
Rethinking 3D-CNN in Hyperspectral Image Super-Resolution



Abstract
:1. Introduction
- We rethink the role that 3D CNN plays in the HSISR field and design a novel full 3D CNN model based on thd U-Net architecture called Full 3D U-Net (F3DUN). Experimentally, it outperforms existing state-of-the-art, single-image SR methods, which proves the effectiveness of full 3D CNN models in this field.
- We develop a mixed 3D/2D model that shares the same structure with F3DUN, termed Mixed U-Net (MUN), for comparison. Extensive analysis on the two models shows that the full 3D CNN model has a larger modeling capacity than the 3D/2D mixed model with the same number of parameters; thus, it performs better with large-scale datasets.
- We explore the relationship between the scale of training samples and the prior of the model. We argue that the full 3D CNN model can obtain competitive results on small-scale training sets compared with the 3D/2D mixed model, which concludes that the full 3D CNN model is more robust with respect to the amount of training samples than commonly thought.
2. Related Work
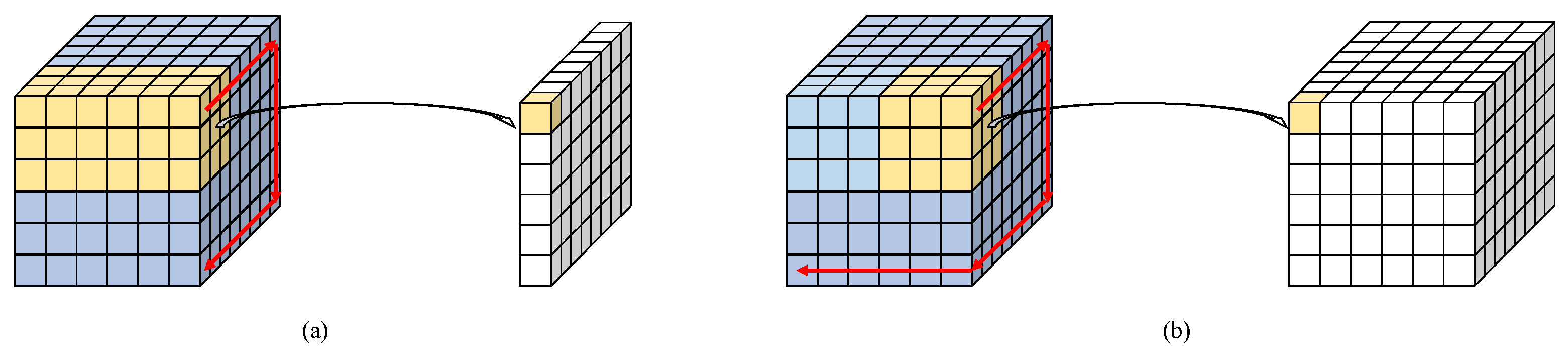
2.1. Three-Dimensional Convolution
2.2. Single Hyperspectral Image Super-Resolution
2.3. Fusion-Based Hyperspectral Image Super-Resolution
2.4. Single Natural Image Super-Resolution
3. Method
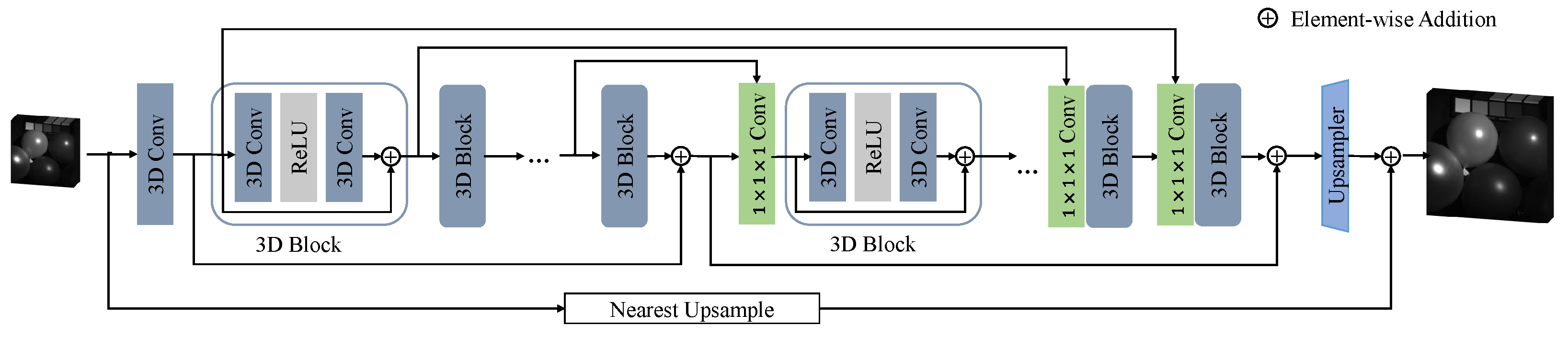
3.1. Full 3D U-Net
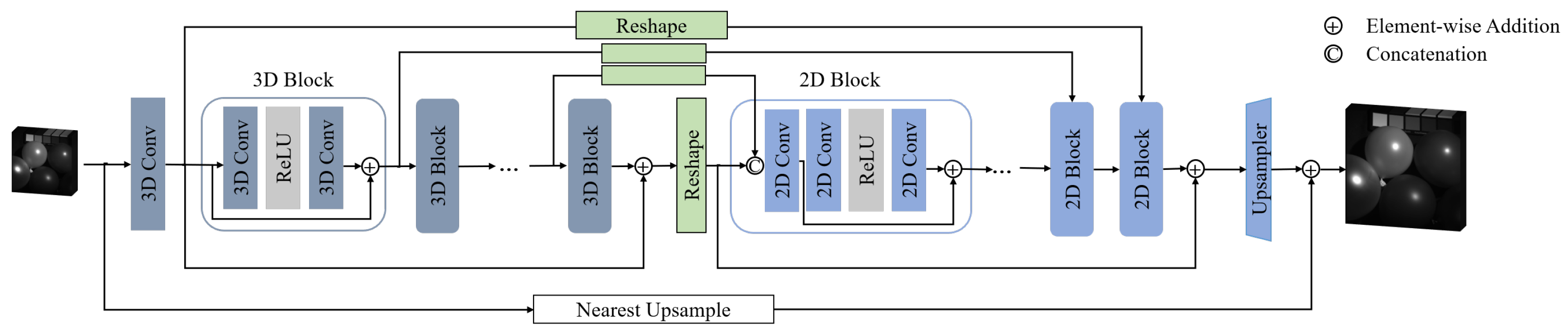
3.2. Mixed U-Net
3.3. Loss Function
3.4. Relationship with Other Methods
- (a)
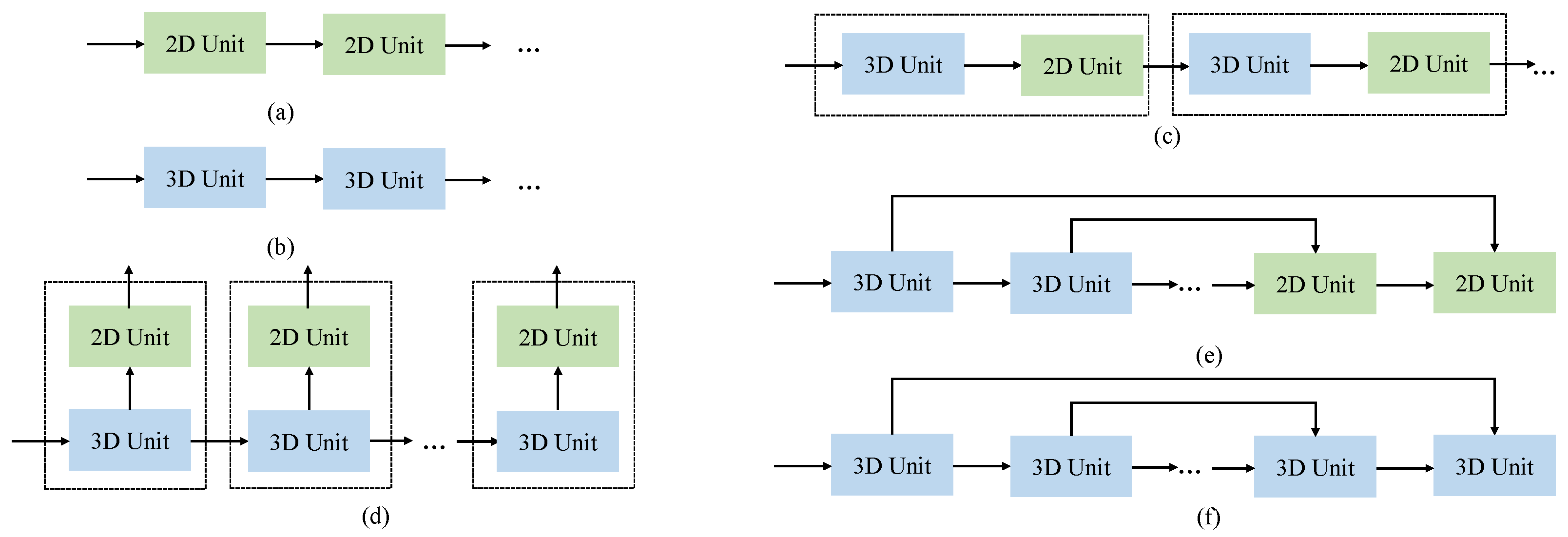
- 3DFCNN: 3DFCNN is the pioneering work of full 3D CNN models for HSISR. It consists of 5 3D convolution layers and uses MSE loss to train. However, there are noticeable drawbacks to it. Most importantly, the model architecture of 3DFCNN is too shallow and it does not combine with advanced ideas of deep learning, such as residual learning and long skip connections. Therefore, in this paper, we rethink the prior of full 3D CNN in HSISR and argue that full 3D CNN models’ bad results are not caused by 3D CNN, but rather a lack of model design. It is obvious that F3DUN is much deeper than 3DFCNN and successfully prevents overfitting and achieves SOTA results.
- (b)
- Two- and three-dimensional mixed models: The main idea of 3D/2D mixed models is to introduce 2D convolutions into 3D CNN in order to boost the ability of spatial enhancement. They have become popular recently and can be seen as a modification to full 3D CNN models. However, there are two potential problems. On the one hand, the 2D convolutions in 3D/2D models are shared in the spectral dimension, which leads to a risk of spectral distortion. On the other hand, 3D/2D mixed models always face the dilemma of balancing the two kinds of convolutions, where features enhanced by 2D convolutions can be polluted by cascading 3D modules. In MUN, we partially solve the two above problems, but we make a step forward: could a full 3D CNN model outperform 3D/2D mixed ones? Model analysis on MUN and F3DUN supports our idea and proves the advantages of the full 3D CNN model compared with 3D/2D mixed models.
4. Experiments and Analysis
4.1. Datasets
- (a)
- CAVE dataset: The CAVE dataset [68] is taken by a cooled CCD camera, and the range of the wavelength is from 400 nm to 700 nm, at a step of 10 nm (31 bands). The 32 hyperspectral images are divided into five sections: real and fake, skin and hair, paints, food and drinks, and stuff. Each image has a size of , and every band is stored as a grayscale picture separately in the form of a PNG.
- (b)
- Harvard dataset: The Harvard dataset [69] contains 77 indoor and outdoor hyperspectral images under daylight illumination collected by the Nuance FX, CRI Inc., camera. Each image covers the wavelength range of 400 nm to 700 nm, evenly divided into 31 bands. The spatial resolution is , and all images are stored as .mat files.
4.2. Implementation Details
4.3. Evaluation Metrics
4.4. Model Analysis
4.4.1. Comparison with 3D-2D Model Prior
4.4.2. Results on Noisy Images
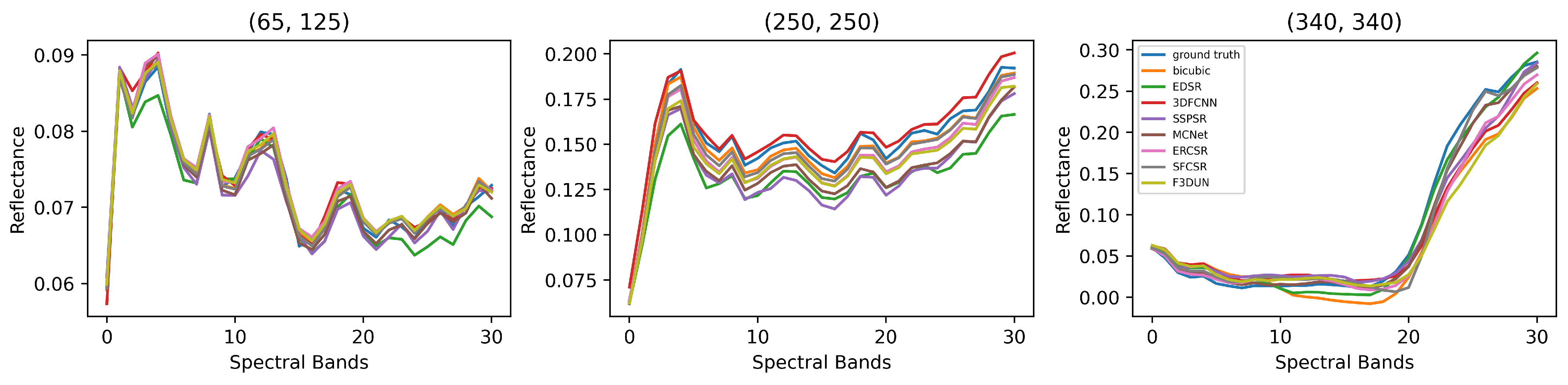
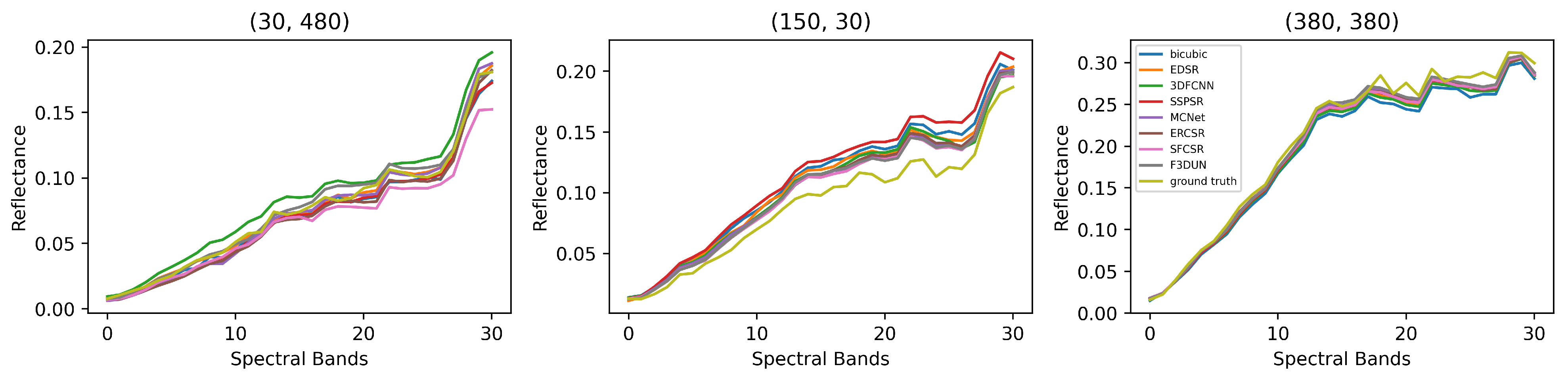
4.5. Comparison with State-of-the-Art Methods

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Scale | PSNR↑ | SSIM↑ | RMSE↓ | SAM↓ | ERGAS↓ | CC↑ |
|---|---|---|---|---|---|---|---|
| Bicubic | 4 | 34.6163 | 0.9287 | 0.0225 | 5.1869 | 6.8047 | 0.9728 |
| EDSR [14] | 4 | 36.1569 | 0.9393 | 0.0202 | 4.4149 | 5.9793 | 0.9758 |
| 3DFCNN [19] | 4 | 35.3479 | 0.9349 | 0.0209 | 4.0415 | 6.0750 | 0.9758 |
| SSPSR [45] | 4 | 36.5934 | 0.9431 | 0.0195 | 3.9691 | 5.7608 | 0.9766 |
| MCNet [20] | 4 | 36.7182 | 0.9434 | 0.0191 | 3.9590 | 5.6281 | 0.9769 |
| ERCSR [21] | 4 | 36.6318 | 0.9436 | 0.0193 | 3.9140 | 5.6610 | 0.9772 |
| SFCSR [47] | 4 | 36.6718 | 0.9438 | 0.0191 | 3.9218 | 5.6409 | 0.9774 |
| F3DUN | 4 | 36.9368 | 0.9458 | 0.0186 | 3.6340 | 5.4429 | 0.9786 |
| Bicubic | 8 | 30.0719 | 0.8511 | 0.0367 | 7.0948 | 10.8664 | 0.9349 |
| EDSR [14] | 8 | 30.9524 | 0.8703 | 0.0347 | 6.0270 | 10.1562 | 0.9393 |
| 3DFCNN [19] | 8 | 30.3622 | 0.8669 | 0.0354 | 5.6714 | 10.2498 | 0.9391 |
| SSPSR [45] | 8 | 30.4524 | 0.8670 | 0.0367 | 5.6093 | 10.7448 | 0.9322 |
| MCNet [20] | 8 | 31.2193 | 0.8790 | 0.0339 | 5.6056 | 9.7672 | 0.9403 |
| ERCSR [21] | 8 | 31.3491 | 0.8808 | 0.0335 | 5.5721 | 9.7204 | 0.9421 |
| SFCSR [47] | 8 | 31.4008 | 0.8814 | 0.0330 | 5.6069 | 9.6230 | 0.9432 |
| F3DUN | 8 | 31.6730 | 0.8849 | 0.0325 | 5.1230 | 9.4327 | 0.9441 |
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Sabins, F.F. Remote sensing for mineral exploration. Ore Geol. Rev. 1999, 14, 157–183. [Google Scholar] [CrossRef]
- Lu, G.; Fei, B. Medical hyperspectral imaging: A review. J. Biomed. Opt. 2014, 19, 010901. [Google Scholar] [CrossRef] [PubMed]
- Lowe, A.; Harrison, N.; French, A.P. Hyperspectral image analysis techniques for the detection and classification of the early onset of plant disease and stress. Plant Methods 2017, 13, 80. [Google Scholar] [CrossRef] [PubMed]
- Hong, D.; Gao, L.; Yao, J.; Zhang, B.; Plaza, A.; Chanussot, J. Graph convolutional networks for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2021, 59, 5966–5978. [Google Scholar] [CrossRef]
- Yang, Y.; Song, S.; Liu, D.; Chan, J.C.W.; Li, J.; Zhang, J. Hyperspectral anomaly detection through sparse representation with tensor decomposition-based dictionary construction and adaptive weighting. IEEE Access 2020, 8, 72121–72137. [Google Scholar] [CrossRef]
- Dong, W.; Zhou, C.; Wu, F.; Wu, J.; Shi, G.; Li, X. Model-guided deep hyperspectral image super-resolution. IEEE Trans. Image Process. 2021, 30, 5754–5768. [Google Scholar] [CrossRef]
- Xie, Q.; Zhou, M.; Zhao, Q.; Meng, D.; Zuo, W.; Xu, Z. Multispectral and hyperspectral image fusion by MS/HS fusion net. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 1585–1594. [Google Scholar]
- Dian, R.; Li, S.; Guo, A.; Fang, L. Deep hyperspectral image sharpening. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 5345–5355. [Google Scholar] [CrossRef] [PubMed]
- Zhang, H.; Ma, J. GTP-PNet: A residual learning network based on gradient transformation prior for pansharpening. ISPRS J. Photogramm. Remote Sens. 2021, 172, 223–239. [Google Scholar] [CrossRef]
- Masi, G.; Cozzolino, D.; Verdoliva, L.; Scarpa, G. Pansharpening by convolutional neural networks. Remote Sens. 2016, 8, 594. [Google Scholar] [CrossRef]
- Wang, Y.; Chen, X.; Han, Z.; He, S. Hyperspectral image super-resolution via nonlocal low-rank tensor approximation and total variation regularization. Remote Sens. 2017, 9, 1286. [Google Scholar] [CrossRef]
- Huang, H.; Yu, J.; Sun, W. Super-resolution mapping via multi-dictionary based sparse representation. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; pp. 3523–3527. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate image super-resolution using very deep convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1646–1654. [Google Scholar]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Mu Lee, K. Enhanced deep residual networks for single image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 136–144. [Google Scholar]
- Doicu, A.; Doicu, A.; Efremenko, D.S.; Loyola, D.; Trautmann, T. An overview of neural network methods for predicting uncertainty in atmospheric remote sensing. Remote Sens. 2021, 13, 5061. [Google Scholar] [CrossRef]
- Todorov, V. Advanced Monte Carlo Methods to Neural Networks. In Proceedings of the Recent Advances in Computational Optimization: Results of the Workshop on Computational Optimization WCO 2021, Online, 17 September 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 303–314. [Google Scholar]
- Zhu, L.; Huang, L.; Fan, L.; Huang, J.; Huang, F.; Chen, J.; Zhang, Z.; Wang, Y. Landslide susceptibility prediction modeling based on remote sensing and a novel deep learning algorithm of a cascade-parallel recurrent neural network. Sensors 2020, 20, 1576. [Google Scholar] [CrossRef] [PubMed]
- Cai, W.; Ning, X.; Zhou, G.; Bai, X.; Jiang, Y.; Li, W.; Qian, P. A Novel Hyperspectral Image Classification Model Using Bole Convolution with Three-Directions Attention Mechanism: Small sample and Unbalanced Learning. IEEE Trans. Geosci. Remote Sens. 2022, 61, 1–17. [Google Scholar] [CrossRef]
- Mei, S.; Yuan, X.; Ji, J.; Zhang, Y.; Wan, S.; Du, Q. Hyperspectral image spatial super-resolution via 3D full convolutional neural network. Remote Sens. 2017, 9, 1139. [Google Scholar] [CrossRef]
- Li, Q.; Wang, Q.; Li, X. Mixed 2D/3D convolutional network for hyperspectral image super-resolution. Remote Sens. 2020, 12, 1660. [Google Scholar] [CrossRef]
- Li, Q.; Wang, Q.; Li, X. Exploring the relationship between 2D/3D convolution for hyperspectral image super-resolution. IEEE Trans. Geosci. Remote Sens. 2021, 59, 8693–8703. [Google Scholar] [CrossRef]
- Ding, Y.; Zhao, X.; Zhang, Z.; Cai, W.; Yang, N.; Zhan, Y. Semi-supervised locality preserving dense graph neural network with ARMA filters and context-aware learning for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–12. [Google Scholar] [CrossRef]
- Ding, Y.; Zhang, Z.; Zhao, X.; Hong, D.; Li, W.; Cai, W.; Zhan, Y. AF2GNN: Graph convolution with adaptive filters and aggregator fusion for hyperspectral image classification. Inf. Sci. 2022, 602, 201–219. [Google Scholar] [CrossRef]
- Ding, Y.; Zhang, Z.; Zhao, X.; Hong, D.; Cai, W.; Yang, N.; Wang, B. Multi-scale receptive fields: Graph attention neural network for hyperspectral image classification. Expert Syst. Appl. 2023, 223, 119858. [Google Scholar] [CrossRef]
- Ding, Y.; Zhang, Z.; Zhao, X.; Cai, W.; Yang, N.; Hu, H.; Huang, X.; Cao, Y.; Cai, W. Unsupervised self-correlated learning smoothy enhanced locality preserving graph convolution embedding clustering for hyperspectral images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–16. [Google Scholar] [CrossRef]
- Ding, Y.; Zhang, Z.; Zhao, X.; Cai, Y.; Li, S.; Deng, B.; Cai, W. Self-supervised locality preserving low-pass graph convolutional embedding for large-scale hyperspectral image clustering. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–16. [Google Scholar] [CrossRef]
- Zhang, Z.; Ding, Y.; Zhao, X.; Siye, L.; Yang, N.; Cai, Y.; Zhan, Y. Multireceptive field: An adaptive path aggregation graph neural framework for hyperspectral image classification. Expert Syst. Appl. 2023, 217, 119508. [Google Scholar] [CrossRef]
- Chen, Z.; Lu, Z.; Gao, H.; Zhang, Y.; Zhao, J.; Hong, D.; Zhang, B. Global to Local: A Hierarchical Detection Algorithm for Hyperspectral Image Target Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15. [Google Scholar] [CrossRef]
- Fan, G.; Ma, Y.; Mei, X.; Fan, F.; Huang, J.; Ma, J. Hyperspectral anomaly detection with robust graph autoencoders. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–14. [Google Scholar]
- Li, Y.; Zhang, H.; Shen, Q. Spectral–spatial classification of hyperspectral imagery with 3D convolutional neural network. Remote Sens. 2017, 9, 67. [Google Scholar] [CrossRef]
- Ji, S.; Zhang, C.; Xu, A.; Shi, Y.; Duan, Y. 3D convolutional neural networks for crop classification with multi-temporal remote sensing images. Remote Sens. 2018, 10, 75. [Google Scholar] [CrossRef]
- Mei, S.; Ji, J.; Geng, Y.; Zhang, Z.; Li, X.; Du, Q. Unsupervised spatial–spectral feature learning by 3D convolutional autoencoder for hyperspectral classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6808–6820. [Google Scholar] [CrossRef]
- Yang, X.; Zhang, X.; Ye, Y.; Lau, R.Y.; Lu, S.; Li, X.; Huang, X. Synergistic 2D/3D convolutional neural network for hyperspectral image classification. Remote Sens. 2020, 12, 2033. [Google Scholar] [CrossRef]
- Jiang, H.; Lu, N. Multi-scale residual convolutional neural network for haze removal of remote sensing images. Remote Sens. 2018, 10, 945. [Google Scholar] [CrossRef]
- Quan, Y.; Fu, D.; Chang, Y.; Wang, C. 3D Convolutional Neural Network for Low-Light Image Sequence Enhancement in SLAM. Remote Sens. 2022, 14, 3985. [Google Scholar] [CrossRef]
- Xu, Z.; Guan, K.; Casler, N.; Peng, B.; Wang, S. A 3D convolutional neural network method for land cover classification using LiDAR and multi-temporal Landsat imagery. ISPRS J. Photogramm. Remote Sens. 2018, 144, 423–434. [Google Scholar] [CrossRef]
- Dong, H.; Zhang, L.; Zou, B. PolSAR image classification with lightweight 3D convolutional networks. Remote Sens. 2020, 12, 396. [Google Scholar] [CrossRef]
- Li, J.; Zhang, S.; Huang, T. Multi-scale 3d convolution network for video based person re-identification. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, Hawaii, USA, 27 January–1 February 2019; Volume 33, pp. 8618–8625. [Google Scholar]
- Ying, X.; Wang, L.; Wang, Y.; Sheng, W.; An, W.; Guo, Y. Deformable 3d convolution for video super-resolution. IEEE Signal Process. Lett. 2020, 27, 1500–1504. [Google Scholar] [CrossRef]
- Akgun, T.; Altunbasak, Y.; Mersereau, R.M. Super-resolution reconstruction of hyperspectral images. IEEE Trans. Image Process. 2005, 14, 1860–1875. [Google Scholar] [CrossRef]
- Bauschke, H.H.; Borwein, J.M. On projection algorithms for solving convex feasibility problems. SIAM Rev. 1996, 38, 367–426. [Google Scholar] [CrossRef]
- Yuan, Y.; Zheng, X.; Lu, X. Hyperspectral image superresolution by transfer learning. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 1963–1974. [Google Scholar] [CrossRef]
- Xie, W.; Jia, X.; Li, Y.; Lei, J. Hyperspectral image super-resolution using deep feature matrix factorization. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6055–6067. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, L.; Dingl, C.; Wei, W.; Zhang, Y. Single hyperspectral image super-resolution with grouped deep recursive residual network. In Proceedings of the 2018 IEEE Fourth International Conference on Multimedia Big Data (BigMM), Xi’an, China, 13–16 September 2018; pp. 1–4. [Google Scholar]
- Jiang, J.; Sun, H.; Liu, X.; Ma, J. Learning spatial-spectral prior for super-resolution of hyperspectral imagery. IEEE Trans. Comput. Imaging 2020, 6, 1082–1096. [Google Scholar] [CrossRef]
- Li, Q.; Wang, Q.; Li, X. Hyperspectral image super-resolution via adjacent spectral fusion strategy. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 1645–1649. [Google Scholar]
- Wang, Q.; Li, Q.; Li, X. Hyperspectral image super-resolution using spectrum and feature context. IEEE Trans. Ind. Electron. 2021, 68, 11276–11285. [Google Scholar] [CrossRef]
- Liu, Y.; Hu, J.; Kang, X.; Luo, J.; Fan, S. Interactformer: Interactive transformer and CNN for hyperspectral image super-resolution. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15. [Google Scholar] [CrossRef]
- Yokoya, N.; Yairi, T.; Iwasaki, A. Coupled nonnegative matrix factorization unmixing for hyperspectral and multispectral data fusion. IEEE Trans. Geosci. Remote Sens. 2011, 50, 528–537. [Google Scholar] [CrossRef]
- Akhtar, N.; Shafait, F.; Mian, A. Bayesian sparse representation for hyperspectral image super resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Tian, X.; Zhang, W.; Yu, D.; Ma, J. Sparse tensor prior for hyperspectral, multispectral, and panchromatic image fusion. IEEE/CAA J. Autom. Sin. 2022, 10, 284–286. [Google Scholar] [CrossRef]
- Dong, W.; Fu, F.; Shi, G.; Cao, X.; Wu, J.; Li, G.; Li, X. Hyperspectral image super-resolution via non-negative structured sparse representation. IEEE Trans. Image Process. 2016, 25, 2337–2352. [Google Scholar] [CrossRef] [PubMed]
- Veganzones, M.A.; Simoes, M.; Licciardi, G.; Yokoya, N.; Bioucas-Dias, J.M.; Chanussot, J. Hyperspectral super-resolution of locally low rank images from complementary multisource data. IEEE Trans. Image Process. 2015, 25, 274–288. [Google Scholar] [CrossRef] [PubMed]
- Dian, R.; Li, S.; Kang, X. Regularizing hyperspectral and multispectral image fusion by CNN denoiser. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 1124–1135. [Google Scholar] [CrossRef] [PubMed]
- Wen, B.; Kamilov, U.S.; Liu, D.; Mansour, H.; Boufounos, P.T. DeepCASD: An end-to-end approach for multi-spectral image super-resolution. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 6503–6507. [Google Scholar]
- Wang, W.; Zeng, W.; Huang, Y.; Ding, X.; Paisley, J. Deep blind hyperspectral image fusion. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Long Beach, CA, USA, 15–20 June 2019; pp. 4150–4159. [Google Scholar]
- Yang, J.; Wright, J.; Huang, T.S.; Ma, Y. Image super-resolution via sparse representation. IEEE Trans. Image Process. 2010, 19, 2861–2873. [Google Scholar] [CrossRef]
- Kim, K.I.; Kwon, Y. Single-image super-resolution using sparse regression and natural image prior. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1127–1133. [Google Scholar]
- Dong, W.; Zhang, L.; Shi, G.; Wu, X. Image deblurring and super-resolution by adaptive sparse domain selection and adaptive regularization. IEEE Trans. Image Process. 2011, 20, 1838–1857. [Google Scholar] [CrossRef]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 295–307. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image super-resolution using very deep residual channel attention networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Dai, T.; Cai, J.; Zhang, Y.; Xia, S.T.; Zhang, L. Second-order attention network for single image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Niu, B.; Wen, W.; Ren, W.; Zhang, X.; Yang, L.; Wang, S.; Zhang, K.; Cao, X.; Shen, H. Single image super-resolution via a holistic attention network. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 191–207. [Google Scholar]
- Mei, Y.; Fan, Y.; Zhou, Y. Image super-resolution with non-local sparse attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 3517–3526. [Google Scholar]
- Chen, H.; Wang, Y.; Guo, T.; Xu, C.; Deng, Y.; Liu, Z.; Ma, S.; Xu, C.; Xu, C.; Gao, W. Pre-trained image processing transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Online, 19–25 June 2021; pp. 12299–12310. [Google Scholar]
- Liang, J.; Cao, J.; Sun, G.; Zhang, K.; Van Gool, L.; Timofte, R. Swinir: Image restoration using swin transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 1833–1844. [Google Scholar]
- Yuhas, R.H.; Goetz, A.F.; Boardman, J.W. Discrimination among semi-arid landscape endmembers using the spectral angle mapper (SAM) algorithm. In Proceedings of the JPL, Summaries of the Third Annual JPL Airborne Geoscience Workshop, Volume 1: AVIRIS Workshop, Pasadena, CA, USA, 1–5 June 1992; Volume 1, pp. 147–149. [Google Scholar]
- Yasuma, F.; Mitsunaga, T.; Iso, D.; Nayar, S.K. Generalized assorted pixel camera: Postcapture control of resolution, dynamic range, and spectrum. IEEE Trans. Image Process. 2010, 19, 2241–2253. [Google Scholar] [CrossRef]
- Chakrabarti, A.; Zickler, T. Statistics of real-world hyperspectral images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2011; pp. 193–200. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the International Conference for Learning Representations, Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Loncan, L.; De Almeida, L.B.; Bioucas-Dias, J.M.; Briottet, X.; Chanussot, J.; Dobigeon, N.; Fabre, S.; Liao, W.; Licciardi, G.A.; Simoes, M.; et al. Hyperspectral pansharpening: A review. IEEE Geosci. Remote Sens. Mag. 2015, 3, 27–46. [Google Scholar] [CrossRef]
- Wald, L. Data Fusion: Definitions and Architectures: Fusion of Images of Different Spatial Resolutions; Presses des MINES: Paris, France, 2002. [Google Scholar]
- Zhang, J.; Cai, Z.; Chen, F.; Zeng, D. Hyperspectral image denoising via adversarial learning. Remote Sens. 2022, 14, 1790. [Google Scholar] [CrossRef]
- Pang, L.; Gu, W.; Cao, X. TRQ3DNet: A 3D quasi-recurrent and transformer based network for hyperspectral image denoising. Remote Sens. 2022, 14, 4598. [Google Scholar] [CrossRef]
- Hao, J.; Xue, J.; Zhao, Y.; Chan, J.C.W. Transformed Structured Sparsity with Smoothness for Hyperspectral Image Deblurring. IEEE Geosci. Remote Sens. Lett. 2022, 20, 1–5. [Google Scholar] [CrossRef]
- Liao, W.; Goossens, B.; Aelterman, J.; Luong, H.Q.; Pižurica, A.; Wouters, N.; Saeys, W.; Philips, W. Hyperspectral image deblurring with PCA and total variation. In Proceedings of the 2013 5th Workshop on Hyperspectral Image and Signal Processing: Evolution in Remote Sensing (WHISPERS), Gainesville, FL, USA, 26–28 June 2013; pp. 1–4. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef]












| Abbreviation | Full Name |
|---|---|
| HSI | hyperspectral image |
| LR | low-resolution |
| HR | high-resolution |
| SR | super-resolution |
| HSISR | hyperspectral image super-resolution |
| SHISR | single-image hyperspectral super-resolution |
| MUN | Mixed U-Net |
| F3DUN | Full 3D U-Net |
| Method | Param. | PSNR↑ | SSIM↑ | RMSE↓ | SAM↓ | ERGAS↓ | CC↑ |
|---|---|---|---|---|---|---|---|
| MUN | 2.4 M | 36.8860 | 0.9452 | 0.0188 | 3.6500 | 5.4975 | 0.9779 |
| F3DUN | 2.5 M | 36.9368 | 0.9458 | 0.0186 | 3.6340 | 5.4429 | 0.9786 |
| Method | Param. | PSNR↑ | SSIM↑ | RMSE↓ | SAM↓ | ERGAS↓ | CC↑ |
|---|---|---|---|---|---|---|---|
| MUN | 2.4M | 36.7015 | 0.9454 | 0.0189 | 3.6472 | 5.5522 | 0.9783 |
| F3DUN | 2.5M | 36.7249 | 0.9453 | 0.0188 | 3.6496 | 5.5330 | 0.9783 |
| Method | Scale | PSNR↑ | SSIM↑ | RMSE↓ | SAM↓ | ERGAS↓ | CC↑ |
|---|---|---|---|---|---|---|---|
| Bicubic | 4 | 42.4128 | 0.9265 | 0.0137 | 3.0520 | 3.4897 | 0.9519 |
| EDSR [14] | 4 | 43.0512 | 0.9359 | 0.0126 | 2.7879 | 3.2591 | 0.9578 |
| 3DFCNN [19] | 4 | 42.8021 | 0.9310 | 0.0129 | 2.8593 | 3.3495 | 0.9554 |
| SSPSR [45] | 4 | 43.4522 | 0.9387 | 0.0120 | 2.6788 | 3.0980 | 0.9615 |
| MCNet [20] | 4 | 43.3126 | 0.9375 | 0.0124 | 2.7428 | 3.1590 | 0.9602 |
| ERCSR [21] | 4 | 43.2983 | 0.9376 | 0.0124 | 2.7416 | 3.1839 | 0.9600 |
| SFCSR [47] | 4 | 43.3817 | 0.9383 | 0.0123 | 2.7571 | 3.1462 | 0.9605 |
| F3DUN | 4 | 43.4855 | 0.9389 | 0.0120 | 2.6555 | 3.0923 | 0.9618 |
| Bicubic | 8 | 38.3909 | 0.8667 | 0.0225 | 3.7980 | 5.4231 | 0.8967 |
| EDSR [14] | 8 | 38.6719 | 0.9359 | 0.0216 | 3.4233 | 5.1530 | 0.9025 |
| 3DFCNN [19] | 8 | 38.8676 | 0.8737 | 0.0210 | 3.4619 | 5.2309 | 0.9047 |
| SSPSR [45] | 8 | 39.1889 | 0.8829 | 0.0204 | 3.2637 | 4.9324 | 0.9127 |
| MCNet [20] | 8 | 39.1702 | 0.8819 | 0.0207 | 3.5117 | 4.9475 | 0.9123 |
| ERCSR [21] | 8 | 39.3185 | 0.8839 | 0.0202 | 3.4649 | 4.8799 | 0.9144 |
| SFCSR [47] | 8 | 39.2607 | 0.8829 | 0.0203 | 3.4426 | 4.9007 | 0.9137 |
| F3DUN | 8 | 39.3265 | 0.8849 | 0.0204 | 3.2739 | 4.8552 | 0.9149 |
| Method | EDSR [14] | 3DFCNN [19] | SSPSR [45] | MCNet [20] | ERCSR [21] | SFCSR [47] | F3DUN |
|---|---|---|---|---|---|---|---|
| Params | 1.54 | 0.04 | 12.89 | 2.17 | 1.59 | 1.22 | 2.40 |
| FLOPs | 36.98 | 328.99 | 977.50 | 4483.56 | 4460.10 | 2011.9 | 4932.08 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Z.; Wang, W.; Ma, Q.; Liu, X.; Jiang, J. Rethinking 3D-CNN in Hyperspectral Image Super-Resolution. Remote Sens. 2023, 15, 2574. https://doi.org/10.3390/rs15102574
Liu Z, Wang W, Ma Q, Liu X, Jiang J. Rethinking 3D-CNN in Hyperspectral Image Super-Resolution. Remote Sensing. 2023; 15(10):2574. https://doi.org/10.3390/rs15102574
Chicago/Turabian StyleLiu, Ziqian, Wenbing Wang, Qing Ma, Xianming Liu, and Junjun Jiang. 2023. "Rethinking 3D-CNN in Hyperspectral Image Super-Resolution" Remote Sensing 15, no. 10: 2574. https://doi.org/10.3390/rs15102574
APA StyleLiu, Z., Wang, W., Ma, Q., Liu, X., & Jiang, J. (2023). Rethinking 3D-CNN in Hyperspectral Image Super-Resolution. Remote Sensing, 15(10), 2574. https://doi.org/10.3390/rs15102574