3.5.1. Image Cropping and Sampling for Object Detection
The image slices are used in image pyramid methods such as SNIP [
11], SNIPER [
12], and AutoFocus [
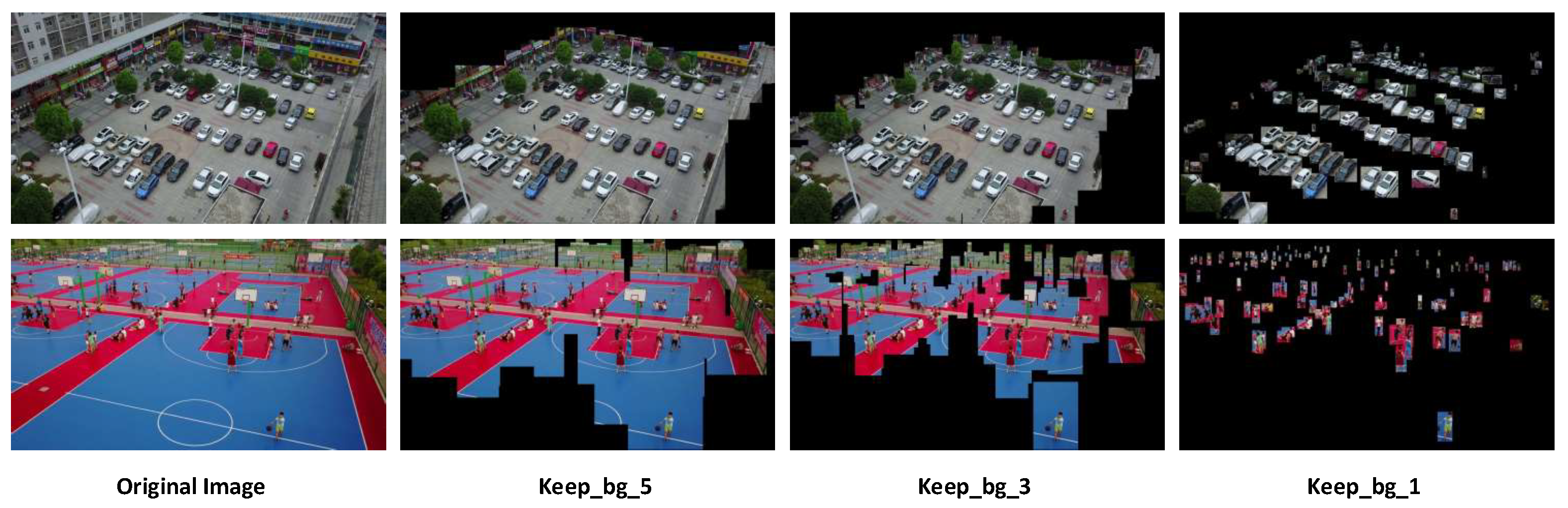
13], which cause the destruction of object detection context. However, feature pyramid networks in this paper use the whole image to train, thus avoiding the same problem. In this section, to study the influences of background context on object detection, we conducted a simple comparative experiment. Based on a RetinaNet trained on the original image, part of the background in the test images was then removed to study the object detection model’s performance changes. Some experimental pictures are shown in
Figure 8.
From the results of
Table 1, it can be seen that after cropping the background area around the target in the original image, it has a significant impact on various metric indicators. As the cropping area decreases, the performance gradually recovers. However, even if it retains five times the background area around the objects (as shown in the second column of
Figure 8) still weakens the detection performance. Therefore, a series of image pyramids based on image region slices nearly destroy the object detection context and cannot achieve optimal performance.
In
Table 2, we conducted an experiment to pointed out the impact of image size changes on detection performance. All images are scaled to a size of
during training the network. Next, in the inference stage, the input images are enlarged or reduced to be tested by the trained model. It can be seen that the mean average accuracy (mAP) of the network trained in the size of
is 0.111, which indicates the overall performance of the detector. As the input images shrink, the mAP gradually decreases, and when the images are enlarged, the mAP increases by 0.032 in absolute value (over 28.8%) at most.
The overall improvement mainly comes from the improvement of medium and small objects. When the image is enlarged, the detection performance of large objects decreases. When the network was retrained at the image size of
, mAP increased by 0.106 (more than 95.4%), and various indicators such as AP_small, AP_medium, and AP_large were significantly improved. Therefore, it can be concluded that compared with the training image size of
, proper image magnification can greatly improve the performance of various indicators of object detection. From the visualized feature map in
Figure 9, it can also be seen that the feature maps of enlarged image have a sharper activation area for small and medium objects, which are easier to achieve higher accuracy in subsequent positioning and recognition steps.
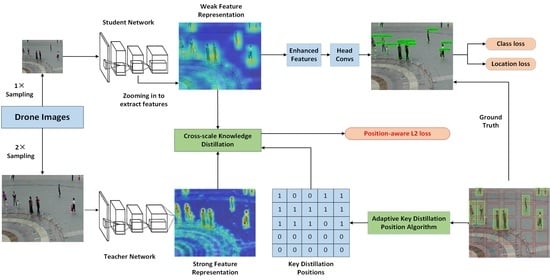
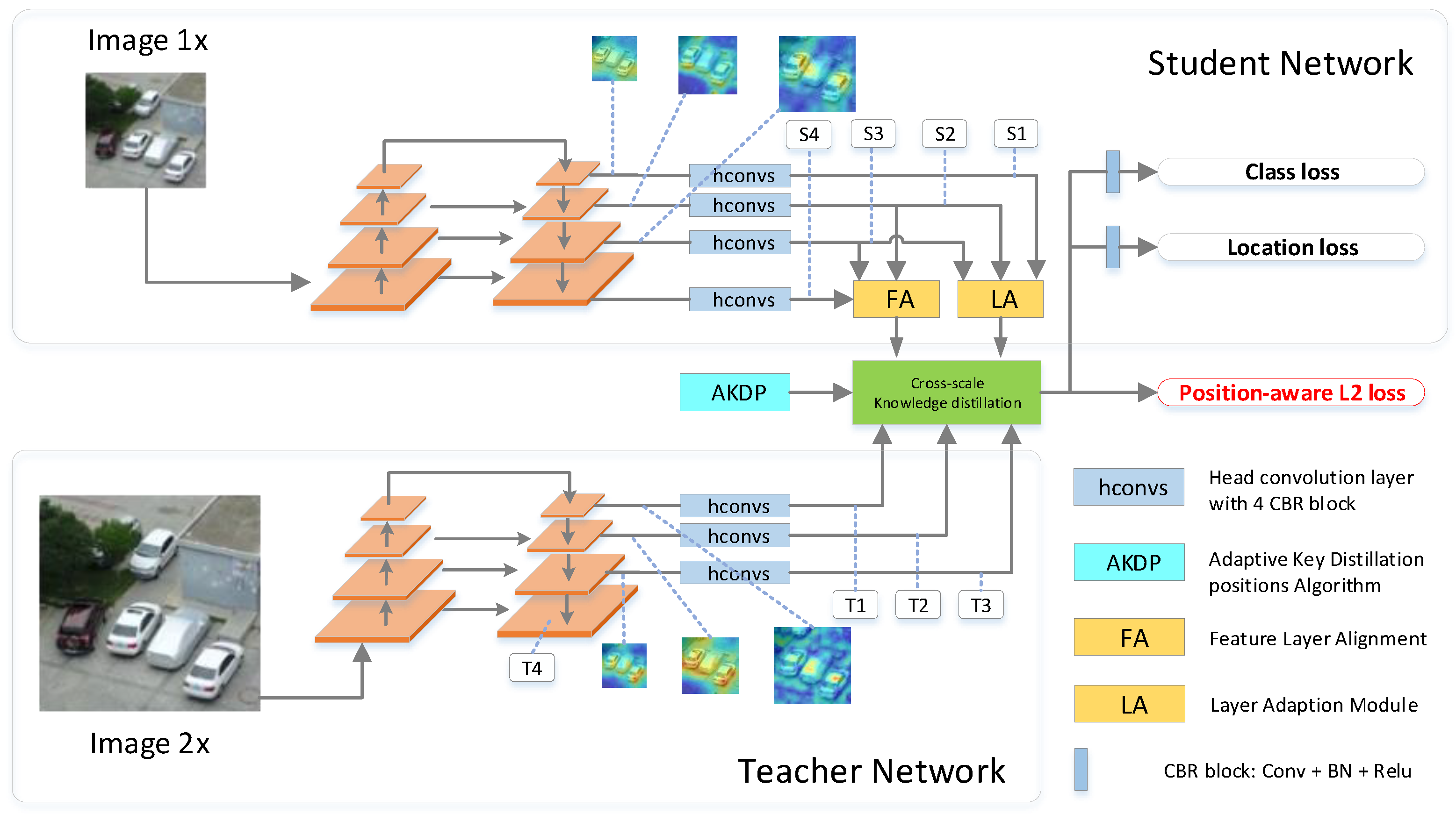
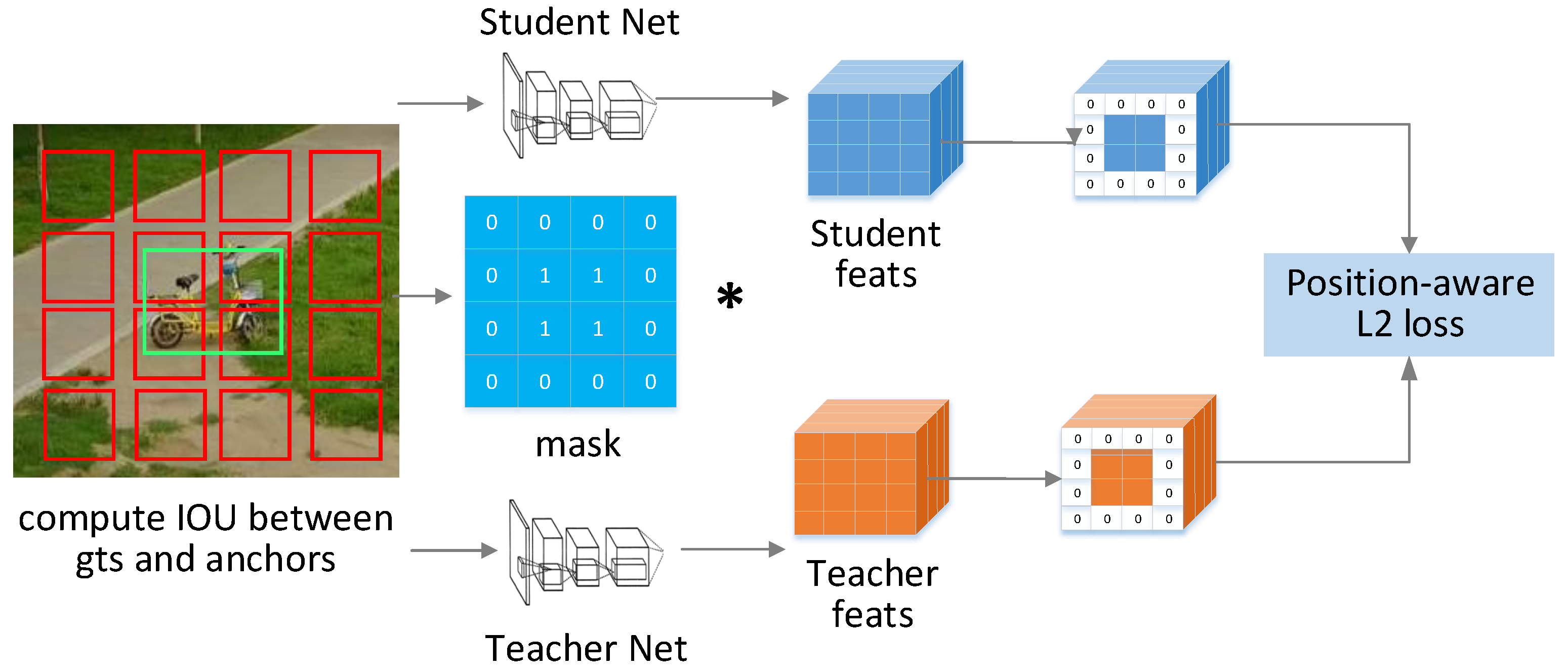
3.5.2. Results of Cross-Scale Knowledge Distillation
We trained the student network (SNet) with the original input images, and trained the teacher network (TNet) with the input of two times the size. In
Table 3, we carried out detailed ablation experiments by gradually adding structures such as layer adaption (LA) and feature layer alignment (FA), and then carried out cross-scale knowledge distillation (CSKD) via adaptive key distillation positions (AKDP) algorithm. For each network with added structure, we compared the changes of calculation and accuracy, in which the amount of calculation was measured by Giga Floating-point Operations Per Second (GFLOPs).
It can be seen in
Table 3 that TNet has the highest performance, but its calculation amount is four times that of SNet, which is difficult to apply in the actual environment. Directly performing knowledge distillation on SNet (subsampling the feature map of the teacher model) can only get a 0.005 (4.5%) mAP improvement, and it can be seen from the
(0.028) that direct distillation without any additional component has no effect on the detection performance of small objects.
After introducing LA, mAP has increased by 0.014 (12.61%) compared with SNet, and has almost doubled (92.85%), indicating that the LA structure we introduced is effective especially for small objects. After the CSKD of the SNet with the layer adaptive structure, the mAP continues to increase to 21.62%, indicating that the introduction structure is conducive to better knowledge distillation. At the same time, by comparing the amount of calculation, it is found that compared with the SNet with 53.3 GFLOPs of calculation consumption, the introduction of LA only brings the calculation of SNet to 58.05 GFLOPs, which only increases by 8.9%.
Because the LA structure only aligns the output size of the two models through upsampling forcibly, the inputs of SNet and TNet are still different, which influences the effectiveness of CSKD. Furthermore, we introduce the FA mechanism to align the feature level, and the mAP is raised from 0.111 to 0.15 (35.13%), and to 0.162 (45.94%) after CSKD, but it also brings a huge increase in computational complexity. This is because the output feature map of the network continues to be convoluted by four layers in RetinaNet, and then the categories and locations of the objects are predicted. The convolution of these four layers leads to a sharp increase in the amount of computation after the introduction of FA. We conducted a comparative experiment using only two-layer convolution (SNet+FA_ThinHead). It is found that after reducing the two-layer convolution, the amount of computation is reduced from 146.09 GFLOPs to 94.56 GFLOPs (35.27%). However, the simplified FA method still increases the mAP from 0.111 to 0.140 (26.13%) and to 0.142 (27.93%) after CSKD, which shows the effectiveness of the FA structure. The amount of computation brought by the FA structure can be optimized by simplifying the subsequent convolution layer of the output feature map. In fact, it can be optimized by the BottleNeck structure used in ResNet [
26] or the depthwise separable convolution used in MobileNet [
43], but it is not the focus of this paper. Here, we only discuss the effectiveness and good optimizability of CSKD based on FA structure.
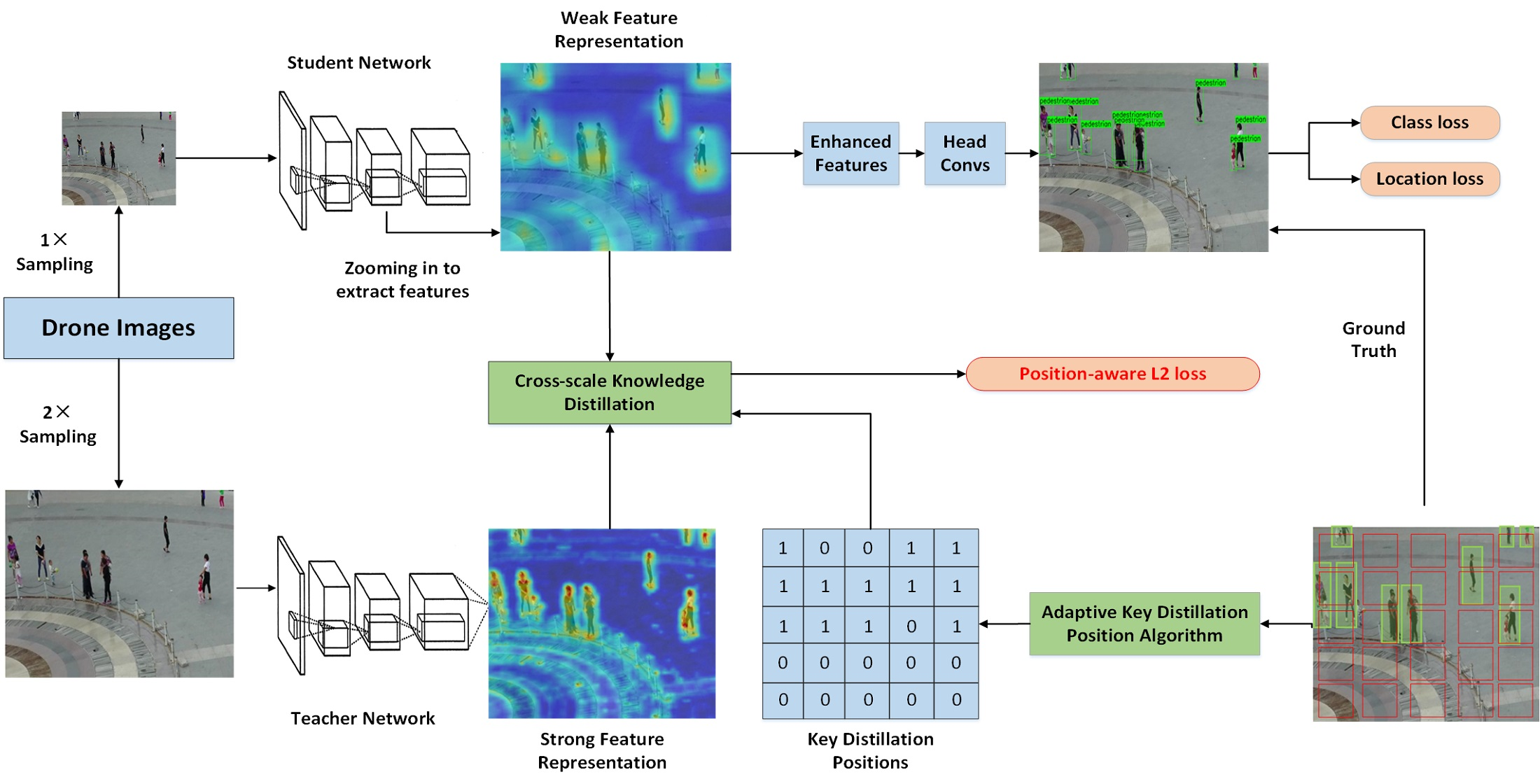
3.5.3. Comparison to the SOTA FPNs
In
Table 4, we compare the large, medium, and small object detection accuracy (AP_S/AP_M/AP_L); recall rate (AR_S/AR_M/AR_L); and mAP with five SOTA feature pyramid methods under unified conditions. Note that Ours-FA_CSKD_th is the same as SNet with FA_ThinHead and CSKD.
Due to the direct use of each feature level for prediction without fusion of shallow and deep features, all metrics of SSD are the worst. Compared with SSD, FPN, PAFPN, NAS-FPN, and Libra-RCNN use different methods for feature fusion, and all indicators have been improved. However, it can be seen that the performance of these methods is very close, which shows that it is difficult to get a more robust feature representation of small objects by relying solely on the feature pyramid fusion.
Based on the most basic feature pyramid structure, we introduced LA, FA, and CSKD strategy, the average detection accuracy has been significantly improved. Because the teacher network in our CSKD architecture is trained by enlarged images, the improvement mainly comes from small and medium-sized objects. It can see that our method exceeds five networks in AP_S, AP_M, AR_S, and AR_M. Among them, LA_CSKD is the lightest version, whose results of mAP, AP_S, AP_M, AR_S, and AR_M are increased by 21.62%, 106.89%, 10.82%, 64.17%, and 12.54%, respectively, compared to SNet.
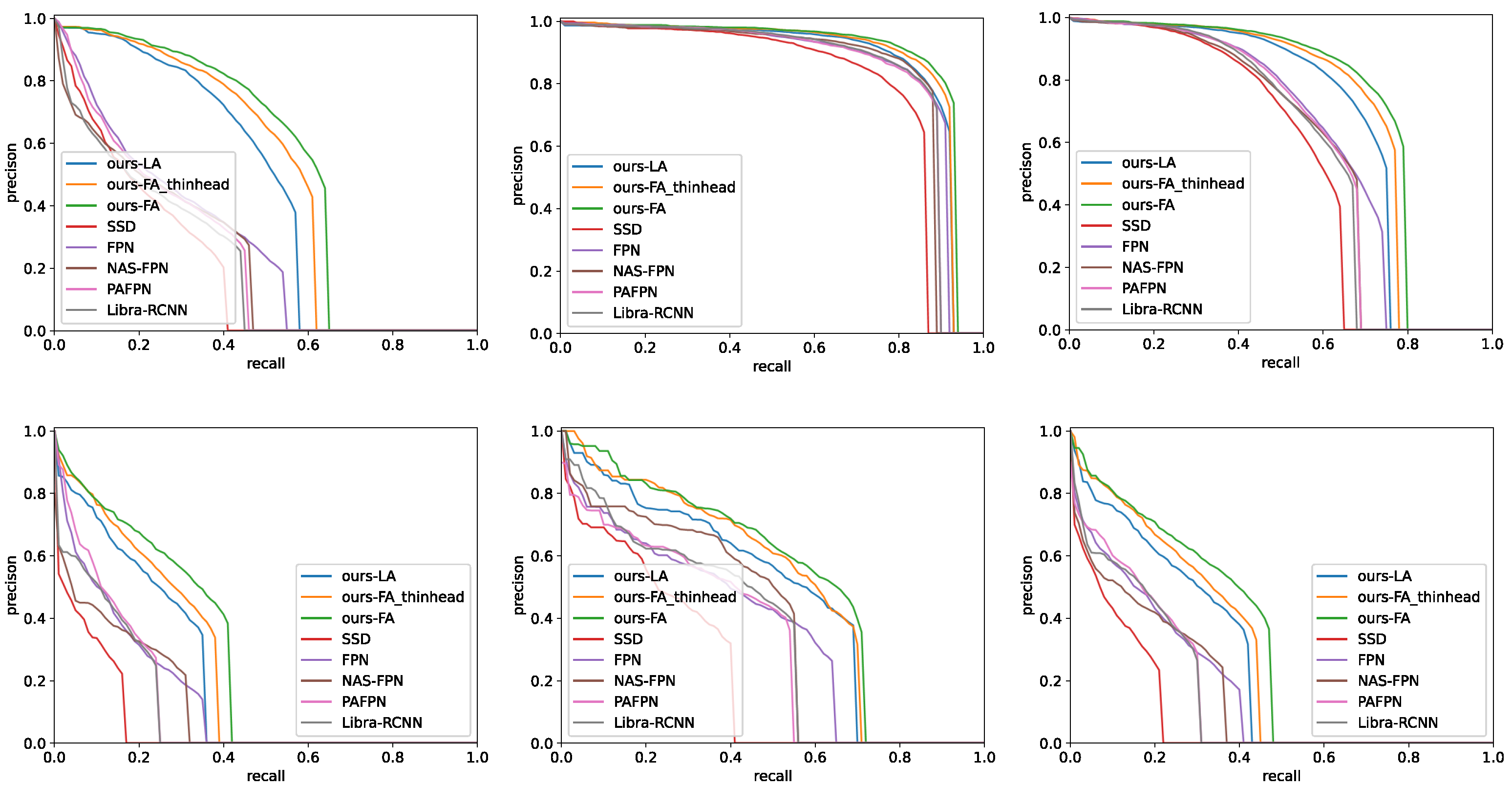
Figure 10 shows the precision–recall (PR) curves of medium, small, and all objects. At the same recall point, the higher the accuracy, the better the model performance. It can be seen that all versions of our method are better than the other five methods in the performance of small and medium objects (
Figure 10a,b), especially the small objects, making the overall performance (
Figure 10c) better than other methods.
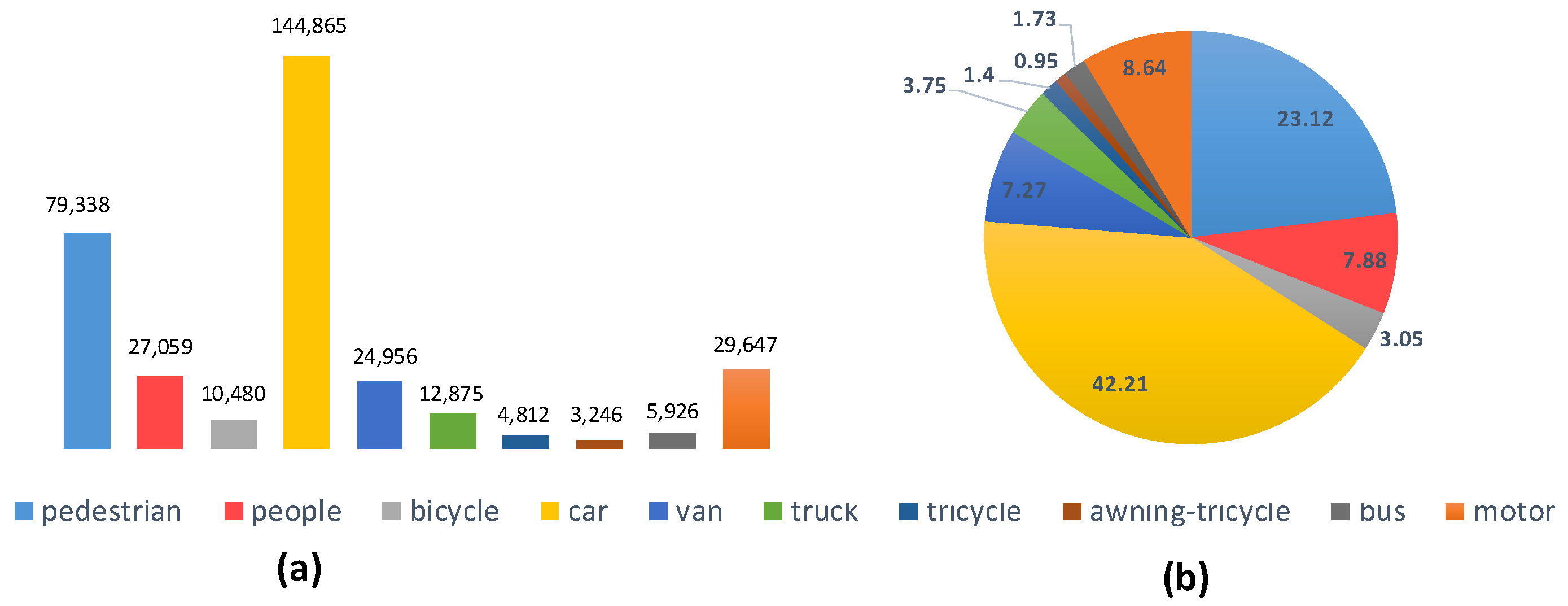
In comparing the average accuracy of each category in
Table 5, we can see that the sample imbalance and size imbalance lead to differences in accuracy. Categories of car, van, and bus with larger sizes have the better average accuracy, while small object categories such as people and pedestrian have worse accuracy. Our proposed approach is superior to the other five mainstream methods in most categories (except truck and awning-tricycle).
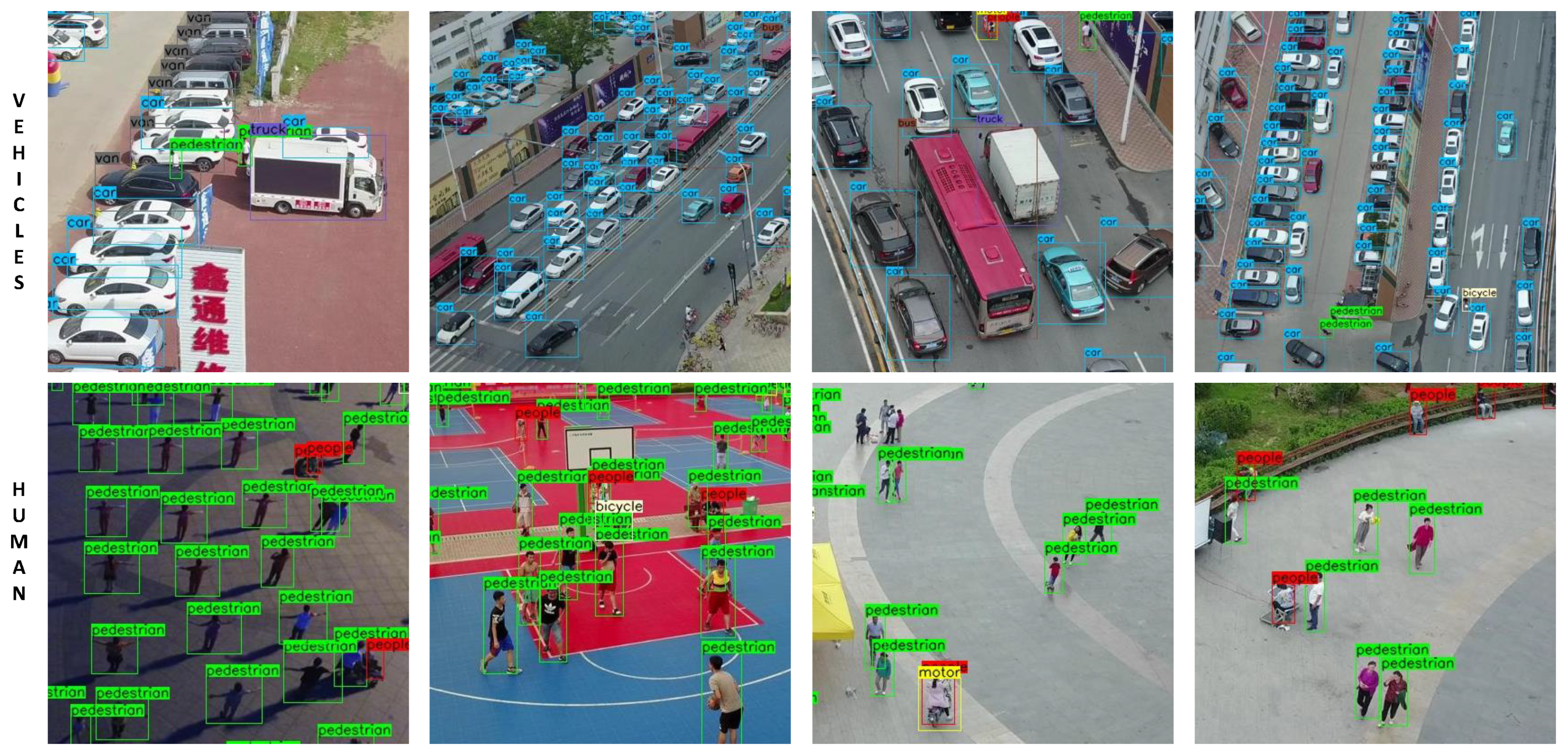
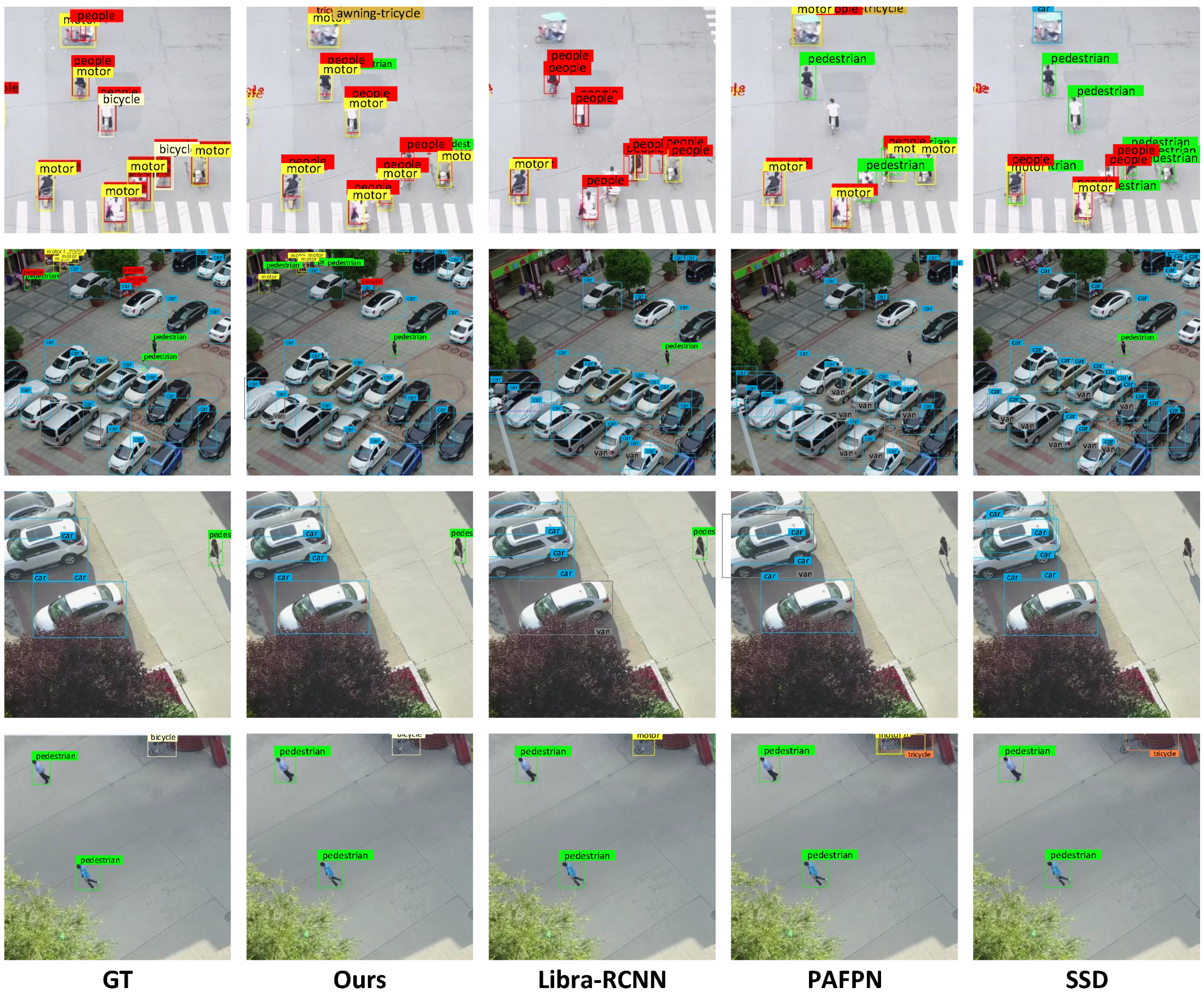
The first row in
Figure 11 shows a difficult situation in the visdrone2018 dataset. People sitting in motors are highly overlapping, but they need to be accurately divided into two categories: people (red) and motor (yellow). It can be seen that Libra-RCNN, PAFPN and SSD almost all missed or misclassified these two categories of objects, while our results have only a few errors. Among them, the green border is a pedestrian. The difference between a pedestrian and a person is that the former is standing and the latter is sitting.
In the second row, several motors and pedestrians in the image have only weak feature representation. Our ZoomInNet successfully detected some of them, while other methods missed all of them. The third and fourth rows are similar, our method always outperforms other methods in detecting small objects.
3.5.4. Comparison to the SOTAs in VisDrone-DET2019
Note that the small detection accuracy is still low in this paper and mAPs of our method are lower than ones of these SOTA reported in VisDrone-DET2019 [
44]. In this section, we conducted experiments to explain the “low accuracy” in this paper. The main reason is that the experiments above are conducted under uniform conditions without additional accessories.
In fact, both VisDrone-DET2018 [
10] and VisDrone-DET2019 are data challenges, which means that any technique or trick can be used for improving the results. Such tricks include data augmentation, deeper backbone network, larger image size and technique in training or inference stages. For example, among the 33 methods represented by A.1–A.33 in VisDrone-DET2019, backbones of ResNet-101 [
26], ResNeXt-101 [
45], and ResNet-50 [
26] are used in methods A.1–A.3, respectively; a guide anchor [
46] is used in A.2 for training; Test time augmentation (TTA) and Soft-NMS [
47] are used for inference in A.13.
In
Table 6, we show that with several tricks, even the baseline of our method can achieve results similar to those reported in VisDrone-DET2019.
It can be seen that with some tricks, the mAP results of our baseline have greatly improved from 11.1% to 28.0%, while the AP_S also rise from 2.8% to 19.2%. Among the six compared methods, DPNet-ensemble (A.15) has the best mAP in [
44]. Without any efficiency optimization, our method roughly uses some tricks, but still achieves a moderate speed with a TITAN RTX 24G. However, the speed of our baseline decreased from 27.8 to 3.9 FPS. Therefore, methods with many tricks in [
44] are hard to apply in real environment. Furthermore, while comparing CSKD with FPNs, the tricks such as multi-scale training or inference become interfering factors. Base on the above analysis, we eliminated all the tricks used in [
44].
To compare the methods in VisDrone-DET2019, we must implement them under unified framework and experimental conditions. Therefore, the detection models mainly involved in 33 algorithms in VisDrone-DET2019 are counted as shown in
Table 7.
According to the statistical results in
Table 7, the number of occurrences of top 6 detectors accounted for 83.3% among the 12 detectors, where RetinaNet and Libra-RCNN have already compared in
Section 3.5.3. For CenterNet, it has no pre-implemented model in the MMDetection [
42] framework. Therefore, we conducted further comparison with Cascade-RCNN, Faster RCNN (FR) with HRNet and Faster RCNN with ResNet-50. The results are shown in
Table 8.
It can be seen that under uniform conditions, our method is better than the three most commonly used methods in [
44] in AP and AR of small objects. Our results on medium and large objects are slightly worse than other methods. This is because we use the small-scale images to train the student network and the large-scale images to train the teacher network. Therefore, what we improve is the detection performance of small objects, but maybe the detection performance of medium and large objects can also be improved with CSKD, which is also the direction of our future work.
3.5.5. Comparison to Fine-Tuning Method
In this paper, we proposed to use CSKD for utilizing the advantages of network trained by large-scale images, while fine-tuning is the other method can achieve the similar purpose. Therefore, in this section, we conducted comparison to the fine-tuning method for further demonstration of the effectiveness of CSKD. To explore it, we pre-trained the baseline using double size images (1024 × 1024) for 20 epochs, which is the same as TNet in
Table 3, and then fine-tuned the network using the original size images (512 × 512) for 10 epochs. There are two ways to set the fine-tune learning rate (LR) in our experiments:
The first setting way considers keeping the LR consistent with the pre-training to keep the initial fine-tuning smooth, and after a few epochs, it becomes smaller to help the model converge to a higher accuracy. The second setting method considers the large difference in image input between pre-training and fine-tuning. In the initial stage of fine-tuning, a smaller learning rate is required to avoid shocks. The results are shown in
Table 9.
With the network pretrained with image size of 1024 × 1024, the mAP obtained by inference under image size of 512 × 512 is 11.7%, which drops a lot compared to inference result under image size of 1024 × 1024 (21.7%), but is still better than the network with image size of 512 × 512 for both training and inference (11.1%). This shows that pre-training at a large size is helpful to improve mAP.
The fine-tuning methods with two LR setting ways can slightly improve the results of mAP, while have almost no influences on the average accuracy and recall rate of small objects. This is consistent with the ablation study in
Table 3. The experiment “SNet + CSKD” shows that without changing the model structure, CSKD also obtained weak effect on mAP and AP_S. After the introduction of LA, the mAP and AP_S have been significantly improved.
In this paper, we aim to use cross-scale models for improving the performance of small objects, and the two most critical points are that
For the fine-tuning method, the huge change in the image size leads to the huge change in the features, which in turn leads to a sharp drop in the model performance during the fine-tuning process. This is because the cross-scale fine-tuning lacks supervised guidance, and the SSM cannot retain the knowledge learned in the LSM. In contrast, our method uses knowledge distillation to play the guiding role of LSM to SSM, and at the same time maintains cross-scale knowledge through two improved structures of LA and FA, which achieve better results.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}