
Deforestation Detection with Fully Convolutional Networks in the Amazon Forest from Landsat-8 and Sentinel-2 Images

 , ,
, ,  ,
,  , , and
, , and 
Abstract
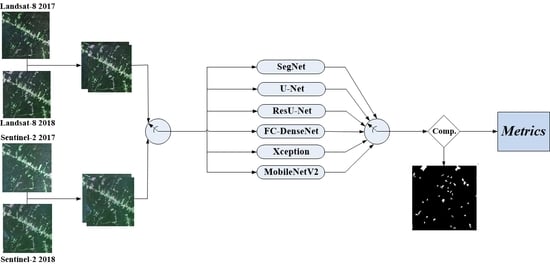
:
1. Introduction
- A comparison of six state-of-the-art FCNs, namely U-Net, ResU-Net, SegNet, Fully Convolutional DenseNet, and Xception and MobileNetV2 variants of Deeplabv3+ for mapping deforestation in Amazon rainforest.
- An evaluation of false-positive vs. false-negative behavior for varying confidence levels of deforestation warnings.
- A assessment of said network architectures for detecting deforestation upon Landsat-8 and Sentinel-2 data.
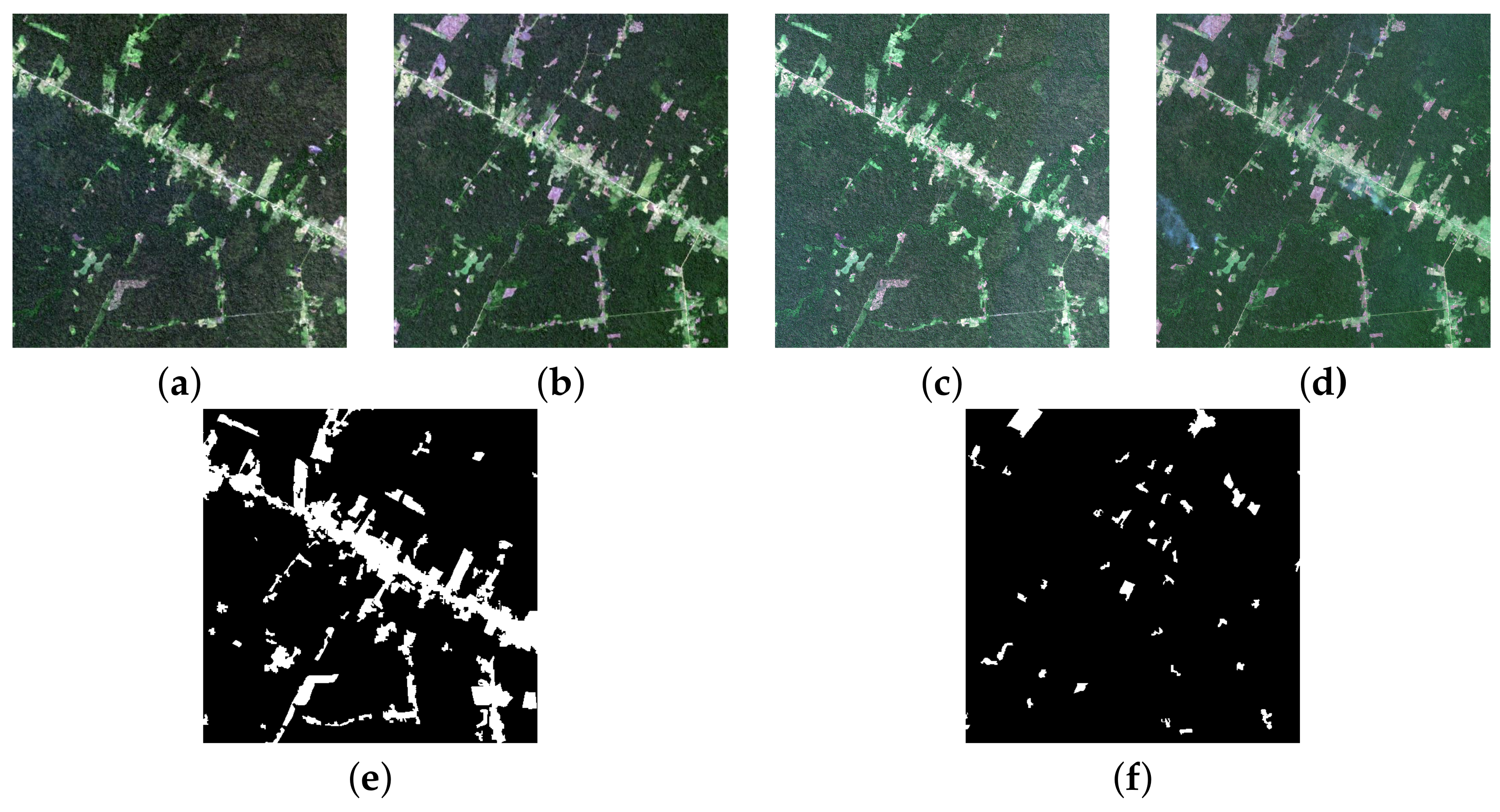
- An unprecedented visual assessment by the PRODES team analysts simulating an audit process of the prediction maps generated by DL networks with the highest performance in both satellites.
2. Methods
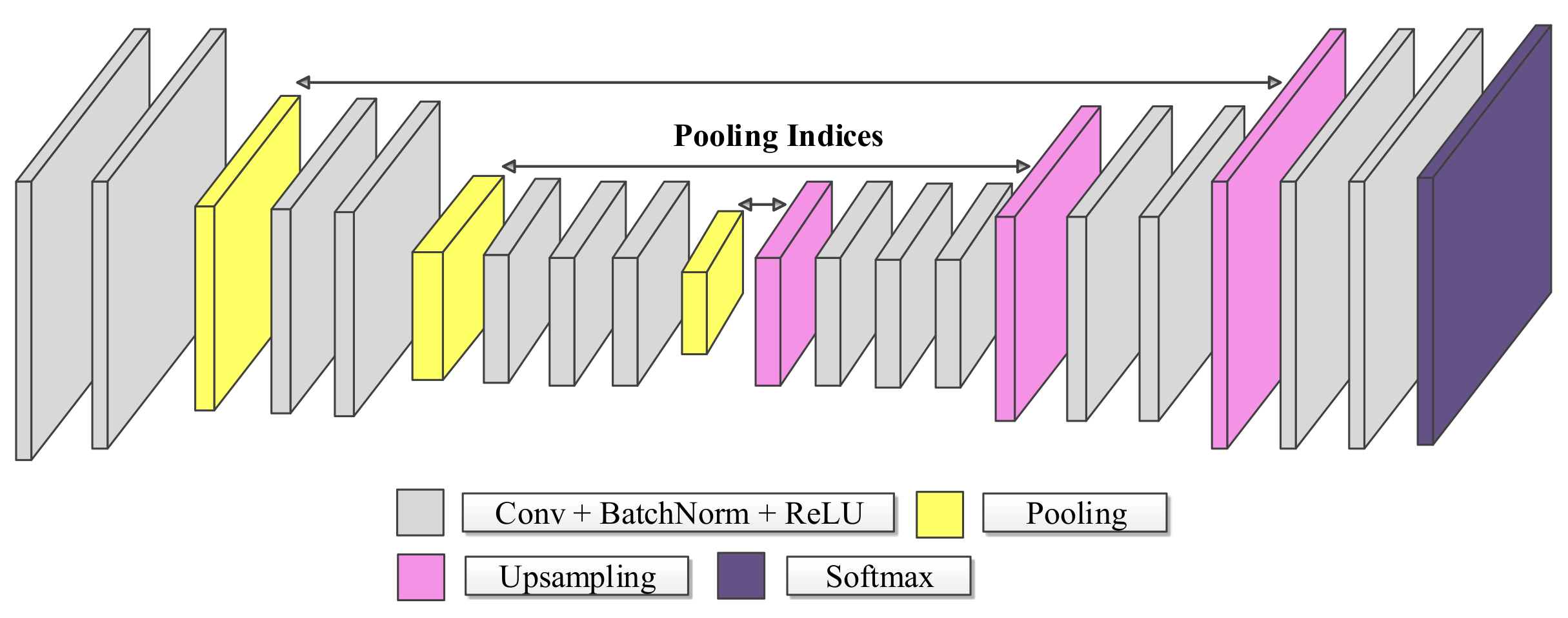
2.1. SegNet
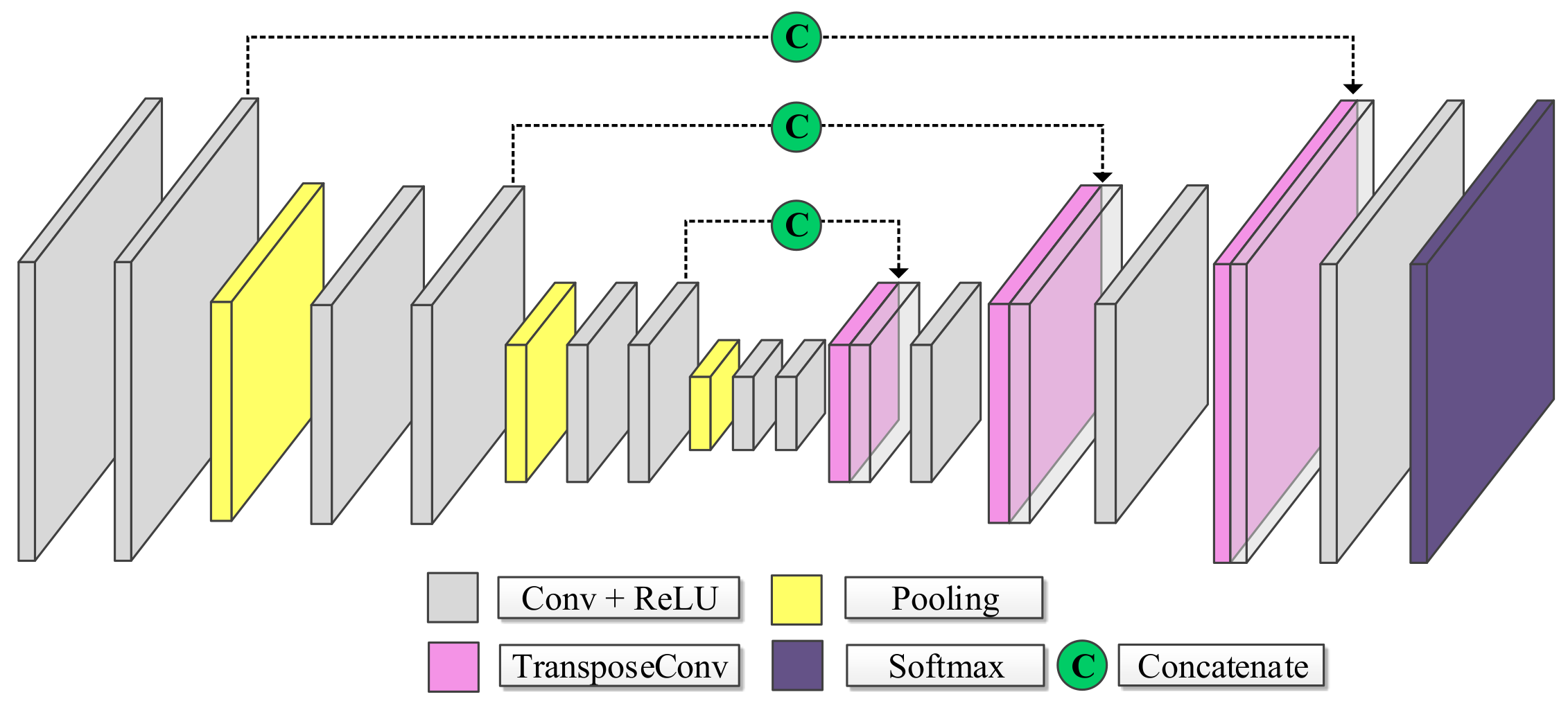
2.2. U-Net
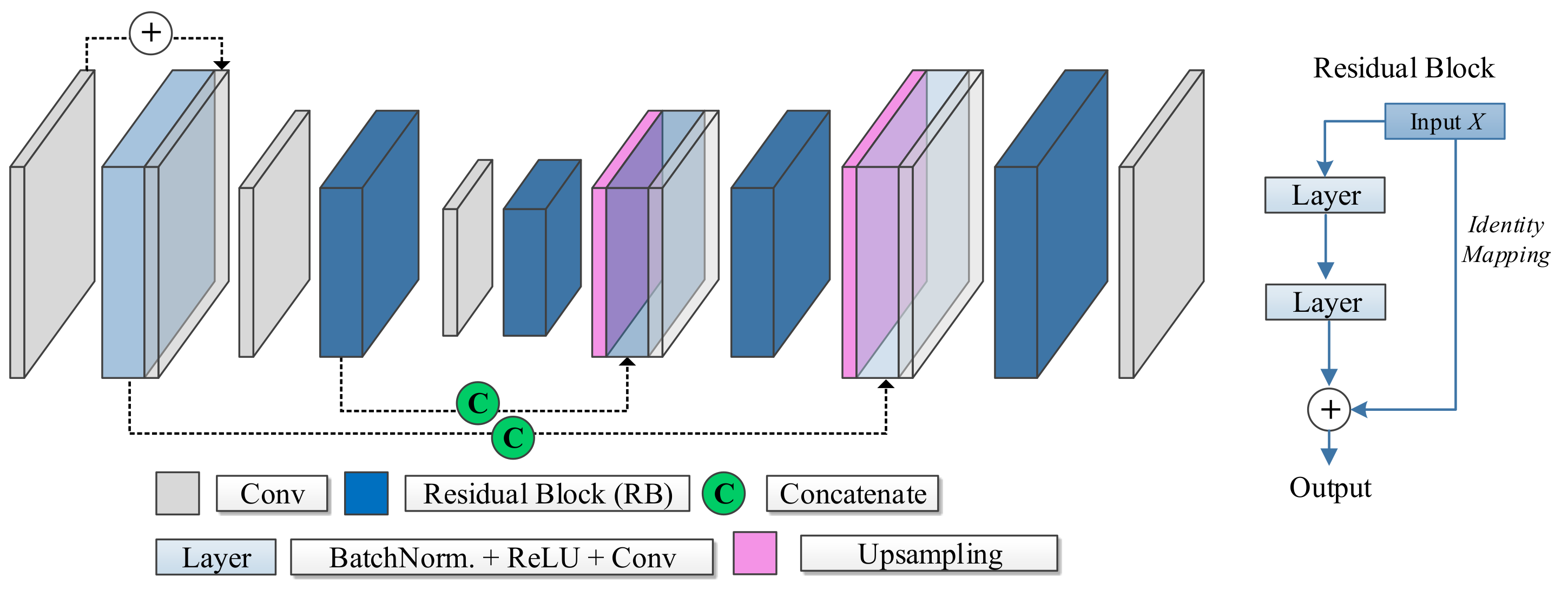
2.3. ResU-Net
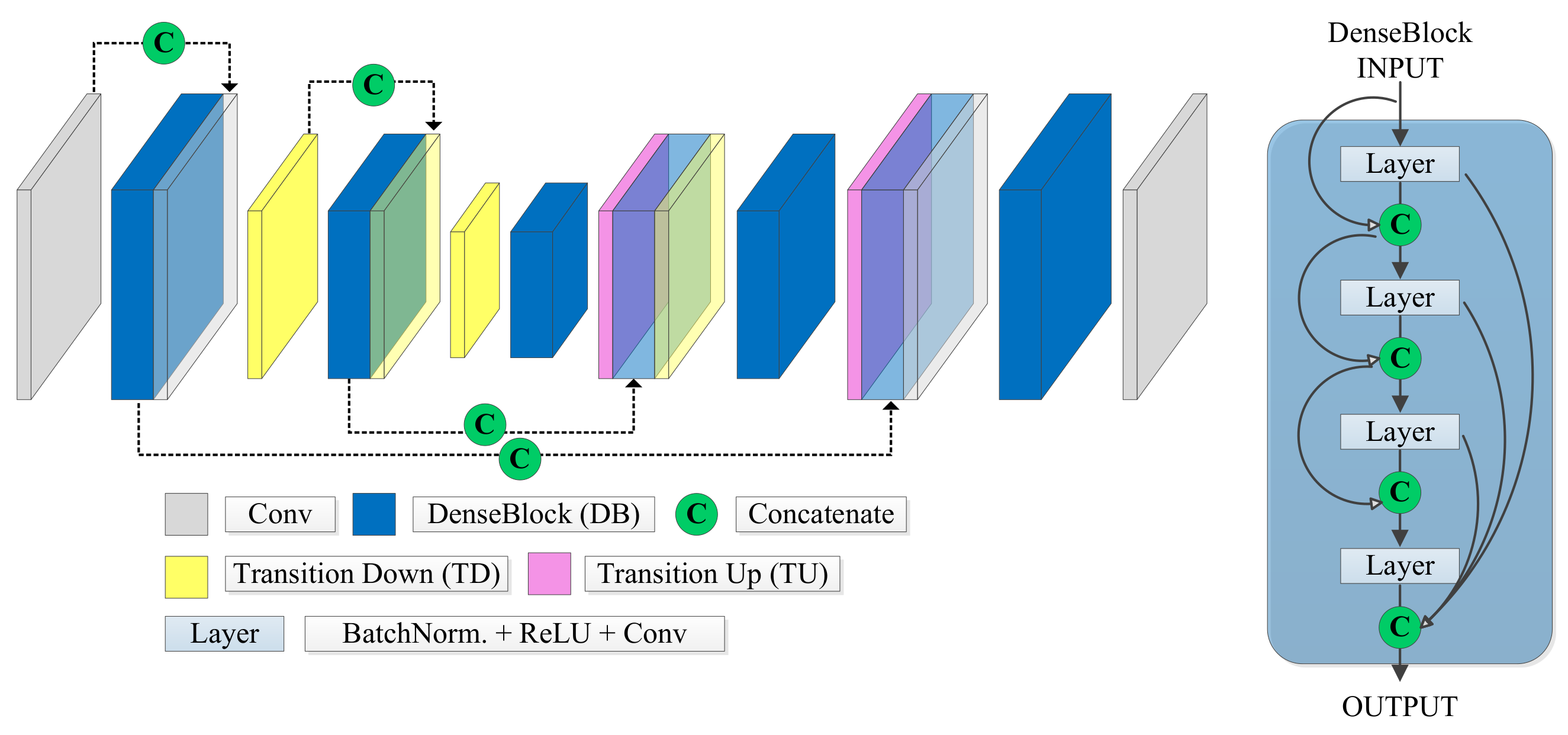
2.4. FC-DenseNet
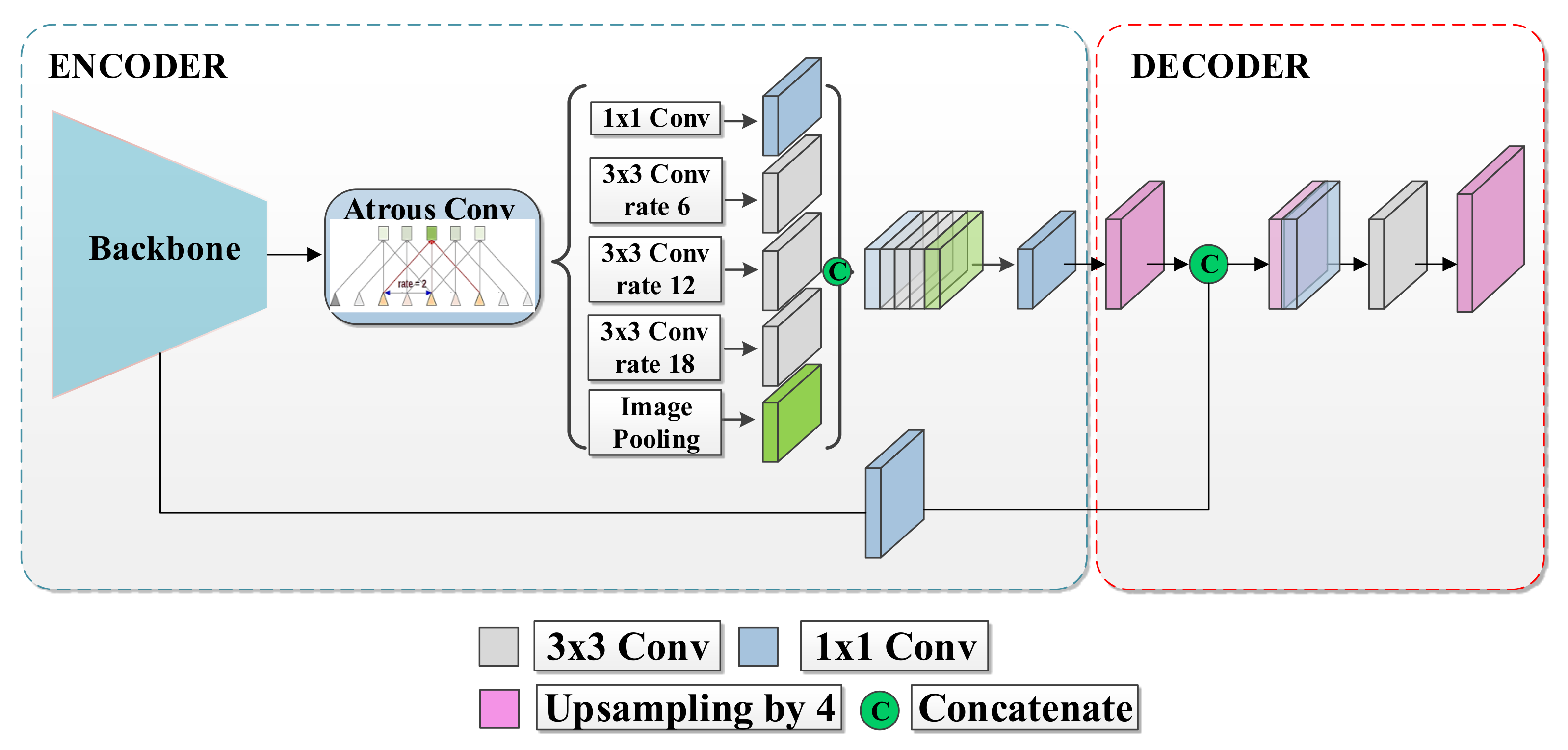
2.5. DeepLabv3+
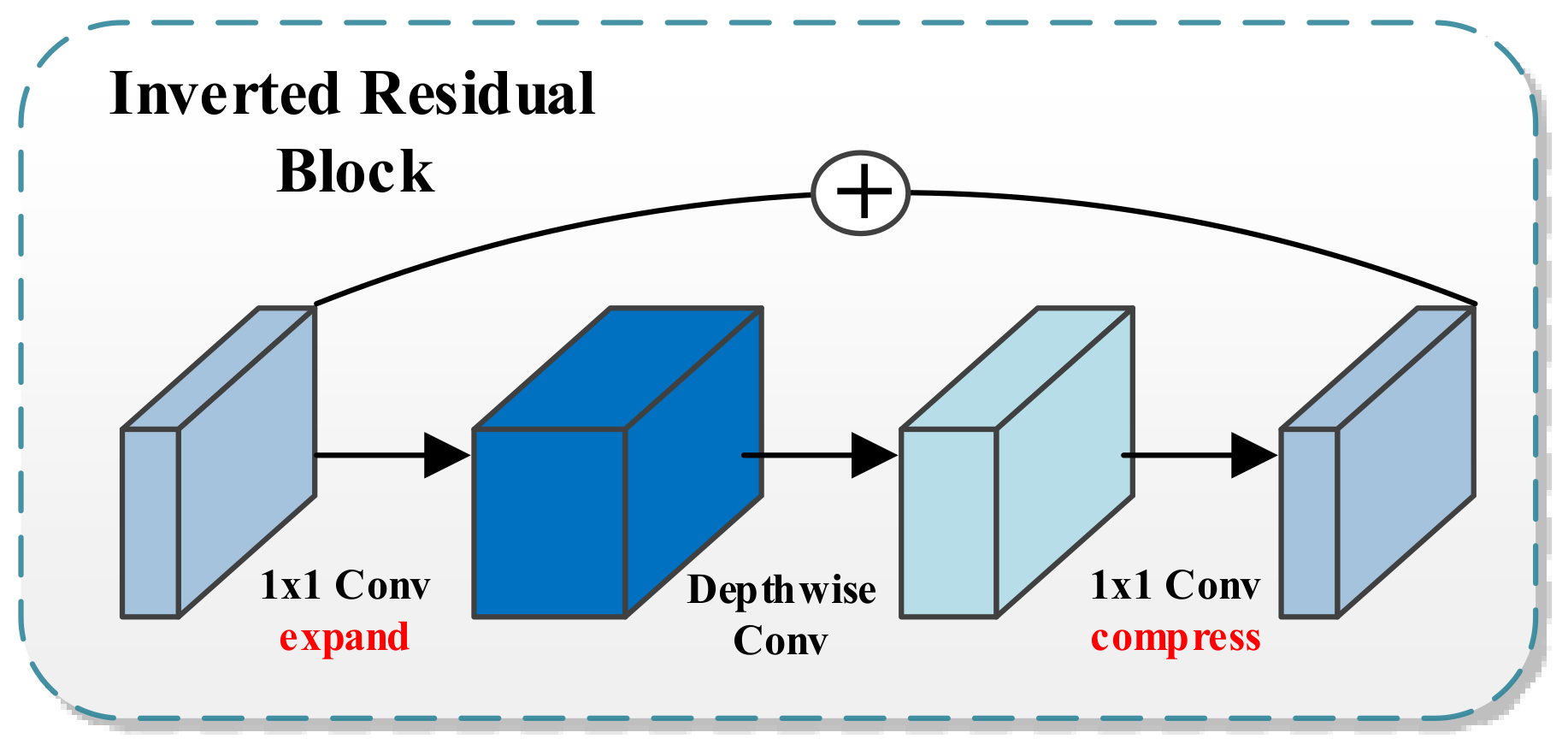
2.6. Mobilenetv2
3. Experimental Analysis
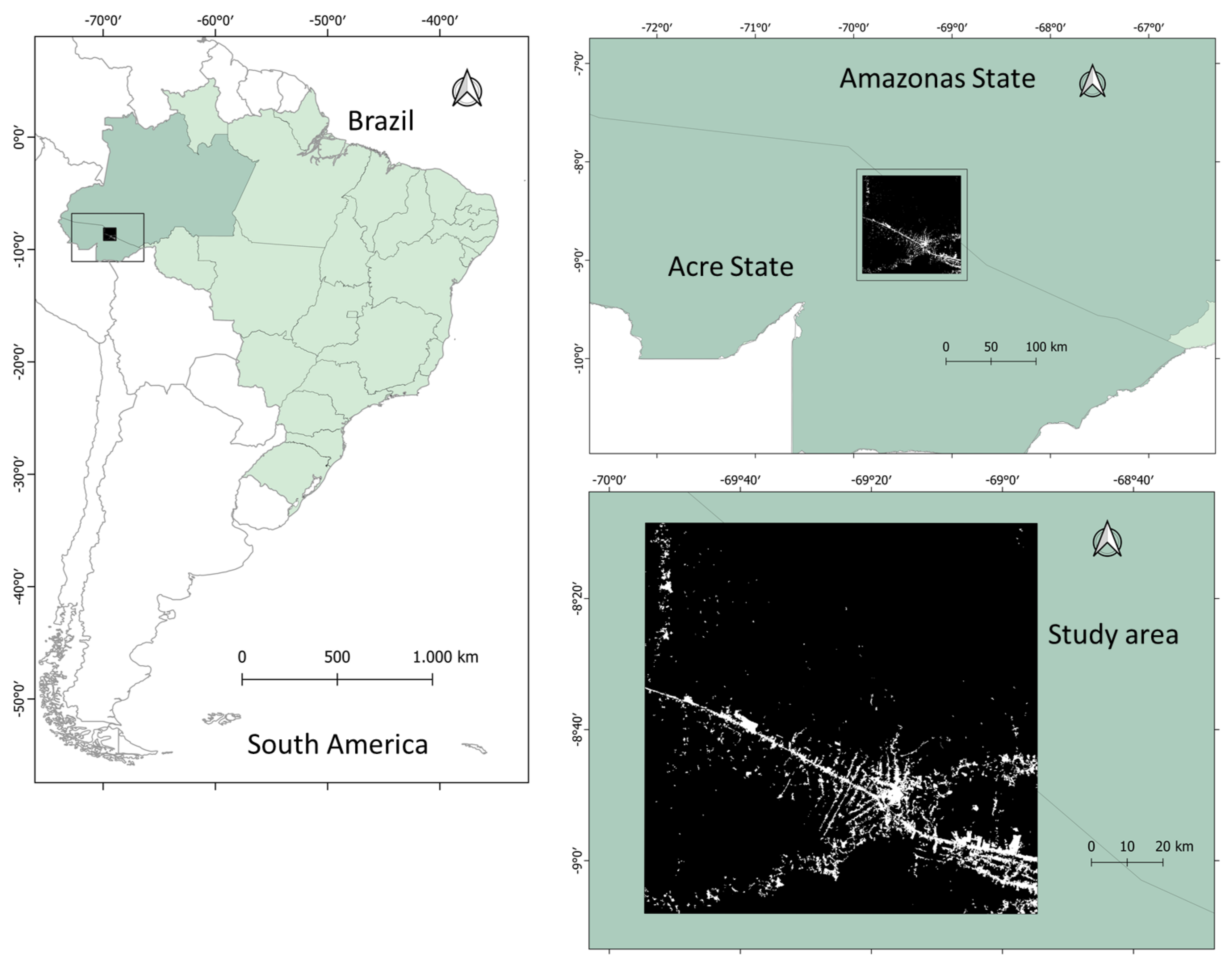
3.1. Study Area
3.2. Datasets
3.3. Experimental Setup
3.4. Networks’ Implementation
3.5. Performance Metrics
4. Results
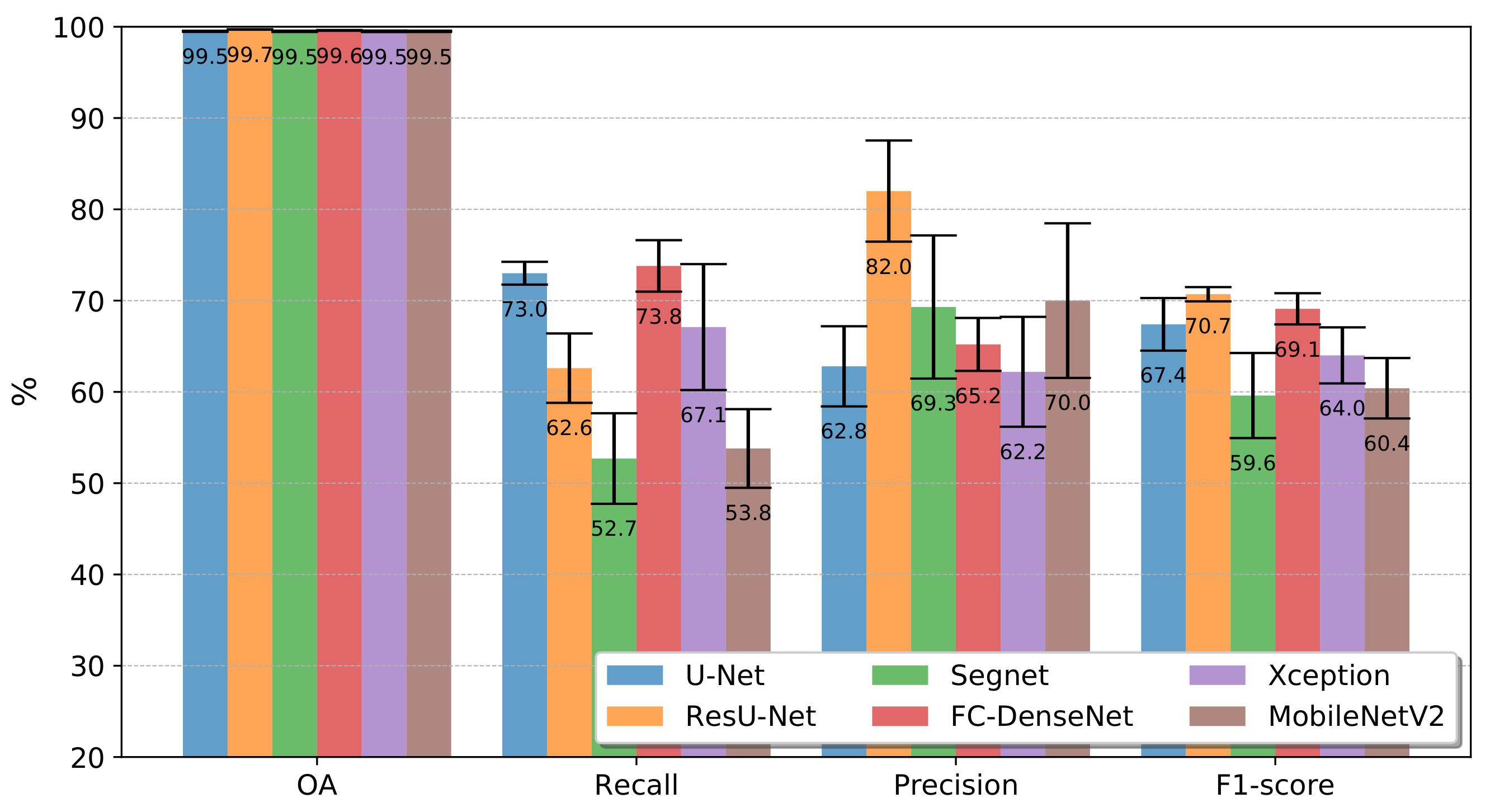
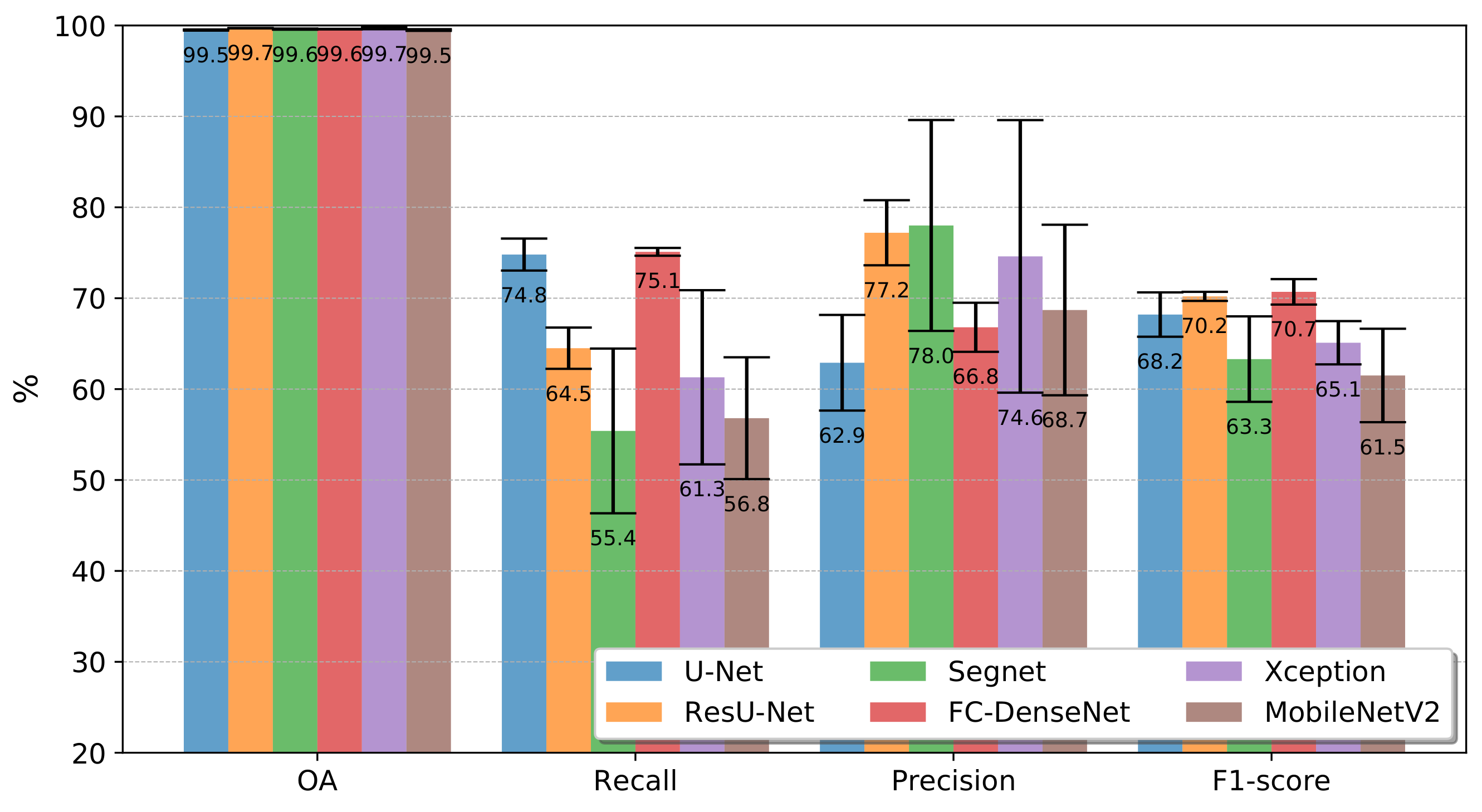
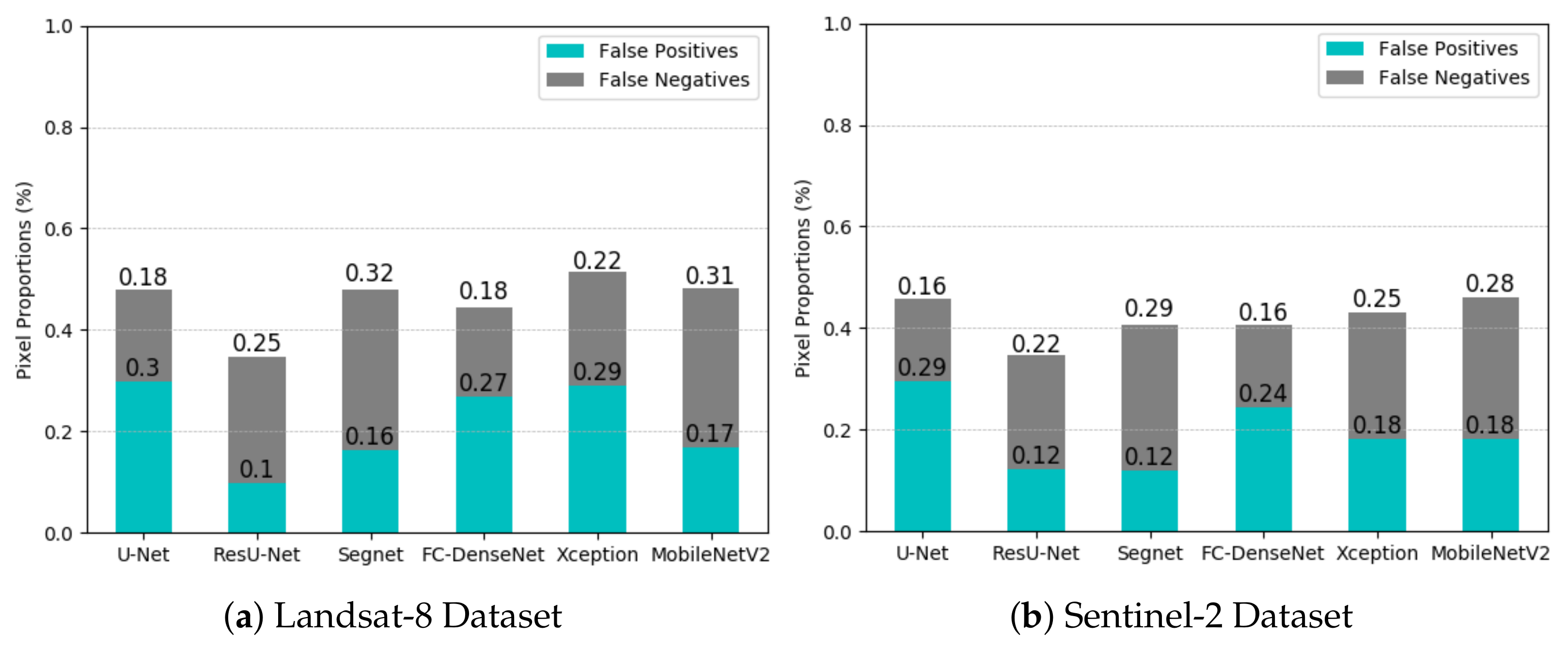
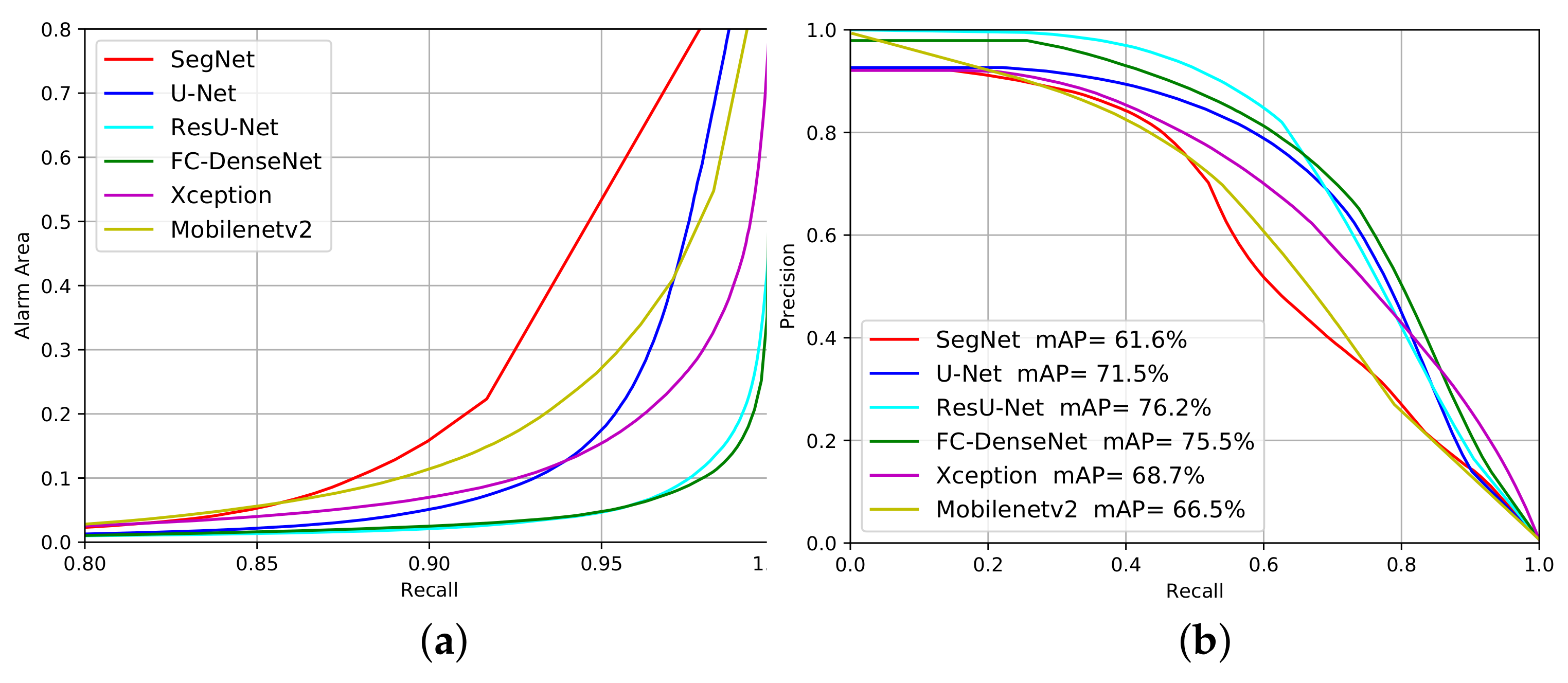
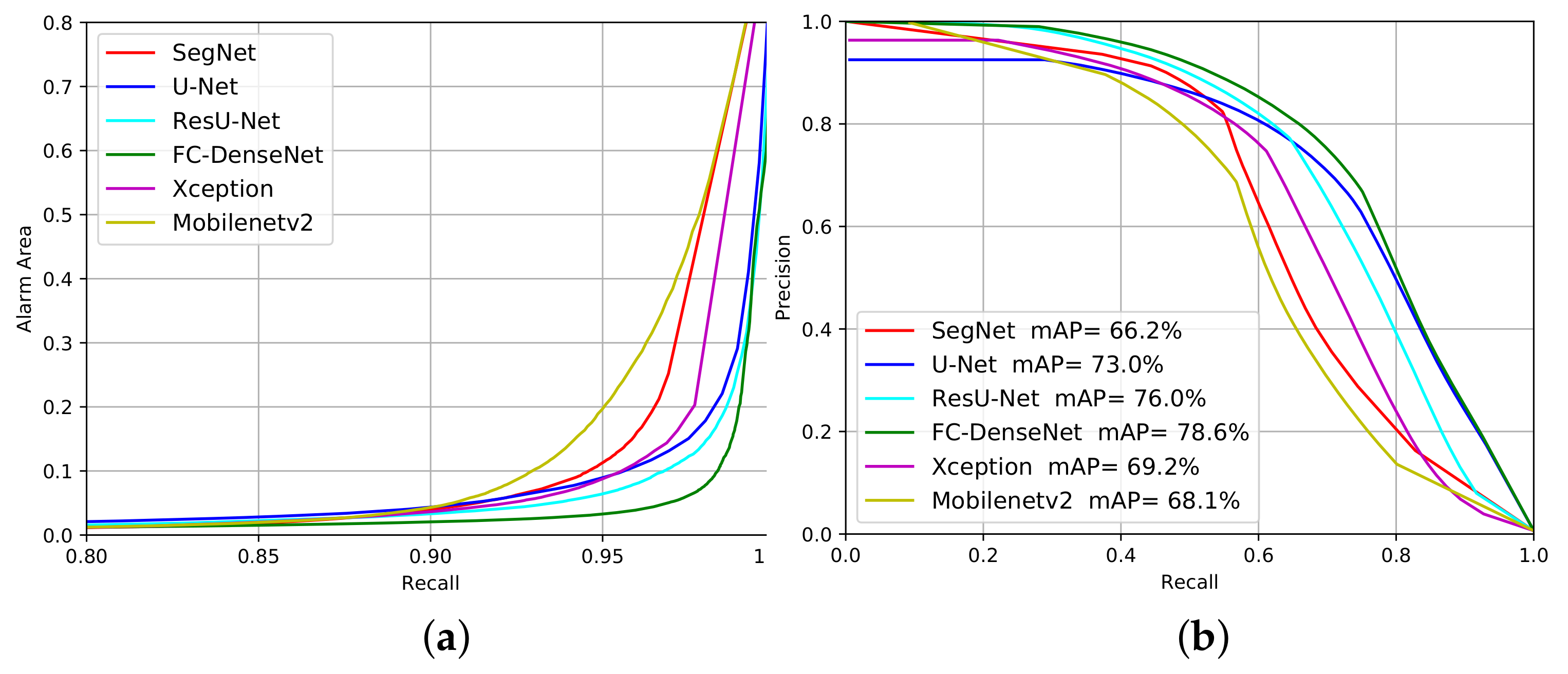
4.1. Segmentation Accuracy for Deforestation Detection
4.2. Computational Complexity
5. Discussion
6. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Davidson, E.A.; de Araújo, A.C.; Artaxo, P.; Balch, J.K.; Brown, I.F.; Bustamante, M.M.; Coe, M.T.; DeFries, R.S.; Keller, M.; Longo, M.; et al. The Amazon basin in transition. Nature 2012, 481, 321–328. [Google Scholar] [CrossRef] [PubMed]
- De Almeida, C.A. Estimativa da Area e do Tempo de Permanência da Vegetação Secundaria na Amazônia Legal por Meio de Imagens Landsat/TM. 2009. Available online: http://mtc-m16c.sid.inpe.br/col/sid.inpe.br/mtc-m18@80/2008/11.04.18.45/doc/publicacao.pdf (accessed on 18 July 2021).
- Fearnside, P.M.; Righi, C.A.; de Alencastro Graça, P.M.L.; Keizer, E.W.; Cerri, C.C.; Nogueira, E.M.; Barbosa, R.I. Biomass and greenhouse-gas emissions from land-use change in Brazil’s Amazonian “arc of deforestation”: The states of Mato Grosso and Rondônia. For. Ecol. Manag. 2009, 258, 1968–1978. [Google Scholar] [CrossRef]
- Junior, C.H.S.; Pessôa, A.C.; Carvalho, N.S.; Reis, J.B.; Anderson, L.O.; Aragão, L.E. The Brazilian Amazon deforestation rate in 2020 is the greatest of the decade. Nat. Ecol. Evol. 2021, 5, 144–145. [Google Scholar] [CrossRef] [PubMed]
- Almeida, C.A.; Maurano, L.E.P. Methodology for Forest Monitoring used in PRODES and DETER Projects; INPE: São José dos Campos, Brazil, 2021. [Google Scholar]
- Diniz, C.G.; de Almeida Souza, A.A.; Santos, D.C.; Dias, M.C.; da Luz, N.C.; de Moraes, D.R.V.; Maia, J.S.; Gomes, A.R.; da Silva Narvaes, I.; Valeriano, D.M.; et al. DETER-B: The new Amazon near real-time deforestation detection system. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 3619–3628. [Google Scholar] [CrossRef]
- Rogan, J.; Miller, J.; Wulder, M.; Franklin, S. Integrating GIS and remotely sensed data for mapping forest disturbance and change. Underst. For. Disturb. Spat. Pattern Remote Sens. GIS Approaches 2006, 133–172. [Google Scholar] [CrossRef]
- Mancino, G.; Nolè, A.; Ripullone, F.; Ferrara, A. Landsat TM imagery and NDVI differencing to detect vegetation change: Assessing natural forest expansion in Basilicata, southern Italy. Ifor.-Biogeosci. For. 2014, 7, 75. [Google Scholar] [CrossRef] [Green Version]
- Hansen, M.C.; Loveland, T.R. A review of large area monitoring of land cover change using Landsat data. Remote Sens. Environ. 2012, 122, 66–74. [Google Scholar] [CrossRef]
- Prakash, A.; Gupta, R. Land-use mapping and change detection in a coal mining area-a case study in the Jharia coalfield, India. Int. J. Remote Sens. 1998, 19, 391–410. [Google Scholar] [CrossRef]
- Asner, G.P.; Keller, M.; Pereira, R., Jr.; Zweede, J.C. Remote sensing of selective logging in Amazonia: Assessing limitations based on detailed field observations, Landsat ETM+, and textural analysis. Remote Sens. Environ. 2002, 80, 483–496. [Google Scholar] [CrossRef]
- Lu, D.; Mausel, P.; Brondizio, E.; Moran, E. Change detection techniques. Int. J. Remote Sens. 2004, 25, 2365–2401. [Google Scholar] [CrossRef]
- Nelson, R.F. Detecting forest canopy change due to insect activity using Landsat MSS. Photogramm. Eng. Remote Sens. 1983, 49, 1303–1314. [Google Scholar]
- Zhu, Z.; Woodcock, C.E. Continuous change detection and classification of land cover using all available Landsat data. Remote Sens. Environ. 2014, 144, 152–171. [Google Scholar] [CrossRef] [Green Version]
- Im, J.; Jensen, J.R. A change detection model based on neighborhood correlation image analysis and decision tree classification. Remote Sens. Environ. 2005, 99, 326–340. [Google Scholar] [CrossRef]
- Schneider, A. Monitoring land cover change in urban and peri-urban areas using dense time stacks of Landsat satellite data and a data mining approach. Remote Sens. Environ. 2012, 124, 689–704. [Google Scholar] [CrossRef]
- Huang, C.; Song, K.; Kim, S.; Townshend, J.R.; Davis, P.; Masek, J.G.; Goward, S.N. Use of a dark object concept and support vector machines to automate forest cover change analysis. Remote Sens. Environ. 2008, 112, 970–985. [Google Scholar] [CrossRef]
- Townshend, J.; Huang, C.; Kalluri, S.; Defries, R.; Liang, S.; Yang, K. Beware of per-pixel characterization of land cover. Int. J. Remote Sens. 2000, 21, 839–843. [Google Scholar] [CrossRef] [Green Version]
- Khan, S.H.; He, X.; Porikli, F.; Bennamoun, M. Forest change detection in incomplete satellite images with deep neural networks. IEEE Trans. Geosci. Remote Sens. 2017, 55, 5407–5423. [Google Scholar] [CrossRef]
- Mou, L.; Bruzzone, L.; Zhu, X.X. Learning Spectral-Spatial-Temporal Features via a Recurrent Convolutional Neural Network for Change Detection in Multispectral Imagery. IEEE Trans. Geosci. Remote Sens. 2019, 57, 924–935. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Chen, X.; Wang, Z.; Wang, Z.J.; Ward, R.K.; Wang, X. Deep learning for pixel-level image fusion: Recent advances and future prospects. Inf. Fusion 2018, 42, 158–173. [Google Scholar] [CrossRef]
- Daudt, R.C.; Le Saux, B.; Boulch, A.; Gousseau, Y. Urban change detection for multispectral earth observation using convolutional neural networks. In Proceedings of the IGARSS 2018—2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; IEEE: New York, NY, USA, 2018; pp. 2115–2118. [Google Scholar]
- Ortega Adarme, M.; Queiroz Feitosa, R.; Nigri Happ, P.; Aparecido De Almeida, C.; Rodrigues Gomes, A. Evaluation of deep learning techniques for deforestation detection in the Brazilian Amazon and cerrado biomes from remote sensing imagery. Remote Sens. 2020, 12, 910. [Google Scholar] [CrossRef] [Green Version]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. CoRR 2014 . Available online: https://arxiv.org/pdf/1411.4038.pdf (accessed on 18 July 2021).
- Caye Daudt, R.; Le Saux, B.; Boulch, A. Fully Convolutional Siamese Networks for Change Detection. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 4063–4067. [Google Scholar]
- De Bem, P.P.; de Carvalho Junior, O.A.; Fontes Guimarães, R.; Trancoso Gomes, R.A. Change Detection of Deforestation in the Brazilian Amazon Using Landsat Data and Convolutional Neural Networks. Remote Sens. 2020, 12, 901. [Google Scholar] [CrossRef] [Green Version]
- Zhang, C.; Yue, P.; Tapete, D.; Jiang, L.; Shangguan, B.; Huang, L.; Liu, G. A deeply supervised image fusion network for change detection in high resolution bi-temporal remote sensing images. ISPRS J. Photogramm. Remote Sens. 2020, 166, 183–200. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Handa, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Robust Semantic Pixel-Wise Labelling. CoRR 2015. Available online: https://arxiv.org/pdf/1511.00561.pdf (accessed on 18 July 2021).
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. CoRR 2015. Available online: https://arxiv.org/pdf/1505.04597.pdf (accessed on 18 July 2021).
- Zhang, Z.; Liu, Q.; Wang, Y. Road extraction by deep residual u-net. IEEE Geosci. Remote Sens. Lett. 2018, 15, 749–753. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Jégou, S.; Drozdzal, M.; Vázquez, D.; Romero, A.; Bengio, Y. The One Hundred Layers Tiramisu: Fully Convolutional DenseNets for Semantic Segmentation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 June 2017; pp. 1175–1183. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–27 June 2017; pp. 2261–2269. [Google Scholar]
- Lobo Torres, D.; Queiroz Feitosa, R.; Nigri Happ, P.; Elena Cué La Rosa, L.; Marcato Junior, J.; Martins, J.; Olã Bressan, P.; Gonçalves, W.N.; Liesenberg, V. Applying fully convolutional architectures for semantic segmentation of a single tree species in urban environment on high resolution UAV optical imagery. Sensors 2020, 20, 563. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. CoRR 2018. Available online: https://arxiv.org/pdf/1802.02611.pdf (accessed on 18 July 2021).
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. CoRR 2016. Available online: https://openaccess.thecvf.com/content_cvpr_2017/papers/Chollet_Xception_Deep_Learning_CVPR_2017_paper.pdf (accessed on 18 July 2021).
- Chen, L.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. CoRR 2017. Available online: https://arxiv.org/pdf/1706.05587.pdf (accessed on 18 July 2021).
- Sandler, M.; Howard, A.G.; Zhu, M.; Zhmoginov, A.; Chen, L. Inverted Residuals and Linear Bottlenecks: Mobile Networks for Classification, Detection and Segmentation. CoRR 2018. Available online: https://arxiv.org/pdf/1801.04381.pdf (accessed on 18 July 2021).
- Maurano, L.; Escada, M.; Renno, C.D. Spatial deforestation patterns and the accuracy of deforestation mapping for the Brazilian Legal Amazon. Ciência Florest. 2019, 29, 1763–1775. [Google Scholar] [CrossRef]
- Keras. Available online: https://keras.io/getting_started/ (accessed on 18 July 2021).
- Sokolova, M.; Japkowicz, N.; Szpakowicz, S. Beyond Accuracy, F-Score and ROC: A Family of Discriminant Measures for Performance Evaluation. In Proceedings of the Australasian Joint Conference on Artificial Intelligence, Hobart, Australia, 4–8 December 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 1015–1021. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SegNet | U-Net | ResU-Net | ||||
|---|---|---|---|---|---|---|
| Layer | Kernel No. | Layer | Kernel No. | Layer | Kernel No. | |
| Encoder | 2 × SB + pool | 32 | UB + pool | 32 | conv1(3 × 3) | 32 |
| 2 × SB + pool | 64 | UB + pool | 64 | Layer | 32 | |
| 3 × SB + pool | 128 | UB + pool | 128 | RB + conv | 64 | |
| UB | 128 | RB + conv | 128 | |||
| Decoder | Up + 2 × SB | 128 | TC + UB | 128 | Up + RB + conv | 128 |
| SB + Up | 64 | TC + UB | 64 | Up + RB + conv | 64 | |
| SB | 64 | TC + UB | 32 | Up + RB + conv | 32 | |
| SB + Up | 32 | |||||
| SB | 32 | |||||
| conv2(1 × 1) | 3 | conv2(1 × 1) | 3 | conv2(1 × 1) | 3 | |
| SoftMax | SoftMax | SoftMax | ||||
| FC-DenseNet | Xception | Mobilenetv2 | ||||
| Layer | Kernel No. | Layer | Kernel No. | Layer | Kernel No. | |
| Encoder | conv1(3 × 3) | 32 | conv1(3 × 3) | 32 | conv1(3 × 3) | 32 |
| conv1(3 × 3) | 64 | |||||
| 3 × (DB + TD ) | 64 | 2 × SC | 128 | IRB | 16 | |
| SC | 128 | 2 × IRB | 24 | |||
| Shortcut | 128 | 3 × IRB | 32 | |||
| 2 × SC | 256 | |||||
| Shortcut | 256 | |||||
| ASPP | ||||||
| Decoder | Bilinear Upsampling × 4 | |||||
| Low-Level Features + output (Bilinear Upsampling × 4) | ||||||
| conv1(3 × 3) | ||||||
| 3 × (TC + DB ) | 128 | Bilinear Upsampling × 4 | ||||
| conv2(1 × 1) | 3 | conv(1 × 1) | ||||
| SoftMax | SoftMax | |||||
| Method | Parameters |
|---|---|
| SegNet | 0.9 M |
| U-Net | 1.4 M |
| ResU-Net | 2.0 M |
| FC-DenseNet | 0.3 M |
| DeepLabv3+ (Xception) | 1.1 M |
| DeepLabv3+ (MobileNetV2) | 0.2 M |
| Method | Median Training | Inference |
|---|---|---|
| Time (min:s) | Time (s) | |
| U-Net | 13:36 | 16.9 |
| ResU-Net | 14:23 | 19.6 |
| SegNet | 32:21 | 36.6 |
| FC-DenseNet | 18:22 | 24.7 |
| DeepLabv3+ (Xception) | 26:21 | 27.1 |
| DeepLabv3+ (MobileNetV2) | 8:41 | 13.2 |
| Method | Median Training | Inference |
|---|---|---|
| Time (min:s) | Time (s) | |
| U-Net | 23:51 | 31.2 |
| ResU-Net | 26:52 | 35.6 |
| SegNet | 36:02 | 42.1 |
| FC-DenseNet | 32:27 | 37.9 |
| DeepLabv3+ (Xception) | 38:08 | 44.4 |
| DeepLabv3+ (MobileNetV2) | 18:04 | 27.9 |
| Accuracy Metrics | ResU-Net (Landsat) | ResU-Net (Sentinel) | ||
|---|---|---|---|---|
| Audited | Not Audited | Audited | Not Audited | |
| Overall accuracy | 99.7 | 99.7 | 99.8 | 99.7 |
| -score | 76.4 | 70.7 | 78.0 | 70.2 |
| Recall | 62.2 | 62.6 | 74.2 | 64.5 |
| Precision | 99.1 | 82.0 | 82.3 | 77.2 |
| False positive | 0.0 | 0.1 | 0.1 | 0.1 |
| False negative | 0.3 | 0.3 | 0.1 | 0.2 |
| True positive | 0.4 | 0.4 | 0.4 | 0.4 |
| True negative | 99.3 | 99.2 | 99.4 | 99.2 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Torres, D.L.; Turnes, J.N.; Soto Vega, P.J.; Feitosa, R.Q.; Silva, D.E.; Marcato Junior, J.; Almeida, C. Deforestation Detection with Fully Convolutional Networks in the Amazon Forest from Landsat-8 and Sentinel-2 Images. Remote Sens. 2021, 13, 5084. https://doi.org/10.3390/rs13245084
Torres DL, Turnes JN, Soto Vega PJ, Feitosa RQ, Silva DE, Marcato Junior J, Almeida C. Deforestation Detection with Fully Convolutional Networks in the Amazon Forest from Landsat-8 and Sentinel-2 Images. Remote Sensing. 2021; 13(24):5084. https://doi.org/10.3390/rs13245084
Chicago/Turabian StyleTorres, Daliana Lobo, Javier Noa Turnes, Pedro Juan Soto Vega, Raul Queiroz Feitosa, Daniel E. Silva, Jose Marcato Junior, and Claudio Almeida. 2021. "Deforestation Detection with Fully Convolutional Networks in the Amazon Forest from Landsat-8 and Sentinel-2 Images" Remote Sensing 13, no. 24: 5084. https://doi.org/10.3390/rs13245084
APA StyleTorres, D. L., Turnes, J. N., Soto Vega, P. J., Feitosa, R. Q., Silva, D. E., Marcato Junior, J., & Almeida, C. (2021). Deforestation Detection with Fully Convolutional Networks in the Amazon Forest from Landsat-8 and Sentinel-2 Images. Remote Sensing, 13(24), 5084. https://doi.org/10.3390/rs13245084