
Target Classification of Similar Spatial Characteristics in Complex Urban Areas by Using Multispectral LiDAR





Abstract
:1. Introduction
2. Materials
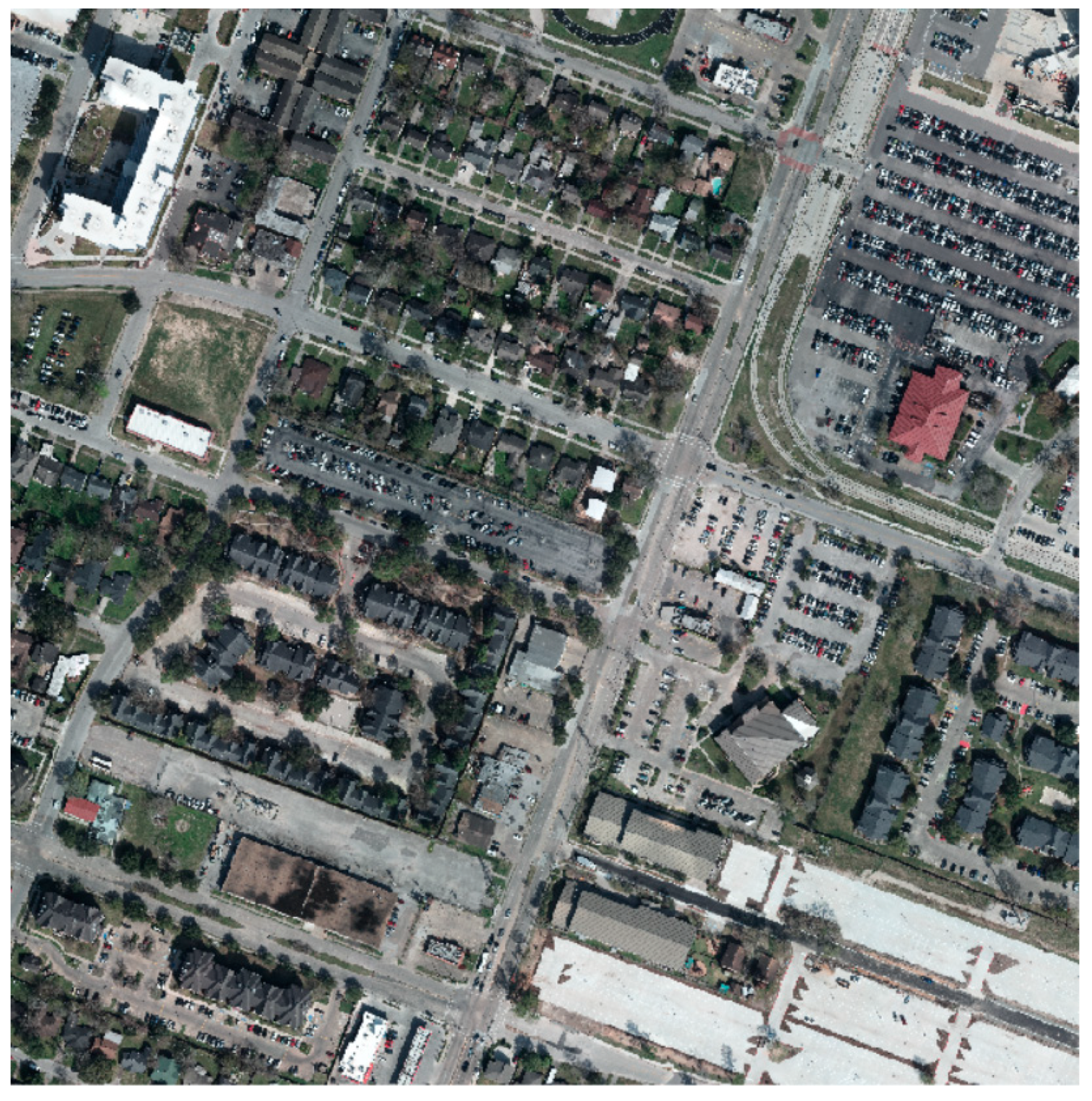
2.1. Multispectral LiDAR Data Acquisition
2.2. Multispectral LiDAR Data Processing
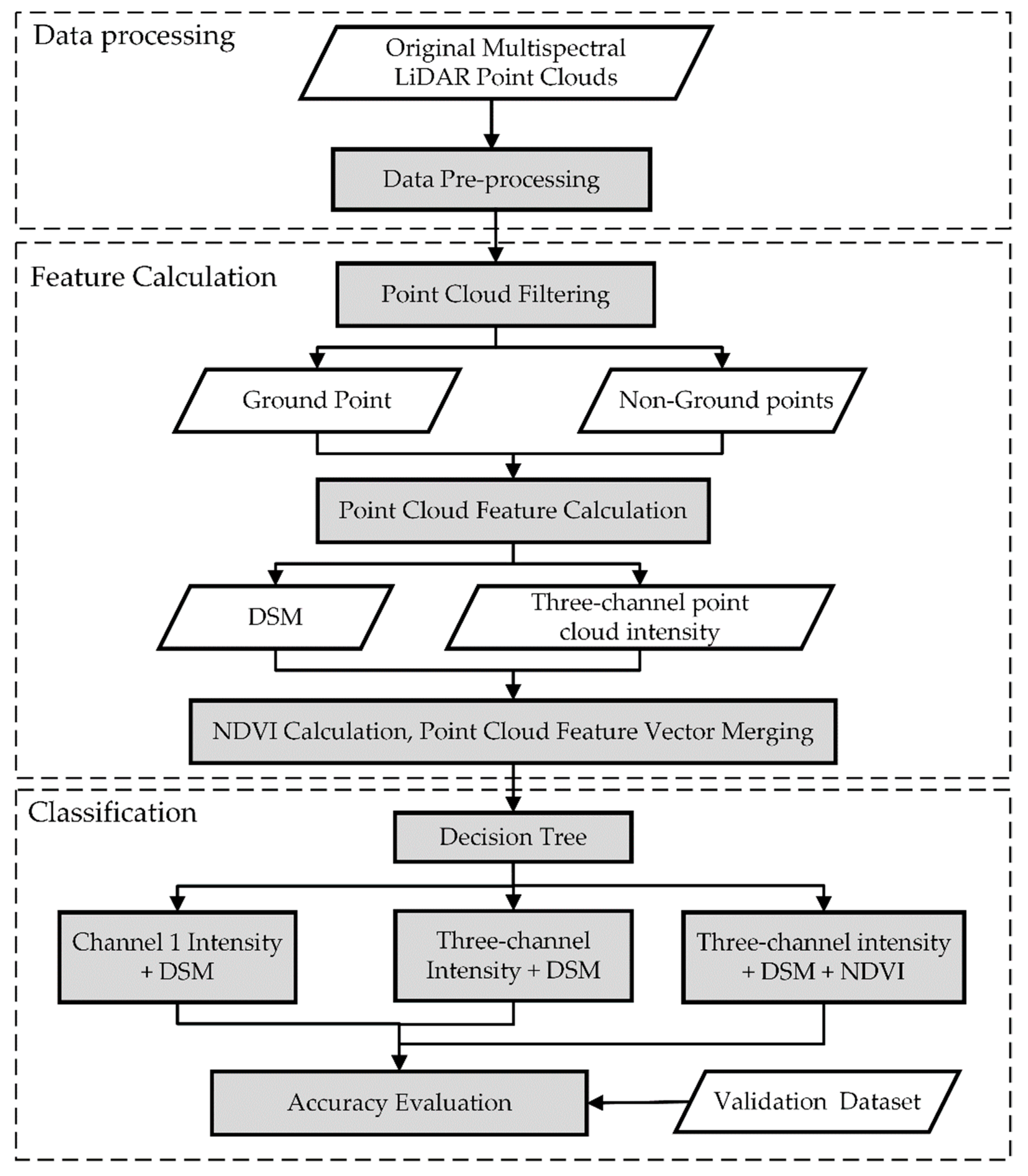
3. Methods
3.1. Point Cloud Filtering
3.2. Produce DSM
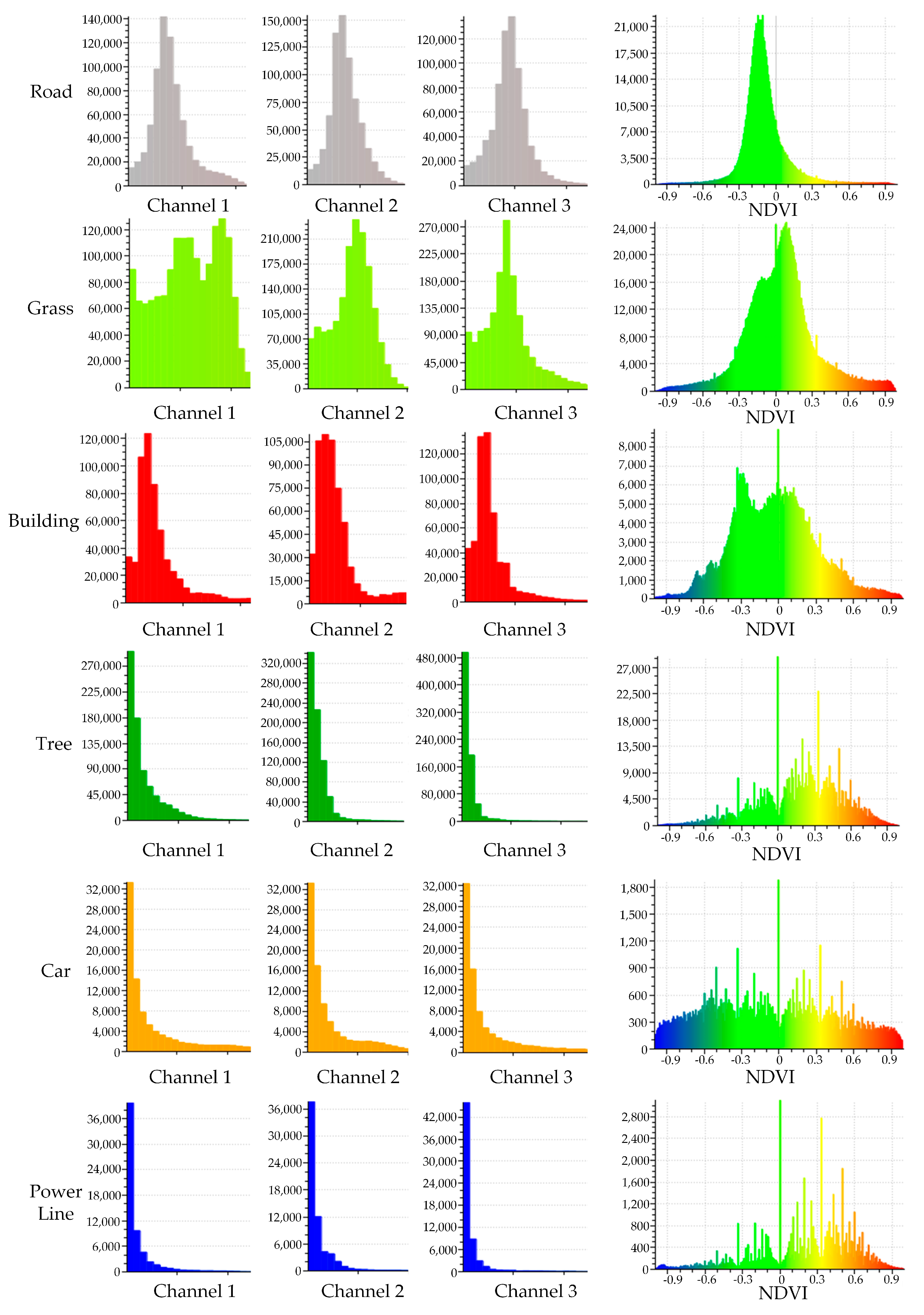
3.3. NDVI Calculation
3.4. Feature Combination
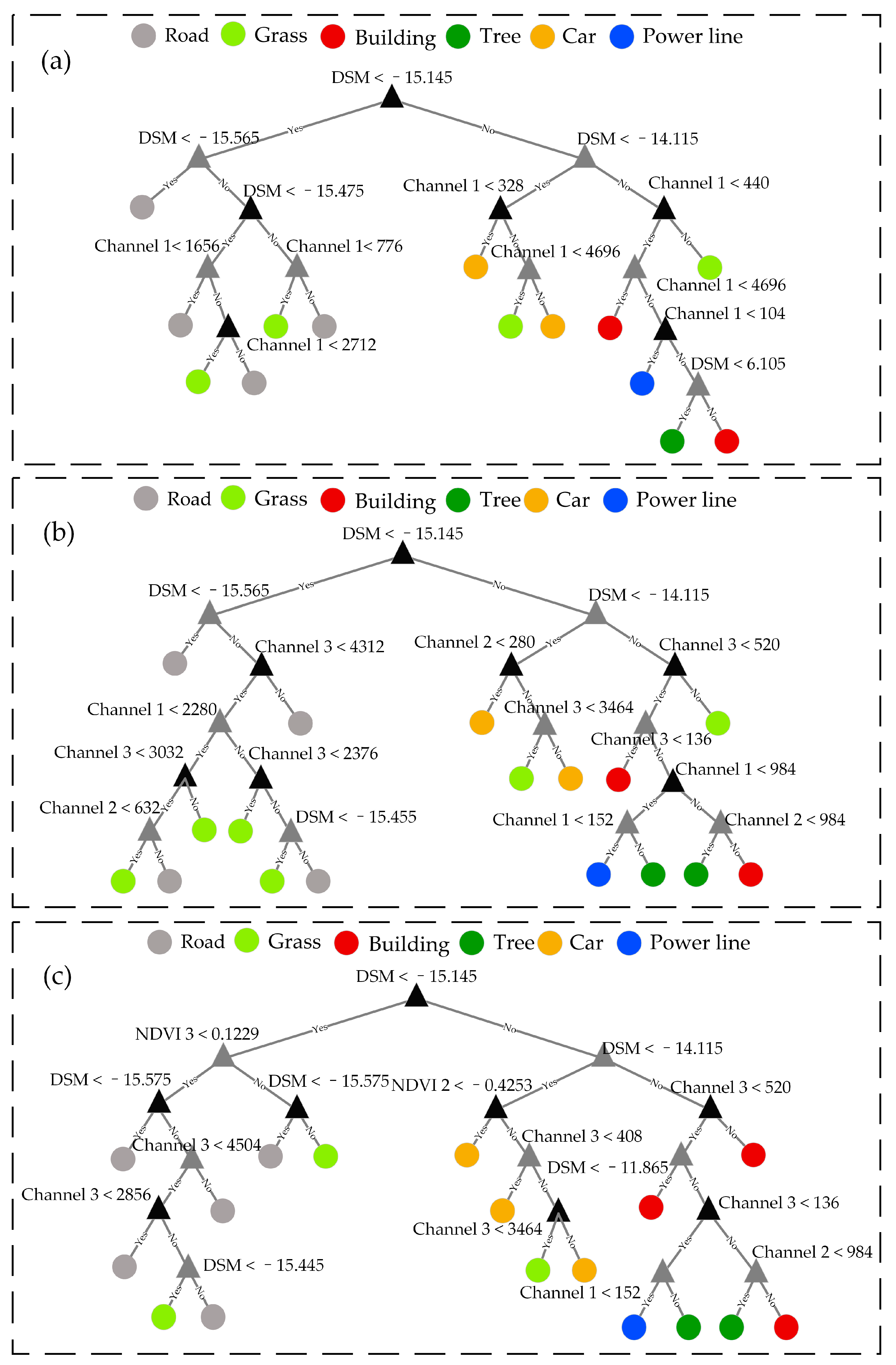
3.5. Decision Tree Construction
4. Results
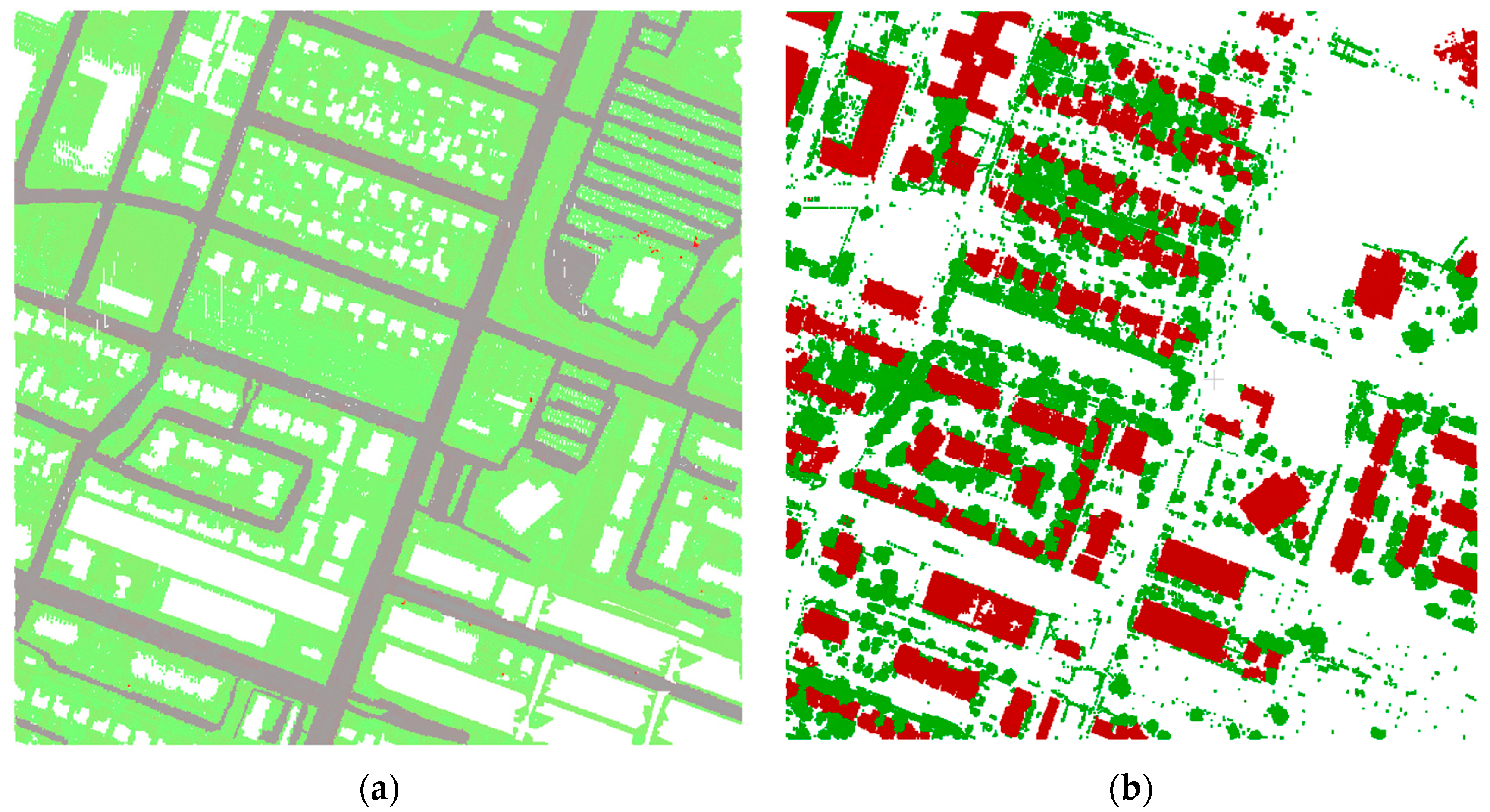
4.1. Point Cloud Filtering Influence on Classification
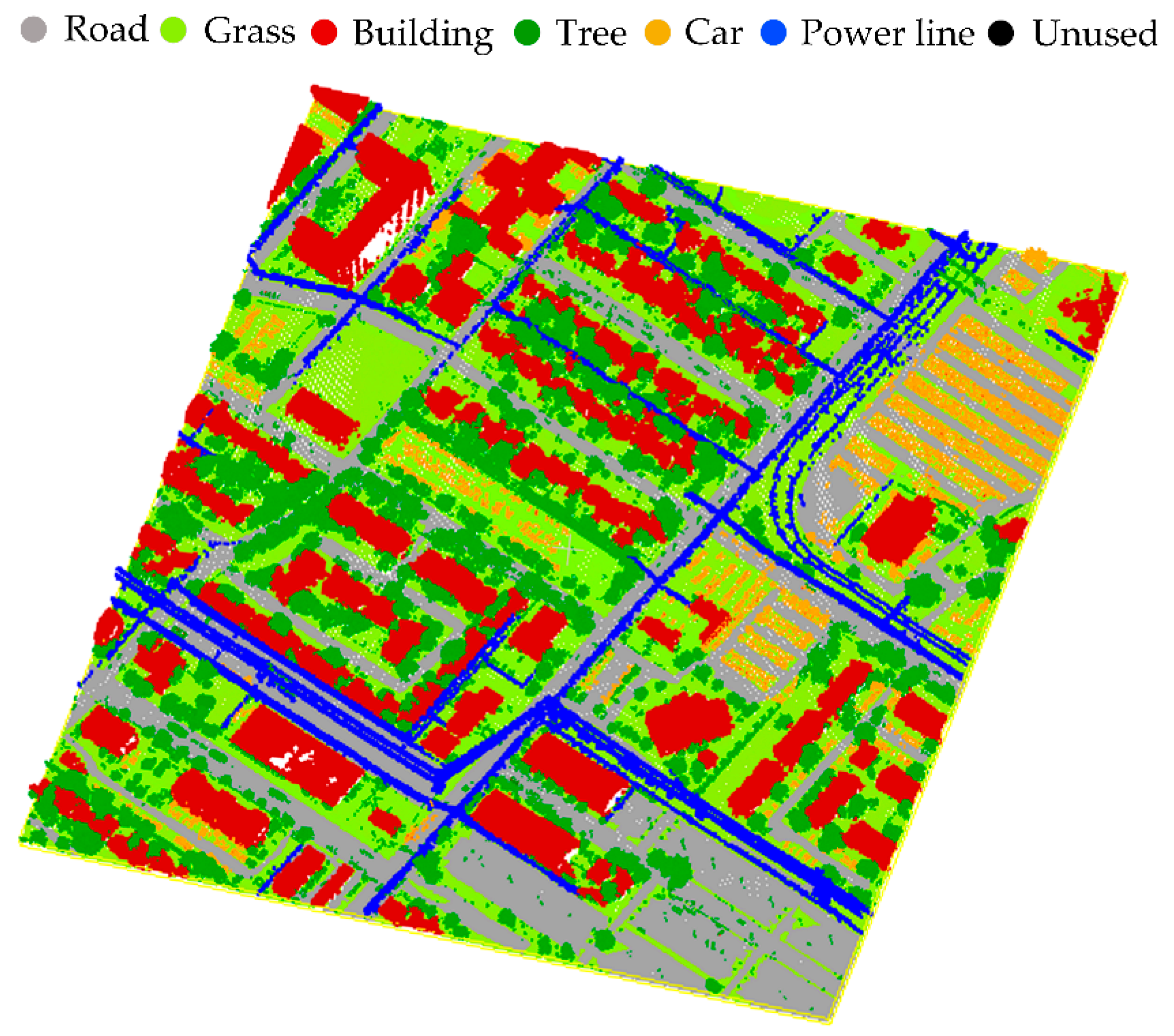
4.2. Decision Tree Classification
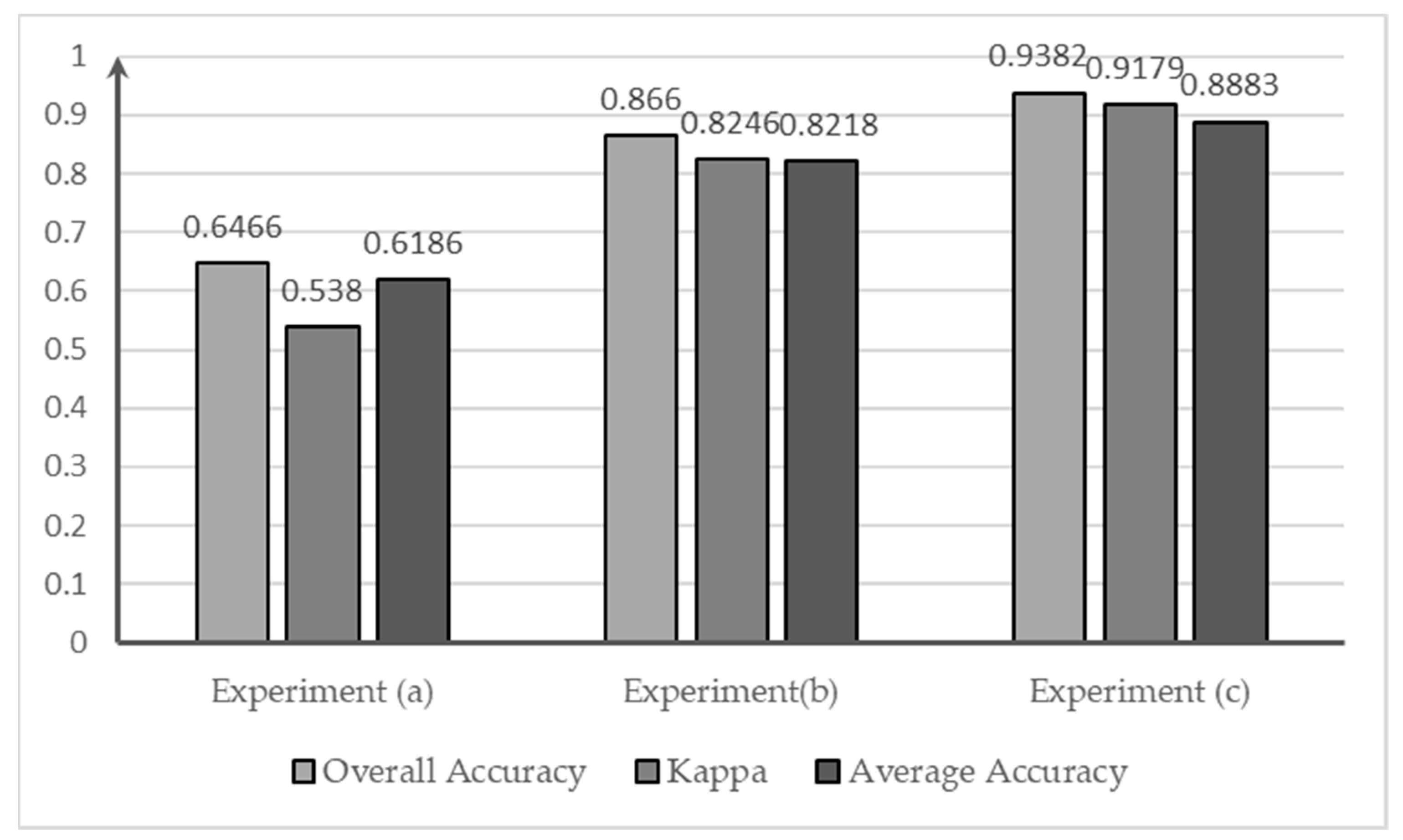
4.3. Comparison of Classification Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Petropoulos, G.P.; Arvanitis, K.; Sigrimis, N. Hyperion hyperspectral imagery analysis combined with machine learning classifiers for land use/cover mapping. Exp. Syst. Appl. 2012, 39, 3800–3809. [Google Scholar] [CrossRef]
- Pal, M. Support vector machine-based feature selection for land cover classification: A case study with DAIS hyperspectral data. Int. J. Remote Sens. 2006, 27, 2877–2894. [Google Scholar] [CrossRef]
- Wei, G.; Shuo, S.; Biwu, C.; Lei, S.S.; Zheng, N.; Cheng, W.; Haiyan, G.; Wei, L.; Shuai, G.; Yi, L.; et al. Development of Hyperspectral Lidar for Earth Observation and Prospects. J. Remote Sens. 2021, 25, 501–513. [Google Scholar]
- Zou, X.; Zhao, G.; Li, J.; Yang, Y.; Fang, Y. 3D land cover classification based on multispectral lidar point clouds. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, 41, 741–747. [Google Scholar] [CrossRef] [Green Version]
- Yan, W.Y.; Shaker, A.; El-Ashmawy, N. Urban land cover classification using airborne LiDAR data: A review. Remote Sens. Environ. 2015, 158, 295–310. [Google Scholar] [CrossRef]
- Axelsson, A.; Lindberg, E.; Olsson, H. Exploring multispectral ALS data for tree species classification. Remote Sens. 2018, 10, 183. [Google Scholar] [CrossRef] [Green Version]
- Grebby, S.; Cunningham, D.; Naden, J.; Tansey, K. Application of airborne LiDAR data and airborne multispectral imagery to structural mapping of the upper section of the Troodos ophiolite, Cyprus. Int. J. Earth Sci. 2012, 101, 1645–1660. [Google Scholar] [CrossRef] [Green Version]
- Yang, J.; Yang, S.; Zhang, Y.; Shi, S.; Du, L. Improving characteristic band selection in leaf biochemical property estimation considering correlations among biochemical parameters based on the PROPSECT-D model. Opt. Express 2021, 29, 400–414. [Google Scholar] [CrossRef] [PubMed]
- Priestnall, G.; Jaafar, J.; Duncan, A. Extracting urban features from LiDAR digital surface models. Comput. Environ. Urban Syst. 2000, 24, 65–78. [Google Scholar] [CrossRef]
- Rubinowicz, P.; Czynska, K. Study of city landscape heritage using LiDAR data and 3D-city models. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2015, 40, 1395. [Google Scholar] [CrossRef] [Green Version]
- Ladefoged, T.N.; McCoy, M.D.; Asner, G.P.; Kirch, P.V.; Puleston, C.O.; Chadwick, O.A.; Vitousek, P.M. Agricultural potential and actualized development in Hawai’i: An airborne LiDAR survey of the leeward Kohala field system (Hawai’i Island). J. Archaeol. Sci. 2011, 38, 3605–3619. [Google Scholar] [CrossRef]
- Chase, A.S.; Weishampel, J. Using LiDAR and GIS to investigate water and soil management in the agricultural terracing at Caracol, Belize. Adv. Archaeol. Pract. 2016, 4, 357–370. [Google Scholar] [CrossRef]
- Buján, S.; González-Ferreiro, E.; Reyes-Bueno, F.; Barreiro-Fernández, L.; Crecente, R.; Miranda, D. Land Use Classification from Lidar Data and Ortho-Images in a Rural Area. Photogramm. Rec. 2012, 27, 401–422. [Google Scholar] [CrossRef]
- Man, Q.; Dong, P.; Guo, H. Pixel-and feature-level fusion of hyperspectral and lidar data for urban land-use classification. Int. J. Remote Sens. 2015, 36, 1618–1644. [Google Scholar] [CrossRef]
- Uthe, E.E. Application of surface based and airborne lidar systems for environmental monitoring. J. Air Pollut. Control Assoc. 1983, 33, 1149–1155. [Google Scholar] [CrossRef]
- Guo, J.; Liu, B.; Gong, W.; Shi, L.; Zhang, Y.; Ma, Y.; Zhang, J.; Chen, T.; Bai, K.; Stoffelen, A.; et al. Technical note: First comparison of wind observations from ESA’s satellite mission Aeolus and ground-based radar wind profiler network of China. Atmos. Chem. Phys. 2021, 21, 2945–2958. [Google Scholar] [CrossRef]
- Shi, T.; Han, G.; Ma, X.; Gong, W.; Chen, W.; Liu, J.; Zhang, X.; Pei, Z.; Gou, H.; Bu, L. Quantifying CO2 Uptakes Over Oceans Using LIDAR: A Tentative Experiment in Bohai Bay. Geophys. Res. Lett. 2021, 48, e2020GL091160. [Google Scholar] [CrossRef]
- Wang, W.; He, J.; Miao, Z.; Du, L. Space-Time Linear Mixed-Effects (STLME) model for mapping hourly fine particulate loadings in the Beijing-Tianjin-Hebei region, China. J. Clean. Prod. 2021, 292, 125993. [Google Scholar] [CrossRef]
- Li, H.; Gu, H.; Han, Y.; Yang, J. Fusion of high-resolution aerial imagery and lidar data for object-oriented urban land-cover classification based on svm. In Proceedings of the ISPRS Workshop on Updating Geo-Spatial Databases with Imagery & the 5th ISPRS Workshop on DMGISs, Urumqi, China, 28–29 August 2007. [Google Scholar]
- Zhou, W. An object-based approach for urban land cover classification: Integrating LiDAR height and intensity data. IEEE Geosci. Remote Sens. Lett. 2013, 10, 928–931. [Google Scholar] [CrossRef]
- Morsy, S.; Shaker, A.; El-Rabbany, A. Multispectral LiDAR data for land cover classification of urban areas. Sensors 2017, 17, 958. [Google Scholar] [CrossRef] [Green Version]
- Dai, W.; Yang, B.; Dong, Z.; Shaker, A. A new method for 3D individual tree extraction using multispectral airborne LiDAR point clouds. ISPRS J. Photogramm. Remote Sens. 2018, 144, 400–411. [Google Scholar] [CrossRef]
- Ekhtari, N.; Glennie, C.; Fernandez-Diaz, J.C. Classification of airborne multispectral lidar point clouds for land cover mapping. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 2068–2078. [Google Scholar] [CrossRef]
- Brennan, R.; Webster, T. Object-oriented land cover classification of lidar-derived surfaces. Can. J. Remote Sens. 2006, 32, 162–172. [Google Scholar] [CrossRef]
- Song, J.-H.; Han, S.-H.; Yu, K.; Kim, Y.-I. Assessing the possibility of land-cover classification using lidar intensity data. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2002, 34, 259–262. [Google Scholar]
- Charaniya, A.P.; Manduchi, R.; Lodha, S.K. Supervised parametric classification of aerial lidar data. In Proceedings of the 2004 Conference on Computer Vision and Pattern Recognition Workshop, Washington, DC, USA, 27 June–2 July 2004; p. 30. [Google Scholar]
- Lodha, S.K.; Kreps, E.J.; Helmbold, D.P.; Fitzpatrick, D. Aerial LiDAR data classification using support vector machines (SVM). In Proceedings of the Third International Symposium on 3D Data Processing, Visualization, and Transmission (3DPVT’06), Chapel Hill, NC, USA, 14–16 June 2006; pp. 567–574. [Google Scholar]
- Antonarakis, A.; Richards, K.S.; Brasington, J. Object-based land cover classification using airborne LiDAR. Remote Sens. Environ. 2008, 112, 2988–2998. [Google Scholar] [CrossRef]
- Singh, K.K.; Vogler, J.B.; Shoemaker, D.A.; Meentemeyer, R.K. LiDAR-Landsat data fusion for large-area assessment of urban land cover: Balancing spatial resolution, data volume and mapping accuracy. ISPRS J. Photogramm. Remote Sens. 2012, 74, 110–121. [Google Scholar] [CrossRef]
- Onojeghuo, A.O.; Onojeghuo, A.R. Object-based habitat mapping using very high spatial resolution multispectral and hyperspectral imagery with LiDAR data. Int. J. Appl. Earth Obs. Geoinf. 2017, 59, 79–91. [Google Scholar] [CrossRef]
- Gong, W.; Song, S.; Zhu, B.; Shi, S.; Li, F.; Cheng, X. Multi-wavelength canopy LiDAR for remote sensing of vegetation: Design and system performance. ISPRS J. Photogramm. Remote Sens. 2012, 69, 1–9. [Google Scholar]
- Sun, J.; Shi, S.; Chen, B.; Du, L.; Yang, J.; Gong, W. Combined application of 3D spectral features from multispectral LiDAR for classification. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; pp. 5264–5267. [Google Scholar]
- Hakala, T.; Suomalainen, J.; Kaasalainen, S.; Chen, Y. Full waveform hyperspectral LiDAR for terrestrial laser scanning. Opt. Express 2012, 20, 7119–7127. [Google Scholar] [CrossRef]
- Chen, B.; Shi, S.; Gong, W.; Zhang, Q.; Yang, J.; Du, L.; Sun, J.; Zhang, Z.; Song, S. Multispectral LiDAR point cloud classification: A two-step approach. Remote Sens. 2017, 9, 373. [Google Scholar] [CrossRef] [Green Version]
- Shaker, A.; Yan, W.Y.; LaRocque, P.E. Automatic land-water classification using multispectral airborne LiDAR data for near-shore and river environments. ISPRS J. Photogramm. Remote Sens. 2019, 152, 94–108. [Google Scholar] [CrossRef]
- Kukkonen, M.; Maltamo, M.; Korhonen, L.; Packalen, P. Comparison of multispectral airborne laser scanning and stereo matching of aerial images as a single sensor solution to forest inventories by tree species. Remote Sens. Environ. 2019, 231, 111208. [Google Scholar] [CrossRef]
- Wichmann, V.; Bremer, M.; Lindenberger, J.; Rutzinger, M.; Georges, C.; Petrini-Monteferri, F. Evaluating the potential of multispectral airborne lidar for topographic mapping and land cover classification. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2015, 2, 113–119. [Google Scholar] [CrossRef] [Green Version]
- Shi, S.; Bi, S.; Gong, W.; Chen, B.; Chen, B.; Tang, X.; Qu, F.; Song, S. Land Cover Classification with Multispectral LiDAR Based on Multi-Scale Spatial and Spectral Feature Selection. Remote Sens. 2021, 13, 4118. [Google Scholar] [CrossRef]
- Cohen, J. A coefficient of agreement for nominal scales. Educ. Psychol. Meas. 1960, 20, 37–46. [Google Scholar] [CrossRef]
- Sithole, G.; Vosselman, G. Filtering of airborne laser scanner data based on segmented point clouds. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2005, 36, W19. [Google Scholar]
- Li, Y.; Wu, H.; Xu, H.; An, R.; Xu, J.; He, Q. A gradient-constrained morphological filtering algorithm for airborne LiDAR. Opt. Laser Technol. 2013, 54, 288–296. [Google Scholar] [CrossRef]
- Zhang, J.; Lin, X. Filtering airborne LiDAR data by embedding smoothness-constrained segmentation in progressive TIN densification. ISPRS J. Photogramm. Remote Sens. 2013, 81, 44–59. [Google Scholar] [CrossRef]
- Zhang, W.; Qi, J.; Wan, P.; Wang, H.; Xie, D.; Wang, X.; Yan, G. An easy-to-use airborne LiDAR data filtering method based on cloth simulation. Remote Sens. 2016, 8, 501. [Google Scholar] [CrossRef]
- Yang, L.J.; Jianrong, F.; Jinghua, X. A comparative study on the accuracy of interpolated DEM based on point cloud data. Mapp. Spat. Geogr. Inf. 2013, 36, 37–40. [Google Scholar]
- Kim, S.; Rhee, S.; Kim, T. Digital Surface Model Interpolation Based on 3D Mesh Models. Remote Sens. 2019, 11, 24. [Google Scholar] [CrossRef] [Green Version]
- Boissonnat, J.-D.; Cazals, F. Smooth surface reconstruction via natural neighbour interpolation of distance functions. Comput. Geom. 2002, 22, 185–203. [Google Scholar] [CrossRef] [Green Version]
- Rouse, J.W.; Haas, R.H.; Schell, J.A.; Deering, D.W. Monitoring vegetation systems in the Great Plains with ERTS. NASA Spec. Publ. 1974, 351, 309. [Google Scholar]
- Quinlan, J.R. Induction of decision trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef] [Green Version]
- Wang, T.; Qin, Z.; Jin, Z.; Zhang, S. Handling over-fitting in test cost-sensitive decision tree learning by feature selection, smoothing and pruning. J. Syst. Softw. 2010, 83, 1137–1147. [Google Scholar] [CrossRef]
- Sundhari, S.S. A knowledge discovery using decision tree by Gini coefficient. In Proceedings of the 2011 International Conference on Business, Engineering and Industrial Applications, Kuala Lump, Malaysia, 5 June 2011; pp. 232–235. [Google Scholar]
- Li, M.; Xu, H.; Deng, Y. Evidential decision tree based on belief entropy. Entropy 2019, 21, 897. [Google Scholar] [CrossRef] [Green Version]
- Yu, Y.-Y. Research on Airborne Lidar Point Cloud Filtering and Classification Algorithm. Master’s Thesis, University of Science and Technology of China, Hefei, China, 2020. [Google Scholar]
- Mallet, C.; Soergel, U.; Bretar, F. Analysis of full-waveform lidar data for classification of urban areas. In Proceedings of the ISPRS Congress, Beijing, China, 3–11 July 2008. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Channel 1 | Channel 2 | Channel 3 |
|---|---|---|---|
| Wavelength | 1550 nm MIR | 1064 nm NIR | 532 nm Green |
| Beam divergence | 0.35 mrad(1/e) | 0.35 mrad(1/e) | 0.70 mrad(1/e) |
| Look angle | 3.5° forward | nadir | 7.0° forward |
| Effective PRF | 50–300 kHZ | 50–300 kHZ | 50–300 kHZ |
| Operating altitudes | Topographic: 300–2000 m AGL, all channels Bathymetric: 300–600 m AGL, 532 nm | ||
| Scan angle (FOV) | Programmable; 0–60° maxium | ||
| Intensity capture | Up to 4 range measurements for each pulse, including last 12 bit dynamic measurement and date range | ||
| Class | Road | Grass | Building | Tree | Car | Power Line | Total |
|---|---|---|---|---|---|---|---|
| Number of Points | 1,276,608 | 1,608,238 | 604,086 | 789,220 | 95,109 | 63,220 | 4,436,481 |
| Method | Data | Classification Features |
|---|---|---|
| Method (a) | DSM Channel 1 | Intensity Elevation |
| Method (b) | DSM Titan Tri-band | Elevation Intensity |
| Method (c) | DSM Titan Tri-band Three NDVIs | Elevation Spectrum Vegetation Index |
| Method | Gini | Entropy |
|---|---|---|
| Method (a) | 0.6113 | 5.9405 |
| Method (b) | 0.2369 | 2.7895 |
| Method (c) | 0.1533 | 1.4372 |
| Classification | Reference Data | Total | User’s Accuracy (%) | |||||
|---|---|---|---|---|---|---|---|---|
| Road | Grass | Building | Tree | Car | Power Line | |||
| Road | 1,097,171 | 97,940 | 103,538 | 5132 | 10,223 | 6321 | 1,320,325 | 83.10% |
| Grass | 212,113 | 759,996 | 63,152 | 2352 | 1630 | 7512 | 1,046,755 | 72.61% |
| Building | 102,331 | 273,251 | 572,886 | 59,479 | 4312 | 15,522 | 1,027,781 | 55.74% |
| Tree | 43,451 | 41,643 | 76,325 | 293,421 | 8133 | 74,321 | 537,294 | 54.61% |
| Car | 97,425 | 22,924 | 32,154 | 3211 | 108,176 | 12,312 | 276,202 | 39.17% |
| Power Line | 42,612 | 55,877 | 49,059 | 43,211 | 313 | 37,034 | 228,106 | 16.24% |
| Total | 1,595,103 | 1,251,631 | 897,114 | 406,824 | 132,787 | 153,022 | 4,436,481 | |
| Producer’s accuracy (%) | 68.78% | 60.72% | 63.86% | 72.12% | 81.46% | 24.20% | ||
| Classification | Reference Data | Total | User’s Accuracy (%) | |||||
|---|---|---|---|---|---|---|---|---|
| Road | Grass | Building | Tree | Car | Power Line | |||
| Road | 1,321,096 | 25,978 | 23,313 | 321 | 19,899 | 411 | 1,391,018 | 94.97% |
| Grass | 75,555 | 1,140,993 | 311 | 12 | 1234 | 24 | 1,218,129 | 93.67% |
| Building | 14,721 | 38,967 | 569,436 | 12,675 | 4124 | 18,322 | 658,245 | 86.51% |
| Tree | 25,091 | 3132 | 12,354 | 586,752 | 223 | 44,451 | 672,003 | 87.31% |
| Car | 61,114 | 12,924 | 29,855 | 6249 | 132,969 | 5753 | 193,864 | 68.59% |
| Power Line | 75,925 | 77,935 | 31,003 | 27,765 | 1231 | 90,636 | 304,495 | 29.77% |
| Total | 1,518,502 | 1,298,929 | 666,272 | 633,774 | 159,407 | 159,597 | 4,436,481 | |
| Producer’s accuracy (%) | 87.00% | 87.84% | 85.47% | 92.58% | 83.41% | 56.79% | ||
| Classification | Reference Data | Total | User’s Accuracy (%) | |||||
|---|---|---|---|---|---|---|---|---|
| Road | Grass | Building | Tree | Car | Power Line | |||
| Road | 1,416,547 | 16,019 | 19,211 | 0 | 7091 | 0 | 1,458,868 | 97.10% |
| Grass | 46,407 | 1,286,950 | 311 | 0 | 1630 | 0 | 1,335,298 | 96.38% |
| Building | 14,721 | 9693 | 621,948 | 12,498 | 3216 | 12,332 | 674,408 | 92.22% |
| Tree | 8608 | 1643 | 20,280 | 587,432 | 8133 | 33,173 | 659,269 | 89.10% |
| Car | 3221 | 2924 | 5222 | 6249 | 141,828 | 5753 | 165,197 | 85.85% |
| Power Line | 1207 | 5877 | 9059 | 18,749 | 1123 | 107,426 | 143,441 | 74.89% |
| Total | 1,490,711 | 1,323,106 | 676,031 | 624,928 | 163,021 | 158,684 | 4,436,481 | |
| Producer’s accuracy (%) | 95.02% | 97.26% | 92.00% | 94.00% | 87.00% | 67.70% | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luo, B.; Yang, J.; Song, S.; Shi, S.; Gong, W.; Wang, A.; Du, L. Target Classification of Similar Spatial Characteristics in Complex Urban Areas by Using Multispectral LiDAR. Remote Sens. 2022, 14, 238. https://doi.org/10.3390/rs14010238
Luo B, Yang J, Song S, Shi S, Gong W, Wang A, Du L. Target Classification of Similar Spatial Characteristics in Complex Urban Areas by Using Multispectral LiDAR. Remote Sensing. 2022; 14(1):238. https://doi.org/10.3390/rs14010238
Chicago/Turabian StyleLuo, Binhan, Jian Yang, Shalei Song, Shuo Shi, Wei Gong, Ao Wang, and Lin Du. 2022. "Target Classification of Similar Spatial Characteristics in Complex Urban Areas by Using Multispectral LiDAR" Remote Sensing 14, no. 1: 238. https://doi.org/10.3390/rs14010238
APA StyleLuo, B., Yang, J., Song, S., Shi, S., Gong, W., Wang, A., & Du, L. (2022). Target Classification of Similar Spatial Characteristics in Complex Urban Areas by Using Multispectral LiDAR. Remote Sensing, 14(1), 238. https://doi.org/10.3390/rs14010238