
Automated School Location Mapping at Scale from Satellite Imagery Based on Deep Learning

 , ,
, ,
Abstract
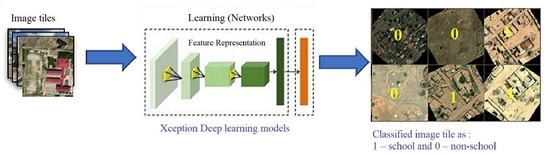
:
1. Introduction
- The development of scalable deep learning models to automatically map school locations at global, regional, and country-level scales in near real-time considering the variability in school structure from rural to urban and from country to country. From our literature review, no study has been carried out in this area with the context of providing a contribution to the research communities and school infrastructure mapping at scale for humanitarian and open-source projects.
- Exploring the generalizability of deep learning models in the context of transfer learning of school features where a DNN model trained in a given geolocation can generalize to detect schools in another geolocation without been re-trained with new datasets.
2. Background
3. Materials and Methods
3.1. Datasets
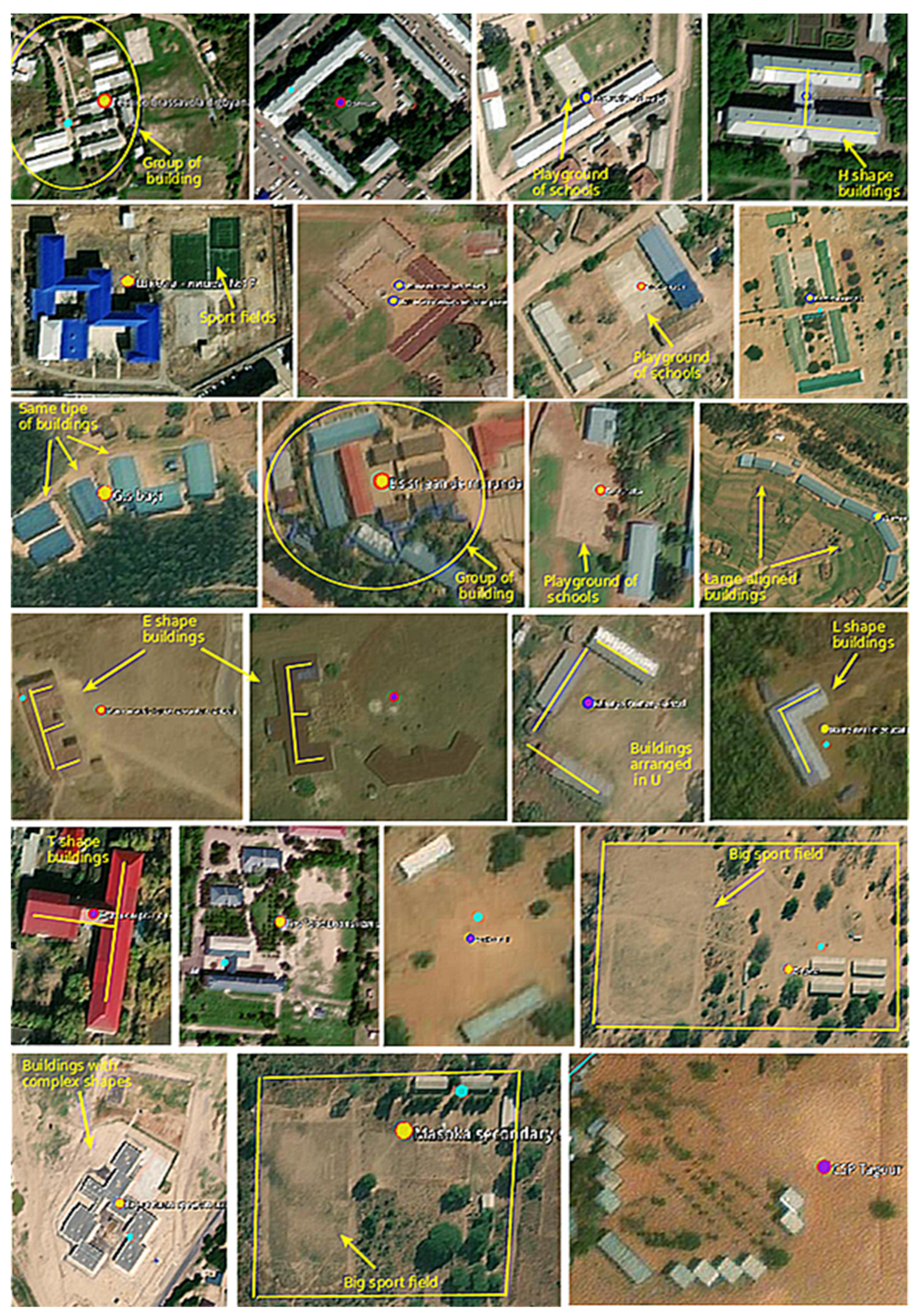
3.2. Training Image Data Preparation
- Step 1:
- Data sources
- Step 2:
- Training data validation
- Step 3:
- Training data generation
- Tile-based School Classifier
3.3. Supertile Generation
4. Results
Differences in Model Performances
- ○
- How do regional and country models perform differently?
- ○
- Is it necessarily true to build country-specific models or can we rely on only the regional model that is generalized well across countries?
- -
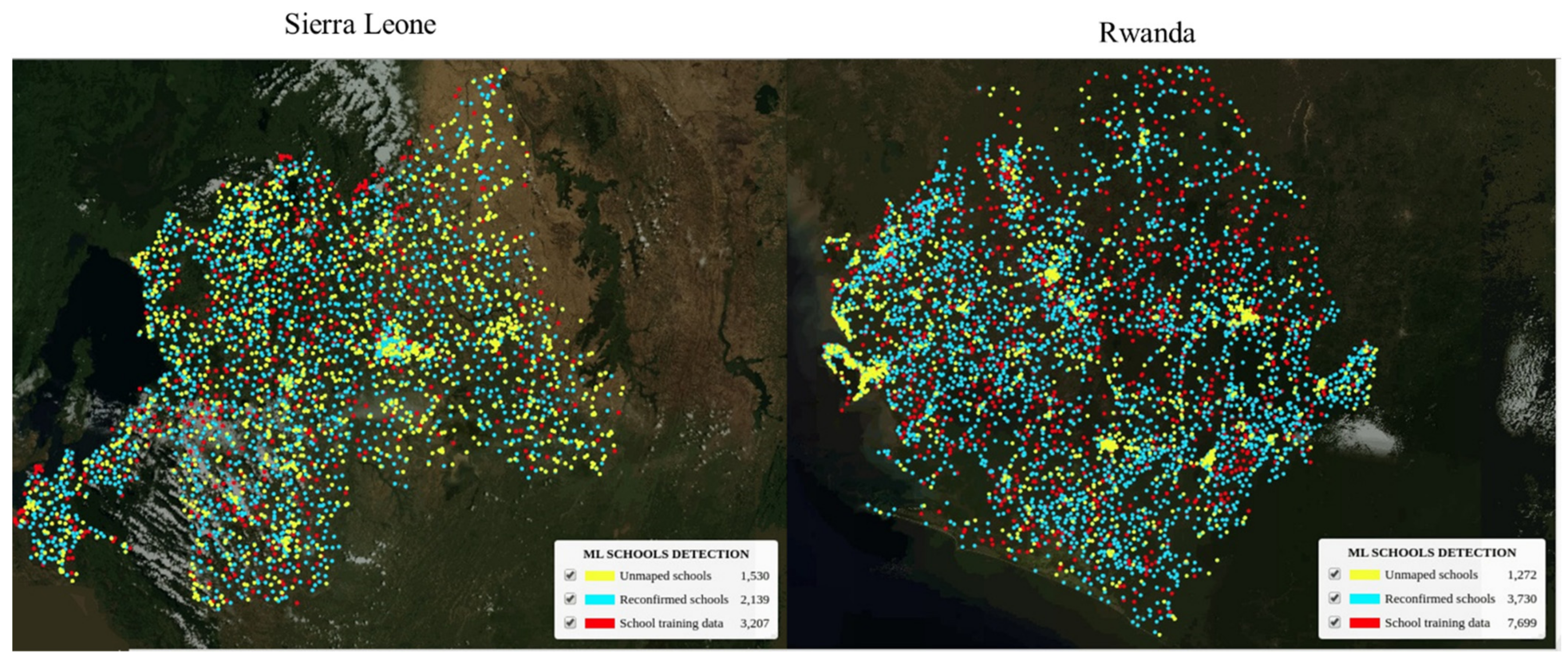
- Both country and regional models performed very well even though the models were only exposed to a quarter of the available known schools in Kenya. Figure 13 also showed that the global model had more false negatives with less true and false positives when compared with the country and regional models, respectively. There is only the blue bar for the global model in the figure because the model result validation has not been done yet due to the lack of man-hours, but we have plans to do that as soon we have the capacity.
- -
- In the future, model transfer-learning or fine-tuning will be used to train a regional model instead of developing country-specific models.
5. Discussion
5.1. Model Scalability
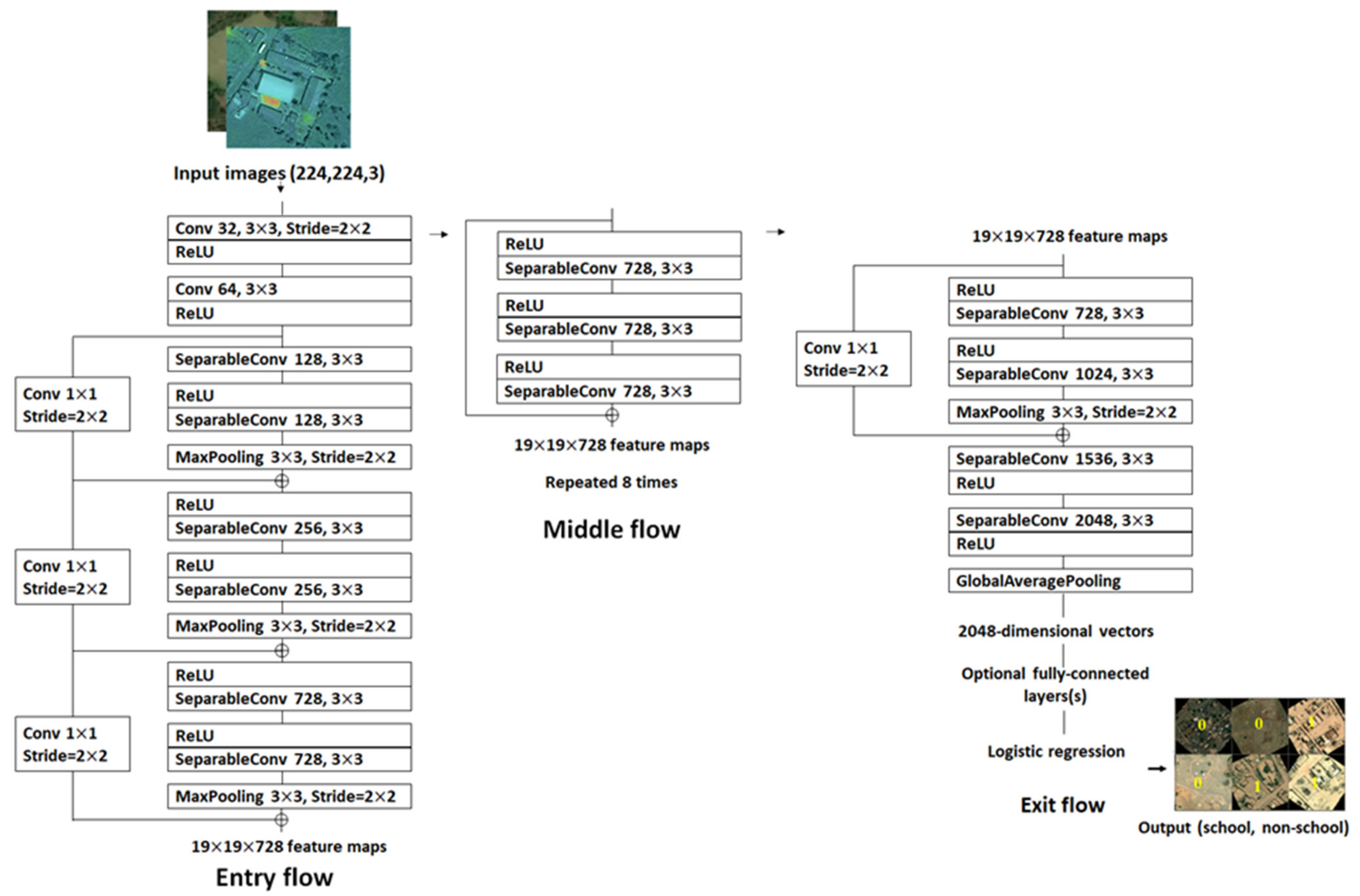
5.2. Comparative Performance of Our Xception Network Model
5.3. AI-Assisted School Mapping Pros and Cons
5.4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- UN General Assembly; Transforming Our Development; Sustainable Development; Sustainable Development Goals; World Bank; World Economic Forum. Sustainable Development Goal 4 Education Brief: SDG4; UNHCR: Geneva, Switzerland, 2015. [Google Scholar]
- Zhuangfang, S.A.; Yi, N.; Zurutuza, N.; Kim, D.-H.; Mendoza, R.L.; Morrissey, M.; Daniels, C.; Ingalls, N.; Farias, J.; Tenorio, K.; et al. Building on Our Success Mapping 23,100 Unmapped Schools in Eight Countries. Available online: https://developmentseed.org/blog/2021-03-18-ai-enabling-school-mapping (accessed on 15 December 2021).
- Connecting Every School in the World to the Internet. Available online: https://projectconnect.unicef.org/map (accessed on 12 November 2021).
- Chen, B.; Tu, Y.; Song, Y.; Theobald, D.M.; Zhang, T.; Ren, Z.; Li, X.; Yang, J.; Wang, J.; Wang, X.; et al. Mapping essential urban land use categories with open big data: Results for five metropolitan areas in the United States of America. ISPRS J. Photogramm. Remote Sens. 2021, 178, 203–218. [Google Scholar] [CrossRef]
- Tu, Y.; Chen, B.; Lang, W.; Chen, T.; Li, M.; Zhang, T.; Xu, B. Uncovering the Nature of Urban Land Use Composition Using Multi-Source Open Big Data with Ensemble Learning. Remote Sens. 2021, 13, 4241. [Google Scholar] [CrossRef]
- Kim, D.-H.; López, G.; Kiedanski, D.; Maduako, I.; Ríos, B.; Descoins, A.; Zurutuza, N.; Arora, S.; Fabian, C. Bias in Deep Neural Networks in Land Use Characterization for International Development. Remote Sens. 2021, 13, 2908. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1800–1807. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2012, arXiv:1704.04861. [Google Scholar]
- Hoeser, T.; Bachofer, F.; Kuenzer, C. Object Detection and Image Segmentation with Deep Learning on Earth Observation Data: A Review—Part II: Applications. Remote Sens. 2020, 12, 3053. [Google Scholar] [CrossRef]
- Goupilleau, A.; Ceillier, T.; Corbineau, M.-C. Active learning for object detection in high-resolution satellite images. arXiv 2021, arXiv:2101.02480. [Google Scholar]
- Abdollahi, A.; Pradhan, B.; Shukla, N.; Chakraborty, S.; Alamri, A. Deep Learning Approaches Applied to Remote Sensing Datasets for Road Extraction: A State-Of-The-Art Review. Remote Sens. 2020, 12, 1444. [Google Scholar] [CrossRef]
- Voulodimos, A.; Doulamis, N.; Doulamis, A.; Protopapadakis, E. Deep Learning for Computer Vision: A Brief Review. Comput. Intell. Neurosci. 2018, 2018, 7068349. [Google Scholar] [CrossRef]
- Ekim, B.; Sertel, E.; Kabadayi, M.E. Automatic Road Extraction from Historical Maps Using Deep Learning Techniques: A Regional Case Study of Turkey in a German World War II Map. ISPRS Int. J. Geo Inf. 2021, 10, 492. [Google Scholar] [CrossRef]
- Lima, B.; Ferreira, L.; Moura, J.M. Helping to detect legal swimming pools with deep learning and data visualization. Procedia Comput. Sci. 2021, 181, 1058–1065. [Google Scholar] [CrossRef]
- Abderrahim, N.Y.Q.; Abderrahim, S.; Rida, A. Road Segmentation using U-Net architecture. In Proceedings of the 2020 IEEE International conference of Moroccan Geomatics (Morgeo), Casablanca, Morocco, 11–13 May 2020; pp. 1–4. [Google Scholar]
- Reddy, M.J.B.; Mohanta, D.K. Condition monitoring of 11 kV distribution system insulators incorporating complex imagery using combined DOST-SVM approach. IEEE Trans. Dielectr. Electr. Insul. 2013, 20, 664–674. [Google Scholar] [CrossRef]
- Mahony, N.O.; Campbell, S.; Carvalho, A.; Harapanahalli, S.; Hernandez, G.V.; Krpalkova, L.; Riordan, D.; Walsh, J. Deep Learning vs. Traditional Computer Vision BT. In Advances in Computer Vision Proceedings of the 2019 Computer Vision Conference (CVC), Las Vegas, NV, USA, 25–26 April 2019; Springer Nature Switzerland AG: Cham, Switzerland, 2019; pp. 128–144. [Google Scholar]
- Alzubaidi, L.; Zhang, J.; Humaidi, A.J.; Al-Dujaili, A.; Duan, Y.; Al-Shamma, O.; Santamaría, J.; Fadhel, M.A.; Al-Amidie, M.; Farhan, L. Review of deep learning: Concepts, CNN architectures, challenges, applications, future directions. J. Big Data 2021, 8, 53. [Google Scholar] [CrossRef]
- Garcia-Garcia, A.; Orts-Escolano, S.; Oprea, S.; Villena-Martinez, V.; Rodriguez, J.G. A Review on Deep Learning Techniques Applied to Semantic Segmentation. arXiv 2017, arXiv:1704.06857. [Google Scholar]
- Grinias, I.; Panagiotakis, C.; Tziritas, G. MRF-based segmentation and unsupervised classification for building and road detection in peri-urban areas of high-resolution satellite images. ISPRS J. Photogramm. Remote Sens. 2016, 122, 145–166. [Google Scholar] [CrossRef]
- Maduako, I.; Igwe, C.; Abah, J.; Onwuasoanya, O.; Chukwu, G.; Ezeji, F.; Okeke, F. Deep Learning for Component Fault Detection in Electricity Lines Transmission. J. Big Data 2021. [Google Scholar] [CrossRef]
- Stewart, C.; Lazzarini, M.; Luna, A.; Albani, S. Deep Learning with Open Data for Desert Road Mapping. Remote Sens. 2020, 12, 2274. [Google Scholar] [CrossRef]
- Henry, C.; Azimi, S.M.; Merkle, N. Road Segmentation in SAR Satellite Images with Deep Fully Convolutional Neural Networks. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1867–1871. [Google Scholar] [CrossRef] [Green Version]
- Yuan, M.; Liu, Z.; Wang, F. Using the wide-range attention U-Net for road segmentation. Remote Sens. Lett. 2019, 10, 506–515. [Google Scholar] [CrossRef]
- Yang, X.; Li, X.; Ye, Y.; Lau, R.Y.K.; Zhang, X.; Huang, X. Road Detection and Centerline Extraction Via Deep Recurrent Convolutional Neural Network U-Net. IEEE Trans. Geosci. Remote Sens. 2019, 57, 7209–7220. [Google Scholar] [CrossRef]
- Şen, N.; Olgun, O.; Ayhan, Ö. Road and railway detection in SAR images using deep learning. In Image and Signal Processing for Remote Sensing XXV; SPIE: Bellingham, WA, USA, 2019; Volume 11155, pp. 125–129. [Google Scholar]
- Cheng, G.; Wang, Y.; Xu, S.; Wang, H.; Xiang, S.; Pan, C. Automatic Road Detection and Centerline Extraction via Cascaded End-to-End Convolutional Neural Network. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3322–3337. [Google Scholar] [CrossRef]
- Zhang, L.; Wang, P.; Shen, C.; Liu, L.; Wei, W.; Zhang, Y.; van den Hengel, A. Adaptive Importance Learning for Improving Lightweight Image Super-Resolution Network. Int. J. Comput. Vis. 2020, 128, 479–499. [Google Scholar] [CrossRef] [Green Version]
- Wu, Z.; Wang, X.; Gonzalez, J.E.; Goldstein, T.; Davis, L.S. ACE: Adapting to Changing Environments for Semantic Segmentation. arXiv 2019, arXiv:1904.06268. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. arXiv 2015, arXiv:1505.04597. [Google Scholar]
- Remi, D.; Romain, G. Cnns fusion for building detection in aerial images for the building detection challenge. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–23 June 2018; pp. 242–246. [Google Scholar]
- Ivanovsky, L.; Khryashchev, V.; Pavlov, V.; Ostrovskaya, A. Building detection on aerial images using U-NET neural networks. In Proceedings of the Conference of Open Innovation Association FRUCT, Helsinki, Finland, 5–8 November 2019; Institute of Electrical and Electronics Engineers (IEEE): New York, NY, USA, 2019; Volume 2019, pp. 116–122. [Google Scholar]
- Chhor, G.; Aramburu, C.B. Satellite Image Segmentation for Building Detection Using U-Net, 1–6. 2017. Available online: http://cs229.stanford.edu/proj2017/final-reports/5243715.pdf (accessed on 20 January 2022).
- Zhang, Q.; Kong, Q.; Zhang, C.; You, S.; Wei, H.; Sun, R.; Li, L. A new road extraction method using Sentinel-1 SAR images based on the deep fully convolutional neural network. Eur. J. Remote Sens. 2019, 52, 572–582. [Google Scholar] [CrossRef] [Green Version]
- Zhao, Z.; Xu, G.; Qi, Y.; Liu, N.; Zhang, T. Multi-patch deep features for power line insulator status classification from aerial images. In Proceedings of the 2016 International Joint Conference on Neural Networks, {IJCNN} 2016, Vancouver, BC, Canada, 24–29 July 2016; pp. 3187–3194. [Google Scholar]
- Lee, H.; Park, M.; Kim, J. Plankton classification on imbalanced large-scale database via convolutional neural networks with transfer learning. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3713–3717. [Google Scholar]
- Pouyanfar, S.; Tao, Y.; Mohan, A.; Tian, H.; Kaseb, A.S.; Gauen, K.; Dailey, R.; Aghajanzadeh, S.; Lu, Y.; Chen, S.; et al. Dynamic Sampling in Convolutional Neural Networks for Imbalanced Data Classification. In Proceedings of the 2018 IEEE Conference on Multimedia Information Processing and Retrieval (MIPR), Miami, FL, USA, 10–12 April 2018; pp. 112–117. [Google Scholar]
- Huang, C.; Li, Y.; Loy, C.C.; Tang, X. Learning Deep Representation for Imbalanced Classification. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 5375–5384. [Google Scholar]
- Van Rest, O.; Hong, S.; Kim, J.; Meng, X.; Chafi, H. PGQL: A property graph query language. In ACM International Conference Proceeding Series; Association for Computing Machinery: New York, NY, USA, 2016; Volume 24. [Google Scholar] [CrossRef]
- Buda, M.; Maki, A.; Mazurowski, M.A. A systematic study of the class imbalance problem in convolutional neural networks. Neural Netw. 2018, 106, 249–259. [Google Scholar] [CrossRef] [Green Version]
- Pereira, R.M.; Costa, Y.M.G.; Silla, C.N., Jr. Toward hierarchical classification of imbalanced data using random resampling algorithms. Inf. Sci. 2021, 578, 344–363. [Google Scholar] [CrossRef]
- Bai, R.; Cao, H.; Yu, Y.; Wang, F.; Dang, W.; Chu, Z. Insulator Fault Recognition Based on Spatial Pyramid Pooling Networks with Transfer Learning (Match 2018). In Proceedings of the 2018 3rd International Conference on Advanced Robotics and Mechatronics (ICARM), Singapore, 18–20 July 2018; pp. 824–828. [Google Scholar]
- Ma, L.; Xu, C.; Zuo, G.; Bo, B.; Tao, F. Detection Method of Insulator Based on Faster R-CNN. In Proceedings of the 2017 IEEE 7th Annual International Conference on CYBER Technology in Automation, Control, and Intelligent Systems, CYBER 2017, Kaiulani, HA, USA, 31 July–4 August 2017; pp. 1410–1414. [Google Scholar]
- Gu, J.; Wang, Z.; Kuen, J.; Ma, L.; Shahroudy, A.; Shuai, B.; Liu, T.; Wang, X.; Wang, G.; Cai, J.; et al. Recent advances in convolutional neural networks. Pattern Recognit. 2018, 77, 354–377. [Google Scholar] [CrossRef] [Green Version]
- Jiang, H.; Qiu, X.; Chen, J.; Liu, X.; Miao, X.; Zhuang, S. Insulator Fault Detection in Aerial Images Based on Ensemble Learning with Multi-Level Perception. IEEE Access 2019, 7, 61797–61810. [Google Scholar] [CrossRef]
- Gonzalez, T.F. Handbook of Approximation Algorithms and Metaheuristics; CRC Press: Boca Raton, FL, USA, 2017; pp. 1–1432. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. Proc. IEEE Comput. Soc. Conf. Comput. Vis. Pattern Recognit. 2016, 2016, 770–778. [Google Scholar]
- Rosebrock, A. Deep Learning for Computer Vision with Python (ImageNet). In Deep Learning for Computer Vision with Python 3; PyImageSearch: Nice, France, 2017. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN2015. Biol. Conserv. 2015, 158, 196–204. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN: Object Detection via Region-based Fully Convolutional Networks. arXiv 2016, arXiv:1605.06409. [Google Scholar]
- Liu, Y.; Pei, S.; Fu, W.; Zhang, K.; Ji, X.; Yin, Z. The discrimination method as applied to a deteriorated porcelain insulator used in transmission lines on the basis of a convolution neural network. IEEE Trans. Dielectr. Electr. Insul. 2017, 24, 3559–3566. [Google Scholar] [CrossRef]
- Chollet, F. Deep Learning with Python; Manning Publications: Shelter Island, NY, USA, 2017. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. Proc. IEEE Comput. Soc. Conf. Comput. Vis. Pattern Recognit. 2016, 2016, 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.; Berg, A.C. SSD: Single Shot MultiBox Detector. Lect. Notes Comput. Sci. 2018, 9905, 21–37. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2015, arXiv:1409.1556. [Google Scholar]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions; IEEE: New York, NY, USA, 2017. [Google Scholar]
- Chollet, F. Keras [Internet]. GitHub. 2015. Available online: https://github.com/fchollet/keras (accessed on 15 December 2021).
- Skaffold.yaml. Available online: https://skaffold.dev/docs/references/yaml/ (accessed on 15 December 2021).
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- OSM, Map Features, OpenStreetMap Wiki. Available online: https://wiki.openstreetmap.org/wiki/Map_features (accessed on 20 October 2021).
- OSM, Zoom levels, OpenStreetMap Wiki. Available online: https://wiki.openstreetmap.org/wiki/Zoom_levels (accessed on 24 October 2021).
- Van der Maaten, L.; Hinton, G. Visualizing Data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Shanmugamani, R.; Rahman, A.G.A.; Moore, S.M.; Koganti, N. Deep Learning for Computer Vision: Expert Techniques to Train Advanced Neural Networks Using Tensorflow and Keras, 1st ed.; Packt Publishing Ltd.: Birmingham, UK, 2018. [Google Scholar]
- WorldPop, Open Spatial Demographic Data and Research. Available online: https://www.worldpop.org/doi/10.5258/SOTON/WP00536 (accessed on 10 December 2021).
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Country | Total Points before Validation | Total Points after Validation | Total Points per Tag after Validation | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Unicef | OSM | Total | Unicef | OSM | Total | Yes | Unrecognized | No | |
| Rwanda | 4233 | 363 | 4596 | 4233 | 85 | 4318 | 3207 | 908 | 203 |
| Sierra Leone | 9516 | 1909 | 11,425 | 9516 | 268 | 9784 | 7699 | 2027 | 58 |
| Niger | 0 | 1430 | 1430 | 0 | 1328 | 1328 | 1062 | 226 | 40 |
| Mali | 0 | 11,411 | 11,411 | 0 | 8299 | 8299 | 2474 | 4335 | 1490 |
| Chad | 0 | 363 | 363 | 0 | 294 | 294 | 274 | 18 | 2 |
| Sudan | 0 | 438 | 438 | 0 | 405 | 405 | 292 | 112 | 1 |
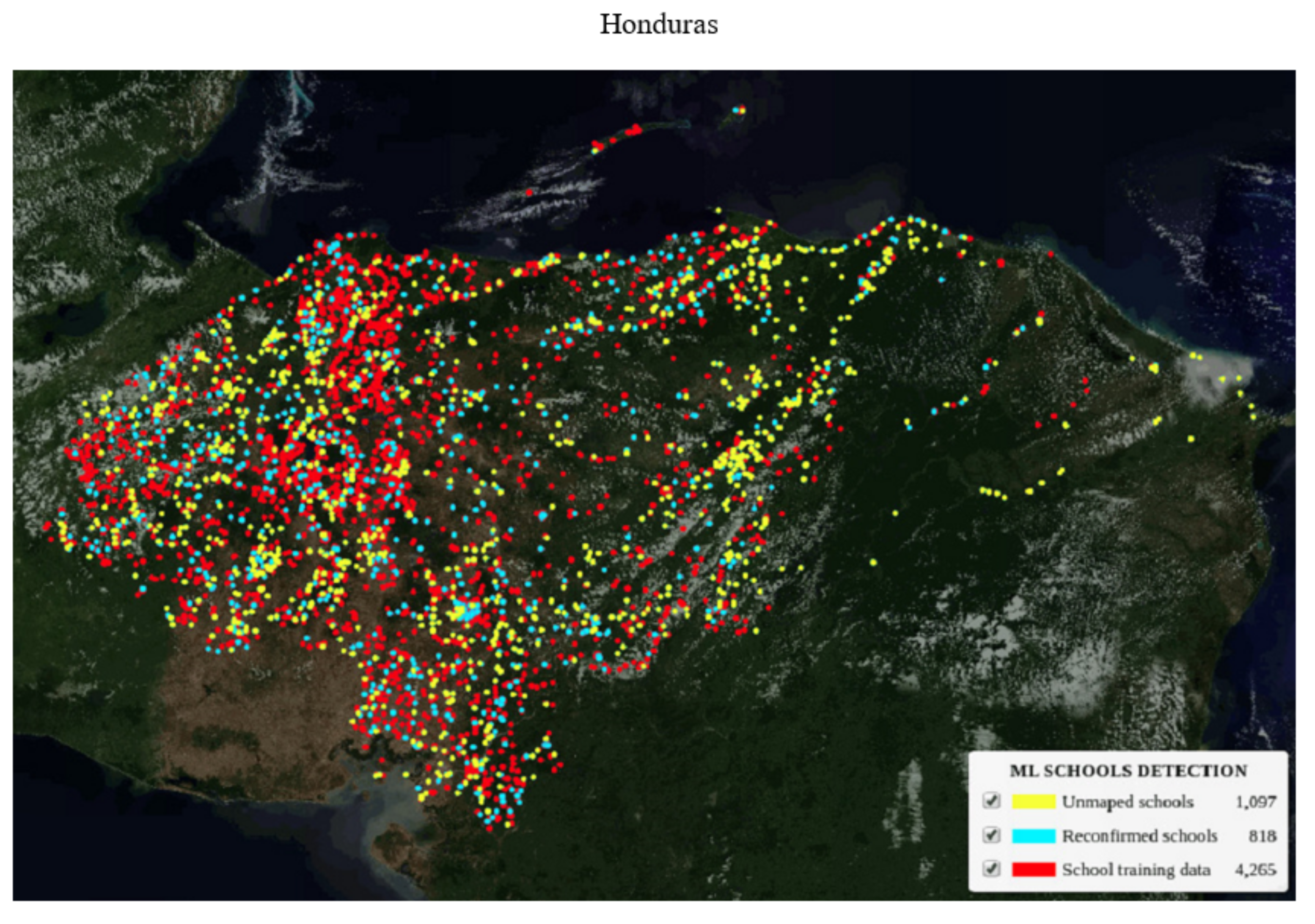
| Honduras | 17,534 | 1064 | 18,598 | 17,534 | 187 | 17,721 | 4265 | 12,400 | 1056 |
| Kazakhstan | 7410 | 2973 | 10,383 | 7410 | 480 | 7890 | 5998 | 1487 | 405 |
| Kenya | 20,381 | 32,485 | 52,866 | 20,381 | 14,985 | 35,366 | 20,422 | 10,377 | 4567 |
| Country | Urban | Rural | Forest | Desert | Water | Not-School | Total Negative | Total Positive |
|---|---|---|---|---|---|---|---|---|
| Chad | 137 | 54 | 27 | 27 | 27 | 272 | 274 | |
| Sierra Leone | 3849 | 1539 | 769 | 769 | 769 | 7695 | 7699 | |
| Niger | 530 | 212 | 106 | 106 | 106 | 1060 | 1060 | |
| Sudan | 146 | 58 | 29 | 29 | 29 | 291 | 292 | |
| Rwanda | 1603 | 641 | 320 | 320 | 320 | 3204 | 3207 | |
| Mali | 1237 | 494 | 247 | 247 | 247 | 2472 | 2474 | |
| Honduras | 2132 | 853 | 639 | 0 | 639 | 4263 | 4265 | |
| Kazakhstan | 2999 | 1199 | 599 | 599 | 599 | 5995 | 5998 | |
| Kenya | 6785 | 3431 | 1697 | 1738 | 1698 | 4565 | 19,914 | 19,822 |
| Country | Zoom 16 Tiles | Zoom 18 Tiles | Zoom 19 Tiles |
|---|---|---|---|
| Kenya | 726,749 | 11,627,984 | 2,906,996 |
| Rwanda | 60,846 | 973,536 | 243,384 |
| Sierra Leone | 169,095 | 2,705,520 | 676,380 |
| Niger | 697,118 | 11,153,888 | 2,788,472 |
| Honduras | 233,336 | 3,733,376 | 933,344 |
| Kazakhstan | 1,346,330 | 21,541,280 | 5,385,320 |
| Ghana (test) | 506,143 | 8,098,288 | 2,024,572 |
| Uzbekistan (test) | 705,648 | 11,290,368 | 2,822,592 |
| Total | 4,445,265 | 71,124,240 | 17,781,060 |
| Model | Training | Best Scores from Model Evaluation |
|---|---|---|
| Honduras | 8528 | F1_Score: 0.90, Precision: 0.90, Recall: 0.90 |
| Sierra Leone | 15,394 | F1_Score: 0.91, Precision: 0.92, Recall: 0.91 |
| Niger | 8195 | F1_Score: 0.87, Precision: 0.89, Recall: 0.89 |
| Rwanda | 6411 | F1_Score: 0.94, Precision: 0.94, Recall: 0.94 |
| Kazakhstan | 11,993 | F1_Score: 0.92, Precision: 0.93, Recall: 0.92 |
| Kenya | 12,200 | F1_Score: 0.90, Precision: 0.92, Recall: 0.92 |
| West Africa | 23,589 | F1_Score: 0.91, Precision: 0.91, Recall: 0.91 |
| East Africa | 18,611 | F1_Score: 0.92, Precision: 0.91, Recall: 0.92 |
| Global model | 62,721 | F1_Score: 0.85, Precision: 0.85, Recall: 0.84 |
| Country |
Known School | Total Detected | ML Output Validation | True Capture | Difference | Double Confirmed | Unmapped | ||
|---|---|---|---|---|---|---|---|---|---|
| Yes | Un-Reg | No | |||||||
| Kenya | 20,422 | 36,792 | 17,616 | 18,582 | 594 | 57% | 7100 | 9968 | 7648 |
| Rwanda | 3207 | 6510 | 3669 | 2726 | 115 | 58% | 1400 | 2139 | 1530 |
| Niger | 1060 | 4885 | 1733 | 1569 | 1583 | 79% | 1542 | 151 | 1582 |
| Sierra Leone | 9784 | 16,940 | 5002 | 8963 | 2975 | 75% | 703 | 3730 | 1272 |
| Ghana (test) | 2943 | 15,485 | 6427 | 8645 | 413 | 17% | 5768 | 509 | 5918 |
| Kazakhstan | 5998 | 8282 | 3989 | 4256 | 37 | 61% | 1273 | 2433 | 1556 |
| Uzbekistan (test) | 3646 | 10,013 | 3141 | 6860 | 12 | 29% | 2184 | 894 | 2247 |
| Honduras | 4265 | 14,410 | 1915 | 12,402 | 93 | 43% | 876 | 818 | 1097 |
| Model Architecture | F1_Score | Precision | Recall | Overall Accuracy | False Positives | False Negatives |
|---|---|---|---|---|---|---|
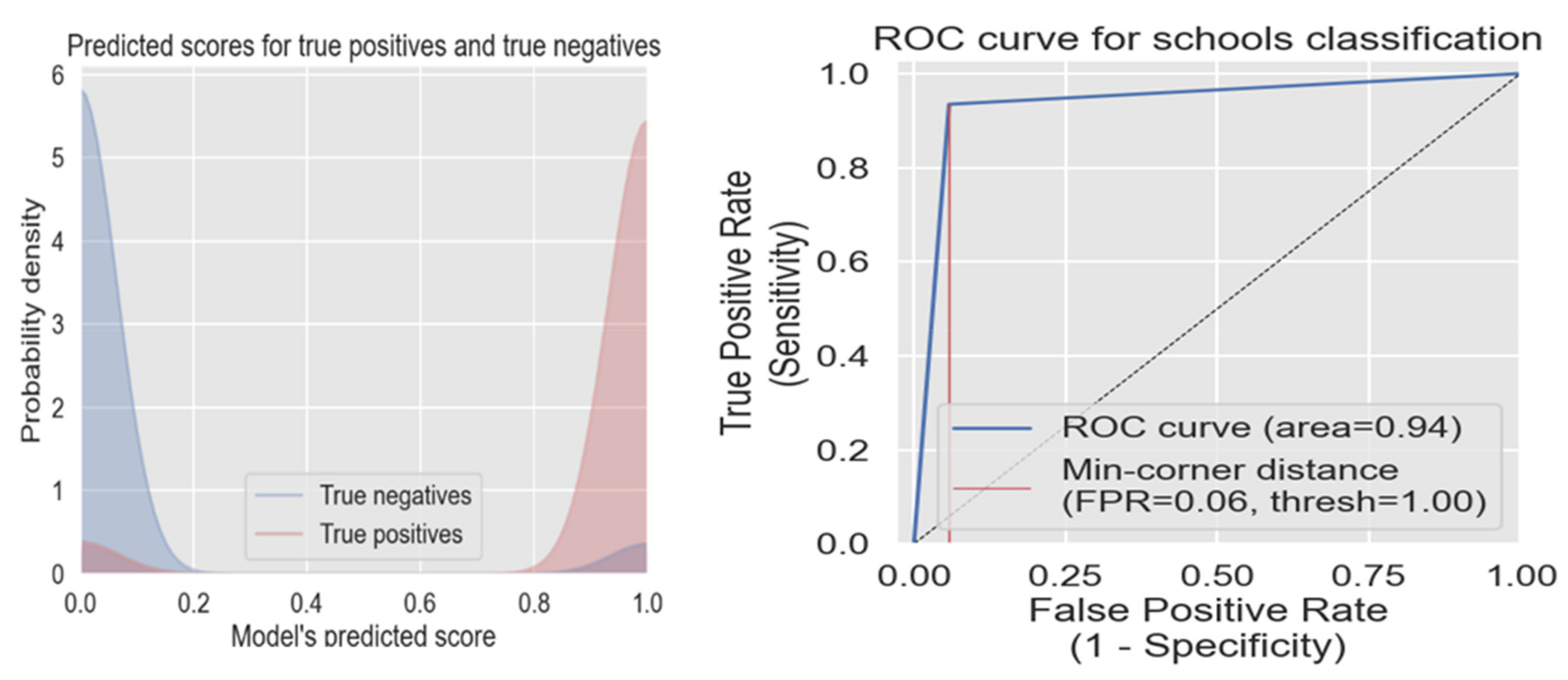
| Xception | 0.955 | 0.951 | 0.959 | 0.945 | 91 | 74 |
| ResNET-152 | 0.928 | 0.934 | 0.922 | 0.942 | 102 | 86 |
| MobileNet-v2 | 0.924 | 0.930 | 0.918 | 0.939 | 107 | 91 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Maduako, I.; Yi, Z.; Zurutuza, N.; Arora, S.; Fabian, C.; Kim, D.-H. Automated School Location Mapping at Scale from Satellite Imagery Based on Deep Learning. Remote Sens. 2022, 14, 897. https://doi.org/10.3390/rs14040897
Maduako I, Yi Z, Zurutuza N, Arora S, Fabian C, Kim D-H. Automated School Location Mapping at Scale from Satellite Imagery Based on Deep Learning. Remote Sensing. 2022; 14(4):897. https://doi.org/10.3390/rs14040897
Chicago/Turabian StyleMaduako, Iyke, Zhuangfang Yi, Naroa Zurutuza, Shilpa Arora, Christopher Fabian, and Do-Hyung Kim. 2022. "Automated School Location Mapping at Scale from Satellite Imagery Based on Deep Learning" Remote Sensing 14, no. 4: 897. https://doi.org/10.3390/rs14040897
APA StyleMaduako, I., Yi, Z., Zurutuza, N., Arora, S., Fabian, C., & Kim, D. -H. (2022). Automated School Location Mapping at Scale from Satellite Imagery Based on Deep Learning. Remote Sensing, 14(4), 897. https://doi.org/10.3390/rs14040897