
AutoML-Based Neural Architecture Search for Object Recognition in Satellite Imagery



Abstract
:1. Introduction
- It provides an in-depth experimental comparative analysis of the top four best-performing CNNs: DeepLabv3, FastFCN, UNET, and MACU on a satellite imagery dataset.
- It introduces an effective NAS implementation of MACU network, NAS-MACU, that is capable of self-discovering the well-performing cell topology and architecture optimized for object recognition in multi-spectral satellite imagery.
- It presents NAS-MACU performance in four different information intensity environments and confirms that NAS-MACU is more suited when the training data (e.g., satellite imagery) has limited availability for practical real-world and economic reasons.
- Finally, it includes a well-annotated and updated satellite imagery dataset for public use and further development in this research field.
2. Related Works
2.1. CNN Networks for Image Segmentation
2.2. Neural Architecture Search
3. Evaluation of Top-Performing CNNs
3.1. Considered Satellite Imagery Dataset
3.2. Experimental Investigation
- TP reflects the number of objects (‘light vehicles’) correctly detected as compared to the ‘ground truth’;
- FP reflects the number of objects (‘light vehicles’) incorrectly detected as compared to the ‘ground truth’;
- TN reflects the number of object size polygons that were correctly identified as area without any object;
- FN reflects the number of objects that were not detected by an algorithm, but object (‘light vehicle’) existed;
- Jaccard index is a pixel-level segmentation accuracy metric of semantic segmentation:
- Recall (sensitivity) is the ratio of correctly predicted objects to all observations in the actual class:
- Precision (positive predictive power) is the relation between true positives and all positive predictions:
- FPO measures overprediction error, i.e., the percentage of objects recognized by the network, not by the annotator:
- F1 combines the precision and recall of a classifier into a single metric by taking their harmonic mean. It is considered the best overall accuracy performance identifier:
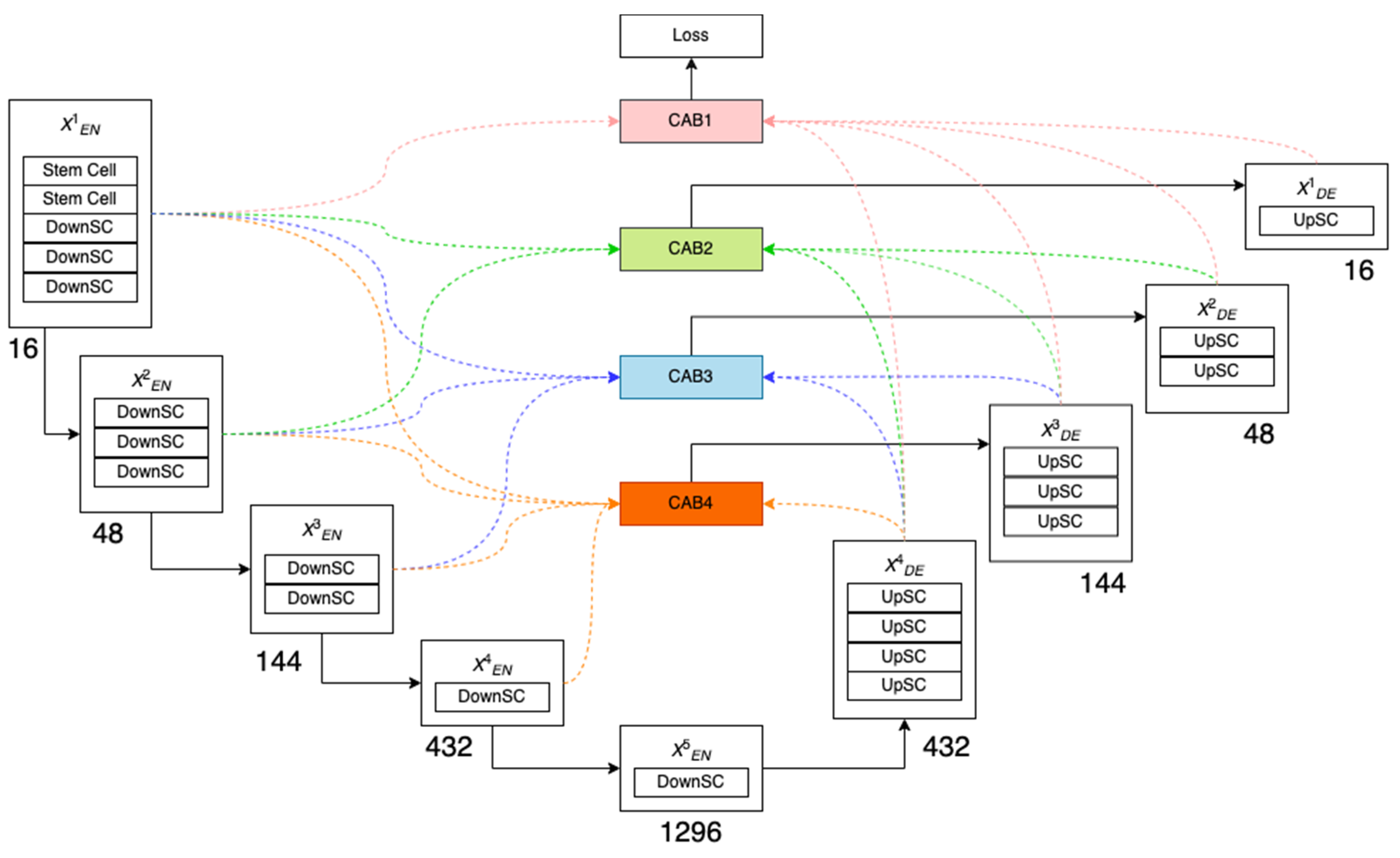
4. The Proposed NAS-MACU Development Process
4.1. Cell-Level Topology Search
4.2. Algorithm That Generates Cell Genotype
| Algorithm 1. Nas-macu cell genotype generation |
|
4.3. MACU and NAS-MACU Comparison
4.4. NAS-MACU Cell Genotypes
5. NAS-MACU Performance Evaluation
6. Conclusions and Future Works
7. Declarations
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Dabboor, M.; Olthof, I.; Mahdianpari, M.; Mohammadimanesh, F.; Shokr, M.; Brisco, B.; Homayouni, S. The RADARSAT Constellation Mission Core Applications: First Results. Remote Sens. 2022, 14, 301. [Google Scholar] [CrossRef]
- Le Quilleuc, A.; Collin, A.; Jasinski, M.F.; Devillers, R. Very High-Resolution Satellite-Derived Bathymetry and Habitat Mapping Using Pleiades-1 and ICESat-2. Remote Sens. 2022, 14, 133. [Google Scholar] [CrossRef]
- European Space Agency. Available online: https://earth.esa.int/eogateway/missions/vision-1 (accessed on 1 August 2022).
- Department of Space of ISRO. Indian Space Research Organization. Available online: https://www.isro.gov.in/Spacecraft/cartosat-3 (accessed on 1 August 2022).
- Singla, J.G.; Sunanda, T. Generation of state of the art very high resolution DSM over hilly terrain using Cartosat-2 multi-view data, its comparison and evaluation. J. Geomat. 2022, 16. [Google Scholar]
- Dixit, M.; Chaurasia, K.; Mishra, V.K. Dilated-ResUnet: A novel deep learning architecture for building extraction from medium resolution multi-spectral satellite imagery. Expert Syst. Appl. 2021, 184, 115530. [Google Scholar] [CrossRef]
- Liheng, H.; Hu, L.; Zhou, H. Deep learning based multi-temporal crop classification. Remote Sens. Environ. 2019, 221, 430–443. [Google Scholar]
- Yang, X. Urban surface water body detection with suppressed built-up noise based on water indices from Sentinel-2 MSI imagery. Remote Sens. Environ. 2019, 219, 259–270. [Google Scholar] [CrossRef]
- Borra, S.; Rohit, T.; Nilanjan, D. Satellite Image Analysis: Clustering and Classification; Springer: Singapore, 2019. [Google Scholar]
- Baier, L.; Jöhren, F.; Seebacher, S. Challenges in the Deployment and Operation of Machine Learning in Practice. ECIS 2019, 1. [Google Scholar]
- Yurtkulu, S.C.; Şahin, Y.; Unal, G. Semantic segmentation with extended DeepLabv3 architecture. In Proceedings of the IEEE 27th Signal Processing and Communications Applications Conference (SIU), Sivas, Turkey, 24–26 April 2019. [Google Scholar]
- Wu, H.; Zhang, J.; Huang, K.; Liang, K.; Yu, Y. Fastfcn: Rethinking dilated convolution in the backbone for semantic segmentation. arXiv 2019, arXiv:1903.11816. [Google Scholar]
- Gudžius, P.; Kurasova, O.; Darulis, V.; Filatovas, E. Deep learning based object recognition in satellite imagery. Mach. Vis. Appl. 2021, 32, 1–14. [Google Scholar] [CrossRef]
- Li, R.; Chenxi, D.; Zheng, S.; Zhang, C.; Atkinson, P. MACU-Net for Semantic Segmentation of Fine-Resolution Remotely Sensed Images. arXiv 2020, arXiv:2007.13083. [Google Scholar] [CrossRef]
- Liu, Y.; Sun, B.; Xue, M.; Zhang, G.; Yen, G.; Tan, K.C. A survey on evolutionary neural architecture search. In IEEE Transactions on Neural Networks and Learning Systems; IEEE: New York, NY, USA, 2021. [Google Scholar]
- Mahesh, B. Machine learning algorithms-a review. Int. J. Sci. Res. (IJSR) 2020, 9, 381–386. [Google Scholar]
- Lindauer, M.; Hutter, F. Best practices for scientific research on neural architecture search. J. Mach. Learn. Res. 2020, 21, 1–18. [Google Scholar]
- Cracknell, A. The development of remote sensing in the last 40 years. Int. J. Remote Sens. 2018, 39, 8387–8427. [Google Scholar] [CrossRef] [Green Version]
- He, X.; Kaiyong, Z.; Xiaowen, C. AutoML: A survey of the state-of-the-art. Knowl. Based Syst. 2021, 212, 106622. [Google Scholar] [CrossRef]
- Meng, D.; Lina, S. Some new trends of deep learning research. Chin. J. Electron. 2019, 28, 1087–1091. [Google Scholar] [CrossRef]
- Elsken, T.; Metzen, J.H.; Hutter, F. Neural architecture search: A survey. J. Mach. Learn. Res. 2019, 20, 1997–2017. [Google Scholar]
- Zoph, B.; Le, Q.V. Neural architecture search with reinforcement learning. arXiv 2016, arXiv:1611.01578. [Google Scholar]
- Zoph, B.; Vasudevan, V.; Shlens, J. Learning transferable architectures for scalable image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Weng, Y.; Zhou, T.; Li, Y.; Qiu, X. NAS-Unet: Neural Architecture Search for Medical Image Segmentation. IEEE Access 2019, 7, 44247–44257. [Google Scholar] [CrossRef]
- Khoreva, A.; Benenson, R.; Hosang, J.; Hein, M.; Schiele, B. Simple does it: Weakly supervised instance and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Noh, H.; Hong, S.; Han, B. Learning deconvolution network for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Las Condes, Chile, 11–18 December 2015; pp. 1520–1528. [Google Scholar]
- Tong, Z.; Xu, P.; Denœux, T. Evidential fully convolutional network for semantic segmentation. Appl. Intell. 2021, 51, 6376–6399. [Google Scholar] [CrossRef]
- Zisserman, A.; Simonyan, B. Very deep convolutional networks for large-scale image recognition. arXiv 2015, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Shaoqing, R.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Corentin, H.; Azimi, S.; Merkle, N. Road segmentation in SAR satellite images with deep fully convolutional neural networks. IEEE Geosci. Remote Sens. 2018, 15, 1867–1871. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Liang-Chieh, C. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar]
- Liang-Chieh, C. Semantic image segmentation with deep convolutional nets and fully connected CRFs. arXiv 2014, arXiv:1412.7062. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [Green Version]
- Le, V.-T.; Yong-Guk, K. Attention-based residual autoencoder for video anomaly detection. Appl. Intell. 2022, 1–15. [Google Scholar] [CrossRef]
- Zhou, Z.; Siddiquee, M.; Tajbakhsh, N.; Liang, J. Unet++: A nested UNET architecture for medical image segmentation. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer: Cham, Switzerland, 2018; pp. 3–11. [Google Scholar]
- Delibasoglu, I.; Cetin, M. Improved U-Nets with inception blocks for building detection. J. Appl. Remote Sens. 2020, 14, 044512. [Google Scholar] [CrossRef]
- Szegedy, C. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Sanghyun, W. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Huang, H.; Lin, L.; Tong, R.; Hu, H.; Zhang, Q. Unet 3+: A full-scale connected unet for medical image segmentation. In Proceedings of the ICASSP 2020–2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 1055–1059. [Google Scholar]
- Nabiee, S.; Harding, M.; Hersh, J.; Bagherzadeh, N. Hybrid U-Net: Semantic segmentation of high-resolution satellite images to detect war destruction. Mach. Learn. Appl. 2022, 9, 100381. [Google Scholar] [CrossRef]
- Cheng, D.; Meng, G.; Cheng, G.; Pan, C. SeNet: Structured edge network for sea–land segmentation. IEEE Geosci. Remote Sens. Lett. 2016, 14, 247–251. [Google Scholar] [CrossRef]
- Wei, Y.; Liu, X.; Lei, J.; Feng, L. Multiscale feature U-Net for remote sensing image segmentation. J. Appl. Remote Sens. 2022, 16, 016507. [Google Scholar] [CrossRef]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar]
- Niu, X.; Zeng, Q.; Luo, X.; Chen, L. CAU-net for the semantic segmentation of fine-resolution remotely sensed images. Remote Sens. 2022, 14, 215. [Google Scholar] [CrossRef]
- Quoc, N.; Huy, V.; Hoang, T. Real-time human ear detection based on the joint of yolo and retinaface. Complexity 2021, 2021, 7918165. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Wang, Y.; Zhou, Y. Transunet: Transformers make strong encoders for medical image segmentation. arXiv 2021, arXiv:2102.04306. [Google Scholar]
- He, X.; Xu, S. Process Neural Networks: Theory and Applications; Springer: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Baker, B.; Gupta, O.; Naik, N.; Raskar, R. Designing neural network architectures using reinforcement learning. arXiv 2016, arXiv:1611.02167. [Google Scholar]
- Real, A.; Aggarwal, Y.; Huang, A.; Le, Q.V. Regularized evolution for image classifier architecture search. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019. [Google Scholar]
- Kandasamy, K.; Neiswanger, W.; Schneider, J.; Poczos, B.; Xing, E.P. Neural architecture search with bayesian optimisation and optimal transport. Adv. Neural Inf. Process. Syst. 2018, 31. [Google Scholar]
- Shin, R.; Packer, C.; Song, D. Differentiable Neural Network Architecture Search; University of California: Berkeley, CA, USA, 2018. [Google Scholar]
- Yao, C.; Pan, X. Neural architecture search based on evolutionary algorithms with fitness approximation. In Proceedings of the International Joint Conference on Neural Networks (IJCNN), Shenzhen, China, 18–22 July 2021. [Google Scholar]
- Liu, H.; Simonyan, K.; Yang, Y. Darts: Differentiable architecture search. arXiv 2018, arXiv:1806.09055. [Google Scholar]
- Yu, Q. C2fnas: Coarse-to-fine neural architecture search for 3d medical image segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Bosma, M.M.; Dushatskiy, A.; Grewal, M.; Alderliesten, T.; Bosman, P. Mixed-block neural architecture search for medical image segmentation. Med. Imaging Image Process. 2022, 12032, 193–199. [Google Scholar]
- Ottelander, T.D.; Dushatskiy, A.; Virgolin, M.; Bosman, P. Local search is a remarkably strong baseline for neural architecture search. In International Conference on Evolutionary Multi-Criterion Optimization; Springer: Cham, Switzerland, 2021; pp. 465–479. [Google Scholar]
- Zhang, M.; Jing, W.; Lin, J.; Fang, N.; Wei, W.; Woźniak, M.; Damaševičius, R. NAS-HRIS: Automatic design and architecture search of neural network for semantic segmentation in remote sensing images. Sensors 2022, 20, 5292. [Google Scholar] [CrossRef] [PubMed]
- Peng, C.; Li, Y.; Jiao, L.; Shang, R. Efficient convolutional neural architecture search for remote sensing image scene classification. IEEE Trans. Geosci. Remote Sens. 2020, 59, 6092–6105. [Google Scholar] [CrossRef]
- Jing, W.; Ren, Q.; Zhou, J.; Song, H. AutoRSISC: Automatic design of neural architecture for remote sensing image scene classification. Pattern Recognit. Lett. 2020, 140, 186–192. [Google Scholar] [CrossRef]
- Jang, E.; Gu, S.; Poole, B. Categorical reparameterization with gumbel-softmax. arXiv 2016, arXiv:1611.01144. [Google Scholar]
- Zhang, Z.; Liu, S.; Zhang, Y.; Chen, W. RS-DARTS: A convolutional neural architecture search for remote sensing image scene classification. Remote Sens. 2021, 14, 141. [Google Scholar] [CrossRef]
- Gudžius, P.; Kurasova, O.; Darulis, V.; Filatovas, E. VU DataScience GitHub Depository. 2021. Available online: https://github.com/VUDataScience/Deep-learning-based-object-recognition-in-multispectral-satellite-imagery-for-low-latency-applicatio (accessed on 1 September 2022).
- Iglovikov, V.; Mushinskiy, S.; Osin, V. Satellite Imagery Feature Detection using Deep Convolutional Neural Network: A Kaggle Competition. arXiv 2017, arXiv:1706.06169. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Architectures | Year | Unique Approaches Deployed |
|---|---|---|
| UNET [13] | 2015 | Uses skip connections from down-sampling layers to up-sampling |
| DeepLabv1 [34] | 2016 | Uses a fully connected conditional random field (CRF) |
| SegNet [32] | 2017 | In skip connection, SegNet transfers only pooling indices to use less memory |
| PSPNet [48] | 2017 | Uses dilated convolutions and pyramid pooling module |
| DANet [43] | 2017 | Its position and channel attention modules followed by ResNet feature extraction |
| UNET++ [37] | 2018 | Improved skip connections from down-sampling layers to up-sampling |
| DeepLabv2 [33] | 2019 | Uses atrous/dilated convolution and fully connected CRF together |
| MACU [40] | 2019 | Has multi-scale skip connections and asymmetric convolution blocks |
| UNet3+ [41] | 2020 | Modifies skip connection and fewer parameters compared to the UNET++. Proposes hybrid loss function |
| DeepLabv3 [11] | 2021 | Improved atrous spatial pyramid pooling (ASPP) |
| Inception-UNET [38] | 2021 | Uses inception modules instead of standard kernels (wider networks) |
| TransUNET [49] | 2021 | Transformers encode the image patches in the encoding stage |
| FastFCN [12] | 2021 | Fully connected network layers |
| INCSA-UNET [40] | 2021 | Uses DropBlock inside inception modules, and also applies attention between encoding and decoding stages |
| Hybrid-U-Net [42] | 2022 | Builds a hybrid U-Net with additional decoder subnetworks and introduces high-resolution satellite images dataset |
| FCAU-NET [46] | 2022 | Coordinates attentions, asymmetric convolution blocks to enhance the extracted features and refinement fusion block (RFB) in skip connections |
| Segmentation Metrics | Object Recognition Metrics (Derived) | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Environment | # of Patched Images | Epochs | Batch Size | Jaccard Index | Recall | Precision | FPO (%) | F1 | |
| Env 1 | 20,000 | 20 | 4 | MACU | 0.659 | 0.956 | 0.942 | 5.820 | 0.949 |
| FastFCN | 0.609 | 0.955 | 0.933 | 6.687 | 0.944 | ||||
| DeepLabv3 | 0.484 | 0.868 | 0.961 | 3.944 | 0.912 | ||||
| UNET | 0.647 | 0.94 | 0.931 | 6.928 | 0.935 | ||||
| Env 2 | 30,000 | 30 | 4 | MACU | 0.661 | 0.948 | 0.945 | 5.501 | 0.946 |
| FastFCN | 0.615 | 0.958 | 0.926 | 7.383 | 0.942 | ||||
| DeepLabv3 | 0.441 | 0.82 | 0.968 | 3.156 | 0.888 | ||||
| UNET | 0.652 | 0.955 | 0.923 | 7.691 | 0.939 | ||||
| Env 3 | 30,000 | 30 | 8 | MACU | 0.667 | 0.953 | 0.933 | 6.675 | 0.943 |
| FastFCN | 0.506 | 0.828 | 0.972 | 2.833 | 0.894 | ||||
| DeepLabv3 | 0.538 | 0.918 | 0.950 | 4.993 | 0.934 | ||||
| UNET | 0.658 | 0.960 | 0.919 | 8.099 | 0.939 | ||||
| Type | Operations |
|---|---|
| down_operations | ‘avg_pool’, ‘max_pool’, ‘down_cweight’, ‘down_dil_conv’, ‘down_dep_conv’, ‘down_conv’ |
| up_operations | ‘up_cweight’, ‘up_dep_conv’, ‘up_conv’, ‘up_dil_conv’ |
| normal_operations | ‘identity’, ‘none’, ‘cweight’, ‘dil_conv’, ‘dep_conv’, ‘shuffle_conv’, ‘conv’ |
| Genotype Version | Structure (Down Operation, Parent Node Number) | Structure (Up Operations, Parent Node Number) | Hyperparameters (Epochs, Batch Size, Cellular Level Depth, Training, Validation Cycle) |
|---|---|---|---|
| NAS-MACU-V1 | (‘down_cweight’, 0), (‘down_conv’, 1), (‘down_conv’, 1), (‘conv’, 2), (‘down_conv’, 0), (‘conv’, 3) | (‘cweight’, 0), (‘up_cweight’, 1), (‘identity’, 0), (‘conv’, 2), (‘shuffle_conv’, 2), (‘conv’, 3) | Epochs 300, batch 4, depth 4, training set 1000, validation set 100, max patience not reached |
| NAS-MACU-V2 | (‘down_conv’, 0), (‘down_deep_conv’, 1), (‘down_conv’, 1), (‘conv’, 2), (‘shuffle_conv’, 2), (‘conv’, 3) | (‘up_cweight’, 1), (‘identity’, 0), (‘‘up_conv’, 0), (‘conv’, 2), (‘shuffle_conv’, 2), (‘conv’, 3 | Epochs 300, batch 4, depth 4, training set 1000, validation set 100, max patience not reached |
| NAS-MACU-V3 | (‘down_dep_conv’, 0), (‘down_conv’, 1), (‘down_conv’, 1), (‘conv’, 2), (‘shuffle_conv’, 2), (‘conv’, 3) | (‘up_cweight’, 1), (‘identity’, 0), (‘identity’, 0), (‘conv’, 2), (‘shuffle_conv’, 2), (‘conv’, 3) | Epochs 500, batch 4, depth 4, training set 1000, validation set 100, max patience not reached |
| NAS-MACU-V4 | (‘down_dil_conv’, 0), (‘down_conv’, 1), (‘down_conv’, 1), (‘conv’, 2), (‘conv’, 3), (‘shuffle_conv’, 2) | (‘up_conv’, 1), (‘identity’, 0), (‘identity’, 0), (‘conv’, 2), (‘shuffle_conv’, 2), (‘identity’, 0) | Epochs 500, batch 8, depth 4, training set 1000, validation set 100, max patience not reached |
| NAS-MACU-V5 | (‘down_dep_conv’, 0), (‘down_conv’, 1), (‘down_dep_conv’, 1), (‘conv’, 2), (‘shuffle_conv’, 2), (‘conv’, 3) | (‘identity’, 0), (‘up_conv’, 1), (‘identity’, 0), (‘conv’, 2), (‘shuffle_conv’, 2), (‘conv’, 3) | Epochs 500, batch 32, depth 4, training set 1000, validation set 100, max patience not reached |
| NAS-MACU-V6 | (‘down_dep_conv’, 0), (‘down_conv’, 1), (‘shuffle_conv’, 2), (‘down_conv’, 1), (‘cweight’, 3), (‘down_cweight’, 1) | (‘conv’, 0), (‘up_conv’, 1), (‘identity’, 0), (‘shuffle_conv’, 2), (‘cweight’, 3), (‘identity’, 0) | Epochs 500, batch 32, depth 4, training set 1000, validation set 100, max patience not reached |
| NAS-MACU-V7 | (‘down_cweight’, 0), (‘down_conv’, 1), (‘down_conv’, 1), (‘conv’, 2), (‘down_conv’, 0), (‘conv’, 3) | (‘up_cweight’, 1), (‘identity’, 0), (‘identity’, 0), (‘conv’, 2), (‘conv’, 3), (‘identity’, 0) | Epochs 500, batch 16, depth 4, training set 2500, validation 500. Stopped after 204 max patience reached |
| NAS-MACU-V8 | (‘down_cweight’, 0), (‘down_conv’, 1), (‘conv’, 2), (‘down_conv’, 1), (‘down_dep_conv’, 0), (‘max_pool’, 1), (‘max_pool’, 1), (‘identity’, 3) | (‘conv’, 0), (‘up_conv’, 1), (‘up_conv’, 1), (‘conv’, 2), (‘identity’, 3), (‘conv’, 2), (‘cweight’, 4), (‘identity’, 3) | Epochs 500, batch 16, depth 5, training set 2500, validation set 500 |
| Object Recognition Metrics (Derived) | ||||
|---|---|---|---|---|
| Genotype Version | Recall | Precision | FPO (%) | F1 |
| MACU | 0.969 | 0.858 | 14.16 | 0.910 |
| NAS-MACU-V1 | 0.949 | 0.880 | 12.038 | 0.913 |
| NAS-MACU-V2 | 0.939 | 0.893 | 10.704 | 0.915 |
| NAS-MACU-V3 | 0.951 | 0.901 | 9.865 | 0.926 |
| NAS-MACU-V4 | 0.945 | 0.904 | 9.552 | 0.924 |
| NAS-MACU-V5 | 0.964 | 0.824 | 17.626 | 0.889 |
| NAS-MACU-V6 | 0.965 | 0.872 | 12.835 | 0.916 |
| NAS-MACU-V7 | 0.957 | 0.924 | 7.616 | 0.931 |
| NAS-MACU-V8 | 0.953 | 0.920 | 8.544 | 0.934 |
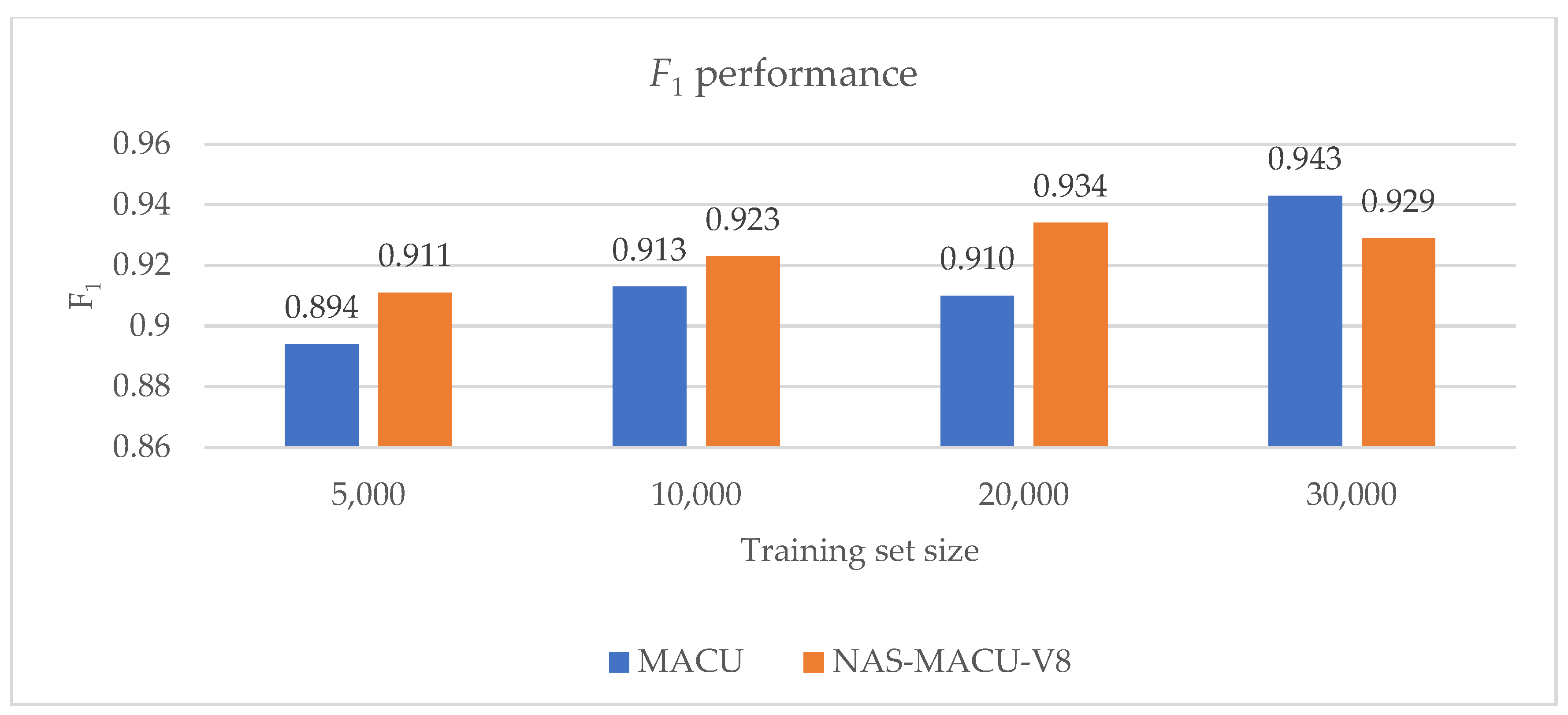
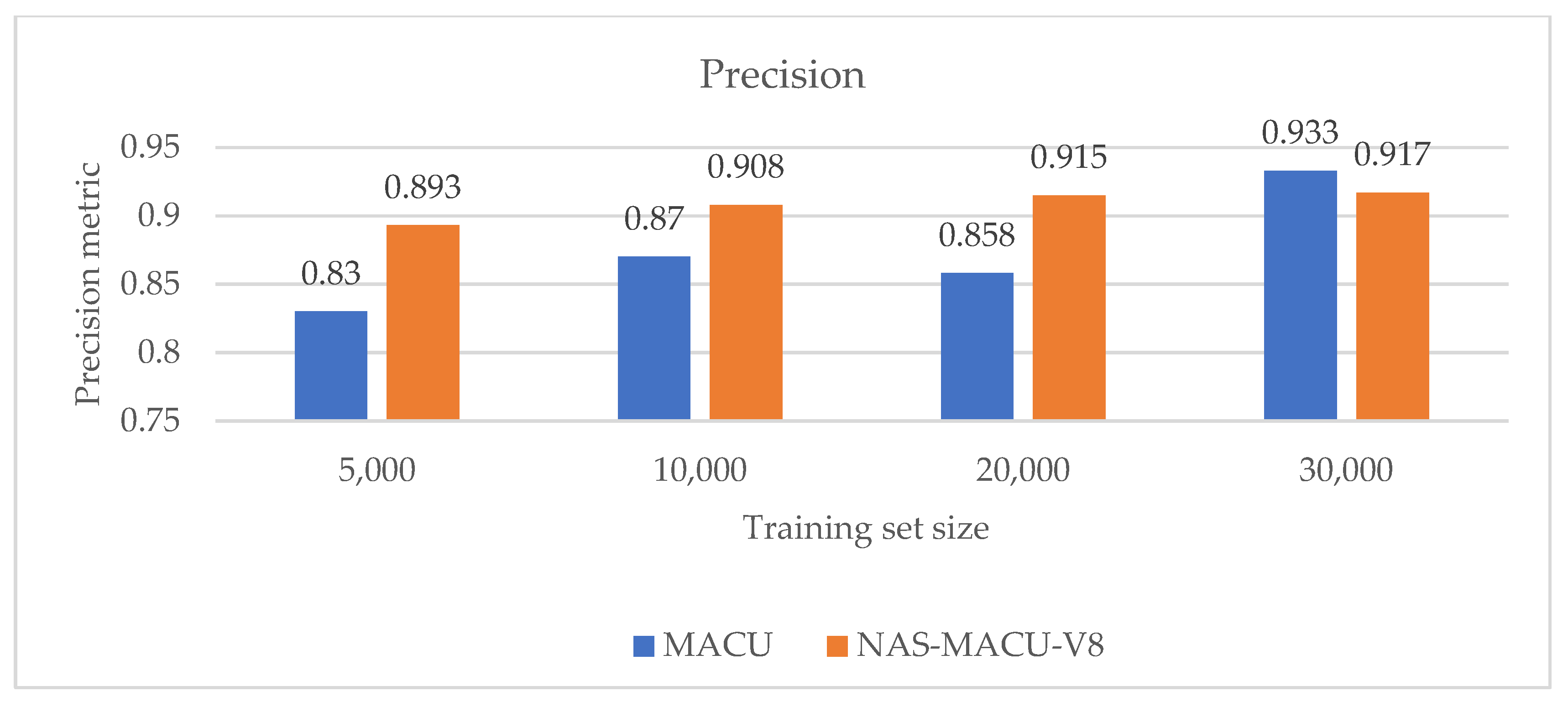
| Object Recognition Metrics (Derived) | |||||
|---|---|---|---|---|---|
| Training Set Size | Network | Recall | Precision | FPO (%) | F1 |
| 5000 | MACU | 0.968 | 0.83 | 16.96 | 0.894 |
| NAS-MACU-V8 | 0.93 | 0.893 | 10.67 | 0.911 | |
| 10,000 | MACU | 0.96 | 0.87 | 13.03 | 0.913 |
| NAS-MACU-V8 | 0.938 | 0.908 | 9.17 | 0.923 | |
| 20,000 | MACU | 0.969 | 0.858 | 14.16 | 0.910 |
| NAS-MACU-V8 | 0.953 | 0.915 | 8.54 | 0.934 | |
| 30,000 | MACU | 0.953 | 0.933 | 6.675 | 0.943 |
| NAS-MACU-V8 | 0.941 | 0.917 | 8.321 | 0.929 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gudzius, P.; Kurasova, O.; Darulis, V.; Filatovas, E. AutoML-Based Neural Architecture Search for Object Recognition in Satellite Imagery. Remote Sens. 2023, 15, 91. https://doi.org/10.3390/rs15010091
Gudzius P, Kurasova O, Darulis V, Filatovas E. AutoML-Based Neural Architecture Search for Object Recognition in Satellite Imagery. Remote Sensing. 2023; 15(1):91. https://doi.org/10.3390/rs15010091
Chicago/Turabian StyleGudzius, Povilas, Olga Kurasova, Vytenis Darulis, and Ernestas Filatovas. 2023. "AutoML-Based Neural Architecture Search for Object Recognition in Satellite Imagery" Remote Sensing 15, no. 1: 91. https://doi.org/10.3390/rs15010091
APA StyleGudzius, P., Kurasova, O., Darulis, V., & Filatovas, E. (2023). AutoML-Based Neural Architecture Search for Object Recognition in Satellite Imagery. Remote Sensing, 15(1), 91. https://doi.org/10.3390/rs15010091