
Full-Coupled Convolutional Transformer for Surface-Based Duct Refractivity Inversion

 ,
,
Abstract
:1. Introduction
2. Method
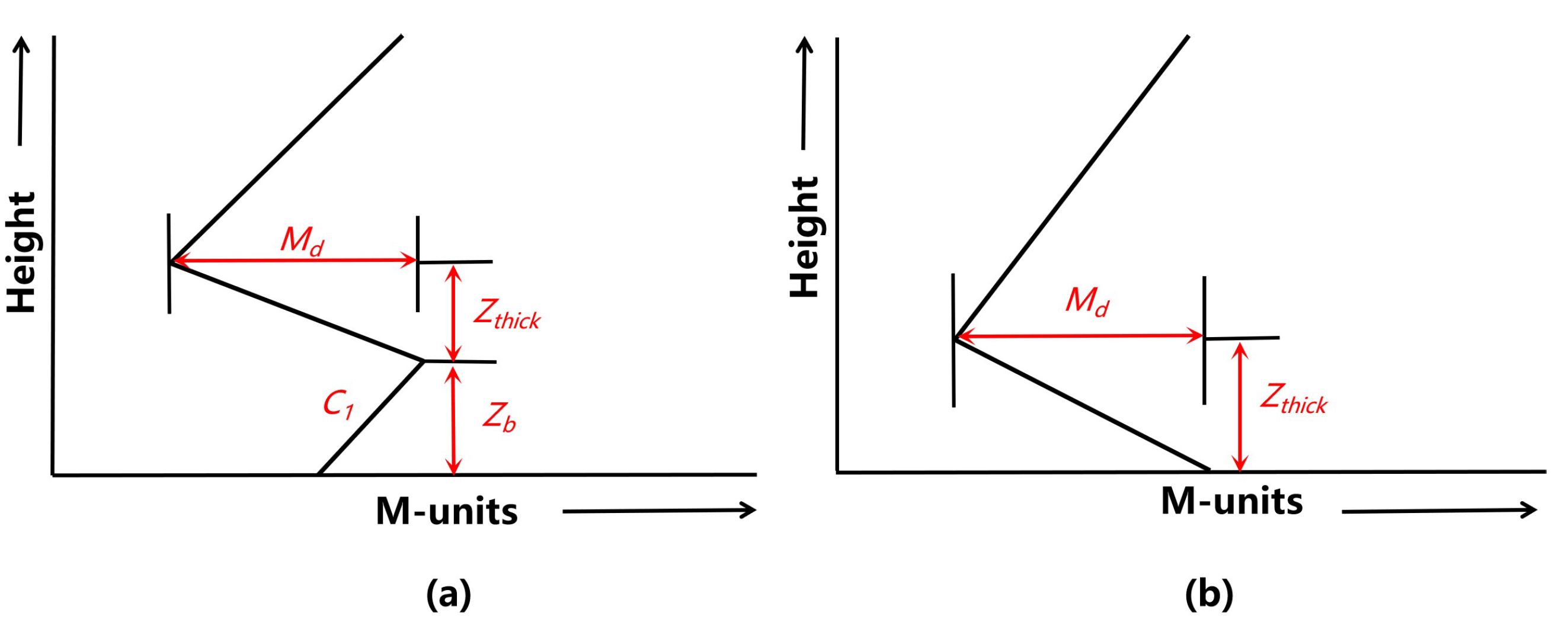
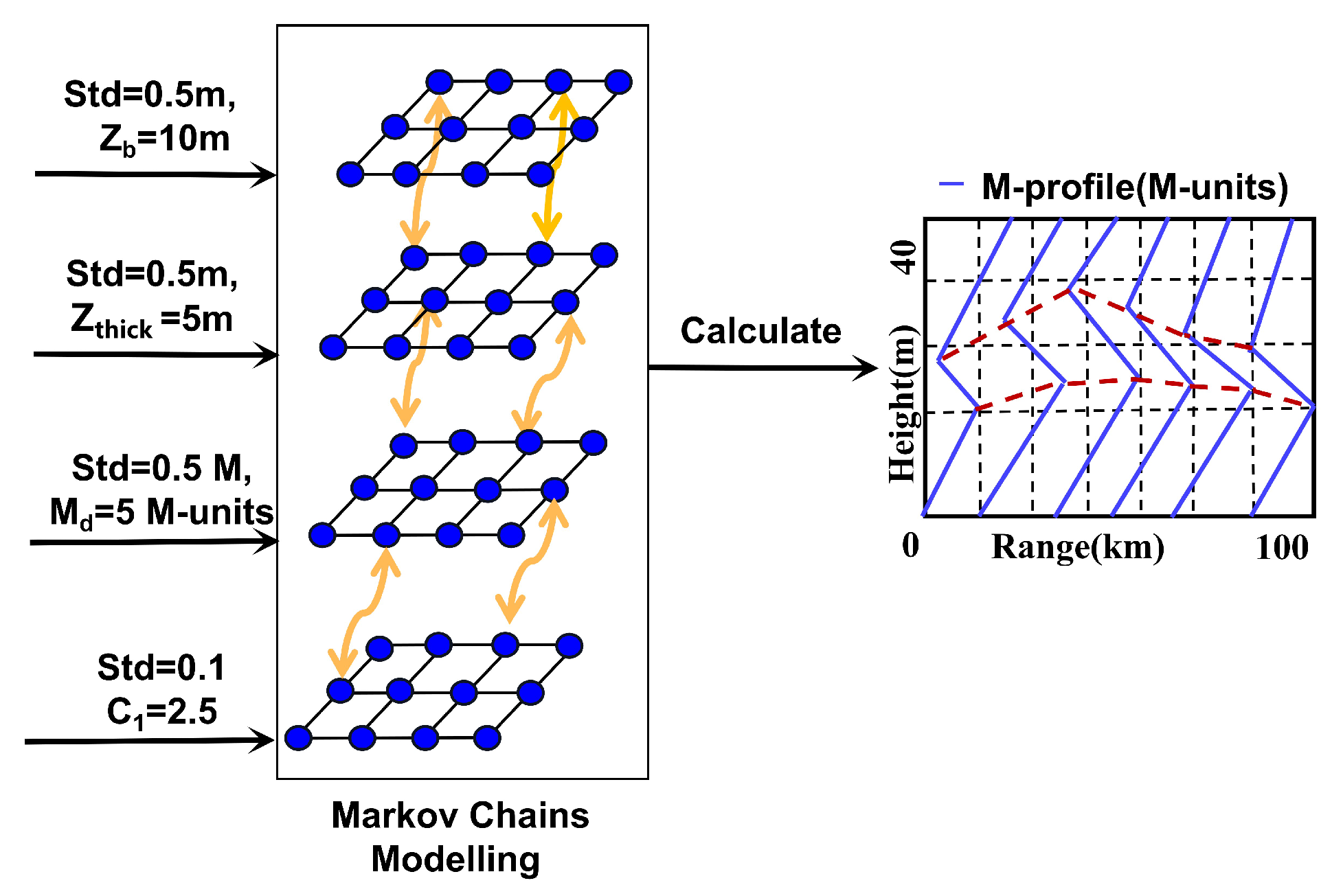
2.1. Modeling of the SBD M-Profile
2.2. Forward Sea Clutter Power Calculation
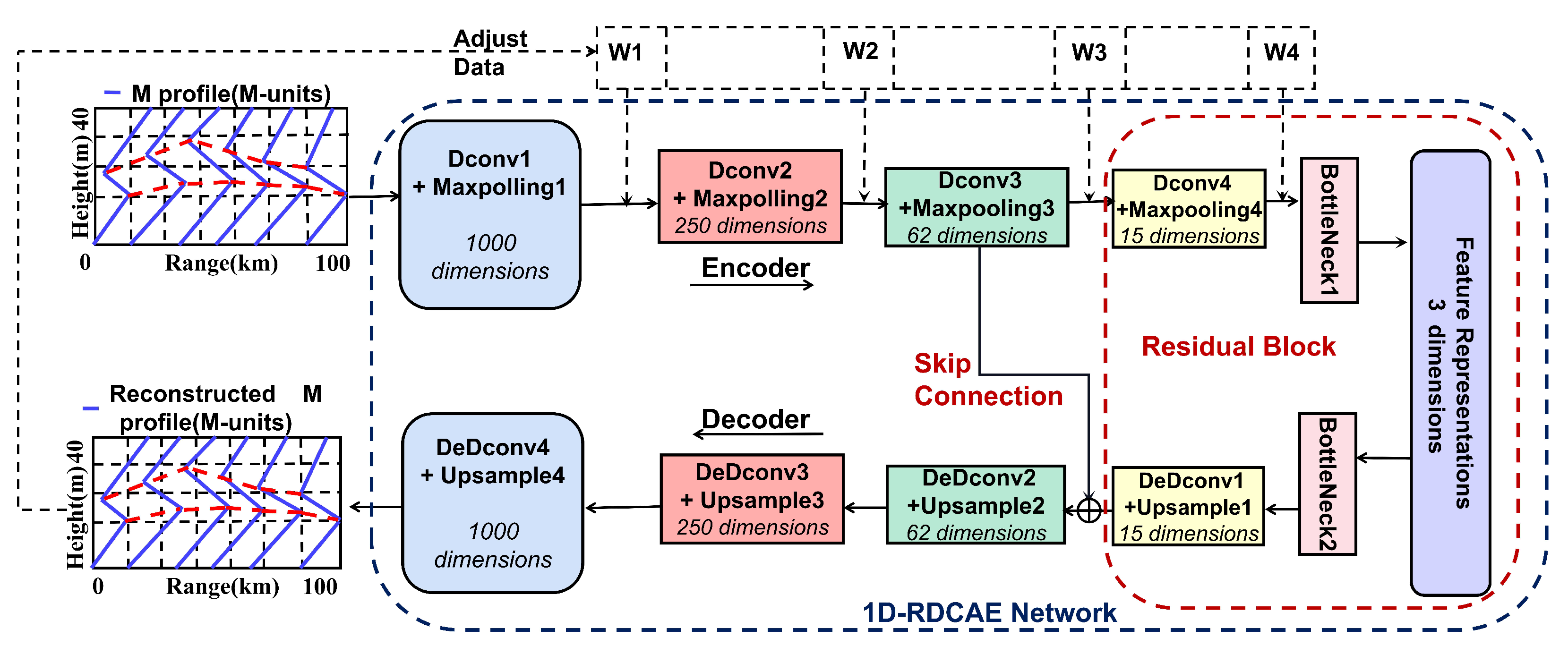
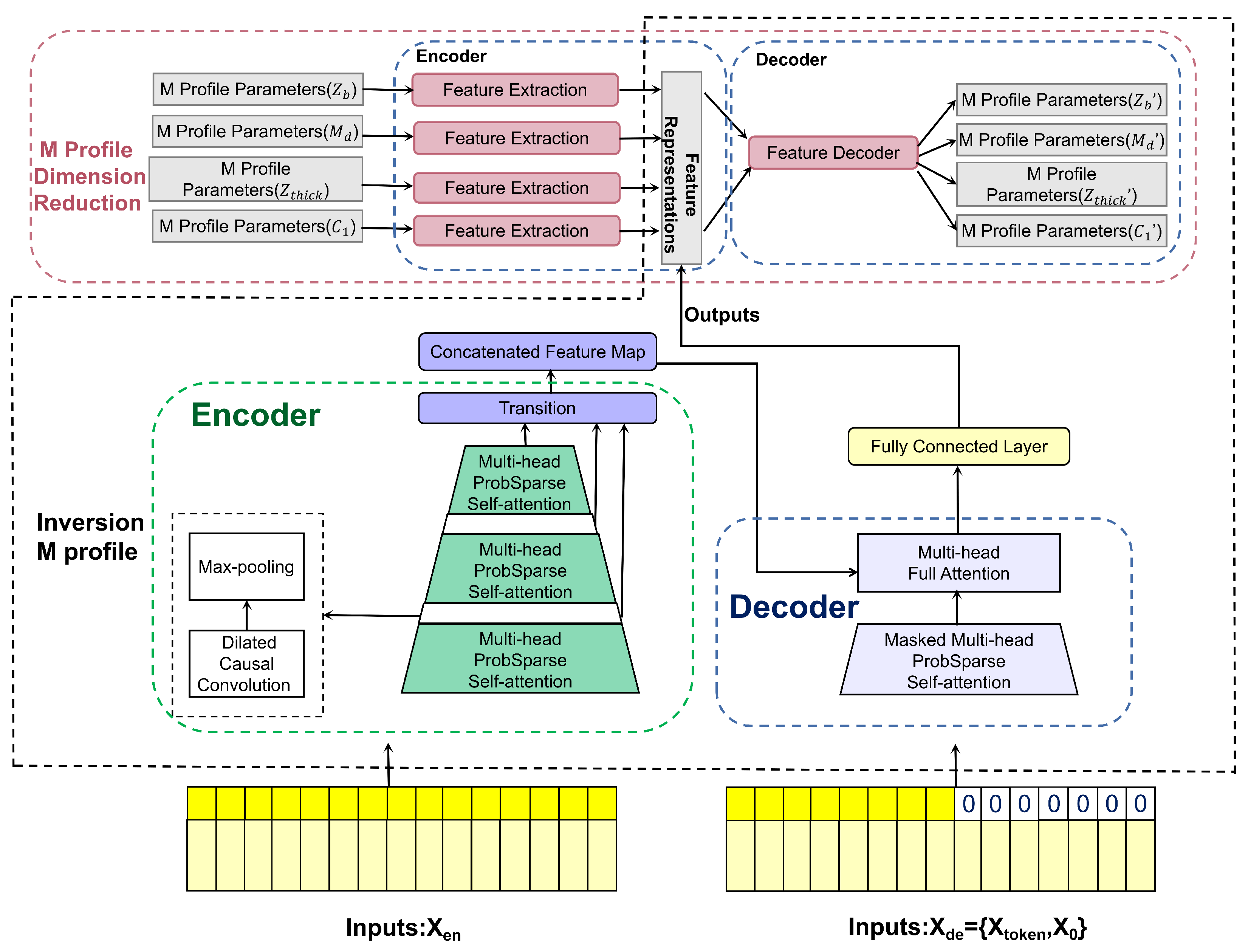
2.3. SBD M-Profile Dimension Reduction
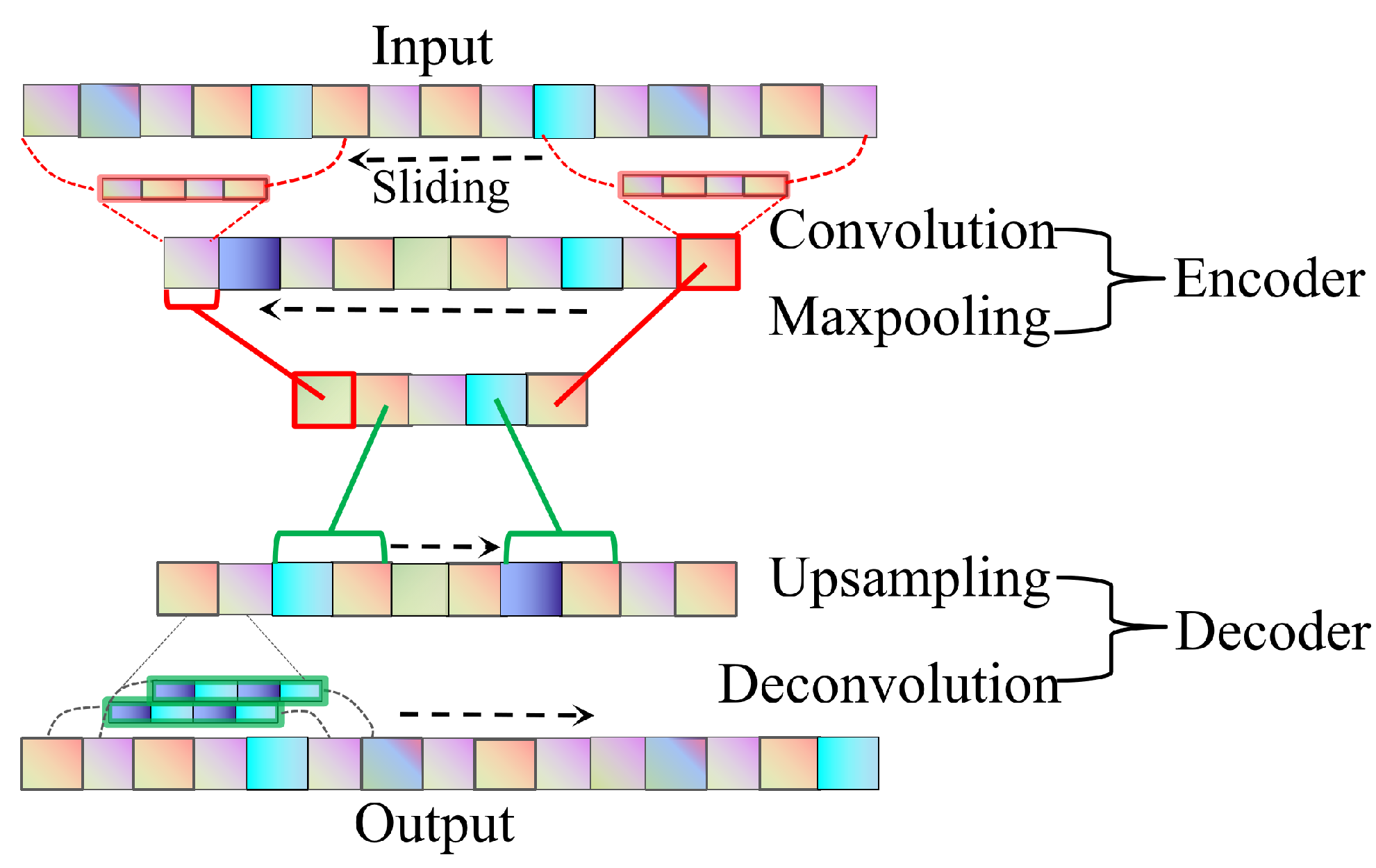
2.3.1. Encoder Network
2.3.2. Decoder Network
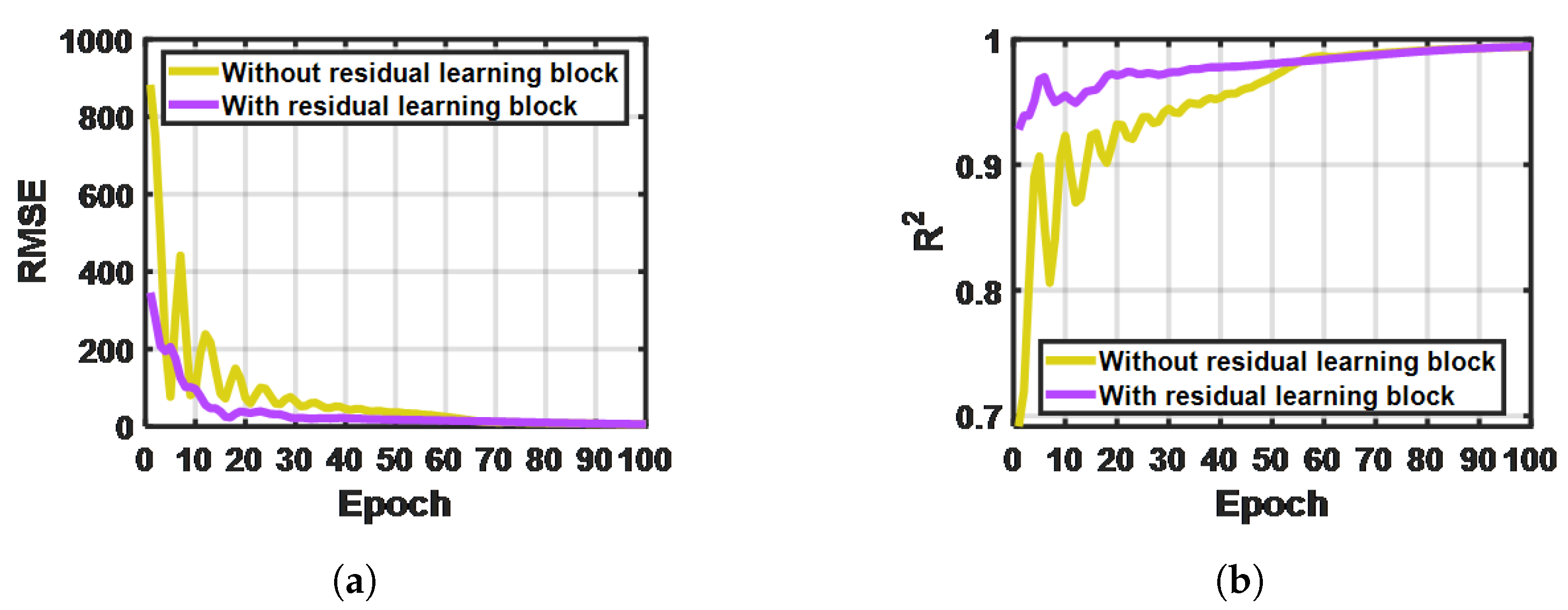
2.3.3. Residual Block
2.4. Inversion of SBD M-Profile
2.4.1. Input Representation
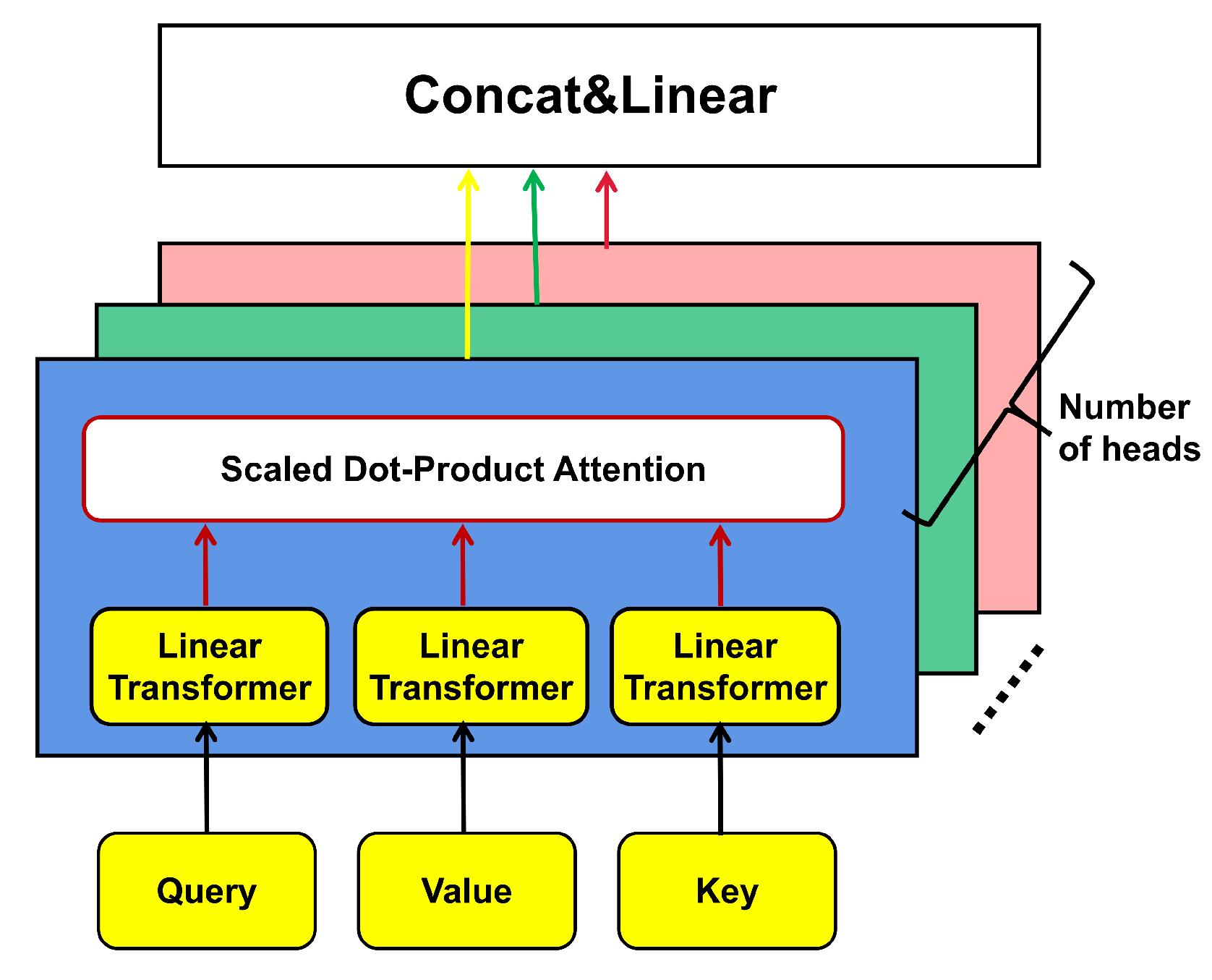
2.4.2. Multi-Head-Attention Mechanisms
| Algorithm 1: Pseudocode of ProbSparse Multi-Head-Attention |
| Input Require: Output : Hyper-Parameters: , h: number of heads 1 randomly selected dot-product pairs from as 2 set the sample score 3 compute the measurement by row 4 set Top- queries under M as 5 set 6 set 7 set by their initial rows 8 9 return |
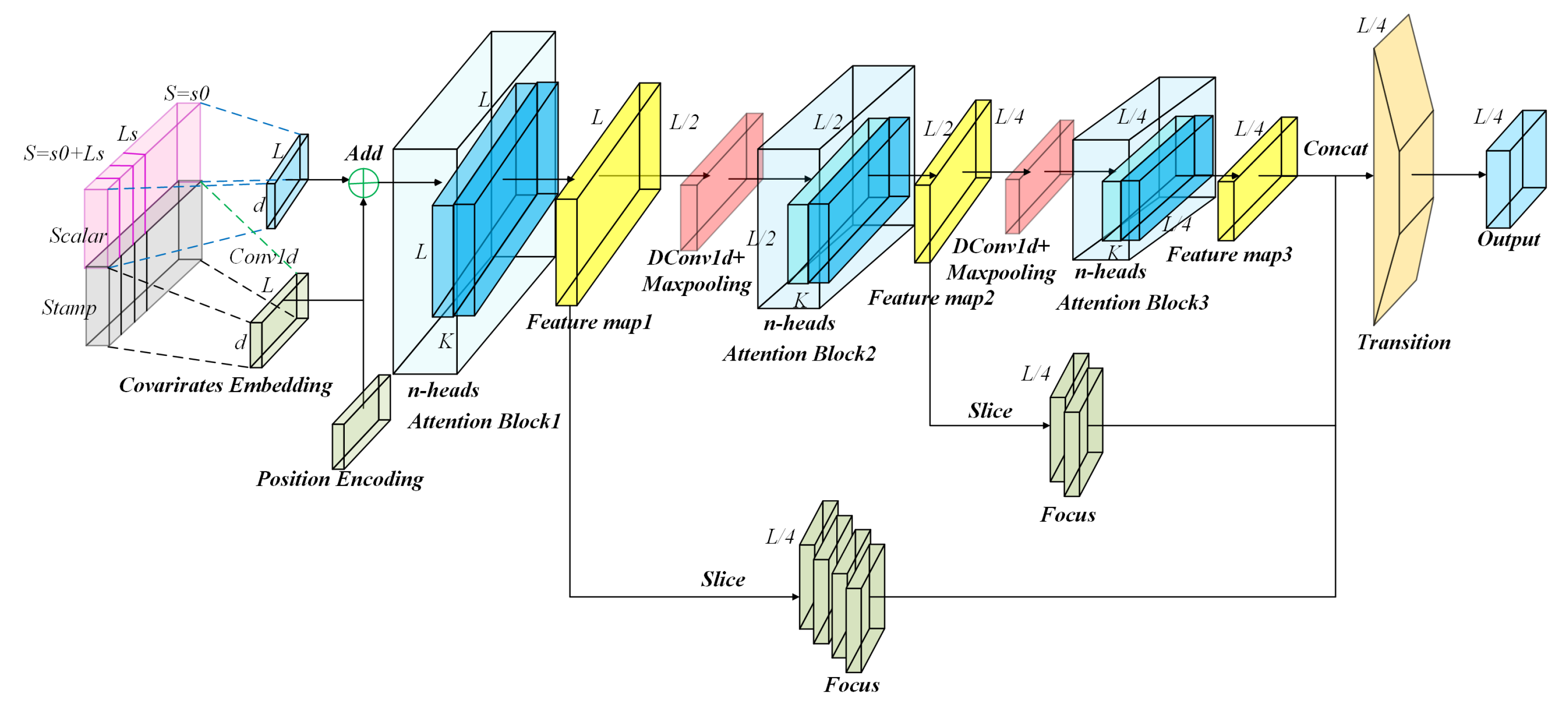
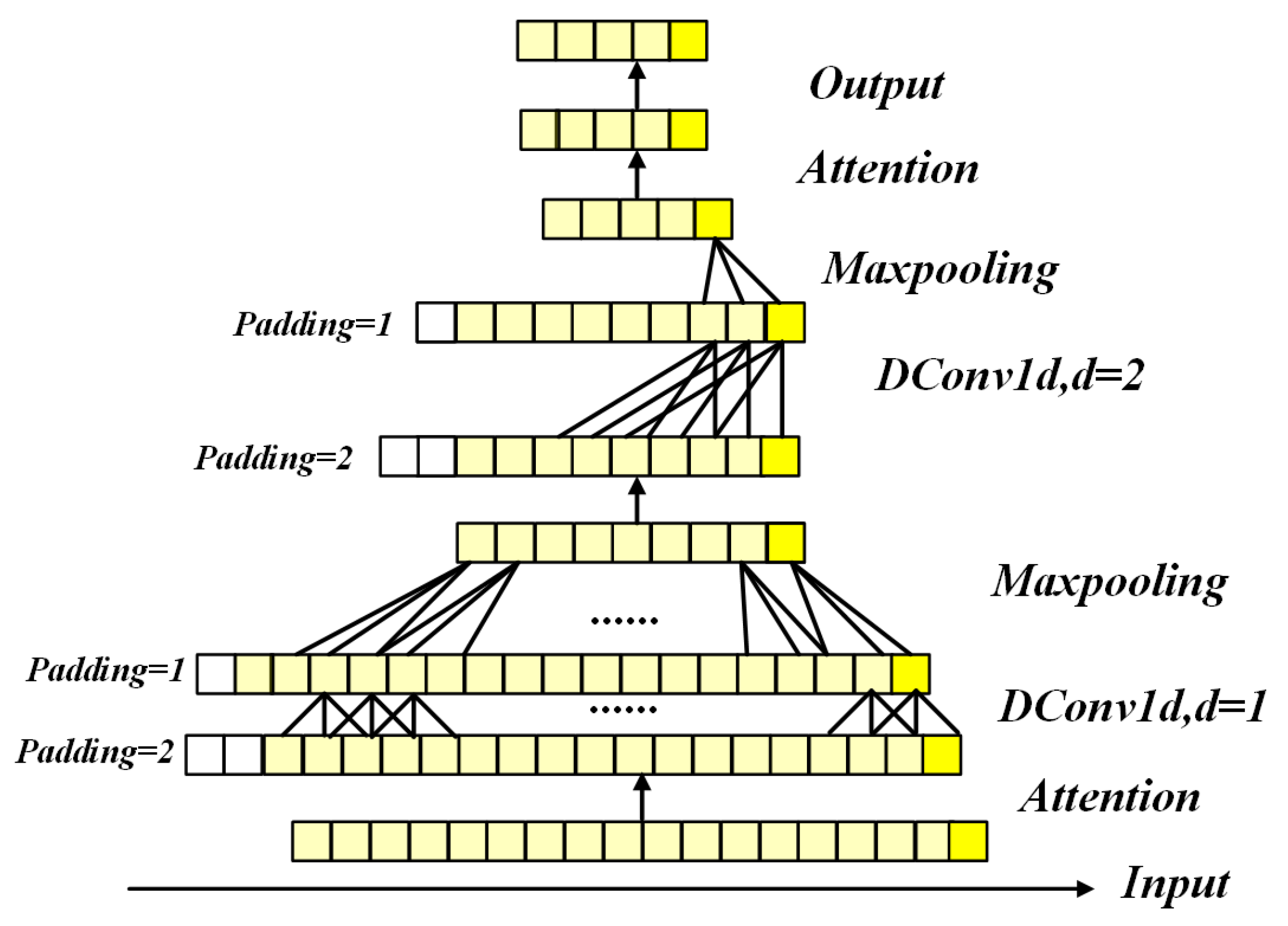
2.4.3. Encoder for Processing Longer Length Ranges Clutter Power Inputs
2.4.4. Decoder: Generating SBD M-Profile Parameter Outputs by Forward Procedure
2.4.5. One-dimensional-RDCAE Decoder Network: Reconstructing Full-Space SBD M-Profile
3. Results and Discussion
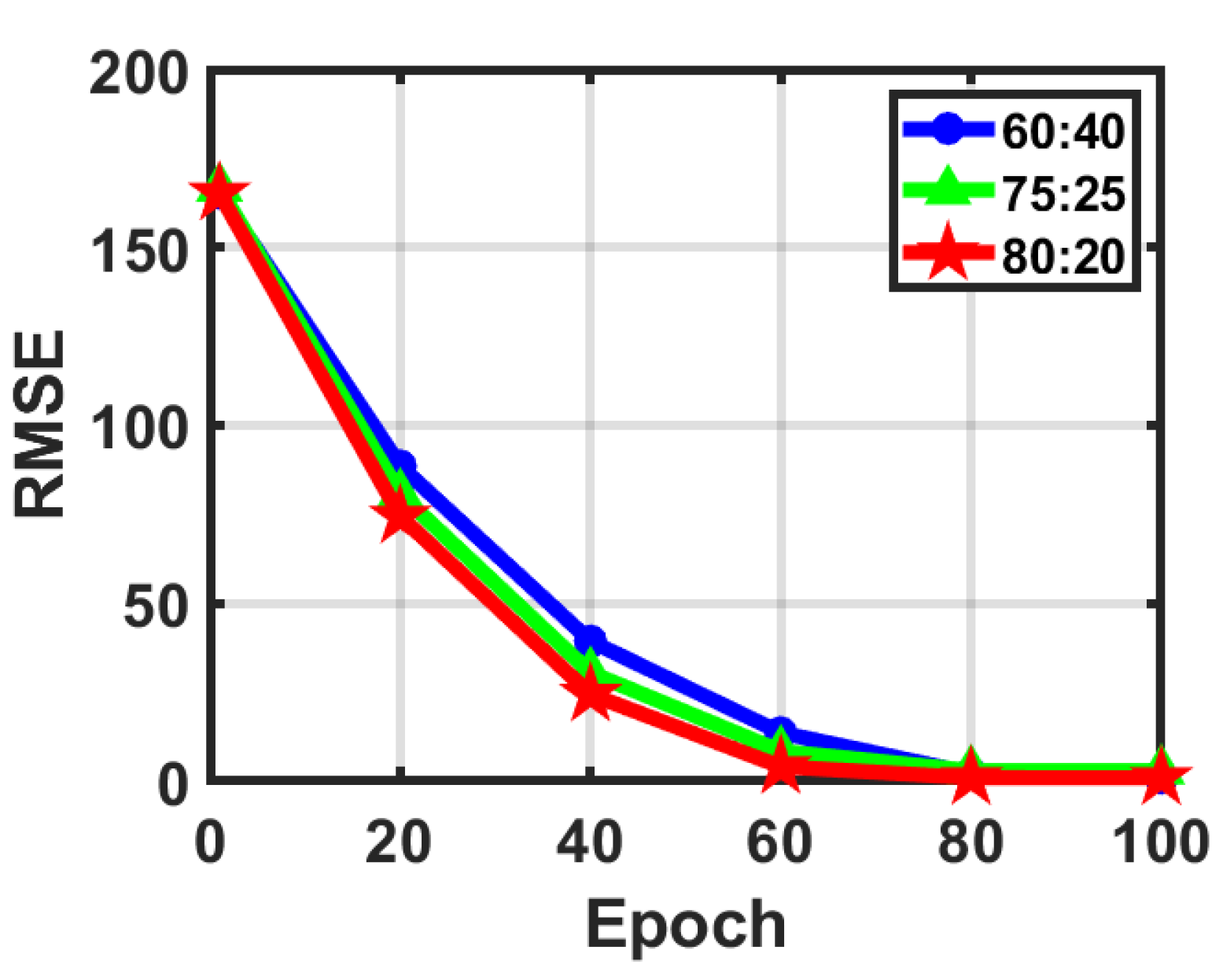
3.1. Dataset
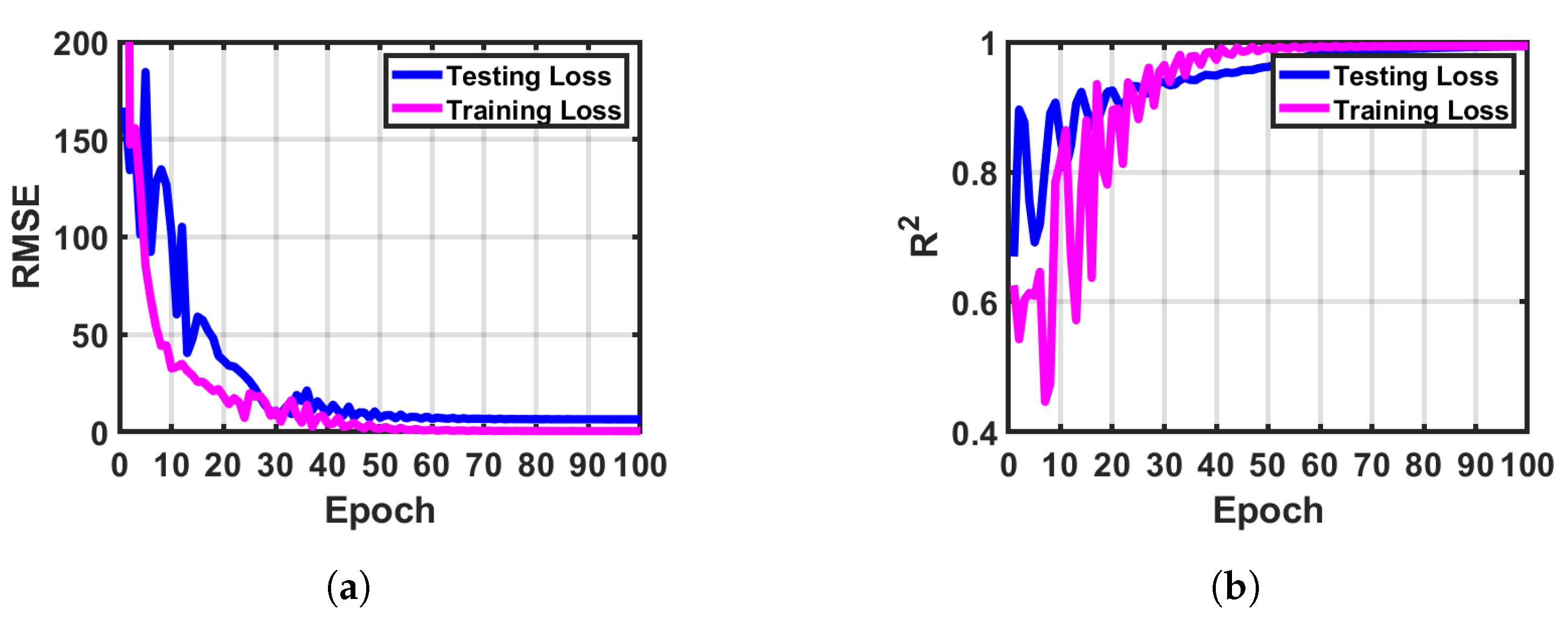
3.2. One-dimensional-RDCAE Used for SBD M-Profile Dimension Reduction
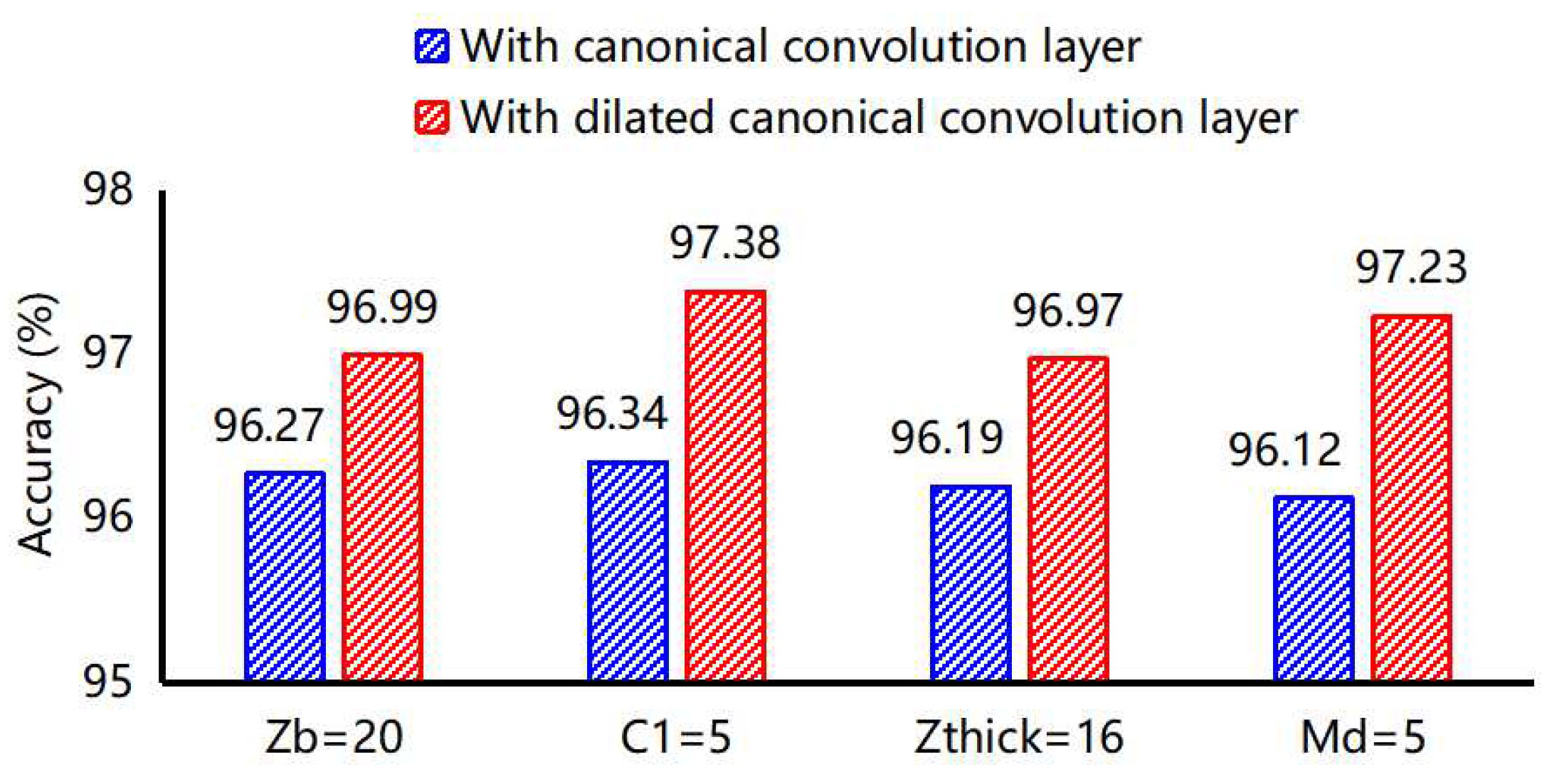
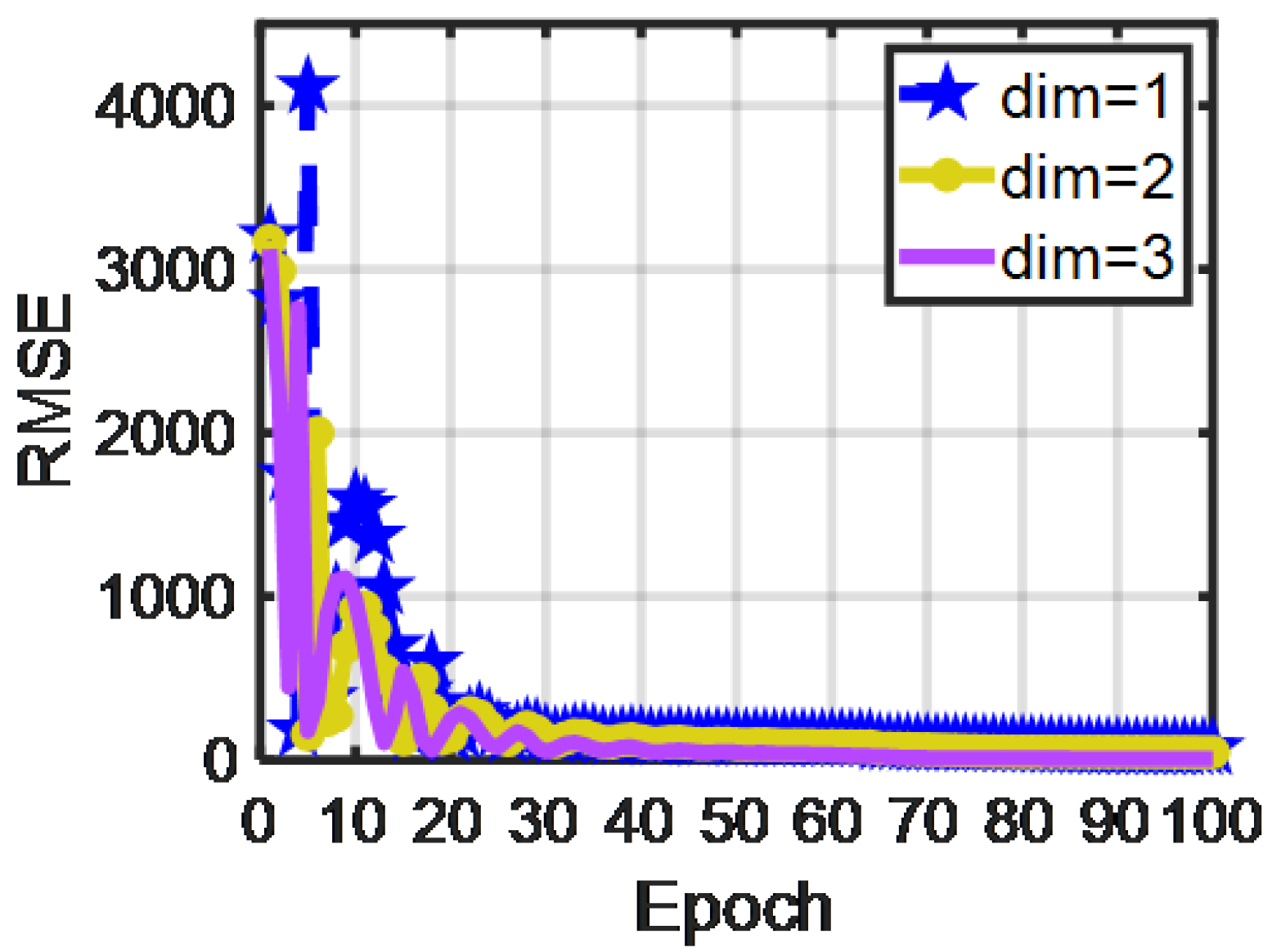
3.2.1. One-dimensional-RDCAE Parameter Analysis
3.2.2. Comparisons of Dimensional Reduction Results
3.3. FCCT Used for Inversion SBD M-Profile Parameters
3.3.1. FCCT Parameters
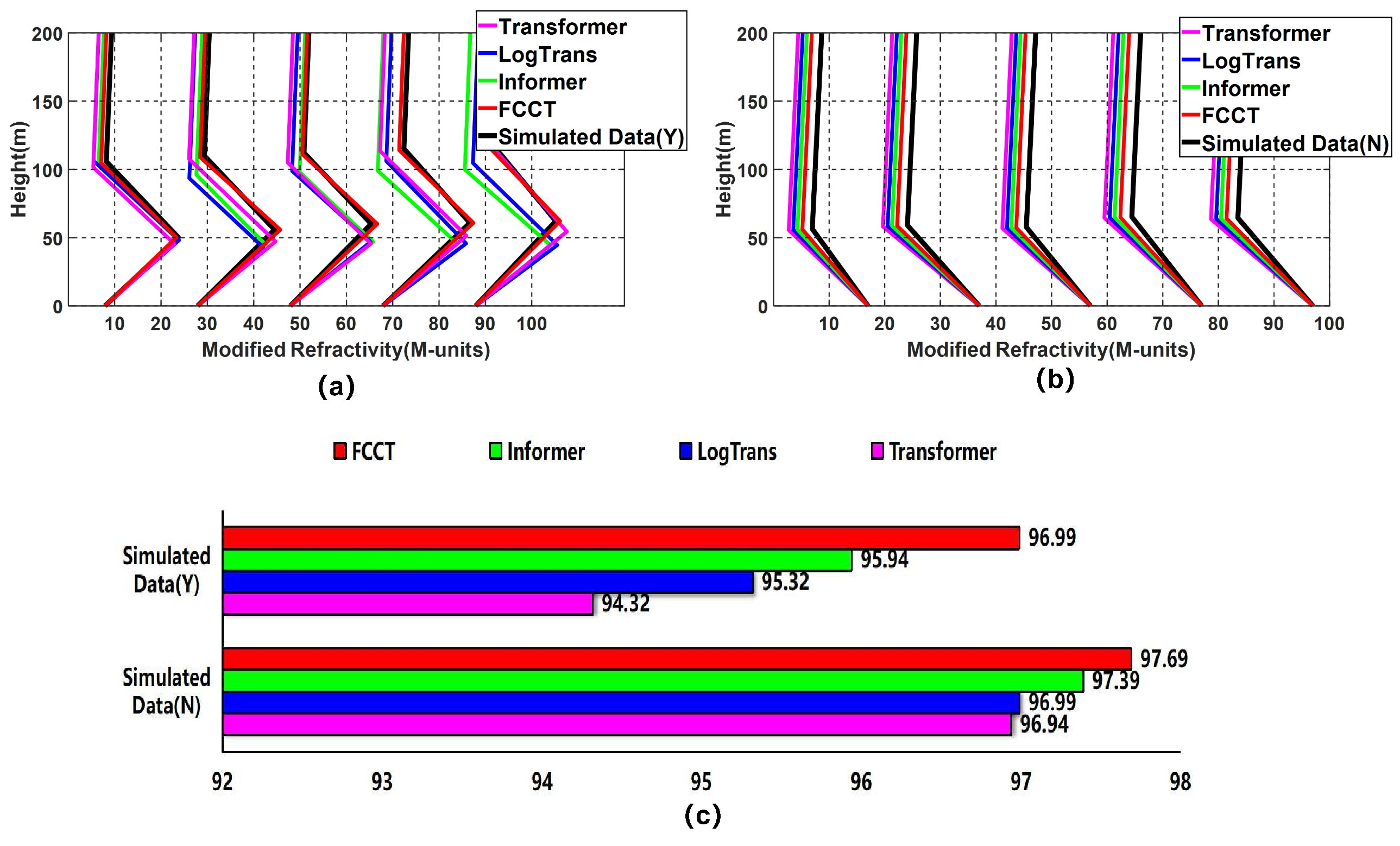
3.3.2. Comparisons of SBD M-Profile Inversion Results
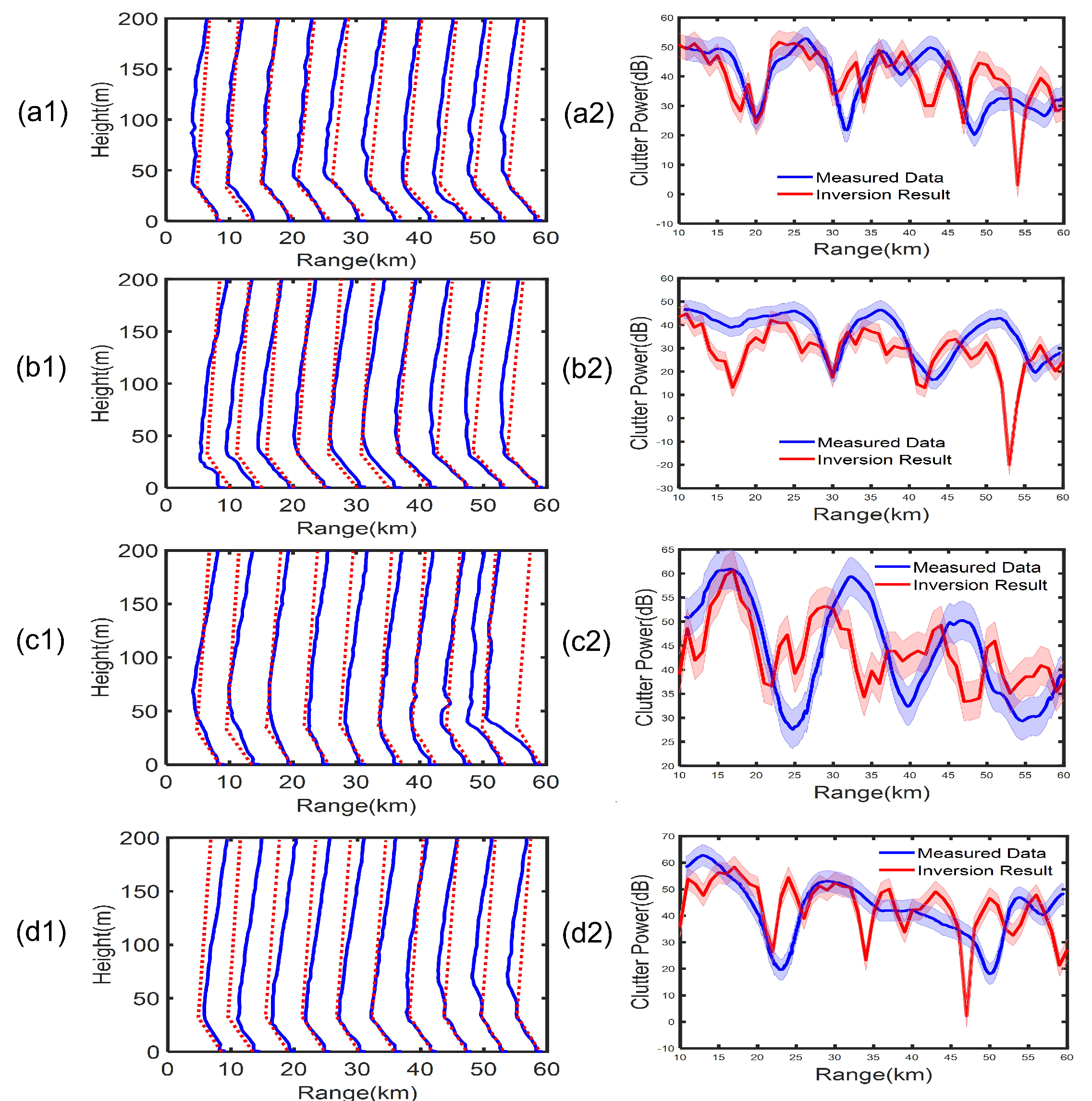
3.3.3. Measured Data Inversion Results
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhang, J. Research on Radar Sea Clutter/GPS Signal Inversion Method for Marine Tropospheric Duct; Xidian University: Xi’an, China, 2012. [Google Scholar]
- Dou, P.; Shen, H.; Li, Z.; Guan, X. Time series remote sensing image classification framework using combination of deep learning and multiple classifiers system. Int. J. Appl. Earth Obs. Geoinf. 2021, 103, 102477. [Google Scholar] [CrossRef]
- Wang, G.; Jia, Q.S.; Zhou, M.; Bi, J.; Qiao, J. Soft-sensing of Wastewater Treatment Process via Deep Belief Network with Event-triggered Learning—ScienceDirect. Neurocomputing 2021, 436, 103–113. [Google Scholar] [CrossRef]
- Yu, J.; Liu, G. Extracting and inserting knowledge into stacked denoising auto-encoders. Neural Netw. 2021, 137, 31–42. [Google Scholar] [CrossRef] [PubMed]
- Paoletti, M.; Haut, J.; Plaza, J.; Plaza, A. A new deep convolutional neural network for fast hyperspectral image classification. ISPRS J. Photogramm. Remote Sens. 2018, 145, 120–147. [Google Scholar] [CrossRef]
- Han, M.; Cong, R.; Li, X.; Fu, H.; Lei, J. Joint spatial-spectral hyperspectral image classification based on convolutional neural network. Pattern Recognit. Lett. 2020, 130, 38–45. [Google Scholar] [CrossRef]
- Dasan, E.; Panneerselvam, I. A novel dimensionality reduction approach for ECG signal via convolutional denoising autoencoder with LSTM. Biomed. Signal Process. Control 2021, 63, 102225. [Google Scholar] [CrossRef]
- Zhang, M.; Gong, M.; Mao, Y.; Li, J.; Wu, Y. Unsupervised Feature Extraction in Hyperspectral Images Based on Wasserstein Generative Adversarial Network. IEEE Trans. Geosci. Remote Sens. 2019, 57, 2669–2688. [Google Scholar] [CrossRef]
- Gerstoft, P.; Rogers, L.T.; Krolik, J.L.; Hodgkiss, W.S. Inversion for refractivity parameters from radar sea clutter. Radio Sci. 2003, 38, 8053. [Google Scholar] [CrossRef]
- Zhang, J.; Zhang, Y.; Wu, Z.; Zhang, Y.; Hu, R. Inversion of regional range-dependent evaporation duct from radar sea clutter. Acta Phys. Sin. 2015, 64, 124101. [Google Scholar] [CrossRef]
- Isaakidis, S.A.; Dimou, I.N.; Xenos, T.D.; Dris, N.A. An artificial neural network predictor for tropospheric surface duct phenomena. Nonlinear Process. Geophys. 2007, 14, 569–573. [Google Scholar] [CrossRef]
- Douvenot, R.; Fabbro, V.; Gerstoft, P.; Bourlier, C.; Saillard, J. A duct mapping method using least squares support vector machines. Radio Seience 2008, 43, 1–12. [Google Scholar] [CrossRef]
- Remi, D.; Vincent, F.; Christophe, B.; Joseph, S.; Hans-Hellmuth, F.; Helmut, E.; Joerg, F. Retrieve the evaporation duct height by least-squares support vector machine algorithm. J. Appl. Remote Sens. 2009, 3, 033503. [Google Scholar]
- Yan, X.; Yang, K.; Ma, Y. Calculation Method for Evaporation Duct Profiles Based on Artificial Neural Network. Antennas Wirel. Propag. Lett. IEEE 2018, 17, 2274–2278. [Google Scholar] [CrossRef]
- Compaleo, J.; Yardim, C.; Xu, L. Refractivity-From-Clutter Capable, Software-Defined, Coherent-on-Receive Marine Radar. Radio Sci. 2021, 56, 1–19. [Google Scholar] [CrossRef]
- Zhou, S.; Gao, H.; Ren, F. Pole Feature Extraction of HF Radar Targets for the Large Complex Ship Based on SPSO and ARMA Model Algorithm. Electronics 2022, 11, 1644. [Google Scholar] [CrossRef]
- Guo, X.; Wu, J.; Zhang, J.; Han, J. Deep learning for solving inversion problem of atmospheric refractivity estimation. Sustain. Cities Soc. 2018, 43, 524–531. [Google Scholar] [CrossRef]
- Zhao, W.; Li, J.; Zhao, J.; Jiang, T.; Zhu, J.; Zhao, D.; Zhao, J. Research on evaporation duct height prediction based on back propagation neural network. IET Microwaves Antennas Propag. 2020, 14, 1547–1554. [Google Scholar] [CrossRef]
- Ji, H.; Yin, B.; Zhang, J.; Zhang, Y. Joint Inversion of Evaporation Duct Based on Radar Sea Clutter and Target Echo Using Deep Learning. Electronics 2022, 11, 2157. [Google Scholar] [CrossRef]
- Lim, B.; Arik, S.O.; Loeff, N.; Pfister, T. Temporal Fusion Transformers for Interpretable Multi-horizon Time Series Forecasting. Int. J. Forecast. 2019, 37, 1748–1764. [Google Scholar] [CrossRef]
- Zhou, H.; Zhang, S.; Peng, J.; Zhang, S.; Li, J.; Xiong, H.; Zhang, W. Informer: Beyond efficient transformer for long sequence time-series forecasting. Proc. AAAI Conf. Artif. Intell. 2021, 35, 11106–11115. [Google Scholar] [CrossRef]
- Yin, H.; Guo, Z.; Zhang, X.; Chen, J.; Zhang, Y. RR-Former: Rainfall-runoff modeling based on Transformer. J. Hydrol. 2022, 609, 127781. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.u.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar] [CrossRef]
- Shen, L.; Wang, Y. TCCT: Tightly-coupled convolutional transformer on time series forecasting. Neurocomputing 2022, 480, 131–145. [Google Scholar] [CrossRef]
- Liu, M.; Li, Z.; Li, Y.; Liu, Y. A Fast and Accurate Method of Power Line Intelligent Inspection Based on Edge Computing. IEEE Trans. Instrum. Meas. 2022, 71, 1–12. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Bai, S.; Kolter, J.Z.; Koltun, V. An empirical evaluation of generic convolutional and recurrent networks for sequence modeling. arXiv 2018, arXiv:1803.01271. [Google Scholar] [CrossRef]
- Stoller, D.; Tian, M.; Ewert, S.; Dixon, S. Seq-u-net: A one-dimensional causal u-net for efficient sequence modelling. arXiv 2019, arXiv:1911.06393. [Google Scholar]
- Chao, Y. A comparison of the machine learning algorithm for evaporationduct estimation. Radioengineering 2013, 22, 657–661. [Google Scholar] [CrossRef]
- Zhu, X.; Li, J.; Min, Z.; Jiang, Z.; Li, Y. An Evaporation Duct Height Prediction Method Based on Deep Learning. IEEE Geoence Remote Sens. Lett. 2018, 15, 1307–1311. [Google Scholar] [CrossRef]
- Li, S.; Jin, X.; Xuan, Y.; Zhou, X.; Chen, W.; Wang, Y.X.; Yan, X. Enhancing the Locality and Breaking the Memory Bottleneck of Transformer on Time Series Forecasting. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, ; 2019; Volume 32. [Google Scholar]
- Rogers, L.T.; Hattan, C.P.; Stapleton, J.K. Estimating evaporation duct heights from radar sea echo. Radio Sci. 2000, 35, 955–966. [Google Scholar] [CrossRef] [Green Version]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Lower | Upper |
|---|---|---|
| The height of the base (m) | 1 | 100 |
| The thickness of the trapping layer (m) | 20 | 100 |
| The refractive index of the trapping layer (M-units) | 20 | 100 |
| The slope of the base layer | 1 | 20 |
| Parameter | Value |
|---|---|
| Radar Transmitting Frequency (GHz) | 2.84 |
| Power (dBm) | 91.40 |
| Antenna gain (dB) | 52.80 |
| Polarization Mode | VV |
| Antenna Height (m) | 30.78 |
| Antenna elevation angle (deg) | 0.0 |
| Beam Width () | 0.39 |
| Distance resolution (m) | 600 |
| Layer | Value |
|---|---|
| Dconvolutional 1 | Kernel Size , Filter |
| Max-pooling 1&2&3&4 | Strides , Pooling Size |
| Dconvolutional 2 | Kernel Size , Filter |
| Dconvolutional 3 | Strides , Filter |
| Dconvolutional 4 | Strides , Filter |
| Bottleneck 1&2 | Strides , Filter |
| DeDconvolution 1 | Strides , Filter |
| Upsampling 1&2&3&4 | Strides , Pooling Size |
| DeDconvolution2 | Strides , Filter |
| DeDconvolution3 | Strides , Filter |
| DeDconvolution4 | Strides , Filter |
| Flatten& Fully Connected | Units |
| Learning Rate | 0.0001 |
| Batch Size | 256 |
| Model | Dimension | Dimension | |||||||
|---|---|---|---|---|---|---|---|---|---|
| RMSE | MAE | Time (s) | RMSE | MAE | Time (s) | ||||
| PCA | 3.62 | 2.47 | 0.91 | 48 | 3.57 | 2.38 | 0.92 | 49 | |
| BPN | 0.72 | 0.61 | 0.94 | 43 | 0.51 | 0.41 | 0.95 | 43 | |
| SAE | 0.69 | 0.59 | 0.94 | 43 | 0.44 | 0.35 | 0.95 | 42 | |
| Zb = 20 | DBN | 0.56 | 0.51 | 0.95 | 43 | 0.38 | 0.31 | 0.96 | 42 |
| 1D-CAE | 0.49 | 0.49 | 0.95 | 41 | 0.36 | 0.33 | 0.97 | 40 | |
| 1D-RCAE | 0.35 | 0.39 | 0.96 | 40 | 0.28 | 0.29 | 0.97 | 39 | |
| 1D-RDCAE | 0.32 | 0.29 | 0.97 | 40 | 0.23 | 0.22 | 0.98 | 39 | |
| Encoder: | ||
|---|---|---|
| Input | 3Conv1d | Embedding () |
| ProbSparse Self-attention Block | Multi-head ProbSparse Attention (, ) | |
| Add Layer Norm, Dropout() | ||
| FFN (dinner ), GELU | ||
| Dropout () | ||
| Distilling | 3DeConv1d, BatchNorm1d, ELU(), Dropout(), | |
| Maxpooling (Kernel size , stride , padding ) | ||
| Focus Layer | 3Conv1d, BatchNorm1d | |
| Decoder: | ||
| Input | 3Conv1d | Embedding () |
| Masked Layer | Add Mask on Attention Block | |
| ProbSparse Self-attention Block | Multi-head ProbSparse Attention (, ) | |
| Add, Layer Norm, Dropout() | ||
| FFN (dinner ), GELU | ||
| Add, Layer Norm, Dropout () | ||
| Final: | ||
| Output | Fully Connected & Reshape() | |
| Learning Rate | 0.0001 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, J.; Wei, Z.; Zhang, J.; Zhang, Y.; Jia, D.; Yin, B.; Yu, Y. Full-Coupled Convolutional Transformer for Surface-Based Duct Refractivity Inversion. Remote Sens. 2022, 14, 4385. https://doi.org/10.3390/rs14174385
Wu J, Wei Z, Zhang J, Zhang Y, Jia D, Yin B, Yu Y. Full-Coupled Convolutional Transformer for Surface-Based Duct Refractivity Inversion. Remote Sensing. 2022; 14(17):4385. https://doi.org/10.3390/rs14174385
Chicago/Turabian StyleWu, Jiajing, Zhiqiang Wei, Jinpeng Zhang, Yushi Zhang, Dongning Jia, Bo Yin, and Yunchao Yu. 2022. "Full-Coupled Convolutional Transformer for Surface-Based Duct Refractivity Inversion" Remote Sensing 14, no. 17: 4385. https://doi.org/10.3390/rs14174385
APA StyleWu, J., Wei, Z., Zhang, J., Zhang, Y., Jia, D., Yin, B., & Yu, Y. (2022). Full-Coupled Convolutional Transformer for Surface-Based Duct Refractivity Inversion. Remote Sensing, 14(17), 4385. https://doi.org/10.3390/rs14174385