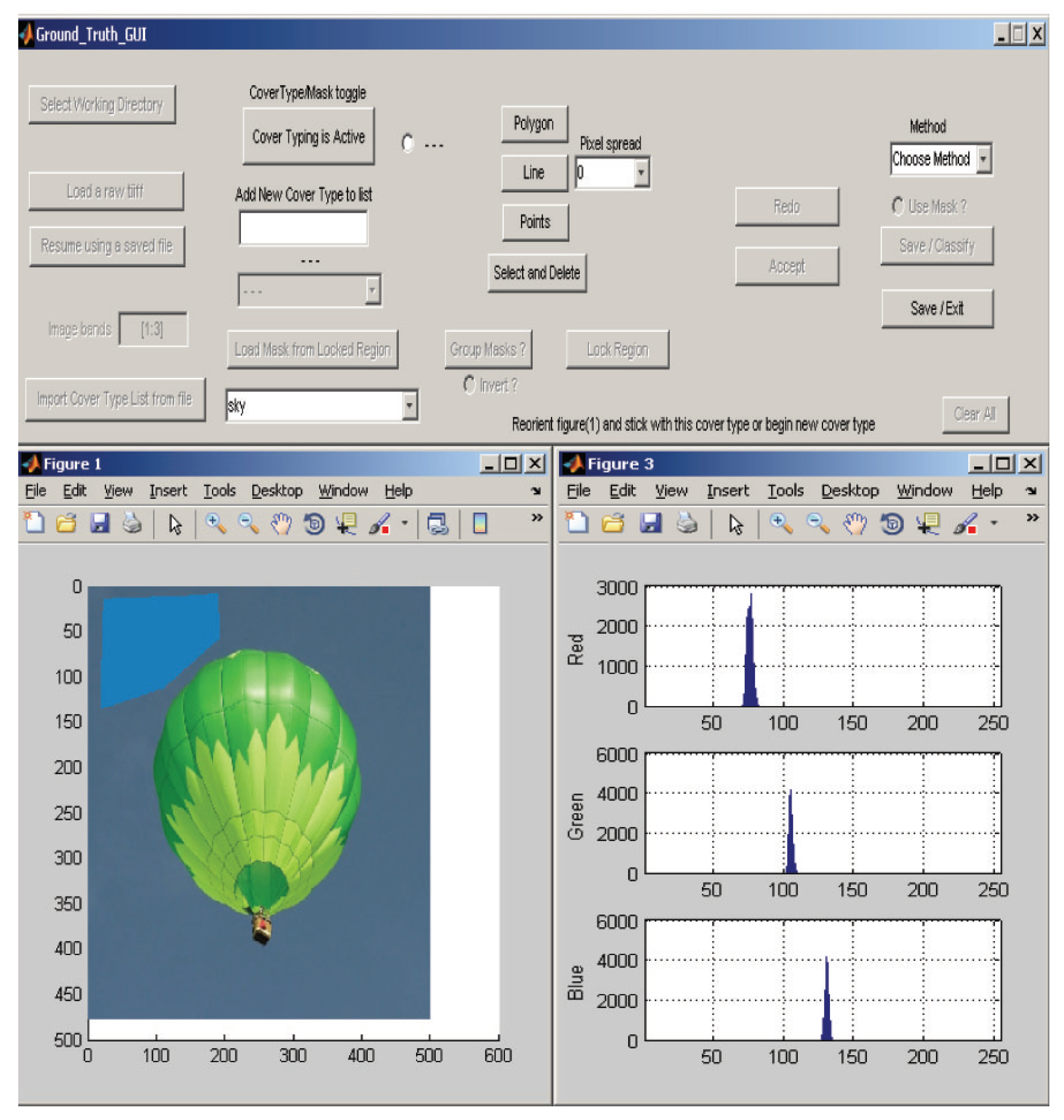
The software contains a graphical user interface (GUI) that enables the user to generate subsets, known as ground-truth data, for building statistical classifiers. Current versions of MATLAB do not contain such software, hence the use of the ground-truth GUI is essential in allowing our classification software to be widely and easily useable.
The software is tested on a number of images—two examples from remote sensing and three generic images—in order to illustrate its usefulness on a broad range of image processing applications. The examples also show that the software is useful, easy to use, and efficient on large-scale problems.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}








