
Unsupervised Generative Adversarial Network with Background Enhancement and Irredundant Pooling for Hyperspectral Anomaly Detection


Abstract
:1. Introduction
- Different from the traditional way, which only considers a pixel spectral value in network training, the BE is proposed to prepare for training data sets. In this part, we adopt the principle that the background energy in each band have a bigger discrimination degree than anomaly.
- The IP is invented in the spectral branch. We apply the grouping max pooling to eliminate the redundant information while highlighting the available feature as much as possible.
- Some strong constrained functions are imposed on the GAN, aimed at making the networks more stable to reconstruct a hyperspectral background image.
- A spectral-spatial joint way, processing the HSI rather than residual image, is integrated in the algorithm proposed to obtain the combination detection result, through which we can make the best use of data.
2. Related Work
2.1. Autoencoder (AE)
2.2. Generative Adversarial Networks (GAN)
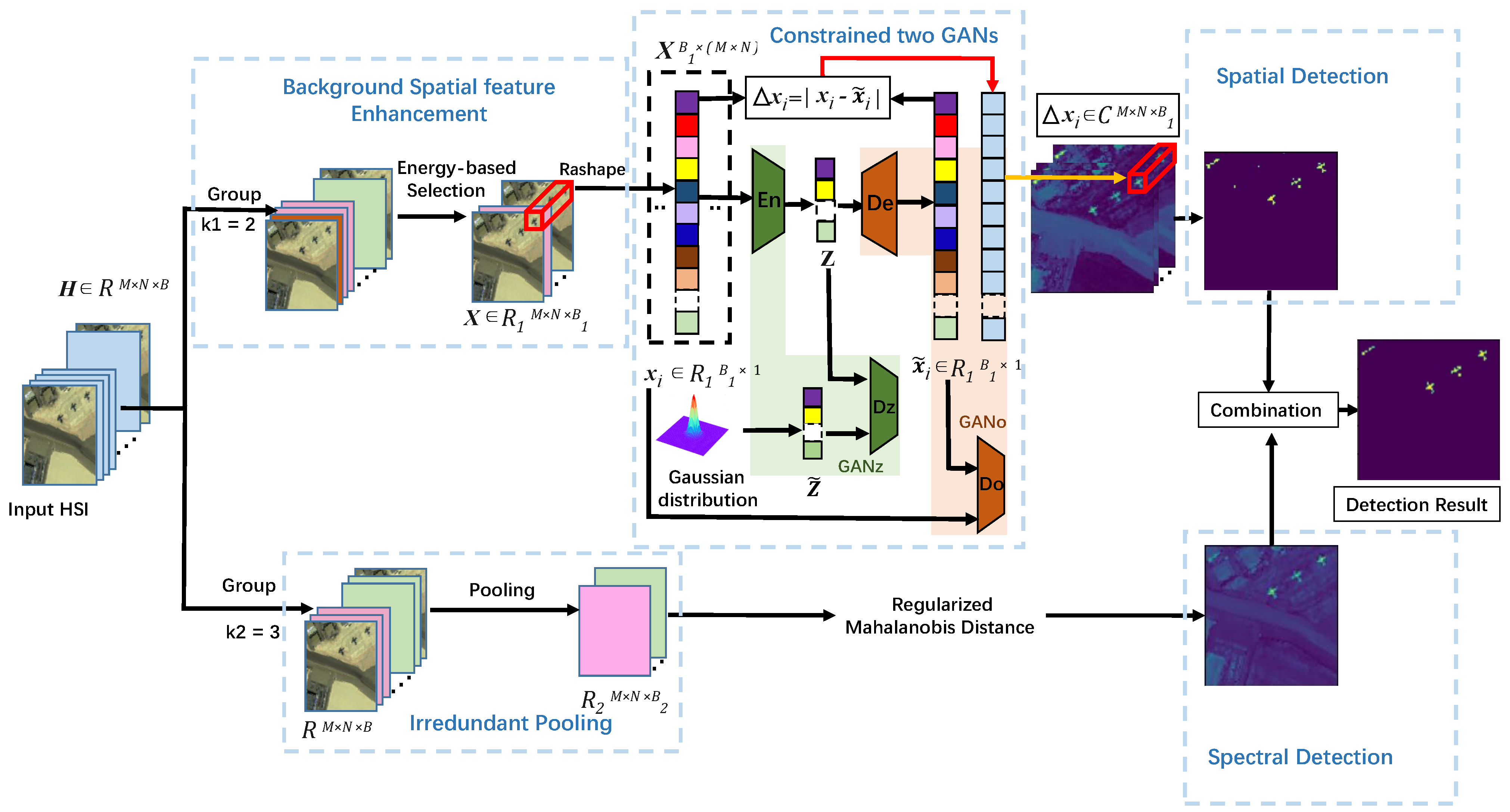
3. Methodology
3.1. BEGAN-Based Spatial Anomaly Detection
3.1.1. Background Spatial Feature Enhancement
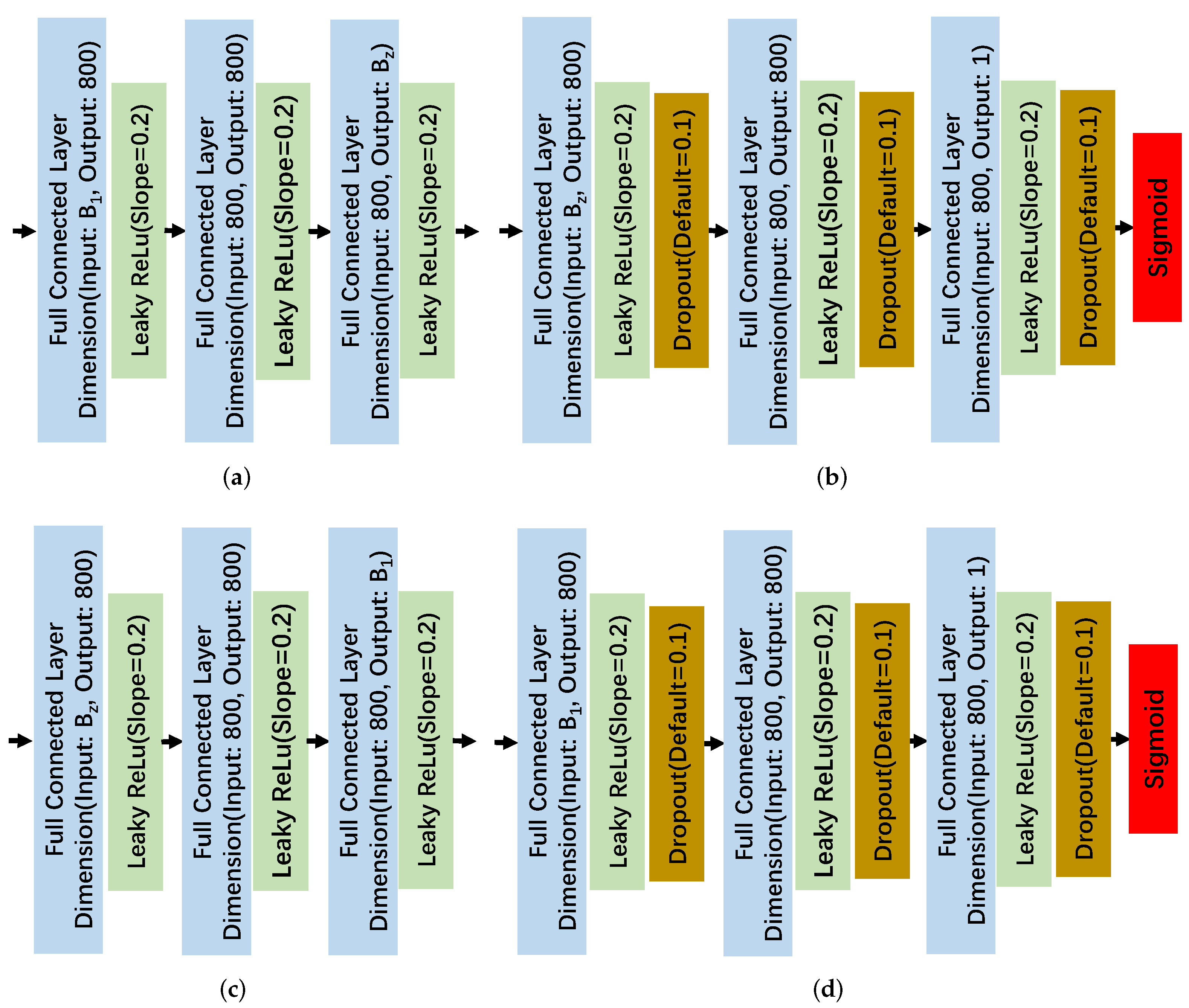
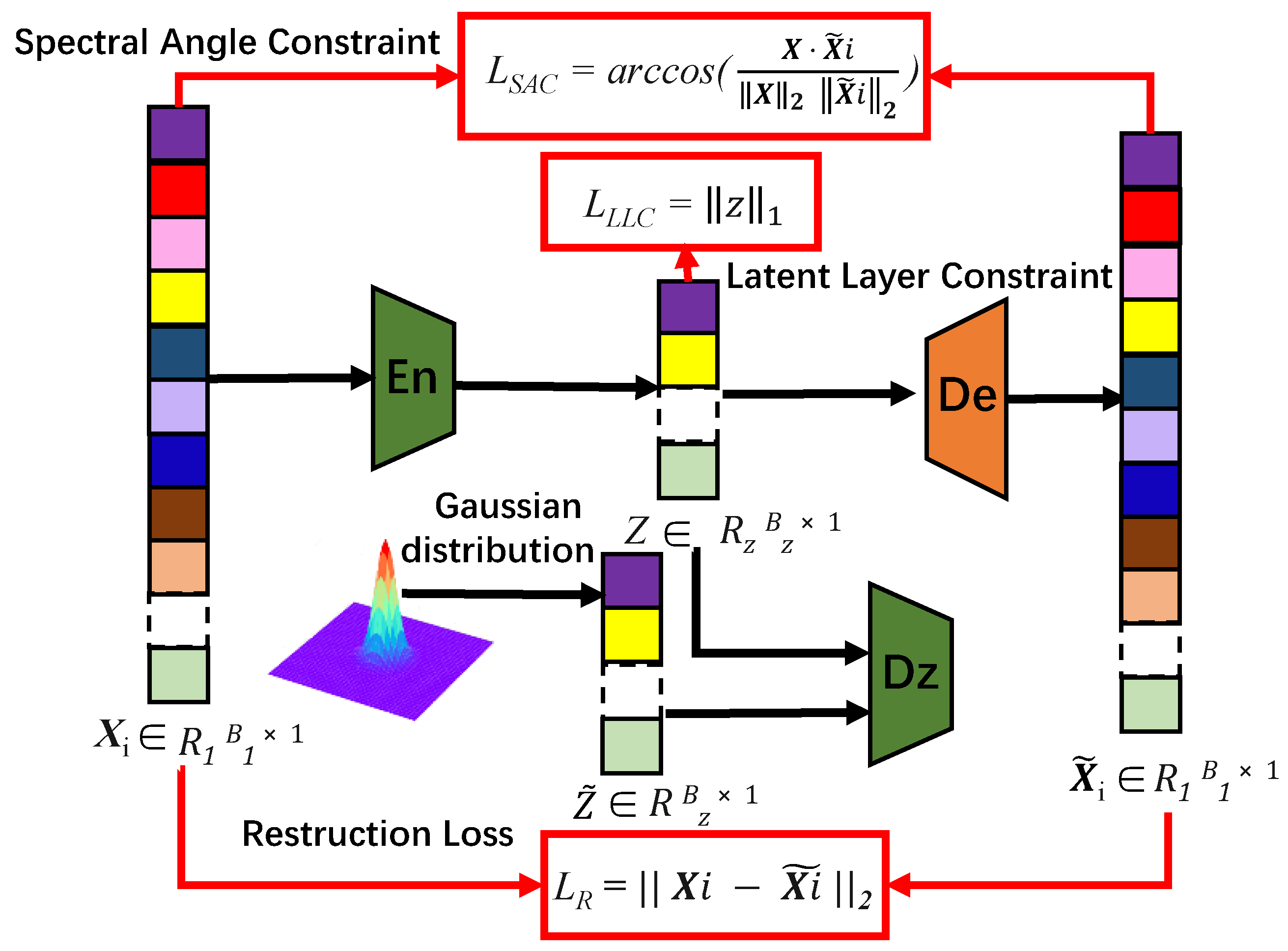
3.1.2. Constrained Two GANs
| Algorithm 1: Background spatial feature enhancement-based constrained two GANs training |
Input: HSI data set , group number Output: , , ,
|
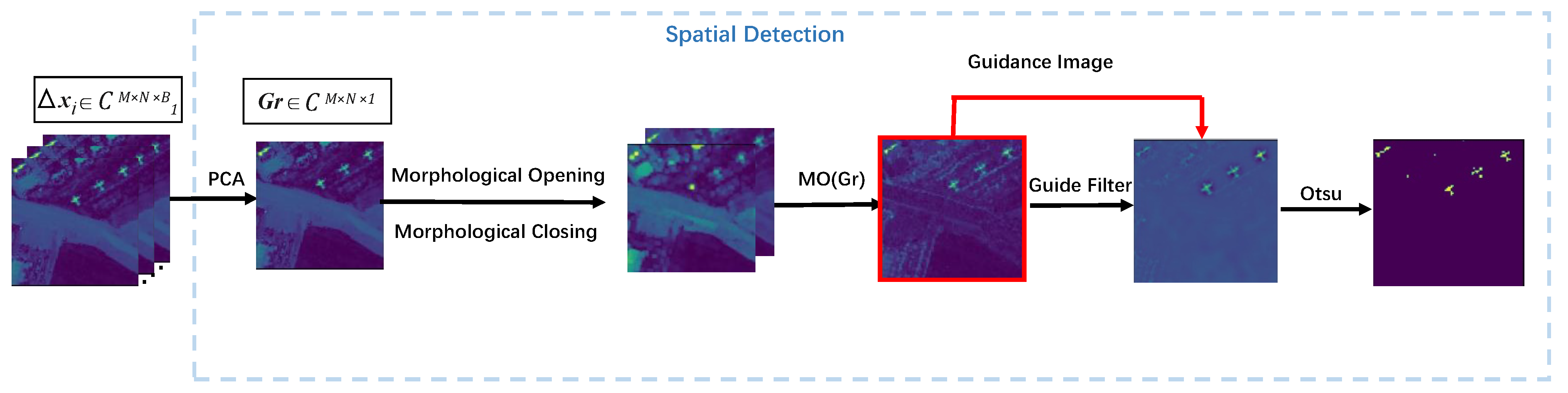
3.1.3. Spatial Detection
3.2. Irredundant Pooling Regularized Mahalanobis Distance-Based Spectral Anomaly Detection
3.2.1. Irredundant Pooling
3.2.2. Regularized Mahalanobis Distance
3.3. Combination
4. Experiments
4.1. Data Description
- San Diego data set: It is taken by the Airborne Visible/Infrared Imaging Spectrometer (AVIRIS) from the San Diego area. They consist of 224 bands, however there are 35 bands of poor quality that are deleted in the experiment, such as water absorption region. Consequently, there are 189 bands in the effective data set and the spatial resolution is 3.5 m. The image size is , where areas from the upper left corners is selected for training and testing. Three aircraft are called anomalies, with a total of 57 anomalous pixels. The pseudo-color image and ground-truth map are shown in Figure 6a,b.
- Los Angeles data set: The region shown in this image acquired by AVIRIS is the part of urban area of Los Angeles. The spatial region size is , the spatial resolution is 7.1 m, and the number of available bands is 205. In the process of AD, ground objects of different shapes, such as aircraft are regarded as anomalies, with a total of 170 abnormal pixels. The pseudo-color and ground-truth image are demonstrated in Figure 7a,b.
- Texas Coast data set (TC-I data set and TC-II data set): It includes some images taken by the AVIRIS in the Texas Coast Area. There are two images with a spatial size of , a spatial resolution of 17.2 m, and 207 available bands in total. Residential houses of different shapes in the image are labeled as anomalous areas, containing 67 and 155 anomalous pixels, respectively. Figure 8a,b describe the pseudo-color and the ground-truth map of TC-I. And Figure 9a,b show the pseudo-color and the ground-truth map of TC-II.
- Bay Champagne data set: It is collected by AVIRIS from the Bay Champagne area. The image is made up of 188 available bands, whose spatial size is and resolution is 4.4 m. Among them, things on the sea surface are considered as anomalies, involving 11 pixels. The pseudo-color and the real ground-truth of the image are given in Figure 10a,b.
4.2. Compared Methods and Evaluation Criteria
4.2.1. Compared Methods
4.2.2. Evaluation Criteria
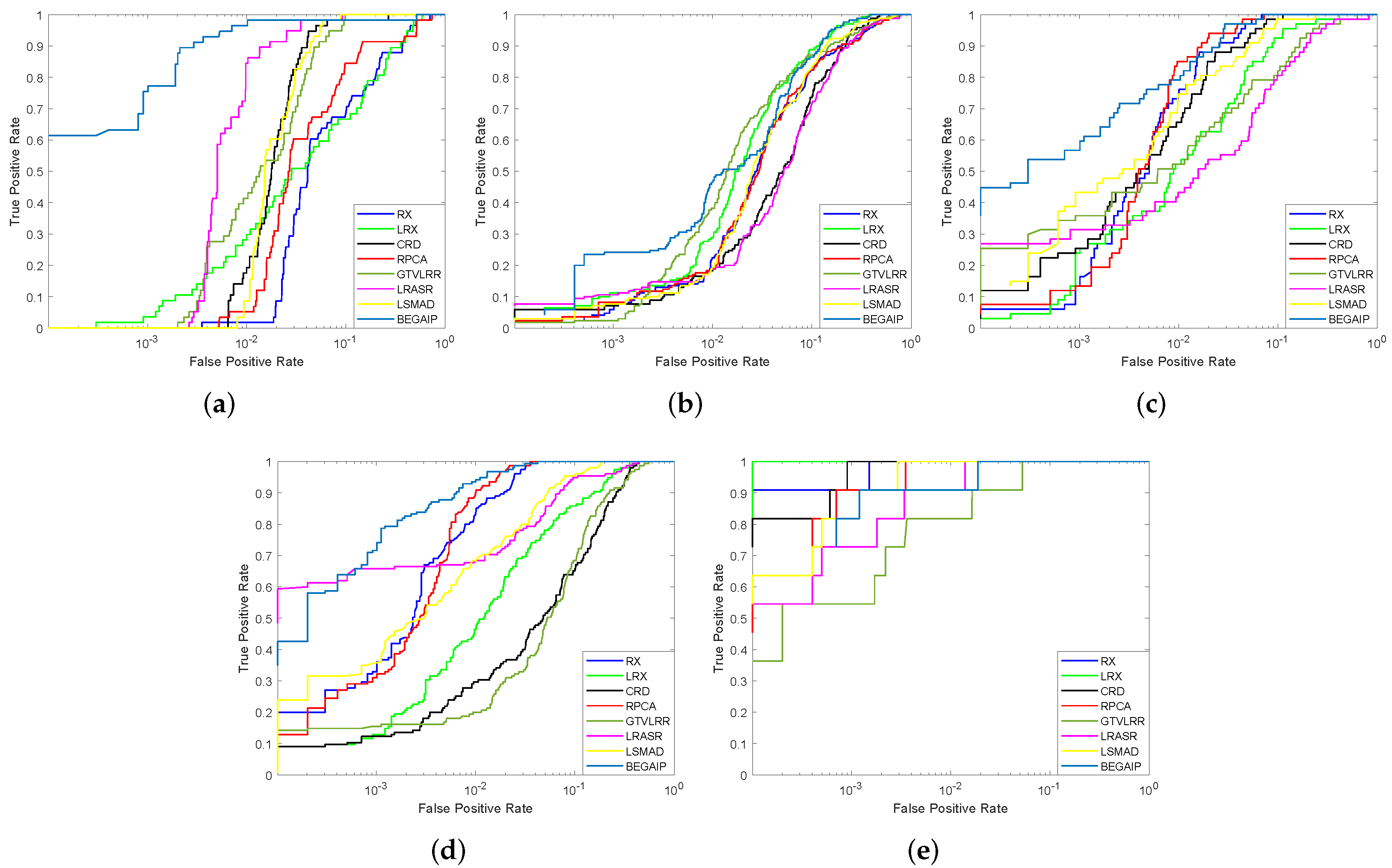
4.3. Detection Performance
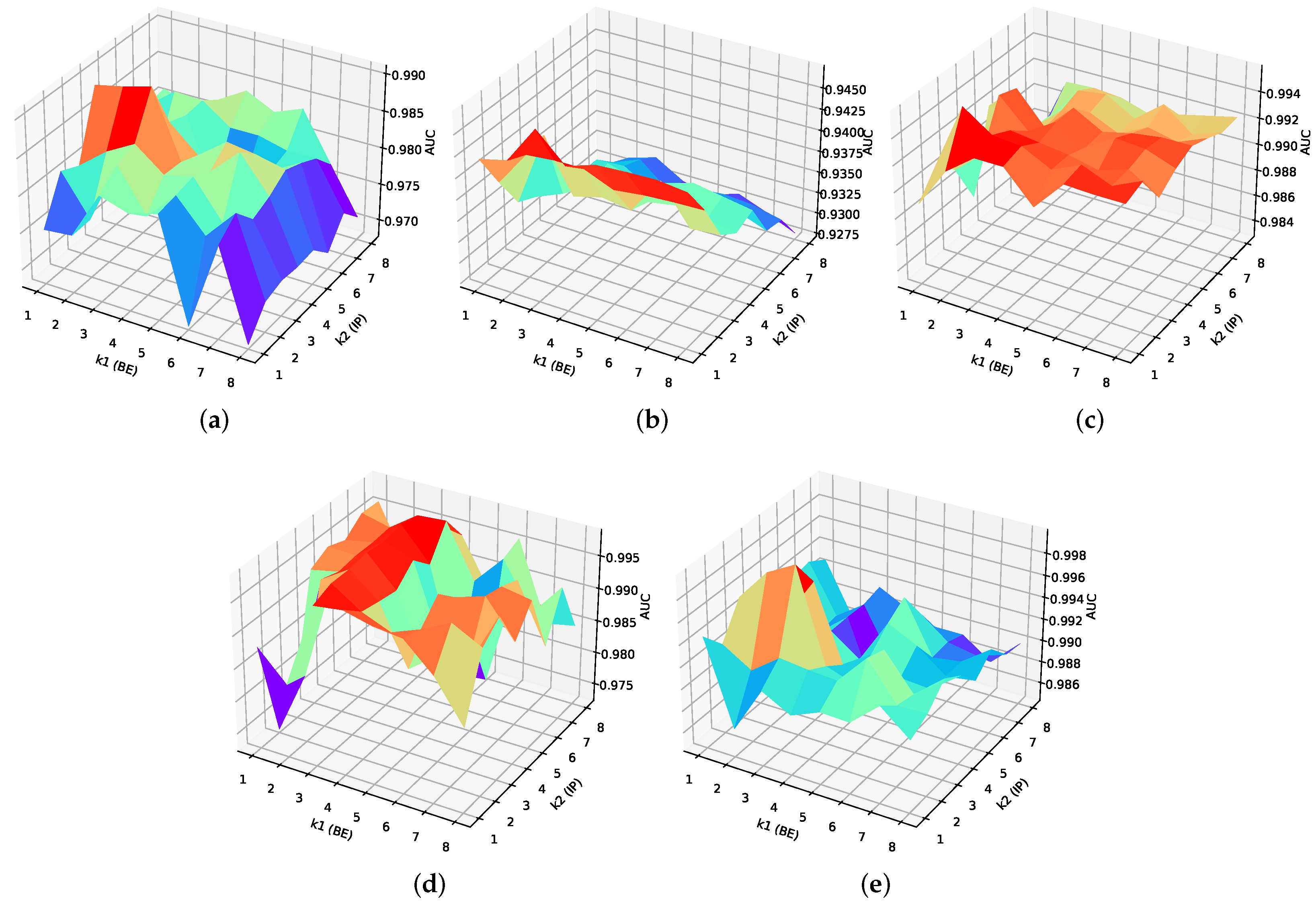
4.4. Parameters Settings
5. Investigations
5.1. Investigation of Different Version Irredundant Pooling (IP)
5.2. Investigation of the Innovative Part
5.3. Investigation of Computing Time
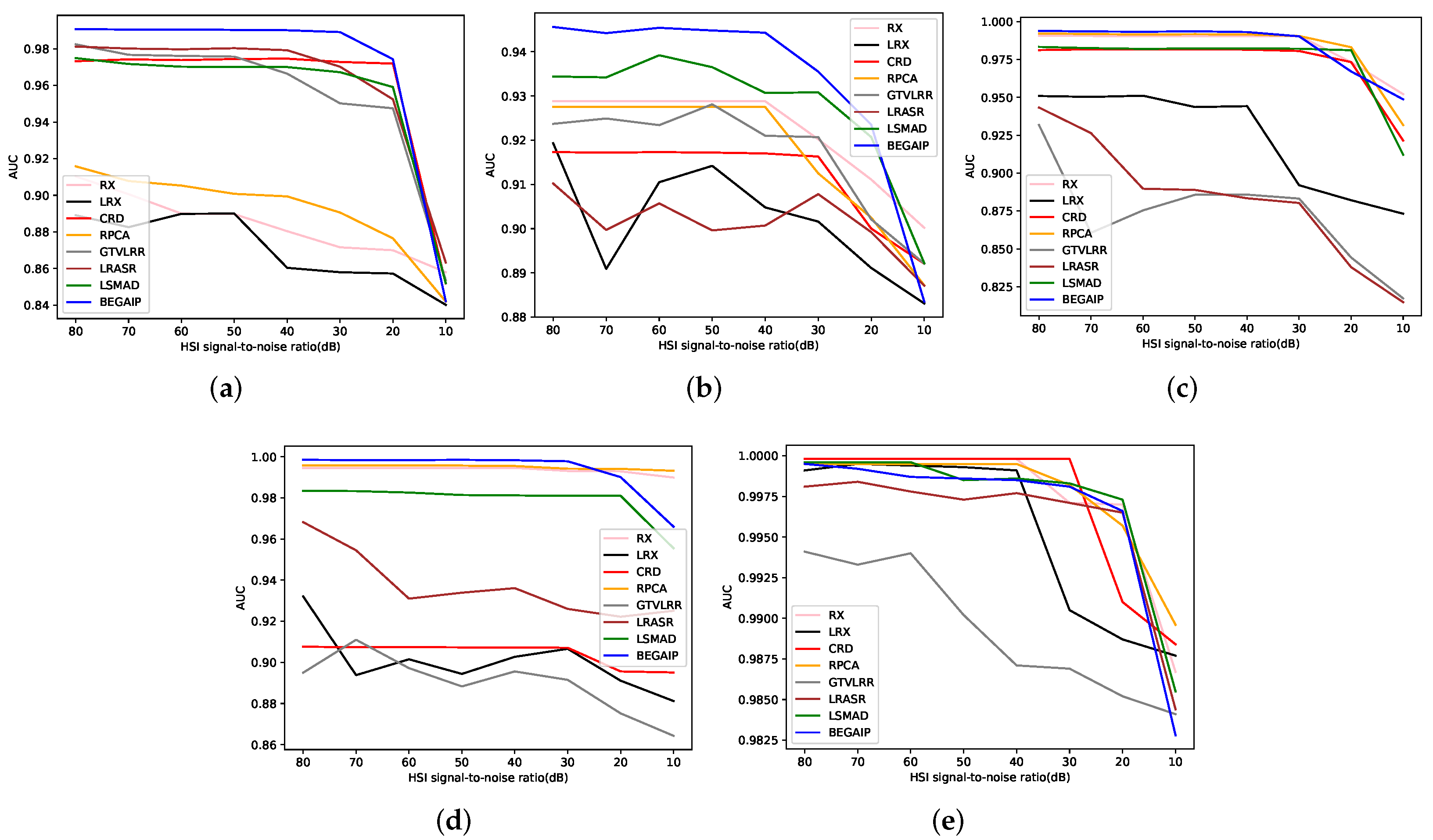
5.4. Investigation of Model BEGAIP for HAD Robustness against Noise
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Bioucas-Dias, J.M.; Plaza, A.; Camps-Valls, G.; Scheunders, P.; Nasrabadi, N.; Chanussot, J. Hyperspectral remote sensing data analysis and future challenges. IEEE Geosci. Remote Sens. Mag. 2013, 1, 6–36. [Google Scholar] [CrossRef] [Green Version]
- Guo, F.; Li, Z.; Xin, Z.; Zhu, X.; Wang, L.; Zhang, J. Dual Graph U-Nets for Hyperspectral Image Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 8160–8170. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, L.; Du, B.; You, J.; Tao, D. Hyperspectral image unsupervised classification by robust manifold matrix factorization. Inf. Sci. 2019, 485, 154–169. [Google Scholar] [CrossRef]
- Li, Z.; Cui, X.; Wang, L.; Zhang, H.; Zhu, X.; Zhang, Y. Spectral and Spatial Global Context Attention for Hyperspectral Image Classification. Remote Sens. 2021, 13, 771. [Google Scholar] [CrossRef]
- Zhang, X.; Li, C.; Zhang, J.; Chen, Q.; Feng, J.; Jiao, L.; Zhou, H. Hyperspectral unmixing via low-rank representation with space consistency constraint and spectral library pruning. Remote Sens. 2018, 10, 339. [Google Scholar] [CrossRef] [Green Version]
- Nasrabadi, N.M. Hyperspectral target detection: An overview of current and future challenges. IEEE Signal Process. Mag. 2013, 31, 34–44. [Google Scholar] [CrossRef]
- Zhong, Y.; Wang, X.; Xu, Y.; Wang, S.; Jia, T.; Hu, X.; Zhao, J.; Wei, L.; Zhang, L. Mini-UAV-borne hyperspectral remote sensing: From observation and processing to applications. IEEE Geosci. Remote Sens. Mag. 2018, 6, 46–62. [Google Scholar] [CrossRef]
- Xie, W.; Zhang, X.; Li, Y.; Wang, K.; Du, Q. Background learning based on target suppression constraint for hyperspectral target detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 5887–5897. [Google Scholar] [CrossRef]
- Zhang, Y.; Wu, K.; Du, B.; Hu, X. Multitask learning-based reliability analysis for hyperspectral target detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 2135–2147. [Google Scholar] [CrossRef]
- Li, L.; Li, W.; Du, Q.; Tao, R. Low-rank and sparse decomposition with mixture of gaussian for hyperspectral anomaly detection. IEEE Trans. Cybern. 2020, 51, 4363–4372. [Google Scholar] [CrossRef]
- Su, H.; Wu, Z.; Zhu, A.; Du, Q. Low rank and collaborative representation for hyperspectral anomaly detection via robust dictionary construction. ISPRS J. Photogramm. Remote Sens. 2020, 169, 195–211. [Google Scholar] [CrossRef]
- Zhao, G.; Li, F.; Zhang, X.; Laakso, K.; Chan, J.C.W. Archetypal Analysis and Structured Sparse Representation for Hyperspectral Anomaly Detection. Remote Sens. 2021, 13, 4102. [Google Scholar] [CrossRef]
- Reed, I.S.; Yu, X. Adaptive multiple-band CFAR detection of an optical pattern with unknown spectral distribution. IEEE Trans. Signal Process. 1990, 38, 1760–1770. [Google Scholar] [CrossRef]
- Goldberg, H.; Kwon, H.; Nasrabadi, N.M. Kernel eigenspace separation transform for subspace anomaly detection in hyperspectral imagery. IEEE Geosci. Remote Sens. Lett. 2007, 4, 581–585. [Google Scholar] [CrossRef]
- Molero, J.M.; Garzon, E.M.; Garcia, I.; Plaza, A. Analysis and optimizations of global and local versions of the RX algorithm for anomaly detection in hyperspectral data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2013, 6, 801–814. [Google Scholar] [CrossRef]
- Li, W.; Du, Q. Collaborative representation for hyperspectral anomaly detection. IEEE Trans. Geosci. Remote Sens. 2014, 53, 1463–1474. [Google Scholar] [CrossRef]
- Xu, Y.; Wu, Z.; Li, J.; Plaza, A.; Wei, Z. Anomaly detection in hyperspectral images based on low-rank and sparse representation. IEEE Trans. Geosci. Remote Sens. 2015, 54, 1990–2000. [Google Scholar] [CrossRef]
- Huyan, N.; Zhang, X.; Zhou, H.; Jiao, L. Hyperspectral anomaly detection via background and potential anomaly dictionaries construction. IEEE Trans. Geosci. Remote Sens. 2018, 57, 2263–2276. [Google Scholar] [CrossRef] [Green Version]
- Alhashim, I.; Wonka, P. High quality monocular depth estimation via transfer learning. arXiv 2018, arXiv:1812.11941. [Google Scholar]
- Demertzis, K.; Iliadis, L. GeoAI: A model-agnostic meta-ensemble zero-shot learning method for hyperspectral image analysis and classification. Algorithms 2020, 13, 61. [Google Scholar] [CrossRef] [Green Version]
- Kendall, A.; Gal, Y.; Cipolla, R. Multi-task learning using uncertainty to weigh losses for scene geometry and semantics. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 7482–7491. [Google Scholar]
- Lei, J.; Xie, W.; Yang, J.; Li, Y.; Chang, C.I. Spectral–spatial feature extraction for hyperspectral anomaly detection. IEEE Trans. Geosci. Remote Sens. 2019, 57, 8131–8143. [Google Scholar] [CrossRef]
- Chalapathy, R.; Chawla, S. Deep learning for anomaly detection: A survey. arXiv 2019, arXiv:1901.03407. [Google Scholar]
- Azarang, A.; Manoochehri, H.E.; Kehtarnavaz, N. Convolutional autoencoder-based multispectral image fusion. IEEE Access 2019, 7, 35673–35683. [Google Scholar] [CrossRef]
- Jiang, T.; Li, Y.; Xie, W.; Du, Q. Discriminative reconstruction constrained generative adversarial network for hyperspectral anomaly detection. IEEE Trans. Geosci. Remote Sens. 2020, 58, 4666–4679. [Google Scholar] [CrossRef]
- Xie, W.; Liu, B.; Li, Y.; Lei, J.; Du, Q. Autoencoder and adversarial-learning-based semisupervised background estimation for hyperspectral anomaly detection. IEEE Trans. Geosci. Remote Sens. 2020, 58, 5416–5427. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27, 2672–2680. [Google Scholar]
- Chao, X.; Cao, J.; Lu, Y.; Dai, Q.; Liang, S. Constrained Generative Adversarial Networks. IEEE Access 2021, 9, 19208–19218. [Google Scholar] [CrossRef]
- Lopez-Martin, M.; Sanchez-Esguevillas, A.; Arribas, J.I.; Carro, B. Supervised contrastive learning over prototype-label embeddings for network intrusion detection. Inf. Fusion 2022, 79, 200–228. [Google Scholar] [CrossRef]
- Xie, W.; Jiang, T.; Li, Y.; Jia, X.; Lei, J. Structure tensor and guided filtering-based algorithm for hyperspectral anomaly detection. IEEE Trans. Geosci. Remote Sens. 2019, 57, 4218–4230. [Google Scholar] [CrossRef]
- Wold, S.; Esbensen, K.; Geladi, P. Principal component analysis. Chemom. Intell. Lab. Syst. 1987, 2, 37–52. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE. 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Choi, J.; Han, B. MCL-GAN: Generative Adversarial Networks with Multiple Specialized Discriminators. arXiv 2021, arXiv:2107.07260. [Google Scholar]
- Lopez-Martin, M.; Carro, B.; Sanchez-Esguevillas, A. Variational data generative model for intrusion detection. Knowl. Inf. Syst. 2019, 60, 569–590. [Google Scholar] [CrossRef]
- Mao, X.; Li, Q.; Xie, H.; Lau, R.Y.; Wang, Z.; Paul Smolley, S. Least squares generative adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2794–2802. [Google Scholar]
- Parhi, R.; Nowak, R.D. The role of neural network activation functions. IEEE Signal Process. Lett. 2020, 27, 1779–1783. [Google Scholar] [CrossRef]
- He, K.; Sun, J.; Tang, X. Guided image filtering. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 1397–1409. [Google Scholar] [CrossRef]
- Eldeeb, H.H.; Zhao, H.; Mohammed, O.A. Detection of TTF in Induction Motor Vector Drives for EV Applications via Ostu’s-Based DDWE. IEEE Trans. Transp. Electrif. 2020, 7, 114–132. [Google Scholar] [CrossRef]
- Xu, Y.; Wu, Z.; Chanussot, J.; Wei, Z. Joint reconstruction and anomaly detection from compressive hyperspectral images using Mahalanobis distance-regularized tensor RPCA. IEEE Trans. Geosci. Remote Sens. 2018, 56, 2919–2930. [Google Scholar] [CrossRef]
- Kang, X.; Zhang, X.; Li, S.; Li, K.; Li, J.; Benediktsson, J.A. Hyperspectral anomaly detection with attribute and edge-preserving filters. IEEE Trans. Geosci. Remote Sens. 2017, 55, 5600–5611. [Google Scholar] [CrossRef]
- Chen, S.Y.; Yang, S.; Kalpakis, K.; Chang, C.I. Low-rank decomposition-based anomaly detection. In Proceedings of the Algorithms and Technologies for Multispectral, Hyperspectral, and Ultraspectral Imagery XIX, Baltimore, MD, USA, 18 May 2013; p. 87430N. [Google Scholar]
- Cheng, T.; Wang, B. Graph and total variation regularized low-rank representation for hyperspectral anomaly detection. IEEE Trans. Geosci. Remote Sens. 2019, 58, 391–406. [Google Scholar] [CrossRef]
- Zhang, Y.; Du, B.; Zhang, L.; Wang, S. A low-rank and sparse matrix decomposition-based Mahalanobis distance method for hyperspectral anomaly detection. IEEE Trans. Geosci. Remote Sens. 2015, 54, 1376–1389. [Google Scholar] [CrossRef]
- Tan, K.; Hou, Z.; Ma, D.; Chen, Y.; Du, Q. Anomaly detection in hyperspectral imagery based on low-rank representation incorporating a spatial constraint. Remote Sens. 2019, 11, 1578. [Google Scholar] [CrossRef] [Green Version]
- Chang, S.; Du, B.; Zhang, L. BASO: A background-anomaly component projection and separation optimized filter for anomaly detection in hyperspectral images. IEEE Trans. Geosci. Remote Sens. 2018, 56, 3747–3761. [Google Scholar] [CrossRef]
- Xiang, P.; Song, J.; Li, H.; Gu, L.; Zhou, H. Hyperspectral anomaly detection with harmonic analysis and low-rank decomposition. Remote Sens. 2019, 11, 3028. [Google Scholar] [CrossRef] [Green Version]
- Xie, W.; Li, Y.; Lei, J.; Yang, J.; Chang, C.I.; Li, Z. Hyperspectral band selection for spectral–spatial anomaly detection. IEEE Trans. Geosci. Remote Sens. 2019, 58, 3426–3436. [Google Scholar] [CrossRef]
- Ma, X.; Zhang, X.; Tang, X.; Zhou, H.; Jiao, L. Hyperspectral anomaly detection based on low-rank representation with data-driven projection and dictionary construction. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 2226–2239. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | San Diego | Los Angeles | TC-I | TC-II | Bay Champagne |
|---|---|---|---|---|---|
| RX | 0.9106 | 0.9288 | 0.9907 | 0.9946 | 0.9998 |
| LRX | 0.8944 | 0.9386 | 0.9670 | 0.9501 | 0.9999 |
| CRD | 0.9754 | 0.9187 | 0.9817 | 0.9311 | 0.9999 |
| RPCA | 0.9165 | 0.9275 | 0.9922 | 0.9957 | 0.9995 |
| GTVLRR | 0.9851 | 0.9277 | 0.9391 | 0.9012 | 0.9943 |
| LRASR | 0.9860 | 0.9143 | 0.9443 | 0.9759 | 0.9984 |
| LSMAD | 0.9767 | 0.9353 | 0.9834 | 0.9838 | 0.9998 |
| BEGAIP | 0.9913 | 0.9478 | 0.9957 | 0.9984 | 0.9998 |
| Methods | San Diego | Los Angeles | TC-I | TC-II | Bay Champagne |
|---|---|---|---|---|---|
| LRX | = 25, = 23 | = 25, = 23 | = 15, = 13 | = 25, = 23 | = 25, = 23 |
| CRD | = 17, = 15 | = 17, = 15 | = 13, = 7 | = 17, = 15 | = 17, = 15 |
| RPCA | |||||
| GTVLRR | , | , | , | , | , |
| LRASR | , | , | , | , | , |
| BEGAIP | = 3, = 4 | = 3, = 1 | = 2, = 2 | = 3, = 6 | = 3, = 3 |
| Versions | Bay Champagne Data Set | TC Data Set-I |
|---|---|---|
| BEGAIP (without IP) | 0.9964 | 0.9935 |
| IP (min) | 0.9920 | 0.9875 |
| IP (average) | 0.9928 | 0.9922 |
| IP (max) | 0.9998 | 0.9957 |
| Versions | San Diego | Los Angeles | TC-I | TC-II | Bay Champagne |
|---|---|---|---|---|---|
| + | 0.9670 | 0.9132 | 0.9815 | 0.9946 | 0.9854 |
| + + | 0.9744 | 0.9316 | 0.9862 | 0.9954 | 0.9909 |
| + + | 0.9673 | 0.9164 | 0.9819 | 0.9959 | 0.9861 |
| + + | 0.9678 | 0.9153 | 0.9833 | 0.9949 | 0.9876 |
| + | 0.9751 | 0.9420 | 0.9875 | 0.9964 | 0.9923 |
| + + | 0.9888 | 0.9442 | 0.9935 | 0.9972 | 0.9964 |
| + + | 0.9820 | 0.9420 | 0.9877 | 0.9975 | 0.9935 |
| + + + | 0.9913 | 0.9478 | 0.9957 | 0.9984 | 0.9998 |
| Methods | San Diego | Los Angeles | TC-I | TC-II | Bay Champagne |
|---|---|---|---|---|---|
| RX | 0.3487 | 0.3394 | 0.3383 | 0.3385 | 0.3295 |
| LRX | 50.182 | 42.242 | 52.412 | 41.355 | 33.013 |
| CRD | 7.9219 | 7.4165 | 17.611 | 7.1397 | 6.7964 |
| RPCA | 8.4508 | 11.005 | 10.850 | 12.244 | 8.6443 |
| GTVLRR | 193.26 | 198.99 | 229.40 | 206.43 | 220.18 |
| LRASR | 47.281 | 56.037 | 52.722 | 57.853 | 98.447 |
| LSMAD | 11.534 | 11.842 | 11.815 | 12.570 | 11.093 |
| BEGAIP | 10.145 | 11.195 | 10.720 | 9.7566 | 10.1674 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Z.; Shi, S.; Wang, L.; Xu, M.; Li, L. Unsupervised Generative Adversarial Network with Background Enhancement and Irredundant Pooling for Hyperspectral Anomaly Detection. Remote Sens. 2022, 14, 1265. https://doi.org/10.3390/rs14051265
Li Z, Shi S, Wang L, Xu M, Li L. Unsupervised Generative Adversarial Network with Background Enhancement and Irredundant Pooling for Hyperspectral Anomaly Detection. Remote Sensing. 2022; 14(5):1265. https://doi.org/10.3390/rs14051265
Chicago/Turabian StyleLi, Zhongwei, Shunxiao Shi, Leiquan Wang, Mingming Xu, and Luyao Li. 2022. "Unsupervised Generative Adversarial Network with Background Enhancement and Irredundant Pooling for Hyperspectral Anomaly Detection" Remote Sensing 14, no. 5: 1265. https://doi.org/10.3390/rs14051265
APA StyleLi, Z., Shi, S., Wang, L., Xu, M., & Li, L. (2022). Unsupervised Generative Adversarial Network with Background Enhancement and Irredundant Pooling for Hyperspectral Anomaly Detection. Remote Sensing, 14(5), 1265. https://doi.org/10.3390/rs14051265