
TCD-Net: A Novel Deep Learning Framework for Fully Polarimetric Change Detection Using Transfer Learning




Abstract
:1. Introduction
1.1. Related Works
1.1.1. DL Supervised Methods for EO Data
1.1.2. DL Unsupervised Methods for EO Data
1.1.3. DL Semi-Supervised Methods for EO Data
1.2. Problem Statements and Contribution
- Developing a new unsupervised DL-based model with three channels for deep feature extraction and evaluating the effectiveness of an intermediate channel by comparing this algorithm with a dual-channel deep network;
- Introducing an adaptive formula for determining the number of filters in the multi-scale block due to the dependence of the deep features on the kernel size;
- Proposing high confidence automatic pseudo-label training sample generation framework using a probabilistic parallel scheme based on a pre-trained neural network model and FCM algorithm;
- Providing highly robust results for PolSAR CD compared with the state-of-the-art (SOTA) unsupervised methods.
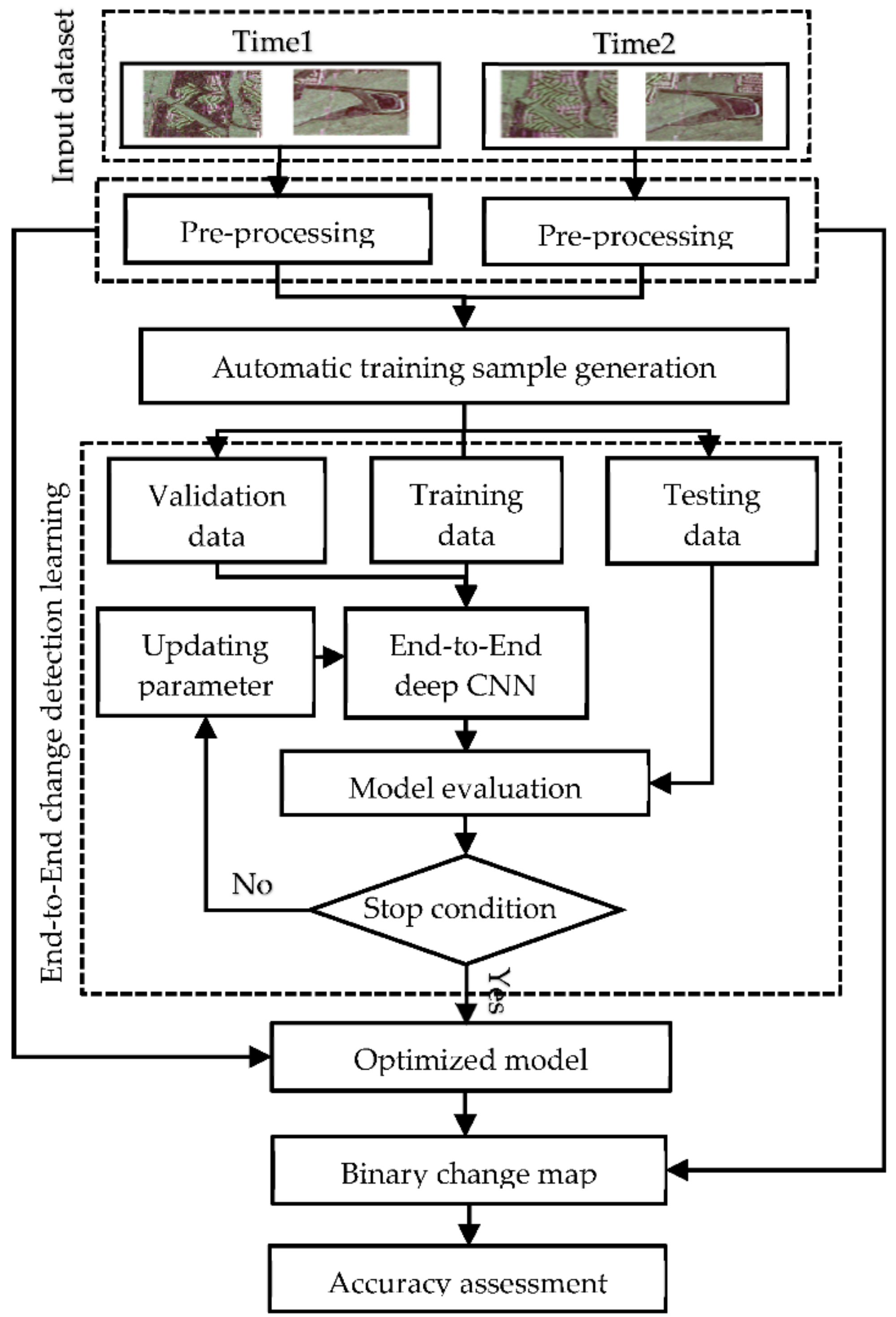
2. Methodology
2.1. Pre-Processing
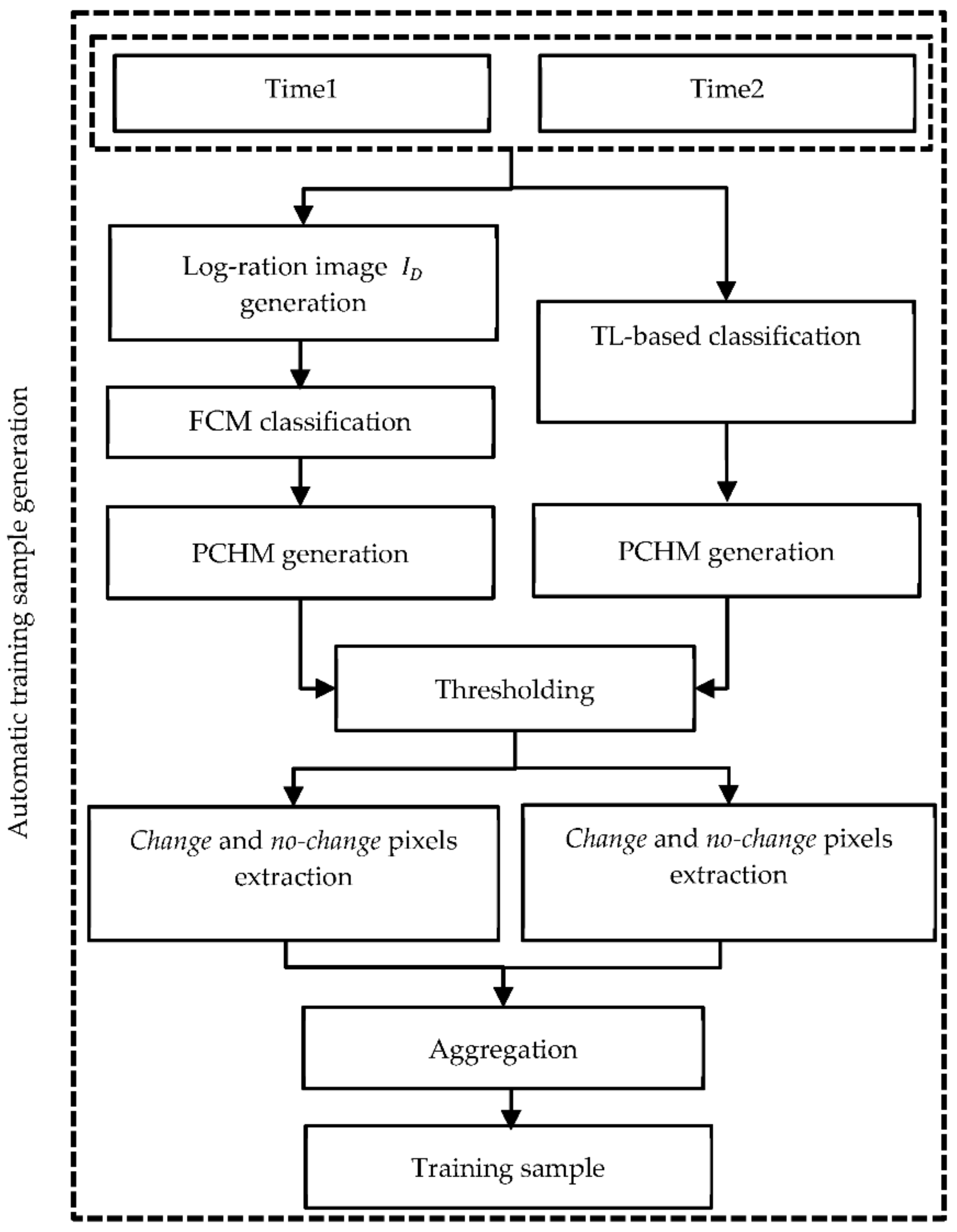
2.2. Automatic Training Sample Generation
- First, we use the CNN-based CD network in [2]. Since this network has previously been trained on UAVSAR data, we call it the pre-trained model. We then calculate the output of the pre-trained model for our datasets. The output of the last softmax layer of the pre-trained model gives a PCHM in two classes: change and no-change classes (i.e., and ). Then, by applying a knowledge-based threshold (0.95) on two classes, the pixels that most probably belong to the change () and no-change () classes are separated, i.e.,: . By selecting a higher threshold value, fewer training samples are generated, but they are more reliable. The remaining pixels are placed in the ambiguous class and are not used in this section.
- Second, we utilize the log-ratio operator to generate the log-ration image . Using the FCM algorithm, we obtain a PCHM in two classes: change and no-change classes (i.e., and ). Similar to the previous approach, by applying a threshold of 0.95, the pixels that most probably belong to the change () and no-change () classes are separated, similarly: ().
- Although we use PCHMs and reliable threshold values, because of the noisy conditions of the SAR images, there may still be pixels that are incorrectly classified. Therefore, to improve accuracy, we aggregate the results of the two methods mentioned in 1 and 2 in parallel, i.e., pixels that both methods labeled as change and no-change are selected using Equation (1).
2.3. End-to-End Change Detection Learning
2.3.1. Convolutional Layer
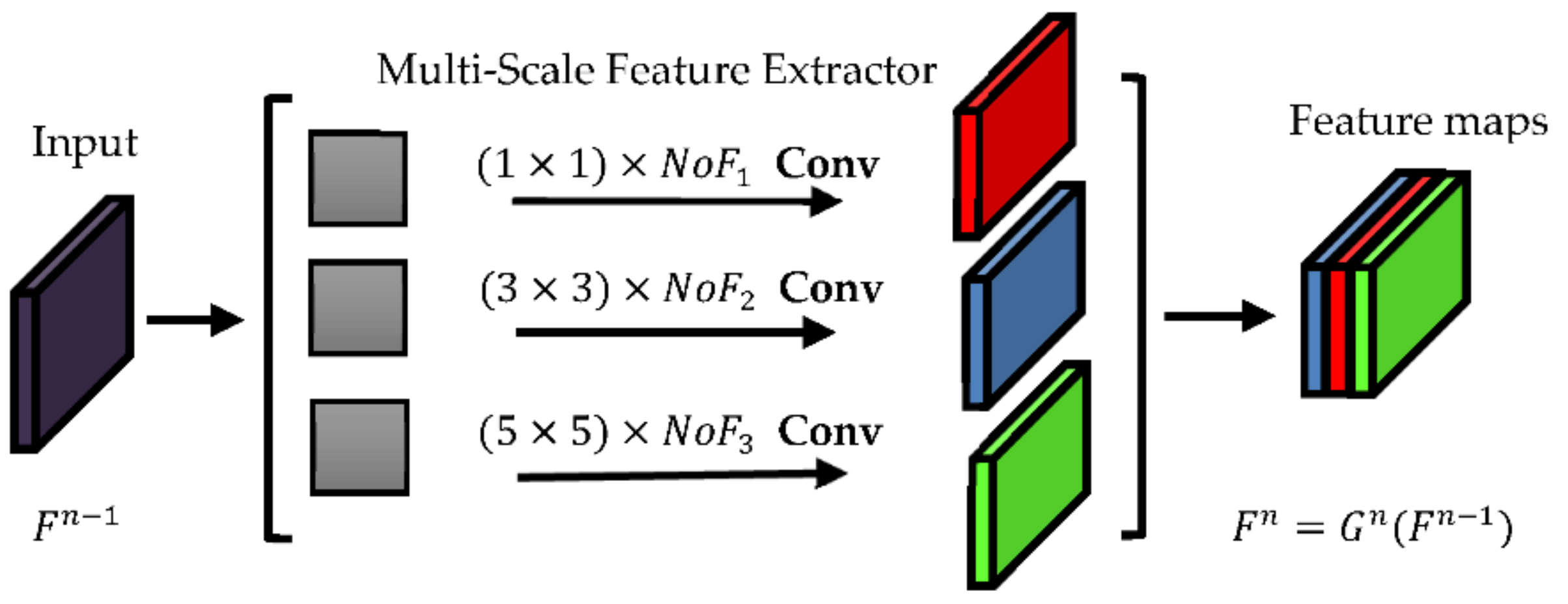
2.3.2. Multi-Scale Block
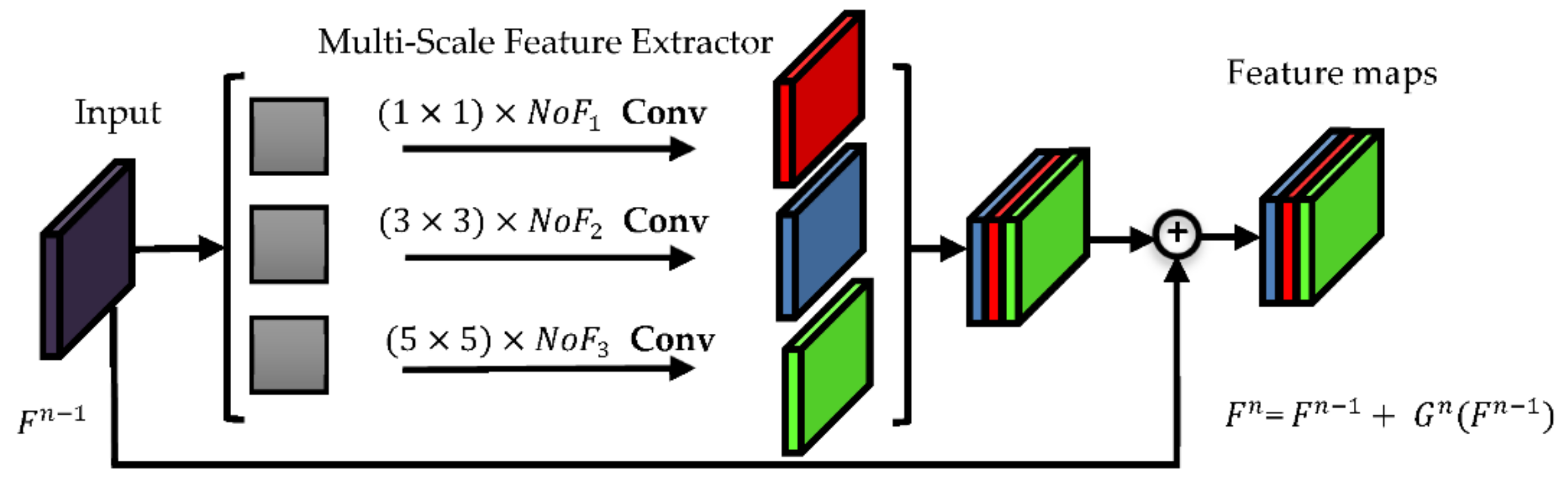
2.3.3. Residual Block
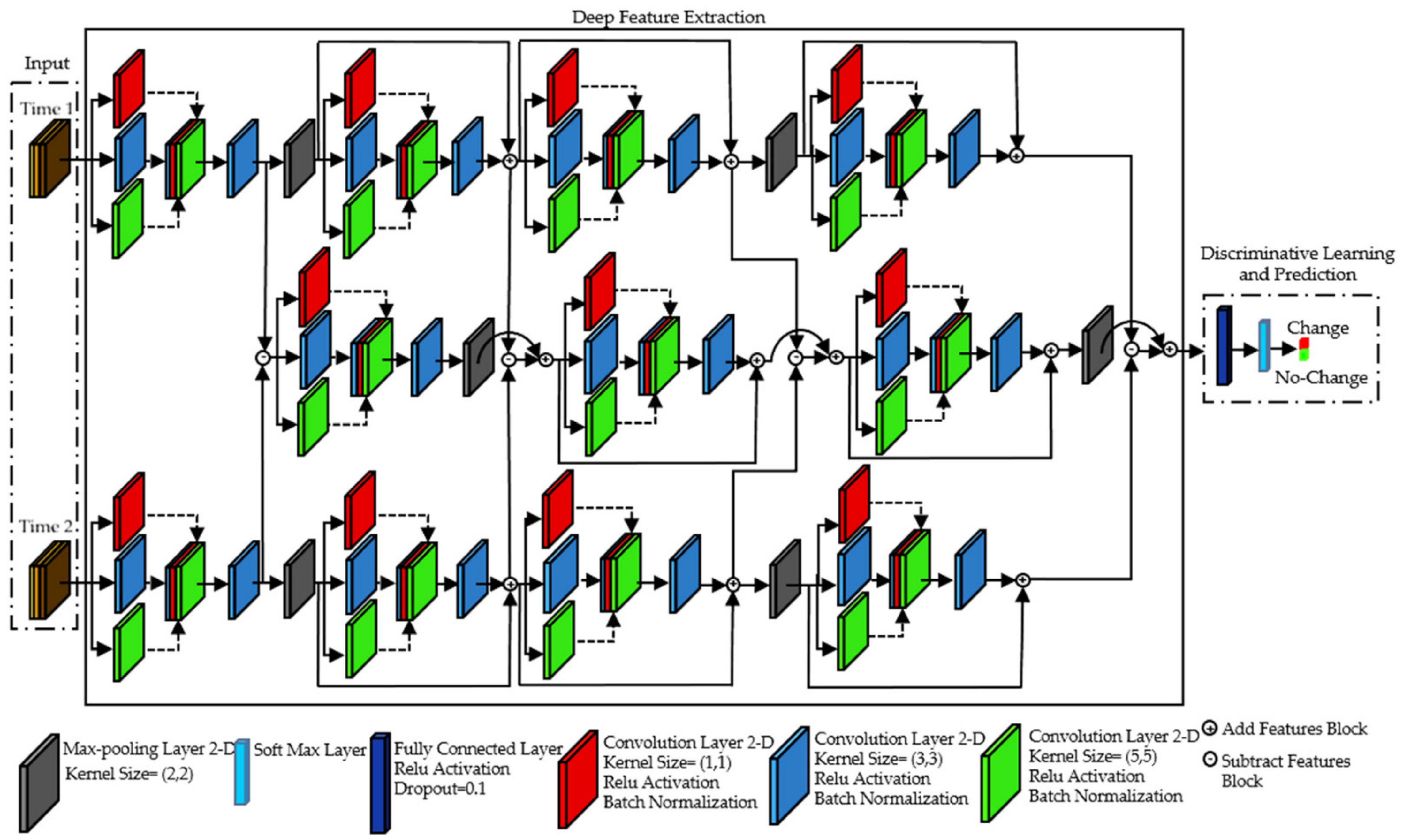
2.3.4. TCD-Net for CD
- Architecture
- Model Optimization
2.3.5. Accuracy Assessment
2.3.6. Comparative Methods
- PCA_kmeans: Initially, the DI is calculated by using the absolute-value difference between two SAR images. Additionally, the DI is separated into non-overlapping h h blocks. Then, using PCA, all blocks are projected into the eigenvector space to obtain representation properties. Finally, each pixel is assigned to a cluster based on the minimum Euclidean distance between its feature vector and the cluster’s mean feature vector, using the k-means clustering.
- NR_ELM: Initially, a neighborhood-based ratio operator and the hierarchical FCM algorithm are used for generating a DI and identifying pixels of interest in it. Secondly, the ELM classifier is trained using pixel-wise patch features centered on the pixels of interest.
- Gabor_PCANet: Initially, a pre-train step is performed using the Gabor wavelet and the FCM classifier. Secondly, by considering a neighborhood with specific dimensions for each training pixel in the two images and juxtaposing the two image patches, PCA features are extracted from the training patches. Then, the SVM algorithm is used to build a model on PCA features. After completing the training phase, the remaining pixels are divided into two categories: changed and no-changed pixels.
- CWNN: A convolutional-wavelet neural network (CWNN) method has been applied in bi-temporal SAR images. Firstly, a virtual sample generation scheme is utilized to generate pseudo-label training samples that are likely changed or no-changed. Secondly, the pseudo-label samples obtained in the previous step are used to train the CWNN network and create a change map.
- DP_PCANet: Firstly, inspired by the convolutional and pooling layers in the CNN, a DDI based on a weighted-pooling kernel has been extracted. Then, using sigmoid nonlinear mapping and parallel FCM, two mapped DDIs are generated. Then, the mapped DDIs are classified into three types of pseudo-label samples, i.e., changed, no-changed and ambiguous samples. Finally, with the SVM model that is trained based on the PCA features, ambiguous samples are classified as changed or no-changed.
3. Case Study
4. Experimental Results and Analysis
4.1. Parameter Setting
4.2. Pseudo-Label Training Sample Generation
4.3. Comparison of Results for Dataset#1
4.4. Comparison of Results for Dataset#2
5. Discussion
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhang, M.; Shi, W. A feature difference convolutional neural network-based change detection method. IEEE Trans. Geosci. Remote Sens. 2020, 58, 7232–7246. [Google Scholar] [CrossRef]
- Seydi, S.T.; Hasanlou, M.; Amani, M. A new end-to-end multi-dimensional CNN framework for land cover/land use change detection in multi-source remote sensing datasets. Remote Sens. 2020, 12, 2010. [Google Scholar] [CrossRef]
- Bouhlel, N.; Akbari, V.; Méric, S. Change Detection in Multilook Polarimetric SAR Imagery With Determinant Ratio Test Statistic. IEEE Trans. Geosci. Remote Sens. 2020, 60, 5200515. [Google Scholar] [CrossRef]
- Peng, D.; Bruzzone, L.; Zhang, Y.; Guan, H.; Ding, H.; Huang, X. SemiCDNet: A semisupervised convolutional neural network for change detection in high resolution remote-sensing images. IEEE Trans. Geosci. Remote Sens. 2020, 59, 5891–5906. [Google Scholar] [CrossRef]
- Sefrin, O.; Riese, F.M.; Keller, S. Deep Learning for Land Cover Change Detection. Remote Sens. 2021, 13, 78. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X. ShipDeNet-20: An only 20 convolution layers and <1-MB lightweight SAR ship detector. IEEE Geosci. Remote Sens. Lett. 2020, 18, 1234–1238. [Google Scholar]
- Zhang, T.; Zhang, X.; Ke, X.; Liu, C.; Xu, X.; Zhan, X.; Wang, C.; Ahmad, I.; Zhou, Y.; Pan, D. HOG-ShipCLSNet: A Novel Deep Learning Network with HOG Feature Fusion for SAR Ship Classification. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5210322. [Google Scholar] [CrossRef]
- Hasanlou, M.; Seydi, S.T. Use of multispectral and hyperspectral satellite imagery for monitoring waterbodies and wetlands. In Southern Iraq’s Marshes: Their Environment and Conservation; Jawad, L.A., Ed.; Springer: Cham, Switzerland, 2021; p. 155. [Google Scholar]
- Mohammadimanesh, F.; Salehi, B.; Mahdianpari, M.; Brisco, B.; Gill, E. Full and simulated compact polarimetry sar responses to canadian wetlands: Separability analysis and classification. Remote Sens. 2019, 11, 516. [Google Scholar] [CrossRef] [Green Version]
- Mahdianpari, M.; Jafarzadeh, H.; Granger, J.E.; Mohammadimanesh, F.; Brisco, B.; Salehi, B.; Homayouni, S.; Weng, Q. A large-scale change monitoring of wetlands using time series Landsat imagery on Google Earth Engine: A case study in Newfoundland. GIScience Remote Sens. 2020, 57, 1102–1124. [Google Scholar] [CrossRef]
- Cloude, S.R.; Pottier, E. An entropy based classification scheme for land applications of polarimetric SAR. IEEE Trans. Geosci. Remote Sens. 1997, 35, 68–78. [Google Scholar] [CrossRef]
- Migliaccio, M.; Gambardella, A.; Tranfaglia, M. SAR polarimetry to observe oil spills. IEEE Trans. Geosci. Remote Sens. 2007, 45, 506–511. [Google Scholar] [CrossRef]
- De Maio, A.; Orlando, D.; Pallotta, L.; Clemente, C. A multifamily GLRT for oil spill detection. IEEE Trans. Geosci. Remote Sens. 2016, 55, 63–79. [Google Scholar] [CrossRef]
- Seydi, S.T.; Hasanlou, M.; Chanussot, J. DSMNN-Net: A Deep Siamese Morphological Neural Network Model for Burned Area Mapping Using Multispectral Sentinel-2 and Hyperspectral PRISMA Images. Remote Sens. 2021, 13, 5138. [Google Scholar] [CrossRef]
- Hasanlou, M.; Shah-Hosseini, R.; Seydi, S.T.; Karimzadeh, S.; Matsuoka, M. Earthquake Damage Region Detection by Multitemporal Coherence Map Analysis of Radar and Multispectral Imagery. Remote Sens. 2021, 13, 1195. [Google Scholar] [CrossRef]
- Bai, Y.; Tang, P.; Hu, C. kCCA transformation-based radiometric normalization of multi-temporal satellite images. Remote Sens. 2018, 10, 432. [Google Scholar] [CrossRef] [Green Version]
- Cao, C.; Dragićević, S.; Li, S. Land-use change detection with convolutional neural network methods. Environments 2019, 6, 25. [Google Scholar] [CrossRef] [Green Version]
- Liu, F.; Jiao, L.; Tang, X.; Yang, S.; Ma, W.; Hou, B. Local restricted convolutional neural network for change detection in polarimetric SAR images. IEEE Trans. Neural Netw. Learn. Syst. 2018, 30, 818–833. [Google Scholar] [CrossRef] [PubMed]
- De Bem, P.P.; de Carvalho Junior, O.A.; Fontes Guimarães, R.; Trancoso Gomes, R.A. Change detection of deforestation in the Brazilian Amazon using landsat data and convolutional neural networks. Remote Sens. 2020, 12, 901. [Google Scholar] [CrossRef] [Green Version]
- Asokan, A.; Anitha, J. Change detection techniques for remote sensing applications: A survey. Earth Sci. Inform. 2019, 12, 143–160. [Google Scholar] [CrossRef]
- Lee, J.-S.; Pottier, E. Polarimetric Radar Imaging: From Basics to Applications; CRC Press: Boca Raton, FL, USA, 2017. [Google Scholar]
- Verma, R. Polarimetric Decomposition Based on General Characterisation of Scattering from Urban Areas and Multiple Component Scattering Model. Master’s Thesis, University of Twente, Enschede, The Netherlands, 2012. [Google Scholar]
- Lee, J.-S.; Pottier, E. Polarimetric Radar Imaging: From Basics to Applications, 2nd ed.; CRC Press: Boca Raton, FL, USA, 2009. [Google Scholar]
- Bruzzone, L.; Prieto, D.F. An adaptive semiparametric and context-based approach to unsupervised change detection in multitemporal remote-sensing images. IEEE Trans. Image Processing 2002, 11, 452–466. [Google Scholar] [CrossRef]
- Gong, M.; Su, L.; Jia, M.; Chen, W. Fuzzy clustering with a modified MRF energy function for change detection in synthetic aperture radar images. IEEE Trans. Fuzzy Syst. 2013, 22, 98–109. [Google Scholar] [CrossRef]
- Inglada, J.; Giros, A. On the possibility of automatic multisensor image registration. IEEE Trans. Geosci. Remote Sens. 2004, 42, 2104–2120. [Google Scholar] [CrossRef]
- Dekker, R. Speckle filtering in satellite SAR change detection imagery. Int. J. Remote Sens. 1998, 19, 1133–1146. [Google Scholar] [CrossRef]
- Li, Y.; Peng, C.; Chen, Y.; Jiao, L.; Zhou, L.; Shang, R. A deep learning method for change detection in synthetic aperture radar images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 5751–5763. [Google Scholar] [CrossRef]
- Inglada, J.; Mercier, G. A new statistical similarity measure for change detection in multitemporal SAR images and its extension to multiscale change analysis. IEEE Trans. Geosci. Remote Sens. 2007, 45, 1432–1445. [Google Scholar] [CrossRef] [Green Version]
- Deng, J.; Wang, K.; Deng, Y.; Qi, G. PCA-based land-use change detection and analysis using multitemporal and multisensor satellite data. Int. J. Remote Sens. 2008, 29, 4823–4838. [Google Scholar] [CrossRef]
- Seydi, S.T.; Shahhoseini, R. Transformation Based Algorithms for Change Detection in Full Polarimetric remote SENSING Images. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2019, 42, 963–967. [Google Scholar] [CrossRef] [Green Version]
- Hasanlou, M.; Seydi, S.T. Hyperspectral change detection: An experimental comparative study. Int. J. Remote Sens. 2018, 39, 7029–7083. [Google Scholar] [CrossRef]
- Kittler, J.; Illingworth, J. Minimum error thresholding. Pattern Recognit. 1986, 19, 41–47. [Google Scholar] [CrossRef]
- Dempster, A.P.; Laird, N.M.; Rubin, D.B. Maximum likelihood from incomplete data via the EM algorithm. J. R. Stat. Soc. Ser. B (Methodol.) 1977, 39, 1–22. [Google Scholar]
- Moser, G.; Serpico, S.B. Generalized minimum-error thresholding for unsupervised change detection from SAR amplitude imagery. IEEE Trans. Geosci. Remote Sens. 2006, 44, 2972–2982. [Google Scholar] [CrossRef]
- Hu, H.; Ban, Y. Unsupervised change detection in multitemporal SAR images over large urban areas. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 3248–3261. [Google Scholar] [CrossRef]
- Su, L.; Gong, M.; Sun, B.; Jiao, L. Unsupervised change detection in SAR images based on locally fitting model and semi-EM algorithm. Int. J. Remote Sens. 2014, 35, 621–650. [Google Scholar] [CrossRef]
- Zheng, Y.; Zhang, X.; Hou, B.; Liu, G. Using combined difference image and $ k $-means clustering for SAR image change detection. IEEE Geosci. Remote Sens. Lett. 2013, 11, 691–695. [Google Scholar] [CrossRef]
- Jia, L.; Li, M.; Zhang, P.; Wu, Y.; Zhu, H. SAR image change detection based on multiple kernel K-means clustering with local-neighborhood information. IEEE Geosci. Remote Sens. Lett. 2016, 13, 856–860. [Google Scholar] [CrossRef]
- Li, H.-C.; Celik, T.; Longbotham, N.; Emery, W.J. Gabor feature based unsupervised change detection of multitemporal SAR images based on two-level clustering. IEEE Geosci. Remote Sens. Lett. 2015, 12, 2458–2462. [Google Scholar]
- Krinidis, S.; Chatzis, V. A robust fuzzy local information C-means clustering algorithm. IEEE Trans. Image Processing 2010, 19, 1328–1337. [Google Scholar] [CrossRef] [PubMed]
- Gong, M.; Zhou, Z.; Ma, J. Change detection in synthetic aperture radar images based on image fusion and fuzzy clustering. IEEE Trans. Image Processing 2011, 21, 2141–2151. [Google Scholar] [CrossRef] [PubMed]
- Liu, G.; Li, L.; Jiao, L.; Dong, Y.; Li, X. Stacked Fisher autoencoder for SAR change detection. Pattern Recognit. 2019, 96, 106971. [Google Scholar] [CrossRef]
- Samadi, F.; Akbarizadeh, G.; Kaabi, H. Change detection in SAR images using deep belief network: A new training approach based on morphological images. IET Image Processing 2019, 13, 2255–2264. [Google Scholar] [CrossRef]
- Saha, S.; Bovolo, F.; Bruzzone, L. Change detection in image time-series using unsupervised lstm. IEEE Geosci. Remote Sens. Lett. 2020, 19, 8005205. [Google Scholar] [CrossRef]
- Petrou, M.; Sturm, P. Pulse Coupled Neural Networks for Automatic Urban Change Detection at Very High Spatial Resolution. In Iberoamerican Congress on Pattern Recognition; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Hou, B.; Liu, Q.; Wang, H.; Wang, Y. From W-Net to CDGAN: Bitemporal change detection via deep learning techniques. IEEE Trans. Geosci. Remote Sens. 2019, 58, 1790–1802. [Google Scholar] [CrossRef] [Green Version]
- Mou, L.; Bruzzone, L.; Zhu, X.X. Learning spectral-spatial-temporal features via a recurrent convolutional neural network for change detection in multispectral imagery. IEEE Trans. Geosci. Remote Sens. 2018, 57, 924–935. [Google Scholar] [CrossRef] [Green Version]
- Jaturapitpornchai, R.; Matsuoka, M.; Kanemoto, N.; Kuzuoka, S.; Ito, R.; Nakamura, R. Newly built construction detection in SAR images using deep learning. Remote Sens. 2019, 11, 1444. [Google Scholar] [CrossRef] [Green Version]
- Sun, S.; Mu, L.; Wang, L.; Liu, P. L-UNet: An LSTM Network for Remote Sensing Image Change Detection. IEEE Geosci. Remote Sens. Lett. 2020, 19, 8004505. [Google Scholar] [CrossRef]
- Cao, X.; Ji, Y.; Wang, L.; Ji, B.; Jiao, L.; Han, J. SAR image change detection based on deep denoising and CNN. IET Image Processing 2019, 13, 1509–1515. [Google Scholar] [CrossRef]
- Wang, J.; Gao, F.; Dong, J. Change detection from SAR images based on deformable residual convolutional neural networks. In Proceedings of the 2nd ACM International Conference on Multimedia in Asia, Online, 7 March 2021; pp. 1–7. [Google Scholar]
- Kiana, E.; Homayouni, S.; Sharifi, M.; Farid-Rohani, M. Unsupervised Change Detection in SAR images using Gaussian Mixture Models. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2015, 40, 407. [Google Scholar] [CrossRef] [Green Version]
- Liu, J.; Gong, M.; Qin, K.; Zhang, P. A deep convolutional coupling network for change detection based on heterogeneous optical and radar images. IEEE Trans. Neural Netw. Learn. Syst. 2016, 29, 545–559. [Google Scholar] [CrossRef] [PubMed]
- Bergamasco, L.; Saha, S.; Bovolo, F.; Bruzzone, L. Unsupervised change-detection based on convolutional-autoencoder feature extraction. In Proceedings of the Image and Signal Processing for Remote Sensing XXV, Strasbourg, France, 9–11 September 2019; p. 1115510. [Google Scholar]
- Huang, F.; Yu, Y.; Feng, T. Automatic building change image quality assessment in high resolution remote sensing based on deep learning. J. Vis. Commun. Image Represent. 2019, 63, 102585. [Google Scholar] [CrossRef]
- Gao, F.; Wang, X.; Gao, Y.; Dong, J.; Wang, S. Sea ice change detection in SAR images based on convolutional-wavelet neural networks. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1240–1244. [Google Scholar] [CrossRef]
- Zhang, X.; Su, H.; Zhang, C.; Atkinson, P.M.; Tan, X.; Zeng, X.; Jian, X. A Robust Imbalanced SAR Image Change Detection Approach Based on Deep Difference Image and PCANet. arXiv 2020, arXiv:2003.01768. [Google Scholar]
- Liu, J.; Chen, K.; Xu, G.; Sun, X.; Yan, M.; Diao, W.; Han, H. Convolutional neural network-based transfer learning for optical aerial images change detection. IEEE Geosci. Remote Sens. Lett. 2019, 17, 127–131. [Google Scholar] [CrossRef]
- Khelifi, L.; Mignotte, M. Deep learning for change detection in remote sensing images: Comprehensive review and meta-analysis. IEEE Access 2020, 8, 126385–126400. [Google Scholar] [CrossRef]
- Kutlu, H.; Avcı, E. A novel method for classifying liver and brain tumors using convolutional neural networks, discrete wavelet transform and long short-term memory networks. Sensors 2019, 19, 1992. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Venugopal, N. Sample selection based change detection with dilated network learning in remote sensing images. Sens. Imaging 2019, 20, 31. [Google Scholar] [CrossRef]
- Yommy, A.S.; Liu, R.; Wu, S. SAR image despeckling using refined Lee filter. In Proceedings of the 2015 7th International Conference on Intelligent Human-Machine Systems and Cybernetics, Hangzhou, China, 26–27 August 2015; pp. 260–265. [Google Scholar]
- Yuan, Q.; Wei, Y.; Meng, X.; Shen, H.; Zhang, L. A multiscale and multidepth convolutional neural network for remote sensing imagery pan-sharpening. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 978–989. [Google Scholar] [CrossRef] [Green Version]
- Celik, T. Unsupervised change detection in satellite images using principal component analysis and $ k $-means clustering. IEEE Geosci. Remote Sens. Lett. 2009, 6, 772–776. [Google Scholar] [CrossRef]
- Gao, F.; Dong, J.; Li, B.; Xu, Q.; Xie, C. Change detection from synthetic aperture radar images based on neighborhood-based ratio and extreme learning machine. J. Appl. Remote Sens. 2016, 10, 046019. [Google Scholar] [CrossRef]
- Gao, F.; Dong, J.; Li, B.; Xu, Q. Automatic change detection in synthetic aperture radar images based on PCANet. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1792–1796. [Google Scholar] [CrossRef]
- Ratha, D.; De, S.; Celik, T.; Bhattacharya, A. Change detection in polarimetric SAR images using a geodesic distance between scattering mechanisms. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1066–1070. [Google Scholar] [CrossRef]
- Nascimento, A.D.; Frery, A.C.; Cintra, R.J. Detecting changes in fully polarimetric SAR imagery with statistical information theory. IEEE Trans. Geosci. Remote Sens. 2018, 57, 1380–1392. [Google Scholar] [CrossRef] [Green Version]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Accuracy Index | Formula |
|---|---|
| FNR | |
| TPR | |
| FPR | |
| OA | |
| Precision | |
| F1-Score | |
| OER | |
| PRE | |
| KC |
| Channel 1 | Channel 2 | Channel 3 | |
|---|---|---|---|
| Inputs (shape) | |||
| Block 1 | Multi-Scale Shallow Block: ) 1 )) Channel Concat. 3 × 3 Conv4 + BN + RELU(256) | Multi-Scale Shallow Block: ) ) ) Channel Concat. 3 × 3 Conv4 + BN + RELU (256) | Multi-Scale Shallow Block: ) ) ) Channel Concat. 3 × 3 Conv4 + BN + RELU(256) |
| 2 × 2 Max-Pooling | 2 × 2 Max-Pooling | 2 × 2 Max-Pooling | |
| Output | 256 | 256 | 256 |
| Block 2 | Multi-Scale Residual Block: ) ) ) Channel Concat. 3 × 3 Conv4 + BN + RELU(256) | Multi-Scale Residual Block: ) ) ) Channel Concat. 3 × 3 Conv4 + BN + RELU(256) | Multi-Scale Residual Block: ) ) ) Channel Concat. 3 × 3 Conv4 + BN + RELU(256) |
| Output | |||
| Block 3 | Multi-Scale Residual Block: ) ) ) Channel Concat. 3 × 3 Conv4 + BN + RELU(256) | Multi-Scale Residual Block: ) ) ) Channel Concat. 3 × 3 Conv4 + BN + RELU(256) | Multi-Scale Residual Block: ) ) ) Channel Concat. 3 × 3 Conv4 + BN + RELU(256) |
| 2 × 2 Max-Pooling | 2 × 2 Max-Pooling | 2 × 2 Max-Pooling | |
| Output | 256 | 256 | 256 |
| Block 4 | Multi-Scale Residual Block:))) Channel Concat. 3 × 3 Conv4 + BN + RELU(256) | Multi-Scale Residual Block:) )) Channel Concat. 3 × 3 Conv4 + BN + RELU(256) | |
| Output | |||
| Flatten | |||
| Classifier | RELU Fully Connected (350) | ||
| Softmax Fully Connected (2) |
| Block | Channel | ||
|---|---|---|---|
| 1 | 2 | 3 | |
| 1 | |||
| 2 | |||
| 3 | |||
| 4 | |||
| Method | Result | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| TN | TP | FP | FN | TPR (%) | FPR (%) | FNR (%) | Precision | OA(%) | F1-Score | DR(%) | KC | OER (%) | |
| [2] dataset#1 | 187,570 | 27,606 | 11,581 | 9043 | 75.33 | 5.82 | 24.67 | 70.45 | 91.25 | 72.86 | 74.02 | 0.68 | 8.76 |
| [2] dataset#2 | 202,423 | 10,710 | 4188 | 12,479 | 46.19 | 2.03 | 53.81 | 71.89 | 92.75 | 56.24 | 29.22 | 0.52 | 7.25 |
| Dataset | Value | ||||||
|---|---|---|---|---|---|---|---|
| Class | Total Number of Pixels | Number of Samples | Percentage (%) | Training | Validation | Testing | |
| dataset#1 | change no-change | 36,649 199,151 | 12,717 165,308 | 34.70 83.01 | 1191 6472 | 357 1493 | 366 1991 |
| dataset#2 | change no-change | 23,189 206,611 | 11,156 81,650 | 48.11 39.52 | 753 6714 | 173 1549 | 231 2066 |
| Method | Result | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| TN | TP | FP | FN | TPR (%) | FPR (%) | FNR (%) | Precision | OA (%) | F1-Score | DR (%) | KC | OER (%) | |
| PCA_kmeans | 196,839 | 12,223 | 2312 | 24,426 | 33.35 | 1.16 | 66.65 | 84.09 | 88.66 | 47.76 | 33.35 | 0.43 | 11.34 |
| NR_ELM | 195,411 | 22,066 | 3740 | 14,583 | 60.21 | 1.88 | 39.79 | 85.51 | 92.26 | 70.66 | 60.21 | 0.66 | 7.74 |
| Gabor_PCANet | 192,837 | 23,449 | 6314 | 13,200 | 63.98 | 3.17 | 36.02 | 78.79 | 91.72 | 70.62 | 63.98 | 0.65 | 8.28 |
| DP_PCANet | 192,994 | 25,298 | 6157 | 11,351 | 69.03 | 3.09 | 30.97 | 80.43 | 92.58 | 74.29 | 69.03 | 0.69 | 7.42 |
| CWNN | 193,141 | 25,603 | 6010 | 11,046 | 69.86 | 3.02 | 30.14 | 80.99 | 92.77 | 75.01 | 69.86 | 0.70 | 7.23 |
| Dual-channel Net | 195,818 | 26,424 | 3333 | 10,225 | 72.10 | 1.67 | 27.90 | 88.80 | 94.25 | 79.58 | 72.10 | 0.76 | 5.75 |
| TCD-Net | 196,646 | 27,390 | 2505 | 9259 | 74.74 | 1.26 | 25.26 | 91.62 | 95.01 | 82.32 | 74.74 | 0.80 | 4.99 |
| Method | Result | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| TN | TP | FP | FN | TPR (%) | FPR (%) | FNR (%) | Precision | OA (%) | F1-Score | DR (%) | KC | OER (%) | |
| PCA_kmeans | 205,826 | 5653 | 785 | 17,536 | 24.38 | 0.38 | 75.62 | 87.81 | 92.03 | 57.16 | 24.38 | 0.35 | 7.97 |
| NR_ELM | 200,774 | 15,525 | 837 | 7664 | 66.95 | 2.83 | 33.05 | 72.68 | 94.12 | 83.85 | 66.95 | 0.66 | 3.70 |
| Gabor_PCANet | 202,050 | 14,884 | 4511 | 8355 | 64.05 | 2.18 | 35.95 | 76.74 | 94.40 | 78.47 | 64.19 | 0.67 | 5.60 |
| DP_PCANet | 202,383 | 15,019 | 4228 | 8170 | 64.77 | 2.05 | 35.23 | 78.03 | 94.60 | 80.32 | 64.77 | 0.68 | 5.40 |
| CWNN | 204,199 | 13,060 | 2412 | 10,129 | 56.32 | 1.17 | 43.68 | 84.41 | 94.54 | 80.33 | 56.32 | 0.65 | 5.46 |
| Dual-channel Net | 203,880 | 15,460 | 2731 | 7729 | 66.67 | 1.32 | 33.33 | 84.99 | 95.45 | 74.72 | 66.67 | 0.72 | 4.55 |
| TCD-Net | 203,284 | 18,949 | 3327 | 4240 | 81.72 | 1.61 | 18.28 | 85.06 | 96.71 | 87.86 | 81.72 | 0.82 | 3.29 |
| Dataset | Indices | Result | |||
|---|---|---|---|---|---|
| Ratha, De, Celik and Bhattacharya [68] | Bouhlel, Akbari and Méric [3] | Nascimento, Frery and Cintra [69] | TCD-Net | ||
| dataset#1 | KC FPR (%) DR (%) | 0.73 6.9 N/A | N/A 10.58 63.38 | 0.62 4.14 42.98 | 0.80 1.26 74.74 |
| dataset#2 | KC FPR (%) DR (%) | 0.75 3.9 N/A | N/A 8.39 51.49 | 0.56 2.17 62.52 | 0.82 1.61 81.72 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Habibollahi, R.; Seydi, S.T.; Hasanlou, M.; Mahdianpari, M. TCD-Net: A Novel Deep Learning Framework for Fully Polarimetric Change Detection Using Transfer Learning. Remote Sens. 2022, 14, 438. https://doi.org/10.3390/rs14030438
Habibollahi R, Seydi ST, Hasanlou M, Mahdianpari M. TCD-Net: A Novel Deep Learning Framework for Fully Polarimetric Change Detection Using Transfer Learning. Remote Sensing. 2022; 14(3):438. https://doi.org/10.3390/rs14030438
Chicago/Turabian StyleHabibollahi, Rezvan, Seyd Teymoor Seydi, Mahdi Hasanlou, and Masoud Mahdianpari. 2022. "TCD-Net: A Novel Deep Learning Framework for Fully Polarimetric Change Detection Using Transfer Learning" Remote Sensing 14, no. 3: 438. https://doi.org/10.3390/rs14030438
APA StyleHabibollahi, R., Seydi, S. T., Hasanlou, M., & Mahdianpari, M. (2022). TCD-Net: A Novel Deep Learning Framework for Fully Polarimetric Change Detection Using Transfer Learning. Remote Sensing, 14(3), 438. https://doi.org/10.3390/rs14030438