
Deep Learning-Based Semantic Segmentation of Urban Features in Satellite Images: A Review and Meta-Analysis




Abstract
:
1. Introduction
2. Deep Learning-Based Semantic Segmentation of Urban Remote Sensing Images
2.1. Semantic Segmentation in Remote Sensing
2.2. Convolutional Neural Networks (CNN)
2.3. Fully Convolutional Network (FCN)
2.4. Symmetrical FCNs with Skip Connections
2.5. Generative Adversarial Networks (GAN)
2.6. Transfer Learning
3. Meta-Analysis
3.1. Methods and Data for Review
- What are the study targets?
- What are the data sources and datasets used?
- How is the training and testing data prepared for deep learning? This question looks for pre-processing, preparations and augmentation methods if used.
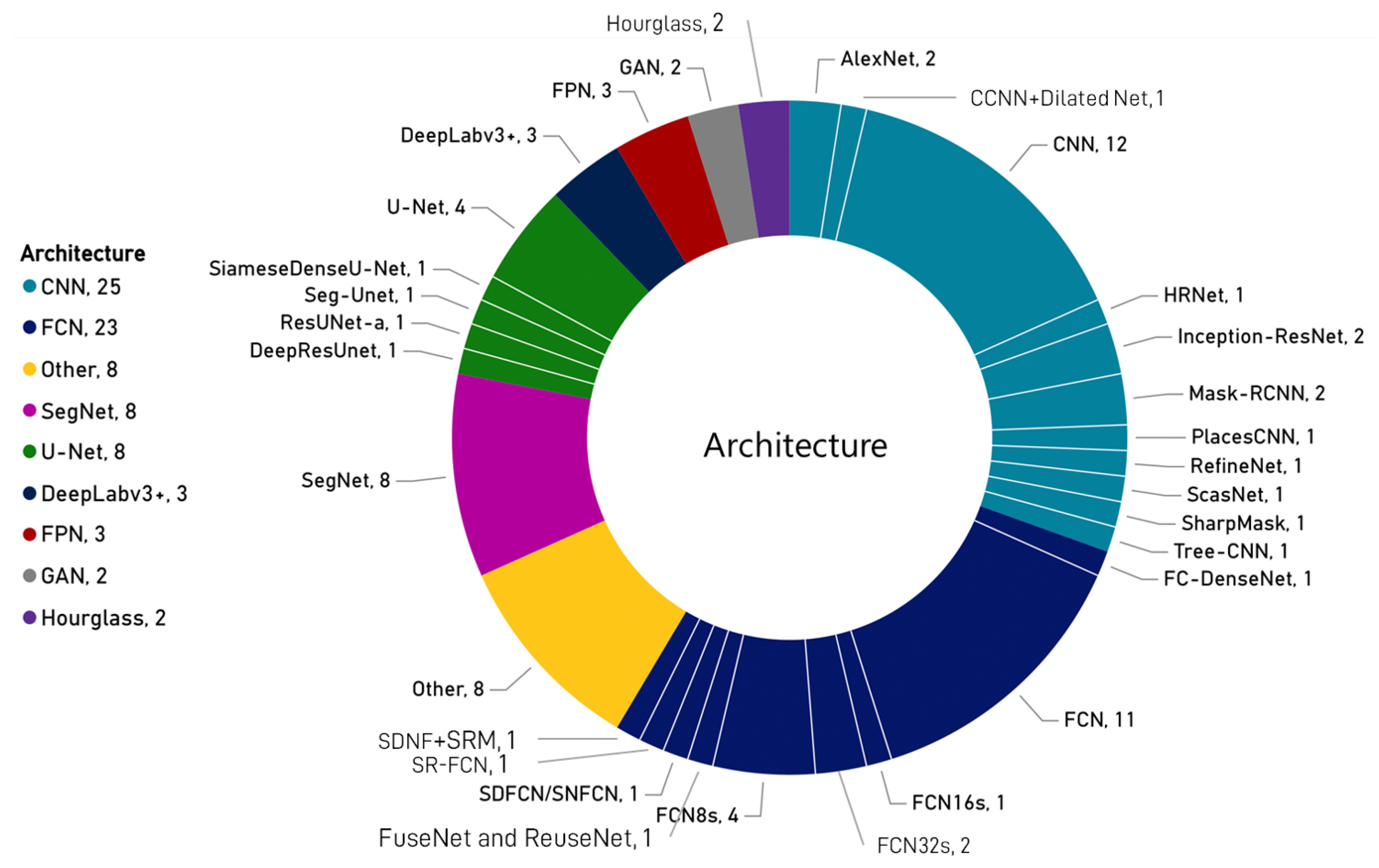
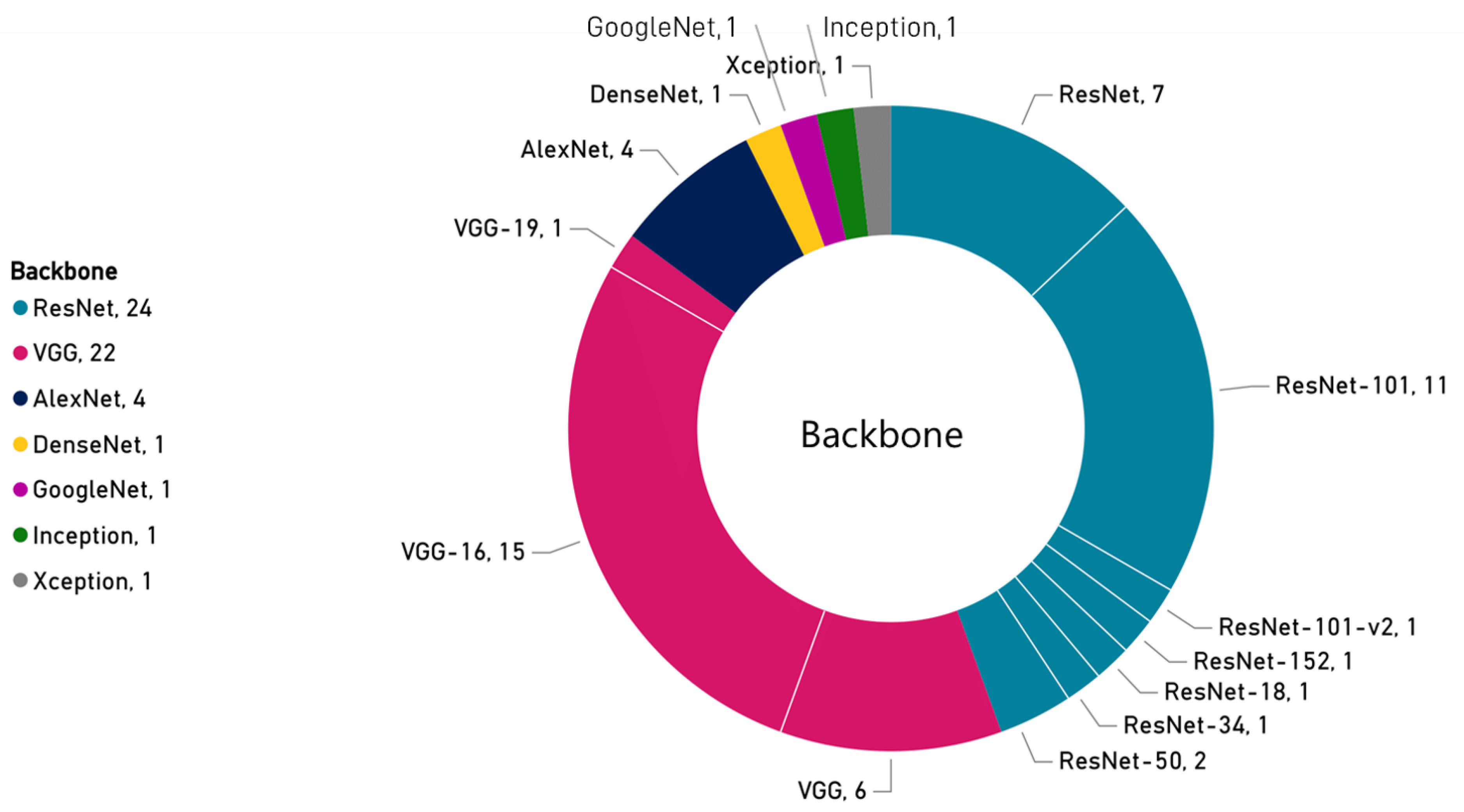
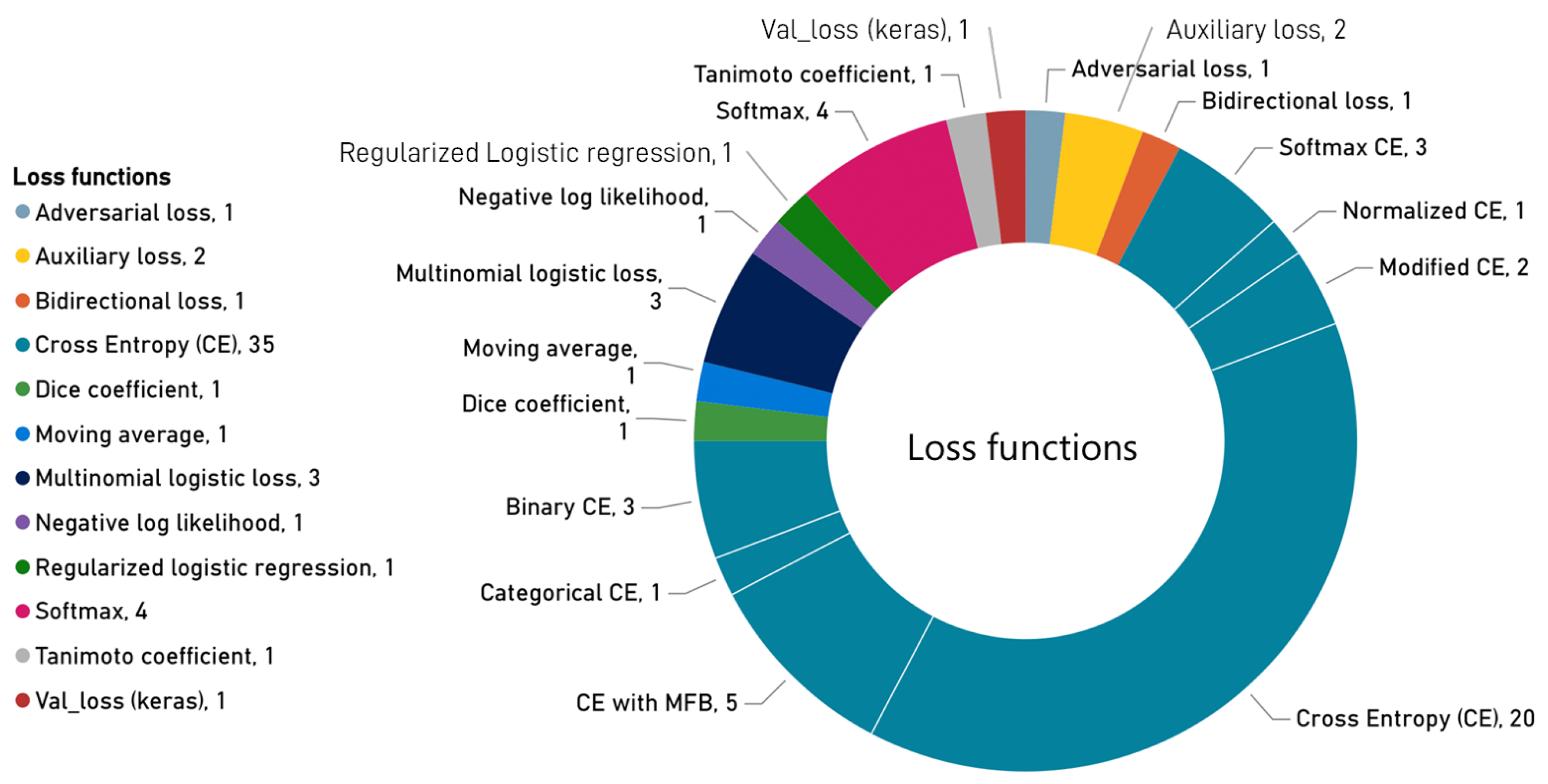
- What are the training details? This question looks for architecture, backbone, framework, optimizer, loss function and hyper-parameters that are mentioned by the papers?
- What is the overall performance of the method? This question looks for the performance metrics used, methods used for comparison, highest performance in each area of study and performance gains over previous methods.
3.2. Dissection and Overview of Research Questions
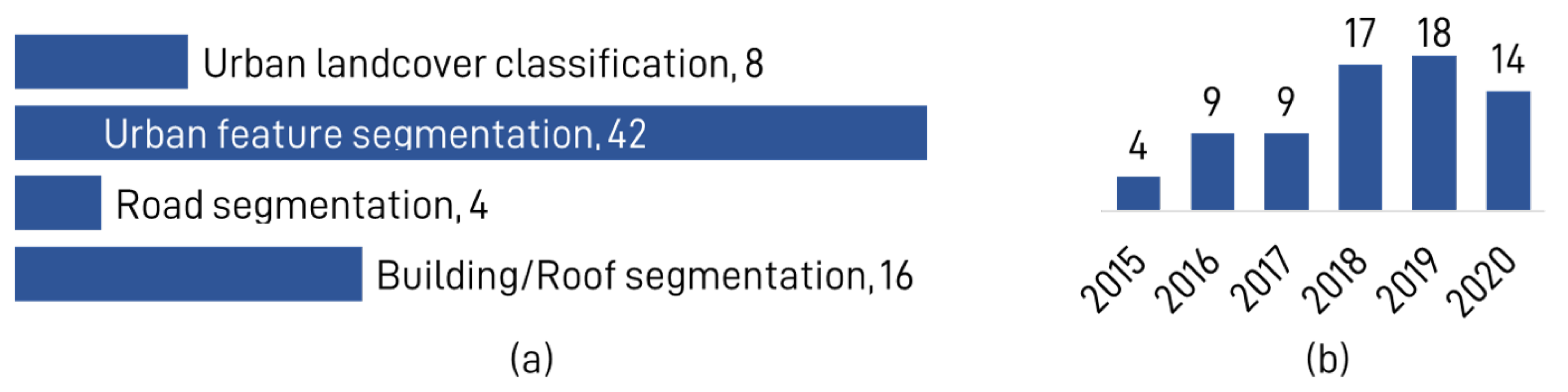
3.2.1. The Study Targets
3.2.2. Data Sources
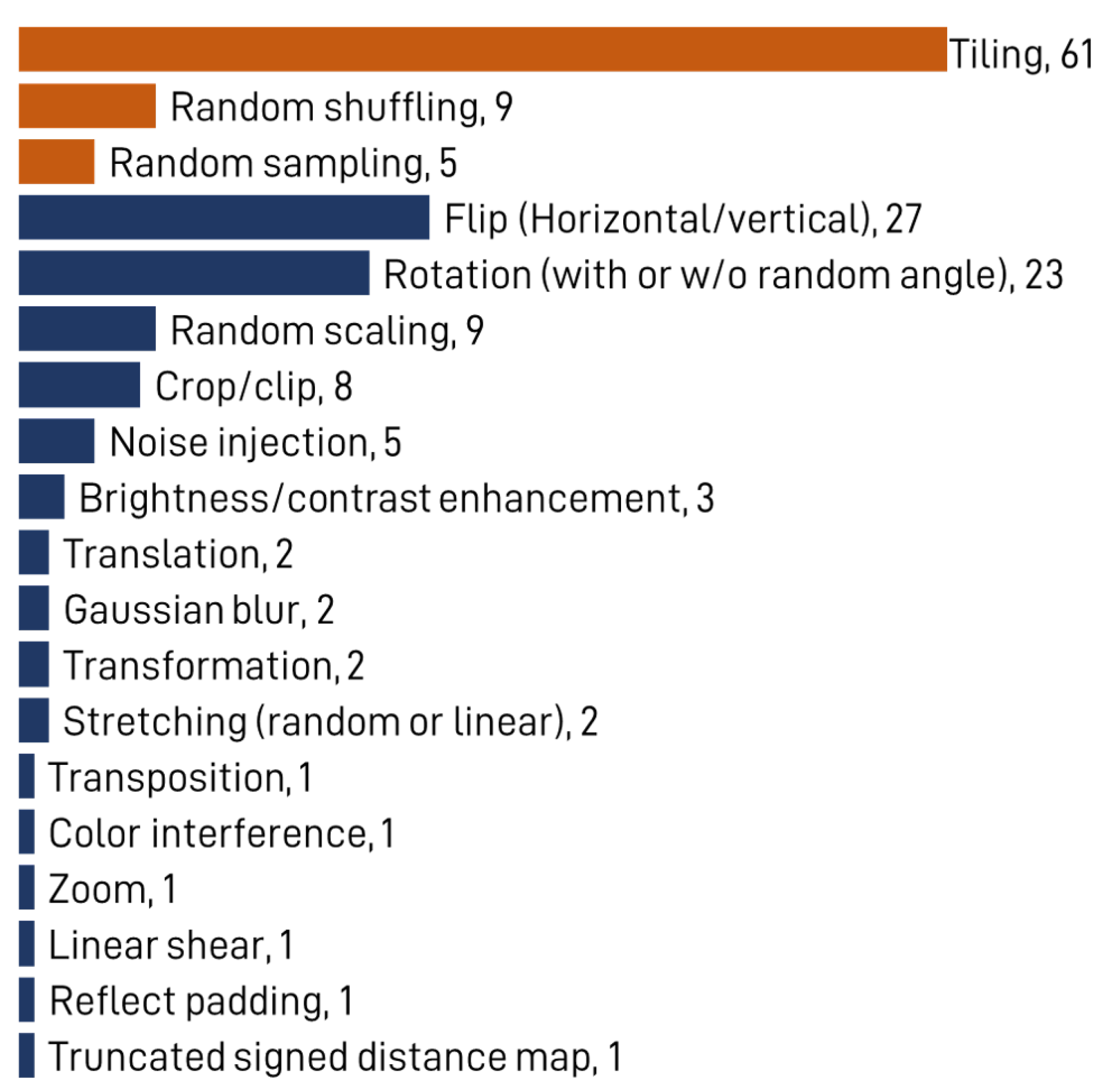
3.2.3. Data Preparation
3.2.4. Training Details
3.2.5. Performance Comparison
4. Discussion
4.1. Helping Hands for DL Models
4.2. Improvements from Deep Learning
4.3. Improvement Boosted by Dataset Challenges
4.4. Problems Addressed by Deep Learning
- Complete ignorance of spatial information: In most of the traditional methods for pixel-level segmentation, spatial information was completely ignored. To solve this problem, several DL-based studies figured out the use of contextual information from lower and higher layers/levels of encoder (or downsampling) block, using skip connection and symmetrical networks. The features maps obtained from these lower to higher levels of encoders are concatenated to the feature maps of decoder (or upsampling) layers in symmetrical networks. As this problem also entails incorrect segmentation caused by similar features of similar categories, concatenation/aggregation or better fusion techniques are sought to merge feature maps of different levels. Table 1 shows 18 papers were motivated to use better fusion techniques. The details of these papers are already presented in Section 2 and Section 3.2.1.
- Boundary pixel classification (aka boundary blur) problem: Several studies were performed to address this problem. Chen et al. (2017) [78] removed max pooling layers and used CRF for post-processing, Badrinarayanan et al. [111] reused pooling indices, and Marmanis et al. (2018) [112] combined semantic segmentation with semantically informed edge detection to make boundary explicit. Other papers [55,163] were also motivated to address this problem. Specifically, encoder-decoder architectures with symmetrical network and skip connections have minimized this problem significantly. Mi et al. [143] alleviated the problem by using superpixel segmentation with region loss to emphasize on homogeneity within and the heterogeneity between superpixels.
- Class imbalance problem: Several studies proposed the use of contextual information to address this problem. Li et al. (2017) [162] used multi-skip network, Liu et al. (2017) [94] proposed a novel Hourglass-Shaped CNN (HSN) to perform multi-scale inference and Li et al. (2018) [154] proposed Contextual Hourglass Network (CxtHGNet). Dong et al. (2019) [110] and Dong et al. (2020) [109] proposed DenseU-Net and SiameseDenseU-Net architecture inspired from [172] to solve this problem. Some used MFB with focal loss to minimize this problem [61,94,109,110,162].
- Salt-and-pepper noise: To minimize the noises produced by pixel-based semantic segmentation, Guo et al. [100] denoised and smoothened the segmentation results by implementing kernel-based morphological methods, and Zhao et al. [156] used CRF to capture contextual information of the semantic segments and refine the classification map.
- Structural stereotype and insufficient training: As highlighted by Sun et al. [115] in 2019, the problem of structural stereotype causes unfair learning and inhomogeneous reasoning in encoder-decoder architectures. They alleviate this problem by random sampling and ensemble inference strategy. They also proposed a novel encoder-decoder architecture called ResegNet to solve insufficient training.
- Domain-shift problem: Another drawback of DL-based method is that the DL performance decreases when the study domains are shifted. To address this problem, and reduce the domain-shift impact caused by imaging sensors, resolution and class representation, Benjdira et al. [127] used GAN consisting of generator and discriminant as explained in Section 2.5. Liu et al. (2020) [107] used two discriminators to minimize the discrepancy between the source and target domains. Also, many others performed multi-modal, multi-scale and multi-resolution training of DL-models [56,80,91,92,93,94,95,96,97,98], for sufficient training of DL model.
5. Conclusions and Future Directions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SN | Area | Data Summary | Pre-Processing/Preparation | Data Augmentation | Classes | DL Model | Framework | Metric | Highest Value | Ref. |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | UL. Cl. | RADARSAT-2 PolSAR data | Multi-spectral images were ortho-rectified using DEM, and converted to Pauli RGB Image using a neighboring window of some size. | No | 10 land cover classes | DBN | N/A | Conf. matrix, OA, K | OA: 0.81 | [136] |
| 2 | Rd. Seg. | Images from camera mounted on a plane, Aerial KITTI, Google Earth Pro | No | No | Sky, Build, Road, Sidewalk, Vegetation, Car | MRF using S-SVM | C++ | P-R Curve and IoU | IoU: 78.71 | [140] |
| 3 | UF. Seg. | ISPRS Vaihingen | nDSMs are generated using lasground tool. 7500 patches are randomly extracted for each class. Image patches of 16 × 16, 32 × 32 and 64 × 64 pixels are used. | N/A | ISPRS: Vaihingen | CNN+RF+CRF (aka. DSTO) | MatConvNet CNN toolbox and MATLAB | OA and F1 | OA: 0.87 | [144] |
| 4 | B/R. Seg. | Massachusetts Buildings and Roads Dataset | Mean value substraction over each patch and division by standard deviation computed over the entire dataset. | Random rotation. | buildings, roads, and others | CNN | Caffe | P, R | P-R: 0.84–0.86 | [158] |
| 5 | B/R. Seg.; Rd. Seg. | Massachusetts Buildings and Roads Dataset | 64 × 64 sized RGB image patch. | Rotation with a random angle and random horizontal flip. | building, road, background | CNN | N/A | P-R Curve | P-R: 0.9–0.97 | [159] |
| 6 | UF. Seg. | ISPRS Vaihingen and Potsdam | Mean subtraction; Vahingen: 128 × 128; Potsdam: 256 × 265; no overlapping | Flip and Rotation of 90 and 10 degree. | ISPRS Vaihingen and Potsdam | FCN with downsampling (DS); FCN without DS (DST_1); DS+RF+CRF (DST_2) | Caffe | OA and F1 | OA: 0.89–0.90 | [31] |
| 7 | UF. Seg. | ISPRS Vaihingen and Potsdam | Random sampling of training data | Random flip and rotation, and noise injection | ISPRS Vaihingen and Potsdam | Encoder-decoder CNN. | DAGNN from MatConvNet | OA, K, AA, and F1 | OA: 0.89–0.90 | [55] |
| 8 | UL. Cl. | IEEE GRSS; Coffee Dataset | Image patch of 7 × 7 and 25 × 25 were used to train the model. | No | AGRICULTURE: coffee crop and non-coffee. URBAN: unclassified, road, trees, red roof, grey roof, concrete roof, vegetation, bare soil | CNN | Torch | OA and K | OA: 0.91 | [137] |
| 9 | UF. Seg. | ISPRS Vaihingen | Patch-based: First extracted a patch with every car at center. Pixel-based: Image patches with 50% overlap. | 1. Patch-based: Rotation. 2. Pixel-based: Flip (horizontal and vertical) and rotation at 90 degree intervals. | ISPRS Vaihingen | CNN and FCN | Caffe | OA and F1 | OA: 0.87 | [61] |
| 10 | UF. Seg. | ISPRS Vaihingen | Randomly sampled 12,000 patches of 259 × 259 px for training. | No | ISPRS Vaihingen | FCN | N/A | Mean acc. and OA | OA: 0.88 | [157] |
| 11 | UF. Seg. | ISPRS Vaihingen and Potsdam | Random sampling to select patches of 256 × 256 for Vaihingen and 512 × 512 for Potsdam, with overlap. | Random flip (vertical, horizontal orboth) and transposition. | ISPRS Vaihingen and Potsdam | FCN-based MLP (INR) | Caffe | OA and F1 | OA: 0.87–0.89 | [145] |
| 12 | UF. Seg. | ISPRS Vaihingen | Prepare a composite of DSM, nDSM and NDVI. Patches of 256 × 256 px are used for training, which are overlapped for testing. | No | ISPRS Vaihingen | SegNet | N/A | P, R and F1 | OA: 0.9 | [92] |
| 13 | B/R. Seg. | Massachusetts Buildings Dataset, European Buildings Dataset, Romanian Roads, Satu mare Dataset | Local Patches: 64 × 64 and Global patches: 256 × 256 | No | Residential Area, Buildings and Roads | CNN: VGGNet based on Alexnet; and ResNet. | Caffe | F1 | F1: 0.94 | [152] |
| 14 | B/R. Seg. | Massachusetts Buildings Dataset, European Buildings Dataset, Romanian Roads, Satu mare Dataset | Local Patches: 64 × 64 and Global patches: 256 × 256 | No | Residential Area, Buildings and Roads | CNN: VGGNet based on Alexnet; and ResNet. | Caffe | F1 | F1: 0.94 | [153] |
| 15 | UF. Seg. | ISPRS Vaihingen and Stanford Background dataset (Scene data) | No | No | ISPRS Vaihingen; Scenes: sky, tree, road, grass, water, building, mountain, and foreground object | CNN (aka. ETH_C) | Python and Matlab | Pixel acc. and Class acc. | Pixel acc: 0.85 | [165] |
| 16 | UF. Seg. | ISPRS Potsdam; OSM; Google Earth | Mean value substraction on every 500 × 500 px patch. | No | Building, road, and background | FCN based on VGG-16 | N/A | F1 | OA: 0.88 | [161] |
| 17 | UF. Seg. | ISPRS Vaihingen and Beijing dataset using Worldview-2 satellite | 18 × 18 image patches used for training | No | ISPRS Vaihingen; Beijing dataset: Commercial buildings, Residential buildings, Roads, Parking lots, Shadows, Impervious surfaces, Bare soils | CNN | N/A | OA and K | OA: 0.86–0.96 | [156] |
| 18 | UF. Seg. | ISPRS Vaihingen | Patches of 600 × 600 with 50% overlap | Rotation of 90 and 180 degrees. Random mirror, rotate between −10 and 10 degrees, resize by factor between 0.5 and 1.5, and gaussian blur. | ISPRS Vaihingen | CNN (named GSN) with ResNet-101 | Caffe | OA and F1 | OA: 0.89 | [87] |
| 19 | UF. Seg. | ISPRS Vaihingen | 256 × 256 patches with 50% overlap | Rotate by step of 90 degrees and flip. | ISPRS Vaihingen | CNN with multiple skip connections (named MSN) | Caffe | OA and F1 | OA: 0.86 | [162] |
| 20 | UF. Seg. | ISPRS Potsdam | nDSM, NDVI were produced from Lidar. 36,000 images and GTs of 224 × 224 px used for training and 50% overlap used on test data. Chose extra data for car category for data balancing. | Random crop | ISPRS Potsdam | FCN | Caffe | OA and F1 | OA: 0.88 | [150] |
| 21 | UF. Seg. | ISPRS Vaihingen and Potsdam | Training: NIR-R-G-B and the nDSMs of 256 × 256 px with 50% of overlap. Testing: 0%, 25%, 50% and 75% overlaps. | Flip (horizontal and vertical) | ISPRS Vaihingen and Potsdam | CNN (named HSN) | Caffe | OA and F1 | OA: 0.89 | [94] |
| 22 | UF. Seg. | ISPRS Vaihingen; IEEE GRSS | Super-pixel segmentation by multi-scale semantic segmentation. Image patches of 32 × 32, 64 × 64 and 128 × 128 are extracted around the superpixel centroid. Superpixel is classified first. Then the multi-scale patches are resized to 228 × 228 and fed to pre-trained AlexNet. | No | Impervious surfaces, Building, Low vegetation, Tree, Car | AlexNet CNN and SegNet with VGG-16 encoder | N/A | OA | OA: 0.89 | [93] |
| 23 | UF. Seg. | ISPRS Vaihingen and Potsdam | A composite image of stacked NDVI, DSM and nDSM are first prepared. Patch size = 128 × 128; stride 32 px and 64 px for two dataset. | No | ISPRS Vaihingen and Potsdam | SegNet-RC, V-FuseNet, ResNet-34-RC, FusResNet. | Caffe | P,R, OA and F1 | OA: 0.90–0.91 | [146] |
| 24 | B/R. Seg.; UF. Seg. | ISPRS Vaihingen and Potsdam; Massachussets Buildings dataset | 400 × 400 patches with the overlap of 100 pixels | Flip (horizontal and vertical) and rotate counterclockwise at the step of 90 degrees. | ISPRS Vaihingen and Potsdam; Massachussets: buildings | ScasNet (aka. CASIA) | Caffe | IoU and F1 | F1: 0.92–0.93 | [151] |
| 25 | UF. Seg.; UL. Cl. | ISPRS Vaihingen and Potsdam; IEEE GRSS; Sentinel-1; Sentinel-2 | ISPRS and IEEE data: Tiling into 224 × 224 without overlap, and random sampling. For Sentinel images: labels were created from OSM. | ISPRS Vaihingen and Potsdam; IEEE GRSS; Sentinel: water, farmland, forest and urban area. | Sevral fusion techniques: CoFsn, LaFsn and LnFsn (aka. RIT_3...RIT_7) | Caffe | OA and F1 | OA: 0.90–0.93 | [147] | |
| 26 | UF. Seg. | ISPRS Vaihingen | 256 × 256 pixels tiles with strides of 150, 200 and 220 px. | Random: scaling, rotation, linear shear, translation and flips (vertical and horizontal axis). | ISPRS Vaihingen | Ensemble of SegNet and two variants of FCN initialized with (i) Pascal and (ii) VGG-16 | N/A | OA, P, R and F1 | OA: 0.85–0.90 | [112] |
| 27 | UF. Seg. | RIT-18 dataset | Pre-trained ResNet-50 FCN and 520 thousand 80 × 80 MSI are randomly shuffled for training. Then again trained the model with 16 × 160 patches of their training dataset for semantic segmentation. | Random horizontal and vertical flips | 18 urban feature classes | SharpMask and RefineNet | Theano/ Keras | Per-class acc., AA and OA | AA: 0.60 | [121] |
| 28 | UF. Seg. | ISPRS Vaihingen and Potsdam | Patches of 128 × 128 × 3 with stride of 48 px (62.5) and 128 px (100) | Random scaling, translation and flips (horizontal and vertical) | ISPRS Vaihingen and Potsdam | FCN (named SDFCN and SNFCN, aka. CVEO) | Keras and Tensorflow. | P, R, OA, K, F1 and mIoU | OA: 0.88–0.89 | [125] |
| 29 | UF. Seg. | ISPRS Vaihingen and Potsdam | Patches of size 256 × 256 from the original images without overlap, and pad 0 s if needed. Further, the training images are split into train and valid sets in the ratio of 9:1. Training data are randomly shuffled. | Random flip (horizontal and vertical), scale and crop image into fix size with padding 0 s if needed. | ISPRS Vaihingen and Potsdam | Cotextual Hourglass Network (named CxtHGNet) | Tensorflow | Pixel acc. and mIoU | Pixel acc: 0.87 | [154] |
| 30 | Rd. Seg. | AerialLanes18 dataset | 1024 × 1024 patches are cropped bt 800 px step in horizontal and vertical directions. Manual annotation of road lane features are prepared. | Random flip | 5 classes including road signs and lane lines | FCN-32s (named Aerial LaneNet) | Tensorflow | Pixel acc., AA, IoU, Dice Sim. Coef., P and R | AA: 0.70 | [142] |
| 31 | UF. Seg. | ISPRS Vaihingen | Method 1. Crop each entire image into 500 × 500 patches, use vertical/horizontal overlap of 100 px. Method 2. Randomly crop these patches again into 473 × 473 to train the network. | Random horizontal flips and resize with five scales, 0.5, 0.75, 1.0, 1.25, and 1.5 | ISPRS Vaihingen | PSPNet with pretrained ResNet101-v2 | Caffe | P, R, and F1 | OA: 0.88 | [89] |
| 32 | UF. Seg. | ISPRS Vaihingen and Potsdam | Potsdam: 512 × 512, Vaihingen: 256 × 256, both with 50% overlap. | Flip (horizontal and vertical) and rotation by steps of 90 degree. | ISPRS Vaihingen and Potsdam | FSN (aka. CASDE2/CASRS1) and FSN-noL (aka. CASDE1/CASRS2) | N/A | OA and F1 | OA: 0.89–0.9 | [148] |
| 33 | B/R. Seg. | Aerial Imagery for Roof Segmentation (AIRS) dataset | Significant misalignment between building footprint and detected roof were corrected and refined. GT dataset was then created containing 226,342 buildings for roof segmentation. | Random horizontal flip, random scaling, crop into 401 × 401 pixel patch and random rotation of 0, 90, 180, 270. | Roof | FPN, FPN + MSFF and PSPNet | TensorFlow | IoU, F1, P and R | F1: 0.95 | [91] |
| 34 | UF. Seg. | ISPRS Vaihingen | Stack of NIR-R-G image, DSM, nDSM, normalization to NIR-R-G to nNIR, nR, nG, NDVI, GNDVI are used to train the model. Image patches of 992 × 992 px with step size of 812 px used for patch-wise prediction. | Random scaling, horizontal flip and rotation of step of 90 degrees. | ISPRS Vaihingen | CNN | MXNet deep learning | OA, mIoU and F1 | OA: 0.86 | [95] |
| 35 | UF. Seg. | ISPRS Potsdam; Inria Aerial Image Labeling Data Set | IRRG images with prepared nDSM are used to train model. Manually annotated labels for Inria dataset. | Flip (horizontal and vertical) done on 3 quarters of image patches. | Impervious surfaces, Building, Low vegetation, Tree, Car, Clutter | RiFCN with forward stream inspired by VGG-16. | TensorFlow | F1, P, R, OA and IoU | OA: 0.88–0.96 | [76] |
| 36 | UF. Seg. | ISPRS Vaihingen; IEEE GRSS | Vaihingen: Images of 256 × 256 px and nDSM. IEEE GRSS: Lidar transformed into DSM an images of 500 × 500 px. | No | Impervious surfaces, Building, Low vegetation, Tree, Car, water and boats | CNN based on modified VGG-16 and CRF | Pylon model | OA, AA and F1 | OA: 0.86 | [163] |
| 37 | UL. Cl. | RGB Urban planning maps of Shibuya, Tokyo. | No | Random rotation and stretch. | 11 classes that are not mentioned. | U-Net | N/A | IoU and OA | OA: 0.99; IoU: 0.94 | [100] |
| 38 | UF. Seg. | ISPRS Vaihingen; Worldview-3 | Vahingen: 128 × 128; Potsdam: 256 × 265; no overlapping | No | ISPRS Vaihingen | FuseNet with ReuseNet (aka. ITCB) | N/A | OA, K, AA and F1 | OA: 0.88 | [149] |
| 39 | UF. Seg. | Bing Maps and Google Street Views | Aerial images, corresponding land use maps, and sparsely sampled street views are collected and prepared to train. | No | 11 classes of building types based on usage | PlacesCNN and SegNet | Pytorch | Pixel acc, mIoU and K | OA: 0.78 | [113] |
| 40 | UL. Cl.; UF. Seg. | ISPRS Vaihingen; Landsat-8 | Mean subtraction done on the images, with patch size 512 × 512. | Random horizontal flip | ISPRS Vaihingen; Landsat: agriculture, forest, miscellaneous, urban, and water. | CNN (named GCN) | Tensorflow | AA, F1 and mIoU | F1: 0.79 | [96] |
| 41 | B/R. Seg. | SpaceNet building dataset; Google Maps; OSM; Map World | A stack of (R,G,B, red edge, coastal) of WorldView-3 and RGB map images collected from auxiliary sources made total 8-channel input for the U-Net architecture. Each 650 × 650 px image was rescaled into 256 × 256 px, or sliced into 3 × 3 sub-images of 256 × 256. | Rotation of step of 90 degrees. | Buildings | U-Net | Keras | P, R and F1 | OA: 0.70 | [101] |
| 42 | UF. Seg. | ISPRS Vaihingen and Potsdam; IEEE GRSS; Coffee dataset (SPOT) | No | No | Coffee: Coffee and non-coffee; IEEE GRSS: trees, vegetation, road, bare soil, red roof, gray roof, and concrete roof; ISPRS Vaihingen and Potsdam | CNN: Dilated6, DenseDilated6, Dilated6Pooling, Dilated8Pooling (aka. UFMG 1 to 5) | Tensorflow | OA, AA, K and F1 | OA: 0.88–0.90 | [155] |
| 43 | UF. Seg. | ISPRS Vaihingen and Potsdam | Patches of 500 × 500 px with overlap of 200 px between neighboring patches | Random horizontal flip, rescale and random crop. | ISPRS Vaihingen and Potsdam | Combination of ResNet-101-v2 and pyramid pooling module. | Caffe | P, R, F1 and OA | OA: 0.89–0.90 | [62] |
| 44 | UF. Seg. | ISPRS Vaihingen and Potsdam; IEEE GRSS | FCN-8s: Images only. MLR: Images and LiDAR data (height, height variations, surface norm), and NDVI. Image patches of 224 × 224 and 1000 pixels are randomly selected, and 50 cars and boats were randomly chosen. Overlap of 50% used on image patches. | No | Impervious surface, buildings, low vegetation, trees, cars, boats and water | FCN (named DNN_HCRF) | Caffe | OA and F1 | OA: 0.88 | [84] |
| 45 | UL. Cl. | WorldView-2 | Used K-means clustering to check the abundance of classes in the study image. Then, they manually labeled eight slices (2048 × 2048) of whole area at pixel-level. Then 128 × 128 patches with 32 px stride were prepared. | Rotation with steps of 90 degree and flip. | Crop Area (CA) and Non-CA | DeepLabv3+ | Tensorflow | OA, F1 and K | OA: 0.95 | [134] |
| 46 | UF. Seg. | QuickBird: BGR-NIR at 2 m res, Sentinel-2: BGR-NIR at 10 m res, and TerraSAR-X: SAR images with 6 m res. | Patches of 224 × 224 with overlap of 28 px used for training. Labeling of reference data is based on a multi-step image analysis procedure through a combination of hierarchical, knowledge-based and object-based classification, machine learning and visual image interpretation with 93% OA. | No | urban, vegetation, water and slums | FCN of VGG19 backbone | Tensorflow | K, PPV, OA and IoU | OA: 0.91 | [135] |
| 47 | B/R. Seg. | ISPRS Potsdam; UK-based building dataset; OSM | RGB, RG-DE, RG-DN, RGB-DE and RGB-DN, where N = normalized pixel values, E = edge-magnitude data for depth channel were used. Any areas missing lidar data and tiles with no building were deleted. Labels for buildings were created using image border extraction algorithm. | No | Buildings | MaskR-CNN and RetinaNet | Tensorflow | mAP, OA and F1 | OA: 0.96–0.99 | [160] |
| 48 | B/R. Seg. | Linz Data Service: VHR satellite images with spatial resolution of 0.075 m for Christchurch and Waimakariri, New Zealand | Patches of 256 × 256 px with stride of 128 during train and stride of 64 during test. Building labels were prepared as polygon shapefiles of building outines. | No | Buildings | DeepResUnet | Keras and Tensorflow. | P, R, F1, K and OA | OA: 0.97 | [103] |
| 49 | UF. Seg. | ISPRS Vaihingen and Potsdam | 512 × 512 training patches. | No | ISPRS Vaihingen and Potsdam | BiseNet with ResNet101 feature extractor and GAN. | Semantic Seg. Suite framework; Keras and tensorflow. | AA, P, R, F1 and IoU | F1: 0.49 | [127] |
| 50 | UF. Seg. | ISPRS Vaihingen | Images of 256 × 256 px with 50% overlap. | Rotated at 0, 90, 180 and 270 degrees and then horizontally flipped. | ISPRS Vaihingen | DenseU-Net | N/A | P, R, F1 and OA | OA: 0.86 | [110] |
| 51 | B/R. Seg. | WHU Building dataset | Relative radiometric calibration strategy and tiles of 512 × 512. | Random resampling of images using one of linear stretching, histogram equalization, gaussian blur, and salt-and-pepper noise | Buildings | SR-FCN with VGG-16 and Atrous conv layers | Keras with TensorFlow | IoU, P, R | IoU: 0.64 | [79] |
| 52 | Rd. Seg. | Mnih 2013 dataset | Tiling: 500 × 500 pixels | N/A | Road | Y-Net | Tensorflow | Mean acc, pixel acc, mIoU, fwIoU, dice coeff., and Matthew correlation coeff. (MCC) | Mean Accuracy: 0.83 | [126] |
| 53 | UF. Seg. | CCF Satellite Image AI Classification and Recognition Competition | Random sampling of image tiles of 512 × 512 | N/A | Background, vegetation, road, building and water body | DeepLabv3 + ASPP + FC-Fusion Path | Tensorflow | Classification acc and mean IoU | Acc: 0.77 | [80] |
| 54 | B/R. Seg. | Inria Aerial Image Labeling Dataset | Crop 24 patches of 384 × 384 px | Random horizontal and vertical flips | Buildings and non-buildings | SegNet | IoU and pixel acc | IoU: 0.74 | [114] | |
| 55 | UF. Seg. | ISPRS Vaihingen and Potsdam | Tiling: 128 × 128 and random position sampling | N/A | ISPRS Vaihingen and Potsdam | ResegNet | N/A | OA and F1 | OA: 0.92 | [115] |
| 56 | B/R. Seg. | Gaofen-2 VHR satellite imagery | Georectification, registration and pan-sharpening. The images are normalized. Labels are delineated manually for segments of connected building roofs. Tiling: 512 × 512 and random sampling | N/A | Buildings and non-buildings | FCN with VGG-16 | Tensorflow | OA, IoU and mIoU | OA: 0.95 | [169] |
| 57 | UF. Seg. | ISPRS Vaihingen and Potsdam | Tiling: 600 × 600 with overlaps alculated using 2D Gaussian function. | Transformation, clipping and rotation | ISPRS Vaihingen and Potsdam | TreeUNet with DeepLabv3+ and TreeUNet with DeepUNet | MXNET deep learning | OA, F1, P, R | OA: 0.90 | [104] |
| 58 | B/R. Seg. | Massachusetts building dataset | Tiling: 384 × 384 | N/A | Buildings | Seg-Unet | Keras with TensorFlow | OA, F1, P, R | OA: 0.93 | [116] |
| 59 | UF. Seg. | ISPRS Vaihingen and Potsdam | Tiling: 512 × 512 | Randomly flipped and rotated | Ground, grass, tree, building, car | BSANet | Pytorch | Pixel acc, K, F1, mIoU | F1: 0.53 | [107] |
| 60 | B/R. Seg. | ISPRS Potsdam and PlanetScope Dove | Band normalization, coregistration, refinement, and a truncated signed distance map (TSDM). Tiling: 256 × 256. | TSDM for the medium-resolution images | Buildings | DSFE with FC-DenseNet | Pytorch | OA, F1 and IoU | OA: 0.93 | [164] |
| 61 | B/R. Seg. | Worldview-2 | Pansharpening of 2 m MS imagery into 0.5 m by nearest neighbor diffusion (NNDiffuse) pan sharpening algorithm. Tiling: 256 × 256 | Random crop; rotating, mirroring, brightness enhancement and adding noise points | Types of buildings: Old house, Old factory, Iron roof building and New building. | U-Net | Keras with TensorFlow | OA, F1 and IoU | OA: 0.87 | [102] |
| 62 | B/R. Seg. | Inria | Tiling: 224 × 224 | N/A | Buildings | SegNet with VGG-16 and FCN | N/A | Val acc (IoU) | 0.90 | [117] |
| 63 | UF. Seg. | ISPRS Vaihingen and Potsdam | Tiling: 500 × 500 | Noise injection (salt pepper noise or Gaussian noise), color interference (change saturation, brightness or contrast), random non-proportional scaling from 0.8 to 1.2 times, random rotation 0 to 360 degree and random flip of 90, 180, or 270. | ISPRS Vaihingen and Potsdam | DeepLabv3+ | N/A | OA and K | OA: 0.91 | [124] |
| 64 | UF. Seg.; UL. Cl. | Zurich dataset, Gaofen Image Dataset (GID), and Data Fountain 2017 | Tiling: 256 × 256 with overlap 80% | Random rotation and random scaling | Zurich dataset: Road, buildings, trees, bare soil, water, grass, rails and pools. Gaofen dataset: land-cover classes | Mask-R-FCN model: Mask-RCNN with RPN and FCN8s with VGG-16 | N/A | OA, AA, F1, P, R | AA: 0.82 | [138] |
| 65 | UF. Seg. | Zurich dataset and ISPRS Vaihingen and Potsdam | Tiling 512 × 512 pixels. Overlap: 100 px for ISPRS and 256 px for Zurich. | Horizontal and vertical flip and random scale rotation. Random changes in brightness, saturation, and contrast were adopted in color. | ISPRS Vaihingen; Zurich dataset: Road, buildings, trees, bare soil, water, grass, rails and pools. | MANet | Pytorch | OA, F1, P, R | OA: 0.88–0.89 | [97] |
| 66 | UF. Seg. | ISPRS Vaihingen and Potsdam | Tiling 512 × 512 pixels | Random-flipping and random-cropping. | ISPRS Vaihingen and Potsdam | HRNet | Pytorch | OA, F1, P, R | Vaihingen OA: 0.90; Potsdam OA: 0.92 | [98] |
| 67 | UF. Seg. | ISPRS Potsdam | Tiling: 256 × 256 with stride of 64 px and 128 px | Geometric data sugmentation: Rotation at random angle, with random centre and zoomed in/out according to random scale factor. Reflect padding. | ISPRS Potsdam | ResUNet-a | MXNET deep learning library | OA, F1, P, R, MCC | OA: 0.91 | [108] |
| 68 | UF. Seg. | ISPRS Vaihingen | Tiling: 256 × 256 with 50% overlap | Rotated at four angles (0, 90, 180, and 270), and each rotated image was horizontally mirrored. | ISPRS Vaihingen | SiameseDenseU-Net | N/A | OA, F1, P, R | OA: 0.86–0.89 | [109] |
| 69 | UF. Seg. | ISPRS Vaihingen and Potsdam | Tiling: Train: Cropped the image to patches of 256 × 256 with random upper left corners. Test: 256 × 256 with 50% overlap | Random enhancement of images. Rotating with a random angle; Random Gamma transformation; Gaussian blur; Adding Gaussian noise. | ISPRS Vaihingen and Potsdam | SDNF+SRM with backbones of ResNet101 and ASPP | N/A | OA, F1, P, R | OA: 0.92–0.93 | [143] |
| 70 | UF. Seg. | NWPU-VHR-10 dataset | An unsharp mask filter followed by a median filter, resized, the median values are obtained from histogram and the images image are pre-filtered. Also, linear contrast filter and a histogram-equalized with a spatial filter. | No | Cars, buildings, ships, trees, tennis courts, basket ball courts, ground track fields, harbors, bridges and airplanes | Tree-based CNN with Decision tree and Atrous conv layers | MatLab | Accuracy, F1, P, R | F1: 0.94 | [106] |
| 71 | UL. Cl. | N/A | Wiener Filter. Crop image into 50 × 50 px and enlarge to 500 × 500 px. | N/A | Water, road, residential area and natural vegetation | GoogLeNet | N/A | F1, P, R | F1: 0.68 | [139] |
Appendix B
| SN | Ref. | Year | Their Model | Models Compared for Vaihingen | Better by | Models Compared for Potsdam | Better by |
|---|---|---|---|---|---|---|---|
| 1 | [144] | 2015 | CNN + RF + CRF (abbr. DSTO) | ||||
| 2 | [55] | 2016 | CNN | ||||
| 3 | [31] | 2016 | FCN + RF + CRF (abbr. DST) | UT_Mev, SVL 3, HUST, ONE_5, ADL_3, UZ_1 [55], DLR_1, DLR_2 | 7% | SVL_1 | 12% |
| 4 | [157] | 2016 | FCN (DLR) | ||||
| 5 | [145] | 2016 | MLP (INR) | CNN + RF and CNN + RF + CRF of [144], Deconvolution [55], Dilation and Dilation + CRF of [31] | 1 to 2% | Dilation, VGG pretr. and VGG + Dilation of (sherrah2016fully) | Reference [31]’s VGG + Dilation was better |
| 6 | [92] | 2016 | Multi-kernel SegNet | SVL_3, RF + CRF (HUST), CNN ensemble (ONE_5), FCN (UZ_1), FCN (UOA), CNN + RF + CRF (ADL_ 3), FCN (DLR_2), FCN + RF + CRF (DST_2) | 1% to 5% | ||
| 7 | [165] | 2017 | CNN (ETH_C) | CNN [144] and CNN_PC [55] | Not better, but smaller model | ||
| 8 | [161] | 2017 | FCN | ||||
| 9 | [87] | 2017 | CNN called GSN | UPB, ETH_C, UOA, ADL_3, RIT_2, DST_2, ONE_7, DLR_9 | 1% to 5% | ||
| 10 | [162] | 2017 | CNN | ||||
| 11 | [150] | 2017 | FCN | ||||
| 12 | [94] | 2017 | CNN called HSN | ||||
| 13 | [151] | 2018 | VGG-Scasnet (CASIA-1) and ResNet-ScasNet (CASIA-2) | SVL_6, UZ_1 [55], ADL_3 [174], DST_2 [31], DLR_8 [157], ONE_7 | 3 to 13% | SVL_3, GU, UZ_1, AZ_1, RIT_2, DST_2 | 1 to 2% |
| 14 | [146] | 2018 | SegNet-RC, V-FuseNet, ResNet-34-RC and FusResNet | FCN of [31,157] | FCN of [157] performed better by 0.3% | FCN of [31,150] | Their V-FuseNet was better compared to [31,150] by 0.3% and 1.2% OA. |
| 15 | [112] | 2018 | Ensemble of SegNet, CNN and FCN (DLR) | DST_2, INR, ONE_6 and ONE_7 | 1% | ||
| 16 | [125] | 2018 | SDFCN-139 (CVEO) | (CASIA, HUSTW4, ADL_3, WUH_C4, RIT_L8, RIT_4, CONC_2, HUST, UPB and Ucal) | CASIA (90.6) and HUSTW4 (89.5) were better than their CVEO (88.3) by 1 and 2% | AMA_1, CASIA2, AZ3, RIT6, BUCT_1, WuhZ, KLab_2, UZ_1, GU | AMA_1 (91.2), CASIA2 (91.1), AZ3 (90.7), RIT6 (90.2) and BUCT_1 (90) were better than CVEO (89) by 1 to 2%. |
| 17 | [89] | 2018 | PSPNet | SVL_3, UT_Mev, ETH_C. UPB, UZ_1 and CAS_L1 | up to 6% | ||
| 18 | [163] | 2018 | CNN | Reference [112]’s single scale, ensemble and full model, [55]’s Segnet, [146]’s SegNet, WUH_W3 (ResNet-101, à-trous conv), CAS_L1 (PSPNet) and HUSTW5 (ensemble of deconv. Net and U-Net) | All of the compared models were better | ||
| 19 | [147] | 2018 | CoFsn, LaFsn and LnFsn (RIT_3 to RIT_7) | DST_2, DLR_10, structured RF and NLPR_3. | NLPR3 was better. | FCN-8s, DST_5 and CASIA2. | CASIA2 was better. |
| 20 | [148] | 2018 | FSN (CASDE2/CASRS1) and FSN-noL (CASDE1/CASRS2) | ONE_7, UZ_1, DST_2 | ONE_7 was better | Ensemble of 5 FCN-8s (BKHN_2) and RITL_7. | BKHN_2 was better |
| 21 | [149] | 2018 | FuseNet with ReuseNet (ITCB) | FCNs of [31], CNN-FPL [55] and AllConvNet. | Their better in OA by 1%. | ||
| 22 | [96] | 2019 | CNN called GCN | DCED of [111] | Their GCN with Res152 backbone had better F1 score than DCED by 2.5% | ||
| 23 | [62] | 2019 | FPN | SP-SVL [171], CNN_HAW [165], CNN-FPL [55] and SegNet-p [112]. | 1 to 4% | SP-SVL, DCNN [121], CNN-FPL and SegNet-p. | 4 to 13% |
| 24 | [84] | 2019 | DNN_HCRF | SVL_3, ADL_3, ONE_7, UZ_1, DLR_10 and UOA | DLR_10 was better by 2.5% | SVL_1, UZ_1, KLab_3 and DST_6 | DST_6 was better by 1.8% |
| 25 | [110] | 2019 | U-Net | 3 hourglass-based models of [94] | Their mode better by 1%. | ||
| 26 | [155] | 2019 | Dilated6, DenseDilated6, Dilated6Pooling, Dilated8Pooling (UFMG 1 to 5) | DLR_9, GSN_3, ONE_7, INR, DST_2, UFMG_2, ADL_3, RIT_2, RIT_L8, UZ_1. | DLR_9, GSN_3, ONE_7 and INR are better by up to 1%. | DST_5, RIT_L7, Klab_2, UZ_1 | DST_5 and RIT_L7 are better by up to 2%. |
| 27 | [115] | 2019 | ResegNet (HUSTW) | 20 model from leaderboard including NLPR and CASIA | HUSTW better than NLPR and CASIA by 0.5 and 0.4% resp | 15 model from leaderboard including AMA and CASIA | HUSTW better than AMA and CASIA by 0.5 and 0.4% resp. |
| 28 | [104] | 2019 | TreeUNet | SVL_3, DST_2, UZ_1, RIT_L7, ONE_7, ADL_3, DLR_10, CASIA2, BKHN10 | BKHN10 and CASIA2 were better than TreeUNet (with DeepUNet) in OA by around 0.6%. | SVL_1, DST_5, UZ_1, RIT_L7, SWJ_2, CASIA2. | SWJ_2 and CASIA2 are better by less than 1%. |
| 29 | [107] | 2020 | BSANet | ||||
| 30 | [164] | 2020 | DSFE-GGCN | FCN-32s, SegNet, FCN16s, U-Net, FCN-8s, ResNet-DUC, CWGAN-GP, FC-DenseNet, GCN, GraphSAGE, and GGNN | Better than DSFE-GCN [175] by 1%. | ||
| 31 | [124] | 2020 | DeepLabv3+ | SVL_3, ADL_3, UT_Mev, HUST, ONE_7, DST_2, UZ_1, DLR_9, IVFL, ETH_C, UCal6, CASIA3, RIT_7, HUSTW3, WUH_C3, CASRS1 and BKHN10 | Their method better than BKHN by 1%. | [150,157] and U-Net | Better than U-net by 1.2% |
| 32 | [97] | 2020 | MANet | FCN, U-net, UZ1, Light-weight RefineNet, DeepLabv3+ and APPD | MANet was better than APPD by 1%. | FCN, U-net, UZ1, Light-weight RefineNet, DeepLabv3+ and APPD | MANet was better than APPD by 1%. |
| 33 | [98] | 2020 | HRNet | FCN, PSPNet, DeepLabv3+, SENet, CBAM, GloRe and DANet. | HRNet was better than DeepLabv3+ in OA by 1.16% | FCN, PSPNet, DeepLabv3+, SENet, CBAM, GloRe and DANet. | HRNet was better than DeepLabv3+ in OA by 1.74% |
| 34 | [108] | 2020 | ResUnet-a | UZ_1, RIT_L7, RIT_4, DST_5, CAS_Y3, CASIA2, DPN_MFFL and HSN + OI + WBP. | Their method better than CASIA2 [151] in OA by 0.4%. | ||
| 35 | [109] | 2020 | SiameseDenseU- Net | HSN [94], U-Net, DenseU-Net (with and without CE loss and MFB Focal loss) | Their SiameseDenseU-Net + MFB_Focalloss was better than DenseU-Net+ MFB_Focalloss by 1% | ||
| 36 | [143] | 2020 | SDNF+SRM | UPB, UZ_1, RIT_L8, ADL_3, CVEO, ITC_B2, DST_2, UFMG_4, INR, MMDN, RIT_7, V-FuseNet, TreeUNet, DLR_9, BKHN11, CASIA2, NLPR3, HUSTW5 | Their method better than HUSTW5 [115] in OA by less than 1%. | UZ_1, Klab_3, UFMG_4, RIT_L7, CVEO, DST_5, RIT6, V-FuseNet, TreeUNet, CASIA3, BKHN_3, AMA_1, HUSTW4, SWJ_2 | Their method better than SWJ_2 in OA by 1%. |
Appendix C
| S.N. | Dataset/ Challenge | Description | Resolution | Tags | Link |
|---|---|---|---|---|---|
| 1 | Linz Data Service | RGB images of New Zealand | 10 m | Land Cover | https://data.linz.govt.nz/ |
| 2 | Massachusetts Bldg./Road Dataset | Train and test images with vector data | 1 m | Building and Road | https://www.cs.toronto.edu/~vmnih/data/ |
| 3 | ISPRS Vaihingen 2D Semantic Labeling | 33 patches of true orthophoto (TOP) with IR-R-G bands, DSM, labelled ground truth (GT) | 9 cm | Imp. surface, bldg., low veg., tree, car | http://www2.isprs.org/commissions/comm3/wg4/2d-sem-label-vaihingen.html |
| 4 | ISPRS Potsdam 2D Semantic Labeling | 38 patches of TOP with different bands (IRRG, RGB, RGBIR), DSM, labelled GT | 5 cm | Imp. surface, bldg., low veg., tree, car, clutter/ background | http://www2.isprs.org/commissions/comm3/wg4/2d-sem-label-potsdam.html |
| 5 | IEEE GRSS Data Fusion | Lidar and image collected by airborne platform | Lidar: 10 cm, Image: 5 cm | Urban land cover | http://www.grss-ieee.org/community/technical-committees/data-fusion/2015-ieee-grss-data-fusion-contest/ |
| 6 | NZAM/ONERA Christchurch dataset | 1785 x ortho-rectified RGB GeoTIFF images | 10 cm | background, building, vegetation and vehicle | https://www.linz.govt.nz/land/maps/linz-topographic-maps/imagery-orthophotos/christchurch-earthquake-imagery |
| 7 | RIT-18 dataset UAS-based spectral dataset | UAS-collected dataset with 18 labeled object classes | 4.7 cm | 18 urban feature classes [121] | https://github.com/rmkemker/RIT-18 |
| 8 | AerialLanes18 dataset | RGB images of size 5616 × 3744 pixels with flight height of 1000 m | 13 cm | Aerial road lanes and vehicles | [142] |
| 9 | Aerial Imagery for Roof Segmentation (AIRS) | Collected from Linz Data Service for Christchurch City; RGB bands | 7.5 cm | contains over 220,000 buildings [91] | https://www.airs-dataset.com/ |
| 10 | Inria Aerial Image Labeling Data Set | 360 ortho-rectified aerial RGB images of 5000 × 5000 px | 30 cm | Building segmentation dataset | https://project.inria.fr/aerialimagelabeling/ |
| 11 | SpaceNet building dataset | Images collected from WorldView-2 and 3 for several locations; 8 band multispectral | 30 cm to 50 cm | Building footprints and roads | https://spacenetchallenge.github.io/ |
| 12 | fMoW Challenge | 4-band and 8-band multispectral imagery | For multiple area | https://www.iarpa.gov/challenges/fmow.html | |
| 13 | UK-based bldg. dataset | RGB image, DSMs, and OSM shapefile | 25 cm | 24,556 images with 169,835 buildings | [160] |
| 14 | DATAFOUNTAIN 2017 | 8 m | [138] | https://www.datafountain.cn/competitions/270 | |
| 15 | WHU Building dataset | Comes from Linz Data Service with training samples for buildings | 0.075 m | Building segmentation dataset | http://study.rsgis.whu.edu.cn/pages/download/ |
| 16 | CCF Satellite Image AI Classification and Recognition Competition | RGB images | sub-meter | Urban features | [80] |
| 17 | NWPU VHR-10 | Images from Google Earth (0.5–2 m) and 0.08 m infrared images from ISPRS Vaihingen dataset | 8 cm to 2 m | Urban features | https://ifpwww.ifp.uni-stuttgart.de/dgpf/DKEP-Allg.html |
| 18 | Zurich Dataset | Quickbird’s multi-spectral images | 0.6 m pan-sharpened | 8 LULC classes | [97,138] |
| 19 | Some more datasets from Signal Processing in Earth Observation | Several Remote Sensing-based datasets for different purpose | For multiple area | https://www.sipeo.bgu.tum.de/downloads |
References
- Drusch, M.; Del Bello, U.; Carlier, S.; Colin, O.; Fernandez, V.; Gascon, F.; Hoersch, B.; Isola, C.; Laberinti, P.; Martimort, P.; et al. Sentinel-2: ESA’s optical high-resolution mission for GMES operational services. Remote Sens. Environ. 2012, 120, 25–36. [Google Scholar] [CrossRef]
- Irons, J.R.; Dwyer, J.L.; Barsi, J.A. The next Landsat satellite: The Landsat data continuity mission. Remote Sens. Environ. 2012, 122, 11–21. [Google Scholar] [CrossRef] [Green Version]
- Myint, S.W.; Gober, P.; Brazel, A.; Grossman-Clarke, S.; Weng, Q. Per-pixel vs. object-based classification of urban land cover extraction using high spatial resolution imagery. Remote Sens. Environ. 2011, 115, 1145–1161. [Google Scholar] [CrossRef]
- Cowen, D.J.; Jensen, J.R.; Bresnahan, P.J.; Ehler, G.B.; Graves, D. The design and implementation of an integrated geographic information system for environmental applications. Photogramm. Eng. Remote Sens. 1995, 61, 1393–1404. [Google Scholar]
- Campbell, J.B.; Wynne, R.H. Introduction to Remote Sensing; Guilford Press: lNew York, NY, USA, 2011. [Google Scholar]
- Walter, V. Object-based classification of remote sensing data for change detection. ISPRS J. Photogramm. Remote Sens. 2004, 58, 225–238. [Google Scholar] [CrossRef]
- Myint, S.W.; Giri, C.P.; Wang, L.; Zhu, Z.; Gillette, S.C. Identifying mangrove species and their surrounding land use and land cover classes using an object-oriented approach with a lacunarity spatial measure. GIScience Remote Sens. 2008, 45, 188–208. [Google Scholar] [CrossRef]
- Navulur, K. Multispectral Image Analysis Using the Object-Oriented Paradigm; CRC Press: Boca Raton, FL, USA, 2006. [Google Scholar]
- Stow, D.; Lopez, A.; Lippitt, C.; Hinton, S.; Weeks, J. Object-based classification of residential land use within Accra, Ghana based on QuickBird satellite data. Int. J. Remote Sens. 2007, 28, 5167–5173. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lu, D.; Weng, Q. A survey of image classification methods and techniques for improving classification performance. Int. J. Remote Sens. 2007, 28, 823–870. [Google Scholar] [CrossRef]
- Neupane, B.; Horanont, T.; Duy, H.N.; Suebvong, S.; Mahattanawutakorn, T. An Open-Source UAV Image Processing Web Service for Crop Health Monitoring. In Proceedings of the 2019 8th IEEE International Congress on Advanced Applied Informatics (IIAI-AAI), lToyama, Japan, 7–12 July 2019; pp. 11–16. [Google Scholar]
- LeCun, Y.; Bengio, Y. Convolutional networks for images, speech, and time series. Handb. Brain Theory Neural Netw. 1995, 3361, 1995. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436. [Google Scholar] [CrossRef] [PubMed]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2009, 22, 1345–1359. [Google Scholar] [CrossRef]
- Reyes, A.K.; Caicedo, J.C.; Camargo, J.E. Fine-tuning Deep Convolutional Networks for Plant Recognition. CLEF (Work. Notes) 2015, 1391, 467–475. [Google Scholar]
- Amara, J.; Bouaziz, B.; Algergawy, A. A Deep Learning-based Approach for Banana Leaf Diseases Classification. In Datenbanksysteme für Business, Technologie und Web (BTW 2017)—Workshopband; Gesellschaft für Informatik e.V.: Bonn, Germany, 2017; pp. 79–88. [Google Scholar]
- Mohanty, S.P.; Hughes, D.P.; Salathé, M. Using deep learning for image-based plant disease detection. Front. Plant Sci. 2016, 7, 1419. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Huang, H.; Deng, J.; Lan, Y.; Yang, A.; Deng, X.; Zhang, L. A fully convolutional network for weed mapping of unmanned aerial vehicle (UAV) imagery. PLoS ONE 2018, 13, e0196302. [Google Scholar]
- Kussul, N.; Lavreniuk, M.; Skakun, S.; Shelestov, A. Deep learning classification of land cover and crop types using remote sensing data. IEEE Geosci. Remote Sens. Lett. 2017, 14, 778–782. [Google Scholar] [CrossRef]
- Mortensen, A.K.; Dyrmann, M.; Karstoft, H.; Jørgensen, R.N.; Gislum, R. Semantic segmentation of mixed crops using deep convolutional neural network. In Proceedings of the CIGR-AgEng Conference, Abstracts and Full Papers, Aarhus, Denmark, 26–29 June 2016; Organising Committee, CIGR: London, UK, 2016; pp. 1–6. [Google Scholar]
- Neupane, B.; Horanont, T.; Hung, N.D. Deep learning based banana plant detection and counting using high-resolution red-green-blue (RGB) images collected from unmanned aerial vehicle (UAV). PLoS ONE 2019, 14, e0223906. [Google Scholar] [CrossRef]
- Dutta, R.; Aryal, J.; Das, A.; Kirkpatrick, J.B. Deep cognitive imaging systems enable estimation of continental-scale fire incidence from climate data. Sci. Rep. 2013, 3, 1–4. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ghorbanzadeh, O.; Blaschke, T.; Gholamnia, K.; Meena, S.R.; Tiede, D.; Aryal, J. Evaluation of different machine learning methods and deep-learning convolutional neural networks for landslide detection. Remote Sens. 2019, 11, 196. [Google Scholar] [CrossRef] [Green Version]
- Ghorbanzadeh, O.; Meena, S.R.; Blaschke, T.; Aryal, J. UAV-based slope failure detection using deep-learning convolutional neural networks. Remote Sens. 2019, 11, 2046. [Google Scholar] [CrossRef] [Green Version]
- Zhu, X.X.; Tuia, D.; Mou, L.; Xia, G.S.; Zhang, L.; Xu, F.; Fraundorfer, F. Deep learning in remote sensing: A comprehensive review and list of resources. IEEE Geosci. Remote Sens. Mag. 2017, 5, 8–36. [Google Scholar] [CrossRef] [Green Version]
- Shadman Roodposhti, M.; Aryal, J.; Lucieer, A.; Bryan, B.A. Uncertainty assessment of hyperspectral image classification: Deep learning vs. random forest. Entropy 2019, 21, 78. [Google Scholar] [CrossRef] [Green Version]
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation applied to handwritten zip code recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Fu, G.; Liu, C.; Zhou, R.; Sun, T.; Zhang, Q. Classification for high resolution remote sensing imagery using a fully convolutional network. Remote Sens. 2017, 9, 498. [Google Scholar] [CrossRef] [Green Version]
- Sherrah, J. Fully convolutional networks for dense semantic labelling of high-resolution aerial imagery. arXiv 2016, arXiv:1606.02585. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Zhang, H.; Xue, X.; Jiang, Y.; Shen, Q. Deep learning for remote sensing image classification: A survey. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2018, 8, e1264. [Google Scholar] [CrossRef] [Green Version]
- Ma, L.; Liu, Y.; Zhang, X.; Ye, Y.; Yin, G.; Johnson, B.A. Deep learning in remote sensing applications: A meta-analysis and review. ISPRS J. Photogramm. Remote Sens. 2019, 152, 166–177. [Google Scholar] [CrossRef]
- Wang, F. Fuzzy supervised classification of remote sensing images. IEEE Trans. Geosci. Remote Sens. 1990, 28, 194–201. [Google Scholar] [CrossRef] [Green Version]
- Anees, A.; Aryal, J. Near-real time detection of beetle infestation in pine forests using MODIS data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 3713–3723. [Google Scholar] [CrossRef]
- Anees, A.; Aryal, J. A statistical framework for near-real time detection of beetle infestation in pine forests using MODIS data. IEEE Geosci. Remote Sens. Lett. 2014, 11, 1717–1721. [Google Scholar] [CrossRef]
- Anees, A.; Aryal, J.; O’Reilly, M.M.; Gale, T.J. A relative density ratio-based framework for detection of land cover changes in MODIS NDVI time series. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 9, 3359–3371. [Google Scholar] [CrossRef]
- Civco, D.L. Artificial neural networks for land-cover classification and mapping. Int. J. Geogr. Inf. Sci. 1993, 7, 173–186. [Google Scholar] [CrossRef]
- Chen, K.; Tzeng, Y.; Chen, C.; Kao, W.; Ni, C. Classification of multispectral imagery using dynamic learning neural network. In Proceedings of the IGARSS’93-IEEE International Geoscience and Remote Sensing Symposium, Tokyo, Japan, 18–21 August 1993; pp. 896–898. [Google Scholar]
- Foody, G.M. Image classification with a neural network: From completely-crisp to fully-fuzzy situations. Adv. Remote Sens. GIS Anal. 1999, 17–37. [Google Scholar]
- Flanagan, M.; Civco, D.L. Subpixel impervious surface mapping. In Proceedings of the 2001 ASPRS Annual Convention, Bethesda, MD, USA, 23–27 April 2001; American Society for Photogrammetry & Remote Sensing: St. Louis, MO, USA, 2001; Volume 23. [Google Scholar]
- Yang, L.; Xian, G.; Klaver, J.M.; Deal, B. Urban land-cover change detection through sub-pixel imperviousness mapping using remotely sensed data. Photogramm. Eng. Remote Sens. 2003, 69, 1003–1010. [Google Scholar] [CrossRef]
- Powell, R.L.; Roberts, D.A.; Dennison, P.E.; Hess, L.L. Sub-pixel mapping of urban land cover using multiple endmember spectral mixture analysis: Manaus, Brazil. Remote Sens. Environ. 2007, 106, 253–267. [Google Scholar] [CrossRef]
- Walton, J.T. Subpixel urban land cover estimation. Photogramm. Eng. Remote Sens. 2008, 74, 1213–1222. [Google Scholar] [CrossRef] [Green Version]
- Deng, C.; Wu, C. A spatially adaptive spectral mixture analysis for mapping subpixel urban impervious surface distribution. Remote Sens. Environ. 2013, 133, 62–70. [Google Scholar] [CrossRef]
- Kavzoglu, T.; Mather, P. The use of backpropagating artificial neural networks in land cover classification. Int. J. Remote Sens. 2003, 24, 4907–4938. [Google Scholar] [CrossRef]
- Chormanski, J.; Van de Voorde, T.; De Roeck, T.; Batelaan, O.; Canters, F. Improving distributed runoff prediction in urbanized catchments with remote sensing based estimates of impervious surface cover. Sensors 2008, 8, 910–932. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mohapatra, R.P.; Wu, C. Subpixel imperviousness estimation with IKONOS imagery: An artificial neural network approach. Remote Sens. Impervious Surfaces 2008, 21–37. [Google Scholar] [CrossRef]
- Weng, Q.; Hu, X. Medium spatial resolution satellite imagery for estimating and mapping urban impervious surfaces using LSMA and ANN. IEEE Trans. Geosci. Remote Sens. 2008, 46, 2397–2406. [Google Scholar] [CrossRef]
- Hu, X.; Weng, Q. Estimating impervious surfaces from medium spatial resolution imagery using the self-organizing map and multi-layer perceptron neural networks. Remote Sens. Environ. 2009, 113, 2089–2102. [Google Scholar] [CrossRef]
- Ji, C.Y. Land-use classification of remotely sensed data using Kohonen self-organizing feature map neural networks. Photogramm. Eng. Remote Sens. 2000, 66, 1451–1460. [Google Scholar]
- Li, Z.; Eastman, J.R. Commitment and typicality measurements for fuzzy ARTMAP neural network. In Proceedings of the Geoinformatics 2006: Geospatial Information Science, International Society for Optics and Photonics, Wuhan, China, 28–29 October 2006; Volume 6420, p. 64201I. [Google Scholar]
- Volpi, M.; Ferrari, V. Semantic segmentation of urban scenes by learning local class interactions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Volpi, M.; Tuia, D. Dense semantic labeling of subdecimeter resolution images with convolutional neural networks. IEEE Trans. Geosci. Remote Sens. 2016, 55, 881–893. [Google Scholar] [CrossRef] [Green Version]
- Audebert, N.; Le Saux, B.; Lefèvre, S. Segment-before-detect: Vehicle detection and classification through semantic segmentation of aerial images. Remote Sens. 2017, 9, 368. [Google Scholar] [CrossRef] [Green Version]
- Achanta, R.; Shaji, A.; Smith, K.; Lucchi, A.; Fua, P.; Süsstrunk, S. SLIC superpixels compared to state-of-the-art superpixel methods. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2274–2282. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Felzenszwalb, P.F.; Huttenlocher, D.P. Efficient graph-based image segmentation. Int. J. Comput. Vis. 2004, 59, 167–181. [Google Scholar] [CrossRef]
- Farabet, C.; Couprie, C.; Najman, L.; LeCun, Y. Learning hierarchical features for scene labeling. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 1915–1929. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pinherio, R.C.P.H.; Pedro, H. Recurrent convolutional neural networks for scene parsing. In Proceedings of the International Conference of Machine Learning, Bejing, China, 22–24 June 2014. [Google Scholar]
- Kampffmeyer, M.; Salberg, A.B.; Jenssen, R. Semantic segmentation of small objects and modeling of uncertainty in urban remote sensing images using deep convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1–9. [Google Scholar]
- Yang, H.; Yu, B.; Luo, J.; Chen, F. Semantic segmentation of high spatial resolution images with deep neural networks. GIScience Remote Sens. 2019, 56, 749–768. [Google Scholar] [CrossRef]
- Hinton, G.E.; Osindero, S.; Teh, Y.W. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef] [PubMed]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [Green Version]
- Salakhutdinov, R.; Hinton, G. Deep boltzmann machines. In Proceedings of the Artificial Intelligence and Statistics, Clearwater Beach, FL, USA, 16–18 April 2009; pp. 448–455. [Google Scholar]
- Vincent, P.; Larochelle, H.; Lajoie, I.; Bengio, Y.; Manzagol, P.A.; Bottou, L. Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion. J. Mach. Learn. Res. 2010, 11, 3371–3408. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2014; pp. 818–833. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Bottou, L. Large-scale machine learning with stochastic gradient descent. In Proceedings of COMPSTAT’2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 177–186. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Mou, L.; Zhu, X.X. RiFCN: Recurrent network in fully convolutional network for semantic segmentation of high resolution remote sensing images. arXiv 2018, arXiv:1805.02091. [Google Scholar]
- Noh, H.; Hong, S.; Han, B. Learning deconvolution network for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1520–1528. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef]
- Ji, S.; Wei, S.; Lu, M. A scale robust convolutional neural network for automatic building extraction from aerial and satellite imagery. Int. J. Remote Sens. 2019, 40, 3308–3322. [Google Scholar] [CrossRef]
- Chen, G.; Li, C.; Wei, W.; Jing, W.; Woźniak, M.; Blažauskas, T.; Damaševičius, R. Fully convolutional neural network with augmented atrous spatial pyramid pool and fully connected fusion path for high resolution remote sensing image segmentation. Appl. Sci. 2019, 9, 1816. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Zheng, S.; Jayasumana, S.; Romera-Paredes, B.; Vineet, V.; Su, Z.; Du, D.; Huang, C.; Torr, P.H. Conditional random fields as recurrent neural networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1529–1537. [Google Scholar]
- Lin, G.; Shen, C.; Van Den Hengel, A.; Reid, I. Efficient piecewise training of deep structured models for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3194–3203. [Google Scholar]
- Liu, Y.; Piramanayagam, S.; Monteiro, S.T.; Saber, E. Semantic segmentation of multisensor remote sensing imagery with deep ConvNets and higher-order conditional random fields. J. Appl. Remote Sens. 2019, 13, 016501. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27-30 June 2016; pp. 770–778. [Google Scholar]
- Wu, Z.; Shen, C.; Hengel, A.V.D. High-performance semantic segmentation using very deep fully convolutional networks. arXiv 2016, arXiv:1604.04339. [Google Scholar]
- Wang, H.; Wang, Y.; Zhang, Q.; Xiang, S.; Pan, C. Gated convolutional neural network for semantic segmentation in high-resolution images. Remote Sens. 2017, 9, 446. [Google Scholar] [CrossRef] [Green Version]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Yu, B.; Yang, L.; Chen, F. Semantic segmentation for high spatial resolution remote sensing images based on convolution neural network and pyramid pooling module. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 3252–3261. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [Green Version]
- Chen, Q.; Wang, L.; Wu, Y.; Wu, G.; Guo, Z.; Waslander, S.L. Aerial imagery for roof segmentation: A large-scale dataset towards automatic mapping of buildings. arXiv 2018, arXiv:1807.09532. [Google Scholar] [CrossRef] [Green Version]
- Audebert, N.; Le Saux, B.; Lefèvre, S. Semantic segmentation of earth observation data using multimodal and multi-scale deep networks. In Asian Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 180–196. [Google Scholar]
- Audebert, N.; Boulch, A.; Randrianarivo, H.; Le Saux, B.; Ferecatu, M.; Lefèvre, S.; Marlet, R. Deep learning for urban remote sensing. In Proceedings of the 2017 IEEE Joint Urban Remote Sensing Event (JURSE), Dubai, United Arab Emirates, 6–8 March 2017; pp. 1–4. [Google Scholar]
- Liu, Y.; Minh Nguyen, D.; Deligiannis, N.; Ding, W.; Munteanu, A. Hourglass-shapenetwork based semantic segmentation for high resolution aerial imagery. Remote Sens. 2017, 9, 522. [Google Scholar] [CrossRef] [Green Version]
- Chen, K.; Weinmann, M.; Sun, X.; Yan, M.; Hinz, S.; Jutzi, B.; Weinmann, M. Semantic Segmentation of Aerial Imagery Via Multi-Scale Shuffling Convolutional Neural Networks with Deep Supervision. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2018, 4, 29–36. [Google Scholar] [CrossRef] [Green Version]
- Panboonyuen, T.; Jitkajornwanich, K.; Lawawirojwong, S.; Srestasathiern, P.; Vateekul, P. Semantic segmentation on remotely sensed images using an enhanced global convolutional network with channel attention and domain specific transfer learning. Remote Sens. 2019, 11, 83. [Google Scholar] [CrossRef] [Green Version]
- Shang, R.; Zhang, J.; Jiao, L.; Li, Y.; Marturi, N.; Stolkin, R. Multi-scale Adaptive Feature Fusion Network for Semantic Segmentation in Remote Sensing Images. Remote Sens. 2020, 12, 872. [Google Scholar] [CrossRef] [Green Version]
- Zhang, J.; Lin, S.; Ding, L.; Bruzzone, L. Multi-scale context aggregation for semantic segmentation of remote sensing images. Remote Sens. 2020, 12, 701. [Google Scholar] [CrossRef] [Green Version]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Guo, Z.; Shengoku, H.; Wu, G.; Chen, Q.; Yuan, W.; Shi, X.; Shao, X.; Xu, Y.; Shibasaki, R. Semantic segmentation for urban planning maps based on U-Net. In Proceedings of the IGARSS 2018-2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 6187–6190. [Google Scholar]
- Li, W.; He, C.; Fang, J.; Zheng, J.; Fu, H.; Yu, L. Semantic segmentation-based building footprint extraction using very high-resolution satellite images and multi-source GIS data. Remote Sens. 2019, 11, 403. [Google Scholar] [CrossRef] [Green Version]
- Pan, Z.; Xu, J.; Guo, Y.; Hu, Y.; Wang, G. Deep Learning Segmentation and Classification for Urban Village Using a Worldview Satellite Image Based on U-Net. Remote Sens. 2020, 12, 1574. [Google Scholar] [CrossRef]
- Yi, Y.; Zhang, Z.; Zhang, W.; Zhang, C.; Li, W.; Zhao, T. Semantic segmentation of urban buildings from vhr remote sensing imagery using a deep convolutional neural network. Remote Sens. 2019, 11, 1774. [Google Scholar] [CrossRef] [Green Version]
- Yue, K.; Yang, L.; Li, R.; Hu, W.; Zhang, F.; Li, W. TreeUNet: Adaptive Tree convolutional neural networks for subdecimeter aerial image segmentation. ISPRS J. Photogramm. Remote Sens. 2019, 156, 1–13. [Google Scholar] [CrossRef]
- Li, R.; Liu, W.; Yang, L.; Sun, S.; Hu, W.; Zhang, F.; Li, W. Deepunet: A deep fully convolutional network for pixel-level sea-land segmentation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 3954–3962. [Google Scholar] [CrossRef] [Green Version]
- Robinson, Y.H.; Vimal, S.; Khari, M.; Hernández, F.C.L.; Crespo, R.G. Tree-based convolutional neural networks for object classification in segmented satellite images. Int. J. High Perform. Comput. Appl. 2020. [Google Scholar] [CrossRef]
- Liu, W.; Su, F.; Jin, X.; Li, H.; Qin, R. Bispace Domain Adaptation Network for Remotely Sensed Semantic Segmentation. IEEE Trans. Geosci. Remote Sens. 2020. [Google Scholar] [CrossRef]
- Diakogiannis, F.I.; Waldner, F.; Caccetta, P.; Wu, C. Resunet-a: A deep learning framework for semantic segmentation of remotely sensed data. ISPRS J. Photogramm. Remote Sens. 2020, 162, 94–114. [Google Scholar] [CrossRef] [Green Version]
- Dong, R.; Bai, L.; Li, F. SiameseDenseU-Net-based Semantic Segmentation of Urban Remote Sensing Images. Math. Probl. Eng. 2020, 2020. [Google Scholar] [CrossRef]
- Dong, R.; Pan, X.; Li, F. DenseU-net-based semantic segmentation of small objects in urban remote sensing images. IEEE Access 2019, 7, 65347–65356. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Marmanis, D.; Schindler, K.; Wegner, J.D.; Galliani, S.; Datcu, M.; Stilla, U. Classification with an edge: Improving semantic image segmentation with boundary detection. ISPRS J. Photogramm. Remote Sens. 2018, 135, 158–172. [Google Scholar] [CrossRef] [Green Version]
- Cao, R.; Qiu, G. Urban land use classification based on aerial and ground images. In Proceedings of the 2018 IEEE International Conference on Content-Based Multimedia Indexing (CBMI), Bordeaux, France, 25–27 June 2018; pp. 1–6. [Google Scholar]
- Bischke, B.; Helber, P.; Folz, J.; Borth, D.; Dengel, A. Multi-task learning for segmentation of building footprints with deep neural networks. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–29 September 2019; pp. 1480–1484. [Google Scholar]
- Sun, Y.; Tian, Y.; Xu, Y. Problems of encoder-decoder frameworks for high-resolution remote sensing image segmentation: Structural stereotype and insufficient learning. Neurocomputing 2019, 330, 297–304. [Google Scholar] [CrossRef]
- Abdollahi, A.; Pradhan, B.; Alamri, A.M. An Ensemble Architecture of Deep Convolutional Segnet and Unet Networks for Building Semantic Segmentation from High-resolution Aerial Images. Geocarto Int. 2020, 1–13. [Google Scholar] [CrossRef]
- Sariturk, B.; Bayram, B.; Duran, Z.; Seker, D.Z. Feature Extraction from Satellite Images Using Segnet and Fully Convolutional Networks (FCN). Int. J. Eng. Geosci. 2020, 5, 138–143. [Google Scholar] [CrossRef]
- Hong, S.; Noh, H.; Han, B. Decoupled deep neural network for semi-supervised semantic segmentation. Advances in neural information processing systems. arXiv 2015, arXiv:1506.04924. [Google Scholar]
- Pinheiro, P.O.; Lin, T.Y.; Collobert, R.; Dollár, P. Learning to refine object segments. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 75–91. [Google Scholar]
- Pinheiro, P.O.; Collobert, R.; Dollár, P. Learning to segment object candidates. Advances in Neural Information Processing Systems. arXiv 2015, arXiv:1506.06204. [Google Scholar]
- Kemker, R.; Salvaggio, C.; Kanan, C. Algorithms for semantic segmentation of multispectral remote sensing imagery using deep learning. ISPRS J. Photogramm. Remote Sens. 2018, 145, 60–77. [Google Scholar] [CrossRef] [Green Version]
- Lin, G.; Milan, A.; Shen, C.; Reid, I. Refinenet: Multi-path refinement networks for high-resolution semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1925–1934. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Du, S.; Du, S.; Liu, B.; Zhang, X. Incorporating DeepLabv3+ and object-based image analysis for semantic segmentation of very high resolution remote sensing images. Int. J. Digit. Earth 2020, 1–22. [Google Scholar] [CrossRef]
- Chen, G.; Zhang, X.; Wang, Q.; Dai, F.; Gong, Y.; Zhu, K. Symmetrical dense-shortcut deep fully convolutional networks for semantic segmentation of very-high-resolution remote sensing images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 1633–1644. [Google Scholar] [CrossRef]
- Li, Y.; Xu, L.; Rao, J.; Guo, L.; Yan, Z.; Jin, S. A Y-Net deep learning method for road segmentation using high-resolution visible remote sensing images. Remote Sens. Lett. 2019, 10, 381–390. [Google Scholar] [CrossRef]
- Benjdira, B.; Bazi, Y.; Koubaa, A.; Ouni, K. Unsupervised domain adaptation using generative adversarial networks for semantic segmentation of aerial images. Remote Sens. 2019, 11, 1369. [Google Scholar] [CrossRef] [Green Version]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Advances in Neural Information Processing Systems; ACM: New York, NY, USA, 2014; pp. 2672–2680. [Google Scholar]
- Lin, D.; Fu, K.; Wang, Y.; Xu, G.; Sun, X. MARTA GANs: Unsupervised representation learning for remote sensing image classification. IEEE Geosci. Remote Sens. Lett. 2017, 14, 2092–2096. [Google Scholar] [CrossRef] [Green Version]
- Zhan, Y.; Hu, D.; Wang, Y.; Yu, X. Semisupervised hyperspectral image classification based on generative adversarial networks. IEEE Geosci. Remote Sens. Lett. 2017, 15, 212–216. [Google Scholar] [CrossRef]
- Torrey, L.; Shavlik, J. Transfer learning. In Handbook of Research on Machine Learning Applications and Trends: Algorithms, Methods, and Techniques; IGI Global: Hershey, PA, USA, 2010; pp. 242–264. [Google Scholar]
- Weiss, K.; Khoshgoftaar, T.M.; Wang, D. A survey of transfer learning. J. Big Data 2016, 3, 9. [Google Scholar] [CrossRef] [Green Version]
- Tan, C.; Sun, F.; Kong, T.; Zhang, W.; Yang, C.; Liu, C. A survey on deep transfer learning. In International Conference on Artificial Neural Networks; Springer: Berlin/Heidelberg, Germany, 2018; pp. 270–279. [Google Scholar]
- Du, Z.; Yang, J.; Ou, C.; Zhang, T. Smallholder crop area mapped with a semantic segmentation deep learning method. Remote Sens. 2019, 11, 888. [Google Scholar] [CrossRef] [Green Version]
- Wurm, M.; Stark, T.; Zhu, X.X.; Weigand, M.; Taubenböck, H. Semantic segmentation of slums in satellite images using transfer learning on fully convolutional neural networks. ISPRS J. Photogramm. Remote Sens. 2019, 150, 59–69. [Google Scholar] [CrossRef]
- Lv, Q.; Dou, Y.; Niu, X.; Xu, J.; Xu, J.; Xia, F. Urban land use and land cover classification using remotely sensed SAR data through deep belief networks. J. Sens. 2015, 2015. [Google Scholar] [CrossRef] [Green Version]
- Nogueira, K.; Dalla Mura, M.; Chanussot, J.; Schwartz, W.R.; dos Santos, J.A. Learning to semantically segment high-resolution remote sensing images. In Proceedings of the 2016 23rd IEEE International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016; pp. 3566–3571. [Google Scholar]
- Zhang, Y.; Chi, M. Mask-R-FCN: A Deep Fusion Network for Semantic Segmentation. IEEE Access 2020, 8, 155753–155765. [Google Scholar] [CrossRef]
- Poomani, M.; Sutha, J.; Soundar, K.R. Wiener filter based deep convolutional network approach for classification of satellite images. J. Ambient. Intell. Humaniz. Comput. 2020. [Google Scholar] [CrossRef]
- Mattyus, G.; Wang, S.; Fidler, S.; Urtasun, R. Enhancing road maps by parsing aerial images around the world. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1689–1697. [Google Scholar]
- Hackel, T.; Wegner, J.D.; Schindler, K. Fast semantic segmentation of 3D point clouds with strongly varying density. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, 3, 177–184. [Google Scholar] [CrossRef] [Green Version]
- Azimi, S.M.; Fischer, P.; Körner, M.; Reinartz, P. Aerial LaneNet: Lane-marking semantic segmentation in aerial imagery using wavelet-enhanced cost-sensitive symmetric fully convolutional neural networks. IEEE Trans. Geosci. Remote Sens. 2018, 57, 2920–2938. [Google Scholar] [CrossRef] [Green Version]
- Mi, L.; Chen, Z. Superpixel-enhanced deep neural forest for remote sensing image semantic segmentation. ISPRS J. Photogramm. Remote Sens. 2020, 159, 140–152. [Google Scholar] [CrossRef]
- Paisitkriangkrai, S.; Sherrah, J.; Janney, P.; Hengel, V.D. Effective semantic pixel labelling with convolutional networks and conditional random fields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Boston, MA, USA, 7–12 June 2015; pp. 36–43. [Google Scholar]
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. High-resolution semantic labeling with convolutional neural networks. arXiv 2016, arXiv:1611.01962. [Google Scholar]
- Audebert, N.; Le Saux, B.; Lefèvre, S. Beyond RGB: Very high resolution urban remote sensing with multimodal deep networks. ISPRS J. Photogramm. Remote Sens. 2018, 140, 20–32. [Google Scholar] [CrossRef] [Green Version]
- Piramanayagam, S.; Saber, E.; Schwartzkopf, W.; Koehler, F.W. Supervised classification of multisensor remotely sensed images using a deep learning framework. Remote Sens. 2018, 10, 1429. [Google Scholar] [CrossRef] [Green Version]
- Pan, X.; Gao, L.; Marinoni, A.; Zhang, B.; Yang, F.; Gamba, P. Semantic labeling of high resolution aerial imagery and LiDAR data with fine segmentation network. Remote Sens. 2018, 10, 743. [Google Scholar] [CrossRef] [Green Version]
- Bergado, J.R.; Persello, C.; Stein, A. Recurrent multiresolution convolutional networks for VHR image classification. IEEE Trans. Geosci. Remote Sens. 2018, 56, 6361–6374. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Piramanayagam, S.; Monteiro, S.T.; Saber, E. Dense semantic labeling of very-high-resolution aerial imagery and lidar with fully-convolutional neural networks and higher-order CRFs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 76–85. [Google Scholar]
- Liu, Y.; Fan, B.; Wang, L.; Bai, J.; Xiang, S.; Pan, C. Semantic labeling in very high resolution images via a self-cascaded convolutional neural network. ISPRS J. Photogramm. Remote Sens. 2018, 145, 78–95. [Google Scholar] [CrossRef] [Green Version]
- Marcu, A.; Leordeanu, M. Dual local-global contextual pathways for recognition in aerial imagery. arXiv 2016, arXiv:1605.05462. [Google Scholar]
- Marcu, A.E.; Leordeanu, M. Object contra context: Dual local-global semantic segmentation in aerial images. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Li, P.; Lin, Y.; Schultz-Fellenz, E. Contextual Hourglass Network for Semantic Segmentation of High Resolution Aerial Imagery. arXiv 2018, arXiv:1810.12813. [Google Scholar]
- Nogueira, K.; Dalla Mura, M.; Chanussot, J.; Schwartz, W.R.; dos Santos, J.A. Dynamic multicontext segmentation of remote sensing images based on convolutional networks. IEEE Trans. Geosci. Remote Sens. 2019, 57, 7503–7520. [Google Scholar] [CrossRef] [Green Version]
- Zhao, W.; Du, S.; Wang, Q.; Emery, W.J. Contextually guided very-high-resolution imagery classification with semantic segments. ISPRS J. Photogramm. Remote Sens. 2017, 132, 48–60. [Google Scholar] [CrossRef]
- Marmanis, D.; Wegner, J.D.; Galliani, S.; Schindler, K.; Datcu, M.; Stilla, U. Semantic segmentation of aerial images with an ensemble of CNSS. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2016 2016, 3, 473–480. [Google Scholar] [CrossRef] [Green Version]
- Saito, S.; Aoki, Y. Building and road detection from large aerial imagery. In Image Processing: Machine Vision Applications VIII; International Society for Optics and Photonics: Bellingham, WA, USA, 2015; Volume 9405, p. 94050K. [Google Scholar]
- Saito, S.; Yamashita, T.; Aoki, Y. Multiple object extraction from aerial imagery with convolutional neural networks. Electron. Imaging 2016, 2016, 1–9. [Google Scholar] [CrossRef]
- Griffiths, D.; Boehm, J. Improving public data for building segmentation from Convolutional Neural Networks (CNNs) for fused airborne lidar and image data using active contours. ISPRS J. Photogramm. Remote Sens. 2019, 154, 70–83. [Google Scholar] [CrossRef]
- Kaiser, P.; Wegner, J.D.; Lucchi, A.; Jaggi, M.; Hofmann, T.; Schindler, K. Learning aerial image segmentation from online maps. IEEE Trans. Geosci. Remote Sens. 2017, 55, 6054–6068. [Google Scholar] [CrossRef]
- Li, J.; Ding, W.; Li, H.; Liu, C. Semantic segmentation for high-resolution aerial imagery using multi-skip network and Markov random fields. In Proceedings of the 2017 IEEE International Conference on Unmanned Systems (ICUS), Beijing, China, 27–29 October 2017; pp. 12–17. [Google Scholar]
- Volpi, M.; Tuia, D. Deep multi-task learning for a geographically-regularized semantic segmentation of aerial images. ISPRS J. Photogramm. Remote Sens. 2018, 144, 48–60. [Google Scholar] [CrossRef] [Green Version]
- Shi, Y.; Li, Q.; Zhu, X.X. Building segmentation through a gated graph convolutional neural network with deep structured feature embedding. ISPRS J. Photogramm. Remote Sens. 2020, 159, 184–197. [Google Scholar] [CrossRef]
- Tschannen, M.; Cavigelli, L.; Mentzer, F.; Wiatowski, T.; Benini, L. Deep structured features for semantic segmentation. In Proceedings of the 2017 25th European Signal Processing Conference (EUSIPCO), Kos, Greece, 28 August–2 September 2017; pp. 61–65. [Google Scholar]
- ISPRS Vaihingen 2D Semantic Labeling Dataset. Available online: http://www2.isprs.org/commissions/comm3/wg4/2d-sem-label-vaihingen.html (accessed on 21 December 2020).
- ISPRS Potsdam 2D Semantic Labeling Dataset. Available online: http://www2.isprs.org/commissions/comm3/wg4/2d-sem-label-potsdam.html (accessed on 21 December 2020).
- Moser, G.; Tuia, D.; Shimoni, M. 2015 IEEE GRSS data fusion contest: Extremely high resolution LidAR and optical data [technical committees]. IEEE Geosci. Remote Sens. Mag. 2015, 3, 40–41. [Google Scholar] [CrossRef]
- Qin, Y.; Wu, Y.; Li, B.; Gao, S.; Liu, M.; Zhan, Y. Semantic segmentation of building roof in dense urban environment with deep convolutional neural network: A case study using GF2 VHR imagery in China. Sensors 2019, 19, 1164. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mnih, V. Machine Learning for Aerial Image Labeling; Citeseer: Forest Grove, OR, USA, 2013. [Google Scholar]
- Gerke, M. Use of the Stair Vision Library within the ISPRS 2D Semantic Labeling Benchmark (Vaihingen). 2014. Available online: https://doi.org/10.13140/2.1.5015.9683 (accessed on 21 December 2020).
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Bisong, E. Google colaboratory. In Building Machine Learning and Deep Learning Models on Google Cloud Platform; Springer: lBerlin/Heidelberg, Germany, 2019; pp. 59–64. [Google Scholar]
- Paisitkriangkrai, S.; Sherrah, J.; Janney, P.; Van Den Hengel, A. Semantic labeling of aerial and satellite imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 2868–2881. [Google Scholar] [CrossRef]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]










| Research Problem | Count | Reference |
|---|---|---|
| Use better fusion technique | 18 | [76,79,80,84,87,92,95,97,98,126,144,145,146,147,148,149,150,151] |
| Use contextual information | 8 | [62,93,151,152,153,154,155,156] |
| Use auxiliary data | 2 | [101,140] |
| Use skip connections | 5 | [94,103,125,149,157] |
| Use transfer learning | 4 | [96,134,135,148] |
| Minimize pre/post processing | 3 | [89,158,159] |
| Improve labeling dataset | 2 | [160,161] |
| Solve class imbalance problem | 5 | [108,109,110,154,162] |
| Improve boundary detection | 9 | [55,109,112,114,124,138,143,163,164] |
| Remove downsampling | 1 | [31] |
| Reduce model size | 1 | [165] |
| Minimize training parameters | 1 | [155] |
| Solve structural stereotype and insufficient training | 1 | [115] |
| Improve with decision tree | 2 | [104,106] |
| Minimize domain shift problem | 2 | [107,127] |
| Improve using pre-processing filters | 1 | [139] |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Neupane, B.; Horanont, T.; Aryal, J. Deep Learning-Based Semantic Segmentation of Urban Features in Satellite Images: A Review and Meta-Analysis. Remote Sens. 2021, 13, 808. https://doi.org/10.3390/rs13040808
Neupane B, Horanont T, Aryal J. Deep Learning-Based Semantic Segmentation of Urban Features in Satellite Images: A Review and Meta-Analysis. Remote Sensing. 2021; 13(4):808. https://doi.org/10.3390/rs13040808
Chicago/Turabian StyleNeupane, Bipul, Teerayut Horanont, and Jagannath Aryal. 2021. "Deep Learning-Based Semantic Segmentation of Urban Features in Satellite Images: A Review and Meta-Analysis" Remote Sensing 13, no. 4: 808. https://doi.org/10.3390/rs13040808
APA StyleNeupane, B., Horanont, T., & Aryal, J. (2021). Deep Learning-Based Semantic Segmentation of Urban Features in Satellite Images: A Review and Meta-Analysis. Remote Sensing, 13(4), 808. https://doi.org/10.3390/rs13040808