1. Introduction
Water is essential and vital for sustaining human life on earth. Although about 71% of the earth is covered with water, only 3% of the world’s water is freshwater, and two-thirds of this water is hidden in glaciers that are frozen or not available for use [
1]. Besides, most of the world’s people lack clean and safe drinking water. Drinking water is defined, according to World Health Organization (WHO) and the United States Environmental Protection Agency (USEPA) guidelines [
2,
3], as water that presents no risks to human health over a lifetime of consumption, including different sensitivities that may arise between stages of his life. Every year, millions of people around the world suffer from various fatal diseases caused by drinking water pollution. The WHO stated in its report, which is released in June 2019 (
https://www.who.int/news-room/fact-sheets/detail/drinking-water, accessed on 15 November 2021) that “Globally, at least 2 billion people use a drinking water source contaminated with feces. Contaminated water can transmit diseases, such as diarrhea, cholera, dysentery, typhoid, and polio. Contaminated drinking water is estimated to cause 485,000 diarrhea deaths each year”. The WHO also states that, by 2025, half of the world’s population will be living in water-stressed areas. These facts show the severe threats and diseases caused to the global population by water scarcity, which encompasses water availability and quality.
Today, with the exponential increase in water use due to the rapid development of the human population, ensuring a safe and accessible water supply is a vital need for all. An effective smart water management system is a must in order to avoid the severe repercussions of water scarcity. In recent years, significant efforts have been made to monitor water quality using a set of Key Performance Indicators (KPIs), such as temperature, the potential of Hydrogen potential (pH), dissolved oxygen, turbidity, conductivity, etc. [
4,
5,
6,
7]. The measures of these KPIs are collected and analyzed using IoT platforms. To rationalize water consumption, with the goal of achieving a reduction in consumption, several water management systems have been developed using different technologies. However, the main drawback of these attempts is the high cost and energy consumption [
8,
9].
Over the past few years, the Internet of Things (IoT) technology has gained significant prominence in several areas, and this is thanks to its added-value capabilities and competitive advantages [
10,
11,
12]. IoT enables the control and processing of information in its ecosystem in order to provide smart applications in different domains, including the water management domain. In this context, the IoT consists of networks of smart devices equipped with physical sensors that collect and monitor water data. For analysis, the latter are transferred to computational platforms. IoT-based water management systems are low-cost solutions that can be easily scaled up while guaranteeing easy access for remote monitoring and control. In fact, low-cost sensors are efficient for measuring water quality indicators. In addition, the adoption of commonly used communication technologies by the IoT allows the deployment in pre-existing systems with few configurations and adaptations carried out.
In the present work, the main objective is to develop a smart water solution to support different water stakeholders (e.g., water and sanitation institutions, agricultural and environmental sectors, farmers, urban consumers, industrial consumers, etc.) in controlling and protecting their provisioned/consumed water resources. To achieve this goal, a novel IoT-based framework is defined to ensure the smart monitoring of water environments. The main contributions are summarized as below:
Designing a service-oriented and an IoT-based multi-layer framework that transforms the water environments into smart zones endowed with sensing and intelligent management capabilities.
Modeling the water environment as a knowledge graph [
13] that defines the involved elements, including water entities, sensors, water problems, monitored data, water management operations, etc. Such a multi-relational and semantic structure will serve as a dictionary that encompasses each information related to the water environment.
Exploiting network embedding [
14,
15] to learn semantics and enrich representations of water entities incrementally and to map them into a low-dimensional vector space according to their similar features, behaviors, and deviations. This step helps classify the affected water entities and efficiently select and trigger the appropriate corrective measures.
Defining a decision mechanism that recommends the appropriate management plan for each class of water problem. This mechanism reduces the complexity of exploring the whole network of water entities and their management costs.
Evaluating and validating the developed solution through several use-cases representing relevant water problems (e.g., sediment detection, bacterial contamination, discoloration, etc.) and using a real-world dataset.
The rest of this paper is organized as follows.
Section 2 discusses recent state-of-the-art solutions related to IoT-based water management.
Section 3 details the architecture of the proposed framework for water quality monitoring.
Section 4 and
Section 5 introduce the water knowledge graph (WKG) and the way it is updated at each monitoring time frame. In
Section 6, an incremental embedding method is proposed to map the water network into a low-dimensional vector space and to classify its content for the decision purpose. In
Section 7, a decision mechanism is defined based on the classification of affected water entities. Implementation and experimental analysis are provided in
Section 8. The summary of this work and the future research directions are provided in
Section 10.
2. Related Work
Many causes have engendered water scarcity in several regions of the globe, such as climate change, altered meteorological conditions, including droughts or floods, increasing pollution, growing human demand, excessive water usage, global warming, governmental access, local conflicts, illegal dumping, and natural catastrophes. To face the dramatic consequences of water scarcity, real-time water management is a critical necessity to ensure a sustainable and safe water supply. Recently, the application of new technologies such as IoT [
16,
17] and service and cloud computing [
18,
19,
20,
21] have proved their efficiency in the water sustainability field [
22]. In the present study, the focus is on reviewing the use of these technologies in the context of water scarcity management.
Using IoT and remote sensing technologies, the authors in [
23] presented a smart water quality monitoring system. For analysis, the proposed system measures four water parameters KPIs (pH, Oxidation-reduction potential (ORP), conductivity, and water temperature) using remote sensors. The collected data are transferred to a cloud server, where the data analysis is performed. For the validation of the system’s measurement accuracy, four different water sources were tested within a period of 12 h at hourly intervals.
Shahanas et al. [
24] developed a Smart Management Water (SMW) system based on IoT techniques and analytics. The authors collected their dataset manually. The proposed solution starts by collecting the water level from different tanks using smart sensors. These collected data are transferred to a centralized server using Arduino and Raspberry Pi to be analyzed, then visualized through a Web interface. The proposed solution allows the detection of the water level in a tank. When the level goes below a threshold, an alert will be sent to the users.
In [
25], the authors presented a context-aware ontology-driven approach to ensure the right water resource management in a smart city. The developed approach is based on the Multimedia Web Ontology Language (MOWL) and consists of three layers: data acquisition layer, context-aware service layer, and application layer. The first layer is responsible for collecting data from different sources through heterogeneous IoT devices such as climate and water-level sensors. Since the collected data are in various formats, they are converted into a predefined RDF format in the second layer resulting in MOWL files. These ontologies support the Dynamic Bayesian Network (BBN), which is responsible for analyzing data and predicting the changing situations in real time. The last layer ensures a clear presentation of the learned knowledge to the water authorities and determines the appropriate recommendation or warning to take suitable actions.
Myint et al. [
26] designed a Water Quality Monitoring (WQM) system for IoT environments based on a reconfigurable smart sensor network. The proposed WQM system collects five water-related data measurements, including pH, water level, turbidity, carbon dioxide on the water’s surface, and water temperature. These data are accumulated from multiple sensor nodes in parallel, in real-time, and at high speed, to be finally checked for monitoring. WQM minimizes the time and cost of detecting water quality, contributing to smart environmental management.
Simmhan et al. [
27] proposed a smart water management application for smart city utilities. The system architecture is based on open Web standards and involves network protocols, cloud computing, edge resources, and big data platforms. The proposed software has been tested on a smart campus at the Indian Institute of Science (IISc). The results have shown the scalability of the application to be applied in the city or for other areas of intelligent utilities.
Mukta et al. [
28] proposed an IoT-based system for Smart Water Quality Monitoring (SWQM) based on four parameters collected using IoT sensors. The used metrics include water temperature, pH, electric conductivity, and turbidity. SWQM system analyzes the extracted sensor data using a fast forest binary classifier to determine whether the tested samples of water are drinkable or not. The performance of this classifier is compared with three other binary classifiers, including support vector machine, logistic regression, and average perceptron algorithms. Among these techniques, the fast forest binary classifier provided the highest accuracy for the same test data. In their work, Mukta et al. used this classifier to develop a desktop application named “Sprinkle: Water Quality Checker” that monitors and assesses the water quality.
Liu et al. [
29] proposed a method based on Long Short-Term Memory (LSTM) deep neural networks to predict the quality of the drinking water in IoT-based environments. For model training, the authors used the water quality monitoring data collected by the automatic monitoring station of Guangzhou Water Source in Yangzhou City for the two years 2016 and 2017. The collected data include temperature, pH, dissolved oxygen, conductivity, turbidity, chemical oxygen demand, and ammoniacal nitrogen (NH3–N). To assess the effectiveness of the proposed model, the predicted results were compared to the measured data. The experimental results have shown that the proposed model offers a feasible approach for predicting the quality of drinking water.
In [
30], a real-time water quality measurement system called Smart Water Quality Monitoring System (SWQMS) was proposed. SWQMS is capable of investigating and providing information related to the local water quality by monitoring four key performance indicators, which are temperature, pH, oxidation-reduction potential, and conductivity. This system is designed on the basis of IoT technologies integrated within a network of wireless sensors. SWQMS is tested to monitor various water sources available in Fiji like coasts, coves, seas, rivers, and taps. The obtained data are analyzed using statistical methods and verified by comparing them to the Fiji national drinking water quality standards.
In [
31], a semantic modeling method based on ontologies and rules building was proposed to monitor the water quality of rivers and to process relevant observational data. It is based on the Observation Process Ontology (OPO) and allows the description of semantic properties related to water resources and the collected observation data. In addition, it can provide semantic relevance among the different concepts involved in the water quality monitoring process. OPO is constructed on the basis of the DOLCE Ultra-Light ontology.
A water management information system architecture, based on the micro-services paradigm and called WISdoM, was proposed in [
32]. WISdoM integrates core functionalities that support the implementation of three use cases of water utilities, namely: long-term water demand forecasts, groundwater data management, and precipitation data management. WISdoM uses several internal and external data sources (e.g., precipitation data, water consumption data, weather data, etc.). Each data source is encapsulated by a micro-service that allows querying the desired data. Data sources can be combined using a message broker service that ensures data reception from different sources. The applicability of the proposed approach and the usability of WISdoM are evaluated by expert users and by executing different scenarios.
The goal of the work presented in [
33] is the implementation of near-term and iterative ecological predictions for freshwater management. A forecasting framework named FLARE was developed to help manage water quality in critical lakes and reservoir ecosystems. Flare uses water quality sensor observations and models to make forecasts of future water quality conditions (i.e., temperature and dissolved oxygen). Forecasts provided by Flare are used by decision support tools for managers. Remote management and transfer orchestration of observations data and decisions are ensured by cloud computing tools.
An architecture for water quality monitoring for an irrigation precision agriculture system was provided in [
34]. The canals for irrigation, the fields, and the urban areas were all considered. The data were being sent via both WiFi and LoRa wireless technologies, with the cluster head node, serving as a WiFi/LoRa bridge that connects the WiFi and LoRa nodes. A tree topology for LoRa with several hops was also provided. This tree enabled for greater distances to be covered while also lowering the quantity of data and messages transferred from one node to another. A heterogeneous communication protocol for a precision agricultural system was also proposed. The protocol was intended to allow communication between devices that use WiFi and LoRa communication technologies. To assess the performance of the proposed protocol, tests were carried out in a real-world context using WiFi and LoRa nodes.
It is clear from the above attempts that water monitoring is essential to ensure the appropriate resource management and provide adequate water supply to the citizens. Efficient management of water requires the identification of the prevailing causes of water scarcity in a geospatial environment. This identification is ensured by analyzing the historical and real-time water-specific information captured through IoT sensor networks. To deal with uncertainties in water resources, a context-aware approach is also needed to predict environmental and climate change and offer timely guidance to the local water authorities. This approach will provide accurate knowledge of the available water resources to meet the competing demands. Besides, a knowledge management system ensuring water flow and quality modeling is needed to predict the drinking-water quality in the future and offer tracking capabilities to manage the issues generated as consequences of water shortages.
Analyzing the above water monitoring systems, the following major drawbacks have been identified:
Most approaches concentrate on the monitoring phase without providing an understanding or taxonomy of water environment entities. Although some attempts have used ontologies to represent the semantics of water-related information, the specification of the water environment entities (water objects, water sensors, management policies, etc.) is performed in isolation, which may lead to conflicting or failed corrective measures. A possible solution to this issue is to provide a semantic and multi-relational modeling of the water network through the use of knowledge graphs [
13] that allow us to explicitly represent the relationships between entities of the smart water environment.
Existing water monitoring systems suffer from scalability and management complexity issues due to the large size of the water networks and the huge volume of water data. This fact leads to an inaccurate analysis of the collected water information and may affect the decision on the water management operations (e.g., predictions, warnings, recommendations). Aiming to face the high computational cost caused by the analysis of the water resources’ monitored data, the incremental representation learning of the water network could be an elegant solution. To this end, metapath2vec [
35] is applied as an embedding technique ensuring the application of incremental learning of partial changes in the water information network (WIN).
Current monitoring systems trigger water management actions for each detected event (e.g., change in the water level), which leads to an increase in the cost of treating abnormal/failed aquatic objects. Since some water areas may experience the same deviations or degradation in water quality, the idea is to exploit the representations learned from the water zones’ features to classify them according to their common features/problems. This enables the appropriate water management plan to be triggered for each class of water zones rather than treating each zone in isolation.
4. Modeling of Smart Water Environment
The first step towards intelligent monitoring of water zones is the correct representation of its related information. Given the complexity, heterogeneity, and large-scale nature of the water network, which requires multi-relational and semantic modeling of its elements, the present approach exploits the strengths of knowledge graphs [
37] as a recent Google technology to explicitly represent the relationships among smart water environment’s entities (see
Figure 3). This new kind of knowledge base was launched, for the first time, in 2012 by Google. Since then, it has been adopted by leading service companies, such as Amazon, Facebook, IBM, Yahoo, etc. These latter’s services (e.g., search, recommendation, advertising, etc.) have been improved thanks to knowledge graphs’ abilities to represent and store complex relationships between real-world entities [
37].
In the present approach, the WKG, also called Water Information Network includes various entities, such as sensors, services, water stations and data, water workflows, management plans, etc. Such entities are the cornerstone of each water zone.
Definition 1. (Water Knowledge Graph) is an heterogeneous information network , where nodes in denote the set of water-related entities (sensors, services, water zones, management policies, etc.), edges in correspond to the connections between the water environment’s actors, and is the set of features characterizing the water network’s entities. denotes the set of facts (triples) in . A fact is a 3-tuple , where are the head and tail entities (e.g., sensors, monitoring hubs, distribution pipelines, management rules, etc.), and denotes a relation (connection) between and . A relation in the WKG is a typed link (e.g., Monitor, ManagedBy, Trigger) between entities and .
Figure 3 shows the software and hardware entities that are involved in the construction of the WIN. Examples of hardware entities include storage reservoirs (Res), distribution pipelines (DP), IoT water sensors (Sen), water supply chain components (SCC), pump stations (PS), water transportation pipelines (TP), rain gauges (RG), smart meters and monitoring hubs (MH) for measuring consumption, acoustic devices (AD) for real-time leakage detection, pressure monitoring hubs (PMH) for leakage detection and pump optimization, etc. Other types of entities include services (e.g., sensor cloud services) and water’s smart management policies (e.g., leakage prediction, burst repair, etc.), which are related to the different water zones (WZ).
Since the WKG results from the aggregation of various types of resources, it is treated as a combination of information sub-networks, also called views [
38]. In fact, the WKG can be seen as a multi-view information network, where each view denotes a sub-network of knowledge (see Definition 2). For instance, the sensors’ view (
) denotes all of the information regarding the hardware entities that are responsible for monitoring the water zones. Whereas the services view (
) is a sub-network of
that groups all the information regarding the value-added and sensor cloud services that process, transform, and aggregate water zones’ data. Each water zone could also be modeled as a view of the water network.
Definition 2. (Water view) A view is a sub-network of the water network , where is a subset of nodes, is a subset of features specific to the elements of the water zone , and is the subset of relations within . The whole WKG can be seen as the aggregation ϕ of all views, where .
6. Smart Water Analytics Based on Network Representation Learning
Once the WKG is updated based on the monitoring data, the next step is to select and trigger the corrective measures for each infected water zone. However, the water environment’s large-scale and complex nature makes it challenging to explore the WKG to locate suitable management operations. Since several water zones may encounter similar problems, classifying their elements (pipelines, reservoirs, etc.) according to their current states (e.g., pipelines’ pressure level) will accelerate the decision process.
To achieve this goal and to reduce the complexity of processing such a huge information network, network representation learning (NRL) [
14] is adopted, as an efficient solution to project the WKG into a low-dimensional vector embedding space, in which the nodes with similar features will be close and classified together. For example, the distribution pipelines with abnormal behavior will be tight in the vector space, whereas the storage reservoirs with similar capacities and the reservoirs with non-drinkable water will be mapped into the same vector embedding space. This powerful approach will allow performing various tasks (e.g., classification, clustering, link prediction, anomaly detection, etc.) on the information network’s content in an efficient and accurate manner [
14]. In the present work, learning the representation of water network nodes is the first step towards efficiently performing some of the following downstream tasks: clustering of sensed data, classification of drinking and non-drinking water zones, repair or substitution of failed hubs or services, anomaly detection at each water zone, etc.
In this paper, a water-specialized network embedding method is proposed to infer meaningful representations of water zones. The proposed method maps the water objects into a low-dimensional vector space. To learn the semantics of water-related information, metapath2vec is adopted, as an incremental embedding technique [
35]. Suitable for dynamic and heterogeneous information networks, the proposed method first learns the embeddings of each node in the water network. Then, at each monitoring time-frame, incremental learning is applied to the updated water network to take the new changes (e.g., water zones’ state) into consideration and to update the closeness degrees between water entities (see
Figure 2).
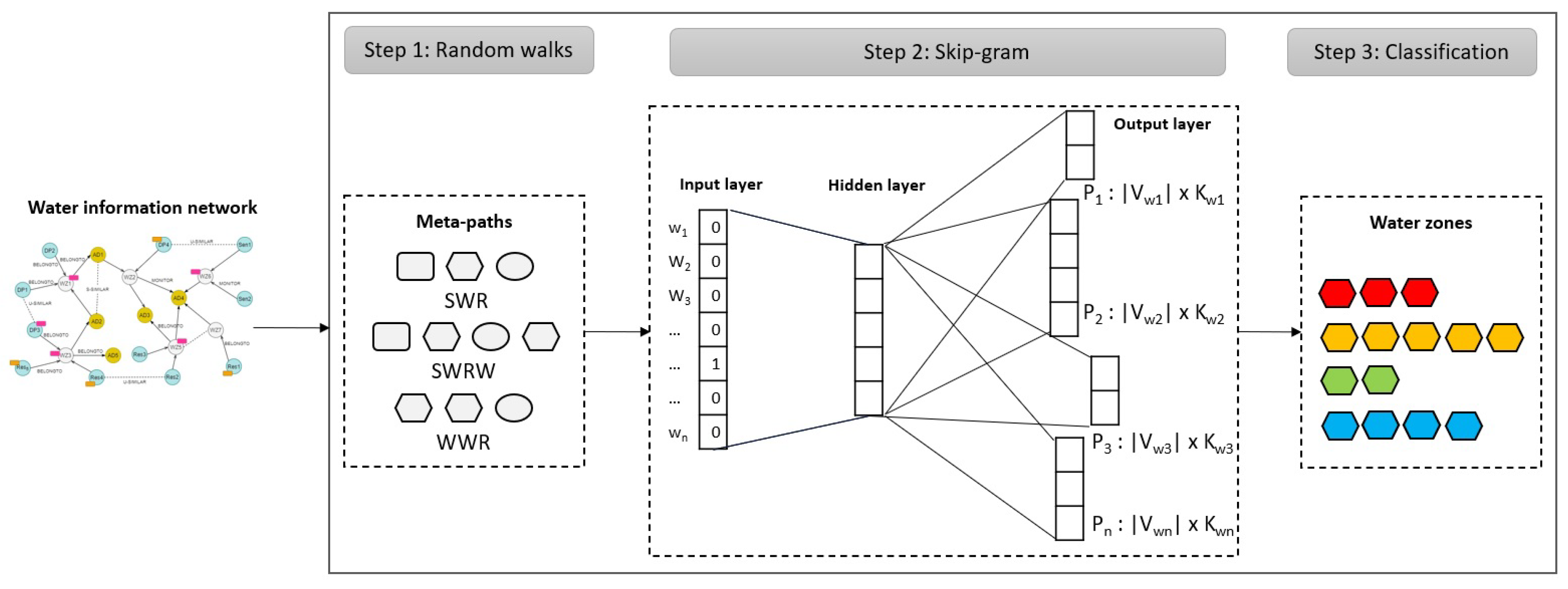
Inspired by metapath2vec, we propose a two-step incremental embedding method that maps the water network into a vector space, facilitating consequently the classification of water zones’ entities, as well as the decision task (see
Figure 5). The embedding model is preceded by a guided random walk that allows extracting the node sequences as input to the Skip-Gram learning model. To correctly capture the semantics and structural relationships between the water network’s nodes and properly incorporate their heterogeneous neighborhood into Skip-Gram, the proposed model follows a metapath-guided random walk in the water network. The basic notations are presented in
Table 4.
Meta-path-based random walks: In this work, a meta-path is a set of heterogeneous nodes which are connected based on their typed relations in the WKG. Formally, a meta-path
has the form
, wherein
denotes a composite relation between the node types
and
. The created meta-paths help training the Skip-Gram learning model, based on complex relations, such as water–water object relations (e.g., distribution pipeline, water reservoirs) and sensor–water object relations. Taking
Figure 6 as example, the meta-path
:
S-W-R denotes a management relationship between a water reservoir
W being monitored by a sensor
S and repaired using a management policy (e.g., repair)
R. Two nodes from the same type can be connected via multiple meta-paths, e.g.,
E-S-E, and
E-R-E. Each one reveals different semantics. For example, the latter meta-path indicates that a water zone’s management policy could be delivered for two water entities with similar behavior.
The meta-paths are used to recursively guide random walkers based on a transition probability, defined as follows [
35]:
Here,
and
denote, respectively, the node
v of type
t and its neighborhood type, which is outputted by the neighborhood function
, where
.
, if the transition (
v,
v) does not exist in the set of edges
E, or the neighbor node’s type is different from the expected node type given in the meta-path
.
The recursive guidance for the meta-path random walkers is defined as:
, if
. For example, the neighborhood of a water pipeline
(see
Figure 4) can be structurally close to other water entities (e.g., pipeline
, reservoirs
). Using the meta-path
:
W-W-R, the random walkers could traverse the water network and incorporate the following node sequence into a neighborhood function:
. Hence, given a water node and a predefined meta-path, the random walkers can determine the node representation that maximizes the probability of predicting an unseen node from a partially seen path in the water network.
The above guided random walk strategy preserves the semantic relationships between the types of nodes for each sequence, which leads to proper learning when these latter are incorporated into Skip-Gram.
Incremental embedding: As in the original metapath2vec, the water meta-paths are used as input to Skip-Gram. This latter is trained in order to obtain node (water objects) representations. The resultant node embeddings are frequently updated by taking into account the monitoring data, i.e., observations at each window time, due to the ever-changing nature of the water network. To do so, consider a set of the nodes whose states are changed after the monitoring task, where is an increment denoting the amount of water network changes (e.g., pipeline removal, newly added reservoir, etc.). For example, a reservoir that is represented by the node may undergo a change in the water quality. In this case, will represent the updated embedding for the node v.
To learn high-quality representations of the water network’s updated content, the model needs to maximize the likelihood of each water node to each context, as well as maximizing the probability that a context
(
) is heterogeneous. Such probability is computed as follows [
35]:
where
denotes the neighborhood of a water object
, and
is defined as a softmax function.
To efficiently predict each node’s neighborhood, the embedding model is based on a heterogeneous negative sampling strategy, in which a heterogeneous set of typed nodes is selected for the normalization and optimization of softmax function, w.r.t. the node context
. Hence, given a typed node-set
in the WKG and a node context
, the softmax function is defined as follows:
By considering the updates in the water network, the overall loss function is decomposed and defined as follows:
As in most approaches, the stochastic gradient descent (SGD) algorithm is used to optimize the embedding model.
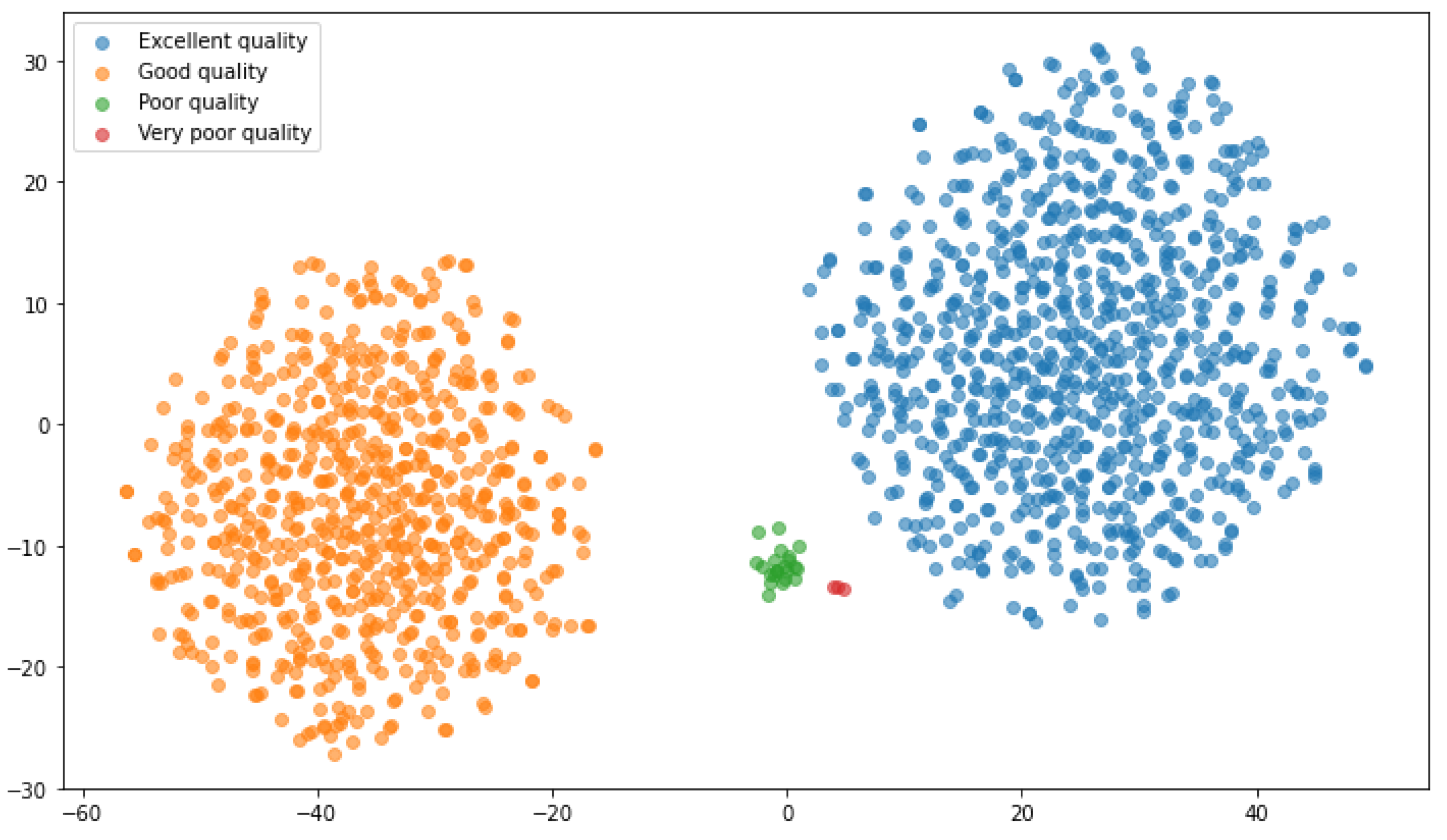
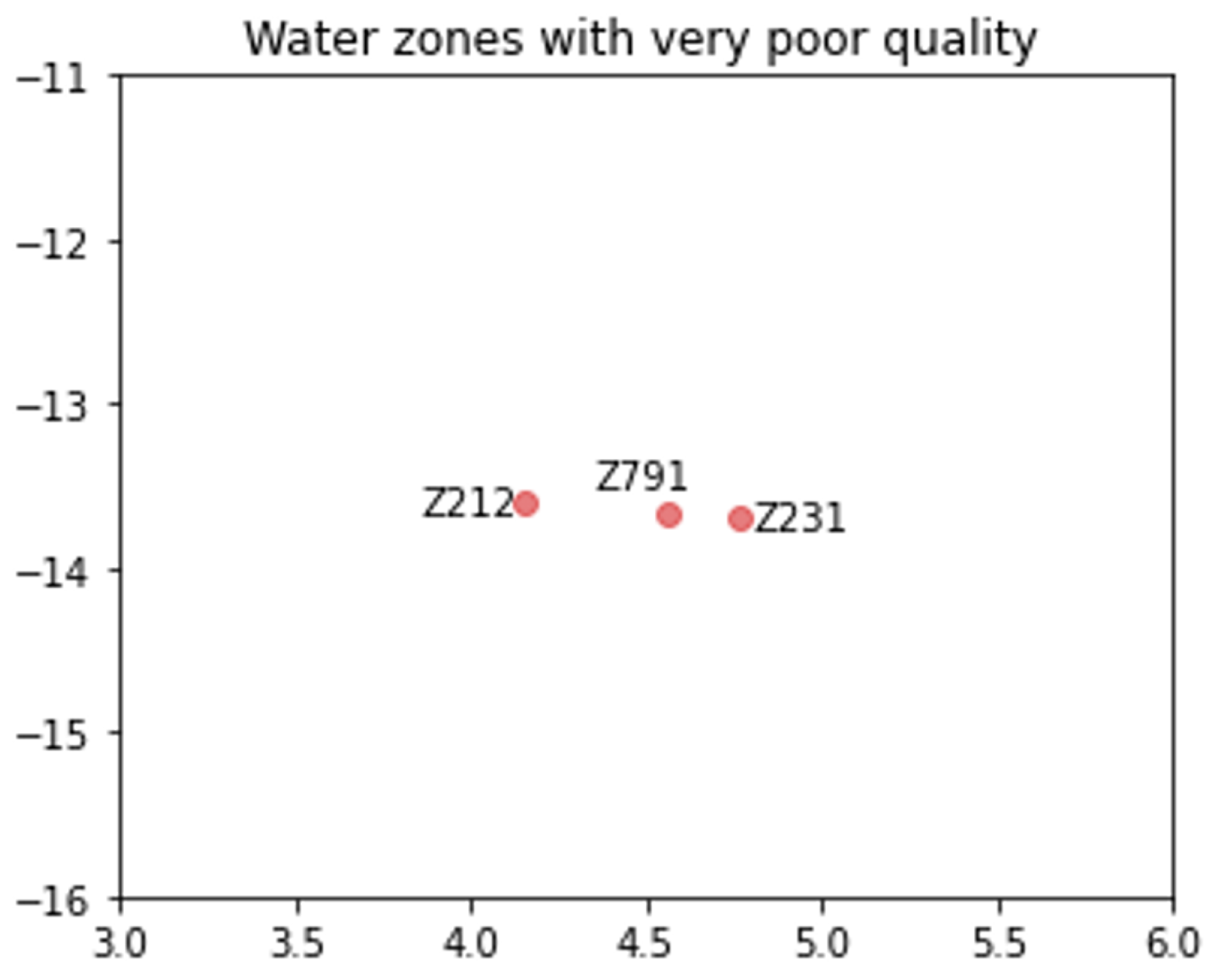
Classification of water zones based on incremental embedding: Based on the embeddings of the water network, and knowing that the water entities that share similar features or encounter the same deviations in their characteristics are close in the embedding space, the last step aims at inferring additional knowledge regarding the water zones, such as their quality (e.g., drinkable, pH level, etc.). By classifying the water network’s entities according to their proximity in the low-dimensional vector space, corrective measures will be triggered for each set of water objects, rather than selecting conflicting management actions for each individual water object. The correct decision on the water quality mainly depends on the accuracy of the learned embeddings in capturing the label of each water entity, based on the monitored data. In the embedding space, the water entities with similar behavior (indicated by the colored labels in
Figure 4) are located closely, which facilitates their classification and, consequently, the selection of non-conflicting corrective measures.
The whole embedding and classification process is summarized in Algorithm 1.
| Algorithm 1 Water zones’ embedding |
- 1:
Input:—Water knowledge graph, —Set of labels. - 2:
Output:—Classification of node embeddings in the water network. - 3:
Begin - 4:
- 5:
for each node do - 6:
X = MetaPathRandomWalk(G, P, , l) - 7:
X = HeterogeneousSkipGram(X, k, ); - 8:
for each node type do - 9:
Learn the representations of node - 10:
Minimize relation’s inference loss for - 11:
- 12:
end for - 13:
end for - 14:
Return
|
Given a water network and a finite set of labels denoting the possible water states, Algorithm 1 determines, for each node , the set of sequences that result from the guided random walks with a length l (lines 5–6). Then, based on Skip-Gram, the node paths are incorporated into the neighborhood function (line 7). Finally, using the labels set , the vectorized forms of each water entity are grouped using a classifier while minimizing the inference loss (lines 8–12).
The complexity of Algorithm 1 mainly depends on the meta-paths length and the number of nodes in the WIN. The guided random walks and the probability calculation based on Skip-Gram are iterated for each water node . Then, these latter representations are determined by considering node types. The complexity of this algorithm is of the order of .
7. Decision Process
At this stage of the smart water surveillance process, the water zones with common abnormal behaviors (e.g., water quality degradation, turbidity, pipeline bursts, etc.) are repaired by triggering suitable management operations. Rather than running throughout the whole WIN, the decision mechanism exploits the groups of labeled nodes that resulted from the classification step (see
Section 6). Since each group of water entities that encounters the same problem (e.g., reservoirs leakage) is mapped into close vectors in the same embedding subspace, a unique management plan is generated for those affected water entities, avoiding then conflicts between corrective measures and reducing the decision complexity.
Knowing that each label denotes a triggering situation, an algorithm is defined in this work, to explore the embedding space and to locate the vectors representing the most appropriate water management actions for each class of water problem (e.g., leakage, high-pressure, etc.). Algorithm 2 takes, as input, the vectorized form of the updated labeled graph
, and outputs a set
P of corrective measures.
| Algorithm 2 Smart water decision-making |
- 1:
Input:—Water knowledge graph, —Set of triggering events. - 2:
Output:P—Set of water management actions. - 3:
Begin - 4:
- 5:
fordo - 6:
for each do - 7:
Locate in - 8:
for each action do ▹ Get management actions for the water entity - 9:
if AND then ▹ Check the fact’s existence in - 10:
add to P ▹ Save corrective measure for the water entity - 11:
end if - 12:
end for - 13:
end for - 14:
end for - 15:
ReturnP
|
Based on a subset of labels (line 5) denoting the classes of detected problems (triggering events), Algorithm 2 starts by locating the affected water entities for the water event l (lines 5–7). Then, for each one, its context is extracted (line 8) so that to evaluate the candidate water management operations. For each class of problem, the suitable corrective measure is selected and saved to repair each water entity (line 10). Finally, a set P of water management operations is returned as the algorithm’s output (line 15).
The computational complexity of Algorithm 2 mainly depends on the number of triggering events () and the water network’s size (). The processing of each event requires parsing the WKG to locate the event context (), including candidate management actions, which also need to be evaluated to select the best corrective measure. Hence, the whole decision process takes .
9. Discussion
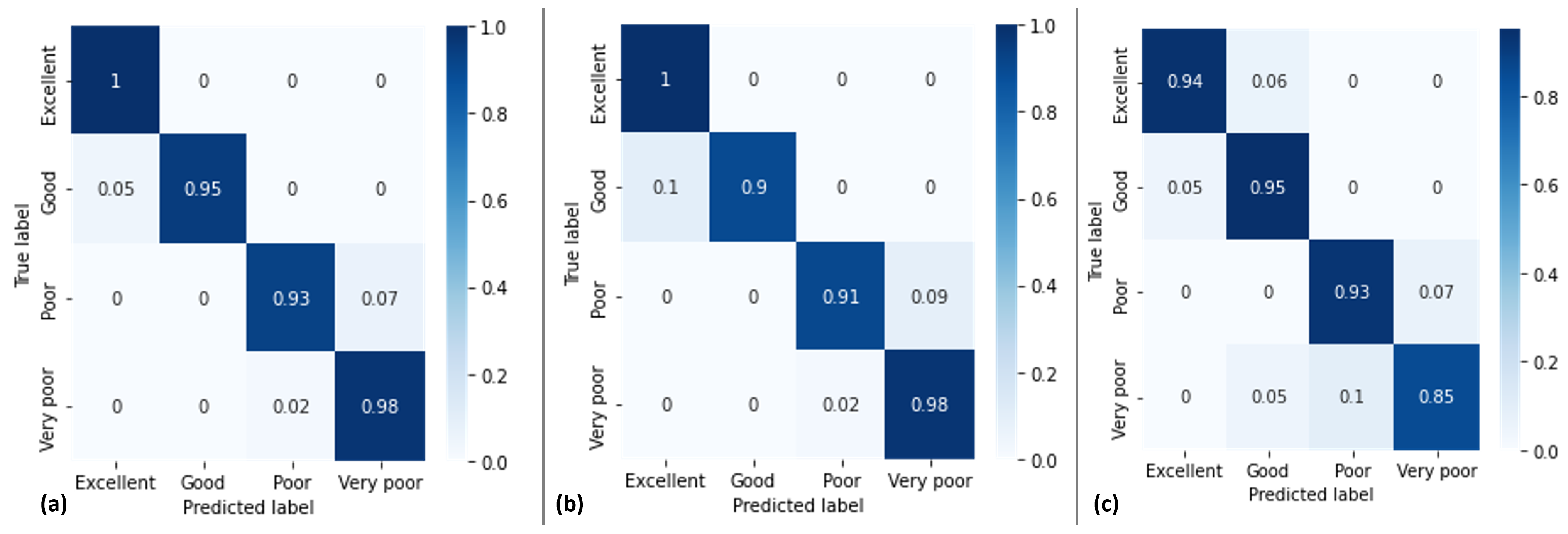
In a context of increasing scarcity of water resources and an increasingly demanding regulatory framework, organizations concerned with the management of water resources, government authorities, and drinking water operators, both public and private, are facing today growing and complex challenges: monitoring water quality, improving the efficiency of water networks, reducing operating costs, improving energy performance, etc. The growth of IoT sensors, the deployment of efficient and intelligent networks for data transfer, the usage of artificial intelligence, and notably machine learning techniques, are all highlighted as challenges that intelligent network management approaches can tackle. In this context, the solution consisted in a novel IoT-based framework for smart monitoring of water environments. The proposed framework relies mainly on the knowledge graph embedding technique that will enable us to progressively learn the semantics and enrich representations of water entities modeled in the form of a knowledge graph and map them into a low-dimensional vector space, according to their characteristics, behaviors, and deviations. This technique makes it possible to classify water entities to detect abnormalities that require effective and urgent intervention to select and initiate appropriate corrective measures.
The experimental studies that were carried out in this work confirmed that the adoption of Knowledge Graph Embedding (KGE) improved the performance of the water management task and the decision-making process. In fact, KGE is usually performed as a step that precedes several downstream tasks (e.g., classification, clustering, anomaly detection, link prediction, etc.) in order to improve the system’s performance and quality [
14]. In this paper, the main goal was to classify water entities in order to reduce the complexity and cost of decision-making. Since the incremental learning of the water network representation made it possible to map the water entities in close vectorized forms, advanced management operations could be efficiently carried out. For example, the anomaly detection problem could be instantiated as part of water management to determine areas of water exhibiting abnormal behavior. These will be isolated since they do not share the same semantics with the rest of the water entities. Another management operation concerns reassigning surveillance actors, such as sensors and their associated services (e.g., sensor cloud services, micro-services), to manage water areas. In fact, some areas may be characterized by a high degree of change in the water quality, while other areas that do not undergo frequent changes will produce a few amounts of water change-related data. In such a situation, embedding the water network will better capture the semantics by factoring the scattered water data into a smooth embedding space. In this way, high-performance sensors will be placed in tight water areas with a high degree of change, making it easier to reconfigure their placement.
In addition to the previously mentioned advantages and applicability cases, in the case of water resource management systems, the adoption of knowledge graph integration can overcome the limitations of usual deep reinforcement learning-based systems [
48,
49]. The deployment of this type of water management systems requires a huge amount of information from IoT sensors. However, knowledge reasoning techniques can solve this problem by using a graph already constructed on prior knowledge of the entities’ correlation and employing integration to derive the correct classification—subsequently, the effective selection of the appropriate corrective actions.


 ,
, 














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}