1. Introduction
Hyperspectral imagery (HSI) is composed of numerous narrow spectral bands typically in the range of 400 nm to 2500 nm. Due to its rich spectral information, it can better reflect the reflectance information of ground objects; therefore, it has been widely used in precise agriculture, mineral detection, environment monitoring, urban planning, and so on [
1]. Unfortunately, because of facility restrictions, atmospheric conditions, and other unknown factors during the collection process [
2], HSI of a real scene is degraded by various noises, such as gaussian noise, impulse noise, stripe, and deadlines. The existence of noise not only reduces visual quality but also limits the processing accuracy in subsequent applications, e.g., unmixing [
3], classification [
4,
5], and target detection [
6]. Consequently, restoration of HSI is a critical preprocessing step for effective applications.
A large number of restoration techniques has hitherto been developed for HSI. Filtering-based methods are commonly used because of simplicity [
7,
8]. However, most of these methods are effective only for a particular noise using a specific filter; the restoration performance is limited for mixed noise. Another popular approach is statistical-based methods [
9] usually with the assumption that the noise obeys some probability distribution. In recent years, optimization-based HSI restoration methods have emerged; these methods consider HSI denoising as an optimization problem consisting of regularization and data-fidelity terms. The regularization term helps to exploit prior knowledge about the underlying properties of HSI and noise; therefore, an accurate description of the regularization is prerequisite to good results under ill-posed conditions.
In optimization-based methods, an HSI can be restored by the one dimensional (1D) vector method [
10], two dimensional (2D) matrix method [
11], or 3 dimensional (3D) tensor method [
12,
13,
14]. In these methods, the HSI is treated as vectors, grayscale matrices, or three-order tensors, respectively. Even though the 1D and 2D methods are always faster, the restoration results are unsatisfactory because they ignore the inherited spectral and spatial correlation of a HSI. To address this issue, various methods to incorporate the prior knowledge of such correlations have been proposed. For instance, a wavelet shrinkage method applied in both spatial and spectral domains was proposed in [
15]. Zhao et al. [
16] proposed a sparse representation method to jointly utilize the spatial-spectral information of HSI. Considering the differences between spectral noise and spatial information, Yuan et al. [
17] proposed a spectral-spatial adaptive total variation model. With the advent of tensor technology, which conveniently deals with the spectral and spatial domain of a HSI simultaneously, increasingly more studies are devoted to tensor-based restoration methods.
A typical HSI has low rank properties. It was claimed in [
12] that HSI
Xhas a specific correlation in both spatial dimensions by observing the obvious decaying trends of the singular value changes of unfolding matrices
X(1) and
X(2), which also indicate that they are low-rank matrices. From the linear mixture point, HSI shows strong spectral correlation, and the mode-3 unfolding matrix
X(3) is a low-rank matrix. As the collected HSIs from real scenes are inevitably contaminated by various noise, they could destroy the low-rank property. Based on the low rank assumption, a low-rank matrix recovery (LRMR) model was proposed in [
2] to remove the mixed noise, where an HSI was decomposed into a low-rank part and a sparse part to represent a clean HSI and sparse noises, respectively. Even LRMR can remove Gaussian and sparse noise simultaneously; this method considers only the local similarity within patches. Subsequently, numerous non-convex norms have been proposed to formulate the low-rank property instead of the nuclear norm, for example, γ-norm [
18] and weighted Schatten p-norm [
19,
20]. However, there are three weaknesses with these methods. Firstly, these methods need to reshape the original 3D HSI into a 2D matrix, which will destroy the spectral correlation. Secondly, computational cost is high because one has to compute the matrix singular value decomposition (SVD) in each of the iterations in optimization. Thirdly, the low rank property exists in both spectral and spatial domains [
12], but these methods consider the low rank property in the spatial domain and spectral domain separately. Consequently, to utilize the global low-rank property and spatial–spectral correlation of HSI, methods based on the low-rank tensor decomposition (LRTD) have been proposed for HSI restoration [
12,
13,
14]. One major challenge is local, structured sparse noise such as stripes or deadlines. Since these noises are regarded as the low rank component, the low-rank constraint will fail to remove them.
In addition to the low rank property of HSI, it also has a piecewise smooth structure as a natural image in the spatial domain, which can be exploited by total variation (TV) regularization methods [
21,
22,
23,
24,
25]. For example, He et al. [
21] combined band-by-band TV (BTV) regularization with low-rank matrix factorization (LRMF) to improve restoration performance. While BTV is useful to characterize spatial piecewise smoothness, it does not consider spectral correlation of HSI.
To overcome spatial over-smoothing of TV methods, many methods incorporate spectral correlation. For example, Yuan et al. [
17] introduced a spectral-spatial adaptive hyperspectral TV (SSAHTV), which realized the band and spatial adaptive denoising process automatically. Zheng et al. [
22] extended it to a band group-wise version. Similar approaches that explicitly evaluate spectral correlation in addition to spatial piecewise-smoothness include the spatial-spectral TV (SSTV) [
23], anisotropic SSTV (ASSTV) [
24], and Cross Total Variation (CrTV) [
25]. In the design of SSTV and ASSTV, spatial correlation is interpreted as spectral piecewise smoothness and is evaluated by the
l1 norm of local differences along the spectral direction, resulting in computationally efficient optimization. Specifically, to evaluate spatial and spectral piecewise smoothness simultaneously, SSTV focuses on local spatial-spectral differences. However, as this method ignores direct local spatial differences, the restored HSI tends to have artifacts, especially in highly noisy scenarios. While ASSTV handles both local spatial and spectral differences directly in parallel, it often produces spectrally over-smoothed images because it strongly suppresses the
l1 norm of direct spectral differences for HSI. SSAHTV can adaptively estimate the denoising strength according to different spatial properties and different noise intensity in bands.
The other method is three-dimensional spectral-spatial TV (3DSSTV, or 3DTV for brief) and its variants. The 3DTV [
26] is defined as
The
,
and
are difference operators along the horizontal, vertical, and spectral directions, respectively. The
are the weights corresponding with
,
and
. The 3DTV has been combined with LRTD [
26] and t-SVD [
27] to remove mixed noise in HSI. In general, the combination of a low-rank tensor and 3DTV regularization restoration model achieves better results. It is noteworthy that the 3DTV is different from the aforementioned SSTV. The SSTV is defined as the TV of the unfolding matrix of HSI, as such SSTV indeed belongs to 2DTV.
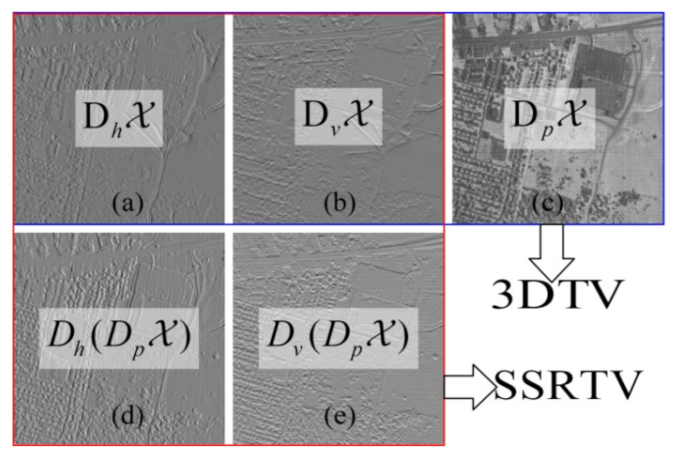
Although the 3DTV defined in Equation (1) considered both spatial and spectral smoothness, there still is one problem. The difference images in 3DTV, which are calculated by
,
and
are presented in
Figure 1.
Figure 1a–c shows the images of
and
for real Urban dataset
, respectively. The 3DTV along the spectrum considers that the content of the adjacent bands is close to each other, and the variation of
is sparse. However, it can be observed from
Figure 1c that the variation along spectrum
still leaves lots of details. Therefore, the real value of 3DTV in HSI is relatively large (see
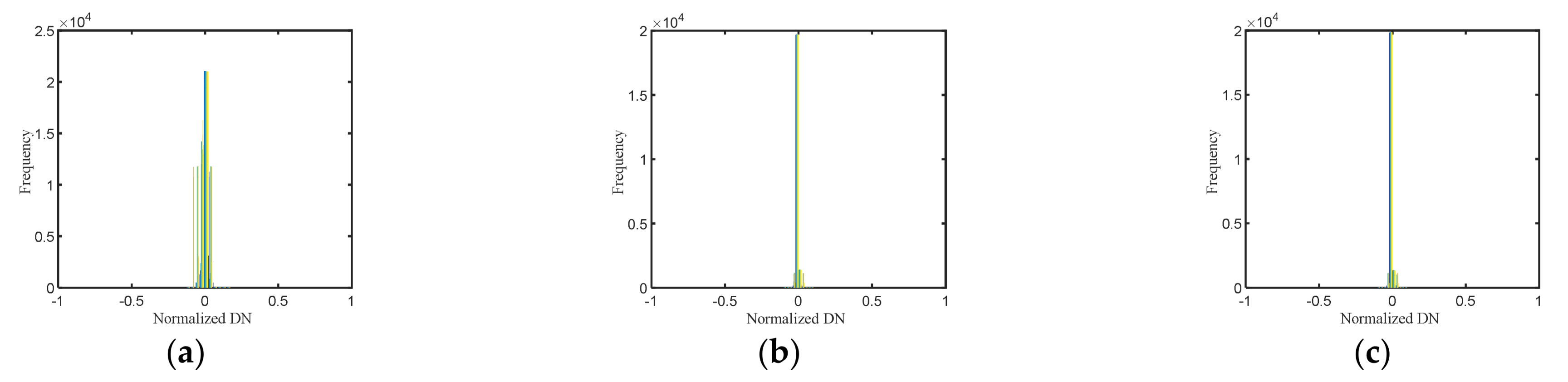
Figure 2a).
Figure 2 shows the histograms of
,
and
, respectively. The more detailed the image is, the larger the real 3DTV norm is. Therefore, if 3DTV is minimized as a constraint condition for HSI restoration, there is a great possibility of loss of image details, with a sub-optimal effect. To overcome the aforementioned drawbacks and effectively utilize the prior knowledge on HSI, we proposed a Spatial-Spectral Residual Total Variation (SSRTV) regularization technique for HSI restoration. The SSRTV is designed to evaluate two types of local differences: direct local spatial differences (
) and local spatial-spectral differences (
) in a unified manner with a balancing weight. This design resolves the drawbacks of the existing TV regularization techniques mentioned above. Generally speaking,
are calculated with the 2DTV on the residual image
. Then, the local correlation within the bands is actually considered, which would promote a much stronger sparsity than
(see
Figure 1d,e, and the corresponding histograms in
Figure 2b,c).
are expressed as:
where
is the difference of band
k + 1 and
k for pixel at spatial location (
i,
j).
Although the SSRTV defined here looks similar to the Hybrid Spatio-Spectral Total Variation (HSSTV) in reference [
28], there are essential differences between them. In fact, the
in HSSTV mean
and
, where
and
are the unfolding matrices along the horizontal (mode-1) and vertical (mode-2).
In addition, the deadlines, stripes, and impulse noises were assumed to be sparse [
2]. Among these sparse noises, the stripes or deadlines showed a certain directional characteristic, as shown in
Figure 3. When the sparse noises at the same place occurred in most of the bands, they were treated as the low-rank component and could not be removed by the low-rank-based method [
21].
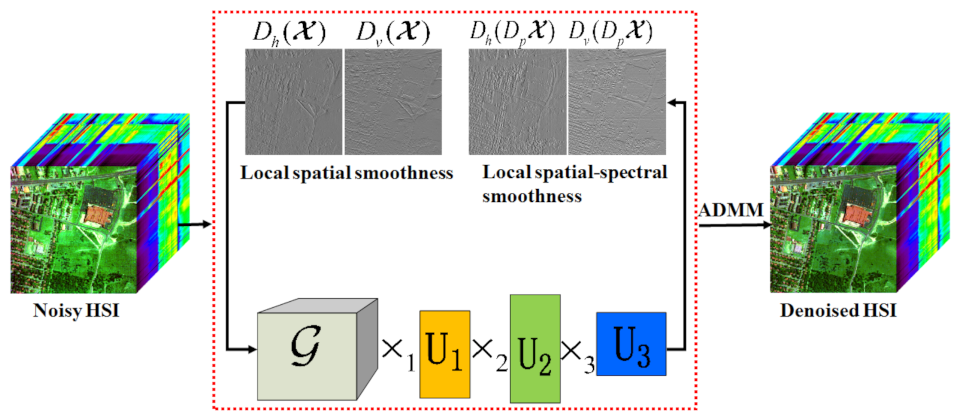
To remove the mixed noise in the HSI, we designed a spatial domain spectral Residual Total Variation regularization approach combined with LRTD (LRTDSSRTV).
Figure 4 presents the flowchart of our method.
It was found that SSRTV is totally different from the previous TV regularization in [
25,
29]. Our proposed HSI restoration method combined SSRTV with the low-rank Tucker decomposition framework. To summarize, the major contributions of this paper are as follows.
- (1)
We designed a Spatial-Spectral Residual Total Variation (SSRTV) to better capture both the direct spatial and spatial-spectral piecewise smoothness of HSI. This can overcome disadvantages of previous TV methods, that is, the low-rank regularization fails to remove the structured sparse noise.
- (2)
The SSRTV was incorporated into the LRTD model to separate the underlying clean HSI from its degraded version with mixed noise. LRTD was adopted to preserve the global spatial and spectral correlation of HSI and restore the clean low-rank HSI.
- (3)
The classical higher-order orthogonal iteration (HOOI) algorithm [
30] was adopted to achieve the Tucker decomposition efficiently, without bringing an extra computational burden. By using alternating direction method of multipliers (ADMM), our method was split into several simpler sub-problems. Compared with the methods based on low-rank matrix/tensor decomposition, the experimental results with the simulations and real data validated the proposed method.
The remaining contents are organized as follows. In
Section 2, we present notations for tensor operations. Our restoration model and its optimization are described in
Section 3. The effectiveness of the proposed method was verified by the experiments of simulated data sets and real remote sensing data sets, shown in
Section 4. Finally, the conclusions are drawn, and outlook is presented in
Section 5.
2. Notations and Preliminaries
In tensor algebra, a tensor is a multi-linear mapping defined on a Cartesian product of some vector spaces and some dual spaces. The order of a tensor is defined as the number of its dimensions or modes. For example, scalar, vector, and matrix are zero-order tensor, one-order tensor, and two-order tensor, respectively. The corresponding representations are a lowercase letter, lowercase boldface letter, and capitalized boldface letter. For instance, the , x, and X are scalar, vector, and matrix, respectively. An N-order (N ≥ 3) tensor is denoted by a capitalized calligraphic letter, i.e., . The HSI data cube is a three-order tensor. For an N-dimensional real valued tensor , we used to represent its element at location (), and its Nth dimension is also called Nth mode. By fixing all the indices but the nth index, we obtained the mode-n fibers. By arranging all the mode-n fibers as columns, we obtained a matrix denoted by or . This process is also called the mode-n matrixing of or unfolding along mode-n. The multi-linear rank of is an array () and ri = rank (X(i)), I = 1, 2, …, N.
The inner product of two tensors
and
was calculated by
. The
l1-norm of tensor
was calculated as
. The
l2,1-norm of matrix X was calculated as
. The tensor-matrix product by mode-n was defined as
. For more information of tensor algebra, please refer to [
30].
4. Experimental Results and Analysis
In this section, the simulated and real datasets were adopted to evaluate the proposed LRTDSSRTV solver. To better validate the advantages of the LRTD and SSRTV regularization, we selected five representative advanced methods to compare, including low-rank matrix recovery (LRMR) [
2], the combination of low-rank matrix factorization with TV regularization (LRTV) [
21], anisotropic spatial-spectral TV regularization with low-rank tensor decomposition (LRTDTV) (
http://gr.xjtu.edu.cn/web/dymeng/3, (accessed on 12 June 2021)) [
12], the spatial-spectral TV model (SSTV) (
https://sites.google.com/view/hkaggarwal/publications (accessed on 12 June 2021)) [
23], and Weighted Group Sparsity-Regularized Low-Rank Tensor Decomposition(LRTDGS) (
http://www.escience.cn/people/yongchen/index.html (accessed on 12 June 2021)) [
32]. LRMR imposes spectral low-rankness in spatial patches. LRTV combines a low-rank constraint of the unfolding matrix with HSI and BTV. LRTDTV jointly considers 3DTV and Tucker decomposition. SSTV applies 1-D total variation on the spectral domain. LRTDGS introduces weighted group sparse regularization to improve the group sparsity of the spatial difference image. According to the authors’ suggestions, we carefully tuned the parameters involved in the compared methods to guarantee optimal results. While for the parameters in our method, a detailed discussion of parameter selection is presented in
Section 4. In addition, all the bands of the HSI were normalized within the range of [0, 1] for easy numerical calculation and visualization, and the HSI was transformed to original grayscale level after restoration.
4.1. Experiment with Simulated Data
(1) Experimental Setting: In this section, we evaluated the robustness of a simulated clean Indian Pines’ dataset with synthetic noise. This dataset contained 224 bands; each band was a grayscale image of 145 × 145 pixels. It was widely used in [
12,
21,
40]. This dataset was firstly used in [
2], which was generated from the real Indian Pines’ dataset. The reflectance values of all the pixels were mapped to [0; 1] through linear transform.
To simulate complicated noise cases in a real scene, six representative types of noise were added. The rules for adding noise were as follows:
Case 1: A zero-means Gaussian noise. In a real scene, the noise density in each band should be different. Therefore, we added randomly selected noise variances to each band within the range of [0, 0.25].
Case 2: Different intensities of Gaussian noise to each band, as in Case 1. Additionally, we added deadlines from bands 141 to 170. The number of the deadline in each band was randomly selected between 3 and 10, and the deadline’s width was randomly generated from 1 to 3 pixels.
Case 3: Gaussian noise was added in the same way as in case 2. Additionally, the impulse noise was added to all bands and the percentages were randomly selected within the range of [0, 20%].
Case 4: On the basis of case 3, we added stripes to bands 161 to 190; the number of stripes in each band was randomly selected in the range of 10 to 30.
Case 5: The deadline was added in the same way as in case 2, and the stripe noise was added as in case 4. Additionally, the impulse noise was also added, and the percentages were varied from 0 to 50% for each band.
Case 6: All the considered noises were added to simulate the most severe noise situation. Gaussian noise, stripes, and impulse noise were added in the same way as in case 4. Additionally, 30 bands were randomly chosen to add deadlines, and the number of deadline were randomly selected from 3 to 10.
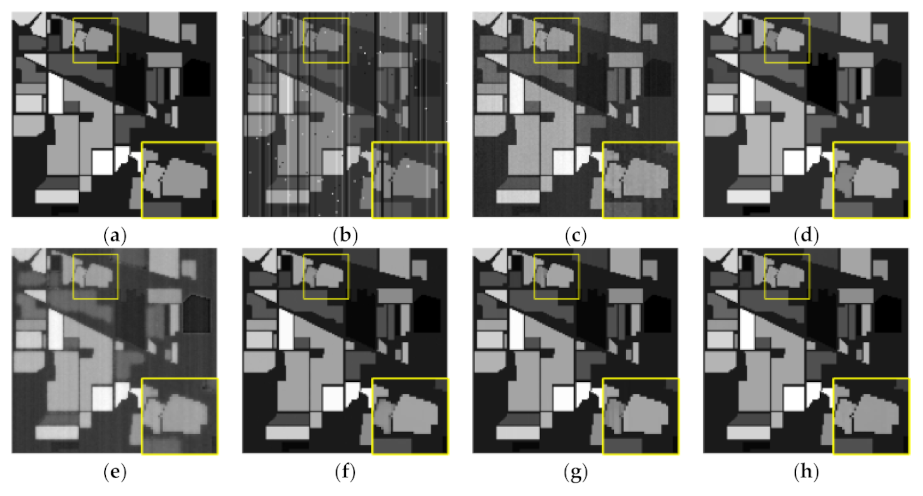
(2) Visual Comparison: One important outcome of restoration is to improve the visual quality. To illustrate, we show three representative cases, 1, 5, and 6, in
Figure 5,
Figure 6 and
Figure 7, respectively, with the restoration results for bands 46, 168, and 162. For better visualization, we provided a zoom with yellow boxes. It can be observed that the denoised result of (c) LRMR and (e) SSTV did not completely eliminate the noise in the presented results (see the zoom boxes). Restoration results of (d) LRTV, (f) LRTDTV, and (g) LRTDGS were satisfactory, completely removing all noises. However, the details of some areas in the image of LRTV and LRTDTV were blurred (see the zoom boxes). Some striped artifacts were observed from the zoom boxes with the result of (g) LRTDGS. Additionally, there was obvious noise in the result of SSTV, as observed in
Figure 7e. By contrast, the proposed LRTDSSRTV method can remove all kinds of noises and maintain an image feature and detail with better visual quality than the comparison methods. This is due to the simultaneous consideration of both spatial spectral piecewise smoothness and direct spatial piecewise smoothness in SSRTV.
(3) Quantitative Comparison: Four objective quantitative evaluation indices (QEI) were used to compare the results of all the methods in each simulated experiment, including peak signal-to-noise ratio (PSNR) [dB] index, the structural similarity (SSIM) index [
41], erreur relative globale adimensionelle de synthese (ERGAS; relative dimensionless global error in synthesis in English), and the spectral angle mapper (SAM) [
42]. For the PSNR and SSIM, we showed the average values (or means) of all the HSI bands, denoted by MPSNR and MSSIM, respectively. The higher values of MPSNR and MSSIM or the lower values of ERGAS and SAM represented better restoration results.
The values of four QEIs of all the methods under the simulated six different noise cases are presented in
Table 1. The best values among the comparison methods are highlighted in bold, while the suboptimal values are underlined. By comparison, we can see that the tensor-based methods (LRTDTV, LRTDGS and LRTDSSRTV) by and large performed better than the matrix-based methods. The main reason is that LRTD can capture the global correlation both in spatial and spectral dimensions. In comparison with LRTDTV and LRTDGS, our method shows superiority in all QEIs under almost all cases. The reason is that the 3DTV norm used in LRTDTV calculates and sums the gradient values in three directions at the same time, and the actual norm results are relatively large. Therefore, minimizing 3DTV as a constraint condition for HSI restoration would tend to lose image details during restoration. For the group sparsity used in LRTDGS, it strengthens the spatial constraints while failing to explore the spectral constraint. Our method remedies the deficiency and makes an improvement in all QEIs for the Indian Pines’ dataset.
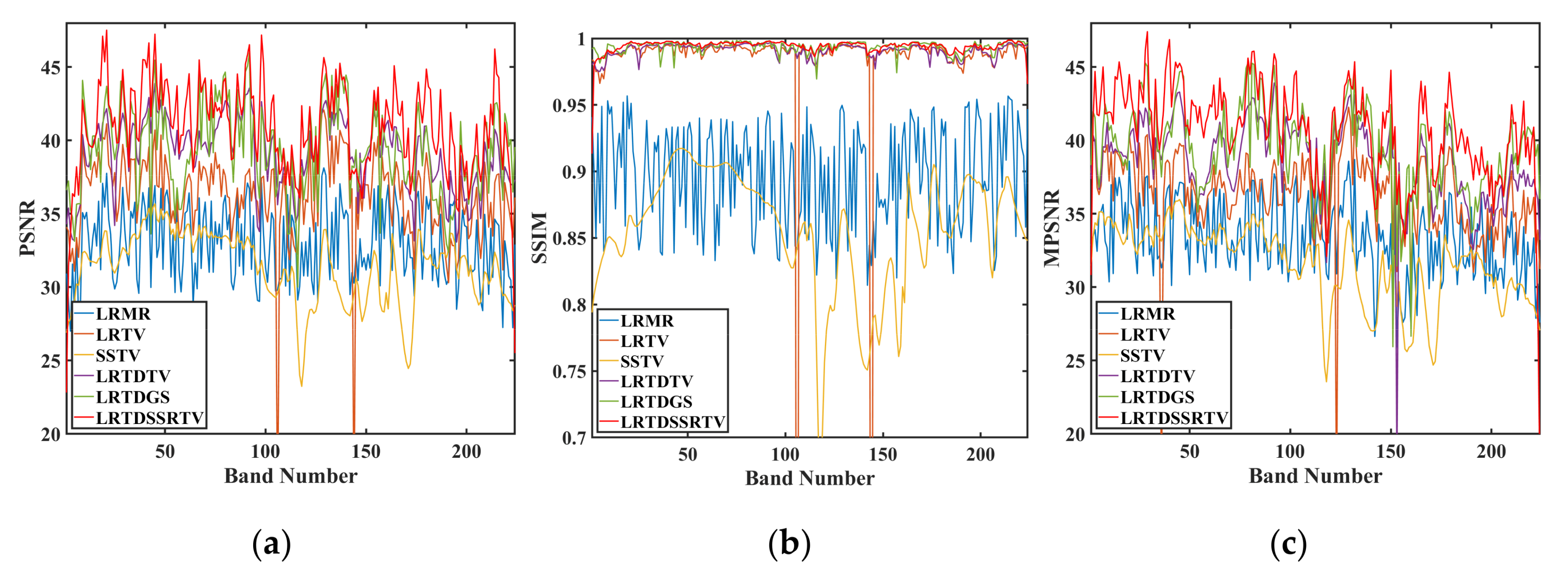
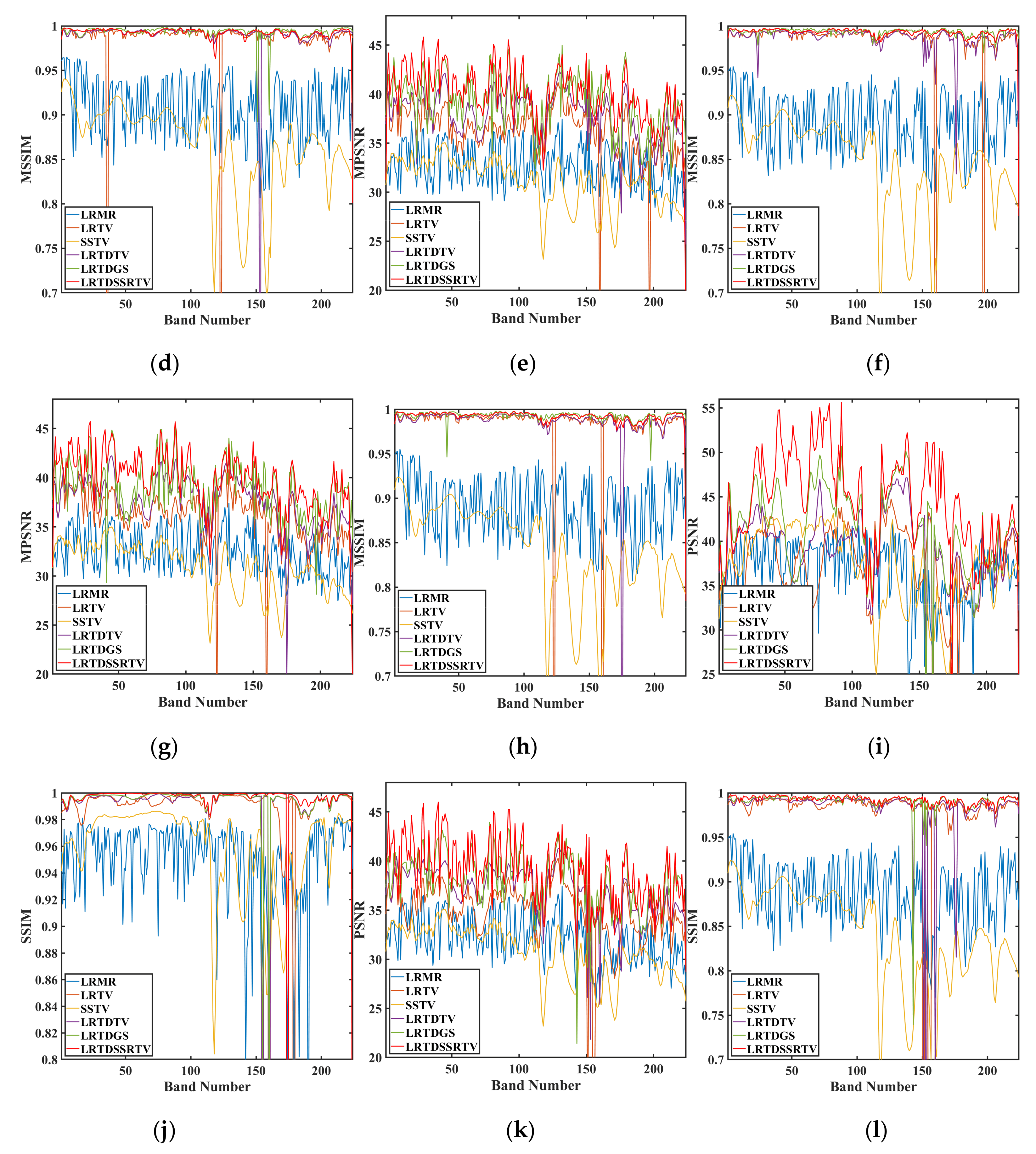
To take a close look at the PSNR and SSIM values of each band.
Figure 8 shows the corresponding curves of these two QEIs in six cases. It is observed that the PSNR and SSIM values of LRMR and SSTV were obviously lower than other four methods. Although the PSNR and SSIM values of LRTV were higher than LRMR and SSTV, this indicates that LRTV can get better denoised results in the spatial domain. We can see that the spectral distortion of LRMR is still serious in
Table 1. Compared with LRTDTV and LRTDGS, the proposed LRTDSSRTV method achieved much higher SSIM and PSNR values for almost all the bands.
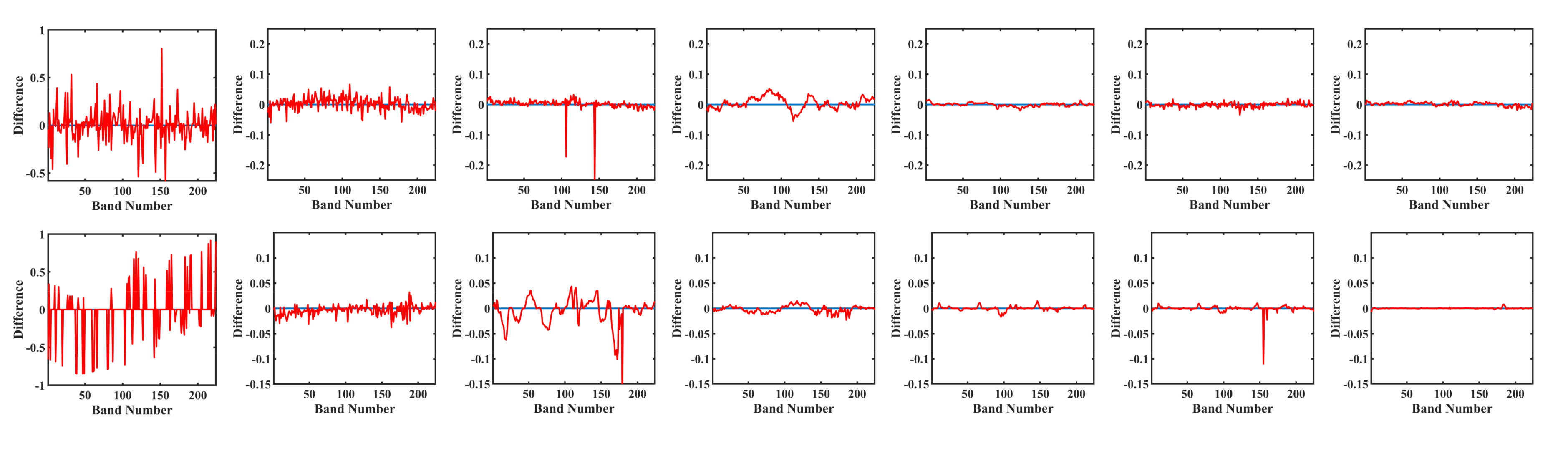
To further illuminate the qualitative comparison in terms of spectral information, the spectral difference between the original spectrums and the restored ones at different locations under cases 1, 5, and 6 are presented in
Figure 9. The horizontal axis in
Figure 9 denotes band number, while the vertical axis denotes the spectral difference. It can be seen from
Figure 9 that the LRTD-based methods (LRTDTV, LRTDGS, and our method) achieved better spectral fidelity than other three methods. This phenomenon indicates that the global LRTD can efficiently preserve the spatial-spectral correlation of HSI. However, compared with LRTDTV and LRTDGS, the spectral differences of our method were the smallest. This result is consistent with the values of the ERGAS index in
Table 1.
4.2. Real-World Data Experiments
In this section, we conducted experiments with two real case datasets. One is the Airborne Visible/Infrared Imaging Spectrometer (AVIRIS) Indian Pines’ dataset and the other is the Hyperspectral Digital Imagery Collection Experiment (HYDICE) urban dataset. Before processing, the pixel value was also normalized to [0, 1] band by band.
4.2.1. AVIRIS Indian Pines’ Dataset
The spatial resolution of this dataset was 145 × 145, and it contained 220 bands. The noises existing in this dataset were mainly Gaussian and impulse noises. For brevity, two typical bands, 104 and 150, were selected to show the restoration results of different methods.
Figure 10a and
Figure 11a correspond to the original bands 104 and 150, respectively. It was found that these two bands were both severely degraded by mixed noise. Therefore, the useful information was almost completely corrupted. After restoration, there were some noises in the results of LRMR. Even the LRTV could remove the noise, but the edges were over-smoothed. The same situation happened in the results of SSTV, LRTDTV, and LRTDGS. Especially, the details of LRTDGS were blurred seriously, as shown in
Figure 11f. Compared with TV regularization methods, our method performed the best in removing noise and preserving edges and local details.
4.2.2. HYDICE Urban Dataset
The spatial resolution of this dataset was 307 × 307, and it contained 210 bands. The noise in this dataset was more complicated than in the AVIRIS Indian Pines’ Dataset. Except for the Gaussian noise, deadlines, impulse noise, and stripes, it may also have been degraded by water absorption, atmosphere, and some other unknown noises. For brevity and readability, two representative noise bands were chosen to compare the denoising performance. The original bands, 108 and 208, and their corresponding denoised results are shown in
Figure 12,
Figure 13 and
Figure 14, respectively.
Figure 12a and
Figure 14a represent the original bands, 108 and 208, respectively. There were mixed noise and bias illumination, which changed the image contrast, in these two bands.
Figure 12b–g and
Figure 14b–g were the denoised results with different restoration methods. It can be seen from the zoom boxes in
Figure 12b–g that there were still a few stripes existing in the results of the methods LRMR, LRTV, SSTV, and LRTDTV. Even though LRTDGS can remove most noise, it resulted in a blurred edge in some regions. It can be seen from
Figure 14a that there were obvious deadlines in the original band. All the five compared methods failed to eliminate the deadlines, and LRMR also failed to remove other noises. A benefit of the SSRTV regularization and global LRTD, as shown in
Figure 12g and
Figure 14g, our method removed not only mixed noises but also bias illumination. By comparison, the LRTV and LRTDTV just considered the
. Therefore, they could not completely get rid of the bias illumination. Both SSTV and LRTDSSRTV considered the
, and the bias illumination was removed, as shown in
Figure 12d and
Figure 14g, while the visual quality of SSTV was not as good as that of LRTDSSRTV for failing to consider
in SSTV.
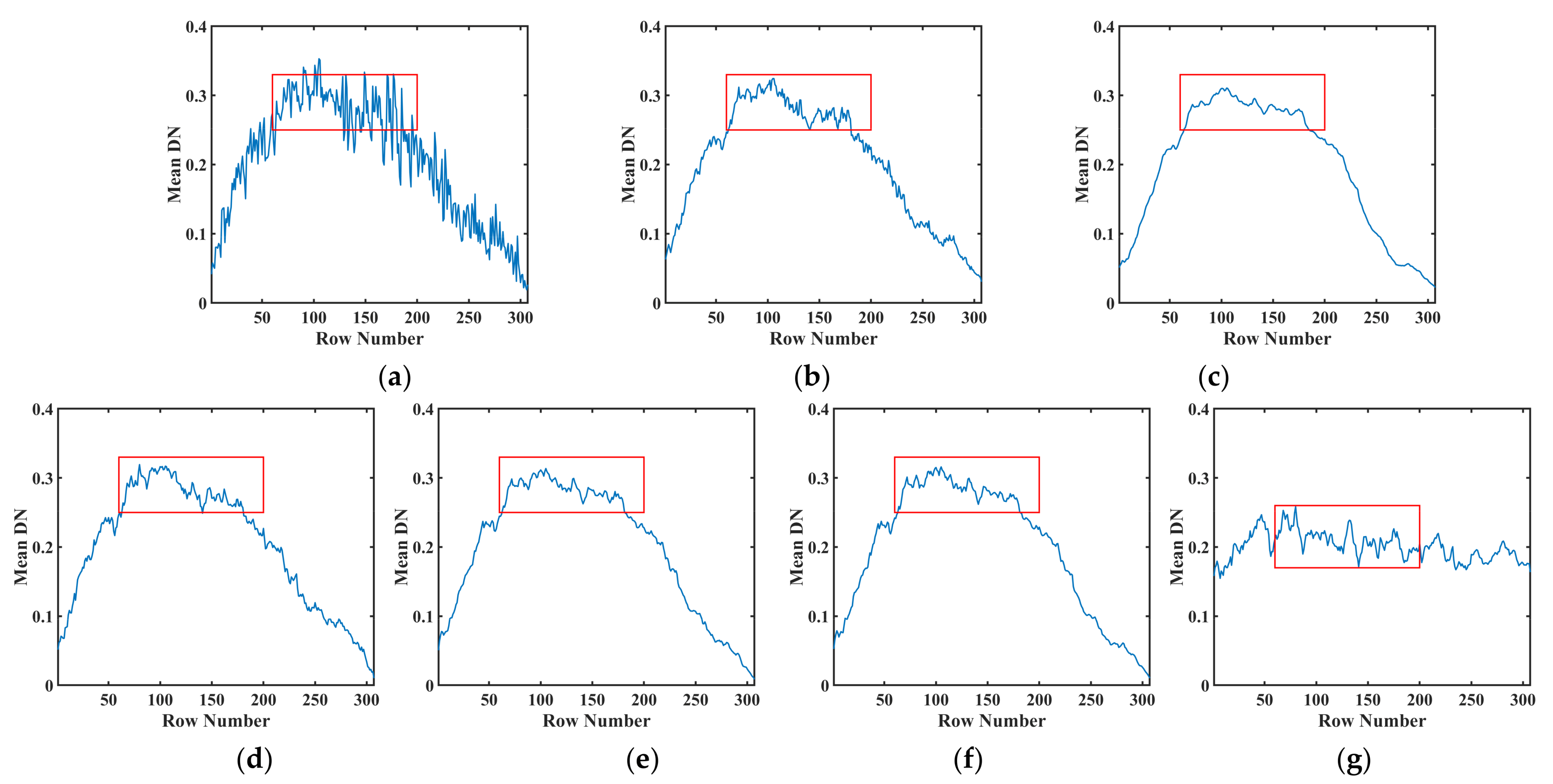
To further compare the restoration results, the mean digital number (MDN) corresponding to
Figure 12 and
Figure 14 is shown in
Figure 13 and
Figure 15, respectively. The horizontal axis represents the row number and the vertical axis denotes the MDN of each row. It can be seen from
Figure 12a that rapid fluctuations occurred in the curve for the existence of stripes and other noises. It is observed from
Figure 13b–g that the fluctuations were reduced by all the methods. As shown in
Figure 13b–e, due to the stripes in the image, there were some minor fluctuations in the curve, which is consistent with the restoration results shown in
Figure 12b–e.
Figure 12f shows the smoothed result of LRTDGS, which can also be confirmed from
Figure 13f. By contrast, the proposed method achieved more reasonable mean profile results, as shown in
Figure 13g.
4.3. Classification Performance Comparison
To further compare the performance of different denoising methods and the influence of denoising on classification application, real dataset, Indian pines, used in
Section 4.2, was selected. The effectiveness of the proposed algorithm and its influence on classification were verified by comparing the classification accuracy with the basic threshold classifier (BTC) [
43].
To compare the classification accuracy of different algorithms obtained by the classifier, three common evaluation indicators were used here: (1) Overall Accuracy (OA), that is, the number of correctly classified samples was divided by the number of test samples. OA is obtained by using 10% of the samples of each class for training and the remaining 90% for testing; (2) average accuracy (AA), namely, the average of classification accuracy of all available categories; and © Kappa coefficient (Ka), which is a statistical measure of the consistency between the final classification map and the real classification map. The formula of Kappa is as follows:
where
m is the column number of error matrix,
represents the element in the position of column
j, and line
j in the error matrix. The
is the sum of row
j in the error matrix. The
is the sum of column
j in the error matrix.
N is the number of test samples.
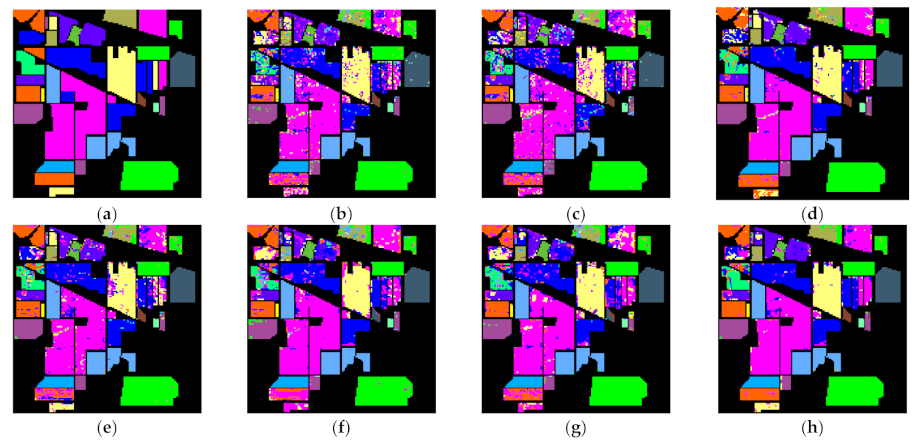
Figure 16b shows the classification map obtained by applying BTC on the original Indian Pines’ data set.
Figure 16c–h shows the classification map obtained by applying BTC after denoising on the Indian Pines’ data set using LRMR, LRTV, SSTV, LRTDTV, LRTDGS, and SSRTV. It was observed that BTC was seriously affected by noise on the original data, which made the classification accuracy low. Different denoising methods reduced this effect more or less and improved the classification accuracy. Compared with other algorithms, the proposed algorithm showed a more excellent performance.
Table 2 shows the indices by using BTC to classify the original Indian pines’ data and the denoised data. Three indices after denoising by all methods increased more or less. Different denoising results had different degrees of improvement in classification accuracy. For example, the denoising results of the LRMR method still contained a large amount of noise, so the Ka, OA, and AA values only increased by about 2%, 2%, and 0.01%, respectively. The Ka, OA, and AA values of the proposed algorithm increased about 12%, 12%, and 0.13%, respectively. Obviously, the proposed algorithm significantly improved the classification accuracy.
5. Discussion
- (1)
Parameters’ selection
In this section, we will address how to determine the parameters in our experiments with systematical analysis. The choosing of parameters was based on the simulated experiment in the Indian pines’ dataset.
In our model, there were two regularization parameters,
ρ and
τ; one penalty parameter,
μ; three weight parameters,
w1,
w2, and
w3; and Tucker rank (
r1,
r2,
r3) among the three HSI modes. For penalty parameter
μ, it was first initialized as
μ = 10
−2 and updated by
μ = min (
ημ,
μmax), where
η = 1.5 and
μmax = 10
6. This strategy of determining the variable
µ has been widely used in the ALM-based method [
12], which can facilitate the convergence of the algorithm.
For the Tucker rank (
r1,
r2,
r3), following the same strategy proposed in [
32], we set
r1 and
r2 as 80% of the width and height of each band image, respectively. In our simulated experiments, we set
r3 = 10. In the real data experiments, the
r3 was estimated by HySime [
44].
The parameter
ρ corresponded to the sparse term. It was set as
by default in the following experiments according to [
12,
32], where
m and
n were the width and height of each band image of HSI and
C was a parameter that needed to be carefully tuned. Therefore, we jointly tuned the parameters
ρ and
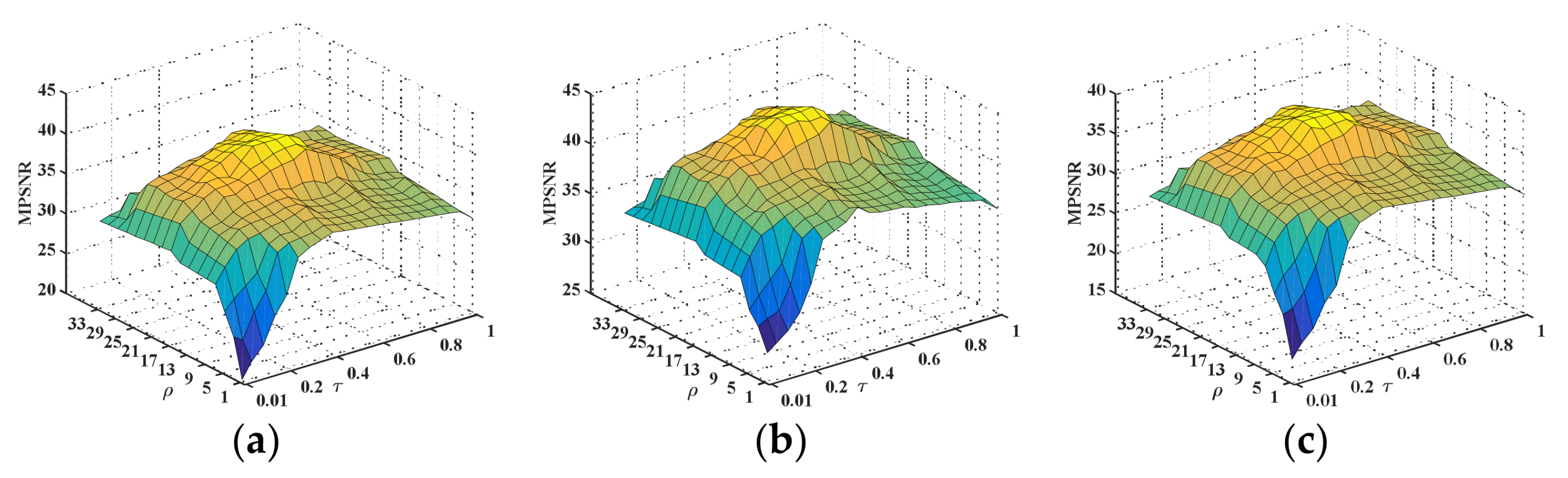
τ. We also chose the simulated cases 1, 5, and 6 to present the sensitivity analyses of these two parameters, and the MPSNR was used as the evaluation index.
Figure 17 shows the MPSNR values as
ρ varied in the set [1, 3, 5, 7, 9, 11, 13, 15, 17, 19, 21, 23, 25, 27, 29, 31, 33] and
τ varied in the set [0.01, 0.05, 0.1, 0.15, 0.2, 0.25, 0.3, 0.35, 0.4, 0.45, 0.5, 0.55, 0.6, 0.65, 0.7, 0.75, 0.8, 0.85, 0.9, 0.95, 1]. From this figure, we can see that the MPSNR values had similar change trends in the three cases, indicating that these two parameters were effective and robust for different noisy cases. Additionally, it can be observed that the MPSNR values were higher when the value of
ρ was changed from 17 to 25 and
τ was changed from 0.4 to 0.6. Consequently, it was suggested that the parameters
ρ and
τ were separately chosen from these ranges according to different noise cases.
The weighted parameters,
w1,
w2, and
w3, were used to balance the weights of spatial TV and SSRTV. It was demonstrated in [
12] that the two weights of spatial TV can be set the same; so, we set
w1 =
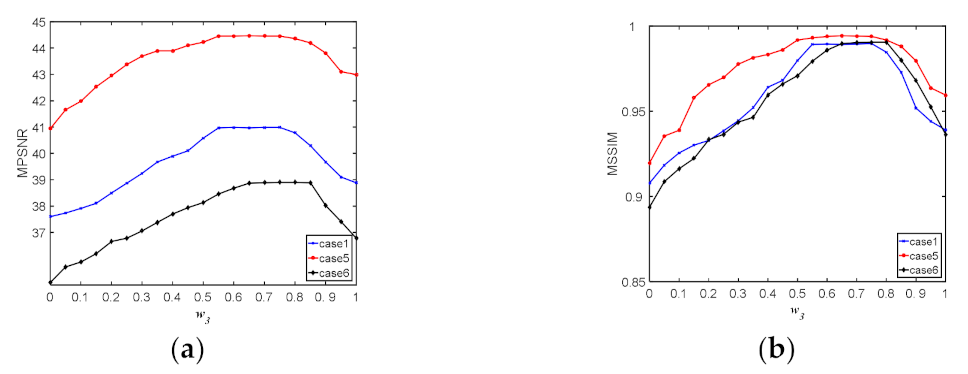
w2 = 1. Then, we tuned the weight of SSRTV in the range of 0 to 1. The parameter
w3 was crucial in keeping the balance of the local spatial smoothness and local spatial-spectral smoothness.
Figure 18 plots the curves of MPSNR and MSSIM values with respect to parameter
w3; it can be observed that when the parameter
w3 was in the range of 0.6 to 0.8, the MPSNR and MSSIM achieved the best values. Therefore, we set
w3 = 0.7 in all the experiments.
- (2)
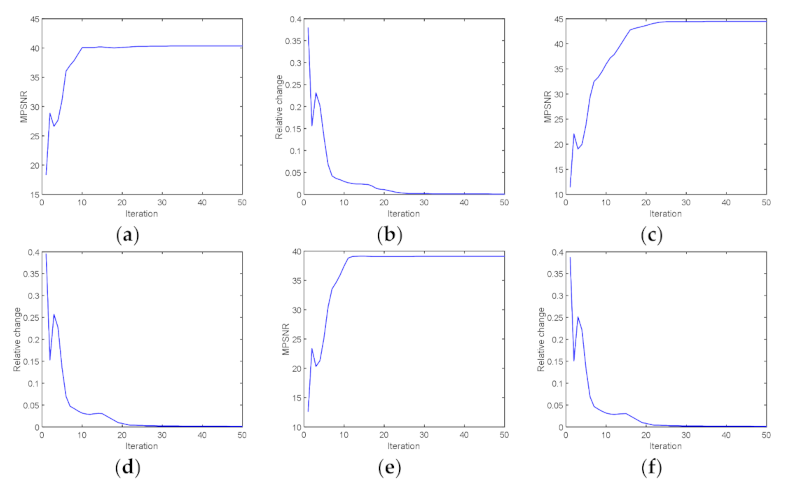
Convergence Analysis
Due to the non-convex constraint of LRTD, our solver was a non-convex optimization problem. Therefore, it was hard to get the globally optimal solution, and theoretical proof of the convergence was hard to guarantee. Nevertheless, to promote convergence of the algorithm, we employed the ALM-based optimization [
39] strategy to update the penalty parameter
μ in each iteration. Additionally, we illustrated the convergence of our solver by means of empirical analysis. The MPSNR and the relative change of the
values gain versus the iteration number under case 1, case 5, and case 6 in the simulated experiment are presented in
Figure 18. It can be recognized that, with the increasing of iterations, even if there were significant jumps in all the subfigures in
Figure 19, the MPSNR values increased rapidly before gradually stabilizing to a value, and the relative change converged to zero after about 20 iterations. This clearly illustrated the convergent behavior of the proposed LRTDSSRTV solver.
- (3)
Operation time analysis
To validate the feasibility and effectiveness of our method, we present the running time of all the compared methods on the real data experiments in
Table 3. All the experiments were carried out in MATLAB R2016a using a desktop of 16-GB RAM, with Intel Core i5-4590H
[email protected] GHz. As shown in
Table 3, our method was not the fastest, but the running time was acceptable and our method performed better. In the future, we will design a more effective algorithm to speed up our method.



























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}