
Adaptive Feature Weighted Fusion Nested U-Net with Discrete Wavelet Transform for Change Detection of High-Resolution Remote Sensing Images

Abstract
:
1. Introduction
- 2-dimensional discrete wavelet transform is introduced into the Nested U-Net, which can reduce the loss of spatial information resulting from pooling during encoding, and provide sufficient feature information for further change detection and change map reconstruction.
- Adaptive weight parameters are calculated in different ways in the feature fusion of the decoding and output stages. Moreover, in the process of training, the relationship between the features is adaptively modeled, which improves the feature representation ability.
- The comparative experiments with seven state-of-the-art methods on two change detection datasets show that the proposed method has better performance than other methods in detecting changed objects of different scales and positioning the boundary of changed objects.
2. Related Work
2.1. Methods of Enhancing Feature Discrimination
2.2. Methods of Feature Fusion
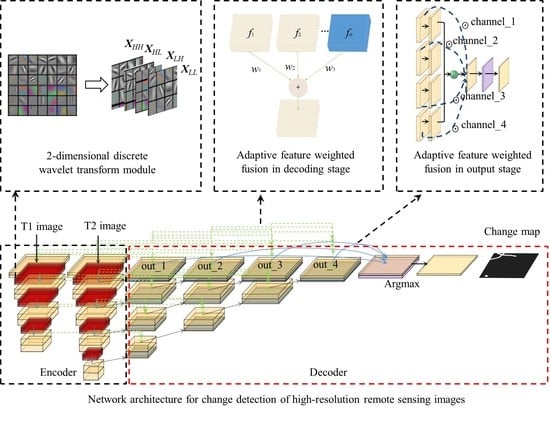
3. Methodology
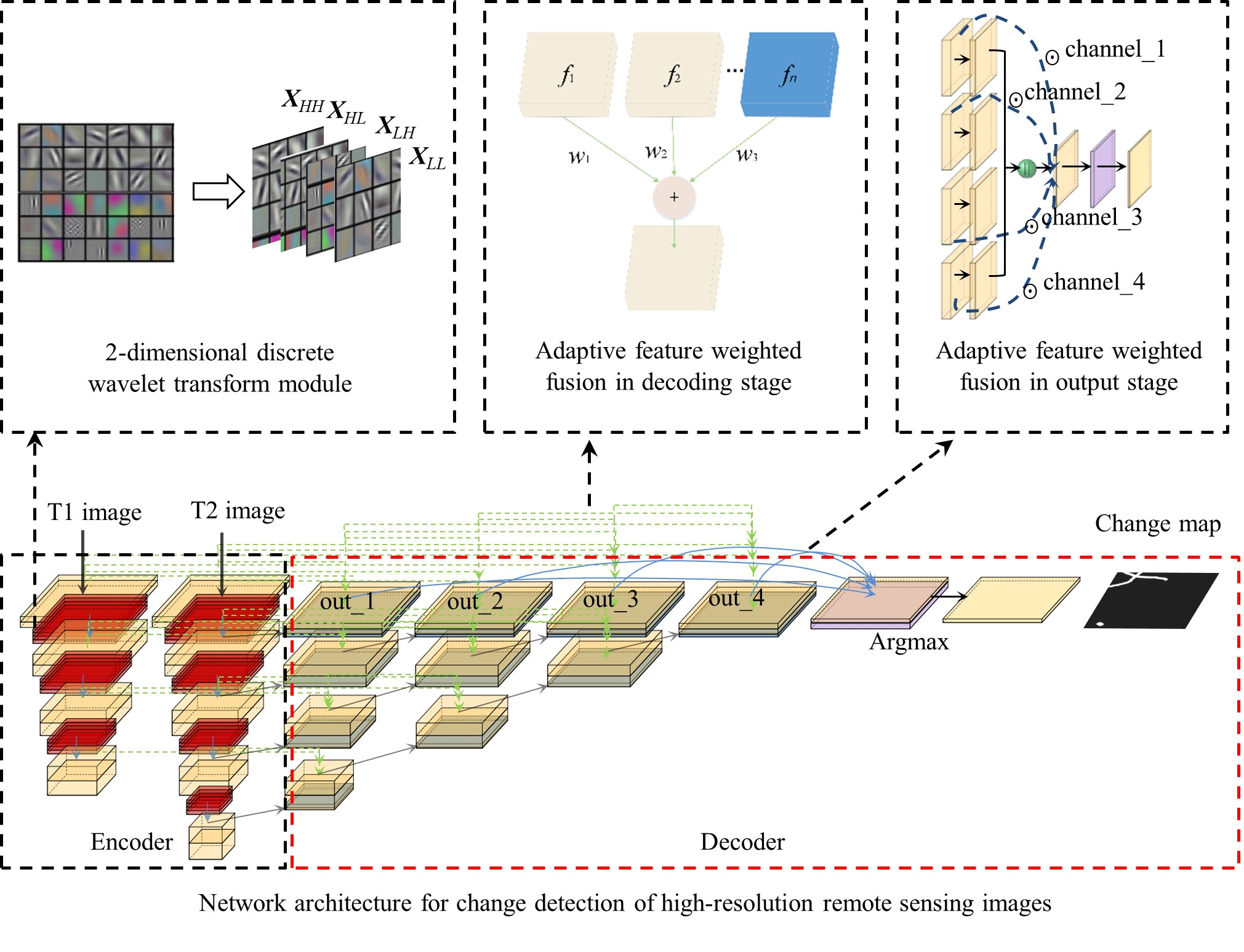
3.1. Network Architecture
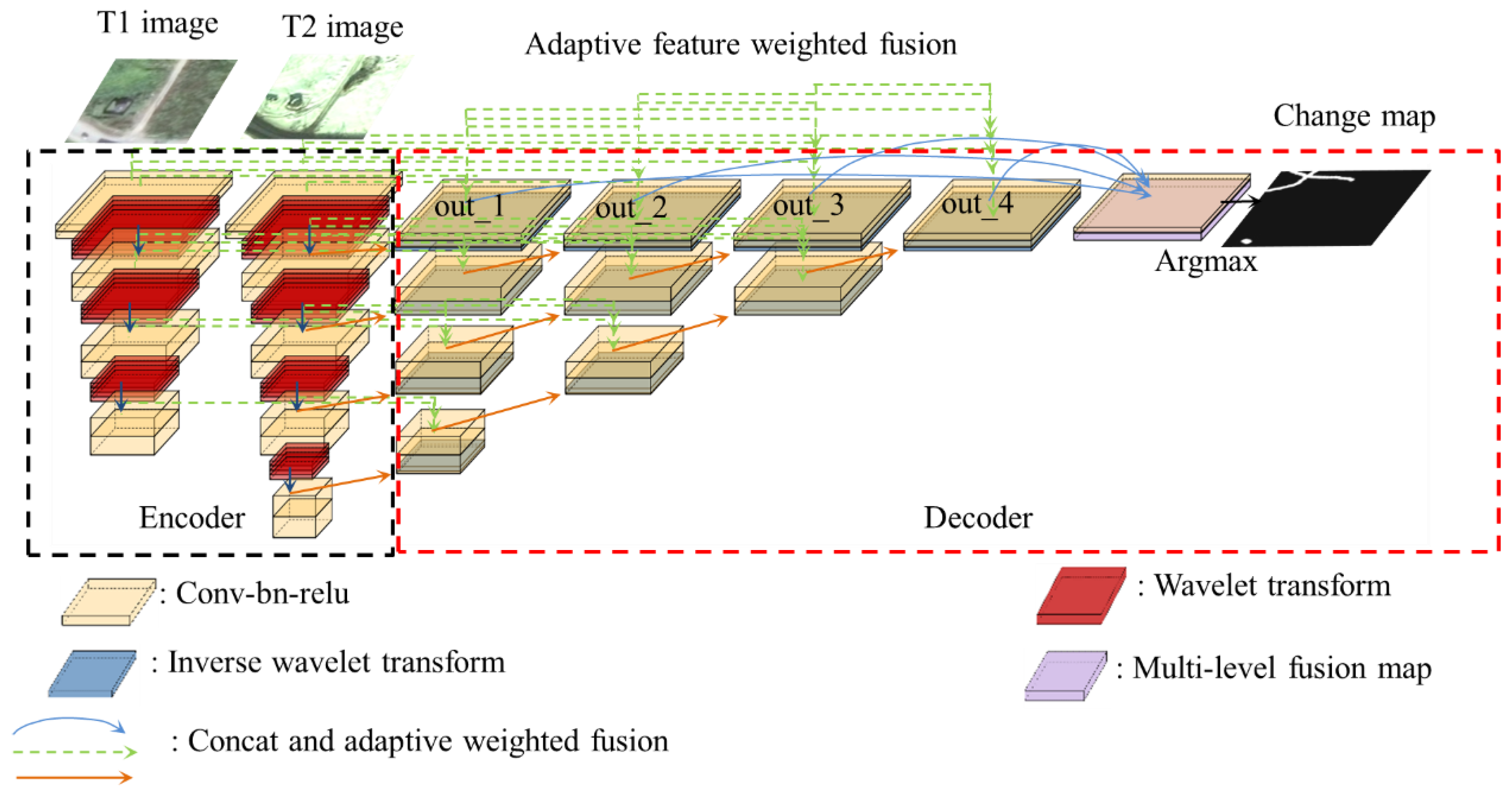
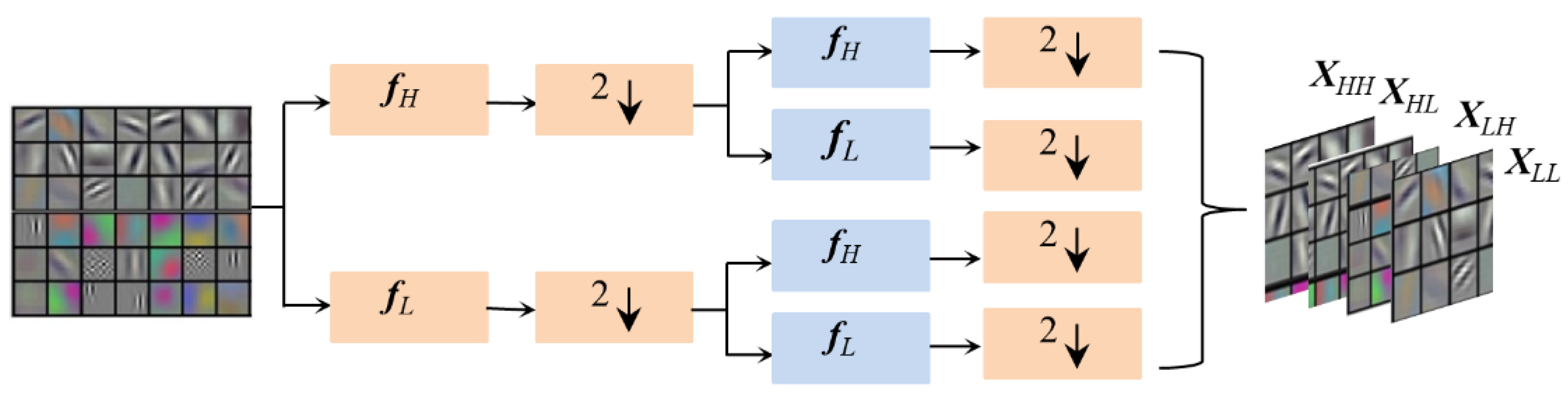
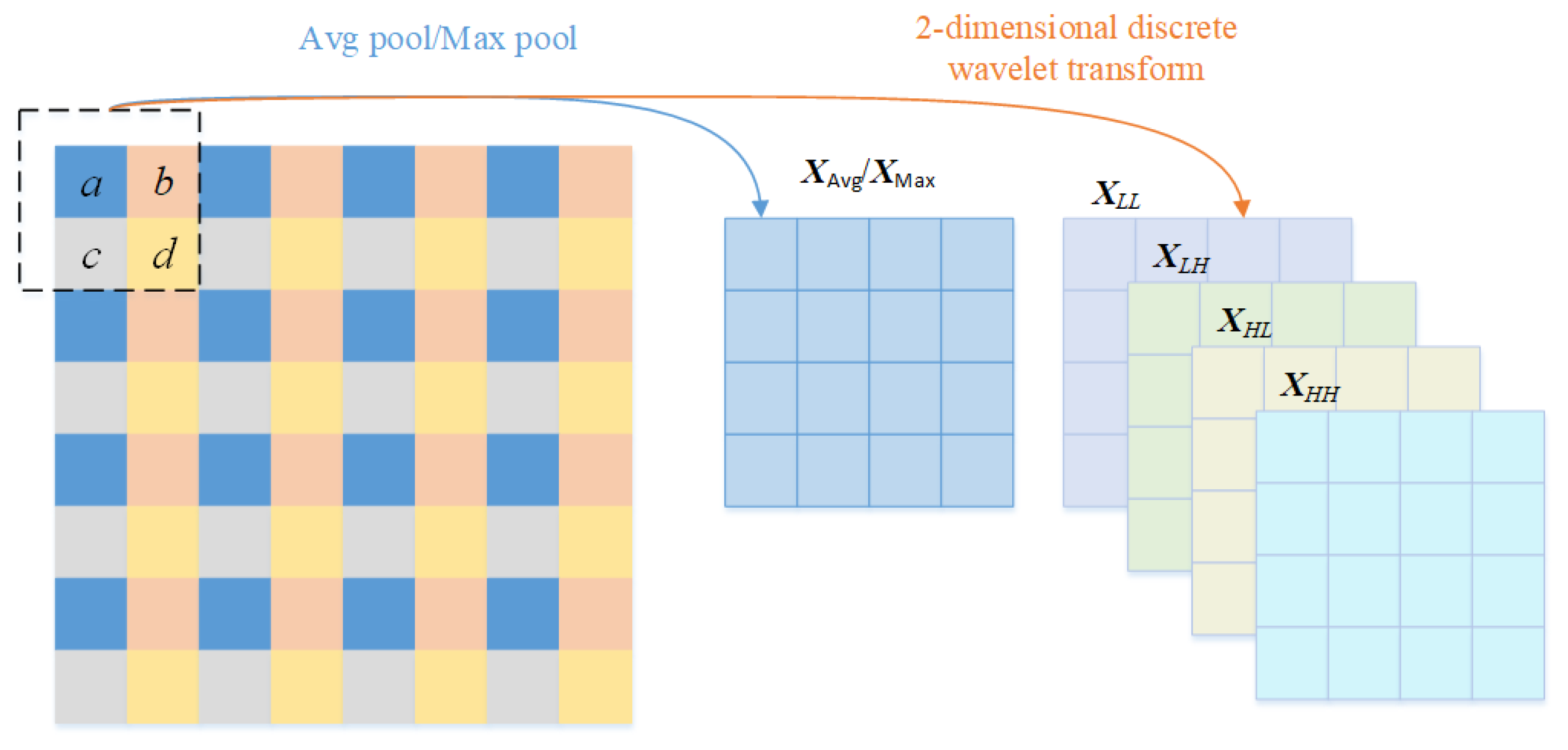
3.2. 2-Dimensional Discrete Wavelet Transform Module
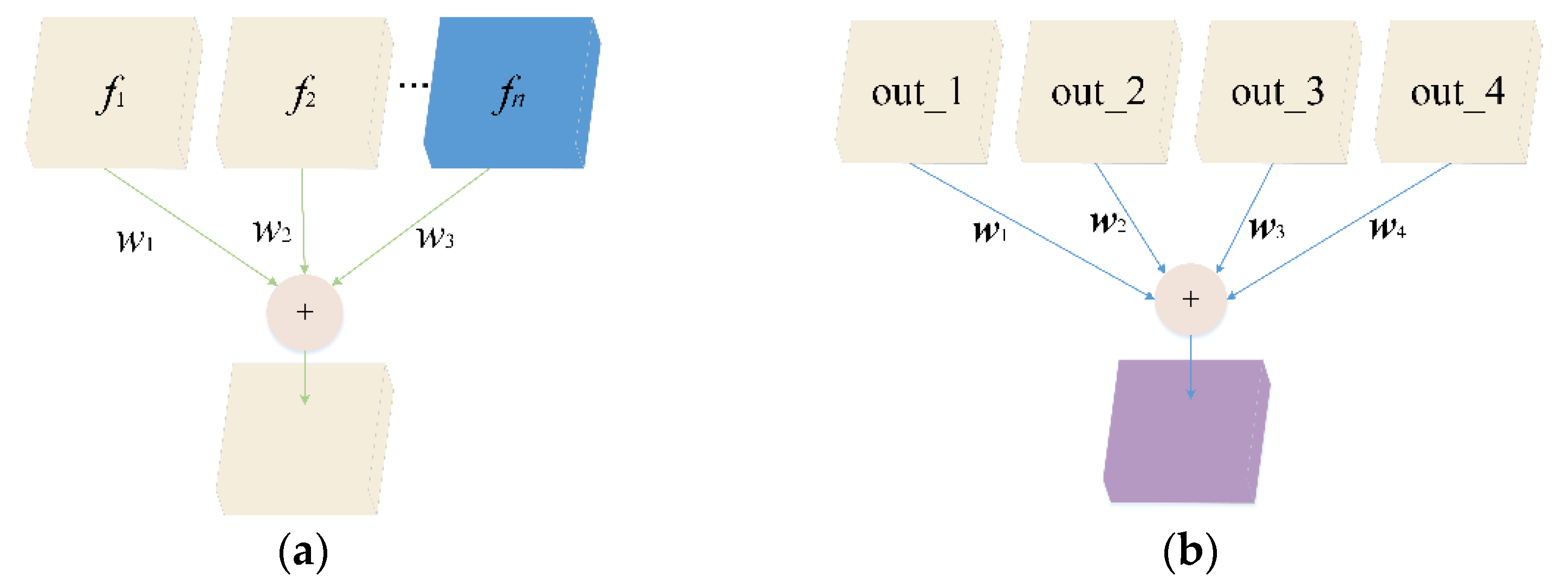
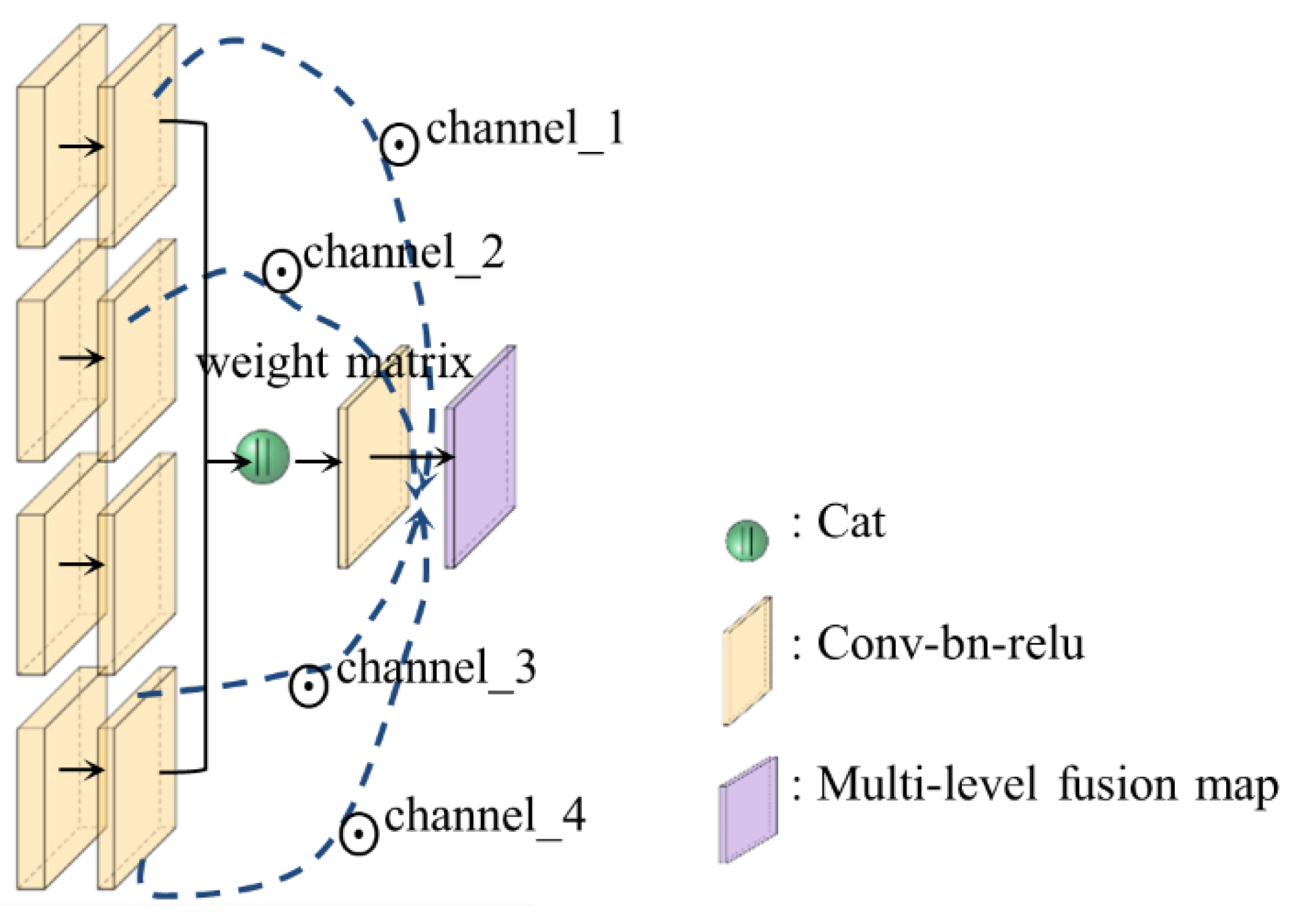
3.3. Adaptive Feature Weighted Fusion Module
4. Experiments and Discussion
4.1. Datasets
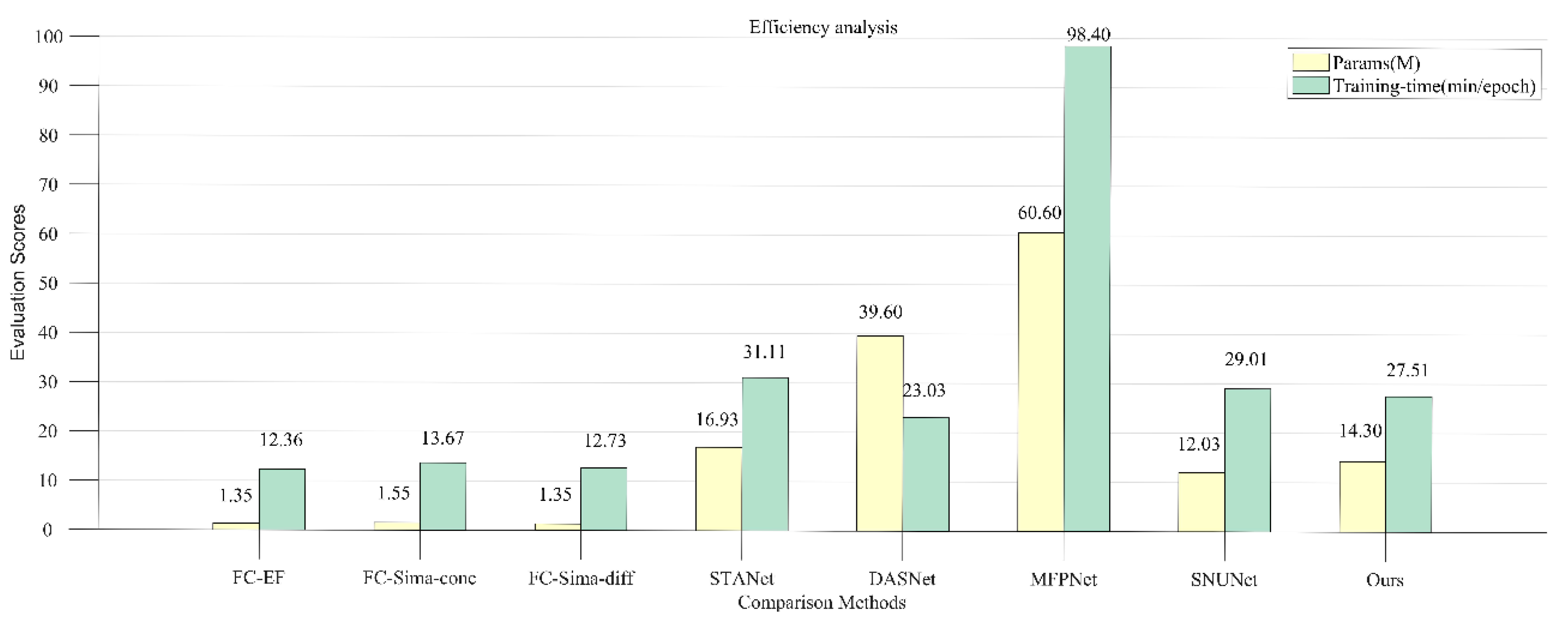
4.2. Comparison Methods
- FC-EF [40]: The method of fully convolutional early fusion, which is an early fusion method in the level of image, takes U-Net as the backbone and concatenates bi-temporal images along the channel. Then, the images with six channels are inputted to network to train.
- FC-Sima-conc [40]: The method of fully convolutional Siamese concatenation extends FC-EF to the Siamese network, and encodes bi-temporal images with shared weights. In the process of decoding, the feature-level fusion method is used to fuse the original encoded features and the joint encoded features of bi-temporal images in a directly connected manner.
- FC-Sima-diff [40]: The fully convolutional Siamese difference method differs from FC-Sima-conc in the joint features of bi-temporal images are constructed in a differential manner rather than concatenation.
- STANet [48]: STANet applies the self-attention mechanism to the network to extract the relationship with time dependence from bi-temporal images. Then, a pyramid spatial-temporal attention module is established to generate a multi-scale spatial-temporal attention map for multi-scale feature fusion.
- DASNet [47]: The starting point of DASNet is to reduce the pseudo-changes in change detection of high-resolution remote sensing images. In the network, features are extracted in a Siamese network with weight sharing, and a dual attention that coupled channel attention and spatial attention is used to perform feature fusion, and the network is trained through metric learning.
- MFPNet [44]: In the MFPNet, a method of multi-directional feature fusion combining bottom-up, top-down, and shortcut-connection is proposed, and features are fused by weighting features from different sources in an adaptive weighting manner. Then, a perceptual similarity module is proposed as a loss function for network training.
- SNUNet [46]: SNUNet aims to improve the accuracy of small objects detection and objects boundary positioning in high-resolution remote sensing images change detection. It applies Nested-UNet to the Siamese network, and proposes an ensemble channel attention module to integrate the output feature maps of different levels, and finally achieves the balance of accuracy and efficiency.
4.3. Loss Function
4.4. Evaluation Indices
4.5. Implementation Settings
4.6. Experiments Results
4.6.1. Performance Comparison on the Lebedev Dataset
4.6.2. Performance Comparison on the SenseTime Dataset
4.6.3. Ablation Study
4.7. Discussion
4.7.1. Analysis of Module Rationality
4.7.2. Analysis of Overall Performance
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Xu, Y.; Yu, L.; Zhao, F.R.; Cai, X.; Zhao, J.; Lu, H.; Gong, P. Tracking annual cropland changes from 1984 to 2016 using time-series Landsat images with a change-detection and post-classification approach: Experiments from three sites in Africa. Remote Sens. Environ. 2018, 218, 13–31. [Google Scholar] [CrossRef]
- Rahnama, M.R. Forecasting land-use changes in Mashhad Metropolitan area using Cellular Automata and Markov chain model for 2016–2030. Sustain. Cities Soc. 2021, 64, 102548. [Google Scholar] [CrossRef]
- Nemmour, H.; Chibani, Y. Multiple support vector machines for land cover change detection: An application for mapping urban extensions. ISPRS J. Photogramm. Remote Sens. 2006, 61, 125–133. [Google Scholar] [CrossRef]
- Raja, R.A.A.; Anand, V.; Kumar, A.S.; Maithani, S.; Kumar, V.A. Wavelet Based Post Classification Change Detection Technique for Urban Growth Monitoring. J. Indian Soc. Remote Sens. 2012, 41, 35–43. [Google Scholar] [CrossRef]
- Papadomanolaki, M.; Verma, S.; Vakalopoulou, M.; Gupta, S.; Karantzalos, K. Detecting urban changes with recurrent neural networks from multitemporal Sentinel-2 data. In Proceedings of the IGARSS 2019–2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 214–217. [Google Scholar]
- Vetrivel, A.; Gerke, M.; Kerle, N.; Nex, F.; Vosselman, G. Disaster damage detection through synergistic use of deep learning and 3D point cloud features derived from very high resolution oblique aerial images, and multiple-kernel-learning. ISPRS J. Photogramm. Remote Sens. 2018, 140, 45–59. [Google Scholar] [CrossRef]
- Yang, X.; Li, S.; Chen, Z.; Chanussot, J.; Jia, X.; Zhang, B.; Li, B.; Chen, P. An attention-fused network for semantic segmentation of very-high-resolution remote sensing imagery. ISPRS J. Photogramm. Remote Sens. 2021, 177, 238–262. [Google Scholar] [CrossRef]
- Zhang, M.; Shi, W. A Feature Difference Convolutional Neural Network-Based Change Detection Method. IEEE Trans. Geosci. Remote Sens. 2020, 58, 7232–7246. [Google Scholar] [CrossRef]
- Hou, X.; Bai, Y.; Li, Y.; Shang, C.; Shen, Q. High-resolution triplet network with dynamic multiscale feature for change detection on satellite images. ISPRS J. Photogramm. Remote Sens. 2021, 177, 103–115. [Google Scholar] [CrossRef]
- Fang, B.; Pan, L.; Kou, R. Dual Learning-Based Siamese Framework for Change Detection Using Bi-Temporal VHR Optical Remote Sensing Images. Remote Sens. 2019, 11, 1292. [Google Scholar] [CrossRef] [Green Version]
- Xu, Q.; Chen, K.; Zhou, G.; Sun, X. Change Capsule Network for Optical Remote Sensing Image Change Detection. Remote Sens. 2021, 13, 2646. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Zhou, Z.; Siddiquee, M.M.R.; Tajbakhsh, N.; Liang, J. Unet++: A nested u-net architecture for medical image segmentation. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer: Berlin/Heidelberg, Germany, 2018; pp. 3–11. [Google Scholar]
- Chopra, S.; Hadsell, R.; LeCun, Y. Learning a similarity metric discriminatively, with application to face verification. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; pp. 539–546. [Google Scholar]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Zheng, Z.; Wan, Y.; Zhang, Y.; Xiang, S.; Peng, D.; Zhang, B. CLNet: Cross-layer convolutional neural network for change detection in optical remote sensing imagery. ISPRS J. Photogramm. Remote Sens. 2021, 175, 247–267. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Wang, F.; Jiang, M.; Qian, C.; Yang, S.; Li, C.; Zhang, H.; Wang, X.; Tang, X. Residual Attention Network for Image Classification. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6450–6458. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Fu, K.; Li, J.; Ma, L.; Mu, K.; Tian, Y. Intrinsic Relationship Reasoning for Small Object Detection. arXiv 2020, arXiv:2009.00833. [Google Scholar]
- Deng, C.; Wang, M.; Liu, L.; Liu, Y.; Jiang, Y. Extended feature pyramid network for small object detection. IEEE Trans. Multimed. 2021, 14, 1. [Google Scholar] [CrossRef]
- Liu, Z.; Gao, G.; Sun, L.; Fang, Z. HRDNet: High-resolution detection network for small objects. In Proceedings of the 2021 IEEE International Conference on Multimedia and Expo (ICME), Shenzhen, China, 5–9 July 2021; pp. 1–6. [Google Scholar]
- Qin, Z.; Zhang, P.; Wu, F.; Li, X. Fcanet: Frequency channel attention networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 783–792. [Google Scholar]
- Liu, P.; Zhang, H.; Zhang, K.; Lin, L.; Zuo, W. Multi-level Wavelet-CNN for Image Restoration. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 773–782. [Google Scholar]
- Zhang, P.; Gong, M.; Su, L.; Liu, J.; Li, Z. Change detection based on deep feature representation and mapping transformation for multi-spatial-resolution remote sensing images. ISPRS J. Photogramm. Remote Sens. 2016, 116, 24–41. [Google Scholar] [CrossRef]
- Wang, M.; Zhang, H.; Sun, W.; Li, S.; Wang, F.; Yang, G. A Coarse-to-Fine Deep Learning Based Land Use Change Detection Method for High-Resolution Remote Sensing Images. Remote Sens. 2020, 12, 1933. [Google Scholar] [CrossRef]
- Du, B.; Ru, L.; Wu, C.; Zhang, L. Unsupervised deep slow feature analysis for change detection in multi-temporal remote sensing images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 9976–9992. [Google Scholar] [CrossRef] [Green Version]
- Wanliang, W.; Zhuorong, L. Advances in generative adversarial network. J. Commun. 2018, 39, 135. [Google Scholar]
- Zhao, W.; Mou, L.; Chen, J.; Bo, Y.; Emery, W.J. Incorporating Metric Learning and Adversarial Network for Seasonal Invariant Change Detection. IEEE Trans. Geosci. Remote Sens. 2020, 58, 2720–2731. [Google Scholar] [CrossRef]
- Hou, B.; Liu, Q.; Wang, H.; Wang, Y. From W-Net to CDGAN: Bitemporal change detection via deep learning techniques. IEEE Trans. Geosci. Remote Sens. 2019, 58, 1790–1802. [Google Scholar] [CrossRef] [Green Version]
- Arjovsky, M.; Bottou, L. Towards principled methods for training generative adversarial networks. arXiv 2017, arXiv:1701.04862. [Google Scholar]
- Niu, X.; Gong, M.; Zhan, T.; Yang, Y. A Conditional Adversarial Network for Change Detection in Heterogeneous Images. IEEE Geosci. Remote Sens. Lett. 2019, 16, 45–49. [Google Scholar] [CrossRef]
- Liu, J.; Gong, M.; Qin, K.; Zhang, P. A Deep Convolutional Coupling Network for Change Detection Based on Heterogeneous Optical and Radar Images. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 545–559. [Google Scholar] [CrossRef] [PubMed]
- Zhang, C.; Yue, P.; Tapete, D.; Jiang, L.; Shangguan, B.; Huang, L.; Liu, G. A deeply supervised image fusion network for change detection in high resolution bi-temporal remote sensing images. ISPRS J. Photogramm. Remote Sens. 2020, 166, 183–200. [Google Scholar] [CrossRef]
- Peng, D.; Zhang, Y.; Guan, H. End-to-End Change Detection for High Resolution Satellite Images Using Improved UNet++. Remote Sens. 2019, 11, 1382. [Google Scholar] [CrossRef] [Green Version]
- Gong, Y.; Yu, X.; Ding, Y.; Peng, X.; Zhao, J.; Han, Z. Effective fusion factor in FPN for tiny object detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 5–9 January 2021; pp. 1160–1168. [Google Scholar]
- Lin, T.-Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 June 2017; pp. 936–944. [Google Scholar]
- Daudt, R.C.; Le Saux, B.; Boulch, A. Fully convolutional siamese networks for change detection. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 4063–4067. [Google Scholar]
- Zhang, Y.; Fu, L.; Li, Y.; Zhang, Y. HDFNet: Hierarchical Dynamic Fusion Network for Change Detection in Optical Aerial Images. Remote Sens. 2021, 13, 1440. [Google Scholar] [CrossRef]
- Zhang, C.; Wei, S.; Ji, S.; Lu, M. Detecting Large-Scale Urban Land Cover Changes from Very High Resolution Remote Sensing Images Using CNN-Based Classification. ISPRS Int. J. Geo-Inf. 2019, 8, 189. [Google Scholar] [CrossRef] [Green Version]
- Jiang, H.; Hu, X.; Li, K.; Zhang, J.; Gong, J.; Zhang, M. PGA-SiamNet: Pyramid Feature-Based Attention-Guided Siamese Network for Remote Sensing Orthoimagery Building Change Detection. Remote Sens. 2020, 12, 484. [Google Scholar] [CrossRef] [Green Version]
- Xu, J.; Luo, C.; Chen, X.; Wei, S.; Luo, Y. Remote Sensing Change Detection Based on Multidirectional Adaptive Feature Fusion and Perceptual Similarity. Remote Sens. 2021, 13, 3053. [Google Scholar] [CrossRef]
- Mnih, V.; Heess, N.; Graves, A. Recurrent models of visual attention. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2204–2212. [Google Scholar]
- Fang, S.; Li, K.; Shao, J.; Li, Z. SNUNet-CD: A Densely Connected Siamese Network for Change Detection of VHR Images. IEEE Geosci. Remote Sens. Lett. 2021, 1–5. [Google Scholar] [CrossRef]
- Chen, J.; Yuan, Z.; Peng, J.; Chen, L.; Huang, H.; Zhu, J.; Liu, Y.; Li, H. DASNet: Dual Attentive Fully Convolutional Siamese Networks for Change Detection in High-Resolution Satellite Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 1194–1206. [Google Scholar] [CrossRef]
- Chen, H.; Shi, Z. A Spatial-Temporal Attention-Based Method and a New Dataset for Remote Sensing Image Change Detection. Remote Sens. 2020, 12, 1662. [Google Scholar] [CrossRef]
- da Silva, E.A.; Ghanbari, M. On the performance of linear phase wavelet transforms in low bit-rate image coding. IEEE Trans. Image Process. 1996, 5, 689–704. [Google Scholar] [CrossRef]
- Antonini, M.; Barlaud, M.; Mathieu, P.; Daubechies, I. Image coding using wavelet transform. IEEE Trans. Image Process. 1992, 1, 205–220. [Google Scholar] [CrossRef] [Green Version]
- Haar, A. Zur theorie der orthogonalen funktionensysteme. Math. Ann. 1910, 69, 331–371. [Google Scholar] [CrossRef]
- Lebedev, M.A.; Vizilter, Y.V.; Vygolov, O.V.; Knyaz, V.A.; Rubis, A.Y. Change Detection in Remote Sensing Images Using Conditional Adversarial Networks. The International Archives of the Photogrammetry. Remote Sens. Spat. Inf. Sci. 2018, XLII-2, 565–571. [Google Scholar] [CrossRef] [Green Version]
- SenseTime. Artificial Intelligence Remote Sensing Interpretation Competition. Available online: https://aistudio.baidu.com/aistudio/datasetdetail/53484 (accessed on 4 April 2021).
- Milletari, F.; Navab, N.; Ahmadi, S.-A. V-net: Fully convolutional neural networks for volumetric medical image segmentation. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 565–571. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Lebedev | ||
|---|---|---|---|
| Precision (%) | Recall (%) | F1 (%) | |
| FC-EF | 44.46 | 23.60 | 27.70 |
| FC-Sima-conc | 66.97 | 39.63 | 46.47 |
| FC-Sima-diff | 69.99 | 34.61 | 42.38 |
| STANet | 85.01 | 95.82 | 90.09 |
| DASNet | 53.41 | 42.18 | 47.13 |
| MFPNet | 94.93 | 89.34 | 91.87 |
| SNUNet | 80.59 | 66.44 | 71.87 |
| Ours | 95.04 | 93.85 | 94.40 |
| Methods | SenseTime | ||
|---|---|---|---|
| Precision (%) | Recall (%) | F1 (%) | |
| FC-EF | 63.97 | 38.53 | 45.56 |
| FC-Sima-conc | 62.22 | 49.32 | 53.07 |
| FC-Sima-diff | 70.86 | 41.16 | 50.05 |
| STANet | 56.04 | 72.43 | 63.18 |
| DASNet | 57.16 | 68.83 | 62.45 |
| MFPNet | 70.83 | 55.86 | 60.46 |
| SNUNet | 65.71 | 61.47 | 62.76 |
| Ours | 70.89 | 67.72 | 68.67 |
| Methods | Lebedev | SenseTime | ||||
|---|---|---|---|---|---|---|
| Precision (%) | Recall (%) | F1 (%) | Precision (%) | Recall (%) | F1 (%) | |
| Baseline | 90.44 | 88.29 | 89.11 | 65.22 | 63.58 | 63.20 |
| Our Network | 95.04 | 93.85 | 94.40 | 70.89 | 67.72 | 68.67 |
| Max pool | 93.01 | 89.89 | 91.12 | 66.63 | 65.81 | 64.89 |
| Avg pool | 94.29 | 90.93 | 92.50 | 67.94 | 65.92 | 65.65 |
| Methods | Lebedev | SenseTime | ||||
|---|---|---|---|---|---|---|
| Precision (%) | Recall (%) | F1 (%) | Precision (%) | Recall (%) | F1 (%) | |
| FC-Sima-conc | 66.97 | 39.63 | 46.47 | 62.22 | 49.32 | 53.07 |
| FC-Sima-conc+ | 68.63 | 42.77 | 50.01 | 63.83 | 53.64 | 56.35 |
| FC-Sima-diff | 69.99 | 34.61 | 42.38 | 70.86 | 41.16 | 50.05 |
| FC-Sima-diff+ | 71.85 | 38.47 | 46.17 | 71.79 | 44.25 | 52.76 |
| Methods | Lebedev | SenseTime | ||||
|---|---|---|---|---|---|---|
| Precision (%) | Recall (%) | F1 (%) | Precision (%) | Recall (%) | F1 (%) | |
| Baseline | 90.44 | 88.29 | 89.11 | 65.22 | 63.58 | 63.20 |
| Our Network | 95.04 | 93.85 | 94.40 | 70.89 | 67.72 | 68.67 |
| Non-decoding fusing | 94.32 | 92.60 | 93.39 | 69.06 | 66.94 | 66.92 |
| Non-output fusing | 94.63 | 92.13 | 93.30 | 70.10 | 65.48 | 67.06 |
| Non-fusing | 93.07 | 91.65 | 92.31 | 68.05 | 65.39 | 65.47 |
| Methods | Lebedev | SenseTime | ||||
|---|---|---|---|---|---|---|
| Precision (%) | Recall (%) | F1 (%) | Precision (%) | Recall (%) | F1 (%) | |
| FC-Sima-conc | 66.97 | 39.63 | 46.47 | 62.22 | 49.32 | 53.07 |
| FC-Sima-conc+ | 67.77 | 40.87 | 47.69 | 64.35 | 50.44 | 54.73 |
| FC-Sima-diff | 69.99 | 34.61 | 42.38 | 70.86 | 41.16 | 50.05 |
| FC-Sima-diff+ | 73.01 | 37.55 | 46.29 | 71.71 | 42.91 | 51.21 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, C.; Sun, W.; Fan, D.; Liu, X.; Zhang, Z. Adaptive Feature Weighted Fusion Nested U-Net with Discrete Wavelet Transform for Change Detection of High-Resolution Remote Sensing Images. Remote Sens. 2021, 13, 4971. https://doi.org/10.3390/rs13244971
Wang C, Sun W, Fan D, Liu X, Zhang Z. Adaptive Feature Weighted Fusion Nested U-Net with Discrete Wavelet Transform for Change Detection of High-Resolution Remote Sensing Images. Remote Sensing. 2021; 13(24):4971. https://doi.org/10.3390/rs13244971
Chicago/Turabian StyleWang, Congcong, Wenbin Sun, Deqin Fan, Xiaoding Liu, and Zhi Zhang. 2021. "Adaptive Feature Weighted Fusion Nested U-Net with Discrete Wavelet Transform for Change Detection of High-Resolution Remote Sensing Images" Remote Sensing 13, no. 24: 4971. https://doi.org/10.3390/rs13244971
APA StyleWang, C., Sun, W., Fan, D., Liu, X., & Zhang, Z. (2021). Adaptive Feature Weighted Fusion Nested U-Net with Discrete Wavelet Transform for Change Detection of High-Resolution Remote Sensing Images. Remote Sensing, 13(24), 4971. https://doi.org/10.3390/rs13244971