1. Introduction
Over the past 20 years, light detection and ranging (LiDAR) technology has rapidly developed. As an active remote sensing technology, LiDAR uses active laser pulse signals to quickly and accurately obtain information about the distance, location, reflectance, and other characteristics of surrounding objects by emitting laser pulses and receiving the reflected signals from objects [
1]. However, a laser point cloud is unable to acquire spectral information of target objects and have a single color, which is not conducive to processing and understanding. Conversely, optical images can obtain rich spectral information and texture details of the land surface, which enables rapid identification of surface features and have better visual effects. Point cloud and optical images have complementary representations of target objects. By registering and fusing three-dimensional (3D) point cloud data with two-dimensional (2D) image data [
2], a colored point cloud with rich texture details can be obtained, enhancing the ability to discriminate between different objects. This can be widely applied in various remote sensing fields such as 3D urban modeling, smart city, urban planning, resource utilization, environmental monitoring and disaster assessment.
The current mobile measurement systems are mainly divided into two types: airborne and vehicle-mounted, which integrate multiple devices such as LiDAR, cameras, Global Positioning System (GPS), and Inertial Measurement Unit (IMU). Although these systems have relatively high measurement accuracy, they are costly and complex. Therefore, in this article we establish an automatic point cloud coloring method for an integrated system of LiDAR and GoPro. The aim is to automatically color the point cloud based on video imagery in the absence of position and orientation system (POS) and IMU. During the experimental process, we mainly encountered three key issues:
- (1)
Due to the significant deformation and motion blur in video images, as well as the existence of trailing phenomena, the video images contained blurred pixels. Therefore, we need to address the issue of reliable selection of corresponding points between adjacent images for relative orientation.
- (2)
The ground mobile LiDAR system without a POS is a loosely coupled integrated system. To achieve automatic colorization of point cloud data and video images, a specific and effective registration strategy is required.
- (3)
During the point cloud coloring process, a 3D point corresponded to multiple video images. Obtaining a uniform and realistic color is the third key issue that this article needs to address.
Based on the three key issues mentioned above, we will briefly describe the methods and processes in the introduction.
1.1. Selecting Reliable Corresponding Points
GoPro cameras are not professional surveying cameras. When used for mobile measurements, nonlinear distortion, motion blur, edge blurring, and other phenomena can often occur in the video images. Therefore, we first calibrate the GoPro camera to compensate for non-linear distortions. Typically, a distortion model is introduced into the central projection imaging equation, and correction coefficients are calculated based on control points or other methods to correct the image [
3]. Brown [
4] first proposed the famous Brown model in 1971, which includes radial and tangential distortion, both of which are nonlinear. Melen and Balchen [
5] subsequently proposed an additional parameter to compensate for linear distortion caused by the horizontal and vertical axes of the image not being perpendicular, although this type of distortion is generally negligible [
6]. Fraser [
7] proposed another type of distortion, called prism distortion, which is mainly caused by poor camera lens design and manufacturing, and which can be compensated for by adding a linear factor after the radial and tangential distortion models [
8]. Based on the above models, Gao et al. [
9] proposed a tangential distortion that accounts for higher-order and cross-order terms, which is suitable for more complex optical distortions. Among these types of distortions, radial and tangential distortions have a much greater impact than other distortions [
10,
11]. Therefore, in this article we use radial and tangential distortion models to correct the GoPro action camera based on chessboard images extracted from video streams, effectively reducing the nonlinear distortion of the image.
After calibration, the video images may still have problems such as trailing and edge blur, which greatly affect the matching of corresponding points. Therefore, we uniformly adopt the method of feature matching [
12] for the selection of corresponding points. Currently, common methods for feature point extraction include the Moravec operator, Harris [
13] operator, Forstner operator, scale-invariant feature transform (SIFT) [
14] algorithm, speeded-up robust features (SURF) [
15] algorithm and oriented FAST and rotated BRIEF (ORB) [
16] algorithms. Although the Moravec operator has a relatively simple feature extraction process, its performance in extracting edges and noise is poor, and it requires manual setting of empirical values. The Forstner operator has high accuracy and fast computation speed, but the algorithm is complex and difficult to implement, requiring continuous experimentation to determine the range of interest and threshold values [
17]. Harris is a signal-based point feature extraction operator [
18] with higher accuracy and reliability in extracting various corner points [
19]. The SIFT algorithm is a feature-based matching method with strong matching ability [
20], stable features, and invariance to rotation, scale, and brightness. However, it is susceptible to external noise and has a slower running speed. The SURF algorithm improves the method of feature extraction and description by using techniques such as integral images and box filters [
21]. It can convert the convolution operation of the image and template into several addition and subtraction operations [
22], making it more efficient, with a detection speed of more than three times that of the SIFT algorithm. The ORB algorithm uses oriented FAST [
23] for feature extraction to solve the speed problem and rotated BRIEF [
24] for feature description to solve the problem of spatial redundancy in feature description. Therefore, the ORB algorithm has both speed and accuracy, and is relatively stable. However, the speed of the ORB algorithm is relatively slow, and it is not robust enough for rotation and scale changes. Based on the above analysis, this article attempts to use the SURF matching algorithm with distance restriction and random sample consensus (RANSAC). SURF is used for rough matching of the corresponding points, then deleting points with excessively long lines connecting corresponding points. Finally, RANSAC is used to eliminate mismatches to achieve precise matching of corresponding points. After these three steps, corresponding points with high accuracy and located in the central region can be filtered out.
1.2. Registration Strategy
The video stream can be captured and sliced into multiple sequential images. Therefore, this article focuses on the problem of automatic registration between multiple sequential images and point clouds. Since there is no POS and IMU, it is challenging to obtain the exterior orientation elements of each image quickly and accurately. Currently, there are many research methods for the registration of point clouds and multiple images, but most of them are based on direct registration of an image-based 3D point cloud. Song and Liu [
25] proposed a method of generating an image-based 3D point cloud from sequential images and obtaining accurate exterior orientation elements of each image by registering the image-based 3D point cloud with a LiDAR point cloud. Liu et al. [
26] further studied this approach by using the 3D-SIFT algorithm to extract feature points from both the LiDAR point cloud and the image-based 3D point cloud, achieving precise registration of the two types of point clouds using the scaling iterative closest point (SICP) algorithm. Obviously, generating an image-based point cloud is a feasible solution, but it requires high-quality image data. In the above-mentioned methods, digital cameras are usually used. In this study, the video images captured by the GoPro camera often suffer from large boundary deformation, unstable interior orientation elements, and blurred pixels. Therefore, problems such as multiple holes and deformation occurred in the image-based point cloud, as shown in
Figure 1. It is apparent that the quality of the 3D point cloud generated from the sequential images is poor. Therefore, it is not recommended to use point cloud registration for colorization between these 3D point clouds. Ultimately, we decided to adopt a 1-to-N registration strategy, which means first registering the point cloud with the first image to obtain the exterior orientation elements of the first image. Then, by using relative and absolute orientation, the exterior orientation elements of the remaining sequential images can be obtained.
1.2.1. Obtain the Exterior Orientation Elements of the First Image
It is clear that achieving high-precision automatic registration of a point cloud and the first image has become a key issue. In recent years, scholars have focused more on feature-based registration methods for such problems. Generally, these methods require projecting the point cloud onto a 2D plane to generate an intensity image or a depth image, extracting effective stable and distinguishable feature points from the image, and performing feature matching by calculating the similarity between features [
27]. Feature-based registration methods convert the analysis of the entire image into the analysis of a certain feature of the image, simplifying the process and having good invariance to grayscale changes and image occlusions. Fang [
28] used different projection methods to project point cloud data and generated a point cloud intensity image. Then, using the SIFT algorithm to extract feature points, the automatic registration between the point cloud intensity image and optical image was achieved. Safdarinezhad et al. [
29] used the point cloud intensity and depth to generate an optical consistent LiDAR product (OCLP) and completed automatic registration with high-resolution satellite images using the SIFT feature extraction method. Pyeon et al. [
30] used a method based on point cloud intensity images and RANSAC algorithms to perform rough matching and then using the nearest point iterative (ICP) matching, greatly improved on the efficiency of the algorithm. Ding et al. [
31] used constraints based on point and line feature to achieve automatic registration of point cloud intensity images and aerial images. Fan et al. [
32] extracted corner points of windows and doors from point cloud intensity images and optical images and used the correlation coefficient method to achieve automatic matching of feature points. In the methods above, the conversion of point cloud to image data results in loss of accuracy and requires the point cloud data to be relatively flat with minimal noise. Therefore, in this paper we propose a registration method based on normalized Zernike moments, which is also a point feature-based registration method. Low-order Zernike moments are mainly used to describe the overall shape characteristics of the image [
33], while high-order Zernike moments are mainly used to reflect texture details and other information of the image [
34]. Normalized Zernike moments can reflect features in multiple dimensions [
35], achieving good results even for low-quality images captured by a GoPro action camera and point cloud intensity images.
1.2.2. Obtain the Exterior Orientation Elements of Sequential Images
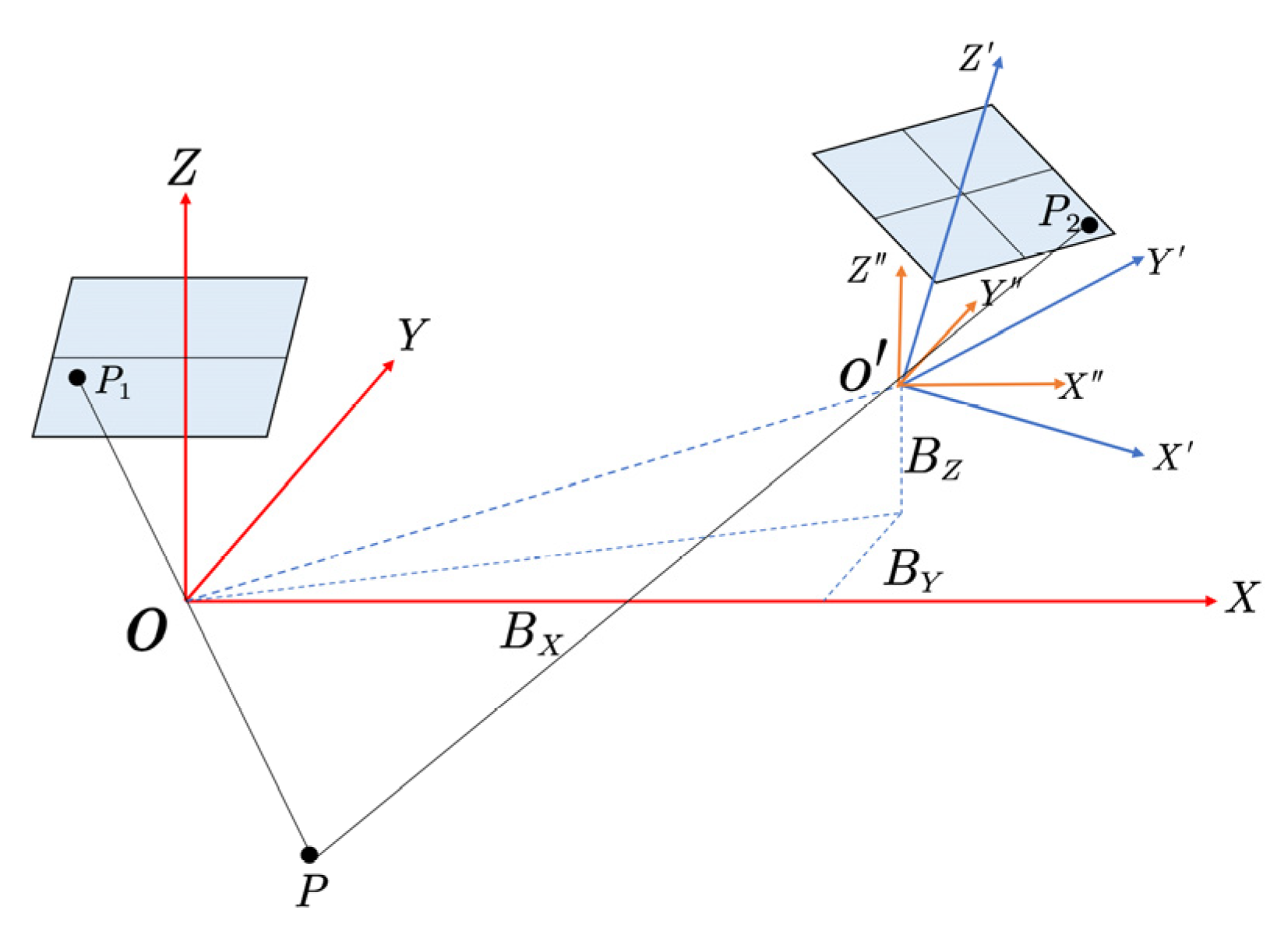
After completing the registration of the first image and the point cloud, relative and absolute orientation are required to transfer the exterior orientation elements for the rest of the sequential images. Relative orientation refers to using an algorithm to calculate the rotation matrix and displacement vector between the right and left image pairs [
36] based on several corresponding points in the stereo image pairs, so that the coincident rays intersect [
37]. According to this principle, if a continuous relative orientation is performed, the relative positional relationship between all stereo image pairs can be obtained. In traditional photogrammetry, continuous relative orientation is based on initial assumptions, typically assuming the initial values of the three angle elements of the rotation matrix are zero, the first component of the baseline vector is one, and the other two components are replaced with small values, assuming the stereo image pairs are taken under approximately vertical photography conditions [
38]. However, in digital close-range photogrammetry, multi-baseline convergence photography is mainly used, such as the GoPro camera used in this paper. Moreover, we obtain video images by capturing video streams. At this time, the relationship between the left and right images in the stereo image pair may be a rotation at any angle, and the forms of angle elements and displacement vectors are complex and diverse. Therefore, traditional relative orientation methods pose difficulty for obtaining correct results [
39]. To address this problem, many methods have been proposed. Zhou et al. [
40] proposed a hybrid genetic algorithm and used unit quaternions to represent the matrix, which quickly converges without given initial values. Li et al. [
41] proposed a normalized eight-point algorithm to calculate the essential matrix and used the Gauss-Newton iteration method to solve the two standard orthogonal matrices produced by decomposing the essential matrix; this improves the accuracy of relative orientation. Therefore, this article intends to use a method based on essential matrix decomposition and nonlinear optimization for relative orientation. Specifically, the essential matrix is first calculated, and its initial value is obtained by performing singular value decomposition [
42]. Then, nonlinear optimization is used to obtain an accurate solution.
The stereo model obtained from relative orientation is based on the image-space coordinate system, and its scale is arbitrary. To determine the true position of the stereo model in the point cloud coordinate system, the final step is to determine the transformation relationship between the image-space coordinate system and the point cloud coordinate system, that is, absolute orientation.
1.3. Realistic and Accurate Point Cloud Coloring Method
In the process of coloring the point cloud, a LiDAR point often corresponds to multiple video images. Due to the low quality of the video images used in this paper, problems such as blurry pixels, trailing images and significant deformation exist, making it challenging to perform point cloud coloring that is both realistic and uniform. Vechersky et al. [
43] proposed that the color set corresponding to each 3D point follows a Gaussian distribution model. Specifically, the mean and covariance of the weighted Gaussian distribution of the color set are estimated, and the mean value is assigned to the color of the 3D point. Based on this, this paper proposes a Gaussian distribution point cloud coloring method with center area restriction. In simple terms, assuming the color set corresponding to the 3D points follows a Gaussian distribution. Meanwhile, the position information of pixels is statistically analyzed, and only pixels within the central area of the image are selected as valid pixels for coloring. This effectively avoids the phenomenon of blurred edge pixels.
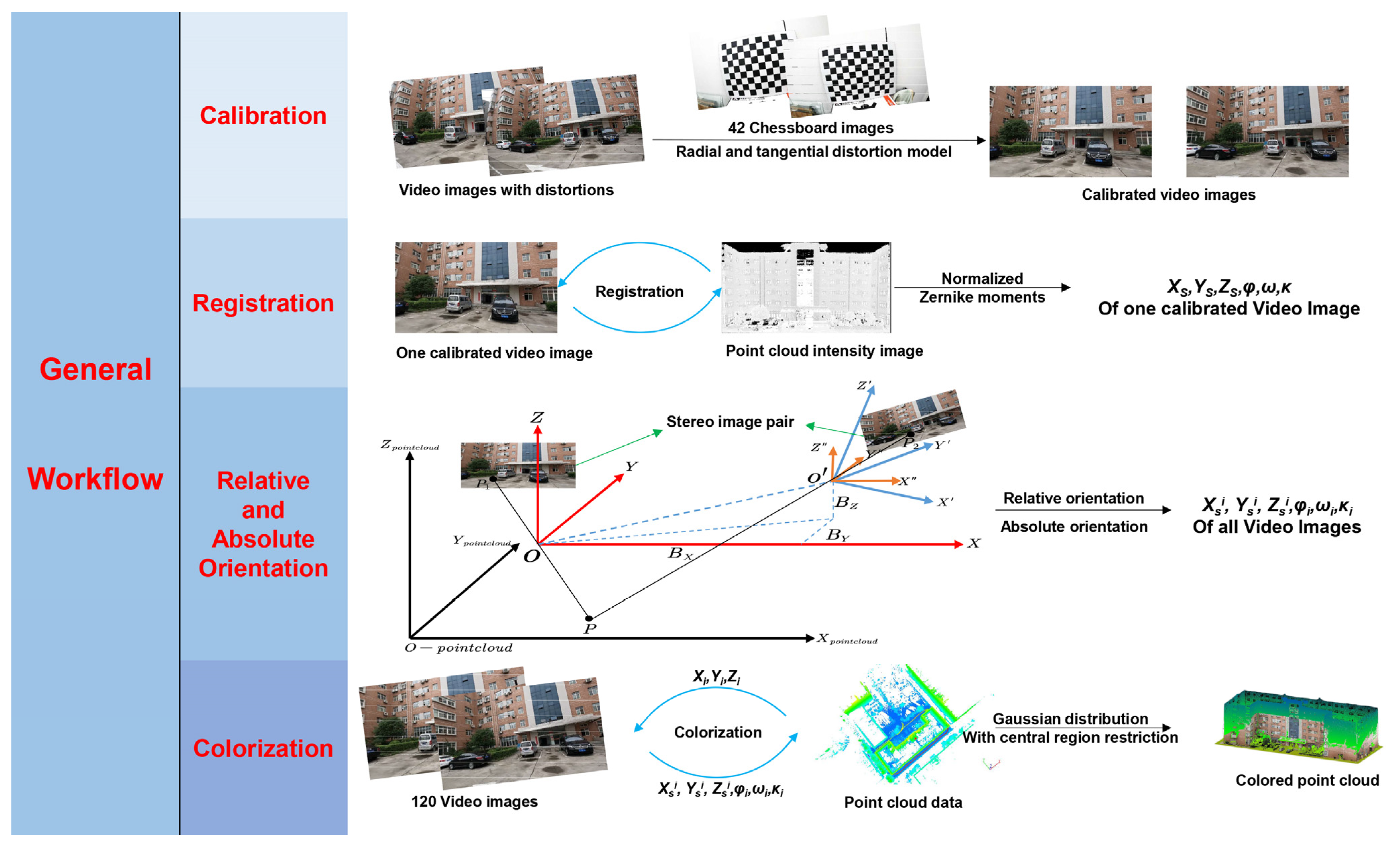
Given the above issues, the chapter arrangement of this article is as follows:
Section 1 introduces the current research status of the registration between the point cloud and images.
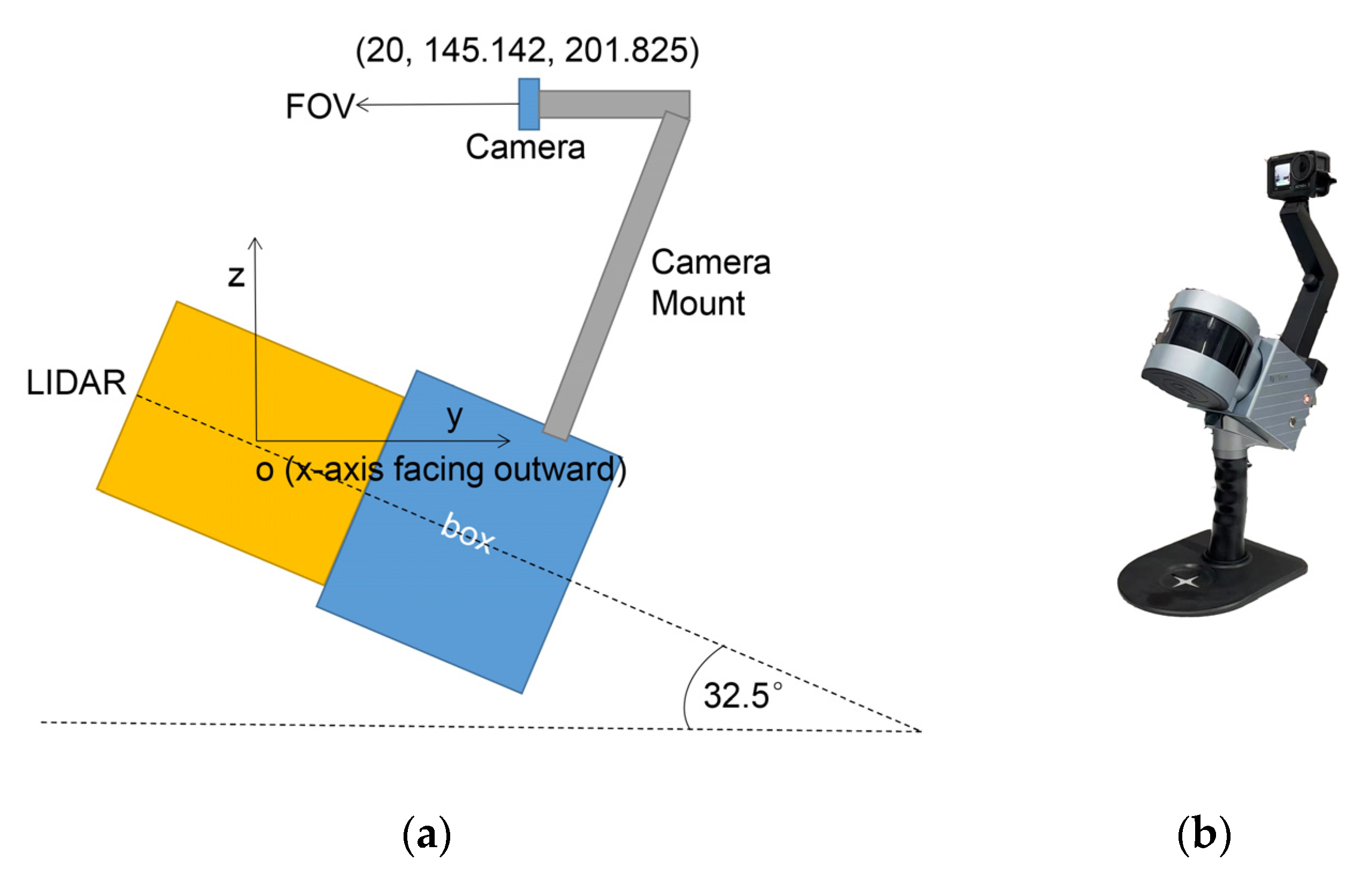
Section 2 briefly introduces the ground mobile LiDAR system and the data used in the experiment.
Section 3 focuses on the point cloud coloring method based on video images without POS, and
Section 3.1 discusses how to handle the problem of nonlinear distortion of GoPro cameras, mainly using radial and tangential distortion models for correction. The principle of automatic registration based on normalized Zernike moments is described in
Section 3.2, from Zernike polynomials to Zernike moments and then to the derivation of normalized Zernike moments. In
Section 3.3, we explain how to achieve automatic registration of the point cloud and sequential images, including the selection of the corresponding point matching method, relative orientation based on essential matrix decomposition and nonlinear optimization, and absolute orientation. A detailed description of the steps and strategies for coloring a point cloud is provided in
Section 3.4.
Section 4 presents experimental results and analysis.
Section 5 gives the discussion about the results.
Section 6 summarizes and gives prospects for future work. In summary, the general workflow of the article is shown in
Figure 2.
5. Discussion
In the beginning of the discussion, we want to explain that we have tried a cheap IMU for registration [
51,
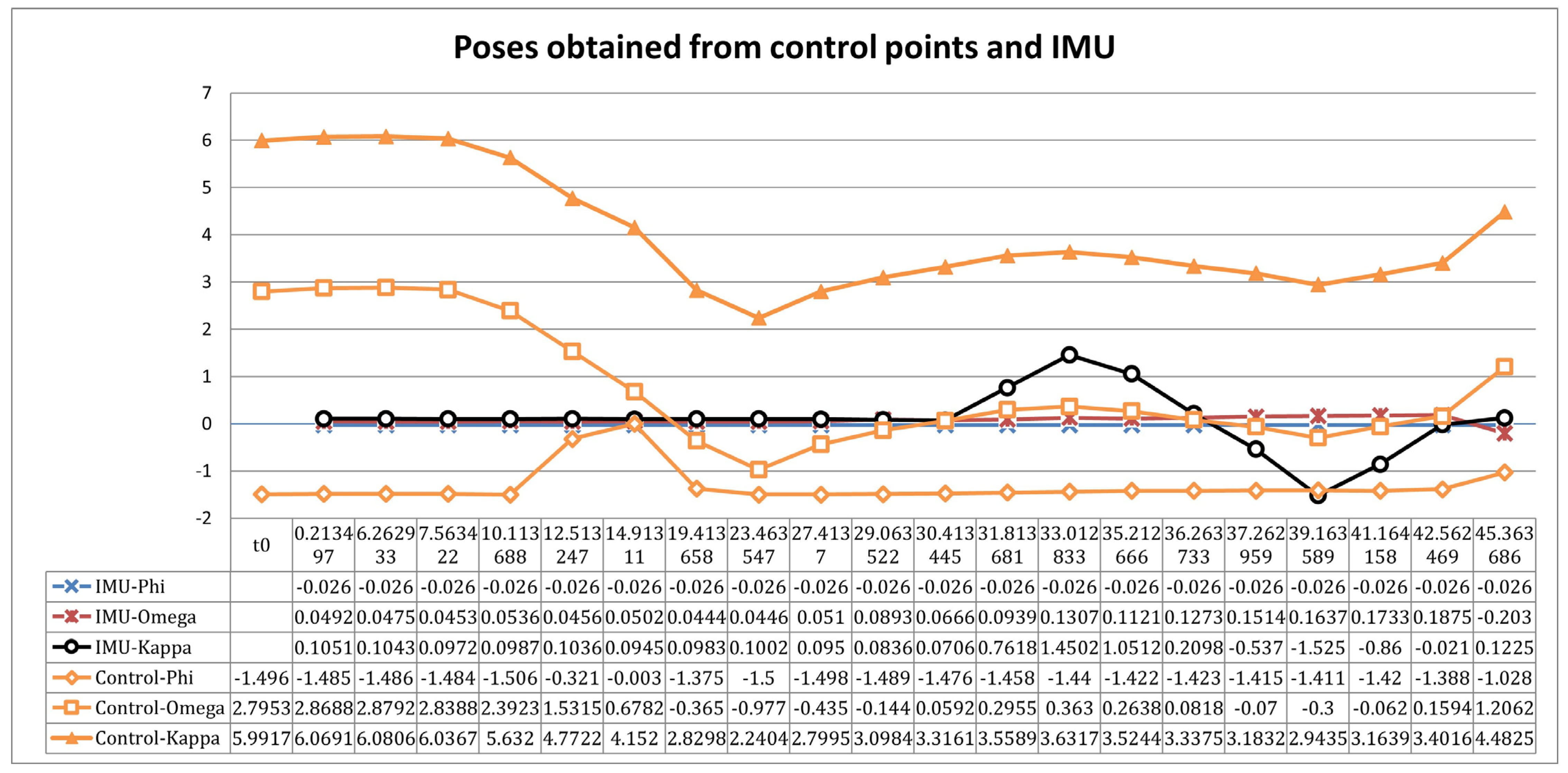
52] and why we finally decided not to use it. Our idea was to install the IMU on the laser to measure the rotation and the scanning angle of the laser. However, the IMU could only provide pitch and heading angles, while the camera’s roll angle could not be obtained. In this case, we assumed that the camera’s roll angle was constant and stable, but it was difficult to achieve this state in actual experiments. We also attempted to use the pitch and heading angles of the IMU for computation, but the resulting poses of the image had a large error compared to the manually selected control points of the images. As shown in
Figure 14, we compared the poses of 20 images obtained from manually selected control points and calculated from the IMU. The results indicate that the IMU has a significant error, which is why we ultimately did not integrate the IMU.
To achieve the automatic coloring of point cloud in our system, we went through several steps: (1) Camera calibration. (2) Registration based on normalized Zernike moments. (3) Corresponding point matching with distance restriction. (4) Relative and absolute orientation. (5) Gaussian distribution point cloud coloring with center region restriction. In the experimental process, each step is crucial, and the accuracy of each intermediate result will directly or indirectly affect the subsequent results.
As the video images used in this paper were captured from a GoPro camera during the mobile measuring process, they suffer from significant distortion. Therefore, Zhang’s camera calibration method was used to correct the nonlinear distortion. According to
Figure 5a–d, it can be seen that the edges of the chessboard and the edges of the house are well corrected. However, the limitation of this method is that it only considers the tangential and radial distortion models which have a greater impact on distortion but does not consider other types of distortion [
5,
6,
7,
8].
Registration based on normalized Zernike moments is actually registration based on point features [
27,
28,
29,
30,
31,
32], and its accuracy mainly depends on the selection of feature points and the descriptor of the feature region. When selecting feature points, as the registration area is the front of the house with many windows and grasses, this paper uses the Harris operator to extract corner points as feature points. Due to the phenomenon of blurred edges in video images, normalized Zernike moments are used to describe the feature region. Low-order Zernike moments describe the overall shape characteristics of the image, while high-order Zernike moments reflect the texture details of the image [
33,
34,
35]. Normalized Zernike moments are invariant to rotation, translation, and scaling and can serve as the determining factor for registration. According to
Figure 9, the registration results based on the collinearity equation are generally acceptable, but there are still some areas around the edges where registration is not accurate, which is due to the system’s mobile measurements, resulting in blurry edges and distortions in video images. On the contrary, normalized Zernike moments utilize information from neighboring pixels when extracting features, which can reflect features in more dimensions and describe the texture details of the image. Therefore, the registration results based on normalized Zernike moments are better. According to
Table 3 and
Table 4, the registration accuracy based on normalized Zernike moments is around 0.5 pixels, which is 1–2 pixels higher than that of the registration accuracy of collinearity equation. However, due to the low accuracy of the video images, direct registration between an image-based point cloud and a laser point cloud cannot be achieved [
25,
26]. In addition, to avoid complex computations and long running times, this paper only uses normalized Zernike moments of 2–4 orders as the vector descriptor of the region, so further progress can be made from higher orders.
Due to the lack of POS and IMU in our system, we cannot directly obtain the exterior orientation elements of the images. Therefore, we adopt a registration strategy from 1 to N, which is to transmit exterior orientation elements through relative and absolute orientation [
36,
37]. The premise of relative orientation is the matching of corresponding points. According to
Figure 7, considering both accuracy and quantity, we choose the SURF algorithm. Due to phenomena such as edge blurring in video images, it is necessary to avoid selecting corresponding points in the edge regions. Therefore, we propose a SURF matching method with distance restrictions. According to
Figure 10a,b, after applying distance restrictions, the number of corresponding points located on the edge of the image is significantly reduced, but there are still many mismatched points in the edge region. After performing RANSAC, according to
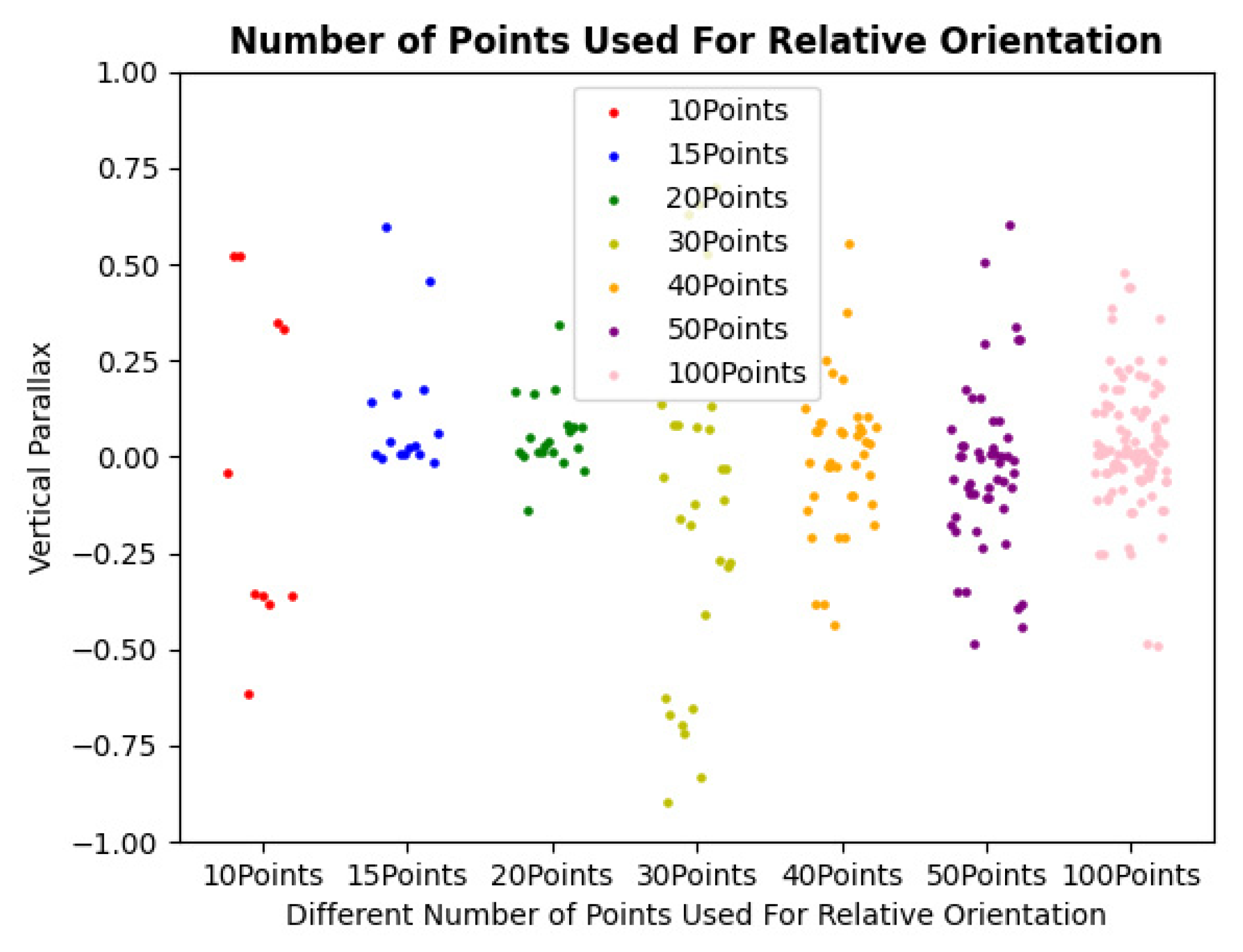
Figure 10c, high-precision corresponding points located in the central region of the image are obtained. In addition, we separately analyzed the influence of the top 10, 15, 20, 30, 40, 50, and 100 corresponding point pairs on relative orientation. As shown in
Figure 11 and
Table 5, selecting the top 20 points yields the smallest vertical parallax and highest accuracy. One area for improvement is that, for convenience, we uniformly selected the top 20 points for relative orientation for each stereo image pair. However, theoretically, each stereo image pair has its optimal number of corresponding points, but this would increase complexity and computation time.
After the above steps, the registration between all images and point clouds is completed. Here, we explain why this paper did not choose the method of registration based on semantic features. Firstly, registration based on semantic features has its own advantages, including better robustness and resistance to image noise [
53]. However, registration based on semantic features requires pre-training, a large amount of data, classification and recognition of objects in advance, and high-quality images. For this paper, which has video images with blurry edges, registration based on semantic features is not suitable. The registration methods used in this paper, including registration based on normalized Zernike moments, SURF, and relative orientation, are all based on point and point features. Our focus has always been on high-precision corresponding points with precise geometric positions. Even with low-quality video images, a good, colored point cloud can be obtained. Therefore, this paper did not adopt the method of registration based on semantic features.
The essence of relative orientation is to solve the essential matrix [
39,
40,
41]. Based on this, this paper uses essential matrix decomposition and nonlinear optimization to perform relative orientation [
42], according to
Figure 12. The method used in this paper has stronger applicability than traditional relative orientation. Traditional relative orientation is based on the assumption of approximately vertical photography and can only converge to the correct result when the rotation angle of the image is small. According to
Figure 12a–c, good results can be obtained for general cases, large rotation angles, and large displacement. There are mainly two aspects to demonstrate the high accuracy: (1) Based on visual interpretation, after relative orientation, the corresponding points of the left and right images have almost completely coincided with each other. For different situations, the corresponding points can still coincide well with each other. (2) According to
Table 4, when selecting the Top 20 corresponding points for relative orientation, the vertical parallax of the stereo image pair model is less than one pixel. At the same time, we can also see the importance of non-linear optimization. After nonlinear optimization, the corresponding points of the left and right images are almost coincident. Absolute orientation is required after relative orientation, and the accuracy of absolute orientation depends on the accuracy of the stereo image model and the precision of control point selection. With the prerequisite of accurate previous steps, good results can also be obtained in absolute orientation. As shown in
Table 6, we use 15 image points from a stereo image pair for absolute orientation, and the MSE of X, Y, and Z are all at the centimeter level.
The phenomenon of edge blurring in video images has been present throughout the entire experimental process and cannot be ignored, even in the final step of point cloud coloring. Therefore, this paper adopts a Gaussian distribution point cloud coloring method with central region restrictions. According to
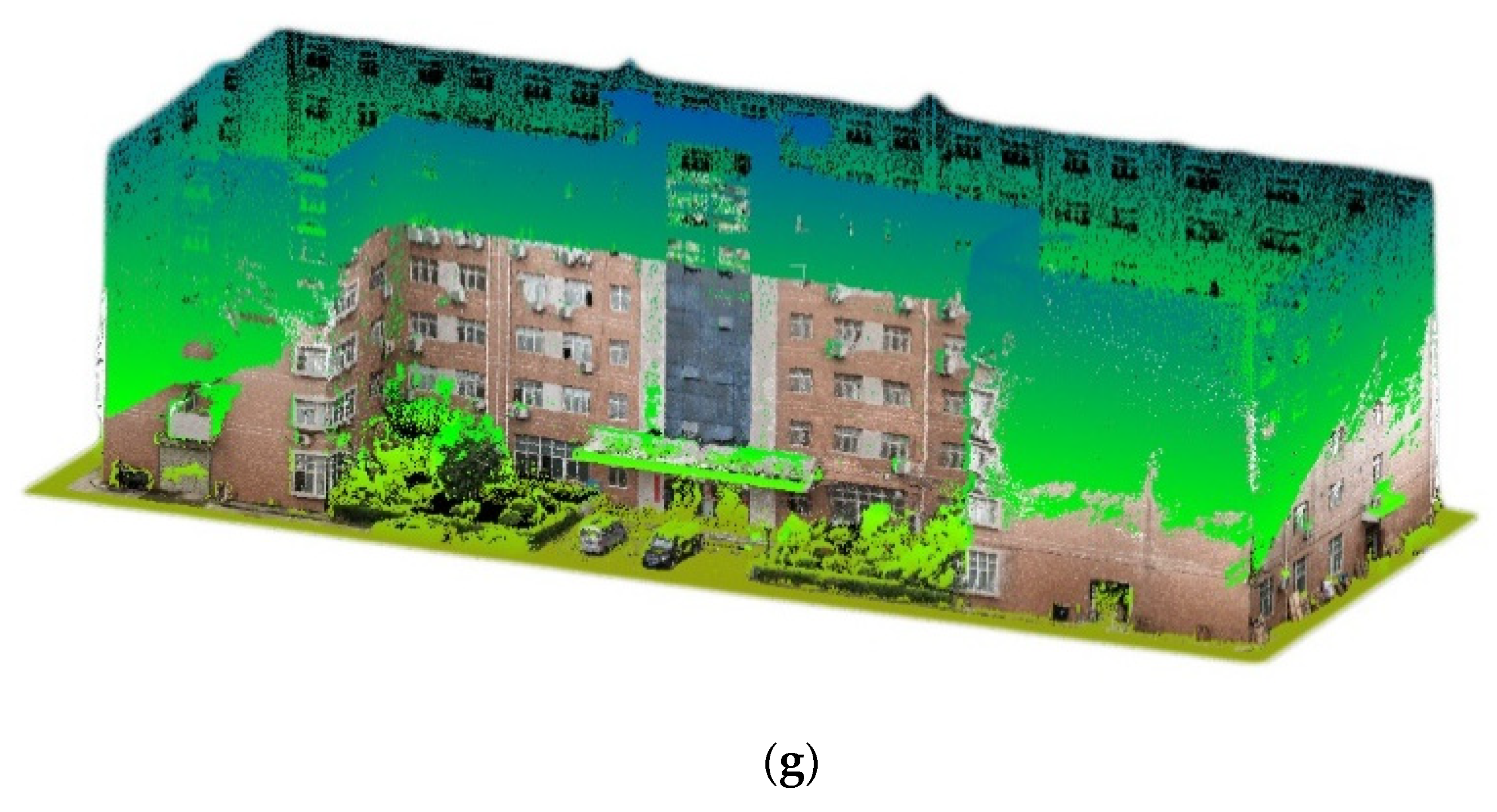
Figure 13g, the point cloud coloring results have overall high accuracy. The textures of buildings are very clear, and the corners of the houses are also very obvious. In addition, targets such as windows, grass, trees, and vehicles can be clearly distinguished. The biggest drawback is that due to the limited range of the video images, the high-altitude point cloud of buildings, the crowns of trees, and the roofs of cars are not colored. Therefore, the next research direction is how to colorize point cloud with high-altitude to obtain a complete, colored point cloud.
Finally, it is declared that the entire process of this article is implemented using the C++ programming language.
Figure 11 and
Figure 12 were visualized using Python. We will also provide the running time for each step, as shown in
Table 7. To unify the units, all time units in
Table 6 are in milliseconds, which is equivalent to 0.001 s. In addition, in
Table 6, the calibration time refers to the total time it took to calibrate 42 chessboard images, while the time for corresponding point matching, essential matrix decomposition, and nonlinear optimization all refer to the processing time for one stereo image pair.
6. Conclusions
In this article, we propose an automatic point cloud colorization method for a ground measurement LiDAR system without POS. The system integrates a LiDAR and a GoPro camera and has the characteristics of simplicity, low cost, light weight, and portability. As a loosely coupled integrated system, it has the possibility of industrial mass production and can complete automatic point cloud registration and colorization without POS. The method mainly consists of four steps: calibration, registration, relative orientation and absolute orientation, and colorization. (1) To solve the problems of video image motion blur, pixel blur, and nonlinear distortion of GoPro, in preprocessing we use radial and tangential distortion models to correct the GoPro camera based on 42 chessboard images extracted from video streams. After calibration, it can be seen that the edges of the chessboard and the edges of the house are well corrected. (2) To achieve image sequence registration without POS, this article proposes a 1-N registration strategy. We only perform registration between the first video image and the point cloud and use the relative and absolute orientation to transfer the exterior orientation elements to all sequential images. In registration, a method based on normalized Zernike moments is proposed to achieve high registration accuracy even for blurry video images. The registration based on Normalized Zernike moments has an error of only 0.5–1 pixel, which is far higher than collinearity equations. (3) In the corresponding point matching, this article proposes a SURF corresponding point matching method with distance restriction and RANSAC to eliminate corresponding points with blurred edges and mismatches. We select the top 20 corresponding points for relative orientation based on essential matrix decomposition and nonlinear optimization. The parallax of the stereo image pair model is less than one pixel. (4) Finally, in the point cloud colorization, we propose a Gaussian distribution coloring method with a central region restriction, which can complete point cloud colorization realistically and evenly. In the colored point cloud, the textures of various objects such as buildings, cars and trees are very clear. Based on the results of the final point cloud colorization, we prove the feasibility of the method proposed in this article, which provides a reference for the future point cloud colorization of ground mobile measurement LiDAR systems.
For the blurry video images, the reliability of corresponding points is questionable. Therefore, the following research will be carried out: (1) Using features such as tie-line or parallel-line attributes to achieve registration between point cloud data. (2) Establishing a joint calibration [
54] field for the motion camera and LiDAR to solve the rigid combination between them and achieve automatic matching of both data. (3) Starting from improving the methods of relative and absolute orientation, adopting more accurate and faster methods. For example, Li et al. [
55] proposed a hybrid conjugate gradient algorithm for large-angle stereo image relative orientation, which is independent of initial values and has high accuracy and fewer iterations. Deng et al. [
56] proposed an absolute orientation algorithm based on line features, which reduces the need for control points and tie points and improves accuracy and stability through joint adjustment. (4) As the scenario in this article is a closed small scene area, we did not use GPS. After relative orientation, we introduced parameters such as scale factor and rotation angle to control the camera’s offset through the laser point cloud—absolute orientation between images and point clouds. Even though the final coloring accuracy is acceptable, there is definitely a cumulative system error when performing continuous relative orientation, and GPS can correct these system errors by providing absolute positions. This is a current weakness of our article. For future experiments, perhaps in large-scene applications, we will add GPS to the system, which is also an important direction for our future research.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}