


Google Earth Engine for Informal Settlement Mapping: A Random Forest Classification Using Spectral and Textural Information



Abstract
:1. Introduction
- (1)
- Present an operational framework based on various Sentinel 2A band-derived spectral and texture feature combinations for capturing informal settlements in Durban, South Africa.
- (2)
- Determine the extent to which GEE’s data analysis capabilities can precisely depict morphologically diverse informal settlements in the Durban landscape.
- (3)
- Statistically assess the deviations in informal settlement spatial extents derived from comparison analysis between modelled outputs and reference area estimates.
2. Materials and Methods
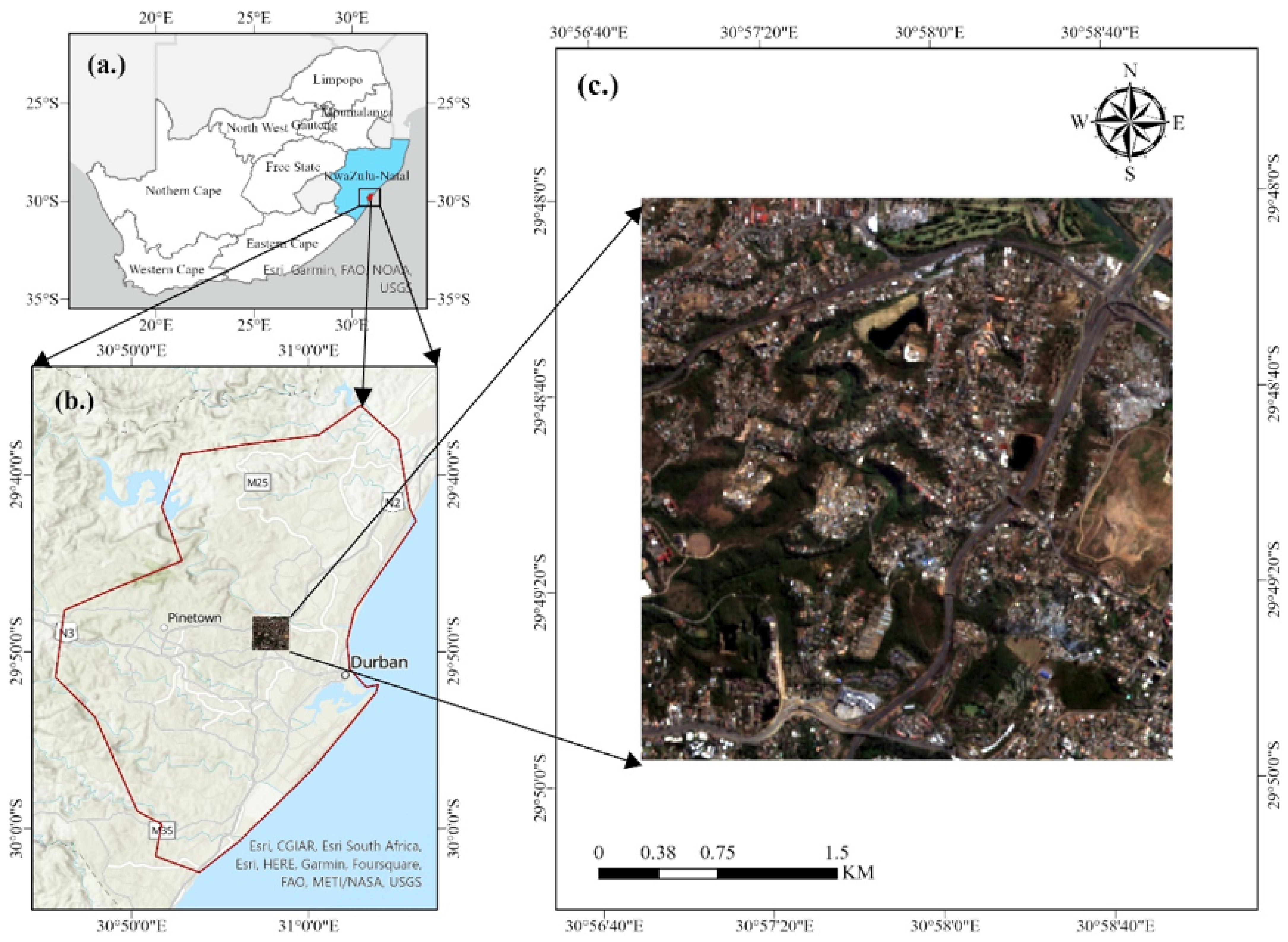
2.1. Study Area
2.2. Datasets
2.3. Methods
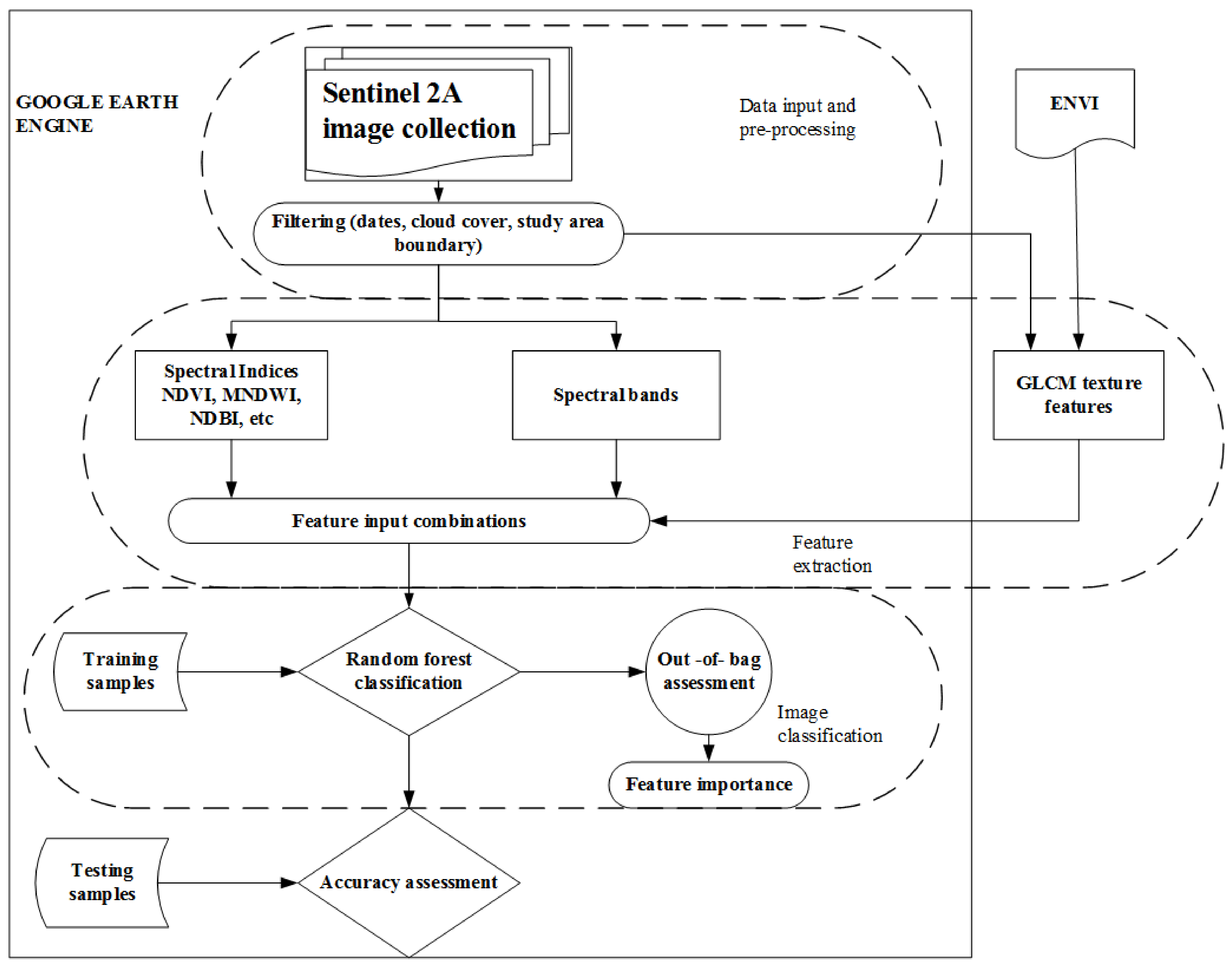
2.3.1. Feature Extraction
Spectral Features
GLCM Textural Features
- CV = coefficient of variation
- ∂ = standard deviation
- µ = mean
2.3.2. Feature Combinations
3. Random Forest Classification
3.1. Variable Importance
3.2. Accuracy Assessment, Classification Comparison, and Statistical Testing
3.2.1. Pixel-Based Accuracy Assessment
3.2.2. Patch-Based Accuracy Assessment
Regression between Extracted Informal Settlement Areas and Ground Truth Data
4. Results
4.1. Evaluation and Comparative Analysis of Classification Results
4.1.1. Visual Analysis of Different Feature Input Models
4.1.2. Accuracy Assessment and Analysis
4.2. Importance of Features for Informal Settlement Mapping
Feature Subset Evaluation
4.3. Patch-Based Accuracy Assessment
5. Discussion
Estimated Informal Settlement Areas
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Samper, J.; Shelby, J.; Behary, D. The Paradox of Informal Settlements Revealed in an ATLAS of Informality: Findings from Mapping Growth in the Most Common Yet Unmapped Forms of Urbanization. Sustainability 2020, 12, 9510. [Google Scholar] [CrossRef]
- UNDP. Human Development Indices and Indicators: 2018 Statistical Updatep; UNDP: New York, NY, USA, 2018. [Google Scholar]
- United-Nations. World Urbanization Prospects 2018; United Nations: New York, NY, USA, 2019. [Google Scholar]
- Fallatah, A.; Jones, S.; Wallace, L.; Mitchell, D. Combining Object-Based Machine Learning with Long-Term Time-Series Analysis for Informal Settlement Identification. Remote Sens. 2022, 14, 1226. [Google Scholar] [CrossRef]
- Mboga, N.; Persello, C.; Bergado, J.R.; Stein, A. Detection of Informal Settlements from VHR Images Using Convolutional Neural Networks. Remote Sens. 2017, 9, 1106. [Google Scholar] [CrossRef] [Green Version]
- Persello, C.; Stein, A. Deep Fully Convolutional Networks for the Detection of Informal Settlements in VHR Images. IEEE Geosci. Remote Sens. Lett. 2017, 14, 2325–2329. [Google Scholar] [CrossRef]
- Wang, J.; Kuffer, M.; Pfeffer, K. The role of spatial heterogeneity in detecting urban slums. Comput. Environ. Urban Syst. 2019, 73, 95–107. [Google Scholar] [CrossRef]
- Prabhu, R.; Parvathavarthini, B. An enhanced approach for informal settlement extraction from optical data using morphological profile-guided filters: A case study of madurai city. Int. J. Remote Sens. 2021, 42, 6688–6705. [Google Scholar] [CrossRef]
- Membele, G.M.; Naidu, M.; Mutanga, O. Using local and indigenous knowledge in selecting indicators for mapping flood vulnerability in informal settlement contexts. Int. J. Disaster Risk Reduct. 2022, 71, 102836. [Google Scholar] [CrossRef]
- Satterthwaite, D.; Archer, D.; Colenbrander, S.; Dodman, D.; Hardoy, J.; Mitlin, D.; Patel, S. Building Resilience to Climate Change in Informal Settlements. One Earth 2020, 2, 143–156. [Google Scholar] [CrossRef] [Green Version]
- Fox, S. The Political Economy of Slums: Theory and Evidence from Sub-Saharan Africa. World Dev. 2014, 54, 191–203. [Google Scholar] [CrossRef]
- Winter, S.C.; Obara, L.M.; McMahon, S. Intimate partner violence: A key correlate of women’s physical and mental health in informal settlements in Nairobi, Kenya. PLoS ONE 2020, 15, e0230894. [Google Scholar] [CrossRef]
- Loggia, C.; Govender, V. A hybrid methodology to map informal settlements in Durban, South Africa. Proc. Inst. Civ. Eng. Eng. Sustain. 2020, 173, 257–268. [Google Scholar] [CrossRef]
- Patel, A.; Joseph, G.; Shrestha, A.; Foint, Y. Measuring deprivations in the slums of Bangladesh: Implications for achieving sustainable development goals. Hous. Soc. 2019, 46, 81–109. [Google Scholar] [CrossRef]
- Balsa-Barreiro, J.; Li, Y.; Morales, A.; Pentland, A.S. Globalization and the shifting centers of gravity of world’s human dynamics: Implications for sustainability. J. Clean. Prod. 2019, 239, 117923. [Google Scholar] [CrossRef]
- Parnell, S.; Crankshaw, O. Urban exclusion and the (false) assumptions of spatial policy reform in South Africa. In Megacities; Zed Books Ltd.: London, UK, 2009; pp. 153–170. [Google Scholar] [CrossRef]
- Quesada-Román, A. Disaster Risk Assessment of Informal Settlements in the Global South. Sustainability 2022, 14, 10261. [Google Scholar] [CrossRef]
- Kuffer, M.; Pfeffer, K.; Sliuzas, R.; Baud, I. Extraction of Slum Areas From VHR Imagery Using GLCM Variance. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 1830–1840. [Google Scholar] [CrossRef]
- Mudau, N.; Mhangara, P. Towards understanding informal settlement growth patterns: Contribution to SDG reporting and spatial planning. Remote Sens. Appl. Soc. Environ. 2022, 27, 100801. [Google Scholar] [CrossRef]
- Kohli, D.; Warwadekar, P.; Kerle, N.; Sliuzas, R.; Stein, A. Transferability of Object-Oriented Image Analysis Methods for Slum Identification. Remote Sens. 2013, 5, 4209–4228. [Google Scholar] [CrossRef] [Green Version]
- Mudau, N.; Mhangara, P. Investigation of Informal Settlement Indicators in a Densely Populated Area Using Very High Spatial Resolution Satellite Imagery. Sustainability 2021, 13, 4735. [Google Scholar] [CrossRef]
- Membele, G.M.; Naidu, M.; Mutanga, O. Examining flood vulnerability mapping approaches in developing countries: A scoping review. Int. J. Disaster Risk Reduct. 2021, 69, 102766. [Google Scholar] [CrossRef]
- Farda, N.M. Multi-temporal Land Use Mapping of Coastal Wetlands Area using Machine Learning in Google Earth Engine. IOP Conf. Series Earth Environ. Sci. 2017, 98, 012042. [Google Scholar] [CrossRef]
- Chen, J.; Chen, J.; Liao, A.; Cao, X.; Chen, L.; Chen, X.; He, C.; Han, G.; Peng, S.; Lu, M.; et al. Global land cover mapping at 30 m resolution: A POK-based operational approach. ISPRS J. Photogramm. Remote Sens. 2015, 103, 7–27. [Google Scholar] [CrossRef] [Green Version]
- Mugiraneza, T.; Nascetti, A.; Ban, Y. WorldView-2 Data for Hierarchical Object-Based Urban Land Cover Classification in Kigali: Integrating Rule-Based Approach with Urban Density and Greenness Indices. Remote Sens. 2019, 11, 2128. [Google Scholar] [CrossRef] [Green Version]
- Stark, T.; Wurm, M.; Zhu, X.X.; Taubenböck, H. Satellite-Based Mapping of Urban Poverty With Transfer-Learned Slum Morphologies. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 5251–5263. [Google Scholar] [CrossRef]
- Mananze, S.; Pôças, I.; Cunha, M. Mapping and Assessing the Dynamics of Shifting Agricultural Landscapes Using Google Earth Engine Cloud Computing, a Case Study in Mozambique. Remote Sens. 2020, 12, 1279. [Google Scholar] [CrossRef] [Green Version]
- Wekesa, B.W.; Steyn, G.S.; Otieno, F.A.O. A review of physical and socio-economic characteristics and intervention approaches of informal settlements. Habitat Int. 2011, 35, 238–245. [Google Scholar] [CrossRef]
- Kuffer, M.; Pfeffer, K.; Sliuzas, R.; Baud, I.; Van Maarseveen, M. Capturing the Diversity of Deprived Areas with Image-Based Features: The Case of Mumbai. Remote Sens. 2017, 9, 384. [Google Scholar] [CrossRef] [Green Version]
- Kuffer, M.; Wang, J.; Nagenborg, M.; Pfeffer, K.; Kohli, D.; Sliuzas, R.; Persello, C. The Scope of Earth-Observation to Improve the Consistency of the SDG Slum Indicator. ISPRS Int. J. Geo-Inf. 2018, 7, 428. [Google Scholar] [CrossRef] [Green Version]
- Leonita, G.; Kuffer, M.; Sliuzas, R.; Persello, C. Machine Learning-Based Slum Mapping in Support of Slum Upgrading Programs: The Case of Bandung City, Indonesia. Remote Sens. 2018, 10, 1522. [Google Scholar] [CrossRef] [Green Version]
- Girija, G.; Nikhila, R.I. Slum Extraction Approaches From High Resolution Satellite Data—A Case Study Of Madurai City. Int.J. Pure. Appl. Math. 2018, 119, 14509–14514. [Google Scholar]
- Kohli, D.; Sliuzas, R.; Stein, A. Urban slum detection using texture and spatial metrics derived from satellite imagery. J. Spat. Sci. 2016, 61, 405–426. [Google Scholar] [CrossRef]
- Prabhu, R.; Raja, R.A.A. Urban Slum Detection Approaches from High-Resolution Satellite Data Using Statistical and Spectral Based Approaches. J. Indian Soc. Remote Sens. 2018, 46, 2033–2044. [Google Scholar] [CrossRef]
- Shabat, A.M.; Tapamo, J.-R. A comparative study of the use of local directional pattern for texture-based informal settlement classification. J. Appl. Res. Technol. 2017, 15, 250–258. [Google Scholar] [CrossRef] [Green Version]
- Ansari, R.A.; Malhotra, R.; Buddhiraju, K.M. Texture Based Identification of Informal Settlements in Contourlet Feature Space. In Proceedings of the 2019 IEEE International Symposium on Multimedia, San Diego, CA, USA, 9–11 December 2019. [Google Scholar]
- Ansari, R.A.; Buddhiraju, K.M. Textural segmentation of remotely sensed images using multiresolution analysis for slum area identification. Eur. J. Remote Sens. 2019, 52, 74–88. [Google Scholar] [CrossRef] [Green Version]
- Fallatah, A.; Jones, S.; Mitchell, D.; Kohli, D. Mapping informal settlement indicators using object-oriented analysis in the Middle East. Int. J. Digit. Earth 2019, 12, 802–824. [Google Scholar] [CrossRef]
- Kit, O.; Lüdeke, M. Automated detection of slum area change in Hyderabad, India using multitemporal satellite imagery. ISPRS J. Photogramm. Remote Sens. 2013, 83, 130–137. [Google Scholar] [CrossRef] [Green Version]
- Kit, O.; Lüdeke, M.; Reckien, D. Texture-based identification of urban slums in Hyderabad, India using remote sensing data. Appl. Geogr. 2012, 32, 660–667. [Google Scholar] [CrossRef]
- Owen, K.K.; Wong, D.W. An approach to differentiate informal settlements using spectral, texture, geomorphology and road accessibility metrics. Appl. Geogr. 2013, 38, 107–118. [Google Scholar] [CrossRef]
- Graesser, J.; Cheriyadat, A.; Vatsavai, R.R.; Chandola, V.; Long, J.; Bright, E. Image Based Characterization of Formal and Informal Neighborhoods in an Urban Landscape. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2012, 5, 1164–1176. [Google Scholar] [CrossRef]
- Owen, K.K.; Wong, D.W. Exploring structural differences between rural and urban informal settlements from imagery: Thebasurerosof Cobán. Geocarto Int. 2013, 28, 562–581. [Google Scholar] [CrossRef]
- Rodriguez-Galiano, V.F.; Pardo-Igúzquiza, E.; Chica-Olmo, M.; Mateos, J.; Rigol-Sánchez, J.P.; Vega, M. A comparative assessment of different methods for Landsat 7/ETM+ pansharpening. Int. J. Remote Sens. 2012, 33, 6574–6599. [Google Scholar] [CrossRef]
- Stromann, O.; Nascetti, A.; Yousif, O.; Ban, Y. Dimensionality Reduction and Feature Selection for Object-Based Land Cover Classification based on Sentinel-1 and Sentinel-2 Time Series Using Google Earth Engine. Remote Sens. 2019, 12, 76. [Google Scholar] [CrossRef] [Green Version]
- Chen, D.; Stow, D.A.; Gong, P. Examining the effect of spatial resolution and texture window size on classification accuracy: An urban environment case. Int. J. Remote Sens. 2004, 25, 2177–2192. [Google Scholar] [CrossRef]
- Shafizadeh-Moghadam, H.; Khazaei, M.; Alavipanah, S.K.; Weng, Q. Google Earth Engine for large-scale land use and land cover mapping: An object-based classification approach using spectral, textural and topographical factors. GISci. Remote Sens. 2021, 58, 914–928. [Google Scholar] [CrossRef]
- Dong, J.; Xiao, X.; Menarguez, M.A.; Zhang, G.; Qin, Y.; Thau, D.; Biradar, C.; Moore, B., III. Mapping paddy rice planting area in northeastern Asia with Landsat 8 images, phenology-based algorithm and Google Earth Engine. Remote Sens. Environ. 2016, 185, 142–154. [Google Scholar] [CrossRef] [Green Version]
- Gorelick, N.; Hancher, M.; Dixon, M.; Ilyushchenko, S.; Thau, D.; Moore, R. Google Earth Engine: Planetary-scale geospatial analysis for everyone. Remote Sens. Environ. 2017, 202, 18–27. [Google Scholar] [CrossRef]
- Zhang, K.; Dong, X.; Liu, Z.; Gao, W.; Hu, Z.; Wu, G. Mapping Tidal Flats with Landsat 8 Images and Google Earth Engine: A Case Study of the China’s Eastern Coastal Zone circa 2015. Remote Sens. 2019, 11, 924. [Google Scholar] [CrossRef] [Green Version]
- Amani, M.; Mahdavi, S.; Afshar, M.; Brisco, B.; Huang, W.; Mohammad Javad Mirzadeh, S.; White, L.; Banks, S.; Montgomery, J.; Hopkinson, C. Canadian Wetland Inventory using Google Earth Engine: The First Map and Preliminary Results. Remote Sens. 2019, 11, 842. [Google Scholar] [CrossRef] [Green Version]
- Tassi, A.; Vizzari, M. Object-Oriented LULC Classification in Google Earth Engine Combining SNIC, GLCM, and Machine Learning Algorithms. Remote Sens. 2020, 12, 3776. [Google Scholar] [CrossRef]
- Patel, N.N.; Angiuli, E.; Gamba, P.; Gaughan, A.; Lisini, G.; Stevens, F.R.; Tatem, A.J.; Trianni, G. Multitemporal settlement and population mapping from Landsat using Google Earth Engine. Int. J. Appl. Earth Obs. Geoinf. ITC J. 2015, 35, 199–208. [Google Scholar] [CrossRef] [Green Version]
- Liang, J.; Xie, Y.; Sha, Z.; Zhou, A. Modeling urban growth sustainability in the cloud by augmenting Google Earth Engine (GEE). Comput. Environ. Urban Syst. 2020, 84, 101542. [Google Scholar] [CrossRef]
- Liu, X.; Hu, G.; Chen, Y.; Li, X.; Xu, X.; Li, S.; Pei, F.; Wang, S. High-resolution multi-temporal mapping of global urban land using Landsat images based on the Google Earth Engine Platform. Remote Sens. Environ. 2018, 209, 227–239. [Google Scholar] [CrossRef]
- Liu, Q.; Huang, C.; Li, H. Quality Assessment by Region and Land Cover of Sharpening Approaches Applied to GF-2 Imagery. Appl. Sci. 2020, 10, 3673. [Google Scholar] [CrossRef]
- Xiong, J.; Thenkabail, P.S.; Tilton, J.C.; Gumma, M.K.; Teluguntla, P.; Oliphant, A.; Congalton, R.G.; Yadav, K.; Gorelick, N. Nominal 30-m cropland extent map of continental Africa by integrating pixel-based and object-based algorithms using Sentinel-2 and Landsat-8 data on Google Earth Engine. Remote Sens. 2017, 9, 1065. [Google Scholar] [CrossRef] [Green Version]
- Phan, T.N.; Kuch, V.; Lehnert, L.W. Land Cover Classification using Google Earth Engine and Random Forest Classifier—The Role of Image Composition. Remote Sens. 2020, 12, 2411. [Google Scholar] [CrossRef]
- Goldblatt, R.; Deininger, K.; Hanson, G. Utilizing publicly available satellite data for urban research: Mapping built-up land cover and land use in Ho Chi Minh City, Vietnam. Dev. Eng. 2018, 3, 83–99. [Google Scholar] [CrossRef]
- Rudiastuti, A.W.; Farda, N.M.; Ramdani, D. Mapping built-up land and settlements: A comparison of machine learning algorithms in Google Earth engine. Seventh Geoinf. Sci. Symp. 2021, 12082, 42–52. [Google Scholar]
- Teluguntla, P.; Thenkabail, P.S.; Oliphant, A.; Xiong, J.; Gumma, M.K.; Congalton, R.G.; Yadav, K.; Huete, A. A 30-m landsat-derived cropland extent product of Australia and China using random forest machine learning algorithm on Google Earth Engine cloud computing platform. ISPRS J. Photogramm. Remote Sens. 2018, 144, 325–340. [Google Scholar] [CrossRef]
- Kelley, L.C.; Pitcher, L.; Bacon, C. Using Google Earth Engine to Map Complex Shade-Grown Coffee Landscapes in Northern Nicaragua. Remote Sens. 2018, 10, 952. [Google Scholar] [CrossRef] [Green Version]
- Tingzon, I.; Dejito, N.; Flores, R.A.; De Guzman, R.; Carvajal, L.; Erazo, K.Z.; Cala, I.E.C.; Villaveces, J.; Rubio, D.; Ghani, R. Mapping New Informal Settlements Using Machine Learning and Time Series Satellite Images: An Application in the Venezuelan Migration Crisis. In Proceedings of the IEEE/ITU International conference on Artificial Intellugence for Good (AI4G), Geneva, Switzerland, 21–25 September 2020. [Google Scholar]
- Kamalipour, H.; Dovey, K. Mapping the visibility of informal settlements. Habitat Int. 2019, 85, 63–75. [Google Scholar] [CrossRef]
- Duque, J.C.; Patino, J.E.; Ruiz, L.A.; Pardo-Pascual, J.E. Measuring intra-urban poverty using land cover and texture metrics derived from remote sensing data. Landsc. Urban Plan. 2015, 135, 11–21. [Google Scholar] [CrossRef]
- Matarira, D.; Mutanga, O.; Naidu, M. Texture analysis approaches in modelling informal settlements: A review. Geocarto Int. 2022, 1–28, accepted. [Google Scholar] [CrossRef]
- Ella, L.A.; van den Bergh, F.; van Wyk, B.J. A comparison of texture feature algorithms for urban settlement classification. In Proceedings of the IGARSS 2008 International Geoscience and Remote Sensing Symposium, Boston, MA, USA, 7–11 July 2008. [Google Scholar]
- Khumalo, P.P.; Tapamo, J.R.; van den Bergh, F. Rotation invariant texture feature algorithms for urban settlement classification. In Proceedings of the 2011 IEEE International Geoscience and Remote Sensing Symposium, Vancouver, BC, Canada, 24–29 July 2011. [Google Scholar]
- Van den Bergh, F. The effects of viewing-and illumination geometry on settlement type classification of quickbird images. In Proceedings of the International Geoscience and Remote Sensing Symposium, Vancouver, BC, Canada, 24–29 July 2011. [Google Scholar]
- Williams, D.S.; Costa, M.M.; Celliers, L.; Sutherland, C. Informal Settlements and Flooding: Identifying Strengths and Weaknesses in Local Governance for Water Management. Water 2018, 10, 871. [Google Scholar] [CrossRef] [Green Version]
- Marx, C.; Charlton, S. Urban Slums Reports: The case of Durban, South Africa. In UN-Habitat, The Challenge of Slums: Global Report on Human Settlements (2003), United Nations Human Settlements Programme; Earthscan Publications Ltd.: London, UK, 2003; pp. 195–223. [Google Scholar]
- Lanaras, C.; Bioucas-Dias, J.; Galliani, S.; Baltsavias, E.; Schindler, K. Super-resolution of Sentinel-2 images: Learning a globally applicable deep neural network. ISPRS J. Photogramm. Remote Sens. 2018, 146, 305–319. [Google Scholar] [CrossRef] [Green Version]
- Phiri, D.; Simwanda, M.; Salekin, S.; Nyirenda, V.R.; Murayama, Y.; Ranagalage, M. Sentinel-2 Data for Land Cover/Use Mapping: A Review. Remote. Sens. 2020, 12, 2291. [Google Scholar] [CrossRef]
- Firozjaei, M.K.; Sedighi, A.; Kiavarz, M.; Qureshi, S.; Haase, D.; Alavipanah, S.K. Automated Built-Up Extraction Index: A New Technique for Mapping Surface Built-Up Areas Using LANDSAT 8 OLI Imagery. Remote Sens. 2019, 11, 1966. [Google Scholar] [CrossRef] [Green Version]
- Wang, Q.; Shi, W.; Li, Z.; Atkinson, P.M. Fusion of Sentinel-2 images. Remote Sens. Environ. 2016, 187, 241–252. [Google Scholar] [CrossRef] [Green Version]
- Li, Q.; Qiu, C.; Ma, L.; Schmitt, M.; Zhu, X.X. Mapping the Land Cover of Africa at 10 m Resolution from Multi-Source Remote Sensing Data with Google Earth Engine. Remote Sens. 2020, 12, 602. [Google Scholar] [CrossRef] [Green Version]
- Gandhi, U.; End-to-End Google Earth Engine Course. Spatial Thoughts. 2021. Available online: https://coursesspatialthoughtscom/end-to-end-geehtml (accessed on 2 August 2022).
- Kaimaris, D.; Patias, P. Identification and Area Measurement of the Built-up Area with the Built-up Index (BUI). Int. J. Adv. Remote Sens. GIS 2016, 5, 1844–1858. [Google Scholar] [CrossRef] [Green Version]
- Adepoju, K.A.; Adelabu, S.A. Improving accuracy of Landsat-8 OLI classification using image composite and multisource data with Google Earth Engine. Remote Sens. Lett. 2019, 11, 107–116. [Google Scholar] [CrossRef]
- Zurqani, H.A.; Post, C.J.; Mikhailova, E.A.; Allen, J.S. Mapping Urbanization Trends in a Forested Landscape Using Google Earth Engine. Remote Sens. Earth Syst. Sci. 2019, 2, 173–182. [Google Scholar] [CrossRef]
- Haralick, R.; Shanmugam, K.; Dinstein, I. Textural features for image classification. IEEE Trans. Syst. Man Cybern. 1973, 3, 610–621. [Google Scholar] [CrossRef]
- Hall-Beyer, M. Practical guidelines for choosing GLCM textures to use in landscape classification tasks over a range of moderate spatial scales. Int. J. Remote Sens. 2017, 38, 1312–1338. [Google Scholar] [CrossRef]
- Ruiz Hernandez, I.E.; Shi, W. A Random Forests classification method for urban land-use mapping integrating spatial metrics and texture analysis. Int. J. Remote Sens. 2018, 39, 1175–1198. [Google Scholar] [CrossRef]
- Zhou, J.; Guo, R.Y.; Sun, M.; Di, T.T.; Wang, S.; Zhai, J.; Zhao, Z. The Effects of GLCM parameters on LAI estimation using texture values from Quickbird Satellite Imagery. Sci. Rep. 2017, 7, 7366. [Google Scholar] [CrossRef] [Green Version]
- Giannini, B.M.; Merola, P. Texture Analysis for Urban Areas Classification in High Resolution Satellite Imagery. Appl. Remote Sens. J. 2012, 2, 65–71. [Google Scholar]
- Kabir, S.; He, D.-C.; A Sanusi, M.; Hussina, W.M.A.W. Texture analysis of IKONOS satellite imagery for urban land use and land cover classification. Imaging Sci. J. 2010, 58, 163–170. [Google Scholar] [CrossRef]
- Lan, Z.; Liu, Y. Study on Multi-Scale Window Determination for GLCM Texture Description in High-Resolution Remote Sensing Image Geo-Analysis Supported by GIS and Domain Knowledge. ISPRS Int. J. Geo-Inf. 2018, 7, 175. [Google Scholar] [CrossRef] [Green Version]
- De Siqueira, F.R.; Schwartz, W.R.; Pedrini, H. Multi-scale gray level co-occurrence matrices for texture description. Neurocomputing 2013, 120, 336–345. [Google Scholar] [CrossRef]
- Kumar, L.; Mutanga, O. Google Earth Engine Applications Since Inception: Usage, Trends, and Potential. Remote Sens. 2018, 10, 1509. [Google Scholar] [CrossRef] [Green Version]
- Trianni, G.; Angiuli, E.; Lisini, G.; Gamba, P. Human settlements from Landsat data using Google Earth Engine. In Proceedings of the 2014 IEEE Geoscience and Remote Sensing Symbosium, Quebec City, QC, Canada, 13–18 July 2014. [Google Scholar]
- Wurm, M.; Taubenböck, H.; Weigand, M.; Schmitt, A. Slum mapping in polarimetric SAR data using spatial features. Remote Sens. Environ. 2017, 194, 190–204. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhu, W.; Wei, P.; Fang, P.; Zhang, X.; Yan, N.; Liu, W.; Zhao, H.; Wu, Q. Classification of Zambian grasslands using random forest feature importance selection during the optimal phenological period. Ecol. Indic. 2022, 135, 108529. [Google Scholar] [CrossRef]
- Shetty, S.; Gupta, P.; Belgiu, M.; Srivastav, S. Assessing the Effect of Training Sampling Design on the Performance of Machine Learning Classifiers for Land Cover Mapping Using Multi-Temporal Remote Sensing Data and Google Earth Engine. Remote Sens. 2021, 13, 1433. [Google Scholar] [CrossRef]
- Jin, Y.; Liu, X.; Chen, Y.; Liang, X. Land-cover mapping using Random Forest classification and incorporating NDVI time-series and texture: A case study of central Shandong. Int. J. Remote Sens. 2018, 39, 8703–8723. [Google Scholar] [CrossRef]
- Belgiu, M.; Drăguţ, L. Random forest in remote sensing: A review of applications and future directions. ISPRS J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Bessinger, M.; Lück-Vogel, M.; Skowno, A.; Conrad, F. Landsat-8 based coastal ecosystem mapping in South Africa using random forest classification in Google Earth Engine. S. Afr. J. Bot. 2022, 150, 928–939. [Google Scholar] [CrossRef]
- Hao, P.; Zhan, Y.; Wang, L.; Niu, Z.; Shakir, M. Feature Selection of Time Series MODIS Data for Early Crop Classification Using Random Forest: A Case Study in Kansas, USA. Remote Sens. 2015, 7, 5347–5369. [Google Scholar] [CrossRef] [Green Version]
- Albretch, F.; Lang, S.; Holbling, D. Spatial accuracy assessment of object boundaries for object-based image analysis. ISPRS—International Archives of the Photogrammetry Remote Sensing and Spatial Information Sciences, XXXVIII-4/C7, Ghent, Belgium, 29 June–2 July 2010. [Google Scholar]
- Gevaert, C.M.; Persello, C.; Sliuzas, R.; Vosselman, G. Classification of informal settlements through the integration of 2D and 3D features extracted from UAV data. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, 3, 317. [Google Scholar] [CrossRef] [Green Version]
- Myint, S.W.; Gober, P.; Brazel, A.; Grossman-Clarke, S.; Weng, Q. Per-pixel vs. object-based classification of urban land cover extraction using high spatial resolution imagery. Remote Sens. Environ. 2011, 115, 1145–1161. [Google Scholar] [CrossRef]
- Li, X.; Chen, W.; Cheng, X.; Wang, L. A Comparison of Machine Learning Algorithms for Mapping of Complex Surface-Mined and Agricultural Landscapes Using ZiYuan-3 Stereo Satellite Imagery. Remote Sens. 2016, 8, 514. [Google Scholar] [CrossRef] [Green Version]
- Lin, J.; Jin, X.; Ren, J.; Liu, J.; Liang, X.; Zhou, Y. Rapid Mapping of Large-Scale Greenhouse Based on Integrated Learning Algorithm and Google Earth Engine. Remote Sens. 2021, 13, 1245. [Google Scholar] [CrossRef]
- Chen, W.; Li, X.; He, H.; Wang, L. Assessing Different Feature Sets’ Effects on Land Cover Classification in Complex Surface-Mined Landscapes by ZiYuan-3 Satellite Imagery. Remote Sens. 2018, 10, 23. [Google Scholar] [CrossRef] [Green Version]
- Dolean, B.-E.; Bilașco, Ș.; Petrea, D.; Moldovan, C.; Vescan, I.; Roșca, S.; Fodorean, I. Evaluation of the Built-Up Area Dynamics in the First Ring of Cluj-Napoca Metropolitan Area, Romania by Semi-Automatic GIS Analysis of Landsat Satellite Images. Appl. Sci. 2020, 10, 7722. [Google Scholar] [CrossRef]
- Maxwell, A.; Strager, M.; Warner, T.; Zégre, N.; Yuill, C. Comparison of NAIP orthophotography and RapidEye satellite imagery for mapping of mining and mine reclamation. GIScience Remote Sens. 2014, 51, 301–320. [Google Scholar] [CrossRef]
- Taubenböck, H.; Kraff, N.J.; Wurm, M. The morphology of the Arrival City—A global categorization based on literature surveys and remotely sensed data. Appl. Geogr. 2018, 92, 150–167. [Google Scholar] [CrossRef]
- Räsänen, A.; Virtanen, T. Data and resolution requirements in mapping vegetation in spatially heterogeneous landscapes. Remote Sens. Environ. 2019, 230, 111207. [Google Scholar] [CrossRef]
- Kpienbaareh, D.; Sun, X.; Wang, J.; Luginaah, I.; Kerr, R.B.; Lupafya, E.; Dakishoni, L. Crop Type and Land Cover Mapping in Northern Malawi Using the Integration of Sentinel-1, Sentinel-2, and PlanetScope Satellite Data. Remote Sens. 2021, 13, 700. [Google Scholar] [CrossRef]
- Rufin, P.; Picoli, M.; Bey, A.; Meyfroidt, P. An operational framework for large-area mapping of active cropland and short-term fallows in smallholder landscapes using PlanetScope data. Int. J. Appl. Earth Obs. Geoinf. 2022, 112, 102937. [Google Scholar]
- Vizzari, M. PlanetScope, Sentinel-2, and Sentinel-1 Data Integration for Object-Based Land Cover Classification in Google Earth Engine. Remote Sens. 2022, 14, 2628. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Image Features | Names | Number of Features |
|---|---|---|
| Spectral bands (SBs) | Band (B2, B3, B4, B5, B6, B7, B8, B8A, B11, B12) | 10 |
| Spectral indices (SIs) | NDVI, NDWI, SAVI, NDBI, UI, NBI, BRBA, MNDWI | 8 |
| Texture metrics (Txts) | B2, B3, B4, (mean, variance, homogeneity, correlation, entropy, dissimilarity, contrast, angular second moment) | 24 |
| Spectral Index | Equation | Main Reference |
|---|---|---|
| NDVI | [47,60,80] | |
| SAVI | )) | [77] |
| NDWI | [47,80] | |
| MNDWI | [60,63] | |
| BRBA | [63] | |
| NDBI | [60,63] | |
| NBI | [60,63] | |
| UI | [63] |
| Model | PA | UA | F-Score |
|---|---|---|---|
| SBs | 83 | 89 | 86 ± 1.98 |
| SIs | 73 | 80 | 76 ± 2.06 |
| Txts | 86 | 94 | 90 ± 1.19 |
| SBs + SIs | 79 | 86 | 82 ± 1.43 |
| SBs + Txts | 91 | 97 | 94 ± 1.27 |
| SIs + Txts | 91 | 94 | 92 ± 0.91 |
| SBs + SIs + Txts | 91 | 96 | 93 ± 1.08 |
| First Model | Second Model | Mean of First Model | Mean of Second Model | p-Value |
|---|---|---|---|---|
| SBs vs | SIs | 86 | 76 | < 0.05 |
| SBs vs | Txts | 86 | 90 | <0.05 |
| SBs vs | SBs + SIs | 86 | 82 | <0.05 |
| SBs vs | SBs + Txts | 86 | 94 | <0.05 |
| SBs vs | SIs + Txts | 86 | 92 | <0.05 |
| SBs vs | SBs + SIs + Txts | 86 | 93 | <0.05 |
| Feature Input Model | F-Score | p-Value | |
|---|---|---|---|
| All Variables | Feature Subset | ||
| Txts | 90 | 90 | |
| SBs + SIs | 82 | 82 | |
| SBs + Txts | 94 | 90 | p < 0.05 |
| SBs + SIs + Txts | 93 | 88 | p < 0.05 |
| SIs + Txts | 92 | 84 | p < 0.05 |
| Classification Model | Patch | Classified Patch Area (ha) | Reference Patch Area (ha) | Difference | Difference (%) | RMSLE | MAPE |
|---|---|---|---|---|---|---|---|
| SBs | A | 2.97 | 3.94 | 0.97 | 24.62 | 1.13 | 0.57 |
| B | 1.89 | 1.86 | −0.03 | −1.61 | |||
| C | 6.96 | 12.43 | 5.47 | 44.01 | |||
| D | 3.89 | 13.55 | 9.66 | 71.29 | |||
| E | 1.83 | 4.49 | 2.66 | 59.24 | |||
| F | 1.97 | 11.22 | 9.25 | 82.44 | |||
| G | 0.95 | 5.09 | 4.14 | 81.34 | |||
| SIs | A | 2.72 | 3.94 | 1.22 | 30.96 | 1.2 | 0.61 |
| B | 1.50 | 1.86 | 0.36 | 19.35 | |||
| C | 6.76 | 12.43 | 5.67 | 45.62 | |||
| D | 3.80 | 13.55 | 9.75 | 71.96 | |||
| E | 1.88 | 4.49 | 2.61 | 58.13 | |||
| F | 1.82 | 11.22 | 9.4 | 83.78 | |||
| G | 0.83 | 5.09 | 4.26 | 83.69 | |||
| Txts | A | 3.25 | 3.94 | 0.69 | 17.51 | 0.51 | 0.36 |
| B | 1.73 | 1.86 | 0.13 | 6.99 | |||
| C | 7.83 | 12.43 | 4.6 | 37.01 | |||
| D | 6.47 | 13.55 | 7.08 | 52.25 | |||
| E | 3.85 | 4.49 | 0.64 | 14.25 | |||
| F | 6.70 | 11,22 | 4.52 | 40.29 | |||
| G | 2.62 | 5,09 | 2.47 | 48.53 | |||
| SBs + SIs | A | 3.11 | 3.94 | 0.83 | 21.07 | 0.88 | 0.50 |
| B | 1.80 | 1.86 | 0.06 | 3.23 | |||
| C | 7.83 | 12.43 | 4.6 | 37.01 | |||
| D | 4.97 | 13.55 | 8.58 | 63.32 | |||
| E | 2.61 | 4.49 | 1.88 | 41.87 | |||
| F | 3.04 | 11.22 | 8.18 | 72.91 | |||
| G | 1.28 | 5.09 | 3.81 | 74.85 | |||
| SBs + Txts | A | 3.88 | 3.94 | 0.06 | 1.52 | 0.63 | 0.38 |
| B | 1.42 | 1.86 | 0.44 | 23.66 | |||
| C | 8.31 | 12.43 | 4.12 | 33.15 | |||
| D | 5.28 | 13.55 | 8.27 | 61.03 | |||
| E | 3.63 | 4.49 | 0.86 | 19.15 | |||
| F | 6.44 | 11.22 | 4.78 | 42.60 | |||
| G | 2.12 | 5.09 | 2.97 | 58.35 | |||
| SIs + Txts | A | 2.93 | 3.94 | 1.01 | 25.63 | 0.68 | 0.44 |
| B | 1.85 | 1.86 | 0.01 | 0.54 | |||
| C | 7.04 | 12.43 | 5.39 | 43.36 | |||
| D | 5.04 | 13.55 | 8.51 | 62.80 | |||
| E | 3.53 | 4.49 | 0.96 | 21.38 | |||
| F | 5.71 | 11.22 | 5.51 | 49.11 | |||
| G | 1.82 | 5.09 | 3.27 | 64.24 | |||
| SBs + SIs + Txts | A | 3.11 | 3.94 | 0.83 | 21.07 | 0.73 | 0.46 |
| B | 1.70 | 1.86 | 0.16 | 8.60 | |||
| C | 6.75 | 12.43 | 5.68 | 45.70 | |||
| D | 4.45 | 13.55 | 9.1 | 67.16 | |||
| E | 3.19 | 4.49 | 1.3 | 28.95 | |||
| F | 5.50 | 11.22 | 5.72 | 50.98 | |||
| G | 1.83 | 5.09 | 3.26 | 64.05 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Matarira, D.; Mutanga, O.; Naidu, M. Google Earth Engine for Informal Settlement Mapping: A Random Forest Classification Using Spectral and Textural Information. Remote Sens. 2022, 14, 5130. https://doi.org/10.3390/rs14205130
Matarira D, Mutanga O, Naidu M. Google Earth Engine for Informal Settlement Mapping: A Random Forest Classification Using Spectral and Textural Information. Remote Sensing. 2022; 14(20):5130. https://doi.org/10.3390/rs14205130
Chicago/Turabian StyleMatarira, Dadirai, Onisimo Mutanga, and Maheshvari Naidu. 2022. "Google Earth Engine for Informal Settlement Mapping: A Random Forest Classification Using Spectral and Textural Information" Remote Sensing 14, no. 20: 5130. https://doi.org/10.3390/rs14205130
APA StyleMatarira, D., Mutanga, O., & Naidu, M. (2022). Google Earth Engine for Informal Settlement Mapping: A Random Forest Classification Using Spectral and Textural Information. Remote Sensing, 14(20), 5130. https://doi.org/10.3390/rs14205130