
A High-Dimensional Indexing Model for Multi-Source Remote Sensing Big Data

Abstract
:1. Introduction
1.1. Research Background
1.2. Paper Organization
2. Materials and Methods
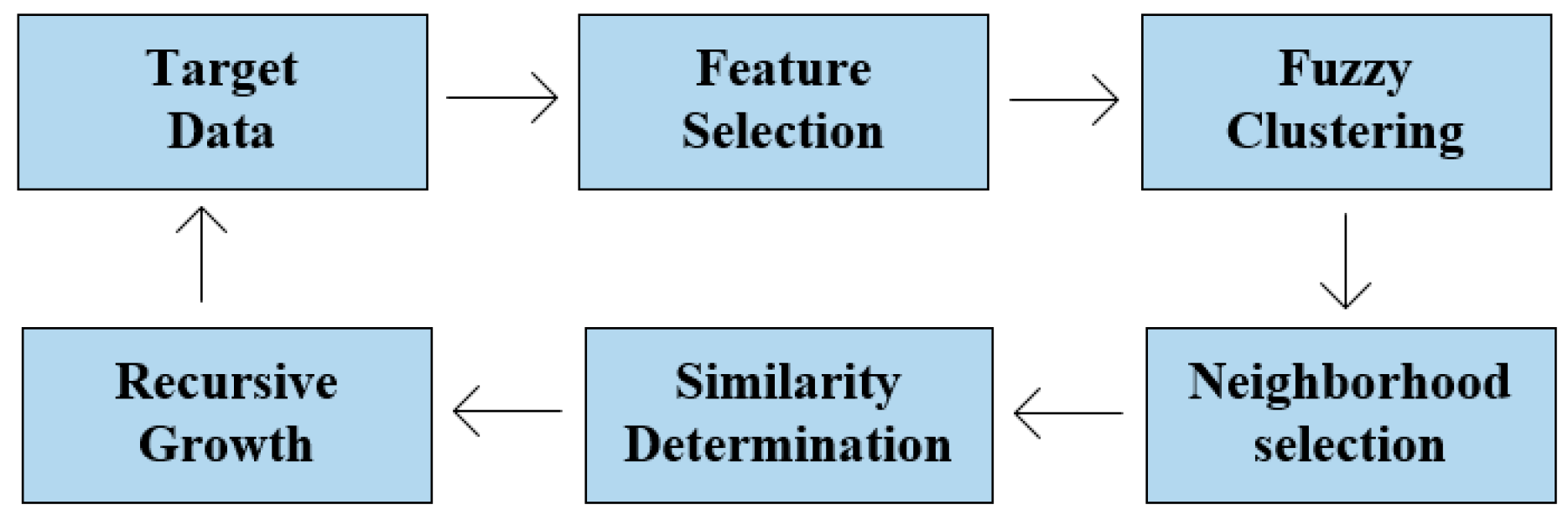
2.1. The Outline of Hierarchical Multi-Dimensional Hybrid Indexing Model
2.1.1. Related Work
2.1.2. HierarchicalMulti-Dimensional Hybrid Indexing Model
- Quadtree [23]. The data structure of the quadtree is to store the data with two-dimensional keys in a tree, and divide the space plan into different levels of tree structure. For evenly distributed spatial data objects, the quadtree structure usually has relatively high spatial data insertion and query efficiency.
- Fuzzy C-Means (FCM) [38]. Clustering is to divide a group of physical or abstract objects into several groups according to the degree of similarity between them. FCM is a typical fuzzy clustering algorithm, whose basic idea is to use the degree of membership to restrict the degree to which each data sample belongs to a certain class to complete data classification [39,40,41,42].
- Regional growth [45,46]. Region growth is a region-based image segmentation technology, which is a process of combining pixels or sub-regions into larger regions according to predefined growth criteria. The basic method of region growth is to start from a set of “seed points“, which neighbor pixels with properties similar to the pre-defined seeds are added to each seed to form these growth regions [46,47].
2.2. Construction of Hierarchical Multi-Dimensional Hybrid Indexing Model
2.2.1. Remote Sensing Data Grid
- Integration across Spatial Resolutions. Refer to the traditional pyramid technology, the remote sensing data grid is the data grid model based on the spatial pyramid, which breaks up data according to uniform rules, associates spatio-temporal information is with data grids of different scales, and optimize data structure using data spatio-temporal attributes.
- Integration across Time Resolutions. We extract remote sensing data in the time dimension by establishing time slices of different thicknesses in the time dimension. The time attribute of the data is decomposed according to the smallest time granularity, and then it is aggregated step by step from low to high resolution in the time dimension to form time series of different scales.
- Integration across Data Structures. From the two aspects, remote sensing data description and remote sensing data content, we carry out data integration between unstructured and structured remote sensing data. In terms of remote sensing data description, we analyze the characteristics of remote sensing data to define a unified meta-information model, which can provide a comprehensive and unified standardized description of remote sensing data. A metadata model can include content such as data identification, data source, geographic location, shooting time, storage path, spatial coordinate reference system, and so on. We use relational databases to store meta-information extracted from remote sensing data. In terms of remote sensing data content integration, we realize unified storage of remote sensing data based on NoSQL database, storing remote sensing data of different structures by expanding different columns. Based on the grid model, the correlation between data is established in spatial and time dimensions, which is defined in the key of remote sensing data retrieval, and the remote sensing data with different structures can be extracted at one time based on a unified data key.
- Associate spatio-temporal information on the basis of the pyramidal grid hierarchy, and establish the correspondence between remote sensing data and grid models according to the spatial resolution and geographic scope of the remote sensing data.
- Copy the remote sensing data to the relevant position in the grid based on the correspondence to obtain a grid generated from the remote sensing data.
- Use resampling algorithm (such as bilinear interpolation algorithm) to down sampling remote sensing data step by step to obtain grid data at lower resolution levels, thereby obtaining a complete remote sensing data pyramid.
- Sample multi-source remote sensing data on a unified remote sensing data pyramid hierarchy to form a hierarchical structure, realize multi-scale management of data, and obtain a global remote sensing data pyramid.
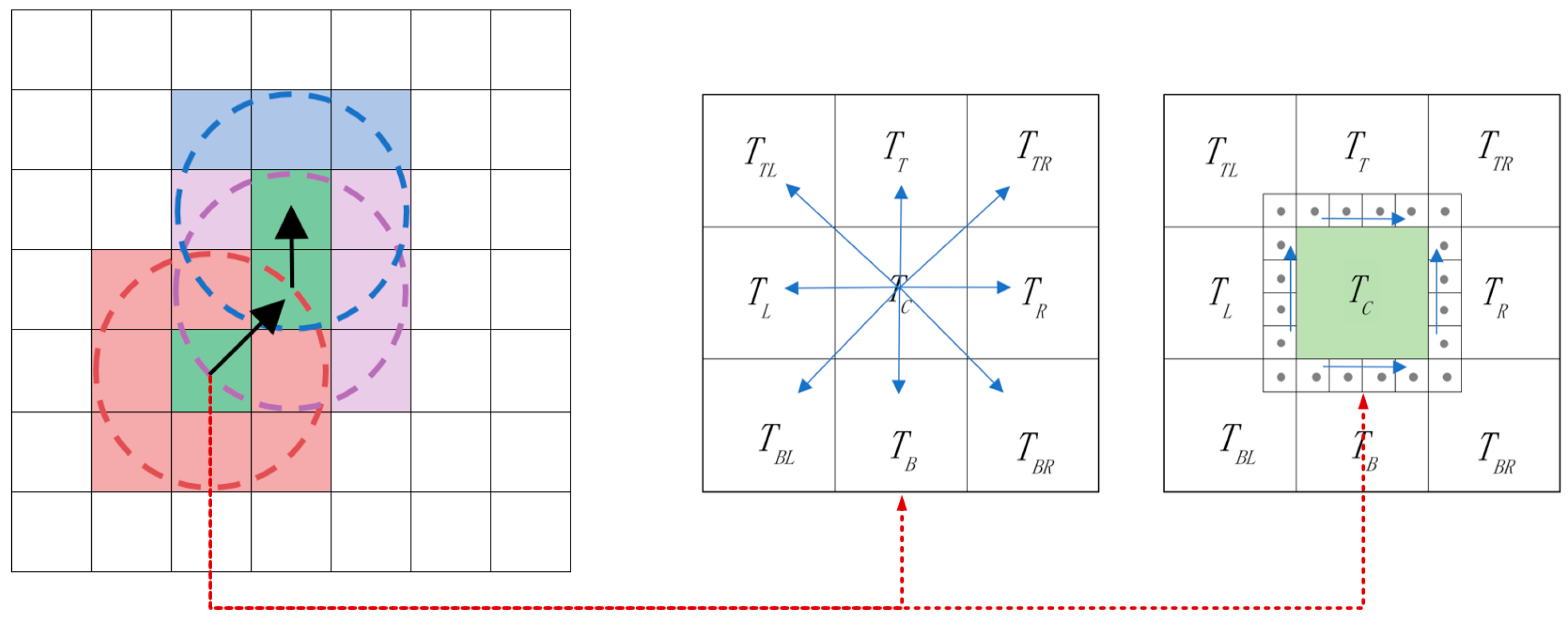
2.2.2. Clustering Optimization Based on Fusion of Spatio-Temporal Feature
- Judgment Criterion of Neighborhood Similarity
- Grid Area Search Based on 8-Neighborhoods
- Judge the similarity between the grid in 8-neighborhoods and the seed grid to determine whether they belong to the same dataset.
- If it belongs to the same dataset, then the 8-neighborhood grid similarity judgment of this neighborhood grid will be performed; otherwise, the search will not continue to the surroundings.
- When judging the similarity of image features in the neighborhood search, it is necessary to judge the cells in the grid from large to small to determine whether they belong to the same dataset.
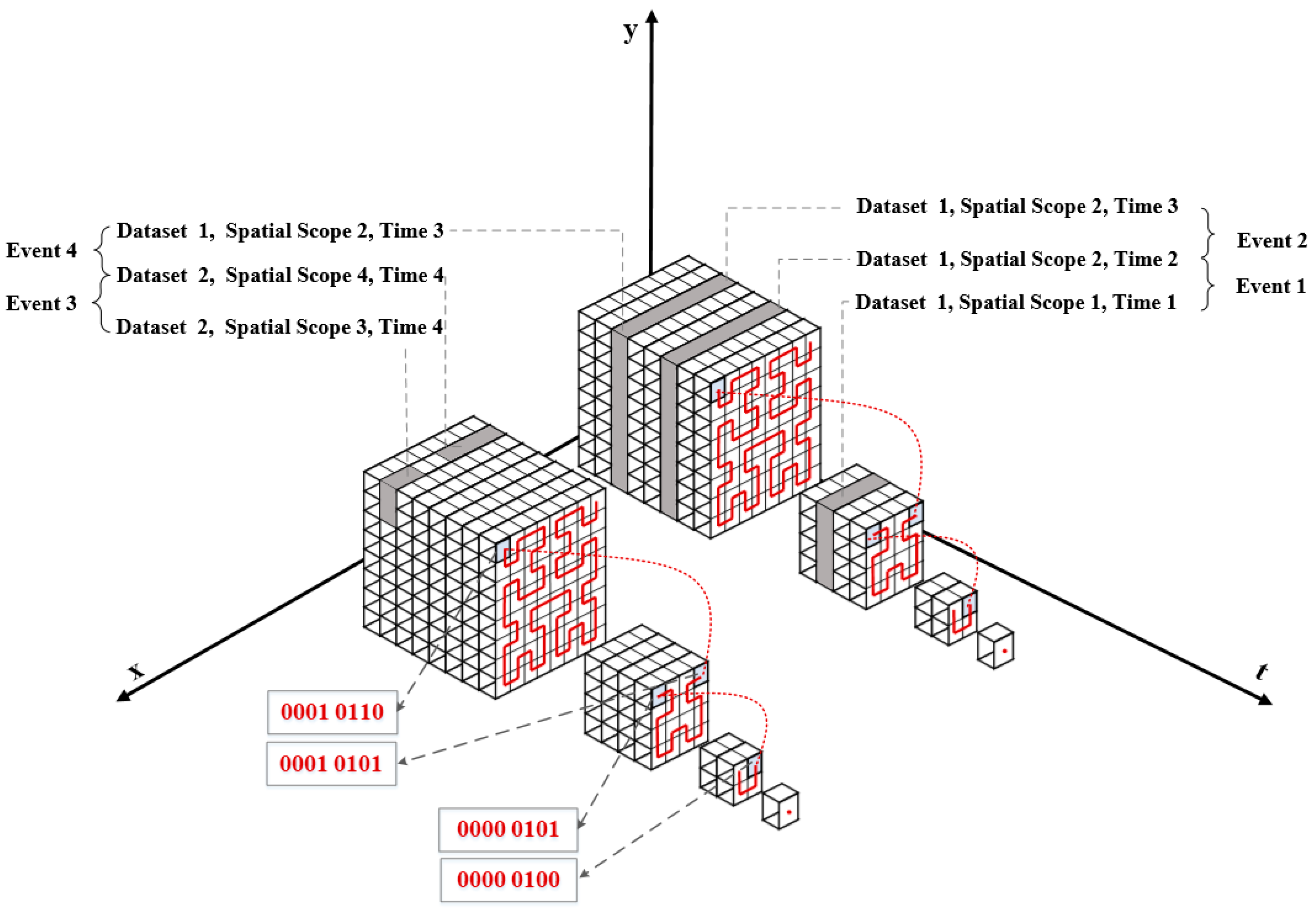
2.3. Coding Mechanism of Hierarchical Multi-dimensional Hybrid Indexing Model
2.3.1. “Cube” Structure
2.3.2. Hybrid Index Coding
- Divide the grid of the node’s level into four regions evenly according to the spatial position, and number the four regions according to the direction of the space filling curve;
- Calculate the grid offset of each region relative to the starting point;
- Continue to subdivide the area to which the node belongs according to the above process until the number of grids contained in the subarea is 1;
- Accumulate the relative offsets of the sub-areas to which the node belongs during the iteration process to obtain the code of the grid node in this level;
- According to the series relationship of the space filling curve at different resolution levels, the number of grid nodes is corrected; that is, the offset is added on the basis of the foregoing encoding result, and the offset is smaller than all grids of the current level Total, get the complete coding result of the grid node in the entire grid pyramid.
- BlockID is the grid block ID obtained by dividing the grid according to space. In order to ensure the hashability of the data in distributed storage, the BlockID is stored in reverse order;
- Index is the storage location of the grid in the grid block. The grid data of a certain spatial location can be obtained by prefix matching;
- Type is the basic category to which the data belongs, 0-basic image, 1-vector map, 2-temporal image, and 4-basic elevation;
- Time is the coarse-grained time attribute value extracted from the data, is the production time of the data, accurate to the year.
- “TIME_yyyyMMdd1_key1” means that the value of the key corresponding to the grid whose time attribute value is “yyyyMMdd1” is key1;
- “TAG_name1_value1_key1” means that the value of the event attribute name1 is the grid data of value1, and the value of the key stored in the data table is key1
- “TIME” and “TAG” are used to distinguish time and event attributes.
2.4. Experimental Materials
2.4.1. Remote Sensing Satellite Image Data
2.4.2. Digital Elevation Data
3. Results and Discussion
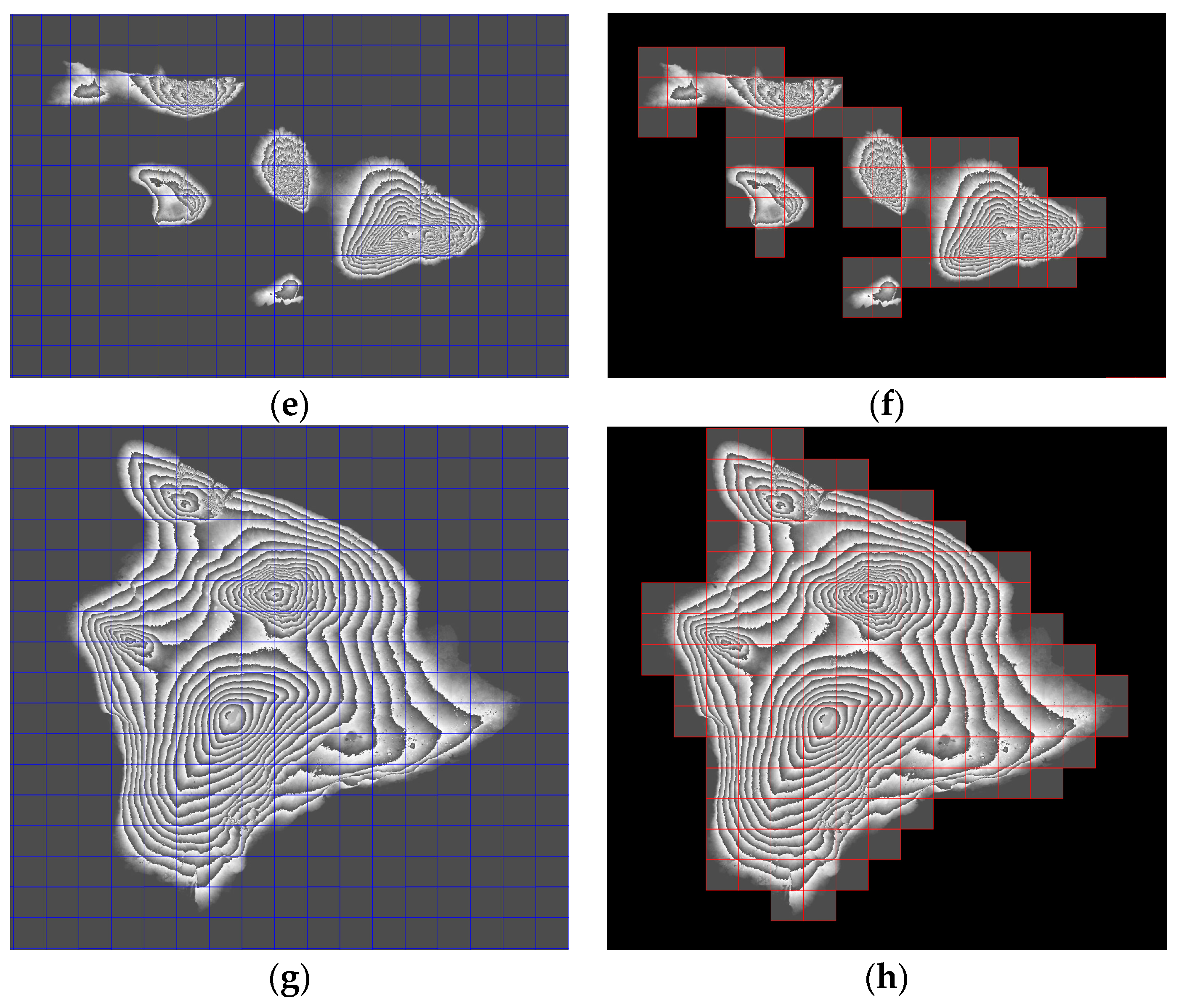
3.1. Construction Results of the HMDH
3.1.1. Construction Results of the HMDH for Remote Sensing Image Data
3.1.2. Construction Results of the HMDH for Digital Elevation Data
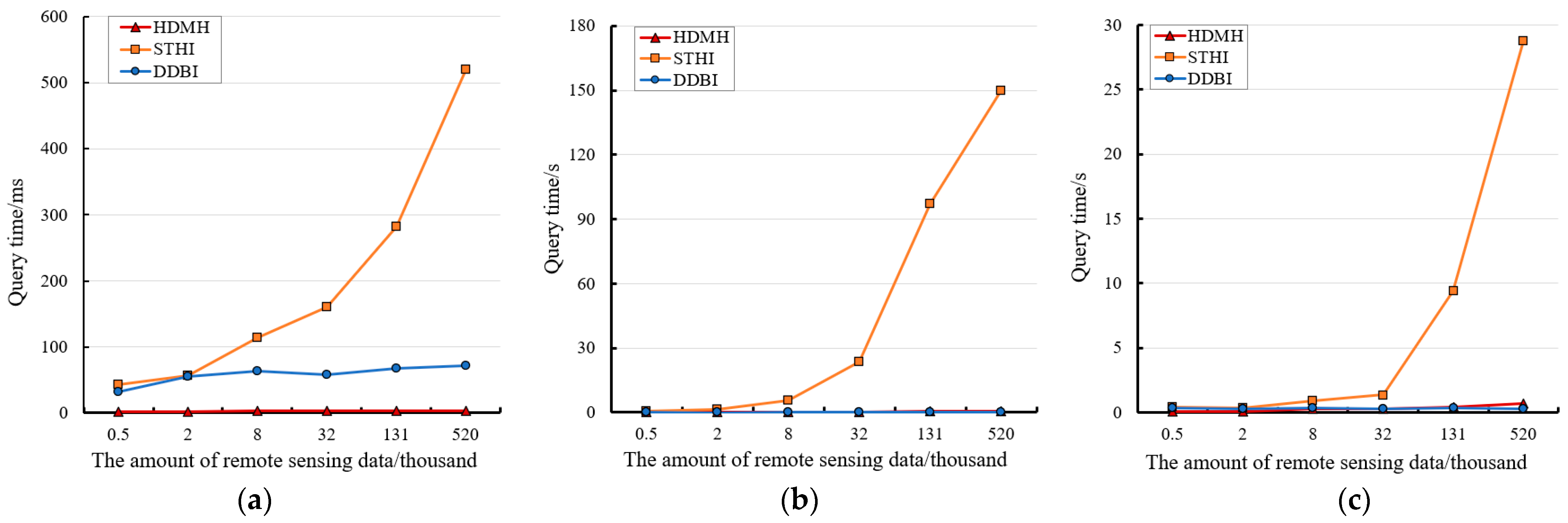
3.2. Query Performance of the HMDH
- Perform data retrieval based on the HMDH proposed in this paper;
- Perform data retrieval based on the distributed database index (DDBI), established on time, spatial and other features of the remote sensing data in distributed database system [34];
- Perform remote sensing data retrieval based on Hilbert code index method for spatiotemporal data of virtual battlefield environment (STHI), proposed in [36].
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhu, J.Z.; Shi, Q.; Chen, F.E. Research status and development trends of remote sensing big data. J. Image Graph. 2016, 21, 1425–1439. [Google Scholar]
- Li, D.R.; Zhang, L.P.; Xia, G.S. Automatic analysisi and mining of remote sensing big data. Acta Geod. Cartogr. Sin. 2014, 43, 1211–1216. [Google Scholar]
- Zhang, B. Remotely Sensed Big Data Era and Intelligent Information Extraction. Geomat. Inf. Sci. Wuhan Univ. 2018, 43, 1861–1871. [Google Scholar] [CrossRef]
- Li, D.R. On Space-Air-Ground Integrated Earth Observation Network. J. Geo Inf. Sci. 2012, 14, 419–425. [Google Scholar] [CrossRef]
- Zhang, Y. Research on the Theory and Key Technology of Global Spatial Information Muti-Grid with China’s Geographic Characteristics Considered; Huazhong University of Science & Technology: Wuhan, China, 2014. [Google Scholar]
- Wang, S.; Zhong, Y.; Wang, E. An integrated GIS platform architecture for remote sensing big data. Future Gener. Comput. Syst. 2019, 94, 160–172. [Google Scholar] [CrossRef]
- Chen, X.; Wu, J.; Yuan, G. Research on the construction of spatio-temporal information cloud platform for big data. Geomat. Spat. Inf. Technol. 2020, 43, 138–140. [Google Scholar]
- Hua, Y.; Zhou, C. Description frame of data model of multi-granularity spatio-temporal object for pan-spatial information system. J. Geo Inf. Sci. 2017, 19, 1142–1149. [Google Scholar]
- Huang, X. Research on Spatio-Temporal Raster Data Modeling Based on Gric Mode; Zhejiang University: Hangzhou, China, 2015. [Google Scholar]
- Yuan, F. A New Strategy of Storage & Retrieval for Massive Tile Data of Remote Sensing Images; University of Electronic Science and Technology of China: Chengdu, China, 2013. [Google Scholar]
- Zhao, Z.M.; Gao, L.R.; Chen, D.; Yue, A.Z.; Chen, J.B.; Liu, D.S.; Yang, J.; Meng, Y. Development of satelliteremote sensing and image processing platform. J. Image Graph. 2019, 24, 2098–2110. [Google Scholar]
- Lü, X.; Cheng, C.; Gong, J.; Guan, L. Review of data storage and management technologies for massive remote sensing data. Sci. China Tech. Sci. 2011, 41, 1561–1573. [Google Scholar] [CrossRef]
- Zheng, W.; Chengming, L.; Pengda, W.; Jianming, S.; Wei, S. Integerated storage and management of vector and raster data based on Oracle database. Acta Geod. Cartogr. Sin. 2017, 46, 639–648. [Google Scholar]
- Lewis, A.; Oliver, S.; Lymburner, L.; Evans, B.; Wyborn, L.; Mueller, N.; Raevksi, G.; Hooke, J.; Woodcock, R.; Sixsmith, J.; et al. The Australian Geoscience Data Cube—Foundations and lessons learned. Remote Sens. Environ. 2017, 202, 276–292. [Google Scholar] [CrossRef]
- Giuliani, G.; Peduzzi, P.; Chatenoux, B.; Richard, J.P.; Poussin, C.; Schaepman, M.; Small, D.; Steinmeier, C.; Psomas, A.; Ginzler, C. The Swiss Data Cube: Earth Observations for monitoring Switzerland’s environment in space and time. In 11th International Symposium on Digital Earth (ISDE 11); IOP Publishing Ltd.: Bristol, UK, 2020. [Google Scholar]
- Zhu, Z. Science of Landsat Analysis Ready Data. Remote Sens. 2019, 11, 2166. [Google Scholar] [CrossRef] [Green Version]
- Sun, W. Research of Some Key Technologies of Efficient Remote Sensing Big Data Services; Shandong University of Science and Technology: Qingdao, China, 2013. [Google Scholar]
- Wang, N.; Yue, L.H.; Yu, P.Q. Multi-source geospatial information association model based on the integration of vector and raster data. In Proceedings of the 29th National Database Conference, Hefei, China, 12–14 October 2012. [Google Scholar]
- Chen, C.C.; Lin, J.F.; Wu, X.Z. Massive geo-spatial data cloud storage and services based on nosql database technique. J. Geo Inf. Sci. 2013, 15, 166–174. [Google Scholar] [CrossRef]
- Hu, X.D.; Zhang, X.; Qu, J.S. Resource storage and management method of massive remote sensing data supported by the big data architecture. J. Geo Inf. Sci. 2016, 18, 681–689. [Google Scholar]
- Finkel, R.A.; Bentley, J.L. Quad trees a data structure for retrieval on composite keys. Acta Inform. 1974, 4, 1–9. [Google Scholar] [CrossRef]
- Bentley, J.L. Multidimensional binary search trees used for associative searching. Commun. ACM 1975, 18, 509–517. [Google Scholar] [CrossRef]
- Robinson, J.T. The K-D-B-tree: A search structure for large multidimensional dynamic indexes. In Proceedings of the ACM SIGMOD International Conference on Management of data, Ann Arbor, MI, USA, 29 April–1 May 1981; ACM: New York, NY, USA, 1981; pp. 10–18. [Google Scholar]
- Guttman, A. R-Trees: A Dynamic Index Structure for Spatial Searching; ACM: New York, NY, USA, 1984; pp. 47–57. [Google Scholar]
- Zhao, N. A hybrid structure of spatial multilevel index based on grids and R-tree. Comput. Technol. Dev. 2009, 19, 91–94. [Google Scholar]
- Deng, H.; Wu, F.; Zhai, R. R-tree index structure for multi-scale representation of spatial data. Chin. J. Comput. 2009, 32, 177–184. [Google Scholar] [CrossRef]
- He, J.; Wu, Y.; Yang, F. Multi-dimensional cloud index based on KD-tree and R-tree. J. Comput. Appl. 2014, 34, 3218–3221, 3278. [Google Scholar]
- Keogh, E.; Mueen, A. Curse of dimensionality. In Encyclopedia of Machine Learning; Springer: New York, NY, USA, 2011; pp. 257–258. [Google Scholar]
- Kamel, I.; Falout, S.; Hilbert, C. Hilbert R-tree: An improved R-tree using fractals. In Proceedings of the 20th International Conference on Very Large Data Bases, Santiago de Chile, Chile, 12–15 September 1994; pp. 500–509. [Google Scholar]
- Nie, Y.; Zhou, W.; Jian, S. Spatial index for tile map service based on Z curve. J. Image Graph. 2012, 17, 286–292. [Google Scholar]
- Yang, Y. Tile quadtree and filling curve realizing massive terrain dataset management. Comput. Eng. Appl. 2016, 52, 192–196. [Google Scholar]
- Moon, B.; Jagadish, H.V.; Faloutsos, C.; Saltz, J.H. Analysis of the clustering properties of Hilbert space-filling curve. IEEE Trans. Knowl. Data Eng. 2001, 13, 124–141. [Google Scholar] [CrossRef] [Green Version]
- Cao, Z.; Zhang, Y.; Li, C. A fast algorithm for the Hilbert curve ordering code based on partitioning. Comput. Eng. Sci. 2006, 28, 63–65. [Google Scholar]
- Hughes, J.N.; Annex, A.; Eichelberger, C.N.; Fox, A.; Hulbert, A.; Ronquest, M. GeoMesa: A distributed architecture for spatio-temporal fusion. In Geospatial Informatics, Fusion, and Motion Video Analytics V; International Society for Optics and Photonics: Baltimore, MD, USA, 2015. [Google Scholar]
- Whitby, M.A.; Fecher, R.; Bennight, C. GeoWave: Utilizing distributed key-value stores for multidimensional data. In Proceedings of the International Symposium on Spatial & Temporal Databases, Arlington, VA, USA, 21–23 August 2017; pp. 105–122. [Google Scholar]
- Wu, Y.H.; Cao, X.F. Hilbert code index method for spatiotemporal data of virtual battlefield environment. Geomat. Inf. Sci. Wuhan Univ. 2020, 45, 1403–1411. [Google Scholar]
- Zhu, J.; Liu, Z.; Qiao, D. Construction and optimization of spatial index model for massive geospatial data based on hbase. Geol. Sci. Technol. Inf. 2019, 38, 253–260. [Google Scholar]
- Lin, J.S. Fuzzy clustering using a compensated fuzzy hopfield network. Neural Process. Lett. 1999, 10, 35–48. [Google Scholar] [CrossRef]
- Zhang, M.; Yu, J. Fuzzy partitional clustering algorithms. J. Softw. 2004, 15, 858–869. [Google Scholar]
- Zhou, K. Theoretical and Applied Research on Fuzzy C-Mean Clustering and Its Cluster Validation; Hefei University of Technology: Hefei, China, 2014. [Google Scholar]
- Li, K.; Liu, Y.S. KFCSA: A novel clustering algorithm for high-dimension data. In Proceedings of the 2nd International Conference on Fuzzy Systems and Knowledge Discovery, Changsha, China, 27–29 August 2005; pp. 531–536. [Google Scholar]
- Piao, S.Z.; Yu, J. Cluster validity indexes for fcm clustering algorithm. Pattern Recognit. Artif. Intell. 2015, 28, 451–461. [Google Scholar]
- Zhang, C.; Wang, T.; Sun, D. Image edge detection based on the Euclidean distance graph. J. Image Graph. 2013, 18, 176–183. [Google Scholar]
- Buades, A.; Coll, B.; Morel, J.M. A non-local algorithm for image denoising. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005; IEEE Computer Society: Washington, DC, USA, 2005; pp. 60–65. [Google Scholar]
- Li, Z. The Segmentation and Realization of High Spatial Resolution Remote Sensing Image Based on Region Growing Algorithm; Guangxi University: Nanning, China, 2008. [Google Scholar]
- Adams, R.; Bischof, L. Seeded region growing. IEEE Trans. Pattern Anal. Mach. 1994, 16, 641–647. [Google Scholar] [CrossRef] [Green Version]
- Methnert, A.; Jackway, P. An improved seeded region growing algorithm. Pattern Recognit. Lett. 1997, 18, 1065–1071. [Google Scholar] [CrossRef]
- Deng, X. Research on Service Architecture and Algorithms for Grid Spatial Data; Information Engineering University: Zhengzhou, China, 2003. [Google Scholar]
- Xu, D. Research on the Key Techniques of Multi-Source Remote Sensing Big Data Management under the Cloud Computing Environment; University of Chinese Academy of Sciences: Beijing, China, 2018. [Google Scholar]
- Song, A. Distributed Multi-Temporal Geoinformation Service Aggregation Based on a Compound Pyramid Model; Wuhan University: Wuhan, China, 2013. [Google Scholar]
- Yan, W. Research on Image Feature Extraction Method; Northwestern Polytechnical University: Xi’an, China, 2007. [Google Scholar]
- Wang, C. Study on Nondestructive Detection Method of Potato Grading Based on Multi-Source Information Fusion; Huazhong Agricultural University: Wuhan, China, 2014. [Google Scholar]
- Qing, Y.; Song, W. Remote sensing image feature extraction and selection and its application in image classification. Sci. Surv. Mapp. 2008, 01, 176–199. [Google Scholar]
- Chen, P. Research on Principal Component Analysis and Its Application in Feature Extraction; Shaanxi Normal University: Xi’an, China, 2014. [Google Scholar]
- Cao, M. Research on Intelligent Recognition and Extraction of Feature Elements Based on Remote Sensing Images; Changan University: Xi’an, China, 2015. [Google Scholar]
- Chen, Z.; Zhao, Z. A multi-scale remote sensing image segmentation algorithm based on region growing. Comput. Eng. Appl. 2005, 35, 7–9. [Google Scholar]
- Wu, M. Hilbert space-filling curve and spatial pattern detection-based spatial partitioning approach to point geospatial data. J. Image Graph. 2013, 18, 1336–1342. [Google Scholar]
- Huihui, Z.; Fan, Z.; Renhai, C.; Zhiyong, F. Efficient index and query algorithm based on geospatial big data. J. Comput. Res. Dev. 2020, 57, 333–345. [Google Scholar]
- Gong, J.Y.; Chen, J.; Xiang, L.G. GeoGlobe: Geo-spatial Information Sharing Platform as Open Virtual Earth. Acta Geod. Cartogr. Sin. 2010, 39, 551–553. [Google Scholar]
- Zhang, F. The Study on the Grid-Oriented Access, Integration and Interoperation of Massive Spatio-Temperal Data; Zhejiang University: Hangzhou, China, 2007. [Google Scholar]
- Chang, F.; Dean, J.; Ghemawat, S.; Hsieh, W.C.; Wallach, D.A.; Burrows, M.; Chandra, T.; Fikes, A.; Gruber, R.E. Bigtable: A distributed storage system for structured data. ACM Trans. Comput. Syst. 2008, 26, 1–26. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Grid | The Amount of Data | Integrity | Accuracy | Redundancy |
|---|---|---|---|---|---|
| Paracel Islands dataset | Traditional grid | 15,000 | 1 | 0.023 | 0.977 |
| the HMDH | 1792 | 1 | 0.20 | 0.8 | |
| Hawaii Islands dataset | Traditional grid | 16,960 | 1 | 0.058 | 0.942 |
| the HMDH | 1072 | 1 | 0.951 | 0.049 | |
| Plateau Lake dataset | Traditional grid | 18,240 | 1 | 0.108 | 0.892 |
| the HMDH | 2601 | 1 | 0.935 | 0.065 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, L.; Su, X.; Tai, X. A High-Dimensional Indexing Model for Multi-Source Remote Sensing Big Data. Remote Sens. 2021, 13, 1314. https://doi.org/10.3390/rs13071314
Zhu L, Su X, Tai X. A High-Dimensional Indexing Model for Multi-Source Remote Sensing Big Data. Remote Sensing. 2021; 13(7):1314. https://doi.org/10.3390/rs13071314
Chicago/Turabian StyleZhu, Lilu, Xiaolu Su, and Xianqing Tai. 2021. "A High-Dimensional Indexing Model for Multi-Source Remote Sensing Big Data" Remote Sensing 13, no. 7: 1314. https://doi.org/10.3390/rs13071314
APA StyleZhu, L., Su, X., & Tai, X. (2021). A High-Dimensional Indexing Model for Multi-Source Remote Sensing Big Data. Remote Sensing, 13(7), 1314. https://doi.org/10.3390/rs13071314