

TranSDet: Toward Effective Transfer Learning for Small-Object Detection

Abstract
:1. Introduction
- (1)
- We propose a meta-learning-based dynamic resolution adaptation scheme for transfer learning that effectively improves the performance of transfer learning in small-object detection.
- (2)
- We propose two network components, an SFA-FPN and an anchor relation module, which are compatible with transfer learning and effectively improve small-object detection performance.
- (3)
- We conduct extensive experiments on the TT100K [22], BUUISE-MO-Lite [11], and COCO [19] datasets. The results demonstrate that our method, TranSDet, achieves significant improvements compared to existing methods. For example, on the TT100K-Lite dataset, TranSDet improves the detection accuracy of Faster R-CNN and RetinaNet by 8.0% and 22.7%, respectively. On the BUUISE-MO-Lite dataset, TranSDet improves the detection accuracy of RetinaNet and YOLOv3 by 32.2% and 12.8%, respectively, compared to the baseline models. These results suggest that TranSDet is an effective method for improving small-object detection accuracy using transfer learning.
2. Related Works
2.1. Small-Object Detection
2.2. Transfer Learning in Object Detection
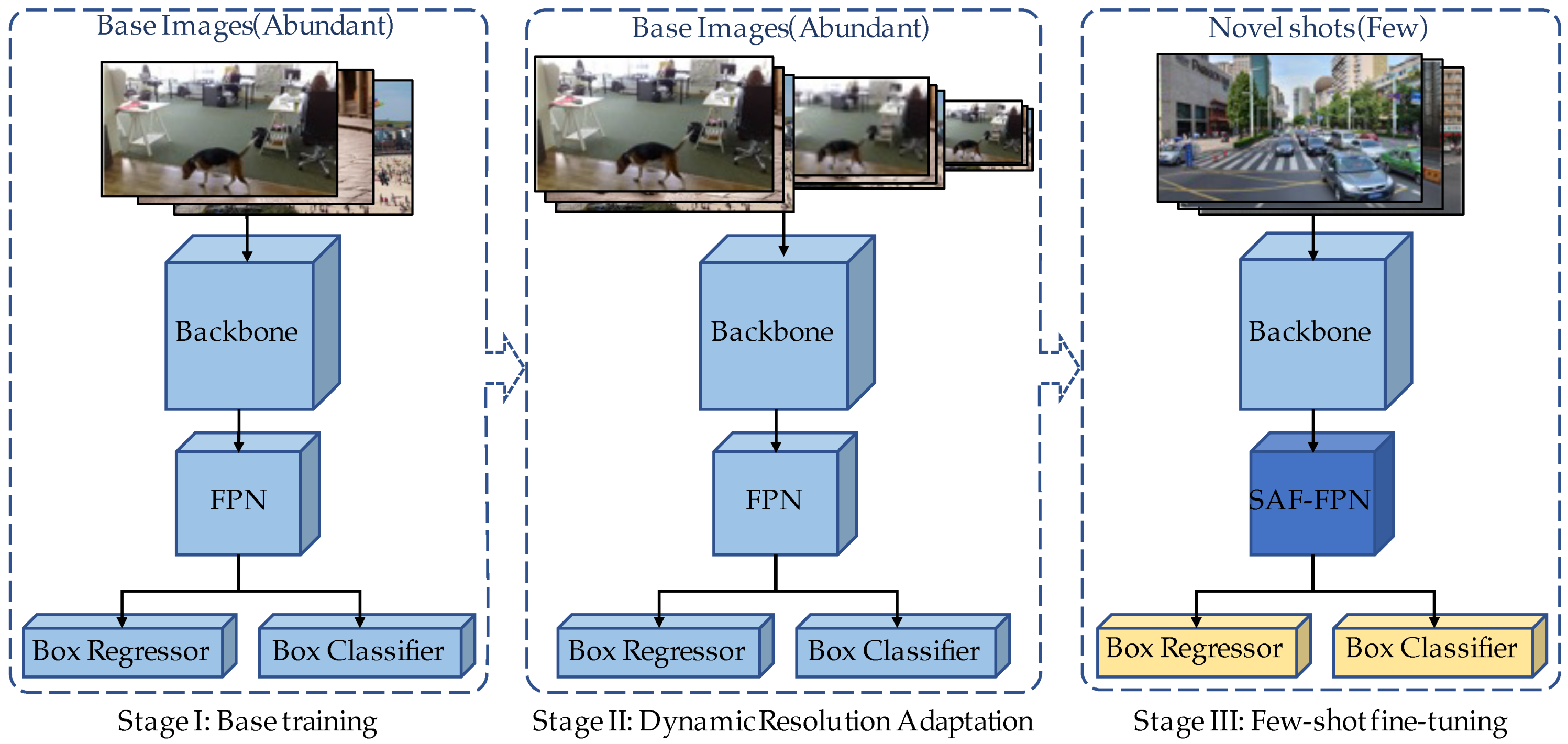
3. Methodology
3.1. Dynamic Resolution Adaptation Transfer Learning
| Algorithm 1 Dynamic resolution adaptation meta-learning |
|
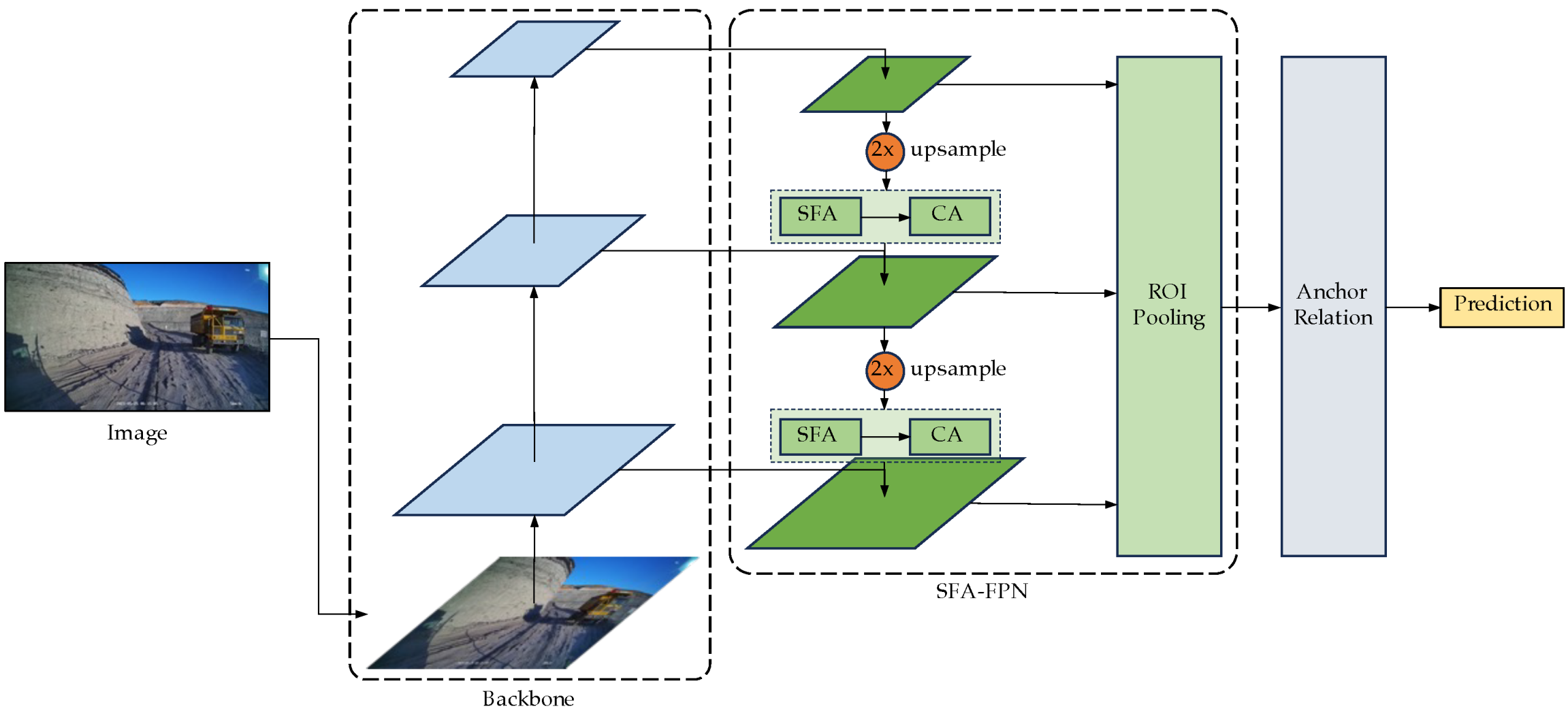
3.2. Enhanced Small-Object Detection for Transfer Learning
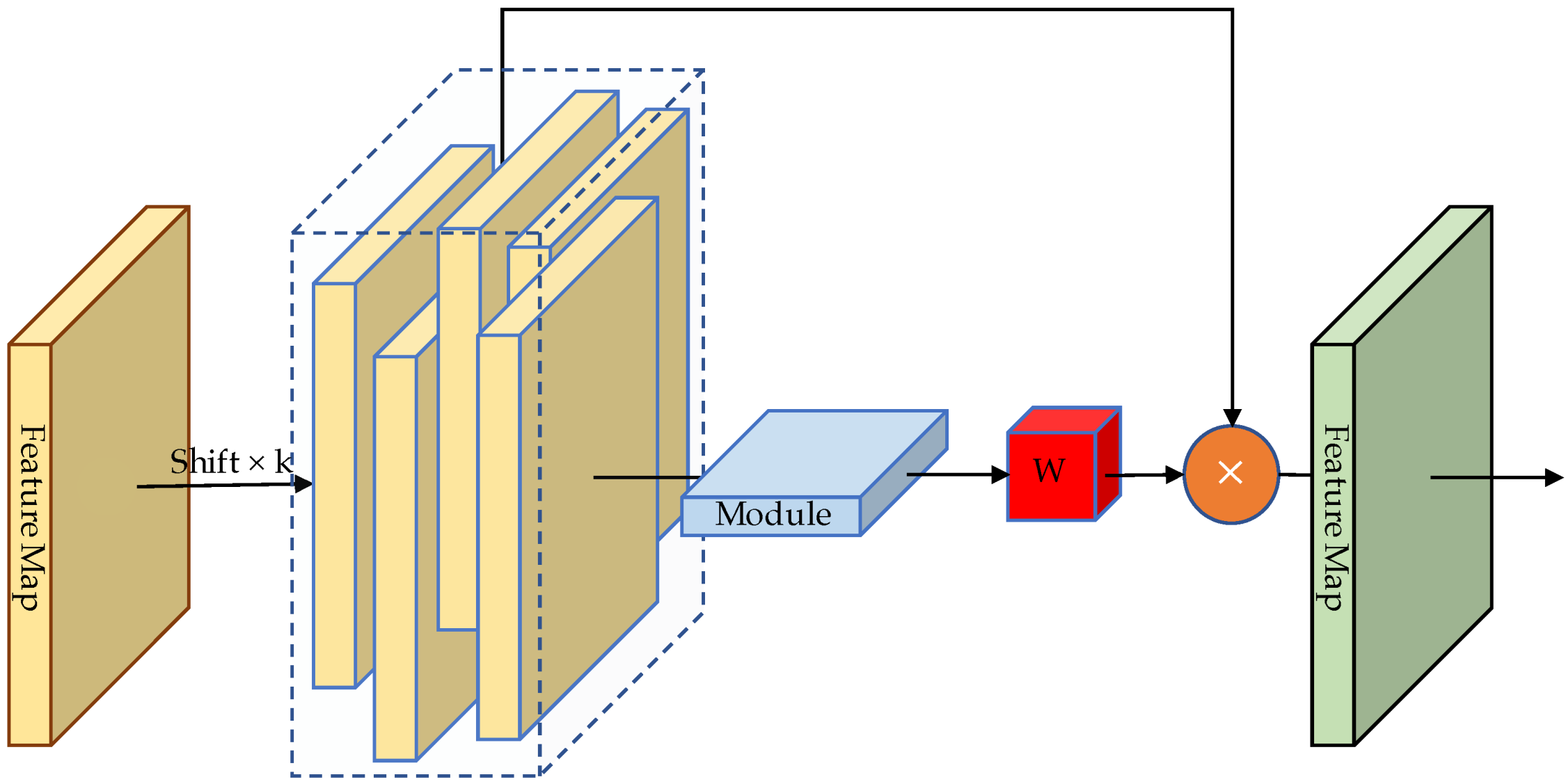
3.2.1. FPN with Shifted Feature Aggregation (SFA-FPN)
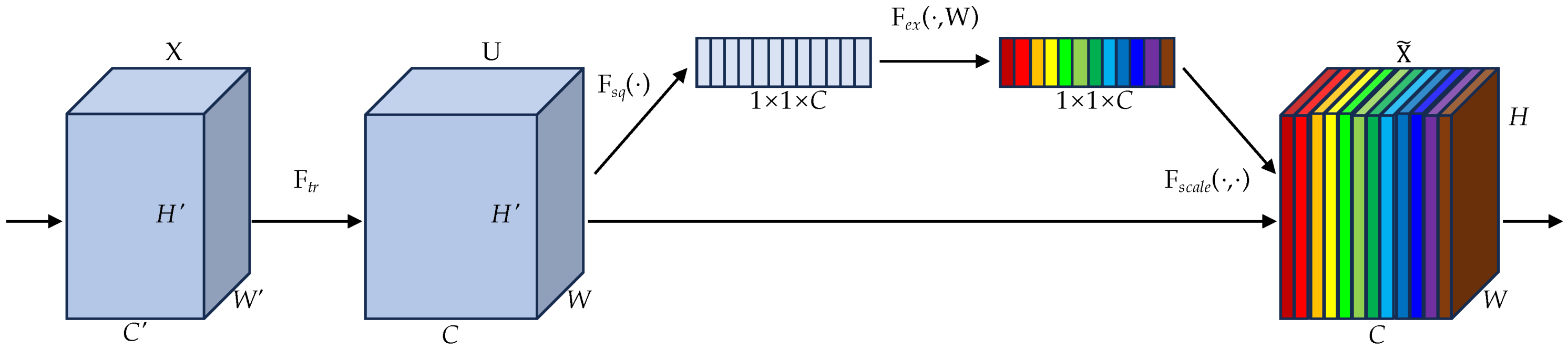
3.2.2. Anchor Relation Module
4. Experiments
4.1. Datasets and Evaluation Metrics
4.2. Models and Training Strategies
4.3. Results on TT100K
4.4. Results on BUUISE-MO
4.5. Small-Object Results on COCO Dataset
4.6. Comparison with Transfer Learning Methods
4.7. Ablation Study
4.7.1. Ablation on the Proposed Modules
4.7.2. Comparison with Previous Small-Object Detection Methods
4.7.3. Effect of Transferring from a Small-Object Dataset
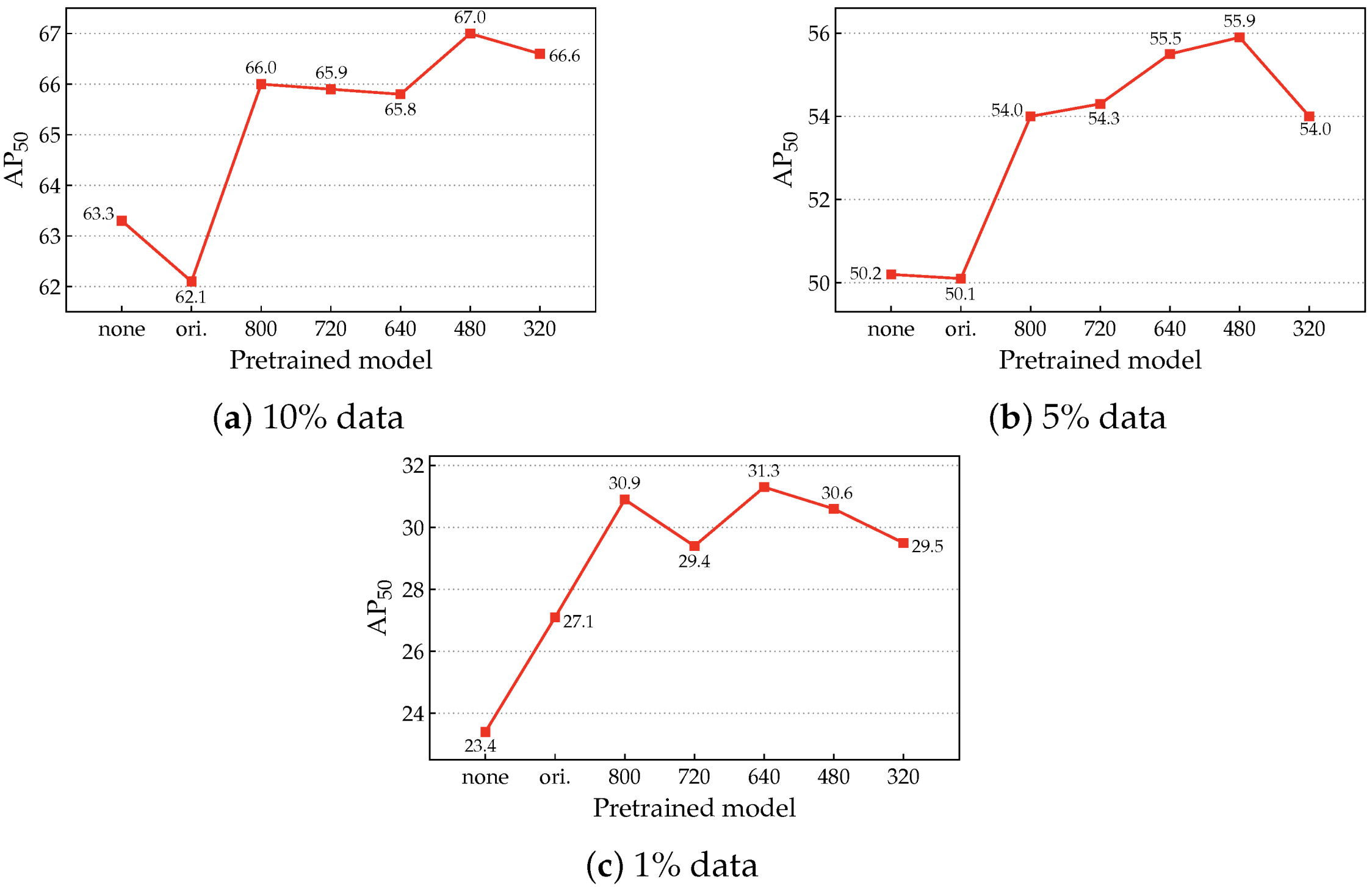
4.7.4. Effects of Different Adaptation Resolutions in DRA
4.8. Complexity Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In IEEE Transactions on Pattern Analysis and Machine Intelligence; IEEE: Piscataway, NJ, USA, 2017; Volume 39, pp. 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Computer Vision—ECCV 2016; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar] [CrossRef] [Green Version]
- Shivappriya, S.N.; Priyadarsini, M.J.P.; Stateczny, A.; Puttamadappa, C.; Parameshachari, B.D. Cascade Object Detection and Remote Sensing Object Detection Method Based on Trainable Activation Function. Remote Sens. 2021, 13, 200. [Google Scholar] [CrossRef]
- Fan, D.P.; Ji, G.P.; Cheng, M.M.; Shao, L. Concealed Object Detection. In IEEE Transactions on Pattern Analysis and Machine Intelligence; IEEE: Piscataway, NJ, USA, 2022; Volume 44, pp. 6024–6042. [Google Scholar] [CrossRef]
- Nnadozie, E.C.; Iloanusi, O.N.; Ani, O.A.; Yu, K. Detecting Cassava Plants under Different Field Conditions Using UAV-Based RGB Images and Deep Learning Models. Remote Sens. 2023, 15, 2322. [Google Scholar] [CrossRef]
- Wu, J.; Xu, W.; He, J.; Lan, M. YOLO for Penguin Detection and Counting Based on Remote Sensing Images. Remote Sens. 2023, 15, 2598. [Google Scholar] [CrossRef]
- Musunuri, Y.R.; Kwon, O.S.; Kung, S.Y. SRODNet: Object Detection Network Based on Super Resolution for Autonomous Vehicles. Remote Sens. 2022, 14, 6270. [Google Scholar] [CrossRef]
- Liang, T.; Bao, H.; Pan, W.; Fan, X.; Li, H. DetectFormer: Category-Assisted Transformer for Traffic Scene Object Detection. Sensors 2022, 22, 4833. [Google Scholar] [CrossRef]
- Rasol, J.; Xu, Y.; Zhang, Z.; Zhang, F.; Feng, W.; Dong, L.; Hui, T.; Tao, C. An Adaptive Adversarial Patch-Generating Algorithm for Defending against the Intelligent Low, Slow, and Small Target. Remote Sens. 2023, 15, 1439. [Google Scholar] [CrossRef]
- Xu, X.; Zhao, S.; Xu, C.; Wang, Z.; Zheng, Y.; Qian, X.; Bao, H. Intelligent Mining Road Object Detection Based on Multiscale Feature Fusion in Multi-UAV Networks. Drones 2023, 7, 250. [Google Scholar] [CrossRef]
- Song, R.; Ai, Y.; Tian, B.; Chen, L.; Zhu, F.; Yao, F. MSFANet: A Light Weight Object Detector Based on Context Aggregation and Attention Mechanism for Autonomous Mining Truck. In IEEE Transactions on Intelligent Vehicles; IEEE: Piscataway, NJ, USA, 2023; Volume 8, pp. 2285–2295. [Google Scholar] [CrossRef]
- Huang, L.; Zhang, X.; Yu, M.; Yang, S.; Cao, X.; Meng, J. FEGNet: A feature enhancement and guided network for infrared object detection in underground mines. Proc. Inst. Mech. Eng. Part D J. Automob. Eng. 2023, 09544070231165627. [Google Scholar] [CrossRef]
- Naz, S.; Ashraf, A.; Zaib, A. Transfer learning using freeze features for Alzheimer neurological disorder detection using ADNI dataset. Multimed. Syst. 2022, 28, 85–94. [Google Scholar] [CrossRef]
- Chen, J.; Sun, J.; Li, Y.; Hou, C. Object detection in remote sensing images based on deep transfer learning. Multimed. Tools Appl. 2022, 81, 12093–12109. [Google Scholar] [CrossRef]
- Neupane, B.; Horanont, T.; Aryal, J. Real-Time Vehicle Classification and Tracking Using a Transfer Learning-Improved Deep Learning Network. Sensors 2022, 22, 3813. [Google Scholar] [CrossRef]
- Ghasemi Darehnaei, Z.; Shokouhifar, M.; Yazdanjouei, H.; Rastegar Fatemi, S.M.J. SI-EDTL: Swarm intelligence ensemble deep transfer learning for multiple vehicle detection in UAV images. Concurr. Comput. Pract. Exp. 2022, 34, e6726. [Google Scholar] [CrossRef]
- Narmadha, C.; Kavitha, T.; Poonguzhali, R.; Hamsadhwani, V.; Jegajothi, B. Robust Deep Transfer Learning Based Object Detection and Tracking Approach. Intell. Autom. Soft Comput. 2023, 35, 3613–3626. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Computer Vision—ECCV 2014; Springer: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar] [CrossRef] [Green Version]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Everingham, M.; Eslami, S.M.A.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes Challenge: A Retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]
- Zhu, Z.; Liang, D.; Zhang, S.; Huang, X.; Li, B.; Hu, S. Traffic-Sign Detection and Classification in the Wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Cheng, G.; Yuan, X.; Yao, X.; Yan, K.; Zeng, Q.; Han, J. Towards large-scale small object detection: Survey and benchmarks. arXiv 2022, arXiv:2207.14096. [Google Scholar] [CrossRef]
- Yu, X.; Gong, Y.; Jiang, N.; Ye, Q.; Han, Z. Scale Match for Tiny Person Detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Snowmass Village, CO, USA, 1–5 March 2020. [Google Scholar]
- Lin, T.Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 936–944. [Google Scholar] [CrossRef] [Green Version]
- Wang, J.; Chen, K.; Xu, R.; Liu, Z.; Loy, C.C.; Lin, D. Carafe: Content-aware reassembly of features. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3007–3016. [Google Scholar]
- Chen, K.; Cao, Y.; Loy, C.C.; Lin, D.; Feichtenhofer, C. Feature pyramid grids. arXiv 2020, arXiv:2004.03580. [Google Scholar]
- Zhang, H.; Wang, K.; Tian, Y.; Gou, C.; Wang, F.Y. MFR-CNN: Incorporating Multi-Scale Features and Global Information for Traffic Object Detection. In IEEE Transactions on Vehicular Technology; IEEE: Piscataway, NJ, USA, 2018; Volume 67, pp. 8019–8030. [Google Scholar] [CrossRef]
- Tong, K.; Wu, Y.; Zhou, F. Recent advances in small object detection based on deep learning: A review. Image Vis. Comput. 2020, 97, 103910. [Google Scholar] [CrossRef]
- Liu, Y.; Sun, P.; Wergeles, N.; Shang, Y. A survey and performance evaluation of deep learning methods for small object detection. Expert Syst. Appl. 2021, 172, 114602. [Google Scholar] [CrossRef]
- Dai, X.; Chen, Y.; Xiao, B.; Chen, D.; Liu, M.; Yuan, L.; Zhang, L. Dynamic Head: Unifying Object Detection Heads with Attentions. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 7369–7378. [Google Scholar] [CrossRef]
- Huang, J.; Shi, Y.; Gao, Y. Multi-Scale Faster-RCNN Algorithm for Small Object Detection. J. Comput. Res. Dev. 2019, 56, 319–327. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8759–8768. [Google Scholar]
- Qi, G.; Zhang, Y.; Wang, K.; Mazur, N.; Liu, Y.; Malaviya, D. Small Object Detection Method Based on Adaptive Spatial Parallel Convolution and Fast Multi-Scale Fusion. Remote Sens. 2022, 14, 420. [Google Scholar] [CrossRef]
- Shi, T.; Gong, J.; Hu, J.; Zhi, X.; Zhang, W.; Zhang, Y.; Zhang, P.; Bao, G. Feature-Enhanced CenterNet for Small Object Detection in Remote Sensing Images. Remote Sens. 2022, 14, 5488. [Google Scholar] [CrossRef]
- Qu, J.; Tang, Z.; Zhang, L.; Zhang, Y.; Zhang, Z. Remote Sensing Small Object Detection Network Based on Attention Mechanism and Multi-Scale Feature Fusion. Remote Sens. 2023, 15, 2728. [Google Scholar] [CrossRef]
- Zhang, J.; Xu, D.; Li, Y.; Zhao, L.; Su, R. FusionPillars: A 3D Object Detection Network with Cross-Fusion and Self-Fusion. Remote Sens. 2023, 15, 2692. [Google Scholar] [CrossRef]
- Cai, Z.; Fan, Q.; Feris, R.S.; Vasconcelos, N. A Unified Multi-scale Deep Convolutional Neural Network for Fast Object Detection. In Computer Vision—ECCV 2016; Springer: Cham, Switzerland, 2016; pp. 354–370. [Google Scholar] [CrossRef] [Green Version]
- Bosquet, B.; Mucientes, M.; Brea, V.M. STDnet: Exploiting high resolution feature maps for small object detection. Eng. Appl. Artif. Intell. 2020, 91, 103615. [Google Scholar] [CrossRef]
- Wu, B.; Shen, Y.; Guo, S.; Chen, J.; Sun, L.; Li, H.; Ao, Y. High Quality Object Detection for Multiresolution Remote Sensing Imagery Using Cascaded Multi-Stage Detectors. Remote Sens. 2022, 14, 2091. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar] [CrossRef] [Green Version]
- Wang, X.; Huang, T.; Gonzalez, J.; Darrell, T.; Yu, F. Frustratingly Simple Few-Shot Object Detection. In Proceedings of the 37th International Conference on Machine Learning, Virtual, 13–18 July 2020; pp. 9919–9928. [Google Scholar]
- Liang, G.; Zheng, L. A transfer learning method with deep residual network for pediatric pneumonia diagnosis. Comput. Methods Programs Biomed. 2020, 187, 104964. [Google Scholar] [CrossRef]
- Wang, X.; Shen, C.; Xia, M.; Wang, D.; Zhu, J.; Zhu, Z. Multi-scale deep intra-class transfer learning for bearing fault diagnosis. Reliab. Eng. Syst. Saf. 2020, 202, 107050. [Google Scholar] [CrossRef]
- Loey, M.; Manogaran, G.; Taha, M.H.N.; Khalifa, N.E.M. A hybrid deep transfer learning model with machine learning methods for face mask detection in the era of the COVID-19 pandemic. Measurement 2021, 167, 108288. [Google Scholar] [CrossRef]
- Tang, Y.P.; Wei, X.S.; Zhao, B.; Huang, S.J. QBox: Partial Transfer Learning with Active Querying for Object Detection. In IEEE Transactions on Neural Networks and Learning Systems; IEEE: Piscataway, NJ, USA, 2021; pp. 1–13. [Google Scholar] [CrossRef]
- Sun, B.; Li, B.; Cai, S.; Yuan, Y.; Zhang, C. FSCE: Few-Shot Object Detection via Contrastive Proposal Encoding. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 7348–7358. [Google Scholar] [CrossRef]
- Zhu, C.; Chen, F.; Ahmed, U.; Shen, Z.; Savvides, M. Semantic Relation Reasoning for Shot-Stable Few-Shot Object Detection. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 8778–8787. [Google Scholar] [CrossRef]
- Kaul, P.; Xie, W.; Zisserman, A. Label, Verify, Correct: A Simple Few Shot Object Detection Method. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 14217–14227. [Google Scholar] [CrossRef]
- Yan, D.; Zhang, H.; Li, G.; Li, X.; Lei, H.; Lu, K.; Zhang, L.; Zhu, F. Improved Method to Detect the Tailings Ponds from Multispectral Remote Sensing Images Based on Faster R-CNN and Transfer Learning. Remote Sens. 2022, 14, 103. [Google Scholar] [CrossRef]
- Finn, C.; Abbeel, P.; Levine, S. Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6 –11 August 2017; pp. 1126–1135. [Google Scholar]
- Deng, C.; Wang, M.; Liu, L.; Liu, Y.; Jiang, Y. Extended Feature Pyramid Network for Small Object Detection. IEEE Trans. Multimed. 2022, 24, 1968–1979. [Google Scholar] [CrossRef]
- Xu, F.; Wang, H.; Peng, J.; Fu, X. Scale-aware feature pyramid architecture for marine object detection. Neural. Comput. Appl. 2021, 33, 3637–3653. [Google Scholar] [CrossRef]
- Peng, F.; Miao, Z.; Li, F.; Li, Z. S-FPN: A shortcut feature pyramid network for sea cucumber detection in underwater images. Expert Syst. Appl. 2021, 182, 115306. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: New York, NY, USA, 2017; Volume 30. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 213–229. [Google Scholar]
- Chen, K.; Wang, J.; Pang, J.; Cao, Y.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Xu, J.; et al. MMDetection: Open MMLab Detection Toolbox and Benchmark. arXiv 2019, arXiv:1906.07155. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Yang, Z.; Liu, S.; Hu, H.; Wang, L.; Lin, S. Reppoints: Point set representation for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October– 2 November 2019; pp. 9657–9666. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable {DETR}: Deformable Transformers for End-to-End Object Detection. In Proceedings of the International Conference on Learning Representations, Vienna, Austria, 3–7 May 2021. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef] [Green Version]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Small Objects | Medium Objects | Large Objects | |
|---|---|---|---|---|
| general object datasets | ILSVRC 2012 [20] | 1.64% | 11.54% | 86.81% |
| VOC 2007 [21] | 11.20% | 34.52% | 54.28% | |
| VOC 2012 [21] | 9.54% | 27.59% | 62.89% | |
| COCO 2017 [19] | 31.13% | 34.90% | 33.97% | |
| small object datasets | TT100K 2016 [22] | 41.28% | 51.66% | 7.06% |
| BUUISE-MO [11] | 44.09% | 33.79% | 22.12% | |
| SODA-D [23] | 48.20% | 28.18% | 23.62% | |
| Tiny Person [24] | 85.80% | 11.54% | 2.66% | |
| Proportion (%) | AP | AP | AP | AP |
|---|---|---|---|---|
| 100 | 89.4 ± 0.90 | 75.4 ± 3.11 | 97.8 ± 0.78 | 91.7 ± 1.79 |
| 10 | 63.3 ± 0.53 | 48.2 ± 1.38 | 78.0 ± 1.22 | 79.4 ± 4.58 |
| 5 | 50.2 ± 0.98 | 40.4 ± 1.02 | 62.2 ± 1.35 | 59.1 ± 4.46 |
| 1 | 23.4 ± 1.44 | 18.5 ± 2.83 | 30.8 ± 0.94 | 43.3 ± 5.45 |
| Pros. (%) | Method | AP | AP | AP | AP |
|---|---|---|---|---|---|
| 10 | FRCNN [1] | 63.3 ± 0.53 | 48.2 ± 1.38 | 78.0 ± 1.22 | 79.4 ± 4.58 |
| FRCNN-TranSDet | 71.3 ± 1.05 | 53.4 ± 1.59 | 85.0 ± 1.87 | 83.3 ± 3.97 | |
| RetinaNet [2] | 33.7 ± 2.34 | 33.3 ± 4.99 | 42.5 ± 2.66 | 55.7 ± 8.48 | |
| RetinaNet-TranSDet | 56.4 ± 0.98 | 45.9 ± 3.90 | 68.4 ± 1.89 | 68.2 ± 7.86 | |
| YOLOv3 [33] | 24.9 ± 0.98 | 15.6 ± 2.83 | 32.6 ± 2.34 | 37.0 ± 4.11 | |
| YOLOv3-TranSDet | 31.5 ± 0.32 | 19.6 ± 1.45 | 38.2 ± 2.05 | 41.7 ± 5.98 | |
| 5 | FRCNN [1] | 50.2 ± 0.98 | 40.4 ± 1.02 | 62.2 ± 1.35 | 59.1 ± 4.46 |
| FRCNN-TranSDet | 61.6 ± 0.72 | 44.8 ± 1.50 | 74.1 ± 1.19 | 70.1 ± 2.44 | |
| RetinaNet [2] | 17.1 ± 2.15 | 18.1 ± 1.72 | 21.5 ± 2.25 | 37.7 ± 8.56 | |
| RetinaNet-TranSDet | 44.1 ± 2.10 | 37.8 ± 0.59 | 56.7 ± 1.69 | 52.6 ± 4.09 | |
| YOLOv3 [33] | 14.6 ± 0.99 | 8.1 ± 1.90 | 19.9 ± 0.55 | 30.9 ± 4.36 | |
| YOLOv3-TranSDet | 22.0 ± 2.14 | 10.9 ± 5.71 | 30.5 ± 1.16 | 34.4 ± 3.20 | |
| 1 | FRCNN [1] | 23.4 ± 1.44 | 18.5 ± 2.83 | 30.8 ± 0.94 | 43.3 ± 5.45 |
| FRCNN-TranSDet | 30.9 ± 1.16 | 26.4 ± 1.35 | 38.7 ± 1.42 | 46.4 ± 4.28 | |
| RetinaNet [2] | 2.2 ± 0.35 | 1.8 ± 0.45 | 3.6 ± 0.55 | 16.2 ± 4.08 | |
| RetinaNet-TranSDet | 17.8 ± 0.89 | 17.6 ± 1.23 | 24.6 ± 2.32 | 37.3 ± 2.90 | |
| YOLOv3 [33] | 3.8 ± 0.14 | 1.9 ± 0.35 | 5.1 ± 1.06 | 16.5 ± 2.40 | |
| YOLOv3-TranSDet | 9.2 ± 0.92 | 3.9 ± 2.76 | 14.7 ± 0.97 | 18.6 ± 3.88 |
| Pros. (%) | Method | AP | AP | AP | AP |
|---|---|---|---|---|---|
| 10 | RetinaNet (Swin) [60] | 36.4 ± 1.73 | 32.3 ± 2.81 | 46.9 ± 1.24 | 55.1 ± 3.32 |
| RetinaNet-TranSDet (Swin) | 61.4 ± 1.46 | 50.2 ± 2.59 | 73.9 ± 1.92 | 67.2 ± 4.81 | |
| RepPoints [61] | 42.3 ± 2.13 | 36.9 ± 3.17 | 50.5 ± 1.62 | 56.0 ± 2.91 | |
| RepPoints-TranSDet | 68.8 ± 1.53 | 51.3 ± 1.16 | 78.6 ± 1.63 | 69.2 ± 3.54 | |
| Def. DETR [62] | 27.8 ± 2.81 | 13.7 ± 3.19 | 38.3 ± 1.96 | 50.4 ± 5.32 | |
| Def. DETR-TranSDet | 54.8 ± 1.35 | 32.6 ± 1.63 | 61.6 ± 1.26 | 63.2 ± 4.63 | |
| 5 | RetinaNet (Swin) [60] | 22.4 ± 1.65 | 19.2 ± 1.92 | 29.5 ± 1.57 | 47.8 ± 5.21 |
| RetinaNet-TranSDet (Swin) | 46.9 ± 1.42 | 40.5 ± 2.51 | 58.1 ± 1.52 | 55.7 ± 4.21 | |
| RepPoints [61] | 31.0 ± 1.43 | 27.4 ± 2.71 | 38.7 ± 1.12 | 45.7 ± 4.83 | |
| RepPoints-TranSDet | 51.7 ± 2.16 | 40.1 ± 1.74 | 63.7 ± 1.76 | 58.2 ± 2.95 | |
| Def. DETR [62] | 15.2 ± 1.84 | 14.9 ± 1.05 | 25.7 ± 1.46 | 35.8 ± 3.69 | |
| Def. DETR-TranSDet | 43.7 ± 1.61 | 35.3 ± 1.31 | 56.9 ± 1.66 | 51.5 ± 5.03 | |
| 1 | RetinaNet (Swin) [60] | 2.30 ± 0.52 | 1.70 ± 0.38 | 3.30 ± 1.15 | 18.1 ± 3.64 |
| RetinaNet-TranSDet (Swin) | 19.5 ± 1.73 | 18.9 ± 1.56 | 28.2 ± 1.27 | 42.3 ± 4.29 | |
| RepPoints [61] | 3.30 ± 1.13 | 3.20 ± 0.94 | 4.51 ± 1.75 | 14.1 ± 2.89 | |
| RepPoints-TranSDet | 19.5 ± 2.04 | 18.2 ± 1.53 | 26.7 ± 1.39 | 40.2 ± 3.15 | |
| Def. DETR [62] | 1.7 ± 0.51 | 1.8 ± 0.37 | 3.28 ± 1.04 | 11.2 ± 2.46 | |
| Def. DETR-TranSDet | 16.2 ± 1.76 | 15.8 ± 1.53 | 24.1 ± 1.64 | 36.6 ± 2.78 |
| Method | AP | AP | AP | AP |
|---|---|---|---|---|
| FRCNN | 57.6 ± 1.07 | 51.8 ± 0.55 | 66.6 ± 2.32 | 64.2 ± 1.88 |
| FRCNN-TranSDet | 61.6 ± 4.07 | 51.7 ± 1.96 | 68.2 ± 0.61 | 72.0 ± 7.76 |
| RetinaNet | 32.8 ± 1.53 | 28.4 ± 3.38 | 44.2 ± 1.26 | 46.7 ± 0.35 |
| RetinaNet-TranSDet | 65.0 ± 3.16 | 52.7 ± 2.25 | 65.9 ± 2.90 | 77.1 ± 2.87 |
| YOLOv3 | 40.2 ± 4.19 | 16.1 ± 2.70 | 49.6 ± 7.28 | 55.4 ± 7.03 |
| YOLOv3-TranSDet | 53.0 ± 2.72 | 28.8 ± 6.84 | 59.1 ± 3.99 | 72.0 ± 4.45 |
| Method | AP | AP | AP | AP | AP | AP |
|---|---|---|---|---|---|---|
| FRCNN | 37.4 | 58.1 | 40.4 | 21.2 | 41.0 | 48.1 |
| + SFA-FPN | 37.8 (+0.4) | 58.3 (+0.2) | 40.8 (+0.4) | 21.8 (+0.6) | 41.3 (+0.3) | 48.2 (+0.1) |
| + SFA-FPN + AR | 38.0 (+0.6) | 58.4 (+0.3) | 41.0 (+0.6) | 22.1 (+0.9) | 41.4 (+0.4) | 48.4 (+0.3) |
| Pros. (%) | Methods | AP | AP | AP | AP |
|---|---|---|---|---|---|
| 10 | PTD [63] | 62.1 ± 1.79 | 46.6 ± 1.38 | 74.7 ± 1.79 | 86.2 ± 3.95 |
| FTD [43] | 55.9 ± 0.71 | 42.9 ± 1.42 | 69.5 ± 1.25 | 72.5 ± 7.04 | |
| TranSDet | 71.3 ± 1.05 | 53.4 ± 1.59 | 85.0 ± 1.87 | 83.3 ± 3.97 | |
| 5 | PTD [63] | 50.1 ± 0.75 | 38.4 ± 2.16 | 61.4 ± 1.49 | 61.9 ± 3.70 |
| FTD [43] | 45.7 ± 1.26 | 35.1 ± 3.16 | 56.7 ± 5.63 | 58.7 ± 3.67 | |
| TranSDet | 61.6 ± 0.72 | 44.8 ± 1.50 | 74.1 ± 1.19 | 70.1 ± 2.44 | |
| 1 | PTD [63] | 27.1 ± 2.30 | 22.1 ± 2.58 | 34.2 ± 1.46 | 48.7 ± 4.18 |
| FTD [43] | 26.2 ± 1.12 | 21.5 ± 3.20 | 32.8 ± 1.36 | 41.7 ± 2.71 | |
| TranSDet | 30.9 ± 1.16 | 26.4 ± 1.35 | 38.7 ± 1.42 | 46.4 ± 4.28 |
| DRA | SFA-FPN | AR | AP | AP |
|---|---|---|---|---|
| × | × | × | 50.2 ± 0.98 | 40.4 ± 1.02 |
| ✓ | × | × | 55.9 ± 1.20 | 44.3 ± 1.49 |
| × | ✓ | × | 56.4 ± 1.81 | 43.5 ± 0.23 |
| × | × | ✓ | 59.2 ± 1.10 | 44.9 ± 2.15 |
| × | ✓ | ✓ | 59.2 ± 2.05 | 43.8 ± 2.44 |
| ✓ | ✓ | ✓ | 61.6 ± 0.72 | 44.8 ± 1.50 |
| Method | AP | AP | AP | AP |
|---|---|---|---|---|
| FRCNN | 67.0 ± 1.15 | 47.4 ± 3.07 | 80.3 ± 2.24 | 81.0 ± 1.39 |
| Carafe [26] | 66.5 ± 1.27 | 51.2 ± 1.16 | 78.4 ± 1.14 | 80.4 ± 5.34 |
| FPG [27] | 35.1 ± 1.61 | 4.3 ± 2.04 | 50.0 ± 2.52 | 62.4 ± 1.61 |
| TranSDet (FRCNN as baseline) | 71.3 ± 1.05 | 53.4 ± 1.59 | 85.0 ± 1.87 | 83.3 ± 3.97 |
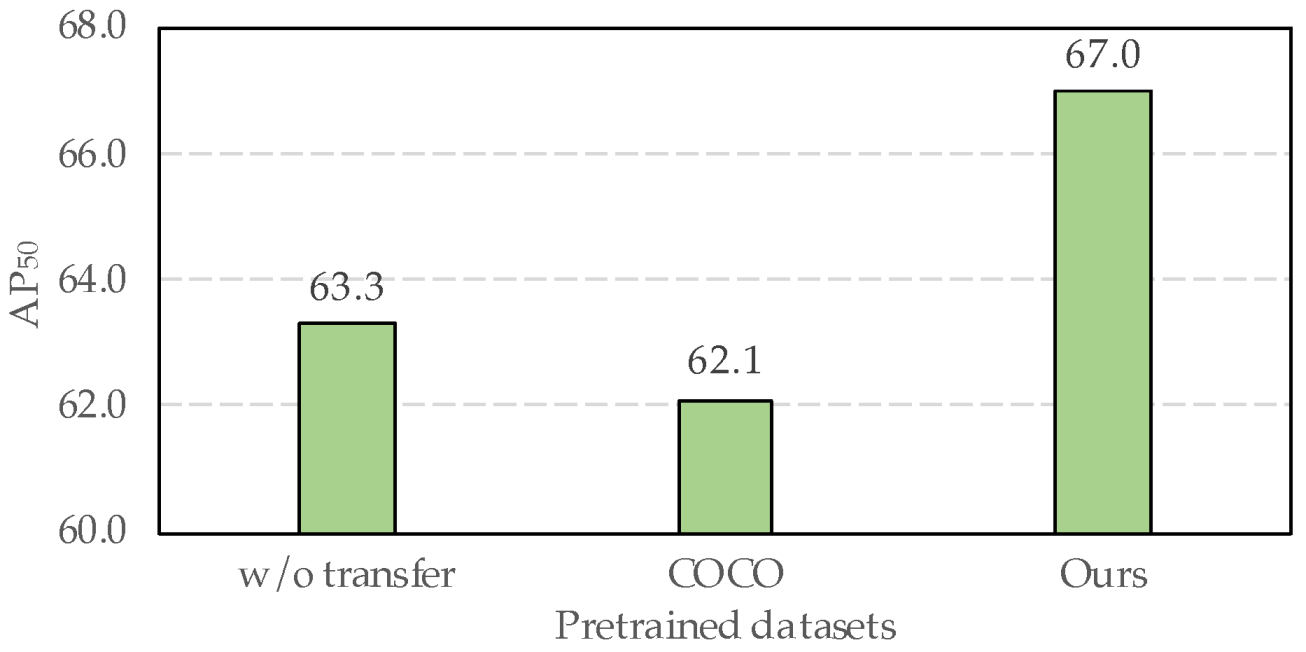
| Pretrained Dataset | AP | AP | AP | AP |
|---|---|---|---|---|
| ILSVRC | 59.4 ± 0.95 | 51.3 ± 1.07 | 70.5 ± 3.48 | 69.5 ± 3.87 |
| TT100K | 52.8 ± 0.49 | 48.1 ± 0.40 | 60.5 ± 1.33 | 59.3 ± 3.91 |
| COCO | 62.4 ± 1.45 | 51.0 ± 1.50 | 66.5 ± 1.66 | 71.7 ± 2.04 |
| COCO-adapted (Ours) | 65.0 ± 3.16 | 52.7 ± 2.25 | 65.9 ± 2.90 | 77.1 ± 2.87 |
| Method | FLOPs (GFLOPs) | Params. (M) | Inference Speed (Image/Second) |
|---|---|---|---|
| FRCNN | 206.89 | 41.35 | 5.8 |
| FRCNN-TranSDet | 267.70 | 48.71 | 5.3 |
| RetinaNet | 223.83 | 37.02 | 6.5 |
| RetinaNet-TranSDet | 237.06 | 39.10 | 6.0 |
| YOLOv3 | 194.79 | 61.76 | 7.3 |
| YOLOv3-TranSDet | 202.47 | 63.00 | 7.1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, X.; Zhang, H.; Ma, Y.; Liu, K.; Bao, H.; Qian, X. TranSDet: Toward Effective Transfer Learning for Small-Object Detection. Remote Sens. 2023, 15, 3525. https://doi.org/10.3390/rs15143525
Xu X, Zhang H, Ma Y, Liu K, Bao H, Qian X. TranSDet: Toward Effective Transfer Learning for Small-Object Detection. Remote Sensing. 2023; 15(14):3525. https://doi.org/10.3390/rs15143525
Chicago/Turabian StyleXu, Xinkai, Hailan Zhang, Yan Ma, Kang Liu, Hong Bao, and Xu Qian. 2023. "TranSDet: Toward Effective Transfer Learning for Small-Object Detection" Remote Sensing 15, no. 14: 3525. https://doi.org/10.3390/rs15143525
APA StyleXu, X., Zhang, H., Ma, Y., Liu, K., Bao, H., & Qian, X. (2023). TranSDet: Toward Effective Transfer Learning for Small-Object Detection. Remote Sensing, 15(14), 3525. https://doi.org/10.3390/rs15143525