
TAE-Net: Task-Adaptive Embedding Network for Few-Shot Remote Sensing Scene Classification



Abstract
:1. Introduction
- A task-adaptive embedding network based on meta-learning, called TAE-Net, is proposed to enhance the generalization performance of the model for unseen remote sensing images in few-shot settings. The proposed TAE-Net can learn generic feature representations by combining pre-training with meta-training, which can allow models to quickly adapt to new categories with extremely few labeled samples.
- A task-adaptive attention module is developed to capture task-specific information, which can remove the effect of task-irrelevant noises. The proposed task-adaptive attention module aims to adaptively and dynamically pick out discriminative semantic features for diverse tasks.
- Comprehensive experiments on three public remote sensing scene classification datasets verify effectiveness of our proposed model, which exceeds existing state-of-the-art few-shot scene classification approaches and acquires new state-of-the-art performance of few-shot scene classification.
2. Related Work
2.1. Remote Sensing Scene Classification
2.2. Few-Shot Learning
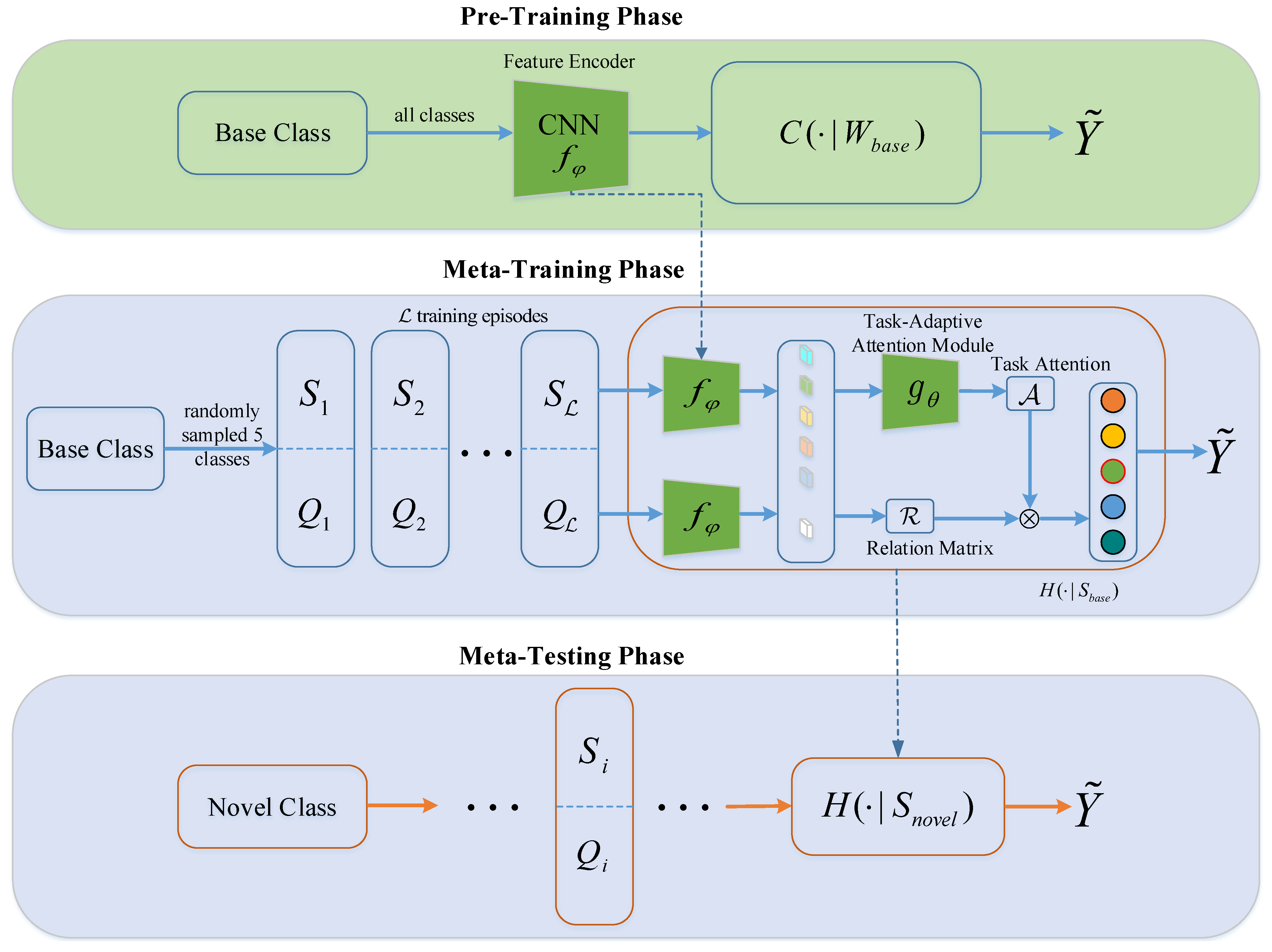
3. Proposed Method
3.1. Overall Architecture
3.2. Problem Formulation
3.3. Pre-Training of Feature Encoder
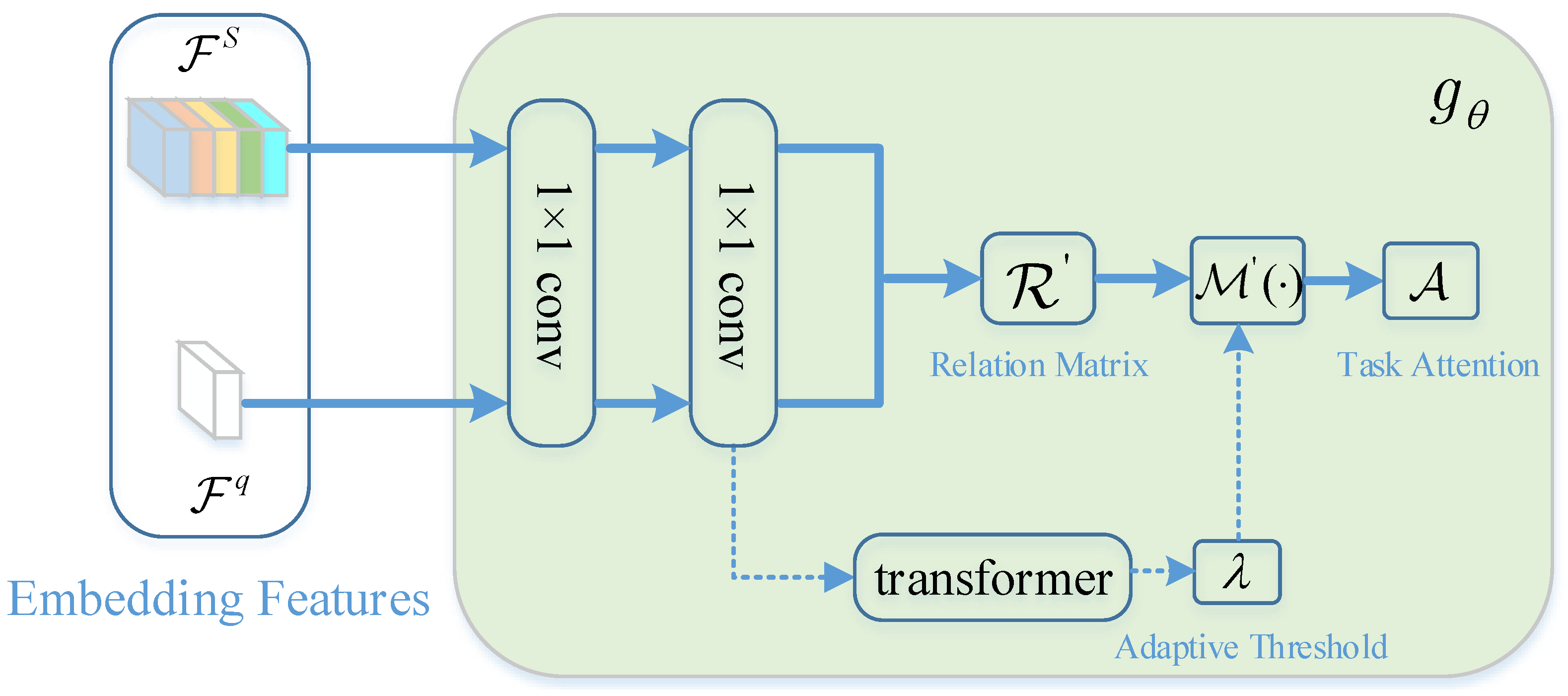
3.4. Meta-Training with Task-Adaptive Attention Module
3.5. Meta-Testing
4. Results and Discussions
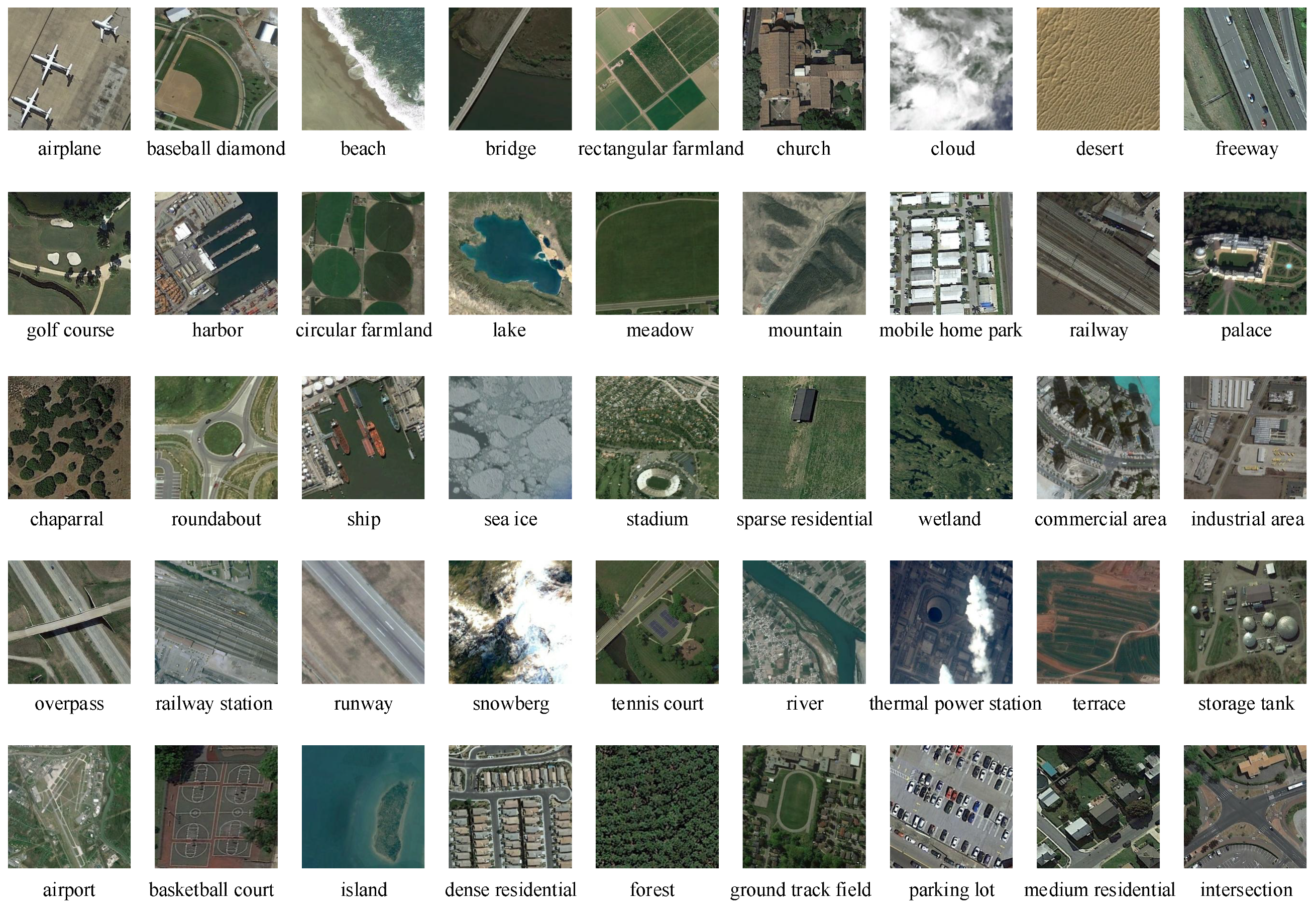
4.1. Dataset Description
4.2. Experimental Settings
4.3. Experimental Results
4.3.1. Experimental Results on UC Merced Dataset
4.3.2. Experimental Results on WHU-RS19 Dataset
4.3.3. Experimental Results on NWPU-RESISC45 Dataset
4.4. Ablation Study
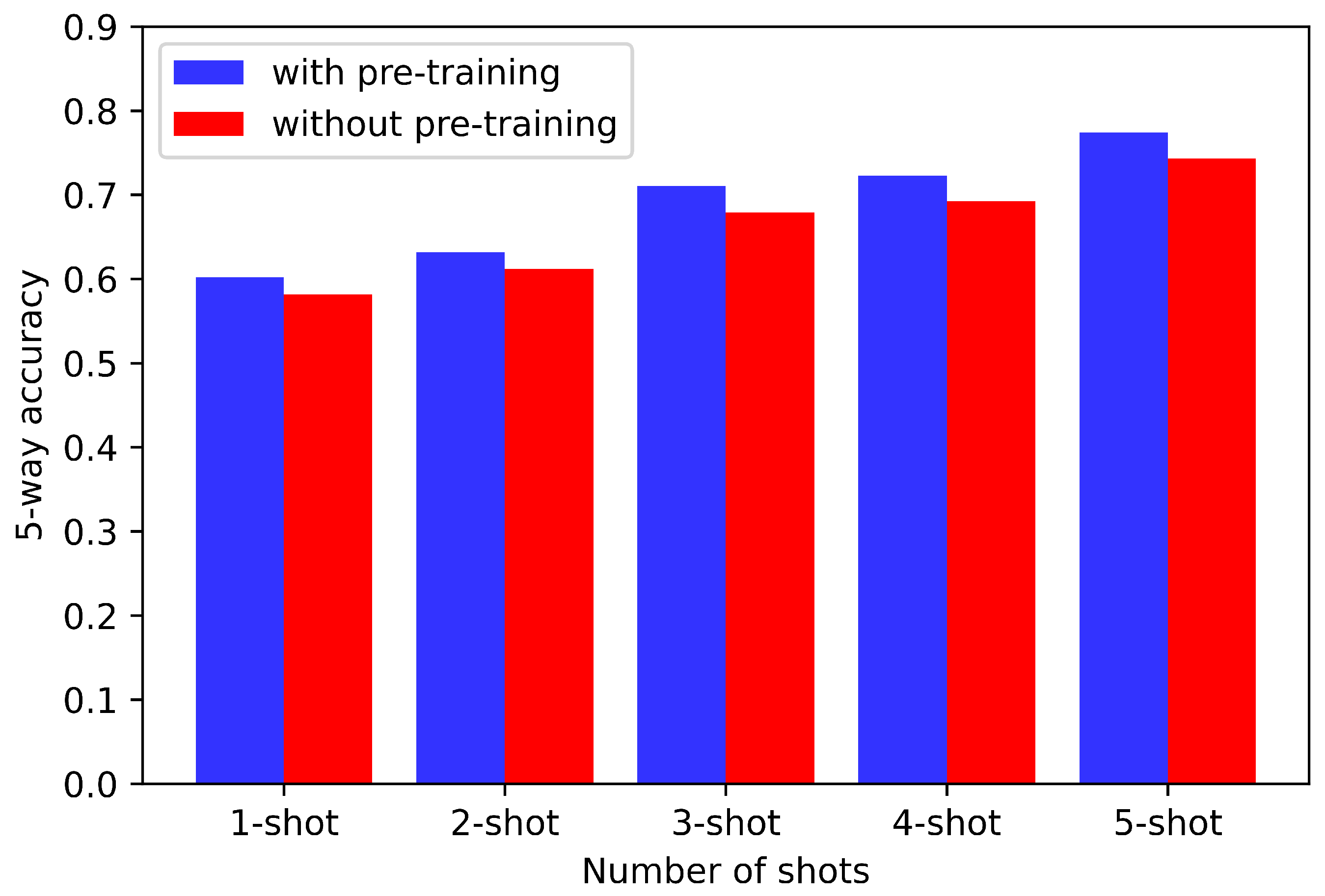
4.4.1. Effect of Pre-Training Strategy
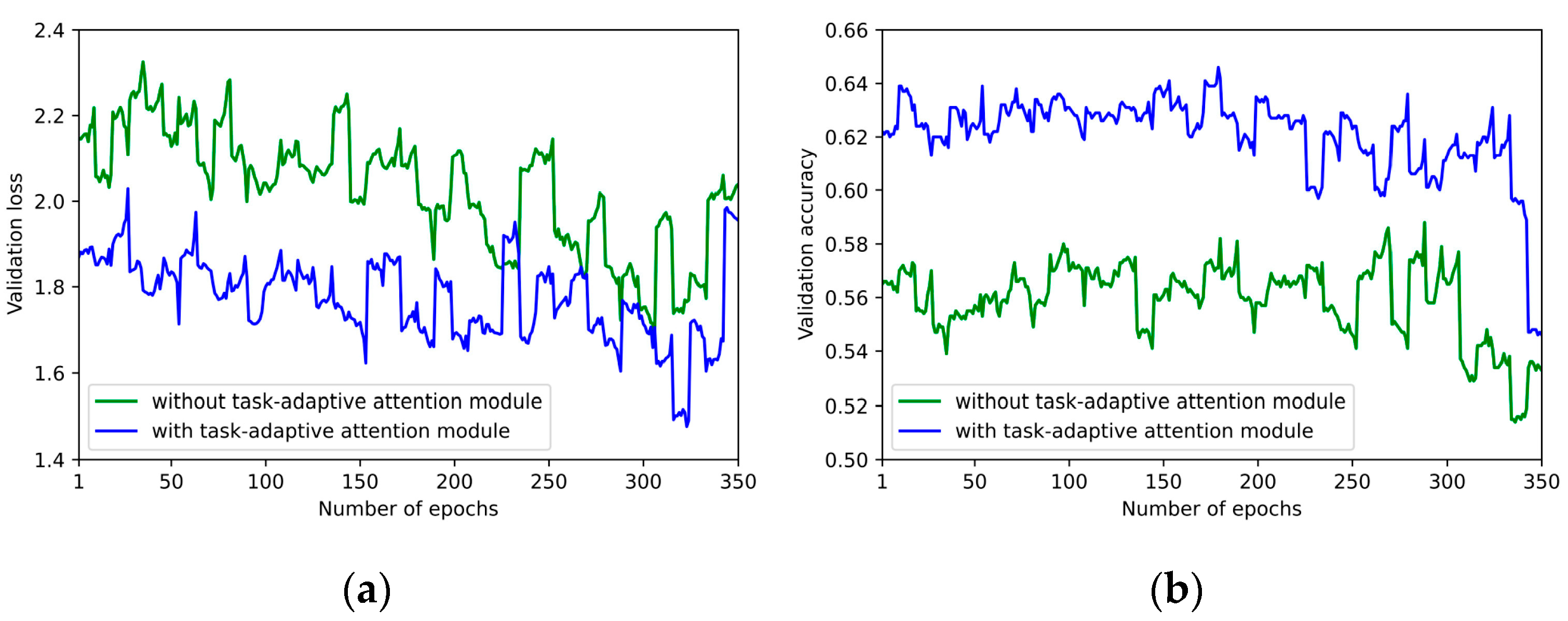
4.4.2. Effect of Task-Adaptive Attention Module
4.4.3. Effect of Shots
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Pham, H.M.; Yamaguchi, Y.; Bui, T.Q. A case study on the relation between city planning and urban growth using remote sensing and spatial metrics. Landsc. Urban Plan. 2011, 100, 223–230. [Google Scholar] [CrossRef]
- Zhang, G.; Lu, S.; Zhang, W. CAD-Net: A context-aware detection network for objects in remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2019, 57, 10015–10024. [Google Scholar] [CrossRef] [Green Version]
- Cheng, G.; Guo, L.; Zhao, T.; Han, J.; Li, H.; Fang, J. Automatic landslide detection from remote-sensing imagery using a scene classification method based on BoVW and pLSA. Int. J. Remote Sens. 2013, 34, 45–59. [Google Scholar] [CrossRef]
- Jahromi, M.N.; Jahromi, M.N.; Pourghasemi, H.R.; Zand-Parsa, S.; Jamshidi, S. Accuracy assessment of forest mapping in MODIS land cover dataset using fuzzy set theory. In Forest Resources Resilience and Conflicts; Elsevier: Amsterdam, The Netherlands, 2021; pp. 165–183. [Google Scholar]
- Li, Y.; Yang, J. Meta-learning baselines and database for few-shot classification in agriculture. Comput. Electron. Agric. 2021, 182, 106055. [Google Scholar] [CrossRef]
- Li, X.; Shao, G. Object-based urban vegetation mapping with high-resolution aerial photography as a single data source. Int. J. Remote Sens. 2013, 34, 771–789. [Google Scholar] [CrossRef]
- Fang, B.; Li, Y.; Zhang, H.; Chan, J.C.W. Semi-supervised deep learning classification for hyperspectral image based on dual-strategy sample selection. Remote Sens. 2018, 10, 574. [Google Scholar] [CrossRef] [Green Version]
- Tai, X.; Li, M.; Xiang, M.; Ren, P. A mutual guide framework for training hyperspectral image classifiers with small data. IEEE Trans. Geosci. Remote Sens. 2021, 1–17. [Google Scholar] [CrossRef]
- Denisova, A.Y.; Kavelenova, L.M.; Korchikov, E.S.; Prokhorova, N.V.; Terentyeva, D.A.; Fedoseev, V.A. Tree species classification for clarification of forest inventory data using Sentinel-2 images. In Proceedings of the Seventh International Conference on Remote Sensing and Geoinformation of the Environment, Paphos, Cyprus, 18–21 March 2019; International Society for Optics and Photonics: Bellingham, WA, USA, 2019; Volume 11174, p. 1117408. [Google Scholar]
- Alajaji, D.; Alhichri, H.S.; Ammour, N.; Alajlan, N. Few-shot learning for remote sensing scene classification. In Proceedings of the 2020 Mediterranean and Middle-East Geoscience and Remote Sensing Symposium (M2GARSS), Tunis, Tunisia, 9–11 March 2020; pp. 81–84. [Google Scholar]
- Cen, F.; Wang, G. Boosting occluded image classification via subspace decomposition-based estimation of deep features. IEEE Trans. Cybern. 2019, 50, 3409–3422. [Google Scholar] [CrossRef] [Green Version]
- Noothout, J.M.; De Vos, B.D.; Wolterink, J.M.; Postma, E.M.; Smeets, P.A.; Takx, R.A.; Leiner, T.; Viergever, M.A.; Išgum, I. Deep learning-based regression and classification for automatic landmark localization in medical images. IEEE Trans. Med. Imaging 2020, 39, 4011–4022. [Google Scholar] [CrossRef]
- Du, L.; Li, L.; Guo, Y.; Wang, Y.; Ren, K.; Chen, J. Two-Stream Deep Fusion Network Based on VAE and CNN for Synthetic Aperture Radar Target Recognition. Remote Sens. 2021, 13, 4021. [Google Scholar] [CrossRef]
- Andriyanov, N.; Dementiev, V.; Gladkikh, A. Analysis of the Pattern Recognition Efficiency on Non-Optical Images. In Proceedings of the 2021 IEEE Ural Symposium on Biomedical Engineering, Radioelectronics and Information Technology (USBEREIT), Yekaterinburg, Russia, 13–14 May 2021; pp. 319–323. [Google Scholar]
- Xu, P.; Li, Q.; Zhang, B.; Wu, F.; Zhao, K.; Du, X.; Yang, C.; Zhong, R. On-Board Real-Time Ship Detection in HISEA-1 SAR Images Based on CFAR and Lightweight Deep Learning. Remote Sens. 2021, 13, 1995. [Google Scholar] [CrossRef]
- Wu, B.; Meng, D.; Zhao, H. Semi-supervised learning for seismic impedance inversion using generative adversarial networks. Remote Sens. 2021, 13, 909. [Google Scholar] [CrossRef]
- Liu, Y.; Zhong, Y.; Fei, F.; Zhang, L. Scene semantic classification based on random-scale stretched convolutional neural network for high-spatial resolution remote sensing imagery. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium, Beijing, China, 10–15 July 2016; pp. 763–766. [Google Scholar]
- Zeng, Q.; Geng, J.; Huang, K.; Jiang, W.; Guo, J. Prototype Calibration with Feature Generation for Few-Shot Remote Sensing Image Scene Classification. Remote Sens. 2021, 13, 2728. [Google Scholar] [CrossRef]
- Geng, J.; Deng, X.; Ma, X.; Jiang, W. Transfer learning for SAR image classification via deep joint distribution adaptation networks. IEEE Trans. Geosci. Remote Sens. 2020, 58, 5377–5392. [Google Scholar] [CrossRef]
- Chang, H.; Yeung, D.Y. Semisupervised metric learning by kernel matrix adaptation. In Proceedings of the International Conference on Machine Learning and Cybernetics, Guangzhou, China, 18–21 August 2005; Volume 5, pp. 3210–3215. [Google Scholar]
- Lee, K.; Maji, S.; Ravichandran, A.; Soatto, S. Meta-learning with differentiable convex optimization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 10657–10665. [Google Scholar]
- Shao, L.; Zhu, F.; Li, X. Transfer learning for visual categorization: A survey. IEEE Trans. Neural Netw. Learn. Syst. 2014, 26, 1019–1034. [Google Scholar] [CrossRef] [PubMed]
- Koch, G.; Zemel, R.; Salakhutdinov, R. Siamese neural networks for one-shot image recognition. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; Volume 2. [Google Scholar]
- Vinyals, O.; Blundell, C.; Lillicrap, T.; Kavukcuoglu, K.; Wierstra, D. Matching networks for one shot learning. Proc. Neural Inf. Process. Syst. 2016, 29, 3630–3638. [Google Scholar]
- Snell, J.; Swersky, K.; Zemel, R.S. Prototypical networks for few-shot learning. Proc. Neural Inf. Process. Syst. 2017, 30, 4077–4087. [Google Scholar]
- Sung, F.; Yang, Y.; Zhang, L.; Xiang, T.; Torr, P.H.; Hospedales, T.M. Learning to compare: Relation network for few-shot learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1199–1208. [Google Scholar]
- Zhang, C.; Cai, Y.; Lin, G.; Shen, C. DeepEMD: Few-Shot Image Classification With Differentiable Earth Mover’s Distance and Structured Classifiers. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 12203–12213. [Google Scholar]
- Xu, Z.; Cao, L.; Chen, X. Learning to learn: Hierarchical meta-critic networks. IEEE Access 2019, 7, 57069–57077. [Google Scholar] [CrossRef]
- Zhai, M.; Liu, H.; Sun, F. Lifelong learning for scene recognition in remote sensing images. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1472–1476. [Google Scholar] [CrossRef]
- Liu, S.; Deng, W. Very deep convolutional neural network based image classification using small training sample size. In Proceedings of the 3rd IAPR Asian Conference on Pattern Recognition, Kuala Lumpur, Malaysia, 3–6 November 2015; pp. 730–734. [Google Scholar]
- Li, H.; Cui, Z.; Zhu, Z.; Chen, L.; Zhu, J.; Huang, H.; Tao, C. RS-MetaNet: Deep meta metric learning for few-shot remote sensing scene classification. arXiv 2020, arXiv:2009.13364. [Google Scholar] [CrossRef]
- Li, L.; Han, J.; Yao, X.; Cheng, G.; Guo, L. DLA-MatchNet for few-shot remote sensing image scene classification. IEEE Trans. Geosci. Remote Sens. 2020, 59, 7844–7853. [Google Scholar] [CrossRef]
- Jiang, W.; Huang, K.; Geng, J.; Deng, X. Multi-scale metric learning for few-shot learning. IEEE Trans. Circuits Syst. 2020, 31, 1091–1102. [Google Scholar] [CrossRef]
- Ma, H.; Yang, Y. Two specific multiple-level-set models for high-resolution remote-sensing image classification. IEEE Geosci. Remote Sens. Lett. 2009, 6, 558–561. [Google Scholar]
- Wang, Q.; Liu, S.; Chanussot, J.; Li, X. Scene classification with recurrent attention of VHR remote sensing images. IEEE Trans. Geosci. Remote Sens. 2018, 57, 1155–1167. [Google Scholar] [CrossRef]
- Tang, X.; Ma, Q.; Zhang, X.; Liu, F.; Ma, J.; Jiao, L. Attention consistent network for remote sensing scene classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 2030–2045. [Google Scholar] [CrossRef]
- Cheng, G.; Xie, X.; Han, J.; Guo, L.; Xia, G.S. Remote sensing image scene classification meets deep learning: Challenges, methods, benchmarks, and opportunities. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 3735–3756. [Google Scholar] [CrossRef]
- Lu, X.; Gong, T.; Zheng, X. Multisource compensation network for remote sensing cross-domain scene classification. IEEE Trans. Geosci. Remote Sens. 2019, 58, 2504–2515. [Google Scholar] [CrossRef]
- Cheng, G.; Yang, C.; Yao, X.; Guo, L.; Han, J. When deep learning meets metric learning: Remote sensing image scene classification via learning discriminative CNNs. IEEE Trans. Geosci. Remote Sens. 2018, 56, 2811–2821. [Google Scholar] [CrossRef]
- Zhang, W.; Tang, P.; Zhao, L. Remote sensing image scene classification using CNN-CapsNet. Remote Sens. 2019, 11, 494. [Google Scholar] [CrossRef] [Green Version]
- Sun, H.; Li, S.; Zheng, X.; Lu, X. Remote sensing scene classification by gated bidirectional network. IEEE Trans. Geosci. Remote Sens. 2019, 58, 82–96. [Google Scholar] [CrossRef]
- Pires de Lima, R.; Marfurt, K. Convolutional neural network for remote-sensing scene classification: Transfer learning analysis. Remote Sens. 2020, 12, 86. [Google Scholar] [CrossRef] [Green Version]
- Xie, H.; Chen, Y.; Ghamisi, P. Remote Sensing Image Scene Classification via Label Augmentation and Intra-Class Constraint. Remote Sens. 2021, 13, 2566. [Google Scholar] [CrossRef]
- Shi, C.; Zhao, X.; Wang, L. A Multi-Branch Feature Fusion Strategy Based on an Attention Mechanism for Remote Sensing Image Scene Classification. Remote Sens. 2021, 13, 1950. [Google Scholar] [CrossRef]
- Oreshkin, B.N.; Rodriguez, P.; Lacoste, A. Tadam: Task dependent adaptive metric for improved few-shot learning. arXiv 2018, arXiv:1805.10123. [Google Scholar]
- Ren, M.; Triantafillou, E.; Ravi, S.; Snell, J.; Swersky, K.; Tenenbaum, J.B.; Larochelle, H.; Zemel, R.S. Meta-learning for semi-supervised few-shot classification. arXiv 2018, arXiv:1803.00676. [Google Scholar]
- Finn, C.; Abbeel, P.; Levine, S. Model-agnostic meta-learning for fast adaptation of deep networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; PMLR: Sydney, Australia, 2017; pp. 1126–1135. [Google Scholar]
- Nichol, A.; Achiam, J.; Schulman, J. On first-order meta-learning algorithms. arXiv 2018, arXiv:1803.02999. [Google Scholar]
- Sun, Q.; Liu, Y.; Chua, T.S.; Schiele, B. Meta-transfer learning for few-shot learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 403–412. [Google Scholar]
- Jamal, M.A.; Qi, G.J. Task agnostic meta-learning for few-shot learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 11719–11727. [Google Scholar]
- Rusu, A.A.; Rao, D.; Sygnowski, J.; Vinyals, O.; Pascanu, R.; Osindero, S.; Hadsell, R. Meta-learning with latent embedding optimization. arXiv 2018, arXiv:1807.05960. [Google Scholar]
- Li, Z.; Zhou, F.; Chen, F.; Li, H. Meta-sgd: Learning to learn quickly for few-shot learning. arXiv 2017, arXiv:1707.09835. [Google Scholar]
- Gupta, A.; Thadani, K.; O’Hare, N. Effective few-shot classification with transfer learning. In Proceedings of the 28th International Conference on Computational Linguistics, Barcelona, Spain, 8–13 December 2020; pp. 1061–1066. [Google Scholar]
- Dhillon, G.S.; Chaudhari, P.; Ravichandran, A.; Soatto, S. A baseline for few-shot image classification. arXiv 2019, arXiv:1909.02729. [Google Scholar]
- Chen, W.Y.; Liu, Y.C.; Kira, Z.; Wang, Y.C.F.; Huang, J.B. A closer look at few-shot classification. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Liu, Y.; Lee, J.; Park, M.; Kim, S.; Yang, E.; Hwang, S.J.; Yang, Y. Learning to propagate labels: Transductive propagation network for few-shot learning. arXiv 2018, arXiv:1805.10002. [Google Scholar]
- Yang, L.; Li, L.; Zhang, Z.; Zhou, X.; Zhou, E.; Liu, Y. Dpgn: Distribution propagation graph network for few-shot learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 13390–13399. [Google Scholar]
- Li, W.; Wang, L.; Xu, J.; Huo, J.; Gao, Y.; Luo, J. Revisiting local descriptor based image-to-class measure for few-shot learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7260–7268. [Google Scholar]
- Yang, Y.; Newsam, S. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 2–5 November 2010; pp. 270–279. [Google Scholar]
- Sheng, G.; Yang, W.; Xu, T.; Sun, H. High-resolution satellite scene classification using a sparse coding based multiple feature combination. Int. J. Remote Sens. 2012, 33, 2395–2412. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.; Lu, X. Remote sensing image scene classification: Benchmark and state of the art. Proc. IEEE 2017, 105, 1865–1883. [Google Scholar] [CrossRef] [Green Version]
- Ravi, S.; Larochelle, H. Optimization as a model for few-shot learning. In Proceedings of the ICLR, Toulon, France, 24–26 April 2017. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Base | Validation | Novel |
|---|---|---|---|
| Agricultural; | |||
| Baseball diamond; | |||
| Buildings; | Airplane; | Beach; | |
| Parking lot; | Forest; | River; | |
| UC Merced | Harbor; | Runway; | Golf course; |
| Medium residential; | Intersection; | Mobile home park; | |
| Dense residential; | Storage tanks; | Sparse residential; | |
| Chaparral; | Tennis court; | ||
| Freeway; | |||
| Overpass; | |||
| Airport; | |||
| Bridge; | |||
| Football field; | Beach; | Meadow; | |
| Desert; | Forest; | Pond; | |
| WHU-RS19 | Mountain; | Farmland; | River; |
| Industrial; | Park; | Viaduct; | |
| Port; | Railway station; | Commercial; | |
| Residential; | |||
| Parking; | |||
| Airplane;Church; | |||
| Baseball diamond; | |||
| Bridge;Beach; | |||
| Cloud;Freeway; | Commercial area; | Airport; | |
| Desert;Island; | Overpass; | Dense residential; | |
| Chaparral; | Industrial area; | Basketball court; | |
| Harbor;Lake; | Railway station; | Circular farmland; | |
| Meadow;Mountain; | Snowberg; | Intersection; | |
| NWPU-RESISC45 | Palace;Ship; | Runway; | Forest; |
| Railway;Stadium; | Storage tank; | Ground track field; | |
| Wetland; | Terrace; | Parking lot; | |
| Golf course; | Thermal power station; | Medium residential; | |
| Mobile home park; | Tennis court; | River; | |
| Sparse residential; | |||
| Sea ice; | |||
| Roundabout; | |||
| Rectangular farmland; |
| Method | 5-Way 1-Shot | 5-Way 5-Shot |
|---|---|---|
| MatchingNet [24] | 46.16 ± 0.71 | 66.73 ± 0.56 |
| Prototypical Network [25] | 52.62 ± 0.70 | 65.93 ± 0.57 |
| MAML [47] | 43.65 ± 0.68 | 58.43 ± 0.64 |
| Meta-SGD [52] | 50.52 ± 2.61 | 60.82 ± 2.00 |
| Relation Network [26] | 48.89 ± 0.73 | 64.10 ± 0.54 |
| TPN [56] | 53.36 ± 0.77 | 68.23 ± 0.52 |
| LLSR [29] | 39.47 | 57.40 |
| RS-MetaNet [31] | 57.23 ± 0.56 | 76.08 ± 0.28 |
| DLA-MatchNet [32] | 53.76 ± 0.60 | 63.01 ± 0.51 |
| TAE-Net (ours) | 60.21 ± 0.72 | 77.44 ± 0.51 |
| Method | 5-Way 1-Shot | 5-Way 5-Shot |
|---|---|---|
| MatchingNet [24] | 60.60 ± 0.68 | 82.99 ± 0.40 |
| Prototypical Network [25] | 70.88 ± 0.65 | 85.62 ± 0.33 |
| MAML [47] | 46.72 ± 0.55 | 79.88 ± 0.41 |
| Meta-SGD [52] | 51.54 ± 2.31 | 61.74 ± 2.02 |
| Relation Network [26] | 60.54 ± 0.71 | 76.24 ± 0.34 |
| TPN [56] | 59.28 ± 0.72 | 71.20 ± 0.55 |
| LLSR [29] | 57.10 | 70.65 |
| DLA-MatchNet [32] | 68.27 ± 1.83 | 79.89 ± 0.33 |
| TAE-Net (ours) | 73.67 ± 0.74 | 88.95 ± 0.53 |
| Method | 5-Way 1-Shot | 5-Way 5-Shot |
|---|---|---|
| MatchingNet [24] | 54.46 ± 0.77 | 67.87 ± 0.59 |
| Prototypical Network [25] | 50.82 ± 0.84 | 74.38 ± 0.59 |
| MAML [47] | 37.36 ± 0.69 | 45.94 ± 0.68 |
| Meta-SGD [52] | 60.63 ± 0.90 | 75.75 ± 0.65 |
| Relation Network [26] | 58.61 ± 0.83 | 78.63 ± 0.52 |
| TPN [56] | 66.51 ± 0.87 | 78.50 ± 0.56 |
| LLSR [29] | 51.43 | 72.90 |
| RS-MetaNet [31] | 52.78 ± 0.09 | 71.49 ± 0.81 |
| DLA-MatchNet [32] | 68.80 ± 0.70 | 81.63 ± 0.46 |
| TAE-Net (ours) | 69.13 ± 0.83 | 82.37 ± 0.52 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, W.; Yuan, Z.; Yang, A.; Tang, C.; Luo, X. TAE-Net: Task-Adaptive Embedding Network for Few-Shot Remote Sensing Scene Classification. Remote Sens. 2022, 14, 111. https://doi.org/10.3390/rs14010111
Huang W, Yuan Z, Yang A, Tang C, Luo X. TAE-Net: Task-Adaptive Embedding Network for Few-Shot Remote Sensing Scene Classification. Remote Sensing. 2022; 14(1):111. https://doi.org/10.3390/rs14010111
Chicago/Turabian StyleHuang, Wendong, Zhengwu Yuan, Aixia Yang, Chan Tang, and Xiaobo Luo. 2022. "TAE-Net: Task-Adaptive Embedding Network for Few-Shot Remote Sensing Scene Classification" Remote Sensing 14, no. 1: 111. https://doi.org/10.3390/rs14010111
APA StyleHuang, W., Yuan, Z., Yang, A., Tang, C., & Luo, X. (2022). TAE-Net: Task-Adaptive Embedding Network for Few-Shot Remote Sensing Scene Classification. Remote Sensing, 14(1), 111. https://doi.org/10.3390/rs14010111