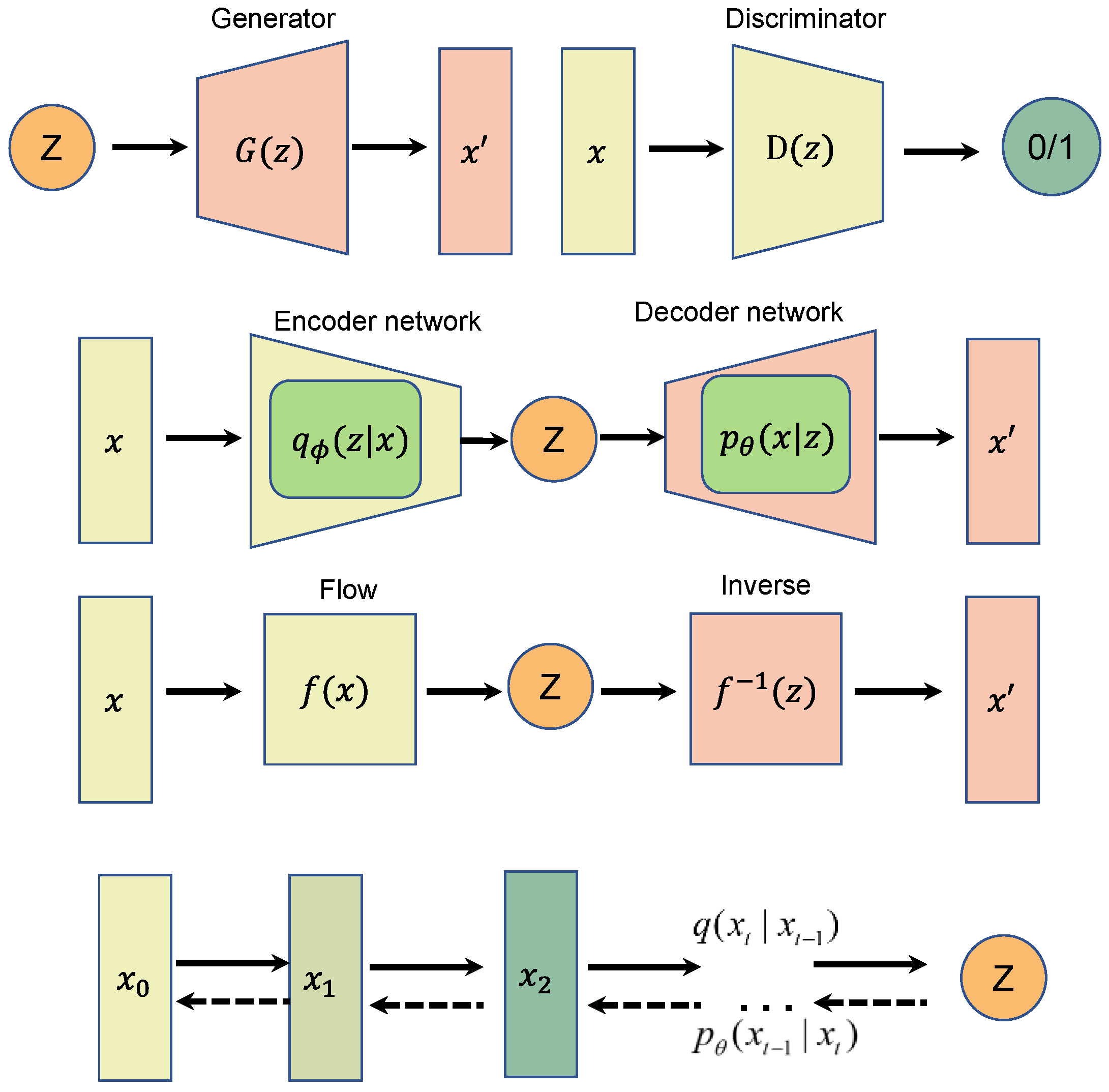
Figure 1.
Comparison between the schematic diagrams of four generative models, from top to bottom: generative adversarial network (GAN), variational autoencoder (VAE), normalizing flow (NF), and diffusion model.
Figure 1.
Comparison between the schematic diagrams of four generative models, from top to bottom: generative adversarial network (GAN), variational autoencoder (VAE), normalizing flow (NF), and diffusion model.
Figure 2.
The diffusion process and reverse diffusion process of the diffusion model used for image super-resolution.
Figure 2.
The diffusion process and reverse diffusion process of the diffusion model used for image super-resolution.
Figure 3.
The primary components of the hybrid conditional diffusion model proposed for super-resolution of remote-sensing images.
Figure 3.
The primary components of the hybrid conditional diffusion model proposed for super-resolution of remote-sensing images.
Figure 4.
Framework of the proposed residual block with parameter (RBWP).
Figure 4.
Framework of the proposed residual block with parameter (RBWP).
Figure 5.
The architecture of conditional noise predictor (U-Net).
Figure 5.
The architecture of conditional noise predictor (U-Net).
Figure 6.
(a) The original image and its corresponding frequency spectrum, (b) the effect after applying a high-pass filter to the frequency spectrum, (c) the effect after applying a low-pass filter to the frequency spectrum.
Figure 6.
(a) The original image and its corresponding frequency spectrum, (b) the effect after applying a high-pass filter to the frequency spectrum, (c) the effect after applying a low-pass filter to the frequency spectrum.
Figure 7.
Schematic diagram of the high-frequency feature loss function.
Figure 7.
Schematic diagram of the high-frequency feature loss function.
Figure 8.
(a–f) depict the process of image reconstruction using the diffusion model, where the image on top represents , and the image at the bottom represents . (g) represents the result of the image reconstruction, where the image on top represents , and the image at the bottom represents .
Figure 8.
(a–f) depict the process of image reconstruction using the diffusion model, where the image on top represents , and the image at the bottom represents . (g) represents the result of the image reconstruction, where the image on top represents , and the image at the bottom represents .
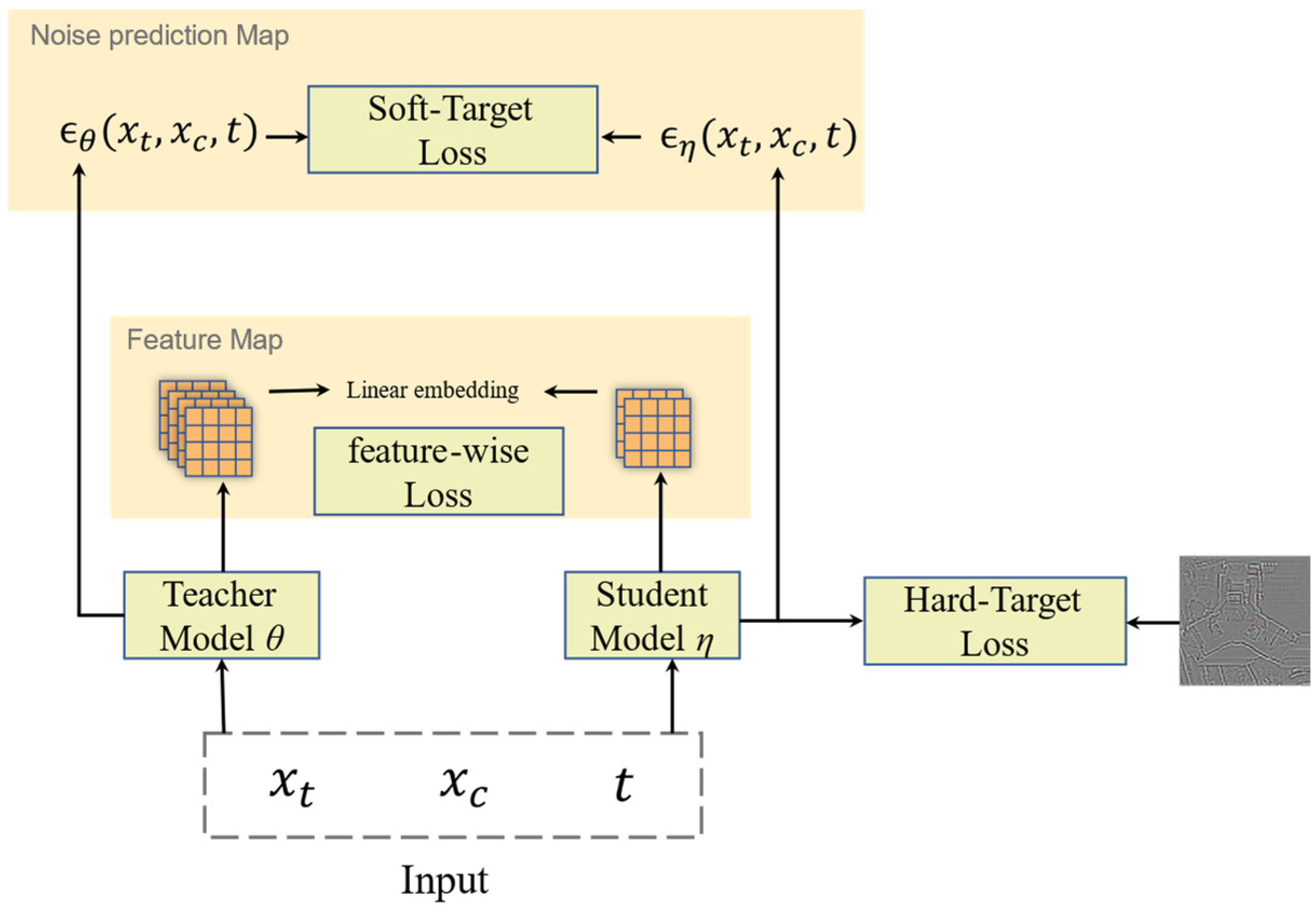
Figure 9.
The feature distillation method applied to diffusion model super resolution.
Figure 9.
The feature distillation method applied to diffusion model super resolution.
Figure 10.
Display of images in different scene categories in the UC Merced Land Use test set.
Figure 10.
Display of images in different scene categories in the UC Merced Land Use test set.
Figure 11.
Display of images in different scene categories in the RSOD test set.
Figure 11.
Display of images in different scene categories in the RSOD test set.
Figure 12.
Display of images in different scene categories in the Gaofen-2 test set.
Figure 12.
Display of images in different scene categories in the Gaofen-2 test set.
Figure 13.
SR results at scale factor of ×4 on the test dataset [
19,
20] using different approaches (
b–
j), and (
a) represents the original high-resolution image for each approach.
Figure 13.
SR results at scale factor of ×4 on the test dataset [
19,
20] using different approaches (
b–
j), and (
a) represents the original high-resolution image for each approach.
Figure 14.
SR results at scale factor of ×8 on the test dataset [
19,
20] using different approaches (
b–
j), and (
a) represents the original high-resolution image for each approach.
Figure 14.
SR results at scale factor of ×8 on the test dataset [
19,
20] using different approaches (
b–
j), and (
a) represents the original high-resolution image for each approach.
Figure 15.
SR results at scale factor of ×2 on the real-world Gaofen-2 dataset [
21] using different approaches (
a–
d). (
a) Bicubic; (
b) SRCNN [
5]; (
c) MHAN [
13]; (
d) Ours.
Figure 15.
SR results at scale factor of ×2 on the real-world Gaofen-2 dataset [
21] using different approaches (
a–
d). (
a) Bicubic; (
b) SRCNN [
5]; (
c) MHAN [
13]; (
d) Ours.
Figure 16.
SR results at scale factor of ×4 on the real-world Gaofen-2 dataset [
21] using different approaches (
a–
d). (
a) Bicubic; (
b) SRCNN; (
c) MHAN; (
d) Ours.
Figure 16.
SR results at scale factor of ×4 on the real-world Gaofen-2 dataset [
21] using different approaches (
a–
d). (
a) Bicubic; (
b) SRCNN; (
c) MHAN; (
d) Ours.
Figure 17.
The visual quality comparison between the original model and the compressed model with a scale factor of ×4. (a) Ground truth; (b) Bicubic; (c) Original; (d) Distillation.
Figure 17.
The visual quality comparison between the original model and the compressed model with a scale factor of ×4. (a) Ground truth; (b) Bicubic; (c) Original; (d) Distillation.
Table 1.
Comparison between different remote-sensing image super-resolution methods on the UCMerced_Land test dataset, with evaluation metrics including PSNR and SSIM values, at scale factors of ×2, ×4, and ×8.
Table 1.
Comparison between different remote-sensing image super-resolution methods on the UCMerced_Land test dataset, with evaluation metrics including PSNR and SSIM values, at scale factors of ×2, ×4, and ×8.
| Method | ×2 | ×4 | ×8 |
|---|
| PSNR/SSIM | PSNR/SSIM | PSNR/SSIM |
|---|
| Bicubic | 30.55/0.890 | 25.37/0.698 | 22.15/0.481 |
| SRCNN [5] | 32.20/0.917 | 26.35/0.730 | 22.52/0.515 |
| VDSR [9] | 33.22/0.925 | 27.02/0.764 | 23.01/0.534 |
| SAN [12] | 33.61/0.934 | 27.42/0.775 | 23.21/0.540 |
| DDBPN [23] | 33.67/0.931 | 27.49/0.771 | 23.54/0.571 |
| RDN [13] | 33.69/0.933 | 27.54/0.781 | 23.52/0.567 |
| MHAN [10] | 33.61/0.927 | 27.40/0.764 | 23.56/0.559 |
| EEGAN [28] | 33.54/0.926 | 27.30/0.770 | 23.44/0.553 |
| Ours | 33.76/0.930 | 27.60/0.788 | 23.68/0.581 |
Table 2.
Comparison between different remote-sensing image super-resolution methods on the RSOD test dataset, with evaluation metrics including PSNR and SSIM values, at scale factors of ×2, ×4, and ×8.
Table 2.
Comparison between different remote-sensing image super-resolution methods on the RSOD test dataset, with evaluation metrics including PSNR and SSIM values, at scale factors of ×2, ×4, and ×8.
| Method | ×2 | ×4 | ×8 |
|---|
| PSNR/SSIM | PSNR/SSIM | PSNR/SSIM |
|---|
| Bicubic | 29.91/0.942 | 26.71/0.807 | 24.21/0.638 |
| SRCNN [5] | 30.42/0.951 | 27.22/0.834 | 24.55/0.656 |
| VDSR [9] | 30.87/0.960 | 27.53/0.859 | 24.89/0.673 |
| SAN [12] | 31.08/0.961 | 27.74/0.865 | 25.08/0.694 |
| DDBPN [23] | 31.13/0.964 | 27.76/0.872 | 25.10/0.703 |
| RDN [13] | 31.16/0.963 | 27.80/0.871 | 25.13/0.704 |
| MHAN [10] | 31.18/0.967 | 27.71/0.862 | 25.19/0.696 |
| EEGAN [28] | 31.19/0.973 | 27.69/0.863 | 25.20/0.702 |
| Ours | 31.16/0.968 | 27.86/0.876 | 25.33/0.710 |
Table 3.
Performance comparison between different remote-sensing image super-resolution methods on the UCMerced_Land test dataset for various scenes at scale factor of ×2, with evaluation metrics including PSNR and SSIM values.
Table 3.
Performance comparison between different remote-sensing image super-resolution methods on the UCMerced_Land test dataset for various scenes at scale factor of ×2, with evaluation metrics including PSNR and SSIM values.
| Scene | SRCNN [5] | VDSR [9] | SAN [12] | DDBPN [23] | RDN [13] | MHAN [13] | EEGAN [28] | Ours |
|---|
| PSNR/SSIM |
|---|
| Agricultural | 32.14/0.831 | 32.18/0.831 | 32.31/0.829 | 32.22/0.829 | 32.33/0.826 | 32.25/0.832 | 32.14/0.827 | 32.32/0.829 |
| Airplane | 32.96/0.924 | 34.46/0.939 | 34.89/0.943 | 35.01/0.944 | 35.10/0.944 | 34.10/0.933 | 34.86/0.943 | 35.20/0.949 |
| Baseball diamond | 35.33/0.892 | 35.84/0.899 | 36.19/0.902 | 36.22/0.902 | 36.25/0.903 | 36.28/0.901 | 36.14/0.902 | 36.24/0.901 |
| Beach | 38.58/0.958 | 39.08/0.963 | 39.33/0.965 | 39.36/0.965 | 39.38/0.965 | 39.34/0.963 | 39.33/0.965 | 39.38/0.963 |
| Buildings | 31.98/0.916 | 33.39/0.931 | 33.94/0.935 | 33.99/0.935 | 34.01/0.936 | 33.93/0.928 | 33.88/0.934 | 34.10/0.938 |
| Chaparral | 30.43/0.929 | 30.86/0.936 | 30.96/0.937 | 31.01/0.937 | 31.05/0.938 | 30.94/0.934 | 30.97/0.937 | 31.01/0.934 |
| Dense residential | 32.72/0.943 | 34.10/0.956 | 34.58/0.959 | 34.64/0.959 | 34.79/0.961 | 34.54/0.951 | 34.42/0.958 | 34.75/0.966 |
| Forest | 33.46/0.907 | 33.88/0.914 | 34.05/0.915 | 34.04/0.915 | 34.09/0.916 | 33.97/0.912 | 34.01/0.915 | 34.11/0.916 |
| Freeway | 33.68/0.942 | 35.82/0.959 | 36.34/0.961 | 36.45/0.962 | 36.51/0.963 | 36.47/0.965 | 36.17/0.961 | 36.50/0.963 |
| Golf course | 35.86/0.902 | 36.31/0.909 | 36.53/0.913 | 36.55/0.913 | 36.57/0.913 | 36.56/0.914 | 36.47/0.912 | 36.58/0.913 |
| Harbor | 29.58/0.955 | 31.42/0.97 | 32.24/0.974 | 32.36/0.974 | 32.54/0.975 | 32.48/0.976 | 32.21/0.973 | 32.50/0.971 |
| Intersection | 33.59/0.934 | 34.58/0.944 | 35.01/0.948 | 35.11/0.949 | 35.17/0.950 | 35.19/0.952 | 34.92/0.948 | 35.22/0.953 |
| Medium residential | 29.10/0.893 | 30.06/0.909 | 30.35/0.913 | 30.41/0.914 | 30.51/0.914 | 30.58/0.916 | 30.30/0.913 | 30.49/0.911 |
| Mobile home park | 28.82/0.911 | 30.05/0.928 | 30.45/0.932 | 30.53/0.933 | 30.59/0.934 | 30.59/0.936 | 30.39/0.932 | 30.55/0.933 |
| Overpass | 31.03/0.914 | 33.01/0.935 | 33.59/0.940 | 33.77/0.941 | 33.72/0.941 | 33.74/0.945 | 33.65/0.940 | 33.78/0.941 |
| Parking lot | 27.46/0.918 | 28.56/0.935 | 29.15/0.940 | 29.28/0.941 | 29.41/0.942 | 29.36/0.946 | 29.09/0.940 | 29.40/0.944 |
| River | 29.87/0.873 | 30.21/0.883 | 30.32/0.886 | 30.34/0.886 | 30.35/0.887 | 30.31/0.889 | 30.32/0.886 | 30.33/0.884 |
| Runway | 33.08/0.916 | 34.54/0.931 | 35.22/0.936 | 35.28/0.937 | 35.44/0.938 | 35.45/0.941 | 35.21/0.935 | 35.46/0.938 |
| Sparse residential | 31.12/0.881 | 31.6/0.889 | 31.75/0.892 | 31.77/0.892 | 31.81/0.893 | 31.85/0.894 | 31.73/0.892 | 31.83/0.891 |
| Storage tanks | 32.05/0.913 | 33.24/0.929 | 33.68/0.933 | 33.74/0.934 | 33.77/0.934 | 34.77/0.936 | 33.63/0.933 | 33.80/0.930 |
| Tennis court | 33.70/0.929 | 35.06/0.944 | 35.51/0.948 | 35.55/0.948 | 35.63/0.949 | 35.53/0.944 | 35.43/0.947 | 35.66/0.952 |
Table 4.
Performance comparison between different remote-sensing image super-resolution methods on the RSOD test dataset for various scenes at scale factor of ×2, with evaluation metrics including PSNR and SSIM values.
Table 4.
Performance comparison between different remote-sensing image super-resolution methods on the RSOD test dataset for various scenes at scale factor of ×2, with evaluation metrics including PSNR and SSIM values.
| Scenes | SRCNN [5] | VDSR [9] | SAN [12] | DDBPN [23] | RDN [13] | MHAN [13] | EEGAN [28] | Ours |
|---|
| PSNR/SSIM |
|---|
| Aircraft | 34.67/0.963 | 35.23/0.968 | 35.34/0.969 | 35.41/0.971 | 35.40/0.970 | 35.45/0.972 | 35.48/0.970 | 35.52/0.973 |
| Oil tank | 29.69/0.974 | 30.05/0.977 | 30.22/0.977 | 30.27/0.979 | 30.27/0.979 | 30.30/0.979 | 30.34/0.980 | 30.38/0.982 |
| Overpass | 28.64/0.932 | 29.07/0.939 | 29.14/0.940 | 29.27/0.942 | 29.25/0.942 | 29.33/0.943 | 29.35/0.943 | 29.35/0.945 |
| Playground | 28.67/0.953 | 29.14/0.959 | 29.30/0.960 | 29.37/0.962 | 29.34/0.962 | 29.43/0.963 | 29.45/0.963 | 29.44/0.963 |
Table 5.
Performance comparison between different remote-sensing image super-resolution methods on the UCMerced_Land test dataset for various scenes at scale factor of ×4, with evaluation metrics including PSNR and SSIM values.
Table 5.
Performance comparison between different remote-sensing image super-resolution methods on the UCMerced_Land test dataset for various scenes at scale factor of ×4, with evaluation metrics including PSNR and SSIM values.
| Scene | SRCNN [5] | VDSR [9] | SAN [12] | DDBPN [23] | RDN [13] | MHAN [13] | EEGAN [28] | Ours |
|---|
| PSNR/SSIM |
|---|
| Agricultural | 25.95/0.489 | 25.95/0.496 | 26.25/0.506 | 26.26/0.506 | 26.38/0.508 | 26.27/0.505 | 26.16/0.503 | 26.45/0.506 |
| Airplane | 26.76/0.778 | 27.98/0.808 | 28.52/0.818 | 28.68/0.821 | 28.69/0.822 | 27.96/0.805 | 28.45/0.816 | 28.72/0.818 |
| Baseball diamond | 30.71/0.758 | 31.17/0.770 | 31.47/0.777 | 31.51/0.778 | 31.55/0.779 | 31.17/0.770 | 31.34/0.775 | 31.57/0.777 |
| Beach | 32.64/0.850 | 33.05/0.863 | 33.20/0.867 | 33.21/0.867 | 33.23/0.868 | 33.02/0.863 | 33.17/0.866 | 33.20/0.867 |
| Buildings | 25.28/0.757 | 26.41/0.794 | 27.05/0.808 | 27.05/0.810 | 27.19/0.812 | 26.54/0.795 | 26.80/0.803 | 27.45/0.808 |
| Chaparral | 24.64/0.736 | 24.99/0.756 | 25.23/0.767 | 25.28/0.769 | 25.34/0.772 | 25.04/0.759 | 25.20/0.765 | 25.43/0.767 |
| Dense residential | 25.38/0.783 | 26.32/0.821 | 26.85/0.835 | 26.95/0.839 | 27.04/0.841 | 26.37/0.820 | 26.70/0.832 | 26.95/0.837 |
| Forest | 27.59/0.692 | 27.77/0.706 | 27.90/0.713 | 27.90/0.713 | 27.92/0.715 | 27.78/0.707 | 27.85/0.711 | 28.07/0.716 |
| Freeway | 27.40/0.802 | 28.63/0.837 | 29.38/0.851 | 29.53/0.855 | 29.58/0.856 | 28.66/0.836 | 29.22/0.85 | 29.58/0.851 |
| Golf course | 31.65/0.782 | 31.99/0.790 | 32.23/0.796 | 32.26/0.797 | 32.30/0.798 | 31.97/0.790 | 32.18/0.795 | 32.23/0.796 |
| Harbor | 21.52/0.784 | 22.35/0.821 | 22.92/0.837 | 22.89/0.839 | 23.01/0.842 | 22.51/0.821 | 22.67/0.829 | 23.12/0.847 |
| Intersection | 26.66/0.770 | 27.32/0.791 | 27.72/0.803 | 27.82/0.806 | 27.92/0.808 | 27.45/0.792 | 27.63/0.801 | 28.05/0.814 |
| Medium residential | 23.66/0.677 | 24.29/0.709 | 24.65/0.723 | 24.73/0.726 | 24.76/0.727 | 24.30/0.707 | 24.53/0.718 | 24.85/0.723 |
| Mobile home park | 23.07/0.725 | 23.73/0.759 | 24.11/0.773 | 24.20/0.777 | 24.22/0.778 | 23.77/0.759 | 24.02/0.769 | 24.33/0.780 |
| Overpass | 25.40/0.724 | 26.39/0.762 | 27.14/0.789 | 27.26/0.791 | 27.31/0.794 | 26.47/0.766 | 26.88/0.779 | 27.34/0.789 |
| Parking lot | 20.76/0.707 | 21.16/0.739 | 21.50/0.752 | 21.60/0.753 | 21.63/0.754 | 21.23/0.737 | 21.39/0.747 | 21.68/0.758 |
| River | 25.61/0.656 | 25.88/0.676 | 26.04/0.686 | 26.05/0.687 | 26.06/0.688 | 25.9/0.677 | 26.01/0.684 | 26.04/0.693 |
| Runway | 27.53/0.777 | 29.41/0.819 | 30.19/0.830 | 30.45/0.833 | 30.38/0.834 | 29.54/0.816 | 30.04/0.828 | 30.39/0.841 |
| Sparse residential | 26.47/0.680 | 26.83/0.699 | 27.04/0.706 | 27.07/0.708 | 27.08/0.709 | 26.85/0.699 | 26.98/0.705 | 27.04/0.706 |
| Storage tanks | 26.43/0.741 | 27.14/0.773 | 27.64/0.790 | 27.72/0.793 | 27.78/0.795 | 27.23/0.775 | 27.52/0.785 | 27.74/0.790 |
| Tennis court | 27.83/0.766 | 28.49/0.790 | 29.01/0.807 | 29.14/0.811 | 29.18/0.813 | 28.55/0.791 | 28.85/0.802 | 29.21/0.807 |
Table 6.
Performance comparison between different remote-sensing image super-resolution methods on the RSOD test dataset for various scenes at scale factor of ×4, with evaluation metrics including PSNR and SSIM values.
Table 6.
Performance comparison between different remote-sensing image super-resolution methods on the RSOD test dataset for various scenes at scale factor of ×4, with evaluation metrics including PSNR and SSIM values.
| Scene | SRCNN [5] | VDSR [9] | SAN [12] | DDBPN [23] | RDN [13] | MHAN [13] | EEGAN [28] | Ours |
|---|
| PSNR/SSIM |
|---|
| Aircraft | 30.23/0.869 | 30.84/0.884 | 30.92/0.887 | 31.16/0.892 | 31.06/0.890 | 31.20/0.893 | 31.25/0.894 | 31.30/0.896 |
| Oil tank | 27.52/0.905 | 27.65/0.914 | 27.74/0.918 | 27.82/0.923 | 27.77/0.920 | 27.82/0.922 | 27.86/0.924 | 27.89/0.928 |
| Overpass | 25.25/0.746 | 25.5/0.768 | 25.55/0.771 | 25.66/0.78 | 25.63/0.778 | 25.68/0.782 | 25.71/0.783 | 25.80/0.788 |
| Playground | 25.88/0.835 | 26.15/0.853 | 26.29/0.856 | 26.32/0.863 | 26.28/0.861 | 26.34/0.864 | 26.37/0.866 | 26.46/0.872 |
Table 7.
Performance comparison between different remote-sensing image super-resolution methods on the UCMerced_Land test dataset for various scenes at scale factor of ×8, with evaluation metrics including PSNR and SSIM values.
Table 7.
Performance comparison between different remote-sensing image super-resolution methods on the UCMerced_Land test dataset for various scenes at scale factor of ×8, with evaluation metrics including PSNR and SSIM values.
| Scene | SRCNN [5] | VDSR [9] | SAN [12] | DDBPN [23] | RDN [13] | MHAN [13] | EEGAN [28] | Ours |
|---|
| PSNR/SSIM |
|---|
| Agricultural | 23.34/0.266 | 23.38/0.276 | 23.36/0.277 | 23.53/0.296 | 23.46/0.291 | 23.46/0.298 | 23.32/0.294 | 23.60/0.316 |
| Airplane | 22.22/0.594 | 23.13/0.637 | 23.44/0.638 | 24.09/0.669 | 24.02/0.664 | 24.01/0.668 | 23.95/0.663 | 24.22/0.672 |
| Baseball diamond | 27.26/0.619 | 27.81/0.636 | 28.00/0.641 | 28.30/0.651 | 28.28/0.653 | 28.22/0.641 | 28.14/0.639 | 28.39/0.662 |
| Beach | 29.29/0.725 | 29.72/0.737 | 29.84/0.740 | 29.98/0.746 | 29.97/0.745 | 29.96/0.742 | 29.88/0.740 | 30.06/0.763 |
| Buildings | 20.53/0.516 | 21.51/0.570 | 21.86/0.58 | 22.47/0.617 | 22.44/0.612 | 22.44/0.588 | 22.36/0.572 | 22.52/0.628 |
| Chaparral | 20.47/0.350 | 20.54/0.370 | 20.59/0.377 | 20.67/0.388 | 20.69/0.390 | 20.63/0.382 | 20.51/0.377 | 20.75/0.394 |
| Dense residential | 20.50/0.512 | 21.21/0.564 | 21.42/0.567 | 21.87/0.604 | 21.86/0.601 | 21.84/0.592 | 21.77/0.596 | 21.92/0.613 |
| Forest | 24.62/0.435 | 24.72/0.450 | 24.78/0.454 | 24.83/0.462 | 24.84/0.463 | 24.87/0.466 | 24.74/0.461 | 24.91/0.471 |
| Freeway | 23.07/0.527 | 23.57/0.555 | 24.02/0.601 | 24.57/0.641 | 24.48/0.641 | 24.46/0.636 | 24.38/0.631 | 24.64/0.653 |
| Golf course | 27.98/0.662 | 28.78/0.681 | 28.96/0.683 | 29.33/0.693 | 29.27/0.691 | 29.23/0.694 | 29.11/0.696 | 29.46/0.697 |
| Harbor | 17.07/0.527 | 17.37/0.563 | 17.61/0.575 | 17.85/0.607 | 17.89/0.606 | 17.84/0.594 | 17.70/0.595 | 17.96/0.617 |
| Intersection | 22.43/0.530 | 22.88/0.558 | 23.12/0.566 | 23.43/0.589 | 23.44/0.587 | 23.42/0.588 | 23.35/0.587 | 23.58/0.595 |
| Medium residential | 20.29/0.424 | 20.73/0.457 | 20.89/0.463 | 21.19/0.491 | 21.17/0.488 | 21.12/0.488 | 21.08/0.483 | 21.25/0.495 |
| Mobile home park | 18.91/0.457 | 19.31/0.491 | 19.56/0.501 | 19.89/0.534 | 19.88/0.529 | 19.82/0.529 | 19.78/0.522 | 19.94/0.538 |
| Overpass | 22.01/0.482 | 22.62/0.516 | 22.84/0.526 | 23.37/0.558 | 23.26/0.556 | 23.27/0.555 | 23.16/0.554 | 23.48/0.562 |
| Parking lot | 17.01/0.403 | 17.21/0.434 | 17.27/0.436 | 17.36/0.463 | 17.36/0.459 | 17.31/0.455 | 17.27/0.458 | 17.44/0.461 |
| River | 23.36/0.475 | 23.60/0.492 | 23.70/0.497 | 23.85/0.509 | 23.84/0.508 | 23.86/0.501 | 23.72/0.496 | 23.96/0.519 |
| Runway | 22.70/0.585 | 23.67/0.621 | 24.33/0.634 | 25.07/0.659 | 25.12/0.658 | 25.16/0.650 | 25.05/0.653 | 25.14/0.670 |
| Sparse residential | 23.15/0.456 | 23.51/0.477 | 23.67/0.482 | 23.80/0.495 | 23.82/0.494 | 23.88/0.491 | 23.77/0.495 | 23.94/0.496 |
| Storage tanks | 23.12/0.551 | 23.53/0.576 | 23.66/0.581 | 23.98/0.602 | 23.93/0.598 | 23.91/0.596 | 23.80/0.589 | 24.06/0.612 |
| Tennis court | 23.91/0.570 | 24.42/0.597 | 24.63/0.602 | 25.04/0.628 | 25.01/0.623 | 25.05/0.627 | 25.02/0.625 | 25.13/0.637 |
Table 8.
Performance comparison between different remote-sensing image super-resolution methods on the RSOD test dataset for various scenes at scale factor of ×8, with evaluation metrics including PSNR and SSIM values.
Table 8.
Performance comparison between different remote-sensing image super-resolution methods on the RSOD test dataset for various scenes at scale factor of ×8, with evaluation metrics including PSNR and SSIM values.
| Scenes | SRCNN [5] | VDSR [9] | SAN [12] | DDBPN [23] | RDN [13] | MHAN [13] | EEGAN [28] | Ours |
|---|
| PSNR/SSIM |
|---|
| Aircraft | 26.67/0.738 | 27.25/0.756 | 27.51/0.764 | 27.46/0.761 | 27.61/0.768 | 27.71/0.772 | 27.70/0.772 | 27.81/0.779 |
| Oil tank | 25.18/0.739 | 25.43/0.753 | 25.73/0.770 | 25.69/0.768 | 25.77/0.771 | 25.80/0.776 | 25.76/0.777 | 25.89/0.786 |
| Overpass | 22.72/0.508 | 22.97/0.531 | 23.12/0.545 | 23.11/0.542 | 23.10/0.545 | 23.25/0.558 | 23.26/0.559 | 23.30/0.561 |
| Playground | 23.62/0.651 | 23.89/0.673 | 24.07/0.685 | 24.05/0.682 | 24.06/0.688 | 24.18/0.695 | 24.20/0.696 | 24.27/0.704 |
Table 9.
Comparison between original model and compressed model in terms of parameters, computation, and time consumption. The size of the input image was 256 × 256 pixels, with a scale factor of ×4.
Table 9.
Comparison between original model and compressed model in terms of parameters, computation, and time consumption. The size of the input image was 256 × 256 pixels, with a scale factor of ×4.
| Model | | GFLOPs | Time (ms) * |
|---|
| Original | 9.07 | 45.2 | 856 |
| Distillation | 4.52 | 22.6 | 463 |
Table 10.
The comparison between quantitative results of the original model and the compressed model on the RSOD test dataset.
Table 10.
The comparison between quantitative results of the original model and the compressed model on the RSOD test dataset.
| RSOD | ×2 | ×4 | ×8 |
|---|
| PSNR/SSIM | PSNR/SSIM | PSNR/SSIM |
|---|
| Original | 31.16/0.968 | 27.86/0.876 | 25.33/0.710 |
| Distillation | 31.10/0.961 | 27.24/0.865 | 25.27/0.704 |
Table 11.
Comparison between the time consumptions of different super-resolution algorithms during the model inference process. The size of the input image was 256 × 256 pixels, with a scale factor of ×4.
Table 11.
Comparison between the time consumptions of different super-resolution algorithms during the model inference process. The size of the input image was 256 × 256 pixels, with a scale factor of ×4.
| Model | SRCNN | VDSR | RDN | MHAN | SAN | DDBPN | EEGAN | Ours |
|---|
| Time (ms) * | 1.7 | 3.0 | 16 | 14.8 | 17.3 | 36.9 | 27.5 | 463 |
Table 12.
This paper investigated the impact of different module combinations in the proposed hybrid conditional diffusion model on the super-resolution performance of remote-sensing images. All experiments were conducted on the UCMerced_Land test dataset.
Table 12.
This paper investigated the impact of different module combinations in the proposed hybrid conditional diffusion model on the super-resolution performance of remote-sensing images. All experiments were conducted on the UCMerced_Land test dataset.
| Description | Different Types of Combinations |
|---|
| Module | 1 | 2 | 3 | 4 | 5 | 6 |
|---|
| Hybrid conditional feature | Transformer network | ✓ | ✗ | ✓ | ✓ | ✗ | ✓ |
| CNN | ✗ | ✓ | ✓ | ✗ | ✓ | ✓ |
| Fourier high-frequency spatial constraint | ✗ | ✗ | ✗ | ✓ | ✓ | ✓ |
| ×2 | PSNR | 33.16 | 33.18 | 33. 25 | 33.47 | 33.59 | 33.76 |
| SSIM | 0.916 | 0.918 | 0.922 | 0.913 | 0.921 | 0.930 |
| ×4 | PSNR | 27.28 | 27.37 | 27.48 | 27.44 | 27.52 | 27.60 |
| SSIM | 0.764 | 0.765 | 0.771 | 0.771 | 0.782 | 0.788 |
| ×8 | PSNR | 23.34 | 23.37 | 23.36 | 23.50 | 23.57 | 23.68 |
| SSIM | 0.548 | 0.550 | 0.551 | 0.572 | 0.571 | 0.581 |


 ,
, 




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}