
Enriching Point Clouds with Implicit Representations for 3D Classification and Segmentation



Abstract
:1. Introduction
- A simple yet effective implicit feature encoding module that enriches point clouds with local geometric information to improve 3D classification and segmentation. Our implicit feature encoding is an efficient and compact solution that does not require any training. This allows it to be integrated directly into deep networks to improve both accuracy and efficiency.
- A novel local canonicalization approach to ensure the transformation-invariance of implicit features. It projects sample spheres (rather than raw point clouds) to their canonical poses, which can be applied to both individual objects and large-scale scenes.
2. Related Work
2.1. Deep Learning on Point Clouds
2.2. Implicit Representations of 3D Shapes
2.3. Transformation-Invariant Analysis
3. Methodology
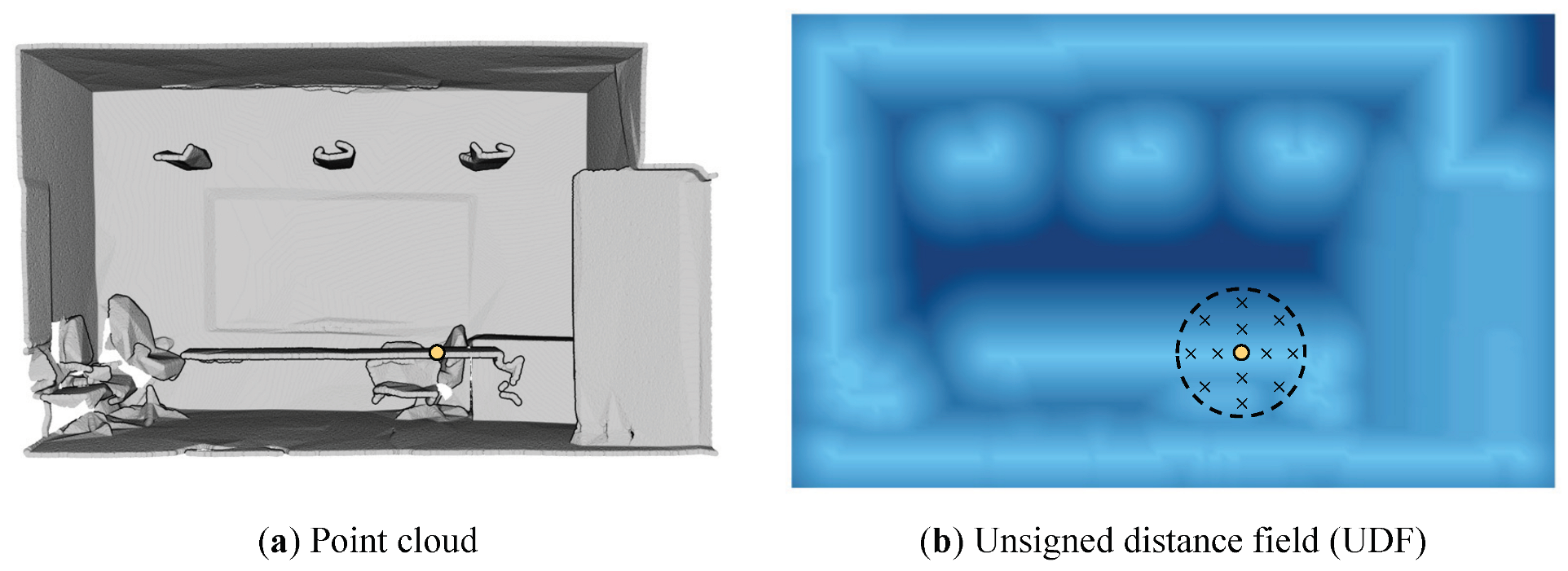
3.1. Implicit Feature Encoding
| Algorithm 1 Implicit feature encoding |
| Input: a point cloud and a sample sphere with a radius r |
| Output: an augmented point cloud |
| 1: Initialization: build a kd-tree from |
| 2: for each do |
| 3: place on |
| 4: transform to its canonical pose considering the local geometry of |
| 5: for each do |
| 6: calculate the shortest distance using the kd-tree |
| 7: concatenate the normalized distance to |
| 8: end for |
| 9: end for |
3.2. Transformation Invariance
- We calculate the canonical pose based on local neighborhoods rather than an entire point cloud instance. Therefore, our approach can be applied to not individual objects but also large scenes containing multiple objects.
- We transform sample spheres instead of raw points, which guarantees the continuity of the encoded features (see Figure 3c). On the contrary, converting raw points of local neighborhoods to their canonical poses will destroy the original geometry of shapes and thus lead to inconsistent features (see Figure 3b). Moreover, canonicalizing sample spheres allows us to employ the pre-built kd-tree structure to accelerate feature encoding.
4. Results and Evaluation
4.1. Implementation Details
4.2. Experiment Setup
4.3. 3D Classification of Individual Objects
- Randomly rotated. We intentionally introduced random 3D rotation to all point clouds in both training and test sets, and we apply our local canonicalization before implicit feature encoding. We used 3D random rotations as data augmentation for the training.
4.4. 3D Semantic Segmentation of Indoor Scenes


4.5. 3D Semantic Segmentation of Outdoor Scenes

5. Discussion
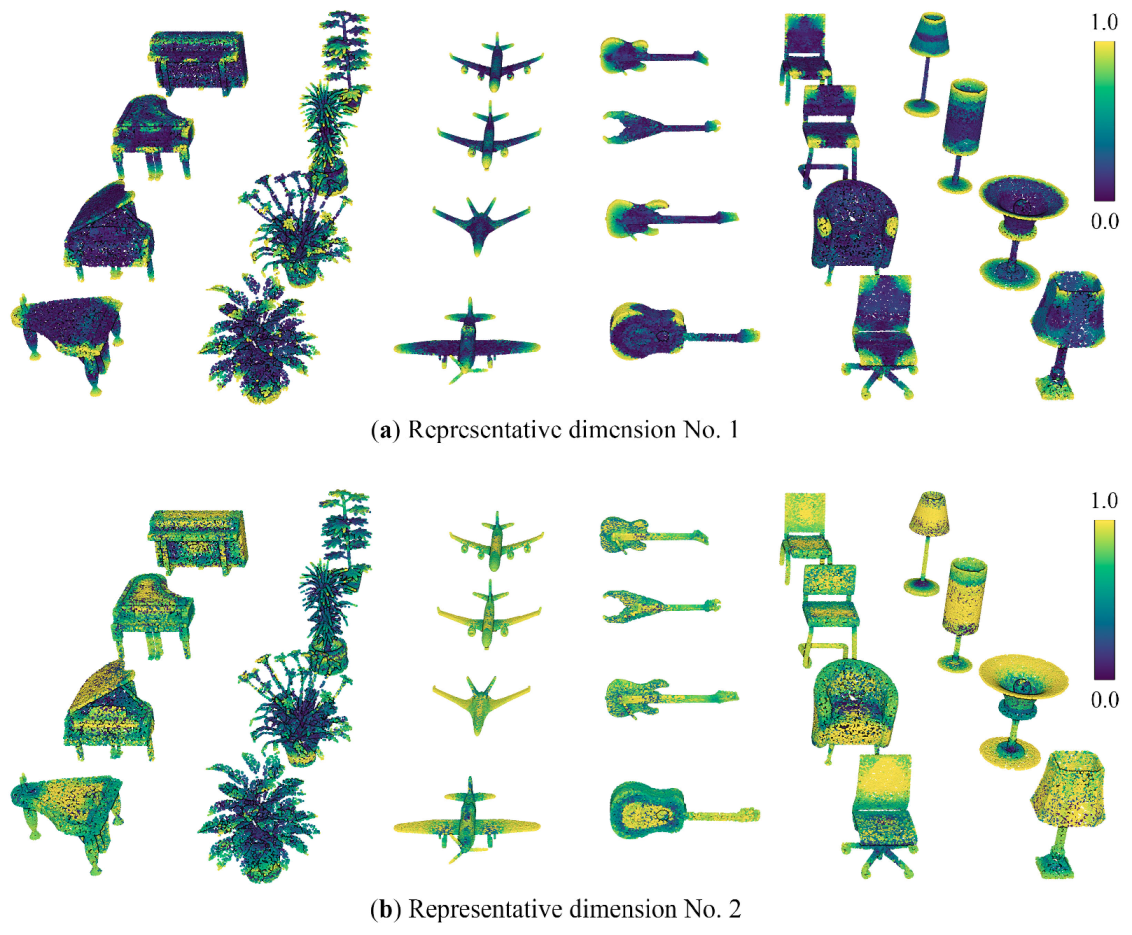
5.1. Feature Visualization
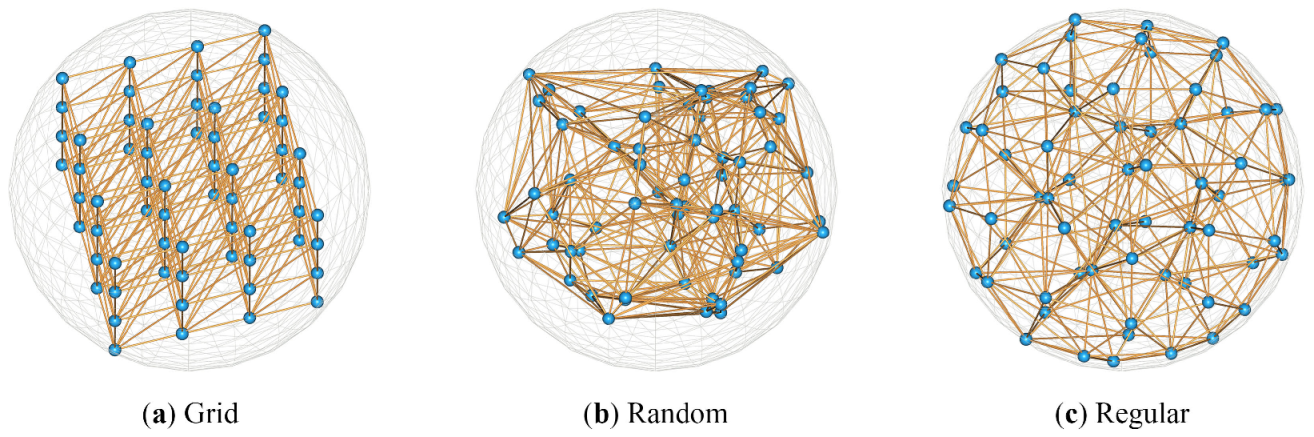
5.2. Parameters
5.3. Efficiency

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | #Files | Downsampled | #Points | Running Times |
|---|---|---|---|---|
| ModelNet [23] | 12,311 objects | - | 123,110,000 | 8.7 min |
| S3DIS [24] | 272 rooms | - | 273,546,487 | 23.8 min |
| 4 cm | 18,610,642 | 58 s | ||
| SensatUrban [25] | 43 blocks | 20 cm | 220,671,929 | 12.6 min |
5.4. Comparison with Point Convolution
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| LiDAR | Light Detection And Ranging |
| UDF | Unsigned Distance Field |
| CNN | Convolutional Neural Network |
| PCA | Principal Component Analysis |
| SVD | Singular Value Decomposition |
| CAD | Computer-Aided Design |
Appendix A
References
- Huang, J.; Stoter, J.; Peters, R.; Nan, L. City3D: Large-Scale Building Reconstruction from Airborne LiDAR Point Clouds. Remote Sens. 2022, 14, 2254. [Google Scholar] [CrossRef]
- Peters, R.; Dukai, B.; Vitalis, S.; van Liempt, J.; Stoter, J. Automated 3D reconstruction of LoD2 and LoD1 models for all 10 million buildings of the Netherlands. Photogramm. Eng. Remote Sens. 2022, 88, 165–170. [Google Scholar] [CrossRef]
- Luo, L.; Wang, X.; Guo, H.; Lasaponara, R.; Zong, X.; Masini, N.; Wang, G.; Shi, P.; Khatteli, H.; Chen, F.; et al. Airborne and spaceborne remote sensing for archaeological and cultural heritage applications: A review of the century (1907–2017). Remote Sens. Environ. 2019, 232, 111280. [Google Scholar] [CrossRef]
- Li, Y.; Ma, L.; Zhong, Z.; Liu, F.; Chapman, M.A.; Cao, D.; Li, J. Deep learning for lidar point clouds in autonomous driving: A review. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 3412–3432. [Google Scholar] [CrossRef]
- Yousif, K.; Bab-Hadiashar, A.; Hoseinnezhad, R. An overview to visual odometry and visual SLAM: Applications to mobile robotics. Intell. Ind. Syst. 2015, 1, 289–311. [Google Scholar] [CrossRef]
- Guo, Y.; Wang, H.; Hu, Q.; Liu, H.; Liu, L.; Bennamoun, M. Deep learning for 3d point clouds: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 4338–4364. [Google Scholar] [CrossRef]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. Adv. Neural Inf. Process. Syst. 2017, 30, 5099–5108. [Google Scholar]
- Zhao, H.; Jiang, L.; Fu, C.W.; Jia, J. Pointweb: Enhancing local neighborhood features for point cloud processing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5565–5573. [Google Scholar]
- Jiang, M.; Wu, Y.; Zhao, T.; Zhao, Z.; Lu, C. Pointsift: A sift-like network module for 3d point cloud semantic segmentation. arXiv 2018, arXiv:1807.00652. [Google Scholar]
- Engelmann, F.; Kontogianni, T.; Schult, J.; Leibe, B. Know what your neighbors do: 3D semantic segmentation of point clouds. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Hua, B.S.; Tran, M.K.; Yeung, S.K. Pointwise convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 984–993. [Google Scholar]
- Wang, S.; Suo, S.; Ma, W.C.; Pokrovsky, A.; Urtasun, R. Deep parametric continuous convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2589–2597. [Google Scholar]
- Engelmann, F.; Kontogianni, T.; Leibe, B. Dilated point convolutions: On the receptive field of point convolutions. arXiv 2019, arXiv:1907.12046. [Google Scholar]
- Thomas, H.; Qi, C.R.; Deschaud, J.E.; Marcotegui, B.; Goulette, F.; Guibas, L.J. Kpconv: Flexible and deformable convolution for point clouds. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6411–6420. [Google Scholar]
- Yang, J.; Zhang, Q.; Ni, B.; Li, L.; Liu, J.; Zhou, M.; Tian, Q. Modeling point clouds with self-attention and gumbel subset sampling. In Proceedings of the IEEE/CVF Conference On Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3323–3332. [Google Scholar]
- Chen, L.Z.; Li, X.Y.; Fan, D.P.; Wang, K.; Lu, S.P.; Cheng, M.M. LSANet: Feature learning on point sets by local spatial aware layer. arXiv 2019, arXiv:1905.05442. [Google Scholar]
- Zhao, C.; Zhou, W.; Lu, L.; Zhao, Q. Pooling scores of neighboring points for improved 3D point cloud segmentation. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 1475–1479. [Google Scholar]
- Landrieu, L.; Simonovsky, M. Large-scale point cloud semantic segmentation with superpoint graphs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4558–4567. [Google Scholar]
- Hu, Q.; Yang, B.; Xie, L.; Rosa, S.; Guo, Y.; Wang, Z.; Trigoni, N.; Markham, A. Learning semantic segmentation of large-scale point clouds with random sampling. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 8338–8354. [Google Scholar] [CrossRef] [PubMed]
- Xiang, T.; Zhang, C.; Song, Y.; Yu, J.; Cai, W. Walk in the cloud: Learning curves for point clouds shape analysis. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 915–924. [Google Scholar]
- Li, L.; He, L.; Gao, J.; Han, X. PSNet: Fast Data Structuring for Hierarchical Deep Learning on Point Cloud. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 6835–6849. [Google Scholar] [CrossRef]
- Wu, Z.; Song, S.; Khosla, A.; Yu, F.; Zhang, L.; Tang, X.; Xiao, J. 3d shapenets: A deep representation for volumetric shapes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1912–1920. [Google Scholar]
- Armeni, I.; Sax, S.; Zamir, A.R.; Savarese, S. Joint 2d-3d-semantic data for indoor scene understanding. arXiv 2017, arXiv:1702.01105. [Google Scholar]
- Hu, Q.; Yang, B.; Khalid, S.; Xiao, W.; Trigoni, N.; Markham, A. Sensaturban: Learning semantics from urban-scale photogrammetric point clouds. Int. J. Comput. Vis. 2022, 130, 316–343. [Google Scholar] [CrossRef]
- Michalkiewicz, M.; Pontes, J.K.; Jack, D.; Baktashmotlagh, M.; Eriksson, A. Implicit surface representations as layers in neural networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 4743–4752. [Google Scholar]
- Ran, H.; Liu, J.; Wang, C. Surface Representation for Point Clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 18942–18952. [Google Scholar]
- Tretschk, E.; Tewari, A.; Golyanik, V.; Zollhöfer, M.; Stoll, C.; Theobalt, C. Patchnets: Patch-based generalizable deep implicit 3d shape representations. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 293–309. [Google Scholar]
- Michalkiewicz, M.; Pontes, J.K.; Jack, D.; Baktashmotlagh, M.; Eriksson, A. Deep level sets: Implicit surface representations for 3d shape inference. arXiv 2019, arXiv:1901.06802. [Google Scholar]
- Park, J.J.; Florence, P.; Straub, J.; Newcombe, R.; Lovegrove, S. Deepsdf: Learning continuous signed distance functions for shape representation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 165–174. [Google Scholar]
- Peng, S.; Niemeyer, M.; Mescheder, L.; Pollefeys, M.; Geiger, A. Convolutional occupancy networks. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 523–540. [Google Scholar]
- Jiang, C.; Sud, A.; Makadia, A.; Huang, J.; Nießner, M.; Funkhouser, T. Local implicit grid representations for 3d scenes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 6001–6010. [Google Scholar]
- Juhl, K.A.; Morales, X.; Backer, O.D.; Camara, O.; Paulsen, R.R. Implicit neural distance representation for unsupervised and supervised classification of complex anatomies. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Strasbourg, France, 27 September–1 October 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 405–415. [Google Scholar]
- Fujiwara, K.; Hashimoto, T. Neural implicit embedding for point cloud analysis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11734–11743. [Google Scholar]
- Lawin, F.J.; Danelljan, M.; Tosteberg, P.; Bhat, G.; Khan, F.S.; Felsberg, M. Deep projective 3D semantic segmentation. In Proceedings of the International Conference on Computer Analysis of Images and Patterns, Ystad, Sweden, 22–24 August 2017; Springer: Berlin/Heidelberg, Germany, 2017; pp. 95–107. [Google Scholar]
- Boulch, A.; Le Saux, B.; Audebert, N. Unstructured point cloud semantic labeling using deep segmentation networks. 3dor@ Eurograph. 2017, 3, 1–8. [Google Scholar]
- Su, H.; Maji, S.; Kalogerakis, E.; Learned-Miller, E. Multi-view convolutional neural networks for 3d shape recognition. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 945–953. [Google Scholar]
- Boulch, A.; Guerry, J.; Le Saux, B.; Audebert, N. SnapNet: 3D point cloud semantic labeling with 2D deep segmentation networks. Comput. Graph. 2018, 71, 189–198. [Google Scholar] [CrossRef]
- Maturana, D.; Scherer, S. Voxnet: A 3d convolutional neural network for real-time object recognition. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–3 October 2015; pp. 922–928. [Google Scholar]
- Meng, H.Y.; Gao, L.; Lai, Y.K.; Manocha, D. Vv-net: Voxel vae net with group convolutions for point cloud segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8500–8508. [Google Scholar]
- Wang, Y.; Sun, Y.; Liu, Z.; Sarma, S.E.; Bronstein, M.M.; Solomon, J.M. Dynamic graph cnn for learning on point clouds. ACM Trans. Graph. 2019, 38, 1–12. [Google Scholar] [CrossRef] [Green Version]
- Li, F.; Fujiwara, K.; Okura, F.; Matsushita, Y. A closer look at rotation-invariant deep point cloud analysis. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 16218–16227. [Google Scholar]
- Li, X.; Li, R.; Chen, G.; Fu, C.W.; Cohen-Or, D.; Heng, P.A. A rotation-invariant framework for deep point cloud analysis. IEEE Trans. Vis. Comput. Graph. 2021, 28, 4503–4514. [Google Scholar] [CrossRef]
- Deng, H.; Birdal, T.; Ilic, S. Ppf-foldnet: Unsupervised learning of rotation invariant 3d local descriptors. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 602–618. [Google Scholar]
- Zhang, Z.; Hua, B.S.; Rosen, D.W.; Yeung, S.K. Rotation invariant convolutions for 3d point clouds deep learning. In Proceedings of the 2019 International Conference on 3d Vision (3DV), Québec City, QC, Canada, 16–19 September 2019; pp. 204–213. [Google Scholar]
- Chen, C.; Li, G.; Xu, R.; Chen, T.; Wang, M.; Lin, L. Clusternet: Deep hierarchical cluster network with rigorously rotation-invariant representation for point cloud analysis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4994–5002. [Google Scholar]
- Yu, R.; Wei, X.; Tombari, F.; Sun, J. Deep positional and relational feature learning for rotation-invariant point cloud analysis. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 217–233. [Google Scholar]
- Kim, S.; Park, J.; Han, B. Rotation-invariant local-to-global representation learning for 3d point cloud. Adv. Neural Inf. Process. Syst. 2020, 33, 8174–8185. [Google Scholar]
- Xiao, Z.; Lin, H.; Li, R.; Geng, L.; Chao, H.; Ding, S. Endowing deep 3d models with rotation invariance based on principal component analysis. In Proceedings of the 2020 IEEE International Conference on Multimedia and Expo (ICME), London, UK, 6–10 July 2020; pp. 1–6. [Google Scholar]
- Shlens, J. A tutorial on principal component analysis. arXiv 2014, arXiv:1404.1100. [Google Scholar]
- Abdi, H.; Williams, L.J. Principal component analysis. Wiley Interdiscip. Rev. Comput. Stat. 2010, 2, 433–459. [Google Scholar] [CrossRef]
- Rusu, R.B.; Cousins, S. 3d is here: Point cloud library (pcl). In Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 1–4. [Google Scholar]
- Dagum, L.; Menon, R. OpenMP: An industry standard API for shared-memory programming. IEEE Comput. Sci. Eng. 1998, 5, 46–55. [Google Scholar] [CrossRef]
- Yan, X. Pointnet/Pointnet++ Pytorch. 2019. Available online: https://github.com/yanx27/Pointnet_Pointnet2_pytorch (accessed on 8 February 2022).
- Li, Y.; Bu, R.; Sun, M.; Wu, W.; Di, X.; Chen, B. Pointcnn: Convolution on x-transformed points. Adv. Neural Inf. Process. Syst. 2018, 31, 820–830. [Google Scholar]







| Task | Dataset | Baseline(s) | ||||||
|---|---|---|---|---|---|---|---|---|
| Name | Scenario | Data Source | Area | #Classes | #Points | RGB | ||
| Classification | ModelNet [23] | Objects | Synthetic | - | 40 | 12 M | No | PN, PSN, CN |
| Segmentation | S3DIS [24] | Indoor scenes | Matterport | 6.0 × 10 m | 13 | 273 M | Yes | PN, SPG, RLN |
| SensatUrban [25] | Urban scenes | UAV photogrammetry | 7.6 × 10 m | 13 | 2847 M | Yes | RLN | |
| Metric | Formula | Task (s) |
|---|---|---|
| Overall Accuracy | Classification & Segmentation | |
| Mean Class Accuracy | Classification & Segmentation | |
| Mean Intersection Over Union | Segmentation |
| Method | Pre-Aligned | Randomly Rotated | ||
|---|---|---|---|---|
| OA | mAcc | OA | mAcc | |
| PointNet [7] | 90.8 | 87.8 | 71.0 | 67.7 |
| PointNet [7] + ours | 93.3 | 90.4 | 86.3 | 82.5 |
| Point Structuring Net [22] | 92.3 | 89.2 | 81.9 | 76.0 |
| Point Structuring Net [22] + ours | 93.4 | 90.5 | 88.3 | 84.3 |
| CurveNet [21] | 93.1 | 90.4 | 87.4 | 83.1 |
| CurveNet [21] + ours | 94.1 | 90.7 | 89.7 | 85.4 |
| NeuralEmbedding [34] | 92.2 | 89.3 | - | - |
| Method | OA | mAcc | mIoU | Ceil. | Floor | Wall | Beam | Col. | Wind. | Door | Table | Chair | Sofa | Book. | Board | Clut. |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PointNet [7] | 77.9 | 51.3 | 40.9 | 87.3 | 97.8 | 69.0 | 0.5 | 5.9 | 35.9 | 4.4 | 57.4 | 42.1 | 8.0 | 48.5 | 38.3 | 36.0 |
| PointNet [7] + ours | 81.9 | 61.8 | 50.6 | 92.4 | 98.0 | 72.2 | 0.0 | 22.1 | 44.0 | 28.9 | 65.2 | 64.2 | 29.4 | 57.6 | 42.4 | 40.9 |
| SPG [19] | 86.4 | 66.5 | 58.0 | 89.4 | 96.9 | 78.1 | 0.0 | 42.8 | 48.9 | 61.6 | 75.4 | 84.7 | 52.6 | 69.8 | 2.1 | 52.2 |
| SPG [19] + ours | 88.5 | 67.8 | 61.3 | 93.0 | 96.8 | 79.2 | 0.0 | 34.4 | 52.2 | 65.9 | 77.8 | 87.3 | 72.9 | 73.1 | 7.7 | 56.2 |
| RandLA-Net [20] | 87.1 | 70.5 | 62.5 | 91.5 | 97.6 | 80.3 | 0.0 | 22.7 | 60.2 | 37.1 | 78.7 | 87.0 | 69.9 | 70.7 | 66.0 | 51.5 |
| RandLA-Net [20] + ours | 88.3 | 73.6 | 65.2 | 93.1 | 96.9 | 82.3 | 0.0 | 32.0 | 59.5 | 53.0 | 76.5 | 88.4 | 70.8 | 72.4 | 68.2 | 54.8 |
| Method | OA | mAcc | mIoU | Ceil. | Floor | Wall | Beam | Col. | Wind. | Door | Table | Chair | Sofa | Book. | Board | Clut. |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PointNet [7] | 78.5 | 61.2 | 48.3 | 88.4 | 93.8 | 69.3 | 29.6 | 20.2 | 44.9 | 50.0 | 52.8 | 43.5 | 15.5 | 41.8 | 37.4 | 41.2 |
| PointNet [7] + ours | 83.7 | 72.2 | 59.1 | 92.3 | 94.3 | 75.5 | 38.7 | 40.2 | 46.4 | 61.3 | 61.3 | 64.7 | 42.4 | 51.9 | 48.3 | 51.0 |
| SPG [19] | 85.5 | 73.0 | 62.1 | 89.9 | 95.1 | 76.4 | 62.8 | 47.1 | 55.3 | 68.4 | 69.2 | 73.5 | 45.9 | 63.2 | 8.7 | 52.9 |
| SPG [19] + ours | 86.9 | 74.7 | 64.0 | 92.0 | 95.6 | 76.6 | 44.5 | 50.4 | 55.7 | 72.5 | 68.9 | 79.0 | 59.8 | 63.1 | 14.6 | 58.9 |
| RandLA-Net [20] | 88.0 | 82.0 | 70.0 | 93.1 | 96.1 | 80.6 | 62.4 | 48.0 | 64.4 | 69.4 | 69.4 | 76.4 | 60.0 | 64.2 | 65.9 | 60.1 |
| RandLA-Net [20] + ours | 88.5 | 82.7 | 71.3 | 94.0 | 96.4 | 81.2 | 60.7 | 53.4 | 63.2 | 72.5 | 70.9 | 77.1 | 68.8 | 65.1 | 62.3 | 61.2 |
| Method | OA | mIoU | Ground | Veg. | Build. | Wall | Bridge | Park. | Rail | Traff. | Street. | Car | Foot. | Bike | Water |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RandLA-Net [20] | 91.2 | 54.2 | 83.9 | 98.2 | 93.9 | 54.5 | 37.7 | 50.3 | 11.3 | 53.1 | 39.3 | 79.0 | 36.1 | 0.0 | 67.9 |
| RandLA-Net [20] + ours | 91.3 | 56.3 | 84.2 | 98.1 | 94.6 | 61.6 | 60.8 | 44.2 | 15.7 | 49.4 | 37.2 | 79.1 | 37.8 | 0.1 | 68.7 |
| Parameter | Distribution | Radius (cm) | Dimension | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Grid | Random | Regular | 25 | 35 | 45 | 16 | 32 | 64 | |
| OA (%) | 85.2 | 85.5 | 86.3 | 83.6 | 86.3 | 85.5 | 85.1 | 86.3 | 86.2 |
| Method | mIoU | Ceil. | Floor | Wall | Beam | Col. | Wind. | Door | Table | Chair | Sofa | Book. | Board | Clut. |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| KPConv [15] | 65.3 | 93.3 | 97.9 | 81.6 | 0.0 | 18.1 | 53.7 | 68.7 | 81.3 | 90.8 | 66.0 | 74.3 | 64.8 | 57.9 |
| KPConv [15] + ours | 65.3 | 93.2 | 98.0 | 80.8 | 0.0 | 17.5 | 54.5 | 69.4 | 80.8 | 91.6 | 71.3 | 74.2 | 60.8 | 56.3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, Z.; Ye, Q.; Stoter, J.; Nan, L. Enriching Point Clouds with Implicit Representations for 3D Classification and Segmentation. Remote Sens. 2023, 15, 61. https://doi.org/10.3390/rs15010061
Yang Z, Ye Q, Stoter J, Nan L. Enriching Point Clouds with Implicit Representations for 3D Classification and Segmentation. Remote Sensing. 2023; 15(1):61. https://doi.org/10.3390/rs15010061
Chicago/Turabian StyleYang, Zexin, Qin Ye, Jantien Stoter, and Liangliang Nan. 2023. "Enriching Point Clouds with Implicit Representations for 3D Classification and Segmentation" Remote Sensing 15, no. 1: 61. https://doi.org/10.3390/rs15010061
APA StyleYang, Z., Ye, Q., Stoter, J., & Nan, L. (2023). Enriching Point Clouds with Implicit Representations for 3D Classification and Segmentation. Remote Sensing, 15(1), 61. https://doi.org/10.3390/rs15010061