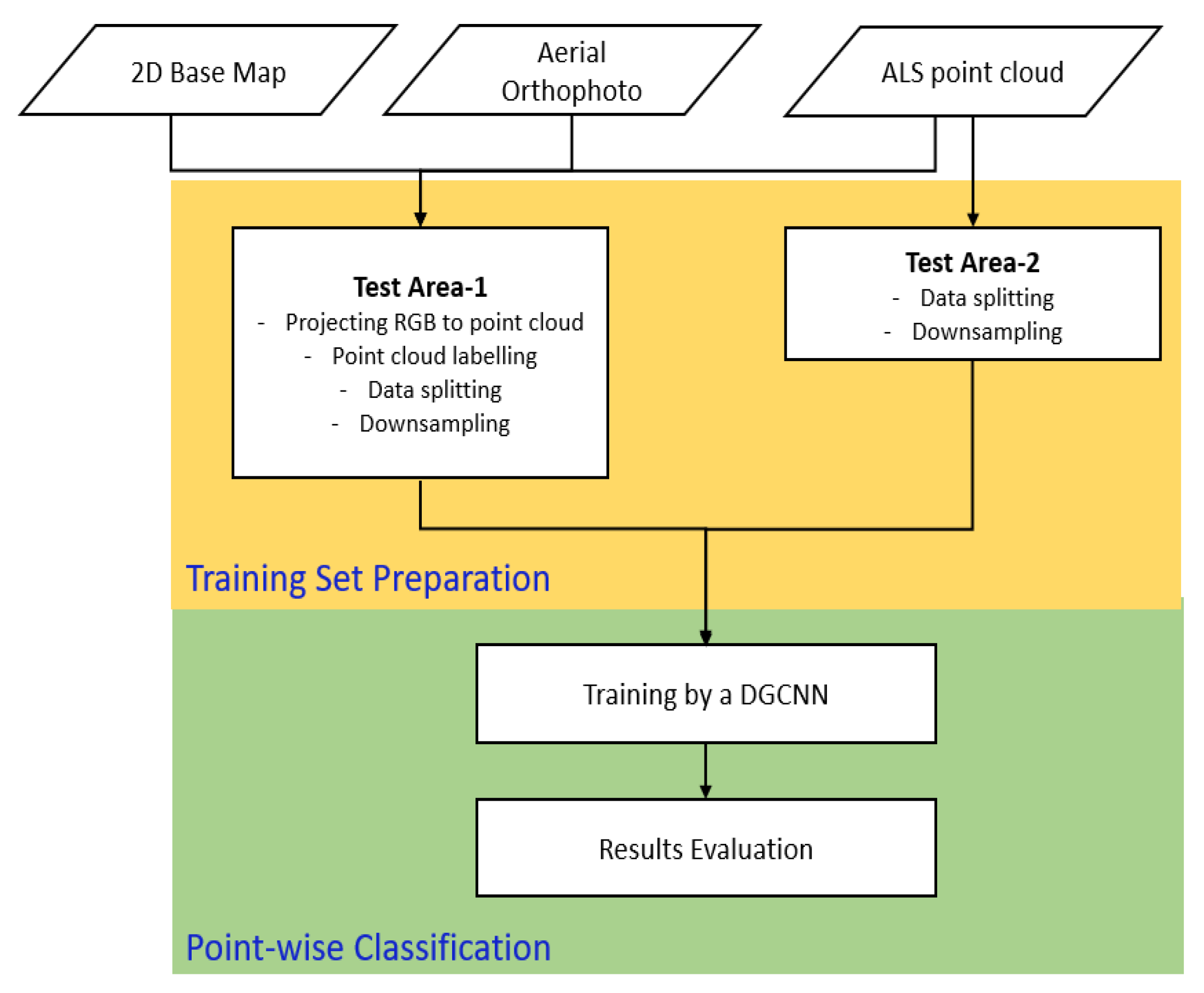
Figure 1.
Methodological workflow used in this study to classify Airborne Laser Scanning (ALS) point clouds of two test areas using Dynamic Graph Convolutional Neural Network (DGCNN) architecture.
Figure 1.
Methodological workflow used in this study to classify Airborne Laser Scanning (ALS) point clouds of two test areas using Dynamic Graph Convolutional Neural Network (DGCNN) architecture.
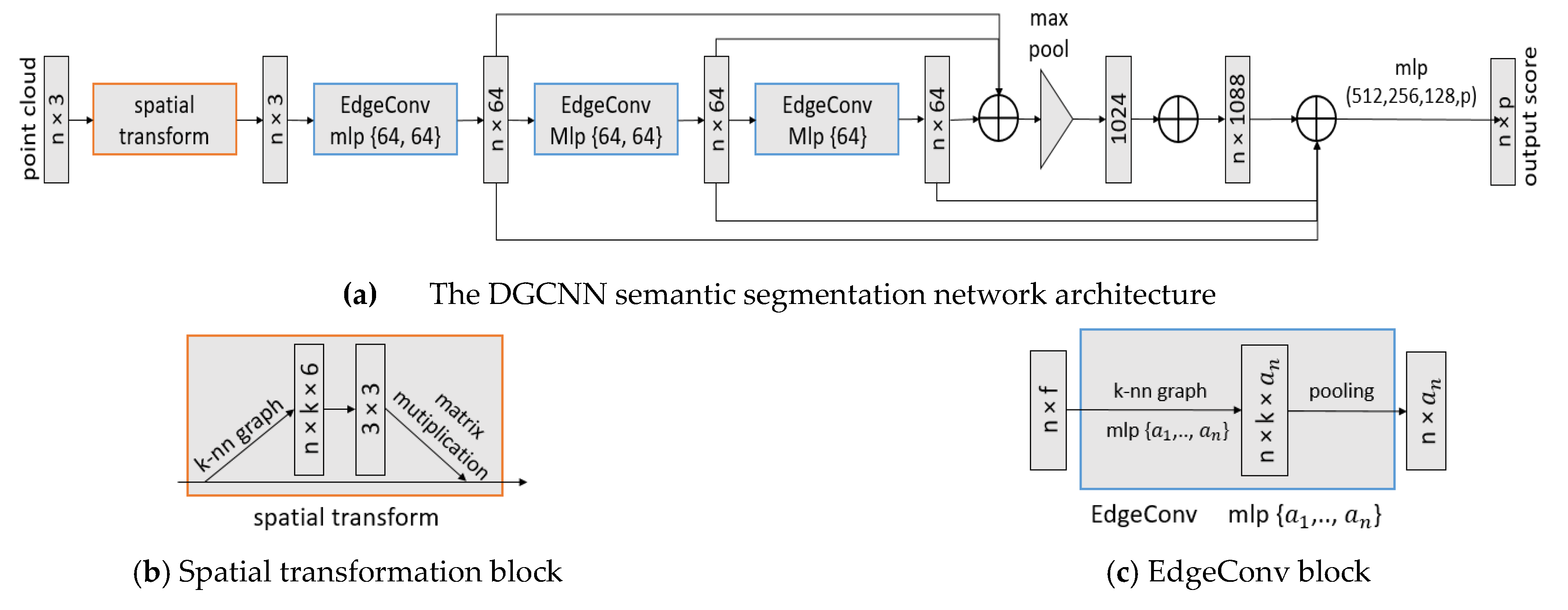
Figure 2.
The DGCNN components for semantic segmentation architecture: (a) The network uses spatial transformation followed by three sequential EdgeConv layers and three fully connected layers. A max pooling operation is performed as a symmetric edge function to solve for the point clouds ordering problem—i.e., it makes the model permutation invariant while capturing global features. The fully connected layers will produce class prediction scores for each point. (b) A spatial transformation module is used to learn the rotation matrix of the points and increase spatial invariance of the input point clouds. (c) EdgeConv which acts as multilayer perceptron (MLP), is applied to learn local geometric features for each point. Source: Wang et al. (2018).
Figure 2.
The DGCNN components for semantic segmentation architecture: (a) The network uses spatial transformation followed by three sequential EdgeConv layers and three fully connected layers. A max pooling operation is performed as a symmetric edge function to solve for the point clouds ordering problem—i.e., it makes the model permutation invariant while capturing global features. The fully connected layers will produce class prediction scores for each point. (b) A spatial transformation module is used to learn the rotation matrix of the points and increase spatial invariance of the input point clouds. (c) EdgeConv which acts as multilayer perceptron (MLP), is applied to learn local geometric features for each point. Source: Wang et al. (2018).
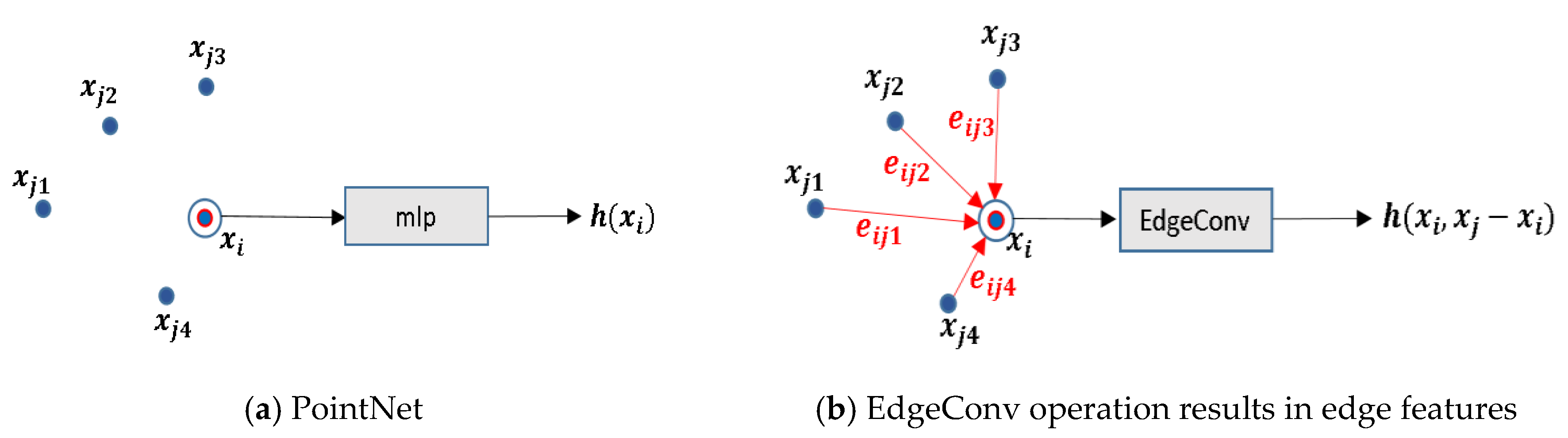
Figure 3.
Basic differences between PointNet and DGCNN. (a) The PointNet output of the feature extraction h(xi), is only related to the point itself. (b) The DGCNN incorporates local geometric relations h(xi,xj−xi) between a point and its neighborhood. Here, a k-nn graph is constructed with k = 4.
Figure 3.
Basic differences between PointNet and DGCNN. (a) The PointNet output of the feature extraction h(xi), is only related to the point itself. (b) The DGCNN incorporates local geometric relations h(xi,xj−xi) between a point and its neighborhood. Here, a k-nn graph is constructed with k = 4.
Figure 4.
Representation of vegetation in one of the city parks in Area-1 (Surabaya city). The vegetation is mostly dominated by trees with rounded canopies. (a) 3D point cloud of trees, (b) Aerial images, (c) Street view of the trees ©GoogleMap2021.
Figure 4.
Representation of vegetation in one of the city parks in Area-1 (Surabaya city). The vegetation is mostly dominated by trees with rounded canopies. (a) 3D point cloud of trees, (b) Aerial images, (c) Street view of the trees ©GoogleMap2021.
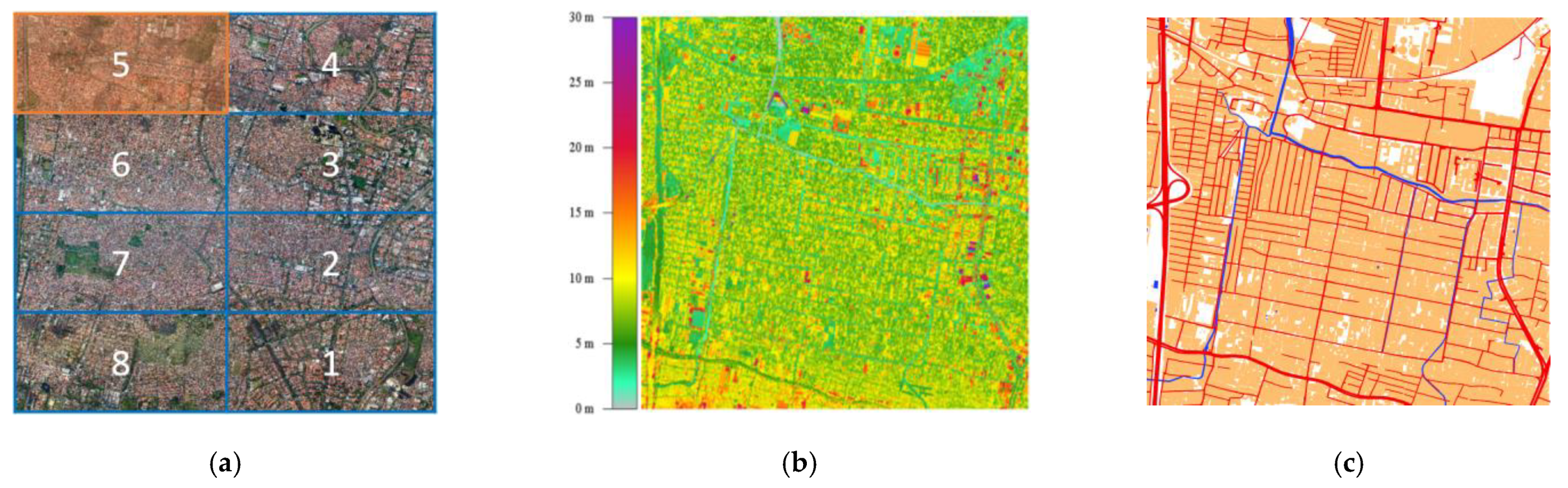
Figure 5.
Input data and coverage of Surabaya city, Indonesia. (a) Orthophoto of the study area covering eight grids, with the test tile shown in orange; (b) ALS point cloud of grids 5 and 6 colored by elevation; (c) the 1:1000 base map of grids 5 and 6 containing buildings (orange), roads (red), and water bodies (blue).
Figure 5.
Input data and coverage of Surabaya city, Indonesia. (a) Orthophoto of the study area covering eight grids, with the test tile shown in orange; (b) ALS point cloud of grids 5 and 6 colored by elevation; (c) the 1:1000 base map of grids 5 and 6 containing buildings (orange), roads (red), and water bodies (blue).
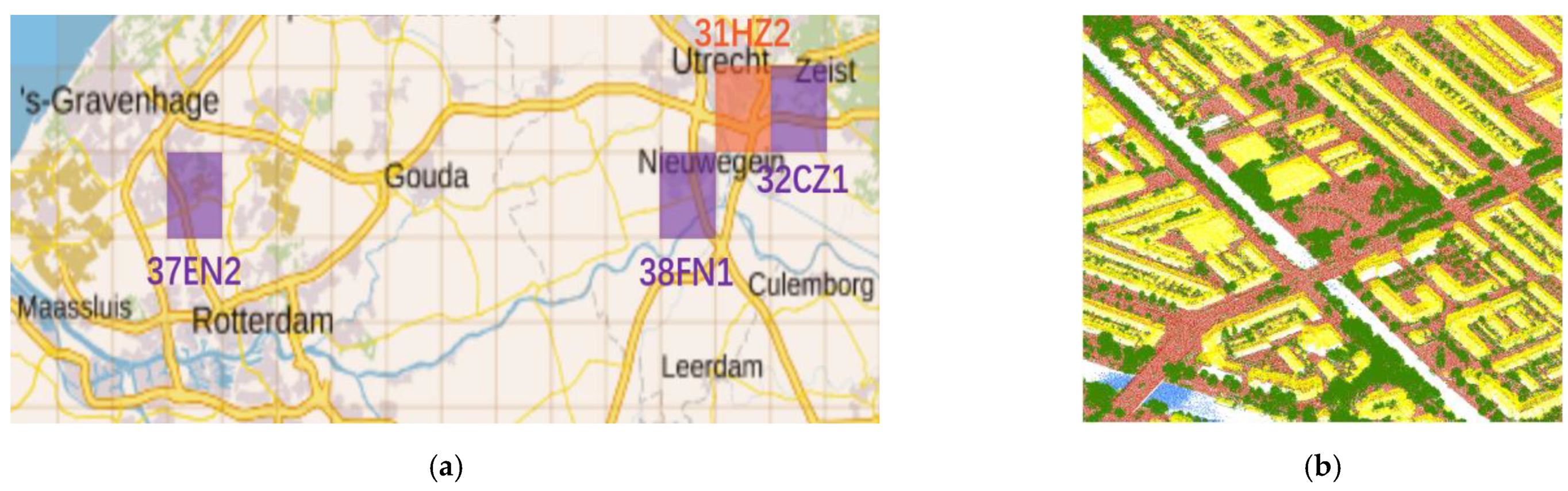
Figure 6.
Dutch up-to-date Elevation Archive File, version 3 (AHN3) grids selected for this study. (a) Grids in purple are used as training while the grid in orange was used as the test area; (b) AHN3 point clouds labeled as bare land (brown), buildings (yellow), water (blue), and “others” (green).
Figure 6.
Dutch up-to-date Elevation Archive File, version 3 (AHN3) grids selected for this study. (a) Grids in purple are used as training while the grid in orange was used as the test area; (b) AHN3 point clouds labeled as bare land (brown), buildings (yellow), water (blue), and “others” (green).
Figure 7.
Labeled point clouds from AHN3 of Area-2 with different block sizes: (a) Block size = 30 m, (b) Block size = 50 m, (c) Block size = 70 m. Brown points represent bare land, yellow points represent buildings, blue points represent water, and points in green represent “other” class.
Figure 7.
Labeled point clouds from AHN3 of Area-2 with different block sizes: (a) Block size = 30 m, (b) Block size = 50 m, (c) Block size = 70 m. Brown points represent bare land, yellow points represent buildings, blue points represent water, and points in green represent “other” class.
Figure 8.
Samples of different feature set results. (a–d): Classification results of four feature combinations in comparison to (e) base map, (f) aerial orthophoto, (g) LiDAR intensity, and (h) Digital Surface Model (DSM). In (a–e), blue color represents bare land, green represents trees, orange represents buildings, and red represents roads, respectively.
Figure 8.
Samples of different feature set results. (a–d): Classification results of four feature combinations in comparison to (e) base map, (f) aerial orthophoto, (g) LiDAR intensity, and (h) Digital Surface Model (DSM). In (a–e), blue color represents bare land, green represents trees, orange represents buildings, and red represents roads, respectively.
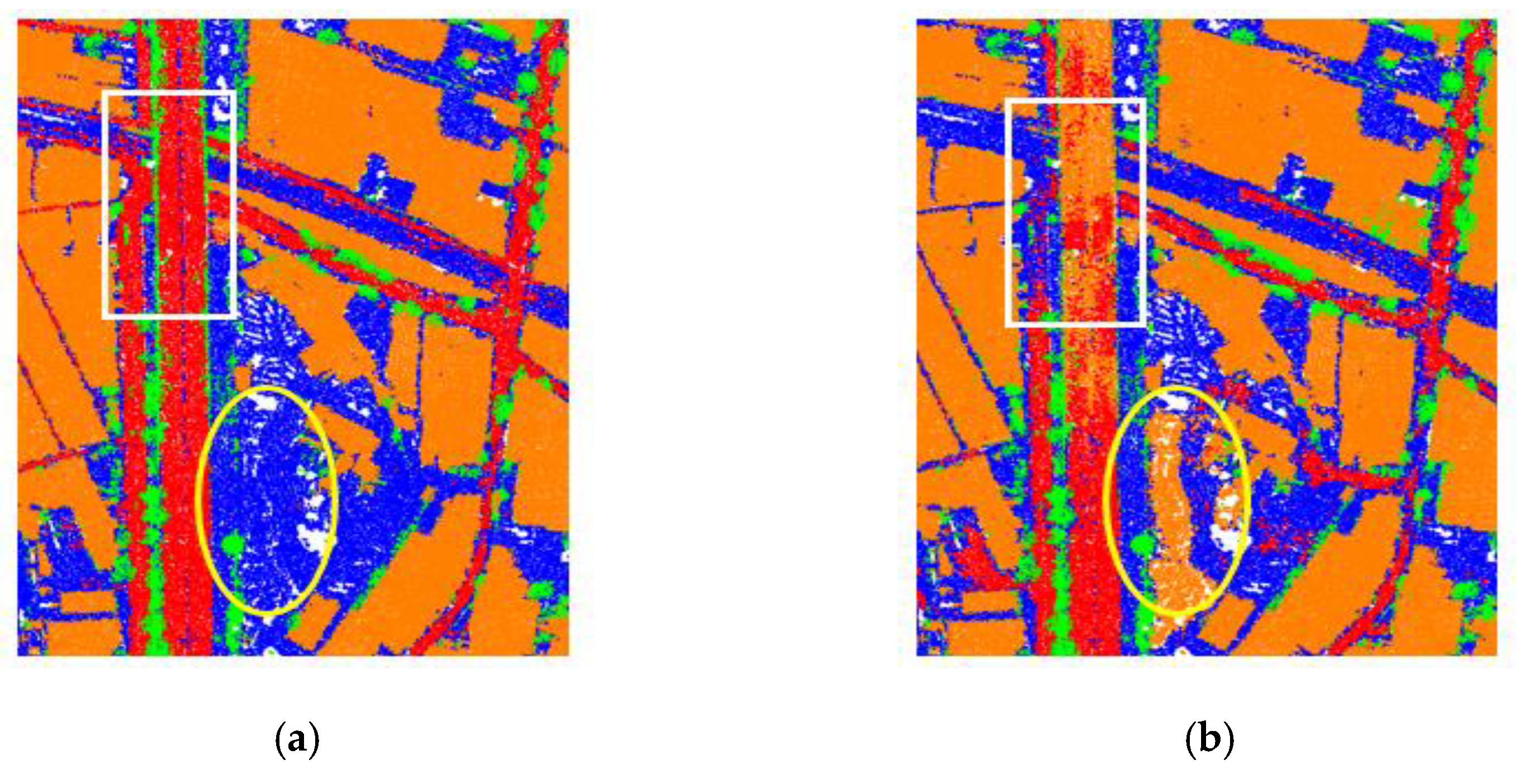
Figure 9.
Comparison of two classification results obtained by two different loss functions. (a) The SCE loss function resulted in more complete roads; (b) using FL resulted in incomplete roads (white rectangle) and it falsely classified a sand pile as building (yellow ellipse).
Figure 9.
Comparison of two classification results obtained by two different loss functions. (a) The SCE loss function resulted in more complete roads; (b) using FL resulted in incomplete roads (white rectangle) and it falsely classified a sand pile as building (yellow ellipse).
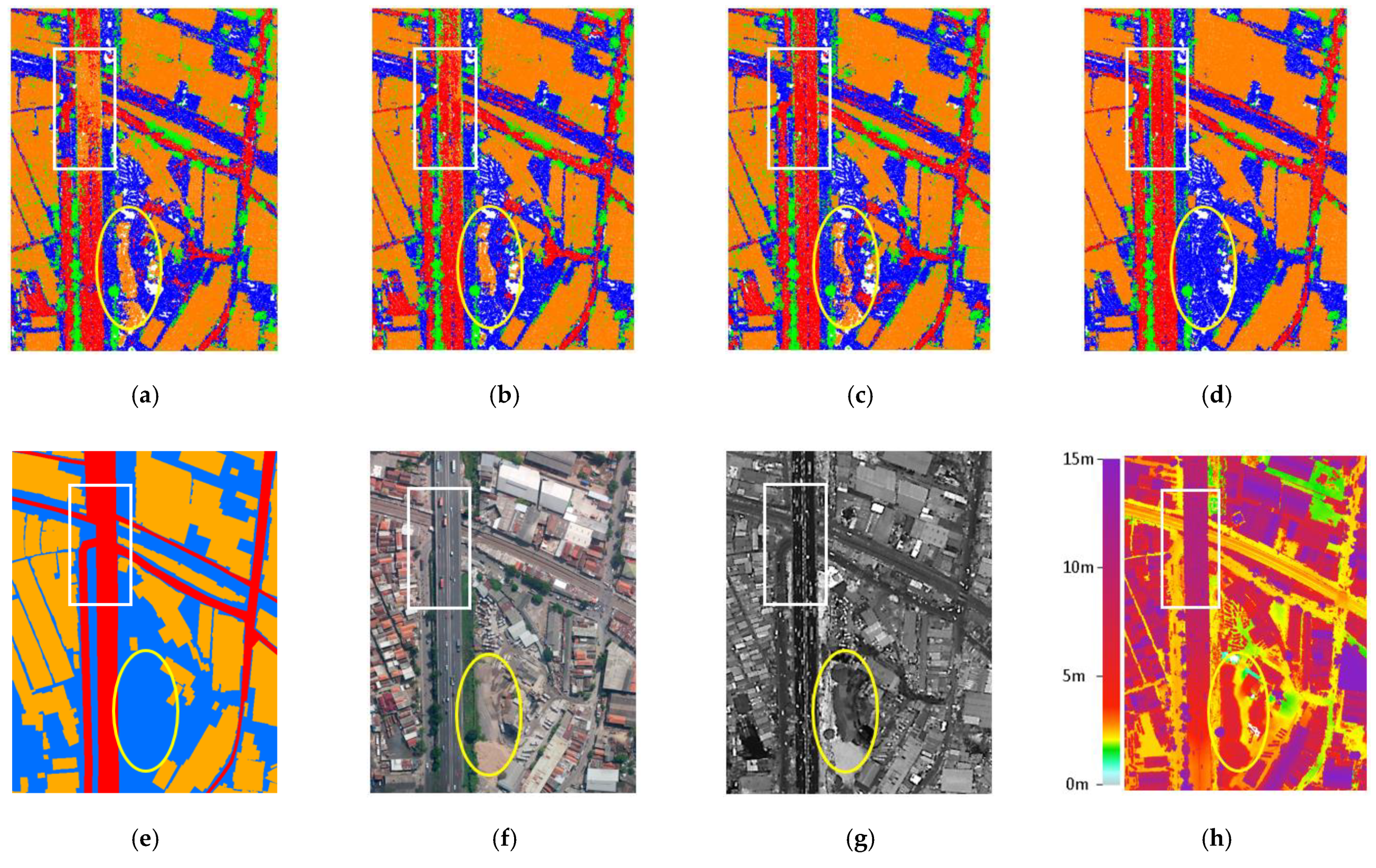
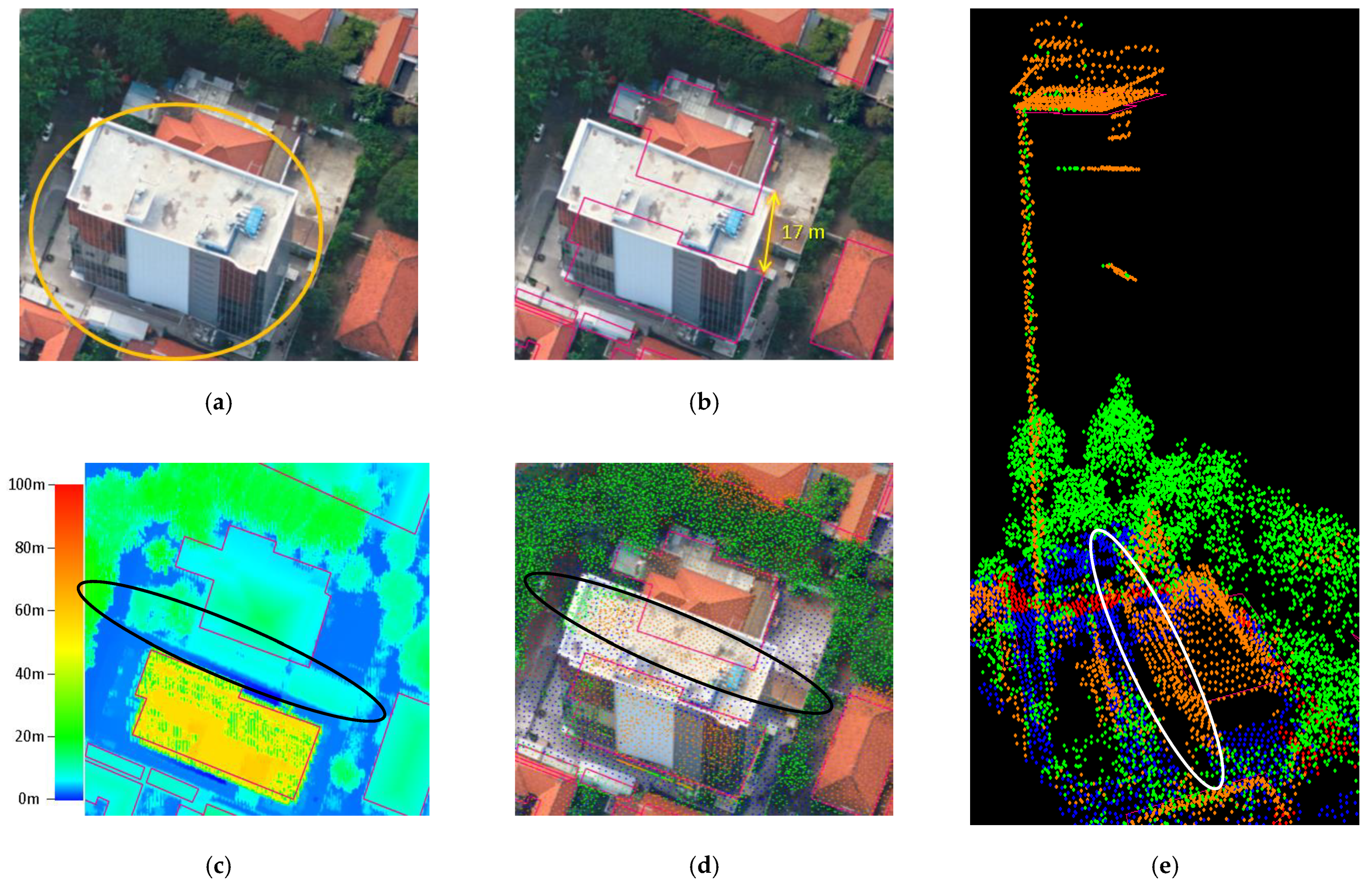
Figure 10.
Relief displacement makes a high-rise building block an adjacent lower building and trees. (a) The leaning of a building (inside orange circle) on an orthophoto indicates relief displacement; (b) the building in the orthophoto has an offset of up to 17 m from the reference polygon (pink outlines); (c) the LiDAR DSM indicates a part of building that does not exist in the base map/reference (inside the black ellipse); (d) DGCNN can detect building points (orange) correctly, including the missing building part (inside the black ellipse); (e) 3D visualization of the classified building points including the missing building part (inside the white ellipse).
Figure 10.
Relief displacement makes a high-rise building block an adjacent lower building and trees. (a) The leaning of a building (inside orange circle) on an orthophoto indicates relief displacement; (b) the building in the orthophoto has an offset of up to 17 m from the reference polygon (pink outlines); (c) the LiDAR DSM indicates a part of building that does not exist in the base map/reference (inside the black ellipse); (d) DGCNN can detect building points (orange) correctly, including the missing building part (inside the black ellipse); (e) 3D visualization of the classified building points including the missing building part (inside the white ellipse).
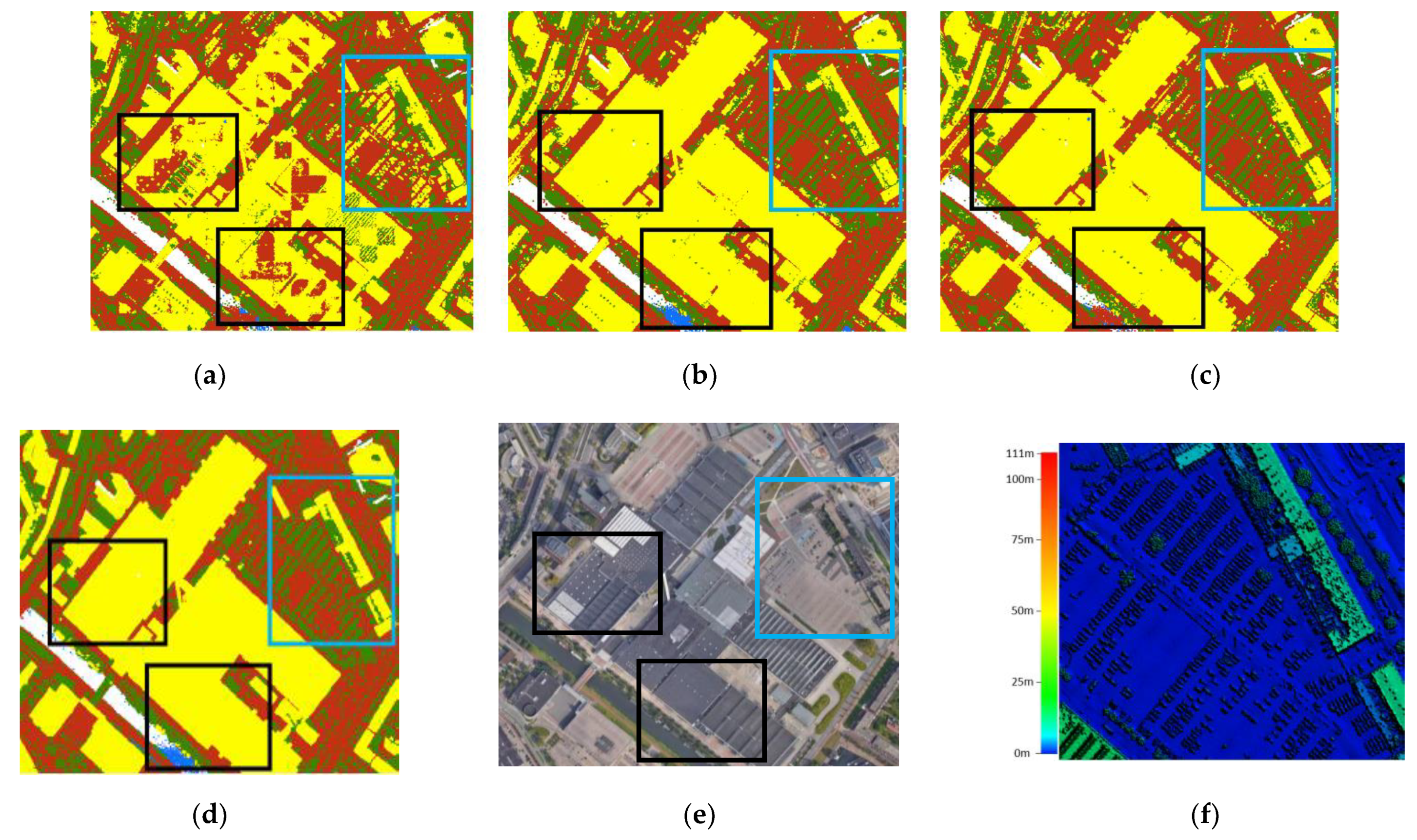
Figure 11.
Visualization of point cloud classification results of a subtile in Area-2 (bare land in brown, buildings in yellow, water in blue, and “others” in green) in comparison with the ground truth. (a) Block size = 30 m, (b) Block size = 50 m, (c) Block size = 70 m, (d) Ground truth, (e) Satellite image ©GoogleMap2020, (f) DSM of the blue box shows that cars are categorized as “others”.
Figure 11.
Visualization of point cloud classification results of a subtile in Area-2 (bare land in brown, buildings in yellow, water in blue, and “others” in green) in comparison with the ground truth. (a) Block size = 30 m, (b) Block size = 50 m, (c) Block size = 70 m, (d) Ground truth, (e) Satellite image ©GoogleMap2020, (f) DSM of the blue box shows that cars are categorized as “others”.
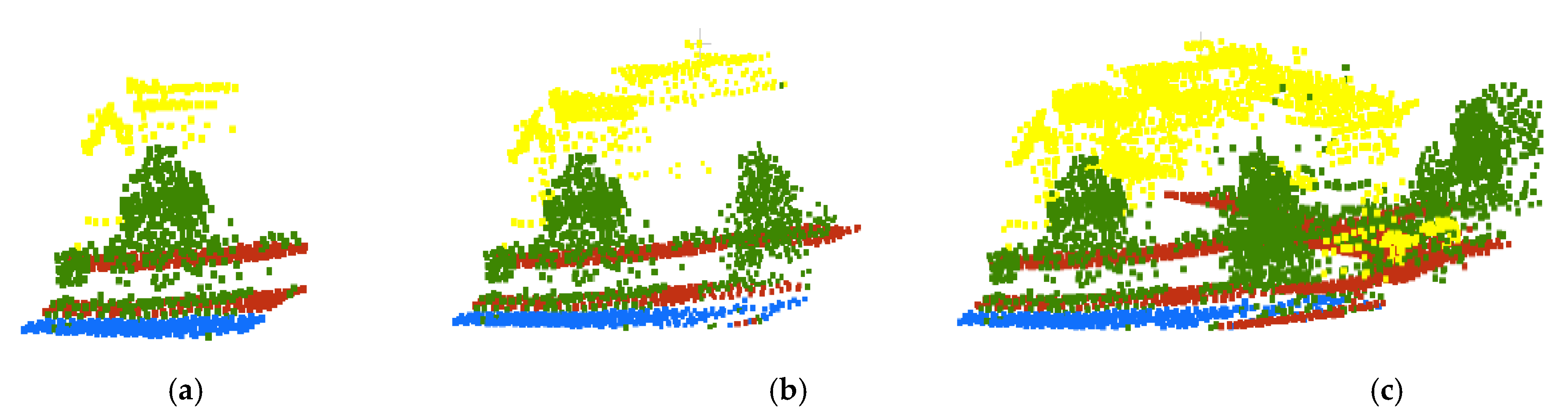
Figure 12.
3D visualization (a–d) and 2D visualization (e–h) of point cloud classification results of different block sizes and ground truths over a subset area of Area-2 (bare land in brown, buildings in yellow, water in blue and “others” in green).
Figure 12.
3D visualization (a–d) and 2D visualization (e–h) of point cloud classification results of different block sizes and ground truths over a subset area of Area-2 (bare land in brown, buildings in yellow, water in blue and “others” in green).
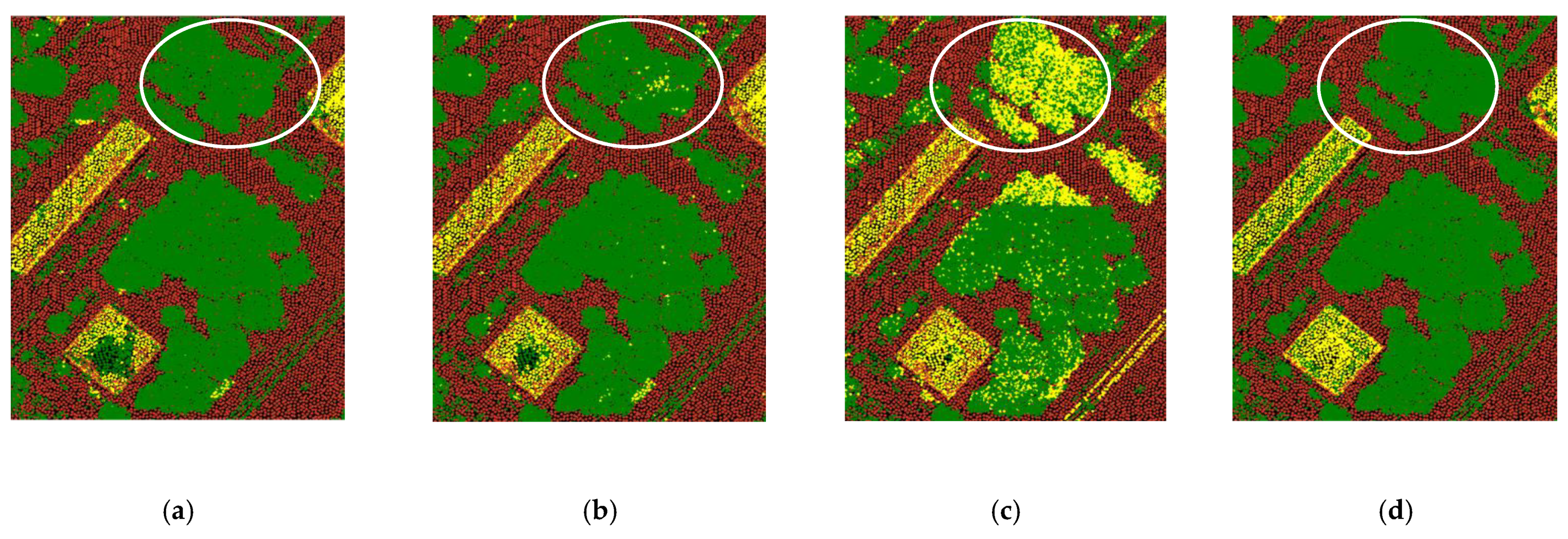
Figure 13.
Comparison of point cloud classification results for different block sizes on a particular highly vegetated area show that bigger block sizes result in more misclassifications on trees (bare land in brown, buildings in yellow, water in blue and “others” (trees) in green). (a) Block size = 30 m, (b) block size = 50 m, (c) block size = 70 m, (d) ground truth.
Figure 13.
Comparison of point cloud classification results for different block sizes on a particular highly vegetated area show that bigger block sizes result in more misclassifications on trees (bare land in brown, buildings in yellow, water in blue and “others” (trees) in green). (a) Block size = 30 m, (b) block size = 50 m, (c) block size = 70 m, (d) ground truth.
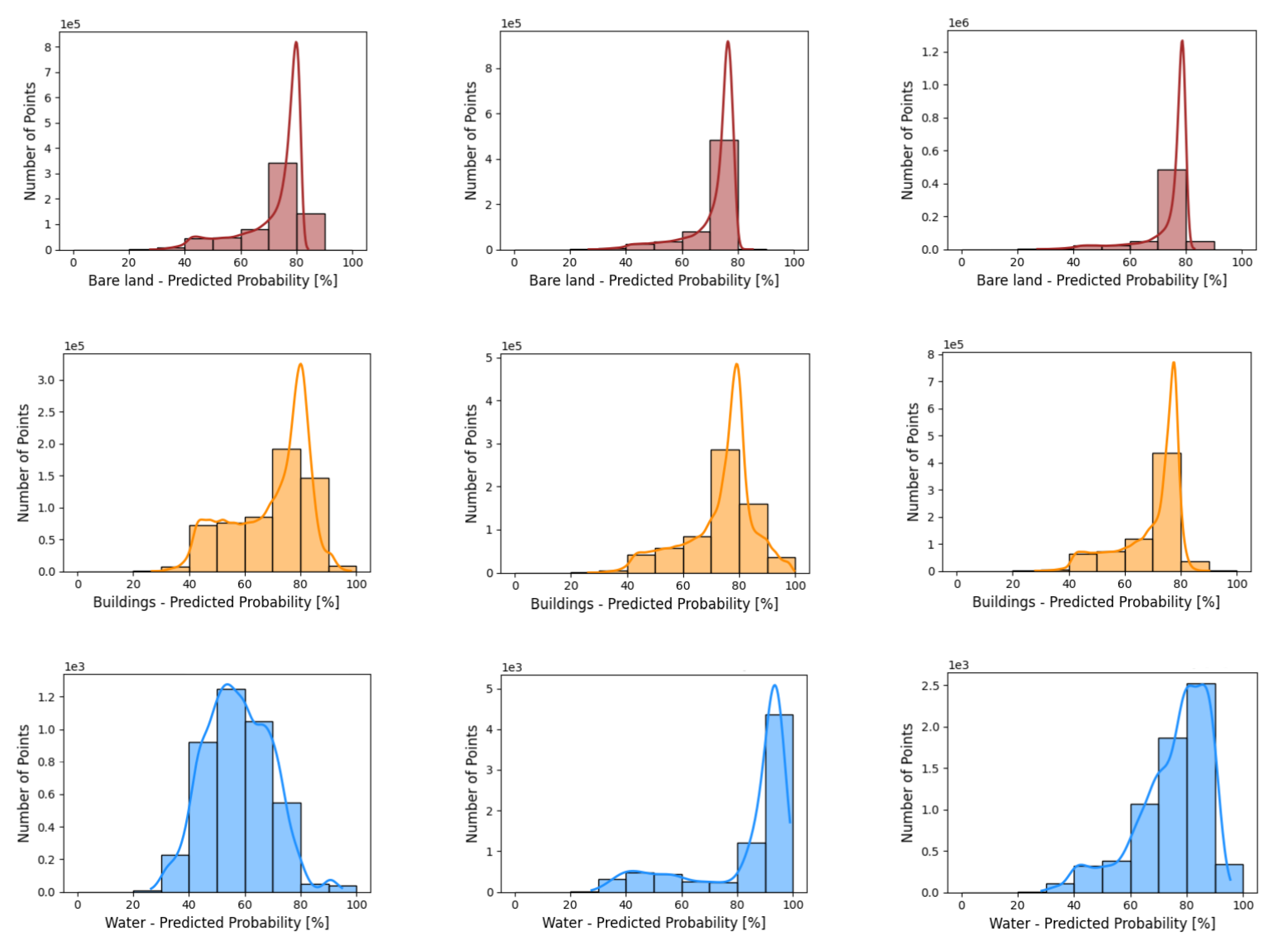
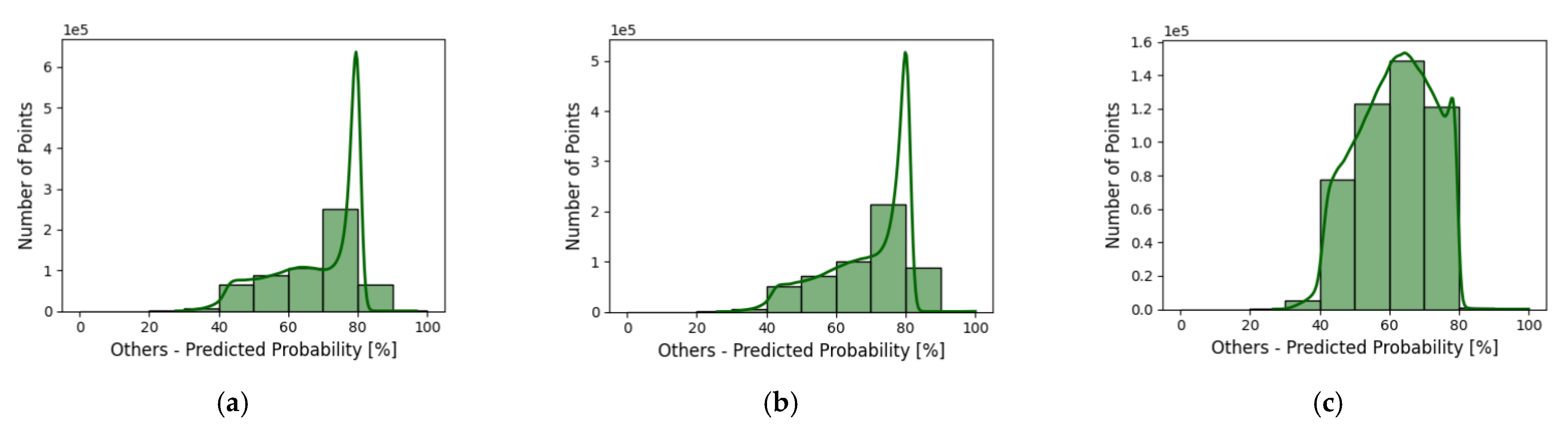
Figure 14.
Per class probability distribution obtained by the network over test area with different block sizes (a–c). From top to bottom: class of bare land (1st row), buildings (2nd row), water (3rd row), and “others” (4th row).
Figure 14.
Per class probability distribution obtained by the network over test area with different block sizes (a–c). From top to bottom: class of bare land (1st row), buildings (2nd row), water (3rd row), and “others” (4th row).
Table 1.
Different input feature combinations.
Table 1.
Different input feature combinations.
| Feature Sets | Set Name | Input Features |
|---|
| Set 1 | RGB | |
| Set 2 | IRnN | |
| Set 3 | RGI | |
| Set 4 | RGBIRnN | |
Table 2.
Overview of AHN3 point clouds (Area-2).
Table 2.
Overview of AHN3 point clouds (Area-2).
| Grid ID | | | Usage |
|---|
| 38FN1 | 47.5 | 25.4 | Training |
| 37EN2 | 50.6 | 28.8 | Training |
| 32CN1 | 87.4 | 27.8 | Training |
| 31HZ2 | 55.9 | 27.4 | Testing |
Table 3.
Point cloud classification results of different feature combinations.
Table 3.
Point cloud classification results of different feature combinations.
| Feature Set | Feature Vector | OA (%) | Avg F1 Score (%) | F1 Score per Class (%) |
|---|
| Bare Land | Trees | Buildings | Roads |
|---|
| Set 1 | | 83.9 | 81.4 | 83.0 | 80.3 | 87.3 | 75.1 |
| Set 2 | | 85.7 | 83.5 | 84.2 | 81.6 | 89.1 | 79.0 |
| Set 3 | | 83.9 | 81.4 | 83.5 | 79.9 | 87.4 | 74.9 |
| Set 4 | | 91.8 | 88.8 | 87.7 | 88.6 | 94.8 | 84.1 |
Table 4.
Per class metrics of point cloud classification of different feature combinations.
Table 4.
Per class metrics of point cloud classification of different feature combinations.
| Feature Set | Bare Land | Trees | Buildings | Roads |
|---|
| Precision | Recall | Precision | Recall | Precision | Recall | Precision | Recall |
|---|
| Set 1 | 76.2% | 91.2% | 81.6% | 79.0% | 87.6% | 87.0% | 83.9% | 68.0% |
| Set 2 | 77.5% | 92.1% | 88.4% | 75.7% | 86.9% | 91.4% | 84.2% | 74.5% |
| Set 3 | 76.3% | 92.1% | 82.3% | 77.7% | 86.9% | 87.8% | 86.1% | 66.2% |
| Set 4 | 85.2% | 90.4% | 93.3% | 84.3% | 93.4% | 96.2% | 86.9% | 81.6% |
Table 5.
Point cloud classification results comparing two different loss functions, Softmax Cross Entropy (SCE) and Focal Loss (FL), on Feature Set 4. Results are quantified in terms of Overall Accuracy (OA) and F1 score.
Table 5.
Point cloud classification results comparing two different loss functions, Softmax Cross Entropy (SCE) and Focal Loss (FL), on Feature Set 4. Results are quantified in terms of Overall Accuracy (OA) and F1 score.
| Loss Function | Feature Vector | OA (%) | F1 Score (%) |
|---|
| Bare Land | Trees | Buildings | Roads |
|---|
| SCE | | 91.8 | 87.7 | 88.6 | 94.8 | 84.1 |
| FL | | 88.1 | 81.8 | 85.3 | 92.7 | 68.6 |
Table 6.
Confusion matrix for results obtained by applying DGCNN on Feature Set 4 when using Focal Loss. The matrix contains numbers of points.
Table 6.
Confusion matrix for results obtained by applying DGCNN on Feature Set 4 when using Focal Loss. The matrix contains numbers of points.
| Feature Set 4 (RGBIRnN) | Reference | Precision |
|---|
| Bare Land | Trees | Buildings | Roads |
|---|
| Prediction | Bare land | 340,132 | 770 | 33,529 | 78,364 | 75.1% |
| Trees | 304 | 553,175 | 105,094 | 42 | 84.0% |
| Building | 18,099 | 83,704 | 1,552,315 | 3367 | 93.7% |
| Road | 20,557 | 97 | 763 | 112,952 | 84.1% |
| Recall | 89.7% | 86.7% | 91.8% | 58.0% | 88.1% |
Table 7.
Area-2 Point cloud classification results for different block sizes.
Table 7.
Area-2 Point cloud classification results for different block sizes.
| Block Size (m) | OA (%) | Avg
F1 Score (%) | F1 Score (%) |
|---|
| Bare Land | Buildings | Water | Others |
|---|
| 30 | 91.7 | 84.8 | 95.2 | 83.1 | 67.8 | 92.9 |
| 50 | 93.3 | 89.7 | 95.8 | 87.7 | 81.1 | 94.0 |
| 70 | 93.0 | 88.05 | 95.8 | 87.3 | 75.5 | 93.6 |
Table 8.
Recap per class metrics of Area-2 point cloud classification for different block sizes.
Table 8.
Recap per class metrics of Area-2 point cloud classification for different block sizes.
| Block Size (m) | Bare Land | Buildings | Water | Others |
|---|
| Precision | Recall | Precision | Recall | Precision | Recall | Precision | Recall |
|---|
| 30 | 92.9% | 97.5% | 92.6% | 75.4% | 81.3% | 58.2% | 90.7% | 95.1% |
| 50 | 94.5% | 97.1% | 90.3% | 85.3% | 81.4% | 80.9% | 93.8% | 94.3% |
| 70 | 97.8% | 94.0% | 86.6% | 87.9% | 66.5% | 87.2% | 92.8% | 94.5% |



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}