
Enhancing the Accuracy and Temporal Transferability of Irrigated Cropping Field Classification Using Optical Remote Sensing Imagery



Abstract
:1. Introduction
2. Materials and Methods
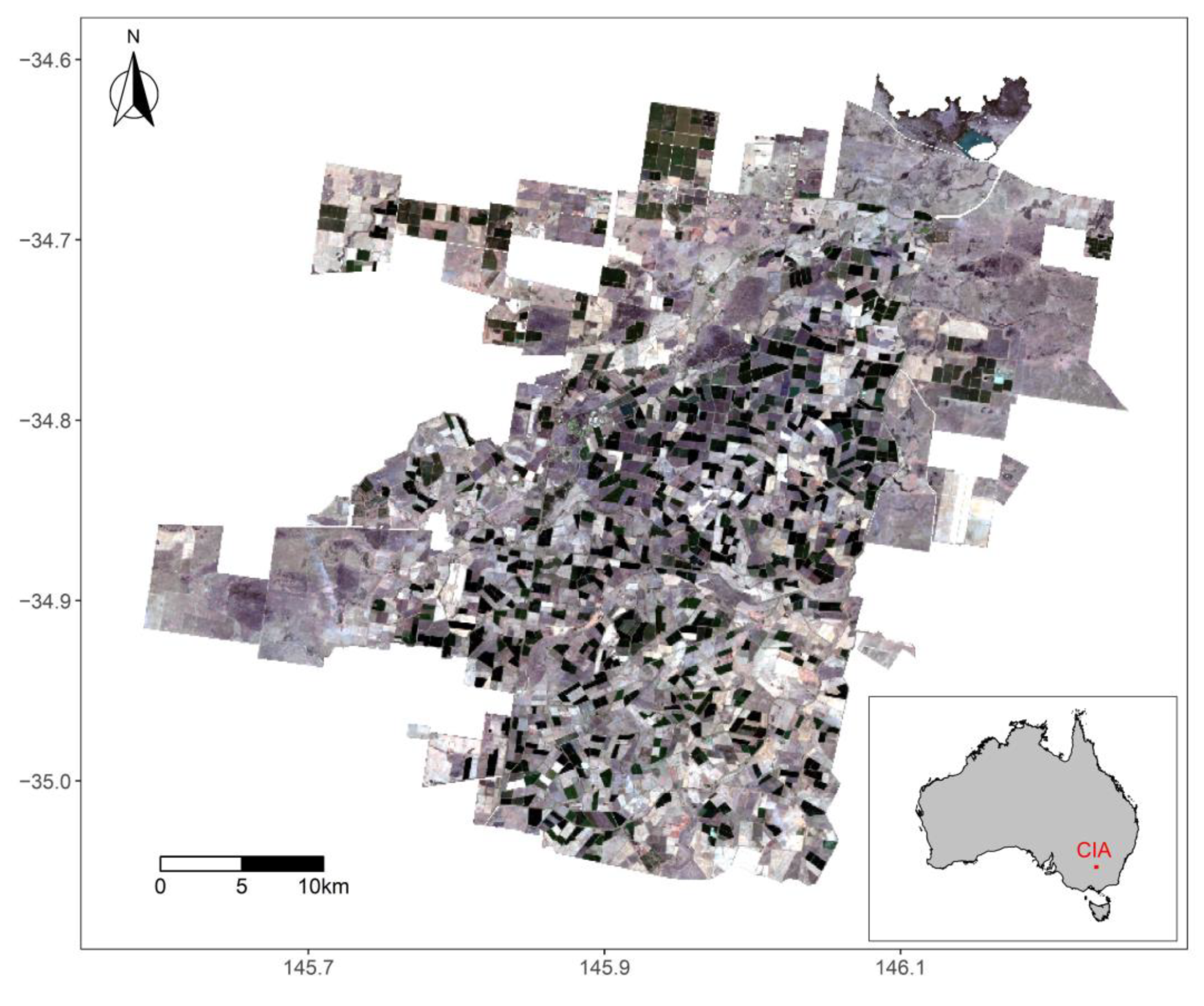
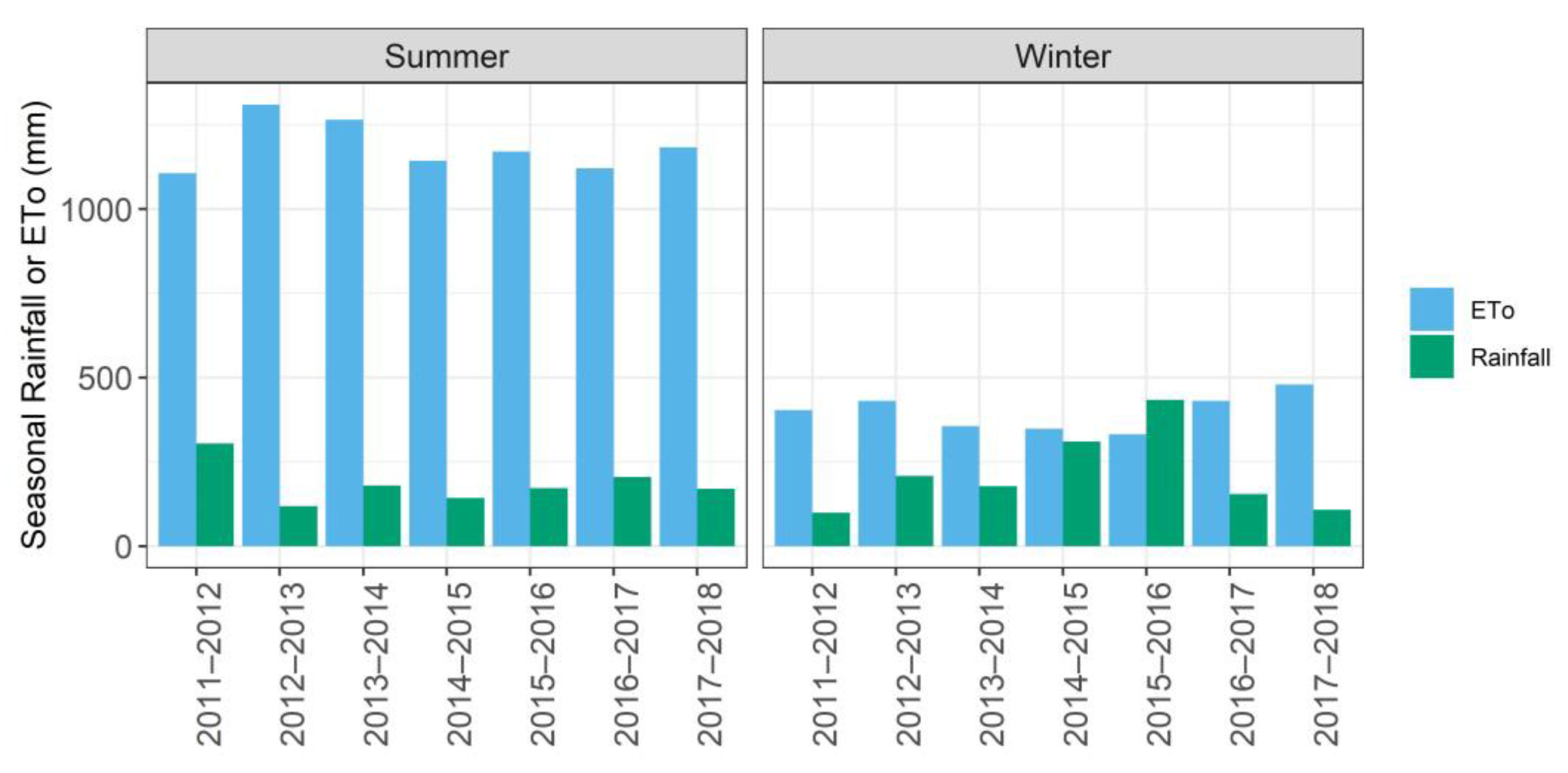
2.1. Study Area
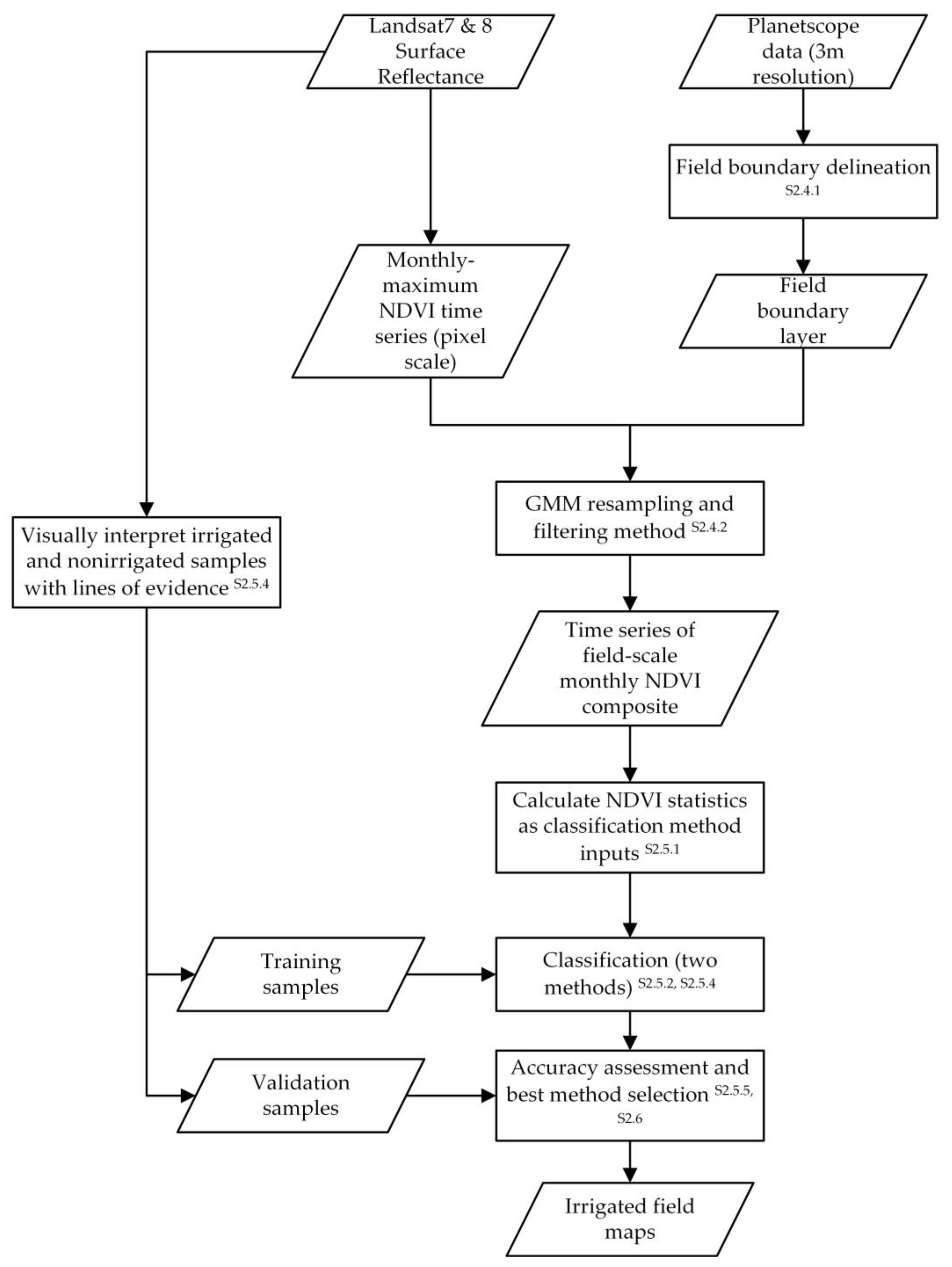
2.2. Research Overview
2.3. Data
2.3.1. Satellite Data
2.3.2. Ancillary Data—Farmer-Reported Cropping Areas
2.4. Data Preprocessing
2.4.1. Field Boundary Delineation
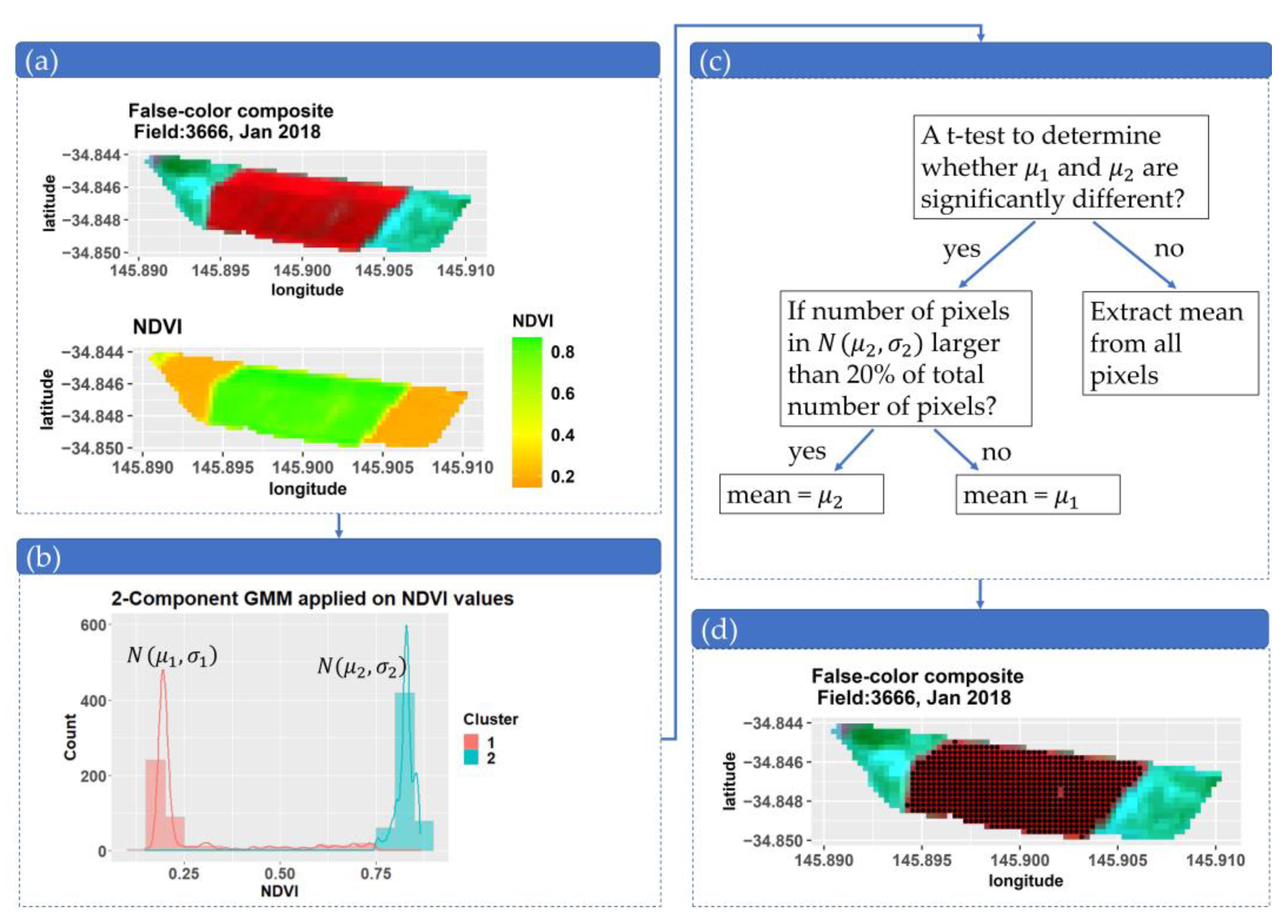
2.4.2. Field-Scale NDVI Filtering Using a Gaussian Mixture Model (GMM)
2.5. Irrigated Field Classification
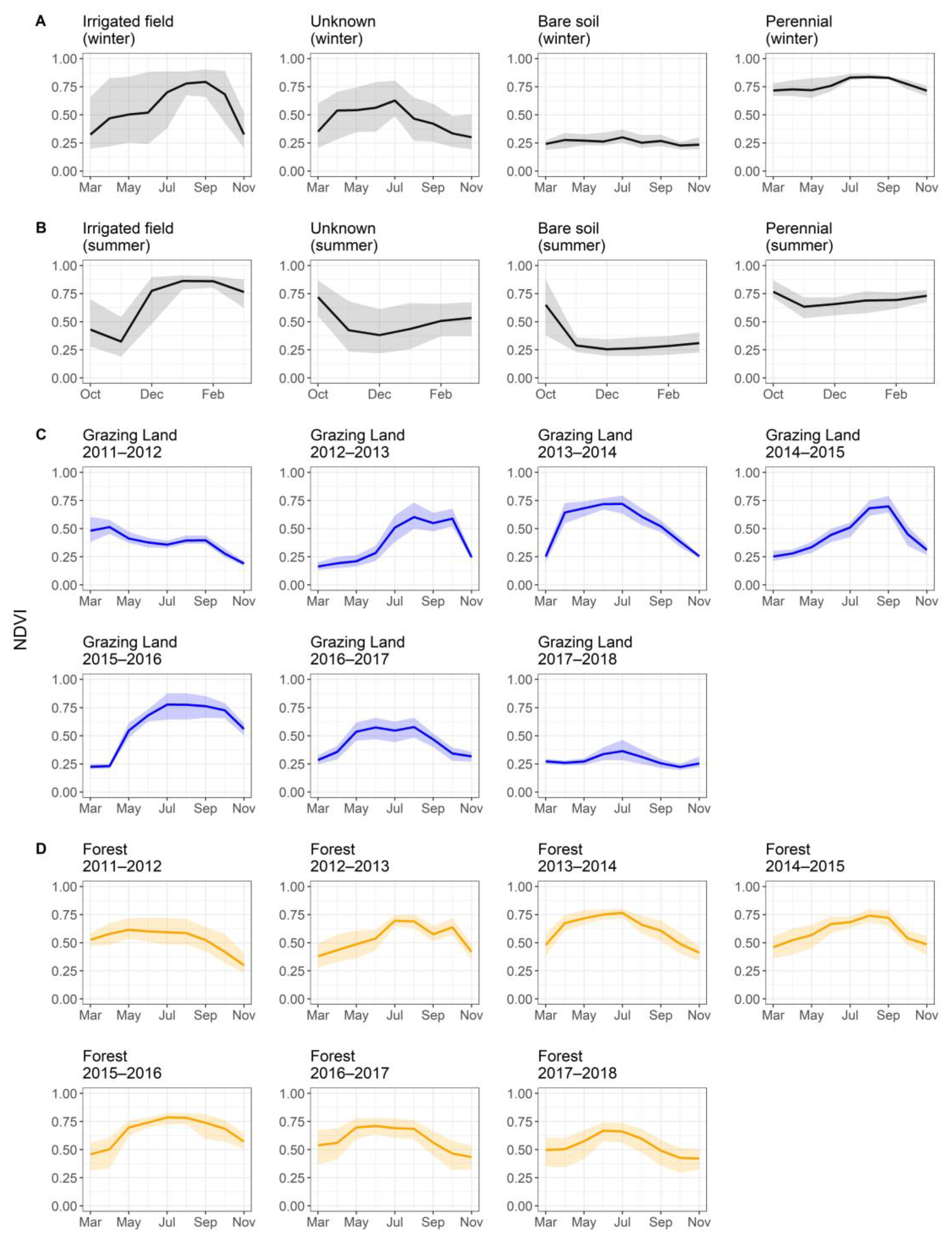
2.5.1. Model Inputs—NDVI Metrics
2.5.2. Dynamic Thresholding Method (Method One)
2.5.3. The Baseline Method (Method—Baseline)
2.5.4. The Random Forest Method (Method Two)
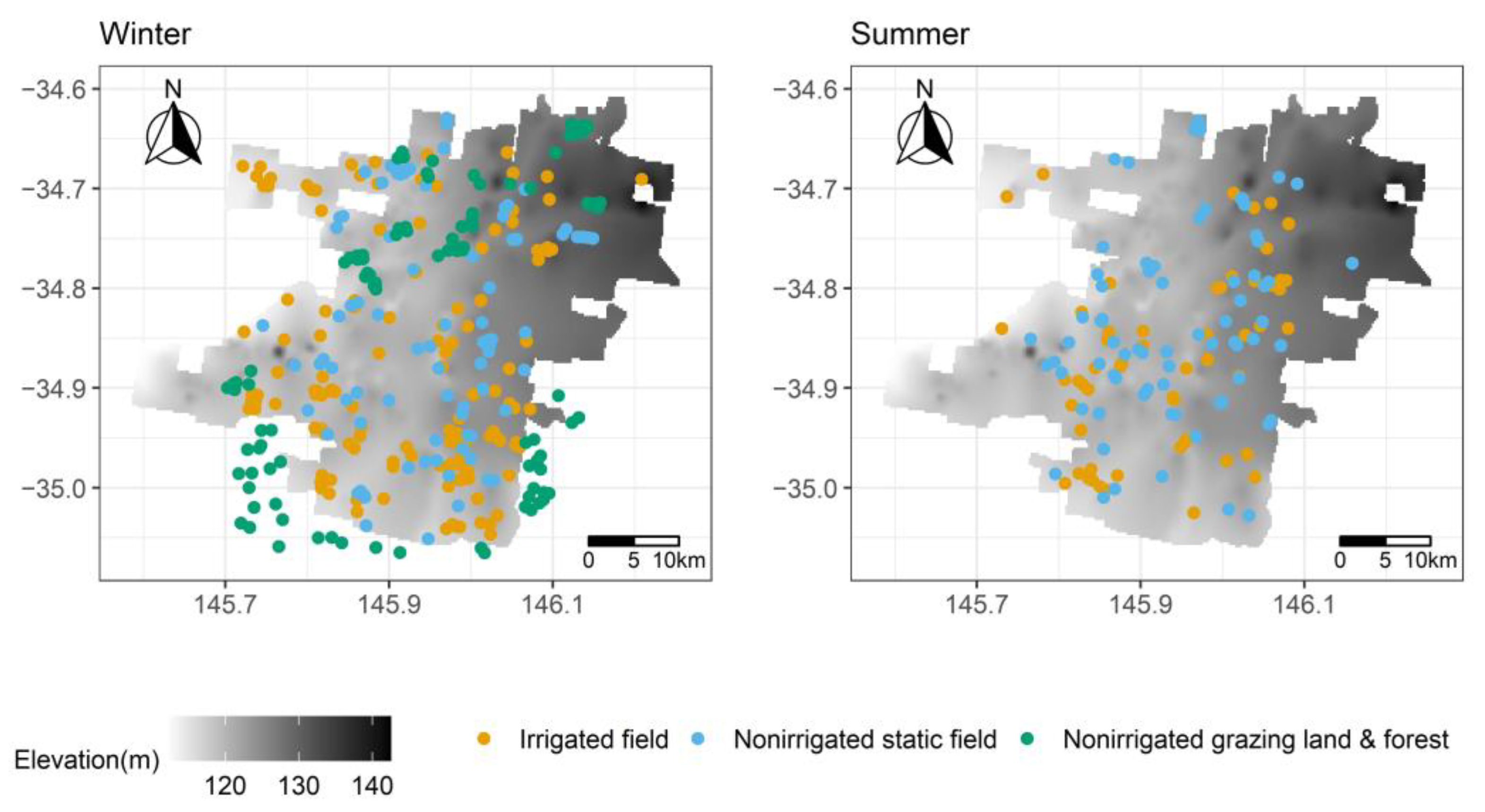
Training Samples
Validation Samples
2.5.5. Model Accuracy Assessment
2.6. Independent Accuracy Evaluation
2.7. Evaluating the Value of GMM-Based Filtering
3. Results
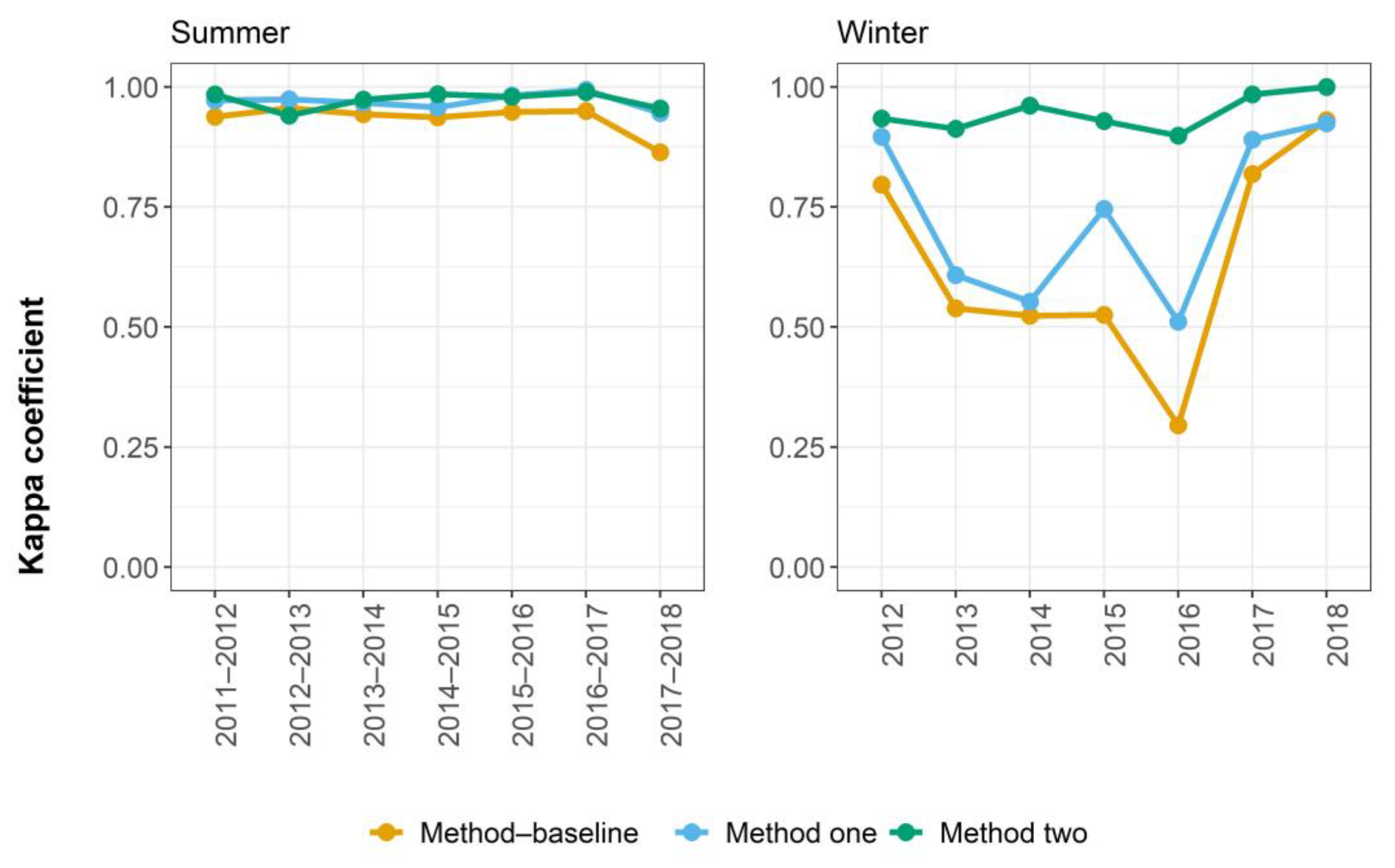
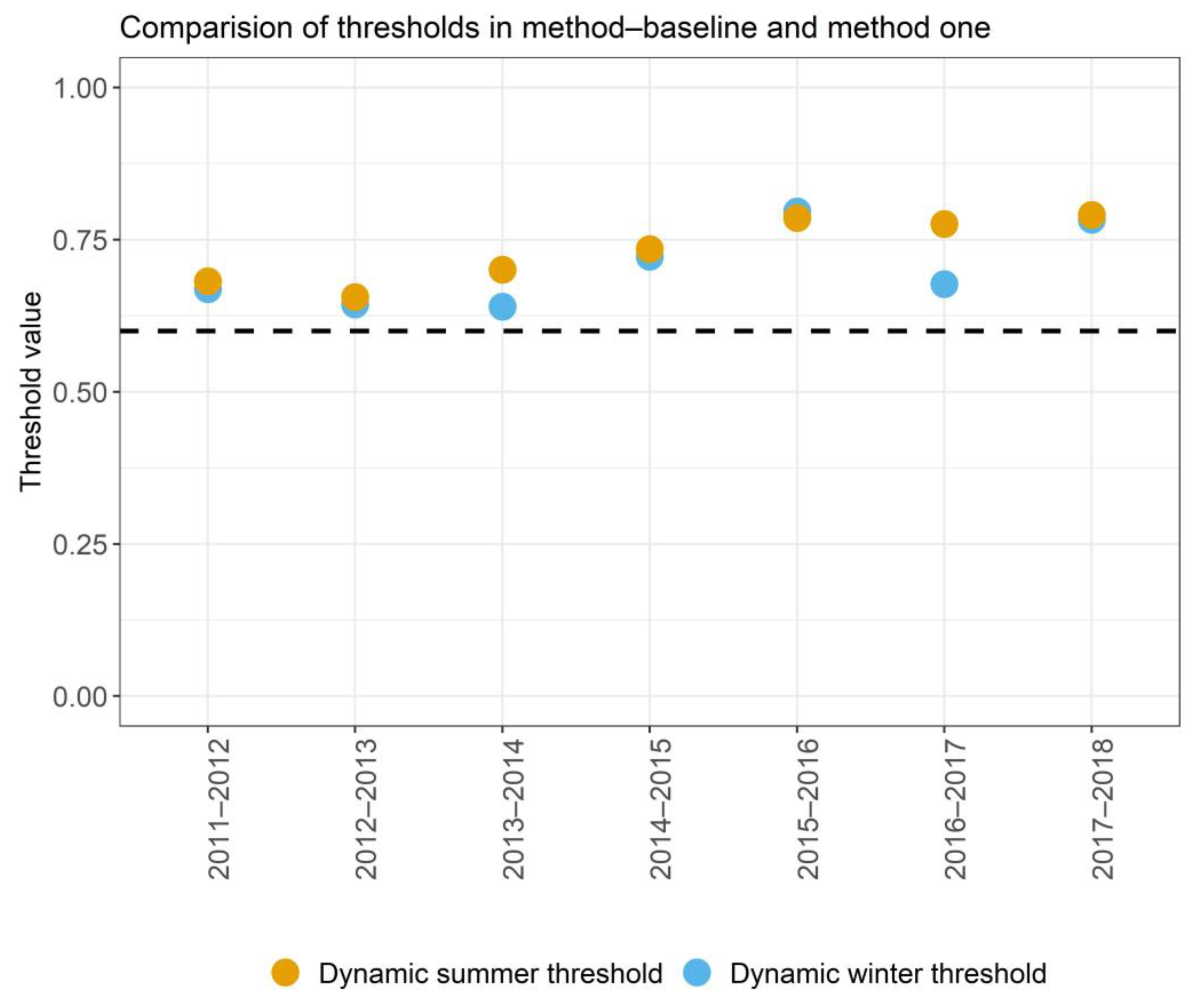
- In Section 3.1. we first compared the kappa coefficients for method one, method two and method—baseline for winter and summer classification and selected the best-performing method. A comparison between method one and method—baseline was also presented to demonstrate the importance of using dynamic thresholds.
- In Section 3.2. we summarized the total classified irrigated area from the best-performing model and their comparisons with the farmer-reported areas (independent evaluation). Classified irrigated cropping maps were also presented.
- In Section 3.3. we demonstrated the improvement in classification using the GMM-based filtering method.
3.1. The Comparison of Method Performances
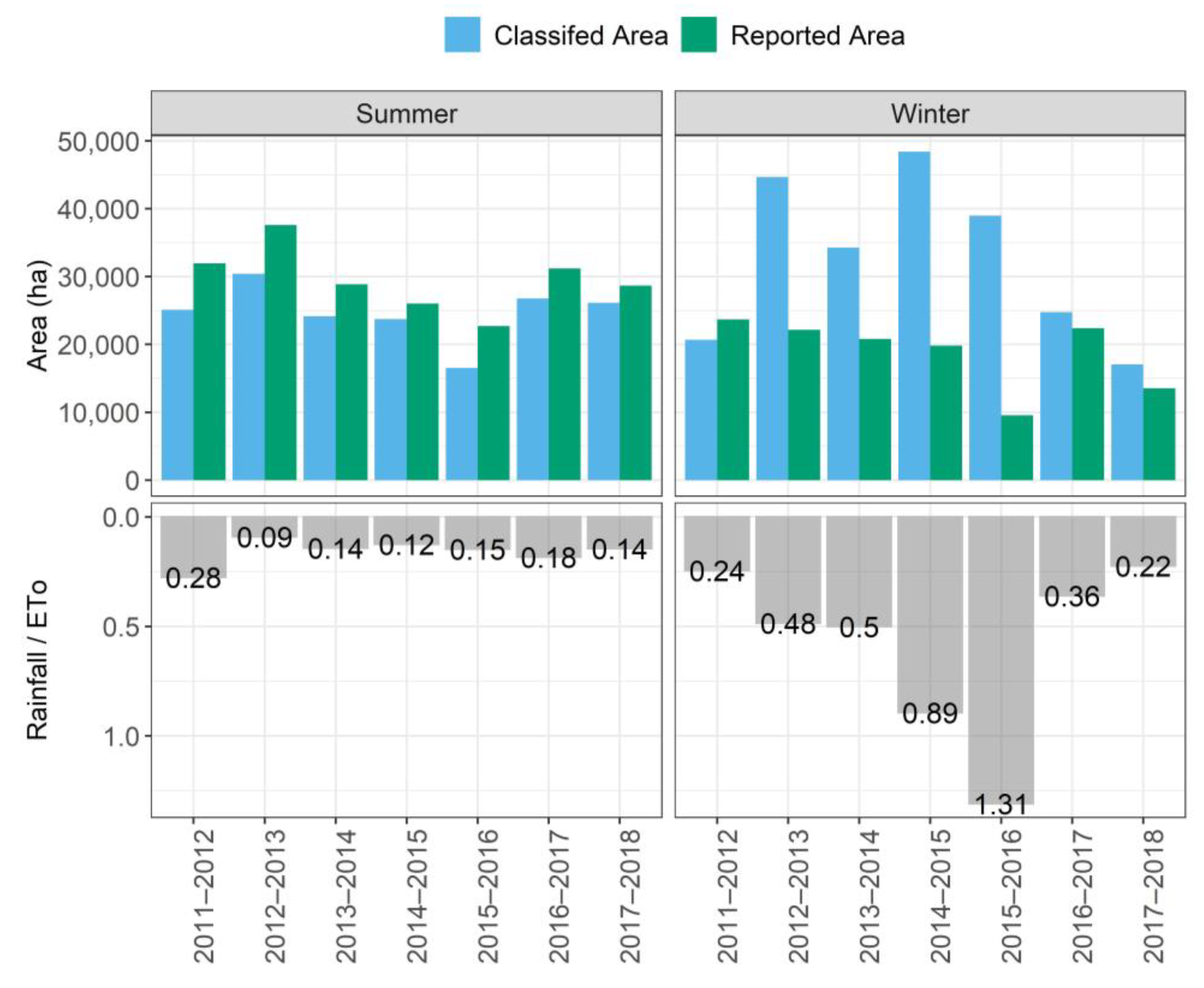
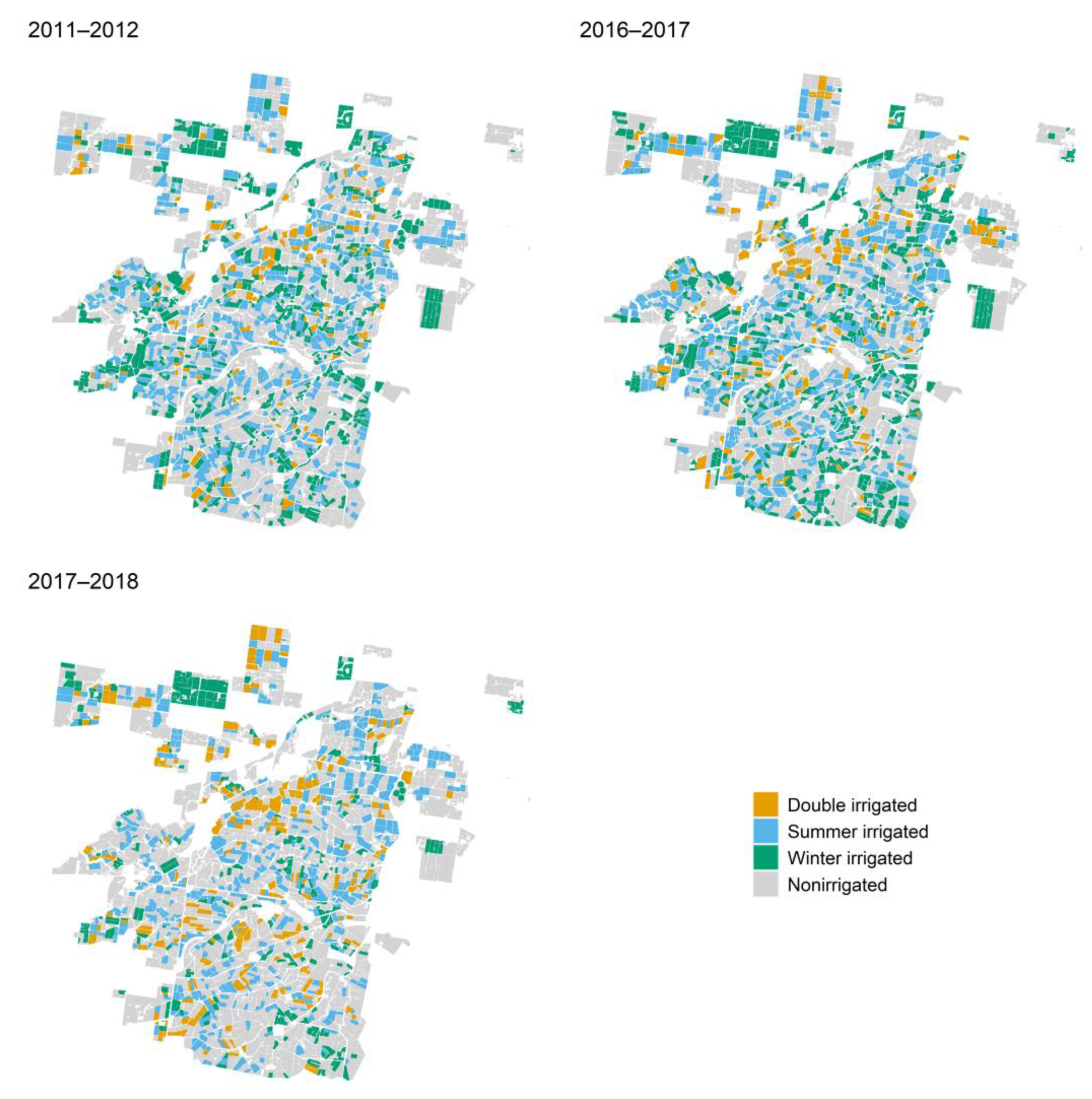
3.2. Irrigated Area Estimation Using the Best Method (Method Two) and Independent Evaluation
3.3. Benefit of GMM-Based NDVI Filtering
4. Discussion
4.1. Classification Methods and Recommendations
4.1.1. Selection of Classification Method
4.1.2. Improvement in Classification Results with GMM-Based Filtered Data
4.2. Multiyear Irrigated Area Monitoring and Water Management
4.3. Study Limitation
5. Conclusions
6. Patents
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Aleksandrova, M.; Lamers, J.P.; Martius, C.; Tischbein, B. Rural vulnerability to environmental change in the irrigated lowlands of Central Asia and options for policy-makers: A review. Environ. Sci. Policy 2014, 41, 77–88. [Google Scholar] [CrossRef]
- McAllister, A.; Whitfield, D.; Abuzar, M. Mapping irrigated farmlands using vegetation and thermal thresholds derived from Landsat and ASTER data in an irrigation district of Australia. Photogramm. Eng. Remote Sens. 2015, 81, 229–238. [Google Scholar] [CrossRef]
- Alexandratos, N.; Bruinsma, J. World Agriculture towards 2030/2050, The 2012 Revision; Food and Agriculture Organization of the United Nations: Rome, Italy, 2012. [Google Scholar] [CrossRef]
- Biggs, T.W.; Thenkabail, P.S.; Gumma, M.K.; Scott, C.A.; Parthasaradhi, G.R.; Turral, H.N. Irrigated area mapping in heterogeneous landscapes with MODIS time series, ground truth and census data, Krishna Basin, India. Int. J. Remote Sens. 2006, 27, 4245–4266. [Google Scholar] [CrossRef]
- Deines, J.M.; Kendall, A.D.; Hyndman, D.W. Annual irrigation dynamics in the US Northern High Plains derived from Landsat satellite data. Geophys. Res. Lett. 2017, 44, 9350–9360. [Google Scholar] [CrossRef]
- Ozdogan, M.; Yang, Y.; Allez, G.; Cervantes, C. Remote sensing of irrigated agriculture: Opportunities and challenges. Remote Sens. 2010, 2, 2274–2304. [Google Scholar] [CrossRef] [Green Version]
- Pervez, M.S.; Budde, M.; Rowland, J. Mapping irrigated areas in Afghanistan over the past decade using MODIS NDVI. Remote Sens. Environ. 2014, 149, 155–165. [Google Scholar] [CrossRef] [Green Version]
- Deines, J.M.; Kendall, A.D.; Crowley, M.A.; Rapp, J.; Cardille, J.A.; Hyndman, D.W. Mapping three decades of annual irrigation across the US High Plains Aquifer using Landsat and Google Earth Engine. Remote Sens. Environ. 2019, 233, 111400. [Google Scholar] [CrossRef]
- Bazzi, H.; Baghdadi, N.; Ienco, D.; El Hajj, M.; Zribi, M.; Belhouchette, H.; Escorihuela, M.J.; Demarez, V. Mapping irrigated areas using Sentinel-1 Time series in Catalonia, Spain. Remote Sens. 2019, 11, 1836. [Google Scholar] [CrossRef] [Green Version]
- Gao, Q.; Zribi, M.; Escorihuela, M.J.; Baghdadi, N.; Segui, P.Q. Irrigation mapping using Sentinel-1 time series at field scale. Remote Sens. 2018, 10, 1495. [Google Scholar] [CrossRef] [Green Version]
- Bousbih, S.; Zribi, M.; El Hajj, M.; Baghdadi, N.; Lili-Chabaane, Z.; Gao, Q.; Fanise, P. Soil moisture and irrigation mapping in A semi-arid region, based on the synergetic use of Sentinel-1 and Sentinel-2 data. Remote Sens. 2018, 10, 1953. [Google Scholar] [CrossRef] [Green Version]
- Holben, B.; Fraser, R.S. Red and near-infrared sensor response to off-nadiir viewing. Int. J. Remote Sens. 1984, 5, 145–160. [Google Scholar] [CrossRef]
- Massey, R.; Sankey, T.T.; Congalton, R.G.; Yadav, K.; Thenkabail, P.S.; Ozdogan, M.; Meador, A.J.S. MODIS phenology-derived, multi-year distribution of conterminous US crop types. Remote Sens. Environ. 2017, 198, 490–503. [Google Scholar] [CrossRef]
- Saadi, S.; Simonneaux, V.; Boulet, G.; Raimbault, B.; Mougenot, B.; Fanise, P.; Ayari, H.; Lili-Chabaane, Z. Monitoring irrigation consumption using high resolution NDVI image time series: Calibration and validation in the Kairouan Plain (Tunisia). Remote Sens. 2015, 7, 13005–13028. [Google Scholar] [CrossRef] [Green Version]
- Zheng, B.; Myint, S.W.; Thenkabail, P.S.; Aggarwal, R.M. A support vector machine to identify irrigated crop types using time-series Landsat NDVI data. Int. J. Appl. Earth Obs. Geoinf. 2015, 34, 103–112. [Google Scholar] [CrossRef]
- Esch, T.; Metz, A.; Marconcini, M.; Keil, M. Combined use of multi-seasonal high and medium resolution satellite imagery for parcel-related mapping of cropland and grassland. Int. J. Appl. Earth Obs. Geoinf. 2014, 28, 230–237. [Google Scholar] [CrossRef]
- Watkins, B.; Van Niekerk, A. A comparison of object-based image analysis approaches for field boundary delineation using multi-temporal Sentinel-2 imagery. Comput. Electron. Agric. 2019, 158, 294–302. [Google Scholar] [CrossRef]
- Chen, G.; Weng, Q.; Hay, G.J.; He, Y. Geographic Object-based Image Analysis (GEOBIA): Emerging trends and future opportunities. GISci. Remote Sens. 2018, 55, 159–182. [Google Scholar] [CrossRef]
- Hossain, M.D.; Chen, D. Segmentation for Object-Based Image Analysis (OBIA): A review of algorithms and challenges from remote sensing perspective. ISPRS J. Photogramm. Remote Sens. 2019, 150, 115–134. [Google Scholar] [CrossRef]
- Asgarian, A.; Soffianian, A.; Pourmanafi, S. Crop type mapping in a highly fragmented and heterogeneous agricultural landscape: A case of central Iran using multi-temporal Landsat 8 imagery. Comput. Electron. Agric. 2016, 127, 531–540. [Google Scholar] [CrossRef]
- Debats, S.R.; Luo, D.; Estes, L.D.; Fuchs, T.J.; Caylor, K.K. A generalized computer vision approach to mapping crop fields in heterogeneous agricultural landscapes. Remote Sens. Environ. 2016, 179, 210–221. [Google Scholar] [CrossRef] [Green Version]
- Wu, B.; Li, Q. Crop planting and type proportion method for crop acreage estimation of complex agricultural landscapes. Int. J. Appl. Earth Obs. Geoinf. 2012, 16, 101–112. [Google Scholar] [CrossRef]
- Conrad, C.; Fritsch, S.; Zeidler, J.; Rücker, G.; Dech, S. Per-field irrigated crop classification in arid Central Asia using SPOT and ASTER data. Remote Sens. 2010, 2, 1035–1056. [Google Scholar] [CrossRef] [Green Version]
- Cai, Y.; Guan, K.; Peng, J.; Wang, S.; Seifert, C.; Wardlow, B.; Li, Z. A high-performance and in-season classification system of field-level crop types using time-series Landsat data and a machine learning approach. Remote Sens. Environ. 2018, 210, 35–47. [Google Scholar] [CrossRef]
- De Castro, A.I.; Six, J.; Plant, R.E.; Peña, J.M. Mapping crop calendar events and phenology-related metrics at the parcel level by object-based image analysis (OBIA) of MODIS-NDVI time-series: A case study in central California. Remote Sens. 2018, 10, 1745. [Google Scholar] [CrossRef] [Green Version]
- Park, S.; Ryu, D.; Fuentes, S.; Chung, H.; Hernández-Montes, E.; O’Connell, M. Adaptive estimation of crop water stress in nectarine and peach orchards using high-resolution imagery from an unmanned aerial vehicle (UAV). Remote Sens. 2017, 9, 828. [Google Scholar] [CrossRef] [Green Version]
- Zhong, L.; Gong, P.; Biging, G.S. Efficient corn and soybean mapping with temporal extendability: A multi-year experiment using Landsat imagery. Remote Sens. Environ. 2014, 140, 1–13. [Google Scholar] [CrossRef]
- Ambika, A.K.; Wardlow, B.; Mishra, V. Remotely sensed high resolution irrigated area mapping in India for 2000 to 2015. Sci. Data 2016, 3, 160118. [Google Scholar] [CrossRef] [Green Version]
- Brief Overview of CICL. Available online: https://www.colyirr.com.au/brief-overview (accessed on 4 January 2022).
- Annual Compliance Report; Coleambally Irrigation Co-Operative Limited (CICL): Coleambally, NSW, Australia, 2020; p. 23. Available online: https://static1.squarespace.com/static/5af3b1ae70e8023a6ac7a10b/t/5b04dca38a922da81bbf74c8/1527045455569/ACR+2016.pdf (accessed on 20 December 2021).
- Evapotranspiration Calculations. Available online: http://www.bom.gov.au/watl/eto/tables/nsw/narrabri_airport/narrabri_airport.shtml (accessed on 4 December 2021).
- Jackson, T.M.; Khan, S.; Hafeez, M. A comparative analysis of water application and energy consumption at the irrigated field level. Agric. Water Manag. 2010, 97, 1477–1485. [Google Scholar] [CrossRef]
- Education and Research Program. Available online: https://www.planet.com/markets/education-and-research/ (accessed on 15 January 2020).
- Gorelick, N.; Hancher, M.; Dixon, M.; Ilyushchenko, S.; Thau, D.; Moore, R. Google Earth Engine: Planetary-scale geospatial analysis for everyone. Remote Sens. Environ. 2017, 202, 18–27. [Google Scholar] [CrossRef]
- Blaschke, T. Object based image analysis for remote sensing. ISPRS J. Photogramm. Remote Sens. 2010, 65, 2–16. [Google Scholar] [CrossRef] [Green Version]
- Laliberte, A.; Rango, A.; Herrick, J.; Fredrickson, E.L.; Burkett, L. An object-based image analysis approach for determining fractional cover of senescent and green vegetation with digital plot photography. J. Arid Environ. 2007, 69, 1–14. [Google Scholar] [CrossRef]
- Ryherd, S.; Woodcock, C. Combining spectral and texture data in the segmentation of remotely sensed images. Photogramm. Eng. Remote Sens. 1996, 62, 181–194. [Google Scholar]
- Extract Segments Only. Available online: https://www.l3harrisgeospatial.com/docs/segmentonly.html (accessed on 4 January 2022).
- Jin, X. Segmentation-Based Image Processing System. U.S. Patent US20090123070A1, 14 May 2009. [Google Scholar]
- Xu, L.; Ming, D.; Zhou, W.; Bao, H.; Chen, Y.; Ling, X. Farmland Extraction from High Spatial Resolution Remote Sensing Images Based on Stratified Scale Pre-Estimation. Remote Sens. 2019, 11, 108. [Google Scholar] [CrossRef] [Green Version]
- Carlson, T.N.; Gillies, R.R.; Perry, E.M. A method to make use of thermal infrared temperature and NDVI measurements to infer surface soil water content and fractional vegetation cover. Remote Sens. Rev. 1994, 9, 161–173. [Google Scholar] [CrossRef]
- Ozelkan, E.; Chen, G.; Ustundag, B.B. Multiscale object-based drought monitoring and comparison in rainfed and irrigated agriculture from Landsat 8 OLI imagery. Int. J. Appl. Earth Obs. Geoinf. 2016, 44, 159–170. [Google Scholar] [CrossRef]
- Tucker, C.J. Red and photographic infrared linear combinations for monitoring vegetation. Remote Sens. Environ. 1979, 8, 127–150. [Google Scholar] [CrossRef] [Green Version]
- Sayler, K. Landsat 8 Collection 1 (C1) Land Surface Reflectance Code (LaSRC) Product Guide. Available online: https://prd-wret.s3.us-west-2.amazonaws.com/assets/palladium/production/atoms/files/LSDS-1368_L8_C1-LandSurfaceReflectanceCode-LASRC_ProductGuide-v3.pdf (accessed on 12 December 2021).
- Zeng, L.; Wardlow, B.D.; Xiang, D.; Hu, S.; Li, D. A review of vegetation phenological metrics extraction using time-series, multispectral satellite data. Remote Sens. Environ. 2020, 237, 111511. [Google Scholar] [CrossRef]
- Fraley, C.; Raftery, A.E.; Murphy, T.B.; Scrucca, L. Mclust Version 4 for R: Normal Mixture Modeling for Model-Based Clustering, Classification, and Density Estimation; Technical Report 597; Department of Statistics, University of Washington: Seattle, WA, USA, 2012. [Google Scholar]
- Senturk, S.; Bagis, S.; Ustundag, B.B. Application of remote sensing techniques in locating dry and irrigated farmland parcels. In Proceedings of the 2014 the Third International Conference on Agro-Geoinformatics, Beijing, China, 11–14 August 2014; pp. 1–4. [Google Scholar]
- Rodriguez-Galiano, V.F.; Ghimire, B.; Rogan, J.; Chica-Olmo, M.; Rigol-Sanchez, J.P.; Sensing, R. An assessment of the effectiveness of a random forest classifier for land-cover classification. ISPRS J. Photogramm. Remote Sens. 2012, 67, 93–104. [Google Scholar] [CrossRef]
- Lebourgeois, V.; Dupuy, S.; Vintrou, É.; Ameline, M.; Butler, S.; Bégué, A. A combined random forest and OBIA classification scheme for mapping smallholder agriculture at different nomenclature levels using multisource data (simulated Sentinel-2 time series, VHRS and DEM). Remote Sens. 2017, 9, 259. [Google Scholar] [CrossRef] [Green Version]
- RColorBrewer, S.; Liaw, M.A. Package ‘randomForest’; University of California, Berkeley: Berkeley, CA, USA, 2018. [Google Scholar]
- Konduri, V.S.; Kumar, J.; Hargrove, W.W.; Hoffman, F.M.; Ganguly, A.R. Mapping crops within the growing season across the United States. Remote Sens. Environ. 2020, 251, 112048. [Google Scholar] [CrossRef]
- Peña-Arancibia, J.L.; McVicar, T.R.; Paydar, Z.; Li, L.; Guerschman, J.P.; Donohue, R.J.; Dutta, D.; Podger, G.M.; van Dijk, A.I.; Chiew, F.H. Dynamic identification of summer cropping irrigated areas in a large basin experiencing extreme climatic variability. Remote Sens. Environ. 2014, 154, 139–152. [Google Scholar] [CrossRef]
- Annual Compliance Report; Coleambally Irrigation Co-Operative Limited (CICL): Coleambally, NSW, Australia, 2016; p. 4. Available online: https://static1.squarespace.com/static/5af3b1ae70e8023a6ac7a10b/t/5b04dca38a922da81bbf74c8/1527045455569/ACR+2016.pdf (accessed on 20 December 2021).













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature Name | Abbreviation | Description |
|---|---|---|
| The seasonal maximum NDVI | MAX | The maximum NDVI value within a season 1. |
| NDVI range | RANGE | The maximum NDVI minus the minimum NDVI. Note: if the minimum NDVI is less than 0.2, use 0.2. |
| Irrigated Cropping Fields | Bare Soil | Nonirrigated Grazing Land | Forest | Perennial Plantations | Unknown | |
|---|---|---|---|---|---|---|
| Summer | 55 | 25 | - | - | 13 | 40 |
| Winter | 147 | 35 | 47 | 52 | 4 | 48 |
| Summer | Winter | |||
|---|---|---|---|---|
| Year | Omission Error | Commission Error | Omission Error | Commission Error |
| 2011–2012 | 32.30% | 0% | 32.10% | 0.20% |
| 2012–2013 | 22.70% | 0% | 17% | 0.50% |
| 2013–2014 | 11.90% | 0% | 14.70% | 0.20% |
| 2014–2015 | 10% | 0% | 13.10% | 1.10% |
| 2015–2016 | 11.90% | 0% | 14.20% | 5.10% |
| 2016–2017 | 7.30% | 0% | 17.20% | 0.50% |
| 2017–2018 | 6.70% | 0% | 9.40% | 0.30% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, Z.; Guo, D.; Ryu, D.; Western, A.W. Enhancing the Accuracy and Temporal Transferability of Irrigated Cropping Field Classification Using Optical Remote Sensing Imagery. Remote Sens. 2022, 14, 997. https://doi.org/10.3390/rs14040997
Gao Z, Guo D, Ryu D, Western AW. Enhancing the Accuracy and Temporal Transferability of Irrigated Cropping Field Classification Using Optical Remote Sensing Imagery. Remote Sensing. 2022; 14(4):997. https://doi.org/10.3390/rs14040997
Chicago/Turabian StyleGao, Zitian, Danlu Guo, Dongryeol Ryu, and Andrew W. Western. 2022. "Enhancing the Accuracy and Temporal Transferability of Irrigated Cropping Field Classification Using Optical Remote Sensing Imagery" Remote Sensing 14, no. 4: 997. https://doi.org/10.3390/rs14040997
APA StyleGao, Z., Guo, D., Ryu, D., & Western, A. W. (2022). Enhancing the Accuracy and Temporal Transferability of Irrigated Cropping Field Classification Using Optical Remote Sensing Imagery. Remote Sensing, 14(4), 997. https://doi.org/10.3390/rs14040997