1. Introduction
Land cover is a determinant of maintaining the stability of terrestrial ecosystems [
1,
2,
3,
4,
5,
6,
7]. Different methods of land cover classification (LCC) have been developed, in large part owing to increased satellite resolution and efficient algorithms. Using remote sensing images for land surface classification can accurately obtain land cover change information. This technology plays a crucial role in land resource management, urban planning, and environmental protection, among others [
8,
9].
Classifying LCC associated with surface mining is important in areas with heterogeneous environments and offers an effective measure to manage the environment. Several multi-spectral image-based data were used and proven to be effective for LCC in heterogeneous mining areas. For example, Li et al. [
10] used multimodal spectral, spatial, and topographic features of ZiYuan-3 satellite images to classify open-pit mining areas and compared various aspects of machine learning algorithms. Chen et al. [
11] studied an optimized support vector machine (SVM) model to improve the pixel-wise classification accuracy of WorldView-3 imagery.
Chen et al. [
12] reviewed LCC of mining areas using remote sensing data, while Li et al. [
13] used a modified deep belief network (DBN) with multi-level outputs to classify mining areas. Qian et al. [
14] proposed a multiscale kernel-based multistream convolutional neural network (CNNs) model to input three data types for fine LCC. However, the utilized multi-spectral images lack fine spectral information.
Since hyperspectral images (HSI) have rich spectral information, they are important for extracting land cover information. The most typical feature of HSI is high spectral resolution. Therefore, compared with multi-spectral data, HSI can enable finer and more accurate detection of material on the earth’s surface [
15,
16,
17,
18,
19,
20,
21].
During the early period of HSI classification, methods were mainly based on spectral features; however, multiple spectral features contain redundant information. To eliminate the information redundancy of high-dimensional features and reduce the computational difficulty, most researchers have optimized and studied the classification methods based on spectral features from the perspective of dimension reduction. Dimension reduction methods include feature extraction and band selection. Feature extraction is used to map data from high-dimensional space to low-dimensional space and is mainly performed via linear discriminant methods (LDA) [
22], principal component analysis (PCA) [
23], and other methods. Band selection refers to selecting a subset from the original band set with lower dimension. Various strategies have been proposed to select a suitable subset of bands, such as ranking strategy, search strategy, sparse strategy, and clustering strategy [
24]. In the unsupervised band selection method, the clustering-based approach aggregates all bands into different classes or subspaces and selects the bands closest to the center of the clusters. Xie et al. [
25] used primarily the K-means algorithm to continuously calculate the distance between all sample points and the current candidate centers to determine the final clustering center, and then, by traversing all clusters, to select the feature bands. Qian et al. [
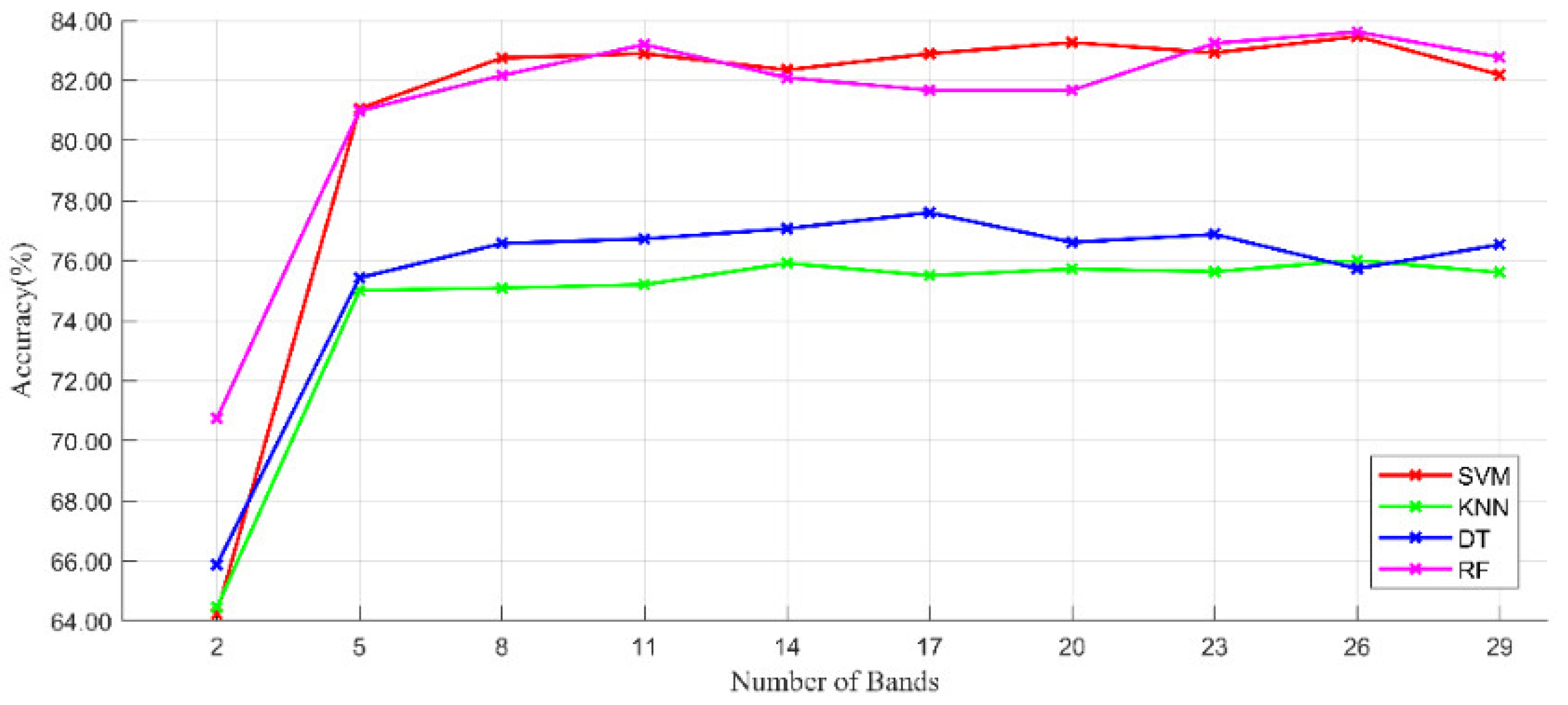
26] proposed a sample-based affinity propagation clustering algorithm that considers the correlation between individual bands and obtained a subset of feature bands by maximizing the objective function. For LCC in heterogeneous mining areas, it is essential to select the effective band subset for HSI.
The method of joint spatial-spectral features utilizes both the spectral features of hyperspectral data and the spatial feature information of images. Kang et al. [
27] used the SVM algorithm and spatial-spectral features to determine the probability of each pixel belonging to a different category. With the continuous advances of deep learning (DL) algorithms, more DL-based methods have been applied to HSI classification owing to their powerful deep feature capture capabilities [
28,
29,
30,
31,
32,
33,
34]. Zheng et al. [
35] studied a learning framework without patches to consider the global information of HSI. In addition, recurrent neural networks (RNN) [
36], DBNs [
37], and generative adversarial networks (GAN) [
38] have also been frequently used for HSI classification. Chen et al. [
39] used a joint channel-space attention mechanism and GAN (JAGAN) model and HSI to classify complex mining landscapes. However, CNNs are most widely used algorithms to capture deep features in HSI classification tasks. Hu et al. [
40] used a one-dimensional CNN for HSI classification, and only used spectral information, while Zhong et al. [
41] proposed a CNN model with a separate two-channel to obtain spectral and spatial features. Makantasis et al. [
42] used a two-dimensional CNN (2D-CNN) that treat spectral bands as feature maps and encode the spectral and spatial information of pixels. Chen et al. [
43] proposed a 3D-CNN model with an L2 regularization spectral and spatial feature extraction method in the classification of HSI. Roy et al. [
33] used 2D-CNN to learn high-level features and 3D-CNN to learn low-level features, which improved classification performance with fewer parameters.
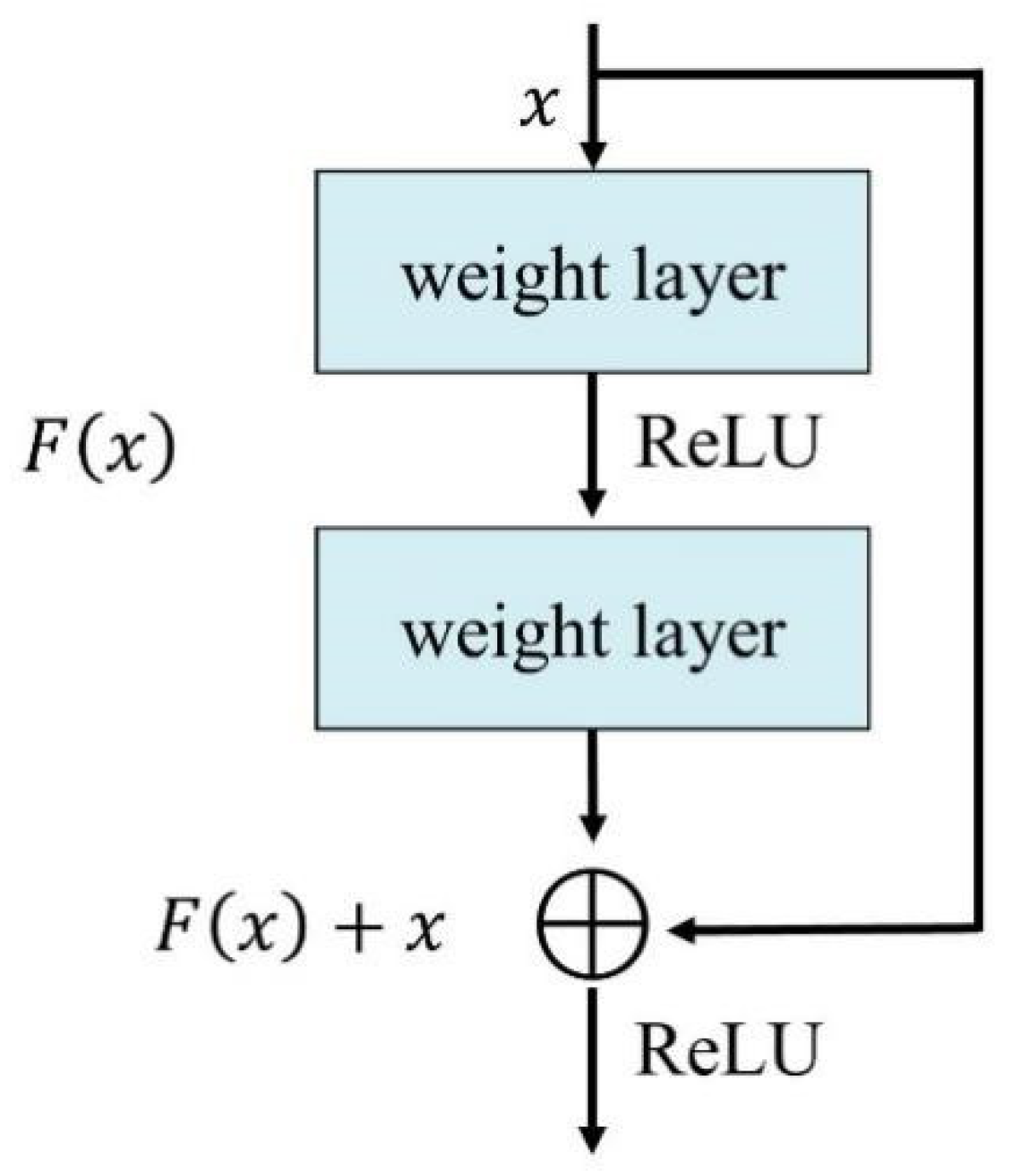
However, traditional CNNs are limited by gradient vanish as the network depth increases, the weights between the layers closer to the input layer cannot be effectively corrected due to how the derivative tends to 0, which may ultimately reduce the classification performance. The gradient often becomes extremely small during the conduction to the input layer, which then causes the connection weights in the lower layers to virtually cease to be updated, and the training never converges to an optimal solution [
44]; to overcome this, residual networks (ResNet) have been proposed [
45]. The internal residual block adds the block’s input directly to the block’s output and activates the ReLU function. A ResNet is constructed by considering several of these residual blocks.
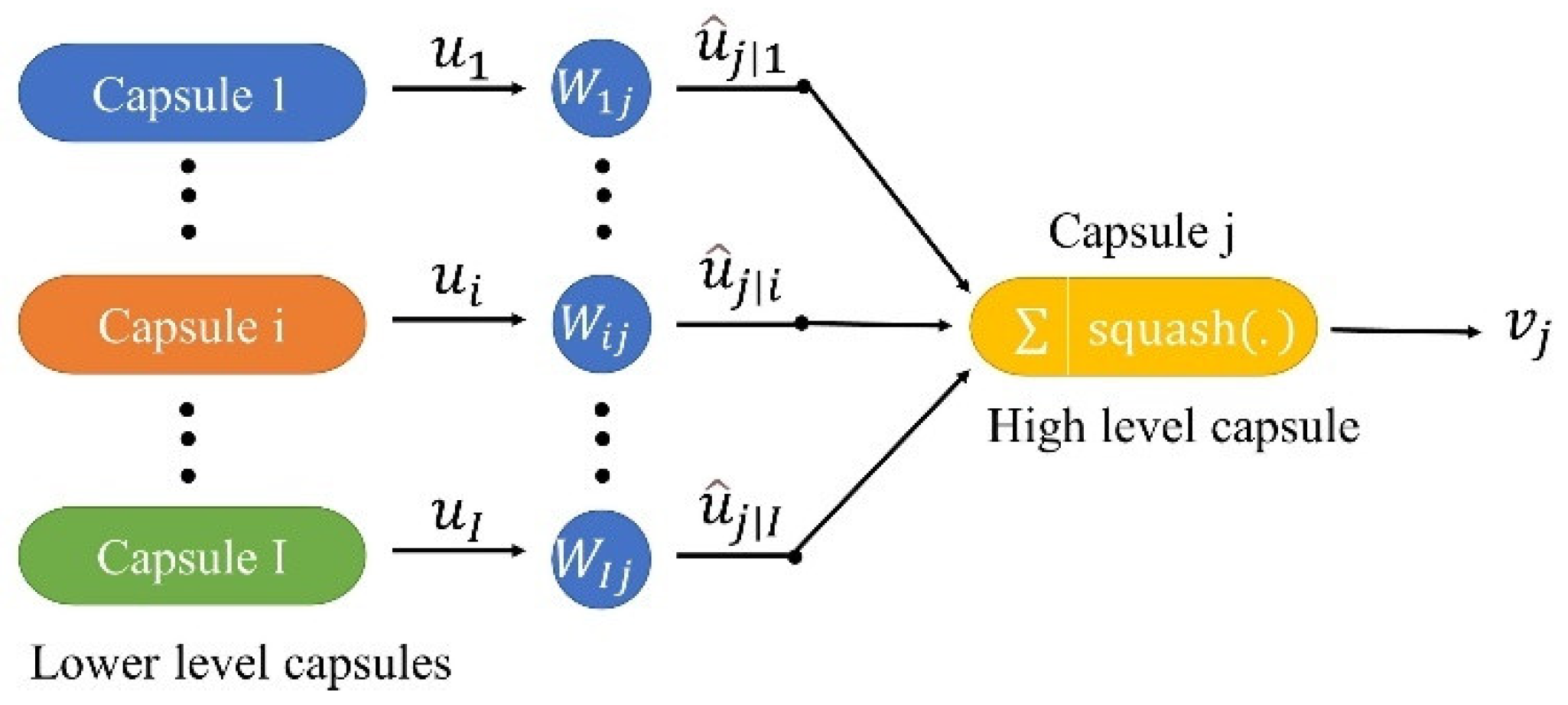
Furthermore, CNNs usually use scalars to represent information, and the ability to exploit the relationships between features detected at different locations in an image is rather limited. When the spatial location of feature information changes, it is difficult for CNNs to identify features. To extract more information, it is necessary to continuously deepen the network layer. The capsule network (CapsNet) [
46] uses capsule vectors and dynamic routing to represent features, which can effectively reveal and learn the discriminative features, and expands new ideas for image classification. Unlike traditional CNN models, these vectors in CapsNet can store the orientation of features. As a result, CapsNet can accurately identify even when the position or angle of the same object changes. Importantly, land covers in heterogeneous mining areas have spatial autocorrelation [
47], and the spatial pattern of remote sensing features may be captured by CapsNet.
Recently, CapsNet has been used in hyperspectral remote sensing image applications. Wang et al. [
48] designed the CapsNet-TripleGAN framework to generate samples and classify HSI efficiently, while Zhu et al. [
49] used a new CapsNet named Conv-CapsNet, reducing the number of model parameters and alleviating the overfitting issue in classification. Paoletti et al. [
50] designed a spectral and spatial CapsNet, which can achieve high-precision classification results of his, while Li et al. [
51] developed a robust CapsNet-based two-channel framework to fuse hyperspectral data with light detection and ranging-derived elevation data for classification. To learn higher level features, Yin et al. [
52] proposed a new architecture to initialize the parameters of the CapsNet for better HSI classification.
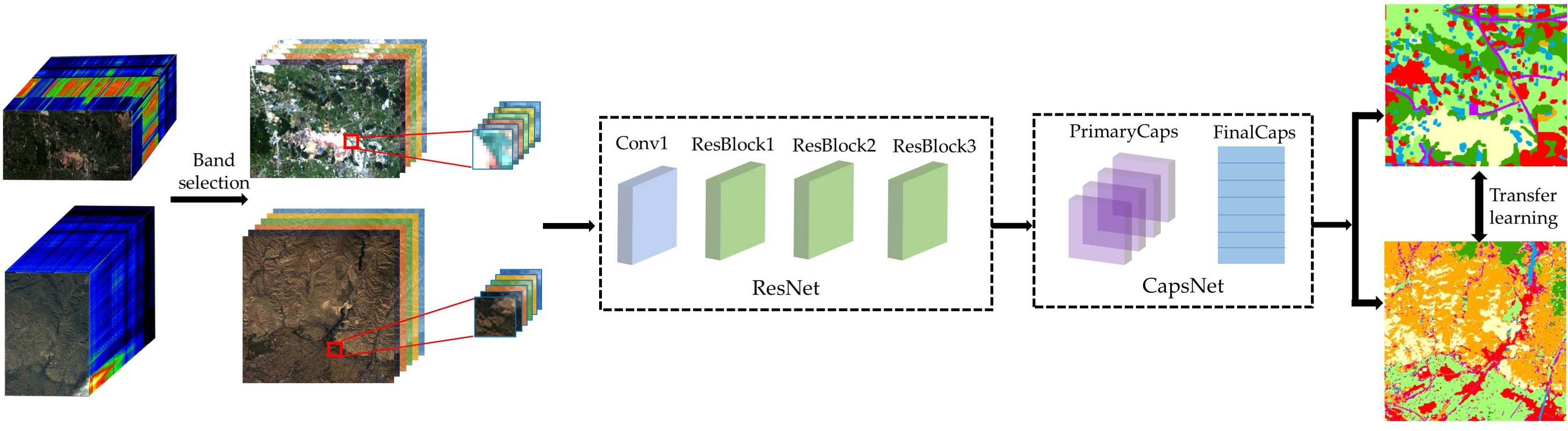
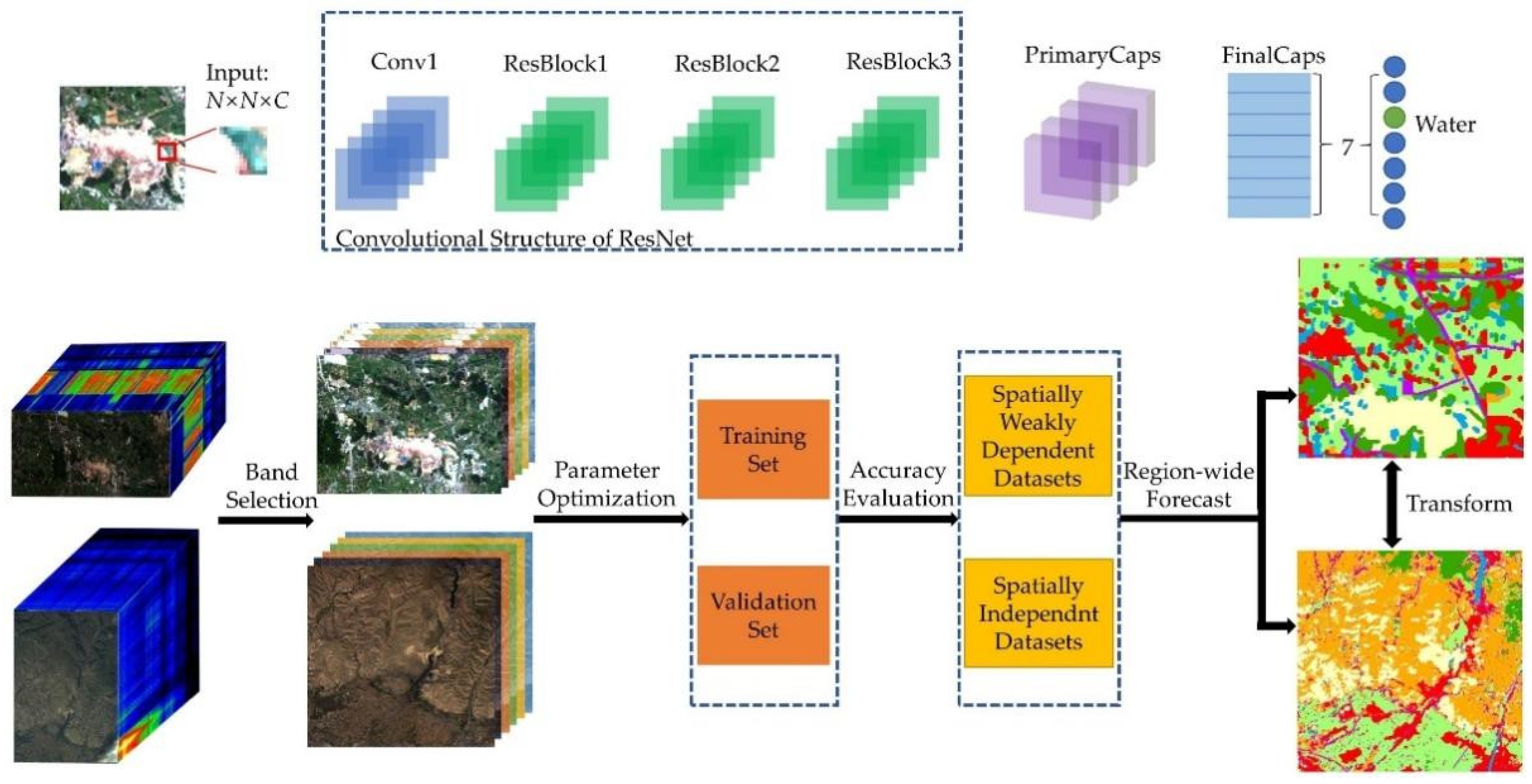
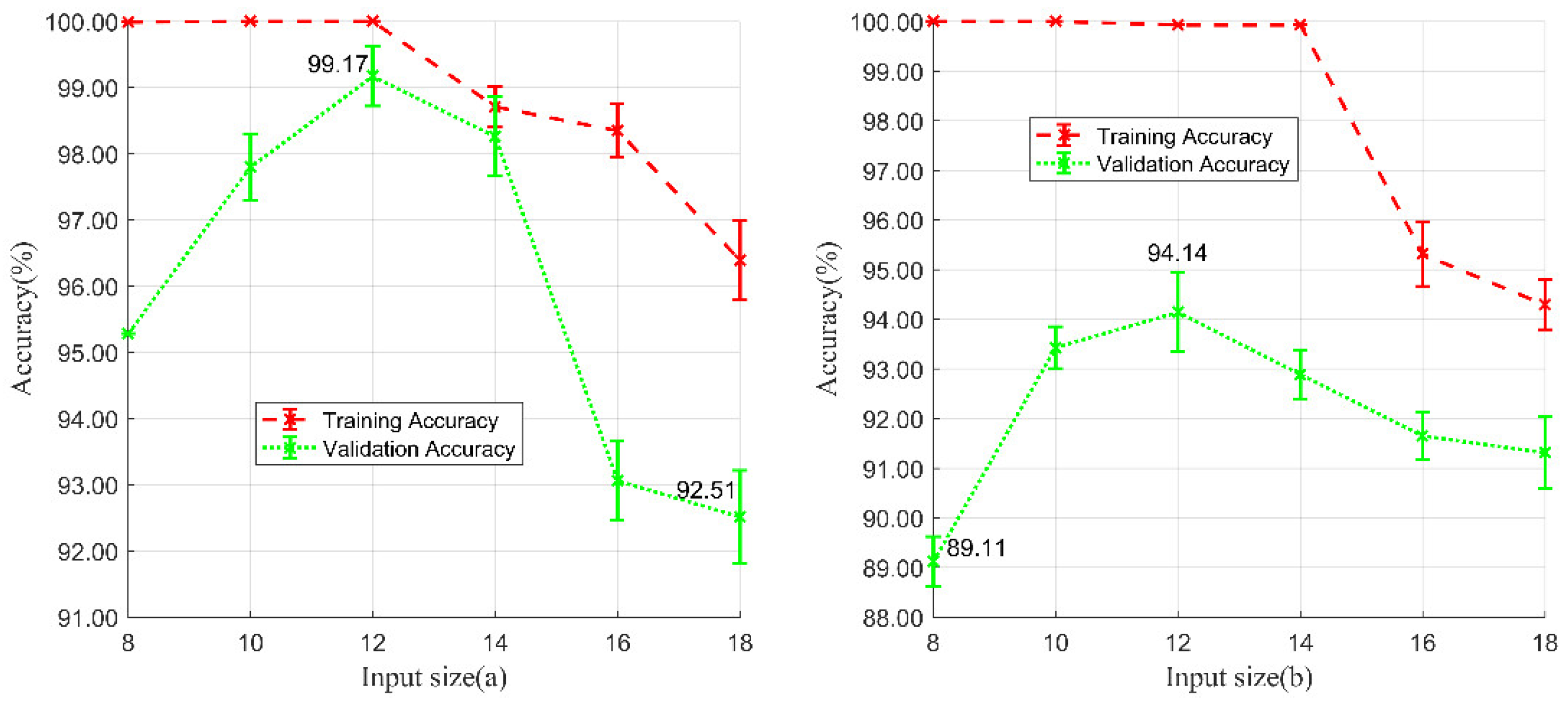
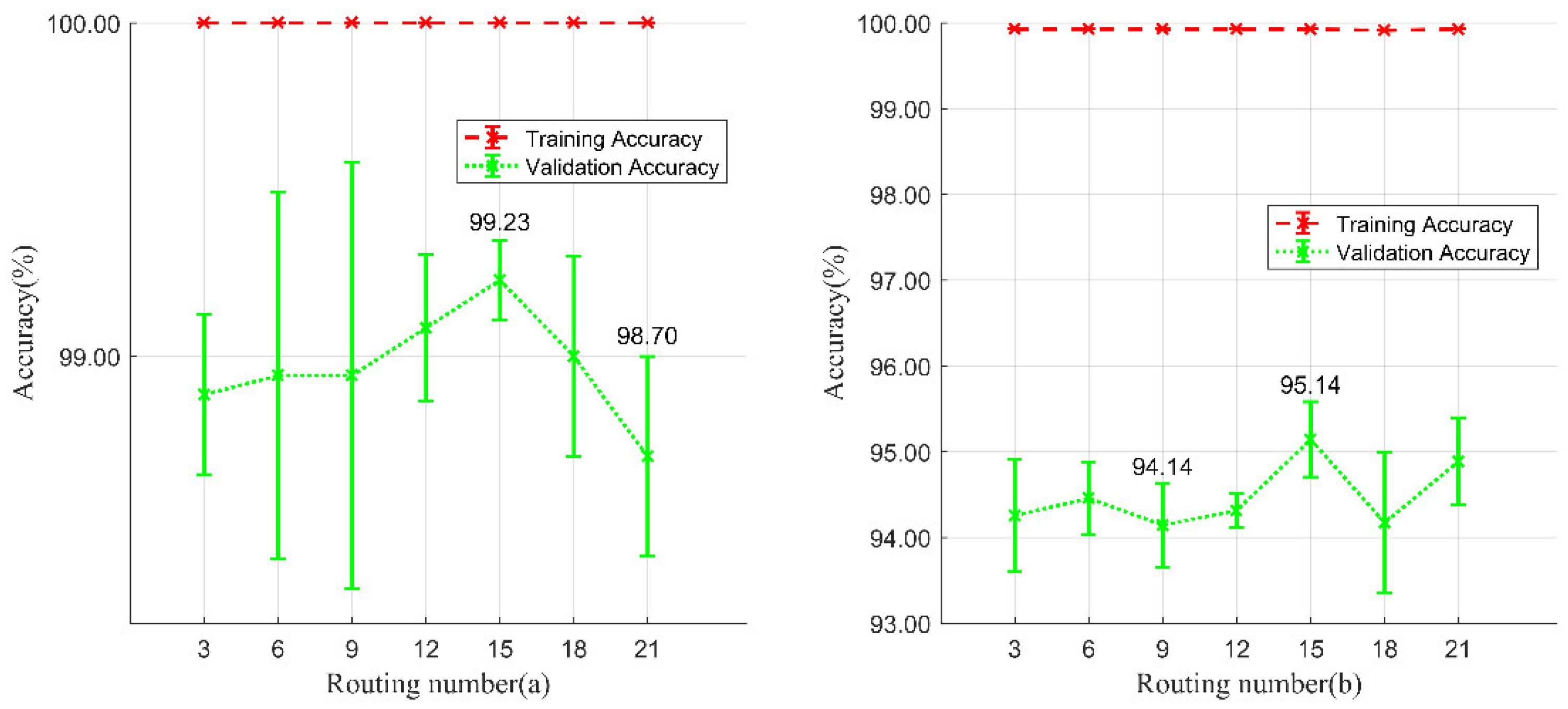
To extract useful spatial and spectral features from HSI, a combined model of ResNet and CapsNet (ResCapsNet) was proposed and tested with Gaofen-5 (GF-5) imagery in this study. There were three main contributions as follows:
(1) A novel framework of ResCapsNet for LCC in heterogeneous mining areas was proposed. First, a clustering-based semi-automated band selection method was conducted to determine the input bands. The ResNet was then used for extraction of deep HSI features, and the high-level features were put into a CapsNet for classification.
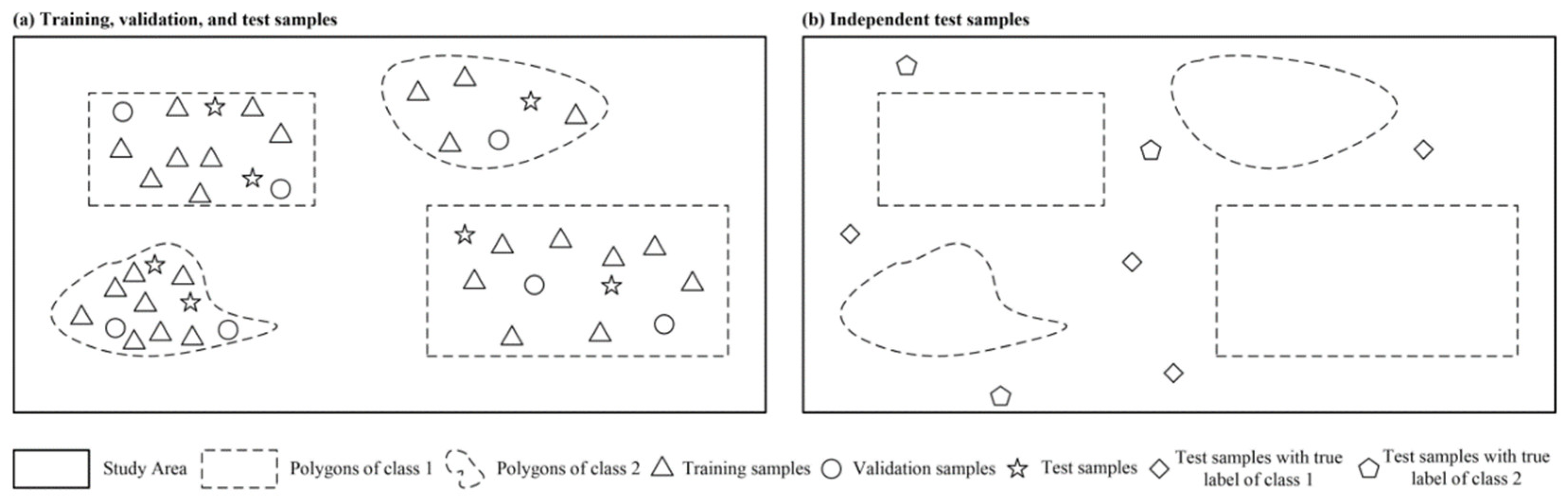
(2) The model was tested on two datasets (a spatially weakly dependent dataset and a spatially basically independent dataset) of two different areas captured by the GF-5 satellite. The purpose of designing two datasets is to test the spatial autocorrelation [
47] of land cover areas in the experimental area.
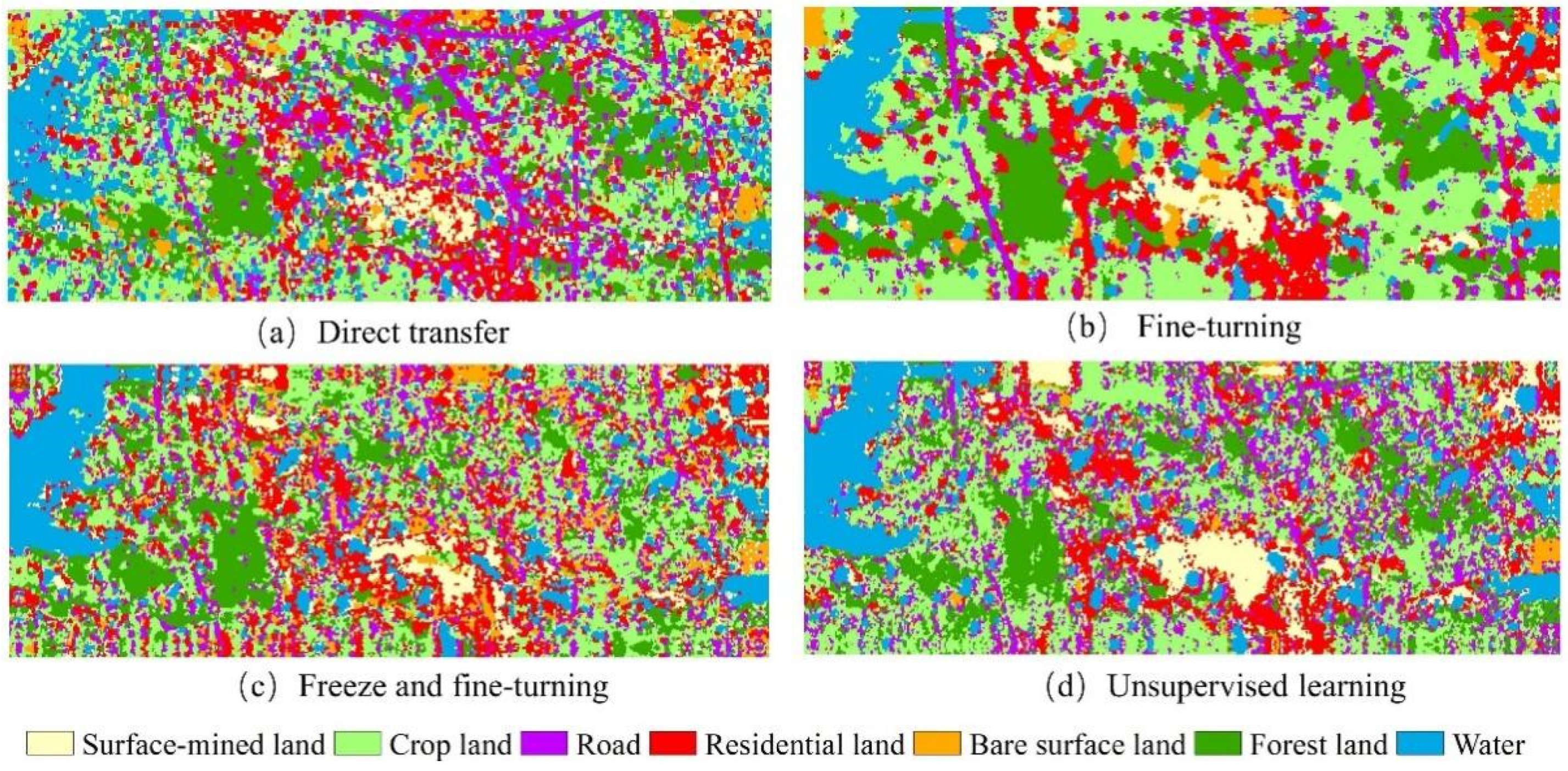
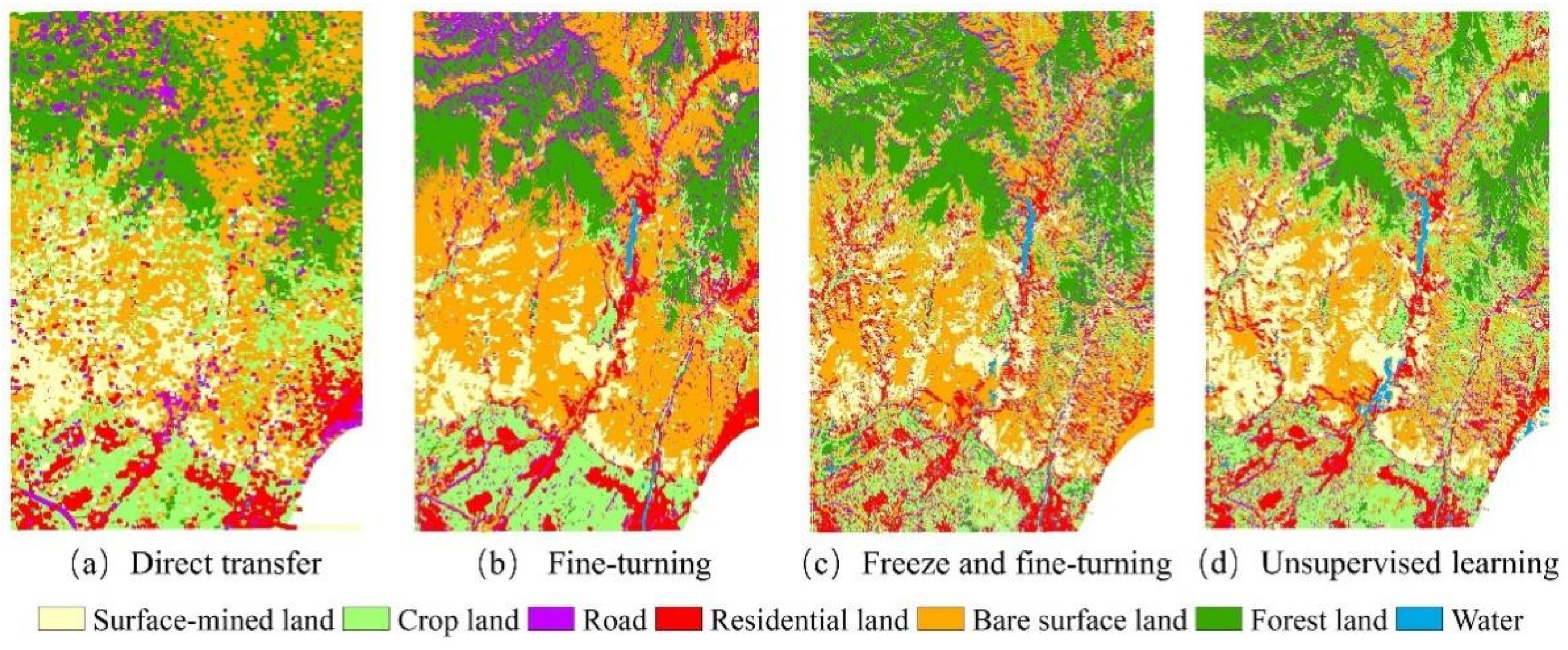
(3) Four transfer learning methods were investigated for cross-training and prediction of those two areas, i.e., direct transfer of trained models for prediction of other areas (hereafter referred to as direct transfer), fine-tuning of trained models (hereafter referred to as fine-tuning), freeze of part structure and fine-tuning (hereafter referred to as free and fine-tuning), and unsupervised feature learning based on maximum mean discrepancy (MMD) [
53] (hereafter referred to as unsupervised learning).
2. Study Areas and Remote Sensing Data Source
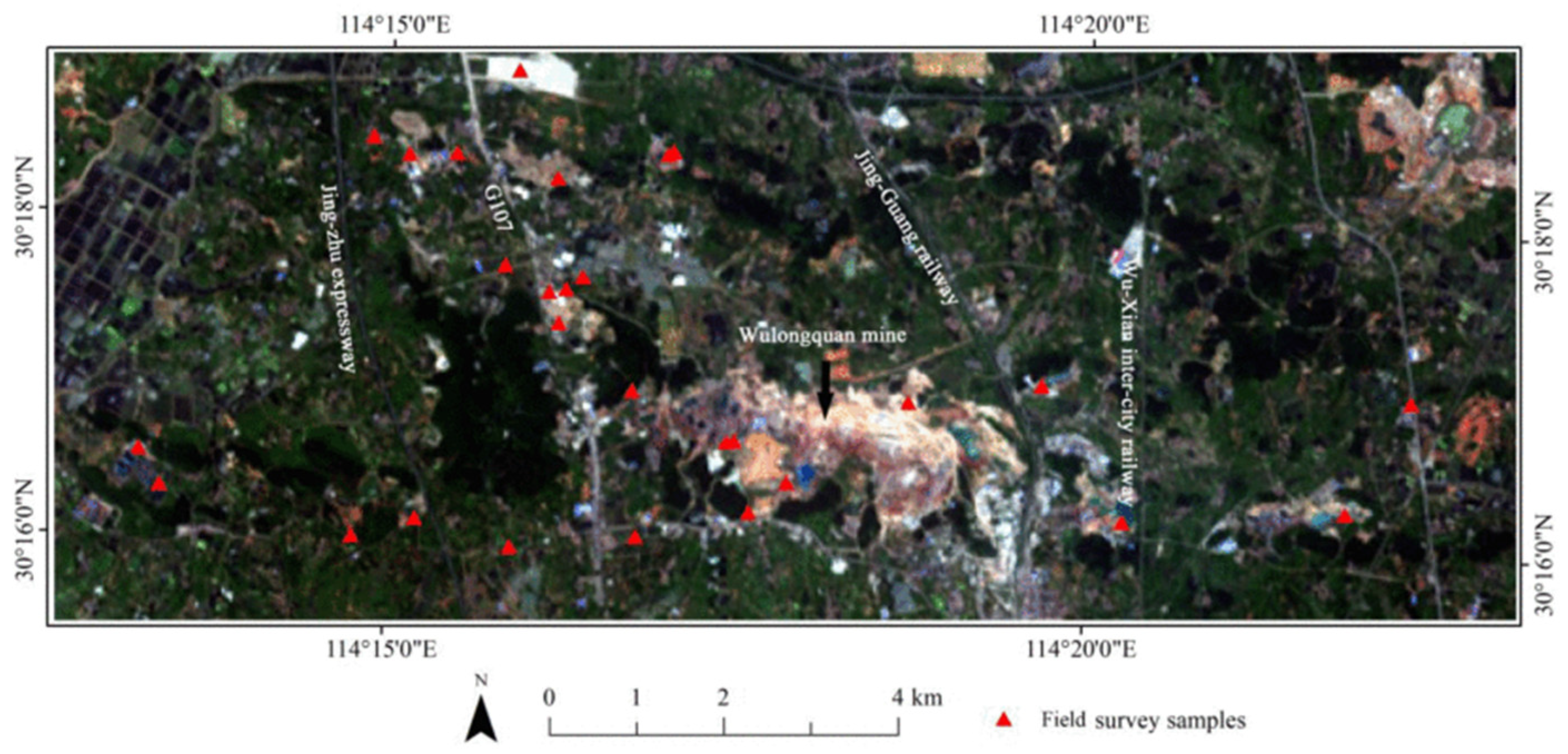
We selected an area in the Jiangxia District of Wuhan City, China (hereafter referred as to Wuhan study area) [
10,
54] (
Figure 1), which belongs to the northern subtropical monsoon and humid climate zone characterized by hot summers and cold winters, abundant sunshine, four distinct seasons, and sufficient rainfall. This area also contains some surface mining and agricultural activities.
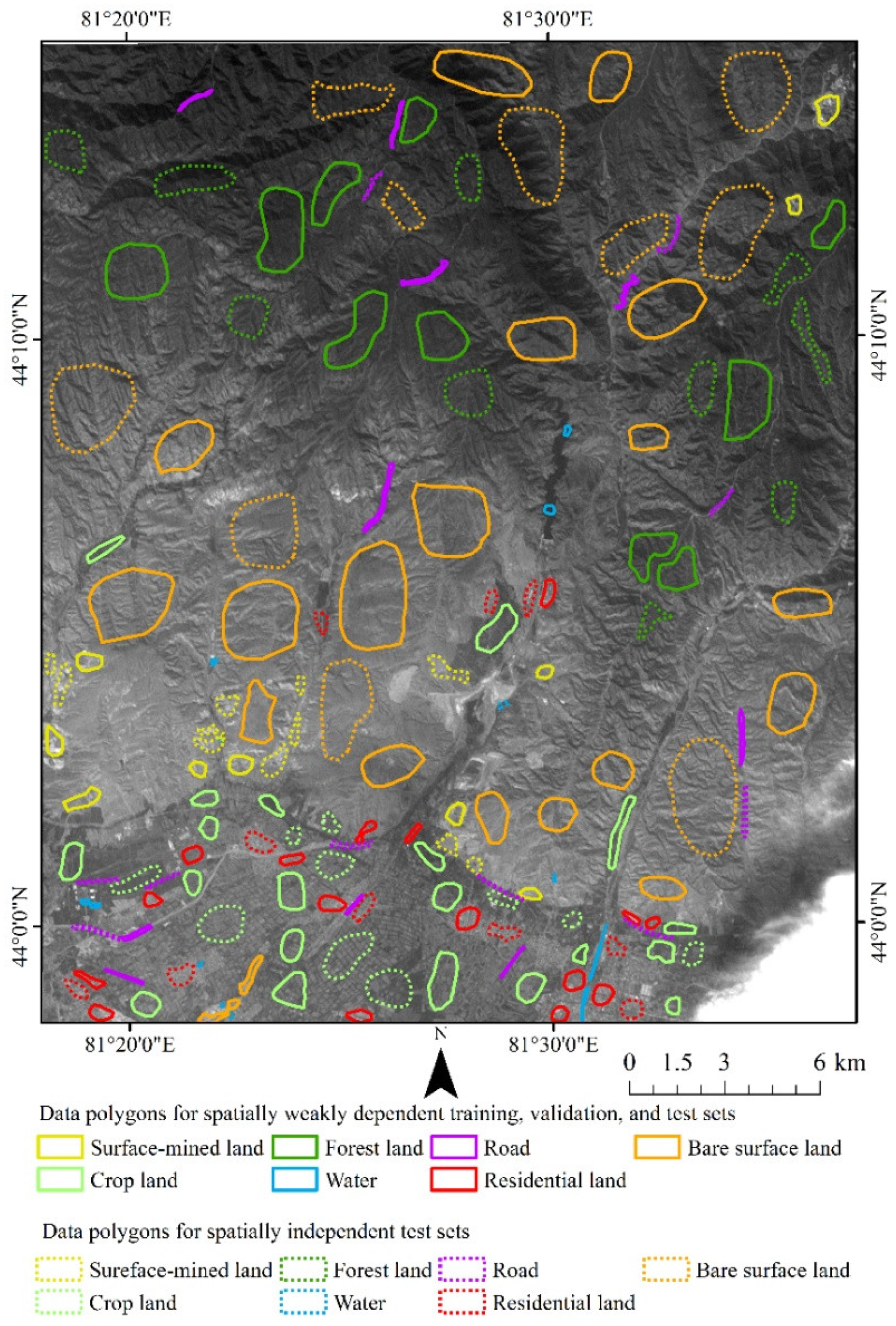
Another study area located in the Ili Kazakh Autonomous Prefecture of Xinjiang Province, China (hereafter referred as to Xinjiang study area) (
Figure 2) characterized by mountains and vast inter-mountain plains, basins, and river valleys, and has a typical temperate continental arid climate was also selected. The average natural precipitation is 155 mm. There are also some surface mining activities.
The GF-5 images on 9 May 2018 and 25 September 2019 for the two areas were obtained. Radiometrically calibrated and orthorectification correction were conducted [
39]. The GF-5 satellite, successfully launched in May 2018, can conduct comprehensive observations of the land and atmosphere at the same time, and can obtain the spectrum range from visible and near-infrared (VNIR) to shortwave infrared (SWIR) (i.e., from 400 to 2500 nm) with a width of 60 km and a spatial resolution of 30 m. There are 330 spectral channels. The GF-5 has two different spectral resolutions: 5 nm for VNIR and 10 nm for SWIR.
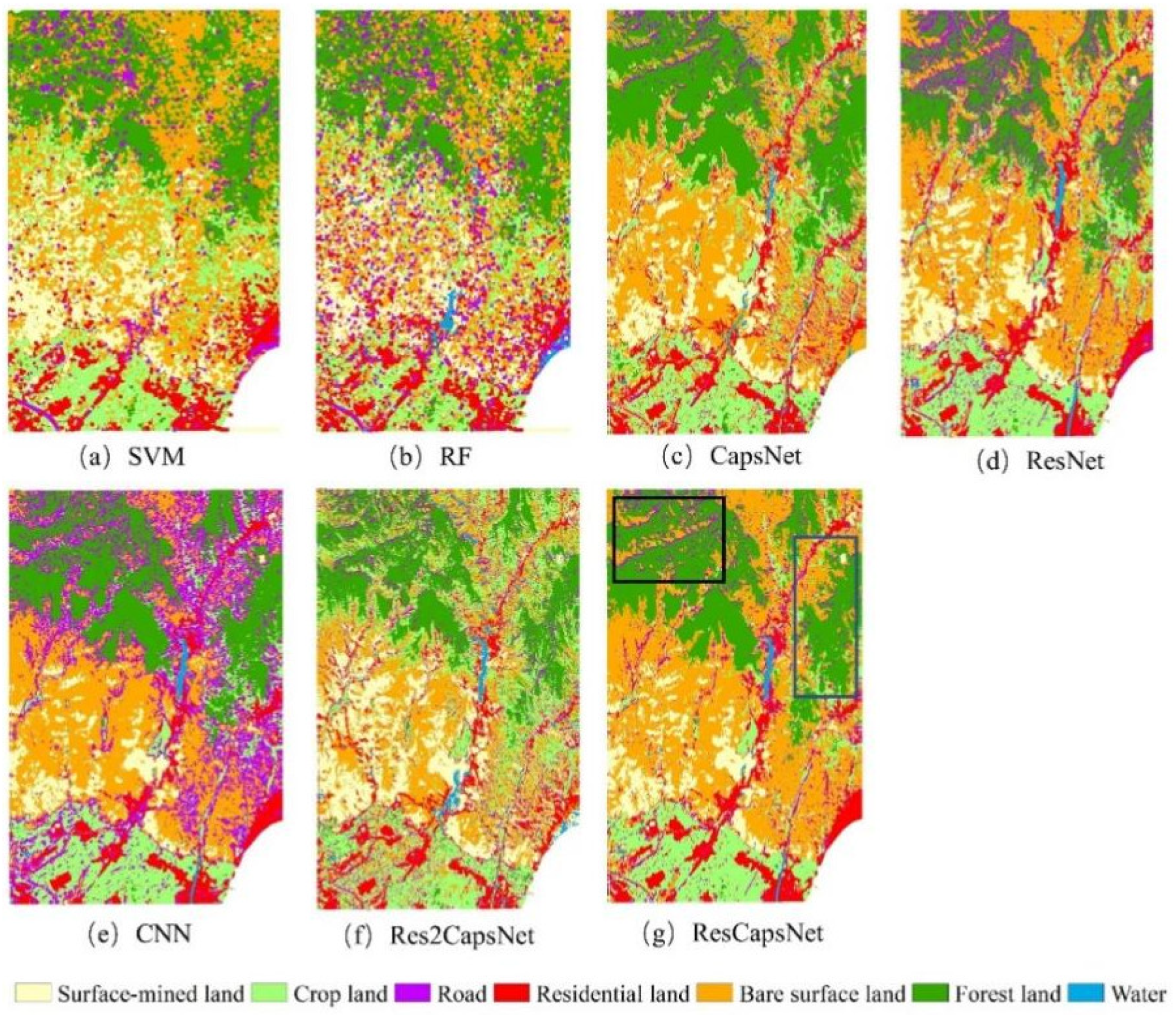
According to the requirements of mine environmental monitoring in China and the previous study [
10], the LCC types were divided into seven categories namely road, cropland, water, residential land, forest land, bare land, and surface-mined land. Details are shown in
Table 1.
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}