


A Robust Star Identification Algorithm Based on a Masked Distance Map

Abstract
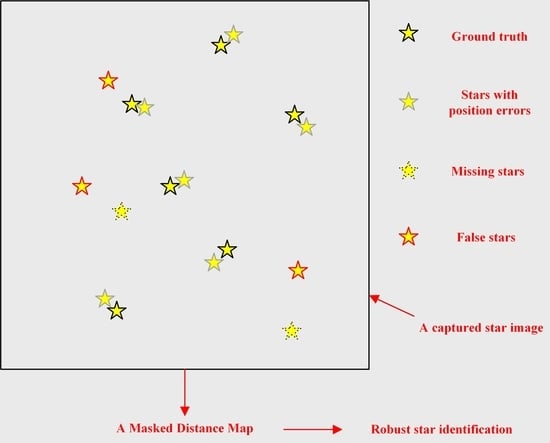
:
1. Introduction
- (1)
- Local scope is introduced to design a masked distance map to further improve the robust of shortest distance transformation.
- (2)
- The introduction of false stars causes very few misidentifications by the proposed algorithm.
- (3)
- The identification rate of our algorithm is high with noise, and it is also efficient.
2. Problem
2.1. Noise and Interfering Stars
2.2. Shortcomings of Existing Algorithms
- (1)
- In the first study, we checked the number of stars remaining in the FOV after the registration process by selecting the point closest to the center of the FOV as the reference star to be identified. According to the results, 12.67% of stars in the FOV were transformed out of the FOV during registration, as shown in Figure 3, which reduced the number of available stars. The utilization rate of stars was low, and the pattern information became sparse, which was not conducive to the subsequent feature extraction and matching processes. In some cases, the number of star points in star images was less than 5; thus, it is very important to retain more star points for the identification of star maps containing fewer star points
- (2)
- In the second study, we analyzed the number of incorrect choices of closest-neighbor stars in an image by applying hard criteria. According to the results, the incorrect selections of the nearest-neighbor star occurred in 0.62% of star images. Under the hard criteria, only one nearest-neighbor star was selected, and its selection error rate increased in the presence of noise and interfering stars, directly leading to subsequent matching errors. Generally, the overall identification accuracy can only be improved by continuously introducing additional reference stars in the verification step [55]. Among the incorrect selections, as shown in Figure 4, 86 cases (0.13%) were caused by the absence of the nearest star in the FOV, while 315 cases (0.49%) were caused by star positioning errors of multiple star points.
- (3)
- In the third study, we analyzed the robustness of traditional feature extraction to positioning errors. Because traditional feature extraction does not make full use of the spatial similarity of stars in an image, it has poor robustness to interfering stars, as shown in Figure 5. It is clear that star points located at the edge of the grid may cause grid feature extraction errors in the case of positioning errors. Better feature extraction should reflect the differences in positions. Therefore, more attention should be given to the spatial distribution characteristics of star points in feature extraction.
- (4)
- The fourth study was performed to analyze the efficiency of the traditional validation method. The traditional method requires the repeated introduction of an additional reference star, which involves high computational complexity and greatly reduces the overall efficiency of the identification algorithm. As shown in Figure 6, it is necessary to continuously introduce a reference star to verify and identify star points until all star points are individually identified. After identification fails for all extracted stars, the image will be refused. It was found that the refuse mechanism has a low efficiency.
3. Method
3.1. Pixel Coordinate Feature
3.2. Construction of the Template Database
3.3. Registration between a Captured Image and the Template
3.4. Shortlisting Similarity
3.4.1. Shortest Distance Transformation
3.4.2. Similarity
3.4.3. Local Scope
3.5. Fast Validation
3.6. Decisive Similarity
3.7. Final Validation
3.8. Overall Framework
4. Simulation Results and Analysis
4.1. Simulation Conditions
4.2. Parameter Analysis
4.3. Ideal Case
4.4. Sensitivity to Star Positioning Errors
4.5. Sensitivity to Missing Stars
4.6. Sensitivity to False Stars
- (1)
- Natural targets (such as planets and natural satellites) and manned objects (such as artificial satellites and space debris) may pass through the camera’s FOV, forming false stars. Due to the reflection of sun rays by the object, a false star produced in this case may have high brightness. Some planets, such as Uranus and Neptune, having visual magnitudes between 6 and 8, are very dim objects, near or beyond the detection threshold of the most wide field of view star trackers.
- (2)
- Various noise sources in the camera, such as flaws in the lens and detector components, may produce false stars. This situation can be controlled by using high-quality components but involves a high cost.
- (3)
- The complex radiation environment of the universe and the impact of high-energy particles may also produce false stars in the camera’s FOV.
- (4)
- Sensitivity calibration errors in the camera detector and the absence of variable or real stars in the onboard star tracker catalog may also cause the appearance of false stars.
- (5)
- Novas, which are stars that temporarily increase in brightness by many orders of magnitude, may also cause the appearance of false stars.
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Rijlaarsdam, D.; Yous, H.; Byrne, J.; Oddenino, D.; Moloney, D. A Survey of Lost-in-Space Star Identification Algorithms Since 2009. Sensors 2020, 20, 2579. [Google Scholar] [CrossRef] [PubMed]
- Liebe, C. Star Trackers for Attitude Determination. IEEE Aerosp. Electron. Syst. Mag. 1995, 10, 10–16. [Google Scholar] [CrossRef]
- Liebe, C.C. Pattern recognition of star constellations for spacecraft applications. IEEE Aerosp. Electron. Syst. Mag. 1993, 8, 31–39. [Google Scholar] [CrossRef]
- Shuster, M.; Oh, S.D. Three-Axis Attitude Determination from Vector Observations. J. Guid. Control Dyn. 1981, 4, 70–77. [Google Scholar] [CrossRef]
- Markley, F.L.; Mortari, D. Quaternion Attitude Estimation Using Vector Observations. J. Astronaut. Sci. 2000, 48, 359–380. [Google Scholar] [CrossRef]
- Schwartz, S.; Ichikawa, S.; Gankidi, P.; Kenia, N.; Dektor, G.; Thangavelautham, J. Optical Navigation for Interplanetary CubeSats. arXiv 2017, arXiv:1701.08201. [Google Scholar]
- Segret, B.; Hestroffer, D.; Quinsac, G.; Agnan, M.; Vannitsen, J. On-Board Orbit Determination for a Deep Space CubeSat. In Proceedings of the International Symposium on Space Flight Dynamics, Ehime, Japan, 3–9 June 2017. [Google Scholar]
- Machuca, P.; Sánchez, J.P.; Greenland, S. Asteroid flyby opportunities using semi-autonomous CubeSats: Mission design and science opportunities. Planet. Space Sci. 2018, 165, 179–193. [Google Scholar] [CrossRef]
- Dotto, E.; Corte, V.D.; Amoroso, M.; Bertini, I.; Fretz, K. LICIACube—The Light Italian Cubesat for Imaging of Asteroids in support of the NASA DART mission towards asteroid (65803) Didymos. Planet. Space Sci. 2021, 199, 105185. [Google Scholar] [CrossRef]
- Machuca, P.; Sánchez, J.-P. CubeSat Autonomous Navigation and Guidance for Low-Cost Asteroid Flyby Missions. J. Spacecr. Rockets 2021, 58, 1858–1875. [Google Scholar] [CrossRef]
- Ho, K. A survey of algorithms for star identification with low-cost star trackers. Acta Astronaut. 2012, 73, 156–163. [Google Scholar] [CrossRef]
- Spratling, B.B.; Daniele, M. A Survey on Star Identification Algorithms. Algorithms 2009, 2, 93–107. [Google Scholar] [CrossRef] [Green Version]
- Liu, H.; Wei, X.; Li, J.; Wang, G. A star identification algorithm based on simplest general subgraph. Acta Astronaut. 2021, 183, 11–22. [Google Scholar] [CrossRef]
- Liu, M.; Wei, X.; Wen, D.; Wang, H. Star Identification Based on Multilayer Voting Algorithm for Star Sensors. Sensors 2021, 21, 3084. [Google Scholar] [CrossRef] [PubMed]
- Kolomenkin, M.; Pollak, S.; Shimshoni, I.; Lindenbaum, M. Geometric voting algorithm for star trackers. IEEE Trans. Aerosp. Electron. Syst. 2008, 44, 441–456. [Google Scholar] [CrossRef]
- Cole, C.L.; Crassidis, J.L. Fast Star-Pattern Recognition Using Planar Triangles. J. Guid. Control Dyn. 2006, 29, 64–71. [Google Scholar] [CrossRef]
- Quine, B.; Durrant-Whyte, H. Rapid star-pattern identification. In Acquisition, Tracking, and Pointing X; SPIE: Bellingham, WA, USA, 1996; pp. 351–360. [Google Scholar]
- Samaan, M.A.; Mortari, D.; Junkins, J.L. Nondimensional star identification for uncalibrated star cameras. J. Astronaut. Sci. 2006, 54, 95–111. [Google Scholar] [CrossRef]
- Mortari, D.; Junkins, J.; Samaan, M. Lost-in-Space Pyramid Algorithm for Robust Star Pattern Recognition. In Proceedings of the Guidance and Control, Breckenridge, CO, USA, 31 January–4 February 2001; pp. 49–68. [Google Scholar]
- Wei, Q.; Liang, X.; Jiancheng, F. A New Star Identification Algorithm based on Improved Hausdorff Distance for Star Sensors. IEEE Trans. Aerosp. Electron. Syst. 2013, 49, 2101–2109. [Google Scholar] [CrossRef]
- Christian, J.A.; Crassidis, J.L. Star Identification and Attitude Determination with Projective Cameras. IEEE Access 2021, 9, 25768–25794. [Google Scholar] [CrossRef]
- Padgett, C.; Kreutz-Delgado, K. A grid algorithm for autonomous star identification. IEEE Trans. Aerosp. Electron. Syst. 1997, 33, 202–213. [Google Scholar] [CrossRef]
- Meng, N.; Zheng, D.; Jia, P. Modified Grid Algorithm for Noisy All-Sky Autonomous Star Identification. IEEE Trans. Aerosp. Electron. Syst. 2009, 45, 516–522. [Google Scholar]
- Yoon, Y. Autonomous Star Identification using Pattern Code. IEEE Trans. Aerosp. Electron. Syst. 2013, 49, 2065–2072. [Google Scholar] [CrossRef]
- Silani, E.; Lovera, M. Star identification algorithms: Novel approach & comparison study. IEEE Trans. Aerosp. Electron. Syst. 2006, 42, 1275–1288. [Google Scholar]
- Udomkesmalee, S.; Alexander, J.W.; Tolivar, A.F. Stochastic Star Identification. J. Guid. Control Dyn. 1994, 17, 1283. [Google Scholar] [CrossRef] [Green Version]
- Gou, B.; Shi, K.-L.; Qi, K.-Y.; Cheng, Y.-M.; Xu, G.-T.; Qian, R.-Z. Method of star image identification based on robust perceptual hash feature. Opt. Eng. 2021, 60, 043101. [Google Scholar] [CrossRef]
- Hong, J.; Dickerson, J.A. Neural-Network-Based Autonomous Star Identification Algorithm. J. Guid. Control Dyn. 2000, 23, 728–735. [Google Scholar] [CrossRef]
- Jiang, J.; Liu, L.; Zhang, G. Star Identification Based on Spider-Web Image and Hierarchical CNN. IEEE Trans. Aerosp. Electron. Syst. 2020, 56, 3055–3062. [Google Scholar] [CrossRef]
- Jin, Z. An Efficient and Robust Star Identification Algorithm Based on Neural Networks. Sensors 2021, 21, 7686. [Google Scholar]
- Xu, L.; Jiang, J.; Liu, L. RPNet: A Representation Learning Based Star Identification Algorithm. IEEE Access 2019, 7, 92193–92202. [Google Scholar] [CrossRef]
- Zhang, W.; Wang, J.; Jin, D.; Oreopoulos, L.; Zhang, Z. A Deterministic Self-Organizing Map Approach and its Application on Satellite Data based Cloud Type Classification. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–14 December 2018. [Google Scholar]
- Wang, X.; Sun, C.; Sun, T. A Novel Two-Step Validation Algorithm for Lost-in-Space Star Identification. IEEE Trans. Aerosp. Electron. Syst. 2020, 56, 2272–2279. [Google Scholar] [CrossRef]
- Wei, X.; Wen, D.; Song, Z.; Xi, J. Star Identification Algorithm Based on Oriented Singular Value Feature and Reliability Evaluation Method. Trans. Jpn. Soc. Aeronaut. Space Sci. 2019, 62, 265–274. [Google Scholar] [CrossRef]
- Yuan, H.; Li, D.; Wang, J. Centroiding method for small celestial bodies with unknown shape and small size. Opt. Eng. 2022, 61, 043101. [Google Scholar] [CrossRef]
- Needelman, D.D.; Alstad, J.P.; Lai, P.C.; Elmasri, H.M. Fast Access and Low Memory Star Pair Catalog for Star Pattern Identification. J. Guid. Control Dyn. 2010, 33, 1396–1403. [Google Scholar] [CrossRef]
- Jiang, J.; Ji, F.; Yan, J.; Sun, L.; Wei, X. Redundant-coded radial and neighbor star pattern identification algorithm. IEEE Trans. Aerosp. Electron. Syst. 2015, 51, 2811–2822. [Google Scholar] [CrossRef]
- Pham, M.D.; Low, K.S.; Chen, S. An Autonomous Star Recognition Algorithm with Optimized Database. IEEE Trans. Aerosp. Electron. Syst. 2013, 49, 1467–1475. [Google Scholar] [CrossRef]
- Mortari, D.; Neta, B. k-Vector Range Searching Technique. Spacefl. Mech. 2000, 105, 449–463. [Google Scholar]
- Spratling, B.B.; Mortari, D. The K-Vector ND and its Application to Building a Non-Dimensional Star Identification Catalog. J. Astronaut. Sci. 2011, 58, 261–274. [Google Scholar] [CrossRef]
- Somayehee, F.; Nikkhah, A.A.; Roshanian, J.; Salahshoor, S. Blind Star Identification Algorithm. IEEE Trans. Aerosp. Electron. Syst. 2020, 56, 547–557. [Google Scholar] [CrossRef]
- Kim, S.; Cho, M. New star identification algorithm using labelling technique. Acta Astronaut. 2019, 162, 367–372. [Google Scholar] [CrossRef]
- Samirbhai, M.D.; Chen, S.; Low, K.S. A Hamming Distance and Spearman Correlation Based Star Identification Algorithm. IEEE Trans. Aerosp. Electron. Syst. 2018, 55, 17–30. [Google Scholar] [CrossRef]
- Fan, Q.; Zhong, X.; Sun, J. A voting-based star identification algorithm utilizing local and global distribution. Acta Astronaut. 2018, 144, 126–135. [Google Scholar] [CrossRef]
- Jian, L.; Wei, X.; Zhang, G. Iterative algorithm for autonomous star identification. IEEE Trans. Aerosp. Electron. Syst. 2015, 51, 536–547. [Google Scholar]
- Zhu, H.; Liang, B.; Tao, Z. A robust and fast star identification algorithm based on an ordered set of points pattern. Acta Astronaut. 2018, 148, 327–336. [Google Scholar] [CrossRef]
- Nah, J.; Yi, Y.; Kim, Y.H. A New Pivot Algorithm for Star Identification. J. Astron. Space Sci. 2014, 31, 205–214. [Google Scholar] [CrossRef]
- Aghaei, M.; Moghaddam, H.A. Grid Star Identification Improvement Using Optimization Approaches. IEEE Trans. Aerosp. Electron. Syst. 2017, 52, 2080–2090. [Google Scholar] [CrossRef]
- Fabbri, R.; da Costa, L.F.; Torelli, J.; Bruno, O. 2D Euclidean distance transform algorithms: A comparative survey. ACM Comput. Surv. (CSUR) 2008, 40, 1–44. [Google Scholar] [CrossRef]
- Delabie, T.; Durt, T.; Vandersteen, J. Highly Robust Lost-in-Space Algorithm Based on the Shortest Distance Transform. J. Guid. Control Dyn. 2013, 36, 476–484. [Google Scholar] [CrossRef]
- Roshanian, J.; Yazdani, S.; Ebrahimi, M. Star identification based on euclidean distance transform, voronoi tessellation, and k-nearest neighbor classification. IEEE Trans. Aerosp. Electron. Syst. 2016, 52, 2940–2949. [Google Scholar] [CrossRef]
- Schiattarella, V.; Spiller, D.; Curti, F. Star identification robust to angular rates and false objects with rolling shutter compensation. Acta Astronaut. 2020, 166, 243–259. [Google Scholar] [CrossRef]
- Jiang, J.; Lei, L.; Guangjun, Z. Robust and accurate star segmentation algorithm based on morphology. Opt. Eng. 2016, 55, 063101. [Google Scholar] [CrossRef]
- Myers, J.; Sande, C.; Miller, A.; Warren, W., Jr.; Tracewell, D. SKY2000-master star catalog-star catalog database. Bull. Am. Astron. Soc. 1997, 191, 128. [Google Scholar]
- Lee, H.; Oh, C.S.; Bang, H. Modified grid algorithm for star pattern identification by using star trackers. In Proceedings of the International Conference on Recent Advances in Space Technologies, Istanbul, Turkey, 20–22 November 2003; pp. 385–391. [Google Scholar]
- Saff, E.B.; Kuijlaars, A.B.J. Distributing Many Points on a Sphere. Math. Intell. 1997, 19, 5–11. [Google Scholar] [CrossRef]
- Semechko, A. Suite of Functions to Perform Uniform Sampling of a Sphere. Available online: https://github.com/AntonSemechko/S2-Sampling-Toolbox (accessed on 18 March 2020).

























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yuan, H.; Li, D.; Wang, J. A Robust Star Identification Algorithm Based on a Masked Distance Map. Remote Sens. 2022, 14, 4699. https://doi.org/10.3390/rs14194699
Yuan H, Li D, Wang J. A Robust Star Identification Algorithm Based on a Masked Distance Map. Remote Sensing. 2022; 14(19):4699. https://doi.org/10.3390/rs14194699
Chicago/Turabian StyleYuan, Hao, Dongxu Li, and Jie Wang. 2022. "A Robust Star Identification Algorithm Based on a Masked Distance Map" Remote Sensing 14, no. 19: 4699. https://doi.org/10.3390/rs14194699
APA StyleYuan, H., Li, D., & Wang, J. (2022). A Robust Star Identification Algorithm Based on a Masked Distance Map. Remote Sensing, 14(19), 4699. https://doi.org/10.3390/rs14194699