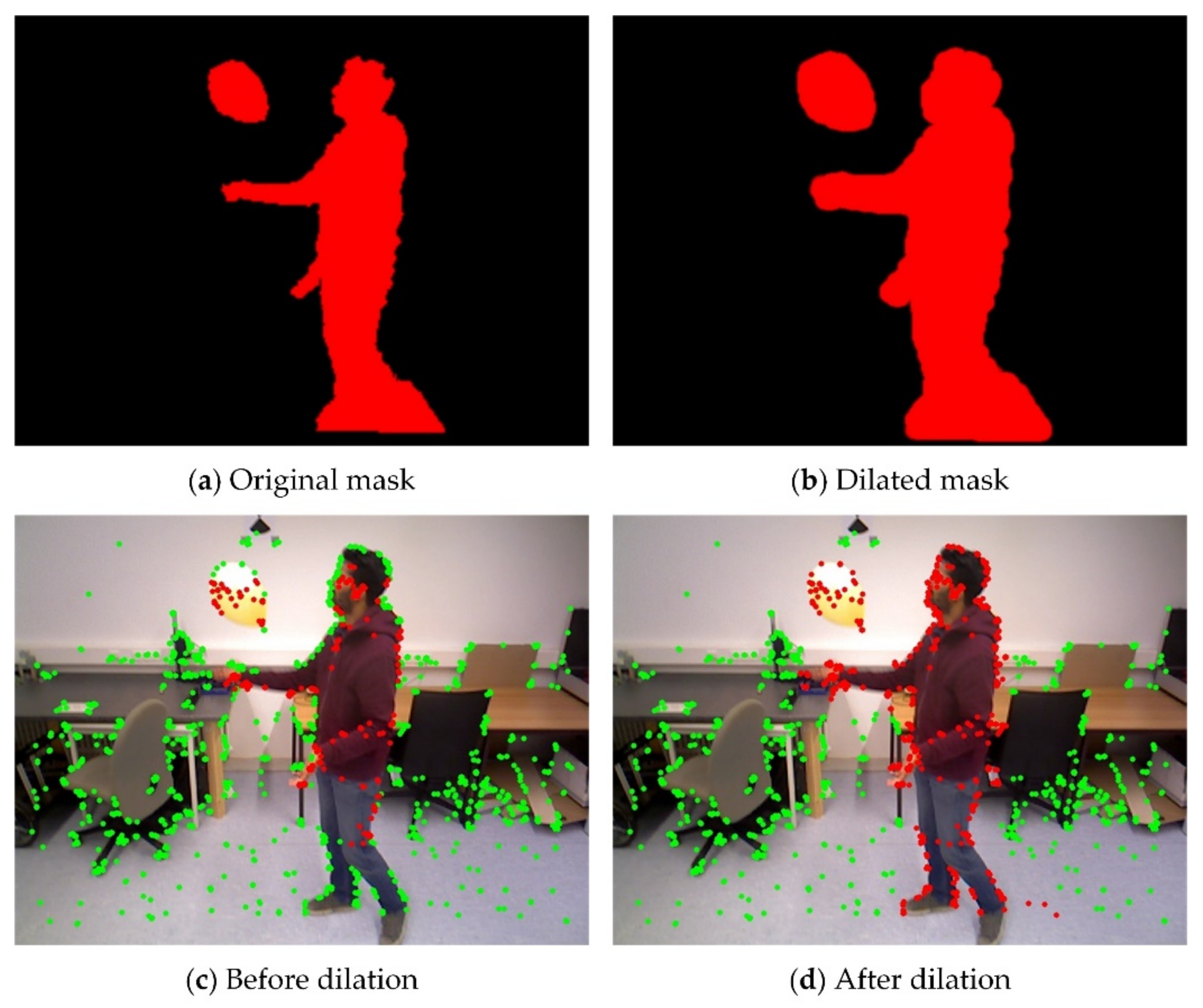
The instance segmentation network can detect motion objects labeled in the training set. However, relying only on semantic segmentation results will have two problems. On the one hand, some moving objects, such as balloons, tables, and chairs, are not priori dynamic objects and cannot be recognized by the semantic detection module. On the other hand, there are stationary cars or people in scenes with low dynamics. The semantic network cannot judge their real motion properties, leading to incorrect segmentation of dynamic objects, thus reducing the number of feature points and the localization accuracy. To this end, we design a dynamic object detection module by combining geometric motion information and potential motion information to achieve segmentation of dynamic objects in the scene.
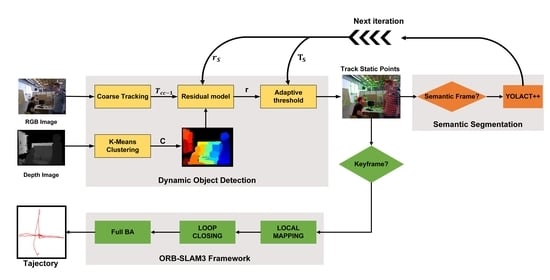
The flowchart of the dynamic object detection module is shown in
Figure 2. First, we use the depth and spatial information-based K-means clustering algorithm for clustering segmentation of depth images. The motion segmentation problem of image pixels can be transformed into the motion segmentation of clusters. Second, we calculate the initial pose of adjacent RGB images using coarse tracking. Then the residual model is built based on the initial pose of the camera, the spatial correlation of the clusters, and the continuity of the motion. Finally, the adaptive threshold is calculated based on the residual distribution of the current frame and the instance segmentation results of the historical semantic frames to realize the motion segmentation of the scene. The dynamic object detection module can not only integrate geometric and semantic information but also run alone without semantic information input.
3.1.2. Residual Model
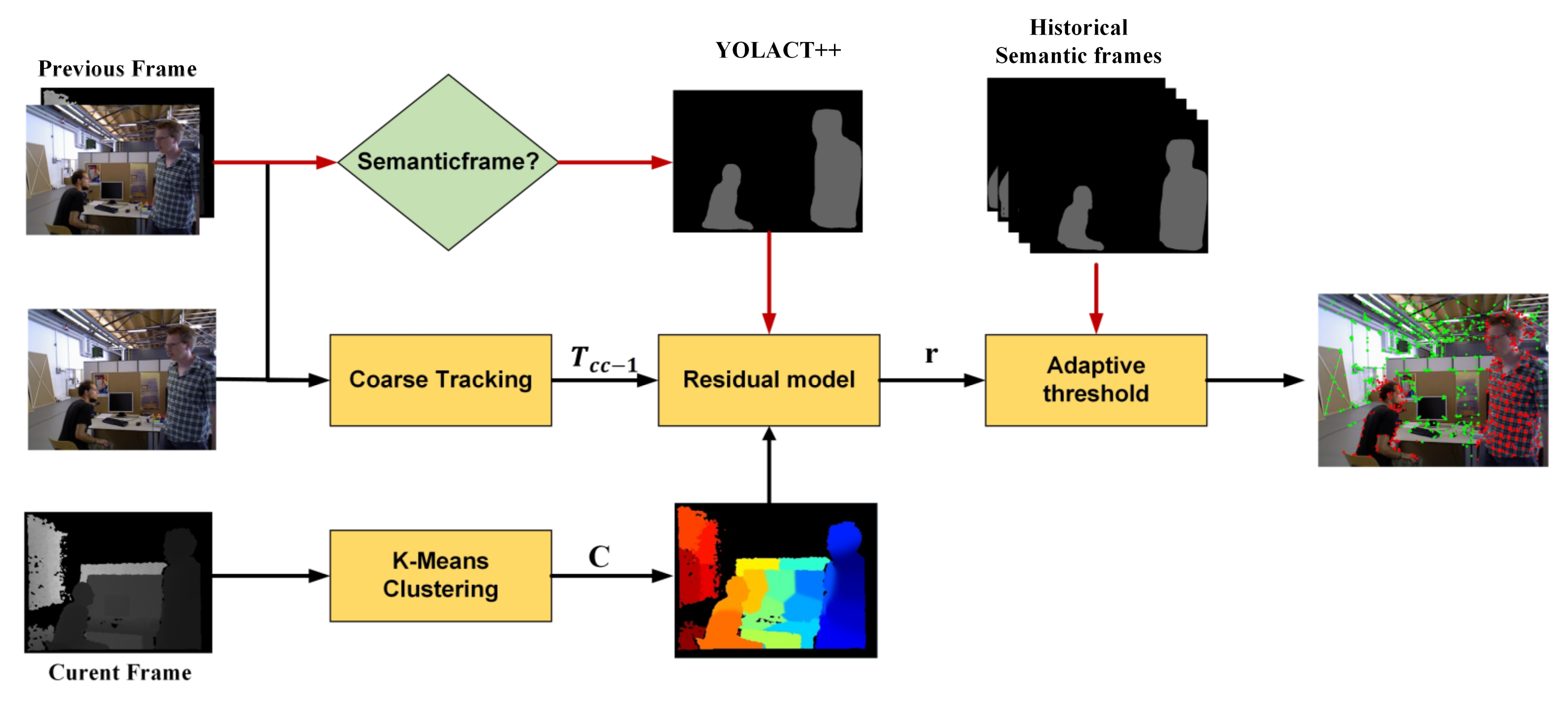
If the camera is stationary in dynamic scenes, the motion segmentation problem becomes very simple. However, the camera is often in motion, and the overall scene is clearly in motion, making it hard to identify dynamic objects directly. To achieve dynamic object detection, the initial pose of the current frame needs to be computed to determine which clusters follow the motion pattern of the camera and which clusters do not. Therefore, we perform coarse tracking of the system to calculate the initial pose of the current frame. According to the motion model, we project the static feature points in the previous frame to the current frame to find the matching points and minimize the reprojection error to optimize the initial pose
. As shown in
Figure 4, the original ORB matching establishes many incorrect correspondences on the human body, which provides unstable data association for camera tracking. In contrast, coarse tracking uses only the static feature points of the previous frame, which reduces the influence of dynamic objects on the positional computation and makes the initial positional
with high accuracy, which is helpful for subsequent motion segmentation of the current frame.
To identify the dynamic and static parts of the scene, motion segmentation needs to be performed according to the residual of the cluster. Therefore, we established a residual model to calculate the residual of each cluster:
where
is the data residual,
is the spatial residual, and
is the priori residual.
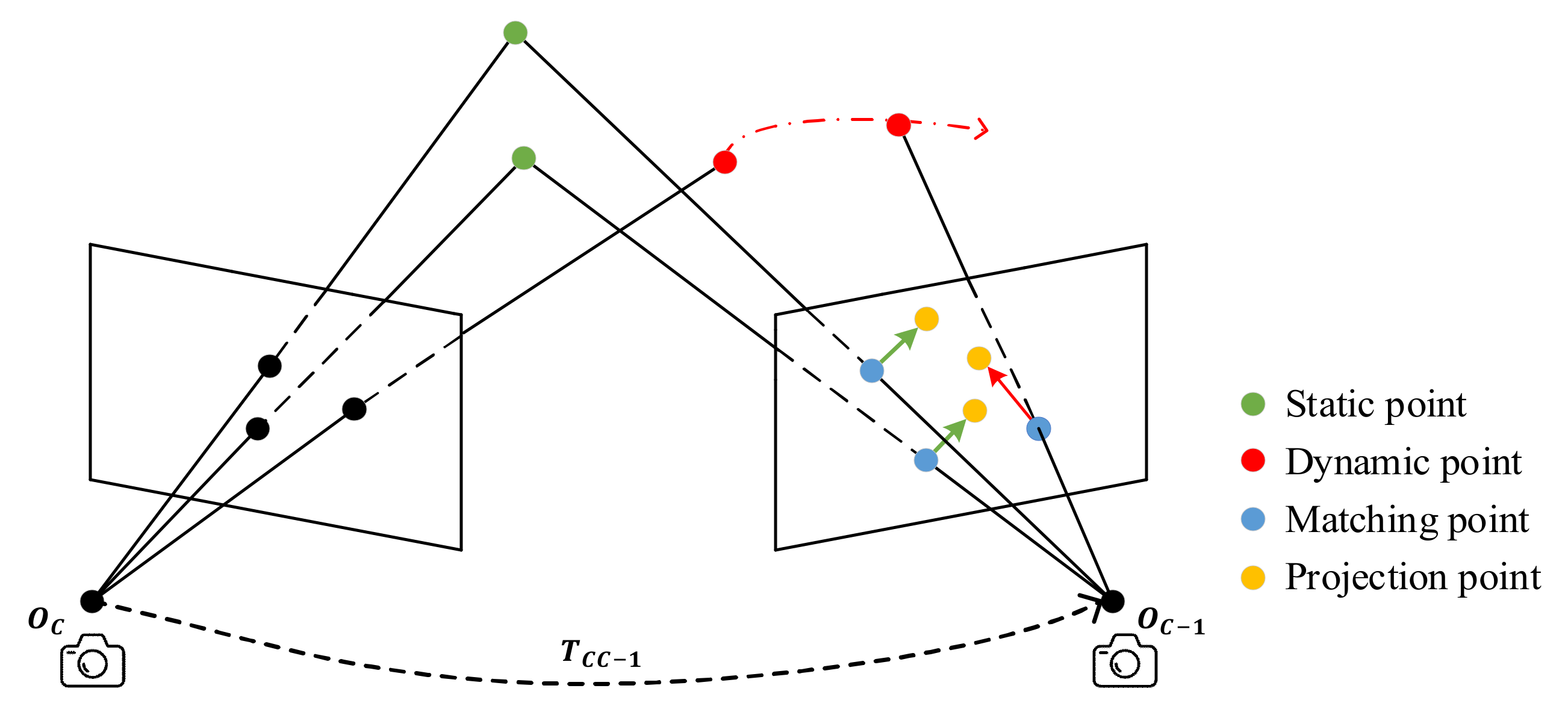
The data residual
is the most important part of the residual model. As shown in
Figure 5, the initial camera pose
calculated by coarse tracking transforms the projection of feature points from the previous frame to the current frame (yellow points). Due to noise and initial pose errors, the static projection point and the matching point (green point) often do not coincide, but their distances and directions are usually similar (green arrows). However, the projection points corresponding to the dynamic points (red points) are significantly different from the matching points in both size and direction (red arrows) from the static points. The dynamic regions in the image can be determined based on this information, so we construct the data residual term
:
where
and
represent the pixel depth and intensity residual, respectively.
is the weight to balance the contribution of depth residuals and intensity residuals. The depth residual
and intensity residual
of cluster
can be calculated, respectively, as:
where
is the pixel coordinate of the previous frame, and current frame pixel
is the projection point of
.
is the average depth of
, n is the number of pixels in
, and
represents the Z coordinate values of the 3D points.
and
represent the depth and intensity of pixels, respectively. Intensity is converted from the color image (0.299R + 0.587G + 0.114B), and depth is from the depth image. The function
:
projects 2D point
to 3D point
according to the pinhole model as follows:
where
is the camera principal point.
In theory, if the initial pose
is accurate, then static objects have low depth and intensity residuals, while moving objects have high residuals. Dynamic targets can be detected based on the data residual. However, in practice the process is much more complicated because data residual is not always a good metric to evaluate precise image alignment. Therefore, we borrow and improve the idea of Jaimez’s method [
15] and add spatial residual.
The purpose of spatial residual
is to encourage contiguous clusters of the same object have similar segmentation results. As shown in
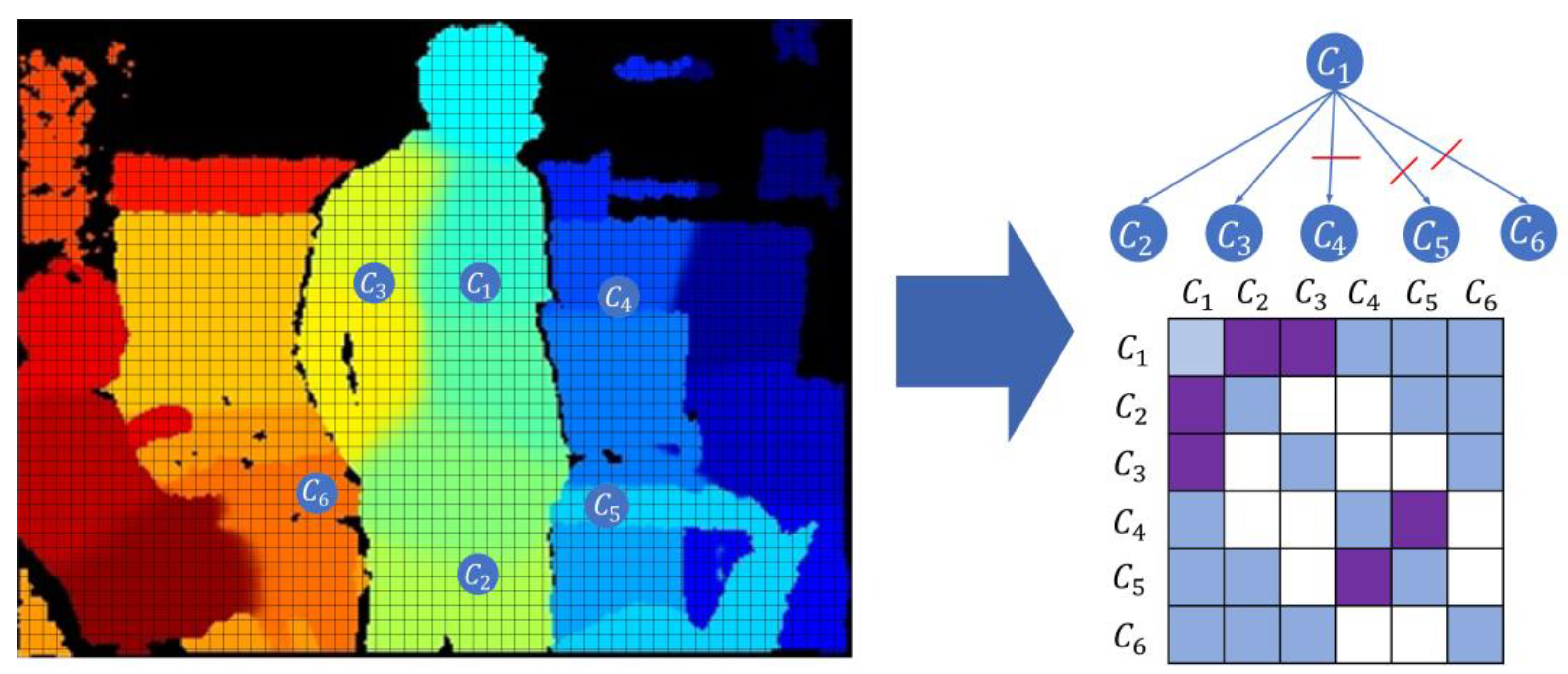
Figure 6, the person is divided into several adjacent clusters after K-means clustering, but they may have similar motion states. Therefore, we build the connectivity graph by determining the clusters’ spatial connectivity status and correlation, which assists in computing the spatial residual
. The specific steps are as follows:
Statistically analyze the spatial connectivity of the clustering and compute the average depth difference
of the boundary pixels of each pair of neighboring clusters as:
where
and
are the neighboring clusters and n is the number of neighboring cluster boundary pixels. Z(x)∈R represent the depth of pixels.
Compare
with the threshold value
. If
is less than
, the two clusters are spatially correlated. Then we can build the connectivity graph as shown in
Figure 6. Finally, based on the connectivity graph, the spatial residual
of cluster
is calculated as:
where K is the number of spatially connected clusters to the cluster
.
and
are the data item residuals of clusters i and j, respectively.
is the clustering correlation function: it is equal to 1 when clusters i and j are spatially correlated and is 0 otherwise.
Figure 6.
The process of building connectivity graph. to are the clusters after K-means clustering. The table on the right shows its connectivity graph. The blue cells indicate that two clusters have spatial connectivity, and the purple cells indicate that two clusters have spatial connectivity and spatial correlation.
Figure 6.
The process of building connectivity graph. to are the clusters after K-means clustering. The table on the right shows its connectivity graph. The blue cells indicate that two clusters have spatial connectivity, and the purple cells indicate that two clusters have spatial connectivity and spatial correlation.
In addition, we believe that the objects in the scene always tend to keep the previous motion state in a shorter period, so we add the a priori residual term
.
contains two parts: the residual
of the previous frame and the residual
of the corresponding region in the semantic mask of the previous frame. The priori residual
of cluster
is defined as:
where
is the pixel coordinate of previous frame,
is the is the projection point of
in current frame, n is the number of pixels in
. If previous frame is semantic frame and
is included in the semantic mask,
, else
.
3.1.3. Scene Motion Segmentation
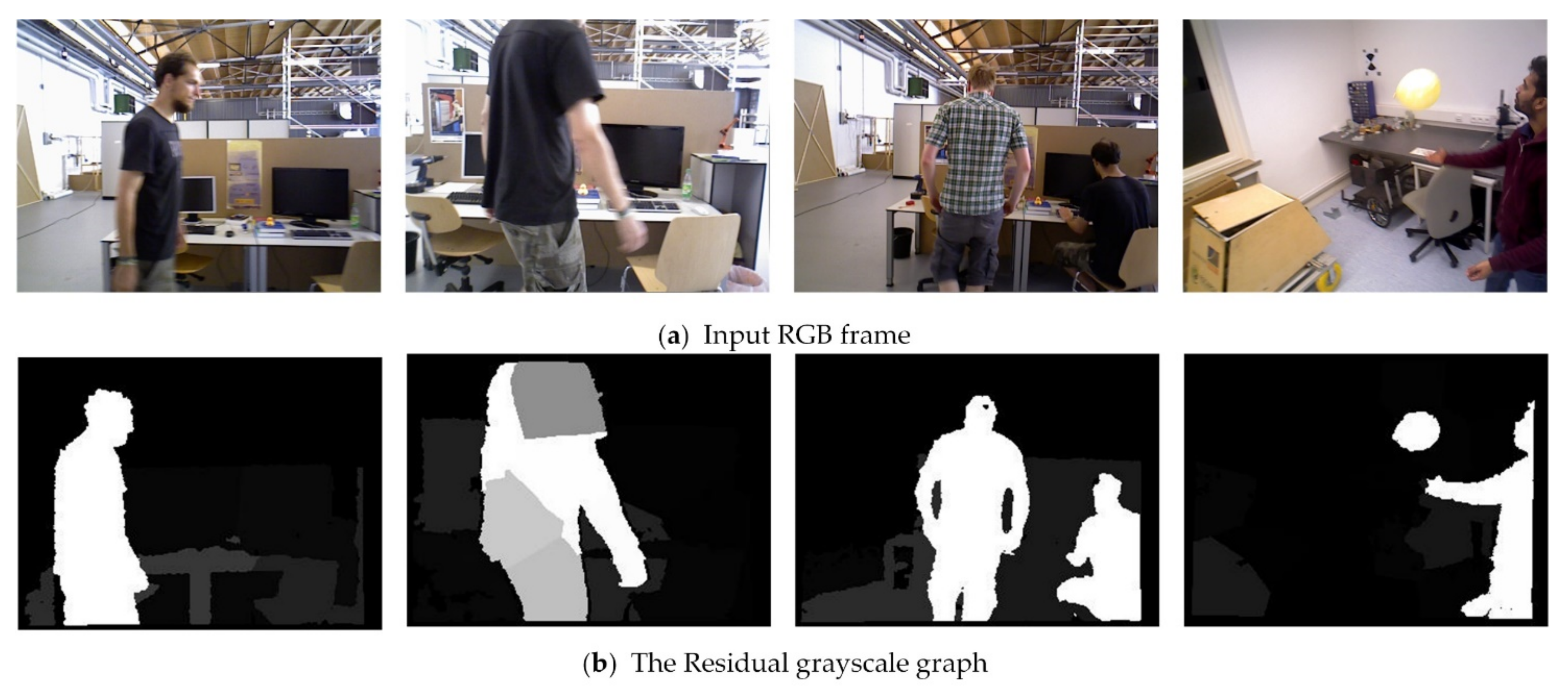
As shown in
Figure 7, the residual gray graph generated by the residual model shows that the residual values of static and dynamic objects are significantly different. Because the motion of the dynamic object itself is independent of the camera, it has a high residual. The residual of static objects is usually small or close to zero. However, the residual distribution is not always the same in different scenarios, so it is difficult to divide the high and low residuals through a fixed threshold. Therefore, we design an adaptive threshold algorithm to realize scene motion segmentation.
Considering the residual distribution of each cluster and the semantic information of the instance segmentation, we define the adaptive residual threshold T as:
where
is a residual distribution threshold calculated based on the residual distribution of the current frame, and
is a semantic residual threshold calculated based on the weighting of historical semantic frames. α serves to balance the current frame and historical semantic frames. A higher value implies more sensitivity to the current segmentation result. Otherwise, it indicates more consideration of historical information from semantic detection. In our experiments, we set α = 0.7. Because semantic detection is unreliable in some scenes, it is easy to treat stationary people or cars as dynamic objects, thus lowering the threshold to misclassify other static objects as dynamic.
- A.
Residual Distribution Threshold
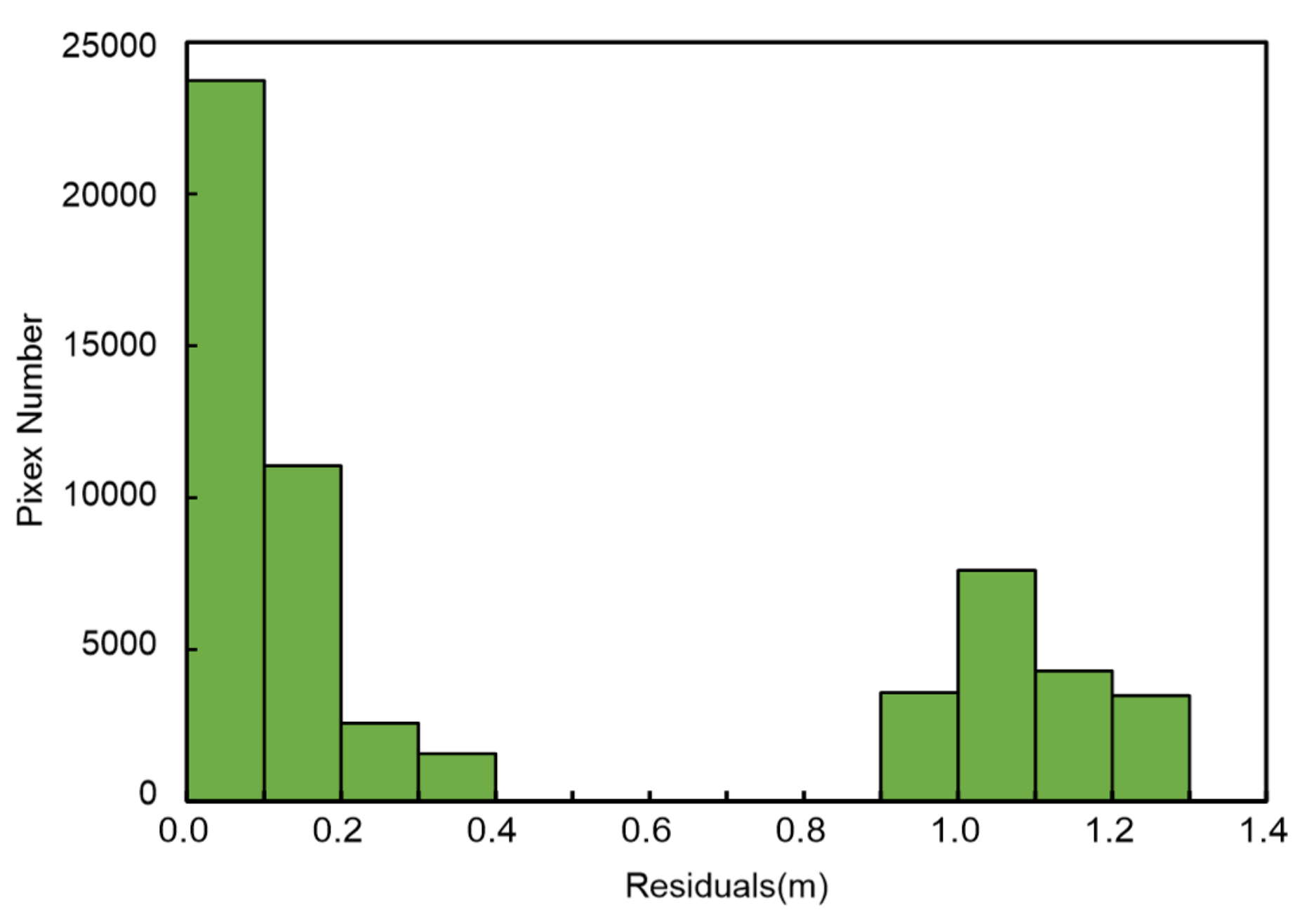
Figure 8 shows an example histogram of the residual distribution for a highly dynamic scene. The residual distribution consists of two distinct peaks corresponding to the residuals in the static and dynamic regions. If the trough between the two peaks can be identified as a threshold, the two types of objects can be easily separated. However, the residual distribution is often discontinuous, with spikes and jitter, making it difficult to calculate an accurate cutoff point. We extend the idea of the Otsu [
40] method to segment the histogram of residual distribution for each frame, which is used to calculate the residual value
between the dynamic objects and static objects. The specific calculation process is as follows:
Compute the normalized residuals histogram. Assume that the initial threshold divides the histogram into two parts, namely dynamic objects D and static objects S. Let be the number of pixels in cluster I, be the number of static object pixels, be the number of dynamic objects pixels, and K be the number of image clusters. Then, the normalized value is
Figure 8.
Example of a residuals histogram in a highly dynamic scene.
Figure 8.
Example of a residuals histogram in a highly dynamic scene.
When the scene is static, the threshold T is calculated to be small, which will incorrectly classify some static objects as dynamic. We set the segmentation function to adjust the threshold T to suit different application scenarios.
- B.
Semantic Residual Threshold
In addition, we use the semantic segmentation results to calculate the semantic residual threshold
to improve the reliability of the adaptive threshold T. Instance segmentation cannot determine whether the target is moving or not, so we choose the five frames with the highest overlap to calculate
. First, we traverse the semantic frame database and calculate the overlap
between the semantic frame and the current frame by the rotation matrix R and the translation vector t:
Second, we select the five frames with the highest overlap among them and calculate the average residual value
of the semantic maskfor each frame:
where
is the number of semantic frame mask pixels. Finally, we calculate the semantic residual threshold
based on the overlap weighting and average residual
of each semantic frame:
We input
and
into Equation (9) to calculate the adaptive threshold T for the current frame. We then use T to classify the clusters of the current frame and determine their motion state:




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}