
A Transformer-Based Coarse-to-Fine Wide-Swath SAR Image Registration Method under Weak Texture Conditions


Abstract
:1. Introduction
- Feature points mainly exist in the strong corner and edge areas, and there are not enough matching point pairs in weak texture areas.
- Due to the special gradient calculation and feature space construction method, the traditional method runs slowly and consumes a lot of memory.
- The existing SAR image registration methods mainly rely on the CNN structure, and lack a complete relative relationship between their features due to the receptive field’s limitations.
- A CNN and Transformer hybrid approach is proposed in order to accurately register SAR images through a coarse-to-fine form.
- A stable partition framework from the full image to sub-images is constructed; in this method, the regions of interest are selected in pairs.
2. Methods
2.1. Deep Learning-Related Background
2.2. Rough Matching of the Down-Sampled Image
2.3. Sub-Image Acquisition from the Cluster Centers
- Regarding Gaussian blur, there are a total of groups of images, and each group consists of s scales; for the original-resolution image NxN, Gaussian filter group isThe corresponding time complexity is . For each pixel, a weighted sum of the surrounding Gaussian filtering is required, with complexity:The complexity of all of the groups is
- To calculate the Gaussian difference, subtract each pixel of adjacent scales once in one direction.
- To calculate the extremum detection in scale space, each point is compared with 26 adjacent points in the scale space. If the whole points are larger or smaller than the point, it is regarded as an extreme point; the complexity is
- For keypoint detection, the principal curvature needs to be calculated. The computational complexity of each point is , so the total time complexity of all of the groups is considering extrema and keypoints.
- For the keypoint orientation distribution, keypoint amplitude, and directionNon-keypoint points with magnitudes close to the peak are added as newly added keypoints. The total number of output points isThe computational complexity of each point is , and the total complexity is .
- For the feature point descriptor generation, the complexity of each point is , and the total complexity is .
- There are often more candidate regions of feature points near the cluster center.
- There is usually enough spatial distance between the clustering centers.
- The clustering center usually does not fall on the edge of the image.
2.4. Dense Matching of the Sub-Image Slices
- The feature extraction network HRNet (High-Resolution Net) [41]: Before this step, we combine ORB and GMS to obtain the image rough matching results, use the K-means++ method to obtain the cluster centers of the rough matching feature points, and obtain several pairs of rough matching image pairs. The input of the HRNet is every rough matching image pair, and the output of the network is the high and low-resolution feature map after HRNet’s feature extraction and fusion.
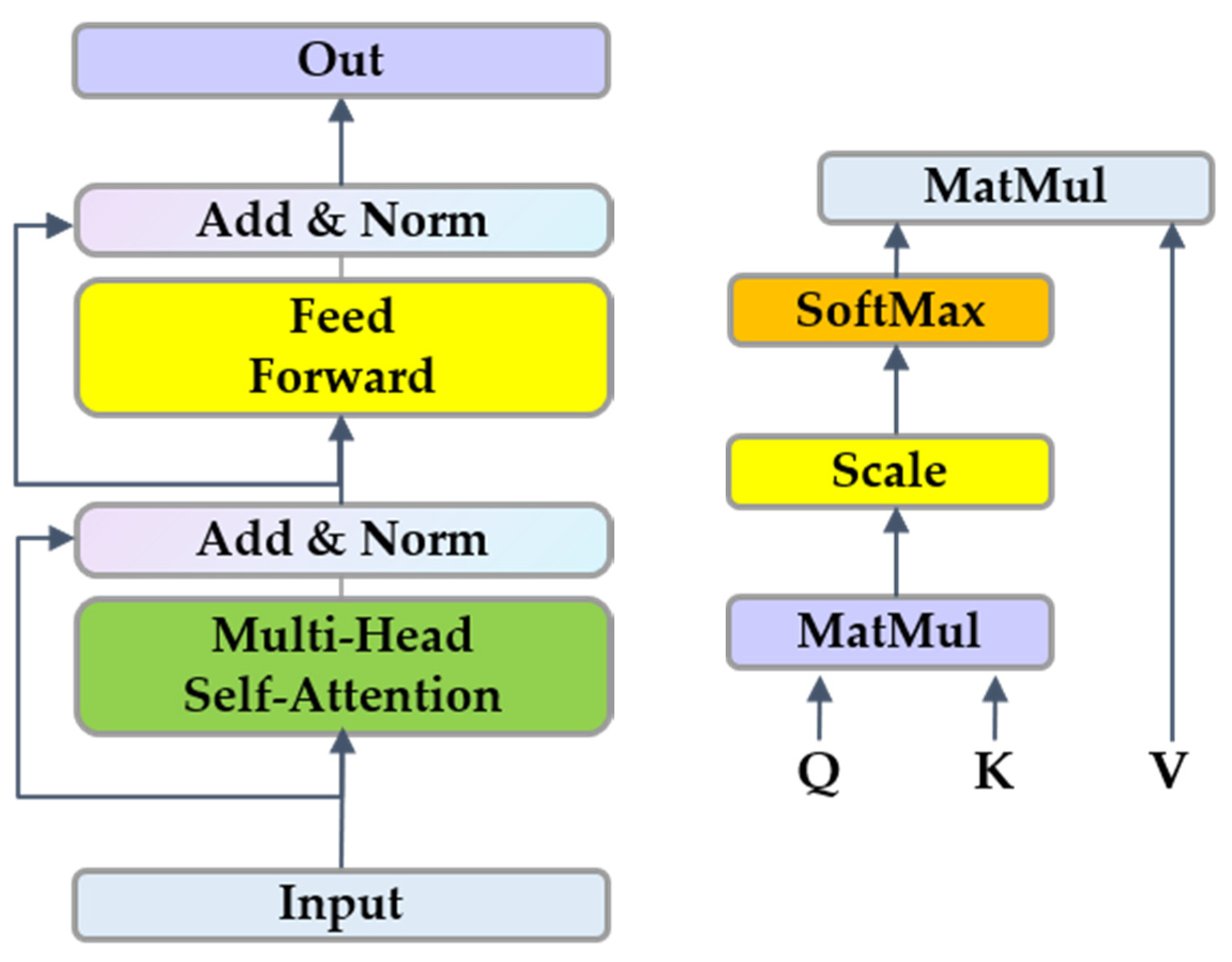
- The low-resolution module: The input is a low-resolution feature map obtained from HRNet, which is expanded into a one-dimensional form and added with positional encoding. The one-dimensional feature vector after position encoding is processed by the Performer [42] to obtain the feature vector weighted by the global information of the image.
- The matching module: The one-dimensional feature vector obtained from the two images in the previous step is operated to obtain a similarity matrix. The confidence matrix is obtained after softmax processing on the similarity matrix. The pairs that are greater than a threshold in the confidence matrix and satisfy the mutual proximity criterion are selected as the rough matching prediction.
- Refine module: For each coarse match obtained by the matching module, a window of size wxw is cut from the corresponding position of the high-resolution feature map. The features contained in the window are weighted by the Performer, and the accurate matching coordinates are finally obtained through cross-correlation and softmax. For each pair of rough matching images, the outputs of the above step are matched point pairs with precise coordinates, and after the addition of the initial offset of rough matching, all of the point pairs are fused into a whole matched point set. After the implementation of the RANSAC filtering algorithm, the final overall matching point pair is generated, and then the spatial transformation solution is completed.
2.4.1. HRNet
2.4.2. Performer
2.4.3. Training Dataset
2.4.4. Loss Function
2.5. Merge and Solve
3. Experimental Results and Analyses
3.1. Experimental Data and Settings
- The root mean square error, RMSE, is calculated by the following formula:
- NCM stands for the number of matching feature point pairs filtered by the RANSAC algorithm, mainly representing the number of feature point pairs participating in the calculation of the spatial transformation model. It is a filtered point subset of the matching point pairs output by algorithms such as SAR-SIFT. For the solution of the affine matrix, the larger the value, the better the image registration effect.
3.2. Performance Comparison
- SAR-SIFT uses SAR-Harris space instead of DOG to find the key points. Unlike the square descriptor of SIFT, SAR-SIFT uses the circular descriptor to describe neighborhood information.
- HardNet proposes the loss that maximizes the nearest negative and positive examples’ interval in a single batch. It uses the loss in metric learning, and outputs feature descriptors with 128 dimensionalities, like SIFT.
- SOSNet adds second-order similarity regularization for local descriptor learning. Intuitively, first-order similarity aims to give descriptors of matching pairs a smaller Euclidean distance than descriptors of non-matching pairs. The second-order similarity can describe more structural information; as a regular term, it helps to improve the matching effect.
- TFeat uses triplets to learn local CNN feature representations. Compared with paired sample training, triplets containing both positive and negative samples can generate better descriptors and improve the training speed.
- LoFTR proposes coarse matching and refining dense matches by a self-attention mechanism. It combines high- and low-resolution feature maps extracted by CNN to determine rough matching and precise matching positions, respectively.
- KAZE-SAR uses a nonlinear diffusion filter to build the scale space.
- CMM-Net uses VGGNet to extract high-dimensional feature maps and build descriptors. It uses triplet margin ranking loss to balance the universality and uniqueness of the feature points.
3.3. Visualization Results
3.4. Analysis of the Performance under Different Resolution Settings
4. Discussion
4.1. Rotation and Scale Test
4.2. Robustness Test of the Algorithm to Noise
4.3. Program Execution Time Comparison
4.4. Change Detection Application
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kulkarni, S.C.; Rege, P.P. Pixel level fusion techniques for SAR and optical images: A review. Inf. Fusion 2020, 59, 13–29. [Google Scholar] [CrossRef]
- Song, S.L.; Jin, K.; Zuo, B.; Yang, J. A novel change detection method combined with registration for SAR images. Remote Sens. Lett. 2019, 10, 669–678. [Google Scholar] [CrossRef]
- Tapete, D.; Cigna, F. Detection of Archaeological Looting from Space: Methods, Achievements and Challenges. Remote Sens. 2019, 11, 2389. [Google Scholar] [CrossRef] [Green Version]
- Suri, S.; Schwind, P.; Reinartz, P.; Uhl, J. Combining mutual information and scale invariant feature transform for fast and robust multisensor SAR image registration. In Proceedings of the American Society of Photogrammetry and Remote Sensing (ASPRS) Annual Conference, Baltimore, MD, USA, 9–13 March 2009. [Google Scholar]
- Stone, H.S.; Orchard, M.T.; Chang, E.; Martucci, S.A.; Member, S. A Fast Direct Fourier-Based Algorithm for Sub-pixel Registration of Images. IEEE Trans. Geosci. Remote Sens. 2001, 39, 2235–2243. [Google Scholar] [CrossRef] [Green Version]
- Xiang, Y.; Wang, F.; You, H. An Automatic and Novel SAR Image Registration Algorithm: A Case Study of the Chinese GF-3 Satellite. Sensors 2018, 18, 672. [Google Scholar] [CrossRef] [Green Version]
- Pallotta, L.; Giunta, G.; Clemente, C. Subpixel SAR image registration through parabolic interpolation of the 2-D cross correlation. IEEE Trans. Geosci. Remote Sens. 2020, 58, 4132–4144. [Google Scholar] [CrossRef] [Green Version]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Yan, K.; Sukthankar, R. PCA-SIFT: A more distinctive representation for local image descriptors. In Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, CVPR 2004, Washington, DC, USA, 27 June–2 July 2004; Volume 2, pp. 506–513. [Google Scholar]
- Dellinger, F.; Delon, J.; Gousseau, Y.; Michel, J.; Tupin, F. SAR-SIFT: A SIFT-like algorithm for SAR images. IEEE Trans. Geosci. Remote Sens. 2014, 53, 453–466. [Google Scholar] [CrossRef] [Green Version]
- Pourfard, M.; Hosseinian, T.; Saeidi, R.; Motamedi, S.A.; Abdollahifard, M.J.; Mansoori, R.; Safabakhsh, R. KAZE-SAR: SAR Image Registration Using KAZE Detector and Modified SURF Descriptor for Tackling Speckle Noise. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5207612. [Google Scholar] [CrossRef]
- Alcantarilla, P.F.; Bartoli, A.; Davison, A.J. KAZE features. In Proceedings of the European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; Springer: Berlin, Germany, 2012; pp. 214–227. [Google Scholar]
- Xiang, Y.; Jiao, N.; Wang, F.; You, H. A Robust Two-Stage Registration Algorithm for Large Optical and SAR Images. IEEE Trans. Geosci. Remote Sens. 2021, in press. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Chen, S.; Wang, H.; Xu, F.; Jin, Y.Q. Target Classification using the Deep Convolutional Networks for SAR Images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 4806–4817. [Google Scholar] [CrossRef]
- Hou, X.; Ao, W.; Song, Q.; Lai, J.; Wang, H.; Xu, F. FUSAR-Ship: Building a high-resolution SAR-AIS matchup dataset of Gaofen-3 for ship detection and recognition. Sci. China Inf. Sci. 2020, 63, 140303. [Google Scholar] [CrossRef] [Green Version]
- Wang, S.; Quan, D.; Liang, X.; Ning, M.; Guo, Y.; Jiao, L. A deep learning framework for remote sensing image registration. ISPRS J. Photogramm. Remote Sens. 2018, 145, 148–164. [Google Scholar] [CrossRef]
- Geng, J.; Ma, X.; Zhou, X.; Wang, H. Saliency-Guided Deep Neural Networks for SAR Image Change Detection. IEEE Trans. Geosci. Remote Sens. 2019, 57, 7365–7377. [Google Scholar] [CrossRef]
- He, H.; Chen, M.; Chen, T.; Li, D. Matching of remote sensing images with complex background variations via Siamese convolutional neural network. Remote Sens. 2018, 10, 355. [Google Scholar] [CrossRef] [Green Version]
- Zheng, Y.; Sui, X.; Jiang, Y.; Che, T.; Zhang, S.; Yang, J.; Li, H. SymReg-GAN: Symmetric Image Registration with Generative Adversarial Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2021, in press. [Google Scholar] [CrossRef]
- Li, Z.; Zhang, H.; Huang, Y. A Rotation-Invariant Optical and SAR Image Registration Algorithm Based on Deep and Gaussian Features. Remote Sens. 2021, 13, 2628. [Google Scholar] [CrossRef]
- Mao, S.; Yang, J.; Gou, S.; Jiao, L.; Xiong, T.; Xiong, L. Multi-Scale Fused SAR Image Registration Based on Deep Forest. Remote Sens. 2021, 13, 2227. [Google Scholar] [CrossRef]
- Luo, X.; Lai, G.; Wang, X.; Jin, Y.; He, X.; Xu, W.; Hou, W. UAV Remote Sensing Image Automatic Registration Based on Deep Residual Features. Remote Sens. 2021, 13, 3605. [Google Scholar] [CrossRef]
- Lan, C.; Lu, W.; Yu, J.; Xu, Q. Deep learning algorithm for feature matching of cross modality remote sensing images. Acta Geodaetica et Cartographica Sinica. 2021, 50, 189. [Google Scholar]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G.R. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011; pp. 2564–2571. [Google Scholar]
- Bian, J.; Lin, W.Y.; Matsushita, Y.; Yeung, S.K.; Nguyen, T.D.; Cheng, M.M. Gms: Grid-based motion statistics for fast, ultra-robust feature correspondence. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 25–30 June 2017; pp. 4181–4190. [Google Scholar]
- Arthur, D.; Vassilvitskii, S. K-means++: The Advantages of Careful Seeding. In Proceedings of the Eighteenth Annual ACM-SIAM Symposium on Discrete Algorithms, New Orleans, LA, USA, 7–9 January 2007; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA; pp. 1027–1035. [Google Scholar]
- Fischler, M.A.; Bolles, R.C. Random sample consensus—A paradigm for model-fitting with applications to image-analysis and automated cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Advances in Neural Information Processing Systems 25; Pereira, F., Burges, C.J.C., Bottou, L., Weinberger, K.Q., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2012; pp. 1097–1105. [Google Scholar]
- Zhang, Z.; Wang, H.; Xu, F.; Jin, Y.Q. Complex-valued convolutional neural network and its application in polarimetric SAR image classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 7177–7188. [Google Scholar] [CrossRef]
- Guo, Q.; Wang, H.; Xu, F. Scattering Enhanced attention pyramid network for aircraft detection in SAR images. IEEE Trans. Geosci. Remote Sens. 2020, 99, 1–18. [Google Scholar] [CrossRef]
- Duan, Y.; Liu, F.; Jiao, L.; Zhao, P.; Zhang, L. SAR Image segmentation based on convolutional-wavelet neural network and markov random field. Pattern Recognit. 2016, 64, 255–267. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2017; pp. 5998–6008. [Google Scholar]
- Wang, Z.; Zhao, J.; Zhang, R.; Li, Z.; Lin, Q.; Wang, X. UATNet: U-Shape Attention-Based Transformer Net for Meteorological Satellite Cloud Recognition. Remote Sens. 2022, 14, 104. [Google Scholar] [CrossRef]
- Zhao, C.; Wang, J.; Su, N.; Yan, Y.; Xing, X. Low Contrast Infrared Target Detection Method Based on Residual Thermal Backbone Network and Weighting Loss Function. Remote Sens. 2022, 14, 177. [Google Scholar] [CrossRef]
- Xu, X.; Feng, Z.; Cao, C.; Li, M.; Wu, J.; Wu, Z.; Shang, Y.; Ye, S. An Improved Swin Transformer-Based Model for Remote Sensing Object Detection and Instance Segmentation. Remote Sens. 2021, 13, 4779. [Google Scholar] [CrossRef]
- Sun, J.; Shen, Z.; Wang, Y.; Bao, H.; Zhou, X. LoFTR: Detector-free local feature matching with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Montreal, QC, Canada, 11–17 October 2021; pp. 8922–8931. [Google Scholar]
- Bay, H.; Tuytelaars, T.; Van Gool, L. SURF: Speeded Up Robust Features. In Proceedings of the 9th European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; pp. 404–417. [Google Scholar]
- Rosten, E.; Drummond, T. Machine learning for high-speed corner detection. In Proceedings of the 9th European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; pp. 430–443. [Google Scholar]
- Calonder, M.; Lepetit, V.; Strecha, C.; Fua, P. BRIEF: Binary Robust Independent Elementary Features. In Proceedings of the 11th European Conference on Computer Vision, Heraklion, Greece, 5–11 September 2010; pp. 778–792. [Google Scholar]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep high-resolution representation learning for human pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 5693–5703. [Google Scholar]
- Choromanski, K.; Likhosherstov, V.; Dohan, D.; Song, X.; Gane, A.; Sarlos, T.; Weller, A. Rethinking attention with performers. In Proceedings of the International Conference on Learning Representations, Virtual, 26 April–1 May 2020. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the International Conference on Learning Representations, Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Lin, T.Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21 July–26 July 2017; IEEE Computer Society: Washington, DC, USA, 2017. [Google Scholar]
- Li, Z.; Snavely, N. MegaDepth: Learning Single-View Depth Prediction from Internet Photos. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 2041–2050. [Google Scholar]
- Mishchuk, A.; Mishkin, D.; Radenovic, F.; Matas, J. Working hard to know your neighbor’s margins: Local descriptor learning loss. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2017; pp. 4826–4837. [Google Scholar]
- Balntas, V.; Riba, E.; Ponsa, D.; Mikolajczyk, K. Learning Local Feature Descriptors with Triplets and Shallow Convolutional Neural Networks. In Proceedings of the British Machine Vision Association (BMVC) 2016, York, UK, 19–22 September 2016; Volume 1, p. 3. [Google Scholar]
- Tian, Y.; Yu, X.; Fan, B.; Wu, F.; Heijnen, H.; Balntas, V. SOSNet: Second Order Similarity Regularization for Local Descriptor Learning. In Proceedings of the Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 11008–11017. [Google Scholar]
- Shi, J.; Tomasi, C. Good features to track. In Proceedings of the 1994 Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 21–23 June 1994; pp. 593–600. [Google Scholar]
- Pu, W. SAE-Net: A Deep Neural Network for SAR Autofocus. IEEE Trans. Geosci. Remote Sens. 2022, in press. [Google Scholar] [CrossRef]
- Celik, T. Unsupervised change detection in satellite images using principal component analysis and k-means clustering. IEEE Geosci. Remote Sens. Lett. 2009, 6, 772–776. [Google Scholar] [CrossRef]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Pair | Sensor | Size | Resolution | Polar | Orbit Direction | Data | Location |
|---|---|---|---|---|---|---|---|
| 1 | GF-3 | 15,470 × 11,093 | 1 m | VV | DEC | 20180420 | USA New Jersey |
| 15,276 × 11,498 | 1 m | VV | DEC | 20180425 | |||
| 2 | GF-3 | 17,110 × 11,635 | 1 m | VV | DEC | 20180804 | China |
| 15,986 × 11,718 | 1 m | HH | DEC | 20180814 | Shaanxi | ||
| 3 | GF-3 | 28,334 × 11,868 | 1 m | HH | DEC | 20190201 | USA |
| 30,752 × 12,384 | 1 m | HH | DEC | 20190208 | Alaska | ||
| 4 | GF-3 | 14,736 × 11,391 | 1 m | HH | ASC | 20180825 | USA |
| 13,840 × 11,349 | 1 m | HH | ASC | 20180820 | Hawaii | ||
| 5 | GF-3 | 13,102 × 10,888 | 1 m | HH | ASC | 20181119 | Philippines |
| 14,554 × 12,287 | 1 m | HH | DEC | 20180715 | Bagan | ||
| 6 | GF-3 | 20,792 × 11,602 | 1 m | VV | ASC | 20180609 | Russia |
| 20,660 × 11,382 | 1 m | VV | ASC | 20180705 | Saratov | ||
| 7 | TerraSAR-X | 8208 × 5572 | 1 m | HH | DEC | 20130314 | China |
| 8208 × 5562 | 1 m | HV | DEC | 20130303 | Shanghai | ||
| 8 | TerraSAR-X | 23,741 × 28,022 | 1 m | HH | ASC | 20160912 | China |
| 23,998 × 29,505 | 1 m | HH | ASC | 20161004 | Liaoning | ||
| 9 | Sentinel-1 | 25,540 × 16,703 | 20 × 22 m | VH | DEC | 20211211 | USA |
| 25,540 × 16,704 | 20 × 22 m | VH | DEC | 20211129 | St. Francis | ||
| 10 | Sentinel-1 | 25,649 × 16,722 | 20 × 22 m | VH | ASC | 20211129 | China |
| 25,649 × 16,722 | 20 × 22 m | VH | ASC | 20211211 | Guangdong | ||
| 11 | Sentinel-1 | 25,336 × 16,707 | 20 × 22 m | VH | ASC | 20211210 | China |
| 25,335 × 16,707 | 20 × 22 m | VH | ASC | 20211128 | Liaoning | ||
| 12 | ALOS | 5600 × 4700 | 20 × 10 m | HH | ASC | 20100717 | USA |
| 5600 × 4700 | 20 × 10 m | HH | ASC | 20100601 | Montana | ||
| 13 | ALOS | 6454 × 5729 | 20 × 10 m | HH | ASC | 20080416 | China |
| 6502 × 5715 | 20 × 10 m | HH | ASC | 20080115 | Jiangsu | ||
| 14 | ALOS | 6291 × 5508 | 20 × 10 m | HH | ASC | 20081121 | China |
| 6464 × 5712 | 20 × 10 m | HH | ASC | 20110221 | Shandong | ||
| 15 | SeaSat | 11,611 × 11,094 | 12.5 m | HH | DEC | 19780922 | Norway |
| 11,399 × 10,952 | 12.5 m | HH | DEC | 19781010 | |||
| 16 | SeaSat | 11,493 × 11,371 | 12.5 m | HH | DEC | 19780811 | Russia |
| 11,717 × 11,135 | 12.5 m | HH | DEC | 19780722 | |||
| 17 | SeaSat | 11,191 × 10,653 | 12.5 m | HH | ASC | 19780902 | UK |
| 11,155 × 10,753 | 12.5 m | HH | ASC | 19780926 |
| Pair | HardNet [48] | SOSNet [50] | TFeat [49] | SAR-SIFT [10] | LoFTR [37] | KAZE-SAR [11] | CMM-Net [24] | Ours | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RMSE | NCM | RMSE | NCM | RMSE | NCM | RMSE | NCM | RMSE | NCM | RMSE | NCM | RMSE | NCM | RMSE | NCM | |
| 1 | 0.629 | 111 | 0.603 | 107 | 0.561 | 78 | 0.628 | 30 | 0.658 | 1063 | 0.685 | 169 | 0.645 | 22 | 0.572 | 8506 |
| 2 | 0.589 | 38 | 0.670 | 51 | 0.658 | 65 | 0.624 | 50 | 0.702 | 298 | 0.653 | 74 | 0.622 | 19 | 0.569 | 1763 |
| 3 | 0.588 | 25 | 0.660 | 27 | 0.455 | 38 | 0.472 | 14 | 0.663 | 178 | 0.664 | 52 | 0.415 | 13 | 0.609 | 2410 |
| 4 | 0.655 | 83 | 0.648 | 109 | 0.652 | 60 | 0.607 | 22 | 0.678 | 156 | 0.665 | 109 | 0.384 | 10 | 0.528 | 6923 |
| 5 | 0.674 | 10 | 0.632 | 8 | - | - | 0.547 | 7 | 0.620 | 133 | 0.592 | 7 | 0.501 | 9 | 0.661 | 223 |
| 6 | - | - | - | - | - | - | 0.453 | 7 | 0.664 | 204 | 0.552 | 6 | 0.492 | 11 | 0.571 | 758 |
| 7 | 0.594 | 1343 | 0.610 | 1441 | 0.604 | 1738 | 0.708 | 1045 | 0.588 | 11,816 | 0.613 | 4253 | 0.570 | 47 | 0.546 | 12,190 |
| 8 | 0.620 | 85 | 0.668 | 74 | 0.603 | 91 | 0.682 | 50 | 0.659 | 891 | 0.659 | 209 | 0.605 | 21 | 0.484 | 3121 |
| 9 | 0.681 | 255 | 0.636 | 256 | 0.660 | 216 | 0.601 | 50 | 0.655 | 3152 | 0.653 | 778 | 0.596 | 30 | 0.503 | 20,319 |
| 10 | 0.637 | 446 | 0.640 | 472 | 0.631 | 398 | 0.715 | 141 | 0.650 | 4073 | 0.642 | 1142 | 0.691 | 30 | 0.485 | 18,270 |
| 11 | 0.643 | 297 | 0.630 | 405 | 0.623 | 315 | 0.691 | 82 | 0.664 | 3626 | 0.641 | 850 | 0.656 | 31 | 0.518 | 23,865 |
| 12 | 0.654 | 1083 | 0.663 | 932 | 0.657 | 1076 | 0.670 | 105 | 0.607 | 12,226 | 0.615 | 2836 | 0.666 | 66 | 0.537 | 24,515 |
| 13 | 0.632 | 920 | 0.653 | 946 | 0.634 | 854 | 0.618 | 483 | 0.634 | 4577 | 0.624 | 2173 | 0.583 | 35 | 0.560 | 21,782 |
| 14 | 0.641 | 22 | - | - | 0.658 | 8 | 0.561 | 15 | 0.654 | 220 | 0.551 | 15 | 0.686 | 10 | 0.538 | 949 |
| 15 | 0.643 | 635 | 0.682 | 520 | 0.664 | 661 | 0.669 | 128 | 0.642 | 446 | 0.629 | 1069 | 0.628 | 27 | 0.696 | 4099 |
| 16 | 0.458 | 152 | 0.596 | 118 | 0.510 | 182 | 0.645 | 47 | 0.663 | 883 | 0.638 | 180 | 0.599 | 23 | 0.555 | 4401 |
| 17 | 0.628 | 415 | 0.669 | 395 | 0.629 | 625 | 0.632 | 82 | 0.663 | 4588 | 0.670 | 755 | 0.583 | 63 | 0.577 | 14,446 |
| Pair | Ours_16_4 | Ours_8_2 | Ours_8_1 | Ours_5_2 | ||||
|---|---|---|---|---|---|---|---|---|
| RMSE | NCM | RMSE | NCM | RMSE | NCM | RMSE | NCM | |
| 1 | 0.683 | 323 | 0.638 | 3789 | 0.665 | 3885 | 0.572 | 8506 |
| 2 | 0.680 | 68 | 0.669 | 533 | 0.680 | 763 | 0.569 | 1763 |
| 3 | 0.703 | 95 | 0.627 | 1012 | 0.673 | 895 | 0.609 | 2410 |
| 4 | 0.676 | 261 | 0.637 | 1288 | 0.671 | 1706 | 0.528 | 6923 |
| 5 | 0.638 | 29 | 0.624 | 149 | 0.636 | 157 | 0.661 | 223 |
| 6 | 0.504 | 26 | 0.618 | 328 | 0.653 | 487 | 0.571 | 758 |
| 7 | 0.685 | 1389 | 0.624 | 8925 | 0.593 | 12,152 | 0.546 | 12,190 |
| 8 | 0.646 | 222 | 0.634 | 2165 | 0.643 | 1955 | 0.484 | 3121 |
| 9 | 0.680 | 658 | 0.641 | 6253 | 0.633 | 7568 | 0.503 | 20,319 |
| 10 | 0.658 | 819 | 0.644 | 2104 | 0.624 | 3348 | 0.485 | 18,270 |
| 11 | 0.659 | 986 | 0.646 | 3025 | 0.642 | 4731 | 0.518 | 23,865 |
| 12 | 0.642 | 1336 | 0.635 | 9616 | 0.612 | 11,253 | 0.537 | 24,515 |
| 13 | 0.636 | 1187 | 0.631 | 4382 | 0.639 | 4906 | 0.560 | 21,782 |
| 14 | 0.638 | 61 | 0.620 | 558 | 0.668 | 603 | 0.538 | 949 |
| 15 | 0.690 | 558 | 0.709 | 1203 | 0.667 | 2478 | 0.696 | 4099 |
| 16 | 0.711 | 195 | 0.643 | 1679 | 0.648 | 2063 | 0.555 | 4401 |
| 17 | 0.654 | 850 | 0.621 | 3339 | 0.668 | 3719 | 0.577 | 14,446 |
| Pair | HardNet [48] | SOSNet [50] | TFeat [49] | SAR-SIFT [10] | LoFTR [37] | Ours |
|---|---|---|---|---|---|---|
| 2 | 42.868 | 24.543 | 21.962 | 513.152 | 19.496 | 21.321 |
| 8 | 43.142 | 43.129 | 40.710 | 1999.966 | 38.633 | 40.553 |
| 12 | 26.514 | 26.980 | 24.730 | 948.620 | 28.974 | 45.687 |
| 17 | 22.611 | 23.085 | 20.772 | 829.606 | 16.344 | 25.033 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fan, Y.; Wang, F.; Wang, H. A Transformer-Based Coarse-to-Fine Wide-Swath SAR Image Registration Method under Weak Texture Conditions. Remote Sens. 2022, 14, 1175. https://doi.org/10.3390/rs14051175
Fan Y, Wang F, Wang H. A Transformer-Based Coarse-to-Fine Wide-Swath SAR Image Registration Method under Weak Texture Conditions. Remote Sensing. 2022; 14(5):1175. https://doi.org/10.3390/rs14051175
Chicago/Turabian StyleFan, Yibo, Feng Wang, and Haipeng Wang. 2022. "A Transformer-Based Coarse-to-Fine Wide-Swath SAR Image Registration Method under Weak Texture Conditions" Remote Sensing 14, no. 5: 1175. https://doi.org/10.3390/rs14051175
APA StyleFan, Y., Wang, F., & Wang, H. (2022). A Transformer-Based Coarse-to-Fine Wide-Swath SAR Image Registration Method under Weak Texture Conditions. Remote Sensing, 14(5), 1175. https://doi.org/10.3390/rs14051175