



An Integrated Method for River Water Level Recognition from Surveillance Images Using Convolution Neural Networks

 ,
, 

Abstract
:1. Introduction
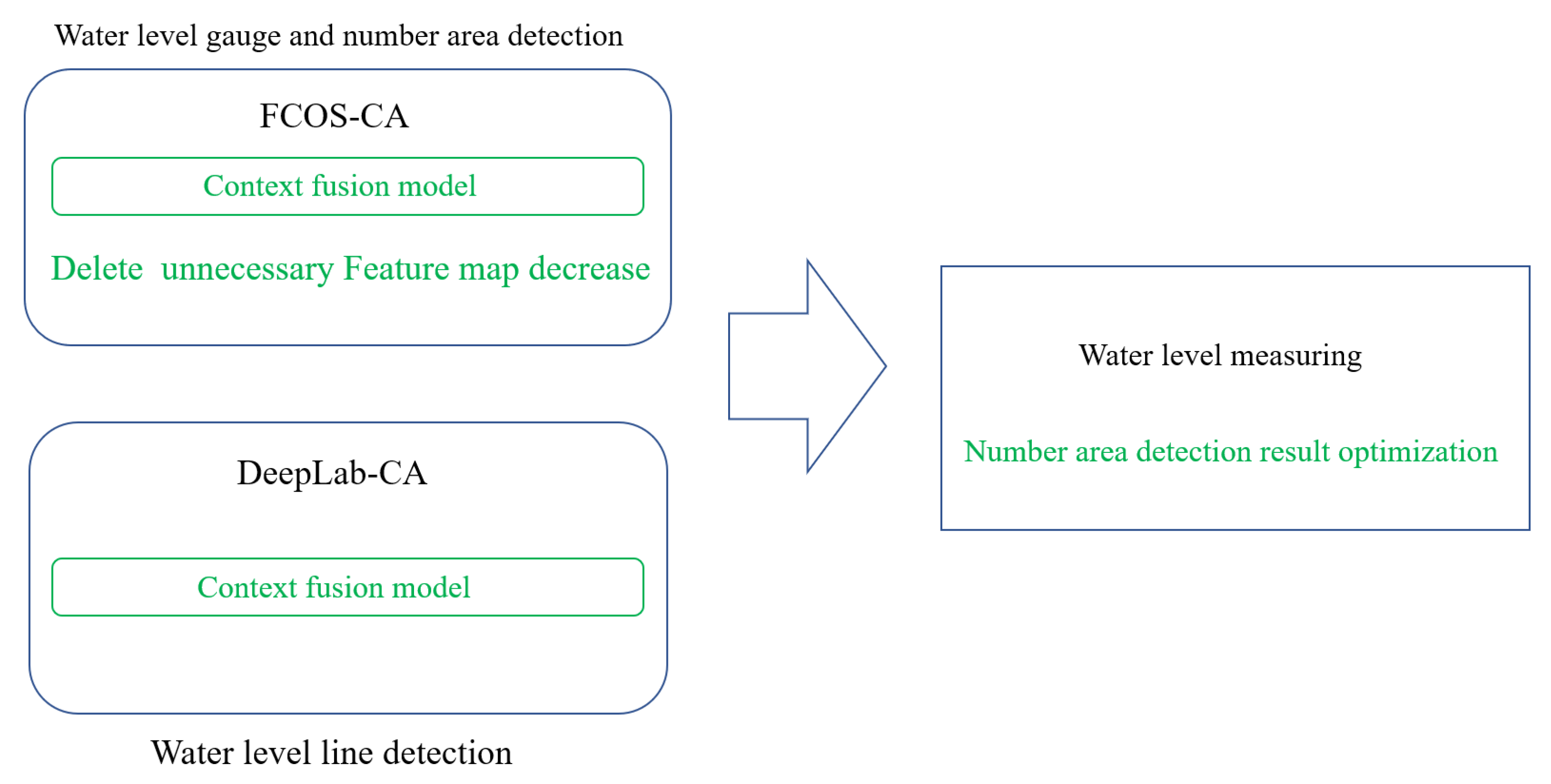
- In order to measure the water level in water gauge images in complex scenes, this article proposes a composite method that can accurately obtain the water level.
- In order to get the position of the water level line, this paper proposes an innovative module that divides features into different levels. This module first obtains high-level segmentation results and then gradually fuses them downward.
- Water gauge images of actual scenes and seven special scenes are used to evaluate the method proposed in this article.
2. Related Work
2.1. Physical Equipment for Water Level Recognition
2.2. Image-Based Water Level Recognition
2.3. Object Detection and Semantic Segmentation
3. Methodology and Raw Data
3.1. Key Steps for Water Level Recognition
3.2. Water Gauge and Gauge Number Detection
3.3. Water Gauge Area Segmentation
3.4. Water Level Recognition
3.4.1. Water Level Line Extraction
3.4.2. Water Level Measurement
3.5. Dataset
4. Experiments and Results
4.1. Evaluation Metrics
- Precision and Recall. These two indicators consist of four base indicators, namely TP, TN, FP, and FN. ‘T’ means true, ‘F’ means false, and the second character means the predicted result: ‘P’ and ‘N’, respectively, are positive and negative. For example, TP represents a positive sample predicted as a positive sample. Precision and recall are calculated as in the equations below. Meanwhile, in order to consider the evaluation of these two metrics together, these two metrics can be used in order to draw a PR curve. The vertical coordinate is the accuracy of detection, and the horizontal coordinate is the recall; then, the area enclosed by the PR curve and the coordinate axis can be used as a new measurement. For a single target, this metric is called the average accuracy. For multiple targets, the average of the AP of each category is represented as mAP.
- Per-pixel acc. is used to indicate the accuracy of the prediction, expressed by the ratio of the count of pixels segmented correctly to all the pixels counted. For different pixel types (represented by i), means the count of accurate predictions of i-type pixels, and means the i-type pixels predicted as categories. It is easy to obtain the expression of the overall accuracy as follows:
4.2. Experiment and Analysis
4.2.1. Water Gauge Detection Experiment
4.2.2. Water Gauge Segmentation Experiment
4.2.3. Water Level Measurement Experiment
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wu, W.; Emerton, R.; Duan, Q.; Wood, A.W.; Wetterhall, F.; Robertson, D.E. Ensemble flood forecasting: Current status and future opportunities. Wiley Interdiscip. Rev. Water 2020, 7, e1432. [Google Scholar] [CrossRef]
- Sunkpho, J.; Ootamakorn, C. Real-time flood monitoring and warning system. Songklanakarin J. Sci. Technol. 2011, 33, 227–235. [Google Scholar]
- Sulistyowati, R.; Sujono, H.A.; Musthofa, A.K. Design and field test equipment of river water level detection based on ultrasonic sensor and SMS gateway as flood early warning. AIP Conf. Proc. 2017, 1855, 50003. [Google Scholar]
- Zhao, M.; Chen, C.; Liu, L.; Lan, D.; Wan, S. Orbital collaborative learning in 6G space-air-ground integrated networks. Neurocomputing 2022, 497, 94–109. [Google Scholar] [CrossRef]
- Taylor, C.J. Ground-Water-Level Monitoring and the Importance of Long-Term Water-Level Data; US Geological Survey: Denver, CO, USA, 2001. [Google Scholar]
- Hernández-Nolasco, J.A.; Ovando, M.A.W.; Acosta, F.D.; Pancardo, P. Water level meter for alerting population about floods. In Proceedings of the 2016 IEEE 30th International Conference on Advanced Information Networking and Applications (AINA), Crans-Montana, Switzerland, 23–25 March 2016; pp. 879–884. [Google Scholar]
- Ministry of Water Resources of People’s Republic of China. Standard Stage Observation; Ministry of Water Resources of People’s Republic of China: Beijing, China, 2010. [Google Scholar]
- Chen, C.; Ma, H.; Yao, G.; Lv, N.; Yang, H.; Li, C.; Wan, S. Remote sensing image augmentation based on text description for waterside change detection. Remote Sens. 2021, 13, 1894. [Google Scholar] [CrossRef]
- Zhong, Z. Method of water level data capturing based on video image recognition. Foreign Electron. Meas. Technol. 2017, 1, 48–51. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision & Pattern Recognition, San Diego, CA, USA, 20–25 June 2005. [Google Scholar]
- Jakkula, V. Tutorial on support vector machine (svm). Sch. Eecs, Wash. State Univ. 2006, 37, 3. [Google Scholar]
- Mori, S.; Suen, C.Y.; Yamamoto, K. Historical Review of OCR Research and Development; IEEE Computer Society Press: Washington, DC, USA, 1995. [Google Scholar]
- Sabbatini, L.; Palma, L.; Belli, A.; Sini, F.; Pierleoni, P. A Computer Vision System for Staff Gauge in River Flood Monitoring. Inventions 2021, 6, 79. [Google Scholar] [CrossRef]
- Viola, P.; Jones, M.J. Robust Real-time Object Detection. Int. J. Comput. Vis. 2001, 57, 87. [Google Scholar]
- Felzenszwalb, P.F.; Girshick, R.S.; McAllester, D.; Ramanan, D. Object Detection with Discriminatively Trained Part-Based Models. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1627–1645. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 1, 2999–3007. [Google Scholar]
- Bojarski, M.; Del Testa, D.; Dworakowski, D.; Firner, B.; Flepp, B.; Goyal, P.; Jackel, L.D.; Monfort, M.; Muller, U.; Zhang, J.; et al. End to end learning for self-driving cars. arXiv 2016, arXiv:1604.07316. [Google Scholar]
- Xu, Z.; Sun, Y.; Liu, M. iCurb: Imitation Learning-based Detection of Road Curbs using Aerial Images for Autonomous Driving. IEEE Robot. Autom. Lett. 2021, 6, 1097–1104. [Google Scholar] [CrossRef]
- Wu, Y.; Feng, S.; Huang, X.; Wu, Z. L4Net: An anchor-free generic object detector with attention mechanism for autonomous driving. IET Comput. Vis. 2021, 15, 36–46. [Google Scholar] [CrossRef]
- Schroff, F.; Kalenichenko, D.; Philbin, J. Facenet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar]
- Jung, J.; Lee, S.; Oh, H.S.; Park, Y.; Park, J.; Son, S. Unified Negative Pair Generation toward Well-discriminative Feature Space for Face Recognition. arXiv 2022, arXiv:2203.11593. [Google Scholar]
- Ying, L. Design of attendance system based on face recognition. Electron. Test 2020, 1, 117–121. [Google Scholar]
- Camps-Valls, G.; Tuia, D.; Zhu, X.X.; Reichstein, M. Deep Learning for the Earth Sciences: A Comprehensive Approach to Remote Sensing, Climate Science and Geosciences; John Wiley & Sons: Hoboken, NJ, USA, 2021. [Google Scholar]
- Albawi, S.; Mohammed, T.A.; Al-Zawi, S. Understanding of a convolutional neural network. In Proceedings of the 2017 International Conference on Engineering and Technology (ICET), Antalya, Turkey, 21–23 August 2017; pp. 1–6. [Google Scholar]
- Yu, Y.; Samali, B.; Rashidi, M.; Mohammadi, M.; Nguyen, T.N.; Zhang, G. Vision-based concrete crack detection using a hybrid framework considering noise effect. J. Build. Eng. 2022, 61, 105246. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. ImageNet Classification with Deep Convolutional Neural Networks. In Advances in Neural Information Processing Systems 25; Curran Associates Inc.: Red Hook, NY, USA, 2012. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef] [Green Version]
- Chauhan, R.; Ghanshala, K.K.; Joshi, R. Convolutional neural network (CNN) for image detection and recognition. In Proceedings of the 2018 First International Conference on Secure Cyber Computing and Communication (ICSCCC), Jalandhar, India, 15–17 December 2018; pp. 278–282. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. arXiv 2013, arXiv:1311.2524. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Xu, Z.; Feng, J.; Zhang, Z.; Duan, C. Water level estimation based on image of staff gauge in smart city. In Proceedings of the 2018 IEEE SmartWorld, Ubiquitous Intelligence & Computing, Advanced & Trusted Computing, Scalable Computing & Communications, Cloud & Big Data Computing, Internet of People and Smart City Innovation (SmartWorld/SCALCOM/UIC/ATC/CBDCom/IOP/SCI), Guangzhou, China, 8–12 October 2018; pp. 1341–1345. [Google Scholar]
- Dou, G.; Chen, R.; Han, C.; Liu, Z.; Liu, J. Research on water-level recognition method based on image processing and convolutional neural networks. Water 2022, 14, 1890. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39, 640–651. [Google Scholar]
- Liu, Y.; Xie, Z.; Liu, H. LB-LSD: A length-based line segment detector for real-time applications. Pattern Recognit. Lett. 2019, 128. [Google Scholar] [CrossRef]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully Convolutional One-Stage Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation; Springer: Cham, Switzerland, 2018. [Google Scholar]
- Karamouz, M.; Zahmatkesh, Z.; Saad, T. Cloud Computing in Urban Flood Disaster Management. In Proceedings of the World Environmental & Water Resources Congress, Cincinnati, OH, USA, 19–23 May 2013; pp. 2747–2757. [Google Scholar]
- Fan, Y.; He, H.; Bo, L.; Ming, L. Research on Flood Disaster Extent Dynamics Monitoring Using HJ-1 CCD—A Case Study in Fuyuan of Heilongjiang Province, Northestern China. Remote Sens. Technol. Appl. 2016, 31, 102–108. [Google Scholar]
- Shafiai, S. Flood Disaster Management in Malaysia: A Review of Issues of Flood Disaster Relief during and Post-Disaster. In Proceedings of the ISSC 2016 International Conference on Soft Science, Kedah, Malaysia, 11–13 April 2016. [Google Scholar]
- Abe, K. Frequency response of pressure type water level meter. Bull. Nippon. Dent. Univ. Gen. Educ. 2001, 30, 49–56. [Google Scholar]
- Tang, X.; Liu, Y.; Shang, X. The Research On Low Power and High Accuracy Ultrasonic Water Level Meter. Hydropower Autom. Dam Monit. 2014, 1, 1. [Google Scholar]
- Zhen, Z.; Yang, Z.; Yuchou, L.; Youjie, Y.; Xurui, L. IP camera-based LSPIV system for on-line monitoring of river flow. In Proceedings of the 2017 13th IEEE International Conference on Electronic Measurement & Instruments (ICEMI), Yangzhou, China, 20–22 October 2017; pp. 357–363. [Google Scholar]
- Lin, Y.T.; Lin, Y.C.; Han, J.Y. Automatic water-level detection using single-camera images with varied poses. Measurement 2018, 127, 167–174. [Google Scholar] [CrossRef]
- Huang, Z.; Xiong, H.; Zhu, M.; Cai, H. Embedded Measurement System and Interpretation Algorithm for Water Gauge Image. Opto-Electron. Eng. 2013, 40, 1–7. [Google Scholar]
- Lin, R.F.; Hai, X.U. Automatic measurement method for canals water level based on imaging sensor. Transducer Microsyst. Technol. 2013, 32, 53–55. [Google Scholar]
- Bruinink, M.; Chandarr, A.; Rudinac, M.; Overloop, P.; Jonker, P. Portable, automatic water level estimation using mobile phone cameras. In Proceedings of the 2015 14th IAPR International Conference on Machine Vision Applications (MVA), Tokyo, Japan, 18–22 May 2015. [Google Scholar]
- Leduc, P.; Ashmore, P.; Sjogren, D. Technical note: Stage and water width measurement of a mountain stream using a simple time-lapse camera. Hydrol. Earth Syst. Sci. Discuss. 2018, 22, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Liu, Q.; Chu, B.; Peng, J.; Tang, S. A Visual Measurement of Water Content of Crude Oil Based on Image Grayscale Accumulated Value Difference. Sensors 2019, 19, 2963. [Google Scholar] [CrossRef] [Green Version]
- Gilmore, T.E.; Birgand, F.; Chapman, K.W. Source and magnitude of error in an inexpensive image-based water level measurement system. J. Hydrol. 2013, 496, 178–186. [Google Scholar] [CrossRef] [Green Version]
- Young, D.S.; Hart, J.K.; Martinez, K. Image analysis techniques to estimate river discharge using time-lapse cameras in remote locations. Comput. Geosci. 2015, 76, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Z.; Zhou, Y.; Wang, H.; Gao, H.; Liu, H. Image-based water level measurement with standard bicolor staff gauge. Yi Qi Yi Biao Xue Bao/Chin. J. Sci. Instrum. 2018, 39, 236–245. [Google Scholar]
- Jiang, X.Y.; Hua, Z.J. Water-Level auto reading based on image processing. Electron. Des. Eng. 2011, 19, 23–25. [Google Scholar]
- Law, H.; Deng, J. Cornernet: Detecting objects as paired keypoints. In Proceedings of the European conference on computer vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 734–750. [Google Scholar]
- Lv, N.; Han, Z.; Chen, C.; Feng, Y.; Su, T.; Goudos, S.; Wan, S. Encoding Spectral-Spatial Features for Hyperspectral Image Classification in the Satellite Internet of Things System. Remote Sens. 2021, 13, 3561. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015; Springer International Publishing: Cham, Switzerland, 2015. [Google Scholar]
- Lv, N.; Ma, H.; Chen, C.; Pei, Q.; Zhou, Y.; Xiao, F.; Li, J. Remote sensing data augmentation through adversarial training. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2021, 14, 9318–9333. [Google Scholar] [CrossRef]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [Green Version]
- Hu, J.; Chen, C.; Cai, L.; Khosravi, M.R.; Pei, Q.; Wan, S. UAV-assisted vehicular edge computing for the 6G internet of vehicles: Architecture, intelligence, and challenges. IEEE Commun. Stand. Mag. 2021, 5, 12–18. [Google Scholar] [CrossRef]
- Chen, C.; Zeng, Y.; Li, H.; Liu, Y.; Wan, S. A Multi-hop Task Offloading Decision Model in MEC-enabled Internet of Vehicles. IEEE Internet Things J. 2022. [Google Scholar] [CrossRef]
- Ma, X.; Li, X.; Tang, X.; Zhang, B.; Yao, R.; Lu, J. Deconvolution Feature Fusion for traffic signs detection in 5G driven unmanned vehicle. Phys. Commun. 2021, 47, 101375. [Google Scholar] [CrossRef]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the IEEE Conference on Computer Vision & Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Park, T.; Liu, M.Y.; Wang, T.C.; Zhu, J.Y. Semantic Image Synthesis With Spatially-Adaptive Normalization. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Yu, J.; Lin, Z.; Yang, J.; Shen, X.; Lu, X.; Huang, T.S. Generative Image Inpainting with Contextual Attention. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. arXiv 2016, arXiv:1612.01105. [Google Scholar]
- Lin, G.; Milan, A.; Shen, C.; Reid, I. RefineNet: Multi-path Refinement Networks for High-Resolution Semantic Segmentation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Lin, T.Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic image segmentation with deep convolutional nets and fully connected crfs. arXiv 2014, arXiv:1412.7062. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Chen, C.; Jiang, J.; Zhou, Y.; Lv, N.; Liang, X.; Wan, S. An edge intelligence empowered flooding process prediction using Internet of things in smart city. J. Parallel Distrib. Comput. 2022, 165, 66–78. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Water Level Type | Advantage | Disadvantage |
|---|---|---|
| Float-type | High measurement accuracy and large measurement range | Installation difficulty and bad flood performance |
| Pressure-type | Easy installation | Can only be used in calm water bodies |
| Ultrasonic-type | Easy installation, good performance in complex environments | Accuracy is impacted by environment |
| Radar-type | Good performance in complex environments | High cost |
| Laser-type | High accuracy and stability | High cost and installation difficulty |
| Model | Precision (%) | Recall (%) | mAP (%) |
|---|---|---|---|
| SSD | 77% | 72% | 75% |
| YOLOv3 | 78% | 74% | 77% |
| FCOS | 91% | 85% | 87% |
| FCOS-CA | 93% | 86% | 89% |
| Model | Pixel Acc (%) | mIOU (%) | Inference Time (s) |
|---|---|---|---|
| FCN | 72% | 75% | 0.23 |
| Unet++ | 85% | 78% | 0.15 |
| DeepLabv3+ | 91% | 82% | 0.13 |
| DeepLab-CA | 93% | 85% | 0.17 |
| Error Range | X < 0.5 | 0.5 < X < 1 | 1 < X < 2 | X > 2 |
|---|---|---|---|---|
| Sample proportion | 35% | 28% | 27% | 10% |
| Error Range | A | B | C | D | E | F | H |
|---|---|---|---|---|---|---|---|
| Manual recognition (cm) | 11.80 | 30.50 | 35.00 | 36.90 | 65.30 | 78.80 | 58.90 |
| Algorithm recognition (cm) | 11.21 | 31.77 | 34.53 | 38.53 | 65.87 | 78.58 | 58.38 |
| Error (cm) | 0.61 | 1.27 | 0.47 | 1.63 | 0.57 | 0.22 | 0.52 |
| Error Range | Manual (cm) | Algorithm (cm) | Error (cm) |
|---|---|---|---|
| Reversed reflection | 34.50 | 34.46 | 0.04 |
| Backlighting | 47.00 | 46.73 | 0.27 |
| Nighttime fill light | 32.50 | 32.07 | 0.43 |
| Wind and waves | 30.50 | 29.80 | 0.70 |
| Soiling | 27.00 | 26.00 | 1.00 |
| Water transparency | 77.00 | 75.90 | 1.11 |
| Sun shadow | 5.00 | 4.70 | 0.30 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, C.; Fu, R.; Ai, X.; Huang, C.; Cong, L.; Li, X.; Jiang, J.; Pei, Q. An Integrated Method for River Water Level Recognition from Surveillance Images Using Convolution Neural Networks. Remote Sens. 2022, 14, 6023. https://doi.org/10.3390/rs14236023
Chen C, Fu R, Ai X, Huang C, Cong L, Li X, Jiang J, Pei Q. An Integrated Method for River Water Level Recognition from Surveillance Images Using Convolution Neural Networks. Remote Sensing. 2022; 14(23):6023. https://doi.org/10.3390/rs14236023
Chicago/Turabian StyleChen, Chen, Rufei Fu, Xiaojian Ai, Chengbin Huang, Li Cong, Xiaohuan Li, Jiange Jiang, and Qingqi Pei. 2022. "An Integrated Method for River Water Level Recognition from Surveillance Images Using Convolution Neural Networks" Remote Sensing 14, no. 23: 6023. https://doi.org/10.3390/rs14236023
APA StyleChen, C., Fu, R., Ai, X., Huang, C., Cong, L., Li, X., Jiang, J., & Pei, Q. (2022). An Integrated Method for River Water Level Recognition from Surveillance Images Using Convolution Neural Networks. Remote Sensing, 14(23), 6023. https://doi.org/10.3390/rs14236023