
Cycle and Self-Supervised Consistency Training for Adapting Semantic Segmentation of Aerial Images


Abstract
:1. Introduction
- We propose a novel UDA framework for RS image semantic segmentation that combines cycle-consistent image-to-image translation techniques and self-supervised transformation consistency training.
- We investigate multiple transformation functions and enforce transformation consistency to provide supervision for self-supervised training of the model on unlabeled target data. These functions provide different perspectives on how to learn domain-invariant features for semantic segmentation.
- Compared with previous methods, the framework we proposed achieves state-of-the-art performance on two challenging benchmarks of UDA for RS image semantic segmentation. Each consistency component independently outperformed some previous methods. This was verified by extensive ablation studies on our framework.
- The proposed domain adaptation framework is easy to implement and is readily embedded in any existing semantic segmentation model to improve the prediction performance on unlabeled data.
2. Methods
2.1. Overview
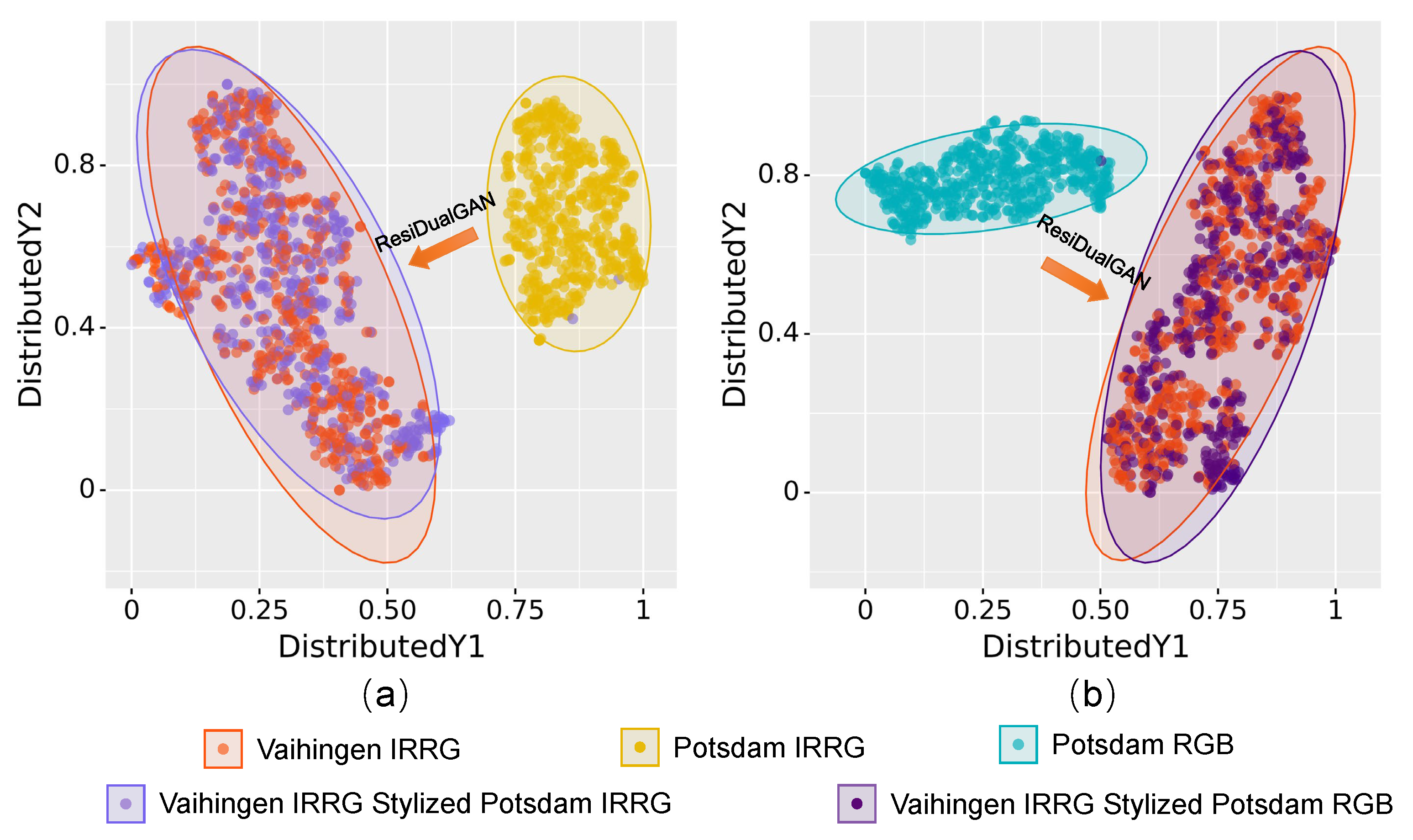
2.2. Cycle Consistency
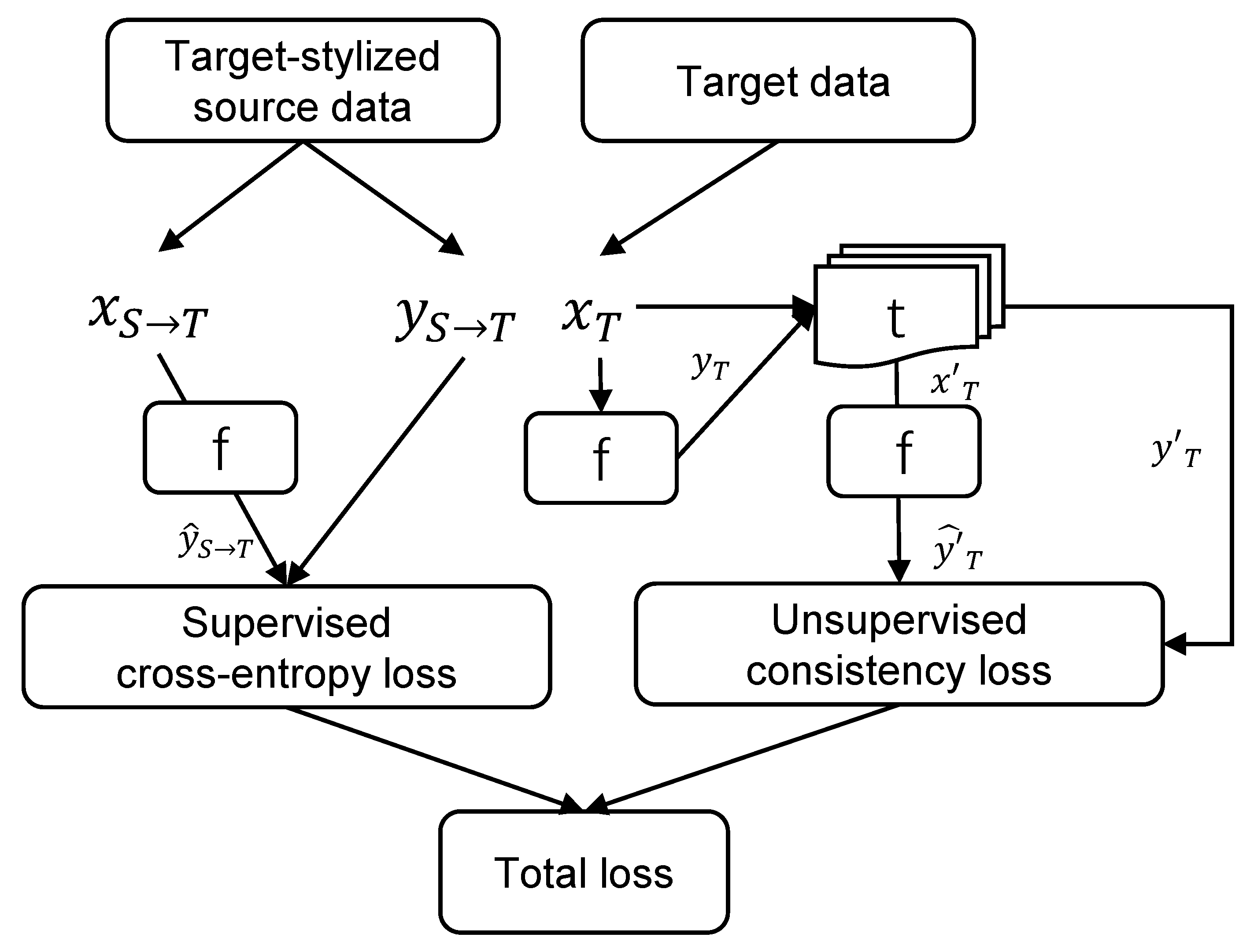
2.3. Self-Supervised Consistency
- Translation consistency: The GAN-based image translation outputs are bidirectional. However, in previous generative-based methods, source-stylized target images are useless in subsequent procedures, which results in a huge waste of computation. With the help of ResiDualGAN, the spatial scale and semantic information are well preserved during target-to-source stylization. Therefore, we regard such translation as transformation and enforce consistency between the model’s outputs on the original target images and the translated target image (Figure 4b).
- Augmentation consistency: Data augmentation in model training is a technique to increase the amount of data by adding modified copies of already existing data. It acts as a regularizer and helps reduce overfitting when training a deep learning model. We randomly augment the target data by flipping, cropping, and brightness-changing. The corresponding augmentation is also performed on pseudolabels (Figure 4c).
- CutMix consistency: CutMix is a regularization method designed for image classification and transfer learning [41]. We leverage this strategy to randomly cut and paste patches from source data to target data. The ground truth labels or pseudolabels are also mixed proportionally. The added patches on target data can be seen as a transformation for consistency training. Pasting patches from the source domain further increases confidence in pseudo labeling (Figure 4d).
3. Experiments
3.1. Datasets
3.2. Implementation Details
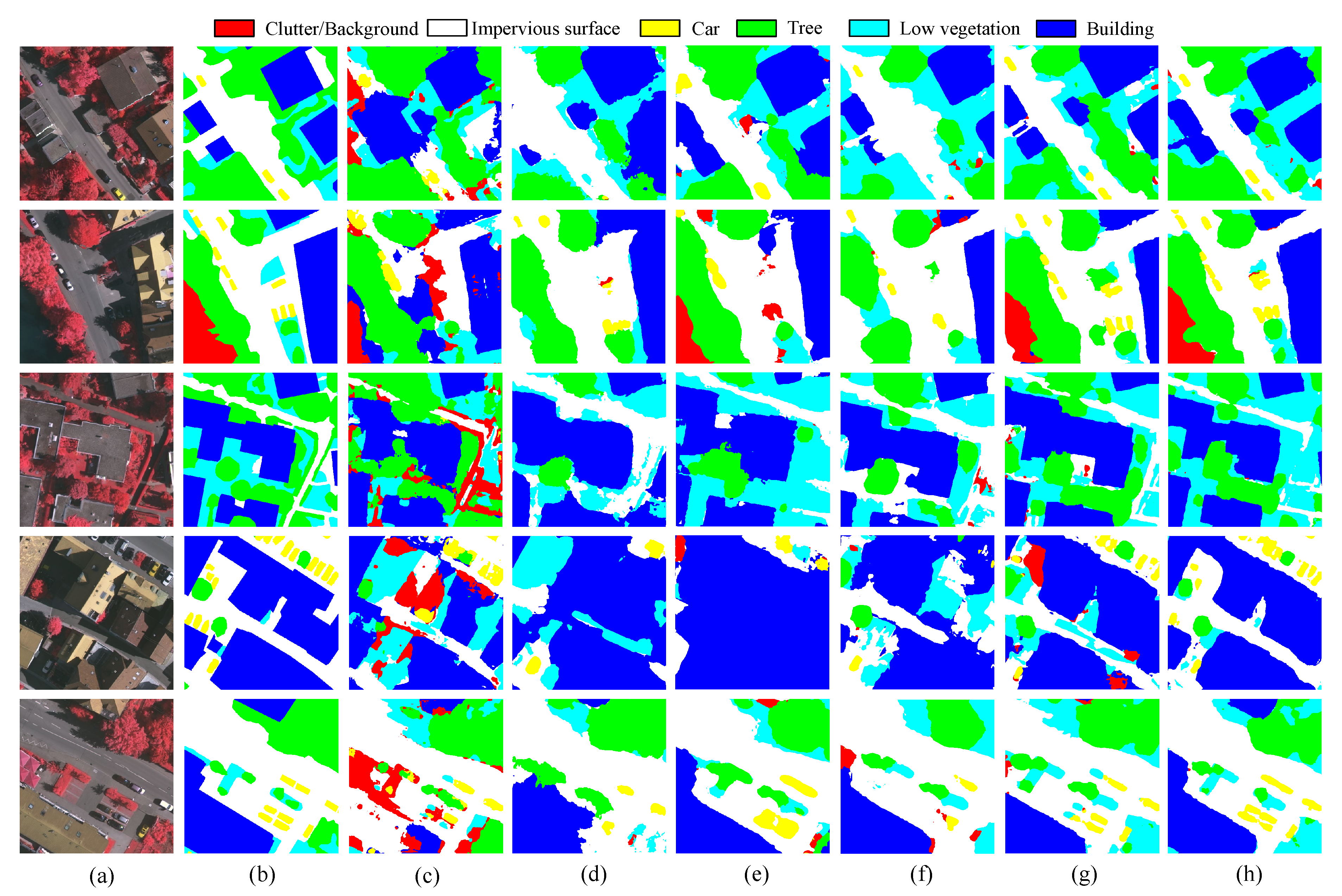
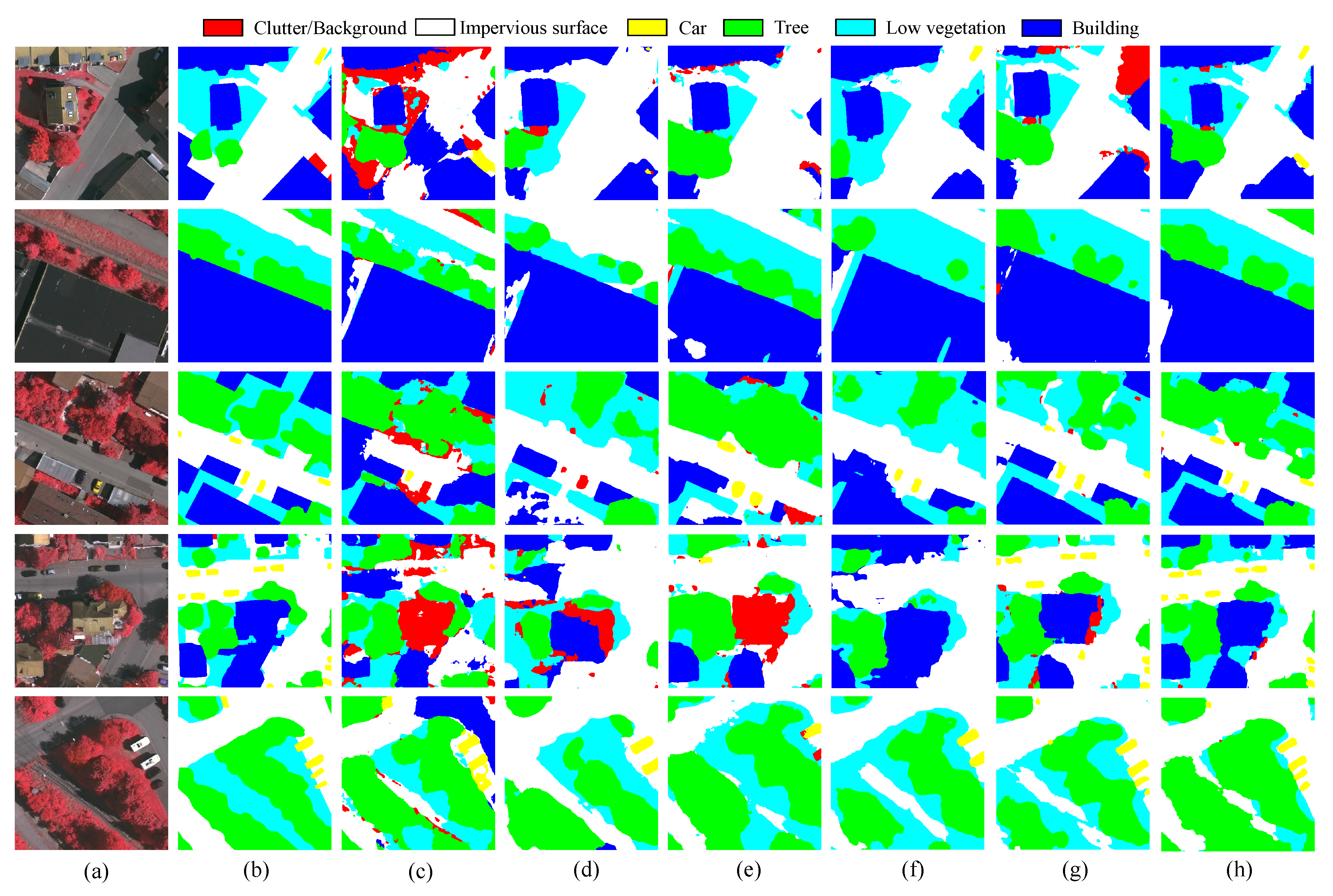
3.3. Performance of the CSC
3.4. Comparison to State-of-the-Art Methods
4. Discussion
4.1. Ablation Study
4.2. Computational Complex Analysis
4.3. Limitations
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Audebert, N. Beyond RGB: Very high resolution urban remote sensing with multimodal deep networks. ISPRS J. Photogramm. Remote Sens. 2018, 140, 20–32. [Google Scholar] [CrossRef] [Green Version]
- Zhou, K.; Chen, Y.; Smal, I.; Lindenbergh, R. Building segmentation from airborne VHR images using Mask R-CNN. ISPRS Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2019, 42, 155–161. [Google Scholar] [CrossRef] [Green Version]
- Chen, K.; Fu, K.; Yan, M.; Gao, X.; Sun, X.; Wei, X. Semantic Segmentation of Aerial Images With Shuffling Convolutional Neural Networks. IEEE Geosci. Remote Sens. Lett. 2018, 15, 5. [Google Scholar] [CrossRef]
- Huang, J.; Zhang, X.; Xin, Q.; Sun, Y.; Zhang, P. Automatic building extraction from high-resolution aerial images and LiDAR data using gated residual refinement network. ISPRS J. Photogramm. Remote Sens. 2019, 151, 91–105. [Google Scholar] [CrossRef]
- Kemker, R.; Salvaggio, C.; Kanan, C. Algorithms for semantic segmentation of multispectral remote sensing imagery using deep learning. ISPRS J. Photogramm. Remote Sens. 2018, 145, 60–77. [Google Scholar] [CrossRef] [Green Version]
- Zhang, L.; Zhang, L.; Du, B. Advances in Machine Learning for Remote Sensing and Geosciences. IEEE Geosci. Remote Sens. Mag. 2016, 19, 22–40. [Google Scholar] [CrossRef]
- Zhu, X.X.; Tuia, D.; Mou, L.; Xia, G.S.; Zhang, L.; Xu, F.; Fraundorfer, F. Deep Learning in Remote Sensing: A Comprehensive Review and List of Resources. IEEE Geosci. Remote Sens. Mag. 2017, 5, 8–36. [Google Scholar] [CrossRef] [Green Version]
- Audebert, N.; Le Saux, B.; Lefèvre, S. Segment-before-Detect: Vehicle Detection and Classification through Semantic Segmentation of Aerial Images. Remote Sens. 2017, 9, 368. [Google Scholar] [CrossRef] [Green Version]
- Zhao, W.; Du, S.; Wang, Q.; Emery, W.J. Contextually guided very-high-resolution imagery classification with semantic segments. ISPRS J. Photogramm. Remote Sens. 2017, 132, 48–60. [Google Scholar] [CrossRef]
- Garcia-Garcia, A.; Orts-Escolano, S.; Oprea, S.; Villena-Martinez, V.; Garcia-Rodriguez, J. A Review on Deep Learning Techniques Applied to Semantic Segmentation. arXiv 2017, arXiv:1704.06857. [Google Scholar]
- Tuia, D.; Persello, C.; Bruzzone, L. Domain Adaptation for the Classification of Remote Sensing Data: An Overview of Recent Advances. IEEE Geosci. Remote Sens. Mag. 2016, 4, 41–57. [Google Scholar] [CrossRef]
- Wang, M.; Deng, W. Deep Visual Domain Adaptation: A Survey. arXiv 2018, arXiv:1802.03601. [Google Scholar] [CrossRef] [Green Version]
- Toldo, M.; Maracani, A.; Michieli, U.; Zanuttigh, P. Unsupervised Domain Adaptation in Semantic Segmentation: A Review. Technologies 2020, 8, 35. [Google Scholar] [CrossRef]
- Benjdira, B.; Bazi, Y.; Koubaa, A.; Ouni, K. Unsupervised Domain Adaptation Using Generative Adversarial Networks for Semantic Segmentation of Aerial Images. Remote Sens. 2019, 11, 1369. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Shi, T.; Zhang, Y.; Chen, W.; Wang, Z.; Li, H. Learning deep semantic segmentation network under multiple weakly-supervised constraints for cross-domain remote sensing image semantic segmentation. ISPRS J. Photogramm. Remote Sens. 2021, 175, 20–33. [Google Scholar] [CrossRef]
- Tasar, O.; Happy, S.L.; Tarabalka, Y.; Alliez, P. ColorMapGAN: Unsupervised Domain Adaptation for Semantic Segmentation Using Color Mapping Generative Adversarial Networks. IEEE Trans. Geosci. Remote Sens. 2020, 58, 7178–7193. [Google Scholar] [CrossRef] [Green Version]
- Tasar, O.; Giros, A.; Tarabalka, Y.; Alliez, P.; Clerc, S. DAugNet: Unsupervised, Multisource, Multitarget, and Life-Long Domain Adaptation for Semantic Segmentation of Satellite Images. IEEE Trans. Geosci. Remote Sens. 2021, 59, 1067–1081. [Google Scholar] [CrossRef]
- Ji, S.; Wang, D.; Luo, M. Generative Adversarial Network-Based Full-Space Domain Adaptation for Land Cover Classification From Multiple-Source Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2021, 59, 3816–3828. [Google Scholar] [CrossRef]
- Wittich, D.; Rottensteiner, F. Appearance based deep domain adaptation for the classification of aerial images. ISPRS J. Photogramm. Remote Sens. 2021, 180, 82–102. [Google Scholar] [CrossRef]
- Mateo-García, G.; Laparra, V.; López-Puigdollers, D.; Gómez-Chova, L. Cross-Sensor Adversarial Domain Adaptation of Landsat-8 and Proba-V Images for Cloud Detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 747–761. [Google Scholar] [CrossRef]
- Soto, P.J.; Costa, G.A.O.P.; Feitosa, R.Q.; Happ, P.N.; Ortega, M.X.; Noa, J.; Almeida, C.A.; Heipke, C. Domain adaptation with cyclegan for change detection in the Amazon forest. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2020, 43, 1635–1643. [Google Scholar] [CrossRef]
- Kou, R.; Fang, B.; Chen, G.; Wang, L. Progressive Domain Adaptation for Change Detection Using Season-Varying Remote Sensing Images. Remote Sens. 2020, 12, 3815. [Google Scholar] [CrossRef]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks. arXiv 2020, arXiv:1703.10593. [Google Scholar]
- Yi, Z.; Zhang, H.; Tan, P.; Gong, M. DualGAN: Unsupervised Dual Learning for Image-to-Image Translation. arXiv 2018, arXiv:1704.02510. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional Generative Adversarial Nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Zhang, Z.; Doi, K.; Iwasaki, A.; Xu, G. Unsupervised Domain Adaptation of High-Resolution Aerial Images via Correlation Alignment and Self Training. IEEE Geosci. Remote Sens. Lett. 2021, 18, 746–750. [Google Scholar] [CrossRef]
- Zhang, B.; Chen, T.; Wang, B. Curriculum-Style Local-to-Global Adaptation for Cross-Domain Remote Sensing Image Segmentation. IEEE Trans. Geosci. Remote Sens. 2021. [Google Scholar] [CrossRef]
- Shen, W.; Wang, Q.; Jiang, H.; Li, S.; Yin, J. Unsupervised domain adaptation for semantic segmentation via self-supervision. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021; pp. 2747–2750. [Google Scholar] [CrossRef]
- Chen, Y.; Ouyang, X.; Zhu, K.; Agam, G. Domain Adaptation on Semantic Segmentation for Aerial Images. arXiv 2020, arXiv:2012.02264. [Google Scholar]
- Liu, W.; Su, F.; Jin, X.; Li, H.; Qin, R. Bispace Domain Adaptation Network for Remotely Sensed Semantic Segmentation. IEEE Trans. Geosci. Remote Sens. 2020, 60, 1–11. [Google Scholar] [CrossRef]
- Kim, T.; Cha, M.; Kim, H.; Lee, J.K.; Kim, J. Learning to Discover Cross-Domain Relations with Generative Adversarial Networks. arXiv 2017, arXiv:1703.05192. [Google Scholar]
- Zhao, Y.; Gao, H.; Guo, P.; Sun, Z. ResiDualGAN: Resize-Residual DualGAN for Cross-Domain Remote Sensing Images Semantic Segmentation. arXiv 2022, arXiv:2201.11523. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Melas-Kyriazi, L.; Manrai, A.K. PixMatch: Unsupervised Domain Adaptation via Pixelwise Consistency Training. arXiv 2021, arXiv:2105.08128. [Google Scholar]
- Araslanov, N.; Roth, S. Self-supervised Augmentation Consistency for Adapting Semantic Segmentation. arXiv 2021, arXiv:2105.00097. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A Simple Framework for Contrastive Learning of Visual Representations. In Proceedings of the 37th International Conference on Machine Learning, PMLR, Virtual Event, 12–18 July 2020; pp. 1597–1607. [Google Scholar]
- Berthelot, D.; Carlini, N.; Goodfellow, I.; Papernot, N.; Oliver, A.; Raffel, C. MixMatch: A Holistic Approach to Semi-Supervised Learning. arXiv 2019, arXiv:1905.02249. [Google Scholar]
- Berthelot, D.; Carlini, N.; Cubuk, E.D.; Kurakin, A.; Sohn, K.; Zhang, H.; Raffel, C. ReMixMatch: Semi-Supervised Learning with Distribution Alignment and Augmentation Anchoring. arXiv 2020, arXiv:1911.09785. [Google Scholar]
- Sohn, K.; Berthelot, D.; Li, C.L.; Zhang, Z.; Carlini, N.; Cubuk, E.D.; Kurakin, A.; Zhang, H.; Raffel, C. FixMatch: Simplifying Semi-Supervised Learning with Consistency and Confidence. Adv. Neural Inf. Process. Syst. 2020, 33, 596–608. [Google Scholar]
- Xie, Q.; Dai, Z.; Hovy, E.; Luong, T.; Le, Q. Unsupervised data augmentation for consistency training. Adv. Neural Inf. Process. Syst. 2020, 33, 6256–6268. [Google Scholar]
- Yun, S.; Han, D.; Oh, S.J.; Chun, S.; Choe, J.; Yoo, Y. Cutmix: Regularization strategy to train strong classifiers with localizable features. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 6023–6032. [Google Scholar]
- Gerke, M. Use of the Stair Vision Library within the ISPRS 2D Semantic Labeling Benchmark (Vaihingen); University of Twente: Enschede, The Netherlands, 2015. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. Adv. Neural Inf. Process. Syst. 2019, 32. Available online: https://proceedings.neurips.cc/paper/2019/hash/bdbca288fee7f92f2bfa9f7012727740-Abstract.html (accessed on 2 January 2022).
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. arXiv 2018, arXiv:1802.02611. [Google Scholar]
- Tsai, Y.H.; Hung, W.C.; Schulter, S.; Sohn, K.; Yang, M.H.; Chandraker, M. Learning to adapt structured output space for semantic segmentation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7472–7481. [Google Scholar] [CrossRef] [Green Version]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Metrics | Clutter/ Background | Impervious Surface | Car | Tree | Low Vegetation | Building | Overall |
|---|---|---|---|---|---|---|---|---|
| Baseline (DeepLabv3+ [44]) | IoU | 2.67 | 40.24 | 18.35 | 53.14 | 12.88 | 52.63 | 29.98 |
| F1-score | 4.65 | 56.93 | 30.40 | 69.19 | 22.68 | 68.74 | 42.10 | |
| GAN-RSDA [14] | IoU | 2.29 | 48.27 | 25.73 | 42.16 | 23.34 | 64.33 | 34.35 |
| F1-score | 3.50 | 64.79 | 40.20 | 59.03 | 37.55 | 78.13 | 47.20 | |
| AdaptSegNet [45] | IoU | 6.26 | 55.91 | 34.09 | 47.56 | 23.18 | 65.97 | 38.83 |
| F1-score | 9.55 | 71.44 | 50.34 | 64.17 | 37.22 | 79.36 | 52.01 | |
| MUCSS [15] | IoU | 5.87 | 54.21 | 27.95 | 43.73 | 26.94 | 68.76 | 37.91 |
| F1-score | 8.77 | 70.04 | 42.89 | 60.53 | 42.09 | 81.26 | 50.93 | |
| CCDA [27] | IoU | 12.38 | 64.47 | 43.43 | 52.83 | 38.37 | 76.87 | 48.06 |
| F1-score | 21.55 | 77.76 | 60.05 | 69.62 | 55.94 | 86.95 | 61.98 | |
| RDG-OSA [32] | IoU | 9.84 | 62.59 | 54.22 | 56.31 | 37.86 | 79.33 | 50.02 |
| F1-score | 14.55 | 76.81 | 70.00 | 71.92 | 54.55 | 88.41 | 62.71 | |
| CSC-Trans | IoU | 5.79 | 57.32 | 52.93 | 51.78 | 30.61 | 74.31 | 45.46 |
| F1-score | 9.16 | 72.69 | 69.02 | 68.11 | 46.40 | 85.13 | 58.42 | |
| CSC-Aug | IoU | 8.12 | 68.91 | 57.41 | 65.47 | 48.33 | 81.78 | 55.00 |
| F1-score | 11.23 | 81.48 | 72.76 | 79.04 | 64.78 | 89.94 | 66.54 | |
| CSC-CutMix | IoU | 10.21 | 10.21 | 53.89 | 56.43 | 37.29 | 78.32 | 49.94 |
| F1-score | 14.81 | 14.81 | 69.74 | 72.00 | 54.02 | 87.74 | 62.64 |
| Method | Metrics | Clutter/ Background | Impervious Surface | Car | Tree | Low Vegetation | Building | Overall |
|---|---|---|---|---|---|---|---|---|
| Baseline (DeepLabv3+ [44]) | IoU | 2.99 | 47.88 | 20.82 | 58.74 | 19.57 | 61.37 | 35.23 |
| F1-score | 5.18 | 64.40 | 33.93 | 73.88 | 32.47 | 75.83 | 47.61 | |
| GAN-RSDA [14] | IoU | 7.26 | 57.32 | 20.04 | 44.27 | 35.47 | 65.35 | 38.28 |
| F1-score | 10.32 | 72.60 | 32.53 | 61.04 | 51.99 | 78.84 | 51.22 | |
| AdaptSegNet [45] | IoU | 6.32 | 62.50 | 29.31 | 55.74 | 40.30 | 70.41 | 44.10 |
| F1-score | 9.67 | 76.66 | 44.81 | 71.36 | 57.01 | 82.50 | 57.00 | |
| MUCSS [15] | IoU | 11.16 | 65.94 | 26.30 | 50.49 | 39.85 | 69.07 | 43.80 |
| F1-score | 14.70 | 79.15 | 40.77 | 66.76 | 56.55 | 81.53 | 56.58 | |
| CCDA [27] | IoU | \ | 58.64 | 28.17 | 53.28 | 30.39 | 60.60 | 46.22 |
| F1-score | \ | 75.13 | 45.81 | 69.52 | 47.62 | 76.89 | 62.99 | |
| RDG-OSA [32] | IoU | 10.70 | 70.31 | 54.04 | 59.22 | 49.03 | 81.20 | 54.08 |
| F1-score | 15.48 | 82.43 | 69.85 | 74.22 | 65.52 | 89.57 | 66.18 | |
| CSC-Trans | IoU | 8.42 | 65.67 | 54.75 | 61.72 | 42.69 | 75.88 | 51.52 |
| F1-score | 12.77 | 79.15 | 70.56 | 76.23 | 59.46 | 86.20 | 64.06 | |
| CSC-Aug | IoU | 13.83 | 75.56 | 56.58 | 65.55 | 52.92 | 84.17 | 58.10 |
| F1-score | 19.59 | 86.01 | 72.01 | 79.09 | 68.96 | 91.38 | 69.50 | |
| CSC-CutMix | IoU | 10.46 | 73.31 | 57.91 | 63.58 | 51.58 | 81.25 | 56.35 |
| F1-score | 14.91 | 84.50 | 73.05 | 77.57 | 67.86 | 89.56 | 67.91 |
| Method | Potsdam RGB → Vaihingen IRRG | Potsdam IRRG → Vaihingen IRRG | ||
|---|---|---|---|---|
| mIoU | mIoU | |||
| Cycle + Self-supervised | 55.00 | 0.00 | 58.10 | 0.00 |
| Cycle consistency only | 48.50 | 54.09 | ||
| Self-supervised consistency only | 36.56 | 48.10 | ||
| Source only | 29.98 | 35.23 | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, H.; Zhao, Y.; Guo, P.; Sun, Z.; Chen, X.; Tang, Y. Cycle and Self-Supervised Consistency Training for Adapting Semantic Segmentation of Aerial Images. Remote Sens. 2022, 14, 1527. https://doi.org/10.3390/rs14071527
Gao H, Zhao Y, Guo P, Sun Z, Chen X, Tang Y. Cycle and Self-Supervised Consistency Training for Adapting Semantic Segmentation of Aerial Images. Remote Sensing. 2022; 14(7):1527. https://doi.org/10.3390/rs14071527
Chicago/Turabian StyleGao, Han, Yang Zhao, Peng Guo, Zihao Sun, Xiuwan Chen, and Yunwei Tang. 2022. "Cycle and Self-Supervised Consistency Training for Adapting Semantic Segmentation of Aerial Images" Remote Sensing 14, no. 7: 1527. https://doi.org/10.3390/rs14071527
APA StyleGao, H., Zhao, Y., Guo, P., Sun, Z., Chen, X., & Tang, Y. (2022). Cycle and Self-Supervised Consistency Training for Adapting Semantic Segmentation of Aerial Images. Remote Sensing, 14(7), 1527. https://doi.org/10.3390/rs14071527