
Object Counting in Remote Sensing via Triple Attention and Scale-Aware Network




Abstract
:1. Introduction
- A triple attention scale-aware network (TASNet) is built in a divide-and-conquer manner to address the problem of background clutter and scale variation for object counting in remote sensing images.
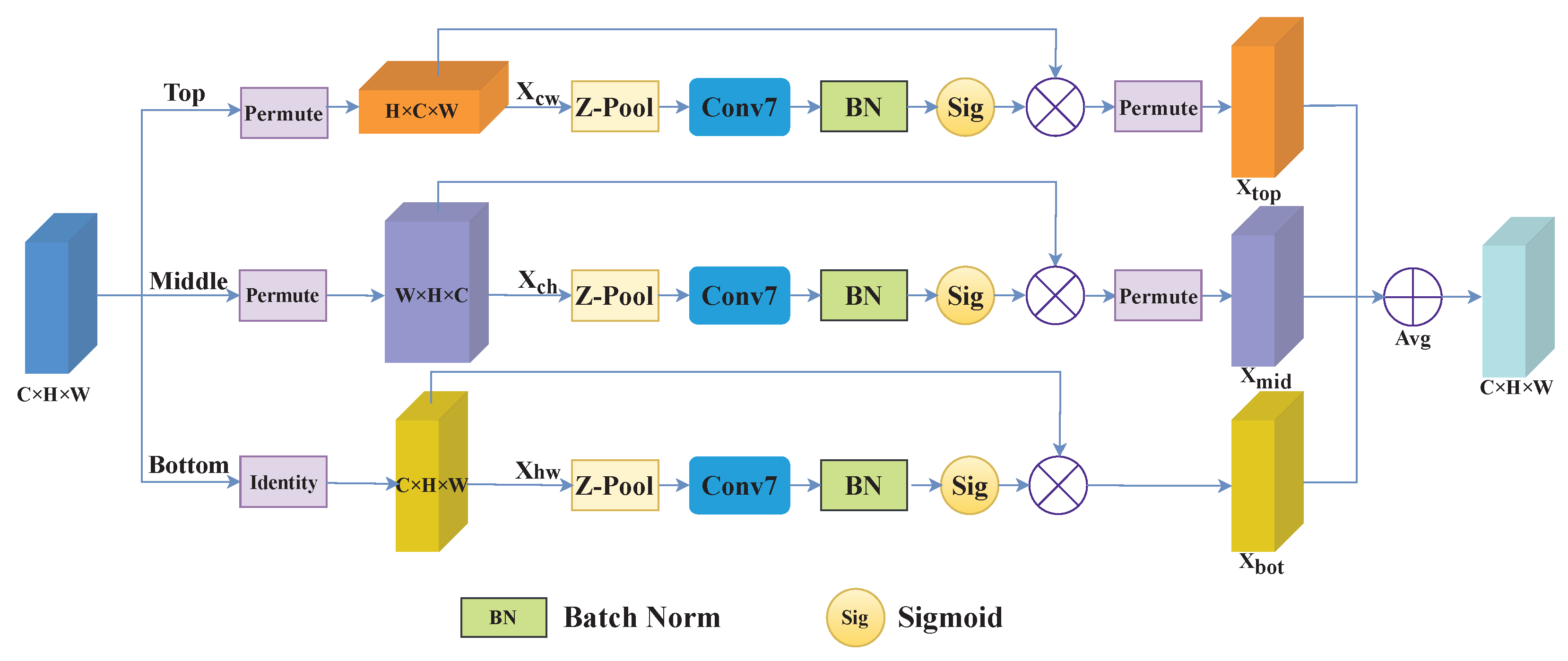
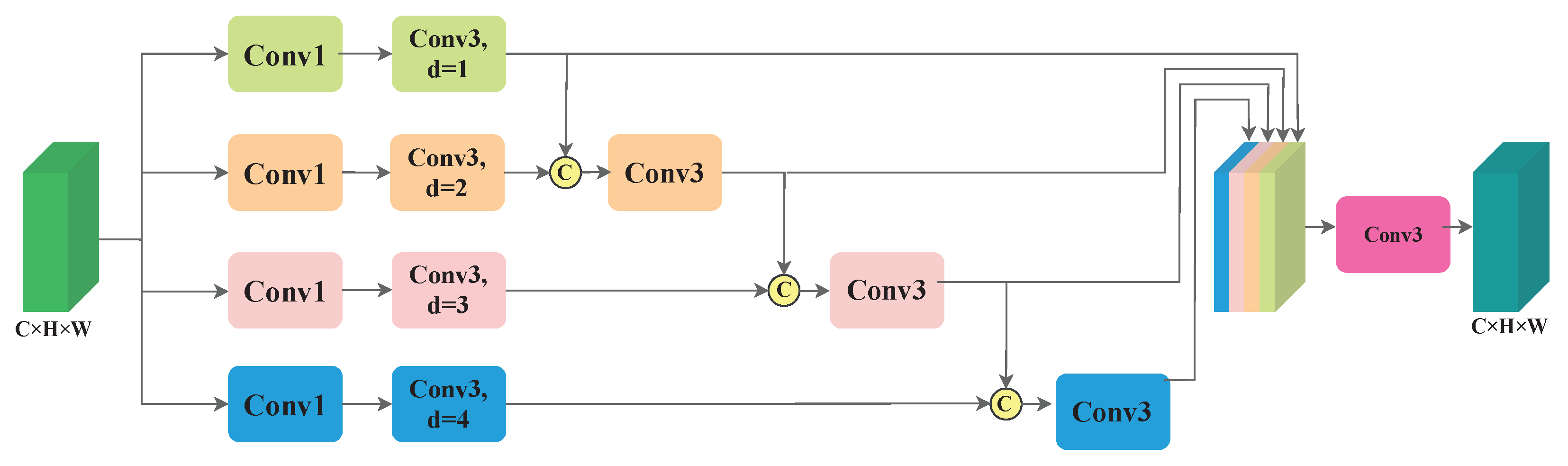
- A TVA module, which executes attention operations on features in three views, is built to deal with the background clutter. A PFA module adopting a four-branch architecture is proposed to capture multiscale information.
- Extensive experiments are carried out to verify the performance of object counting in challenging remote sensing scenarios. Meanwhile, detailed ablation studies are conducted to prove the effectiveness of the different compound modes, backbone networks and the multiscale feature fusion mechanisms within the proposed model.
2. Related Literature
2.1. Solutions for Background Clutter
2.2. Solutions for Scale Variation
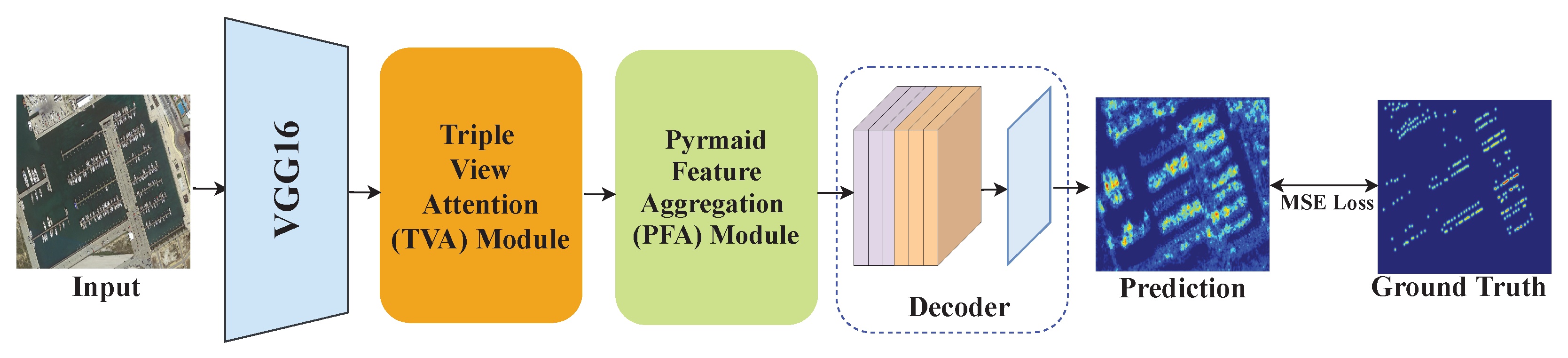
3. Methodology
3.1. Network Architecture
3.2. TVA Module
3.3. PFA Module
3.4. Density Map Generation
3.5. Loss Function
4. Experiments
4.1. Datasets
4.2. Implementation Details
4.3. Evaluation Protocols
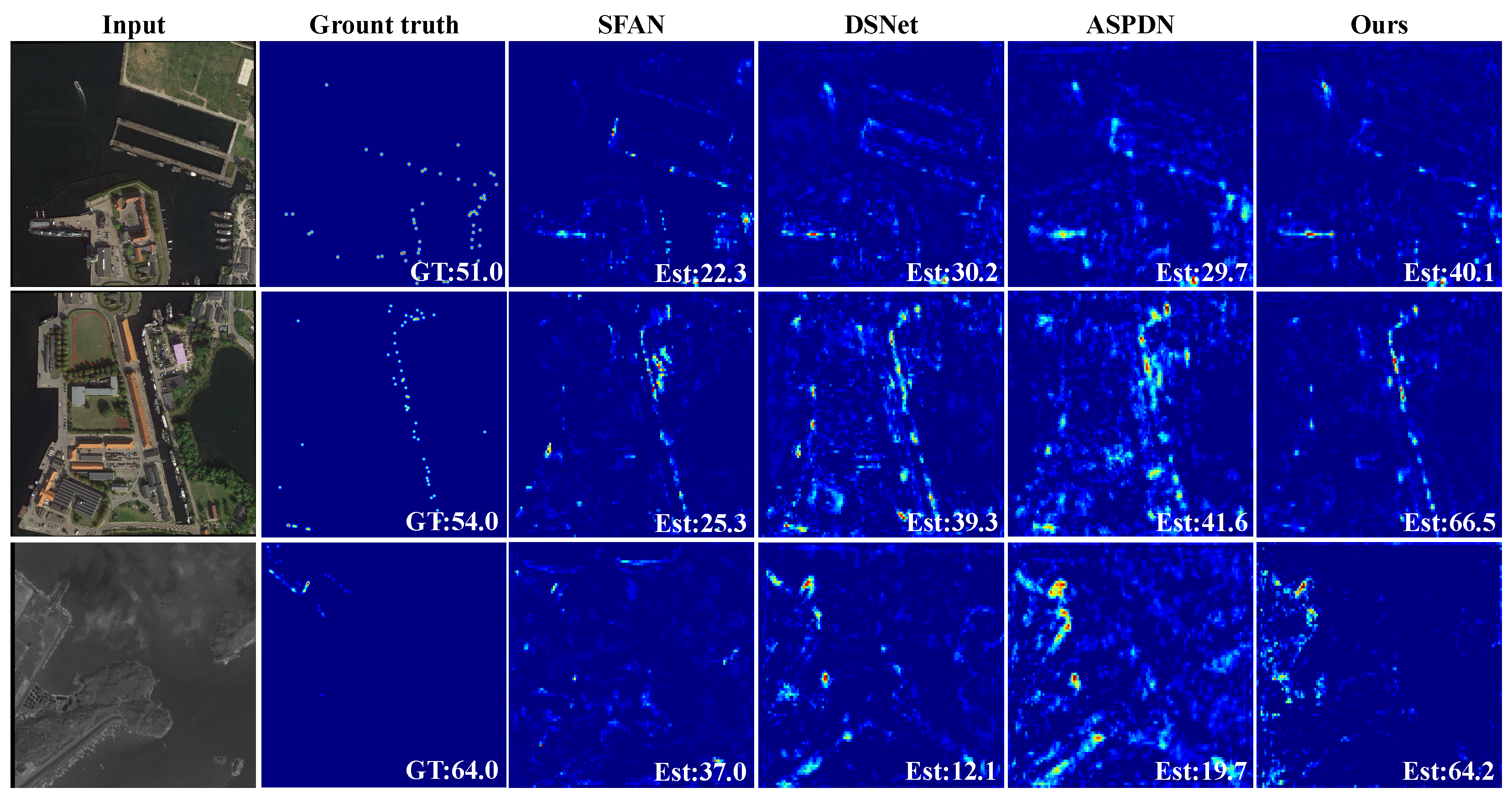
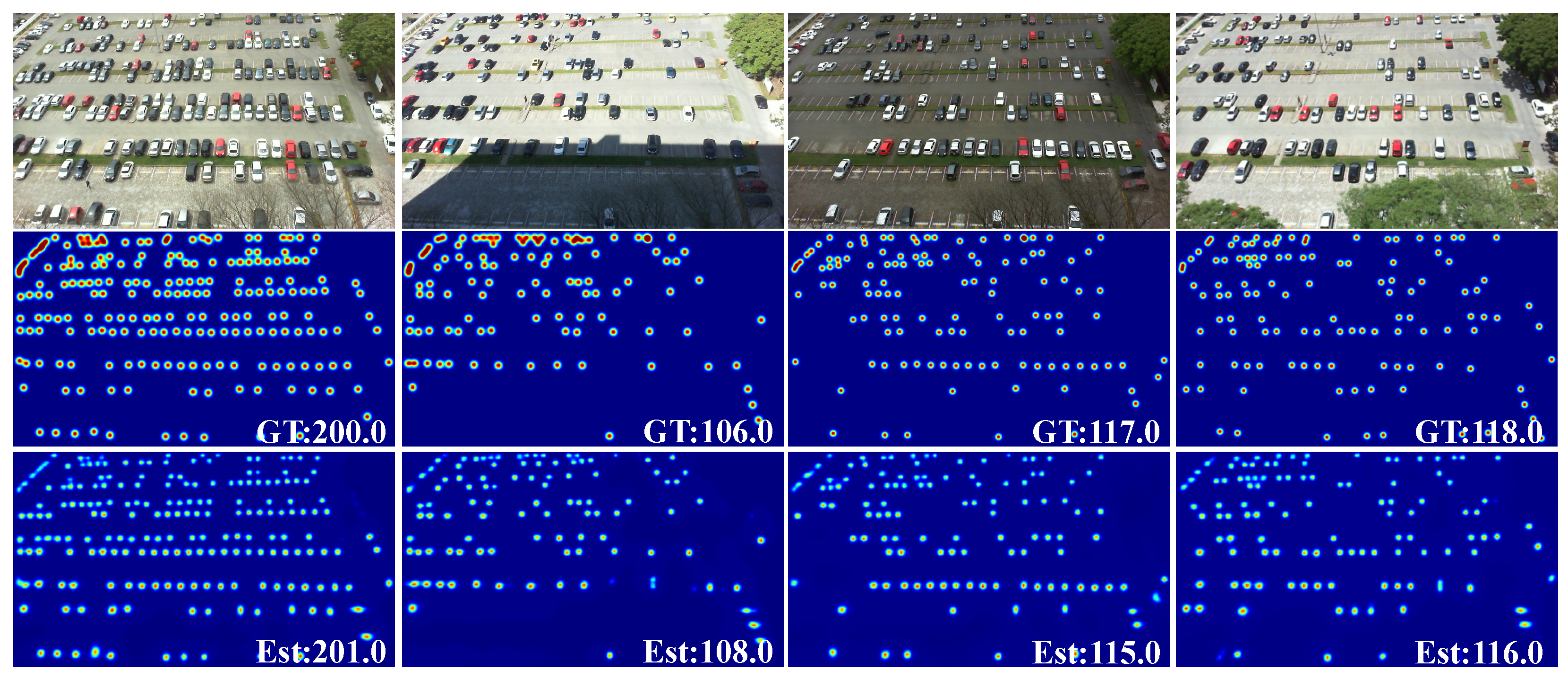
4.4. Experiments on the RSOC Dataset
4.5. Experiments on the CARPK Dataset
4.6. Experiments on the PUCPR+ Dataset
4.7. Ablation Studies
4.7.1. Ablation Studies on the Modules
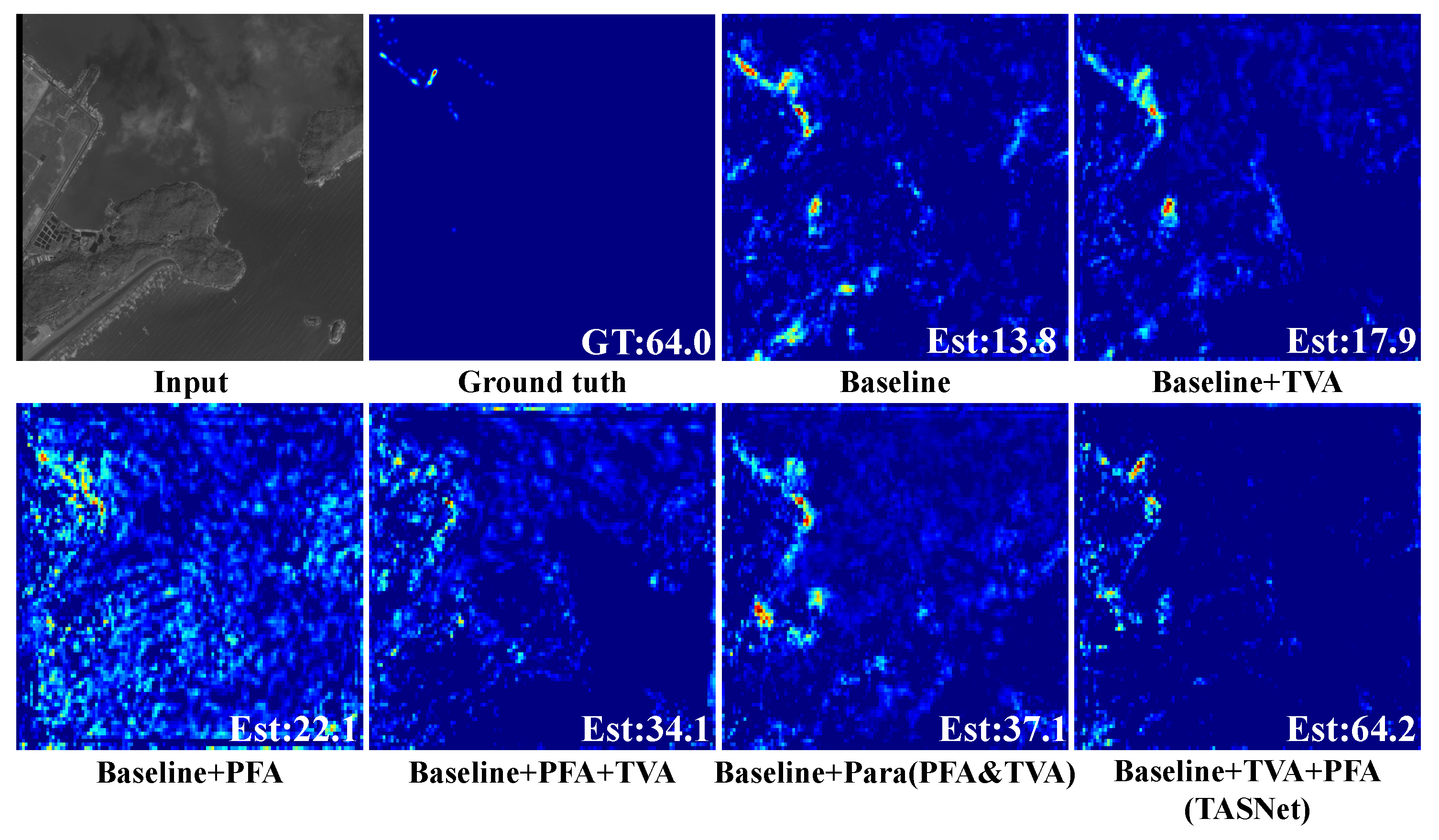
- Baseline: The baseline is considered as the pre-trained VGG16 with the decoder. It shows that the output results of the baseline are the worst.
- Baseline + TVA: The combination is to insert the TVA module between VGG16 and the decoder. One can see that the TVA module is beneficial in boosting the counting performance.
- Baseline + PFA: The group embeds the PFA module into the baseline. It proves that the PFA module is also conducive to the estimated performance.
- Baseline + PFA + TVA: Insert PFA and TVA modules successively in the baseline. It can be observed that the MAE and RMSE are improved by 10.7% and 20.9% compared with the baseline, respectively. It reveals that the combination of PFA and TVA modules is better than that of a single module.
- Baseline + Parallel (TVA and PFA): Connect the PFA and TVA modules in parallel and then add them to the baseline. Again, the results show that the performance improves more than the aforementioned compound modes.
- Baseline + TVA + PFA: Embed the TVA and PFA modules successively in the baseline. Intuitively, it exhibits the best performance in MAE and RMSE compared with all the configurations mentioned above.
4.7.2. Ablation Studies on Backbone Networks
4.7.3. Ablation Studies on Multiscale Feature Fusion Mechanisms
4.8. Efficiency Comparison
4.9. Failure Cases
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhang, Q.; Cong, R.; Li, C.; Cheng, M.M.; Fang, Y.; Cao, X.; Zhao, Y.; Kwong, S.T.W. Dense Attention Fluid Network for Salient Object Detection in Optical Remote Sensing Images. IEEE Trans. Image Process. 2021, 30, 1305–1317. [Google Scholar] [CrossRef]
- Gadamsetty, S.; Ch, R.; Ch, A.; Iwendi, C.; Gadekallu, T.R. Hash-Based Deep Learning Approach for Remote Sensing Satellite Imagery Detection. Water 2022, 14, 707. [Google Scholar] [CrossRef]
- Bazi, Y.; Bashmal, L.; Rahhal, M.M.A.; Dayil, R.A.; Ajlan, N.A. Vision Transformers for Remote Sensing Image Classification. Remote. Sens. 2021, 13, 516. [Google Scholar] [CrossRef]
- Zhang, S.; Yuan, Q.; Li, J.; Sun, J.; Zhang, X. Scene-Adaptive Remote Sensing Image Super-Resolution Using a Multiscale Attention Network. IEEE Trans. Geosci. Remote. Sens. 2020, 58, 4764–4779. [Google Scholar] [CrossRef]
- Rathore, M.M.; Ahmad, A.; Paul, A.; Rho, S. Urban planning and building smart cities based on the Internet of Things using Big Data analytics. Comput. Netw. 2016, 101, 63–80. [Google Scholar] [CrossRef]
- Grinias, I.; Panagiotakis, C.; Tziritas, G. MRF-based segmentation and unsupervised classification for building and road detection in peri-urban areas of high-resolution satellite images. Isprs J. Photogramm. Remote. Sens. 2016, 122, 145–166. [Google Scholar] [CrossRef]
- Benedek, C.; Descombes, X.; Zerubia, J. Building Development Monitoring in Multitemporal Remotely Sensed Image Pairs with Stochastic Birth-Death Dynamics. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 33–50. [Google Scholar] [CrossRef] [Green Version]
- Fan, Y.; Wen, Q.; Wang, W.; Wang, P.; Li, L.; Zhang, P. Quantifying Disaster Physical Damage Using Remote Sensing Data—A Technical Work Flow and Case Study of the 2014 Ludian Earthquake in China. Int. J. Disaster Risk Sci. 2017, 8, 471–488. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.K.; Girshick, R.B.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef] [Green Version]
- Girshick, R.B. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar] [CrossRef]
- Pham, V.Q.; Kozakaya, T.; Yamaguchi, O.; Okada, R. COUNT Forest: CO-Voting Uncertain Number of Targets Using Random Forest for Crowd Density Estimation. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 3253–3261. [Google Scholar] [CrossRef]
- Dai, F.; Liu, H.; Ma, Y.; Cao, J.; Zhao, Q.; Zhang, Y. Dense Scale Network for Crowd Counting. In Proceedings of the 2021 International Conference on Multimedia Retrieval, Tokyo, Japan, 22–24 March 2021. [Google Scholar] [CrossRef]
- Gao, J.; Gong, M.; Li, X. Global Multi-Scale Information Fusion for Multi-Class Object Counting in Remote Sensing Images. Remote. Sens. 2022, 14, 4026. [Google Scholar] [CrossRef]
- Gao, G.; Gao, J.; Liu, Q.; Wang, Q.; Wang, Y. CNN-based Density Estimation and Crowd Counting: A Survey. arXiv 2020, arXiv:2003.12783. [Google Scholar]
- Zhang, Y.; Zhou, D.; Chen, S.; Gao, S.; Ma, Y. Single-Image Crowd Counting via Multi-Column Convolutional Neural Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 589–597. [Google Scholar] [CrossRef]
- Gao, G.; Liu, Q.; Hu, Z.; Li, L.; Wen, Q.; Wang, Y. PSGCNet: A Pyramidal Scale and Global Context Guided Network for Dense Object Counting in Remote-Sensing Images. IEEE Trans. Geosci. Remote. Sens. 2022, 60, 1–12. [Google Scholar] [CrossRef]
- Gao, G.; Liu, Q.; Wang, Y. Counting From Sky: A Large-Scale Data Set for Remote Sensing Object Counting and a Benchmark Method. IEEE Trans. Geosci. Remote. Sens. 2021, 59, 3642–3655. [Google Scholar] [CrossRef]
- Lan, M.; Zhang, Y.; Zhang, L.; Du, B. Global context based automatic road segmentation via dilated convolutional neural network. Inf. Sci. 2020, 535, 156–171. [Google Scholar] [CrossRef]
- Chen, X.; Bin, Y.; Sang, N.; Gao, C. Scale Pyramid Network for Crowd Counting. In Proceedings of the 2019 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 7–11 January 2019; pp. 1941–1950. [Google Scholar] [CrossRef]
- Guo, X.; Gao, M.; Zhai, W.; Shang, J.; Li, Q. Spatial-Frequency Attention Network for Crowd Counting. Big Data 2022, 10, 453–465. [Google Scholar] [CrossRef] [PubMed]
- Zhai, W.; Gao, M.; Anisetti, M.; Li, Q.; Jeon, S.; Pan, J. Group-split attention network for crowd counting. J. Electron. Imaging 2022, 31, 41214. [Google Scholar] [CrossRef]
- Gao, J.; Wang, Q.; Yuan, Y. SCAR: Spatial-/channel-wise attention regression networks for crowd counting. Neurocomputing 2019, 363, 1–8. [Google Scholar] [CrossRef] [Green Version]
- Zhu, L.; Zhao, Z.; Lu, C.; Lin, Y.; Peng, Y.; Yao, T. Dual Path Multi-Scale Fusion Networks with Attention for Crowd Counting. arXiv 2019, arXiv:1902.01115. [Google Scholar]
- Jiang, X.; Zhang, L.; Xu, M.; Zhang, T.; Lv, P.; Zhou, B.; Yang, X.; Pang, Y. Attention Scaling for Crowd Counting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 4705–4714. [Google Scholar] [CrossRef]
- Khan, K.; Khan, R.; Albattah, W.; Nayab, D.; Qamar, A.M.; Habib, S.; Islam, M. Crowd Counting Using End-to-End Semantic Image Segmentation. Electronics 2021, 10, 1293. [Google Scholar] [CrossRef]
- Meng, Y.; Zhang, H.; Zhao, Y.; Yang, X.; Qian, X.; Huang, X.; Zheng, Y. Spatial Uncertainty-Aware Semi-Supervised Crowd Counting. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 15529–15539. [Google Scholar] [CrossRef]
- Gao, J.; Wang, Q.; Li, X. PCC Net: Perspective Crowd Counting via Spatial Convolutional Network. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 3486–3498. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Liu, L.; Wang, P.; Zhang, P.; Lei, Y. Semi-Supervised Crowd Counting via Self-Training on Surrogate Tasks. arXiv 2020, arXiv:2007.03207. [Google Scholar] [CrossRef]
- Cao, X.; Wang, Z.; Zhao, Y.; Su, F. Scale Aggregation Network for Accurate and Efficient Crowd Counting. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, X.; Chen, D. CSRNet: Dilated Convolutional Neural Networks for Understanding the Highly Congested Scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 1091–1100. [Google Scholar] [CrossRef] [Green Version]
- Liu, L.; Qiu, Z.; Li, G.; Liu, S.; Ouyang, W.; Lin, L. Crowd Counting With Deep Structured Scale Integration Network. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1774–1783. [Google Scholar] [CrossRef] [Green Version]
- Liu, W.; Salzmann, M.; Fua, P. Context-Aware Crowd Counting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 5094–5103. [Google Scholar] [CrossRef]
- Zhu, F.; Yan, H.; Chen, X.; Li, T.; Zhang, Z. A multi-scale and multi-level feature aggregation network for crowd counting. Neurocomputing 2021, 423, 46–56. [Google Scholar] [CrossRef]
- Duan, Z.; Wang, S.; Di, H.; Deng, J. Distillation Remote Sensing Object Counting via Multi-Scale Context Feature Aggregation. IEEE Trans. Geosci. Remote. Sens. 2022, 60, 1–12. [Google Scholar] [CrossRef]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. GhostNet: More Features From Cheap Operations. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 1577–1586. [Google Scholar] [CrossRef]
- Chen, J.; Wang, K.; Su, W.; Wang, Z. SSR-HEF: Crowd Counting With Multiscale Semantic Refining and Hard Example Focusing. IEEE Trans. Ind. Inform. 2022, 18, 6547–6557. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2015, arXiv:1409.1556. [Google Scholar]
- Misra, D.; Nalamada, T.; Arasanipalai, A.U.; Hou, Q. Rotate to Attend: Convolutional Triplet Attention Module. In Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2021; pp. 3138–3147. [Google Scholar] [CrossRef]
- Zhai, W.; Gao, M.; Souri, A.; Li, Q.; Guo, X.; Shang, J.; Zou, G. An attentive hierarchy ConvNet for crowd counting in smart city. Clust. Comput. 2022. [Google Scholar] [CrossRef]
- Hsieh, M.R.; Lin, Y.L.; Hsu, W.H. Drone-Based Object Counting by Spatially Regularized Regional Proposal Network. In Proceedings of the International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 4165–4173. [Google Scholar] [CrossRef] [Green Version]
- Wang, P.; Gao, C.; Wang, Y.; Li, H.; Gao, Y. MobileCount: An efficient encoder-decoder framework for real-time crowd counting. Neurocomputing 2020, 407, 292–299. [Google Scholar] [CrossRef]
- Sindagi, V.; Patel, V. CNN-Based cascaded multi-task learning of high-level prior and density estimation for crowd counting. In Proceedings of the IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Lecce, Italy, 29 August–1 September 2017; pp. 1–6. [Google Scholar] [CrossRef] [Green Version]
- Wang, Q.; Gao, J.; Lin, W.; Yuan, Y. Learning From Synthetic Data for Crowd Counting in the Wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 8190–8199. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.B.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. TPAMI 2015, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Stahl, T.; Pintea, S.L.; Gemert, J.C.V. Divide and Count: Generic Object Counting by Image Divisions. IEEE Trans. Image Process. 2019, 28, 1035–1044. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.E.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.Y.; Goyal, P.; Girshick, R.B.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef] [Green Version]
- Mundhenk, T.N.; Konjevod, G.; Sakla, W.A.; Boakye, K. A Large Contextual Dataset for Classification, Detection and Counting of Cars with Deep Learning. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar] [CrossRef] [Green Version]
- Ma, Z.; Wei, X.; Hong, X.; Gong, Y. Bayesian Loss for Crowd Count Estimation With Point Supervision. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6141–6150. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Xie, S.; Girshick, R.B.; Dollár, P.; Tu, Z.; He, K. Aggregated Residual Transformations for Deep Neural Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5987–5995. [Google Scholar] [CrossRef] [Green Version]
- Yu, X.; Han, Z.; Gong, Y.; Jan, N.; Zhao, J. The 1st Tiny Object Detection Challenge: Methods and Results. In Proceedings of the 2020 ECCV Workshops, Glasgow, UK, 23–28 August 2020. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Platform | Images | Train/Test | Size (Avg.) | Annotation Format |
|---|---|---|---|---|---|
| RSOC_Building | Satellite | 2468 | 1205/163 | 512 × 512 | Center point |
| RSOC_Large-vehicle | Satellite | 172 | 108/64 | 1552 × 1573 | Bounding box |
| RSOC_Small-vehicle | Satellite | 280 | 222/58 | 2473 × 2339 | Bounding box |
| RSOC_Ship | Satellite | 137 | 97/40 | 2558 × 2668 | Bounding box |
| CARPK | Drone | 1448 | 989/459 | 720 × 1280 | Bounding box |
| PUCPR+ | Camera | 125 | 100/25 | 720 × 1280 | Bounding box |
| Method | Building | Small-Vehicle | Large-Vehicle | Ship | ||||
|---|---|---|---|---|---|---|---|---|
| MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE | |
| MCNN [15] | 13.65 | 16.56 | 488.65 | 1317.44 | 36.56 | 55.55 | 263.91 | 412.30 |
| CMTL [42] | 12.78 | 15.99 | 490.53 | 1321.11 | 61.02 | 78.25 | 251.17 | 403.07 |
| SANet [29] | 29.01 | 32.96 | 497.22 | 1276.66 | 62.78 | 79.65 | 302.37 | 436.91 |
| CSRNet [30] | 8.00 | 11.78 | 443.72 | 1252.22 | 34.10 | 46.42 | 240.01 | 394.81 |
| SCAR [22] | 26.90 | 31.35 | 497.22 | 1276.65 | 62.78 | 79.64 | 302.37 | 436.92 |
| SPN [19] | 7.74 | 11.48 | 455.16 | 1252.92 | 36.21 | 50.65 | 241.43 | 392.88 |
| CAN [32] | 9.12 | 13.38 | 457.36 | 1260.39 | 34.56 | 49.63 | 282.69 | 423.44 |
| SFCN [43] | 8.94 | 12.87 | 440.70 | 1248.27 | 33.93 | 49.74 | 240.16 | 394.81 |
| DSNet [12] | 8.93 | 12.61 | 405.83 | 1254.16 | 27.44 | 42.38 | 206.25 | 346.96 |
| SFANet [23] | 8.18 | 11.75 | 435.29 | 1284.15 | 29.04 | 47.01 | 201.61 | 332.87 |
| ASPDN [17] | 7.54 | 10.52 | 433.23 | 1238.61 | 18.76 | 31.06 | 193.83 | 318.95 |
| TASNet (Ours) | 7.63 | 11.25 | 394.89 | 1196.83 | 22.75 | 37.13 | 191.82 | 278.17 |
| Methods | CARPK | PUCPR+ | ||
|---|---|---|---|---|
| MAE | RMSE | MAE | RMSE | |
| YOLO [9] | 102.89 | 110.02 | 156.72 | 200.54 |
| FRCN [44] | 103.48 | 110.64 | 156.76 | 200.59 |
| LEP [45] | 51.83 | - | 15.17 | - |
| LPN [40] | 23.80 | 36.79 | 22.76 | 34.46 |
| SSD [46] | 37.33 | 42.32 | 119.24 | 132.22 |
| RetinaNet [47] | 16.62 | 22.30 | 24.58 | 33.12 |
| One-Look Regression [48] | 59.46 | 66.84 | 21.88 | 36.73 |
| MCNN [15] | 39.10 | 43.30 | 21.86 | 29.53 |
| CSRNet [30] | 11.48 | 13.32 | 8.65 | 10.24 |
| BL [49] | 9.58 | 11.38 | 6.54 | 8.13 |
| PSGCNet [16] | 8.15 | 10.46 | 5.24 | 7.36 |
| TASNet (Ours) | 7.16 | 10.23 | 5.16 | 6.76 |
| Methods | MAE | RMSE |
|---|---|---|
| Baseline | 240.01 | 394.81 |
| Baseline + TVA | 237.88 | 373.97 |
| Baseline + PFA | 223.11 | 362.42 |
| Baseline + PFA + TVA | 214.22 | 312.35 |
| Baseline+Parallel (TVA & PFA) | 205.54 | 291.72 |
| Baseline + TVA + PFA | 191.82 | 278.17 |
| Methods | MAE | RMSE |
|---|---|---|
| TASNet (Resnet-50) | 215.39 | 346.81 |
| TASNet (ResneXt) | 197.83 | 327.66 |
| TASNet (VGG-16) | 191.82 | 278.17 |
| Methods | MAE | RMSE |
|---|---|---|
| Baseline + TVA + SPM | 192.69 | 329.45 |
| Baseline + TVA + DDCB | 194.48 | 294.46 |
| Baseline + TVA + PSM | 220.58 | 330.71 |
| Baseline + TVA + PFA | 191.82 | 278.17 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, X.; Anisetti, M.; Gao, M.; Jeon, G. Object Counting in Remote Sensing via Triple Attention and Scale-Aware Network. Remote Sens. 2022, 14, 6363. https://doi.org/10.3390/rs14246363
Guo X, Anisetti M, Gao M, Jeon G. Object Counting in Remote Sensing via Triple Attention and Scale-Aware Network. Remote Sensing. 2022; 14(24):6363. https://doi.org/10.3390/rs14246363
Chicago/Turabian StyleGuo, Xiangyu, Marco Anisetti, Mingliang Gao, and Gwanggil Jeon. 2022. "Object Counting in Remote Sensing via Triple Attention and Scale-Aware Network" Remote Sensing 14, no. 24: 6363. https://doi.org/10.3390/rs14246363
APA StyleGuo, X., Anisetti, M., Gao, M., & Jeon, G. (2022). Object Counting in Remote Sensing via Triple Attention and Scale-Aware Network. Remote Sensing, 14(24), 6363. https://doi.org/10.3390/rs14246363