
Multivariate Analysis for Solar Resource Assessment Using Unsupervised Learning on Images from the GOES-13 Satellite

 , ,
, ,  ,
,  ,
,
Abstract
:1. Introduction
2. Materials and Methods
3. Theory/Calculation
3.1. Clustering Analysis
- (1)
- Expectation step
- (a)
- Initialize , and with random values.
- (b)
- Estimate with the parameters .
- (2)
- Maximization step
- (a)
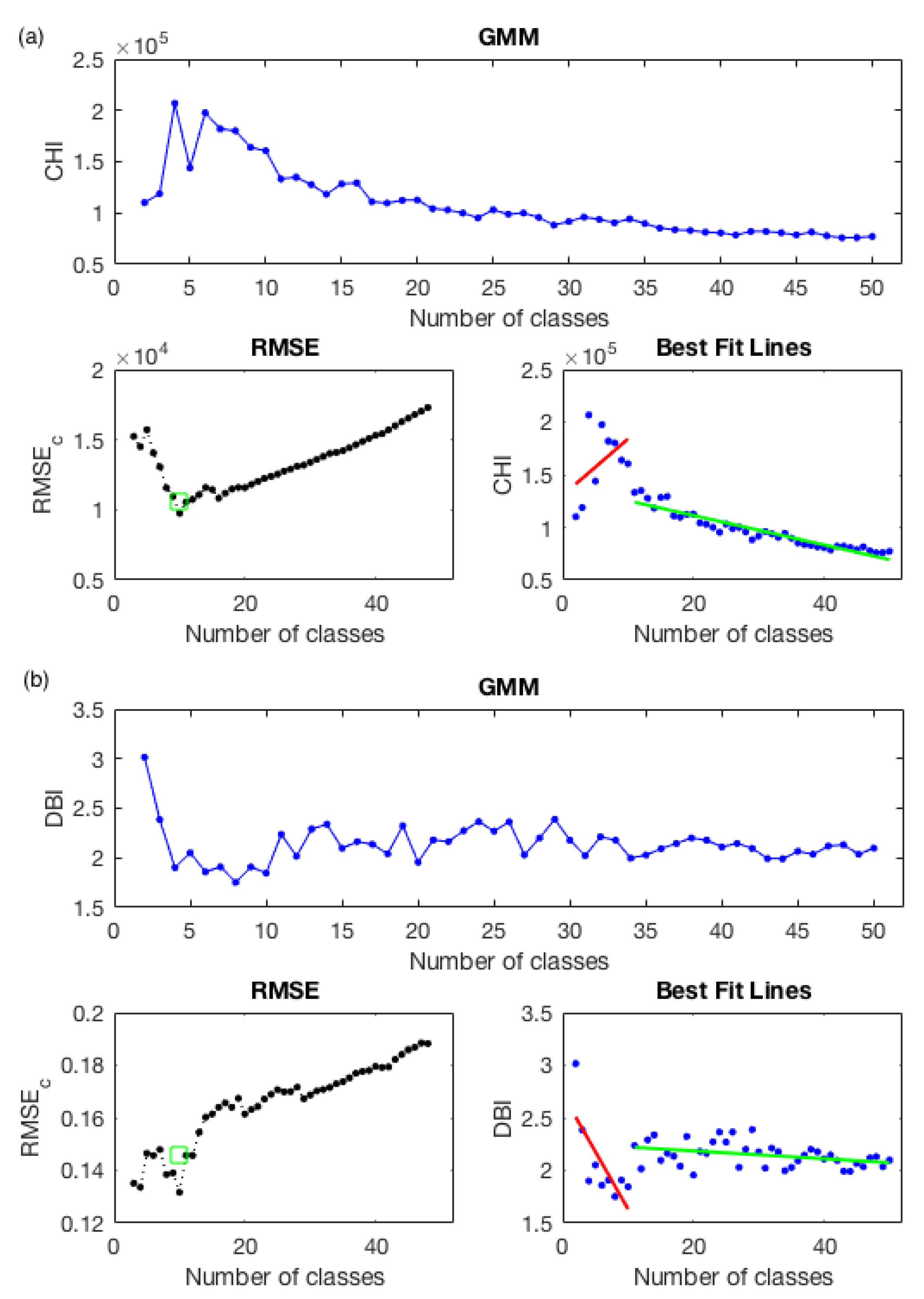
Clustering Evaluation
4. Results
4.1. Preprocessing Results
4.1.1. Clustering Analysis and Validation (Results)
4.1.2. Relationship between Clusters and the Solar Radiation
5. Discussion
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| CH | Calinski Harabasz |
| DB | Davis Bouldin |
| EM | expectation–maximization |
| EMAS | automatic weather station |
| GHI | global horizontal irradiance |
| GMM | Gaussian mixture models |
| GOES-13 | Geostationary Operational Environmental Satellite-13 |
| Lat | latitude |
| Lon | longitude |
| mAMSL | meters above mean sea level |
| NEDIS | National Environmental Satellite Data and Information Service |
| NetCDF | network common data form |
| NOAA | National Oceanic and Atmospheric Administration |
| PCA | principal component analysis |
| coefficient of determination | |
| RMSEc | root mean squared error of a critical point c |
| RMSELc | root mean squared error on the left side of the critical point c |
| RMSERc | root mean squared error on the right side of the critical point c |
| SI | silhouette index |
| SMN | National Weather Service |
| SVM | support vector machine |
| TL2 | Linke turbidity |
| UNAM | National Autonomous University of Mexico |
| XDB | database of the variables |
References
- Aitken, D. Transitioning to a Renewable Energy Future; ISES White Paper; International Solar Energy Society: Freiburg, Germany, 2003. [Google Scholar]
- Holm, D.; McIntosh, J. Renewable energy–the future for the developing world. Renew. Energy Focus 2008, 9, 56–61. [Google Scholar] [CrossRef]
- Riveros-Rosas, D.; Bonifaz, R.; Valdes, M.; Rivas, R. Análisis por Región de Información Solarimétrica en la República Mexicana. In Proceedings of the XI Congreso Iberoamericano de Energía Solar y XXXVIII Semana Nacional de Energía Solar, Querétaro, México, 6–10 October 2014. [Google Scholar]
- Sengupta, M.; Habte, A.; Wilbert, S.; Gueymard, C.; Remund, J. Best Practices Handbook for the Collection and Use of Solar Resource Data for Solar Energy Applications; Technical Report; National Renewable Energy Lab. (NREL): Golden, CO, USA, 2021. [Google Scholar]
- Zagouras, A.; Kolovos, A.; Coimbra, C.F. Objective framework for optimal distribution of solar irradiance monitoring networks. Renew. Energy 2015, 80, 153–165. [Google Scholar] [CrossRef] [Green Version]
- Martín-Pomares, L.; Romeo, M.G.; Polo, J.; Frías-Paredes, L.; Fernández-Peruchena, C. Sampling Design Optimization of Ground Radiometric Stations. In Solar Resources Mapping; Springer: Berlin/Heidelberg, Germany, 2019; pp. 253–281. [Google Scholar]
- Carvalho, M.; Melo-Gonçalves, P.; Teixeira, J.; Rocha, A. Regionalization of Europe based on a K-Means Cluster Analysis of the climate change of temperatures and precipitation. Phys. Chem. Earth Parts A/B/C 2016, 94, 22–28. [Google Scholar] [CrossRef] [Green Version]
- Zagouras, A.; Kazantzidis, A.; Nikitidou, E.; Argiriou, A. Determination of measuring sites for solar irradiance, based on cluster analysis of satellite-derived cloud estimations. Sol. Energy 2013, 97, 1–11. [Google Scholar] [CrossRef]
- Journée, M.; Müller, R.; Bertrand, C. Solar resource assessment in the Benelux by merging Meteosat-derived climate data and ground measurements. Sol. Energy 2012, 86, 3561–3574. [Google Scholar] [CrossRef]
- Watanabe, T.; Takamatsu, T.; Nakajima, T.Y. Evaluation of variation in surface solar irradiance and clustering of observation stations in Japan. J. Appl. Meteorol. Climatol. 2016, 55, 2165–2180. [Google Scholar] [CrossRef]
- Vindel, J.M.; Valenzuela, R.X.; Navarro, A.A.; Zarzalejo, L.F. Methodology for optimizing a photosynthetically active radiation monitoring network from satellite-derived estimations: A case study over mainland Spain. Atmos. Res. 2018, 212, 227–239. [Google Scholar] [CrossRef]
- Vindel, J.M.; Valenzuela, R.; Navarro, A.A.; Zarzalejo, L.F.; Paz-Gallardo, A.; Souto, J.A.; Méndez-Gómez, R.; Cartelle, D.; Casares, J.J. Modeling Photosynthetically Active Radiation from Satellite-Derived Estimations over Mainland Spain. Remote Sens. 2018, 10, 849. [Google Scholar] [CrossRef] [Green Version]
- Thanh Nga, P.T.; Ha, P.T.; Hang, V.T. Satellite-Based Regionalization of Solar Irradiation in Vietnam by k-Means Clustering. J. Appl. Meteorol. Climatol. 2021, 60, 391–402. [Google Scholar] [CrossRef]
- Laguarda, A.; Alonso-Suárez, R.; Terra, R. Solar irradiation regionalization in Uruguay: Understanding the interannual variability and its relation to El Niño climatic phenomena. Renew. Energy 2020, 158, 444–452. [Google Scholar] [CrossRef]
- De Lima, F.J.L.; Martins, F.R.; Costa, R.S.; Gonçalves, A.R.; Dos Santos, A.P.P.; Pereira, E.B. The seasonal variability and trends for the surface solar irradiation in northeastern region of Brazil. Sustain. Energy Technol. Assess. 2019, 35, 335–346. [Google Scholar]
- Polo, J.; Gastón, M.; Vindel, J.; Pagola, I. Spatial variability and clustering of global solar irradiation in Vietnam from sunshine duration measurements. Renew. Sustain. Energy Rev. 2015, 42, 1326–1334. [Google Scholar] [CrossRef]
- Olcoz Larraéyoz, A. Implementación del Método Heliosat para la Estimación de la Radiación Solar a Partir de Imágenes de Satélite; Technical Report; Universidad Pública de Navarra: Pamplona, Spain, 2014. [Google Scholar]
- Rigollier, C.; Lefèvre, M.; Wald, L. The method Heliosat-2 for deriving shortwave solar radiation from satellite images. Sol. Energy 2004, 77, 159–169. [Google Scholar] [CrossRef] [Green Version]
- Gueymard, C.A.; Lara-fanego, V.; Sengupta, M.; Xie, Y. Surface albedo and reflectance: Review of definitions, angular and spectral effects, and intercomparison of major data sources in support of advanced solar irradiance modeling over the Americas. Sol. Energy 2019, 182, 194–212. [Google Scholar] [CrossRef]
- Laguarda, A.; Abal, G. Índice de turbidez de Linke a partir de irradiación solar global en Uruguay. Av. En Energ. Renov. Y Medio Ambiente 2016, 20, 35–46. [Google Scholar]
- Géron, A. Hands-On Machine Learning with Scikit-Learn and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems; O’Reilly Media: Sebastopol, CA, USA, 2017. [Google Scholar]
- Lantz, B. Machine Learning with R: Expert Techniques for Predictive Modeling; Packt Publishing Ltd.: Birmingham, England, 2019. [Google Scholar]
- Bishop, C.M. Pattern Recognition and Machine Learning (Information Science and Statistics); Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Murphy, K.P. Machine Learning a Probabilistic Perspective, 1st ed.; The MIT Press: Cambridge, MA, USA, 2012; p. 1067. [Google Scholar]
- Zagouras, A.; Pedro, H.T.; Coimbra, C.F. Clustering the solar resource for grid management in island mode. Sol. Energy 2014, 110, 507–518. [Google Scholar] [CrossRef]
- Chi, Y. R Tutorial with Bayesian Statistics Using Stan, 1st ed.; R Tutorials: Cupertino, CA, USA, 2009; p. 563. [Google Scholar]
- Govender, P.; Brooks, M.J.; Matthews, A.P. Cluster analysis for classification and forecasting of solar irradiance in Durban, South Africa. J. Energy S. Afr. 2018, 29, 51–62. [Google Scholar]
- Riveros-Rosas, D.; Arancibia-Bulnes, C.; Bonifaz, R.; Medina, M.; Peón, R.; Valdés, M. Analysis of a solarimetric database for Mexico and comparison with the CSR Model. Renew. Energy 2015, 75, 21–29. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature | Number of Pixels | Number of PCAs | Explained Variance |
|---|---|---|---|
| Albedo | 1,130,253 | 6 | 90.06% |
| TL2 | 1,130,253 | 3 | 95.53% |
| Cloudy Sky index | 1,130,253 | 6 | 93.05% |
| Altitude | 1,130,253 | 1 | 100.0% |
| Station | Lat. °N | Lon. °E | Annual Average Daily Irradiation (Wh/m2) | K-Means: 17 Cl. | K-Means: 4 Cl. | GMM 10 Cl. |
|---|---|---|---|---|---|---|
| Nueva Rosita | 27.92 | 101.33 | 4736.95 | 14 | 3 | 9 |
| Matías Romero | 16.88 | 95.03 | 4744.03 | 1 | 4 | 3 |
| Paraíso | 18.42 | 93.15 | 5348.72 | 1 | 4 | 3 |
| Centla | 18.40 | 92.64 | 4899.53 | 1 | 4 | 3 |
| Mexicali | 32.66 | 115.29 | 5759.59 | 15 | 1 | 7 |
| Presa Abelardo | 32.44 | 116.90 | 5953.55 | 15 | 1 | 7 |
| Ocampo | 28.82 | 102.52 | 5478.52 | 2 | 1 | 5 |
| Maguarachi | 27.85 | 107.99 | 5440.13 | 17 | 1 | 5 |
| Obispo | 24.25 | 107.18 | 5378.4 | 11 | 4 | 4 |
| Monclova | 18.05 | 90.82 | 5242.85 | 4 | 4 | 8 |
| Acaponeta | 22.46 | 105.38 | 5297.43 | 7 | 4 | 1 |
| Agustín Melgar | 25.26 | 104.00 | 5197.85 | 12 | 1 | 5 |
| Metehuala | 23.64 | 100.65 | 5649.75 | 12 | 1 | 2 |
| Oxktzcab | 20.29 | 89.39 | 5250.9 | 4 | 4 | 8 |
| Petacalco | 17.98 | 102.12 | 5402.63 | 7 | 4 | 10 |
| Nevados Toluca | 19.12 | 99.77 | 4390.92 | 16 | 2 | 10 |
| Apatzingan | 19.08 | 102.37 | 5797.92 | 7 | 4 | 10 |
| Angamacutiro | 20.12 | 101.72 | 5913.77 | 10 | 2 | 10 |
| Atoyac | 17.20 | 100.44 | 5471.69 | 7 | 4 | 10 |
| Ixtla | 19.09 | 98.64 | 5060.64 | 16 | 2 | 10 |
| Atlacomulco | 19.79 | 98.87 | 5405.35 | 5 | 2 | 2 |
| Perote | 19.54 | 97.26 | 5607.01 | 16 | 2 | 10 |
| Altzomonil | 19.11 | 98.65 | 4747.28 | 16 | 2 | 10 |
| Miahuatlan | 16.34 | 96.57 | 5636.19 | 7 | 4 | 10 |
| Nochistlan | 17.43 | 97.24 | 5636.27 | 10 | 2 | 10 |
| Nogales | 31.29 | 110.91 | 5959.9 | 8 | 1 | 7 |
| Evaluation: k-means-17 Classes | |||||
|---|---|---|---|---|---|
| Class | Annual Daily Irradiation (Wh/m2) | Albedo | TL2 | Cloudy Sky Index | Altitude (mAMSL) |
| 16 | 4952.0 | 0.7651 | 3.7766 | 0.0706 | 2010 |
| 14 | 4737.0 | 1.5362 | 4.1138 | 0.0797 | 279 |
| 1 | 4997.4 | 0.9692 | 4.1138 | 0.0768 | 282 |
| 12 | 5423.8 | 1.1008 | 3.1486 | 0.0458 | 1890 |
| 4 | 5246.9 | 0.9216 | 4.2178 | 0.0662 | 83 |
| 11 | 5378.4 | 1.407 | 3.8554 | 0.049 | 259 |
| 5 | 5405.4 | 0.9852 | 3.2987 | 0.0456 | 2190 |
| 17 | 5440.1 | 0.8627 | 3.488 | 0.0515 | 2050 |
| 2 | 5478.5 | 1.5647 | 3.6405 | 0.0448 | 1.340 |
| 7 | 5521.2 | 0.9344 | 3.9526 | 0.0435 | 616 |
| 10 | 5775.0 | 0.9273 | 3.792 | 0.039 | 1.450 |
| 15 | 5856.6 | 3.0128 | 3.4441 | 0.041321 | 211 |
| 8 | 5959.9 | 1.7008 | 2.8913 | 0.0386 | 660 |
| Evaluation: k-means-4 Classes | |||||
| Class | Annual Daily Irradiation (Wh/m2) | Albedo | TL2 | Cloudy Sky Index | Altitude (mAMSL) |
| 3 | 4736.95 | 1.4228 | 3.9373 | 0.0724 | 417 |
| 2 | 5251.6 | 0.9089 | 3.5908 | 0.0493 | 1880 |
| 4 | 5315.5 | 1.0929 | 4.0504 | 0.0597 | 300 |
| 1 | 5634.2 | 1.3156 | 3.3587 | 0.0467 | 1410 |
| Evaluation: GMM-10 Classes | |||||
| Class | Annual Daily Irradiation (Wh/m2) | Albedo | TL2 | Cloudy Sky Index | Altitude (mAMSL) |
| 9 | 4736.95 | 1.3981 | 3.9828 | 0.0758 | 412 |
| 3 | 4997.43 | 1.0493 | 3.1392 | 0.045 | 1.900 |
| 8 | 5246.9 | 0.9156 | 4.2207 | 0.0662 | 66 |
| 1 | 5297.4 | 0.9402 | 3.4437 | 0.0467 | 1670 |
| 10 | 5366.4 | 0.8934 | 3.7703 | 0.0455 | 1350 |
| 5 | 5372.2 | 1.5972 | 3.6213 | 0.0458 | 1540 |
| 4 | 5378.4 | 1.2612 | 3.8461 | 0.0501 | 590 |
| 2 | 5528 | 1.0493 | 3.1392 | 0.045 | 1900 |
| 7 | 5891.0 | 1.9808 | 3.1757 | 0.0398 | 528 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Salinas-González, J.D.; García-Hernández, A.; Riveros-Rosas, D.; Moreno-Chávez, G.; Zarzalejo, L.F.; Alonso-Montesinos, J.; Galván-Tejada, C.E.; Mauricio-González, A.; González-Cabrera, A.E. Multivariate Analysis for Solar Resource Assessment Using Unsupervised Learning on Images from the GOES-13 Satellite. Remote Sens. 2022, 14, 2203. https://doi.org/10.3390/rs14092203
Salinas-González JD, García-Hernández A, Riveros-Rosas D, Moreno-Chávez G, Zarzalejo LF, Alonso-Montesinos J, Galván-Tejada CE, Mauricio-González A, González-Cabrera AE. Multivariate Analysis for Solar Resource Assessment Using Unsupervised Learning on Images from the GOES-13 Satellite. Remote Sensing. 2022; 14(9):2203. https://doi.org/10.3390/rs14092203
Chicago/Turabian StyleSalinas-González, Jared D., Alejandra García-Hernández, David Riveros-Rosas, Gamaliel Moreno-Chávez, Luis F. Zarzalejo, Joaquín Alonso-Montesinos, Carlos E. Galván-Tejada, Alejandro Mauricio-González, and Adriana E. González-Cabrera. 2022. "Multivariate Analysis for Solar Resource Assessment Using Unsupervised Learning on Images from the GOES-13 Satellite" Remote Sensing 14, no. 9: 2203. https://doi.org/10.3390/rs14092203
APA StyleSalinas-González, J. D., García-Hernández, A., Riveros-Rosas, D., Moreno-Chávez, G., Zarzalejo, L. F., Alonso-Montesinos, J., Galván-Tejada, C. E., Mauricio-González, A., & González-Cabrera, A. E. (2022). Multivariate Analysis for Solar Resource Assessment Using Unsupervised Learning on Images from the GOES-13 Satellite. Remote Sensing, 14(9), 2203. https://doi.org/10.3390/rs14092203