
From Model-Based Optimization Algorithms to Deep Learning Models for Clustering Hyperspectral Images



Abstract
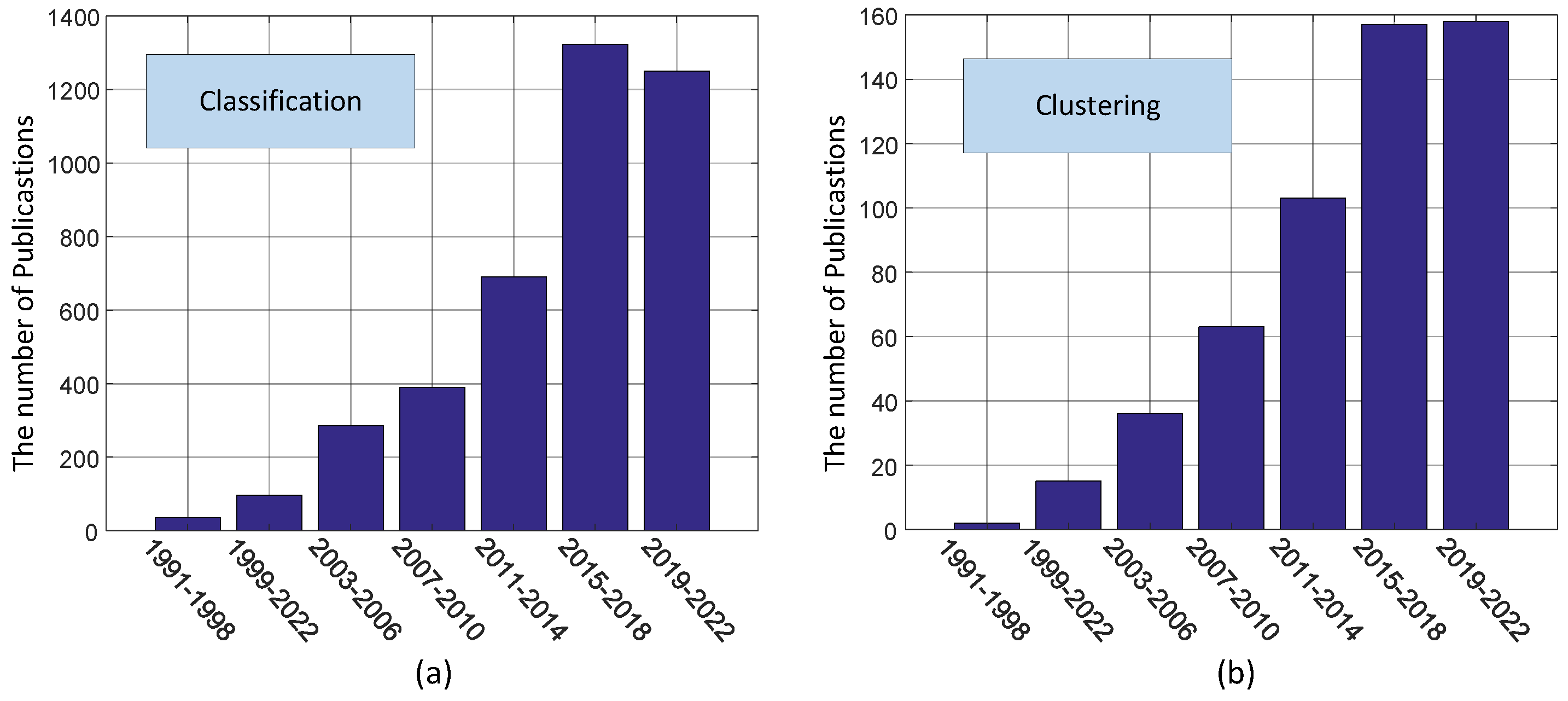
:1. Introduction
2. The Challenges in the Clustering of HSI
- Clustering of high dimensional data, such as HSI, is difficult in general, due to the so-called “curse of dimensionality” problem [41]. The redundant bands of HSI make the inherent meaningful clusters sparse in a higher dimension. Using conventional distances such as Euclidean distance to measure the similarity of data points is no longer effective due to the participation of irrelevant dimensions.
- Clustering of HSI at pixel-level needs efficient algorithms to process large volumes of hyperspectral data. However, advanced models are often required to fit with the complex cluster structure of data to yield accurate clustering results, which results in computationally expensive algorithms. How to make a good balance between efficiency and accuracy is difficult.
- Influenced by sensor noise, varying imaging conditions and spectral mixing, hyperspectral data often show large within-class spectral variabilities, leading to a mixture of different clusters to a certain degree. The data distribution within-class can be arbitrary, which makes the centroid-based approaches infeasible.
- Estimation of the number of clusters in HSI is not trivial. Similar clusters can be merged as a major cluster or on the contrary a major cluster can be divided into more sub-clusters. Current clustering approaches mostly assume that the number of clusters is known.
3. Notation
4. Model-Based Optimization Methods for HSI Clustering
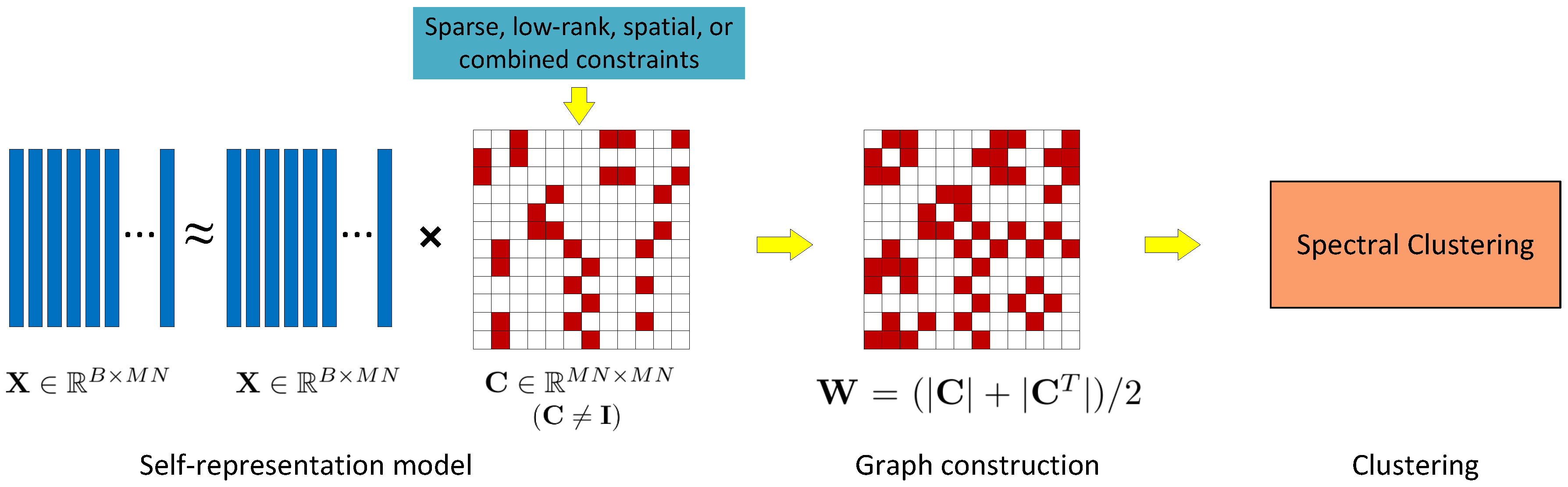
4.1. Self-Representation Based Clustering Methods
- The number of nearest neighbours in the graph is adaptively determined for each data point by sparsity or low-rank constraint in the representation models, which avoids specifying a fixed number of neighbours for all the data points in KNN graph.
- Selecting an effective similarity measurement between data points is difficult in general, especially for high-dimensional data where “curse of dimensionality” problem might be suffered. In the self-representation based models, the representation coefficients matrix is utilized to build a similarity matrix, avoiding thereby the ad-hoc selection of similarity measurements.
4.1.1. Spectral-Based Clustering Methods
4.1.2. Spatial-Spectral Clustering Methods
4.1.3. Object-Based Clustering Methods
4.1.4. Semi-Supervised Clustering Methods
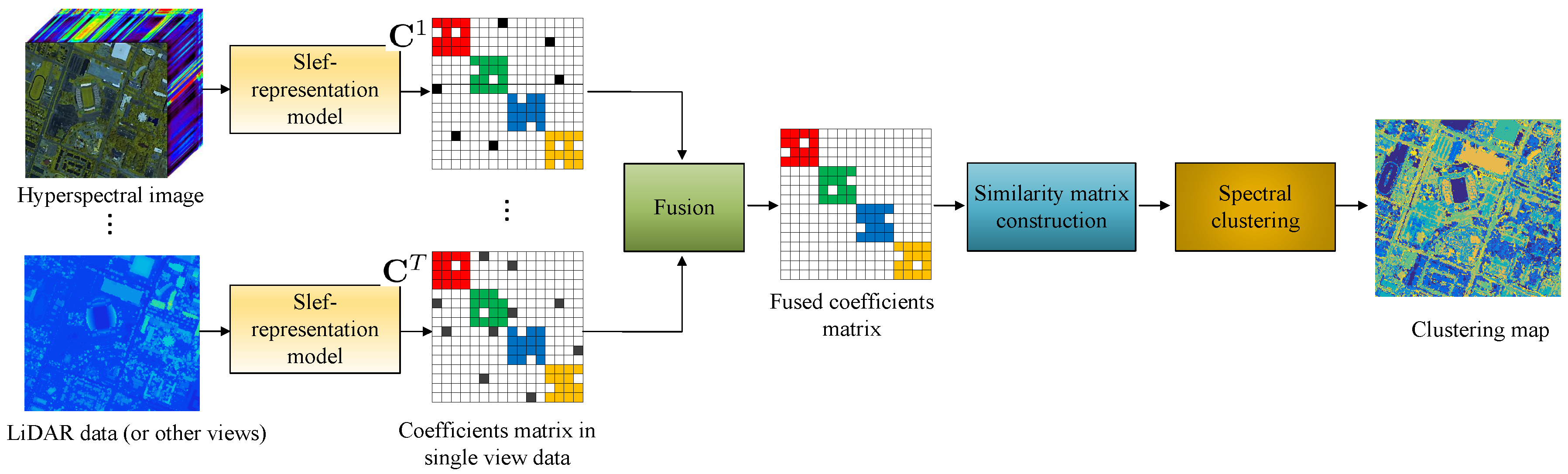
4.1.5. Multi-View Clustering Methods
4.1.6. Kernel-Based Clustering Methods
4.1.7. Graph Learning Based Clustering Methods
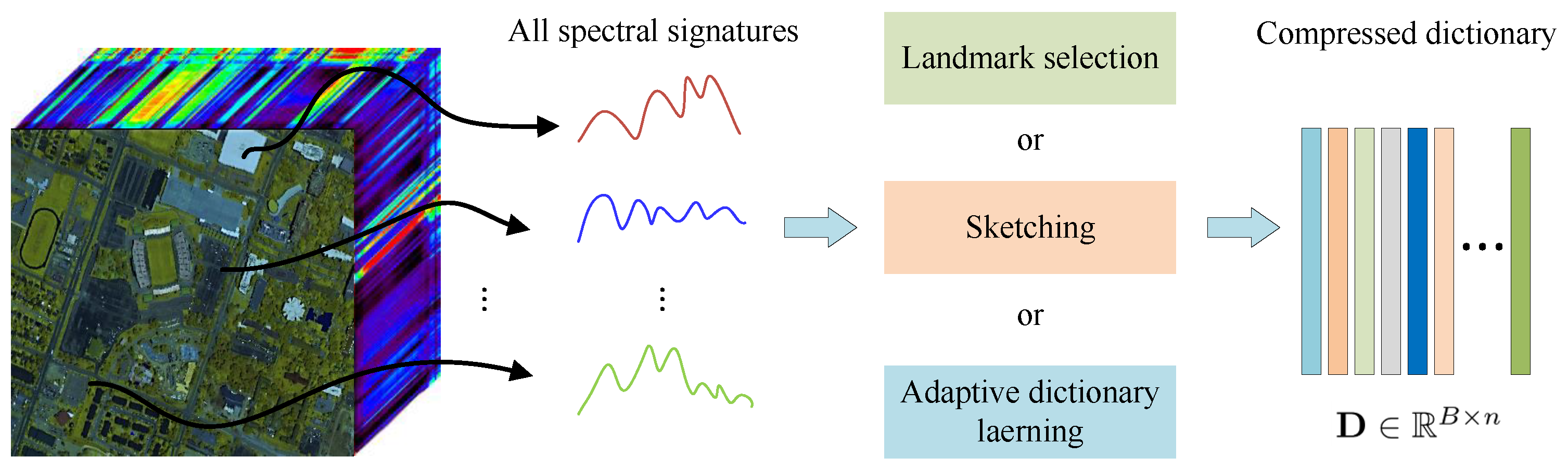
4.2. Dictionary Learning Based Clustering Methods
4.2.1. Landmark-Based Clustering Methods
4.2.2. Sketch-Based Clustering Methods
4.2.3. Adaptive Dictionary Based Clustering Methods
4.3. NMF-Based Clustering Methods
4.3.1. Spectral-Based NMF Clustering Methods
4.3.2. Spatial-Spectral-Based NMF Clustering Methods
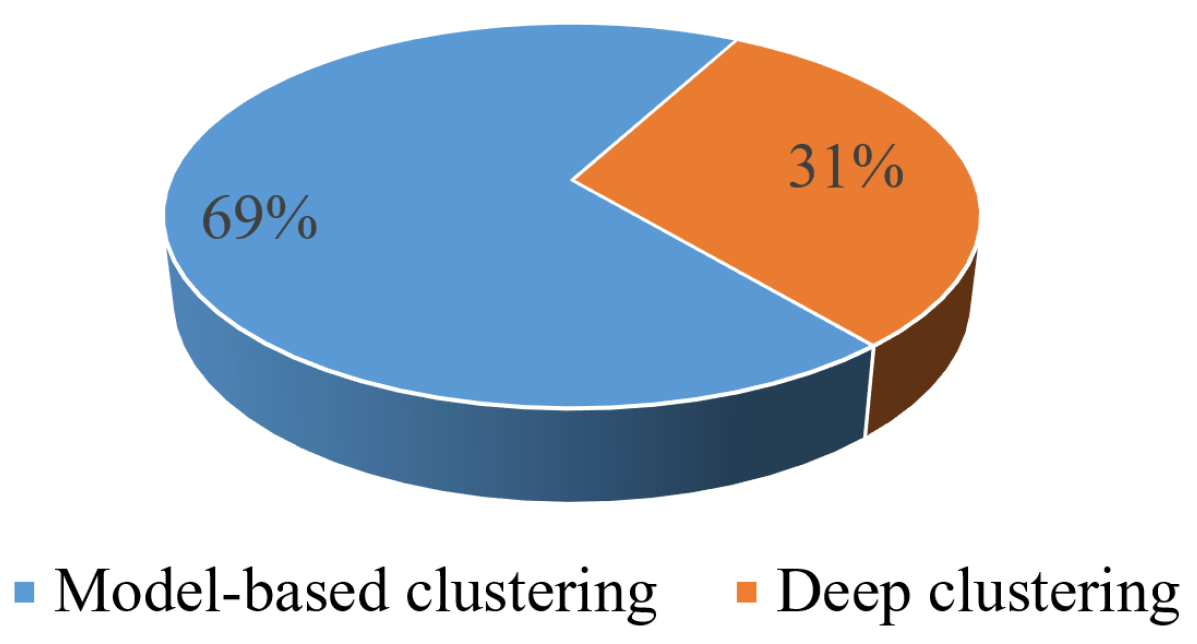
5. Deep Clustering Methods
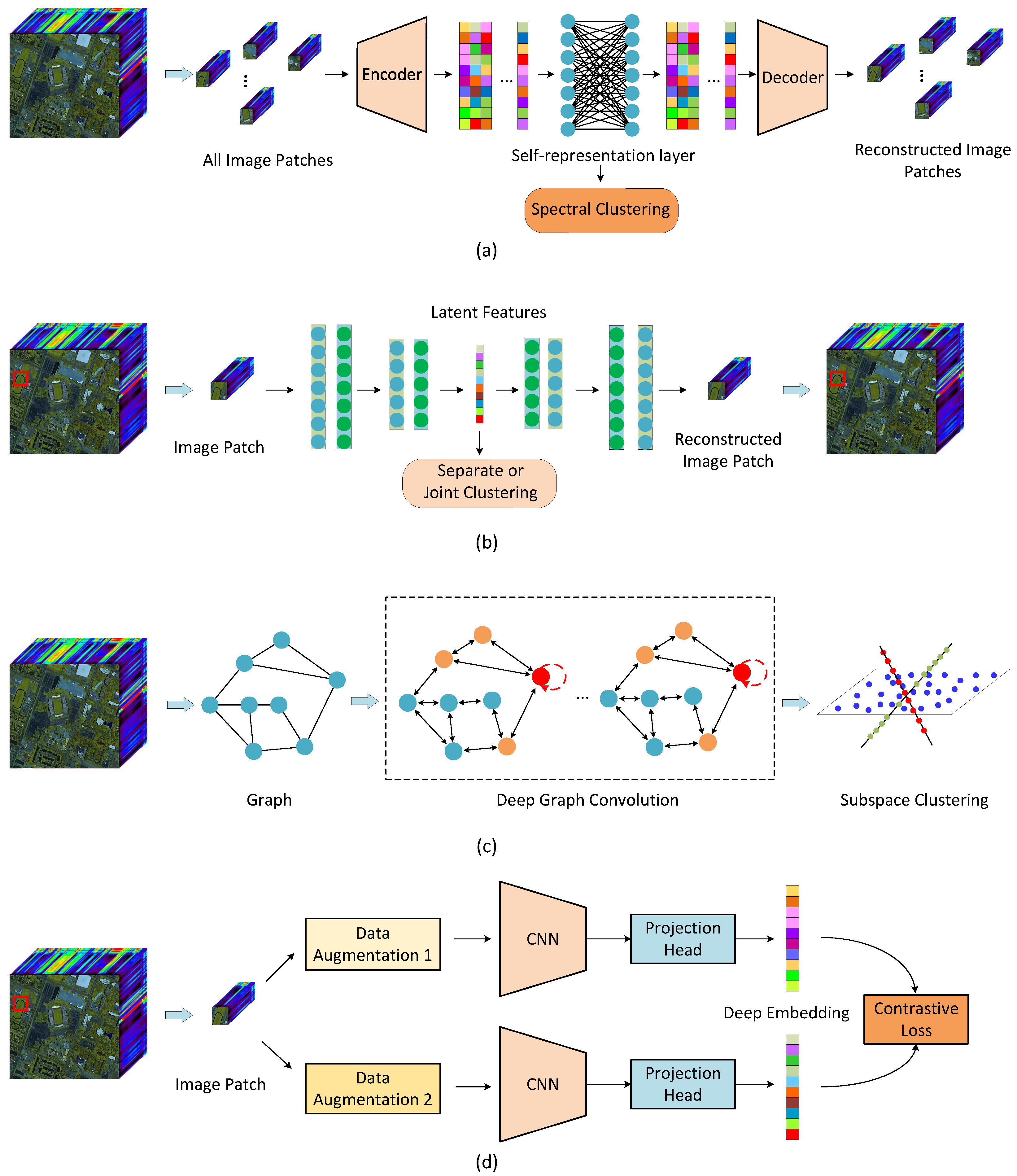
5.1. Self-Representation Based Deep Clustering (SDC)
5.2. AE-Based Deep Clustering (AEDC)
5.3. Graph Convolution Based Deep Clustering (GCDC)
5.4. Contrastive Learning Based Deep Clustering (CLDC)
6. Experiments
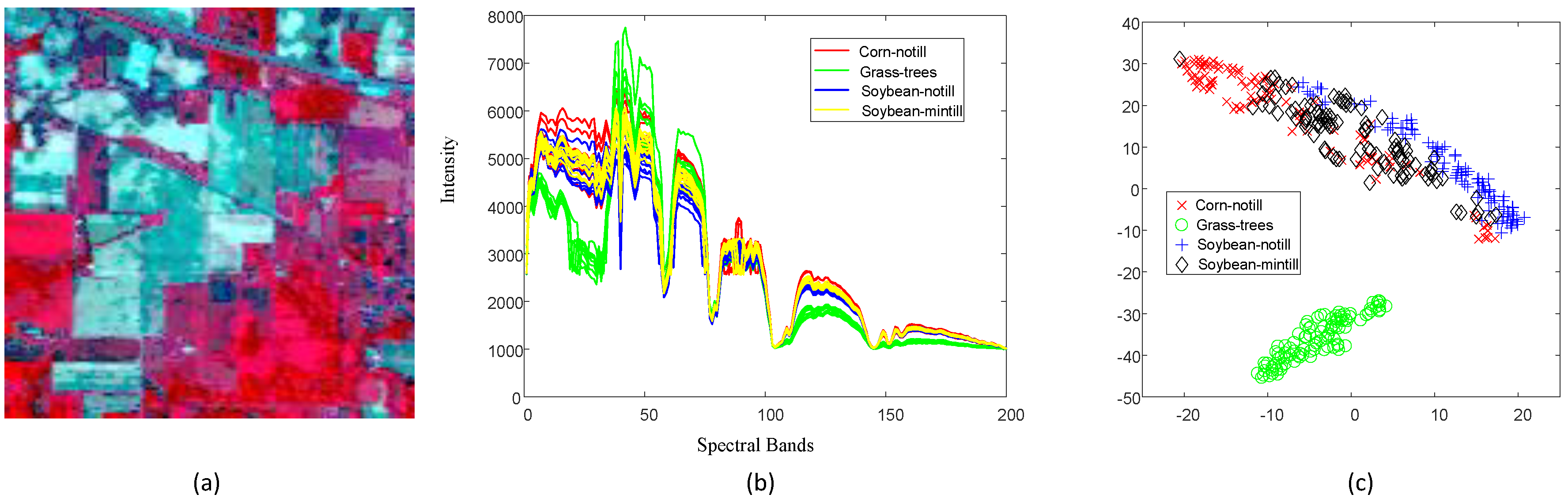
6.1. Data Sets
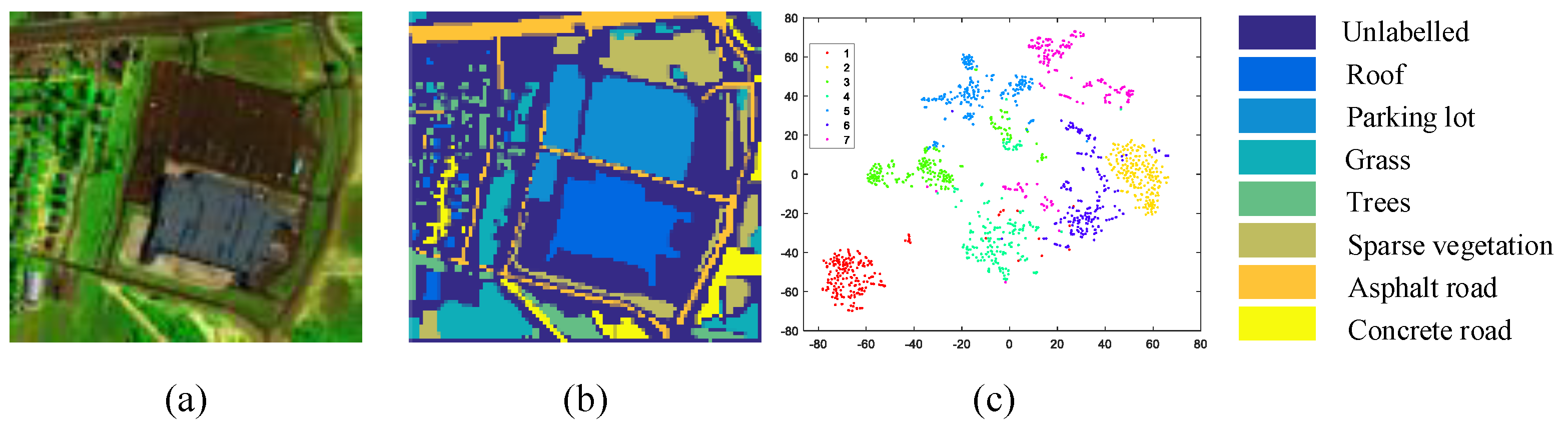
6.1.1. HYDICE Urban
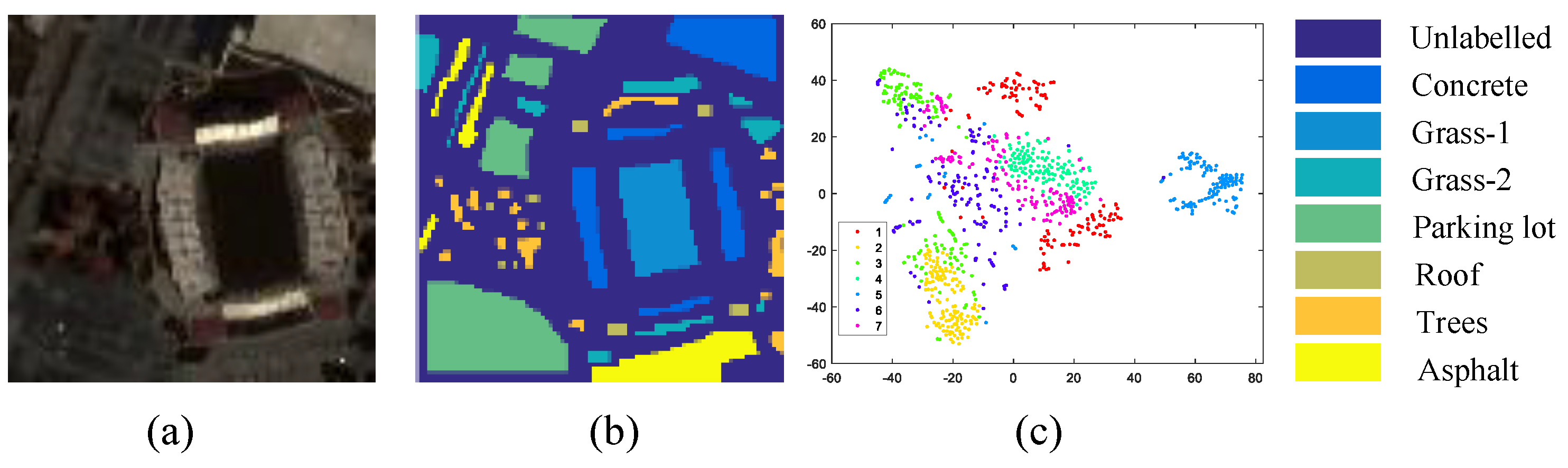
6.1.2. University of Houston (Houston)
6.2. Compared Methods
- K-means [19]: a commonly used clustering algorithm due to its simplicity and efficiency.
- NMF [36]: a classical clustering method based on NMF.
- ONMF-TV [85]: a spatial-spectral NMF clustering method which integrates orthogonal constraint and TV spatial regularization.
- SSC [31]: a self-representation-based subspace clustering model with a sparsity constraint.
- JSSC [55]: a spatial-spectral SSC model with joint sparsity on the coefficients of segmented super-pixels.
- ODL [79]: a scalable subspace clustering model with online dictionary learning.
- Sketch-TV [73]: a scalable spatial-spectral subspace clustering model by integrating dictionary sketching and a TV spatial regularization.
- GCSC [66]: a graph convolution-based subspace clustering model.
- AEC [100]: an autoencoder-based clustering model where a three-layers stacked denoising AE was used to extract deep features of HSI and k-means was adopted to obtain the final clustering result.
- DEC [100]: a symmetric AE-based deep clustering model, which is an extended version of AEC by introducing a KL divergence clustering loss to jointly learn the encoder and cluster centroids.
- RNNC [97]: an asymmetric AE-based clustering model where recurrent neural nets (RNNs) are employed to build the encoder and a multilayer perceptron was used as the decoder. In our experiments, RNNs were built with long short-term memory (LSTM). The extracted latent features by the encoder of RNNC were fed to k-means to yield clustering results.
- HyperAE [92]: a recent self-representation-based deep clustering model, which integrates the self-expressiveness of data points and graph-based manifold regularization in the autoencoder, resulting in an improved similarity matrix for spectral clustering.
6.3. Evaluation Metrics
6.4. Performance Comparison
7. Summary and Conclusions
- Recent deep clustering methods outperform the shallow clustering methods in most cases. The experimental results show that some traditional shallow clustering methods such as Sketch-TV can yield competitive or even better clustering accuracy compared with the state-of-the-art deep clustering methods.
- Deep feature extraction by autoencoder indeed improves the discriminability between different clusters compared with using raw data. However, the accuracy improvement might be limited by the employed inappropriate clustering algorithm or by the unconsidered spatial information of HSI. Our results show that the traditional NMF feature extraction fails to yield improved performance.
- It is shown that spatial-spectral clustering methods often perform better than the spectral-based clustering methods. However, the degree of performance improvement highly relies on the adopted spatial regularizations, demonstrating the importance of an effective spatial constraint.
- Self-representation-based shallow and deep clustering methods are very competitive compared with other clustering methods. However, the computational complexities of self-representation models are much higher than others, which limits their applications on large-scale data.
- Clustering methods, which combine representation learning and clustering in a unified model, yield improved accuracies compared with the methods that perform the two steps separately. This demonstrates that introducing clustering-related loss function improves the clustering performance.
- Most existing clustering methods assume that the number of clusters is known, and very few studies in remote sensing focus on the estimation of the number of clusters. Thus, there is an urgent need to design an effective method to calculate the number of clusters for real applications.
- As data-driven deep clustering methods are typically trained on a specific target data set, the trained models often cannot be well generalized to new data sets. When the trained neural network is applied to a different HSI, the learned features might not be discriminative for clustering due to the different ground objects, varying spatial resolutions and different levels of noise. Improving the robustness and generalization of deep clustering methods is crucial in the domain.
- Although deep clustering methods often yield better clustering results, theoretical explanation of the superior performance is still absent, which means that existing deep clustering methods of HSI still lack interpretability for experts to deal with occasional failures on some data sets. A deeper and more clear understanding of the mechanism of deep clustering models is needed. Thus, explainable AI on the clustering of HSI is a very interesting research direction.
- Current clustering methods of HSI rely on a single clustering algorithm, whose performance is highly limited by the separability of features and the clustering ability of the selected clustering algorithm. It is known that different clustering methods have different advantages. Thus, it is more desirable to combine the clustering results of different clustering methods (also known as ensemble clustering) to find a consensus, which will effectively improve the clustering accuracy and robustness to noise.
- Clustering methods of HSI are mostly designed for a single data source, which is vulnerable to noise and other degradations. Recent advances in remote sensing greatly increase the types of sensors for Earth observation, resulting in different data modalities such as LiDAR, SAR, multispectral image, etc. Moreover, various hand-crafted features, which capture different data properties of HSI from different views, are demonstrated to be helpful in the classification of HSI. Incorporating the complementary information from different image modalities in the clustering of HSI can break the performance limitation of single-source clustering methods, which also improves the robustness of model to various degradations.
- Current advanced clustering methods either perform feature extraction and clustering of data separately or integrate the two steps in a unified clustering framework. All of them still rely on the conventional clustering algorithms, such as k-means, spectral clustering, GMM, and density-based methods, to yield the final clustering results. Designing a completely data-driven deep clustering model, which gets rid of the conventional clustering algorithm, might lead to a significant performance improvement.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- He, W.; Zhang, H.; Shen, H.; Zhang, L. Hyperspectral image denoising using local low-rank matrix recovery and global spatial–spectral total variation. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2018, 11, 713–729. [Google Scholar] [CrossRef]
- Esposito, M.; Marchi, A.Z. In-orbit demonstration of the first hyperspectral imager for nanosatellites. Proc. SPIE 2019, 11180, 1118020. [Google Scholar]
- Sun, W.; Du, Q. Hyperspectral band selection: A review. IEEE Geosci. Remote Sens. Mag. 2019, 7, 118–139. [Google Scholar] [CrossRef]
- Huang, S.; Zhang, H.; Pižurica, A. A structural subspace clustering approach for hyperspectral band selection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15. [Google Scholar] [CrossRef]
- Huang, S.; Zhang, H.; Xue, J.; Pižurica, A. Heterogeneous Regularization-Based Tensor Subspace Clustering for Hyperspectral Band Selection. IEEE Trans. Neural Netw. Learn. Syst. 2022, 1–15. [Google Scholar] [CrossRef]
- Azimpour, P.; Bahraini, T.; Yazdi, H.S. Hyperspectral image denoising via clustering-based latent variable in variational Bayesian framework. IEEE Trans. Geosci. Remote Sens. 2021, 59, 3266–3276. [Google Scholar] [CrossRef]
- Zhang, L.; Wei, W.; Bai, C.; Gao, Y.; Zhang, Y. Exploiting clustering manifold structure for hyperspectral imagery super-resolution. IEEE Trans. Image Process. 2018, 27, 5969–5982. [Google Scholar] [CrossRef]
- Xu, X.; Li, J.; Wu, C.; Plaza, A. Regional clustering-based spatial preprocessing for hyperspectral unmixing. Remote Sens. Environ. 2018, 204, 333–346. [Google Scholar] [CrossRef]
- Shang, X.; Yang, T.; Han, S.; Song, M.; Xue, B. Interference-suppressed and cluster-optimized hyperspectral target extraction based on density peak clustering. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2021, 14, 4999–5014. [Google Scholar] [CrossRef]
- Yao, W.; Lian, C.; Bruzzone, L. ClusterCNN: Clustering-based feature learning for hyperspectral image classification. IEEE Geosci. Remote Sens. Lett. 2020, 18, 1991–1995. [Google Scholar] [CrossRef]
- Zhang, X.; Chew, S.E.; Xu, Z.; Cahill, N.D. SLIC superpixels for efficient graph-based dimensionality reduction of hyperspectral imagery. Proc. SPIE 2015, 9472, 92–105. [Google Scholar]
- Deng, C.; Xue, Y.; Liu, X.; Li, C.; Tao, D. Active transfer learning network: A unified deep joint spectral–spatial feature learning model for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2018, 57, 1741–1754. [Google Scholar] [CrossRef]
- Qu, Y.; Baghbaderani, R.K.; Li, W.; Gao, L.; Zhang, Y.; Qi, H. Physically constrained transfer learning through shared abundance space for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2021, 59, 10455–10472. [Google Scholar] [CrossRef]
- Liu, B.; Yu, X.; Yu, A.; Zhang, P.; Wan, G.; Wang, R. Deep few-shot learning for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2018, 57, 2290–2304. [Google Scholar] [CrossRef]
- Wang, Y.; Liu, M.; Yang, Y.; Li, Z.; Du, Q.; Chen, Y.; Li, F.; Yang, H. Heterogeneous Few-Shot Learning for Hyperspectral Image Classification. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum contrast for unsupervised visual representation learning. In Proceedings of the he IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 9729–9738. [Google Scholar]
- Van Gansbeke, W.; Vandenhende, S.; Georgoulis, S.; Proesmans, M.; Van Gool, L. Scan: Learning to classify images without labels. In ECCV 2020: Computer Vision—ECCV 2020 Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 268–285. [Google Scholar]
- Ohri, K.; Kumar, M. Review on self-supervised image recognition using deep neural networks. Knowl. Based Syst. 2021, 224. [Google Scholar] [CrossRef]
- Lloyd, S. Least squares quantization in PCM. IEEE Trans. Inf. Theory 1982, 28, 129–137. [Google Scholar] [CrossRef]
- Niazmardi, S.; Homayouni, S.; Safari, A. An improved FCM algorithm based on the SVDD for unsupervised hyperspectral data classification. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2013, 6, 831–839. [Google Scholar] [CrossRef]
- Azimpour, P.; Shad, R.; Ghaemi, M.; Etemadfard, H. Hyperspectral image clustering with Albedo recovery Fuzzy C-Means. Int. J. Remote Sens. 2020, 41, 6117–6134. [Google Scholar] [CrossRef]
- Rodriguez, A.; Laio, A. Clustering by fast search and find of density peaks. Science 2014, 344, 1492–1496. [Google Scholar] [CrossRef]
- Cariou, C.; Chehdi, K. Nearest neighbor-density-based clustering methods for large hyperspectral images. In Proceedings of the SPIE 2017, 10427, 104270I. [Google Scholar]
- Xie, H.; Zhao, A.; Huang, S.; Han, J.; Liu, S.; Xu, X.; Luo, X.; Pan, H.; Du, Q.; Tong, X. Unsupervised hyperspectral remote sensing image clustering based on adaptive density. IEEE Geosci. Remote Sens. Lett. 2018, 15, 632–636. [Google Scholar] [CrossRef]
- Acito, N.; Corsini, G.; Diani, M. An unsupervised algorithm for hyperspectral image segmentation based on the Gaussian mixture model. Proc. IEEE IGARSS 2003, 6, 3745–3747. [Google Scholar]
- Shah, C.; Varshney, P.; Arora, M. ICA mixture model algorithm for unsupervised classification of remote sensing imagery. Int. J. Remote Sens. 2007, 28, 1711–1731. [Google Scholar] [CrossRef]
- Jiao, Y.; Ma, Y.; Gu, Y. Hyperspectral image clustering based on variational expectation maximization. In Proceedings of the 2020 IEEE 11th Sensor Array and Multichannel Signal Processing Workshop (SAM), Hangzhou, China, 8–11 June 2020; pp. 1–5. [Google Scholar]
- Zhong, Y.; Zhang, L.; Huang, B.; Li, P. An unsupervised artificial immune classifier for multi/hyperspectral remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2006, 44, 420–431. [Google Scholar] [CrossRef]
- Zhong, Y.; Zhang, L.; Gong, W. Unsupervised remote sensing image classification using an artificial immune network. Int. J. Remote Sens. 2011, 32, 5461–5483. [Google Scholar] [CrossRef]
- Liu, G.; Lin, Z.; Yu, Y. Robust subspace segmentation by low-rank representation. In Proceedings of the 27th International Conference on Machine Learning (ICML-10), Haifa, Israel, 21–24 June 2010; pp. 663–670. [Google Scholar]
- Elhamifar, E.; Vidal, R. Sparse subspace clustering: Algorithm, theory, and applications. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 2765–2781. [Google Scholar] [CrossRef] [PubMed]
- Zhai, H.; Zhang, H.; Zhang, L.; Li, P. Total Variation Regularized Collaborative Representation Clustering With a Locally Adaptive Dictionary for Hyperspectral Imagery. IEEE Trans. Geosci. Remote Sens. 2018, 57, 166–180. [Google Scholar] [CrossRef]
- Sun, J.; Wang, W.; Wei, X.; Fang, L.; Tang, X.; Xu, Y.; Yu, H.; Yao, W. Deep clustering with intraclass distance constraint for hyperspectral images. IEEE Trans. Geosci. Remote Sens. 2020, 59, 4135–4149. [Google Scholar] [CrossRef]
- Lei, J.; Li, X.; Peng, B.; Fang, L.; Ling, N.; Huang, Q. Deep spatial-spectral subspace clustering for hyperspectral image. IEEE Trans. Circuits Syst. Video Technol. 2020, 31, 2686–2697. [Google Scholar] [CrossRef]
- Donoho, D.L. Compressed sensing. IEEE Trans. Inf. Theory 2006, 52, 1289–1306. [Google Scholar] [CrossRef]
- Cai, D.; He, X.; Han, J.; Huang, T.S. Graph regularized nonnegative matrix factorization for data representation. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 1548–1560. [Google Scholar]
- Vidal, R. Subspace clustering. IEEE Signal Process. Mag. 2011, 28, 52–68. [Google Scholar] [CrossRef]
- Oktar, Y.; Turkan, M. A review of sparsity-based clustering methods. Signal Process. 2018, 148, 20–30. [Google Scholar] [CrossRef]
- Zhai, H.; Zhang, H.; Zhang, L.; Li, P. Hyperspectral Image Clustering: Current Achievements and Future Lines. IEEE Geosci. Remote Sens. Mag. 2021, 9, 35–67. [Google Scholar] [CrossRef]
- Abdolali, M.; Gillis, N. Beyond linear subspace clustering: A comparative study of nonlinear manifold clustering algorithms. Comput. Sci. Rev. 2021, 42, 100435. [Google Scholar] [CrossRef]
- Hughes, G. On the mean accuracy of statistical pattern recognizers. IEEE Trans. Inf. Theory 1968, 14, 55–63. [Google Scholar] [CrossRef]
- Zhang, H.; Zhai, H.; Zhang, L.; Li, P. Spectral–spatial sparse subspace clustering for hyperspectral remote sensing images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 3672–3684. [Google Scholar] [CrossRef]
- Liu, G.; Lin, Z.; Yan, S.; Sun, J.; Yu, Y.; Ma, Y. Robust recovery of subspace structures by low-rank representation. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 171–184. [Google Scholar] [CrossRef]
- Wang, Y.X.; Xu, H.; Leng, C. Provable subspace clustering: When LRR meets SSC. Adv. Neural Inf. Process. Syst. 2013, 26. [Google Scholar] [CrossRef]
- Tian, L.; Du, Q.; Kopriva, I. L 0-Motivated Low Rank Sparse Subspace Clustering for Hyperspectral Imagery. In Proceedings of the IGARSS 2020–2020 IEEE International Geoscience and Remote Sensing Symposium, Waikoloa, HI, USA, 26 September–2 October 2020; pp. 1038–1041. [Google Scholar]
- Huang, S.; Zhang, H.; Pižurica, A. Joint sparsity based sparse subspace clustering for hyperspectral images. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 3878–3882. [Google Scholar]
- Guo, Y.; Gao, J.; Li, F. Spatial subspace clustering for hyperspectral data segmentation. Proc. SDIWC 2013, 1, 3. [Google Scholar]
- Zhai, H.; Zhang, H.; Zhang, L.; Li, P.; Plaza, A. A new sparse subspace clustering algorithm for hyperspectral remote sensing imagery. IEEE Geosci. Remote Sens. Lett. 2017, 14, 43–47. [Google Scholar] [CrossRef]
- Hinojosa, C.; Bacca, J.; Arguello, H. Coded aperture design for compressive spectral subspace clustering. IEEE J. Sel. Top. Signal Process. 2018, 12, 1589–1600. [Google Scholar] [CrossRef]
- Liu, S.; Huang, N.; Xiao, L. Locally Constrained Collaborative Representation Based Fisher’s LDA for Clustering of Hyperspectral Images. In Proceedings of the IGARSS 2020–2020 IEEE International Geoscience and Remote Sensing Symposium, Waikoloa, HI, USA, 26 September–2 October 2020; pp. 1046–1049. [Google Scholar]
- Xu, J.; Fowler, J.E.; Xiao, L. Hypergraph-regularized low-rank subspace clustering using superpixels for unsupervised spatial–spectral hyperspectral classification. IEEE Geosci. Remote Sens. Lett. 2020, 18, 871–875. [Google Scholar] [CrossRef]
- Zhai, H.; Zhang, H.; Zhang, L.; Li, P. Reweighted mass center based object-oriented sparse subspace clustering for hyperspectral images. J. Appl. Remote Sens. 2016, 10, 046014. [Google Scholar] [CrossRef]
- Wang, L.; Niu, S.; Gao, X.; Liu, K.; Lu, F.; Diao, Q.; Dong, J. Fast high-order sparse subspace clustering with cumulative MRF for hyperspectral images. IEEE Geosci. Remote Sens. Lett. 2020, 18, 152–156. [Google Scholar] [CrossRef]
- Yan, Q.; Ding, Y.; Xia, Y.; Chong, Y.; Zheng, C. Class probability propagation of supervised information based on sparse subspace clustering for hyperspectral images. Remote Sens. 2017, 9, 1017. [Google Scholar] [CrossRef]
- Huang, S.; Zhang, H.; Pižurica, A. Semisupervised sparse subspace clustering method with a joint sparsity constraint for hyperspectral remote sensing images. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2019, 12, 989–999. [Google Scholar] [CrossRef]
- Fang, X.; Xu, Y.; Li, X.; Lai, Z.; Wong, W.K. Robust semi-supervised subspace clustering via non-negative low-rank representation. IEEE Trans. Cybern. 2015, 46, 1828–1838. [Google Scholar] [CrossRef]
- Yang, J.; Zhang, D.; Li, T.; Wang, Y.; Yan, Q. Semi-supervised subspace clustering via non-negative low-rank representation for hyperspectral images. In Proceedings of the IEEE RCAR, Kandima, Maldives, 1–5 August 2018; pp. 108–111. [Google Scholar]
- Tian, L.; Du, Q.; Kopriva, I.; Younan, N. Spatial-spectral Based Multi-view Low-rank Sparse Sbuspace Clustering for Hyperspectral Imagery. In Proceedings of the IEEE IGARSS, Valencia, Spain, 22–27 July 2018; pp. 8488–8491. [Google Scholar]
- Chen, Z.; Zhang, C.; Mu, T.; Yan, T.; Chen, Z.; Wang, Y. An Efficient Representation-Based Subspace Clustering Framework for Polarized Hyperspectral Images. Remote Sens. 2019, 11, 1513. [Google Scholar] [CrossRef]
- Tian, L.; Du, Q.; Kopriva, I.; Younan, N. Kernel spatial-spectral based multi-view low-rank sparse sbuspace clustering for hyperspectral imagery. In Proceedings of the IEEE WHISPERS, Amsterdam, The Netherlands, 23–26 September 2018; pp. 1–4. [Google Scholar]
- Huang, S.; Zhang, H.; Pižurica, A. Hybrid-Hypergraph Regularized Multiview Subspace Clustering for Hyperspectral Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–16. [Google Scholar] [CrossRef]
- De Morsier, F.; Tuia, D.; Borgeaucft, M.; Gass, V.; Thiran, J.P. Non-linear low-rank and sparse representation for hyperspectral image analysis. In Proceedings of the IEEE IGARSS, Quebec City, QC, Canada, 13–18 July 2014; pp. 4648–4651. [Google Scholar]
- Zhang, H.; Zhai, H.; Liao, W.; Cao, L.; Zhang, L.; Pizurica, A. Hyperspectral image kernel sparse subspace clustering with spatial max pooling operation. In Proceedings of the ISPRS, Prague, Czech Republic, 12–19 July 2016; Volume 41, pp. 945–948. [Google Scholar]
- De Morsier, F.; Borgeaud, M.; Gass, V.; Thiran, J.P.; Tuia, D. Kernel low-rank and sparse graph for unsupervised and semi-supervised classification of hyperspectral images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 3410–3420. [Google Scholar] [CrossRef]
- Bacca, J.; Hinojosa, C.A.; Arguello, H. Kernel sparse subspace clustering with total variation denoising for hyperspectral remote sensing images. In Proceedings of the Mathematics in Imaging 2017, San Francisco, CA, USA, 26–29 June 2017. [Google Scholar]
- Cai, Y.; Zhang, Z.; Cai, Z.; Liu, X.; Jiang, X.; Yan, Q. Graph convolutional subspace clustering: A robust subspace clustering framework for hyperspectral image. IEEE Trans. Geosci. Remote Sens. 2020, 59, 4191–4202. [Google Scholar] [CrossRef]
- Xu, J.; Xiao, L.; Yang, J. Unified Low-Rank Subspace Clustering with Dynamic Hypergraph for Hyperspectral Image. Remote Sens. 2021, 13, 1372. [Google Scholar] [CrossRef]
- Chen, J.; Wu, Q.; Sun, K. Unsupervised Feature Extraction for Reliable Hyperspectral Imagery Clustering via Dual Adaptive Graphs. IEEE Access 2021, 9, 63319–63330. [Google Scholar] [CrossRef]
- Zhai, H.; Zhang, H.; Zhang, L.; Li, P. Sparsity-based clustering for large hyperspectral remote sensing images. IEEE Trans. Geosci. Remote Sens. 2021, 59, 10410–10424. [Google Scholar] [CrossRef]
- Huang, S.; Zhang, H.; Pižurica, A. Landmark-based large-scale sparse subspace clustering method for hyperspectral images. In Proceedings of the IEEE IGARSS, Yokohama, Japan, 28 July 28–2 August 2019; pp. 799–802. [Google Scholar]
- Hinojosa, C.; Vera, E.; Arguello, H. A Fast and Accurate Similarity-Constrained Subspace Clustering Algorithm for Hyperspectral Image. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2021, 14, 10773–10783. [Google Scholar] [CrossRef]
- Wan, Y.; Zhong, Y.; Ma, A.; Zhang, L. Multi-objective sparse subspace clustering for hyperspectral imagery. IEEE Trans. Geosci. Remote Sens. 2019, 58, 2290–2307. [Google Scholar] [CrossRef]
- Huang, S.; Zhang, H.; Du, Q.; Pižurica, A. Sketch-based subspace clustering of hyperspectral images. Remote Sens. 2020, 12, 775. [Google Scholar] [CrossRef]
- Huang, S.; Zhang, H.; Pižurica, A. Sketched Sparse Subspace Clustering for Large-Scale Hyperspectral Images. In Proceedings of the IEEE ICIP, Abu Dhabi, United Arab Emirates, 25–28 October 2020; pp. 1766–1770. [Google Scholar]
- Zhai, H.; Zhang, H.; Zhang, L.; Li, P. Nonlocal means regularized sketched reweighted sparse and low-rank subspace clustering for large hyperspectral images. IEEE Trans. Geosci. Remote Sens. 2021, 59, 4164–4178. [Google Scholar] [CrossRef]
- Huang, N.; Xiao, L. Hyperspectral image clustering via sparse dictionary-based anchored regression. IET Image Process. 2019, 13, 261–269. [Google Scholar] [CrossRef]
- Huang, N.; Xiao, L.; Xu, Y. Bipartite graph partition based coclustering with joint sparsity for hyperspectral images. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2019, 12, 4698–4711. [Google Scholar] [CrossRef]
- Huang, S.; Zhang, H.; Pižurica, A. Subspace Clustering for Hyperspectral Images via Dictionary Learning with Adaptive Regularization. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–17. [Google Scholar] [CrossRef]
- Bruton, J.; Wang, H. Dictionary learning for clustering on hyperspectral images. Signal Image Video Process. 2021, 15, 255–261. [Google Scholar] [CrossRef]
- Gillis, N.; Kuang, D.; Park, H. Hierarchical clustering of hyperspectral images using rank-two nonnegative matrix factorization. IEEE Trans. Geosci. Remote Sens. 2014, 53, 2066–2078. [Google Scholar] [CrossRef]
- Manning, L.; Ballard, G.; Kannan, R.; Park, H. Parallel hierarchical clustering using rank-two nonnegative matrix factorization. In Proceedings of the IEEE HiPC, Virtual, 16–18 December 2020; pp. 141–150. [Google Scholar]
- Fernsel, P.; Maass, P. Regularized Orthogonal Nonnegative Matrix Factorization and K-means Clustering. arXiv 2021, arXiv:2112.07641. [Google Scholar]
- Malhotra, A.; Schizas, I.D. Milp-based unsupervised clustering. IEEE Signal Process. Lett. 2018, 25, 1825–1829. [Google Scholar] [CrossRef]
- Tian, L.; Du, Q.; Kopriva, I.; Younan, N. Orthogonal graph-regularized non-negative matrix factorization for hyperspectral image clustering. In Proceedings of the IEEE IGARSS, Yokohama, Japan, 28 July–2 August 2019; pp. 795–798. [Google Scholar]
- Fernsel, P. Spatially Coherent Clustering Based on Orthogonal Nonnegative Matrix Factorization. J. Imaging 2021, 7, 194. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, L.; Du, B.; You, J.; Tao, D. Hyperspectral image unsupervised classification by robust manifold matrix factorization. Inf. Sci. 2019, 485, 154–169. [Google Scholar] [CrossRef]
- Qin, Y.; Li, B.; Ni, W.; Quan, S.; Wang, P.; Bian, H. Affinity matrix learning via nonnegative matrix factorization for hyperspectral imagery clustering. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2020, 14, 402–415. [Google Scholar] [CrossRef]
- Huang, N.; Xiao, L.; Liu, J.; Chanussot, J. Graph convolutional sparse subspace coclustering with nonnegative orthogonal factorization for large hyperspectral images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–16. [Google Scholar] [CrossRef]
- Ji, P.; Zhang, T.; Li, H.; Salzmann, M.; Reid, I. Deep subspace clustering networks. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Zeng, M.; Cai, Y.; Liu, X.; Cai, Z.; Li, X. Spectral-spatial clustering of hyperspectral image based on Laplacian regularized deep subspace clustering. In Proceedings of the IEEE IGARSS, Yokohama, Japan, 28 July 28–2 August 2019; pp. 2694–2697. [Google Scholar]
- Cai, Y.; Zeng, M.; Cai, Z.; Liu, X.; Zhang, Z. Graph regularized residual subspace clustering network for hyperspectral image clustering. Inf. Sci. 2021, 578, 85–101. [Google Scholar] [CrossRef]
- Cai, Y.; Zhang, Z.; Cai, Z.; Liu, X.; Jiang, X. Hypergraph-structured autoencoder for unsupervised and semisupervised classification of hyperspectral image. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Li, T.; Cai, Y.; Zhang, Y.; Cai, Z.; Liu, X. Deep Mutual Information Subspace Clustering Network for Hyperspectral Images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Goel, A.; Majumdar, A. Sparse Subspace Clustering Friendly Deep Dictionary Learning for Hyperspectral Image Classification. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Li, K.; Qin, Y.; Ling, Q.; Wang, Y.; Lin, Z.; An, W. Self-supervised deep subspace clustering for hyperspectral images with adaptive self-expressive coefficient matrix initialization. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2021, 14, 3215–3227. [Google Scholar] [CrossRef]
- Cai, Y.; Zhang, Z.; Ghamisi, P.; Ding, Y.; Liu, X.; Cai, Z.; Gloaguen, R. Superpixel Contracted Neighborhood Contrastive Subspace Clustering Network for Hyperspectral Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–13. [Google Scholar] [CrossRef]
- Tulczyjew, L.; Kawulok, M.; Nalepa, J. Unsupervised feature learning using recurrent neural nets for segmenting hyperspectral images. IEEE Geosci. Remote Sens. Lett. 2020, 18, 2142–2146. [Google Scholar] [CrossRef]
- Rahimzad, M.; Homayouni, S.; Alizadeh Naeini, A.; Nadi, S. An Efficient Multi-Sensor Remote Sensing Image Clustering in Urban Areas via Boosted Convolutional Autoencoder (BCAE). Remote Sens. 2021, 13, 2501. [Google Scholar] [CrossRef]
- Shahi, K.R.; Ghamisi, P.; Rasti, B.; Scheunders, P.; Gloaguen, R. Unsupervised Data Fusion With Deeper Perspective: A Novel Multisensor Deep Clustering Algorithm. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2021, 15, 284–296. [Google Scholar] [CrossRef]
- Xie, J.; Girshick, R.; Farhadi, A. Unsupervised deep embedding for clustering analysis. In Proceedings of the ICML, New York, NY, USA, 19–24 June 2016; pp. 478–487. [Google Scholar]
- Nalepa, J.; Myller, M.; Imai, Y.; Honda, K.i.; Takeda, T.; Antoniak, M. Unsupervised segmentation of hyperspectral images using 3D convolutional autoencoders. IEEE Geosci. Remote Sens. Lett. 2020, 17, 1948–1952. [Google Scholar] [CrossRef]
- Zhang, Z.; Cai, Y.; Gong, W.; Ghamisi, P.; Liu, X.; Gloaguen, R. Hypergraph Convolutional Subspace Clustering With Multihop Aggregation for Hyperspectral Image. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2021, 15, 676–686. [Google Scholar] [CrossRef]
- Cai, Y.; Zhang, Z.; Cai, Z.; Liu, X.; Ding, Y.; Ghamisi, P. Fully Linear Graph Convolutional Networks for Semi-Supervised Learning and Clustering. arXiv 2021, arXiv:2111.07942. [Google Scholar]
- Cao, Z.; Li, X.; Feng, Y.; Chen, S.; Xia, C.; Zhao, L. ContrastNet: Unsupervised feature learning by autoencoder and prototypical contrastive learning for hyperspectral imagery classification. Neurocomputing 2021, 460, 71–83. [Google Scholar] [CrossRef]
- Kang, J.; Fernandez-Beltran, R.; Duan, P.; Liu, S.; Plaza, A.J. Deep unsupervised embedding for remotely sensed images based on spatially augmented momentum contrast. IEEE Trans. Geosci. Remote Sens. 2020, 59, 2598–2610. [Google Scholar] [CrossRef]
- Hu, X.; Li, T.; Zhou, T.; Peng, Y. Deep Spatial-Spectral Subspace Clustering for Hyperspectral Images Based on Contrastive Learning. Remote Sens. 2021, 13, 4418. [Google Scholar] [CrossRef]
- Cai, Y.; Zhang, Z.; Liu, Y.; Ghamisi, P.; Li, K.; Liu, X.; Cai, Z. Large-Scale Hyperspectral Image Clustering Using Contrastive Learning. arXiv 2021, arXiv:2111.07945. [Google Scholar]
- Malioutov, D.; Cetin, M.; Willsky, A.S. A sparse signal reconstruction perspective for source localization with sensor arrays. IEEE Trans. Signal Process. 2005, 53, 3010–3022. [Google Scholar] [CrossRef]
- Rubinstein, R.; Zibulevsky, M.; Elad, M. Double sparsity: Learning sparse dictionaries for sparse signal approximation. IEEE Trans. Signal Process. 2009, 58, 1553–1564. [Google Scholar] [CrossRef]
- Cho, N.; Kuo, C.C.J. Sparse music representation with source-specific dictionaries and its application to signal separation. IEEE Trans. Audio Speech Lang. Process. 2010, 19, 326–337. [Google Scholar] [CrossRef]
- Shojaeilangari, S.; Yau, W.Y.; Nandakumar, K.; Li, J.; Teoh, E.K. Robust representation and recognition of facial emotions using extreme sparse learning. IEEE Trans. Image Process. 2015, 24, 2140–2152. [Google Scholar] [CrossRef] [PubMed]
- Dong, W.; Zhang, L.; Lukac, R.; Shi, G. Sparse representation based image interpolation with nonlocal autoregressive modeling. IEEE Trans. Image Process. 2013, 22, 1382–1394. [Google Scholar] [CrossRef]
- Xue, J.; Zhao, Y.Q.; Bu, Y.; Liao, W.; Chan, J.C.W.; Philips, W. Spatial-spectral structured sparse low-rank representation for hyperspectral image super-resolution. IEEE Trans. Image Process. 2021, 30, 3084–3097. [Google Scholar] [CrossRef]
- Zeng, H.; Huang, S.; Chen, Y.; Luong, H.; Philips, W. Low-rank Meets Sparseness: An Integrated Spatial-Spectral Total Variation Approach to Hyperspectral Denoising. arXiv 2022, arXiv:2204.12879. [Google Scholar]
- Wright, J.; Ma, Y.; Mairal, J.; Sapiro, G.; Huang, T.S.; Yan, S. Sparse representation for computer vision and pattern recognition. Proc. IEEE 2010, 98, 1031–1044. [Google Scholar] [CrossRef]
- Han, J.; He, S.; Qian, X.; Wang, D.; Guo, L.; Liu, T. An object-oriented visual saliency detection framework based on sparse coding representations. IEEE Trans. Circuits Syst. Video Technol. 2013, 23, 2009–2021. [Google Scholar] [CrossRef]
- Jia, S.; Deng, X.; Zhu, J.; Xu, M.; Zhou, J.; Jia, X. Collaborative Representation-Based Multiscale Superpixel Fusion for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 7770–7784. [Google Scholar] [CrossRef]
- Yuan, Y.; Zheng, X.; Lu, X. Spectral–spatial kernel regularized for hyperspectral image denoising. IEEE Trans. Geosci. Remote Sens. 2015, 53, 3815–3832. [Google Scholar] [CrossRef]
- Zhang, H.; Liu, L.; He, W.; Zhang, L. Hyperspectral image denoising with total variation regularization and nonlocal low-rank tensor decomposition. IEEE Trans. Geosci. Remote Sens. 2020, 58, 3071–3084. [Google Scholar] [CrossRef]
- Zhang, H.; Cai, J.; He, W.; Shen, H.; Zhang, L. Double Low-Rank Matrix Decomposition for Hyperspectral Image Denoising and Destriping. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–9. [Google Scholar] [CrossRef]
- Zhang, H.; Song, Y.; Han, C.; Zhang, L. Remote sensing image spatiotemporal fusion using a generative adversarial network. IEEE Trans. Geosci. Remote Sens. 2020, 59, 4273–4286. [Google Scholar] [CrossRef]
- Yi, C.; Zhao, Y.Q.; Chan, J.C.W. Hyperspectral Image Super-Resolution Based on Spatial and Spectral Correlation Fusion. IEEE Trans. Geosci. Remote Sens. 2018, 56, 4165–4177. [Google Scholar] [CrossRef]
- Xu, J.; Huang, N.; Xiao, L. Spectral-spatial subspace clustering for hyperspectral images via modulated low-rank representation. In Proceedings of the IEEE IGARSS, Fort Worth, TX, USA, 23–28 July 2017; pp. 3202–3205. [Google Scholar]
- Wang, Y.; Mei, J.; Zhang, L.; Zhang, B.; Li, A.; Zheng, Y.; Zhu, P. Self-supervised low-rank representation (SSLRR) for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2018, 56, 5658–5672. [Google Scholar] [CrossRef]
- Li, A.; Qin, A.; Shang, Z.; Tang, Y.Y. Spectral-spatial sparse subspace clustering based on three-dimensional edge-preserving filtering for hyperspectral image. Int. J. Pattern Recognit. Artif. Intell. 2019, 33, 1955003. [Google Scholar] [CrossRef]
- Hinojosa, C.A.; Rojas, F.; Castillo, S.; Arguello, H. Hyperspectral image segmentation using 3D regularized subspace clustering model. J. Appl. Remote Sens. 2021, 15, 016508. [Google Scholar] [CrossRef]
- Guo, Y.; Gao, J.; Li, F. Random spatial subspace clustering. Knowl. Based Syst. 2015, 74, 106–118. [Google Scholar] [CrossRef]
- Sumarsono, A.; Du, Q.; Younan, N. Hyperspectral image segmentation with low-rank representation and spectral clustering. In Proceedings of the IEEE WHISPERS, Tokyo, Japan, 2–5 June 2015; pp. 1–4. [Google Scholar]
- Yan, Q.; Ding, Y.; Zhang, J.J.; Xia, Y.; Zheng, C.H. A discriminated similarity matrix construction based on sparse subspace clustering algorithm for hyperspectral imagery. Cogn. Syst. Res. 2019, 53, 98–110. [Google Scholar] [CrossRef]
- Long, Y.; Deng, X.; Zhong, G.; Fan, J.; Liu, F. Gaussian kernel dynamic similarity matrix based sparse subspace clustering for hyperspectral images. In Proceedings of the IEEE CIS, Macao, China, 13–16 December 2019; pp. 211–215. [Google Scholar]
- Comaniciu, D.; Meer, P. Mean shift: A robust approach toward feature space analysis. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 603–619. [Google Scholar] [CrossRef]
- Achanta, R.; Shaji, A.; Smith, K.; Lucchi, A.; Fua, P.; Süsstrunk, S. SLIC superpixels compared to state-of-the-art superpixel methods. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2274–2282. [Google Scholar] [CrossRef]
- Wright, J.; Yang, A.Y.; Ganesh, A.; Sastry, S.S.; Ma, Y. Robust face recognition via sparse representation. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 31, 210–227. [Google Scholar] [CrossRef]
- Benediktsson, J.A.; Palmason, J.A.; Sveinsson, J.R. Classification of hyperspectral data from urban areas based on extended morphological profiles. IEEE Trans. Geosci. Remote Sens. 2005, 43, 480–491. [Google Scholar] [CrossRef]
- Jia, S.; Shen, L.; Zhu, J.; Li, Q. A 3D Gabor phase-based coding and matching framework for hyperspectral imagery classification. IEEE Trans. Cybern. 2017, 48, 1176–1188. [Google Scholar] [CrossRef] [PubMed]
- Li, W.; Chen, C.; Su, H.; Du, Q. Local binary patterns and extreme learning machine for hyperspectral imagery classification. IEEE Trans. Geosci. Remote Sens. 2015, 53, 3681–3693. [Google Scholar] [CrossRef]
- Chen, Z.; Zhang, C. Efficient sparse subspace clustering for polarized hyperspectral images. Proc. SPIE 2019, 11052, 110520Z. [Google Scholar]
- Zhai, H.; Zhang, H.; Xu, X.; Zhang, L.; Li, P. Kernel sparse subspace clustering with a spatial max pooling operation for hyperspectral remote sensing data interpretation. Remote Sens. 2017, 9, 335. [Google Scholar] [CrossRef]
- He, X.; Niyogi, P. Locality preserving projections. In Proceedings of the Advances in Neural Information Processing Systems 16 (NIPS 2003), Vancouver, BC, Canada, 8–13 December 2003; Volume 16. [Google Scholar]
- Peng, X.; Zhang, L.; Yi, Z. Scalable sparse subspace clustering. In Proceedings of the IEEE CVPR, Washington, DC, USA, 23–28 June 2013; pp. 430–437. [Google Scholar]
- Liu, W.; He, J.; Chang, S.F. Large graph construction for scalable semi-supervised learning. In Proceedings of the ICML, Haifa, Israel, 21–24 June 2010; pp. 679–686. [Google Scholar]
- Cai, D.; Chen, X. Large scale spectral clustering via landmark-based sparse representation. IEEE Trans. Cybern. 2014, 45, 1669–1680. [Google Scholar]
- Traganitis, P.A.; Giannakis, G.B. Sketched subspace clustering. IEEE Trans. Signal Process. 2017, 66, 1663–1675. [Google Scholar] [CrossRef]
- Zhang, Q.; Li, B. Discriminative K-SVD for dictionary learning in face recognition. In Proceedings of the IEEE CVPR, San Francisco, CA, USA, 13–18 June 2010; pp. 2691–2698. [Google Scholar]
- Mairal, J.; Bach, F.; Ponce, J. Task-driven dictionary learning. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 34, 791–804. [Google Scholar] [CrossRef] [PubMed]
- Jiang, Z.; Lin, Z.; Davis, L.S. Label consistent K-SVD: Learning a discriminative dictionary for recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 2651–2664. [Google Scholar] [CrossRef]
- Fu, W.; Li, S.; Fang, L.; Benediktsson, J.A. Contextual online dictionary learning for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2017, 56, 1336–1347. [Google Scholar] [CrossRef]
- Han, X.; Yu, J.; Luo, J.; Sun, W. Reconstruction from multispectral to hyperspectral image using spectral library-based dictionary learning. IEEE Trans. Geosci. Remote Sens. 2018, 57, 1325–1335. [Google Scholar] [CrossRef]
- Yuan, Y.; Ma, D.; Wang, Q. Hyperspectral anomaly detection via sparse dictionary learning method of capped norm. IEEE Access 2019, 7, 16132–16144. [Google Scholar] [CrossRef]
- Dhillon, I.S. Co-clustering documents and words using bipartite spectral graph partitioning. In Proceedings of the ACM SIGKDD, San Francisco, CA, USA, 26–29 August 2001; pp. 269–274. [Google Scholar]
- Paatero, P.; Tapper, U. Positive matrix factorization: A non-negative factor model with optimal utilization of error estimates of data values. Environmetrics 1994, 5, 111–126. [Google Scholar] [CrossRef]
- Lu, X.; Wu, H.; Yuan, Y.; Yan, P.; Li, X. Manifold regularized sparse NMF for hyperspectral unmixing. IEEE Trans. Geosci. Remote Sens. 2012, 51, 2815–2826. [Google Scholar] [CrossRef]
- Wang, W.; Qian, Y.; Tang, Y.Y. Hypergraph-regularized sparse NMF for hyperspectral unmixing. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2016, 9, 681–694. [Google Scholar] [CrossRef]
- Zhang, S.; Zhang, G.; Li, F.; Deng, C.; Wang, S.; Plaza, A.; Li, J. Spectral-spatial hyperspectral unmixing using nonnegative matrix factorization. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–13. [Google Scholar] [CrossRef]
- Févotte, C.; Vincent, E.; Ozerov, A. Single-channel audio source separation with NMF: Divergences, constraints and algorithms. In Audio Source Separation; Springer: Cham, Switzerland, 2018; pp. 1–24. [Google Scholar]
- Yuan, Z.; Oja, E. Projective nonnegative matrix factorization for image compression and feature extraction. In SCIA 2005: Image Analysis, Proceedings of the Scandinavian Conference on Image Analysis, Joensuu, Finland, 19–22 June 2005; Springer: Berlin/Heidelberg, Germany, 2005; pp. 333–342. [Google Scholar]
- Leng, C.; Zhang, H.; Cai, G.; Chen, Z.; Basu, A. Total variation constrained non-negative matrix factorization for medical image registration. IEEE/CAA J. Autom. Sin. 2021, 8, 1025–1037. [Google Scholar] [CrossRef]
- Wang, Y.X.; Zhang, Y.J. Nonnegative matrix factorization: A comprehensive review. IEEE Trans. Knowl. Data Eng. 2012, 25, 1336–1353. [Google Scholar] [CrossRef]
- Zheng, C.H.; Huang, D.S.; Zhang, L.; Kong, X.Z. Tumor clustering using nonnegative matrix factorization with gene selection. IEEE Trans. Inf. Technol. Biomed. 2009, 13, 599–607. [Google Scholar] [CrossRef]
- Zheng, C.H.; Zhang, L.; Ng, V.T.Y.; Shiu, C.K.; Huang, D.S. Molecular pattern discovery based on penalized matrix decomposition. IEEE/ACM Trans. Comput. Biol. Bioinform. 2011, 8, 1592–1603. [Google Scholar] [CrossRef]
- Gillis, N. Sparse and unique nonnegative matrix factorization through data preprocessing. J. Mach. Learn. Res. 2012, 13, 3349–3386. [Google Scholar]
- Pompili, F.; Gillis, N.; Absil, P.A.; Glineur, F. Two algorithms for orthogonal nonnegative matrix factorization with application to clustering. Neurocomputing 2014, 141, 15–25. [Google Scholar] [CrossRef]
- Xu, W.; Liu, X.; Gong, Y. Document clustering based on non-negative matrix factorization. In Proceedings of the ACM SIGIR, Toronto, ON, Canada, 28 July–1 August 2003; pp. 267–273. [Google Scholar]
- Ding, C.; He, X.; Simon, H.D. On the equivalence of nonnegative matrix factorization and spectral clustering. In Proceedings of the SDM, SIAM, Newport Beach, CA, USA, 21–23 April 2005; pp. 606–610. [Google Scholar]
- Roy, S.; Menapace, W.; Oei, S.; Luijten, B.; Fini, E.; Saltori, C.; Huijben, I.; Chennakeshava, N.; Mento, F.; Sentelli, A.; et al. Deep learning for classification and localization of COVID-19 markers in point-of-care lung ultrasound. IEEE Trans. Med. Imaging 2020, 39, 2676–2687. [Google Scholar] [CrossRef] [PubMed]
- Zhao, X.; Tao, R.; Li, W.; Philips, W.; Liao, W. Fractional gabor convolutional network for multisource remote sensing data classification. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–18. [Google Scholar] [CrossRef]
- Li, Y.; Wang, W.; Liu, M.; Jiang, Z.; He, Q. Speaker clustering by co-optimizing deep representation learning and cluster estimation. IEEE Trans. Multimed. 2020, 23, 3377–3387. [Google Scholar] [CrossRef]
- Lee, K.; Jeong, W.K. ISCL: Interdependent self-cooperative learning for unpaired image denoising. IEEE Trans. Med. Imaging 2021, 40, 3238–3248. [Google Scholar] [CrossRef] [PubMed]
- Deshpande, V.S.; Bhatt, J.S. A Practical Approach for Hyperspectral Unmixing Using Deep Learning. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar]
- Ruff, L.; Kauffmann, J.R.; Vandermeulen, R.A.; Montavon, G.; Samek, W.; Kloft, M.; Dietterich, T.G.; Müller, K.R. A unifying review of deep and shallow anomaly detection. Proc. IEEE 2021, 109, 756–795. [Google Scholar] [CrossRef]
- Scarselli, F.; Gori, M.; Tsoi, A.C.; Hagenbuchner, M.; Monfardini, G. The graph neural network model. IEEE Trans. Neural Netw. 2008, 20, 61–80. [Google Scholar] [CrossRef]
- Zhou, J.; Cui, G.; Hu, S.; Zhang, Z.; Yang, C.; Liu, Z.; Wang, L.; Li, C.; Sun, M. Graph neural networks: A review of methods and applications. AI Open 2020, 1, 57–81. [Google Scholar] [CrossRef]
- Lee, H.; Kwon, H. Self-Supervised Contrastive Learning for Cross-Domain Hyperspectral Image Representation. In Proceedings of the IEEE ICASSP, Singapore, 23–27 May 2022; pp. 3239–3243. [Google Scholar]
- Xu, H.; He, W.; Zhang, L.; Zhang, H. Unsupervised Spectral–Spatial Semantic Feature Learning for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–14. [Google Scholar] [CrossRef]
- Hou, S.; Shi, H.; Cao, X.; Zhang, X.; Jiao, L. Hyperspectral Imagery Classification Based on Contrastive Learning. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–13. [Google Scholar] [CrossRef]
- Zhao, L.; Luo, W.; Liao, Q.; Chen, S.; Wu, J. Hyperspectral Image Classification With Contrastive Self-Supervised Learning Under Limited Labeled Samples. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. In Proceedings of the ICML, Virtual, 13–18 July 2020; pp. 1597–1607. [Google Scholar]
- Oord, A.v.d.; Li, Y.; Vinyals, O. Representation learning with contrastive predictive coding. arXiv 2018, arXiv:1807.03748. [Google Scholar]
- Zbontar, J.; Jing, L.; Misra, I.; LeCun, Y.; Deny, S. Barlow twins: Self-supervised learning via redundancy reduction. In Proceedings of the ICML, Virtual, 18–24 July 2021; pp. 12310–12320. [Google Scholar]
- Li, Y.; Hu, P.; Liu, Z.; Peng, D.; Zhou, J.T.; Peng, X. Contrastive clustering. In Proceedings of the AAAI, Virtual, 2–9 February 2021. [Google Scholar]
- Lovász, L.; Plummer, M.D. Matching Theory; American Mathematical Society: Providence, RI, USA, 2009; Volume 367. [Google Scholar]
- Abdi, H.; Williams, L.J. Principal component analysis. Wiley Interdiscip. Rev. Comput. Stat. 2010, 2, 433–459. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Subcategory | Sub-Subcategory | Algorithms | Remarks |
|---|---|---|---|---|
| Model based clustering | Self-repre sentation based | Spectral based | SSC [31], LRR [43], LRSSC [44], /-LRSSC [45] | Adopt self-representation models to learn the similarity matrix of data points for spectral clustering. Only spectral information of HSI is exploited. |
| Spatial-spectral based | JSSC [46], SpatSC [47], L2-SSC [48], TV-CRC-LAD [32], SC [42], S-SSC [49], LCR-FLDA [50], SPHG-LRSC [51] | Extensions of spectral based methods by incorporating spatial information of HSI. | ||
| Object based | RMC-OOSSC [52], FHoSSC [53] | Clustering is performed in object level, which is much faster compared with the pixel-based algorithms. | ||
| Semi-supervised | CPPSSC [54], JSSC-L [55], NNLRR [56,57] | Supervised information is incorporated with a few labelled data. | ||
| Multi-view | SSMLC [58], FSP-SSC [59], K-SSMLC [60], HMSC [61] | Rich information from different data sources is exploited. | ||
| Kernel based | KLRSSC [62], KSSC-SMP [63], KLRS-SC [64], KSSC-SMP-TV [65], EKGCSC [66] | Kernel versions of the traditional self-representation models by using the kernel trick. | ||
| Graph learning based | UDHLR [67], DAG-SC [68] | Adopt adaptively learned graph in graph embedding within self-representation framework. | ||
| Dictionary learning based | Landmark based | JSCC [69], LSSC-TV [70], SC-SSC [71], MOMSSC-L0-TV [72] | Computationally efficient clustering methods due to the adopted landmark dictionaries. | |
| Sketch based | Sketch-TV [73,74], NL-SSLR [75] | More scalable to big data than self-representation models due to the adopted sketched dictionary. | ||
| Adaptive dictionary based | SS-SDAR [76], BPG-JSDL [77], IDLSC [78], SC-SC [79] | More scalable to big data than self-representation models. | ||
| NMF based | Spectral based | H2NMF [80], PH2NMF [81], RONMF [82], SNMF [83] | The clustering results can be directly obtained from the factorization matrix of NMF. | |
| Spatial-spectral based | GONMF [84], ONMFTV [85], RMMF [86], NMFAML [87], GCSSC [88] | Extensions of spectral based NMF clustering methods by incorporating spatial information of HSI. | ||
| Deep clustering | Self-representation based | DSC [89], LRDSC [90], GR-RSCNet [91], HyperAE [92], DMISC [93], DS3C-Net [34], DDL-SSC [94], SDSC-AI [95], NCSC [96] | Deep version of the traditional shallow self-representation clustering models by integrating deep generative neural networks with SSC. | |
| AE-based | RNN-AE [97], BCAE [98], MDC [99], DCIDC [33], DEC [100], 3D-CAE [101] | The extracted features by autoencoders make AE-based clustering methods more effective to cluster data. | ||
| Graph convolution based | EGCSC [66], HGCSC [102], FLGC [103] | Aggregate neighbourhood information of data in the affinity learning by integrating graph convolution. | ||
| Contrastive learning based | ContrastNet [104], SauMoCo [105], DS3C [106], SSCC [107] | Compared with AE-based models, the extracted features by contrastive learning are more discriminative. | ||
| Symbols | Definition | Symbols | Definition |
|---|---|---|---|
| i-th slice of a 3D tensor | |||
| The i-th column of | The sum of the singular values of | ||
| The absolute value of c | |||
| The number of non-zeros of | |||
| ) | and () |
| Methods | Spatial Regularization | Remarks |
|---|---|---|
| JSSC [46] | is the coefficients corresponding to the pixels within the i-th super-pixel | |
| SpatSC [47] | is a difference matrix for 1-D hyperspectral data | |
| L2-SSC [48] | is the index set of horizontal and vertical neighbours of the i-th pixel | |
| TV-CRC-LAD [32] | is the index set of horizontal and vertical neighbours of the i-th pixel | |
| SC [42] | is the smoothed matrix of with a 2-D mean filter | |
| S-SSC [49] | is the smoothed matrix of with a 3D median filter | |
| LCR-FLDA [50] | is the Laplacian matrix of a normal graph | |
| SPHG-LRSC [51] | is the Laplacian matrix of a hypergraph |
| No. | HYDICE Urban | University of Houston |
|---|---|---|
| 1 | Roof | Concrete |
| 2 | Parking lot | Grass-1 |
| 3 | Grass | Grass-2 |
| 4 | Trees | Parking lot |
| 5 | Sparse vegetation | Roof |
| 6 | Asphalt road | Trees |
| 7 | Concrete road | Asphalt |
| No. | Shallow Models | Deep Models | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| k-Means | NMF | ONMF-TV | SSC | JSSC | ODL | Sketch-TV | GCSC | AEC | DEC | RNNC | HyperAE | |
| 1 | 87.07 | 87.30 | 98.94 | 86.15 | 90.83 | 82.96 | 89.00 | 93.15 | 91.70 | 91.55 | 92.37 | 97.64 |
| 2 | 100.00 | 90.37 | 93.17 | 68.87 | 97.72 | 48.12 | 94.80 | 100.00 | 89.38 | 84.45 | 99.96 | 95.68 |
| 3 | 39.27 | 72.56 | 67.81 | 85.44 | 72.97 | 47.74 | 67.34 | 60.73 | 79.64 | 55.97 | 84.63 | 67.69 |
| 4 | 94.41 | 46.89 | 0 | 1.76 | 89.54 | 89.03 | 91.30 | 91.93 | 77.64 | 82.09 | 85.51 | 77.95 |
| 5 | 56.44 | 65.21 | 95.69 | 75.83 | 67.00 | 68.84 | 66.21 | 99.00 | 94.06 | 78.56 | 97.69 | 59.96 |
| 6 | 0 | 22.56 | 53.04 | 51.74 | 24.62 | 81.13 | 91.59 | 0 | 6.02 | 72.72 | 0 | 59.22 |
| 7 | 62.86 | 2.88 | 28.60 | 80.38 | 0 | 0 | 0.22 | 84.37 | 89.80 | 83.92 | 92.68 | 99.00 |
| OA | 63.67 | 62.91 | 72.49 | 68.17 | 68.98 | 62.06 | 77.51 | 75.92 | 75.46 | 78.64 | 79.10 | 79.61 |
| AA | 62.86 | 55.40 | 62.46 | 64.31 | 63.24 | 59.69 | 71.50 | 75.60 | 75.46 | 78.47 | 78.98 | 79.59 |
| 0.5665 | 0.5528 | 0.6696 | 0.6277 | 0.6322 | 0.5514 | 0.7325 | 0.7100 | 0.7068 | 0.7484 | 0.7485 | 0.7582 | |
| NMI | 0.6341 | 0.5111 | 0.6928 | 0.6338 | 0.6175 | 0.5273 | 0.7022 | 0.7746 | 0.7284 | 0.6893 | 0.7865 | 0.7321 |
| ARI | 0.5290 | 0.4344 | 0.6326 | 0.5447 | 0.5754 | 0.4100 | 0.6409 | 0.6472 | 0.6416 | 0.6337 | 0.6848 | 0.6619 |
| Purity | 0.6630 | 0.6507 | 0.7436 | 0.7443 | 0.7104 | 0.6216 | 0.7841 | 0.7648 | 0.7683 | 0.7864 | 0.7952 | 0.7961 |
| Time | 3 | 1 | 12 | 3997 | 8518 | 190 | 37 | 283 | 422 | 476 | 136 | 1029 |
| No. | Shallow Models | Deep Models | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| k-Means | NMF | ONMF-TV | SSC | JSSC | ODL | Sketch-TV | GCSC | AEC | DEC | RNNC | HyperAE | |
| 1 | 47.99 | 8.12 | 48.66 | 46.57 | 45.90 | 45.31 | 46.50 | 53.50 | 46.42 | 52.01 | 46.50 | 53.50 |
| 2 | 96.41 | 99.88 | 100.00 | 9.18 | 99.77 | 43.34 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 |
| 3 | 27.42 | 25.81 | 10.57 | 86.20 | 78.85 | 54.30 | 63.08 | 56.45 | 46.42 | 78.85 | 65.59 | 0 |
| 4 | 99.75 | 99.25 | 65.00 | 92.36 | 94.36 | 97.40 | 99.85 | 96.66 | 64.90 | 76.24 | 99.90 | 97.10 |
| 5 | 76.92 | 92.31 | 100.00 | 77.69 | 100.00 | 0 | 0 | 100.00 | 92.31 | 0 | 100.00 | 100.00 |
| 6 | 27.36 | 33.17 | 0 | 0.24 | 18.64 | 9.69 | 68.04 | 0 | 25.42 | 0 | 0 | 87.65 |
| 7 | 0 | 11.57 | 94.09 | 0.75 | 49.18 | 8.05 | 68.30 | 68.30 | 76.35 | 80.5 | 0 | 75.72 |
| OA | 62.91 | 56.55 | 61.52 | 72.03 | 72.17 | 54.72 | 76.39 | 73.80 | 63.52 | 68.28 | 65.27 | 75.69 |
| AA | 53.69 | 52.87 | 59.76 | 66.14 | 69.53 | 36.87 | 63.68 | 67.84 | 64.55 | 55.37 | 58.86 | 73.43 |
| 0.5180 | 0.4169 | 0.5296 | 0.6425 | 0.6567 | 0.3882 | 0.7101 | 0.6721 | 0.5491 | 0.6157 | 0.5513 | 0.6953 | |
| NMI | 0.5904 | 0.5706 | 0.5945 | 0.6498 | 0.7129 | 0.3985 | 0.7864 | 0.7710 | 0.5942 | 0.6693 | 0.7171 | 0.8067 |
| ARI | 0.5089 | 0.3811 | 0.4078 | 0.5459 | 0.7178 | 0.2569 | 0.7827 | 0.7125 | 0.4639 | 0.5921 | 0.5717 | 0.7374 |
| Purity | 0.7187 | 0.5685 | 0.6171 | 0.7448 | 0.8096 | 0.5686 | 0.8568 | 0.8403 | 0.6473 | 0.7846 | 0.7703 | 0.8591 |
| Time | 2 | 1 | 6 | 735 | 3098 | 191 | 29 | 91 | 207 | 267 | 116 | 210 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, S.; Zhang, H.; Zeng, H.; Pižurica, A. From Model-Based Optimization Algorithms to Deep Learning Models for Clustering Hyperspectral Images. Remote Sens. 2023, 15, 2832. https://doi.org/10.3390/rs15112832
Huang S, Zhang H, Zeng H, Pižurica A. From Model-Based Optimization Algorithms to Deep Learning Models for Clustering Hyperspectral Images. Remote Sensing. 2023; 15(11):2832. https://doi.org/10.3390/rs15112832
Chicago/Turabian StyleHuang, Shaoguang, Hongyan Zhang, Haijin Zeng, and Aleksandra Pižurica. 2023. "From Model-Based Optimization Algorithms to Deep Learning Models for Clustering Hyperspectral Images" Remote Sensing 15, no. 11: 2832. https://doi.org/10.3390/rs15112832
APA StyleHuang, S., Zhang, H., Zeng, H., & Pižurica, A. (2023). From Model-Based Optimization Algorithms to Deep Learning Models for Clustering Hyperspectral Images. Remote Sensing, 15(11), 2832. https://doi.org/10.3390/rs15112832