1. Introduction
Benefiting from the increased spectral resolution of remote sensing sensors, the hyperspectral imaging technique shows great potential for obtaining high-quality land-cover information. Hyperspectral image (HSI) contains much spectral and spatial information, and each pixel contains hundreds of continuous and narrow spectral bands ranging from visible to near-infrared. Therefore, it has been widely used in many fields, such as urban planning [
1], precision agriculture [
2], and mineral exploration [
3]. Among these applications, HSI classification is an important technical tool that aims to assign a unique class to each pixel [
4]. However, due to the insufficient labeled samples and much redundant information, HSI classification remains a challenging task [
5].
In the last decade, various methods have been proposed for HSI classification. These classification methods can be divided into two main categories: traditional machine-learning-based (ML-based) and modern deep-learning-based (DL-based) methods [
6]. Generally, in ML-based methods, researchers first perform feature extraction on the raw HSI and then use classifiers to classify the extracted features. According to the types of features, they can be further divided into the spectral-based method and the spatial–spectral-based method. Commonly, the spectral-based method directly classifies the spectral vector of each pixel, such as random forest [
7], k-nearest neighbors [
8], and support vector machine (SVM) [
9]. Moreover, many methods focus on reducing redundant spectral dimensions, which aim to map the high-dimensional spectral vector into a low-dimensional space, such as principal component analysis (PCA) [
10], linear discriminant analysis [
11], and independent component analysis [
12]. However, it is difficult to identify the land-cover types using spectral features alone. The classification results are often filled with much salt-and-pepper noise. Alternatively, many researchers have discovered that spatial features can provide additional useful information for classification tasks. On the basis of this consideration, researchers have proposed a series of spatial–spectral-based methods for HSI classification, such as Gabor wavelet transform [
13], local binary patterns [
14], and morphological profiles [
15]. Although the above methods can improve the classification accuracy, the feature extraction process relies on a priori knowledge and appropriate parameter settings. These limitations may affect the robustness and discrimination of the extracted features, making it difficult to achieve satisfactory results in complex scenarios [
16].
In recent years, with the continuous improvement of computing power, the development of deep learning techniques has been greatly promoted. Deep neural network models can automatically extract highly robust and discriminative features from the raw data. They have made significant breakthroughs in many computer vision tasks, including image classification [
17], semantic segmentation [
18], and remote sensing image processing [
19]. Naturally, in the field of HSI classification, research methods are gradually converging to state-of-art deep learning techniques. Currently, many effective classification models based on deep learning methods have been proposed. Chen et al. [
20] proposed a stacked autoencoder deep neural network for spatial–spectral classification. It is the first application of DL-based methods to HSI classification. After that, many DL-based classification methods were proposed, and especially convolutional neural networks have attracted much attention.
Convolutional neural network (CNN) with multiple hidden layers has a powerful feature learning capability. It can provide more discriminative features with fine quality for HSI classification. Hu et al. [
21] first used a one-dimensional (1-D) CNN to extract deep spectral features from each pixel for HSI classification. In addition, Yu et al. [
22] proposed an improved 1-D CNN framework, which embeds pre-extracted hashing features in the network. To fully utilize the spatial context information, some two-dimensional (2-D) CNN has been applied to HSI classification and achieved desirable performance. Chen et al. [
23] extracted the first principal component from the HSI data by PCA along the spectral dimension and then fed it into a 2-D CNN model to extract the spatial depth features. Yu et al. [
24] applied a multiple 2-D CNN layer with a 1 × 1 convolutional kernel to extract deep spatial features for HSI classification. However, the high spectral dimension in HSI may increase the number of learnable parameters of the 2-D CNN model, and the correlation of local spectra may be neglected. Compared with the 2-D CNN model, the three-dimensional (3-D) CNN model can simultaneously extract joint spatial–spectral features. Mei et al. [
25] proposed an unsupervised 3-D convolutional autoencoder to extract the joint spatial-spectral feature. Roy et al. [
26] proposed a hybrid 3-D and 2-D CNN model for HSI classification (HYNN). This model first uses 3-D CNN to extract shallow joint spatial-spectral features and then uses 2-D CNN to extract more abstract spatial texture features. Moreover, to reduce the computational cost of 3-D CNN, Zhang et al. [
27] proposed a 3-D depth-wise separable CNN for HSI classification. Recently, inspired by the residual network [
28], Zhong et al. [
29] proposed a spectral–spatial residual network (SSRN), which uses spectral and spatial 3-D residual blocks to learn deep-level features of HSI. Subsequently, inspired by SSRN and DenseNet [
30], Wang et al. [
31] proposed an end-to-end fast densely connected spectral-spatial classification framework (FDSS), which can more effectively reuse features in a few training samples. Although these CNN-based classification models can extract rich spatial and spectral features of HSI, since the convolution kernel is localized, it needs to expand the field of perception by stacking convolution layers, which may lead to a large number of useless features propagated to the deeper convolutional layers. Those useless features will affect the learning efficiency of the model and eventually lead to a decrease in classification accuracy. Thus, finding and focusing on the discriminative features of HSI is an important problem.
Inspired by the human visual system, many researchers have introduced the attention mechanism to computer vision tasks, such as object detection [
32], image caption [
33], and image enhancement [
34]. Since the attention mechanism can pay attention to valuable features or regions in the feature map, some researchers have successfully introduced it to HSI classification. Fang et al. [
35] proposed a densely connected spectral-wise attention mechanism network, in which the squeeze-and-excitation (SE) attention module [
36] is applied to recalibrate each spectral contribution. Later, many similar spectral attention modules were introduced for HSI classification to highlight valuable spectral and suppress unless ones. For example, Li et al. [
37] proposed a spectral band attention module through the adversarial learning method, in which the attention module can explore the contribution of each band and avoid the spectral distortion. Roy et al. [
38] proposed a fused SE attention module, in which two different squeezing operations, global pooling and max pooling, are used to generate the excitation weight. To make the network simultaneously boost and suppress features in both spectral and spatial dimensions, many networks based on spectral–spatial attention modules have been proposed for HSI classification. Inspired by SSRN and convolutional block attention module (CBAM) [
39], Ma et al. [
40] proposed a double-branch multi-attention network (DBMA), in which the spectral and spatial branches are equipped with spectral-wise attention and spatial-wise attention, respectively. Subsequently, Li et al. [
41] constructed a double-branch dual attention (DBDA) network for HSI classification, in which the dual attention network (DANet) [
42] is inserted separately into two branches. Compared with CBAM, DANet can adaptively integrate local features and global dependencies. In addition, to obtain the long-distance spatial and spectral features, Shi et al. [
43] proposed a 3-D coordination attention mechanism network, and the 3-D attention module could be better adapted to the 3-D structure of the HSI. Li et al. [
44] proposed a spectral–spatial global context attention [
45] network (SSGC) with less time cost to capture more discriminative features. Moreover, in [
46], Shi et al. proposed a pyramidal convolution and iterative attention network (PCIA), in which each branch can extract hierarchical features. Although the above three attention-based methods can achieve good classification results, they compress a large spatial or spectral resolution in obtaining the attention feature map. Meanwhile, the feature extraction process requires a high computational cost due to their simple application dense connection modules.
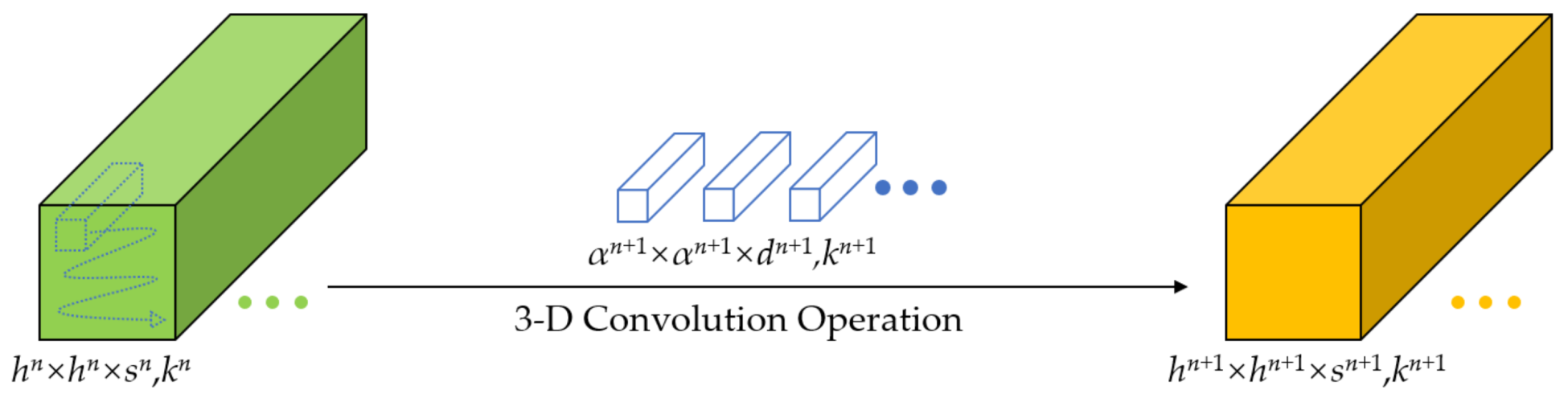
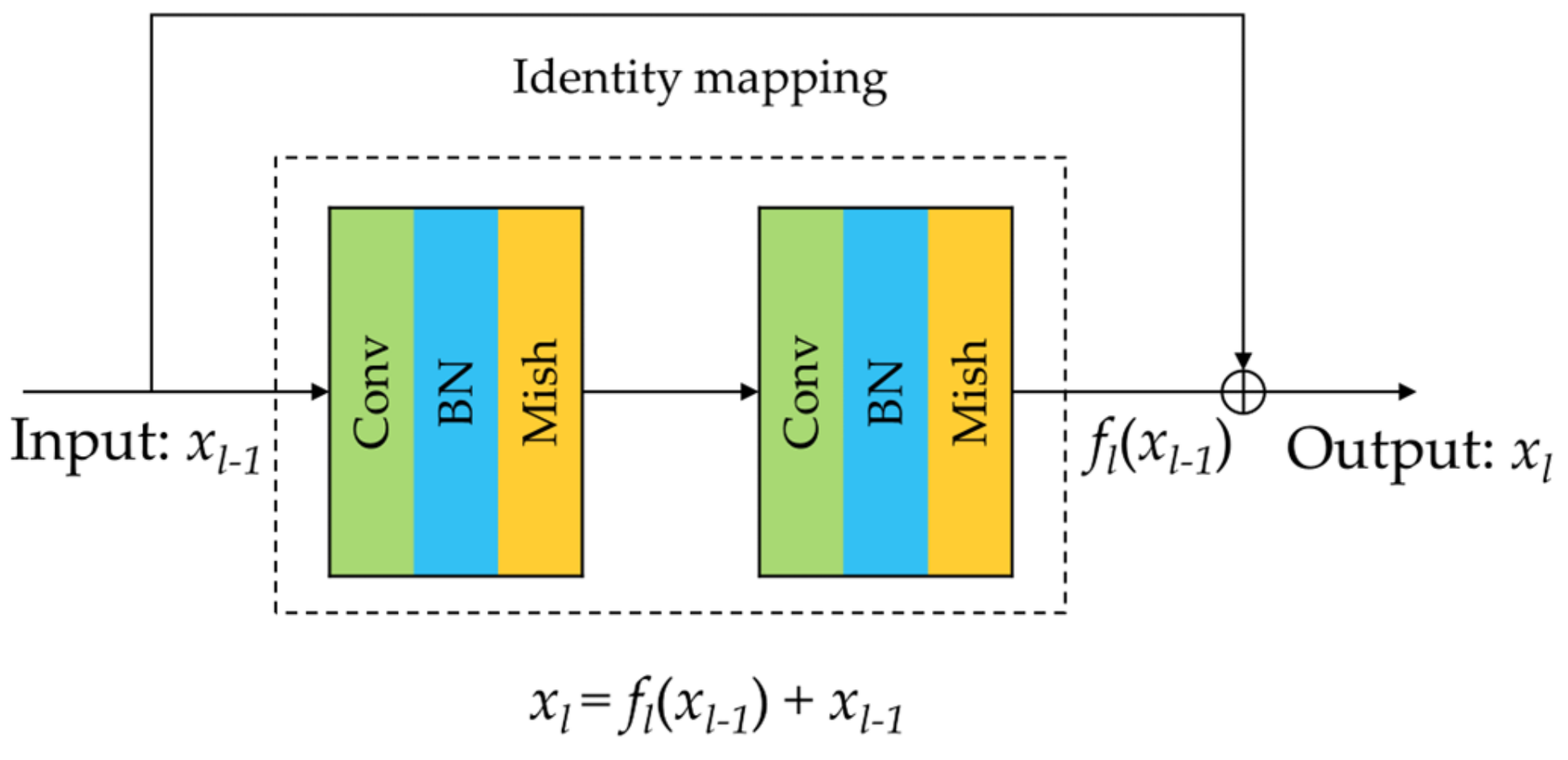
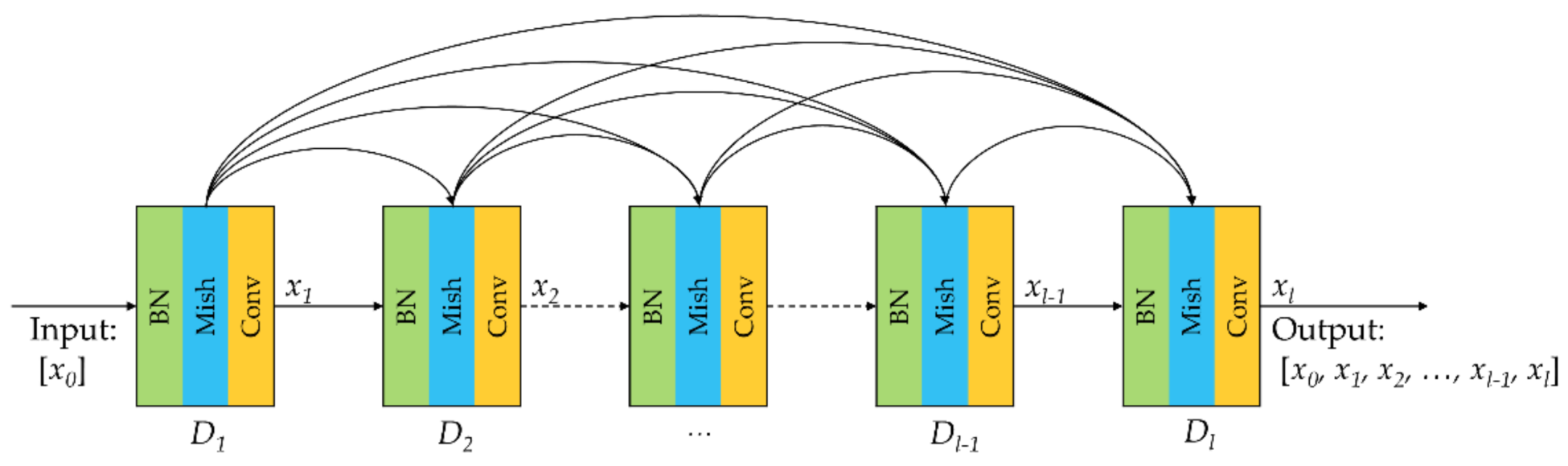
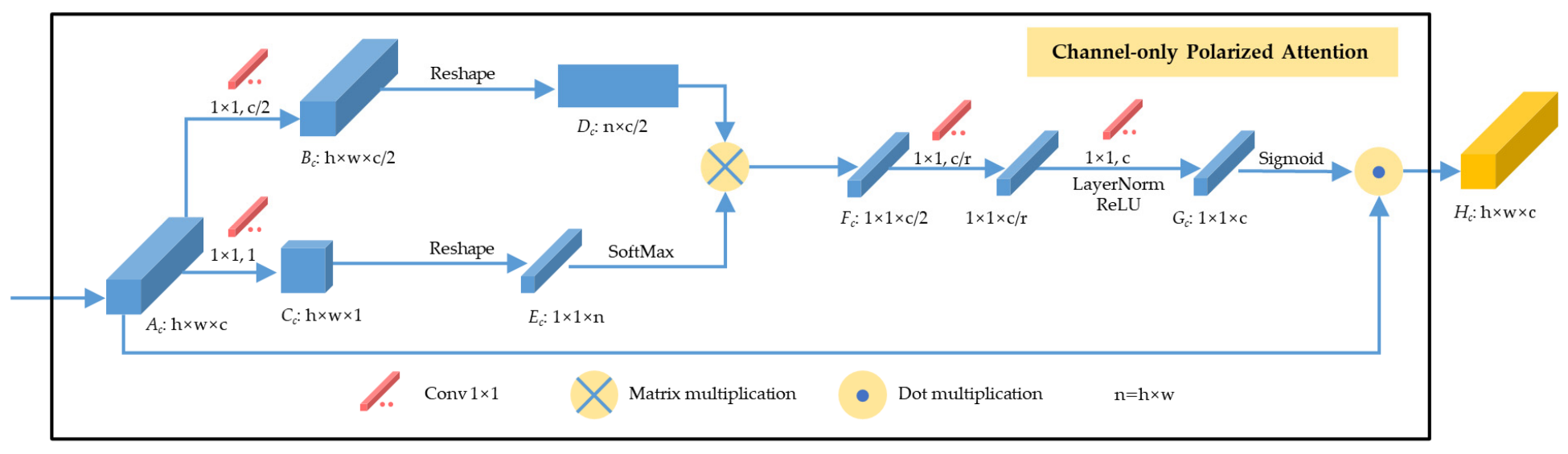
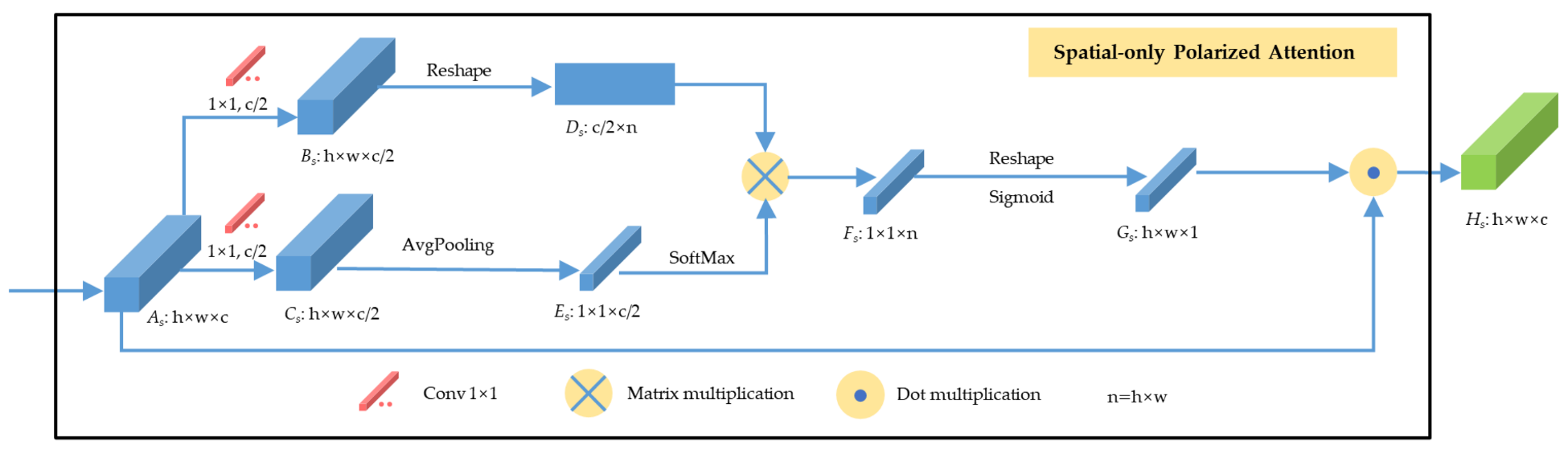
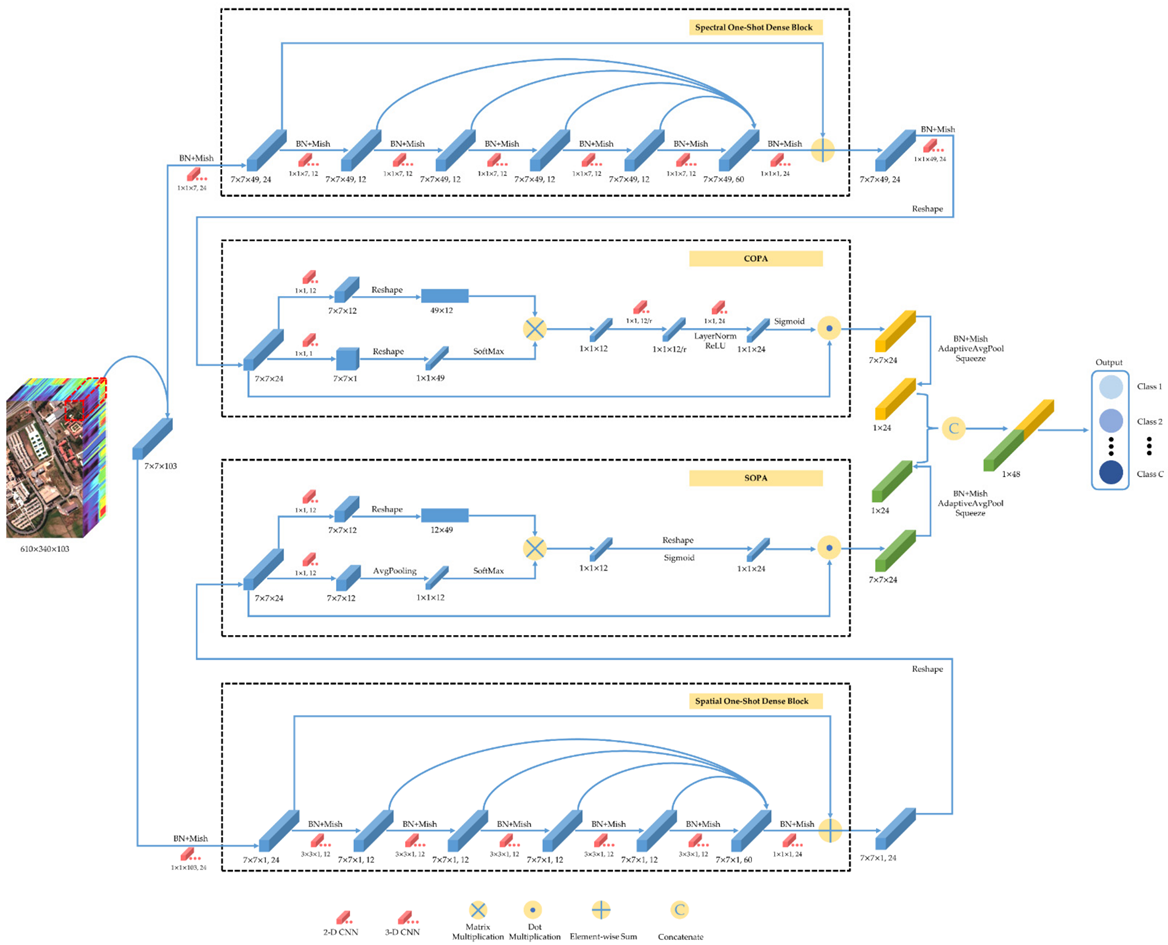
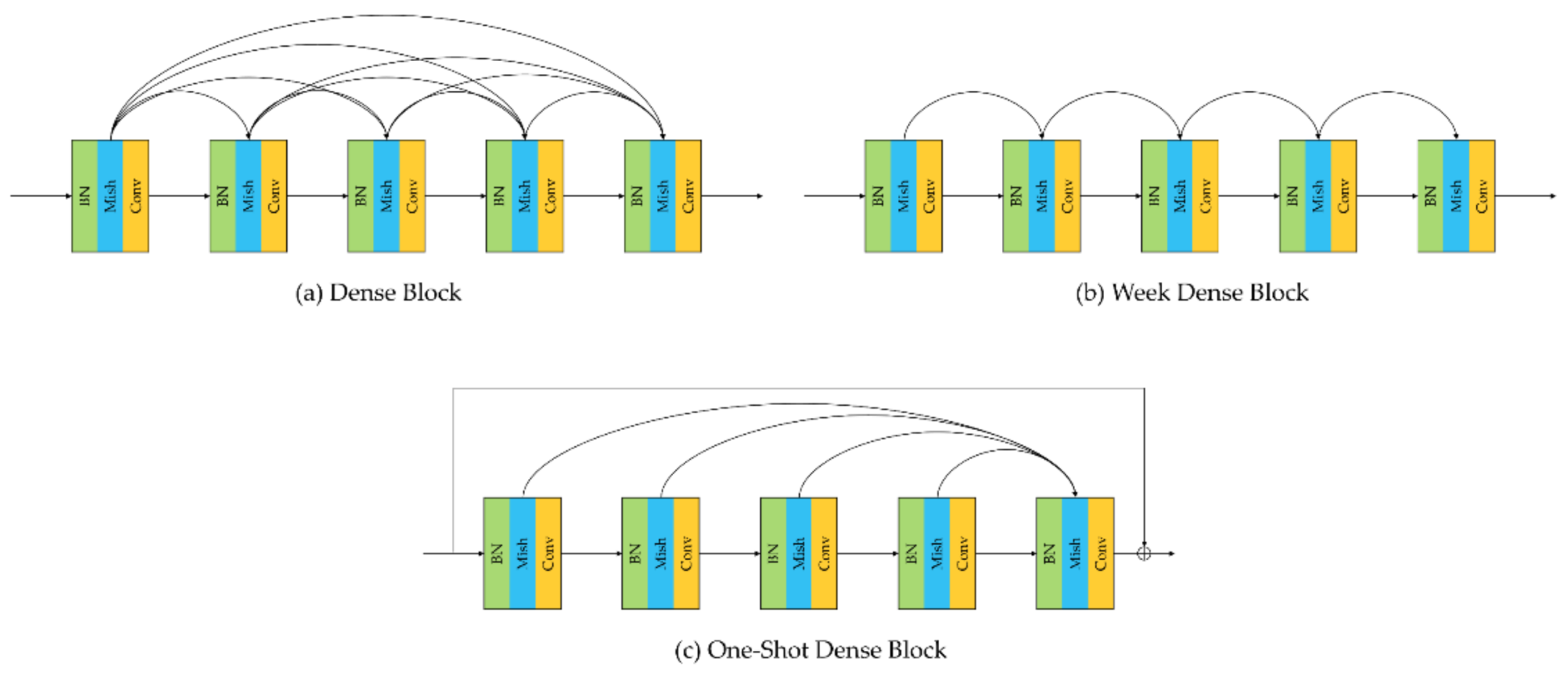
To solve the above problems, inspired by the latest technology and predecessors, we propose a one-shot dense network with polarized attention for HSI classification. Instead of following the 3-D dense connection method used by predecessors to extract features from HSI, we propose a one-shot dense connection block that maintains good classification accuracy and consumes less computational cost. Meanwhile, we add residual connections in this block, enhancing feature transfer and mitigating the gradient disappearance problem. In addition, the latest proposed polarized attention mechanism (PAM) [
47] is introduced in the network to mine finer and higher quality features. Compared with other attention mechanisms [
36,
39,
42,
45], it can maintain a relatively high resolution in spectral and spatial dimensions and thus reduce the loss of features. Furthermore, the proposed network is composed of two branches that can perform feature extraction in spectral and spatial realms, respectively. The channel-only and spatial-only attention mechanisms are inserted into each branch to recalibrate feature maps. After extracting the enhanced features from the two branches, we fuse them with a concatenation operation to obtain the spectral–spatial features. Finally, the fused features are fed into the fully connected layer to obtain the classification results. The main contributions of this paper are summarized as follows:
- (1)
We propose a novel spectral–spatial network based on one-shot dense block and polarized attention for HSI classification. The proposed network has two independent feature extraction branches: the spectral branch with channel-only polarized attention applied to obtain spectral features, and the spatial branch with spatial-only polarized attention used to capture spatial features.
- (2)
By one-shot dense block, the number of parameters and computational complexity of the network are greatly reduced. Meanwhile, the residual connection is added to the block, which can alleviate the performance saturation and gradient disappearance problems.
- (3)
We apply both channel-only and spatial-only polarized attention in the proposed network. The channel-only polarized attention emphasizes valuable channel features and suppresses useless ones. The spatial-only attention is more focused on areas with more discriminative features. In addition, the attention mechanism can preserve more resolution in both channel and spatial dimensions and consume less computational costs.
- (4)
Some advanced technologies, including cosine annealing learning rate, Mish activation function [
48], Dropout, and early stopping, are employed in the proposed network. For reproducibility, the code of the proposed network is available at
https://github.com/HaiZhu-Pan/OSDN (accessed on 5 May 2022).
To show the effectiveness of the proposed network, a large number of experiments were carried out on five real-world HSI datasets, namely, PU, KSC, BS, HS, and SV. The experimental results consistently demonstrate that the proposed network can achieve better accuracy than several widely used ML- and DL-based methods in a few training samples and computational resources.
The remainder of this article is structured as follows: Some close backgrounds are reviewed in
Section 2. In
Section 3, our proposed network is presented with three parts in detail. In
Section 4 and
Section 5, comparative experiments and ablation analyses are performed to demonstrate the effectiveness of the proposed network. Finally,
Section 6 provides some concluding remarks and suggestions for future work.
4. Experiment
4.1. Hyperspectral Dataset Description
In this paper, we employed five well-known HSI datasets, namely, PU, KSC, BS, HS, and SV, to validate the generality and effectiveness of our proposed method. A detailed description of the above five datasets is presented as follows:
PU: The PU dataset was photographed by the Reflective Optics System Imaging Spectrometer (ROSIS) sensor over the University of Pavia. Its spatial dimensions and geometric resolutions are 610 × 340 and 1.3 m, respectively. Every pixel includes 115 spectral bands ranging from 430 nm to 860 nm. After dropping 12 noise-contaminated spectral bands, the number of spectral bands used for the experiment was 103. The ground truth consists of nine urban land-cover types with 42,776 labeled samples.
KSC: The KSC dataset was taken by the Airborne Visible/Infrared Imaging Spectrometer (AVIRIS) sensor over the Kennedy Space Center, Florida, on 23 March 1996. The spatial dimensions and resolutions are 512 × 614 and 18 m, respectively. Each pixel includes 176 spectral bands ranging from 400 to 2500 nm. In addition, this dataset includes 13 land-cover types with 5211 labeled pixels.
BS: The BS dataset was acquired by the NASA EO-1 satellite over the Okavango Delta, Botswana, on 31 May 2001. The spatial size of this dataset is 1476 × 256, and the spatial resolution is 30 m. Furthermore, the dataset contains 145 spectral bands ranging from 400 to 2500 nm. The dataset contains 3248 labeled pixels, which are divided into 14 classes.
HS: The HS dataset was captured over the University of Houston campus and the neighboring urban area on 23 June 2012, through the NSF-funded Center for Airborne Laser Mapping (NCALM). Its height and width are 349 and 1905, respectively, and its spatial resolution is up to 2.5 m. This dataset consists of 144 spectral bands in the 380 to 1050 nm region. This dataset has 664,845 pixels with 15,029 labeled samples, divided into 15 land-cover types.
SV: The SV dataset was also gathered by the AVIRIS sensor, but it was collected in the Salinas Valley region of California. Its spatial dimensions and resolutions are 512 × 217 and 3.7 m, respectively. The raw SV dataset has 224 spectral bands ranging from 400 to 2500 nm. Twenty water absorption bands are abandoned. Therefore, this article uses 204 bands for the experimental dataset. This dataset contains 16 land-cover types with 54,129 labeled samples.
4.2. Experimental Evaluation Indicators
In this work, three evaluation indicators, namely, overall accuracy (
OA), average accuracy (
AA), and
Kappa coefficient (
Kappa), are used to assess the classification performance of the proposed method [
49].
OA refers to the percentage of correctly classified labeled samples to the total labeled samples.
AA is the average accuracy for each class, which assigns the same importance to each category.
Kappa is the consistency between classification results and ground truth. It is calculated from −1 to 1, but usually, it falls between 0 and 1. All in all, the closer the above three indicators are to 1, the better the classification model will be.
To explain the above three evaluation indicators more intuitively, we first define the confusion matrix. In the confusion matrix, each column represents the predicted label, and each row represents the actual label. The composition of the confusion matrix (
) is defined as follows:
where element
indicates the number of samples in class
i classified as class
j, and
and
indicate the sum of samples in each row and column, respectively. Then, the values of
OA,
AA, and
Kappa can be defined as follows:
4.3. Experimental Setting
The experiments were implemented on a deep learning workstation with a 2× Intel Xeon E5-2680 v4 processor, 35 M of L3 cache, a clock speed of 2.4 GHz, and 14 physical cores/28 way multitask processing. Furthermore, it is equipped with 128 GB of DDR4 RAM and 8× NVIDIA GeForce RTX 2080Ti super graphical processing unit (GPU) with 11 GB of memory. The software environment is CUDA v11.2, PyTorch 1.1.0, and Python 3.7.
To validate the effectiveness of our proposed method, we selected seven representative methods for comparison: one representative ML-based method and seven state-of-the-art DL-based methods. All comparison methods are briefly described as follows:
- (1)
SVM: The SVM with radial basis function (RBF) kernel is employed as a representative of the traditional method for HSI classification. It is implemented by scikit-learn [
50]. Each labeled sample in the HSI has a continuous spectral vector. They are directly fed into the SVM without feature extraction and dimensionality reduction. The penalty parameter
C and the RBF kernel width
σ are selected by Grid SearchCV, both in the range of (10
−2, 10
2).
- (2)
HYSN [
26]: The HYSN model has three 3-D convolution layers, one 2-D convolution layer, and two fully connected layers. The sizes of the convolution kernels of the 3-D convolution layers are 3 × 3 × 7, 3 × 3 × 5, and 3 × 3 × 3, respectively. The size of the convolution kernel of the 2-D convolution layer is 3 × 3.
- (3)
SSRN [
29]: The SSRN model consists of two residual convolutional blocks with convolution kernel sizes of 1 × 1 × 7 and 3 × 3 × 1, respectively. They are connected sequentially to extract deep-level spectral and spatial features, in which BN and ReLu are added after each convolutional layer.
- (4)
FDSS [
31]: The network structure of FDSS is connected by three convolutional parts, including a densely connected spectral feature extraction part, a reducing dimension part, and a densely connected spatial feature extraction part. The shapes of the three partial convolution kernels are 1 × 1 × 7, 1 × 1 × b (b represents the spectral depth of the generated feature map), and 3 × 3 × 1, respectively. Moreover, BN and ReLu are added before each convolutional layer.
- (5)
DBMA [
40]: The DBMA model is designed with a two-branch network structure. Each branch has a dense block and an attention block. Its dense block is the same as in FDSS. Moreover, the attention block is inspired by CBAM [
39].
- (6)
DBDA [
41]: The DBDA model uses DANet [
42] as the attention mechanism, and the rest of the network structures are the same as DBMA. In particular, it adopts the Mish as the activation function.
- (7)
PCIA [
46]: The PCIA model uses an iterative approach to construct an attention mechanism. This network structure also consists of two branches, but each branch uses a pyramid convolution module to perform feature extraction.
- (8)
SSGC [
44]: The GCNet [
45] attention mechanism is introduced to the SSGC. The rest of the network architecture is the same as DBMA.
To ensure the impartiality of the comparison experiments, we took the same hyperparameters on these methods. For the training set of the proposed method, we applied the Adam optimizer [
51] to update the parameters for 100 training epochs, where the initial learning rate is 0.0005 for all datasets. The learning rate is dynamically adjusted every 25 epochs by the cosine annealing [
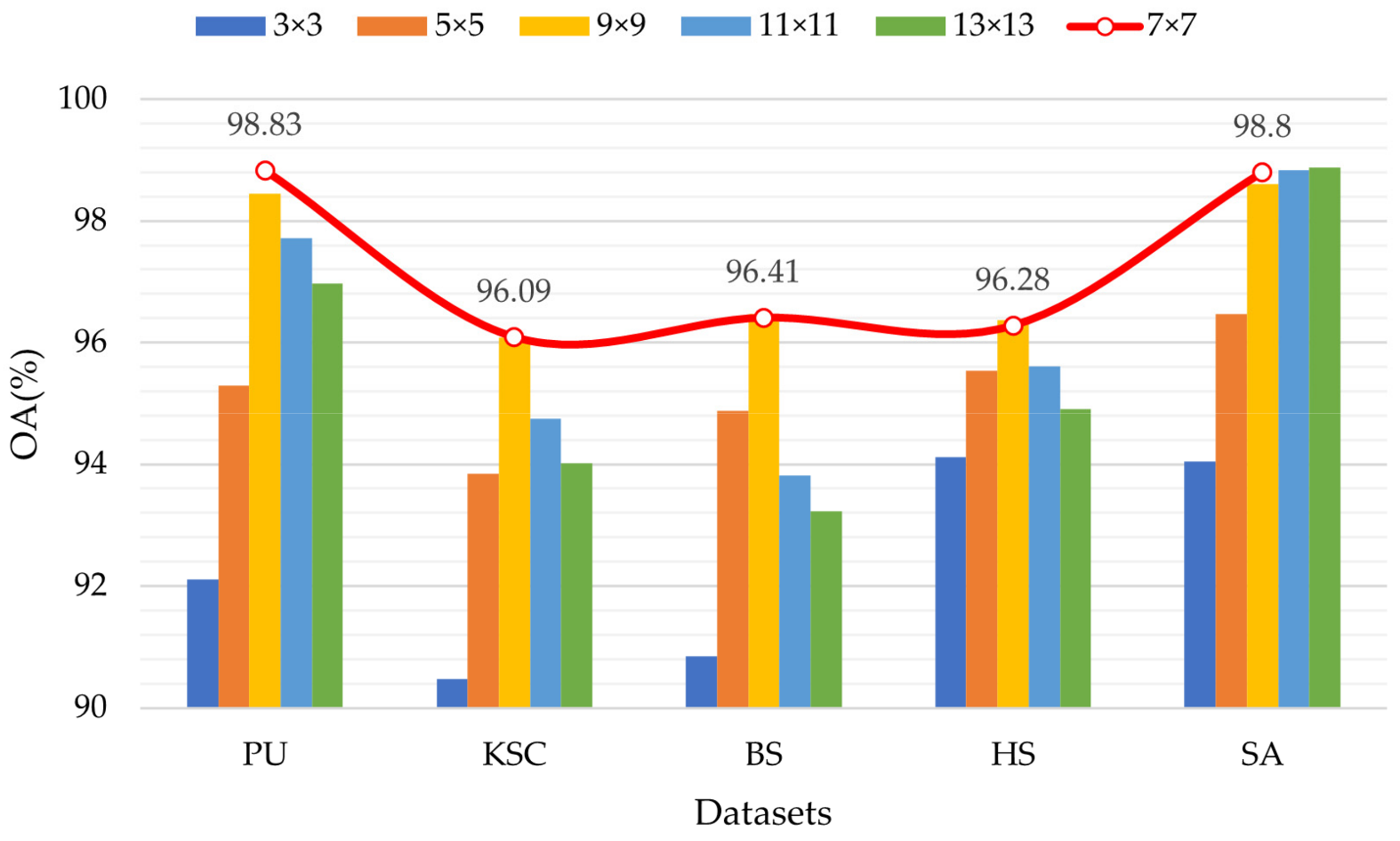
52]. Furthermore, if the loss on the validation set does not change within 10 epochs, the network will move to the test session. To balance efficiency and effectiveness, the spatial size of the HSI patch cube was set to 7 × 7, and the batch size was set to 32.
Table 6,
Table 7,
Table 8,
Table 9 and
Table 10 provide the detailed distribution of the training, validation, and testing samples of PU, KSC, BS, HS, and SA datasets. To seek reproducibility, the proposed network code is available publicly at
https://github.com/HaiZhu-Pan/OSDN (accessed on 5 May 2022).
4.4. Experimental Results
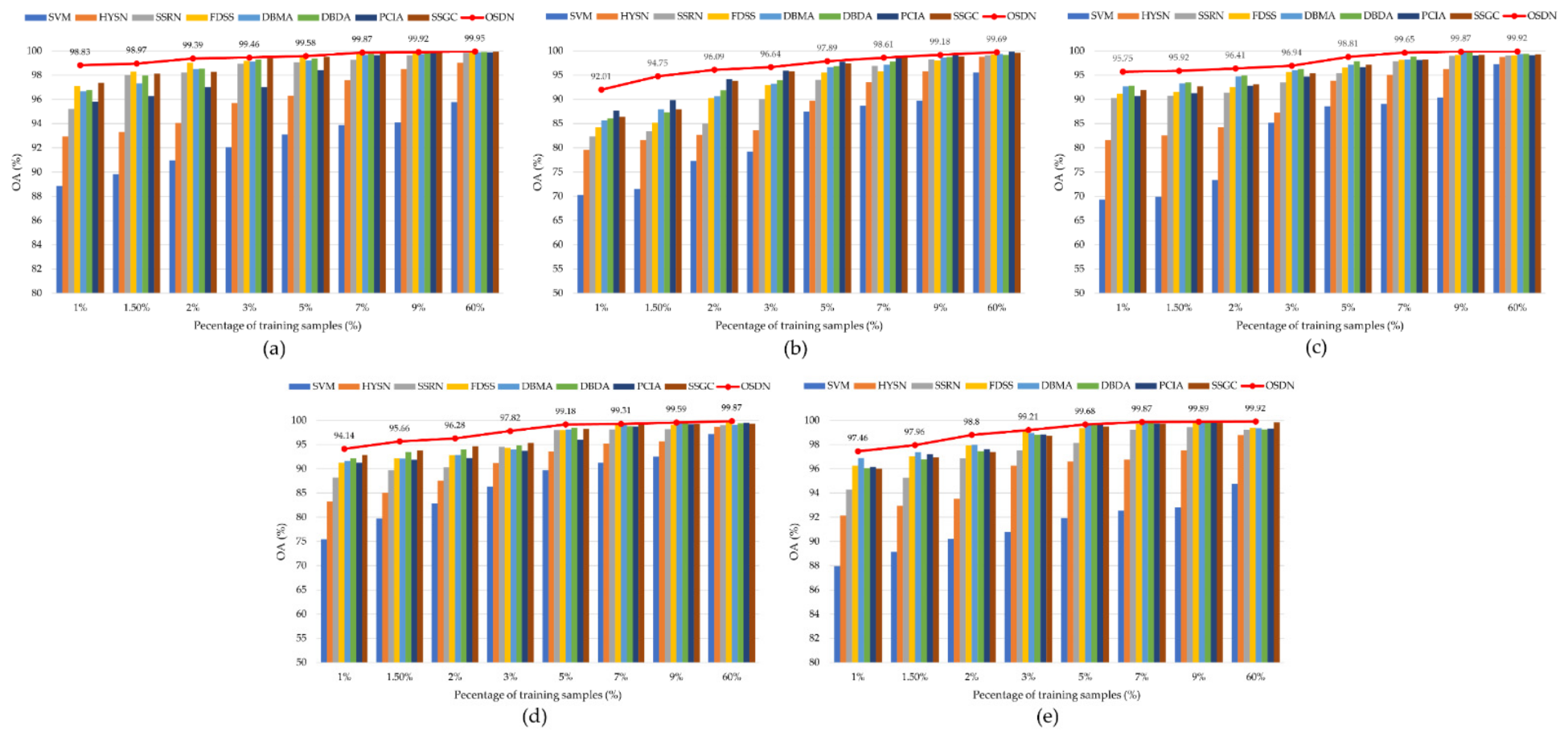
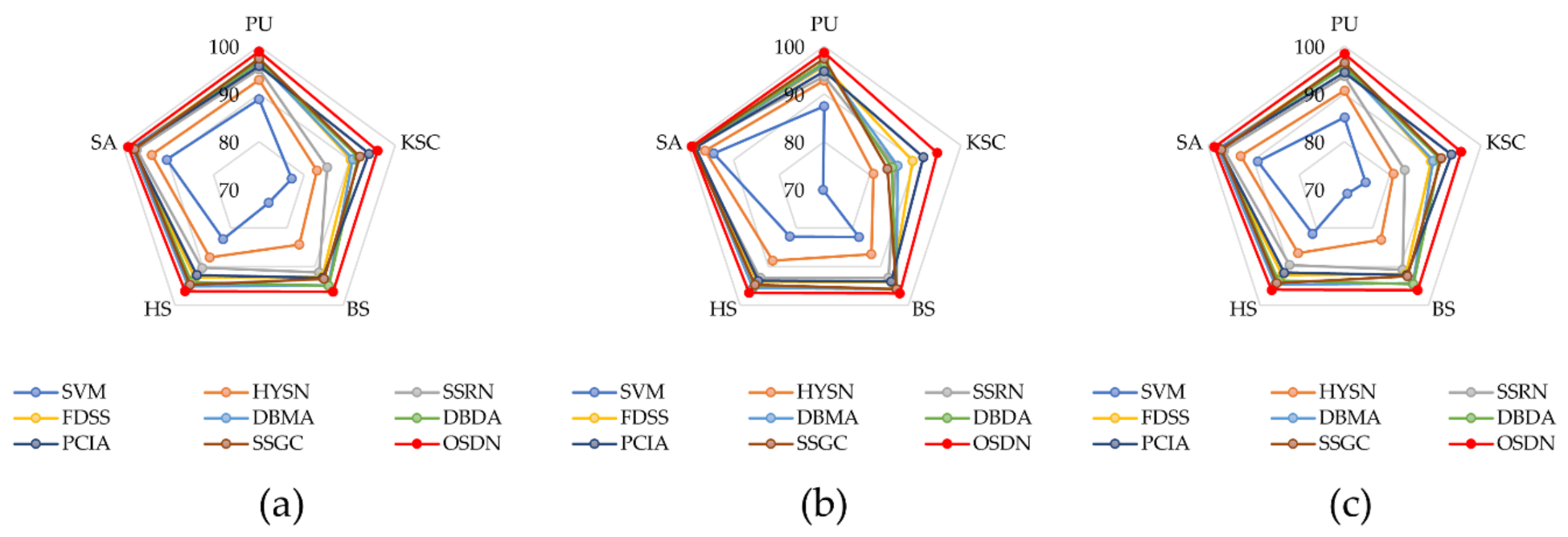
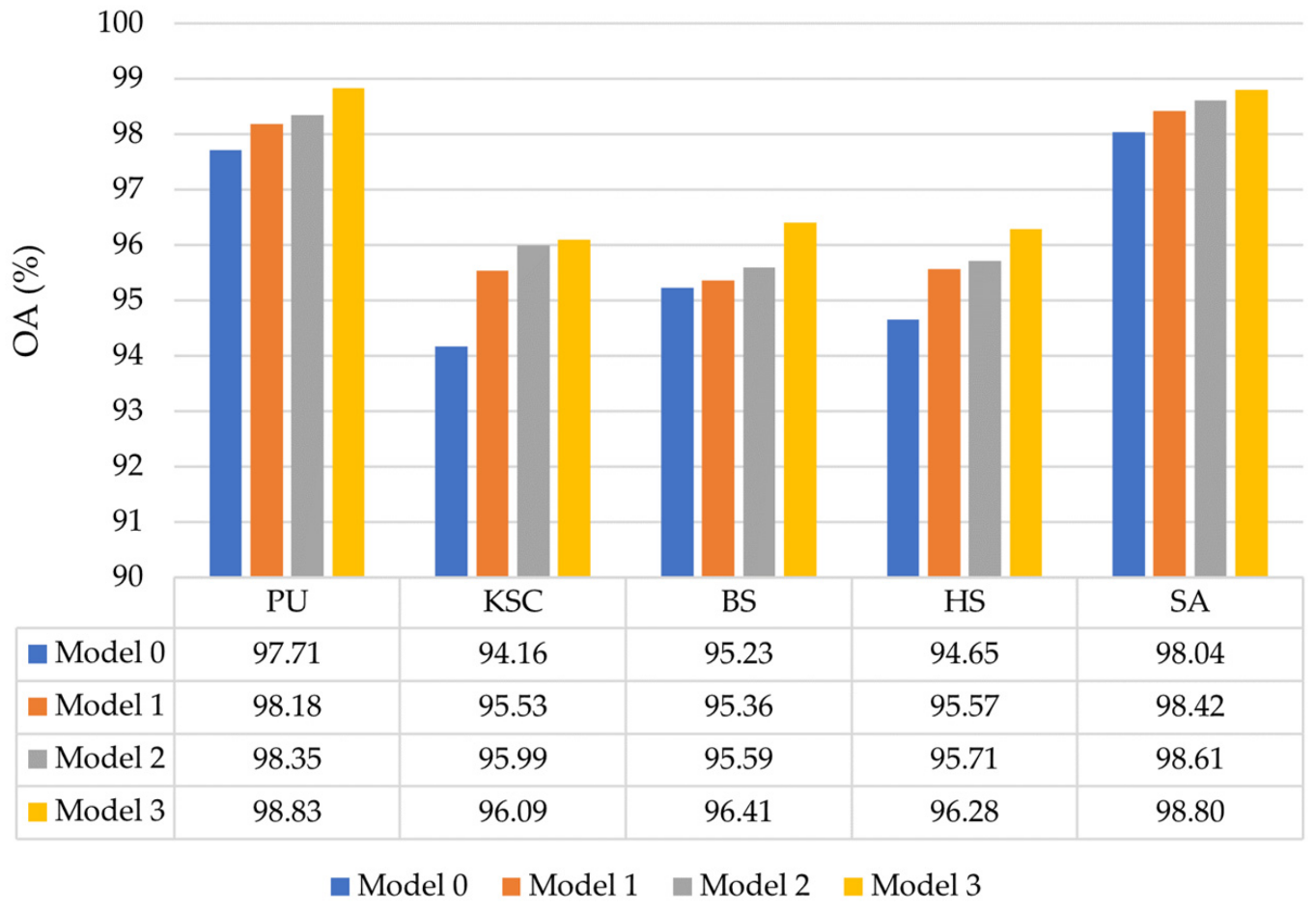
Table 11,
Table 12,
Table 13,
Table 14 and
Table 15 report the classification accuracy of each category,
OA,
AA, and
Kappa, on five datasets. It is clear that the proposed OSDN produces the best
OA,
AA, and
Kappa and provides a significant improvement over the other methods on all datasets. For example, when 1% of the samples are randomly chosen for training on the PU dataset (
Table 11), the improvement in
OA compared to SVM, HYSN, SSRN, FDSS, DBMA, DBDA, PCIA, and SSGC methods are 9.96%, 5.87%, 3.60%, 1.72%, 2.16%, 2.06%, 2.99%, and 1.45%, respectively. Specifically, since SVM only uses spectral information to perform classification, its accuracy on all datasets is much lower than other methods. Conversely, the other eight DL-based methods (i.e., HYSN, SSRN, FDSS, DBMA, DBDA, SSGC, PCIA, and OSDN) all achieved good classification results on five datasets because they could automatically extract deep, high-level, and discriminative spatial–spectral information from the 3-D patch cube. Furthermore, compared to SSRN and HYSN, the
OA of FDSS was improved approximately by 1–8% on all datasets, which indicates that the densely connected structure can extract features more adequately in a few training samples. In addition, the network structures of DBMA, DBDA, PCIA, and SSGC are very similar. Their classification models are based on two main ideas: dual-branch 3-D dense convolution block and dual-branch attention mechanism. Among these dual-branch attention models, SSGC achieved the best classification results in most datasets due to its ability to focus on global contextual information. In addition, the classification accuracy obtained by OSDN was higher than that of FDSS and SSCG because the PAM module in OSDN not only retained a large amount of spectral and spatial resolution but also dynamically enhanced the feature maps. Finally, compared with the best comparison methods in the five datasets, the
OA of OSDN was improved by 1.45%, 1.86%, 1.46%, 1.62%, and 0.82%, respectively. At the same time,
AA and
Kappa improved to different degrees on the five datasets.
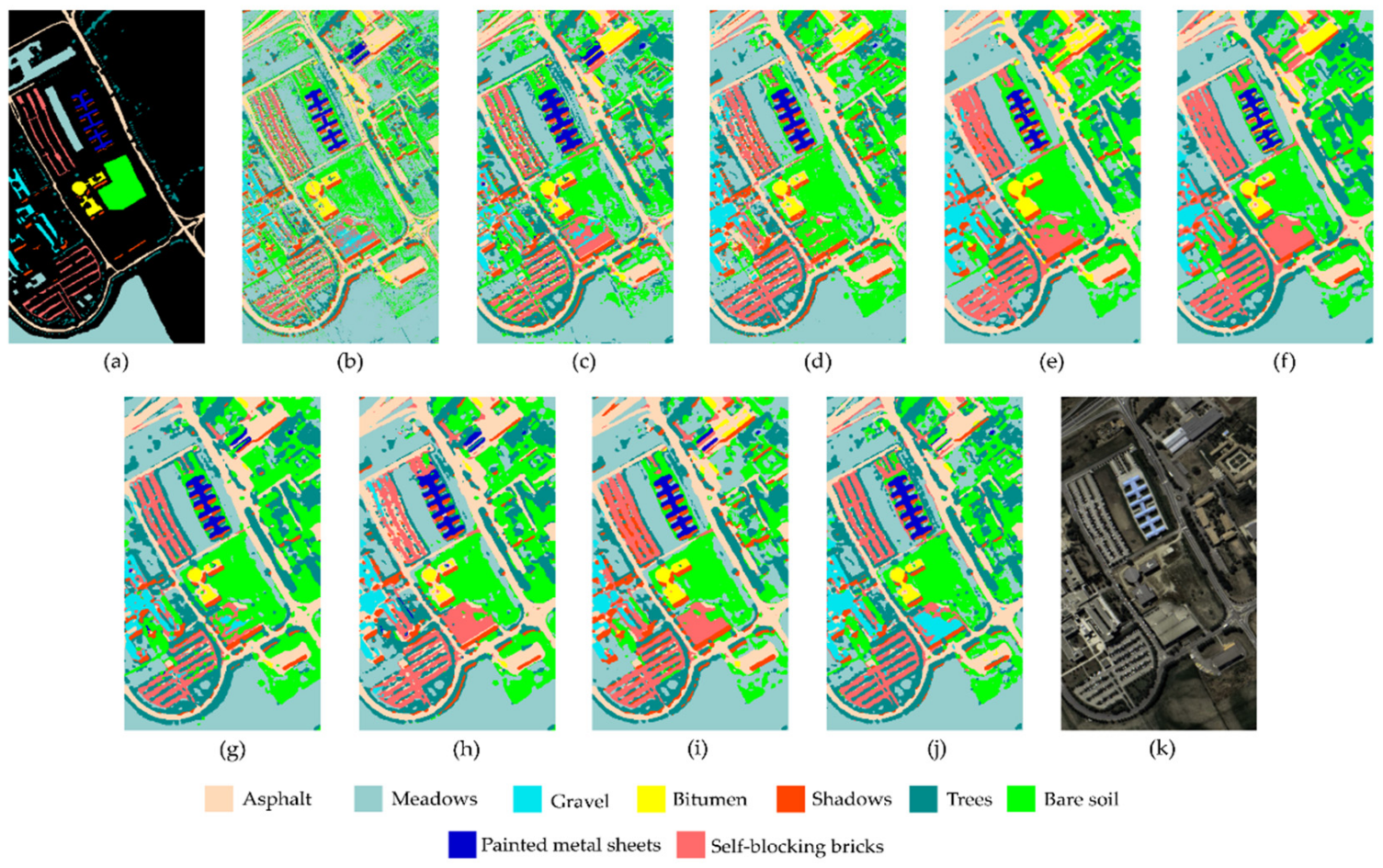
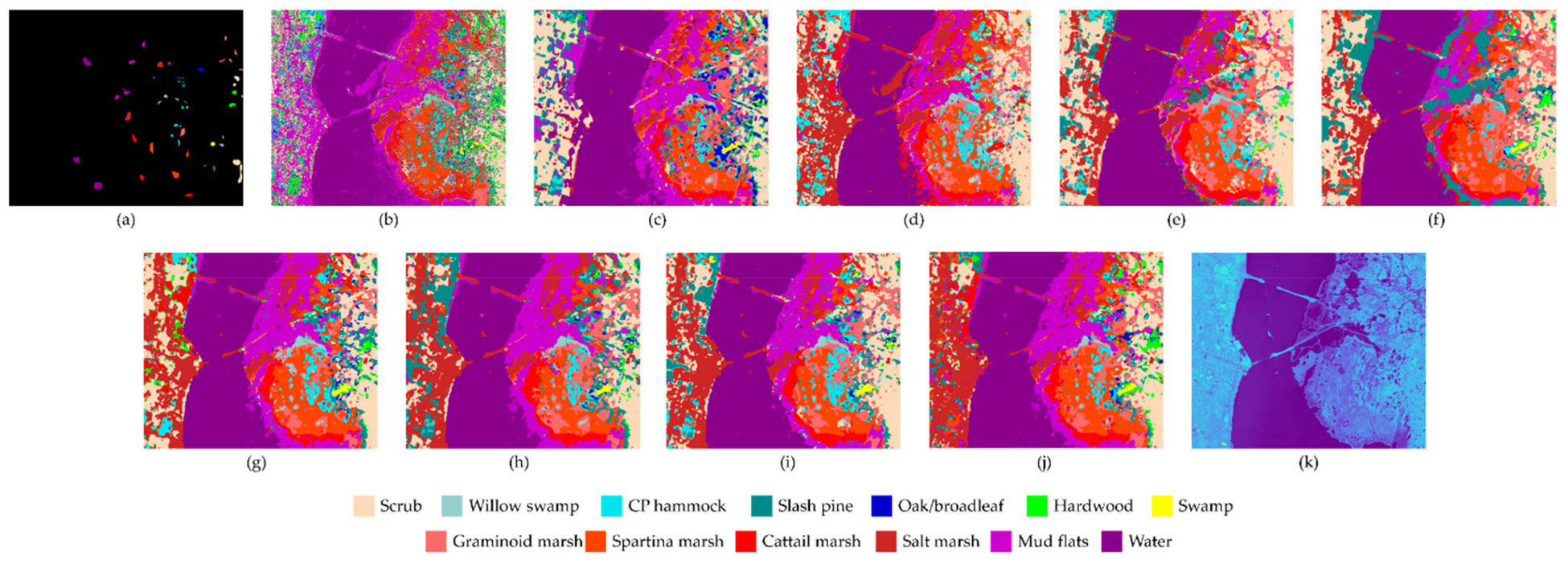
Figure 7,
Figure 8,
Figure 9,
Figure 10 and
Figure 11 show the ground truth, false-color image, and classification maps of all methods on the five datasets. Generally, the outline of each category was smoother and clearer in the proposed OSDN classification map on all datasets. Because the SVM method cannot effectively extract the spatial feature, its classification map had a large amount of salt-and-pepper noise on the five datasets (
Figure 7b,
Figure 8b,
Figure 9b,
Figure 10b and
Figure 11b). In addition, benefiting from the PAM module, our proposed OSDN was found to be significantly better than other methods in predicting those unlabeled categories. Taking the PU dataset as an example, looking carefully at
Figure 7k, we can see that there may have been several trees (C4) in the lower side area of the bare soil (C6). However, no method can predict as many trees in this area as possible. On the contrary, it is clear from
Figure 7j that our proposed OSDN can predict eight trees in this area. Similarly, in the left area of these eight trees, the proposed OSDN was able to visualize the area more completely than other methods. All observations validate that our proposed OSDN can accurately predict labeled categories and reasonably predict unlabeled categories on all datasets. Moreover, the above results further verify that the proposed one-shot dense connection can also extract sufficient features in a few training samples, while the PAM module can focus on extracting finer features to perform classification.





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}