
An Analysis of the Optimal Features for Sentinel-1 Oil Spill Datasets Based on an Improved J–M/K-Means Algorithm


Abstract
:1. Introduction
2. Related Studies
2.1. Feature Parameters of Dual-Polarized SAR
- Mean Mean
- Maximum Max
- Variance Varwhere µ is the mean of .
- Contrast Con
- Second-order moment ASM
- Second-order entropy Ent
- Homogeneity Hom
- Dissimilarity Dis
2.2. K-Means Clustering Algorithm
2.3. Jeffries–Matusita Distance
3. Methods
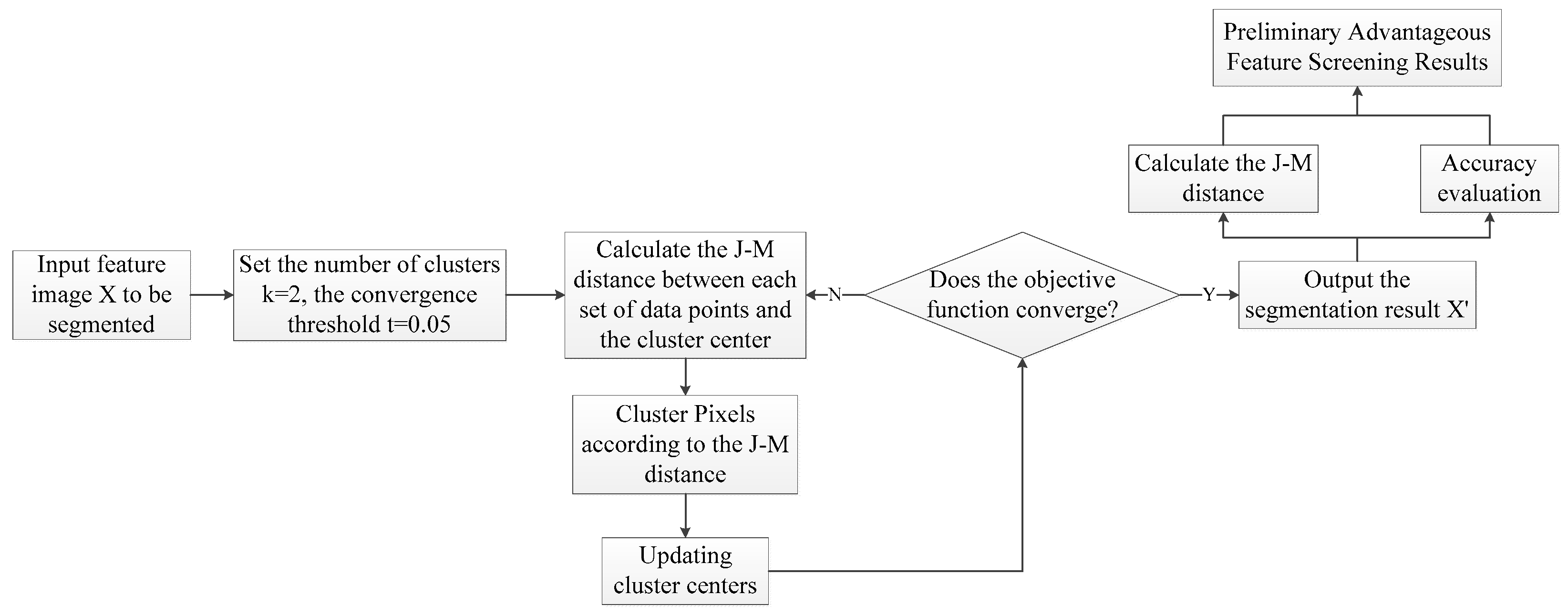
3.1. Improved J–M/K-Means Algorithm
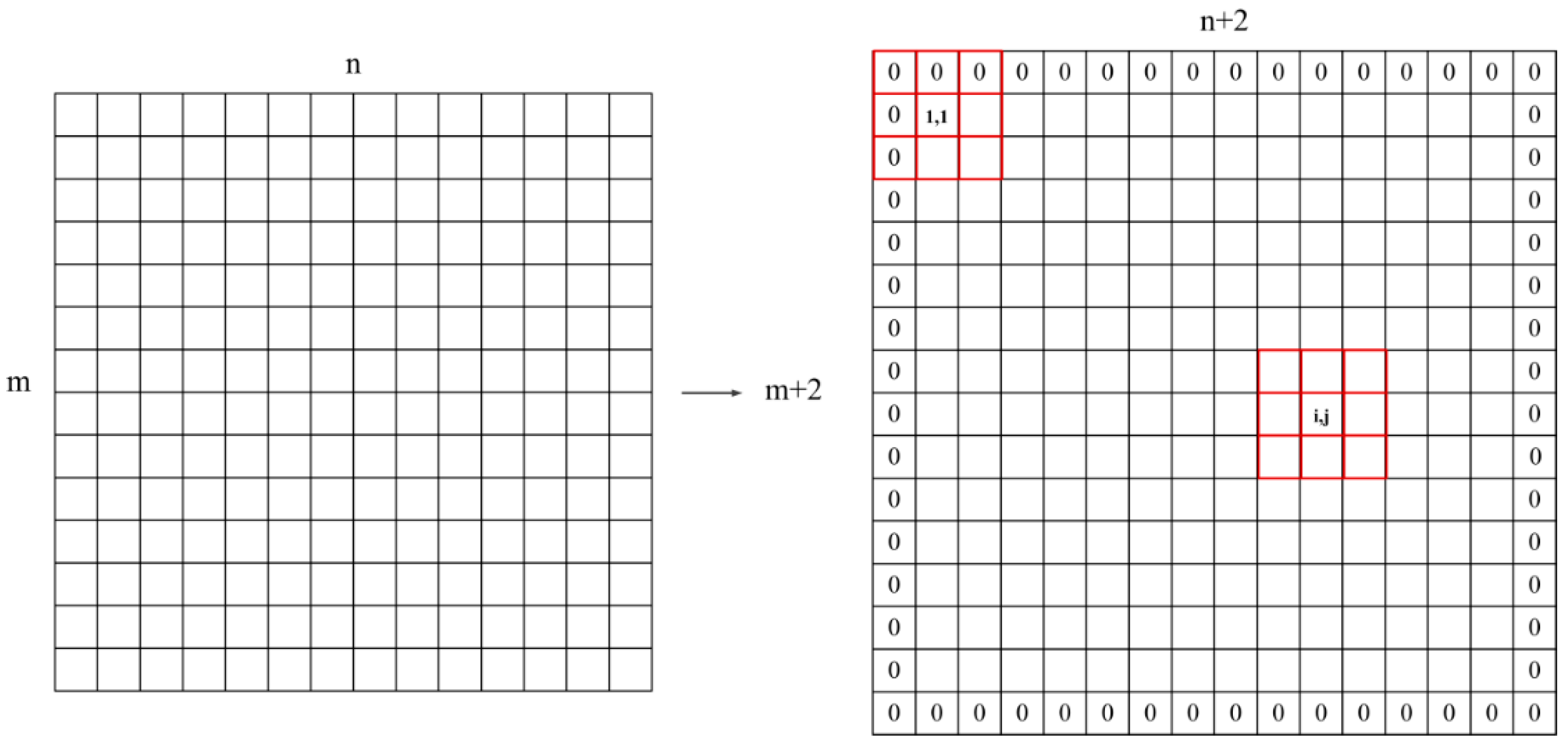
3.1.1. Selection of Data Point
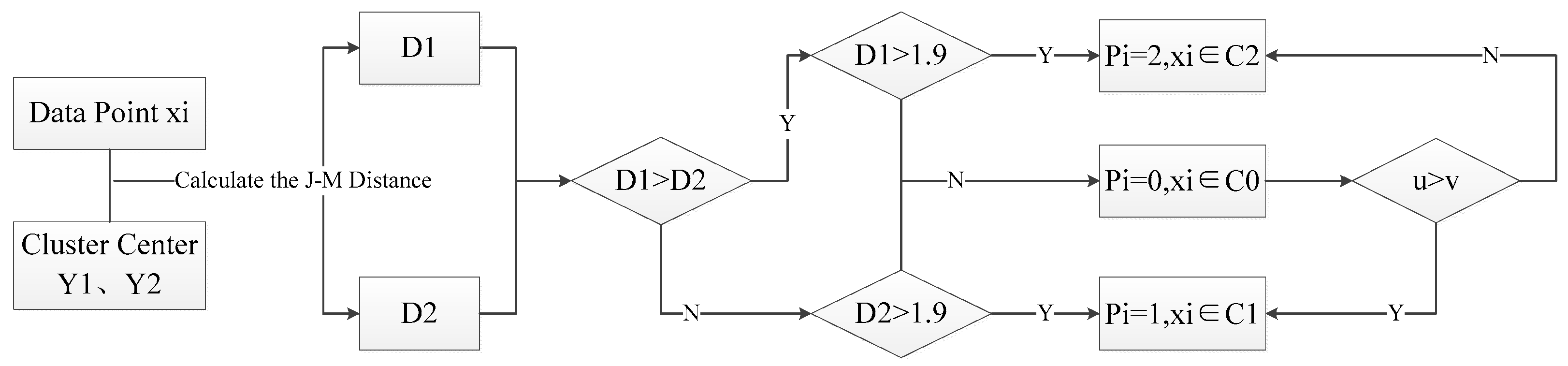
3.1.2. Calculation of J–M Distance and Determination on the Categories of Pixels
3.1.3. Iterations
3.1.4. Integrated Filtering of Optimal Features
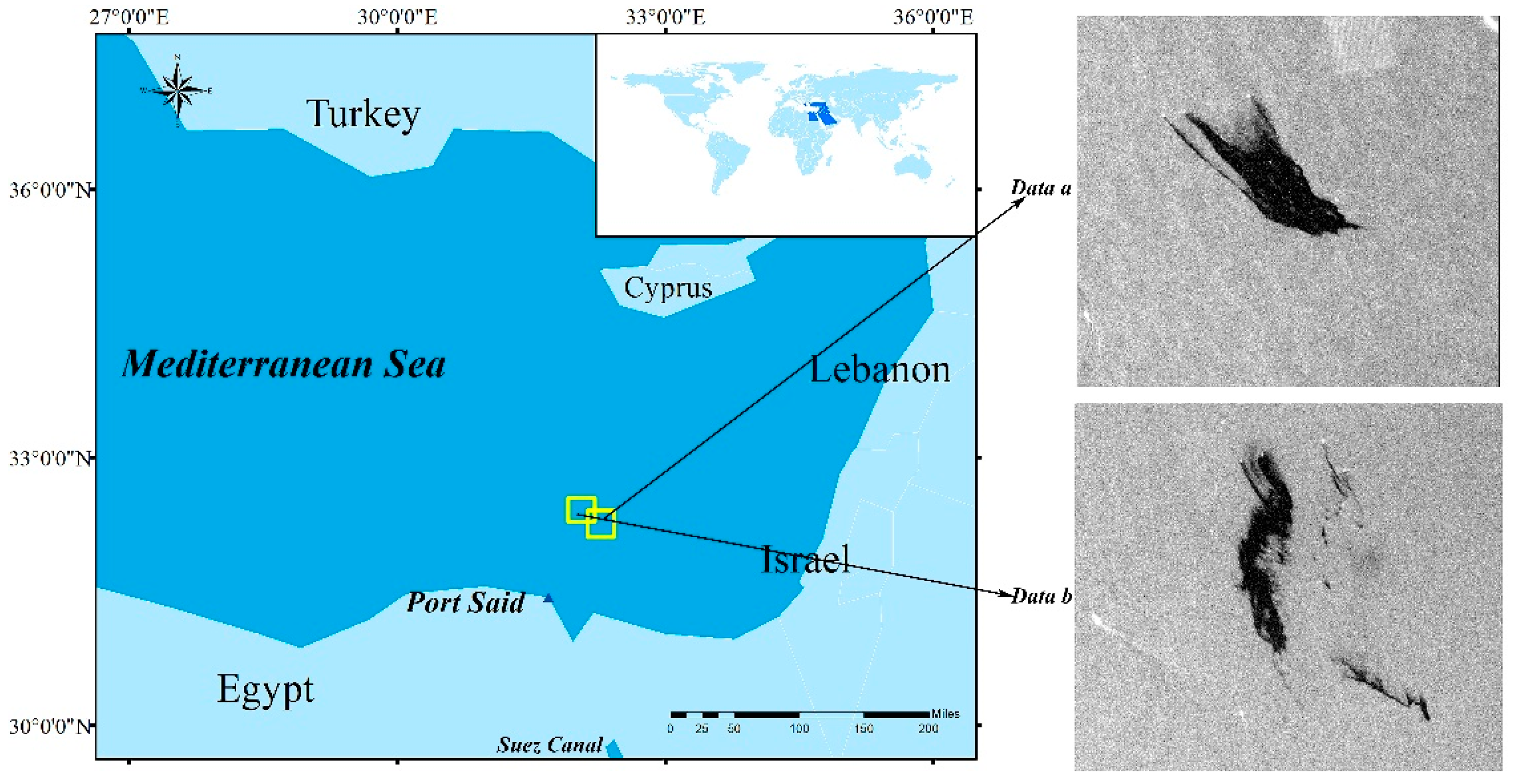
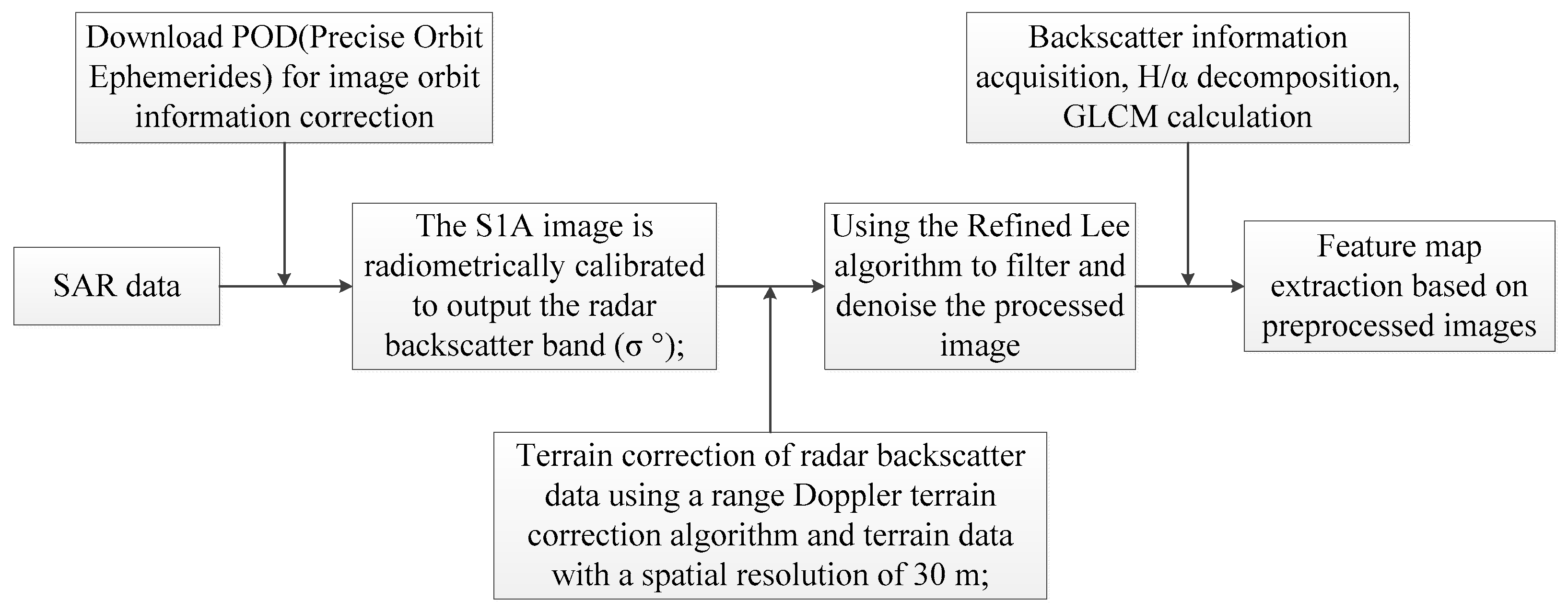
3.2. Data Acquisition and Processing
4. Results
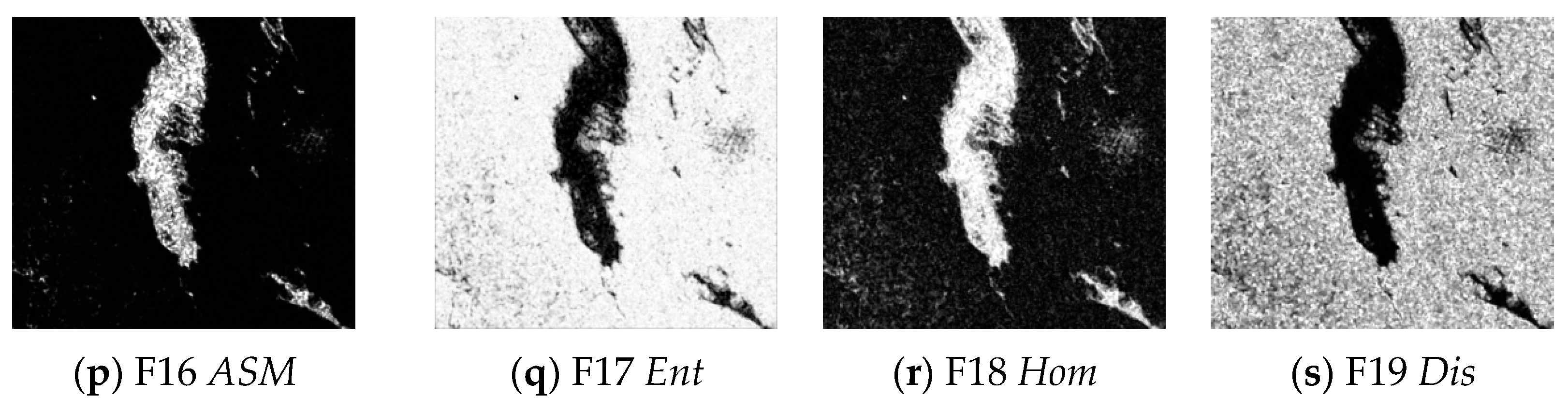
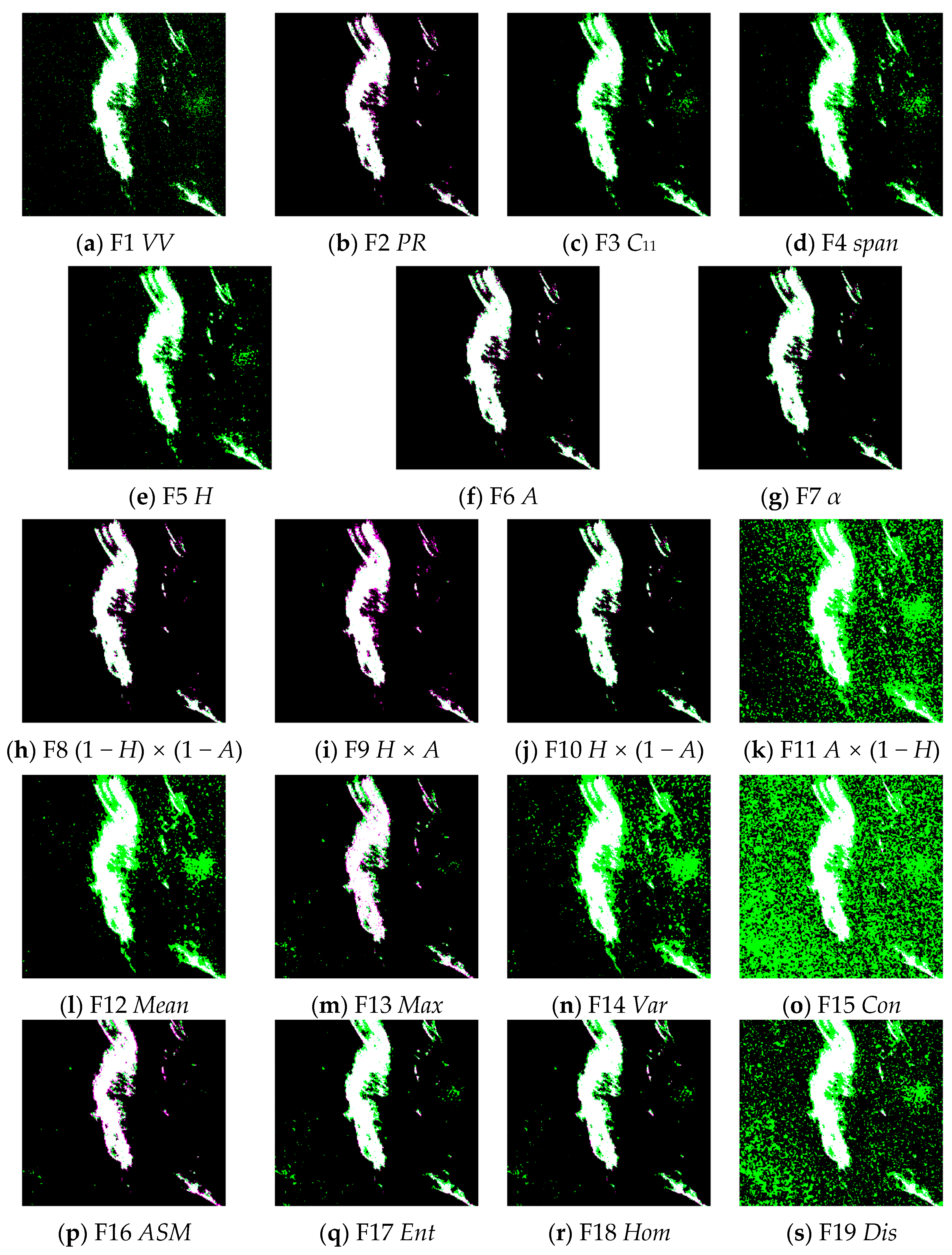
4.1. Feature Extraction
4.2. Oil Spill Extraction Results
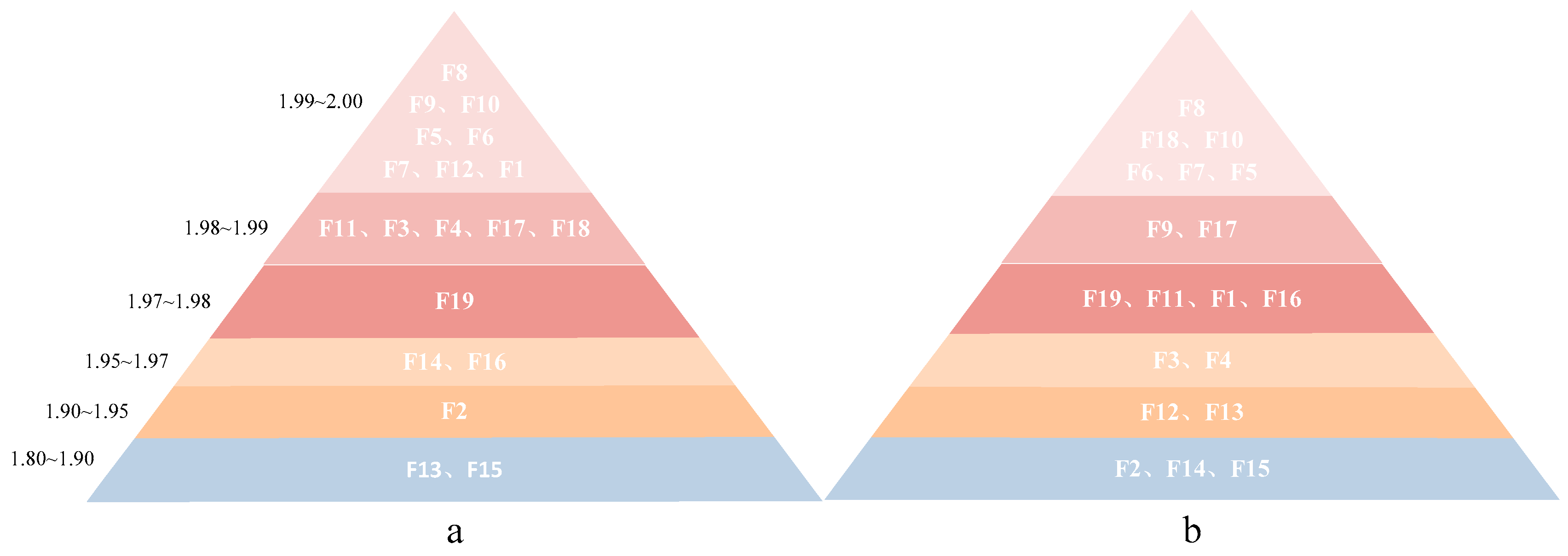
4.3. Optimal Feature Evaluation
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- El-Magd, I.A.; Zakzouk, M.; Abdulaziz, A.M.; Ali, E.M. The potentiality of operational mapping of oil pollution in the mediterranean sea near the entrance of the suez canal using sentinel-1 SAR data. Remote Sens. 2020, 12, 1352. [Google Scholar] [CrossRef]
- Brekke, C.; Solberg, A.H.S. Oil spill detection by satellite remote sensing. Remote Sens. Environ. 2005, 95, 1–13. [Google Scholar] [CrossRef]
- Singha, S.; Bellerby, T.J.; Trieschmann, O. Detection and classification of oil spill and look-alike spots from SAR imagery using an Artificial Neural Network. In Proceedings of the 2012 IEEE International Geoscience and Remote Sensing Symposium, Munich, Germany, 22–27 July 2012. [Google Scholar] [CrossRef]
- Fingas, M. The Basics of Oil Spill Cleanup; CRC Press: Boca Raton, FL, USA, 2013. [Google Scholar] [CrossRef]
- Alpers, W.; Holt, B.; Zeng, K. Oil spill detection by imaging radars: Challenges and pitfalls. Remote Sens. Environ. 2017, 201, 133–147. [Google Scholar] [CrossRef]
- Fingas, M.; Brown, C. Review of oil spill remote sensing. Mar. Pollut. Bull. 2014, 83, 9–23. [Google Scholar] [CrossRef]
- Nunziata, F.; Gambardella, A.; Migliaccio, M. On the mueller scattering matrix for SAR sea oil slick observation. IEEE Geosci. Remote Sens. Lett. 2008, 5, 691–695. [Google Scholar] [CrossRef]
- Harris, A.H.S.; Chen, C.; Weisner, C.M.; Chalk, M.; Capoccia, V.; Thomas, C.P. Response to Dr Fiscella: Transparency and debate are essential to improve guidelines and measures. J. Addict. Med. 2016, 10, 453–454. [Google Scholar] [CrossRef]
- Topouzelis, K.; Stathakis, D.; Karathanassi, V. Investigation of genetic algorithms contribution to feature selection for oil spill detection. Int. J. Remote Sens. 2009, 30, 611–625. [Google Scholar] [CrossRef]
- Singha, S.; Velotto, D.; Lehner, S. Dual-polarimetric feature extraction and evaluation for oil spill detection: A near real time perspective. In Proceedings of the International Geoscience and Remote Sensing Symposium (IGARSS), Milan, Italy, 26–31 July 2015. [Google Scholar] [CrossRef]
- Mera, D.; Bolon-Canedo, V.; Cotos, J.; Alonso-Betanzos, A. On the use of feature selection to improve the detection of sea oil spills in SAR images. Comput. Geosci. 2017, 100, 166–178. [Google Scholar] [CrossRef]
- Niu, X.; Ban, Y.; Dou, Y. RADARSAT-2 fine-beam polarimetric and ultra-fine-beam SAR data for urban mapping: Comparison and synergy. Int. J. Remote Sens. 2015, 37, 2810–2830. [Google Scholar] [CrossRef]
- Skrunes, S.; Brekke, C.; Eltoft, T. Characterization of marine surface slicks by radarsat-2 multipolarization features. IEEE Trans. Geosci. Remote Sens. 2013, 52, 5302–5319. [Google Scholar] [CrossRef]
- Singha, S.; Ressel, R.; Velotto, D.; Lehner, S. A Combination of Traditional and Polarimetric Features for Oil Spill Detection Using TerraSAR-X. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 4979–4990. [Google Scholar] [CrossRef]
- Yu, L.; Liu, H. Feature Selection for High-Dimensional Data: A Fast Correlation-Based Filter Solution. In Proceedings of the Twentieth International Conference on Machine Learning, Washington, DC, USA, 21–24 August 2003. [Google Scholar]
- Sulaiman, M.A.; Labadin, J. Feature selection based on mutual information. In Proceedings of the 2015 9th International Conference on IT in Asia (CITA), Sarawak, Malaysia, 4–5 August 2015. [Google Scholar] [CrossRef]
- Ma, X.; Xu, J.; Wu, P.; Kong, P. Oil Spill Detection Based on Deep Convolutional Neural Networks Using Polarimetric Scattering Information from Sentinel-1 SAR Images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–13. [Google Scholar] [CrossRef]
- Prastyani, R.; Basith, A. Utilisation of Sentinel-1 SAR Imagery for Oil Spill Mapping: A Case Study of Balikpapan Bay Oil Spill. JGISE J. Geospat. Inf. Sci. Eng. 2018, 1, 22–26. [Google Scholar] [CrossRef]
- Kim, D.; Jung, H.S. Mapping oil spills from dual-polarized sar images using an artificial neural network: Application to oil spill in the kerch strait in november 2007. Sensors 2018, 18, 2237. [Google Scholar] [CrossRef] [PubMed]
- Li, H.; Perrie, W.; He, Y.; Wu, J.; Luo, X. Analysis of the Polarimetric SAR Scattering Properties of Oil-Covered Waters. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 8, 3751–3759. [Google Scholar] [CrossRef]
- Chaturvedi, S.K.; Banerjee, S.; Lele, S. An assessment of oil spill detection using Sentinel 1 SAR-C images. J. Ocean Eng. Sci. 2019, 5, 116–135. [Google Scholar] [CrossRef]
- Alpers, W.; Hühnerfuss, H. The damping of ocean waves by surface films: A new look at an old problem. J. Geophys. Res. 1989, 94, 6251–6265. [Google Scholar] [CrossRef]
- Cloude, S.R.; Pottier, E. An entropy based classification scheme for land applications of polarimetric SAR. IEEE Trans. Geosci. Remote Sens. 1997, 35, 68–78. [Google Scholar] [CrossRef]
- Schuler, D.L.; Lee, J.S. Mapping ocean surface features using biogenic slick-fields and SAR polarimetric decomposition techniques. IEE Proc. Radar Sonar Navig. 2006, 153, 260–270. [Google Scholar] [CrossRef]
- Mubea, K.; Menz, G. Monitoring Land-Use Change in Nakuru (Kenya) Using Multi-Sensor Satellite Data. Adv. Remote Sens. 2012, 1, 74–84. [Google Scholar] [CrossRef]
- Shi, N.; Liu, X.; Guan, Y. Research on k-means clustering algorithm: An improved k-means clustering algorithm. In Proceedings of the 2010 Third International Symposium on Intelligent Information Technology and Security Informatics, Jian, China, 2–4 April 2010. [Google Scholar] [CrossRef]
- Sun, J.G.; Liu, J.; Zhao, L.Y. Clustering algorithms research. J. Softw. 2008, 19, 48–61. [Google Scholar] [CrossRef]
- Fahim, A.M.; Salem, A.M.; Torkey, F.A.; Ramadan, M.A. Efficient enhanced k-means clustering algorithm. J. Zhejiang Univ. Sci. 2006, 7, 1626–1633. [Google Scholar] [CrossRef]
- Bruzzone, L.; Roli, F.; Serpico, S.B. An Extension of the Jeffreys-Matusita Distance to Multiclass Cases for Feature Selection. IEEE Trans. Geosci. Remote Sens. 1995, 33, 1318–1321. [Google Scholar] [CrossRef]
- Dabboor, M.; Howell, S.; Shokr, M.; Yackel, J. The Jeffries–Matusita distance for the case of complex Wishart distribution as a separability criterion for fully polarimetric SAR data. Int. J. Remote Sens. 2014, 35, 6859–6872. [Google Scholar] [CrossRef]
- Klein, D.; Moll, A.; Menz, G. Land cover/land use classification in a semiarid environment in East Africa using multi-temporal alternating polarisation ENVISAT ASAR data. In Proceedings of the 2004 Envisat & ERS Symposium (ESA SP-572), Salzburg, Austria, 6–10 September 2004. [Google Scholar]
- Duda, R.O.; Hart, P.E.; Stork, D.G. Pattern Classification and Scene Analysis; Wiley: New York, NY, USA, 2001; Volume 10. [Google Scholar]
- Torres, R.; Snoeij, P.; Geudtner, D.; Bibby, D.; Davidson, M.; Attema, E.; Potin, P.; Rommen, B.; Floury, N.; Brown, M.; et al. GMES Sentinel-1 mission. Remote Sens. Environ. 2012, 120, 9–24. [Google Scholar] [CrossRef]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Feature Parameters | No. | Feature Parameters |
|---|---|---|---|
| F1 | VV | F11 | |
| F2 | PR | F12 | Mean |
| F3 | F13 | Max | |
| F4 | span | F14 | Var |
| F5 | H | F15 | Con |
| F6 | A | F16 | ASM |
| F7 | α | F17 | Ent |
| F8 | F18 | Hom | |
| F9 | F19 | Dis | |
| F10 |
| Features | Data a | ||||
|---|---|---|---|---|---|
| J–M Distance | J–M/K-Means | K-Means | |||
| OA (%) | F1-Score | OA (%) | F1-Score | ||
| F1 | 1.9921 | 98.7484 | 0.9473 | 98.3521 | 0.9727 |
| F2 | 1.9458 | 97.8102 | 0.9131 | 96.9753 | 0.9459 |
| F3 | 1.9881 | 98.5437 | 0.9400 | 90.6547 | 0.7100 |
| F4 | 1.9873 | 98.3641 | 0.9335 | 88.4134 | 0.6643 |
| F5 | 1.9978 | 98.3938 | 0.9342 | 95.7515 | 0.8448 |
| F6 | 1.9977 | 98.4757 | 0.9372 | 98.2294 | 0.9391 |
| F7 | 1.9967 | 98.4797 | 0.9373 | 98.3945 | 0.9342 |
| F8 | 1.9991 | 98.4354 | 0.9357 | 98.3945 | 0.9342 |
| F9 | 1.9980 | 98.5409 | 0.9373 | 98.3544 | 0.9386 |
| F10 | 1.9980 | 98.4439 | 0.9361 | 98.5897 | 0.9412 |
| F11 | 1.9888 | 98.1813 | 0.9265 | 93.3088 | 0.7757 |
| F12 | 1.9945 | 98.3279 | 0.9321 | 97.1466 | 0.8902 |
| F13 | 1.8528 | 95.0325 | 0.8175 | 94.4387 | 0.7939 |
| F14 | 1.9556 | 97.881 | 0.9156 | 80.0580 | 0.5361 |
| F15 | 1.8622 | 91.5522 | 0.7221 | 84.8239 | 0.5816 |
| F16 | 1.9547 | 96.888 | 0.8760 | 96.0729 | 0.9130 |
| F17 | 1.9866 | 97.7798 | 0.9082 | 88.7230 | 0.6580 |
| F18 | 1.9833 | 97.1032 | 0.9031 | 97.5047 | 0.8855 |
| F19 | 1.9778 | 96.5964 | 0.8650 | 94.9984 | 0.8131 |
| Features | Data b | ||||
|---|---|---|---|---|---|
| J–M Distance | J–M/K-Means | K-Means | |||
| OA (%) | F1-Score | OA (%) | F1-Score | ||
| F1 | 1.9747 | 97.9358 | 0.9002 | 94.6913 | 0.8912 |
| F2 | 1.8959 | 95.3243 | 0.8105 | 93.4798 | 0.9220 |
| F3 | 1.9639 | 97.4621 | 0.8861 | 98.2877 | 0.8440 |
| F4 | 1.965 | 97.3563 | 0.8821 | 94.1398 | 0.7743 |
| F5 | 1.9927 | 97.3739 | 0.8812 | 95.3569 | 0.8122 |
| F6 | 1.9963 | 97.9493 | 0.9025 | 96.6453 | 0.9334 |
| F7 | 1.9955 | 97.8863 | 0.8998 | 98.3303 | 0.9213 |
| F8 | 1.9987 | 98.0025 | 0.9038 | 97.6323 | 0.9310 |
| F9 | 1.9855 | 97.9671 | 0.9003 | 98.0781 | 0.9085 |
| F10 | 1.9973 | 97.9644 | 0.9029 | 97.4353 | 0.9257 |
| F11 | 1.9763 | 95.2649 | 0.8562 | 73.0269 | 0.4272 |
| F12 | 1.9305 | 94.741 | 0.7916 | 89.4161 | 0.6552 |
| F13 | 1.9214 | 96.7051 | 0.8503 | 97.0304 | 0.8575 |
| F14 | 1.8726 | 91.966 | 0.7141 | 84.4316 | 0.5637 |
| F15 | 1.8327 | 89.9984 | 0.6641 | 48.7413 | 0.2810 |
| F16 | 1.9744 | 97.2142 | 0.8666 | 97.1910 | 0.8784 |
| F17 | 1.9808 | 93.8082 | 0.7570 | 94.8436 | 0.8618 |
| F18 | 1.9981 | 96.2694 | 0.8780 | 96.0215 | 08680 |
| F19 | 1.9774 | 95.2649 | 0.8056 | 80.6899 | 0.5090 |
| Category | No. | Feature | J–M Distance | Correlation Coefficient | ||
|---|---|---|---|---|---|---|
| with VV | with | with Hom | ||||
| Features based on backscatter information | F1 | VV | 1.9834 | 1 | 0.8830 | −0.7925 |
| F4 | span | 1.9761 | 0.8998 | 0.8242 | −0.7512 | |
| F3 | 1.9760 | 0.9033 | 0.8283 | −0.7506 | ||
| Features based on H-α polarimetric decomposition | F8 | 1.9989 | 0.8830 | 1 | −0.8548 | |
| F10 | 1.9977 | −0.9114 | −0.9788 | 0.8470 | ||
| F6 | A | 1.9970 | 0.9123 | 0.9719 | −0.8404 | |
| F7 | α | 1.9961 | −0.9121 | −0.9634 | 0.8353 | |
| F5 | H | 1.9953 | −0.8958 | −0.9026 | 0.7991 | |
| F9 | 1.9917 | 0.8405 | 0.9852 | −0.8221 | ||
| Features based on gray level co-occurrence matrix | F18 | Hom | 1.9907 | −0.7925 | −0.8548 | 1 |
| F16 | ASM | 1.9645 | −0.8271 | −0.9113 | 0.9303 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cheng, L.; Li, Y.; Zhang, X.; Xie, M. An Analysis of the Optimal Features for Sentinel-1 Oil Spill Datasets Based on an Improved J–M/K-Means Algorithm. Remote Sens. 2022, 14, 4290. https://doi.org/10.3390/rs14174290
Cheng L, Li Y, Zhang X, Xie M. An Analysis of the Optimal Features for Sentinel-1 Oil Spill Datasets Based on an Improved J–M/K-Means Algorithm. Remote Sensing. 2022; 14(17):4290. https://doi.org/10.3390/rs14174290
Chicago/Turabian StyleCheng, Lingxiao, Ying Li, Xiaohui Zhang, and Ming Xie. 2022. "An Analysis of the Optimal Features for Sentinel-1 Oil Spill Datasets Based on an Improved J–M/K-Means Algorithm" Remote Sensing 14, no. 17: 4290. https://doi.org/10.3390/rs14174290
APA StyleCheng, L., Li, Y., Zhang, X., & Xie, M. (2022). An Analysis of the Optimal Features for Sentinel-1 Oil Spill Datasets Based on an Improved J–M/K-Means Algorithm. Remote Sensing, 14(17), 4290. https://doi.org/10.3390/rs14174290