Automated Machine Learning for High-Throughput Image-Based Plant Phenotyping



Abstract
:
1. Introduction
2. Materials and Methods
2.1. Field Experiment
2.2. Image Acquisition and Processing
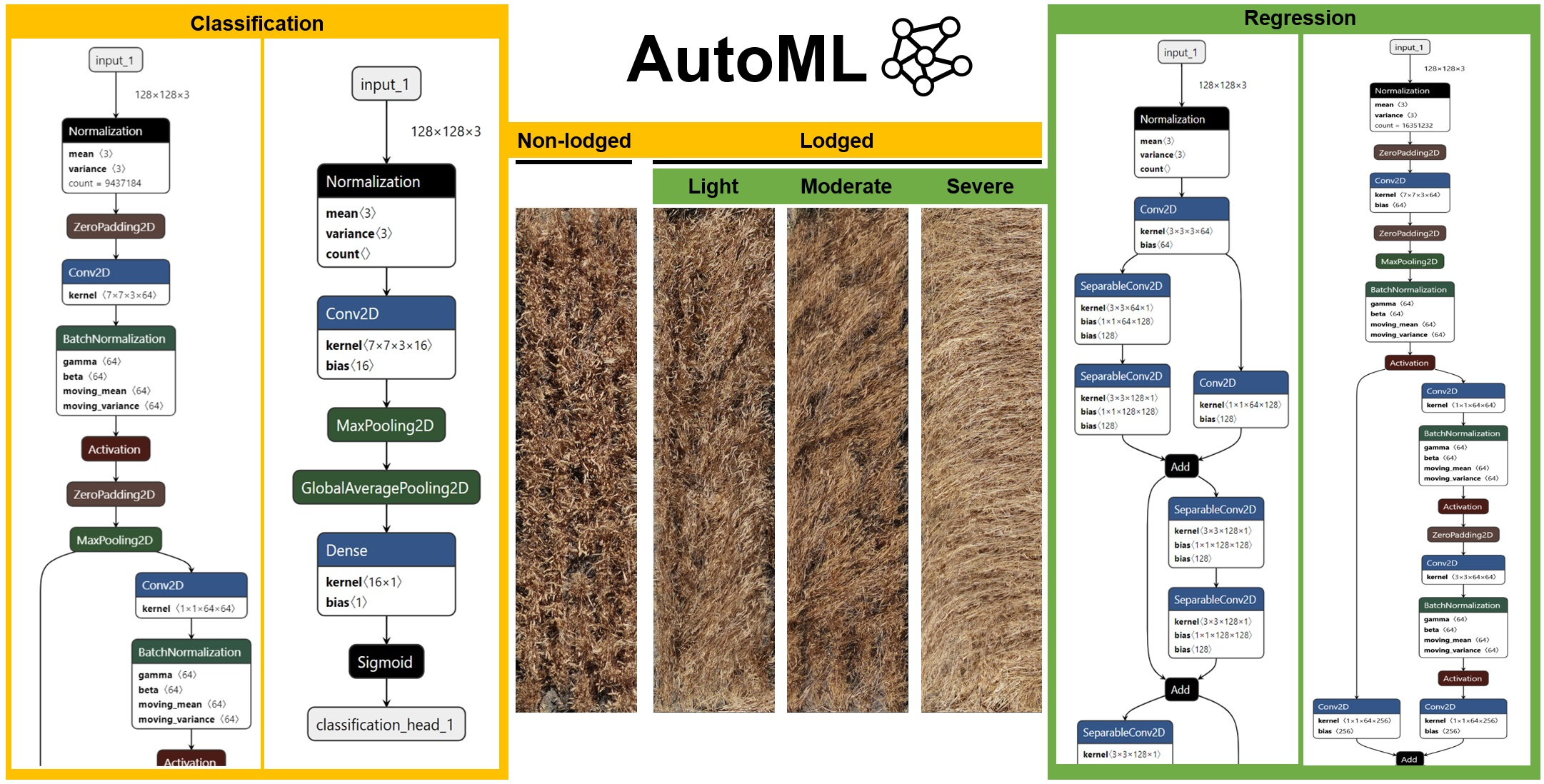
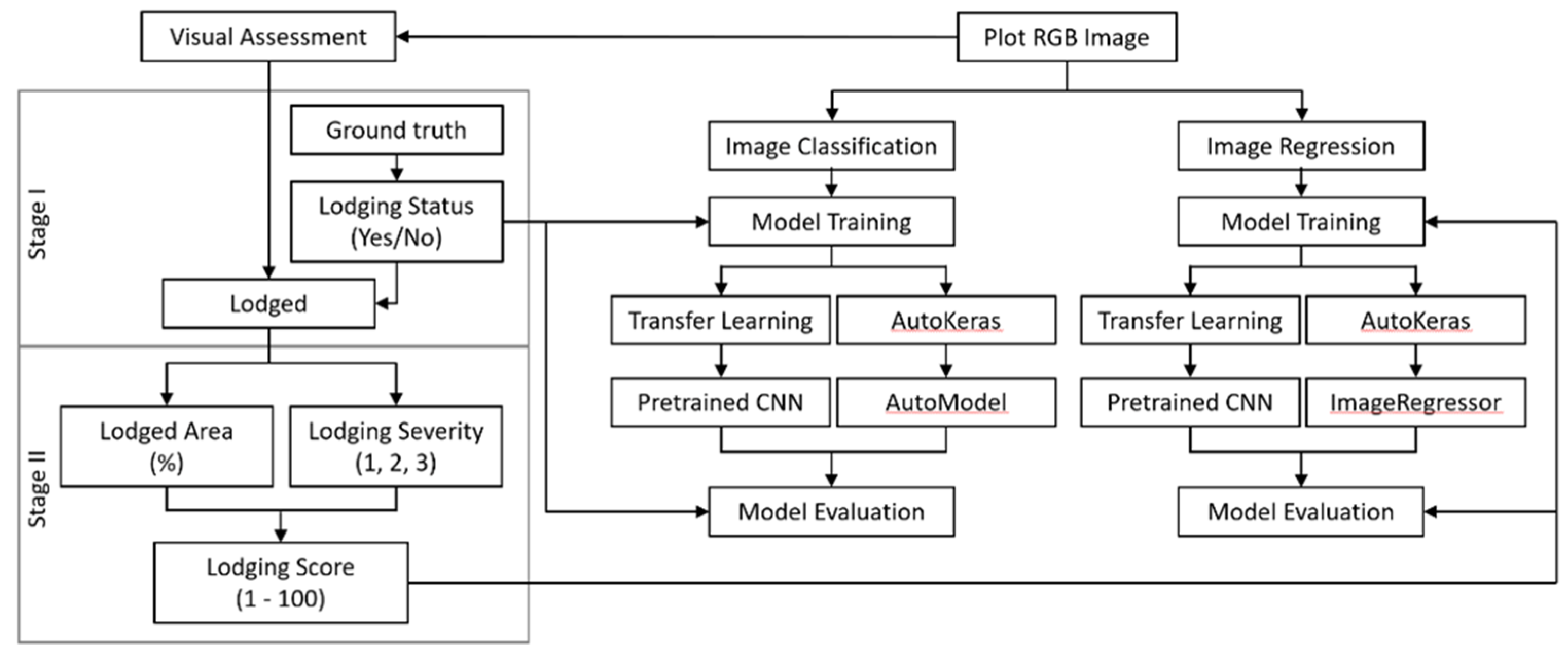
2.3. Lodging Assessment
2.4. Deep Learning Experiments
2.4.1. Training, Validation, and Test Datasets
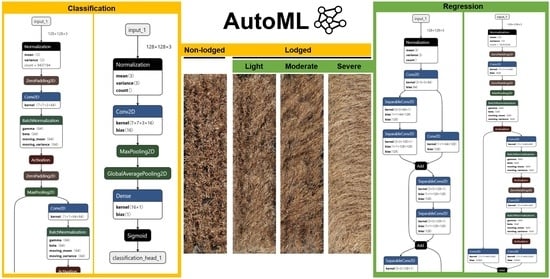
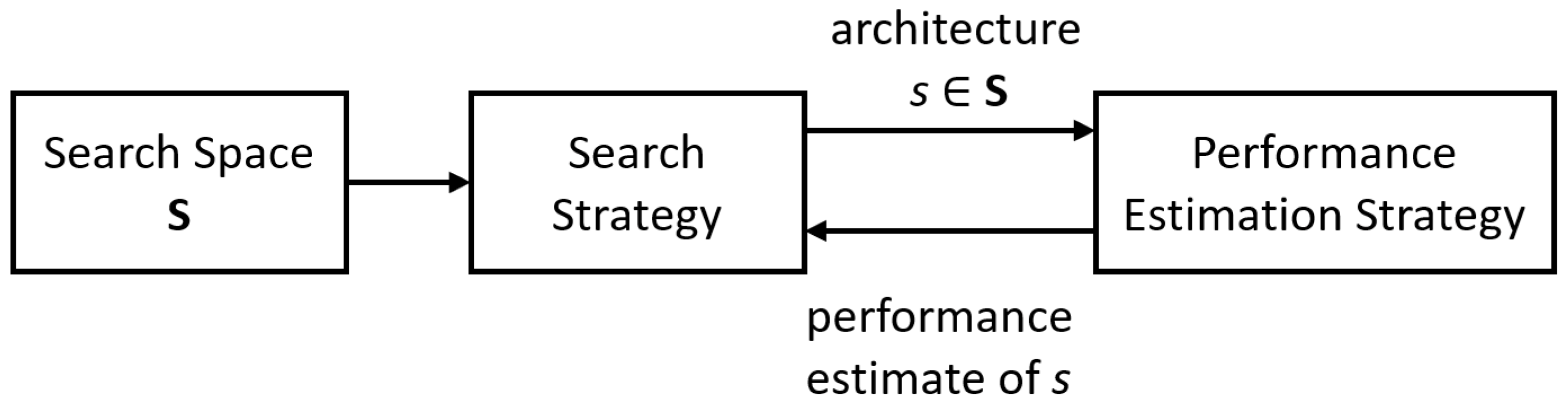
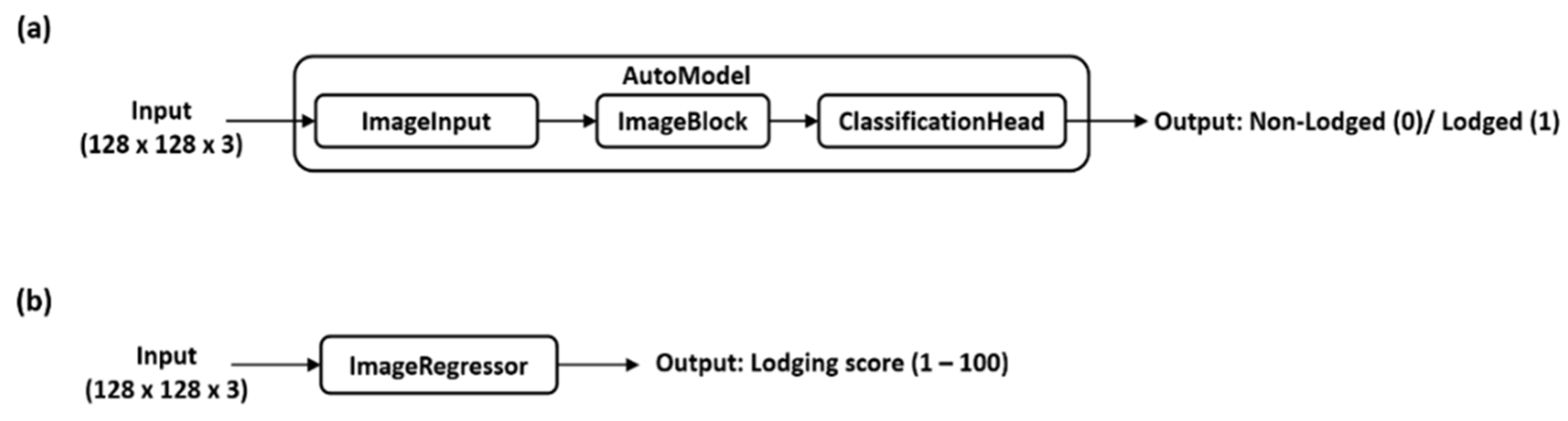
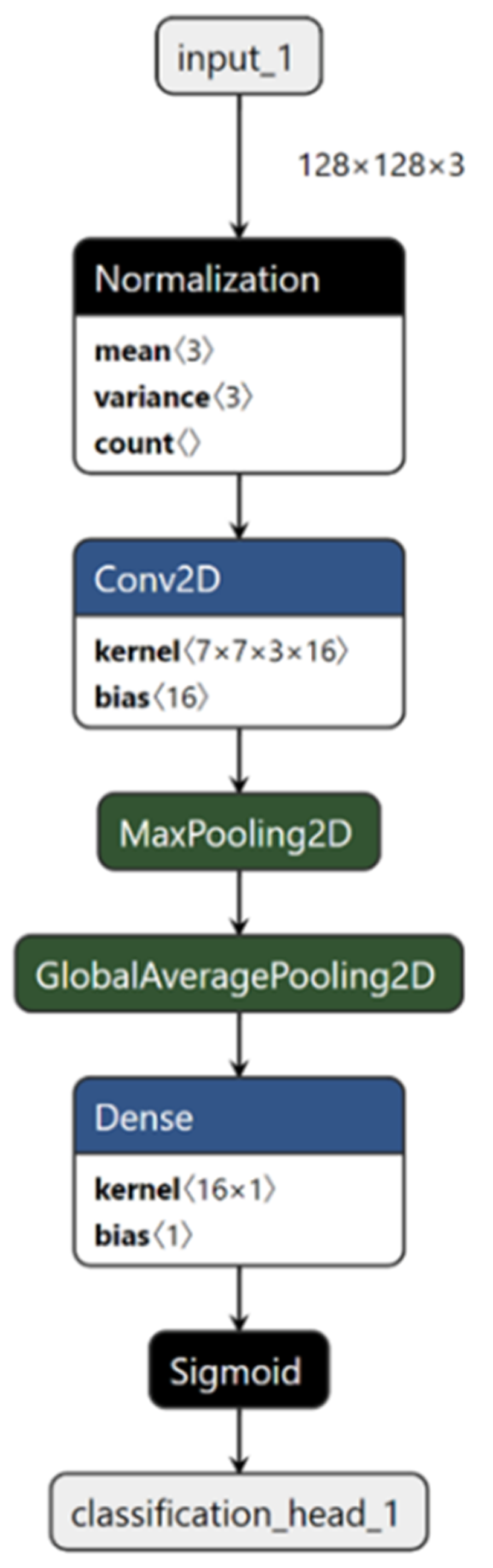
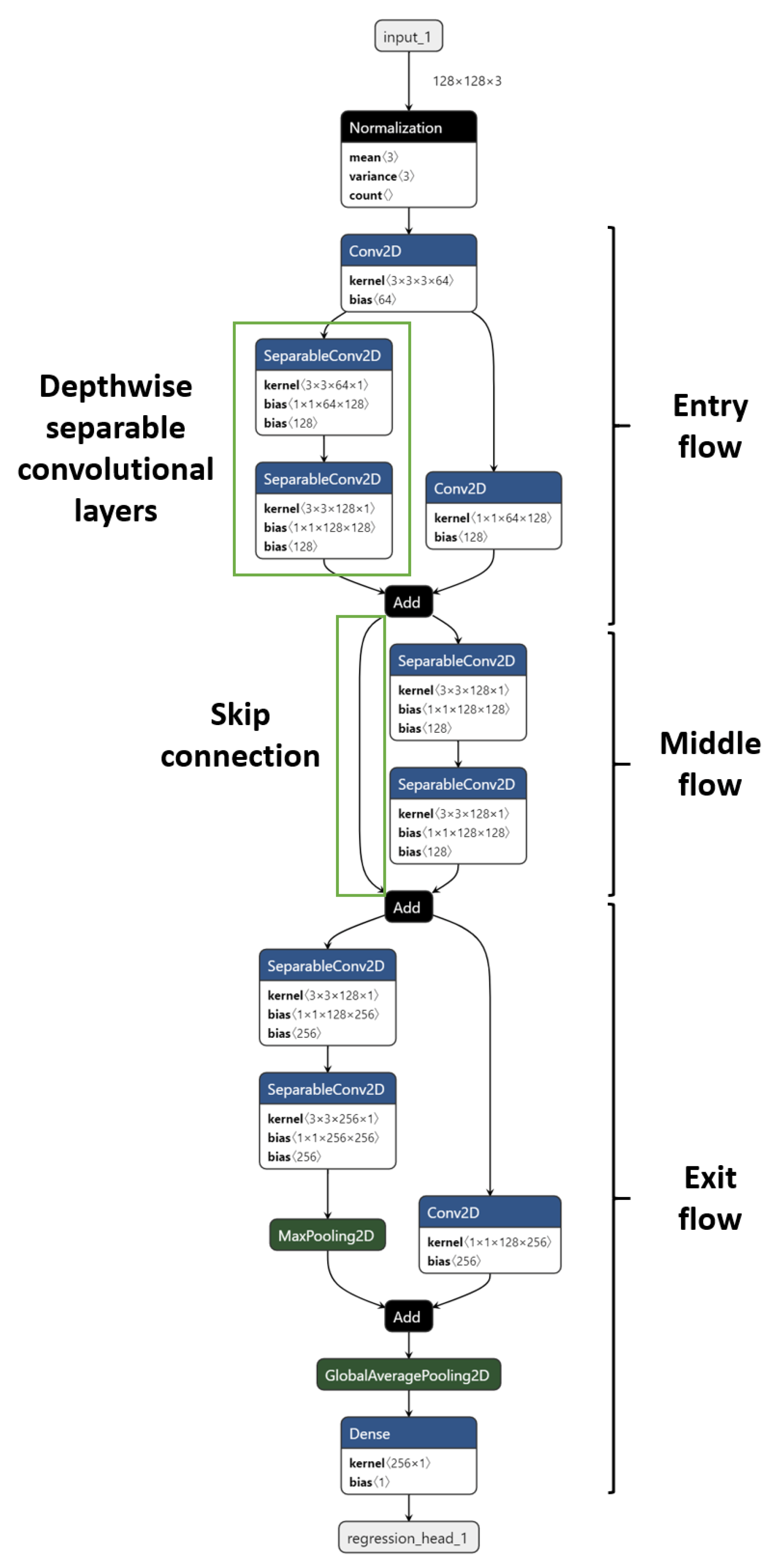
2.4.2. AutoML with AutoKeras
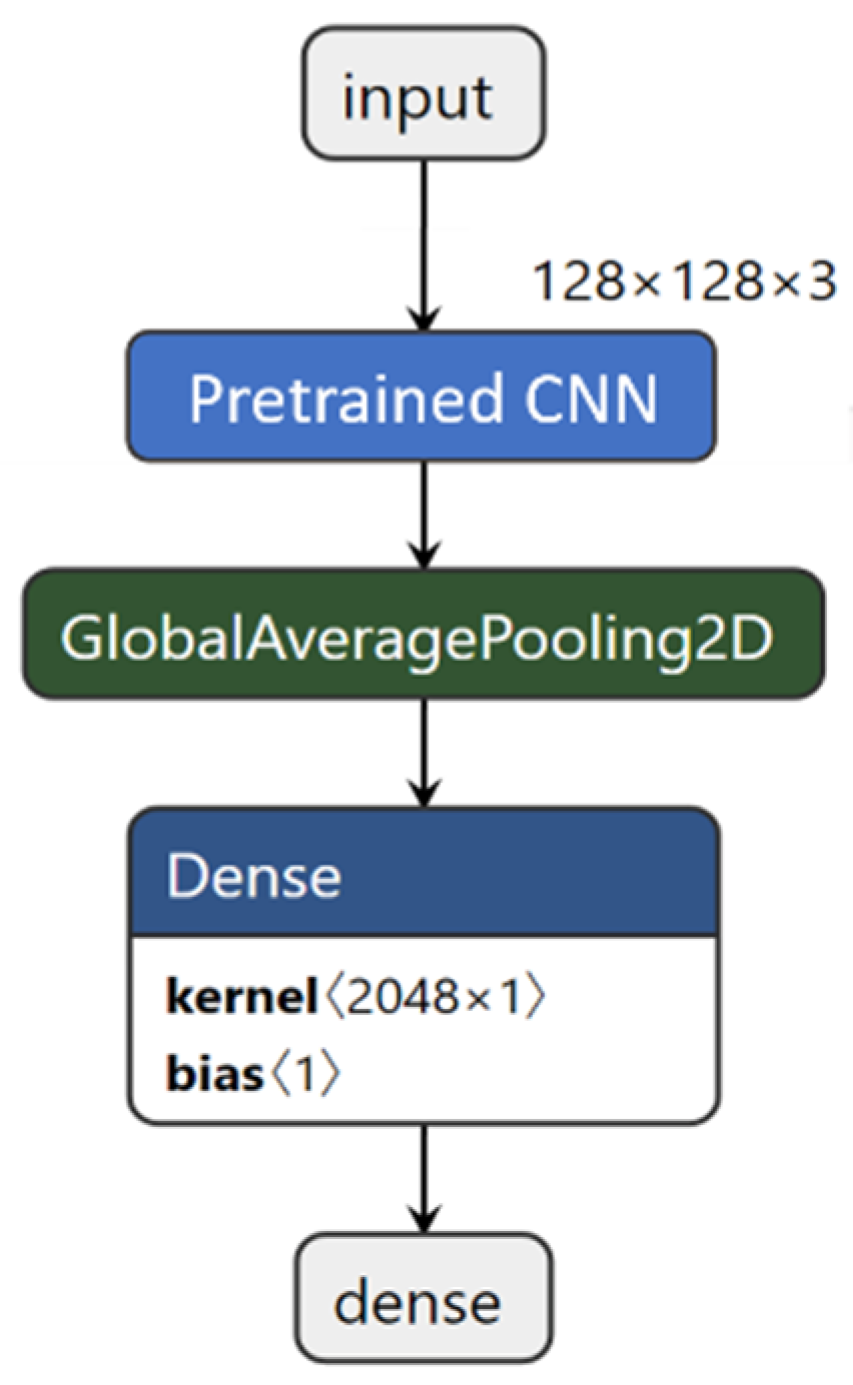
2.4.3. Transfer Learning with Pretrained CNNs
2.4.4. Model Evaluation Metrics
- Accuracy: accuracy represents the proportion of correctly predicted data points over all data points. It is the most common way to evaluate a classification model and works well when the dataset is balanced.where tp = true positives, fp = false positives, tn = true negatives, and fn = false negatives.
- Cohen’s kappa coefficient: Cohen’s kappa () expresses the level of agreement between two annotators, which in this case, is the classifier and the human operator on a classification problem. The kappa score ranges between −1 to 1, with scores above 0.8 generally considered good agreement.where is the empirical probability of agreement on the label assigned to any sample (the observed agreement ratio), and is the expected agreement when both annotators assign labels randomly.
- Root mean-squared error (RMSE): root mean-squared error provides an idea of how much error a model typically makes in its prediction, with a higher weight for large errors. As such, RMSE is sensitive to outliers, and other performance metrics may be more suitable when there are many outlier districts.where … are predicted values, … are observed values, and n is the number of observations.
- Mean absolute error (MAE): mean absolute error, also called the average absolute deviation is another common metric used to measure prediction errors in a model by taking the sum of absolute value of error. Compared to RMSE, MAE gives equal weight to all errors and as such may be less sensitive to the effects of outliers.where … are predicted values, … are observed values, and n is the number of observations.
- Mean absolute percentage error (MAPE): mean absolute percentage error is the percentage equivalent of MAE, with the errors scaled against the observed values. MAPE may be less sensitive to the effects of outliers compared to RMSE but is biased towards predictions that are systematically less than the actual values due to the effects of scaling.where … are predicted values, … are observed values, and n is the number of observations.
- Coefficient of determination (R2): the coefficient of determination is a value between 0 and 1 that measures how well a regression line fits the data. It can be interpreted as the proportion of variance in the independent variable that can be explained by the model.where … are predicted values, … are observed values, is the mean of observed values, and n is the number of observations.
3. Results
3.1. Image Classification
3.2. Image Regression
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ninomiya, S.; Baret, F.; Cheng, Z.-M.M. Plant Phenomics: Emerging Transdisciplinary Science. Plant Phenom. 2019, 2019, 1–3. [Google Scholar] [CrossRef] [PubMed]
- Tardieu, F.; Cabrera-Bosquet, L.; Pridmore, T.; Bennett, M. Plant Phenomics, From Sensors to Knowledge. Curr. Biol. 2017, 27, R770–R783. [Google Scholar] [CrossRef] [PubMed]
- Mir, R.R.; Reynolds, M.; Pinto, F.; Khan, M.A.; Bhat, M.A. High-throughput phenotyping for crop improvement in the genomics era. Plant Sci. 2019, 282, 60–72. [Google Scholar] [CrossRef] [PubMed]
- Jiang, Y.; Li, C. Convolutional Neural Networks for Image-Based High-Throughput Plant Phenotyping: A Review. Plant Phenom. 2020, 2020, 1–22. [Google Scholar] [CrossRef] [Green Version]
- Chen, M.; Tang, Y.; Zou, X.; Huang, K.; Huang, Z.; Zhou, H.; Wang, C.; Lian, G. Three-dimensional perception of orchard banana central stock enhanced by adaptive multi-vision technology. Comput. Electron. Agric. 2020, 174, 105508. [Google Scholar] [CrossRef]
- Fu, L.; Gao, F.; Wu, J.; Li, R.; Karkee, M.; Zhang, Q. Application of consumer RGB-D cameras for fruit detection and localization in field: A critical review. Comput. Electron. Agric. 2020, 177, 105687. [Google Scholar] [CrossRef]
- Khan, A.; Sohail, A.; Zahoora, U.; Qureshi, A.S. A survey of the recent architectures of deep convolutional neural networks. Artif. Intell. Rev. 2020, 53, 5455–5516. [Google Scholar] [CrossRef] [Green Version]
- Minaee, S.; Boykov, Y.Y.; Porikli, F.; Plaza, A.J.; Kehtarnavaz, N.; Terzopoulos, D. Image Segmentation Using Deep Learning: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021. [Google Scholar] [CrossRef] [PubMed]
- Wu, X.; Sahoo, D.; Hoi, S.C.H. Recent advances in deep learning for object detection. Neurocomputing 2020, 396, 39–64. [Google Scholar] [CrossRef] [Green Version]
- Balasubramanian, V.N.; Guo, W.; Chandra, A.L.; Desai, S.V. Computer Vision with Deep Learning for Plant Phenotyping in Agriculture: A Survey. Adv. Comput. Commun. 2020. Epub ahead of printing. [Google Scholar] [CrossRef]
- Watt, M.; Fiorani, F.; Usadel, B.; Rascher, U.; Muller, O.; Schurr, U. Phenotyping: New Windows into the Plant for Breeders. Annu. Rev. Plant Biol. 2020, 71, 689–712. [Google Scholar] [CrossRef] [PubMed]
- Tang, Y.; Chen, M.; Wang, C.; Luo, L.; Li, J.; Lian, G.; Zou, X. Recognition and Localization Methods for Vision-Based Fruit Picking Robots: A Review. Front. Plant Sci. 2020, 11, 510. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.; Lee, W.S.; Gan, H.; Peres, N.; Fraisse, C.; Zhang, Y.; He, Y. Strawberry Yield Prediction Based on a Deep Neural Network Using High-Resolution Aerial Orthoimages. Remote Sens. 2019, 11, 1584. [Google Scholar] [CrossRef] [Green Version]
- Fu, L.; Majeed, Y.; Zhang, X.; Karkee, M.; Zhang, Q. Faster R–CNN-based apple detection in dense-foliage fruiting-wall trees using RGB and depth features for robotic harvesting. Biosyst. Eng. 2020, 197, 245–256. [Google Scholar] [CrossRef]
- Chen, S.; Tang, M.; Kan, J. Predicting Depth from Single RGB Images with Pyramidal Three-Streamed Networks. Sensors 2019, 19, 667. [Google Scholar] [CrossRef] [Green Version]
- He, X.; Zhao, K.; Chu, X. AutoML: A survey of the state-of-the-art. Knowl. Based Syst. 2021, 212, 106622. [Google Scholar] [CrossRef]
- Truong, A.; Walters, A.; Goodsitt, J.; Hines, K.; Bruss, C.B.; Farivar, R. Towards Automated Machine Learning: Evaluation and Comparison of AutoML Approaches and Tools. In Proceedings of the 31st International Conference on Tools with Artificial Intelligence (ICTAI), Portland, OR, USA, 4–6 November 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1471–1479. [Google Scholar]
- Zöller, M.-A.; Huber, M.F. Benchmark and Survey of Automated Machine Learning Frameworks. J. Artif. Intell. Res. 2021, 70, 409–472. [Google Scholar] [CrossRef]
- Zoph, B.; Le, Q.V. Neural Architecture Search with Reinforcement Learning. arXiv 2016, arXiv:1611.01578. [Google Scholar]
- Elsken, T.; Metzen, J.H.; Hutter, F. Neural Architecture Search: A Survey. arXiv 2019, arXiv:1808.05377. [Google Scholar]
- Wistuba, M.; Rawat, A.; Pedapati, T. A Survey on Neural Architecture Search. arXiv 2019, arXiv:1905.01392. [Google Scholar]
- Pham, H.; Guan, M.; Zoph, B.; Le, Q.; Dean, J. Efficient Neural Architecture Search via Parameters Sharing. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 4095–4104. [Google Scholar]
- Zhong, Z.; Yan, J.; Liu, C. Practical Network Blocks Design with Q-Learning. arXiv 2017, arXiv:1708.05552. [Google Scholar]
- Zoph, B.; Vasudevan, V.; Shlens, J.; Le, Q.V. Learning Transferable Architectures for Scalable Image Recognition. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 8697–8710. [Google Scholar]
- Liu, H.; Simonyan, K.; Vinyals, O.; Fernando, C.; Kavukcuoglu, K. Hierarchical Representations for Efficient Architecture Search. arXiv 2018, arXiv:1711.00436. [Google Scholar]
- Chen, T.; Goodfellow, I.J.; Shlens, J. Net2Net: Accelerating Learning via Knowledge Transfer. arXiv 2016, arXiv:1511.05641. [Google Scholar]
- Wei, T.; Wang, C.; Rui, Y.; Chen, C.W. Network Morphism. In Proceedings of the 33rd International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016; pp. 564–572. [Google Scholar]
- Jin, H.; Song, Q.; Hu, X. Auto-Keras: An Efficient Neural Architecture Search System. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 3–7 August 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 1946–1956. [Google Scholar]
- Mendoza, H.; Klein, A.; Feurer, M.; Springenberg, J.T.; Urban, M.; Burkart, M.; Dippel, M.; Lindauer, M.; Hutter, F. Towards Automatically-Tuned Deep Neural Networks. In Automated Machine Learning: Methods, Systems, Challenges; Hutter, F., Kotthoff, L., Vanschoren, J., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 135–149. [Google Scholar] [CrossRef] [Green Version]
- Real, E.; Moore, S.; Selle, A.; Saxena, S.; Suematsu, Y.L.; Tan, J.; Le, Q.V.; Kurakin, A. Large-Scale Evolution of Image Classifiers. arXiv 2017, arXiv:1703.01041. [Google Scholar]
- Stanley, K.O.; Miikkulainen, R. Evolving Neural Networks through Augmenting Topologies. Evol. Comput. 2002, 10, 99–127. [Google Scholar] [CrossRef]
- Baker, B.; Gupta, O.; Naik, N.; Raskar, R. Designing Neural Network Architectures using Reinforcement Learning. arXiv 2017, arXiv:1611.02167. [Google Scholar]
- Liu, H.; Simonyan, K.; Yang, Y. DARTS: Differentiable Architecture Search. arXiv 2019, arXiv:1806.09055. [Google Scholar]
- Zela, A.; Klein, A.; Falkner, S.; Hutter, F. Towards Automated Deep Learning: Efficient Joint Neural Architecture and Hyperparameter Search. arXiv 2018, arXiv:1807.06906. [Google Scholar]
- Klein, A.; Falkner, S.; Springenberg, J.T.; Hutter, F. Learning Curve Prediction with Bayesian Neural Networks. In Proceedings of the 5th International Conference on Learning Representations (ICRL 2017), Toulon, France, 24–26 April 2017. [Google Scholar]
- Swersky, K.; Snoek, J.; Adams, R. Freeze-Thaw Bayesian Optimization. arXiv 2014, arXiv:1406.3896. [Google Scholar]
- Elsken, T.; Metzen, J.H.; Hutter, F. Efficient Multi-Objective Neural Architecture Search via Lamarckian Evolution. arXiv 2019, arXiv:1804.09081. [Google Scholar]
- Bender, G.; Kindermans, P.; Zoph, B.; Vasudevan, V.; Le, Q.V. Understanding and Simplifying One-Shot Architecture Search. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018. [Google Scholar]
- Cai, H.; Zhu, L.; Han, S. ProxylessNAS: Direct Neural Architecture Search on Target Task and Hardware. arXiv 2019, arXiv:1812.00332. [Google Scholar]
- Xie, S.; Zheng, H.; Liu, C.; Lin, L. SNAS: Stochastic Neural Architecture Search. arXiv 2019, arXiv:1812.09926. [Google Scholar]
- Tan, M.; Le, Q.V. Efficientnet: Rethinking model scaling for convolutional neural networks. arXiv 2019, arXiv:1905.11946. [Google Scholar]
- Wang, N.; Gao, Y.; Chen, H.; Wang, P.; Tian, Z.; Shen, C.; Zhang, Y. NAS-FCOS: Fast Neural Architecture Search for Object Detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 11940–11948. [Google Scholar]
- Weng, Y.; Zhou, T.; Li, Y.; Qiu, X. NAS-Unet: Neural Architecture Search for Medical Image Segmentation. IEEE Access 2019, 7, 44247–44257. [Google Scholar] [CrossRef]
- Fischer, R.A.; Stapper, M. Lodging effects on high-yielding crops of irrigated semidwarf wheat. Field Crops Res. 1987, 17, 245–258. [Google Scholar] [CrossRef]
- Sun, Q.; Sun, L.; Shu, M.; Gu, X.; Yang, G.; Zhou, L. Monitoring Maize Lodging Grades via Unmanned Aerial Vehicle Multispectral Image. Plant Phenom. 2019, 2019, 1–16. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 770–778. [Google Scholar]
- Xie, S.; Girshick, R.; Dollar, P.; Tu, Z.; He, K. Aggregated Residual Transformations for Deep Neural Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1492–1500. [Google Scholar]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1800–1807. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2015, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 2818–2826. [Google Scholar]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; IEEE: New York, NY, USA, 2017; pp. 2261–2269. [Google Scholar]
- Cohen, J. A Coefficient of Agreement for Nominal Scales. Educ. Psychol. Meas. 1960, 20, 37–46. [Google Scholar] [CrossRef]
- Mardanisamani, S.; Maleki, F.; Kassani, S.H.; Rajapaksa, S.; Duddu, H.; Wang, M.; Shirtliffe, S.; Ryu, S.; Josuttes, A.; Zhang, T.; et al. Crop Lodging Prediction From UAV-Acquired Images of Wheat and Canola Using a DCNN Augmented with Handcrafted Texture Features. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Long Beach, CA, USA, 16–20 June 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 2657–2664. [Google Scholar]
- Salama, A.I.; Ostapenko, O.; Klein, T.; Nabi, M. Pruning at a Glance: Global Neural Pruning for Model Compression. arXiv 2019, arXiv:1912.00200. [Google Scholar]
- Du, X.; Lin, T.-Y.; Jin, P.; Ghiasi, G.; Tan, M.; Cui, Y.; Le, Q.V.; Song, X. SpineNet: Learning Scale-Permuted Backbone for Recognition and Localization. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 11589–11598. [Google Scholar]
- Li, L.; Talwalkar, A. Random Search and Reproducibility for Neural Architecture Search. In Proceedings of the 35th Uncertainty in Artificial Intelligence Conference, Tel Aviv, Israel, 22–25 July 2019. [Google Scholar]
- Koh, J.; Spangenberg, G.; Kant, S. Automated Machine Learning for High-Throughput Image-Based Plant Phenotyping. Zenodo 2020. preprint. [Google Scholar] [CrossRef]
- Koh, J.; Spangenberg, G.; Kant, S. Source Codes for AutoML Manuscript. Available online: https://github.com/AVR-PlantPhenomics/automl_paper (accessed on 28 January 2021).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network | Task | 1st Training * | 2nd Training * |
|---|---|---|---|
| VGG16 | classification | 1 × 10−2 | 1 × 10−4 |
| VGG19 | classification | 1 × 10−1 | 1 × 10−4 |
| ResNet−50 | classification | 1 × 10−1 | 1 × 10−4 |
| ResNet−101 | classification | 1 × 10−2 | 1 × 10−4 |
| InceptionV3 | classification | 1 × 10−1 | 1 × 10−4 |
| Xception | classification | 1 × 10−1 | 1 × 10−4 |
| DenseNet−169 | classification | 1 × 10−2 | 1 × 10−3 |
| DenseNet−201 | classification | 1 × 10−2 | 1 × 10−3 |
| VGG16 | regression | 1 × 10−1 | 1 × 10−4 |
| VGG19 | regression | 1 × 10−2 | 1 × 10−5 |
| ResNet−50 | regression | 1 × 10−2 | 1 × 10−3 |
| ResNet−101 | regression | 1 × 10−1 | 1 × 10−3 |
| InceptionV3 | regression | 1 × 10−1 | 1 × 10−3 |
| Xception | regression | 1 × 10−2 | 1 × 10−3 |
| DenseNet−169 | regression | 1 × 10−1 | 1 × 10−3 |
| DenseNet−201 | regression | 1 × 10−2 | 1 × 10−3 |
| Network | Parameters | Training (min) | Inference (ms) | Accuracy (%) | Kappa |
|---|---|---|---|---|---|
| VGG16 | 14,715,201 | 6.03 | 0.5868 ± 0.0821 | 92.0 | 0.8355 |
| VGG19 | 20,024,897 | 7.01 | 0.6468 ± 0.1035 | 91.6 | 0.8269 |
| ResNet-50 | 23,589,761 | 5.89 | 0.4776 ± 0.0621 | 92.4 | 0.8449 |
| ResNet-101 | 42,660,225 | 9.88 | 0.7469 ± 0.1046 | 92.8 | 0.8524 |
| InceptionV3 | 21,804,833 | 5.42 | 0.4022 ± 0.0603 | 92.8 | 0.8521 |
| Xception | 20,863,529 | 9.06 | 0.5928 ± 0.0831 | 93.2 | 0.8612 |
| DenseNet-169 | 12,644,545 | 9.23 | 0.6113 ± 0.0917 | 92.8 | 0.8528 |
| DenseNet-201 | 18,323,905 | 11.79 | 0.7524 ± 0.0568 | 93.2 | 0.8599 |
| AK-10_trials | 23,566,856 | 16.06 | 0.4094 ± 0.0573 | 86.8 | 0.7484 |
| AK-25_trials | 23,566,856 | 29.18 | 0.4418 ± 0.0533 | 88.4 | 0.7595 |
| AK-50_trials | 43,859 | 102.43 | 0.0233 ± 0.0026 | 89.6 | 0.7901 |
| AK-100_trials | 43,859 | 251.80 | 0.0228 ± 0.0005 | 92.4 | 0.8457 |
| Model | Classes | Non-Lodged | Lodged |
|---|---|---|---|
| Xception | Non-lodged | 98 | 3 |
| Lodged | 14 | 135 | |
| DenseNet-201 | Non-lodged | 95 | 6 |
| Lodged | 11 | 138 | |
| AK-100_trials | Non-Lodged | 99 | 2 |
| Lodged | 17 | 132 |
| Network | Parameters | Training (min) | Inference (ms) | R2 | RMSE | MAE | MAPE (%) |
|---|---|---|---|---|---|---|---|
| VGG16 | 14,715,201 | 3.71 | 0.6310 ± 0.0883 | 0.7590 | 11.37 | 8.97 | 14.02 |
| VGG19 | 20,024,897 | 4.32 | 0.7213 ± 0.1141 | 0.7707 | 11.03 | 9.19 | 16.01 |
| ResNet-50 | 23,589,761 | 3.55 | 0.5502 ± 0.0716 | 0.7844 | 10.79 | 8.28 | 15.51 |
| ResNet-101 | 42,660,225 | 5.85 | 0.7977 ± 0.1117 | 0.7730 | 11.10 | 8.38 | 15.67 |
| InceptionV3 | 21,804,833 | 3.32 | 0.4318 ± 0.0648 | 0.7642 | 11.09 | 8.07 | 13.90 |
| Xception | 20,863,529 | 5.33 | 0.6452 ± 0.0903 | 0.7709 | 11.08 | 8.22 | 13.51 |
| DenseNet-169 | 12,644,545 | 6.65 | 0.6545 ± 0.0982 | 0.7985 | 10.31 | 7.68 | 13.63 |
| DenseNet-201 | 18,323,905 | 7.01 | 0.8141 ± 0.1059 | 0.8303 | 9.55 | 7.03 | 12.54 |
| AK-10_trials | 23,566,856 | 32.25 | 0.5574 ± 0.0009 | 0.7568 | 12.43 | 9.54 | 14.55 |
| AK-25_trials | 23,566,856 | 123.08 | 0.5719 ± 0.0008 | 0.7772 | 12.28 | 8.62 | 14.38 |
| AK-50_trials | 207,560 | 184.91 | 0.0198 ± 0.0008 | 0.8133 | 10.71 | 8.31 | 13.92 |
| AK-100_trials | 207,560 | 325.62 | 0.0199 ± 0.0008 | 0.8273 | 10.65 | 8.24 | 13.87 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Koh, J.C.O.; Spangenberg, G.; Kant, S. Automated Machine Learning for High-Throughput Image-Based Plant Phenotyping. Remote Sens. 2021, 13, 858. https://doi.org/10.3390/rs13050858
Koh JCO, Spangenberg G, Kant S. Automated Machine Learning for High-Throughput Image-Based Plant Phenotyping. Remote Sensing. 2021; 13(5):858. https://doi.org/10.3390/rs13050858
Chicago/Turabian StyleKoh, Joshua C.O., German Spangenberg, and Surya Kant. 2021. "Automated Machine Learning for High-Throughput Image-Based Plant Phenotyping" Remote Sensing 13, no. 5: 858. https://doi.org/10.3390/rs13050858
APA StyleKoh, J. C. O., Spangenberg, G., & Kant, S. (2021). Automated Machine Learning for High-Throughput Image-Based Plant Phenotyping. Remote Sensing, 13(5), 858. https://doi.org/10.3390/rs13050858