
A Mutual Teaching Framework with Momentum Correction for Unsupervised Hyperspectral Image Change Detection


Abstract
:1. Introduction
- (1)
- We introduce to a novel mutual teaching framework with momentum correction for resisting noisy labels generated by traditional methods in unsupervised HSI-CD. Due to mutual teaching and dynamic label learning, pseudo-labels can be continuously updated and refined in iterations, and thus the proposed method can achieve superior results.
- (2)
- A group confidence-based sample selection approach is proposed to avoid selecting the two most extreme types of samples, and it is used alternately with another selection mechanism in iteration to ensure that complex samples can participate in training.
- (3)
- An end-to-end 3DCNN is designed as a classifier for HSI-CD and the basic model of the proposed framework. Experiments on four datasets demonstrate that our framework can effectively improve model performance.
2. Related Work
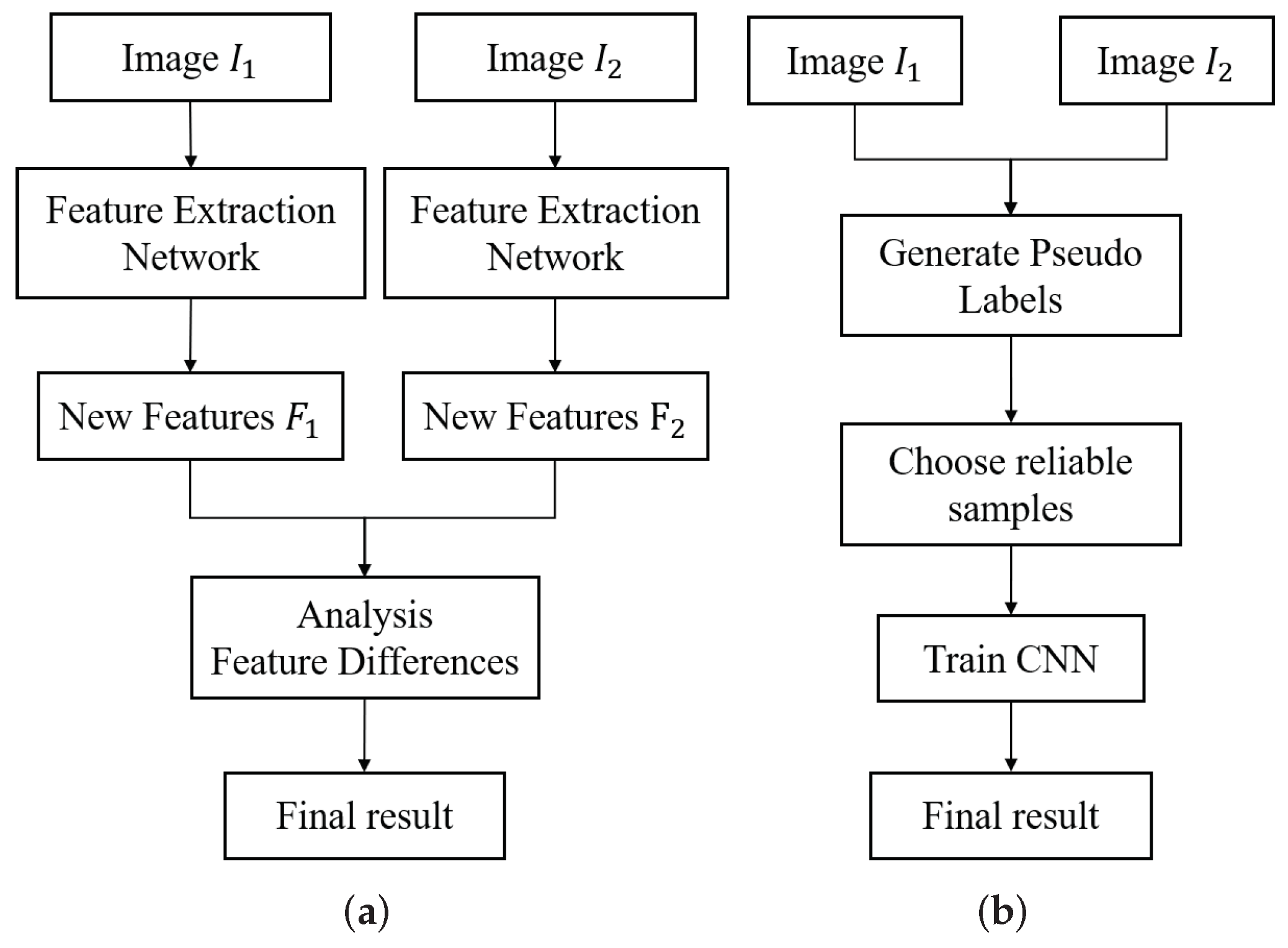
2.1. Unsupervised Deep Methods for Change Detection
2.2. Deep Learning with Noisy Labels
2.3. Mutual Teaching Paradigm
3. Methodology
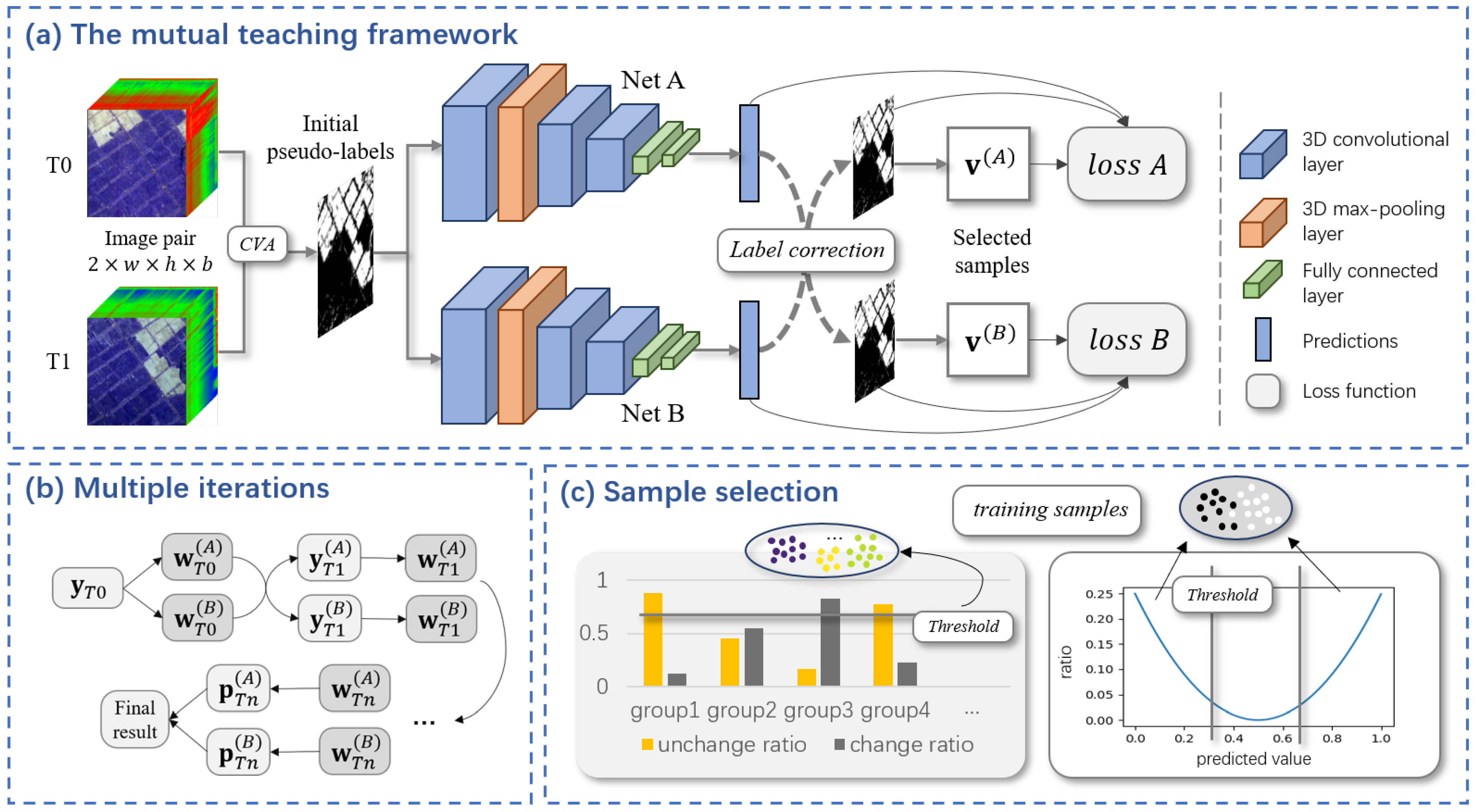
3.1. The Mutual Teaching Framework
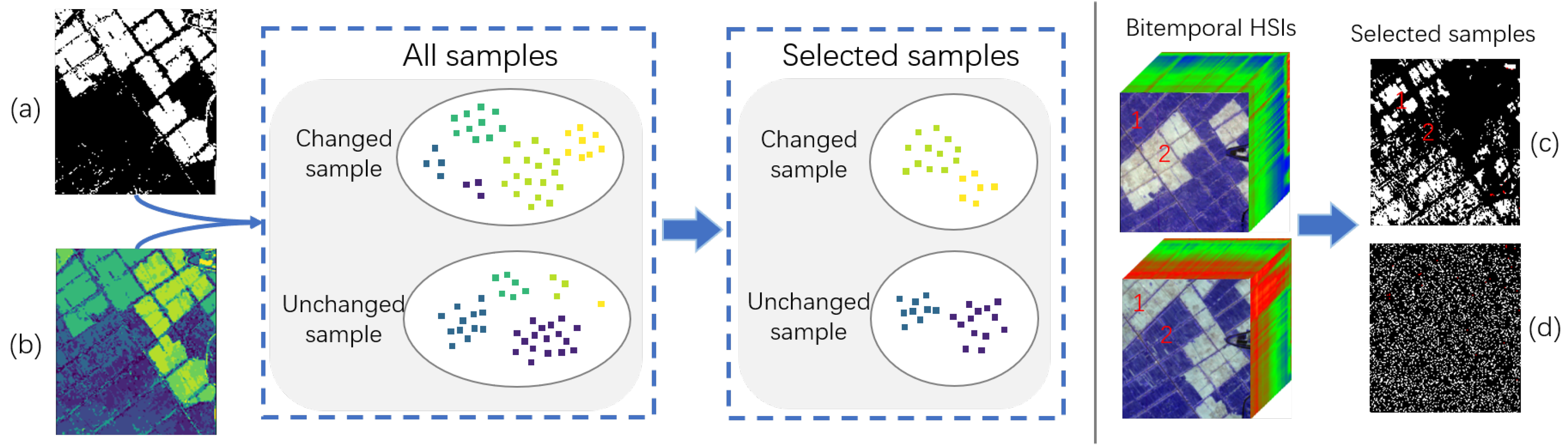
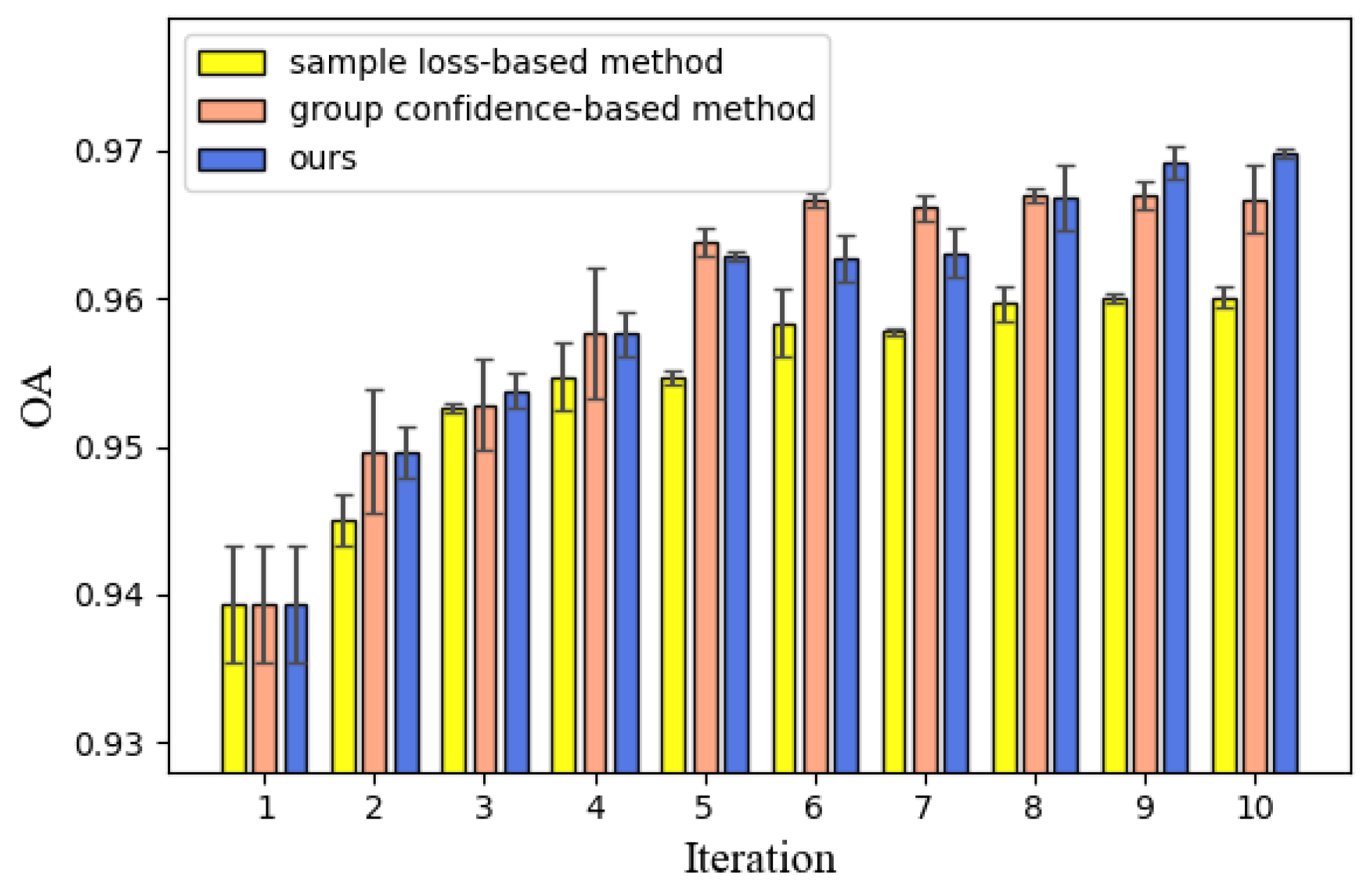
3.2. Sample Selection
| Algorithm 1: Procedure of the proposed method. |
Input: Two images and ; thresholds and ; the number of iterations ; the momentum parameter . Output: The final result . // Initialization Get pseudo-labels and multiclass map ; initialize and ; Randomly initialize and ; for to do if then Update selected sample and by (6); else Update selected sample and by (3); end Update pseudo-labels and by (2); end , |
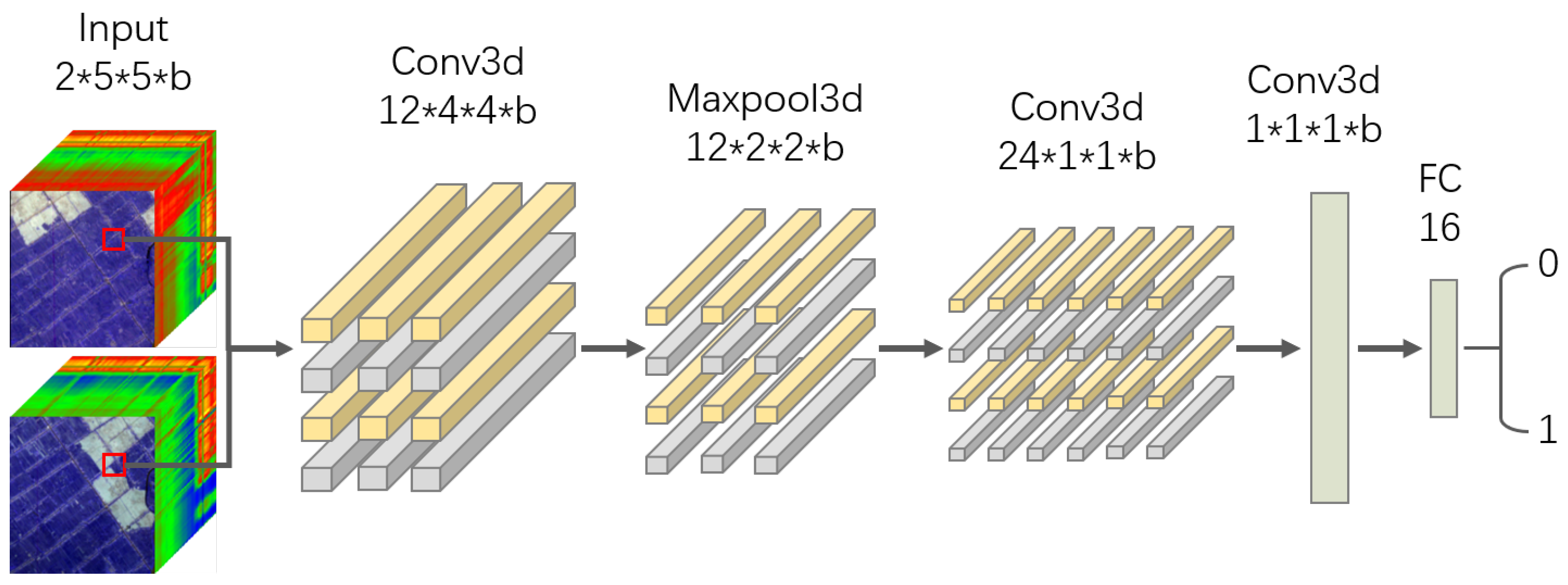
3.3. A 3D Convolutional Neural Network Establishment
4. Result
4.1. Introduction to Datasets
4.2. Evaluation Measures and Experimental Configurations
4.3. Comparison with Other Methods
4.3.1. Experiments on the Bastrop Dataset
4.3.2. Experiments on the Umatilla Dataset
4.3.3. Experiments on the Yancheng Dataset
4.3.4. Experiments on the River Dataset
5. Discussion
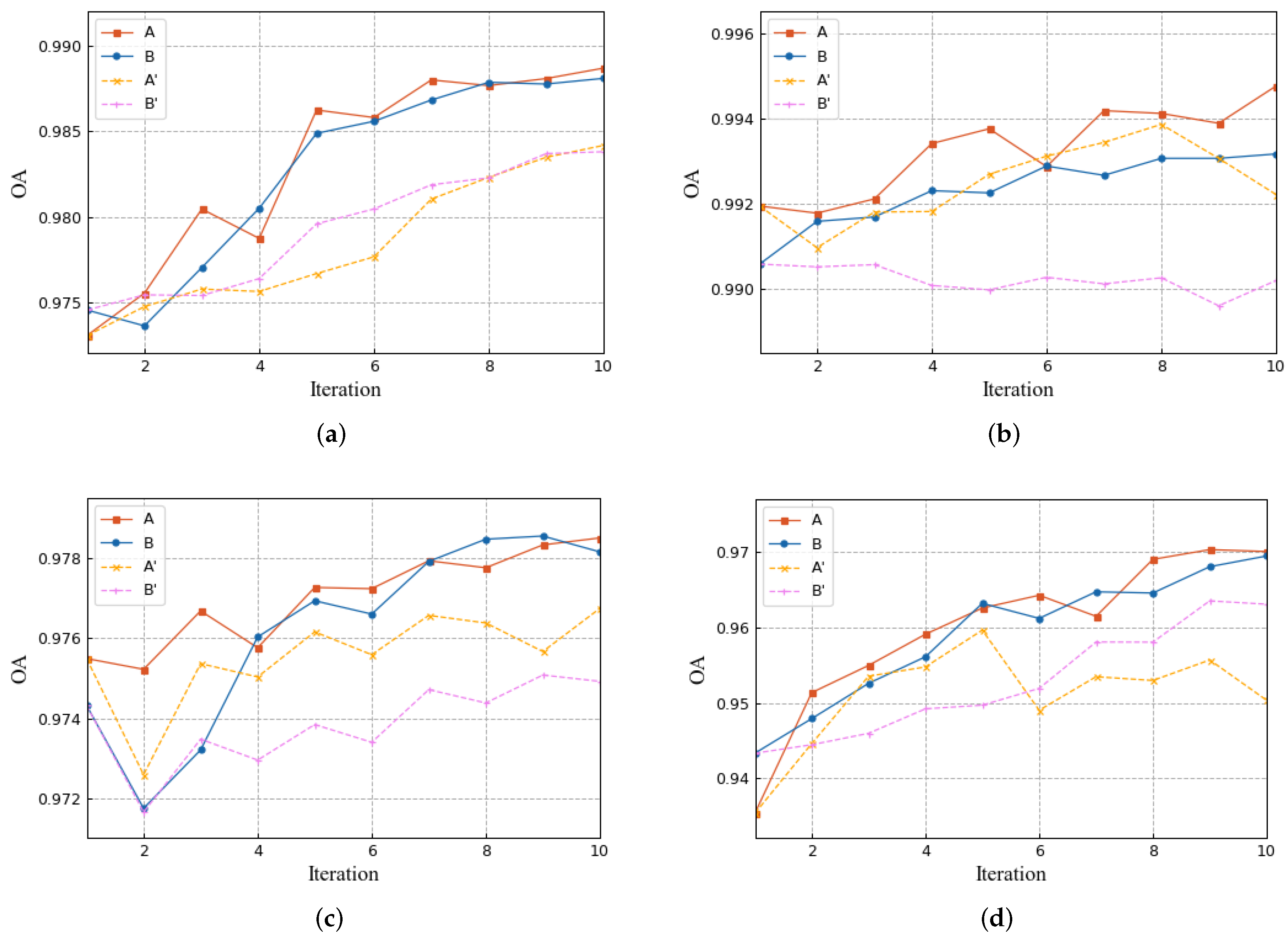
5.1. Ablation Study
5.2. Compatibility of the Proposed Framework with Other Models
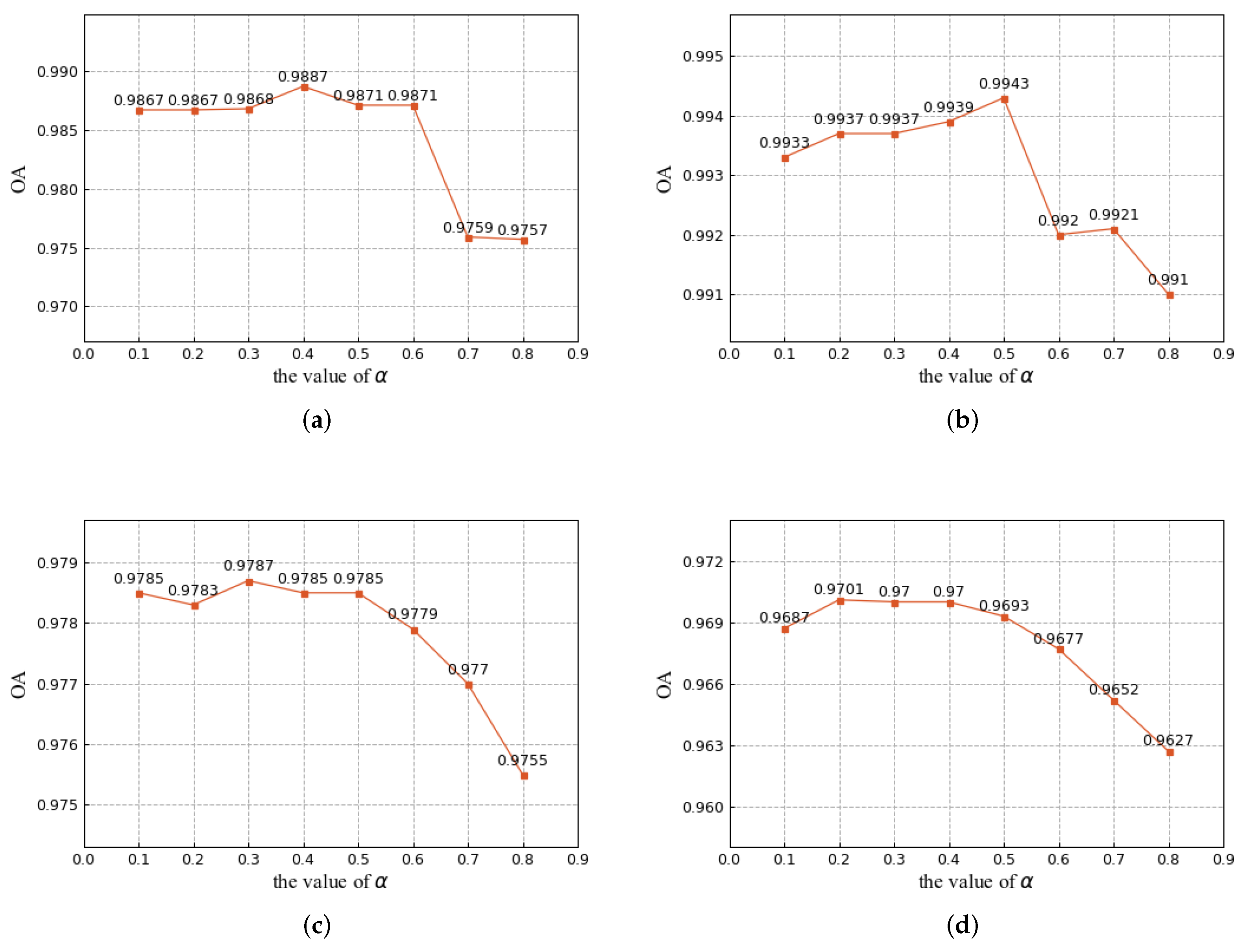
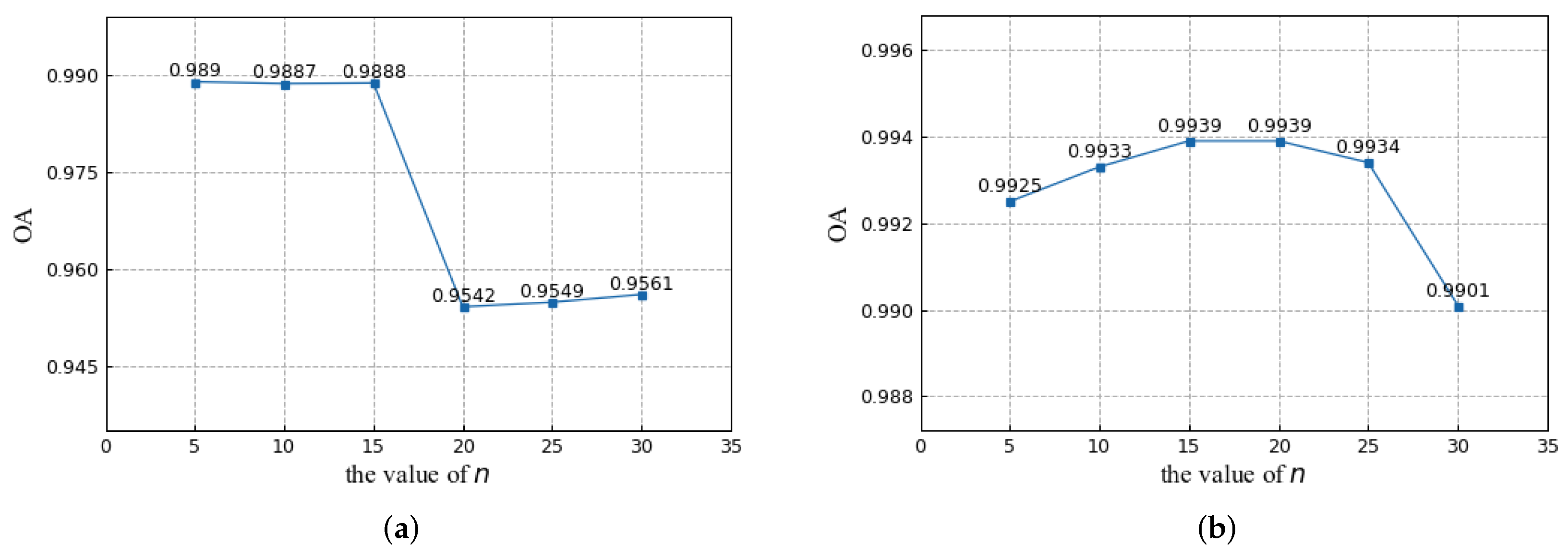
5.3. Hyperparametric Analysis
5.3.1. Analysis of the Pseudo-Label Update Rate
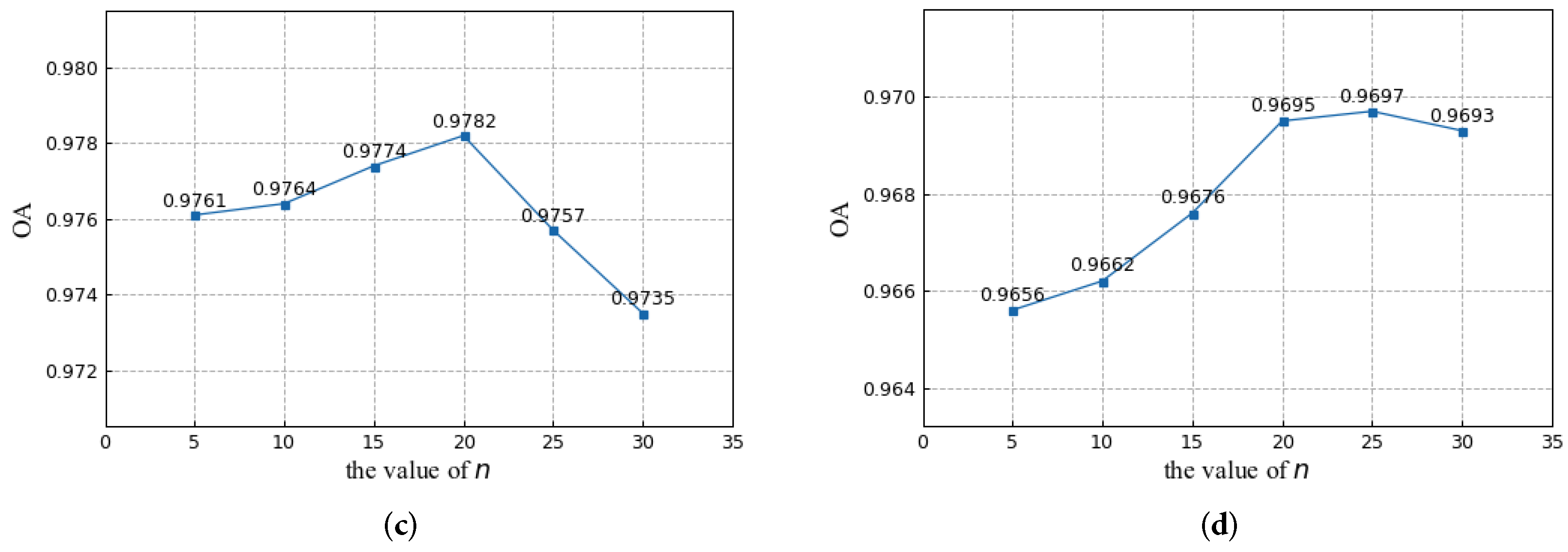
5.3.2. Analysis of the Number of Groups
5.4. Computing Time
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Scafutto, R.D.M.; de Souza Filho, C.R.; de Oliveira, W.J. Hyperspectral remote sensing detection of petroleum hydrocarbons in mixtures with mineral substrates: Implications for onshore exploration and monitoring. ISPRS J. Photogramm. Remote Sens. 2017, 128, 146–157. [Google Scholar] [CrossRef]
- Carrino, T.A.; Crósta, A.P.; Toledo, C.L.B.; Silva, A.M. Hyperspectral remote sensing applied to mineral exploration in southern Peru: A multiple data integration approach in the Chapi Chiara gold prospect. Int. J. Appl. Earth Obs. Geoinf. 2018, 64, 287–300. [Google Scholar] [CrossRef]
- Zhang, X.; Sun, Y.; Shang, K.; Zhang, L.; Wang, S. Crop classification based on feature band set construction and object-oriented approach using hyperspectral images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 4117–4128. [Google Scholar] [CrossRef]
- Vali, A.; Comai, S.; Matteucci, M. Deep learning for land use and land cover classification based on hyperspectral and multispectral earth observation data: A review. Remote Sens. 2020, 12, 2495. [Google Scholar] [CrossRef]
- Shimoni, M.; Haelterman, R.; Perneel, C. Hypersectral imaging for military and security applications: Combining myriad processing and sensing techniques. IEEE Geosci. Remote Sens. Mag. 2019, 7, 101–117. [Google Scholar] [CrossRef]
- Singh, A. Review article digital change detection techniques using remotely-sensed data. Int. J. Remote Sens. 1989, 10, 989–1003. [Google Scholar] [CrossRef] [Green Version]
- Bovolo, F.; Bruzzone, L. A theoretical framework for unsupervised change detection based on change vector analysis in the polar domain. IEEE Trans. Geosci. Remote Sens. 2006, 45, 218–236. [Google Scholar] [CrossRef] [Green Version]
- Celik, T. Unsupervised change detection in satellite images using principal component analysis and k-means clustering. IEEE Geosci. Remote Sens. Lett. 2009, 6, 772–776. [Google Scholar] [CrossRef]
- Nielsen, A.A.; Conradsen, K.; Simpson, J.J. Multivariate alteration detection (MAD) and MAF postprocessing in multispectral, bitemporal image data: New approaches to change detection studies. Remote Sens. Environ. 1998, 64, 1–19. [Google Scholar] [CrossRef] [Green Version]
- Nielsen, A.A. The regularized iteratively reweighted MAD method for change detection in multi-and hyperspectral data. IEEE Trans. Image Process. 2007, 16, 463–478. [Google Scholar] [CrossRef] [Green Version]
- Coppin, P.; Jonckheere, I.; Nackaerts, K.; Muys, B.; Lambin, E. Review ArticleDigital change detection methods in ecosystem monitoring: A review. Int. J. Remote Sens. 2004, 25, 1565–1596. [Google Scholar] [CrossRef]
- Wu, C.; Du, B.; Zhang, L. Slow feature analysis for change detection in multispectral imagery. IEEE Trans. Geosci. Remote Sens. 2013, 52, 2858–2874. [Google Scholar] [CrossRef]
- Ahlqvist, O. Extending post-classification change detection using semantic similarity metrics to overcome class heterogeneity: A study of 1992 and 2001 US National Land Cover Database changes. Remote Sens. Environ. 2008, 112, 1226–1241. [Google Scholar] [CrossRef]
- Wan, L.; Xiang, Y.; You, H. A post-classification comparison method for SAR and optical images change detection. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1026–1030. [Google Scholar] [CrossRef]
- Liu, T.; Yang, L.; Lunga, D. Change detection using deep learning approach with object-based image analysis. Remote Sens. Environ. 2021, 256, 112308. [Google Scholar] [CrossRef]
- Mou, L.; Bruzzone, L.; Zhu, X.X. Learning spectral-spatial-temporal features via a recurrent convolutional neural network for change detection in multispectral imagery. IEEE Trans. Geosci. Remote Sens. 2018, 57, 924–935. [Google Scholar] [CrossRef] [Green Version]
- Wang, Q.; Yuan, Z.; Du, Q.; Li, X. GETNET: A general end-to-end 2-D CNN framework for hyperspectral image change detection. IEEE Trans. Geosci. Remote Sens. 2018, 57, 3–13. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.; Jiang, H.; Li, C.; Jia, X.; Ghamisi, P. Deep feature extraction and classification of hyperspectral images based on convolutional neural networks. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6232–6251. [Google Scholar] [CrossRef] [Green Version]
- Du, B.; Ru, L.; Wu, C.; Zhang, L. Unsupervised deep slow feature analysis for change detection in multi-temporal remote sensing images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 9976–9992. [Google Scholar] [CrossRef] [Green Version]
- Li, X.; Yuan, Z.; Wang, Q. Unsupervised deep noise modeling for hyperspectral image change detection. Remote Sens. 2019, 11, 258. [Google Scholar] [CrossRef] [Green Version]
- Li, Q.; Gong, H.; Dai, H.; Li, C.; He, Z.; Wang, W.; Feng, Y.; Han, F.; Tuniyazi, A.; Li, H.; et al. Unsupervised Hyperspectral Image Change Detection via Deep Learning Self-generated Credible Labels. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 9012–9024. [Google Scholar] [CrossRef]
- Zhang, C.; Bengio, S.; Hardt, M.; Recht, B.; Vinyals, O. Understanding deep learning (still) requires rethinking generalization. Commun. ACM 2021, 64, 107–115. [Google Scholar] [CrossRef]
- Yu, X.; Han, B.; Yao, J.; Niu, G.; Tsang, I.; Sugiyama, M. How does disagreement help generalization against label corruption? In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019; pp. 7164–7173. [Google Scholar]
- Yao, Q.; Yang, H.; Han, B.; Niu, G.; Kwok, J.T.Y. Searching to exploit memorization effect in learning with noisy labels. In Proceedings of the International Conference on Machine Learning, Virtual Event, 13–18 July 2020; pp. 10789–10798. [Google Scholar]
- Shang, R.; Yuan, Y.; Jiao, L.; Meng, Y.; Ghalamzan, A.M. A self-paced learning algorithm for change detection in synthetic aperture radar images. Signal Proc. 2018, 142, 375–387. [Google Scholar] [CrossRef] [Green Version]
- Gong, M.; Duan, Y.; Li, H. Group self-paced learning with a time-varying regularizer for unsupervised change detection. IEEE Trans. Geosci. Remote Sens. 2019, 58, 2481–2493. [Google Scholar] [CrossRef]
- Han, B.; Yao, Q.; Yu, X.; Niu, G.; Xu, M.; Hu, W.; Tsang, I.; Sugiyama, M. Co-teaching: Robust Training of Deep Neural Networks with Extremely Noisy Labels. In Proceedings of the International Conference on Neural Information Processing Systems, Stockholm, Sweden, 10–15 July 2018; pp. 8536–8546. [Google Scholar]
- Li, P.; Xu, Y.; Wei, Y.; Yang, Y. Self-correction for human parsing. arXiv 2020, arXiv:1910.09777. [Google Scholar] [CrossRef]
- Zheng, G.; Awadallah, A.H.; Dumais, S. Meta label correction for noisy label learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual Event, 2–9 February 2021. [Google Scholar]
- Liu, J.; Gong, M.; Qin, K.; Zhang, P. A deep convolutional coupling network for change detection based on heterogeneous optical and radar images. IEEE Trans. Neural Netw. Learn. Syst. 2016, 29, 545–559. [Google Scholar] [CrossRef] [PubMed]
- Zhang, P.; Gong, M.; Zhang, H.; Liu, J.; Ban, Y. Unsupervised difference representation learning for detecting multiple types of changes in multitemporal remote sensing images. IEEE Trans. Geosci. Remote Sens. 2018, 57, 2277–2289. [Google Scholar] [CrossRef]
- Liu, J.; Zhang, W.; Liu, F.; Xiao, L. A Probabilistic Model Based on Bipartite Convolutional Neural Network for Unsupervised Change Detection. IEEE Trans. Geosci. Remote Sens. 2021, 60, 4701514. [Google Scholar] [CrossRef]
- Gong, M.; Zhao, J.; Liu, J.; Miao, Q.; Jiao, L. Change detection in synthetic aperture radar images based on deep neural networks. IEEE Trans. Neural Netw. Learn. Syst. 2015, 27, 125–138. [Google Scholar] [CrossRef]
- Li, Y.; Peng, C.; Chen, Y.; Jiao, L.; Zhou, L.; Shang, R. A deep learning method for change detection in synthetic aperture radar images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 5751–5763. [Google Scholar] [CrossRef]
- Goldberger, J.; Ben-Reuven, E. Training deep neural-networks using a noise adaptation layer. In Proceedings of the International Conference of Learning Representations (ICLR), San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Ghosh, A.; Kumar, H.; Sastry, P. Robust loss functions under label noise for deep neural networks. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31. [Google Scholar]
- Lee, K.H.; He, X.; Zhang, L.; Yang, L. Cleannet: Transfer learning for scalable image classifier training with label noise. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5447–5456. [Google Scholar]
- Jiang, L.; Zhou, Z.; Leung, T.; Li, L.J.; Li, F.-F. Mentornet: Learning data-driven curriculum for very deep neural networks on corrupted labels. In Proceedings of the International Conference on Machine Learning, PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 2304–2313. [Google Scholar]
- Blum, A.; Mitchell, T. Combining labeled and unlabeled data with co-training. In Proceedings of the Eleventh Annual Conference on Computational Learning Theory, Madison, WI, USA, 24–26 July 1998; pp. 92–100. [Google Scholar]
- Zhang, Y.; Xiang, T.; Hospedales, T.M.; Lu, H. Deep mutual learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4320–4328. [Google Scholar]
- Ge, Y.; Chen, D.; Li, H. Mutual mean-teaching: Pseudo label refinery for unsupervised domain adaptation on person re-identification. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Yang, F.; Li, K.; Zhong, Z.; Luo, Z.; Sun, X.; Cheng, H.; Guo, X.; Huang, F.; Ji, R.; Li, S. Asymmetric co-teaching for unsupervised cross-domain person re-identification. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12597–12604. [Google Scholar]
- Liu, J.; Li, R.; Sun, C. Co-Correcting: Noise-tolerant Medical Image Classification via mutual Label Correction. IEEE Trans. Med. Imag. 2021, 40, 3580–3592. [Google Scholar] [CrossRef] [PubMed]
- Tai, X.; Li, M.; Xiang, M.; Ren, P. A Mutual Guide Framework for Training Hyperspectral Image Classifiers with Small Data. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5510417. [Google Scholar] [CrossRef]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Volpi, M.; Camps-Valls, G.; Tuia, D. Spectral alignment of multi-temporal cross-sensor images with automated kernel canonical correlation analysis. ISPRS J. Photogramm. Remote Sens. 2015, 107, 50–63. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | FP | FN | OA | Kappa | F1 |
|---|---|---|---|---|---|
| CVA | 10,272 | 46,813 | 0.9539 | 0.7241 | 0.7487 |
| IRMAD | 13,490 | 54,000 | 0.9455 | 0.6688 | 0.6977 |
| ISFA | 10,082 | 32,010 | 0.9660 | 0.8073 | 0.8259 |
| SVM | 2799 | 83,435 | 0.9304 | 0.4992 | 0.5290 |
| GETNET | 6744 | 31,319 | 0.9693 | 0.8241 | 0.8408 |
| 2DCNN | 6923 | 34,276 | 0.9668 | 0.8076 | 0.8257 |
| 3DCNN | 7420 | 26,299 | 0.9728 | 0.8473 | 0.8623 |
| ours | 7212 | 6811 | 0.9887 | 0.9406 | 0.9469 |
| Methods | FP | FN | OA | Kappa | F1 |
|---|---|---|---|---|---|
| CVA | 1092 | 198 | 0.9835 | 0.9258 | 0.9352 |
| IRMAD | 452 | 246 | 0.9911 | 0.9586 | 0.9637 |
| ISFA | 506 | 191 | 0.9911 | 0.9588 | 0.9639 |
| SVM | 256 | 2125 | 0.9695 | 0.8442 | 0.8612 |
| GETNET | 216 | 337 | 0.9929 | 0.9667 | 0.9707 |
| 2DCNN | 210 | 445 | 0.9916 | 0.9604 | 0.9651 |
| 3DCNN | 277 | 291 | 0.9927 | 0.9660 | 0.9701 |
| ours | 151 | 309 | 0.9941 | 0.9723 | 0.9756 |
| Methods | FP | FN | OA | Kappa | F1 |
|---|---|---|---|---|---|
| CVA | 1833 | 1158 | 0.9525 | 0.8860 | 0.9197 |
| IRMAD | 2268 | 356 | 0.9583 | 0.9019 | 0.9318 |
| ISFA | 1303 | 296 | 0.9746 | 0.9394 | 0.9574 |
| SVM | 512 | 4619 | 0.9186 | 0.7882 | 0.8419 |
| GETNET | 810 | 792 | 0.9746 | 0.9383 | 0.9562 |
| 2DCNN | 1162 | 611 | 0.9719 | 0.9323 | 0.9522 |
| 3DCNN | 554 | 1059 | 0.9744 | 0.9373 | 0.9553 |
| ours | 548 | 817 | 0.9783 | 0.9472 | 0.9624 |
| Methods | FP | FN | OA | Kappa | F1 |
|---|---|---|---|---|---|
| CVA | 6196 | 1123 | 0.9344 | 0.7103 | 0.7467 |
| IRMAD | 3343 | 3089 | 0.9424 | 0.7005 | 0.7328 |
| ISFA | 10,244 | 1355 | 0.8961 | 0.5897 | 0.6453 |
| SVM | 2595 | 6007 | 0.9229 | 0.5373 | 0.5784 |
| GETNET | 4185 | 1369 | 0.9502 | 0.7636 | 0.7915 |
| 2DCNN | 3618 | 1127 | 0.9575 | 0.7958 | 0.8196 |
| 3DCNN | 2447 | 2215 | 0.9582 | 0.7827 | 0.8061 |
| ours | 1595 | 1809 | 0.9695 | 0.8387 | 0.8558 |
| Bastrop | Umatilla | Yancheng | River | |
|---|---|---|---|---|
| 3DCNN | 343.52 | 51.18 | 46.94 | 67.99 |
| ours | 2919.93 | 414.29 | 339.44 | 496.96 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, J.; Liu, J.; Hu, L.; Wei, Z.; Xiao, L. A Mutual Teaching Framework with Momentum Correction for Unsupervised Hyperspectral Image Change Detection. Remote Sens. 2022, 14, 1000. https://doi.org/10.3390/rs14041000
Sun J, Liu J, Hu L, Wei Z, Xiao L. A Mutual Teaching Framework with Momentum Correction for Unsupervised Hyperspectral Image Change Detection. Remote Sensing. 2022; 14(4):1000. https://doi.org/10.3390/rs14041000
Chicago/Turabian StyleSun, Jia, Jia Liu, Ling Hu, Zhihui Wei, and Liang Xiao. 2022. "A Mutual Teaching Framework with Momentum Correction for Unsupervised Hyperspectral Image Change Detection" Remote Sensing 14, no. 4: 1000. https://doi.org/10.3390/rs14041000
APA StyleSun, J., Liu, J., Hu, L., Wei, Z., & Xiao, L. (2022). A Mutual Teaching Framework with Momentum Correction for Unsupervised Hyperspectral Image Change Detection. Remote Sensing, 14(4), 1000. https://doi.org/10.3390/rs14041000