
GSAP: A Global Structure Attention Pooling Method for Graph-Based Visual Place Recognition

Abstract
:
1. Introduction
- The viewpoint of the same place can change drastically when the place is revisited.
- The appearance can change due to the illumination and seasonal change.
- Having a large number of images in the database causes high computational cost.
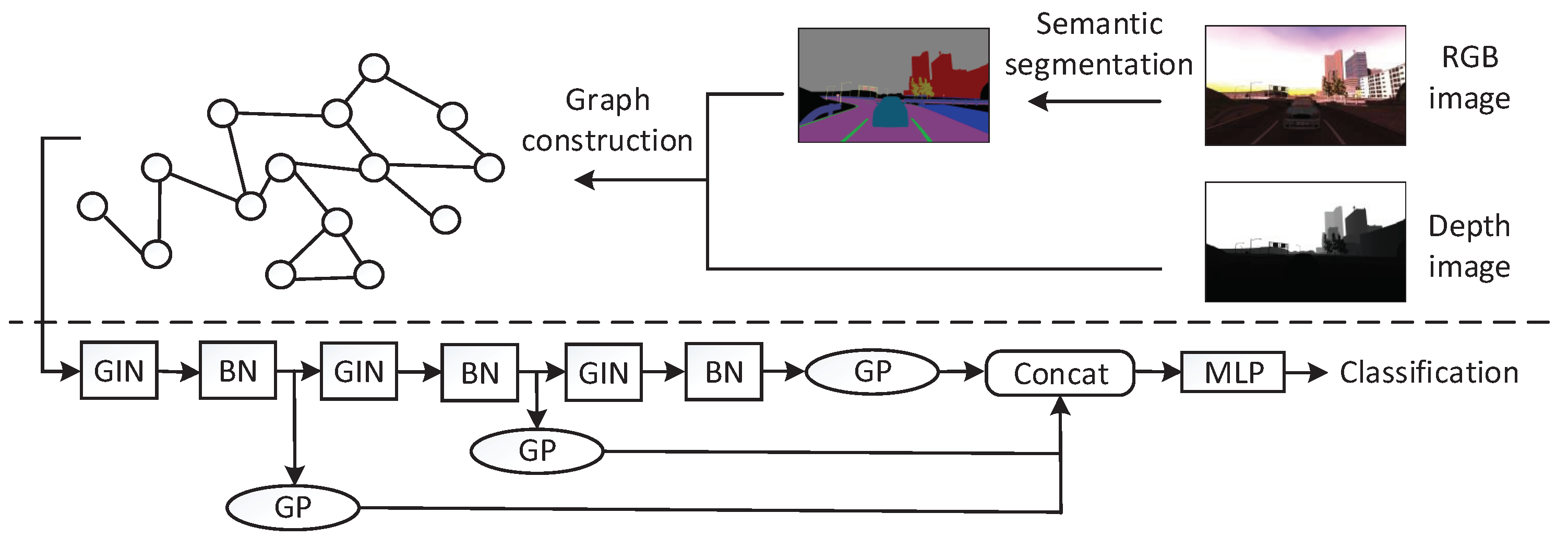
- Based on the graph construction approach in X-View [14], we propose a graph data construction approach that transforms the RGB image and the depth image into the graph for place recognition by extracting both semantic and geometry information.
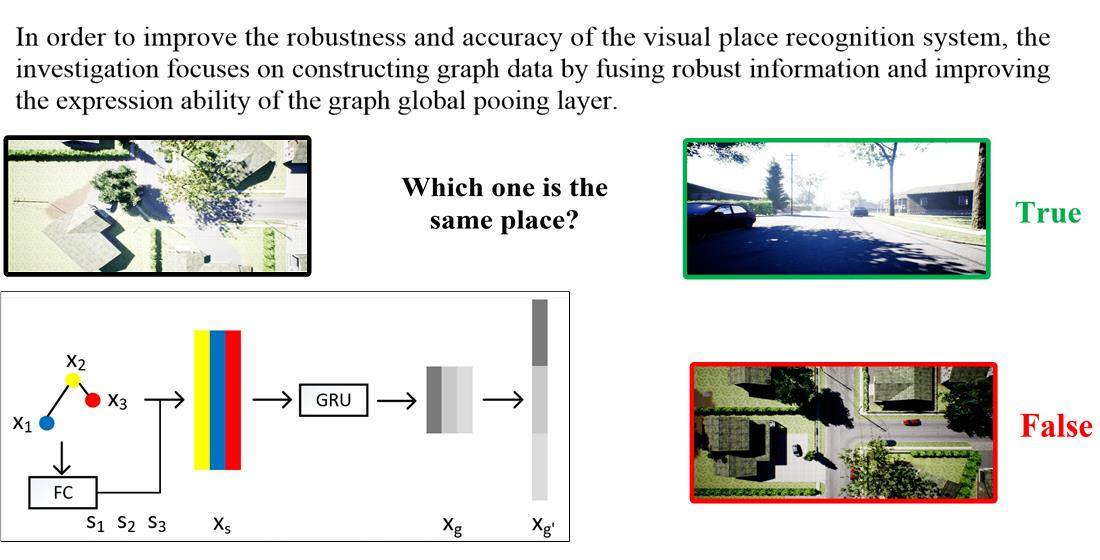
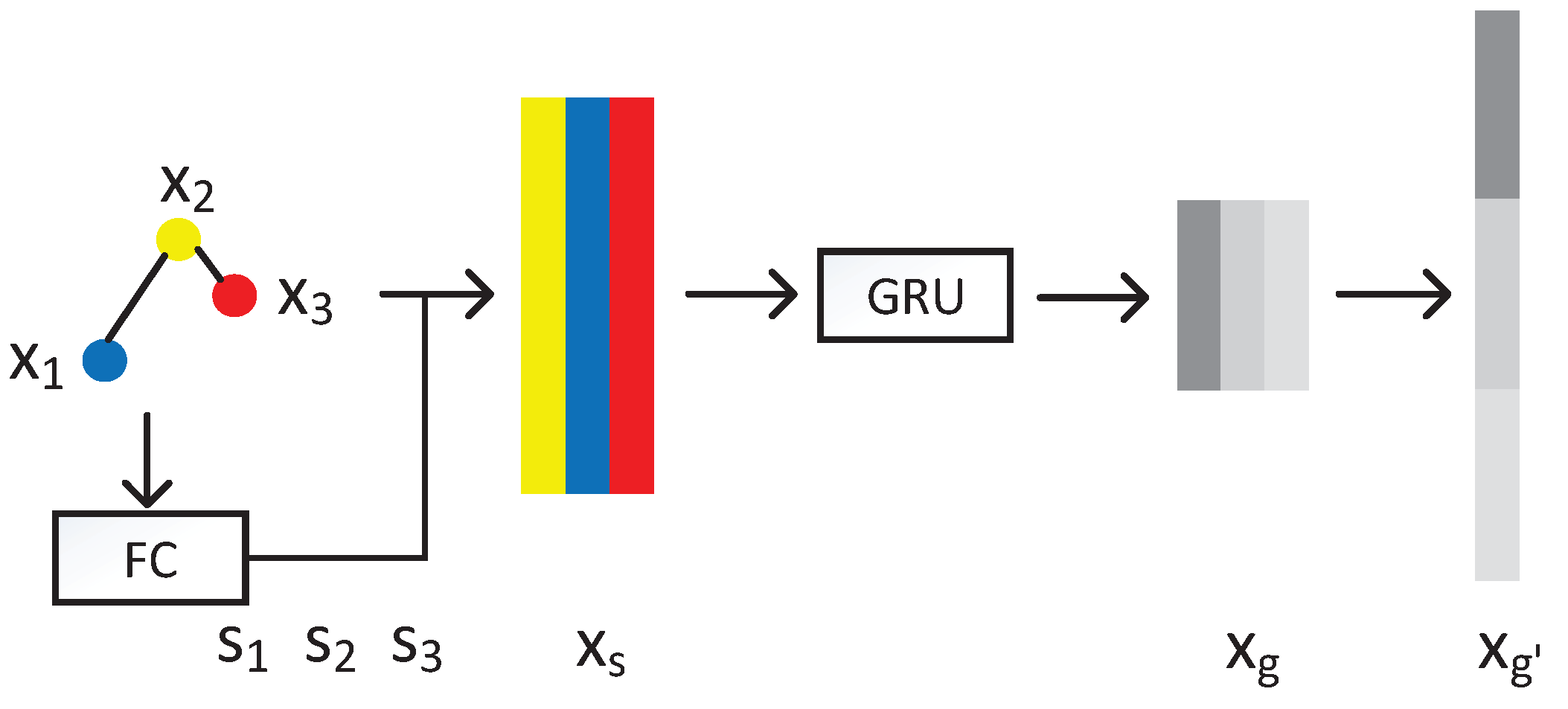
- To improve the expression ability of the GNN architecture, we propose a Global Pool method—Global Structure Attention Pooling. Compared with the most commonly used global pooling methods, e.g., global mean pooling, global max pooling, and global sum pooling, our pooling method is a trainable pooling method improving the expression ability. Compared with other trainable pooling methods, our work not only catches the first-order neighbor information by learning attention scores, but also models the spatial relation by the Gate Recurrent Unit (GRU) for higher-order neighbor information.
2. Related Work
2.1. Visual Place Recognition
2.2. Image Retrieval
2.3. Graph Classification
3. Methodology
3.1. Overview of the VPR Pipeline
3.2. Graph Construction
| Algorithm 1 Graph Construction |
| Input: RGB image I, depth image D |
| Output: constructed graph |
| 1: compute semantic segmentation results S |
| 2: extract blobs in S |
| 3: blobs |
| 4: for each blob do |
| 5: compute |
| 6: find node label in S |
| 7: find the depth corresponding to in D |
| 8: compute |
| 9: |
| 10: end for |
| 11: for every two blobs do |
| 12: bitwise or → |
| 13: compute N in |
| 14: compute |
| 15: if and then |
| 16: edge connected, edge |
| 17: else |
| 18: do nothing |
| 19: end if |
| 20: end for |
3.2.1. Nodes Determination and Node Labels
3.2.2. Node Attributes
3.2.3. Edges Determination
3.2.4. Node Features
3.3. Global Structure Attention Pooling
4. Results
4.1. Datasets
4.1.1. Airsim
4.1.2. SYNTHIA
4.2. Evaluation Metrics
4.3. Task Setting
4.4. Methods to Compare
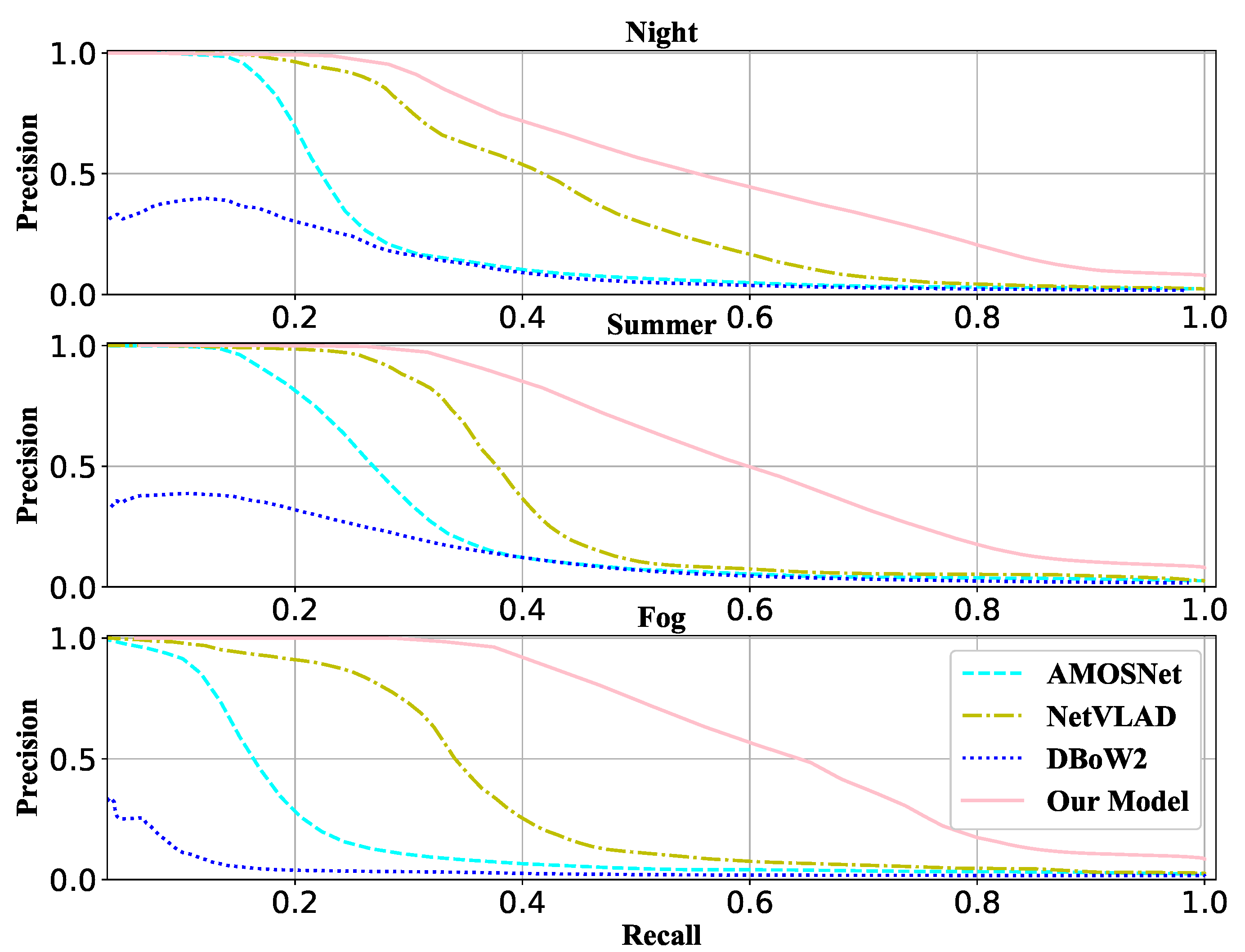
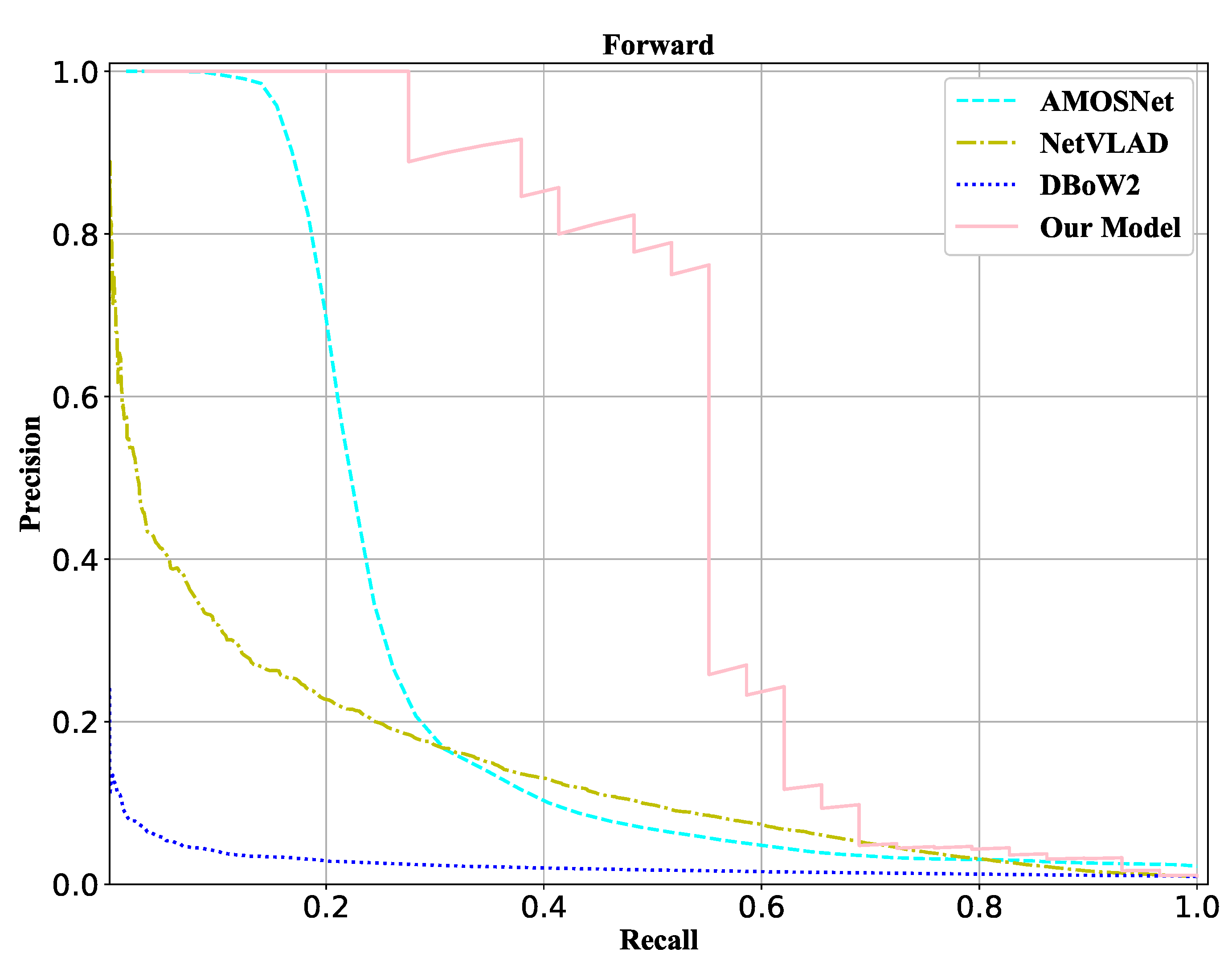
- NetVLAD [7]: This is a deep learning method that combines Locally Aggregated Descriptors (VLAD) with Convolutional Neural Networks. For a fair comparison, we use MLP to classify after getting the global descriptor, and the training and test processes are also the same as our VPR method.
- AMOSNet [8]: This is also a deep leaning method using a 2-D image. It uses a convolution kernel, and the feature map is fed into two fully connected layers.
- DBoW2 [2]: It extracts the handicraft features, generates the dictionary by clustering these features, and looks for the corresponding words of a query image in the dictionary.
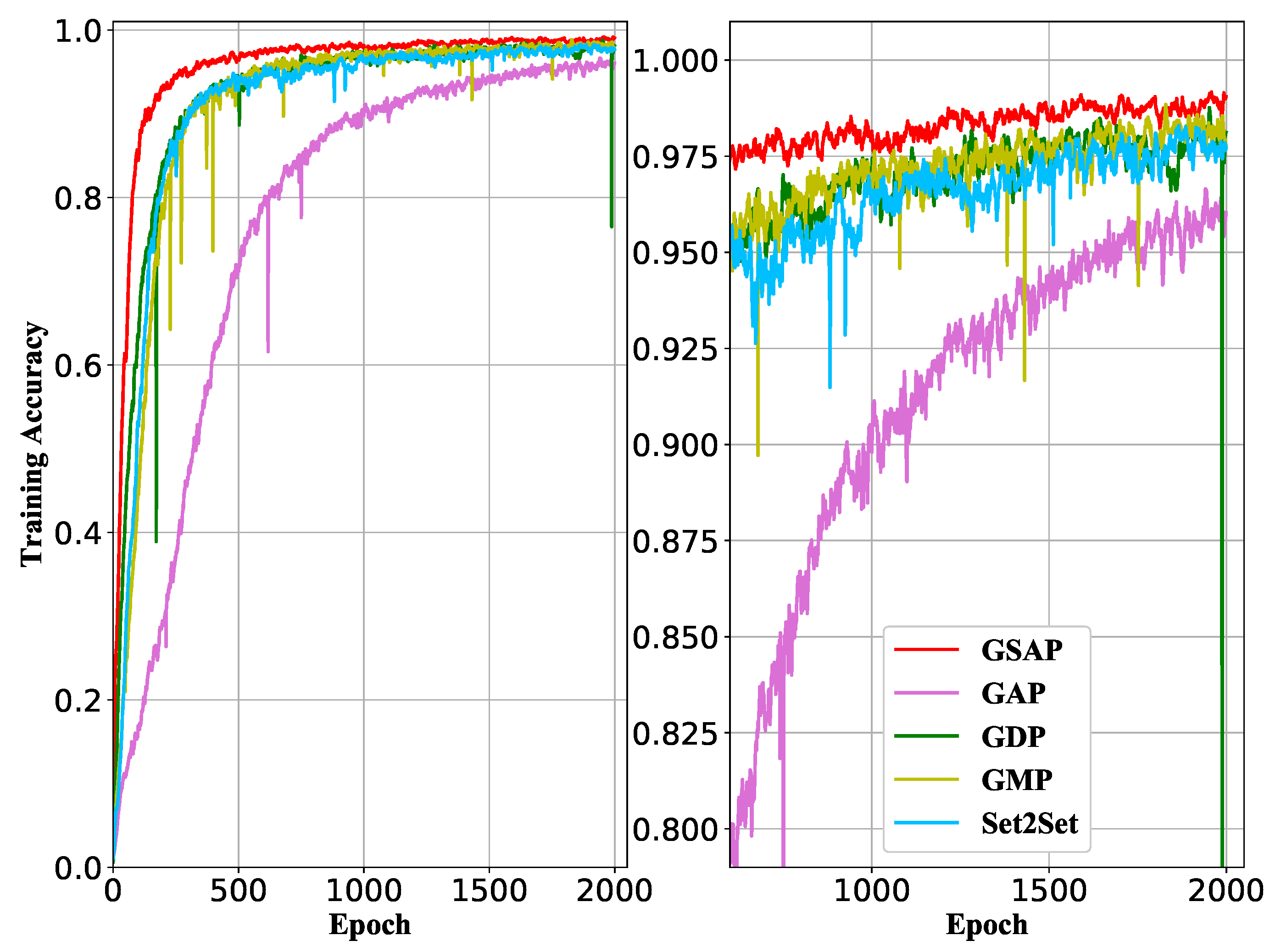
- Global Add Pooling (GDP): It returns batch-wise graph-level outputs by adding node features across the node dimension.
- Global Mean Pooling (GMP): It returns batch-wise graph-level outputs by averaging node features across the node dimension.
- Global Max Pooling (GAP): It returns batch-wise graph-level outputs by taking the channel-wise maximum across the node dimension.
- Set2Set [55]: Based on iterative content-based attention, it has the property that the vector retrieved from our memory would not change if we randomly shuffled the memory to output sequences.
- Semantic Information based [14]: It extracts semantic labels, and instances center 3-D locations as graph features.
- Geometric Information based: We evaluate the effectiveness of the geometric information separately. It extracts the instance center 3-D location; the top left corner coordinate of the external polygon of a blob; and the width, height, and area of the external polygon of a blob as graph feature.
4.5. Results and Analysis
5. Discussions
5.1. Effect of Structure Attention Pooling Method
5.2. Effect of Graph Construction
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Lowry, S.; Sunderhauf, N.; Newman, P.; Leonard, J.J.; Cox, D.D.; Corke, P.; Milford, M. Visual Place Recognition: A Survey. IEEE Trans. Robot. 2016, 32, 1–19. [Google Scholar] [CrossRef] [Green Version]
- Galvezlopez, D.; Tardos, J.D. Bags of Binary Words for Fast Place Recognition in Image Sequences. IEEE Trans. Robot. 2012, 28, 1188–1197. [Google Scholar] [CrossRef]
- Mustaqeem; Kwon, S. MLT-DNet: Speech emotion recognition using 1D dilated CNN based on multi-learning trick approach. Expert Syst. Appl. 2021, 167, 114177. [Google Scholar] [CrossRef]
- Mustaqeem; Kwon, S. A CNN-Assisted Enhanced Audio Signal Processing for Speech Emotion Recognition. Sensors 2019, 20, 183. [Google Scholar] [CrossRef] [Green Version]
- Mustaqeem; Kwon, S. Att-Net: Enhanced emotion recognition system using lightweight self-attention module. Appl. Soft Comput. 2021, 102, 102. [Google Scholar]
- Sunderhauf, N.; Shirazi, S.; Dayoub, F.; Upcroft, B.; Milford, M. On the performance of ConvNet features for place recognition. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 4297–4304. [Google Scholar]
- Arandjelovic, R.; Gronat, P.; Torii, A.; Pajdla, T.; Sivic, J. NetVLAD: CNN Architecture for Weakly Supervised Place Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 1437–1451. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, Z.; Jacobson, A.; Sunderhauf, N.; Upcroft, B.; Liu, L.; Shen, C.; Reid, I.; Milford, M. Deep learning features at scale for visual place recognition. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 3223–3230. [Google Scholar]
- Latif, Y.; Garg, R.; Milford, M.; Reid, I. Addressing Challenging Place Recognition Tasks Using Generative Adversarial Networks. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; pp. 2349–2355. [Google Scholar]
- Yin, P.; Xu, L.; Li, X.; Yin, C.; Li, Y.; Srivatsan, R.A.; Li, L.; Ji, J.; He, Y. A Multi-Domain Feature Learning Method for Visual Place Recognition. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 319–324. [Google Scholar]
- Li, Q.; Li, K.; You, X.; Bu, S.; Liu, Z. Place recognition based on deep feature and adaptive weighting of similarity matrix. Neurocomputing 2016, 199, 114–127. [Google Scholar] [CrossRef]
- Mao, J.; Hu, X.; He, X.; Zhang, L.; Wu, L.; Milford, M. Learning to Fuse Multiscale Features for Visual Place Recognition. IEEE Access 2019, 7, 5723–5735. [Google Scholar] [CrossRef]
- Zhang, W.; Yan, Z.; Wang, Q.; Wu, X.; Zuo, W. Learning Second-order Statistics for Place Recognition based on Robust Covariance Estimation of CNN Features. Neurocomputing 2020, 398, 197–208. [Google Scholar] [CrossRef]
- Gawel, A.; Don, C.D.; Siegwart, R.; Nieto, J.I.; Cadena, C. X-View: Graph-Based Semantic Multi-View Localization. IEEE Robot. Autom. Lett. 2018, 3, 1687–1694. [Google Scholar] [CrossRef] [Green Version]
- Kong, X.; Yang, X.; Zhai, G.; Zhao, X.; Zeng, X.; Wang, M.; Liu, Y.; Li, W.; Wen, F. Semantic Graph Based Place Recognition for 3D Point Clouds. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 25–29 October 2020; pp. 8216–8223. [Google Scholar]
- Wu, Z.; Pan, S.; Chen, F.; Long, G.; Zhang, C.; Yu, P.S. A Comprehensive Survey on Graph Neural Networks. IEEE Trans. Neural Netw. 2020, 32, 1–21. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xu, K.; Hu, W.; Leskovec, J.; Jegelka, S. How powerful are graph neural networks? arXiv 2018, arXiv:1810.00826. [Google Scholar]
- Zaffar, M.; Ehsan, S.; Milford, M.; McDonald-Maier, K. CoHOG: A Light-Weight, Compute-Efficient, and Training-Free Visual Place Recognition Technique for Changing Environments. IEEE Robot. Autom. Lett. 2020, 5, 1835–1842. [Google Scholar] [CrossRef] [Green Version]
- Shimoda, S.; Ozawa, T.; Yamada, K.; Ichitani, Y. Long-term associative memory in rats: Effects of familiarization period in object-place-context recognition test. bioRxiv 2019, 728295. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Qiu, Y.; Cheng, P.; Duan, X. Robust Loop Closure Detection Integrating Visual–Spatial–Semantic Information via Topological Graphs and CNN Features. Remote Sens. 2020, 12, 3890. [Google Scholar] [CrossRef]
- Garg, S.; Suenderhauf, N.; Milford, M. Don’t Look Back: Robustifying Place Categorization for Viewpoint- and Condition-Invariant Place Recognition. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australi, 21–25 May 2018; pp. 3645–3652. [Google Scholar]
- Tsintotas, K.A.; Bampis, L.; Gasteratos, A. Assigning Visual Words to Places for Loop Closure Detection. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australi, 21–25 May 2018; pp. 5979–5985. [Google Scholar]
- Garg, S.; Jacobson, A.; Kumar, S.; Milford, M. Improving condition- and environment-invariant place recognition with semantic place categorization. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 6863–6870. [Google Scholar]
- Cascianelli, S.; Costante, G.; Bellocchio, E.; Valigi, P.; Fravolini, M.L.; Ciarfuglia, T.A. Robust visual semi-semantic loop closure detection by a covisibility graph and CNN features. Robot. Auton. Syst. 2017, 92, 53–65. [Google Scholar] [CrossRef]
- Garg, S.; Suenderhauf, N.; Milford, M. Semantic-geometric visual place recognition: A new perspective for reconciling opposing views. Int. J. Robot. Res. 2019, 0278364919839761. [Google Scholar] [CrossRef]
- Milford, M.J.; Wyeth, G.F. SeqSLAM: Visual route-based navigation for sunny summer days and stormy winter nights. In Proceedings of the 2012 IEEE International Conference on Robotics and Automation, Saint Paul, MN, USA, 14–18 May 2012; pp. 1643–1649. [Google Scholar]
- Talbot, B.; Garg, S.; Milford, M. OpenSeqSLAM2.0: An Open Source Toolbox for Visual Place Recognition Under Changing Conditions. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 7758–7765. [Google Scholar]
- Yue, H.; Miao, J.; Yu, Y.; Chen, W.; Wen, C. Robust Loop Closure Detection based on Bag of SuperPoints and Graph Verification. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 3787–3793. [Google Scholar]
- Stumm, E.; Mei, C.; Lacroix, S.; Nieto, J.; Hutter, M.; Siegwart, R. Robust Visual Place Recognition with Graph Kernels. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 4535–4544. [Google Scholar]
- Cao, S.; Snavely, N. Graph-Based Discriminative Learning for Location Recognition. Int. J. Comput. Vis. 2015, 112, 239–254. [Google Scholar] [CrossRef] [Green Version]
- Sun, Q.; Liu, H.; He, J.; Fan, Z.; Du, X. DAGC: Employing Dual Attention and Graph Convolution for Point Cloud based Place Recognition. In Proceedings of the 2020 International Conference on Multimedia Retrieval, Dublin, Ireland, 26–29 October 2020; pp. 224–232. [Google Scholar]
- Zhang, X.; Wang, L.; Zhao, Y.; Su, Y. Graph-Based Place Recognition in Image Sequences with CNN Features. J. Intell. Robot. Syst. 2019, 95, 389–403. [Google Scholar] [CrossRef]
- Tzelepi, M.; Tefas, A. Deep convolutional learning for Content Based Image Retrieval. Neurocomputing 2018, 275, 2467–2478. [Google Scholar] [CrossRef]
- Tang, J.; Lin, J.; Li, Z.; Yang, J. Discriminative Deep Quantization Hashing for Face Image Retrieval. IEEE Trans. Neural Netw. 2018, 29, 6154–6162. [Google Scholar] [CrossRef]
- Bai, C.; Huang, L.; Pan, X.; Zheng, J.; Chen, S. Optimization of deep convolutional neural network for large scale image retrieval. Neurocomputing 2018, 303, 60–67. [Google Scholar] [CrossRef]
- Zhu, L.; Huang, Z.; Li, Z.; Xie, L.; Shen, H.T. Exploring Auxiliary Context: Discrete Semantic Transfer Hashing for Scalable Image Retrieval. IEEE Trans. Neural Netw. 2018, 29, 5264–5276. [Google Scholar] [CrossRef] [PubMed]
- Radenovic, F.; Tolias, G.; Chum, O. Fine-Tuning CNN Image Retrieval with No Human Annotation. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 1655–1668. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Song, J. Binary Generative Adversarial Networks for Image Retrieval. In Proceedings of the Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Xu, P.; Yin, Q.; Huang, Y.; Song, Y.; Ma, Z.; Wang, L.; Xiang, T.; Kleijn, W.B.; Guo, J. Cross-modal subspace learning for fine-grained sketch-based image retrieval. Neurocomputing 2018, 278, 75–86. [Google Scholar] [CrossRef] [Green Version]
- Pang, K.; Li, K.; Yang, Y.; Zhang, H.; Hospedales, T.M.; Xiang, T.; Song, Y.Z. Generalising Fine-Grained Sketch-Based Image Retrieval. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 677–686. [Google Scholar]
- Dutta, A.; Akata, Z. Semantically Tied Paired Cycle Consistency for Zero-Shot Sketch-Based Image Retrieval. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 5089–5098. [Google Scholar]
- Guo, X.; Wu, H.; Cheng, Y.; Rennie, S.J.; Tesauro, G.; Feris, R.S. Dialog-based Interactive Image Retrieval. arXiv 2018, arXiv:1805.00145. [Google Scholar]
- Kipf, T.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Velickovic, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph Attention Networks. arXiv 2017, arXiv:1710.10903. [Google Scholar]
- Hamilton, W.L.; Ying, Z.; Leskovec, J. Inductive Representation Learning on Large Graphs. 2017. Available online: https://arxiv.org/abs/1706.02216 (accessed on 16 February 2021).
- Schlichtkrull, M.S.; Kipf, T.N.; Bloem, P.; van den Berg, R.; Titov, I.; Welling, M. Modeling Relational Data with Graph Convolutional Networks. In Proceedings of the 15th International Conference on Extended Semantic Web Conference, ESWC 2018, Heraklion, Crete, Greece, 3–7 June 2018; pp. 593–607. [Google Scholar]
- Gilmer, J.; Schoenholz, S.S.; Riley, P.F.; Vinyals, O.; Dahl, G.E. Neural Message Passing for Quantum Chemistry. In Proceedings of the 34th International Conference on Machine Learning-Volume 70, Sydney, Australia, 6–11 August 2017; pp. 1263–1272. [Google Scholar]
- Wang, X.; Girshick, R.B.; Gupta, A.; He, K. Non-local Neural Networks. arXiv 2017, arXiv:1711.07971. [Google Scholar]
- Battaglia, P.W.; Hamrick, J.B.; Bapst, V.; Sanchezgonzalez, A.; Zambaldi, V.; Malinowski, M.; Tacchetti, A.; Raposo, D.; Santoro, A.; Faulkner, R.; et al. Relational inductive biases, deep learning, and graph networks. arXiv 2018, arXiv:1806.01261. [Google Scholar]
- Cangea, C.; Veličković, P.; Jovanović, N.; Kipf, T.; Liò, P. Towards Sparse Hierarchical Graph Classifiers. arXiv 2018, arXiv:1811.01287. [Google Scholar]
- Knyazev, B.; Taylor, G.W.; Amer, M.R. Understanding attention in graph neural networks. arXiv 2019, arXiv:1905.02850. [Google Scholar]
- Lee, J.; Lee, I.; Kang, J. Self-Attention Graph Pooling. In Proceedings of the 36th International Conference on Machine Learning, ICML 2019, Beach, CA, USA, 10–15 June 2019; pp. 3734–3743. [Google Scholar]
- Diehl, F. Edge contraction pooling for graph neural networks. arXiv 2019, arXiv:1905.10990. [Google Scholar]
- Ranjan, E.; Sanyal, S.; Talukdar, P. ASAP: Adaptive Structure Aware Pooling for Learning Hierarchical Graph Representations. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 5470–5477. [Google Scholar]
- Vinyals, O.; Bengio, S.; Kudlur, M. Order Matters: Sequence to sequence for sets. In Proceedings of the ICLR 2016: International Conference on Learning Representations 2016, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Li, Y.; Tarlow, D.; Brockschmidt, M.; Zemel, R.S. Gated Graph Sequence Neural Networks. ICLR (Poster). arXiv 2016, arXiv:1511.05493. [Google Scholar]
- Zhang, M.; Cui, Z.; Neumann, M.; Chen, Y. An End-to-End Deep Learning Architecture for Graph Classification. In Proceedings of the AAAI Conference on Artificial Intelligence AAAI, New Orleans, LA, USA, 2–7 February 2018; pp. 4438–4445. [Google Scholar]
- Mustaqeem; Kwon, S. CLSTM: Deep Feature-Based Speech Emotion Recognition Using the Hierarchical ConvLSTM Network. Mathematics 2020, 8, 2133. [Google Scholar] [CrossRef]
- Mustaqeem; Sajjad, M.; Kwon, S. Clustering-Based Speech Emotion Recognition by Incorporating Learned Features and Deep BiLSTM. IEEE Access 2020, 8, 79861–79875. [Google Scholar] [CrossRef]
- Cho, K.; van Merrienboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1724–1734. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Mesquita, D.P.P.; Souza, A.H.; Kaski, S. Rethinking Pooling in Graph Neural Networks. 2020. Available online: https://arxiv.org/pdf/2010.11418.pdf (accessed on 16 February 2021).
- Prince, D.S.J.D. Computer Vision: Models, Learning, and Inference; Cambridge University Press: Cambridge, MA, USA, 2012. [Google Scholar]
- Ros, G.; Sellart, L.; Materzynska, J.; Vazquez, D.; Lopez, A.M. The SYNTHIA Dataset: A Large Collection of Synthetic Images for Semantic Segmentation of Urban Scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Valada, A.; Vertens, J.; Dhall, A.; Burgard, W. AdapNet: Adaptive semantic segmentation in adverse environmental conditions. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 4644–4651. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Statistics | Airsim | SYNTHIA |
|---|---|---|
| Number of Graphs | 10,000 | 10,479 |
| Number of Classes | 100 | 89 |
| Class Imbalance | No | Yes |
| Average of Nodes per Graph | 27.19 | 68.60 |
| Average of Edges per Graph | 64.11 | 88.58 |
| Hyperparameter | Range |
|---|---|
| Learning rate | 1 × 10−4, 5 × 10−3, 1 × 10−3, 1 × 10−2 |
| Hidden size | 128, 256, 512 |
| Weight decay | 0, 1 × 10−2, 1 × 10−3, 1 × 10−4 |
| Number of nodes reserved | 50–100 |
| Method | Component |
|---|---|
| Our model | Graph construction + GSAPs |
| NetVLAD | 2D image + deep feature + trainable pooling |
| AMOSNet | 2D image + deep feature |
| DBoW2 | 2D image + handicraft feature |
| Global Pooling Methods | Accuracy |
| GDP | 91.485 ± 0.716 |
| GMP | 91.315 ± 1.255 |
| GAP | 90.270 ± 0.567 |
| Set2Set | 88.570 ± 1.314 |
| Our GSAP | 93.575 ± 0.699 |
| Graph Construction Methods | Accuracy |
| Semantic based | 87.630 ± 0.361 |
| Geometric based | 90.063 ± 1.892 |
| Semantic and geometric based | 93.575 ± 0.699 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, Y.; Ma, B.; Liu, X.; Zhao, L.; Huang, S. GSAP: A Global Structure Attention Pooling Method for Graph-Based Visual Place Recognition. Remote Sens. 2021, 13, 1467. https://doi.org/10.3390/rs13081467
Yang Y, Ma B, Liu X, Zhao L, Huang S. GSAP: A Global Structure Attention Pooling Method for Graph-Based Visual Place Recognition. Remote Sensing. 2021; 13(8):1467. https://doi.org/10.3390/rs13081467
Chicago/Turabian StyleYang, Yukun, Bo Ma, Xiangdong Liu, Liang Zhao, and Shoudong Huang. 2021. "GSAP: A Global Structure Attention Pooling Method for Graph-Based Visual Place Recognition" Remote Sensing 13, no. 8: 1467. https://doi.org/10.3390/rs13081467
APA StyleYang, Y., Ma, B., Liu, X., Zhao, L., & Huang, S. (2021). GSAP: A Global Structure Attention Pooling Method for Graph-Based Visual Place Recognition. Remote Sensing, 13(8), 1467. https://doi.org/10.3390/rs13081467