
MSDRN: Pansharpening of Multispectral Images via Multi-Scale Deep Residual Network


Abstract
:1. Introduction
- Inspired by the idea of coarse-to-fine reconstruction, a multi-scale pansharpening network is constructed. The proposed network adopts a progressive reconstruction strategy to make full use of the multi-scale information contained in the original images.
- Residual learning is introduced into the network to further improve fusion performance. First, it can effectively alleviate the problem of gradient disappearance in deepening the network to make the network extract more complex and abstract features. Second, it enables the input of the network to be completely transmitted to the output of the network to preserve more spectral and spatial information. Finally, it makes network training easier.
- Experiments were conducted on different satellite datasets. Meanwhile, qualitative evaluation based on visual observation and quantitative evaluation based on indicator calculation were performed on the fused images. The experimental results based on simulated data and real data show that the proposed method achieves better or competitive performance than the state-of-the-art methods.
2. Related Works
2.1. Deep Learning and Convolution Neural Network
2.2. Residual Learning
2.3. CNN-Based Methods for Pansharpening
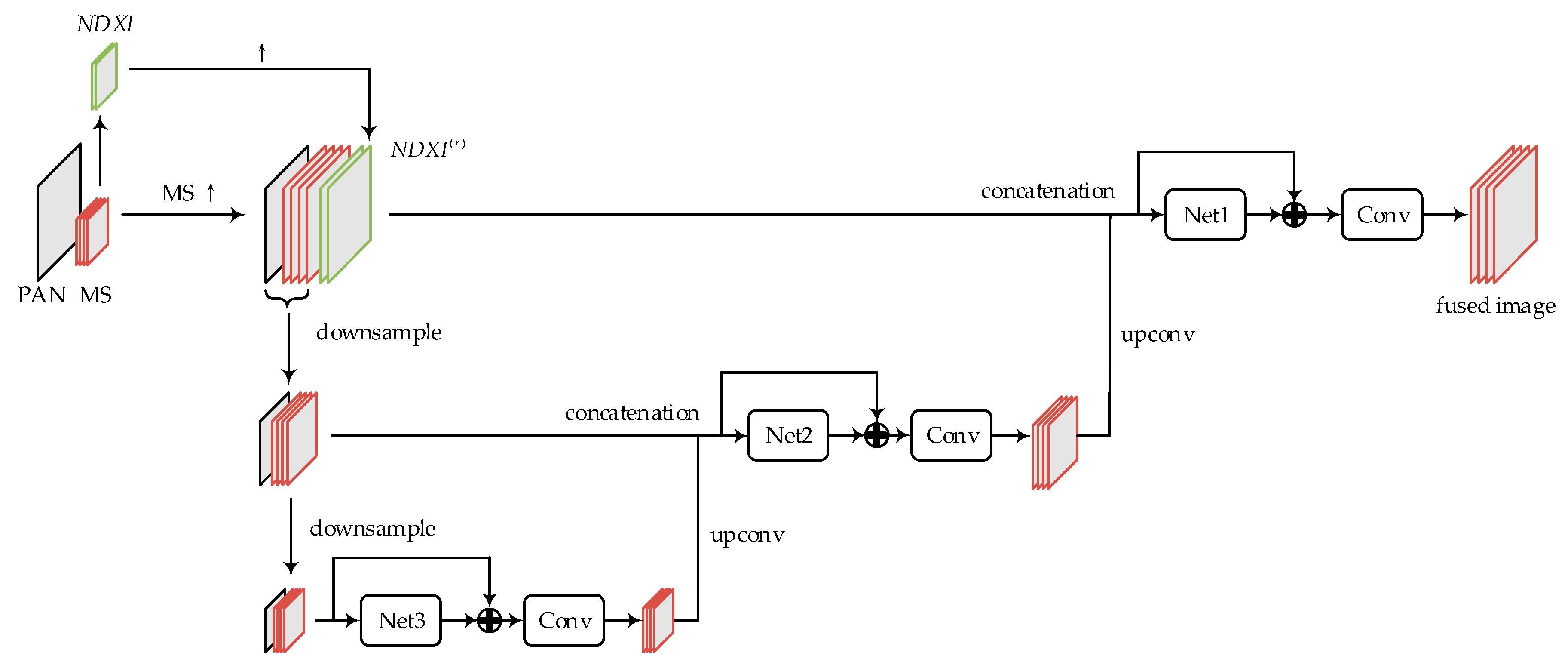
3. The Proposed CNN-Based Pansharpening Method
3.1. Motivation
3.2. The Architecture of Proposed Network
3.3. Training of Network
4. Experiments
4.1. Datasets and Settings
4.2. Quality Indicators
- SAM measures the spectral similarity between the pansharpened image and the corresponding reference image. A smaller value of SAM indicates a higher spectral similarity between two images. SAM is defined by the following formula
- ERGAS represents the degree of spatial distortion between the fused image and the reference image. The smaller the ERGAS, the higher the quality of the fused image. ERGAS is defined aswhere is the ratio of the spatial resolution between PAN and MS; is the number of MS bands; is the root mean square error between the band of the fused image and the reference image, and is the average of the original MS image band .
- RMSE measures the difference between pixel values of the fused image and the reference image. The smaller the RMSE, the closer the fused image to the reference image. RMSE is defined aswhere , and respectively represent the height, width, and band number of the MS image.
- CC reflects the strength of the correlation between the fused image and the reference image. The closer the CC is to 1, the stronger the correlation between the two objects. CC can be calculated by the following formulawhere represents the covariance between and , and represents the variance.
- Q can be used to estimate the global quality of the fused image. It measures the degree of correlation, the similarity of average brightness, and the similarity of contrast between the fused image and the reference image. The closer the value of Q is to 1, the better the quality of the fused image. The definition of Q iswhere represents the standard deviation of the image; represents the mean value of the image; represents the covariance between and .
- is an extended version of Q. It is also called Q4 when applied to four-band MS image, and Q8 when applied to eight-band MS image. It is defined aswhere and represent two quaternions (for four-band MS images) or two octonions (for eight-band MS images), which are respectively composed of radiation values of given image pixels in each band of reference MS image and fused MS image. introduces the measurement of spectral distortion of fused image based on Q. The closer the value is to 1, the better the fused image quality is.
- is an indicator that measures the spectral similarity between the fused image and the low-resolution MS image. The closer the value of is to 0, the more similar the spectral information between the fused image and the low-resolution MS image is. is defined byIn this formula, represents the fused image; represents the low-resolution MS image; Q represents the Q index; is the number of bands of the MS image; is a constant, and it is usually set to 1.
- is a measure of the spatial similarity between the fused image and the PAN image. The closer the value of is to 0, the smaller the spatial distortion of the fused image. is defined byIn the formula, refers to the PAN image and refers to the degraded PAN image; is a constant, and it is usually set to 1.
- QNR can measure both the spectral distortion and spatial distortion of the fused image, which is based on the spectral distortion index and the spatial distortion index . QNR is defined aswhere and control the relative degree of correlation between the spectral index and the spatial index. If and equal to 0 at the same time, QNR obtains the optimal value of 1.
4.3. Comparison Algorithms
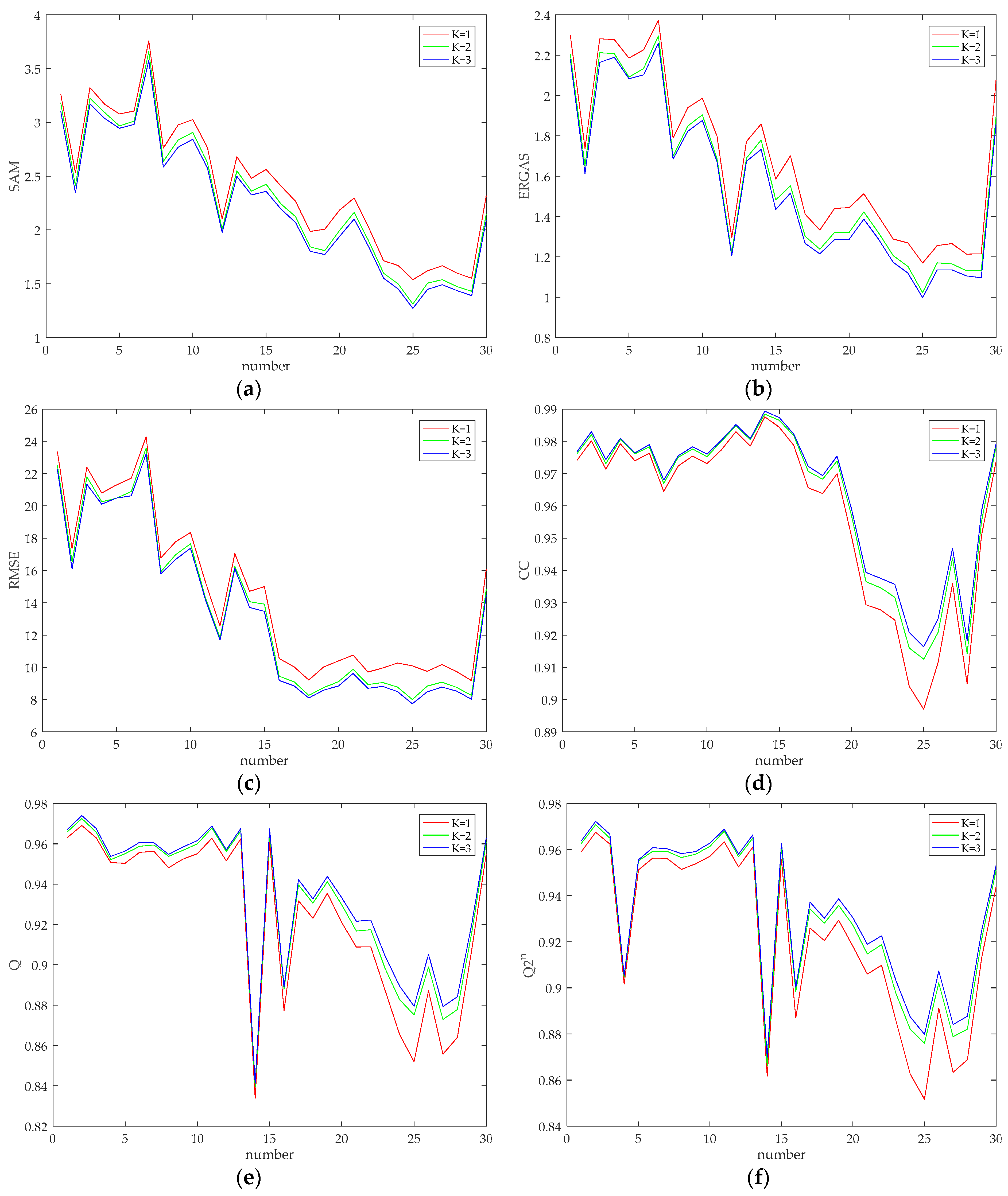
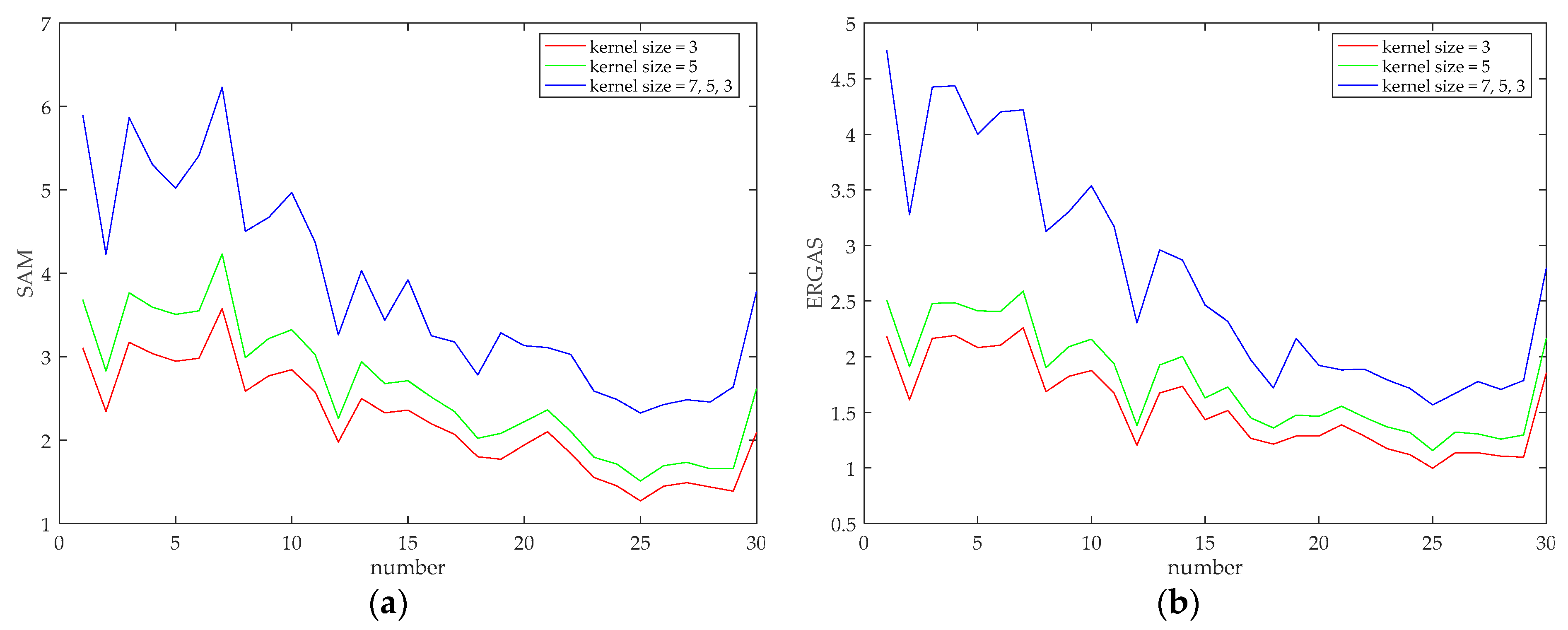
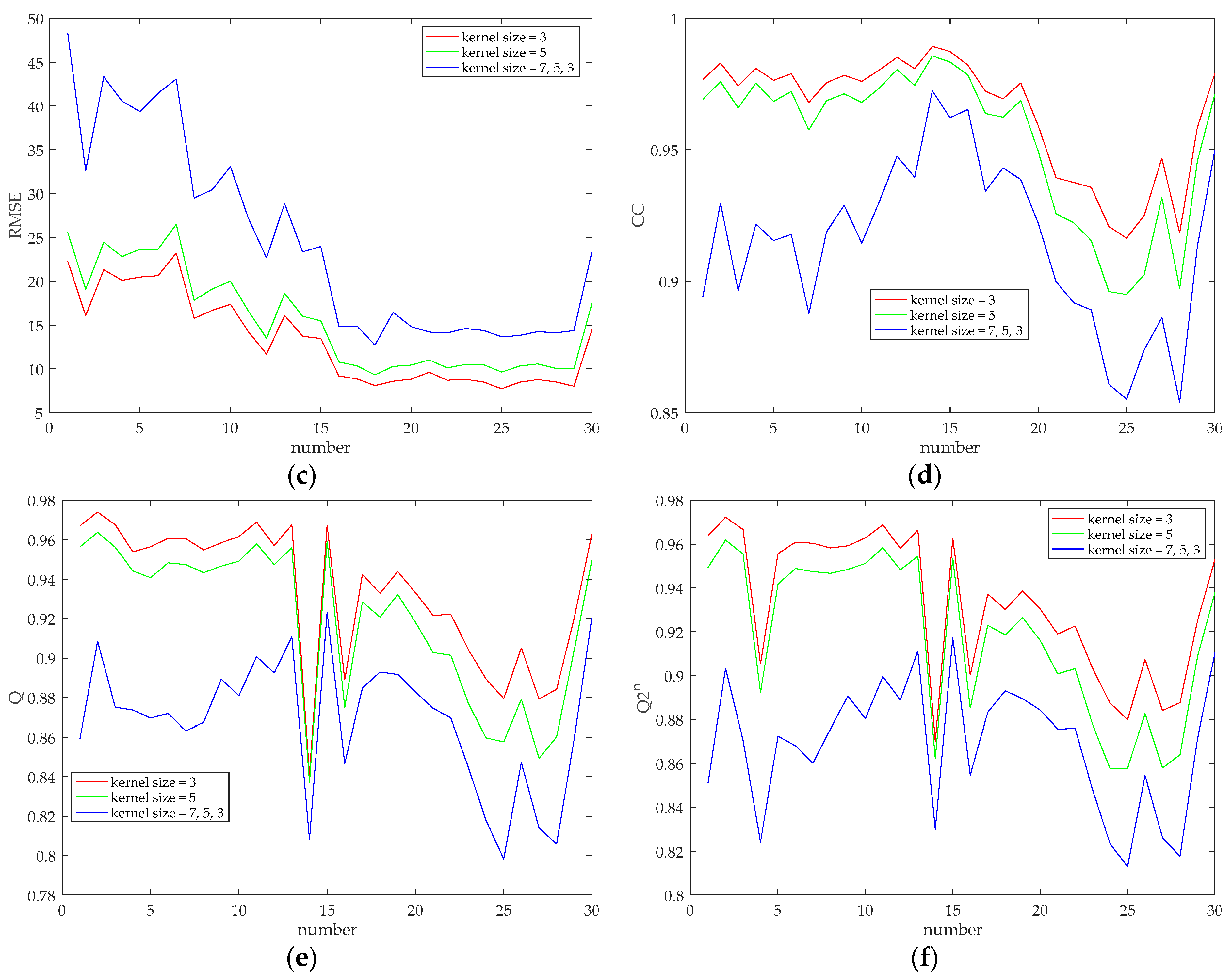
4.4. The Influences of Scale Levels and Kernel Sizes
4.5. Simulated Experiments
4.6. Real Data Experiments
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Vivone, G.; Alparone, L.; Chanussot, J.; Dalla Mura, M.; Garzelli, A.; Licciardi, G.A.; Restaino, R.; Wald, L. A critical comparison among pansharpenig algorithms. IEEE Trans. Geosci. Remote Sens. 2015, 53, 2565–2586. [Google Scholar] [CrossRef]
- Tu, T.M.; Su, S.C.; Shyu, H.C.; Huang, P.S. A new look at IHS-like image fusion methods. Inf. Fusion. 2001, 2, 177–186. [Google Scholar] [CrossRef]
- Tu, T.M.; Huang, P.S.; Hung, C.L.; Chang, C.P. A fast intensity hue-saturation fusion technique with spectral adjustment for IKONOS imagery. IEEE Geosci. Remote Sens. Lett. 2004, 1, 309–312. [Google Scholar] [CrossRef]
- Shahdoosti, H.R.; Ghassemian, H. Combining the spectral PCA and spatial PCA fusion methods by an optimal filter. Inf. Fusion. 2016, 27, 150–160. [Google Scholar] [CrossRef]
- Laben, C.; Brower, B. Process for Enhancing the Spatial Resolution of Multispectral Imagery Using Pan-Sharpening. U.S. Patent 6,011,875, 4 January 2000. [Google Scholar]
- Gillespie, A.; Kahle, A.B.; Walker, R.E. Color enhancement of highly correlated images-II. Channel ration and “Chromaticity” Transform techniques. Remote Sens. Environ. 1987, 22, 343–365. [Google Scholar] [CrossRef]
- Choi, J.; Yu, K.; Kim, Y. A new adaptive component-substitution-based satellite image fusion by using partial replacement. IEEE Trans. Geosci. Remote Sens. 2011, 49, 295–309. [Google Scholar] [CrossRef]
- Garzelli, A.; Nencini, F.; Capobianco, L. Optimal MMSE pansharpening of very high resolution multispectral images. IEEE Trans. Geosci. Remote Sens. 2008, 46, 228–236. [Google Scholar] [CrossRef]
- Vivone, G.; Restaino, R.; Mura, M.D.; Licciardi, G.; Chanussot, J. Contrast and Error-Based Fusion Schemes for Multispectral Image Pansharpening. IEEE Geosci. Remote Sens. Lett. 2014, 11, 930–934. [Google Scholar] [CrossRef] [Green Version]
- Shensa, M.J. The discrete wavelet transform: Wedding the à trous and Mallat algorithm. IEEE Trans. Signal Process. 1992, 40, 2464–2482. [Google Scholar] [CrossRef] [Green Version]
- Nencini, F.; Garzelli, A.; Baronti, S.; Alparone, L. Remote sensing image fusion using the curvelet transform. Inf. Fusion 2007, 8, 143–156. [Google Scholar] [CrossRef]
- Aiazzi, B.; Alparone, L.; Baronti, S.; Garzelli, A.; Selva, M. An MTF-based spectral distortion minimizing model for pan-sharpening of very high resolution multispectral images of urban areas. In Proceedings of the 2nd GRSS/ISPRS Joint Workshop on Remote Sensing and Data Fusion over Urban Areas, Berlin, Germany, 22–23 May 2003. [Google Scholar] [CrossRef]
- Chavez, P.S., Jr.; Sides, S.C.; Anderson, A. Comparison of three different methods to merge multiresolution and multispectral data: Landsat TM and SPOT panchromatic. Photogramm. Eng. Remote Sens. 1991, 57, 295–303. [Google Scholar] [CrossRef] [Green Version]
- Otazu, X.; González-Audìcana, M.; Fors, O.; Nùñez, J. Introduction of sensor spectral response into image fusion methods. Application to wavelet-based methods. IEEE Trans. Geosci. Remote Sens. 2005, 43, 2376–2385. [Google Scholar] [CrossRef] [Green Version]
- Zhong, S.W.; Zhang, Y.; Chen, Y.S.; Wu, D. Combining component substitution and multiresolution analysis: A novel generalized BDSD pansharpening algorithm. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 2867–2875. [Google Scholar] [CrossRef]
- Li, S.; Yang, B. A new pansharpening method using a compressed sensing technique. IEEE Trans. Geosci. Remote Sens. 2011, 49, 738–746. [Google Scholar] [CrossRef]
- Li, S.; Yin, H.; Fang, L. Remote Sensing Image Fusion via Sparse Representations Over Learned Dictionaries. IEEE Trans. Geosci. Remote Sens. 2013, 51, 4779–4789. [Google Scholar] [CrossRef]
- Ayas, S.; Gormus, E.T.; Ekinci, M. An Efficient PanSharpening via Texture Based Dictionary Learning and Sparse Representation. IEEE J. Sel. Topics Appl. Earth Obs. Remote Sens. 2018, 7, 2448–2460. [Google Scholar] [CrossRef]
- Zhu, X.X.; Bamler, R. A sparse image fusion algorithm with application to pansharpening. IEEE Trans. Geosci. Remote Sens. 2013, 51, 2827–2836. [Google Scholar] [CrossRef]
- Fei, R.; Zhang, J.; Liu, J.; Du, F.; Chang, P.; Hu, J. Convolutional Sparse Representation of Injected Details for Pansharpening. IEEE Goesci. Remote Sens. Lett. 2019, 16, 1595–1599. [Google Scholar] [CrossRef]
- Yin, H. Sparse representation based pansharpening with details injection model. Signal Process. 2015, 113, 218–227. [Google Scholar] [CrossRef]
- Dong, C.; Loy, C.; He, K.; Tang, X. Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 295–307. [Google Scholar] [CrossRef] [Green Version]
- Zhang, K.; Zuo, W.; Chen, Y.; Meng, D.; Zhang, L. Beyond a Gaussian denoiser: Residual learning of deep CNN for image denoising. IEEE Trans. Image Process. 2017, 26, 3142–3155. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Svoboda, P.; Hradis, M.; Marŝík, L.; Zemcík, P. CNN for license plate motion deblurring. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016. [Google Scholar] [CrossRef] [Green Version]
- Zhang, P.; Gong, M.; Su, L.; Liu, J.; Li, Z. Change detection based on deep feature representation and mapping transformation for multi-spatial resolution remote sensing images. ISPRS J. Photogramm. Remote Sens. 2016, 116, 24–41. [Google Scholar] [CrossRef]
- Masi, G.; Cozzolino, D.; Verdoliva, L.; Scarpa, G. Pansharpening by convolutional neural networks. Remote Sens. 2016, 8, 594. [Google Scholar] [CrossRef] [Green Version]
- Scarpa, G.; Vitale, S.; Cozzolino, D. Target-Adaptive CNN-Based Pansharpening. IEEE Trans. Geosci. Remote Sens. 2018, 56, 5443–5457. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar] [CrossRef] [Green Version]
- Wei, Y.; Yuan, Q.; Shen, H.; Zhang, L. Boosting the Accuracy of Multispectral Image Pansharpening by Learning a Deep Residual Network. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1795–1799. [Google Scholar] [CrossRef] [Green Version]
- Yuan, Q.; Wei, Y.; Meng, X.; Shen, H.; Zhang, L. A Multiscale and Multidepth Convolutional Neural Network for Remote Sensing Imagery Pan-Sharpening. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 3, 978–989. [Google Scholar] [CrossRef] [Green Version]
- Liu, X.; Liu, Q.; Wang, Y. Remote sensing image fusion based on two-stream fusion network. Inf. Fusion. 2020, 55, 1–15. [Google Scholar] [CrossRef] [Green Version]
- Zhong, J.; Yang, B.; Huang, G.; Zhong, F.; Chen, Z. Remote sensing image fusion with convolutional neural network. Sens. Imaging 2016, 17, 1–16. [Google Scholar] [CrossRef]
- Wang, D.; Li, Y.; Ma, L.; Bai, Z.; Chan, J.C.W. Going Deeper with Densely Connected Convolutional Neural Networks for Multispectral Pansharpening. Remote Sens. 2019, 11, 2608. [Google Scholar] [CrossRef] [Green Version]
- Yang, Y.; Tu, W.; Huang, S.; Lu, H. PCDRN: Progressive Cascade Deep Residual Network for Pansharpening. Remote Sens. 2020, 12, 676. [Google Scholar] [CrossRef] [Green Version]
- Nah, S.; Kim, T.H.; Lee, K.M. Deep Multi-scale Convolutional Neural Network for Dynamic Scene Deblurring. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef] [Green Version]
- Denton, E.L.; Chintala, S.; Fergus, R. Deep generative image models using a laplacian pyramid of adversarial networks. In Proceedings of the 28th International Conference on Neural Information Processing Systems, Palais des Congrès de Montréal, Montréal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Eigen, D.; Puhrsch, C.; Fergus, R. Depth map prediction from a single image using a multi-scale deep network. In Proceedings of the 27th International Conference on Neural Information Processing Systems, Montréal, QC, Canada, 8–13 December 2014. [Google Scholar]
- Pan, H.; Li, X.; Wang, W.; Qi, C. Mariculture Zones Extraction Using NDWI and NDVI. Adv. Mater. Res. 2013, 659, 153–155. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–657. [Google Scholar] [CrossRef]
- Wald, L.; Ranchin, T.; Mangolini, M. Fusion of satellite images of different spatial resolution:Assessing the quality of resulting images. Photogramm. Eng. Remote Sens. 1997, 63, 691–699. [Google Scholar] [CrossRef]
- Kingma, D.; Ba, J.L. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference for Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Aiazzi, B.; Alparone, L.; Baronti, S.; Garzelli, A. Context-driven fusion of high spatial and spectral resolution images based on oversampled multiresolution analysis. IEEE Trans. Geosci. Remote Sens. 2002, 40, 2300–2312. [Google Scholar] [CrossRef]
- PyTorch. Available online: https://pytorch.org (accessed on 12 December 2020).
- Yuhas, R.H.; Goetz, A.F.H.; Boardman, J.W. Discrimination among semi-arid landscape endmembers using the Spectral AngleMapper (SAM) algorithm. In Summaries of the Third Annual JPL Airborne Geoscience Workshop; AVIRIS Workshop: Pasadena, CA, USA, 1992; pp. 147–149. [Google Scholar]
- Wald, L. Data Fusion: Definitions and Architectures-Fusion of Images of Different Spatial Resolutions; Presses des Mines: Paris, France, 2002. [Google Scholar]
- Wang, Z.; Bovik, A. A universal image quality index. IEEE Signal Process. Lett. 2002, 9, 81–84. [Google Scholar] [CrossRef]
- Garzelli, A.; Nencini, F. Hypercomplex quality assessment of multi/hyper-spectral images. IEEE Geosci. Remote Sens. Lett. 2009, 6, 662–665. [Google Scholar] [CrossRef]
- Alparone, L.; Aiazzi, B.; Baronti, S.; Garzelli, A.; Nencini, F.; Selva, M. Multispectral and panchromatic data fusion assessment without reference. Photogramm. Eng. Remote Sens. 2008, 74, 193–200. [Google Scholar] [CrossRef] [Green Version]
- Vivone, G. Robust Band-Dependent Spatial-Detail Approaches for Panchromatic Sharpening. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6421–6433. [Google Scholar] [CrossRef]
- Liu, J. Smoothing filter-based intensity modulation: A spectral preserve image fusion technique for improving spatial details. Int. J. Remote Sens. 2000, 21, 3461–3472. [Google Scholar] [CrossRef]
- Ranchin, T.; Wald, L. Fusion of high spatial and spectral resolution images: The ARSIS concept and its implementation. Photogramm. Eng. Remote Sens. 2000, 66, 49–61. [Google Scholar] [CrossRef] [Green Version]
- Khan, M.M.; Chanussot, J.; Condat, L.; Montavert, A. Indusion: Fusion of multispectral and panchromatic images using the induction scaling technique. IEEE Trans. Geosci. Remote Sens. 2008, 5, 98–102. [Google Scholar] [CrossRef] [Green Version]
- Aiazzi, B.; Alparone, L.; Baronti, S.; Garzelli, A.; Selva, M. MTF tailored multiscale fusion of high-resolution MS and pan imagery. Photogramm. Eng. Remote Sens. 2006, 72, 591–596. [Google Scholar] [CrossRef]
- Vivone, G.; Alparone, L.; Garzelli, A.; Lolli, S. Fast reproducible pansharpening based on instrument and acquisition modeling: AWLP Revisited. Remote Sens. 2019, 11, 2315. [Google Scholar] [CrossRef] [Green Version]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Input Channels | Kernel Size/Padding | Output Channels | Ratio | |
|---|---|---|---|---|---|
| Fine-level | 1 | 11 | 3/1 | 64 | / |
| 2~9 | 64 | 3/1 | 64 | / | |
| 10 | 64 | 3/1 | 11 | / | |
| 11 | 11 | 3/1 | 4 | / | |
| Medium-level | 1 | 9 | 3/1 | 64 | / |
| 2~9 | 64 | 3/1 | 64 | / | |
| 10 | 64 | 3/1 | 9 | / | |
| 11 | 9 | 3/1 | 4 | / | |
| up-convolution | 4 | 3/1 | 4 | 2 | |
| Coarse-level | 1 | 5 | 3/1 | 64 | / |
| 2~9 | 64 | 3/1 | 64 | / | |
| 10 | 64 | 3/1 | 5 | / | |
| 11 | 5 | 3/1 | 4 | / | |
| up-convolution | 4 | 3/1 | 4 | 2 |
| Satellites | Spectral Bands (nm) | Spatial Resolution (m) | |||||
|---|---|---|---|---|---|---|---|
| Blue | Green | Red | Nir | PAN | MS | PAN | |
| GeoEye-1 | 450–510 | 510–580 | 655–690 | 780–920 | 450–800 | 2.0 | 0.5 |
| QuickBird | 450–520 | 520–600 | 630–690 | 760–900 | 450–900 | 2.4 | 0.6 |
| Satellites | Training Set | Test Set |
|---|---|---|
| GeoEye-1 | 37632 | 30 |
| Quickbird | 32320 | 23 |
| Methods | SAM↓ | ERGAS↓ | RMSE↓ | CC↑ | Q↑ | |
|---|---|---|---|---|---|---|
| IHS | 4.4140 | 3.1285 | 26.4895 | 0.8513 | 0.7727 | 0.7694 |
| PCA | 3.9789 | 3.0007 | 26.5368 | 0.8927 | 0.7977 | 0.7965 |
| BDSD | 3.9735 | 2.7022 | 23.5327 | 0.9079 | 0.8484 | 0.8561 |
| RBDSD | 3.9825 | 3.0700 | 25.8186 | 0.9023 | 0.8360 | 0.8366 |
| PRACS | 4.3271 | 3.0731 | 29.4296 | 0.8704 | 0.7666 | 0.7913 |
| SFIM | 3.5414 | 2.5713 | 22.6677 | 0.9154 | 0.8545 | 0.8597 |
| AWLP_H | 3.4584 | 2.6888 | 24.2338 | 0.9166 | 0.8703 | 0.8736 |
| ATWT_M3 | 4.5294 | 3.2148 | 29.0548 | 0.8881 | 0.7711 | 0.7884 |
| Indusion | 4.0914 | 3.0006 | 26.4354 | 0.8796 | 0.8142 | 0.8069 |
| MTF_GLP | 3.6305 | 2.7271 | 23.8208 | 0.9119 | 0.8596 | 0.8645 |
| PNN | 3.0958 | 2.1421 | 18.6478 | 0.9351 | 0.8876 | 0.8857 |
| DRPNN | 2.4700 | 1.7173 | 14.7505 | 0.9568 | 0.9221 | 0.9222 |
| MSDRN | 2.2316 | 1.5520 | 13.2829 | 0.9642 | 0.9342 | 0.9332 |
| Methods | SAM↓ | ERGAS↓ | RMSE↓ | CC↑ | Q↑ | |
|---|---|---|---|---|---|---|
| IHS | 7.2528 | 8.7268 | 65.9077 | 0.8657 | 0.7748 | 0.7591 |
| PCA | 6.9194 | 8.5394 | 65.7315 | 0.8895 | 0.8022 | 0.7931 |
| BDSD | 6.8038 | 8.2385 | 62.7310 | 0.8892 | 0.8315 | 0.8268 |
| RBDSD | 7.2400 | 9.3112 | 71.0934 | 0.8749 | 0.8127 | 0.8061 |
| PRACS | 6.2884 | 7.7160 | 58.8591 | 0.9003 | 0.8454 | 0.8444 |
| SFIM | 6.0100 | 7.7309 | 58.7138 | 0.8998 | 0.8476 | 0.8452 |
| AWLP_H | 6.2810 | 8.1511 | 62.1131 | 0.9008 | 0.8543 | 0.8527 |
| ATWT_M3 | 6.9392 | 8.4402 | 64.6093 | 0.8897 | 0.7977 | 0.7989 |
| Indusion | 7.5891 | 8.8763 | 67.4352 | 0.8650 | 0.7915 | 0.7806 |
| MTF_GLP | 7.0071 | 8.0474 | 61.2067 | 0.8435 | 0.8954 | 0.8405 |
| PNN | 5.0045 | 4.8858 | 36.8934 | 0.9579 | 0.9293 | 0.9238 |
| DRPNN | 4.2391 | 4.1576 | 31.3161 | 0.9689 | 0.9444 | 0.9425 |
| MSDRN | 3.8476 | 3.5824 | 26.7683 | 0.9766 | 0.9571 | 0.9543 |
| Methods | GeoEye-1 | QuickBird | ||||
|---|---|---|---|---|---|---|
| QNR | QNR | |||||
| IHS | 0.8386 | 0.0696 | 0.0993 | 0.7351 | 0.0817 | 0.2003 |
| PCA | 0.8327 | 0.0543 | 0.1195 | 0.7978 | 0.0537 | 0.1571 |
| BDSD | 0.9128 | 0.0237 | 0.0651 | 0.8623 | 0.0312 | 0.1099 |
| RBDSD | 0.8785 | 0.0429 | 0.0825 | 0.8083 | 0.0399 | 0.1584 |
| PRACS | 0.8909 | 0.0244 | 0.0868 | 0.8367 | 0.0342 | 0.1338 |
| SFIM | 0.8453 | 0.0767 | 0.0854 | 0.8496 | 0.0625 | 0.0945 |
| AWLP_H | 0.8453 | 0.0768 | 0.0852 | 0.7784 | 0.0889 | 0.1466 |
| ATWT_M3 | 0.8729 | 0.0511 | 0.0803 | 0.9104 | 0.0528 | 0.0389 |
| Indusion | 0.8544 | 0.0624 | 0.0891 | 0.8607 | 0.0717 | 0.0735 |
| MTF_GLP | 0.8053 | 0.0951 | 0.1113 | 0.7961 | 0.0720 | 0.1428 |
| PNN | 0.9265 | 0.0336 | 0.0412 | 0.8810 | 0.0651 | 0.0574 |
| DRPNN | 0.8882 | 0.0450 | 0.0700 | 0.9072 | 0.0531 | 0.0422 |
| MSDRN | 0.8819 | 0.0418 | 0.0797 | 0.9238 | 0.0455 | 0.0324 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, W.; Zhou, Z.; Liu, H.; Xie, G. MSDRN: Pansharpening of Multispectral Images via Multi-Scale Deep Residual Network. Remote Sens. 2021, 13, 1200. https://doi.org/10.3390/rs13061200
Wang W, Zhou Z, Liu H, Xie G. MSDRN: Pansharpening of Multispectral Images via Multi-Scale Deep Residual Network. Remote Sensing. 2021; 13(6):1200. https://doi.org/10.3390/rs13061200
Chicago/Turabian StyleWang, Wenqing, Zhiqiang Zhou, Han Liu, and Guo Xie. 2021. "MSDRN: Pansharpening of Multispectral Images via Multi-Scale Deep Residual Network" Remote Sensing 13, no. 6: 1200. https://doi.org/10.3390/rs13061200
APA StyleWang, W., Zhou, Z., Liu, H., & Xie, G. (2021). MSDRN: Pansharpening of Multispectral Images via Multi-Scale Deep Residual Network. Remote Sensing, 13(6), 1200. https://doi.org/10.3390/rs13061200