
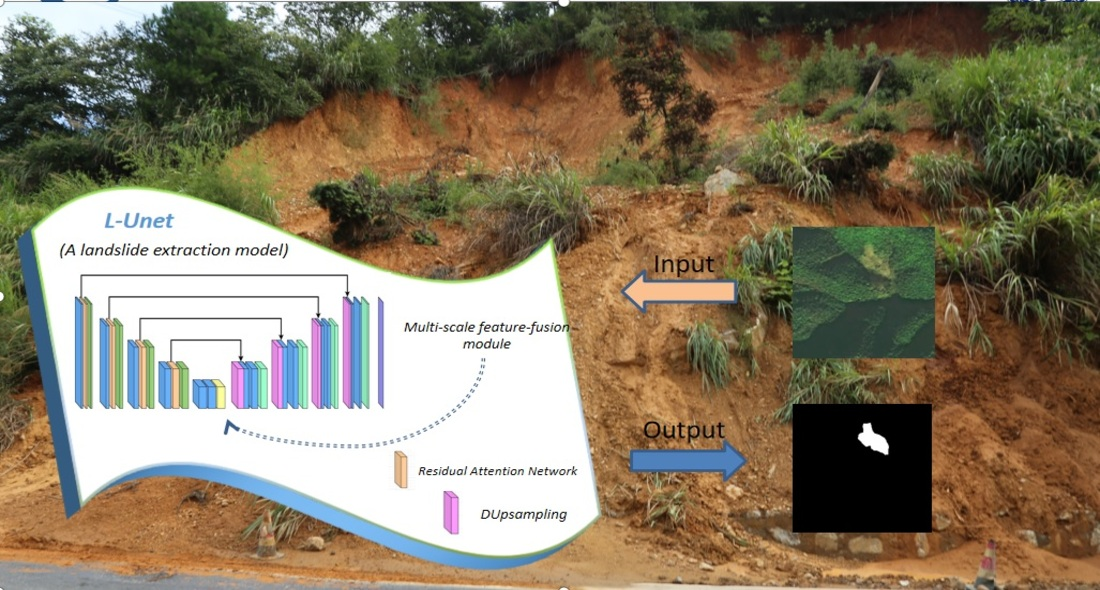
L-Unet: A Landslide Extraction Model Using Multi-Scale Feature Fusion and Attention Mechanism

Abstract
:
1. Introduction
2. Model
2.1. U-Net
2.2. L-Unet
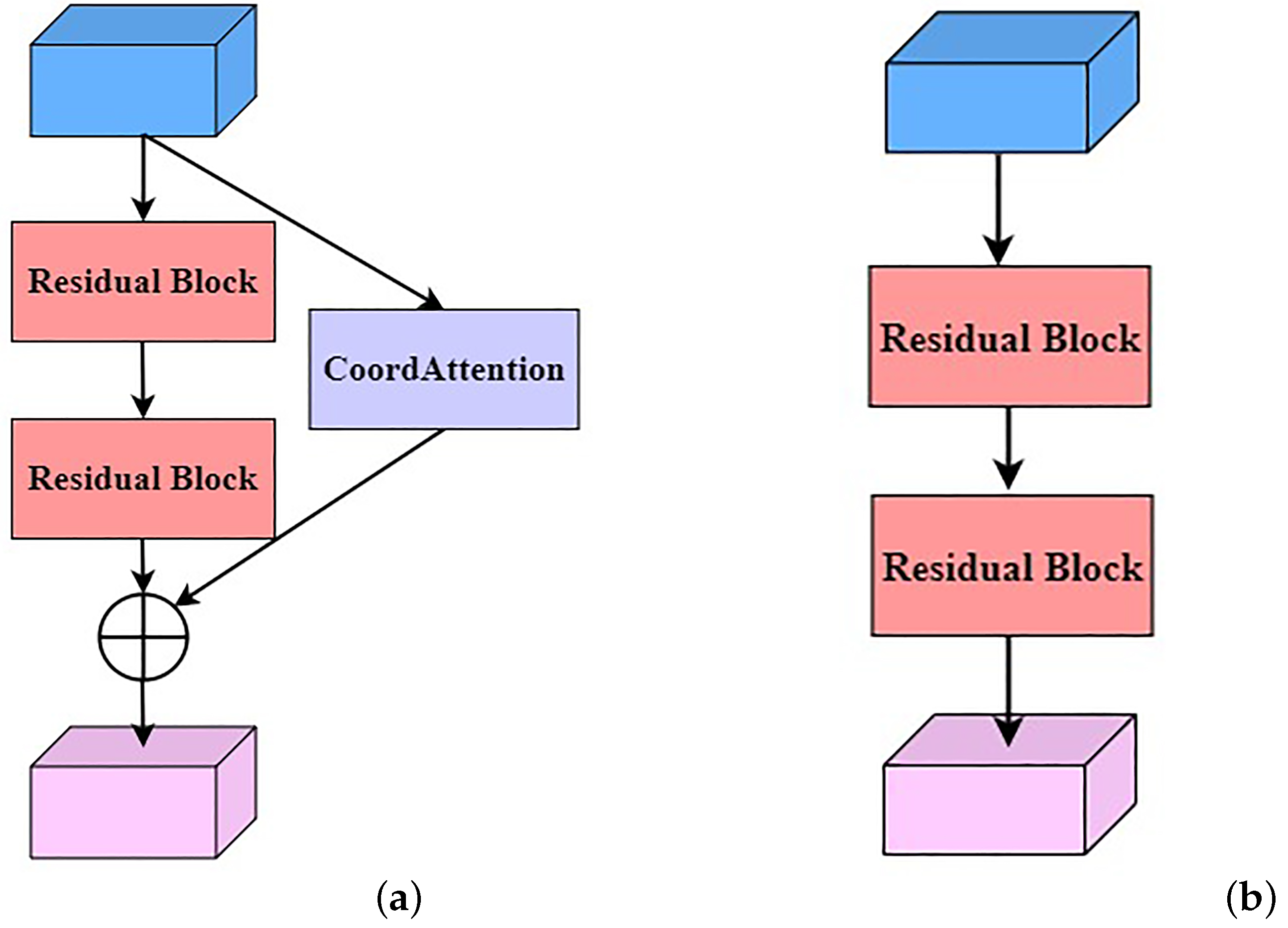
2.2.1. Residual Attention Network
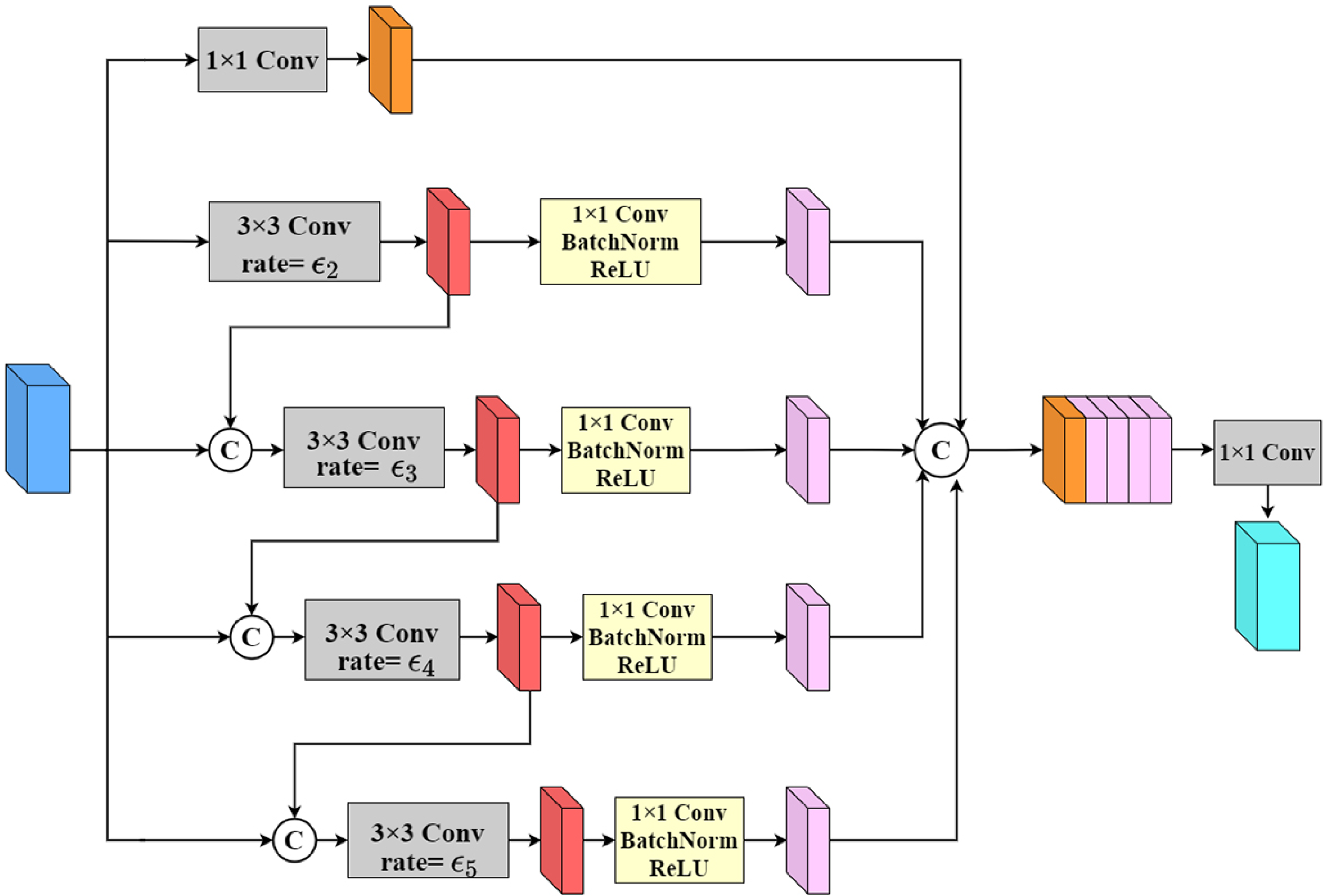
2.2.2. MFF Module
2.2.3. DUpsampling
2.2.4. Loss Function
2.3. Evaluation Indicators
3. Experiment
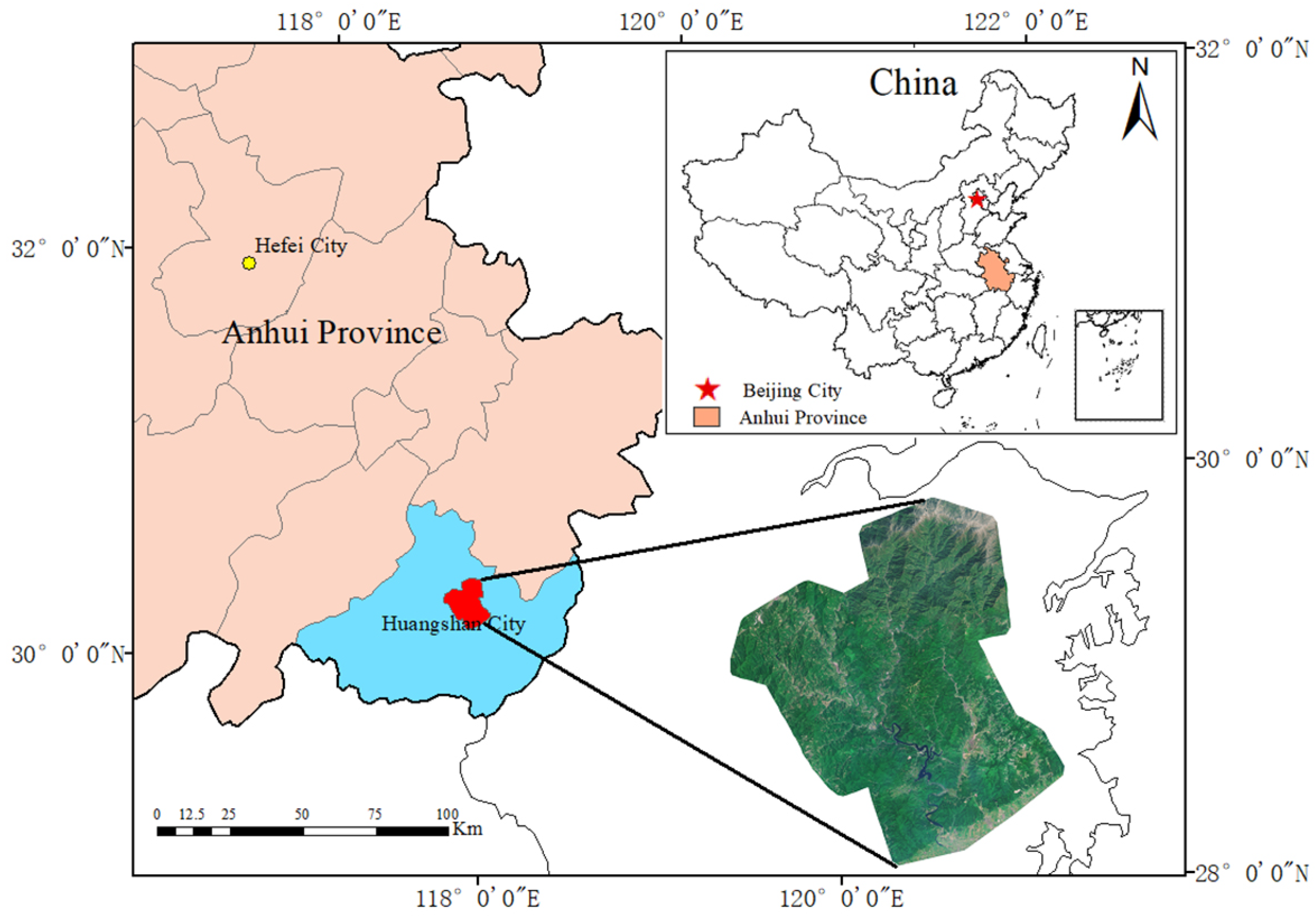
3.1. Study Area
3.2. Dataset
3.3. Experimental Environment
3.4. Results
3.4.1. Comparison of L-Unet with the Baseline Model
3.4.2. Comparison of L-Unet with Other Models
3.4.3. Application Analysis
3.4.4. Comparison of L-Unet with Other Models on a New Dataset
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wang, S.; Zhuang, J.; Zheng, J.; Fan, H.; Kong, J.; Zhan, J. Application of Bayesian Hyperparameter Optimized Random Forest and XGBoost Model for Landslide Susceptibility Mapping. Front. Earth Sci. 2021, 9, 617. [Google Scholar] [CrossRef]
- Tien Bui, D.; Shahabi, H.; Shirzadi, A.; Chapi, K.; Alizadeh, M.; Chen, W.; Mohammadi, A.; Ahmad, B.B.; Panahi, M.; Hong, H.; et al. Landslide detection and susceptibility mapping by airsar data using support vector machine and index of entropy models in cameron highlands, malaysia. Remote Sens. 2018, 10, 1527. [Google Scholar] [CrossRef] [Green Version]
- Hammad, M.; Leeuwen, B.V.; Mucsi, L. Integration of GIS and advanced remote sensing techniques for landslide hazard assessment: A case study of northwest Syria. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2020, 6, 27–34. [Google Scholar] [CrossRef]
- Uddin, M.P.; Mamun, M.A.; Hossain, M.A. PCA-based feature reduction for hyperspectral remote sensing image classification. IETE Tech. Rev. 2021, 38, 377–396. [Google Scholar] [CrossRef]
- Fu, W.; Hong, J. Discussion on application of support vector machine technique in extraction of information on landslide hazard from remote sensing images. Res. Soil Water Conserv. 2006, 13, 120–122. [Google Scholar]
- Xu, C. Automatic extraction of earthquake-triggered landslides based on maximum likelihood method and its validation. Chin. J. Geol. Hazard Control. 2013, 24, 19–25. [Google Scholar]
- Li, X.; Cheng, X.; Chen, W.; Chen, G.; Liu, S. Identification of forested landslides using LiDar data, object-based image analysis, and machine learning algorithms. Remote Sens. 2015, 7, 9705–9726. [Google Scholar] [CrossRef] [Green Version]
- Blaschke, T.; Feizizadeh, B.; Hölbling, D. Object-based image analysis and digital terrain analysis for locating landslides in the Urmia Lake Basin, Iran. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2014, 7, 4806–4817. [Google Scholar] [CrossRef]
- Yang, Y.; Xie, G.; Qu, Y. Real-time Detection of Aircraft Objects in Remote Sensing Images Based on Improved YOLOv4. In Proceedings of the 2021 IEEE 5th Advanced Information Technology, Electronic and Automation Control Conference (IAEAC), Chongqing, China, 12–14 March 2021; pp. 1156–1164. [Google Scholar]
- Niu, R.; Sun, X.; Tian, Y.; Diao, W.; Chen, K.; Fu, K. Hybrid multiple attention network for semantic segmentation in aerial images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–18. [Google Scholar] [CrossRef]
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. Convolutional neural networks for large-scale remote-sensing image classification. IEEE Trans. Geosci. Remote Sens. 2016, 55, 645–657. [Google Scholar] [CrossRef] [Green Version]
- Sameen, M.I.; Pradhan, B. Landslide detection using residual networks and the fusion of spectral and topographic information. IEEE Access 2019, 7, 114363–114373. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, X.; Jian, J. Remote sensing landslide recognition based on convolutional neural network. Math. Probl. Eng. 2019, 2019, 8389368. [Google Scholar] [CrossRef]
- Ghorbanzadeh, O.; Blaschke, T.; Gholamnia, K.; Meena, S.R.; Tiede, D.; Aryal, J. Evaluation of different machine learning methods and deep-learning convolutional neural networks for landslide detection. Remote Sens. 2019, 11, 196. [Google Scholar] [CrossRef] [Green Version]
- Zhang, P.; Xu, C.; Ma, S.; Shao, X.; Tian, Y.; Wen, B. Automatic Extraction of Seismic Landslides in Large Areas with Complex Environments Based on Deep Learning: An Example of the 2018 Iburi Earthquake, Japan. Remote Sens. 2020, 12, 3992. [Google Scholar] [CrossRef]
- Lu, H.; Ma, L.; Fu, X.; Liu, C.; Wang, Z.; Tang, M.; Li, N. Landslides information extraction using object-oriented image analysis paradigm based on deep learning and transfer learning. Remote Sens. 2020, 12, 752. [Google Scholar] [CrossRef] [Green Version]
- Ji, S.; Yu, D.; Shen, C.; Li, W.; Xu, Q. Landslide detection from an open satellite imagery and digital elevation model dataset using attention boosted convolutional neural networks. Landslides 2020, 17, 1337–1352. [Google Scholar] [CrossRef]
- Liu, P.; Wei, Y.; Wang, Q.; Xie, J.; Chen, Y.; Li, Z.; Zhou, H. A research on landslides automatic extraction model based on the improved mask R-CNN. ISPRS Int. J. Geo-Inf. 2021, 10, 168. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the 2015 International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Soares, L.P.; Dias, H.C.; Grohmann, C.H. Landslide Segmentation with U-Net: Evaluating Different Sampling Methods and Patch Sizes. arXiv 2020, arXiv:2007.06672. [Google Scholar]
- Liu, P.; Wei, Y.; Wang, Q.; Chen, Y.; Xie, J. Research on post-earthquake landslide extraction algorithm based on improved U-Net model. Remote Sens. 2020, 12, 894. [Google Scholar] [CrossRef] [Green Version]
- Ghorbanzadeh, O.; Crivellari, A.; Ghamisi, P.; Shahabi, H.; Blaschke, T. A comprehensive transferability evaluation of U-Net and ResU-Net for landslide detection from Sentinel-2 data (case study areas from Taiwan, China, and Japan). Sci. Rep. 2021, 11, 14629. [Google Scholar] [CrossRef]
- Ghorbanzadeh, O.; Shahabi, H.; Crivellari, A.; Homayouni, S.; Blaschke, T.; Ghamisi, P. Landslide detection using deep learning and object-based image analysis. Landslides 2022, 19, 929–939. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 13708–13717. [Google Scholar]
- Tian, Z.; He, T.; Shen, C.; Yan, Y. Decoders matter for semantic segmentation: Data-dependent decoding enables flexible feature aggregation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3121–3130. [Google Scholar]
- Shelhamer, E.; Long, J.; Darrell, T. Fully convolutional networks for semantic segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 640–651. [Google Scholar] [CrossRef] [PubMed]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6230–6239. [Google Scholar]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep high-resolution representation learning for human pose estimation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 5686–5696. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the 2018 European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Liu, Q.; Kampffmeyer, M.; Jenssen, R.; Salberg, A. Dense Dilated Convolutions Merging Network for Semantic Mapping of Remote Sensing Images. In Proceedings of the 2019 Joint Urban Remote Sensing Event (JURSE), Vannes, France, 22–24 May 2019; pp. 1–4. [Google Scholar]
- Li, R.; Duan, C.; Zheng, S.; Zhang, C.; Atkinson, P.M. MACU-Net for Semantic Segmentation of Fine-Resolution Remotely Sensed Images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Precision/% | Recall/% | MIoU/% | F1/% |
|---|---|---|---|---|
| U-Net | 84.39 | 80.89 | 70.36 | 82.60 |
| U-Net+MFF | 87.52 | 81.42 | 72.95 | 84.36 |
| U-Net+MFF+ResNet | 88.34 | 82.65 | 74.52 | 85.40 |
| L-Unet | 88.54 | 83.54 | 75.18 | 85.97 |
| Model | Precision/% | Recall/% | MIoU/% | F1/% |
|---|---|---|---|---|
| FCN-8s | 82.93 | 81.01 | 69.43 | 81.96 |
| SegNet | 85.24 | 77.82 | 68.58 | 81.36 |
| PspNet | 80.58 | 83.27 | 69.35 | 81.90 |
| HRNet | 78.98 | 71.65 | 60.17 | 75.13 |
| Deeplab v3+ | 83.36 | 85.84 | 73.20 | 84.58 |
| Liu et al. [21] | 83.51 | 82.62 | 71.04 | 83.07 |
| DDCM-Net | 86.21 | 83.28 | 74.06 | 84.72 |
| MACU-Net | 80.94 | 81.68 | 68.50 | 81.31 |
| L-Unet | 88.54 | 83.54 | 75.18 | 85.97 |
| Model | Precision/% | Recall/% | MIoU/% | F1/% |
|---|---|---|---|---|
| U-Net | 81.67 | 73.03 | 62.28 | 77.10 |
| FCN-8s | 78.34 | 72.76 | 60.58 | 75.45 |
| Deeplab v3+ | 84.23 | 74.26 | 63.98 | 78.93 |
| DDCM-Net | 84.89 | 70.24 | 62.17 | 76.87 |
| MACU-Net | 80.37 | 74.03 | 62.69 | 77.07 |
| L-Unet | 86.24 | 76.82 | 66.03 | 81.26 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dong, Z.; An, S.; Zhang, J.; Yu, J.; Li, J.; Xu, D. L-Unet: A Landslide Extraction Model Using Multi-Scale Feature Fusion and Attention Mechanism. Remote Sens. 2022, 14, 2552. https://doi.org/10.3390/rs14112552
Dong Z, An S, Zhang J, Yu J, Li J, Xu D. L-Unet: A Landslide Extraction Model Using Multi-Scale Feature Fusion and Attention Mechanism. Remote Sensing. 2022; 14(11):2552. https://doi.org/10.3390/rs14112552
Chicago/Turabian StyleDong, Zhangyu, Sen An, Jin Zhang, Jinqiu Yu, Jinhui Li, and Daoli Xu. 2022. "L-Unet: A Landslide Extraction Model Using Multi-Scale Feature Fusion and Attention Mechanism" Remote Sensing 14, no. 11: 2552. https://doi.org/10.3390/rs14112552
APA StyleDong, Z., An, S., Zhang, J., Yu, J., Li, J., & Xu, D. (2022). L-Unet: A Landslide Extraction Model Using Multi-Scale Feature Fusion and Attention Mechanism. Remote Sensing, 14(11), 2552. https://doi.org/10.3390/rs14112552