
Toward a Yearly Country-Scale CORINE Land-Cover Map without Using Images: A Map Translation Approach


Abstract
:
1. Introduction
- A comprehensive analysis of the land-cover translation task with underlying challenges and potential methodological solutions.
- A novel framework, applied at a national scale, based on Convolutional Neural Networks that simultaneously and contextually translates semantic and spatial concepts from a state-of-the-art remote sensing based land-cover map (OSO, France) to an authoritative product, CORINE Land Cover. This framework paves the way for an annual update of CLC at country-scale.
- An application of our framework to three distinct use cases, in order to assess its performance under operational constraints and its relevance with respect to other conceivable solutions.
2. Related Work
2.1. Problem Description
2.1.1. Semantic Translation:
2.1.2. Spatial Transformation:
2.2. Literature Review
3. Case Study: Generating CLC from a High Resolution Land-Cover Map
3.1. Presentation of OSO and CLC Land-Cover Maps
3.2. OSO to CLC Translation Characteristics
3.3. Land-Cover Translation Scenarios
3.4. Data Set Preparation
4. Deep Learning Based Map Translation
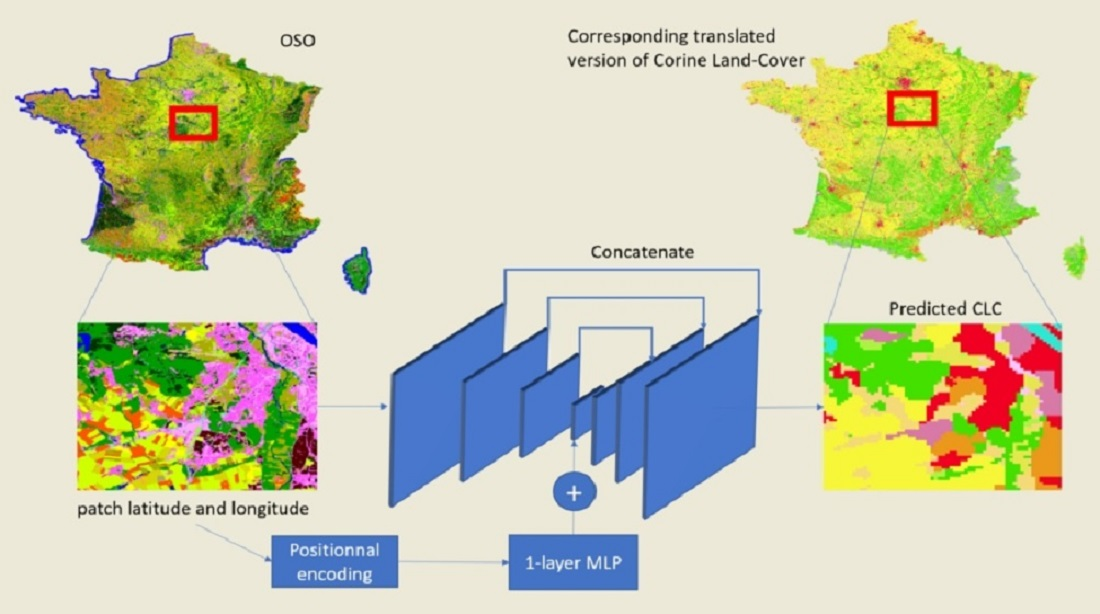
4.1. The Proposed Neural Network Architecture
4.2. Geographical Context
4.3. Loss Function
4.4. Quality Assessment
- General aspect: does the translated map look like the reference one?
- General quality: are any classes under or over-estimated?
- Geometric preservation: is the shape of each predicted structure in the map close to its reference counterpart? Which shapes are harder to translate?
- Two different operators double-checked the CLC official validation dataset while ours includes only one interpretation for each point.
- The official validation is achieved with respect to the CLC initial segmentation (to avoid taking into account geometric errors, separately evaluated), while ours corrects wrong segmentations. Therefore, our interpretation of the same point might differ on edges.
- The official validation is performed on the vector data while ours is performed on a rasterized version, which tends to amplify CLC segmentation errors.
4.5. Comparison with Other Solutions
- “Naive semantic”: we directly translate the OSO nomenclature into the CLC one. For each OSO class, we associate the closest CLC class by our own expert knowledge. Then, we evaluate the differences between the translation and CLC, based on random points sampled over the full spatial extent of the map.
- “Naive down-sampling”: the second method integrates the change of spatial resolution. The spatial resolution of OSO is 10 m, i.e., ten times superior to CLC. Therefore, we convert a set of 10 × 10 pixels of OSO into one CLC class using a majority vote.
- “Auto-semantic”: the third one translates a set of 10 × 10 pixels of OSO into a single CLC class using a Random Forest classifier. The features are the frequencies of each OSO class in each area of interest, in an Entangled Random Forest flavor. Training is performed on the same training set as the neural network in Scenario 1.
5. Experiments and Discussion
5.1. Scenario 1
- Urban Fabric, Arable land, Forest and Open spaces with little or no vegetation achieved a very high F1-score with, respectively, 0.84, 0.89, 0.91, and 0.82 values.
- The class Coastal wetland obtained a high 0.83 F1-score despite being absent in OSO. This is partly explained by the fact we provided a marine water mask to the network helping the contextual translation over such areas.
- Artificial non-agricultural vegetated areas is the class with the lower F1-score (0.3). This can be partly explained by the fact that this class mainly refers to land-use categories (green urban areas/sport and leisure facilities), out of OSO classes. This class could be recovered with contextual information by increasing the size of the receptive field (e.g., stadiums have distinguishable shapes). However, this would be detrimental to a correct shape retrieval for other classes.
- Mine/Dump/Construction sites obtained a 0.5 F1-score despite having no clearly defined semantically close class in OSO. OSO maps usually mix a lot of classes on those areas, giving them a unique and contextually recognizable texture to translate.
- Heterogeneous crops are difficult to predict since the class corresponds to a mix of several OSO classes, explaining their limited F1-score (0.55). Thus, it is not surprising that it performs worse than most classes. Again, it can only be determined through contextual analysis.
- Industrial, commercial and transport units (ICT) are poorly predicted while close semantic correspondences exist with OSO Industrial and commercial units and Road Surfaces. Working with the full 23 OSO labels (decomposition of Summer crops and Winter crops into a more detailed crop nomenclature) fosters a vast uprising of the ICT F1-score from the observed 0.44 to 0.7. Thus, we hypothesize that the observed low value stems from errors in the OSO data (some of the ICT being confused with crops).
5.2. Scenario 2
5.3. Scenario 3
5.4. Comparison with Other Solutions
6. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Data Set

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| OSO Classes | CLC Classes | Observed |
|---|---|---|
| Dense urban | Urban fabric | 87% |
| Sparse urban | 45% | |
| Industrial and commercial | Industrial/Commercial/transport | 14% |
| Roads | 16% | |
| Rapeseeds | Arable land Heterogeneous agricultural areas | 91% |
| Cereals | 90% | |
| Protein Crops | 91% | |
| Soy | 91% | |
| Sunflower | 89% | |
| Maize | 83% | |
| Rice | 96% | |
| Tubers | 96% | |
| Orchards | Permanent crops Heterogeneous agricultural areas | 62% |
| Vineyards | 82% | |
| Pastures | Pastures Heterogeneous agricultural areas Artificial non-agricultural vegetated areas | 69% |
| Lawn | Shrub and/or herbaceous | 39% |
| Shrub | 41% | |
| Broad leaved | Forest Artificial non-agricultural vegetated areas Heterogeneous agricultural areas | 82% |
| Coniferous | 79% | |
| Mineral surfaces | Open space with little or no vegetation Mine/Dump/Construction | 86% |
| Sand | Open space with little or no vegetation | 65% |
| Glaciers and snow | 100% | |
| Water | Inland water Marine Water | 84% |
Appendix B. Scenario 1
Appendix B.1. Agreement between Prediction and CLC 2018

Appendix B.2. Comparison between Predicted Areas
| UBF | ICT | MCD | AVA | ARl | PEC | PAS | HET | FOR | SHV | LNV | IWE | MWE | IWA | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Precision on ground truth (%) | 77 | 70 | 56 | 40 | 89 | 65 | 73 | 55 | 86 | 67 | 88 | 0 | 71 | 73 |
| Recall on ground truth (%) | 85 | 37 | 42 | 26 | 89 | 75 | 69 | 53 | 92 | 61 | 79 | 0 | 85 | 66 |
| area Predicted/ area CLC (%) | 113 | 63 | 72 | 65 | 93 | 113 | 106 | 104 | 101 | 106 | 78 | 36 | 125 | 106 |
Appendix C. Role of the Coordinates Sub-Module
- Some areas are more complex to translate due to difficult classes and or geometry (small parcels of heterogeneous crops for example).
- Some areas might contain more errors in both source and target data.
- Some classes cannot be obtained without knowledge of the geographical situation. For example, the coastline of Corsica Island (South East) is mostly classified as forests in the OSO nomenclature while being considered as shrubs in the CLC nomenclature. The choice of the shrub class is explained by the fact that forests on the Mediterranean sea coastline are usually low covered. Thus, this translation is impossible from OSO without taking the information of the geolocation into account.

References
- Grekousis, G.; Mountrakis, G.; Kavouras, M. An overview of 21 global and 43 regional land-cover mapping products. Int. J. Remote Sens. 2015, 36, 5309–5335. [Google Scholar] [CrossRef]
- Li, Z.; White, J.C.; Wulder, M.A.; Hermosilla, T.; Davidson, A.M.; Comber, A.J. Land cover harmonization using Latent Dirichlet Allocation. Int. J. Geogr. Inf. Sci. 2020, 1–27. [Google Scholar] [CrossRef]
- Homer, C.; Dewitz, J.; Jin, S.; Xian, G.; Costello, C.; Danielson, P.; Gass, L.; Funk, M.; Wickham, J.; Stehman, S.; et al. Conterminous United States land cover change patterns 2001–2016 from the 2016 National Land Cover Database. ISPRS J. Photogramm. Remote Sens. 2020, 162, 184–199. [Google Scholar] [CrossRef]
- Yang, L.; Jin, S.; Danielson, P.; Homer, C.; Gass, L.; Bender, S.M.; Case, A.; Costello, C.; Dewitz, J.; Fry, J.; et al. A new generation of the United States National Land Cover Database: Requirements, research priorities, design, and implementation strategies. ISPRS J. Photogramm. Remote Sens. 2018, 146, 108–123. [Google Scholar] [CrossRef]
- Comber, A.; Fisher, P.; Wadsworth, R. Integrating land-cover data with different ontologies: Identifying change from inconsistency. Int. J. Geogr. Inf. Sci. 2004, 18, 691–708. [Google Scholar] [CrossRef] [Green Version]
- Buchhorn, M.; Lesiv, M.; Tsendbazar, N.E.; Herold, M.; Bertels, L.; Smets, B. Copernicus Global Land Cover Layers—Collection 2. Remote Sens. 2020, 12, 1044. [Google Scholar] [CrossRef] [Green Version]
- Fritz, S.; See, L. Comparison of land cover maps using fuzzy agreement. Int. J. Geogr. Inf. Sci. 2005, 19, 787–807. [Google Scholar] [CrossRef] [Green Version]
- Neumann, K.; Herold, M.; Hartley, A.; Schmullius, C. Comparative assessment of CORINE2000 and GLC2000: Spatial analysis of land cover data for Europe. Int. J. Appl. Earth Obs. Geoinf. 2007, 9, 425–437. [Google Scholar] [CrossRef]
- Ahlqvist, O. Using uncertain conceptual spaces to translate between land cover categories. Int. J. Geogr. Inf. Sci. 2005, 19, 831–857. [Google Scholar] [CrossRef]
- Herold, M.; Woodcock, C.; di Gregorio, A.; Mayaux, P.; Belward, A.; Latham, J.; Schmullius, C. A joint initiative for harmonization and validation of land cover datasets. IEEE Trans. Geosci. Remote Sens. 2006, 44, 1719–1727. [Google Scholar] [CrossRef]
- Pérez-Hoyos, A.; Udías, A.; Rembold, F. Integrating multiple land cover maps through a multi-criteria analysis to improve agricultural monitoring in Africa. Int. J. Appl. Earth Obs. Geoinf. 2020, 88, 102064. [Google Scholar] [CrossRef]
- Fritz, S.; See, L.; McCallum, I.; You, L.; Bun, A.; Moltchanova, E.; Duerauer, M.; Albrecht, F.; Schill, C.; Perger, C.; et al. Mapping global cropland and field size. Glob. Chang. Biol. 2015, 21, 1980–1992. [Google Scholar] [CrossRef] [PubMed]
- Feng, M.; Bai, Y. A global land cover map produced through integrating multi-source datasets. Big Earth Data 2019, 3, 191–219. [Google Scholar] [CrossRef] [Green Version]
- Ruas, A. Map Generalization. In Encyclopedia of GIS; Springer: Berlin/Heidelberg, Germany, 2008; pp. 631–632. [Google Scholar] [CrossRef]
- Yang, H.; Li, S.; Chen, J.; Zhang, X.; Xu, S. The Standardization and Harmonization of Land Cover Classification Systems towards Harmonized Datasets: A Review. ISPRS Int. J. Geo. Inf. 2017, 6, 154. [Google Scholar] [CrossRef] [Green Version]
- Kavouras, M.; Kokla, M.; Tomai, E. Comparing categories among geographic ontologies. Comput. Geosci. 2005, 31, 145–154. [Google Scholar] [CrossRef]
- Köhl, M.; Traub, B.; Päivinen, R. Harmonisation and standardisation in multi-national environmental statistics—mission impossible? Environ. Monit. Assess. 2000, 63, 361–380. [Google Scholar] [CrossRef]
- Jansen, L.J.; Groom, G.; Carrai, G. Land-cover harmonisation and semantic similarity: Some methodological issues. J. Land Use Sci. 2008, 3, 131–160. [Google Scholar] [CrossRef]
- Hu, J.; Ge, Y.; Chen, Y.; Li, D. Super-Resolution Land Cover Mapping Based on Multiscale Spatial Regularization. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 2031–2039. [Google Scholar] [CrossRef]
- Li, X.; Ling, F.; Foody, G.M.; Ge, Y.; Zhang, Y.; Wang, L.; Shi, L.; Li, X.; Du, Y. Spatial–Temporal Super-Resolution Land Cover Mapping With a Local Spatial–Temporal Dependence Model. IEEE Trans. Geosci. Remote Sens. 2019, 57, 4951–4966. [Google Scholar] [CrossRef]
- Malkin, K.; Robinson, C.; Hou, L.; Soobitsky, R.; Czawlytko, J.; Samaras, D.; Saltz, J.; Joppa, L.; Jojic, N. Label Super-Resolution Networks; ICLR: Vienna, Austria, 2019. [Google Scholar]
- Töpfer, F.; Pillewizer, W. The Principles of Selection. Cartogr. J. 1966, 3, 10–16. [Google Scholar] [CrossRef]
- Kilpeläinen, T. Knowledge Acquisition for Generalization Rules. Cartogr. Geogr. Inf. Sci. 2000, 27, 41–50. [Google Scholar] [CrossRef]
- Anderson, J.R.; Hardy, E.E.; Roach, J.T.; Witmer, R.E. A land Use and Land Cover Classification System for Use with Remote Sensor Data; US Government Printing Office: Washington, DC, USA, 1976. [CrossRef] [Green Version]
- Xu, Q. Modelling Semantic Uncertainty of Land Classification System. Ph.D. Thesis, The Hong Kong Polytechnic University, Hong Kong, 2016. [Google Scholar]
- Kosmidou, V.; Petrou, Z.; Bunce, R.G.; Mücher, C.A.; Jongman, R.H.; Bogers, M.M.; Lucas, R.M.; Tomaselli, V.; Blonda, P.; Padoa-Schioppa, E.; et al. Harmonization of the Land Cover Classification System (LCCS) with the General Habitat Categories (GHC) classification system. Ecol. Indic. 2014, 36, 290–300. [Google Scholar] [CrossRef] [Green Version]
- Herold, M.; Mayaux, P.; Woodcock, C.; Baccini, A.; Schmullius, C. Some challenges in global land cover mapping: An assessment of agreement and accuracy in existing 1 km datasets. Remote Sens. Environ. 2008, 112, 2538–2556. [Google Scholar] [CrossRef]
- Paris, C.; Bruzzone, L.; Fernandez-Prieto, D. A Novel Approach to the Unsupervised Update of Land-Cover Maps by Classification of Time Series of Multispectral Images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 4259–4277. [Google Scholar] [CrossRef]
- Adamo, M.; Tarantino, C.; Tomaselli, V.; Kosmidou, V.; Petrou, Z.; Manakos, I.; Lucas, R.M.; Mücher, C.A.; Veronico, G.; Marangi, C.; et al. Expert knowledge for translating land cover/use maps to General Habitat Categories (GHC). Landsc. Ecol. 2014, 29, 1045–1067. [Google Scholar] [CrossRef] [Green Version]
- Al-Mubaid, H.; Nguyen, H. Measuring Semantic Similarity Between Biomedical Concepts Within Multiple Ontologies. IEEE Trans. Syst. Man Cybern. Part C (Appl. Rev.) 2009, 39, 389–398. [Google Scholar] [CrossRef] [Green Version]
- Kavouras, M.; Kokla, M. A method for the formalization and integration of geographical categorizations. Int. J. Geogr. Inf. Sci. 2002, 16, 439–453. [Google Scholar] [CrossRef]
- Rodríguez, M.A.; Egenhofer, M.J.; Rugg, R.D. Assessing Semantic Similarities among Geospatial Feature Class Definitions. In Interoperating Geographic Information Systems; Springer: Berlin, Germany, 1999; pp. 189–202. [Google Scholar] [CrossRef]
- Feng, C.C.; Flewelling, D. Assessment of semantic similarity between land use/land cover classification systems. Comput. Environ. Urban Syst. 2004, 28, 229–246. [Google Scholar] [CrossRef]
- Di Gregorio, A. Land Cover Classification System: Classification Concepts and User Manual: LCCS; Food and Agriculture Organization of the United Nations: Rome, Italy, 2005; Chapter 2; Volume 2, p. 3. [Google Scholar]
- Tomaselli, V.; Dimopoulos, P.; Marangi, C.; Kallimanis, A.S.; Adamo, M.; Tarantino, C.; Panitsa, M.; Terzi, M.; Veronico, G.; Lovergine, F.; et al. Translating land cover/land use classifications to habitat taxonomies for landscape monitoring: A Mediterranean assessment. Landsc. Ecol. 2013, 28, 905–930. [Google Scholar] [CrossRef] [Green Version]
- Arnold, S.; Smith, G.; Hazeu, G.; Kosztra, B.; Perger, C.; Banko, G.; Soukup, T.; Strand, G.H.; Sanz, N.; Bock, M. The EAGLE Concept: A Paradigm Shift in Land Monitoring. In Land Use and Land Cover Semantics; CRC Press: Boca Raton, FL, USA, 2015; pp. 107–144. [Google Scholar] [CrossRef]
- Vancutsem, C.; Marinho, E.; Kayitakire, F.; See, L.; Fritz, S. Harmonizing and Combining Existing Land Cover/Land Use Datasets for Cropland Area Monitoring at the African Continental Scale. Remote Sens. 2012, 5, 19–41. [Google Scholar] [CrossRef] [Green Version]
- Chen, J.; Cao, X.; Peng, S.; Ren, H. Analysis and Applications of GlobeLand30: A Review. ISPRS Int. J. Geo-Inf. 2017, 6, 230. [Google Scholar] [CrossRef] [Green Version]
- Wu, Y.; Schuster, M.; Chen, Z.; Le, Q.V.; Norouzi, M.; Macherey, W.; Krikun, M.; Cao, Y.; Gao, Q.; Macherey, K.; et al. Google’s Neural Machine Translation System: Bridging the Gap Between Human and Machine Translation. CoRR 2016. Available online: http://xxx.lanl.gov/abs/1609.08144 (accessed on 25 January 2021).
- Waser, L.T.; Schwarz, M. Comparison of large-area land cover products with national forest inventories and CORINE land cover in the European Alps. Int. J. Appl. Earth Obs. Geoinf. 2006, 8, 196–207. [Google Scholar] [CrossRef]
- Lu, M.; Wu, W.; You, L.; Chen, D.; Zhang, L.; Yang, P.; Tang, H. A Synergy Cropland of China by Fusing Multiple Existing Maps and Statistics. Sensors 2017, 17, 1613. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhao, M.; Hou, L.; Le, H.; Samaras, D.; Jojic, N.; Fassler, D.; Kurc, T.; Gupta, R.; Malkin, K.; Kenneth, S.; et al. Label Super Resolution with Inter-Instance Loss. arXiv 2020, arXiv:cs.CV/1904.04429. [Google Scholar]
- Courtial, A.; Ayedi, A.E.; Touya, G.; Zhang, X. Exploring the Potential of Deep Learning Segmentation for Mountain Roads Generalisation. ISPRS Int. J. Geo-Inf. 2020, 9, 338. [Google Scholar] [CrossRef]
- Inglada, J.; Vincent, A.; Arias, M.; Tardy, B.; Morin, D.; Rodes, I. Operational High Resolution Land Cover Map Production at the Country Scale Using Satellite Image Time Series. Remote Sens. 2017, 9, 95. [Google Scholar] [CrossRef] [Green Version]
- Heymann, Y. CORINE Land Cover: Technical Guide; European Commission, Directorate-General, Environment, Nuclear Safety and Civil Protection: Luxembourg, 1994. [Google Scholar]
- Bechtel, B.; Demuzere, M.; Stewart, I.D. A Weighted Accuracy Measure for Land Cover Mapping: Comment on Johnson et al. Local Climate Zone (LCZ) Map Accuracy Assessments Should Account for Land Cover Physical Characteristics that Affect the Local Thermal Environment. Remote Sens. 2019, 11, 1769. [Google Scholar] [CrossRef]
- Moiret-Guigand, A.; Jaffrain, G.; Pennec, A.; Dufourmont, H. CLC2018 / CLCC1218 Validation Report; Technical Report; GMES Initial Operations/Copernicus Land Monitoring Services: Villeneuve d’Ascq, France, 2021. [Google Scholar]
- Reinhart, V.; Fonte, C.; Hoffmann, P.; Bechtel, B.; Rechid, D.; Boehner, J. Comparison of ESA climate change initiative land cover to CORINE land cover over Eastern Europe and the Baltic States from a regional climate modeling perspective. Int. J. Appl. Earth Obs. Geoinf. 2021, 94, 102221. [Google Scholar] [CrossRef]
- Arsanjani, J.J.; See, L.; Tayyebi, A. Assessing the suitability of GlobeLand30 for mapping land cover in Germany. Int. J. Digit. Earth 2016, 9, 873–891. [Google Scholar] [CrossRef] [Green Version]
- Vilar, L.; Garrido, J.; Echavarría, P.; Martínez-Vega, J.; Martín, M. Comparative analysis of CORINE and climate change initiative land cover maps in Europe: Implications for wildfire occurrence estimation at regional and local scales. Int. J. Appl. Earth Obs. Geoinf. 2019, 78, 102–117. [Google Scholar] [CrossRef]
- Marcos, D.; Volpi, M.; Kellenberger, B.; Tuia, D. Land cover mapping at very high resolution with rotation equivariant CNNs: Towards small yet accurate models. ISPRS J. Photogramm. Remote Sens. 2018, 145, 96–107. [Google Scholar] [CrossRef] [Green Version]
- Ienco, D.; Interdonato, R.; Gaetano, R.; Ho Tong Minh, D. Combining Sentinel-1 and Sentinel-2 Satellite Image Time Series for land cover mapping via a multi-source deep learning architecture. ISPRS J. Photogramm. Remote Sens. 2019, 158, 11–22. [Google Scholar] [CrossRef]
- Pashaei, M.; Kamangir, H.; Starek, M.J.; Tissot, P. Review and Evaluation of Deep Learning Architectures for Efficient Land Cover Mapping with UAS Hyper-Spatial Imagery: A Case Study Over a Wetland. Remote Sens. 2020, 12, 959. [Google Scholar] [CrossRef] [Green Version]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar] [CrossRef]
- Zazkis, R.; Campbell, S. Prime decomposition: Understanding uniqueness. J. Math. Behav. 1996, 15, 207–218. [Google Scholar] [CrossRef] [Green Version]
- Ardeshir, S.; Zamir, A.R.; Torroella, A.; Shah, M. GIS-Assisted Object Detection and Geospatial Localization; ECCV: Glasgow, UK, 2014; pp. 602–617. [Google Scholar]
- Berg, T.; Liu, J.; Lee, S.W.; Alexander, M.L.; Jacobs, D.W.; Belhumeur, P.N. Birdsnap: Large-Scale Fine-Grained Visual Categorization of Birds; CVPR: Salt Lake City, UT, USA, 2014; pp. 2019–2026. [Google Scholar]
- Jiang, W.; Knight, B.R.; Cornelisen, C.; Barter, P.; Kudela, R. Simplifying Regional Tuning of MODIS Algorithms for Monitoring Chlorophyll-a in Coastal Waters. Front. Mar. Sci. 2017, 4. [Google Scholar] [CrossRef] [Green Version]
- Aodha, O.M.; Cole, E.; Perona, P. Presence-Only Geographical Priors for Fine-Grained Image Classification; ICCV: Montreal, QV, Canada, 2019. [Google Scholar] [CrossRef] [Green Version]
- Chu, G.; Potetz, B.; Wang, W.; Howard, A.; Song, Y.; Brucher, F.; Leung, T.; Adam, H. Geo-Aware Networks for Fine-Grained Recognition. In Proceedings of the ICCV Workshop, Seoul, Korea, 27 October–2 November 2019. [Google Scholar] [CrossRef] [Green Version]
- Liao, S.; Li, X.; Shen, H.T.; Yang, Y.; Du, X. Tag Features for Geo-Aware Image Classification. IEEE Trans. Multimed. 2015, 17, 1058–1067. [Google Scholar] [CrossRef]
- Tang, K.; Paluri, M.; Fei-Fei, L.; Fergus, R.; Bourdev, L. Improving Image Classification with Location Context; ICCV: Montreal, QV, Canada, 2015. [Google Scholar] [CrossRef] [Green Version]
- Sakai, M.; Homma, N.; Gupta, M.; Abe, K. Statistical approximation learning of discontinuous functions using simultaneous recurrent neural networks. In Proceedings of the IEEE Internatinal Symposium on Intelligent Control, Monterey, CA, USA, 27–29 August 2002. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. NIPS. arXiv 2017, arXiv:cs.CL/1706.03762. [Google Scholar]
- Parmar, N.; Vaswani, A.; Uszkoreit, J.; Kaiser, L.; Shazeer, N.; Ku, A.; Tran, D. Image Transformer. In Proceedings of the Machine Learning Research, PMLR, Stockholm, Sweden, 10–15 July 2018; Volume 80, pp. 4055–4064. [Google Scholar]
- Salehi, S.S.M.; Erdogmus, D.; Gholipour, A. Tversky Loss Function for Image Segmentation Using 3D Fully Convolutional Deep Networks. In Machine Learning in Medical Imaging; Springer International Publishing: Cham, Switzerland, 2017; pp. 379–387. [Google Scholar] [CrossRef]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar] [CrossRef] [Green Version]
- Ho, Y.; Wookey, S. The Real-World-Weight Cross-Entropy Loss Function: Modeling the Costs of Mislabeling. IEEE Access 2020, 8, 4806–4813. [Google Scholar] [CrossRef]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection; ICCV: Montreal, QV, Canada, 2017. [Google Scholar]
- Milletari, F.; Navab, N.; Ahmadi, S.A. V-Net: Fully Convolutional Neural Networks for Volumetric Medical Image Segmentation; 3DV; IEEE: Piscatway, NJ, USA, 2016. [Google Scholar] [CrossRef] [Green Version]
- Khened, M.; Kollerathu, V.A.; Krishnamurthi, G. Fully convolutional multi-scale residual DenseNets for cardiac segmentation and automated cardiac diagnosis using ensemble of classifiers. Med. Image Anal. 2019, 51, 21–45. [Google Scholar] [CrossRef] [Green Version]
- Isensee, F.; Petersen, J.; Klein, A.; Zimmerer, D.; Jaeger, P.F.; Kohl, S.; Wasserthal, J.; Koehler, G.; Norajitra, T.; Wirkert, S.; et al. nnU-Net: Self-adapting Framework for U-Net-Based Medical Image Segmentation. In Informatik Aktuell; Springer Fachmedien Wiesbaden: Berlin, Germany, 2019. [Google Scholar] [CrossRef]
- Wong, K.C.L.; Moradi, M.; Tang, H.; Syeda-Mahmood, T. 3D Segmentation with Exponential Logarithmic Loss for Highly Unbalanced Object Sizes. In Medical Image Computing and Computer Assisted Intervention—MICCAI 2018; Springer International Publishing: Cham, Switzerland, 2018. [Google Scholar] [CrossRef]
- Peng, D.; Zhang, Y.; Guan, H. End-to-End Change Detection for High Resolution Satellite Images Using Improved UNet++. Remote Sens. 2019, 11, 1382. [Google Scholar] [CrossRef] [Green Version]
- Russo, F. New Method for Performance Evaluation of Grayscale Image Denoising Filters. IEEE Signal Process. Lett. 2010, 17, 417–420. [Google Scholar] [CrossRef]
- Yu, Q.; Ni, D.; Jiang, Y.; Yan, Y.; An, J.; Sun, T. Universal SAR and optical image registration via a novel SIFT framework based on nonlinear diffusion and a polar spatial-frequency descriptor. ISPRS J. Photogramm. Remote Sens. 2021, 171, 1–17. [Google Scholar] [CrossRef]
- Sattar, F.; Floreby, L.; Salomonsson, G.; Lovstrom, B. Image enhancement based on a nonlinear multiscale method. IEEE Trans. Image Process. 1997, 6, 888–895. [Google Scholar] [CrossRef]












| OSO Level 1 | OSO Level 2 |
|---|---|
| 1. Artificial surfaces | Continuous urban fabric (CUF) |
| Discontinuous urban fabric (DUF) | |
| Industrial and commercial units (ICU) | |
| Road surfaces (RSF) | |
| 2. Agricultural areas | Annual winter crops (AWC) |
| Annual summer crops (ASC) | |
| Intensive Grasslands (IGL) | |
| Orchards (ORC) | |
| Vineyards (VIN) | |
| 3. Forests and semi-natural areas | Broad leaved forests (BLF) |
| Coniferous forests (COF) | |
| Natural Grasslands (NGL) | |
| Woody Moorlands (WOM) | |
| Bare rock (BRO) | |
| Beaches, dunes and sand (BDS) | |
| Glaciers and permanent snow (GPS) | |
| 5. Water bodies | Water (WAT) |
| CLC Level 1 | CLC Level 2 | CLC Level 3 |
|---|---|---|
| 1. Artificial surfaces | 1.1. Urban fabric (UBF) | 1.1.1. Continuous urban fabric |
| 1.1.2. Discontinuous urban fabric | ||
| 1.2. Industrial, commercial and transport units (ICT) | 1.2.1. Industrial or commercial units | |
| 1.2.2. Road and rail networks and associated land | ||
| 1.2.3. Port areas | ||
| 1.2.4. Airports | ||
| 1.3. Mine, dump and construction sites (MCD) | 1.3.1. Mineral extraction sites | |
| 1.3.2. Dump sites | ||
| 1.3.3. Construction sites | ||
| 1.4. Artificial non-agricultural vegetated areas (AVA) | 1.4.1. Green urban areas | |
| 1.4.2. Sport and leisure facilities | ||
| 2. Agricultural areas | 2.1. Arable land (ARL) | 2.1.1. Non-irrigated arable land |
| 2.1.2. Permanently irrigated land | ||
| 2.1.3. Rice fields | ||
| 2.2. Permanent crops (PEC) | 2.2.1. Vineyards | |
| 2.2.2. Fruit trees and berry plantations | ||
| 2.2.3. Olive groves | ||
| 2.3. Pastures (PAS) | 2.3.1. Pastures | |
| 2.4. Heterogeneous agricultural areas (HET) | 2.4.1. Annual crops associated with permanent crops | |
| 2.4.2. Complex cultivation | ||
| 2.4.3. Land principally occupied by agriculture, with significant areas of natural vegetation | ||
| 2.4.4. Agro-forestry areas | ||
| 3. Forests and semi-natural areas | 3.1. Forests (FOR) | 3.1.1. Broad-leaved forest |
| 3.1.2. Coniferous forest | ||
| 3.1.3. Mixed forest | ||
| 3.2. Shrub and/or herbaceous vegetation association (SHV) | 3.2.1. Natural grassland | |
| 3.2.2. Moors and heathland | ||
| 3.2.3. Sclerophyllous vegetation | ||
| 3.2.4. Transitional woodland shrub | ||
| 3.3. Open spaces with little or no vegetation (LNV) | 3.3.1. Beaches, dunes, and sand plains | |
| 3.3.2. Bare rock | ||
| 3.3.3. Sparsely vegetated areas | ||
| 3.3.4. Burnt areas | ||
| 3.3.5. Glaciers and perpetual snow | ||
| 4. Wetlands | 4.1. Inland wetlands (IWE) | 4.1.1. Inland marshes |
| 4.1.2. Peatbogs | ||
| 4.2. Coastal wetlands (CWE) | 4.2.1. Salt marshes | |
| 4.2.2. Salines | ||
| 4.2.3. Intertidal flats | ||
| 5. Water bodies | 5.1. Inland waters (IWA) | 5.1.1. Water courses |
| 5.1.2. Water bodies | ||
| 5.2. Marine waters (MWA) | 5.2.1. Coastal lagoons | |
| 5.2.2. Estuaries | ||
| 5.2.3 Sea and Ocean |
| Classes | UBF | ICT | MCD | AVA | ARL | PEC | PAS | HET | FOR | SHV | LNV | IWE | MWE | IWA | MWA |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Precision | 0.90 | 0.86 | 1.00 | 0.88 | 0.91 | 0.69 | 0.81 | 0.71 | 0.93 | 0.88 | 0.91 | 0.64 | 1.00 | 0.97 | 1.00 |
| Recall | 0.83 | 0.90 | 0.60 | 0.93 | 0.90 | 0.92 | 0.79 | 0.78 | 0.92 | 0.80 | 0.92 | 1.00 | 0.94 | 0.84 | 1.00 |
| F1-score | 0.86 | 0.88 | 0.75 | 0.90 | 0.90 | 0.79 | 0.80 | 0.74 | 0.92 | 0.84 | 0.91 | 0.78 | 0.97 | 0.90 | 1.00 |
| Nb samples | 290 | 61 | 5 | 15 | 1685 | 90 | 916 | 730 | 1581 | 373 | 116 | 7 | 36 | 38 | 79 |
| Naive Semantic | Naive Down-Sampling | Auto Semantic | Scenario 1 No Coordinates | Scenario 1 | Scenario 2 | Scenario 3 | |
|---|---|---|---|---|---|---|---|
| Accuracy | 0.68 | 0.72 | 0.71 | 0.79 | 0.81 | 0.79 | 0.80 |
| kappa | 0.61 | 0.65 | 0.63 | 0.74 | 0.76 | 0.74 | 0.75 |
| EPI (on CLC 2018) | 0.34 | 0.38 | 0.37 | 0.43 | 0.44 | 0.43 | 0.44 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Baudoux, L.; Inglada, J.; Mallet, C. Toward a Yearly Country-Scale CORINE Land-Cover Map without Using Images: A Map Translation Approach. Remote Sens. 2021, 13, 1060. https://doi.org/10.3390/rs13061060
Baudoux L, Inglada J, Mallet C. Toward a Yearly Country-Scale CORINE Land-Cover Map without Using Images: A Map Translation Approach. Remote Sensing. 2021; 13(6):1060. https://doi.org/10.3390/rs13061060
Chicago/Turabian StyleBaudoux, Luc, Jordi Inglada, and Clément Mallet. 2021. "Toward a Yearly Country-Scale CORINE Land-Cover Map without Using Images: A Map Translation Approach" Remote Sensing 13, no. 6: 1060. https://doi.org/10.3390/rs13061060
APA StyleBaudoux, L., Inglada, J., & Mallet, C. (2021). Toward a Yearly Country-Scale CORINE Land-Cover Map without Using Images: A Map Translation Approach. Remote Sensing, 13(6), 1060. https://doi.org/10.3390/rs13061060