
3D-SiamMask: Vision-Based Multi-Rotor Aerial-Vehicle Tracking for a Moving Object


Abstract
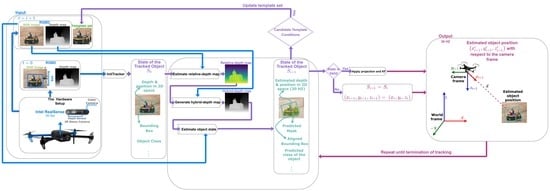
:
1. Introduction
- (i)
- The subject moves very slightly between two successive frames, preventing a significant change in appearance;
- (ii)
- There are few or no distractions in the target’s environment.
- Utilize a monocular-based hybrid-depth estimation technique to overcome the limitations of sensor depth maps.
- Employ the template set to cover the target object in a variety of poses over time.
- Introduce the auxiliary object classifier to improve the overall performance of the visual tracker.
2. Related Work
- Predicting the future location of the object.
- Forecast correction based on current measurements.
- Noise reduction caused by incorrect diagnosis.
- The watermark must include all the required information while remaining placeable and noticeable, even on tiny photos. The created watermark must be compact while still having the ability to hold sufficient information.
- The watermark must be invisible to the human eye to prevent easy tampering (and, preferably, to basic image parsing tools). If the malefactor is unaware of the existence of the watermark, they may not even attempt to remove or disable it.
3. Methodology
| Algorithm 1 Object visual tracker |
| Input: Undistorted RGB & depth frames |
| Input: Undistorted RGB & depth frames |
|
- GerenateHybridDepthMap by applying Equation (4). To estimate the hybrid-depth map that has the depth information of the moving object in meters. The process of generating the hybrid-depth map is divided into 3 main steps, as follows
- (i)
- Preprocess the depth map by replacing all non-numeric values with zeros. The result is a 2D array with values measured in meters.
- (ii)
- Generate from the relative depth map a 2D array with values .
- (iii)
- Apply Equation (4).
- EstimatingObjectState takes the state vector of the moving object as the input and returns the updated state as the output . has the details of the target object such as the hybrid-depth maps and the RGB frames of the current and previous time steps . The position will be defined in 2D space as the center of the object . The depth is .To update the template set there are conditions the candidate template needs to meet. These conditions are as follows
- Class-specific tracker: the object should be classified by the auxiliary classifier as the desired class.
- Both trackers: if the detected object satisfies the inequalities (3) below, then the candidate template will be inserted to the template set at after the original template frame and before the other templates in the template set:where and are the area for the generated mask and the bounding box, respectively. and are small fractions.
Therefore, if the candidate template violates any of the corresponding conditions, the new candidate template will not be inserted to the template set. Before we explain how the template set is used, we need to know that the original template frame has index at every time step. The usage of the template set is as follows- (i)
- Use the original template frame.
- (ii)
- The conditions (3) above must be satisfied and the objectness probability (RPN score) should be greater than a threshold . Other than that, the template frame is skipped to the next most recent frame in the template set.
- (iii)
- Repeat (ii) if needed for n times (in our experiments ).
- (iv)
- Return the estimated object state.
- Generic moving-object tracker: in this case, the object will be classified using the Siamese tracker with the help of the frames in the template set.
- Class-specific moving-object tracker: in this case, the tracker will have an auxiliary object classifier which makes sure to avoid distractors and the possible foreground/background confusions by the RPN network.
4. Results
4.1. Experiment 1: Generic and Class-Specific Trackers
- Generic tracker. Figure 7 shows how the tracker, using the Siamese tracker with the help of the template set and the hybrid depth map, was able to track the target object. The experiment showed that the tracker passed the moving object.
- Class-specific tracker. Figure 8 shows that by involving the auxiliary object classifier, the object tracker did not pass the moving object. The responsibility of this classifier is to stabilize the tracking process.
4.2. Experiment 2: Different Case Scenarios
4.2.1. The Basic Moving-Object Tracking
4.2.2. Tracking One of Multiple Identical Objects
4.2.3. Tracking a Far Moving Object
4.3. Depth-Estimation Analysis
- Short (typical) range (5 m or less)
- Medium range (between 5 and 10 m)
- Long range (more than 10 m)

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| x [m] | y [m] | z [m] | Position [m] | |
|---|---|---|---|---|
| RMSE | 1.1156 | 0.1618 | 0.2628 | 1.1576 |
| MSE | 1.0314 | 0.1566 | 0.2625 | 1.34 |
| MAE | 1.245 | 0.0262 | 0.0691 | 1.4506 |
4.3.1. Short (Typical) Range
4.3.2. Medium Range
4.3.3. Long Range
4.4. Visual Object-Tracker Evaluation
5. Conclusions
- Non-contrastive learning will be used for the opportunity of having a better representation [62] which could tackle problems such as occlusion, illumination variation, etc.
- Self-supervised incremental learning will be used to create a more effective tracking framework which could be trained on the new classes without suffering from the forgetting problem [63].
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Qi, C.R.; Zhou, Y.; Najibi, M.; Sun, P.; Vo, K.; Deng, B.; Anguelov, D. Offboard 3d object detection from point cloud sequences. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 6134–6144. [Google Scholar]
- Yan, X.; Zheng, C.; Li, Z.; Wang, S.; Cui, S. Pointasnl: Robust point clouds processing using nonlocal neural networks with adaptive sampling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5589–5598. [Google Scholar]
- Yan, X.; Gao, J.; Li, J.; Zhang, R.; Li, Z.; Huang, R.; Cui, S. Sparse single sweep lidar point cloud segmentation via learning contextual shape priors from scene completion. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 2–9 February 2021; Volume 35, pp. 3101–3109. [Google Scholar]
- Thys, S.; Van Ranst, W.; Goedemé, T. Fooling automated surveillance cameras: Adversarial patches to attack person detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Wang, Q.; Zhang, L.; Bertinetto, L.; Hu, W.; Torr, P.H. Fast online object tracking and segmentation: A unifying approach. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 1328–1338. [Google Scholar]
- Zhu, Z.; Wang, Q.; Li, B.; Wu, W.; Yan, J.; Hu, W. Distractor-aware siamese networks for visual object tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 101–117. [Google Scholar]
- Zheng, C.; Yan, X.; Zhang, H.; Wang, B.; Cheng, S.; Cui, S.; Li, Z. Beyond 3D Siamese Tracking: A Motion-Centric Paradigm for 3D Single Object Tracking in Point Clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 8111–8120. [Google Scholar]
- Bertinetto, L.; Valmadre, J.; Henriques, J.F.; Vedaldi, A.; Torr, P.H. Fully-convolutional siamese networks for object tracking. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 850–865. [Google Scholar]
- Li, B.; Yan, J.; Wu, W.; Zhu, Z.; Hu, X. High performance visual tracking with siamese region proposal network. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8971–8980. [Google Scholar]
- Zhang, T.; Liu, S.; Xu, C.; Yan, S.; Ghanem, B.; Ahuja, N.; Yang, M.H. Structural sparse tracking. In Proceedings of the IEEE conference on computer vision and pattern recognition, Boston, MA, USA, 7–12 June 2015; pp. 150–158. [Google Scholar]
- Collins, R.T.; Liu, Y.; Leordeanu, M. Online selection of discriminative tracking features. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1631–1643. [Google Scholar] [CrossRef] [PubMed]
- Ross, D.A.; Lim, J.; Lin, R.S.; Yang, M.H. Incremental learning for robust visual tracking. Int. J. Comput. Vis. 2008, 77, 125–141. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The kitti vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Ranftl, R.; Lasinger, K.; Hafner, D.; Schindler, K.; Koltun, V. Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset transfer. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 1623–1637. [Google Scholar] [CrossRef] [PubMed]
- Luo, W.; Xing, J.; Milan, A.; Zhang, X.; Liu, W.; Kim, T.K. Multiple object tracking: A literature review. Artif. Intell. 2021, 293, 103448. [Google Scholar] [CrossRef]
- Soleimanitaleb, Z.; Keyvanrad, M.A. Single Object Tracking: A Survey of Methods, Datasets, and Evaluation Metrics. arXiv 2022, arXiv:2201.13066. [Google Scholar]
- Wang, Q.; Chen, F.; Xu, W.; Yang, M.H. An experimental comparison of online object-tracking algorithms. Wavelets Sparsity XIV 2011, 8138, 311–321. [Google Scholar]
- Wu, Y.; Lim, J.; Yang, M.H. Online object tracking: A benchmark. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 2411–2418. [Google Scholar]
- Kalman, R.E. A new approach to linear filtering and prediction problems. J. Basic Eng. 1960, 82, 35–45. [Google Scholar] [CrossRef] [Green Version]
- Najafzadeh, N.; Fotouhi, M.; Kasaei, S. Multiple soccer players tracking. In Proceedings of the 2015 The International Symposium on Artificial Intelligence and Signal Processing (AISP), Mashhad, Iran, 3–5 March 2015; pp. 310–315. [Google Scholar]
- Julier, S.J.; Uhlmann, J.K. New extension of the Kalman filter to nonlinear systems. In Proceedings of the Signal Processing, Sensor Fusion, and Target Recognition VI, Orlando, FL, USA, 21–25 April 1997; Volume 3068, pp. 182–193. [Google Scholar]
- Boers, Y.; Driessen, J.N. Particle filter based detection for tracking. In Proceedings of the 2001 American Control Conference, (Cat. No. 01CH37148), Arlington, VA, USA, 25–27 June 2001; Volume 6, pp. 4393–4397. [Google Scholar]
- Fortmann, T.; Bar-Shalom, Y.; Scheffe, M. Sonar tracking of multiple targets using joint probabilistic data association. IEEE J. Ocean. Eng. 1983, 8, 173–184. [Google Scholar] [CrossRef] [Green Version]
- Musicki, D.; Evans, R. Joint integrated probabilistic data association: JIPDA. IEEE Trans. Aerosp. Electron. Syst. 2004, 40, 1093–1099. [Google Scholar] [CrossRef]
- Svensson, L.; Svensson, D.; Guerriero, M.; Willett, P. Set JPDA Filter for Multitarget Tracking. IEEE Trans. Signal Process. 2011, 59, 4677–4691. [Google Scholar] [CrossRef] [Green Version]
- Lucas, B.D.; Kanade, T. An Iterative Image Registration Technique with an Application to Stereo Vision. In Proceedings of the 7th International Joint Conference on Artificial Intelligence (IJCAI ’81), Vancouver, BC, Canada, 24–28 August 1981; Volume 81. [Google Scholar]
- Hu, Y.; Zhao, W.; Wang, L. Vision-based target tracking and collision avoidance for two autonomous robotic fish. IEEE Trans. Ind. Electron. 2009, 56, 1401–1410. [Google Scholar]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Li, C.; Xing, Q.; Ma, Z. HKSiamFC: Visual-tracking framework using prior information provided by staple and kalman filter. Sensors 2020, 20, 2137. [Google Scholar] [CrossRef] [PubMed]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the 28th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Danelljan, M.; Bhat, G.; Khan, F.S.; Felsberg, M. Atom: Accurate tracking by overlap maximization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 4660–4669. [Google Scholar]
- Wang, N.; Zhou, W.; Wang, J.; Li, H. Transformer meets tracker: Exploiting temporal context for robust visual tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 1571–1580. [Google Scholar]
- Geiger, A.; Lauer, M.; Wojek, C.; Stiller, C.; Urtasun, R. 3d traffic scene understanding from movable platforms. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 36, 1012–1025. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lee, S.; Im, S.; Lin, S.; Kweon, I.S. Learning monocular depth in dynamic scenes via instance-aware projection consistency. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 2–9 February 2021; Volume 35, pp. 1863–1872. [Google Scholar]
- Chang, J.R.; Chen, Y.S. Pyramid stereo matching network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5410–5418. [Google Scholar]
- Sun, D.; Yang, X.; Liu, M.Y.; Kautz, J. Pwc-net: Cnns for optical flow using pyramid, warping, and cost volume. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8934–8943. [Google Scholar]
- Zhang, H.; Wang, G.; Lei, Z.; Hwang, J.N. Eye in the sky: Drone-based object tracking and 3d localization. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 899–907. [Google Scholar]
- Wang, G.; Wang, Y.; Zhang, H.; Gu, R.; Hwang, J.N. Exploit the connectivity: Multi-object tracking with trackletnet. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 482–490. [Google Scholar]
- Fang, Z.; Zhou, S.; Cui, Y.; Scherer, S. 3d-siamrpn: An end-to-end learning method for real-time 3d single object tracking using raw point cloud. IEEE Sens. J. 2020, 21, 4995–5011. [Google Scholar] [CrossRef]
- Qi, H.; Feng, C.; Cao, Z.; Zhao, F.; Xiao, Y. P2b: Point-to-box network for 3d object tracking in point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 6329–6338. [Google Scholar]
- Keselman, L.; Iselin Woodfill, J.; Grunnet-Jepsen, A.; Bhowmik, A. Intel realsense stereoscopic depth cameras. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 1–10. [Google Scholar]
- Hata, K.; Savarese, S. Cs231a Course Notes 4: Stereo Systems and Structure from Motion. Available online: https://web.stanford.edu/class/cs231a/course_notes/04-stereo-systems.pdf (accessed on 1 April 2022).
- Guo, D.; Shao, Y.; Cui, Y.; Wang, Z.; Zhang, L.; Shen, C. Graph attention tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 9543–9552. [Google Scholar]
- Chen, X.; Yan, B.; Zhu, J.; Wang, D.; Yang, X.; Lu, H. Transformer tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 8126–8135. [Google Scholar]
- Voigtlaender, P.; Luiten, J.; Torr, P.H.; Leibe, B. Siam r-cnn: Visual tracking by re-detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 6578–6588. [Google Scholar]
- Danelljan, M.; Gool, L.V.; Timofte, R. Probabilistic regression for visual tracking. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, Seattle, WA, USA, 14–19 June 2020; pp. 7183–7192. [Google Scholar]
- Li, B.; Wu, W.; Wang, Q.; Zhang, F.; Xing, J.; Yan, J. Siamrpn++: Evolution of siamese visual tracking with very deep networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 4282–4291. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Krause, J.; Stark, M.; Deng, J.; Fei-Fei, L. 3d object representations for fine-grained categorization. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Sydney, NSW, Australia, 2–8 December 2013; pp. 554–561. [Google Scholar]
- Cimpoi, M.; Maji, S.; Kokkinos, I.; Mohamed, S.; Vedaldi, A. Describing textures in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 3606–3613. [Google Scholar]
- Kristan, M.; Leonardis, A.; Matas, J.; Felsberg, M.; Pflugfelder, R.; Čehovin Zajc, L.; Vojir, T.; Hager, G.; Lukezic, A.; Eldesokey, A.; et al. The Visual Object Tracking VOT2016 Challenge Results. In Proceedings of the Computer Vision—ECCV 2016 Workshops, Amsterdam, The Netherlands, 8–10 and 15–16 October 2016; Springer International Publishing: Cham, Switzerland, 2016; pp. 777–823. [Google Scholar]
- Kristan, M.; Leonardis, A.; Matas, J.; Felsberg, M.; Pflugfelder, R.; Čehovin Zajc, L.; Vojir, T.; Bhat, G.; Lukezic, A.; Eldesokey, A.; et al. The sixth visual object tracking vot2018 challenge results. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Kristan, M.; Matas, J.; Leonardis, A.; Felsberg, M.; Pflugfelder, R.; Kamarainen, J.K.; Čehovin Zajc, L.; Drbohlav, O.; Lukezic, A.; Berg, A.; et al. The seventh visual object tracking vot2019 challenge results. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Kristan, M.; Matas, J.; Leonardis, A.; Felsberg, M.; Cehovin, L.; Fernandez, G.; Vojir, T.; Hager, G.; Nebehay, G.; Pflugfelder, R.; et al. The Visual Object Tracking VOT2015 Challenge Results. In Proceedings of the 2015 IEEE International Conference on Computer Vision Workshop (ICCVW), Santiago, Chile, 7–13 December 2015; pp. 564–586. [Google Scholar] [CrossRef] [Green Version]
- Kulathunga, G.; Devitt, D.; Klimchik, A. Trajectory tracking for quadrotors: An optimization-based planning followed by controlling approach. J. Field Robot. 2022, 39, 1003–1013. [Google Scholar] [CrossRef]
- Li, L. Time-of-flight Camera—An Introduction. Technical White Paper. 2014. Available online: https://www.ti.com/lit/wp/sloa190b/sloa190b.pdf (accessed on 15 November 2021).
- JdeRobot. CustomRobots. Available online: https://github.com/JdeRobot/CustomRobots (accessed on 1 March 2022).
- Lukezic, A.; Vojir, T.; Cehovin Zajc, L.; Matas, J.; Kristan, M. Discriminative correlation filter with channel and spatial reliability. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6309–6318. [Google Scholar]
- Sauer, A.; Aljalbout, E.; Haddadin, S. Tracking holistic object representations. arXiv 2019, arXiv:1907.12920. [Google Scholar]
- Yeom, S. Long Distance Ground Target Tracking with Aerial Image-to-Position Conversion and Improved Track Association. Drones 2022, 6, 55. [Google Scholar] [CrossRef]
- LeCun, Y.; Misra, I. Self-supervised learning: The dark matter of intelligence. Meta AI 2021, 23. [Google Scholar]
- Tian, Y.; Chen, X.; Ganguli, S. Understanding self-supervised learning dynamics without contrastive pairs. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual Event, 18–24 July 2021; pp. 10268–10278. [Google Scholar]
















| Approach | Space | Backbone | Modules | Localization Method | Training Scheme | Input | FPS | Update | Redetection |
|---|---|---|---|---|---|---|---|---|---|
| -Track/2022 [7] | 3D | PointNet | - | binary classification, BBR | Cross-entropy + Huber-loss + Adam | Lidar | 57 | no-update | N |
| 3D-SiamRPN/2021 [40] | 3D | PointNet-++ | - | binary classification, BBR | Focal-loss + Smooth L1-loss | Lidar | 20.8 | no-update | N |
| SiamGAT/2021 [44] | 2D | Google-LeNet | Inception-V3 | binary classification, BBR | BCE-loss+IoU loss+SGD | RGB | 70 | no-update | N |
| TransT/2021 [45] | 2D | ResNet-50 | Block-4 | binary classification, BBR | giou loss+ L1-loss + cross-entropy | RGB | 50 | no-update | N |
| P2B/20 [41] | 3D | PointNet-++ | - | binary classification, BBR | BCE-loss + Huber-loss + Adam | Lidar | 40 | non-linear | N |
| SiamR-CNN/2020 [46] | 2D | ResNet-101-FPN | Block-2,3,4,5 | binary classification, BBR | BCE-loss + Huber loss + Momentum | RGB | 4.7 | no-update | Y |
| PrDiMP/2020 [47] | 2D | ResNet-18/50 | Block-4 | probabilistic density regression, IoU-prediction | KL-divergence + loss steepest descent method | RGB | 30 | non-linear | N |
| SiamMask/2019 [5] | 2D | ResNet-50 | Stage-1,2,3,4 | binary classification, BBR, logistic loss | BCE-loss + SGD | RGB | 55 | no-update | N |
| ATOM/2019 [32] | 2D | ResNet-18 | Block-3,4 | binary classification, BBR | MSE + Adam(R), L2-loss + Conjugate Gradient(C) | RGB | 30 | non-linear | N |
| SiamRPN++/2019 [48] | 2D | ResNet-50 | Block-3,4,5 | binary classification, BBR | BCE-loss + L1-loss + SGD | RGB | 35 | no-update | N |
| SiamRPN/2018 [9] | 2D | modified AlexNet | conv5 | binary classification, BBR | Smooth L1-Loss + BCE-loss + SGD | RGB | 200 | no-update | N |
| DaSiam-RPN/2018 [6] | 2D | modified AlexNet | conv5 | binary classification, BBR | Smooth L1-Loss + BCE-loss + SGD | RGB | 160 | linear | Y |
| SiamFC/2017 [8] | 2D | AlexNet | conv5 | binary classification, scales searching | logistic loss+SGD | RGB | 86 | no-update | N |
| VOT-2016 | |||
|---|---|---|---|
| EAO ↑ | Accuracy ↑ | Robustness ↓ | |
| SiamMask [5] | 0.433 | 0.639 | 0.214 |
| The proposed generic tracker | 0.433 | 0.639 | 0.210 |
| VOT-2019 | |||
|---|---|---|---|
| EAO ↑ | Accuracy ↑ | Robustness ↓ | |
| The proposed generic tracker | 0.281 | 0.610 | 0.527 |
| EAO ↑ | Accuracy ↑ | Robustness ↓ | Speed (fps) ↑ | |
|---|---|---|---|---|
| The proposed generic tracker | 0.381 | 0.61 | 0.286 | 36 |
| SiamMask [5] | 0.380 | 0.609 | 0.276 | 55 |
| DaSiamRPN [6] | 0.326 | 0.569 | 0.337 | 160 |
| SiamRPN [9] | 0.244 | 0.490 | 0.460 | 200 |
| SiamRPN++ [48] | 0.414 | 0.600 | 0.234 | 35 |
| PrDiMP [47] | 0.385 | 0.607 | 0.217 | 40 |
| CSRDCF [59] | 0.263 | 0.466 | 0.318 | 48.9 |
| SiamR-CNN [46] | 0.408 | 0.609 | 0.220 | 15 |
| THOR [60] | 0.416 | 0.5818 | 0.234 | 112 |
| TrDiMP [33] | 0.462 | 0.600 | 0.141 | 26 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Al Mdfaa, M.; Kulathunga, G.; Klimchik, A. 3D-SiamMask: Vision-Based Multi-Rotor Aerial-Vehicle Tracking for a Moving Object. Remote Sens. 2022, 14, 5756. https://doi.org/10.3390/rs14225756
Al Mdfaa M, Kulathunga G, Klimchik A. 3D-SiamMask: Vision-Based Multi-Rotor Aerial-Vehicle Tracking for a Moving Object. Remote Sensing. 2022; 14(22):5756. https://doi.org/10.3390/rs14225756
Chicago/Turabian StyleAl Mdfaa, Mohamad, Geesara Kulathunga, and Alexandr Klimchik. 2022. "3D-SiamMask: Vision-Based Multi-Rotor Aerial-Vehicle Tracking for a Moving Object" Remote Sensing 14, no. 22: 5756. https://doi.org/10.3390/rs14225756
APA StyleAl Mdfaa, M., Kulathunga, G., & Klimchik, A. (2022). 3D-SiamMask: Vision-Based Multi-Rotor Aerial-Vehicle Tracking for a Moving Object. Remote Sensing, 14(22), 5756. https://doi.org/10.3390/rs14225756