
Large-Scale Semantic Scene Understanding with Cross-Correction Representation


Abstract
:
1. Introduction
- We propose a novel model named SSI-Net that can be appropriate for both indoor and outdoor point cloud semantic segmentation to implement real-time scene perception guidance. SSI-Net highly aggregates high-level semantic information and spatial geometric patterns to enhance the descriptor’s representation ability. Thus, robust non-local features of indoor and outdoor scenes can be obtained to improve the precision of semantic segmentation on point clouds.
- We propose the Spatial–Semantic Cross-correction (SSC) module, which can delicately interconnect high-level semantic and spatial geometric features in the latent space through two intersecting point cloud nearest neighbor clustering branches. Specifically, the constraints of high-level semantic information reduce the error rate of geometric expression, and conversely, spatial features can expand the scope of high-level semantic information. As a consequence, the mutual promotion and fusion provide more sufficient context information for point cloud semantic segmentation.
- Being computationally efficient, SSI-Net meets the needs of large-scale scenes. Results on several indoor and outdoor public datasets for point cloud segmentation demonstrate the state-of-the-art power of our proposed method in terms of Intersection-over-Union and overall accuracy for large-scale processing.
2. Related Work
2.1. Deep Learning on Point Cloud Segmentation
2.2. Large-Scale Point Cloud Semantic Segmentation
3. Proposed Method
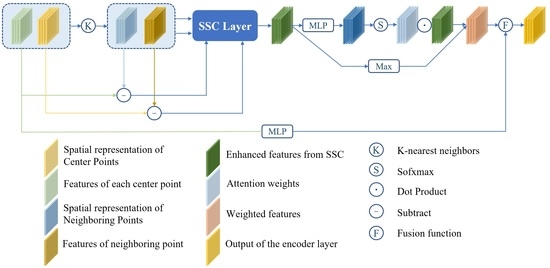
3.1. Spatial-Semantic Cross-Correction Module
3.1.1. Semantic-Aware Spatial Block
3.1.2. Attention Block
3.2. Feature Aggregation
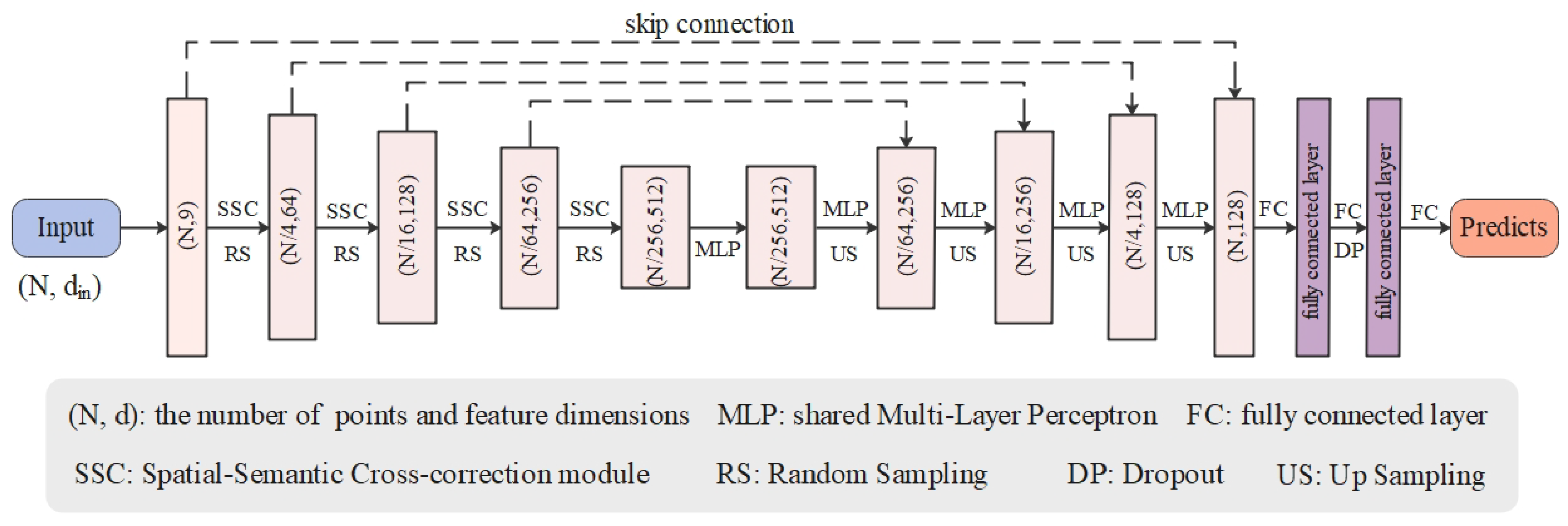
3.3. Our Network Architecture
4. Experiments
4.1. Experimental Settings
4.2. Performance Comparison
4.2.1. Results of S3DIS
4.2.2. Results of SemanticKITTI
4.3. Ablation Studies
- (1)
- Removing the semantic-aware information of spatial location encoding: this part aims to encode more detailed local geometry with position and high-level information;
- (2)
- Replacing the attentional semantic encoding by general MLP layers;
- (3)
- Aggregating local features only by max operation.
- (1)
- Encoding the neighboring points and deformable neighboring points ;
- (2)
- Encoding the relative position: and , and corresponding Euclidean distance: and ;
- (3)
- Encoding the point , the relative position: and , and Euclidean distance: and ;
- (4)
- Encoding the neighboring points: and , the relative position: and , and the Euclidean distance: and .
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sun, W.; Zhang, Z.; Huang, J. RobNet: Real-time road-object 3D point cloud segmentation based on SqueezeNet and cyclic CRF. Soft Comput. 2020, 24, 5805–5818. [Google Scholar] [CrossRef]
- Hao, F.; Li, J.; Song, R.; Li, Y.; Cao, K. Mixed Feature Prediction on Boundary Learning for Point Cloud Semantic Segmentation. Remote Sens. 2022, 14, 4757. [Google Scholar] [CrossRef]
- Lan, S.; Yu, R.; Yu, G.; Davis, L.S. Modeling local geometric structure of 3d point clouds using geo-cnn. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Wu, W.; Qi, Z.; Fuxin, L. Pointconv: Deep convolutional networks on 3d point clouds. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- He, T.; Shen, C.; Hengel, A. Dynamic Convolution for 3D Point Cloud Instance Segmentation. arXiv 2021, arXiv:2107.08392. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Sun, Y.; Liu, Z.; Sarma, S.E.; Bronstein, M.M.; Solomon, J.M. Dynamic graph cnn for learning on point clouds. ACM Trans. Graph. (TOG) 2019, 38, 1–12. [Google Scholar] [CrossRef] [Green Version]
- Li, G.; Muller, M.; Thabet, A.; Ghanem, B. DeepGCNs: Can gcns go as deep as cnns? In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Wang, L.; Huang, Y.; Hou, Y.; Zhang, S.; Shan, J. Graph attention convolution for point cloud semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Landrieu, L.; Simonovsky, M. Large-scale point cloud semantic segmentation with superpoint graphs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Hu, Q.; Yang, B.; Xie, L.; Rosa, S.; Guo, Y.; Wang, Z.; Trigoni, N.; Markham, A. Learning Semantic Segmentation of Large-Scale Point Clouds with Random Sampling. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 8338–8354. [Google Scholar] [CrossRef] [PubMed]
- Boulch, A.; Guerry, J.; Le Saux, B.; Audebert, N. Snapnet: 3d point cloud semantic labeling with 2d deep segmentation networks. Comput. Graph. 2018, 71, 189–198. [Google Scholar] [CrossRef]
- Tchapmi, L.; Choy, C.; Armeni, I.; Gwak, J.; Savarese, S. Segcloud: Semantic segmentation of 3d point clouds. In Proceedings of the 2017 International Conference on 3D Vision, Qingdao, China, 10 October 2017; pp. 537–547. [Google Scholar]
- Wang, P.S.; Liu, Y.; Guo, Y.X.; Sun, C.Y.; Tong, X. O-cnn: Octree-based convolutional neural networks for 3d shape analysis. ACM Trans. Graph. (TOG) 2017, 36, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Meng, H.Y.; Gao, L.; Lai, Y.K.; Manocha, D. Vv-net: Voxel vae net with group convolutions for point cloud segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Riegler, G.; Osman Ulusoy, A.; Geiger, A. Octnet: Learning deep 3d representations at high resolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; 2017. [Google Scholar]
- Park, J.; Kim, C.; Jo, K. PCSCNet: Fast 3D Semantic Segmentation of LiDAR Point Cloud for Autonomous Car using Point Convolution and Sparse Convolution Network. arXiv 2022, arXiv:2202.10047. [Google Scholar] [CrossRef]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep Learning on Point Sets for 3D Classification and Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. PointNet++: Deep hierarchical feature learning on point sets in a metric space. In Proceedings of the 2017 Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Zhang, D.; He, F.; Tu, Z.; Zou, L.; Hen, Y. Pointwise geometric and semantic learning network on 3D point clouds. Integr.-Comput.-Aided Eng. 2020, 27, 57–75. [Google Scholar] [CrossRef]
- Zhao, H.; Jiang, L.; Fu, C.W.; Jia, J. Pointweb: Enhancing local neighborhood features for point cloud processing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Han, W.; Wen, C.; Wang, C.; Li, X.; Li, Q. Point2Node: Correlation learning of dynamic-node for point cloud feature modeling. Proc. AAAI Conf. Artif. Intell. 2020, 34, 10925–10932. [Google Scholar] [CrossRef]
- Yan, X.; Zheng, C.; Li, Z.; Wang, S.; Cui, S. PointASNL: Robust point clouds processing using nonlocal neural networks with adaptive sampling. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seoul, Korea, 14–19 June 2020. [Google Scholar]
- Chen, J.; Kakillioglu, B.; Velipasalar, S. Background-Aware 3D Point Cloud Segmentation with Dynamic Point Feature Aggregation. arXiv 2021, arXiv:2111.07248. [Google Scholar]
- Chen, C.; Chen, Z.; Zhang, J.; Tao, D. SASA: Semantics-Augmented Set Abstraction for Point-based 3D Object Detection. arXiv 2022, arXiv:2201.01976. [Google Scholar] [CrossRef]
- Srivastava, S.; Sharma, G. Exploiting local geometry for feature and graph construction for better 3d point cloud processing with graph neural networks. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 5 June 2021. [Google Scholar]
- Rethage, D.; Wald, J.; Sturm, J.; Navab, N.; Tombari, F. Fully-convolutional point networks for large-scale point clouds. In Proceedings of the 15th European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Chen, S.; Niu, S.; Lan, T.; Liu, B. PCT: Large-scale 3D point cloud representations via graph inception networks with applications to autonomous driving. In Proceedings of the 26th IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019. [Google Scholar]
- Luo, C.; Li, X.; Cheng, N.; Li, H.; Lei, S.; Li, P. MVP-Net: Multiple View Pointwise Semantic Segmentation of Large-Scale Point Clouds. arXiv 2022, arXiv:2201.12769. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2018. [Google Scholar]
- Gong, J.; Xu, J.; Tan, X.; Zhou, J.; Qu, Y.; Xie, Y.; Ma, L. Boundary-aware geometric encoding for semantic segmentation of point clouds. arXiv 2021, arXiv:2101.02381. [Google Scholar] [CrossRef]
- Wang, X.; He, J.; Ma, L. Exploiting local and global structure for point cloud semantic segmentation with contextual point representations. Adv. Neural Inf. Process. Syst. 2019, 32, 4571–4581. [Google Scholar]
- Li, Y.; Bu, R.; Sun, M.; Wu, W.; Di, X.; Chen, B. Pointcnn: Convolution on X-transformed points. In Proceedings of the 2018 Conference on Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018. [Google Scholar]
- Wang, S.; Suo, S.; Ma, W.; Pokrovsky, A.; Urtasun, R. Deep parametric continuous convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Choy, C.; Gwak, J.; Savarese, S. 4d spatio-temporal convnets: Minkowski convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Liu, Y.; Hu, Q.; Lei, Y.; Xu, K.; Li, J.; Guo, Y. Box2Seg: Learning Semantics of 3D Point Clouds with Box-Level Supervision. arXiv 2022, arXiv:2201.02963. [Google Scholar]
- Huang, Q.; Wang, W.; Neumann, U. Recurrent slice networks for 3d segmentation of point clouds. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June2018. [Google Scholar]
- Ye, X.; Li, J.; Huang, H.; Du, L.; Zhang, X. 3D recurrent neural networks with context fusion for point cloud semantic segmentation. In Proceedings of the 15th European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Zhang, Z.; Hua, B.S.; Yeung, S.K. Shellnet: Efficient point cloud convolutional neural networks using concentric shells statistics. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Thomas, H.; Qi, C.R.; Deschaud, J.; Marcotegui, B.; Goulette, F.; Guibas, L.J. Kpconv: Flexible and deformable convolution for point clouds. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Su, H.; Jampani, V.; Sun, D.; Maji, S.; Kalogerakis, E.; Yang, M.; Kautz, J. SPLATNet: Sparse lattice networks for point cloud processing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Tatarchenko, M.; Park, J.; Koltun, V.; Zhou, Q. Tangent convolutions for dense prediction in 3D. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Wu, B.; Wan, A.; Yue, X.; Keutzer, K. Squeezeseg: Convolutional neural nets with recurrent crf for real-time road-object segmentation from 3D lidar point cloud. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018. [Google Scholar]
- Wu, B.; Zhou, X.; Zhao, S.; Yue, X.; Keutzer, K. Squeezesegv2: Improved model structure and unsupervised domain adaptation for road-object segmentation from a lidar point cloud. In Proceedings of the International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019. [Google Scholar]
- Behley, J.; Garbade, M.; Milioto, A.; Quenzel, J.; Behnke, S.; Stachniss, C.; Gall, J. SemanticKITTI: A dataset for semantic scene understanding of lidar sequences. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Zhang, Y.; Zhou, Z.; David, P.; Yue, X.; Xi, Z.; Gong, B.; Foroosh, H. Polarnet: An 10 improved grid representation for online lidar point clouds semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Milioto, A.; Vizzo, I.; Behley, J.; Stachniss, C. RangeNet++: Fast and accurate lidar semantic segmentation. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macao, China, 3–8 November 2019. [Google Scholar]
- Cortinhal, T.; Tzelepis, G.; Aksoy, E.E. SalsaNext: Fast semantic segmentation of lidar point clouds for autonomous driving. arXiv 2020, arXiv:2003.03653. [Google Scholar]
- Rosu, R.A.; Sch¨utt, P.; Quenzel, J.; Behnke, S. LatticeNet: Fast point cloud segmentation using permutohedral lattices. arXiv 2019, arXiv:1912.05905. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | OA | mACC | mIoU |
|---|---|---|---|
| PointNet [17] | - | 49.0 | 41.1 |
| SegCloud [12] | - | 57.4 | 48.9 |
| PointCNN [32] | 85.9 | 63.9 | 57.3 |
| SPG [9] | 86.4 | 66.5 | 58.0 |
| PCCN [33] | - | 67.0 | 58.3 |
| PointWeb [20] | 86.9 | 66.6 | 60.3 |
| ELGS [31] | 88.4 | - | 60.1 |
| MinkowskiNet20 [34] | - | 62.6 | 69.6 |
| MinkowskiNet32 [34] | - | 65.4 | 71.7 |
| BoundaryAwareGEM [30] | - | - | 61.4 |
| DPFA [23] | 87.4 | - | 53.0 |
| DPFA+BF Reg [23] | 88.0 | - | 55.2 |
| 3D GrabCut [35] | - | - | 57.7 |
| Box2Seg (AST) [35] | - | - | 60.4 |
| SSI-Net | 88.3 | 73.2 | 65.1 |
| Methods | Ceil. | Floor | Wall | Beam | Col. | Wind. | Door | Table | Chair | Sofa | Book. | Board | Clut. |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PointNet [17] | 88.8 | 97.3 | 69.8 | 0.05 | 3.9 | 46.3 | 10.8 | 52.6 | 58.9 | 40.3 | 5.9 | 26.4 | 33.2 |
| SegCloud [12] | 90.1 | 96.1 | 69.9 | 0.0 | 18.4 | 38.4 | 23.1 | 75.9 | 70.4 | 58.4 | 40.9 | 13.0 | 41.6 |
| PointCNN [32] | 92.3 | 98.2 | 79.4 | 0.0 | 17.6 | 22.8 | 62.1 | 74.4 | 80.6 | 31.7 | 66.7 | 62.1 | 56.7 |
| SPG [9] | 89.4 | 96.9 | 78.1 | 0.0 | 42.8 | 48.9 | 61.6 | 84.7 | 75.4 | 69.8 | 52.6 | 2.1 | 52.2 |
| PCCN [32] | 92.3 | 96.2 | 75.9 | 0.3 | 5.98 | 69.5 | 63.5 | 66.9 | 65.6 | 47.3 | 68.9 | 59.1 | 46.2 |
| PointWeb [20] | 92.0 | 98.5 | 79.4 | 0.0 | 21.1 | 59.9 | 34.8 | 76.3 | 88.3 | 46.9 | 69.3 | 64.9 | 52.5 |
| 3D GrabCut [35] | 80.3 | 88.7 | 69.6 | 0.0 | 28.8 | 61.0 | 35.2 | 66.5 | 71.7 | 69.2 | 69.7 | 61.7 | 48.2 |
| Box2Seg (AST) [35] | 82.0 | 92.0 | 70.8 | 0.0 | 28.8 | 61.9 | 38.1 | 71.4 | 85.3 | 74.3 | 68.4 | 63.6 | 48.0 |
| DPFA [23] | 93.7 | 98.7 | 75.5 | 0.0 | 14.5 | 50.1 | 31.8 | 73.7 | 73.4 | 13.7 | 55.5 | 57.1 | 51.2 |
| DPFA+BF Reg [23] | 93.0 | 98.6 | 80.2 | 0.0 | 14.7 | 55.8 | 42.8 | 72.3 | 73.5 | 27.3 | 55.9 | 53.0 | 50.5 |
| SSI-Net | 93.1 | 97.7 | 81.7 | 0.0 | 24.5 | 61.9 | 54.2 | 79.4 | 87.7 | 67.0 | 70.4 | 72.0 | 56.0 |
| Methods | OA | mACC | mIoU | Ceil. | Floor | Wall | Beam | Col. | Wind. | Door | Table | Chair | Sofa | Book. | Board | Clut. |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PointNet [17] | 78.6 | 66.2 | 47.6 | 88.0 | 88.7 | 69.3 | 42.4 | 23.1 | 47.5 | 51.6 | 54.1 | 42.0 | 9.6 | 38.2 | 29.4 | 35.2 |
| RSNet [36] | - | 66.5 | 56.5 | 92.5 | 92.8 | 78.6 | 32.8 | 34.4 | 51.6 | 68.1 | 59.7 | 60.1 | 16.4 | 50.2 | 44.9 | 52.0 |
| 3P-RNN [37] | 86.9 | - | 56.3 | 92.9 | 93.8 | 73.1 | 42.5 | 25.9 | 47.6 | 59.2 | 60.4 | 66.7 | 24.8 | 57.0 | 36.7 | 51.6 |
| PointCNN [32] | 88.1 | 75.6 | 65.4 | 94.8 | 97.3 | 75.8 | 63.3 | 51.7 | 58.4 | 57.2 | 71.6 | 69.1 | 39.1 | 61.2 | 52.2 | 58.6 |
| ShellNet [38] | 87.1 | - | 66.8 | 90.2 | 93.6 | 79.9 | 60.4 | 44.1 | 64.9 | 52.9 | 71.6 | 84.7 | 53.8 | 64.6 | 48.6 | 59.4 |
| PointWeb [20] | 87.3 | 76.2 | 66.7 | 93.5 | 94.2 | 80.8 | 52.4 | 41.3 | 64.9 | 68.1 | 71.4 | 67.1 | 50.3 | 62.7 | 62.2 | 58.5 |
| KPConv [39] | - | 78.1 | 69.6 | 93.7 | 92.0 | 82.5 | 62.5 | 49.5 | 65.7 | 77.3 | 57.8 | 64.0 | 68.8 | 71.7 | 60.1 | 59.6 |
| KPConv [39] | - | 79.1 | 70.6 | 93.6 | 92.4 | 83.1 | 63.9 | 54.3 | 66.1 | 76.6 | 57.8 | 64.0 | 69.3 | 74.9 | 61.3 | 60.3 |
| PointASNL [22] | 88.8 | 79.0 | 68.7 | 95.3 | 97.9 | 81.9 | 47.0 | 48.0 | 67.3 | 70.5 | 71.3 | 77.8 | 50.7 | 60.4 | 63.0 | 62.8 |
| RandLA [10] | 88.0 | 82.0 | 70.0 | 93.1 | 96.1 | 80.6 | 62.4 | 48.0 | 64.4 | 69.4 | 69.4 | 76.4 | 60.0 | 64.2 | 65.9 | 60.1 |
| SSI-Net | 88.0 | 82.3 | 70.5 | 93.7 | 96.8 | 80.1 | 61.9 | 44.0 | 65.0 | 69.7 | 72.8 | 74.6 | 67.6 | 63.2 | 66.0 | 60.6 |
| Testing Area | OA | mACC | mIoU | Ceil. | Floor | Wall | Beam | Col. | Wind. | Door | Table | Chair | Sofa | Book. | Board | Clut. |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Area1 | 89.2 | 75.7 | 87.6 | 96.3 | 95.1 | 77.1 | 54.3 | 51.9 | 80.1 | 83.4 | 73.3 | 81.4 | 76.5 | 62.8 | 70.4 | 67.7 |
| Area2 | 84.2 | 55.4 | 70.8 | 89.0 | 95.5 | 76.8 | 21.4 | 26.6 | 52.2 | 64.6 | 49.8 | 60.3 | 56.0 | 50.0 | 28.3 | 49.8 |
| Area3 | 91.1 | 79.2 | 89.4 | 95.7 | 98.2 | 81.4 | 70.2 | 33.3 | 82.1 | 88.5 | 74.7 | 84.8 | 85.0 | 74.5 | 88.6 | 73.0 |
| Area4 | 85.1 | 62.1 | 76.6 | 94.1 | 97.0 | 77.8 | 39.9 | 48.8 | 31.8 | 60.5 | 68.6 | 77.7 | 65.5 | 46.1 | 39.7 | 60.0 |
| Area5 | 88.3 | 65.1 | 73.2 | 93.1 | 97.7 | 81.7 | 0.0 | 24.5 | 61.9 | 54.2 | 79.4 | 87.7 | 67.0 | 70.4 | 72.0 | 56.0 |
| Area6 | 91.9 | 80.0 | 92.2 | 96.7 | 97.5 | 84.4 | 82.0 | 72.0 | 80.9 | 86.4 | 75.9 | 84.2 | 62.1 | 72.4 | 75.1 | 70.8 |
| Methods | mIoU | Road | Sidewalk | Parking | Other-ground | Building | Car | Truck | Bicycle | Motorcycle | Other-Vehicle | Vegetation | Trunk | Terrain | Person | Bicyclist | Motorcyclist | Fence | Pole | Traffic-sign |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PointNet [17] | 14.6 | 61.6 | 35.7 | 15.8 | 1.4 | 41.4 | 46.3 | 0.1 | 1.3 | 0.3 | 0.8 | 31.0 | 4.6 | 17.6 | 0.2 | 0.2 | 0.0 | 12.9 | 2.4 | 3.7 |
| SPG [9] | 17.4 | 45.0 | 28.5 | 0.6 | 0.6 | 64.3 | 49.3 | 0.1 | 0.2 | 0.2 | 0.8 | 48.9 | 27.2 | 24.6 | 0.3 | 2.7 | 0.1 | 20.8 | 15.9 | 0.8 |
| SPLATNet [40] | 18.4 | 64.6 | 39.1 | 0.4 | 0.0 | 58.3 | 58.2 | 0.0 | 0.0 | 0.0 | 0.0 | 71.1 | 9.9 | 19.3 | 0.0 | 0.0 | 0.0 | 23.1 | 5.6 | 0.0 |
| PointNet++ [18] | 20.1 | 72.0 | 41.8 | 18.7 | 5.6 | 62.3 | 53.7 | 0.9 | 1.9 | 0.2 | 0.2 | 46.5 | 13.8 | 30.0 | 0.9 | 1.0 | 0.0 | 16.9 | 6.0 | 8.9 |
| TangentConv [41] | 40.9 | 83.9 | 63.9 | 33.4 | 15.4 | 83.4 | 90.8 | 15.2 | 2.7 | 16.5 | 12.1 | 79.5 | 49.3 | 58.1 | 23.0 | 28.4 | 8.1 | 49.0 | 35.8 | 28.5 |
| SqueezeSeg [42] | 29.5 | 85.4 | 54.3 | 26.9 | 4.5 | 57.4 | 68.8 | 3.3 | 16.0 | 4.1 | 3.6 | 60.0 | 24.3 | 53.7 | 12.9 | 13.1 | 0.9 | 29.9 | 17.5 | 24.5 |
| SqueezeSegV2 [43] | 39.7 | 88.6 | 67.6 | 45.8 | 17.7 | 73.7 | 81.8 | 13.4 | 18.5 | 17.9 | 14.0 | 71.8 | 35.8 | 60.2 | 20.1 | 25.1 | 3.9 | 41.1 | 20.2 | 36.3 |
| DarkNet21Seg [44] | 47.4 | 91.4 | 74.0 | 57.0 | 26.4 | 81.9 | 85.4 | 18.6 | 26.2 | 26.5 | 15.6 | 77.6 | 48.4 | 63.6 | 31.8 | 33.6 | 4.0 | 52.3 | 36.0 | 50.0 |
| DarkNet53Seg [44] | 49.9 | 91.8 | 74.6 | 64.8 | 27.9 | 84.1 | 86.4 | 25.5 | 24.5 | 32.7 | 22.6 | 78.3 | 50.1 | 64.0 | 36.2 | 33.6 | 4.7 | 55.0 | 38.9 | 52.2 |
| RangeNet53++ [46] | 52.2 | 91.8 | 75.2 | 65.0 | 27.8 | 87.4 | 91.4 | 25.7 | 25.7 | 34.4 | 23.0 | 80.5 | 55.1 | 64.6 | 38.3 | 38.8 | 4.8 | 58.6 | 47.9 | 55.9 |
| SalsaNext [47] | 54.5 | 90.9 | 74.0 | 58.1 | 27.8 | 87.9 | 90.9 | 21.7 | 36.4 | 29.5 | 19.9 | 81.8 | 61.7 | 66.3 | 52.0 | 52.7 | 16.0 | 58.2 | 51.7 | 58.0 |
| LatticeNet [48] | 52.2 | 88.8 | 73.8 | 64.6 | 25.6 | 86.9 | 88.6 | 43.4 | 12.0 | 20.8 | 24.8 | 76.4 | 57.9 | 54.7 | 34.2 | 39.9 | 60.9 | 55.2 | 41.5 | 42.7 |
| PointASNL [22] | 46.8 | 87.4 | 74.3 | 24.3 | 1.8 | 83.1 | 87.9 | 39.0 | 0.0 | 25.1 | 29.2 | 84.1 | 52.2 | 70.6 | 34.2 | 57.6 | 0.0 | 43.9 | 57.8 | 36.9 |
| RandLA-Net [10] | 53.9 | 90.7 | 73.7 | 60.3 | 20.4 | 86.9 | 94.2 | 40.1 | 26.0 | 25.8 | 38.9 | 81.4 | 61.3 | 66.8 | 49.2 | 48.2 | 7.2 | 56.3 | 49.2 | 47.7 |
| PolarNet [45] | 54.3 | 90.8 | 74.4 | 61.7 | 21.7 | 90.0 | 93.8 | 22.9 | 40.3 | 30.1 | 28.5 | 84.0 | 65.5 | 67.8 | 43.2 | 40.2 | 5.6 | 67.8 | 51.8 | 57.5 |
| MVP-Net [28] | 53.9 | 91.4 | 75.9 | 61.4 | 25.6 | 85.8 | 92.7 | 20.2 | 37.2 | 17.7 | 13.8 | 83.2 | 64.5 | 69.3 | 50.0 | 55.8 | 12.9 | 55.2 | 51.8 | 59.2 |
| SSI-Net | 55.4 | 92.2 | 12.9 | 36.9 | 72.0 | 27.8 | 55.0 | 66.4 | 0.0 | 92.9 | 42.2 | 79.6 | 0.8 | 89.5 | 54.2 | 86.8 | 66.0 | 76.1 | 58.6 | 41.9 |
| S3DIS | SemanticKITTI | |||
|---|---|---|---|---|
| Methods | OA | mACC | mIoU | mIoU |
| Removing semantic-aware information | 86.1 | 72.2 | 63.6 | 53.8 |
| Removing attentional semantic block | 85.2 | 71.8 | 61.9 | 51.7 |
| Max operation | 86.7 | 73.0 | 63.1 | 52.9 |
| With full units | 88.3 | 73.2 | 65.1 | 55.4 |
| S3DIS | SemanticKITTI | |
|---|---|---|
| Methods | mIoU | mIoU |
| (1) | 63.5 | 52.0 |
| (2) | 65.0 | 53.1 |
| (3) | 63.4 | 54.0 |
| (4) | 65.1 | 55.4 |
| Samplings | mIoU | Ceil. | Floor | Wall | Beam | Col. | Wind. | Door | Table | Chair | Sofa | Book. | Board | Clut. |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Farthest Point Sampling (FPS) | 65.2 | 93.9 | 97.5 | 82.0 | 0.0 | 30.2 | 62.2 | 48.9 | 80.4 | 87.4 | 62.5 | 72.4 | 72.5 | 57.4 |
| Random Sampling (RS) | 65.1 | 93.1 | 97.7 | 81.7 | 0.0 | 24.5 | 61.9 | 54.2 | 79.4 | 87.7 | 67.0 | 70.4 | 72.0 | 56.0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, Y.; Zhang, J.; Ma, J.; Xu, S. Large-Scale Semantic Scene Understanding with Cross-Correction Representation. Remote Sens. 2022, 14, 6022. https://doi.org/10.3390/rs14236022
Zhao Y, Zhang J, Ma J, Xu S. Large-Scale Semantic Scene Understanding with Cross-Correction Representation. Remote Sensing. 2022; 14(23):6022. https://doi.org/10.3390/rs14236022
Chicago/Turabian StyleZhao, Yuehua, Jiguang Zhang, Jie Ma, and Shibiao Xu. 2022. "Large-Scale Semantic Scene Understanding with Cross-Correction Representation" Remote Sensing 14, no. 23: 6022. https://doi.org/10.3390/rs14236022
APA StyleZhao, Y., Zhang, J., Ma, J., & Xu, S. (2022). Large-Scale Semantic Scene Understanding with Cross-Correction Representation. Remote Sensing, 14(23), 6022. https://doi.org/10.3390/rs14236022