
An Automatic Procedure for Forest Fire Fuel Mapping Using Hyperspectral (PRISMA) Imagery: A Semi-Supervised Classification Approach


Abstract
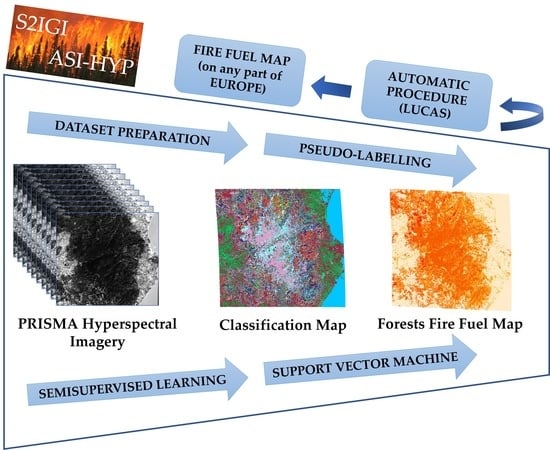
:
1. Introduction
2. Data and Methods
2.1. Study Area
2.2. PRISMA Data
2.3. Reference Data
2.4. Methods Implemented
2.4.1. Guided Image Filtering
2.4.2. Jeffries–Matusita Spectral Angle Mapper
2.4.3. K-Means Clustering
2.4.4. Support Vector Machine for HSI Classification
2.4.5. Linear Mixing Model
2.4.6. JRC—Anderson Fuel Models Correlation
3. Proposed Framework
3.1. Preprocessing
3.2. Pixel Extraction
3.3. Dataset Preparation
3.4. Classification Algorithm Details
3.5. Further Classification
3.6. Linear Unmixing
3.7. Fuel Mapping
4. Results and Discussion
4.1. Classification and Fuel Map
4.2. Validation
4.3. Stability Analysis
4.4. Repeatability and Reproducibility Analysis
4.5. Extension of Procedure for Europe-Wide Fuel Mapping with LUCAS Database
4.6. Possible Applications of the Fuel Map
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Bond, W.J.; Keeley, J.E. Fire as a global ‘herbivore’: The ecology and evolution of flammable ecosystems. Trends Ecol. Evol. 2005, 20, 387–394. [Google Scholar] [CrossRef] [PubMed]
- Informazioni su Questo Libro. Available online: http://books.google.com (accessed on 15 September 2021).
- Vakalis, D.; Sarimveis, H.; Kiranoudis, C.; Alexandridis, A.; Bafas, G. A GIS based operational system for wildland fire crisis management I. Mathematical modelling and simulation. Appl. Math. Model. 2004, 28, 389–410. [Google Scholar] [CrossRef]
- Vakalis, D.; Sarimveis, H.; Kiranoudis, C.; Alexandridis, A.; Bafas, G. A GIS based operational system for wildland fire crisis management II. System architecture and case studies. Appl. Math. Model. 2004, 28, 411–425. [Google Scholar] [CrossRef]
- Keramitsoglou, I.; Kiranoudis, C.T.; Sarimvels, H.; Sifakis, N. A Multidisciplinary Decision Support System for Forest Fire Crisis Management. Environ. Manag. 2004, 33, 212–225. [Google Scholar] [CrossRef] [PubMed]
- Whelan, R.J. The Ecology of Fire-Developments since 1995 and Outstanding Questions Long-Term Trends in Flowering and Fruit Set in Banksia View Project Pollination of Diuris (Orchidaceae) View Project. 2009. Available online: https://www.researchgate.net/publication/30387859 (accessed on 15 September 2021).
- Barmpoutis, P.; Papaioannou, P.; Dimitropoulos, K.; Grammalidis, N. A Review on Early Forest Fire Detection Systems Using Optical Remote Sensing. Sensors 2020, 20, 6442. [Google Scholar] [CrossRef] [PubMed]
- Goodenough, D.; Dyk, A.; Niemann, K.; Pearlman, J.; Chen, H.; Han, T.; Murdoch, M.; West, C. Processing hyperion and ali for forest classification. IEEE Trans. Geosci. Remote Sens. 2003, 41, 1321–1331. [Google Scholar] [CrossRef]
- Yeosang, Y.; Yongseung, K. Application of Hyperion Hyperspectral Remote Sensing Data for Wildfire Fuel Map-ping. Korean J. Remote Sens. 2007, 23, 21–32. Available online: https://www.koreascience.or.kr/article/JAKO200712242534560.pdf (accessed on 28 November 2021).
- Smith, C.; Panda, S.; Bhatt, U.; Meyer, F. Improved Boreal Forest Wildfire Fuel Type Mapping in Interior Alaska Using AVIRIS-NG Hyperspectral Data. Remote Sens. 2021, 13, 897. [Google Scholar] [CrossRef]
- Badola, A.; Panda, S.; Roberts, D.; Waigl, C.; Bhatt, U.; Smith, C.; Jandt, R. Hyperspectral Data Simulation (Sentinel-2 to AVIRIS-NG) for Improved Wildfire Fuel Mapping, Boreal Alaska. Remote Sens. 2021, 13, 1693. [Google Scholar] [CrossRef]
- Veraverbeke, S.; Dennison, P.; Gitas, I.; Hulley, G.; Kalashnikova, O.; Katagis, T.; Kuai, L.; Meng, R.; Roberts, D.; Stavros, N. Hyperspectral remote sensing of fire: State-of-the-art and future perspectives. Remote Sens. Environ. 2018, 216, 105–121. [Google Scholar] [CrossRef]
- Niroumand-Jadidi, M.; Bovolo, F.; Bruzzone, L. Water Quality Retrieval from PRISMA Hyperspectral Images: First Experience in a Turbid Lake and Comparison with Sentinel-2. Remote Sens. 2020, 12, 3984. [Google Scholar] [CrossRef]
- Gewali, U.B.; Monteiro, S.T.; Saber, E. Machine Learning Based Hyperspectral Image Analysis: A Survey. February 2018. Available online: http://arxiv.org/abs/1802.08701 (accessed on 15 September 2021).
- Talukdar, S.; Singha, P.; Mahato, S.; Shahfahad; Pal, S.; Liou, Y.-A.; Rahman, A. Land-Use Land-Cover Classification by Machine Learning Classifiers for Satellite Observations—A Review. Remote Sens. 2020, 12, 1135. [Google Scholar] [CrossRef] [Green Version]
- Schmitt, M.; Ahmadi, S.A.; Hansch, R. There is No Data Like More Data–Current Status of Machine Learning Datasets in Remote Sensing. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021; pp. 1206–1209. [Google Scholar]
- Sarvia, F.; De Petris, S.; Borgogno-Mondino, E. Mapping Ecological Focus Areas within the EU CAP Controls Framework by Copernicus Sentinel-2 Data. Agronomy 2022, 12, 406. [Google Scholar] [CrossRef]
- Foody, G.M.; Pal, M.; Rocchini, D.; Garzon-Lopez, C.X.; Bastin, L. The Sensitivity of Mapping Methods to Reference Data Quality: Training Supervised Image Classifications with Imperfect Reference Data. ISPRS Int. J. Geo-Inf. 2016, 5, 199. [Google Scholar] [CrossRef] [Green Version]
- Cervantes, J.; Garcia-Lamont, F.; Rodríguez-Mazahua, L.; Lopez, A. A comprehensive survey on support vector machine classification: Applications, challenges and trends. Neurocomputing 2020, 408, 189–215. [Google Scholar] [CrossRef]
- Archibald, R.; Fann, G. Feature Selection and Classification of Hyperspectral Images with Support Vector Machines. IEEE Geosci. Remote Sens. Lett. 2007, 4, 674–677. [Google Scholar] [CrossRef]
- Advance EFFIS Report on Forest Fires in Europe, Middle East and North Africa 2018; Publications Office of the European Union: Luxembourg, 2019. [CrossRef]
- Toukiloglou, P.; Eftychidis, G.; Gitas, I.; Tompoulidou, M. ArcFuel methodology for mapping forest fuels in Europe. In Proceedings of the First International Conference on Remote Sensing and Geoinformation of Environment, Paphos, Cyprus, 8–10 April 2013; Volume 8795. [Google Scholar] [CrossRef]
- European Commission, Joint Research Centre; San-Miguel-Ayanz, J.; Durrant, T.; Boca, R. Forest Fires in Europe, Middle East and North Africa 2020. 2021. Available online: https://data.europa.eu/doi/10.2760/059331 (accessed on 15 September 2021).
- Mossa, L.; Bacchetta, G.; Angiolino, C.; Ballero, M. A contribution to the floristic knowledge of the Monti del Sulcis: Monte Arcosu (S.W. Sardinia). Flora Mediterr. 2016, 6, 157–190. [Google Scholar]
- European Commission, Joint Research Centre. European Atlas of Forest Tree Species; San-Miguel-Ayanz, J., Caudullo, G., De Rigo, D., Mauri, A., Houston Durrant, T., Eds.; European Comission: Brussels, Belgium, 2022; Available online: https://data.europa.eu/doi/10.2760/233115 (accessed on 15 September 2021).
- Duveau, S. Frozen data? Polar research and fieldwork in a pandemic era. Polar Record 2021, 57, E34. [Google Scholar] [CrossRef]
- Jawak, S.D.; Andersen, B.N.; Pohjola, V.A.; Godøy; Hübner, C.; Jennings, I.; Ignatiuk, D.; Holmén, K.; Sivertsen, A.; Hann, R.; et al. SIOS’s Earth Observation (EO), Remote Sensing (RS), and Operational Activities in Response to COVID-19. Remote. Sens. 2021, 13, 712. [Google Scholar] [CrossRef]
- U.S. Global Development Lab. Guide for Adopting Remote Monitoring Approaches during COVID-19. Available online: https://www.usaid.gov/digital-development/covid19-remote-monitoring-guide (accessed on 15 September 2021).
- Santarsiero, V. A Remote Sensing Methodology to Assess the Abandoned Arable Land Using NDVI Index in Basili-cata Region. In Proceedings of the Computational Science and Its Applications–ICCSA 2021, Cagliari, Italy, 13–16 September 2021; pp. 695–703. [Google Scholar]
- Tucci, B.; Nolè, G.; Lanorte, A.; Santarsiero, V.; Cillis, G.; Scorza, F.; Murgante, B. Assessment and Monitoring of Soil Erosion Risk and Land Degradation in Arable Land Combining Remote Sensing Methodologies and RUSLE Factors. In Information for a Better World: Shaping the Global Future; Springer Science and Business Media LLC: Berlin/Heidelberg, Germany, 2021; pp. 704–716. [Google Scholar]
- EEA. Copernicus Land Monitoring Service 2020. Available online: https://land.copernicus.eu/ (accessed on 15 May 2020).
- Büttner, G. CORINE Land Cover and Land Cover Change Products. In Land Use and Land Cover Mapping in Europe; Manakos, I., Braun, M., Eds.; Springer Science and Business Media LLC: Dordrecht, Switzerland, 2014; Volume 18, pp. 55–74. [Google Scholar]
- He, K.; Sun, J.; Tang, X. Guided Image Filtering. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1397–1409. [Google Scholar] [CrossRef]
- He, K.; Sun, J.; Tang, X. Guided Image Filtering (Presentation). In Proceedings of the 2012 European Conference on Computer Vision, Florence, Italy, 7–13 October 2021; pp. 1–14. [Google Scholar]
- Huang, S.; Lu, Y.; Wang, W.; Sun, K. Multi-scale guided feature extraction and classification algorithm for hyperspectral images. Sci. Rep. 2021, 11, 18396. [Google Scholar] [CrossRef]
- He, K.; Sun, J.; Tang, X. Guided Image Filtering. In Proceedings of the 11th European Conference on Computer Vision, Crete, Greece, 5–11 September 2010. [Google Scholar]
- Vishnu, S.; Nidamanuri, R.R.; Bremananth, R. Spectral material mapping using hyperspectral imagery: A review of spectral matching and library search methods. Geocarto Int. 2013, 28, 171–190. [Google Scholar] [CrossRef]
- Chang, C.-C.; Du, Y.; Ren, H.; Jensen, J.O.; D’Amico, F.M. New hyperspectral discrimination measure for spectral characterization. Opt. Eng. 2004, 43, 1777–1786. [Google Scholar] [CrossRef] [Green Version]
- Laliberte, A.; Browning, D.; Rango, A. A comparison of three feature selection methods for object-based classification of sub-decimeter resolution UltraCam-L imagery. Int. J. Appl. Earth Obs. Geoinf. 2012, 15, 70–78. [Google Scholar] [CrossRef]
- Padma, S.; Sanjeevi, S. Jeffries Matusita based mixed-measure for improved spectral matching in hyperspectral image analysis. Int. J. Appl. Earth Obs. Geoinf. 2014, 32, 138–151. [Google Scholar] [CrossRef]
- Oppenheimer, C. Richards, J.A. & Jia Xiuping. 1999. Remote Sensing Digital Image Analysis. An Introduction, 3rd revised and enlarged edition. xxi + 363 pp. Berlin, Heidelberg, New York, London, Paris, Tokyo, Hong Kong: Springer-Verlag. Price DM 139.00, Ös 1015.00, SFr 126.50, £53.30, US $89.95 (hard covers). ISBN 3 540 64860 7. Geol. Mag. 2000, 137, 335–342. [Google Scholar] [CrossRef]
- Du, Y.; Chang, C.-I.; Ren, H.; D’Amico, F.M.; Jensen, J.O. New hyperspectral discrimination measure for spectral similarity. In Proc. SPIE 5093, Algorithms and Technologies for Multispectral, Hyperspectral, and Ultraspectral Imagery IX, Proceedings of the AEROSENSE 2003, Orlando, FL, USA, 21–25 April 2003; SPIE: Bellingham, WA, USA, 2003. [Google Scholar] [CrossRef]
- Jones, P.J.; James, M.K.; Davies, M.J.; Khunti, K.; Catt, M.; Yates, T.; Rowlands, A.V.; Mirkes, E.M. FilterK: A new outlier detection method for k-means clustering of physical activity. J. Biomed. Inform. 2020, 104, 103397. [Google Scholar] [CrossRef]
- Nguyen, T.-H.T.; Dinh, T.; Sriboonchitta, S.; Huynh, V.-N. A method for k-means-like clustering of categorical data. J. Ambient Intell. Humaniz. Comput. 2019, 10, 1–11. [Google Scholar] [CrossRef]
- Kang, X.; Li, S.; Benediktsson, J.A. Spectral–Spatial Hyperspectral Image Classification with Edge-Preserving Filtering. IEEE Trans. Geosci. Remote Sens. 2014, 52, 2666–2677. [Google Scholar] [CrossRef]
- Thai, L.H.; Hai, T.S.; Thuy, N.T. Image Classification using Support Vector Machine and Artificial Neural Network. Int. J. Inf. Technol. Comput. Sci. 2012, 4, 32–38. [Google Scholar] [CrossRef] [Green Version]
- Guo, Y.; Yin, X.; Zhao, X.; Yang, D.; Bai, Y. Hyperspectral image classification with SVM and guided filter. EURASIP J. Wirel. Commun. Netw. 2019, 2019, 56. [Google Scholar] [CrossRef]
- Sabat-Tomala, A.; Raczko, E.; Zagajewski, B. Comparison of Support Vector Machine and Random Forest Algorithms for Invasive and Expansive Species Classification Using Airborne Hyperspectral Data. Remote Sens. 2020, 12, 516. [Google Scholar] [CrossRef] [Green Version]
- Maxwell, A.E.; Warner, T.A.; Fang, F. Implementation of machine-learning classification in remote sensing: An applied review. Int. J. Remote Sens. 2018, 39, 2784–2817. [Google Scholar] [CrossRef] [Green Version]
- Manolakis, D.; Siracusa, C.; Shaw, G. Hyperspectral subpixel target detection using the linear mixing model. IEEE Trans. Geosci. Remote Sens. 2001, 39, 1392–1409. [Google Scholar] [CrossRef]
- Heinz, D.; Chang, C.I.; Althouse, M.L.G. Fully constrained least-squares based linear unmixing [hyperspectral image classification. In Proceedings of the IEEE 1999 International Geoscience and Remote Sensing Symposium. IGARSS’99 (Cat. No.99CH36293), Hamburg, Germany, 28 June–2 July 1999; pp. 1401–1403. [Google Scholar]
- Wei, J.; Wang, X. An Overview on Linear Unmixing of Hyperspectral Data. Math. Probl. Eng. 2020, 2020, 1–12. [Google Scholar] [CrossRef]
- Scott, J.H.; Burgan, R.E. Standard fire behavior fuel models: A comprehensive set for use with Rothermel’s surface fire spread model. Stand. Fire Behav. Fuel Models: Compr. Set Use Rothermel’s Surf. Fire Spread Model 2005, 153, 1–80. [Google Scholar] [CrossRef]
- San-Miguel-Ayanz, J. Advance EFFIS Report on Forest Fires in Europe. In Middle East and North Africa; Publications Office of the European Union: Luxembourg, 2017. [Google Scholar]
- Anderson, H.E. Aids to Determining Fuel Models for Estimating Fire Behavior; General Technical Report INT-122, April; USDA Forest Service, Intermountain Forest and Range Experiment Station: Ogden, UT, USA, 1982; 28p.
- Busetto, L.; Ranghetti, L. Prismaread: A tool for facilitating access and analysis of PRISMA L1/L2 hyperspectral imagery v1.0.0. 2020. Available online: https://irea-cnr-mi.github.io/prismaread/ (accessed on 15 September 2021).
- Pettinari, M.L.; Chuvieco, E. Generation of a global fuel data set using the Fuel Characteristic Classification System. Biogeosciences 2016, 13, 2061–2076. [Google Scholar] [CrossRef] [Green Version]
- Atchley, A.L.; Linn, R.; Jonko, A.; Hoffman, C.; Hyman, J.D.; Pimont, F.; Sieg, C.; Middleton, R.S. Effects of fuel spatial distribution on wildland fire behaviour. Int. J. Wildland Fire 2021, 30, 179. [Google Scholar] [CrossRef]
- Bonazountas, M.; Astyakopoulos, A.; Martirano, G.; Sebastian, A.; De la Fuente, D.; Ribeiro, L.; Viegas, D.; Eftychidis, G.; Gitas, I.; Toukiloglou, P. LIFE ArcFUEL: Mediterranean fuel-type maps geodatabase for wildland & forest fire safety. In Advances in Forest Fire Research; Imprensa da Universidade de Coimbra: Coimbra, Portugal, 2014; pp. 1723–1735. [Google Scholar]
- Martirano, G. INSPIRE Land Cover Data Specifications to Model Fuel Maps in Europe: The Experience of the ArcFUEL LIFE+ project (Presentation). In Proceedings of the INSPIRE Conference, Florence, Italy, 23–27 June 2013. [Google Scholar]
- Jallu, S.B.; Shaik, R.U.; Srivastav, R.; Pignatta, G. Assessing the Effect of COVID-19 Lockdown on Surface Urban Heat Island for Different Land Use/Cover Types Using Remote Sensing. Energy Nexus 2022, 5, 100056. [Google Scholar] [CrossRef]
- Laneve, G.; Pampanoni, V.; Shaik, R. The Daily Fire Hazard Index: A Fire Danger Rating Method for Mediterranean Areas. Remote Sens. 2020, 12, 2356. [Google Scholar] [CrossRef]
- Uddien, R.S.; Pampanoni, V.; Laneve, G. Support Wildfire Management in Mediterranean Territories Using Multi-Source Satellite Data S2IGI: An Integrated System for Wildfire Management View project Maestria en Aplicaciones Espa-ciales de Alerta y Respuesta Temprana a Emergencias View project. 2019. Available online: https://www.researchgate.net/publication/336312431 (accessed on 15 September 2021).
- Huang, H.-Y.; Broughton, M.; Mohseni, M.; Babbush, R.; Boixo, S.; Neven, H.; McClean, J.R. Power of data in quantum machine learning. Nat. Commun. 2021, 12, 1–9. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| FT Code | FT Description | Anderson Code |
|---|---|---|
| FT_1 | Peat bogs | 5 |
| FT_2 | Wooded peatbogs | 6 |
| FT_3 | Pastures | 1 |
| FT_4 | Sparse grasslands | 1 |
| FT_5 | Mediterranean grasslands and steppes | 2 |
| FT_6 | Temperate, Alpine and Northern grasslands | 1 |
| FT_7 | Mediterranean moors and heathlands | 5 |
| FT_8 | Temperate, Alpine and Northern moors and heathlands | 5 |
| FT_9 | Mediterranean open shrublands (sclerophyllous) | 2 |
| FT_10 | Mediterranean shrublands (sclerophyllous) | 4 |
| FT_11 | Deciduous broadleaved shrublands (thermophilus) | 5 |
| FT_12 | Alpine open shrublands (conifers) | 6 |
| FT_13 | Shrublands in Mediterranean conifer forest | 7 |
| FT_14 | Shrublands in Mediterranean sclerophyllous forest | 4 |
| FT_15 | Shrublands in Mediterranean mountain conifers forest | 7 |
| FT_16 | Shrublands in thermophilus broadleaved forest | 5 |
| FT_17 | Shrublands in beach and mesophytic broadleaved forest | 5 |
| FT_18 | Northern open shrublands in broadleaved forest | 5 |
| FT_19 | Shrublands in Alpine and Northern conifers forest | 7 |
| FT_20 | Mediterranean long-needled conifer forest (Mediterranean pines) | 10 |
| FT_21 | Mediterranean scale-needled open woodlands (Juniperus, Cupressus) | 8 |
| FT_22 | Mediterranean mountain long-needled conifer forest (black and Scots pines) | 10 |
| FT_23 | Mediterranean mountain short-needled conifer forest (firs, cedar) | 8 |
| FT_24 | Temperate conifer plantation | 8 |
| FT_25 | Alpine long-needled conifer forest (pines) | 10 |
| FT_26 | Alpine short-needled conifer forest (fir, alp, spruce) | 8 |
| FT_27 | Northern long-needled conifer forest (Scots pines) | 10 |
| FT_28 | Northern short-needled conifer forest (spruce) | 8 |
| FT_29 | Mediterranean evergreen broadleaved forest | 4 |
| FT_30 | Thermophilus broadleaved forest | 9 |
| FT_31 | Mesophytic broadleaved forest | 9 |
| FT_32 | Beach forest | 9 |
| FT_33 | Mountain beach forest | 10 |
| FT_34 | White birch boreal forest | 10 |
| FT_35 | Mixed Mediterranean evergreen broadleaved with conifer forest | 4 |
| FT_36 | Mixed mesophytic broadleaved with conifer forest | 9 |
| FT_37 | Mixed mesophytic broadleaved with conifer forest | 10 |
| FT_38 | Mixed beach with conifer forest | 9 |
| FT_39 | Riparian vegetation | 5 |
| FT_40 | Coastal inland and halophytic vegetation and dunes | 1 |
| FT_41 | Aquatic marshes | 3 |
| FT_42 | Agroforestry areas | 2 |
| Class | JRC Fuel Type | Anderson Code |
|---|---|---|
| 1 | FT_40 | 1 |
| 2 | FT_29 | 4 |
| 3 | FT_10 | 4 |
| 4 | FT_14 | 4 |
| 5 | FT_14 | 4 |
| 6 | FT_9 | 2 |
| 7 | FT_9 | 2 |
| 8 | FT_10 | 4 |
| 9 | FT_10 | 4 |
| 10 | FT_4 | 1 |
| 11 | FT_4 | 1 |
| 12 | FT_32 | 9 |
| 13 | FT_42 | 2 |
| 14 | FT_29 | 4 |
| 15 | FT_29 | 4 |
| 16 | FT_4 | 1 |
| 17 | FT_20 | 10 |
| 18 | FT_15 | 7 |
| Class | Precision | Recall | F1 Score | Classification Accuracy (%) |
|---|---|---|---|---|
| 1 | 0.95 | 0.70 | 0.80 | 70 |
| 2 | 0.83 | 0.86 | 0.85 | 86 |
| 3 | 0.85 | 0.72 | 0.78 | 80 |
| 4 | 0.86 | 0.86 | 0.86 | 86 |
| 5 | 0.89 | 0.86 | 0.88 | 86 |
| 6 | 0.83 | 0.83 | 0.83 | 83 |
| 7 | 0.80 | 0.93 | 0.86 | 93 |
| 8 | 0.86 | 0.90 | 0.94 | 90 |
| 9 | 1 | 0.86 | 0.77 | 86 |
| 10 | 0.70 | 0.86 | 0.89 | 86 |
| 11 | 0.92 | 0.90 | 0.87 | 90 |
| 12 | 0.84 | 0.93 | 0.94 | 93 |
| 13 | 0.96 | 0.86 | 0.91 | 86 |
| 14 | 0.96 | 0.93 | 0.96 | 93 |
| 15 | 1 | 0.90 | 0.85 | 90 |
| 16 | 0.81 | 0.90 | 0.87 | 90 |
| 17 | 0.84 | 0.96 | 0.92 | 96 |
| 18 | 0.87 | 0.86 | 0.83 | 86 |
| Fuel Types Value | Number of Pixels on 27 June 2021 Image | Number of Pixels on 31 July 2021 Image | Difference (in %) |
|---|---|---|---|
| 2 | 33,255 | 33,465 | ~1 |
| 4 | 57,339 | 44,804 | ~20 |
| 5 | 8259 | 10,647 | ~20 |
| 10 | 7472 | 5473 | ~26 |
| 0 | 1,419,353 | 1,382,612 | ~3 |
| Sample No. | Fuel Types | Anderson Fuel Models |
|---|---|---|
| 1 | Winter Oak | Mesophytic Broadleaved Forest (9) |
| 2 | White Pine | Broadleaved with Coniferous Forest (9) |
| 3 | Black Pine | Broadleaved with Coniferous Forest (6) |
| 4 | Hairy Oak | Agroforestry (2) |
| 5 | Pasture and Meadows | Pasture/Sparse grassland (1) |
| 6 | Mixed Land Use | Pasture/Grassland (1) |
| S.No. | 1 | 2 | 6 | 9 | User Accuracy | Commission Error (%) |
|---|---|---|---|---|---|---|
| 1 | 27 | 2 | 1 | 0 | 0.90 | 10 |
| 2 | 2 | 24 | 4 | 0 | 0.80 | 20 |
| 6 | 0 | 1 | 26 | 3 | 0.86 | 13.33 |
| 9 | 0 | 1 | 3 | 25 | 0.86 | 13.33 |
| Producer Accuracy | 93.10 | 85.17 | 76.47 | 89.65 | ||
| Omission Error (%) | 6.89 | 14.28 | 23.52 | 10.34 | OA ≅ 84% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shaik, R.U.; Laneve, G.; Fusilli, L. An Automatic Procedure for Forest Fire Fuel Mapping Using Hyperspectral (PRISMA) Imagery: A Semi-Supervised Classification Approach. Remote Sens. 2022, 14, 1264. https://doi.org/10.3390/rs14051264
Shaik RU, Laneve G, Fusilli L. An Automatic Procedure for Forest Fire Fuel Mapping Using Hyperspectral (PRISMA) Imagery: A Semi-Supervised Classification Approach. Remote Sensing. 2022; 14(5):1264. https://doi.org/10.3390/rs14051264
Chicago/Turabian StyleShaik, Riyaaz Uddien, Giovanni Laneve, and Lorenzo Fusilli. 2022. "An Automatic Procedure for Forest Fire Fuel Mapping Using Hyperspectral (PRISMA) Imagery: A Semi-Supervised Classification Approach" Remote Sensing 14, no. 5: 1264. https://doi.org/10.3390/rs14051264
APA StyleShaik, R. U., Laneve, G., & Fusilli, L. (2022). An Automatic Procedure for Forest Fire Fuel Mapping Using Hyperspectral (PRISMA) Imagery: A Semi-Supervised Classification Approach. Remote Sensing, 14(5), 1264. https://doi.org/10.3390/rs14051264