

TRQ3DNet: A 3D Quasi-Recurrent and Transformer Based Network for Hyperspectral Image Denoising



Abstract
:1. Introduction
- We propose TRQ3DNet, a residual encoder–decoder network for HSI denoising, which consists of two branches. One is based on convolution, and the other is transformer. The model can extract both the global correlation along spectrum and the local–global spatial features.
- We present a bidirectional integration bridge, which aggregates the global features from convolution layers and the local features from window-based attention mechanism, so as to exploit a better representation of image features.
- We conduct both synthetic and real HSI denoising experiments. Quantitative evaluation results reveal that our model achieves a better performance than other state-of-the-art model-based and deep-learning-based methods.
2. Proposed Method
2.1. Notations
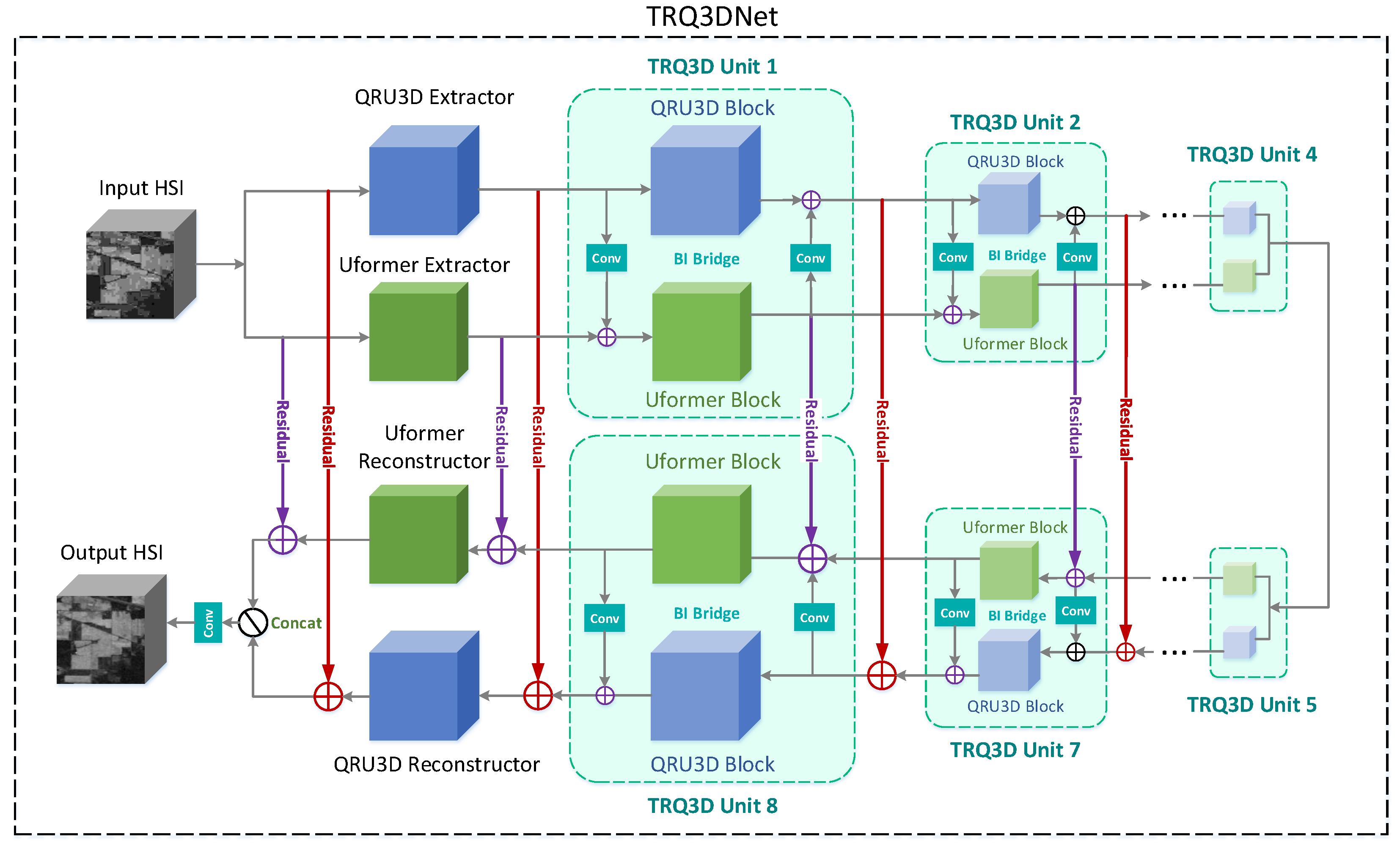
2.2. Overall Architecture
2.3. 3D Quasi-Recurrent Block
- (1)
- 3D Convolution Module: We apply two sets of 3D convolution [39,40] to the inputs, which activates the convolution output with two different nonlinear functions, and generates two tensors, named candidate tensor and forget gate tensor . The process is formulated aswhere is the input feature map from the last layer, and is the number of input channels. represents a certain activation function, e.g., tanh, relu or without activation. and are the number of output channels. are 3D convolution kernels. Notice that we only use sigmoid for gate tensor F, in order to map the output to values between 0 and 1. Compared with 2D convolution, 3D convolution can not only aggregate spatial domain information, but also exploit the spectral information of the input.
- (2)
- Quasi-Recurrent Pooling Module: Considering that the 3D convolution can only aggregate the information in adjacent bands, motivated by the QRNN3D [22], we introduce the quasi-recurrent pooling operation and dynamic gating mechanism in order to fully exploit global correlation along all the bands. We split the candidate tensor and forget gate tensor along the spectrum direction, obtaining sequences and . Then, these sequences are applied with the quasi-recurrent pooling operation, as shown below:where is the i-th hidden state (), and ⊙ represents the Hadamard product. The value of controls the weight of candidate tensor and states from the last step . The sigmoid is used as the activation function for the forget gate. All are concatenated along the spectral dimension, generating the output. The benefits of quasi-recurrent pooling are that the module will automatically preserve the information of each spectrum through the training process, and achieve global correlation along all spectra. Notice that the hidden state only depends on the current band of the input feature map, so the gate tensor relies more on the input as well as the parameters learned from the training process.
2.4. Uformer Block
- (1)
- Window-based Multi-head Self-Attention: The projection layer transforms the bands value of the input feature maps, from to . Each band of the feature maps is seen as a 2D map, which is partitioned into non-overlapping windows with size , expressed as , where is the number of windows (also called patches), and . Then, we flatten these image patches with size , and calculate the multi-head self-attention on each of them. Given the total number of head K, we can draw that the dimension of k-th head is , and the k-th self-attention of is calculated aswhere are learnable weight matrices. When calculating the self-attention, we also employ the relative position bias to each head, following the work of [37]. Thus, the attention mechanism isand represent the query, key, and value, separately. The values in are taken from a smaller bias matrix with learnable parameter [42,43]. For N patches , we obtain corresponding N output feature maps of k-th head, described as in a whole. Finally, outputs of K heads are concatenated together followed by a linear transform to generate the result of the LeWin transformer block.
- (2)
- Locally-enhanced Feed-Forward Network: The feed-forward network (FFN) in the standard transformer model provides linear dimensional transformation and nonlinear activation to the tokens from the W-MSA module, which enhances the ability of feature representation. The limitation is that the spatial correlation among neighboring pixels is ignored. To overcome this problem, we replace the FFN with a locally-enhanced feed-forward network (LeFF), because the latter model provides depth-wise convolution to extract the spatial information. The process is as follows. First, the input feature maps are fed into a linear layer, and projected to a higher dimension. Next, we reshape the feature maps to 2D feature, using a depth-wise convolution to capture local information. Then, we flatten back the features and shrink the channels via another linear layer to match the dimension of the input channels. For each linear and convolution layer, GELU [44] is used as the activation function since it has been proven to achieve comparable denoising results compared with other activation functions [36,37].
2.5. Bidirectional Integration Bridge
2.6. Training Loss Function
3. Experiments
3.1. Experimental Setup
3.2. Synthetic Experiments
3.3. Real HSI Denoising
3.4. Ablation Study
4. Analysis and Discussion
4.1. Training Strategy
4.2. Feature Analysis
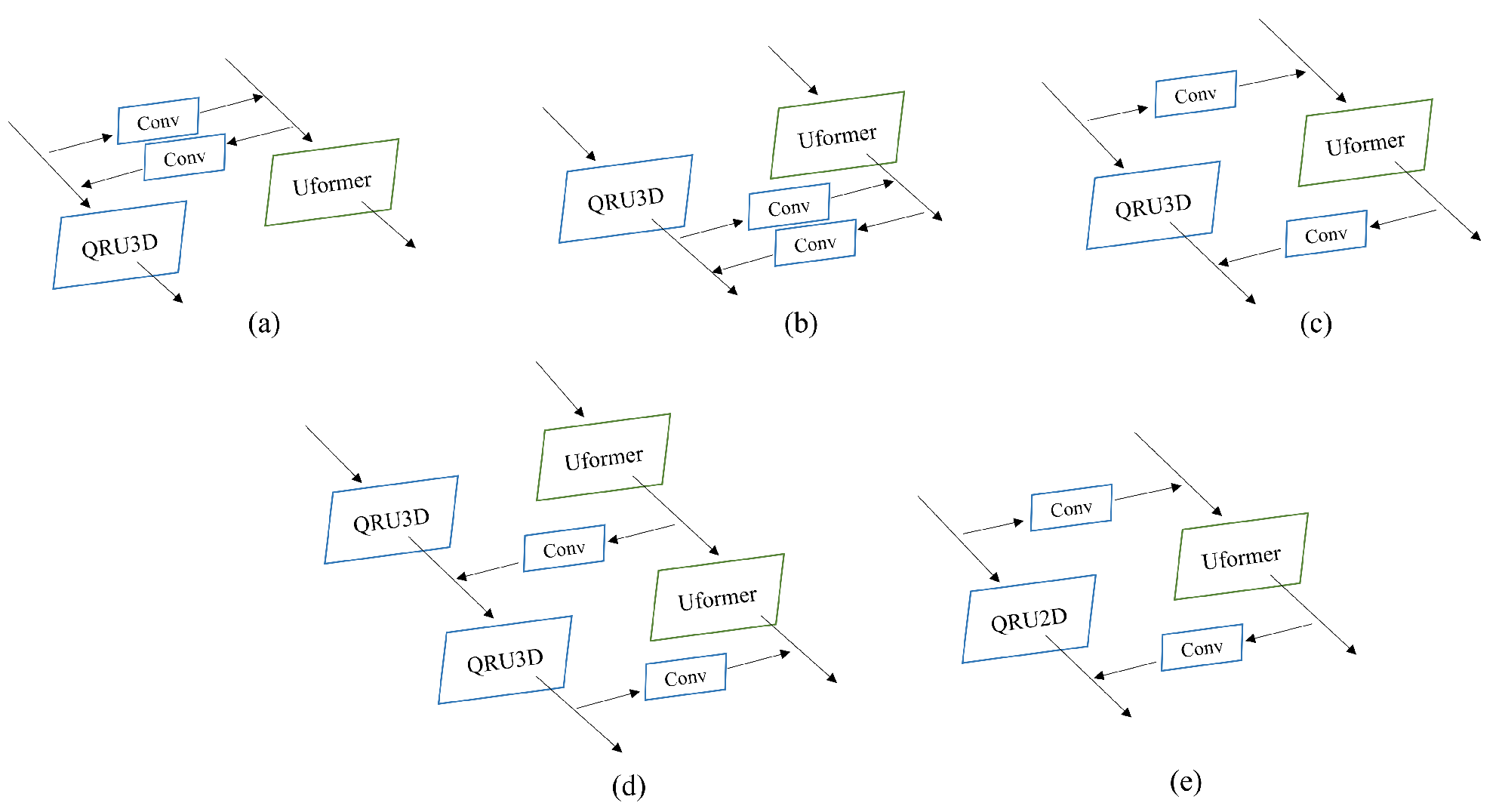
4.3. Structure Analysis
4.4. Practical Implications
4.5. Limitations Analysis
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Akhtar, N.; Mian, A. Nonparametric coupled bayesian dictionary and classifier learning for hyperspectral classification. Neural Netw. Learn. Syst. IEEE Trans. 2018, 29, 4038–4050. [Google Scholar] [CrossRef] [PubMed]
- Camps-Valls, G.; Tuia, D.; Bruzzone, L.; Benediktsson, J.A. Advances in hyperspectral image classification: Earth monitoring with statistical learning methods. IEEE Signal Process. Mag. 2013, 31, 45–54. [Google Scholar] [CrossRef]
- Zhong, P.; Wang, R. Jointly learning the hybrid crf and mlr model for simultaneous denoising and classification of hyperspectral imagery. IEEE Trans. Neural Netw. Learn. Syst. 2014, 25, 1319–1334. [Google Scholar] [CrossRef]
- Wang, Q.; Lin, J.; Yuan, Y. Salient band selection for hyperspectral image classification via manifold ranking. IEEE Trans. Neural Netw. Learn. Syst. 2017, 27, 1279–1289. [Google Scholar] [CrossRef]
- Yang, S.; Feng, Z.; Min, W.; Kai, Z. Self-paced learning-based probability subspace projection for hyperspectral image classification. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 630–635. [Google Scholar] [CrossRef]
- Ayerdi, B.; Marques, I.; Grana, M. Spatially regularized semisupervised ensembles of extreme learning machines for hyperspectral image segmentation. Neurocomputing 2015, 149, 373–386. [Google Scholar] [CrossRef]
- Noyel, G.; Angulo, J.; Jeulin, D. On distances, paths and connections for hyperspectral image segmentation. arXiv 2016, arXiv:1603.08497. [Google Scholar]
- Li, J.; Agathos, A.; Zaharie, D.; Bioucas-Dias, J.M.; Plaza, A.; Li, X. Minimum volume simplex analysis: A fast algorithm for linear hyperspectral unmixing. IEEE Trans. Geosci. Remote Sens. 2015, 53, 5067–5082. [Google Scholar]
- Rasti, B.; Chang, Y.; Dalsasso, E.; Denis, L.; Ghamisi, P. Image restoration for remote sensing: Overview and toolbox. arXiv 2021, arXiv:2107.00557. [Google Scholar] [CrossRef]
- Peng, Y.; Meng, D.; Xu, Z.; Gao, C.; Yang, Y.; Zhang, B. Decomposable nonlocal tensor dictionary learning for multispectral image denoising. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2949–2956. [Google Scholar]
- Maggioni, M.; Katkovnik, V.; Egiazarian, K.; Foi, A. Nonlocal transform-domain filter for volumetric data denoising and reconstruction. IEEE Trans. Image Process. 2012, 22, 119–133. [Google Scholar] [CrossRef]
- Xie, Q.; Zhao, Q.; Meng, D.; Xu, Z.; Gu, S.; Zuo, W.; Zhang, L. Multispectral images denoising by intrinsic tensor sparsity regularization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1692–1700. [Google Scholar]
- Chang, Y.; Yan, L.; Zhong, S. Hyper-laplacian regularized unidirectional low-rank tensor recovery for multispectral image denoising. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4260–4268. [Google Scholar]
- Zhang, H.; He, W.; Zhang, L.; Shen, H.; Yuan, Q. Hyperspectral image restoration using low-rank matrix recovery. IEEE Trans. Geosci. Remote Sens. 2013, 52, 4729–4743. [Google Scholar] [CrossRef]
- He, W.; Zhang, H.; Zhang, L.; Shen, H. Total-variation-regularized low-rank matrix factorization for hyperspectral image restoration. IEEE Trans. Geosci. Remote Sens. 2015, 54, 178–188. [Google Scholar] [CrossRef]
- Chen, Y.; Cao, X.; Zhao, Q.; Meng, D.; Xu, Z. Denoising hyperspectral image with non-iid noise structure. IEEE Trans. Cybern. 2017, 48, 1054–1066. [Google Scholar] [CrossRef]
- Wang, Y.; Peng, J.; Zhao, Q.; Leung, Y.; Zhao, X.; Meng, D. Hyperspectral image restoration via total variation regularized low-rank tensor decomposition. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 11, 1227–1243. [Google Scholar] [CrossRef]
- Dabov, K.; Foi, A.; Katkovnik, V.; Egiazarian, K. Image denoising by sparse 3-d transform-domain collaborative filtering. IEEE Trans. Image Process. 2007, 16, 2080–2095. [Google Scholar] [CrossRef]
- Chang, Y.; Yan, L.; Fang, H.; Zhong, S.; Liao, W. Hsi-denet: Hyperspectral image restoration via convolutional neural network. IEEE Trans. Geosci. Remote Sens. 2018, 57, 667–682. [Google Scholar] [CrossRef]
- Yuan, Q.; Zhang, Q.; Li, J.; Shen, H.; Zhang, L. Hyperspectral image denoising employing a spatial-spectral deep residual convolutional neural network. IEEE Trans. Geosci. Remote Sens. 2018, 57, 1205–1218. [Google Scholar] [CrossRef]
- Tai, Y.; Yang, J.; Liu, X.; Xu, C. Memnet: A persistent memory network for image restoration. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 4549–4557. [Google Scholar]
- Wei, K.; Fu, Y.; Huang, H. 3-d quasi-recurrent neural network for hyperspectral image denoising. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 363–375. [Google Scholar] [CrossRef]
- Cao, X.; Fu, X.; Xu, C.; Meng, D. Deep spatial-spectral global reasoning network for hyperspectral image denoising. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–14. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Heo, B.; Yun, S.; Han, D.; Chun, S.; Choe, J.; Oh, S.J. Rethinking spatial dimensions of vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual, 11–17 October 2021; pp. 11936–11945. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Houlsby, N. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Vaswani, A.; Ramachandran, P.; Srinivas, A.; Parmar, N.; Shlens, J. Scaling local self-attention for parameter efficient visual backbones. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 11–17 October 2021; pp. 12894–12904. [Google Scholar]
- Maji, B.; Swain, M. Advanced fusion-based speech emotion recognition system using a dual-attention mechanism with conv-caps and bi-gru features. Electronics 2022, 11, 1328. [Google Scholar] [CrossRef]
- Yu, W.; Luo, M.; Zhou, P.; Si, C.; Zhou, Y.; Wang, X.; Feng, J.; Yan, S. Metaformer is actually what you need for vision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 21–24 June 2022; pp. 10819–10829. [Google Scholar]
- Chu, X.; Tian, Z.; Wang, Y.; Zhang, B.; Ren, H.; Wei, X.; Xia, H.; Shen, C. Twins: Revisiting the design of spatial attention in vision transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 9355–9366. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Jiang, Y.; Chang, S.; Wang, Z. Transgan: Two pure transformers can make one strong gan, and that can scale up. Adv. Neural Inf. Process. Syst. 2021, 34, 14745–14758. [Google Scholar]
- Zhao, L.; Zhang, Z.; Chen, T.; Metaxas, D.N.; Zhang, H. Improved transformer for high-resolution gans. Adv. Neural Inf. Process. Syst. 2021, 34, 18367–18380. [Google Scholar]
- Xu, R.; Xu, X.; Chen, K.; Zhou, B.; Chen, C.L. Stransgan: An empirical study on transformer in gans. arXiv 2021, arXiv:2110.13107. [Google Scholar]
- Liang, J.; Cao, J.; Sun, G.; Zhang, K.; Gool, L.V.; Timofte, R. Swinir: Image restoration using swin transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual, 11–17 October 2021; pp. 1833–1844. [Google Scholar]
- Wang, Z.; Cun, X.; Bao, J.; Zhou, W.; Liu, J.; Li, H. Uformer: A general u-shaped transformer for image restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 17683–17693. [Google Scholar]
- Xu, B.; Wang, N.; Chen, T.; Li, M. Empirical evaluation of rectified activations in convolutional network. arXiv 2015, arXiv:1505.00853. [Google Scholar]
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3d convolutional neural networks for human action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 221–231. [Google Scholar] [CrossRef]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning spatiotemporal features with 3d convolutional networks. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 4489–4497. [Google Scholar]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Virtual, 11–17 October 2021; pp. 9992–10002. [Google Scholar]
- Shaw, P.; Uszkoreit, J.; Vaswani, A. Self-attention with relative position representations. arXiv 2018, arXiv:1803.02155. [Google Scholar]
- Hendrycks, D.; Gimpel, K. Bridging Nonlinearities and Stochastic Regularizers with Gaussian Error Linear Units. 2016. Available online: https://openreview.net/forum?id=Bk0MRI5lg (accessed on 8 September 2022).
- Arad, B.; Ben-Shahar, O. Sparse recovery of hyperspectral signal from natural rgb images. In Computer Vision—ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 19–34. [Google Scholar]
- Park, J.I.; Lee, M.H.; Grossberg, M.D.; Nayar, S.K. Multispectral imaging using multiplexed illumination. In Proceedings of the IEEE International Conference on Computer Vision, Rio De Janeiro, Brazi, 14–21 October 2007. [Google Scholar]
- Gamba, P. A collection of data for urban area characterization. In Proceedings of the IGARSS 2004. 2004 IEEE International Geoscience and Remote Sensing Symposium, Anchorage, AK, USA, 20–24 September 2004; Volume 1, p. 72. [Google Scholar]
- Mnih, V.; Hinton, G.E. Learning to detect roads in high-resolution aerial images. In European Cnference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2010; pp. 210–223. [Google Scholar]
- Landgrebe, D.A. Signal Theory Methods in Multispectral Remote Sensing; John Wiley & Sons: Hoboken, NJ, USA, 2003. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the International Conference on Learning Representations, Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [Green Version]
- Yuhas, R.H.; Boardman, J.W.; Goetz, A.F.H. Determination of Semi-Arid Landscape Endmembers and Seasonal Trends Using Convex Geometry Spectral Unmixing Techniques; NTRS: Chicago, IL, USA, 1993. [Google Scholar]
- Liu, X.; Tanaka, M.; Okutomi, M. Noise level estimation using weak textured patches of a single noisy image. In Proceedings of the IEEE International Conference on Image Processing, Melbourne, Australia, 15–18 September 2013. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the 2015 IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Peng, Z.; Huang, W.; Gu, S.; Xie, L.; Wang, Y.; Jiao, J.; Ye, Q. Conformer: Local features coupling global representations for visual recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 367–376. [Google Scholar]
- Makantasis, K.; Karantzalos, K.; Doulamis, A.; Doulamis, N. Deep supervised learning for hyperspectral data classification through convolutional neural networks. In Proceedings of the 2015 IEEE International Geoscience and Remote Sensing Symposium (IGARSS) 2015, Milan, Italy, 26–31 July 2015. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Image Size | Bands | Acquired Tool |
|---|---|---|---|
| ICVL [45] | 1392 × 1300 | 31 | Hyperspectral camera |
| Urban [48] | 307 × 307 | 201 | HYDICE Hyperspectral system |
| Indian Pines [49] | 145 × 145 | 224 | AVIRIS sensor |
| CAVE [46] | 512 × 512 | 31 | Cooled CCD camera |
| Pavia Centre [47] | 1096 × 715 | 102 | ROSIS sensor |
| Pavia University [47] | 610 × 340 | 103 | ROSIS sensor |
| Sigma | Index | Methods | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Noisy | BM4D [11] | TDL [10] | ITSReg [12] | LLRT [13] | HSID-CNN [20] | swinir [36] | QRNN3D [22] | Ours | ||
| 30 | PSNR | 18.59 | 38.32 | 41.04 | 41.26 | 42.16 | 39.25 | 37.44 | 42.48 | 42.63 |
| SSIM | 0.111 | 0.925 | 0.953 | 0.947 | 0.963 | 0.980 | 0.970 | 0.989 | 0.990 | |
| SAM | 0.898 | 0.187 | 0.101 | 0.177 | 0.077 | 0.081 | 0.121 | 0.048 | 0.046 | |
| 50 | PSNR | 14.15 | 35.39 | 38.35 | 38.71 | 38.93 | 36.62 | 35.00 | 40.47 | 40.79 |
| SSIM | 0.047 | 0.876 | 0.924 | 0.909 | 0.936 | 0.967 | 0.941 | 0.983 | 0.985 | |
| SAM | 1.060 | 0.236 | 0.144 | 0.201 | 0.103 | 0.106 | 0.160 | 0.059 | 0.050 | |
| 70 | PSNR | 11.23 | 33.52 | 36.65 | 36.57 | 37.23 | 34.54 | 32.82 | 38.54 | 39.41 |
| SSIM | 0.025 | 0.833 | 0.896 | 0.883 | 0.916 | 0.949 | 0.901 | 0.975 | 0.980 | |
| SAM | 1.160 | 0.275 | 0.172 | 0.228 | 0.120 | 0.132 | 0.200 | 0.078 | 0.055 | |
| Blind | PSNR | 15.70 | 36.42 | 39.35 | 39.43 | 39.98 | 38.66 | 36.61 | 42.04 | 42.28 |
| SSIM | 0.083 | 0.889 | 0.931 | 0.923 | 0.941 | 0.975 | 0.957 | 0.987 | 0.989 | |
| SAM | 1.010 | 0.221 | 0.131 | 0.184 | 0.097 | 0.086 | 0.130 | 0.050 | 0.046 | |
| Time of blind (s) | 0.000 | 350.3 | 34.39 | 871.9 | 1828.0 | 0.993 | 1.110 | 0.200 | 0.389 | |
| Case | Index | Methods | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Noisy | LRMR [14] | LRTV [15] | NMoG [16] | LRTDTV [17] | HSID-CNN [20] | swinir [36] | QRNN3D [22] | Ours | ||
| 1 | PSNR | 17.83 | 28.68 | 32.61 | 33.81 | 36.27 | 39.06 | 34.30 | 42.84 | 43.15 |
| SSIM | 0.169 | 0.547 | 0.877 | 0.813 | 0.923 | 0.980 | 0.944 | 0.991 | 0.992 | |
| SAM | 0.713 | 0.241 | 0.061 | 0.117 | 0.063 | 0.068 | 0.130 | 0.042 | 0.037 | |
| 2 | PSNR | 18.02 | 28.57 | 32.82 | 34.11 | 36.20 | 38.50 | 34.08 | 42.54 | 42.86 |
| SSIM | 0.179 | 0.549 | 0.882 | 0.820 | 0.922 | 0.978 | 0.940 | 0.990 | 0.992 | |
| SAM | 0.703 | 0.238 | 0.058 | 0.142 | 0.064 | 0.074 | 0.139 | 0.044 | 0.038 | |
| 3 | PSNR | 17.10 | 27.62 | 31.57 | 32.79 | 34.41 | 38.28 | 33.28 | 42.31 | 42.74 |
| SSIM | 0.161 | 0.532 | 0.873 | 0.818 | 0.907 | 0.976 | 0.938 | 0.990 | 0.992 | |
| SAM | 0.735 | 0.257 | 0.088 | 0.143 | 0.083 | 0.073 | 0.138 | 0.044 | 0.039 | |
| 4 | PSNR | 14.90 | 24.23 | 31.35 | 28.30 | 35.41 | 35.93 | 30.51 | 40.58 | 41.30 |
| SSIM | 0.123 | 0.400 | 0.858 | 0.661 | 0.915 | 0.949 | 0.881 | 0.977 | 0.984 | |
| SAM | 0.781 | 0.392 | 0.132 | 0.353 | 0.071 | 0.149 | 0.212 | 0.079 | 0.063 | |
| 5 | PSNR | 13.96 | 23.27 | 29.99 | 27.84 | 33.29 | 34.94 | 29.46 | 39.52 | 40.36 |
| SSIM | 0.105 | 0.397 | 0.845 | 0.684 | 0.897 | 0.946 | 0.860 | 0.976 | 0.982 | |
| SAM | 0.797 | 0.426 | 0.170 | 0.410 | 0.091 | 0.146 | 0.230 | 0.083 | 0.063 | |
| Time of case 5 (s) | 0.000 | 14.10 | 221.2 | 609.5 | 549.3 | 0.864 | 1.150 | 0.200 | 0.389 | |
| Index | Methods | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Noisy | LRMR [14] | LRTV [15] | NMoG [16] | LRTDTV [17] | HSID-CNN [20] | swinir [36] | QRNN3D [22] | Ours | |
| PSNR | 14.19 | 23.61 | 29.04 | 25.30 | 32.91 | 33.02 | 26.68 | 36.19 | 36.41 |
| SSIM | 0.103 | 0.465 | 0.806 | 0.589 | 0.887 | 0.879 | 0.637 | 0.934 | 0.950 |
| SAM | 1.087 | 0.793 | 0.579 | 0.748 | 0.314 | 0.458 | 0.615 | 0.319 | 0.258 |
| Index | Methods | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Noisy | LRMR [14] | LRTV [15] | NMoG [16] | TDTV [17] | HSIDCNN [20] | swinir [36] | QRNN3D [22] | Ours- S | Ours- P | Ours- F | |
| PSNR | 14.09 | 22.59 | 26.46 | 28.64 | 26.62 | 30.41 | 27.05 | 34.66 | 27.75 | 34.97 | 36.01 |
| SSIM | 0.181 | 0.494 | 0.696 | 0.787 | 0.697 | 0.914 | 0.854 | 0.964 | 0.829 | 0.966 | 0.972 |
| SAM | 0.887 | 0.485 | 0.281 | 0.477 | 0.132 | 0.130 | 0.181 | 0.091 | 0.196 | 0.087 | 0.075 |
| Datasets | Methods | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Noisy | BM4D [11] | TDL [10] | ITSReg [12] | LLRT [13] | LRMR [14] | LRTV [15] | NMoG [16] | LRTDTV [17] | QRNN3D [22] | Ours | |
| Indian Pines | 0.359 | 0.239 | 0.326 | 0.113 | 0.230 | 0.173 | 0.084 | 0.159 | 0.031 | 0.060 | 0.030 |
| Urban | 3.043 | 2.004 | 2.928 | 1.170 | 1.771 | 1.526 | 0.101 | 1.004 | 0.136 | 0.097 | 0.058 |
| Case | Index | Methods | |||||||
|---|---|---|---|---|---|---|---|---|---|
| swinir [36] | QRNN3D [22] | QRU3D | WQRU3D | TR | WTR | WithoutI | Ours | ||
| 1 | PSNR | 35.45 | 42.82 | 42.01 | 42.49 | 40.08 | 41.62 | 42.12 | 43.09 |
| SSIM | 0.961 | 0.991 | 0.990 | 0.991 | 0.985 | 0.989 | 0.990 | 0.992 | |
| SAM | 0.118 | 0.043 | 0.046 | 0.044 | 0.049 | 0.045 | 0.042 | 0.038 | |
| 2 | PSNR | 35.19 | 42.58 | 41.83 | 42.32 | 39.43 | 41.24 | 41.95 | 42.87 |
| SSIM | 0.947 | 0.991 | 0.990 | 0.991 | 0.984 | 0.989 | 0.990 | 0.992 | |
| SAM | 0.124 | 0.044 | 0.046 | 0.044 | 0.051 | 0.046 | 0.043 | 0.039 | |
| 3 | PSNR | 34.01 | 42.33 | 41.67 | 42.18 | 39.02 | 40.57 | 41.67 | 42.72 |
| SSIM | 0.943 | 0.990 | 0.989 | 0.990 | 0.983 | 0.988 | 0.990 | 0.992 | |
| SAM | 0.126 | 0.045 | 0.047 | 0.045 | 0.054 | 0.050 | 0.044 | 0.039 | |
| 4 | PSNR | 26.85 | 40.47 | 40.02 | 40.49 | 36.53 | 38.59 | 39.59 | 41.17 |
| SSIM | 0.815 | 0.977 | 0.978 | 0.979 | 0.964 | 0.974 | 0.979 | 0.984 | |
| SAM | 0.183 | 0.080 | 0.070 | 0.070 | 0.088 | 0.073 | 0.069 | 0.063 | |
| 5 | PSNR | 27.05 | 39.55 | 39.47 | 39.84 | 35.24 | 37.44 | 39.20 | 40.33 |
| SSIM | 0.811 | 0.976 | 0.978 | 0.980 | 0.961 | 0.975 | 0.979 | 0.983 | |
| SAM | 0.188 | 0.081 | 0.072 | 0.072 | 0.079 | 0.067 | 0.068 | 0.063 | |
| Time of case 5 (s) | 1.15 | 0.200 | 0.180 | 0.270 | 0.100 | 0.130 | 0.320 | 0.389 | |
| Params(M) | 5.99 | 0.860 | 0.440 | 0.680 | 0.240 | 0.850 | 0.660 | 0.680 | |
| Depth | Width | PSNR (dB) | Time (s) | Params (#) |
|---|---|---|---|---|
| 6 | 16 | 40.11 | 0.3 | 0.52 |
| 8 | 40.23 | 0.39 | 0.68 | |
| 10 | 40.22 | 0.45 | 1.28 | |
| 8 | 12 | 40.10 | 0.32 | 0.40 |
| 16 | 40.23 | 0.39 | 0.68 | |
| 20 | 40.33 | 0.57 | 1.04 |
| Sigma | Index | Cases | ||||
|---|---|---|---|---|---|---|
| a | b | c | d | e | ||
| 30 | PSNR | 41.83 | 41.72 | 42.04 | 41.79 | 41.05 |
| SSIM | 0.988 | 0.988 | 0.989 | 0.988 | 0.986 | |
| SAM | 0.058 | 0.057 | 0.058 | 0.058 | 0.065 | |
| 50 | PSNR | 40.13 | 40.01 | 40.23 | 40.05 | 39.48 |
| SSIM | 0.983 | 0.983 | 0.983 | 0.982 | 0.981 | |
| SAM | 0.063 | 0.064 | 0.063 | 0.063 | 0.073 | |
| 70 | PSNR | 38.78 | 38.70 | 38.86 | 38.72 | 38.14 |
| SSIM | 0.977 | 0.977 | 0.977 | 0.977 | 0.974 | |
| SAM | 0.070 | 0.072 | 0.068 | 0.071 | 0.083 | |
| Blind | PSNR | 41.31 | 41.24 | 41.53 | 41.28 | 40.52 |
| SSIM | 0.986 | 0.986 | 0.986 | 0.986 | 0.984 | |
| SAM | 0.060 | 0.059 | 0.059 | 0.059 | 0.067 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pang, L.; Gu, W.; Cao, X. TRQ3DNet: A 3D Quasi-Recurrent and Transformer Based Network for Hyperspectral Image Denoising. Remote Sens. 2022, 14, 4598. https://doi.org/10.3390/rs14184598
Pang L, Gu W, Cao X. TRQ3DNet: A 3D Quasi-Recurrent and Transformer Based Network for Hyperspectral Image Denoising. Remote Sensing. 2022; 14(18):4598. https://doi.org/10.3390/rs14184598
Chicago/Turabian StylePang, Li, Weizhen Gu, and Xiangyong Cao. 2022. "TRQ3DNet: A 3D Quasi-Recurrent and Transformer Based Network for Hyperspectral Image Denoising" Remote Sensing 14, no. 18: 4598. https://doi.org/10.3390/rs14184598
APA StylePang, L., Gu, W., & Cao, X. (2022). TRQ3DNet: A 3D Quasi-Recurrent and Transformer Based Network for Hyperspectral Image Denoising. Remote Sensing, 14(18), 4598. https://doi.org/10.3390/rs14184598