
Multi-Exposure Image Fusion Techniques: A Comprehensive Review

Abstract
:1. Introduction
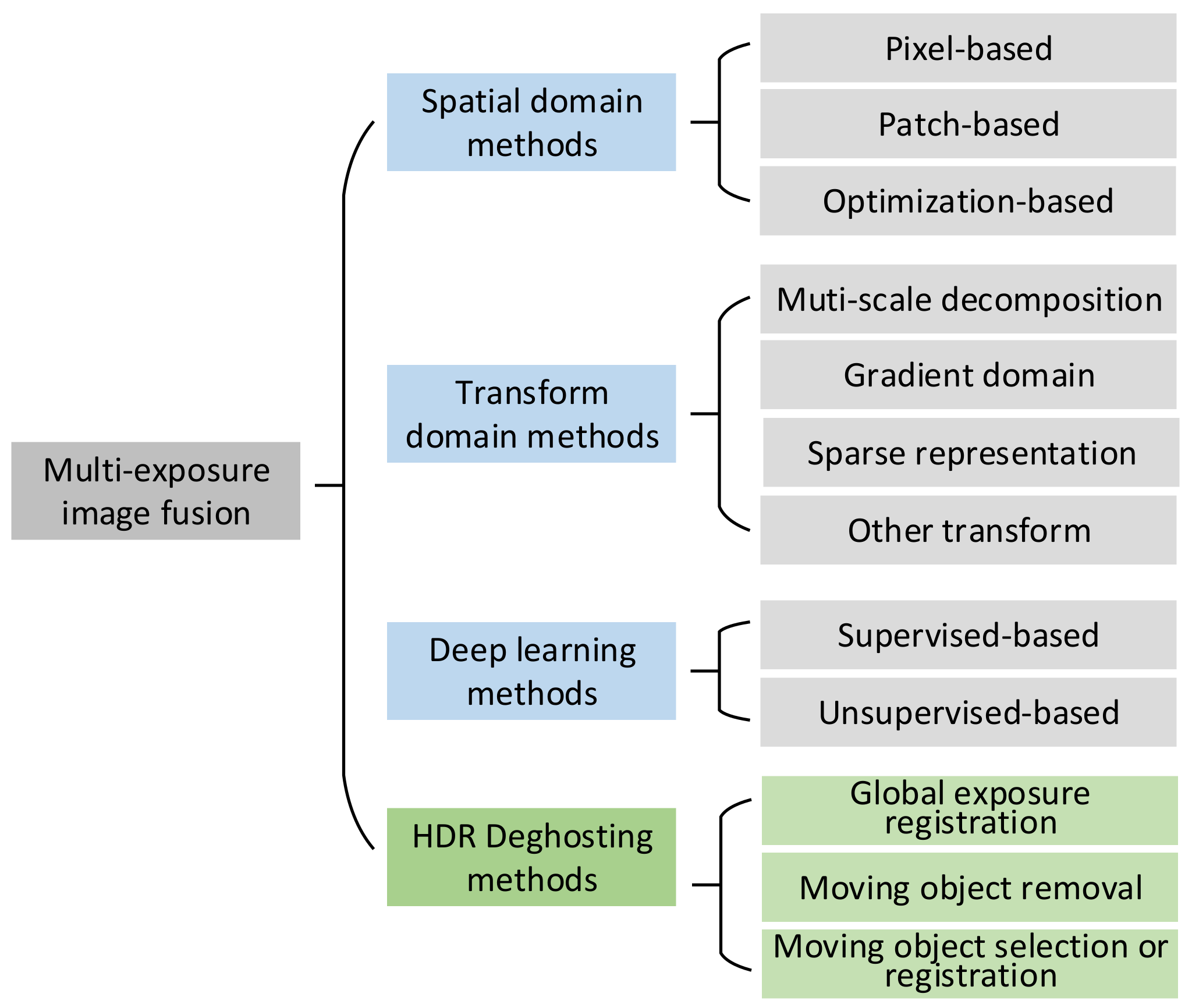
2. A Review on MEF
2.1. Spatial Domain Methods
2.1.1. Pixel-Based Methods
2.1.2. Patch-Based Methods
2.1.3. Optimization-Based Methods
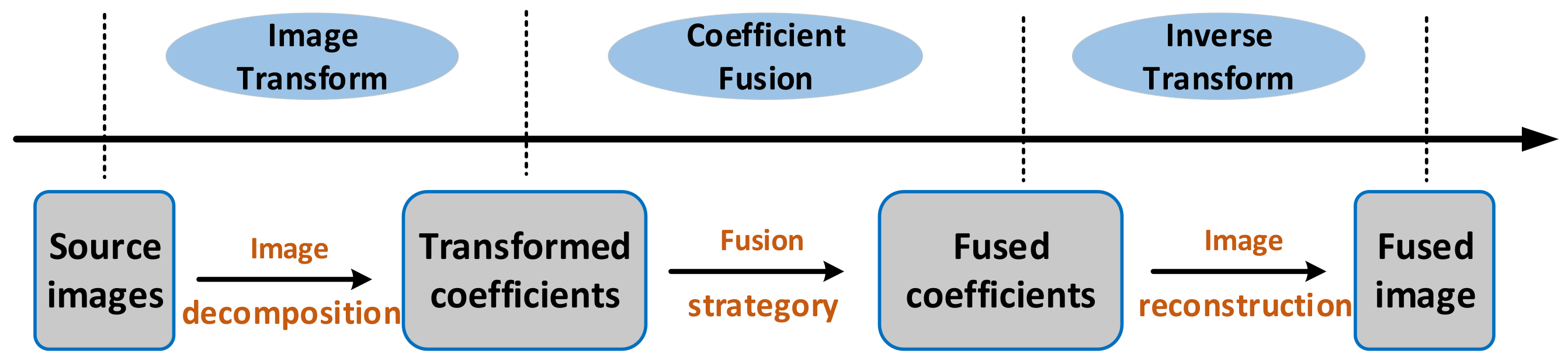
2.2. Transform Domain Methods
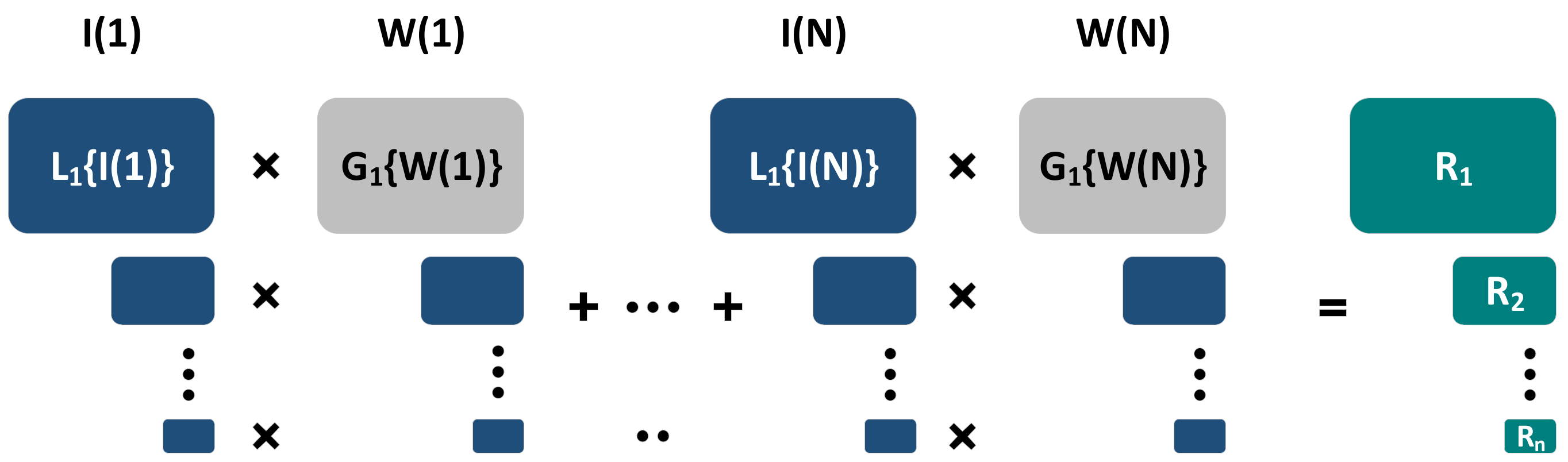
2.2.1. Multi-Scale Decomposition-Based Methods
2.2.2. Gradient-Based Methods
2.2.3. Sparse Representation-Based Methods
2.2.4. Other Transform-Based Methods
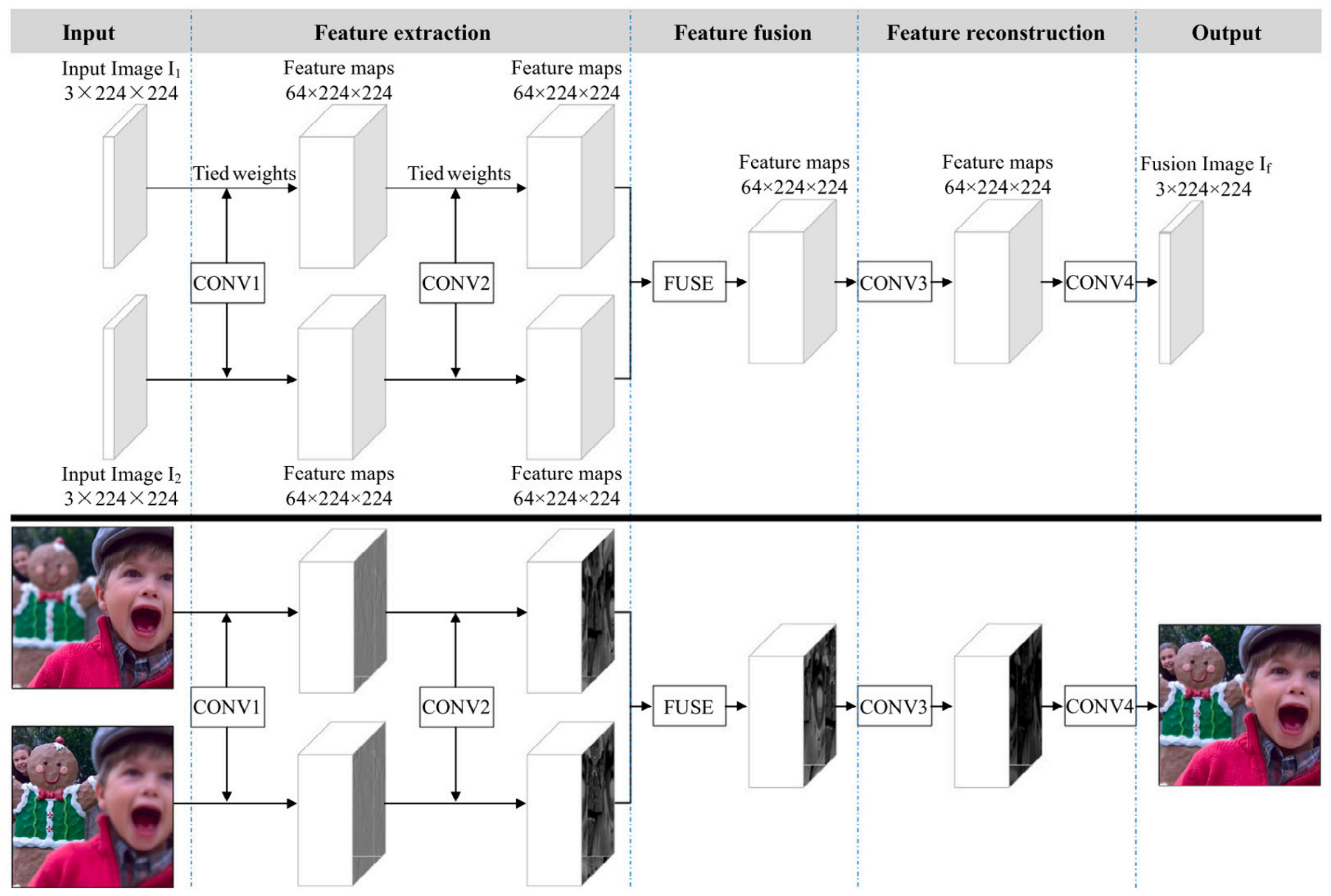
2.3. Deep Learning Methods
2.3.1. Supervised Methods
2.3.2. Unsupervised Methods
2.4. HDR Deghosting Methods
2.4.1. Global Exposure Registration
2.4.2. Moving Object Removal
2.4.3. Moving Object Selection or Registration
3. Experiments
3.1. Image Dataset
3.2. Performance Comparison
3.2.1. Subjective Qualitative Evaluation
3.2.2. Objective Quantitative Comparison

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
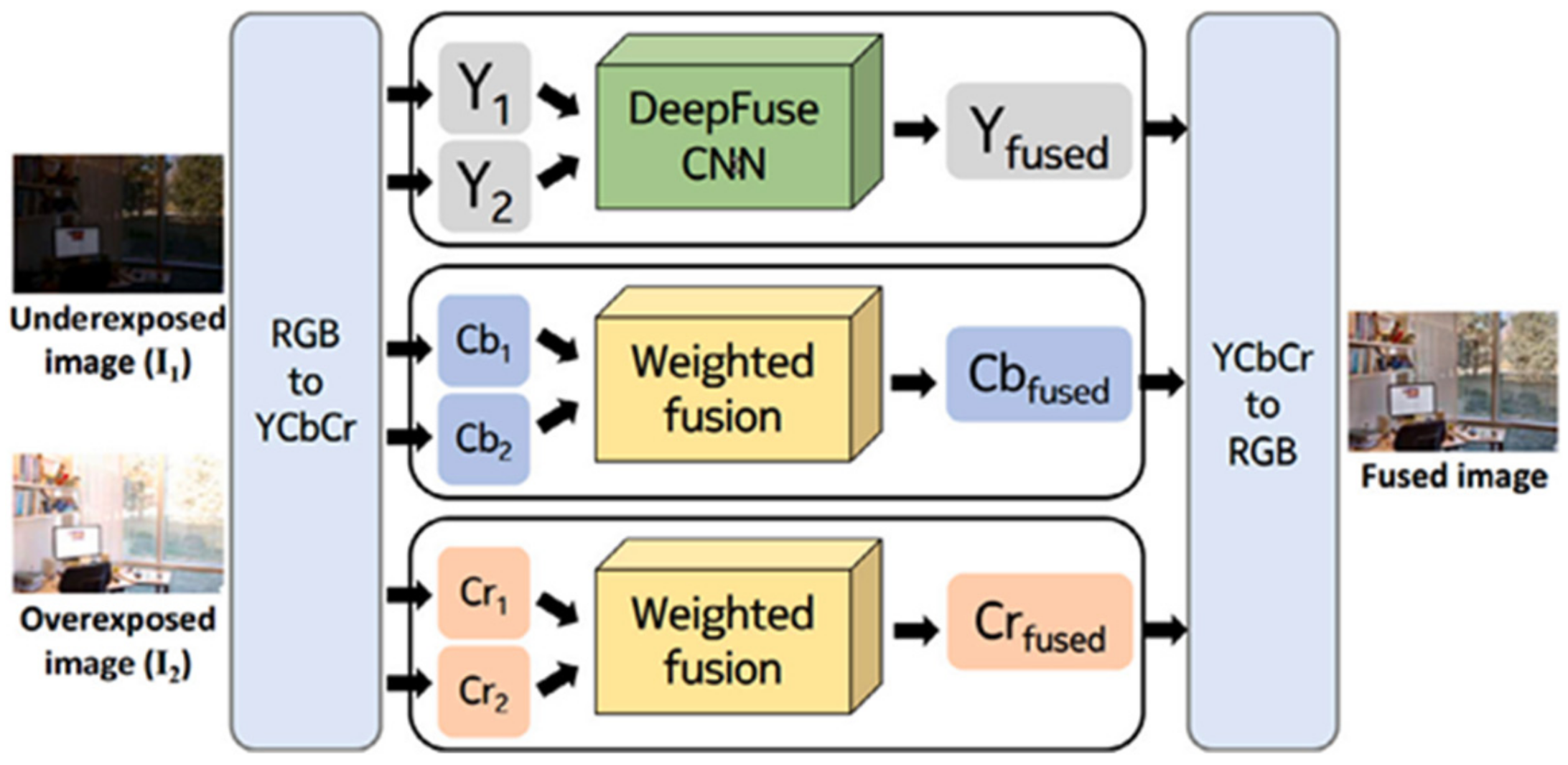{kind=link}
{kind=link}
{kind=link}
{kind=link}
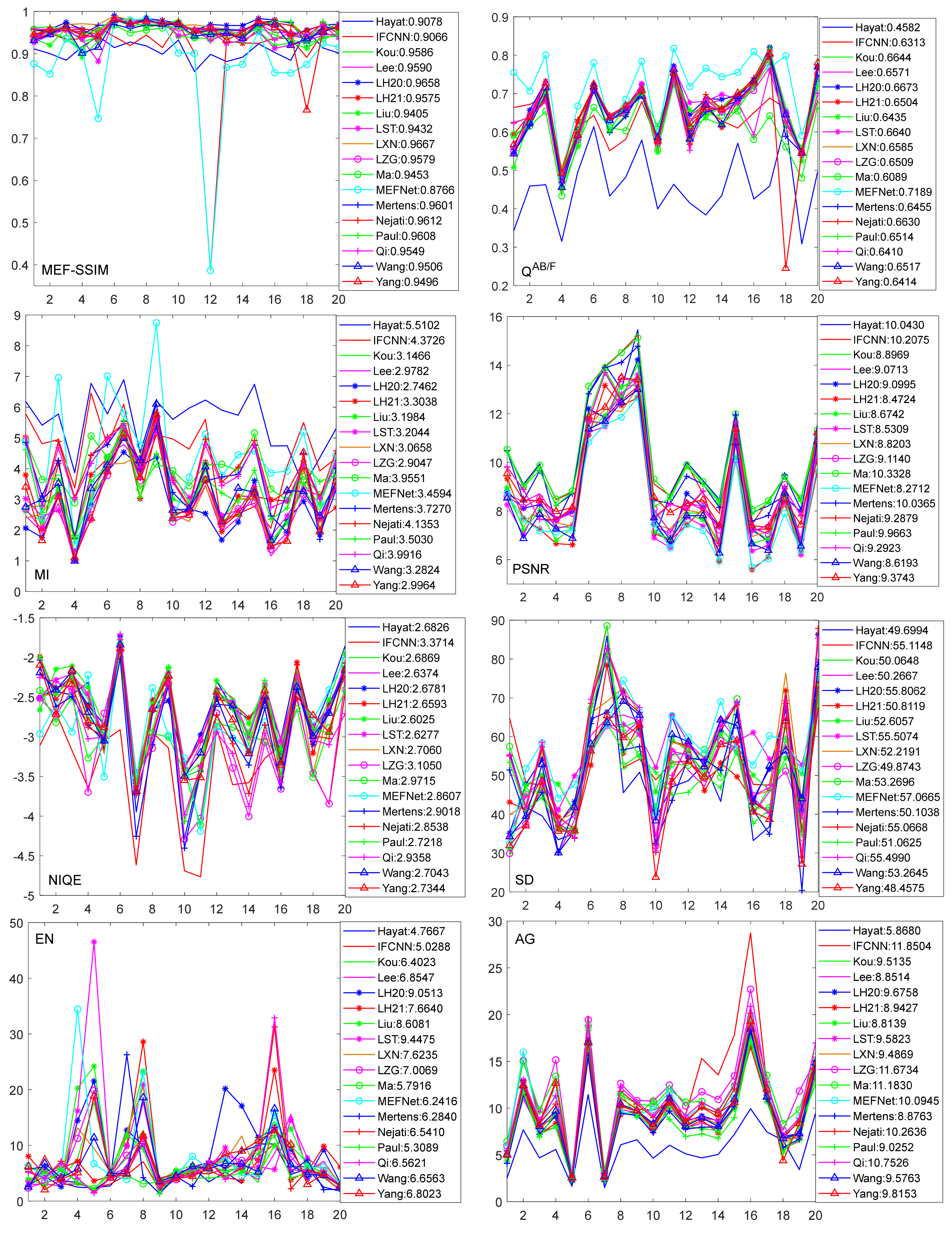{kind=link}
{kind=link}
{kind=link}
| NO. | Metric | References | Remarks |
|---|---|---|---|
| 1 | Structural similarity index measure (MEF-SSIM) | Huang [1]; Yang [13]; MEF-GAN [17]; Liu [58]; Yang [62]; Martorell [64]; Li [77]; Liu [80]; Chen [81]; Deepfuse [84]; MEFNet [86]; U2fusion [88]; Gao [89]; LXN [123]; Shao [134]; Wu [135]; Merianos [136] | The larger, the better |
| 2 | QAB/F | Nie [6]; Liu [38]; LST [42]; Hayat [115]; Shao [134] | The larger, the better |
| 3 | MEF-SSIMc | Martorell [64]; UMEF [87]; Shao [134] | The larger, the better |
| 4 | Mutual information (MI) | Nie [6]; Wang [34]; Gao [89]; Choi [137] | The larger, the better |
| 5 | Peak signal-to-noise ratio (PSNR) | Kim [7]; MEF-GAN [17]; Chen [81]; U2fusion [88]; Gao [89]; Shao [134] | The larger, the better |
| 6 | Natural image quality evaluator (NIQE) | Huang [1]; Hayat [115]; Wu [135]; Xu [138] | The smaller, the better |
| 7 | Standard deviation (SD) | MEF-GAN [17]; Gao [89]; Wu [135] | The larger, the better |
| 8 | Entropy (EN) | Gao [89]; Wu [135] | The larger, the better |
| 9 | Average gradient (AG) | Nie [6]; Wu [135] | The larger, the better |
| 10 | Visual information fidelity (VIF) | Liu [58]; LST [42]; Yang [62] | The larger, the better |
| 11 | Correlation coefficient (CC) | MEF-GAN [17]; U2fusion [88] | The larger, the better |
| 12 | Spatial frequency (SF) | Gao [89]; | The larger, the better |
| 13 | Q0 | Liu [38]; LST [42] | The larger, the better |
| 14 | Edge content (EC) | Hara [56] | The larger, the better |
| 15 | Lightness order error (LOE) | Liu [38] | The smaller, the better |
| 16 | DIIVINE | Shao [61] | The larger, the better |
3.3. Comparisons of Different MEF Methods
3.3.1. Testing for Static Scene
3.3.2. Testing for Dynamic Scene
3.3.3. Computational Efficiency
4. Future Prospects
- (1)
- Deep learning-based MEF
- (2)
- MEF in dynamic scene
- (3)
- The higher-quality MEF evaluation metrics
- (4)
- Task-oriented MEF
- (5)
- Real-time MEF
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Huang, L.; Li, Z.; Xu, C.; Feng, B. Multi-exposure image fusion based on feature evaluation with adaptive factor. IET Image Process. 2021, 15, 3211–3220. [Google Scholar] [CrossRef]
- Shen, R.; Cheng, I.; Basu, A. QoE-based multi-exposure fusion in hierarchical multivariate gaussian CRF. IEEE Trans. Image Process. 2013, 22, 2469–2478. [Google Scholar] [CrossRef]
- Aggarwal, M.; Ahuja, N. Split aperture imaging for high dynamic range. In Proceedings of the 8th IEEE International Conference on Computer Vision(ICCV), Vancouver, BC, Canada, 7–14 July 2001; pp. 10–16. [Google Scholar]
- Tumblin, J.; Agrawal, A.; Raskar, R. Why I want a gradient camera. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition(CVPR), San Diego, CA, USA, 20–25 June 2005; pp. 103–110. [Google Scholar]
- Li, S.; Kang, X.; Fang, L.; Hu, J.; Yin, H. Pixel-level image fusion: A survey of the state of the art. Inf. Fusion 2017, 33, 100–112. [Google Scholar] [CrossRef]
- Nie, T.; Huang, L.; Liu, H.; Xiansheng Li, X. Multi-exposure fusion of gray images under low illumination based on low-rank decomposition. Remote Sens. 2021, 13, 204. [Google Scholar] [CrossRef]
- Kim, J.; Ryu, J.; Kim, J. Deep gradual flash fusion for low-light enhancement. J. Vis. Commun. Image Represent. 2020, 72, 102903. [Google Scholar] [CrossRef]
- Galdran, A. Image dehazing by artificial multiple-exposure image fusion. Signal Process. 2018, 149, 135–147. [Google Scholar] [CrossRef]
- Wang, X.; Sun, Z.; Zhang, Q.; Fang, Y. Multi-exposure decomposition-fusion model for high dynamic range image saliency detection. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 4409–4420. [Google Scholar] [CrossRef]
- Zhang, X. Benchmarking and comparing multi-exposure image fusion algorithms. Inf. Fusion 2021, 74, 111–131. [Google Scholar] [CrossRef]
- Burt, P.; Kolczynski, R. Enhanced image capture through fusion. In Proceedings of the International Conference on Computer Vision (ICCV), Berlin, Germany, 11–14 May 1993; pp. 173–182. [Google Scholar]
- Bertalmío, M.; Levine, S. Variational approach for the fusion of exposure bracketed pairs. IEEE Trans. Image Process. 2013, 22, 712–723. [Google Scholar] [CrossRef]
- Yang, Y.; Wu, S.; Wang, X.; Li, Z. Exposure interpolation for two large-exposure-ratio images. IEEE Access 2020, 8, 227141–227151. [Google Scholar] [CrossRef]
- Prabhakar, K.R.; Agrawal, S.; Babu, R.V. Self-gated memory recurrent network for efficient scalable HDR deghosting. IEEE Trans. Comput. Imaging 2021, 7, 1228–1239. [Google Scholar]
- Liu, Y.; Wang, L.; Cheng, J.; Chang, L.; Xun, C. Multi-focus image fusion: A Survey of the state of the art. Inf. Fusion 2020, 64, 71–91. [Google Scholar] [CrossRef]
- Chen, Y.; Jiang, G.; Yu, M.; Yang, Y.; Ho, Y.S. Learning stereo high dynamic range imaging from a pair of cameras with different exposure parameters. IEEE Trans. Comput. Imaging 2020, 6, 1044–1058. [Google Scholar] [CrossRef]
- Xu, H.; Ma, J.; Zhang, X. MEF-GAN: Multi-exposure image fusion via generative adversarial networks. IEEE Trans. Image Process. 2020, 29, 7203–7216. [Google Scholar] [CrossRef]
- Chang, M.; Feng, H.; Xu, Z.; Li, Q. Robust ghost-free multiexposure fusion for dynamic scenes. J. Electron. Imaging 2018, 27, 033023. [Google Scholar] [CrossRef]
- Karaduzovic-Hadziabdic, K.; Telalovic, J.H.; Mantiuk, R.K. Assessment of multi-exposure HDR image deghosting methods. Comput. Graph. 2017, 63, 1–17. [Google Scholar] [CrossRef] [Green Version]
- Bruce, N.D.B. Expoblend: Information preserving exposure blending based on normalized log-domain entropy. Comput. Graph. 2014, 39, 12–23. [Google Scholar] [CrossRef]
- Lee, L.-H.; Park, J.S.; Cho, N.I. A multi-exposure image fusion based on the adaptive weights reflecting the relative pixel intensity and global gradient. In Proceedings of the 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 1737–1741. [Google Scholar]
- Kinoshita, Y.; Kiya, H. Scene segmentation-based luminance adjustment for multi-exposure image fusion. IEEE Trans. Image Process. 2019, 28, 4101–4115. [Google Scholar] [CrossRef] [Green Version]
- Xu, Y.; Sun, B. Color-compensated multi-scale exposure fusion based on physical features. Optik 2020, 223, 165494. [Google Scholar] [CrossRef]
- Ulucan, O.; Karakaya, D.; Turkan, M. Multi-exposure image fusion based on linear embeddings and watershed masking. Signal Process. 2021, 178, 107791. [Google Scholar] [CrossRef]
- Raman, S.; Chaudhuri, S. Bilateral Filter Based Compositing for Variable Exposure Photography. The Eurographics Association: Geneve, Switzerland, 2009; pp. 1–4. [Google Scholar]
- Li, S.; Kang, X. Fast multi-exposure image fusion with median filter and recursive filter. IEEE Trans. Consum. Electron. 2012, 58, 626–632. [Google Scholar] [CrossRef] [Green Version]
- Wang, C.; He, C.; Xu, M. Fast exposure fusion of detail enhancement for brightest and darkest regions. Vis. Comput. 2021, 37, 1233–1243. [Google Scholar] [CrossRef]
- Goshtasby, A.A. Fusion of multi-exposure images. Image Vis. Comput. 2005, 23, 611–618. [Google Scholar] [CrossRef]
- Huang, F.; Zhou, D.; Nie, R. A Color Multi-exposure image fusion approach using structural patch decomposition. IEEE Access 2018, 6, 42877–42885. [Google Scholar] [CrossRef]
- Ma, K.; Wang, Z. Multi-exposure image fusion: A patch-wise approach. In Proceedings of the 2015 IEEE International Conference on Image Processing, Quebec City, QC, Canada, 27–30 September 2015; pp. 1717–1721. [Google Scholar]
- Ma, K.; Li, H.; Yong, H.; Wang, Z.; Meng, D.; Zhang, L. Robust multi-exposure image fusion: A structural patch decomposition approach. IEEE Trans. Image Process. 2017, 26, 2519–2532. [Google Scholar] [CrossRef]
- Li, H.; Ma, K.; Yong, H.; Zhang, L. Fast multi-scale structural patch decomposition for multi-exposure image fusion. IEEE Trans. Image Process. 2020, 29, 5805–5816. [Google Scholar] [CrossRef]
- Li, H.; Chan, T.N.; Qi, X.; Xie, W. Detail-preserving multi-exposure fusion with edge-preserving structural patch decomposition. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 1–12. [Google Scholar] [CrossRef]
- Wang, S.; Zhao, Y. A novel patch-based multi-exposure image fusion using super-pixel segmentation. IEEE Access 2020, 8, 39034–39045. [Google Scholar] [CrossRef]
- Shen, R.; Cheng, I.; Shi, J.; Basu, A. Generalized random walks for fusion of multi-exposure images. IEEE Trans. Image Process. 2011, 20, 3634–3646. [Google Scholar] [CrossRef]
- Li, Z.; Zheng, J.; Rahardja, S. Detail-enhanced exposure fusion. IEEE Trans. Image Process. 2012, 21, 4672–4676. [Google Scholar]
- Song, M.; Tao, D.; Chen, C. Probabilistic exposure fusion. IEEE Trans. Image Process. 2012, 21, 341–357. [Google Scholar] [CrossRef] [PubMed]
- Liu, S.; Zhang, Y. Detail-preserving underexposed image enhancement via optimal weighted multi-exposure fusion. IEEE Trans. Consum. Electron. 2019, 65, 303–311. [Google Scholar] [CrossRef]
- Ma, K.; Duanmu, Z.; Yeganeh, H.; Wang, Z. Multi-exposure image fusion by optimizing a structural similarity index. IEEE Trans. Comput. Imaging 2018, 4, 60–72. [Google Scholar] [CrossRef]
- Qi, G.; Chang, L.; Luo, Y.; Chen, Y. A precise multi-exposure image fusion method based on low-level features. Sensors 2020, 20, 1597. [Google Scholar] [CrossRef] [Green Version]
- Mertens, T.; Kautz, J.; Reeth, F.V. Exposure fusion. In Proceedings of the 15th Pacific Conference on Computer Graphics and Applications, Maui, HI, USA, 4 December 2007; pp. 382–390. [Google Scholar]
- Li, S.; Kang, X.; Hu, J. Image fusion with guided filtering. IEEE Trans. Image Process. 2013, 22, 2864–2875. [Google Scholar] [PubMed]
- Shen, J.; Zhao, Y.; Yan, S.; Li, X. Exposure fusion using boosting laplacian pyramid. IEEE Trans. Cybern. 2014, 44, 1579–1590. [Google Scholar] [CrossRef]
- Singh, H.; Kumar, V.; Bhooshan, S. A novel approach for detail-enhanced exposure fusion using guided filter. Sci. World J. 2014, 2014, 659217. [Google Scholar] [CrossRef]
- Nejati, M.; Karimi, M.; Soroushmehr, S.M.R.; Karimi, N.; Samavi, S.; Najarian, K. Fast exposure fusion using exposuredness function. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 2234–2238. [Google Scholar]
- Li, Z.; Wen, C.; Zheng, J. Detail-enhanced multi-scale exposure fusion. IEEE Trans. Image Process. 2017, 26, 1243–1252. [Google Scholar] [CrossRef]
- Yan, Q.; Zhu, Y.; Zhou, Y.; Sun, J.; Zhang, L.; Zhang, Y. Enhancing image visuality by multi-exposure fusion. Pattern Recognit. Lett. 2019, 127, 66–75. [Google Scholar] [CrossRef]
- Wang, Q.; Chen, W.; Wu, X.; Li, Z. Detail-enhanced multi-scale exposure fusion in YUV color space. IEEE Trans. Circuits Syst. Video Technol. 2019, 26, 1243–1252. [Google Scholar] [CrossRef]
- Kou, F.; Li, Z.; Wen, C.; Chen, W. Edge-preserving smoothing pyramid based multi-scale exposure fusion. J. Vis. Commun. Image Represent. 2018, 53, 235–244. [Google Scholar] [CrossRef]
- Yang, Y.; Cao, W.; Wu, S.; Li, Z. Multi-scale fusion of two large-exposure-ratio image. IEEE Signal Process. Lett. 2018, 25, 1885–1889. [Google Scholar] [CrossRef]
- Qu, Z.; Huang, X.; Chen, K. Algorithm of multi-exposure image fusion with detail enhancement and ghosting removal. J. Electron. Imaging 2019, 28, 013022. [Google Scholar] [CrossRef]
- Lin, Y.-H.; Hua, K.-L.; Lu, H.-H.; Sun, W.-L.; Chen, Y.-Y. An adaptive exposure fusion method using fuzzy logic and multivariate normal conditional random fields. Sensors 2019, 19, 1–23. [Google Scholar] [CrossRef] [Green Version]
- Gu, B.; Li, W.; Wong, J.; Zhu, M.; Wang, M. Gradient field multi-exposure images fusion for high dynamic range image visualization. J. Vis. Commun. Image Represent. 2012, 23, 604–610. [Google Scholar] [CrossRef]
- Zhang, W.; Cham, W.-K. Gradient-directed multiexposure composition. IEEE Trans. Image Process. 2012, 21, 2318–2323. [Google Scholar] [CrossRef]
- Wang, C.; Yang, Q.; Tang, X.; Ye, Z. Salience preserving image fusion with dynamic range compression. In Proceedings of the IEEE International Conference on Image Processing, Atlanta, GA, USA, 8–11 October 2006; pp. 989–992. [Google Scholar]
- Hara, K.; Inoue, K.; Urahama, K. A differentiable approximation approach to contrast aware image fusion. IEEE Signal Process. Lett. 2014, 21, 742–745. [Google Scholar] [CrossRef]
- Paul, S.; Sevcenco, J.S.; Agathoklis, P. Multi-exposure and multi-focus image fusion in gradient domain. J. Circuits Syst. Comput. 2016, 25, 1650123. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Zhou, D.; Nie, R.; Hou, R.; Ding, Z. Construction of high dynamic range image based on gradient information transformation. IET Image Process. 2020, 14, 1327–1338. [Google Scholar] [CrossRef]
- Wang, X.; Shen, S.; Ning, C.; Huang, F.; Gao, H. Multiclass remote sensing object recognition based on discriminative sparse representation. Appl. Opt. 2016, 55, 1381–1394. [Google Scholar] [CrossRef]
- Wang, J.; Liu, H.; He, N. Exposure fusion based on sparse representation using approximate K-SVD. Neurocomputing 2014, 135, 145–154. [Google Scholar] [CrossRef]
- Shao, H.; Jiang, G.; Yu, M.; Song, Y.; Jiang, H.; Peng, Z.; Chen, F. Halo-free multi-exposure image fusion based on sparse representation of gradient features. Appl. Sci. 2018, 8, 1543. [Google Scholar] [CrossRef] [Green Version]
- Yang, Y.; Wu, J.; Huang, S.; Lin, P. Multi-exposure estimation and fusion based on a sparsity exposure dictionary. IEEE Trans. Instrum. Meas. 2020, 69, 4753–4767. [Google Scholar] [CrossRef]
- Lee, G.-Y.; Lee, S.-H.; Kwon, H.-J. DCT-based HDR exposure fusion using multiexposed image sensors. J. Sensors 2017, 2017, 1–14. [Google Scholar] [CrossRef]
- Martorell, O.; Sbert, C.; Buades, A. Ghosting-free DCT based multi-exposure image fusion. Signal Process. Image Commun. 2019, 78, 409–425. [Google Scholar] [CrossRef]
- Zhang, W.; Liu, X.; Wang, W.; Zeng, Y. Multi-exposure image fusion based on wavelet transform. Int. J. Adv. Robot. Syst. 2018, 15, 1–19. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Liu, T.; Singh, M.; Cetintas, E.; Luo, Y.; Rivenson, Y.; Larin, K.V.; Ozcan, A. Neural network-based image reconstruction in swept-source optical coherence tomography using undersampled spectral data. Light. Sci. Appl. 2021, 10, 390–400. [Google Scholar] [CrossRef]
- Li, X.; Zhang, G.; Qiao, H.; Bao, F.; Deng, Y.; Wu, J.; He, Y.; Yun, J.; Lin, X.; Xie, H.; et al. Unsupervised content-preserving transformation for optical microscopy. Light. Sci. Appl. 2021, 10, 1658–1671. [Google Scholar] [CrossRef]
- Wu, S.; Xu, J.; Tai, Y.W. Deep high dynamic range imaging with large foreground motions. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 9 October 2018; pp. 120–135. [Google Scholar]
- Yan, Q.; Gong, D.; Zhang, P. Multi-scale dense networks for deep high dynamic range imaging. In Proceedings of the 2019 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 7–11 January 2019; pp. 41–50. [Google Scholar]
- Yan, Q.; Gong, D.; Shi, Q. Attention guided network for ghost-free high dynamic range imaging. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 1751–1760. [Google Scholar]
- Wang, J.; Li, X.; Liu, H. Exposure fusion using a relative generative adversarial network. IEICE Trans. Inf. Syst. 2021, E104D, 1017–1027. [Google Scholar] [CrossRef]
- Vu, T.; Nguyen, C.V.; Pham, T.X.; Luu, T.M.; Yoo, C.D. Fast and efficient image quality enhancement via desubpixel convolutional neural networks. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 23 January 2019; pp. 243–259. [Google Scholar]
- Jeon, M.; Jeong, Y.S. Compact and accurate scene text detector. Appl. Sci. 2020, 10, 2096. [Google Scholar] [CrossRef] [Green Version]
- Kalantari, N.K.; Ramamoorthi, R. Deep high dynamic range imaging of dynamic scenes. ACM Trans. Graph. 2017, 36, 144. [Google Scholar] [CrossRef]
- Wang, J.; Wang, W.; Xu, G.; Liu, H. End-to-end exposure fusion using convolutional neural network. IEICE Trans. Inf. Syst. 2018, 101, 560–563. [Google Scholar] [CrossRef] [Green Version]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F.F. Imagenet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition(CVPR), Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Li, H.; Zhang, L. Multi-exposure fusion with CNN features. In Proceedings of the 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 1723–1727. [Google Scholar]
- Lahoud, F.; Süsstrunk, S. Fast and efficient zero-learning image fusion. arXiv 2019, arXiv:1902.00730. [Google Scholar]
- Cai, J.; Gu, S.; Zhang, L. Learning a deep single image contrast enhancer from multi-exposure images. IEEE Trans. Image Process. 2018, 27, 2049–2062. [Google Scholar] [CrossRef]
- Liu, Q.; Leung, H. Variable augmented neural network for decolorization and multi-exposure fusion. Inf. Fusion 2019, 46, 114–127. [Google Scholar] [CrossRef]
- Chen, Y.; Yu, M.; Jiang, G.; Peng, Z.; Chen, F. End-to-end single image enhancement based on a dual network cascade model. J. Vis. Commun. Image Represent. 2019, 61, 284–295. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, Y.; Sun, P.; Yan, H.; Zhao, X.; Zhang, L. IFCNN: A general image fusion framework based on convolutional neural network. Inf. Fusion 2020, 54, 99–118. [Google Scholar] [CrossRef]
- Fang, A.; Zhao, X.; Yang, J.; Qin, B.; Zhang, Y. A light-weight, efficient, and general cross-modal image fusion network. Neurocomputing 2021, 463, 198–211. [Google Scholar] [CrossRef]
- Prabhakar, K.P.; Srikar, V.S.; Babu, R.V. Deepfuse: A deep unsupervised approach for exposure fusion with extreme exposure image pairs. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 4724–4732. [Google Scholar]
- Ma, K.; Zeng, K.; Wang, Z. Perceptual quality assessment for multi-exposure image fusion. IEEE Trans. Image Process. 2015, 24, 3345–3356. [Google Scholar] [CrossRef]
- Ma, K.; Duanmu, Z.; Zhu, H.; Fang, Y.; Wang, Z. Deep guided learning for fast multi-exposure image fusion. IEEE Trans. Image Process. 2020, 29, 2808–2819. [Google Scholar] [CrossRef]
- Qi, Y.; Zhou, S.; Zhang, Z.; Luo, S.; Lin, X.; Wang, L.; Qiang, B. Deep unsupervised learning based on color un-referenced loss functions for multi-exposure image fusion. Inf. Fusion 2021, 66, 18–39. [Google Scholar] [CrossRef]
- Xu, H.; Ma, J.; Jiang, J.; Guo, X.; Ling, H. U2Fusion: A unified unsupervised image fusion network. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 502–518. [Google Scholar] [CrossRef] [PubMed]
- Gao, M.; Wang, J.; Chen, Y.; Du, C. An improved multi-exposure image fusion method for intelligent transportation system. Electronics 2021, 10, 383. [Google Scholar] [CrossRef]
- Chen, S.Y.; Chuang, Y.Y. Deep exposure fusion with deghosting via homography estimation and attention learning. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 1464–1468. [Google Scholar]
- Yang, Z.; Chen, Y.; Le, Z.; Ma, Y. GANFuse: A novel multi-exposure image fusion method based on generative adversarial networks. Neural Comput. Appl. 2021, 33, 6133–6145. [Google Scholar] [CrossRef]
- Tursun, O.T.; Akyüz, A.O.; Erdem, A.; Erdem, E. The state of the art in HDR deghosting: A survey and evaluation. Comput. Graphics 2015, 34, 683–707. [Google Scholar] [CrossRef]
- Yan, Q.; Gong, D.; Shi, J.Q.; Hengel, A.; Sun, J.; Zhu, Y.; Zhang, Y. High dynamic range imaging via gradient-aware context aggregation network. Pattern Recogn. 2022, 122, 108342. [Google Scholar] [CrossRef]
- Woo, S.M.; Ryu, J.H.; Kim, J.O. Ghost-free deep high-dynamic-range imaging using focus pixels for complex motion scenes. IEEE Trans. Image Process. 2021, 30, 5001–5016. [Google Scholar] [CrossRef] [PubMed]
- Cerman, L.; Hlaváč, V. Exposure time estimation for high dynamic range imaging with hand held camera. In Proceedings of the Computer Vision Winter Workshop, Telc, Czech Republic, 6–8 February 2006; pp. 1–6. [Google Scholar]
- Gevrekci, M.; Gunturk, K.B. On geometric and photometric registration of images. In Proceedings of the 2007 IEEE International Conference on Acoustics, Speech and Signal Processing, Honolulu, HI, USA, 15–20 April 2007; pp. 1261–1264. [Google Scholar]
- Yao, S. Robust image registration for multiple exposure high dynamic range image synthesis. In Proceedings of the SPIE, Conference on Image Processing: Algorithms and Systems IX, San Francisco, CA, USA, 24–25 January 2011. [Google Scholar]
- Im, J.; Lee, S.; Paik, J. Improved elastic registration for ghost artifact free high dynamic range imaging. IEEE Trans. Consum. Electron. 2011, 57, 932–935. [Google Scholar] [CrossRef]
- Khan, E.A.; Akyuz, A.O.; Reinhard, E. Ghost removal in high dynamic range images. In Proceedings of the IEEE International Conference on Image Processing, Atlanta, GA, USA, 8–11 October 2006; pp. 2005–2008. [Google Scholar]
- Pedone, M.; Heikkil, J. Constrain propagation for ghost removal in high dynamic range images. VISAPP 2008. In Proceedings of the 3rd International Conference on Computer Vision Theory and Applications, Funchal, Madeira, Portugal, 22–25 January 2008; pp. 36–41. [Google Scholar]
- Zhang, W.; Cham, W.K. Gradient-directed composition of multi-exposure images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010; pp. 530–536. [Google Scholar]
- Wang, Z.; Liu, Q.; Ikenaga, T. Robust ghost-free high-dynamic-range imaging by visual salience based bilateral motion detection and stack extension based exposure fusion. IEICE Trans. Fundam. Electron. Commun. Computer Sci. 2017, E100, 2266–2274. [Google Scholar] [CrossRef]
- Li, Z.; Zheng, J.; Zhu, Z.; Wu, S. Selectively detail-enhanced fusion of differently exposed images with moving objects. IEEE Trans. Image Process. 2014, 23, 4372–4382. [Google Scholar] [CrossRef]
- Jacobs, K.; Loscos, C.; Ward, G. Automatic high-dynamic range image generation for dynamic scenes. IEEE Comput. Graph. Appl. 2008, 28, 84–93. [Google Scholar] [CrossRef] [PubMed]
- Pece, F.; Kautz, J. Bitmap movement detection: HDR for dynamic scenes. In Proceedings of the IEEE Conference on Visual Media Production, London, UK, 17–18 November 2010; pp. 1–8. [Google Scholar]
- Silk, S.; Lang, J. Fast high dynamic range image deghosting for arbitrary scene motion. In Proceedings of the Graphics Interface, Toronto, ON, Canada, 28–30 May 2012; pp. 85–92. [Google Scholar]
- Zhang, W.; Cham, W.K. Reference-guided exposure fusion in dynamic scenes. J. Vis. Commun. Image Represent. 2012, 23, 467–475. [Google Scholar] [CrossRef]
- Granados, M.; Tompkin, J.; Kim, K.I.; Theobalt, C. Automatic noise modeling for ghost-free HDR reconstruction. ACM Trans. Graph. 2013, 32, 201. [Google Scholar] [CrossRef]
- Lee, C.; Li, Y.; Monga, V. Ghost-free high dynamic range imaging via rank minimization. IEEE Signal Process. Lett. 2014, 21, 1045–1049. [Google Scholar]
- Wang, C.; He, C. A novel deghosting method for exposure fusion. Multimed. Tools Appl. 2018, 77, 31911–31928. [Google Scholar] [CrossRef]
- Zimmer, H.; Bruhn, A.; Weickert, J. Freehand HDR Imaging of Moving Scenes with Simultaneous Resolution Enhancement. Comput. Graph. 2011, 30, 405–414. [Google Scholar] [CrossRef]
- Jinno, T.; Okuda, M. Multiple exposure fusion for high dynamic range image acquisition. IEEE Trans. Image Process. 2012, 21, 358–365. [Google Scholar] [CrossRef]
- Ferradans, S.; Bertalmío, M.; Provenzi, E.; Caselles, V. Generation of HDR images in non-static conditions based on gradient fusion. In Proceedings of the 3rd International Conference on Computer Vision Theory and Applications, Barcelona, Spain, 11 September 2012; pp. 31–37. [Google Scholar]
- Liu, Y.; Wang, Z. Dense SIFT for ghost-free multi-exposure fusion. J. Vis. Commun. Image Represent. 2015, 31, 208–224. [Google Scholar] [CrossRef]
- Hayat, N.; Imran, M. Ghost-free multi exposure image fusion technique using dense sift descriptor and guided filter. J. Vis. Commun. Image Represent. 2019, 62, 295–308. [Google Scholar] [CrossRef]
- Zhang, W.; Hu, S.; Liu, K.; Yao, J. Motion-free exposure fusion based on inter-consistency and intra-consistency. Inf. Sci. 2017, 376, 190–201. [Google Scholar] [CrossRef]
- Sen, P.; Kalantari, N.K.; Yaesoubi, M.; Darabi, S. Robust patch-based HDR reconstruction of dynamic scenes. ACM Trans. Graph. 2012, 31, 203. [Google Scholar] [CrossRef]
- Hu, J.; Gallo, Q.; Pulli, K. Exposure stacks of live scenes with hand-held cameras. In Proceedings of the European Conference on Computer Vision (ECCV), Firenze, Italy, 7–13 October 2012; pp. 499–512. [Google Scholar]
- Hu, J.; Gallo, O.; Pulli, K.; Sun, X. HDR deghosting: How to deal with saturation? In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 1163–1170. [Google Scholar]
- Tursun, O.T.; Akyüz, A.O.; Erdem, A.; Erdem, E. Evaluating deghosting algorithms for HDR images. In Proceedings of the Signal Processing and Communications Applications Conference (SIU), Trabzon, Turkey, 23–25 April 2014; pp. 1275–1278. [Google Scholar]
- Nosko, S.; Musil, M.; Zemcik, P.; Juranek, R. Color HDR video processing architecture for smart camera. J. Real-Time Image Pr. 2020, 17, 555–566. [Google Scholar] [CrossRef]
- Castro, T.K.; Chapiro, A.; Cicconet, M.; Velho, L. Towards mobile HDR video. In Proceedings of the Eurographics Areas Papers, Llandudno, UK, 11–15 April 2011; pp. 75–76. [Google Scholar]
- Liu, X.; Liu, Y.; Zhu, C. Perceptual multi-exposure image fusion. IEEE Trans. Multimed. 2022. submitted for publication. [Google Scholar]
- Tursun, O.; Akyüz, A.; Erdem, A.; Erdem, E. An objective deghosting quality metric for HDR images. Euro Graph. 2016, 35, 1–14. [Google Scholar] [CrossRef]
- Liu, Z.; Blasch, E.; Xue, Z. Objective assessment of multiresolution image fusion algorithms for context enhancement in night vision: A comparative study. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 94–109. [Google Scholar] [CrossRef] [PubMed]
- Xydeas, C.; Petrovic, V. Objective image fusion performance measure. Electron. Lett. 2000, 36, 308–309. [Google Scholar] [CrossRef] [Green Version]
- Haghighat, M.; Aghagolzadeh, A.; Seyedarabi, H. A non-reference image fusion metric based on mutual information of image features. Comput. Electr. Eng. 2011, 37, 744–756. [Google Scholar] [CrossRef]
- Jagalingam, P.; Hegde, A.V. A review of quality metrics for fused image. Aquat. Procedia 2015, 4, 133–142. [Google Scholar] [CrossRef]
- Roberts, J.W.; Aardt, J.; Ahmed, F. Assessment of image fusion procedures using entropy, image quality, and multispectral classification. J. Appl. Remote Sens. 2008, 2, 023522. [Google Scholar]
- Cui, G.; Feng, H.; Xu, Z.; Li, Q.; Chen, Y. Detail preserved fusion of visible and infrared images using regional saliency extraction and multi-scale image decomposition. Opt. Commun. 2015, 341, 199–209. [Google Scholar] [CrossRef]
- Zhang, W.; Hu, S.; Liu, K. Patch-based correlation for deghosting in exposure fusion. Inf. Sci. 2017, 415, 19–27. [Google Scholar] [CrossRef]
- Mantiuk, R.; Kim, K.J.; Rempel, A.G.; Heidrich, W. HDR-VDP-2: A calibrated visual metric for visibility and quality predictions in all luminance conditions. ACM Trans. Graph. 2011, 30, 1–14. [Google Scholar] [CrossRef]
- Fang, Y.; Zhu, H.; Ma, K.; Wang, Z.; Li, S. Perceptual evaluation for multi-exposure image fusion of dynamic scenes. IEEE Trans. Image Process. 2020, 29, 1127–1138. [Google Scholar] [CrossRef] [PubMed]
- Shao, H.; Yu, M.; Jiang, G.; Pan, Z.; Peng, Z.; Chen, F. Strong ghost removal in multi-exposure image fusion using hole-filling with exposure congruency. J. Vis. Commun. Image Represent. 2021, 75, 103017. [Google Scholar] [CrossRef]
- Wu, L.; Hu, J.; Yuan, C.; Shao, Z. Details-preserving multi-exposure image fusion based on dual-pyramid using improved exposure evaluation. Results Opt. 2021, 2, 100046. [Google Scholar] [CrossRef]
- Merianos, I.; Mitianoudis, N. Multiple-exposure image fusion for HDR image synthesis using learned analysis transformations. J. Imaging 2019, 5, 32. [Google Scholar] [CrossRef] [Green Version]
- Xu, Y.; Yang, C.; Sun, B.; Yan, X.; Chen, M. A novel multi-scale fusion framework for detail-preserving low-light image enhancement. Inf. Sci. 2021, 548, 378–397. [Google Scholar] [CrossRef]
- Choi, S.; Kwon, O.J.; Lee, J. A method for fast multi-exposure image fusion. IEEE Access 2017, 5, 7371–7380. [Google Scholar] [CrossRef]
- Yan, Q.; Wang, B.; Li, P.; Li, X.; Zhang, A.; Shi, Q.; You, Z.; Zhu, Y.; Sun, J.; Zhang, Y. Ghost removal via channel attention in exposure fusion. Comput. Vis. Image Und. 2020, 201, 103079. [Google Scholar] [CrossRef]












| Dataset | Year | Image Sequences | Total Number | Number of Inputs | Link of Source Code | Remarks |
|---|---|---|---|---|---|---|
| MEFB [10] | 2020 | 100 | 200 | =2 | https://github.com/xingchenzhang/MEFB (9 January 2022) | Static |
| SICE [79] | 2018 | 589 | 4413 | >2 | https://github.com/csjcai/SICE (9 January 2022) | Static |
| TrafficSign [89] | 2020 | 2000 | 6000 | =2 | https://github.com/chenyi-real/TrafficSign (9 January 2022) | Static |
| HRP [123] | 2019 | 169 | 986 | ≥2 | https://github.com/hangxiaotian/Perceptual-Multi-exposure-Image-Fusion (9 January 2022) | Static |
| DeghostingI-QASet [31] | 2020 | 20 | 84 | >2 | https://github.com/h4nwei/MEF-SSIMd (9 January 2022) | Dynamic |
| Dataset [124] | 2016 | 17 | 153 | >2 | https://user.ceng.metu.edu.tr/~akyuz/files/eg2201/index.html (9 January 2022) | Dynamic |
| NO. | Metric | References | Remarks |
|---|---|---|---|
| 1 | HDR-VDP-2 | Kim [7]; Karađuzović-Hadžiabdić [19]; Tursun [120]; Yan [139] | The larger, the better |
| 2 | MEF-SSIMd | Shao [134] | The larger, the better |
| Method | MEF-SSIM | QAB/F | MI | PSNR | NIQE | SD | EN | AG |
|---|---|---|---|---|---|---|---|---|
| Liu [114] | 0.9405 | 0.6435 | 3.1984 | 8.6742 | 2.6025 | 52.6057 | 8.6081 | 8.8139 |
| Ma [31] | 0.9453 | 0.6089 | 3.9551 | 10.3328 | 2.9715 | 53.2696 | 5.7916 | 11.1830 |
| Lee [21] | 0.9590 | 0.6571 | 2.9782 | 9.0713 | 2.6374 | 50.2667 | 6.8547 | 8.8514 |
| Hayat [115] | 0.9078 | 0.4582 | 5.5102 | 10.0430 | 2.6826 | 49.6994 | 4.7667 | 5.8680 |
| Qi [40] | 0.9549 | 0.6410 | 3.9916 | 9.2923 | 2.9358 | 55.4990 | 6.5621 | 10.7526 |
| LH20 [32] | 0.9658 | 0.6673 | 2.7462 | 9.0995 | 2.6781 | 55.8062 | 9.0513 | 9.6758 |
| LH21 [33] | 0.9575 | 0.6504 | 3.3038 | 8.4724 | 2.6593 | 50.8119 | 7.6640 | 8.9427 |
| Mertens [41] | 0.9601 | 0.6455 | 3.7270 | 10.0365 | 2.9018 | 50.1038 | 6.2840 | 8.8763 |
| LST [42] | 0.9432 | 0.6640 | 3.2044 | 8.5309 | 2.6277 | 55.5074 | 9.4475 | 9.5823 |
| Paul [57] | 0.9608 | 0.6514 | 3.5030 | 9.9663 | 2.7218 | 51.0625 | 5.3089 | 9.0252 |
| Nejati [45] | 0.9612 | 0.6630 | 4.1353 | 9.2879 | 2.8538 | 55.0668 | 6.5410 | 10.2636 |
| LZG [46] | 0.9579 | 0.6509 | 2.9047 | 9.1140 | 3.1050 | 49.8743 | 7.0069 | 11.6734 |
| Kou [49] | 0.9586 | 0.6644 | 3.1466 | 8.8969 | 2.6869 | 50.0648 | 6.4023 | 9.5135 |
| Yang [50] | 0.9496 | 0.6414 | 2.9964 | 9.3743 | 2.7344 | 48.4575 | 6.8023 | 9.8153 |
| LXN [123] | 0.9667 | 0.6585 | 3.0658 | 8.8203 | 2.7060 | 52.2191 | 7.6235 | 9.4869 |
| Wang [48] | 0.9506 | 0.6517 | 3.2824 | 8.6193 | 2.7043 | 53.2645 | 6.6563 | 9.5763 |
| IFCNN [81] | 0.9066 | 0.6313 | 4.3726 | 10.2075 | 3.3714 | 55.1148 | 5.0288 | 11.8504 |
| MEFNet [86] | 0.8766 | 0.7189 | 3.4594 | 8.2712 | 2.8607 | 57.0665 | 6.2416 | 10.0945 |
| Sequence | Liu [114] | Ma [31] | Hayat [115] | Qi [40] | LH20 [32] | LH21 [33] |
|---|---|---|---|---|---|---|
| Arch | 42.1539 | 43.8774 | 43.4479 | 39.4118 | 43.8846 | 47.7516 |
| Brunswick | 53.9745 | 68.7604 | 39.1341 | 34.9105 | 64.9440 | 73.2189 |
| Campus | 50.7968 | 68.5215 | 48.8127 | 67.4566 | 49.3895 | 50.5085 |
| Cliff | 46.3294 | 67.1114 | 48.7778 | 51.7876 | 69.2225 | 70.7965 |
| Forest | 66.6202 | 70.5719 | 56.6106 | 59.8429 | 68.8709 | 66.8502 |
| Horse | 52.8578 | 65.9682 | 43.5756 | 61.2289 | 66.3404 | 65.7502 |
| Lady | 49.7846 | 52.8730 | 45.1670 | 51.0440 | 45.4192 | 51.1117 |
| Llandudno | 37.1335 | 65.0071 | 54.5771 | 37.0104 | 56.7933 | 61.1436 |
| Men | 40.3770 | 45.3716 | 32.1539 | 40.6552 | 38.8748 | 55.7015 |
| Office | 33.3883 | 33.2980 | 36.1874 | 38.4133 | 34.6107 | 38.6722 |
| ProfJeonEigth | 39.9871 | 55.7125 | 42.0014 | 38.2431 | 46.6209 | 42.4667 |
| Puppets | 31.7485 | 54.8099 | 38.3072 | 36.8180 | 27.9814 | 56.7586 |
| Readingman | 35.1225 | 60.8870 | 30.9186 | 37.8561 | 42.4045 | 60.4606 |
| Russ1 | 67.5083 | 70.3890 | 50.7266 | 58.2271 | 69.7728 | 72.7040 |
| SculptureGarden | 26.7691 | 39.3931 | 37.4966 | 31.8801 | 45.1903 | 40.0277 |
| Square | 48.4465 | 66.8230 | 39.0180 | 38.6824 | 71.5442 | 65.3453 |
| Tate3 | 51.9602 | 54.9352 | 40.3044 | 42.4331 | 42.5136 | 53.1564 |
| Wroclav | 44.3532 | 52.2975 | 33.4461 | 32.3816 | 48.7993 | 56.5951 |
| YWFusionopolis | 40.9657 | 68.6462 | 46.2158 | 36.7817 | 40.3490 | 43.5701 |
| 137 | 59.2770 | 67.9392 | 52.7393 | 62.8411 | 58.9021 | 70.3419 |
| 138 | 60.8126 | 56.3963 | 43.0310 | 27.6285 | 52.0746 | 50.8200 |
| 269 | 56.7095 | 40.8084 | 54.8627 | 49.5950 | 43.6533 | 47.4784 |
| Street | 33.6765 | 36.0854 | 26.5961 | 30.7094 | 35.9272 | 36.2446 |
| AgiaGalini | 30.1654 | 48.1653 | 40.0907 | 48.8657 | 55.9823 | 74.2082 |
| MarketMires2 | 56.9971 | 51.1316 | 55.4768 | 49.3215 | 66.5522 | 64.8403 |
| Cars | 51.4744 | 50.1511 | 41.4154 | 49.4603 | 46.6479 | 49.3922 |
| Building | 45.0889 | 57.9390 | 35.6322 | 54.6528 | 51.1381 | 55.1796 |
| Method | Time (s) | Method | Time(s) | Method | Time (s) |
|---|---|---|---|---|---|
| Liu [114] | 3.0940 | LH21 [33] | 0.0523 | Kou [49] | 2.4438 |
| Ma [31] | 4.4762 | Mertens [41] | 1.3583 | Yang [50] | 8.0385 |
| Lee [21] | 1.6389 | LST [42] | 1.4190 | LXN [123] | 2.0184 |
| Hayat [115] | 3.8754 | Paul [57] | 1.8119 | Wang [48] | 1.5095 |
| Qi [40] | 6.9607 | Nejati [45] | 0.3878 | ||
| LH20 [32] | 1.2923 | LZG [46] | 8.2330 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, F.; Liu, J.; Song, Y.; Sun, H.; Wang, X. Multi-Exposure Image Fusion Techniques: A Comprehensive Review. Remote Sens. 2022, 14, 771. https://doi.org/10.3390/rs14030771
Xu F, Liu J, Song Y, Sun H, Wang X. Multi-Exposure Image Fusion Techniques: A Comprehensive Review. Remote Sensing. 2022; 14(3):771. https://doi.org/10.3390/rs14030771
Chicago/Turabian StyleXu, Fang, Jinghong Liu, Yueming Song, Hui Sun, and Xuan Wang. 2022. "Multi-Exposure Image Fusion Techniques: A Comprehensive Review" Remote Sensing 14, no. 3: 771. https://doi.org/10.3390/rs14030771
APA StyleXu, F., Liu, J., Song, Y., Sun, H., & Wang, X. (2022). Multi-Exposure Image Fusion Techniques: A Comprehensive Review. Remote Sensing, 14(3), 771. https://doi.org/10.3390/rs14030771